
Forecasting High-Dimensional Financial Functional Time Series: An Application to Constituent Stocks in Dow Jones Index



Abstract
:1. Introduction
2. Methodology
2.1. Data Conversion
2.2. Model
2.3. Interpretation
2.4. Estimation
3. Forecasting Method
3.1. Point Forecasts
3.1.1. Matrix-Valued Factor Model
3.1.2. Twofold Dimensional Reduction Model
- Eigen analysis is performed on the estimated long-run covariance functions to reduce dimensions of functions into a finite number of principal components p(dynamic FPCA);
- The p principal components from N functional time series are organized into p vectors of length N. p Factor models is applied separately to these vectors of the principal component scores to further reduce the dimensions of the functional time series N into r so that we have factors.
- Univariate time series model is fitted to each factor to produce forecasts of factors before constructing point forecasts of functions.
3.1.3. Univariate Functional Time Series Model
3.2. Interval Forecasts
4. Measure Forecast Accuracy
4.1. Point Forecast Accuracy Evaluation
4.2. Interval Forecast Accuracy Evaluation
5. Empirical Results
5.1. Data
5.2. Forecast Evaluation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| DJIA | Dow Jones Industrial Average |
| FPCA | Functional Principal Component Analysis |
| HDFTS | High-Dimensional Functional Time Series |
| MFMTS | Matrix Factor Model for Matrix-Valued Time Series |
| UFTS | Univariate Functional Time Series |
| 1 | This paper focuses on normal trading period, and thus, we exclude the more volatile sample that might be affected by the COVID-19 pandemic. |
References
- Aue, Alexander, Diogo Dubart Norinho, and Siegfried Hörmann. 2015. On the prediction of stationary functional time series. Journal of the American Statistical Association 110: 378–92. [Google Scholar] [CrossRef] [Green Version]
- Berrendero, José Ramón, Ana Justel, and Marcela Svarc. 2011. Principal components for multivariate functional data. Computational Statistics & Data Analysis 55: 2619–34. [Google Scholar]
- Bühlmann, Peter, and Sara Van De Geer. 2011. Statistics for High-Dimensional Data: Methods, Theory and Applications. Berlin: Springer Science & Business Media. [Google Scholar]
- Cai, Tony, and Xiaotong Chen. 2010. High-Dimensional Data Analysis. Beijing: Higher Education Press. [Google Scholar]
- Cardot, Hervé. 2000. Nonparametric estimation of smoothed principal components analysis of sampled noisy functions. Journal of Nonparametric Statistics 12: 503–38. [Google Scholar] [CrossRef]
- Chiou, Jeng-Min, Yu-Ting Chen, and Ya-Fang Yang. 2014. Multivariate functional principal component analysis: A normalization approach. Statistica Sinica 24: 1571–96. [Google Scholar] [CrossRef] [Green Version]
- Chiou, Jeng-Min, and Hans-Georg Müller. 2009. Modeling hazard rates as functional data for the analysis of cohort lifetables and mortality forecasting. Journal of the American Statistