
Exchange Rate Forecasting with Advanced Machine Learning Methods


Abstract
:1. Introduction
- Q:
- Do fundamentals from the PPP, UIP or MM model have forecasting power with regard to exchange rate movements, regardless of the functional form of the estimation equation?
- Q1:
- Can complex ML methods with economic fundaments beat the RW predictions in forecasting exchange rate differentials?
- Q2:
- Can complex ML methods with economic fundaments beat the RW predictions in forecasting exchange rate movement directions?
2. Related Literature
3. Methodology
3.1. Uncovered Interest Rate Parity (UIP) Model
3.2. Purchasing Power Parity (PPP) Model
3.3. Monetary Model (MM)
3.4. Artificial Neural Networks (ANN)
3.5. EXtreme Gradient Boosting (XGboost)
4. Data
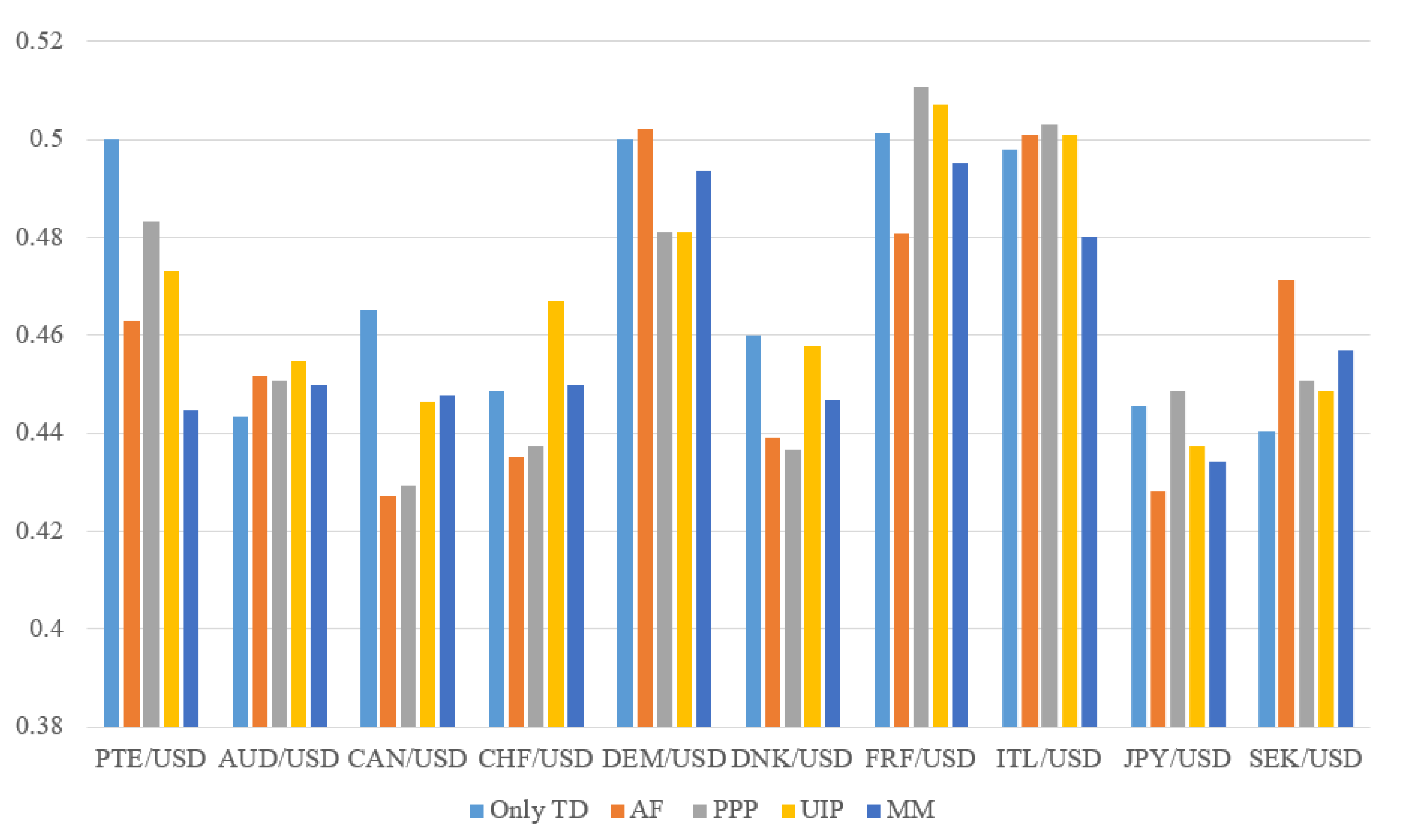
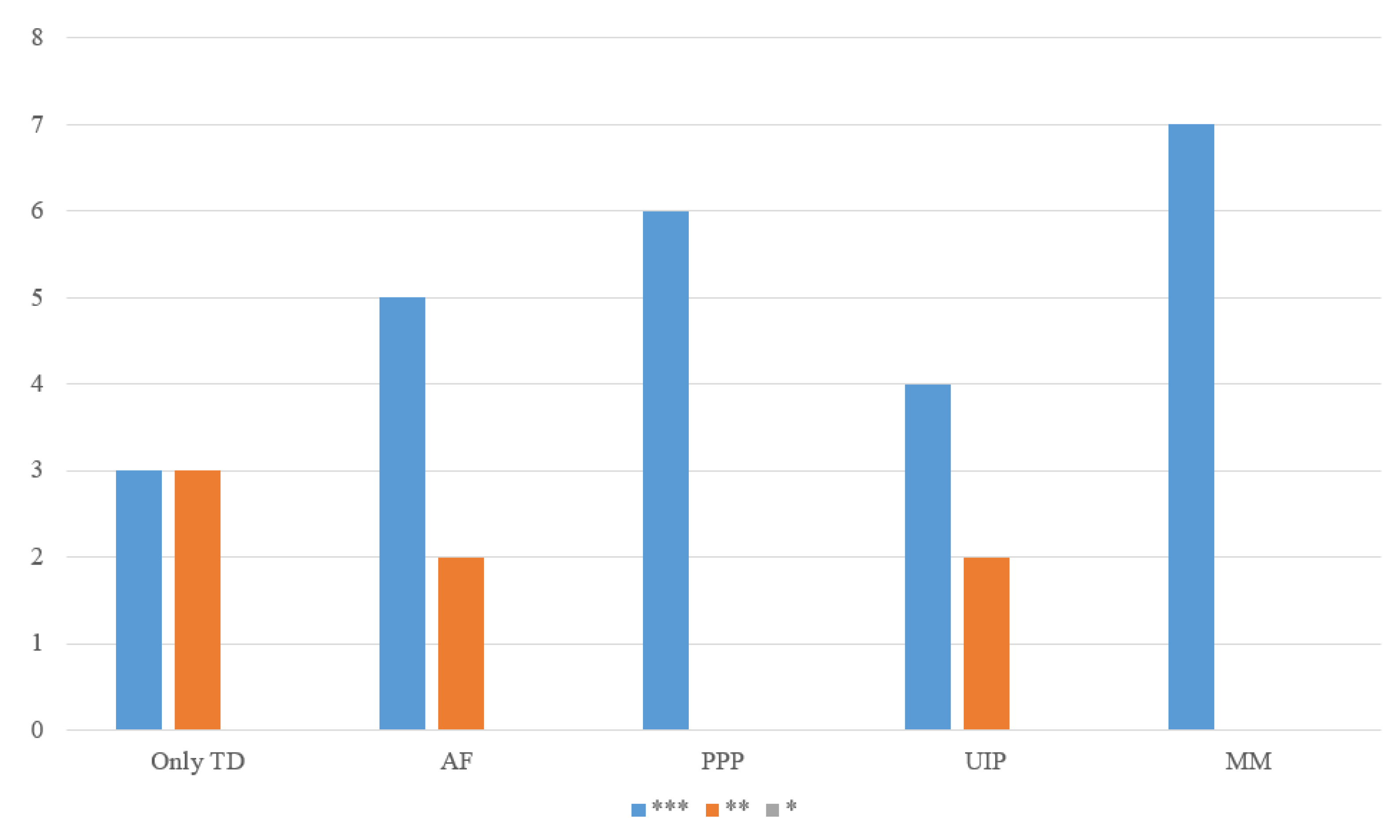
5. Results
6. Discussion
7. Conclusions
Funding
Conflicts of Interest
References
- Alvarez, Fernando, Andrew Atkeson, and Patrick J. Kehoe. 2007. If Exchange Rates are Random Walks, Then Almost Everything We Say About Monetary Policy is Wrong. American Economic Review 97: 339–45. [Google Scholar] [CrossRef]
- Amat, Christophe, Tomasz Michalski, and Gilles Stoltz. 2018. Fundamentals and exchange rate forecastability with simple machine learning methods. Journal of International Money and Finance 88: 1–24. [Google Scholar] [CrossRef]
- Amat, Christophe, Tomasz Michalski, and Gilles Stoltz. 2020. Data set and programs to reproduce the forecasts Fundamentals and exchange rate forecastability with simple machine learning methodss. Mendeley Data V1. [Google Scholar] [CrossRef]
- Bacchetta, Philippe, and Eric van Wincoop. 2004. A Scapegoat Model of Exchange Rate Fluctuations. Working Paper 10245. Cambridge, MA, USA: National Bureau of Economic Research. [Google Scholar] [CrossRef]
- Bajari, Patrick, Denis Nekipelov, Stephen P. Ryan, and Miaoyu Yang. 2015. Demand Estimation with Machine Learning and Model Combination. Working Paper 20955. Cambridge, MA, USA: National Bureau of Economic Research. [Google Scholar] [CrossRef]
- Chen, Tianqi, and Carlos Guestrin. 2016. Xgboost: A Scalable Tree Boosting System. Available online: http://arxiv.org/abs/1603.02754 (accessed on 29 October 2021).
- Dal Bianco, Marcos, Maximo Camacho, and Gabriel Perez Quiros. 2012. Short-run forecasting of the euro-dollar exchange rate with economic fundamentals. Journal of International Money and Finance 31: 377–96. [Google Scholar] [CrossRef] [Green Version]
- Edison, Hali J., and Jan Tore Klovland. 1987. A quantitative reassessment of the purchasing power parity hypothesis: Evidence from norway and the united kingdom. Journal of Applied Econometrics 2: 309–33. [Google Scholar] [CrossRef] [Green Version]
- Engel, Charles, Dohyeon Lee, Chang Liu, Chenxin Liu, and Steve Pak Yeung Wu. 2017. The Uncovered Interest Parity Puzzle, Exchange Rate Forecasting, and Taylor Rules. Working Paper 24059. Cambridge, MA, USA: National Bureau of Economic Research. [Google Scholar] [CrossRef]
- Goodfellow, Ian, Yoshua Bengio, and Aaron Courville. 2016. Deep Learning. Cambridge: MIT Press, Available online: http://www.deeplearningbook.org (accessed on 29 October 2021).
- Hornik, Kurt. 1991. Approximation capabilities of multilayer feedforward networks. Neural Networks 4: 251–57. [Google Scholar] [CrossRef]
- Juselius, Katarina. 1995. Do purchasing power parity and uncovered interest rate parity hold in the long run? an example of likelihood inference in a multivariate time-series model. Journal of Econometrics 69: 211–40. [Google Scholar] [CrossRef]
- Kingma, Diederik P., and Jimmy Ba. 2015. Adam: A method for stochastic optimization. Paper present at 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7–9; Edited by Yoshua Bengio and Yan LeCun. Conference Track Proceedings. [Google Scholar]
- Mark, Nelson C. 1995. Exchange rates and fundamentals: Evidence on long-horizon predictability. The American Economic Review 85: 201–18. [Google Scholar]
- Meese, Richard A., and Kenneth Rogoff. 1983. Empirical exchange rate models of the seventies: Do they fit out of sample? Journal of International Economics 14: 3–24. [Google Scholar] [CrossRef]
- Meredith, Guy, and Menzie D. Chinn. 1998. Long-Horizon Uncovered Interest Rate Parity. Working Paper 6797. Cambridge, MA, USA: National Bureau of Economic Research. [Google Scholar] [CrossRef]
- Neely, Christopher, and Lucio Sarno. 2002. How Well Do Monetary Fundamentals Forecast Exchange Rates? Working Papers 2002-007. St. Louis, MO, USA: Federal Reserve Bank of St. Louis. [Google Scholar]
- Plakandaras, Vasilios, Theophilos Papadimitriou, and Periklis Gogas. 2015. Forecasting daily and monthly exchange rates with machine learning techniques. Journal of Forecasting 34: 560–73. [Google Scholar] [CrossRef]
- Qureshi, Shafiullah, Ba M. Chu, and Fanny S. Demers. 2020. Forecasting Canadian GDP Growth Using XGBoost. Carleton Economic Papers 20-14. Ottawa: Department of Economics, Carleton University. [Google Scholar]
- Srivastava, Nitish, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. 2014. Dropout: A simple way to prevent neural networks from overfitting. Journal of Machine Learning Research 15: 1929–58. [Google Scholar]
- Vitek, Francis. 2005. The Exchange Rate Forecasting Puzzle. International Finance 0509005. Munich: University Library of Munich, Germany. [Google Scholar]
- Yao, Yuan, Lorenzo Rosasco, and Andrea Caponnetto. 2007. On early stopping in gradient descent learning. Constructive Approximation 26: 289–315. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
| XGBoost—Regression—With Time Dummies | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| All fundamentals | MM fundamentals | PPP fundamentals | UIP fundamentals | |||||||||
| Currency pair | DM | p-value | Theil Ratio | DM | p-value | Theil Ratio | DM | p-value | Theil Ratio | DM | p-value | Theil Ratio |
| PTE/USD | 2.8188 | 0.005 *** | 1.037 | −0.2974 | 0.7663 | 0.9966 | −1.4645 | 0.1436 | 0.9888 | −0.0099 | 0.9921 | 0.9999 |
| AUD/USD | 0.3755 | 0.7074 | 1.0027 | 0.86 | 0.39 | 1.0066 | −0.4406 | 0.6596 | 0.997 | 0.5876 | 0.5569 | 1.0039 |
| CAN/USD | 0.3755 | 0.7074 | 1.0027 | 0.86 | 0.39 | 1.0066 | −0.4406 | 0.6596 | 0.997 | 0.5876 | 0.5569 | 1.0039 |
| CHF/USD | 0.3755 | 0.7074 | 1.0027 | 0.86 | 0.39 | 1.0066 | −0.4406 | 0.6596 | 0.997 | 0.5876 | 0.5569 | 1.0039 |
| DEM/USD | 2.0298 | 0.0427 ** | 1.0144 | 0.3154 | 0.7526 | 1.0025 | 1.7917 | 0.0735 * | 1.0114 | 0.7116 | 0.4769 | 1.0045 |
| DNK/USD | 0.3176 | 0.7509 | 1.0024 | 0.3046 | 0.7607 | 1.0025 | 0.6475 | 0.5175 | 1.0036 | −0.3226 | 0.7471 | 0.9981 |
| FRF/USD | 5.4862 | 0.0000 *** | 1.0465 | 2.7878 | 0.0054 * | 1.0292 | 1.9342 | 0.0534 * | 1.0139 | 2.5725 | 0.0103 *** | 1.0247 |
| ITL/USD | 2.0298 | 0.0427 ** | 1.0144 | 0.3154 | 0.7526 | 1.0025 | 1.7917 | 0.0735 * | 1.0114 | 0.7116 | 0.4769 | 1.0045 |
| JPY/USD | 0.3755 | 0.7074 | 1.0027 | 0.86 | 0.39 | 1.0066 | −0.4406 | 0.6596 | 0.997 | 0.5876 | 0.5569 | 1.0039 |
| SEK/USD | 0.3755 | 0.7074 | 1.0027 | 0.86 | 0.39 | 1.0066 | −0.4406 | 0.6596 | 0.997 | 0.5876 | 0.5569 | 1.0039 |
| XGBoost—Regression—No Time Dummies | ||||||||||||
| All fundamentals | MM fundamentals | PPP fundamentals | UIP fundamentals | |||||||||
| Currency pair | DM | p-value | Theil Ratio | DM | p-value | Theil Ratio | DM | p-value | Theil Ratio | DM | p-value | Theil Ratio |
| PTE/USD | 2.8006 | 0.0053 ** | 1.0503 | 1.7965 | 0.0729 * | 1.0194 | 1.7516 | 0.0804 * | 1.0218 | 1.3372 | 0.1817 | 1.0216 |
| AUD/USD | 0.5369 | 0.5914 | 1.005 | 2.0364 | 0.042 ** | 1.0162 | 2.231 | 0.0259 ** | 1.018 | 1.5522 | 0.1209 | 1.0092 |
| CAN/USD | 0.5369 | 0.5914 | 1.005 | 2.0364 | 0.042 ** | 1.0162 | 2.231 | 0.0259 ** | 1.018 | 1.5522 | 0.1209 | 1.0092 |
| CHF/USD | 0.5369 | 0.5914 | 1.005 | 2.0364 | 0.042 ** | 1.0162 | 2.231 | 0.0259 ** | 1.018 | 1.5522 | 0.1209 | 1.0092 |
| DEM/USD | 2.7782 | 0.0056 * | 1.027 | 1.7247 | 0.0849 ** | 1.013 | 2.3919 | 0.017 ** | 1.0234 | 0.8883 | 0.3746 | 1.0059 |
| DNK/USD | 1.6858 | 0.0922 * | 1.0198 | 3.3895 | 0.0007 *** | 1.0262 | 3.2347 | 0.0013 *** | 1.0233 | 1.9187 | 0.0553 | 1.0131 |
| FRF/USD | 2.7165 | 0.0067 * | 1.0342 | 2.0077 | 0.045 ** | 1.0209 | 3.4899 | 0.0005 *** | 1.0451 | 0.5599 | 0.5757 | 1.0053 |
| ITL/USD | 2.7782 | 0.0056 * | 1.027 | 1.7247 | 0.0849 * | 1.013 | 2.3919 | 0.017 ** | 1.0234 | 0.8883 | 0.3746 | 1.0059 |
| JPY/USD | 0.5369 | 0.5914 | 1.005 | 2.0364 | 0.042 ** | 1.0162 | 2.231 | 0.0259 ** | 1.018 | 1.5522 | 0.1209 | 1.0092 |
| SEK/USD | 0.5369 | 0.5914 | 1.005 | 2.0364 | 0.042 ** | 1.0162 | 2.231 | 0.0259 ** | 1.018 | 1.5522 | 0.1209 | 1.0092 |
| ANN—Regression—With Time Dummies | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| All fundamentals | MM fundamentals | PPP fundamentals | UIP fundamentals | |||||||||
| Currency pair | DM | p-value | Theil Ratio | DM | p-value | Theil Ratio | DM | p-value | Theil Ratio | DM | p-value | Theil Ratio |
| PTE/USD | 2.0587 | 0.04 ** | 1.0472 | 2.3238 | 0.0205 ** | 1.0663 | 2.3042 | 0.0216 ** | 1.0507 | 1.905 | 0.0573 * | 1.0378 |
| AUD/USD | −0.4744 | 0.6353 | 0.995 | 0.3059 | 0.7598 | 1.0023 | −1.2247 | 0.221 | 0.9966 | −0.3437 | 0.7312 | 0.9984 |
| CAN/USD | −1.5079 | 0.1319 | 0.9887 | −0.8013 | 0.4231 | 0.998 | −1.1149 | 0.2652 | 0.9931 | 0.2258 | 0.8214 | 1.0033 |
| CHF/USD | −0.6049 | 0.5454 | 1.0074 | −0.3143 | 0.7533 | 1.0031 | −0.6113 | 0.5411 | 0.995 | −0.5662 | 0.5714 | 0.9974 |
| DEM/USD | 4.544 | 0.0000 *** | 1.0469 | 4.1126 | 0.0000 *** | 1.0447 | 5.3071 | 0.0000 *** | 1.0435 | 3.783 | 0.0002 *** | 1.027 |
| DNK/USD | −1.3697 | 0.1711 | 0.9945 | −0.1012 | 0.9194 | 1.0107 | −0.2069 | 0.8361 | 1.0101 | 0.5283 | 0.5974 | 1.0122 |
| FRF/USD | 5.895 | 0.0000 *** | 1.1146 | 6.4874 | 0.0000 *** | 1.0893 | 4.816 | 0.0000 *** | 1.0641 | 5.0974 | 0.0000 *** | 1.0781 |
| ITL/USD | 4.9056 | 0.0000 *** | 1.0452 | 4.6223 | 0.0000 *** | 1.0659 | 5.0842 | 0.0000 *** | 1.0547 | 4.112 | 0.0000 *** | 1.0385 |
| JPY/USD | 1.4623 | 0.144 | 1.0208 | −1.3256 | 0.1853 | 0.9942 | −1.4138 | 0.1577 | 0.9963 | −0.3669 | 0.7138 | 1.0038 |
| SEK/USD | −1.1639 | 0.2448 | 0.9982 | −0.9254 | 0.355 | 0.9967 | 0.0905 | 0.9279 | 1.0082 | 0.1046 | 0.9167 | 1.0017 |
| ANN—Regression—No Time Dummies | ||||||||||||
| All fundamentals | MM fundamentals | PPP fundamentals | UIP fundamentals | |||||||||
| Currency pair | DM | p-value | Theil Ratio | DM | p-value | Theil Ratio | DM | p-value | Theil Ratio | DM | p-value | Theil Ratio |
| PTE/USD | 2.8867 | 0.004 *** | 1.0027 | 0.2556 | 0.7983 | 0.9958 | 0.7651 | 0.4445 | 0.9969 | −0.2006 | 0.8411 | 0.9947 |
| AUD/USD | 1.529 | 0.1266 | 1.0026 | 1.3829 | 0.167 | 0.9988 | 1.0547 | 0.2918 | 0.9976 | 1.1906 | 0.2341 | 0.9984 |
| CAN/USD | 0.1696 | 0.8654 | 0.9989 | 1.5529 | 0.1208 | 0.9994 | 2.0126 | 0.0444 ** | 1.0009 | 2.6056 | 0.0093 *** | 1.0043 |
| CHF/USD | 1.7308 | 0.0838 | 1.002 | 2.3972 | 0.0167 ** | 1.0029 | 2.6225 | 0.0089 *** | 1.0026 | 2.484 | 0.0132 ** | 1.0021 |
| DEM/USD | −1.434 | 0.1519 | 1.0001 | −2.4894 | 0.013 ** | 0.995 | −1.1249 | 0.2609 | 1.0028 | −1.4956 | 0.1351 | 0.9967 |
| DNK/USD | 0.0051 | 0.9959 | 0.9977 | 0.498 | 0.6186 | 0.9972 | 2.7943 | 0.0053 *** | 1.0046 | 2.1206 | 0.0342 ** | 1.0005 |
| FRF/USD | −1.3868 | 0.1659 | 0.9982 | −1.3869 | 0.1659 | 0.9957 | −1.1267 | 0.2602 | 0.9985 | −1.5057 | 0.1325 | 0.9978 |
| ITL/USD | −1.4885 | 0.137 | 0.9972 | −1.7542 | 0.0797 | 0.9959 | −1.2554 | 0.2096 | 0.9977 | −1.7742 | 0.0763 * | 0.9977 |
| JPY/USD | 1.4867 | 0.1374 | 1.001 | 1.8733 | 0.0613 | 1.0002 | 1.3946 | 0.1634 | 0.9988 | 2.7358 | 0.0063 *** | 1.0027 |
| SEK/USD | 2.2396 | 0.0253 ** | 1.0039 | 3.186 | 0.0015 ** | 1.0079 | 1.8933 | 0.0586 * | 0.9995 | 1.7569 | 0.0792 * | 1.0001 |
| XGBoost—Classification—With Time Dummies | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| All fundamentals | MM fundamentals | PPP fundamentals | UIP fundamentals | |||||||||
| Currency pair | DM | p-value | CE | DM | p-value | CE | DM | p-value | CE | DM | p-value | CE |
| PTE/USD | −2.4682 | 0.0139 ** | 0.4497 | −1.5584 | 0.1197 | 0.4681 | −1.5584 | 0.1197 | 0.4681 | −1.1472 | 0.2517 | 0.4765 |
| AUD/USD | −0.6406 | 0.5219 | 0.4897 | −1.2821 | 0.2001 | 0.4795 | −1.2821 | 0.2001 | 0.4795 | −0.2562 | 0.7978 | 0.4959 |
| CAN/USD | −0.6406 | 0.5219 | 0.4897 | −1.2821 | 0.2001 | 0.4795 | −1.2821 | 0.2001 | 0.4795 | −0.2562 | 0.7978 | 0.4959 |
| CHF/USD | −0.6406 | 0.5219 | 0.4897 | −1.2821 | 0.2001 | 0.4795 | −1.2821 | 0.2001 | 0.4795 | −0.2562 | 0.7978 | 0.4959 |
| DEM/USD | −1.2293 | 0.2192 | 0.4801 | −1.0998 | 0.2717 | 0.4822 | −1.4887 | 0.1369 | 0.4759 | −1.0998 | 0.2717 | 0.4822 |
| DNK/USD | −1.2657 | 0.206 | 0.4789 | −0.9322 | 0.3515 | 0.4845 | −1.3324 | 0.1831 | 0.4778 | −0.9989 | 0.3181 | 0.4834 |
| FRF/USD | −0.6915 | 0.4894 | 0.488 | −0.6223 | 0.5339 | 0.4892 | −0.8299 | 0.4068 | 0.4856 | −1.1762 | 0.2399 | 0.4797 |
| ITL/USD | −1.2293 | 0.2192 | 0.4801 | −1.0998 | 0.2717 | 0.4822 | −1.4887 | 0.1369 | 0.4759 | −1.0998 | 0.2717 | 0.4822 |
| JPY/USD | −0.6406 | 0.5219 | 0.4897 | −1.2821 | 0.2001 | 0.4795 | −1.2821 | 0.2001 | 0.4795 | −0.2562 | 0.7978 | 0.4959 |
| SEK/USD | −0.6406 | 0.5219 | 0.4897 | −1.2821 | 0.2001 | 0.4795 | −1.2821 | 0.2001 | 0.4795 | −0.2562 | 0.7978 | 0.4959 |
| XGBoost—Classification- No Time Dummies | ||||||||||||
| All fundamentals | MM fundamentals | PPP fundamentals | UIP fundamentals | |||||||||
| Currency pair | DM | p-value | CE | DM | p-value | CE | DM | p-value | CE | DM | p-value | CE |
| PTE/USD | −0.0819 | 0.9348 | 0.4983 | −3.981 | 0.0001 *** | 0.4195 | −3.981 | 0.0001 *** | 0.4195 | −0.737 | 0.4614 | 0.4849 |
| AUD/USD | −0.2562 | 0.7978 | 0.4959 | 0.1922 | 0.8477 | 0.5031 | −0.3203 | 0.7488 | 0.4949 | −1.4106 | 0.1587 | 0.4774 |
| CAN/USD | −0.2562 | 0.7978 | 0.4959 | 0.1922 | 0.8477 | 0.5031 | −0.3203 | 0.7488 | 0.4949 | −1.4106 | 0.1587 | 0.4774 |
| CHF/USD | −0.2562 | 0.7978 | 0.4959 | 0.1922 | 0.8477 | 0.5031 | −0.3203 | 0.7488 | 0.4949 | −1.4106 | 0.1587 | 0.4774 |
| DEM/USD | −1.4887 | 0.1369 | 0.4759 | −1.4238 | 0.1548 | 0.477 | −1.4238 | 0.1548 | 0.477 | −0.3233 | 0.7466 | 0.4948 |
| DNK/USD | −0.5991 | 0.5492 | 0.49 | 0.1331 | 0.8941 | 0.5022 | −1.0656 | 0.2869 | 0.4823 | −0.7323 | 0.4642 | 0.4878 |
| FRF/USD | −1.1762 | 0.2399 | 0.4797 | −1.94 | 0.0527 * | 0.4665 | −1.94 | 0.0527 * | 0.4665 | 0.6915 | 0.4894 | 0.512 |
| ITL/USD | −1.4887 | 0.1369 | 0.4759 | −1.4238 | 0.1548 | 0.477 | −1.4238 | 0.1548 | 0.477 | −0.3233 | 0.7466 | 0.4948 |
| JPY/USD | −0.2562 | 0.7978 | 0.4959 | 0.1922 | 0.8477 | 0.5031 | −0.3203 | 0.7488 | 0.4949 | −1.4106 | 0.1587 | 0.4774 |
| SEK/USD | −0.2562 | 0.7978 | 0.4959 | 0.1922 | 0.8477 | 0.5031 | −0.3203 | 0.7488 | 0.4949 | −1.4106 | 0.1587 | 0.4774 |
| ANN—Classification—With Time Dummies | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| All fundamentals | MM fundamentals | PPP fundamentals | UIP fundamentals | |||||||||
| Currency pair | DM | p-value | CE | DM | p-value | CE | DM | p-value | CE | DM | p-value | CE |
| PTE/USD | −1.8057 | 0.0715 * | 0.4631 | −0.819 | 0.4131 | 0.4832 | −1.3116 | 0.1902 | 0.4732 | −2.7179 | 0.0068 *** | 0.4446 |
| AUD/USD | −3.0245 | 0.0026 *** | 0.4517 | −3.0895 | 0.0021 *** | 0.4507 | −2.8298 | 0.0048 *** | 0.4548 | −3.1545 | 0.0017 *** | 0.4497 |
| CAN/USD | −4.5968 | 0.0000 *** | 0.4271 | −4.4646 | 0.0000 *** | 0.4292 | −3.3498 | 0.0008 *** | 0.4466 | −3.2847 | 0.0011 *** | 0.4476 |
| CHF/USD | −4.0694 | 0.0001 *** | 0.4353 | −3.9381 | 0.0001 *** | 0.4374 | −2.0541 | 0.0402 ** | 0.4671 | −3.1545 | 0.0017 *** | 0.4497 |
| DEM/USD | 0.1293 | 0.8971 | 0.5021 | −1.1645 | 0.2445 | 0.4812 | −1.1645 | 0.2445 | 0.4812 | −0.3879 | 0.6982 | 0.4937 |
| DNK/USD | −3.6881 | 0.0002 *** | 0.439 | −3.8243 | 0.0001 *** | 0.4368 | −2.5381 | 0.0113 ** | 0.4579 | −3.2129 | 0.0014 *** | 0.4468 |
| FRF/USD | −1.1069 | 0.2687 | 0.4809 | 0.6223 | 0.5339 | 0.5108 | 0.4148 | 0.6784 | 0.5072 | −0.2765 | 0.7822 | 0.4952 |
| ITL/USD | 0.0647 | 0.9485 | 0.501 | 0.194 | 0.8463 | 0.5031 | 0.0647 | 0.9485 | 0.501 | −1.2293 | 0.2192 | 0.4801 |
| JPY/USD | −4.5306 | 0.0000 *** | 0.4281 | −3.2196 | 0.0013 *** | 0.4487 | −3.9381 | 0.0001 *** | 0.4374 | −4.1351 | 0.0000 *** | 0.4343 |
| SEK/USD | −1.7964 | 0.0727 * | 0.4713 | −3.0895 | 0.0021 *** | 0.4507 | −3.2196 | 0.0013 *** | 0.4487 | −2.7002 | 0.007 *** | 0.4569 |
| ANN—Classification—No Time Dummies | ||||||||||||
| All fundamentals | MM fundamentals | PPP fundamentals | UIP fundamentals | |||||||||
| Currency pair | DM | p-value | CE | DM | p-value | CE | DM | p-value | CE | DM | p-value | CE |
| PTE/USD | 0.6551 | 0.5127 | 0.5134 | 0.1637 | 0.87 | 0.5034 | 0.0819 | 0.9348 | 0.5017 | 0.5731 | 0.5668 | 0.5117 |
| AUD/USD | 1.9896 | 0.0469 ** | 0.5318 | 1.9896 | 0.0469 ** | 0.5318 | 1.3463 | 0.1785 | 0.5216 | 2.1831 | 0.0293 ** | 0.5349 |
| CAN/USD | 1.6677 | 0.0957 * | 0.5267 | 1.732 | 0.0836 * | 0.5277 | 1.732 | 0.0836 * | 0.5277 | 2.3122 | 0.021 ** | 0.537 |
| CHF/USD | 1.732 | 0.0836 * | 0.5277 | 1.6034 | 0.1092 | 0.5257 | 2.3122 | 0.021 ** | 0.537 | 2.3122 | 0.021 ** | 0.537 |
| DEM/USD | 0.0000 *** | 1.0 | 0.50 | −0.6466 | 0.518 | 0.4895 | −0.6466 | 0.518 | 0.4895 | −0.0647 | 0.9485 | 0.499 |
| DNK/USD | 1.5996 | 0.11 | 0.5266 | 1.7333 | 0.0834 * | 0.5288 | 2.4037 | 0.0164 ** | 0.5399 | 2.875 | 0.0041 *** | 0.5477 |
| FRF/USD | −0.3457 | 0.7297 | 0.494 | −1.5924 | 0.1117 | 0.4725 | −0.1383 | 0.8901 | 0.4976 | −0.2765 | 0.7822 | 0.4952 |
| ITL/USD | −0.0647 | 0.9485 | 0.499 | −1.6834 | 0.0926 * | 0.4728 | −0.1293 | 0.8971 | 0.4979 | −0.0647 | 0.9485 | 0.499 |
| JPY/USD | 1.732 | 0.0836 * | 0.5277 | 1.8608 | 0.0631 * | 0.5298 | 2.3122 | 0.021 ** | 0.537 | 1.9252 | 0.0545 * | 0.5308 |
| SEK/USD | 1.9896 | 0.0469 ** | 0.5318 | 1.732 | 0.0836 * | 0.5277 | 2.1186 | 0.0344 ** | 0.5339 | 1.9896 | 0.0469 ** | 0.5318 |
| XGBoost Regression | XGBoost Classification | |||||
|---|---|---|---|---|---|---|
| Currency pair | DM | p-value | Theil Ratio | DM | p-value | CE |
| PTE/USD | −0.664 | 0.5069 | 0.9939 | −2.4682 | 0.0139 ** | 0.5503 |
| AUD/USD | 0.5155 | 0.6063 | 1.0032 | −1.0254 | 0.3054 | 0.5164 |
| CAN/USD | 0.5155 | 0.6063 | 1.0032 | −1.0254 | 0.3054 | 0.5164 |
| CHF/USD | 0.5155 | 0.6063 | 1.0032 | −1.0254 | 0.3054 | 0.5164 |
| DEM/USD | 1.1951 | 0.2323 | 1.0062 | −1.0998 | 0.2717 | 0.5178 |
| DNK/USD | 0.9425 | 0.3462 | 1.006 | −1.7333 | 0.0834 * | 0.5288 |
| FRF/USD | 1.4999 | 0.134 | 1.0099 | −1.1762 | 0.2399 | 0.5203 |
| ITL/USD | 1.1951 | 0.2323 | 1.0062 | −1.0998 | 0.2717 | 0.5178 |
| JPY/USD | 0.5155 | 0.6063 | 1.0032 | −1.0254 | 0.3054 | 0.5164 |
| SEK/USD | 0.5155 | 0.6063 | 1.0032 | −1.0254 | 0.3054 | 0.5164 |
| ANN Regression | ANN Classification | |||||
| Currency pair | DM | p-value | Theil Ratio | DM | p-value | CE |
| PTE/USD | 1.6533 | 0.0988 * | 1.0365 | 0.0000 | 1.0000 | 0.5000 |
| AUD/USD | 0.7242 | 0.4691 | 1.0174 | −3.5455 | 0.0004 *** | 0.4435 |
| CAN/USD | 0.2173 | 0.828 | 1.0104 | −2.1831 | 0.0293 ** | 0.4651 |
| CHF/USD | 0.8895 | 0.3739 | 1.0139 | −3.2196 | 0.0013 ** | 0.4487 |
| DEM/USD | 4.0828 | 0.0000 *** | 1.0302 | 0.0000 | 1.0000 | 0.5000 |
| DNK/USD | 1.2517 | 0.211 | 1.0219 | −2.4037 | 0.0164 ** | 0.4601 |
| FRF/USD | 5.234 | 0.0000 *** | 1.0734 | 0.0691 | 0.9449 | 0.5012 |
| ITL/USD | 4.3449 | 0.0000 *** | 1.0398 | −0.1293 | 0.8971 | 0.4979 |
| JPY/USD | −0.4738 | 0.6357 | 1.0067 | −3.415 | 0.0007 *** | 0.4456 |
| SEK/USD | −0.3102 | 0.7565 | 1.0019 | −3.7416 | 0.0002 *** | 0.4405 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pfahler, J.F. Exchange Rate Forecasting with Advanced Machine Learning Methods. J. Risk Financial Manag. 2022, 15, 2. https://doi.org/10.3390/jrfm15010002
Pfahler JF. Exchange Rate Forecasting with Advanced Machine Learning Methods. Journal of Risk and Financial Management. 2022; 15(1):2. https://doi.org/10.3390/jrfm15010002
Chicago/Turabian StylePfahler, Jonathan Felix. 2022. "Exchange Rate Forecasting with Advanced Machine Learning Methods" Journal of Risk and Financial Management 15, no. 1: 2. https://doi.org/10.3390/jrfm15010002
APA StylePfahler, J. F. (2022). Exchange Rate Forecasting with Advanced Machine Learning Methods. Journal of Risk and Financial Management, 15(1), 2. https://doi.org/10.3390/jrfm15010002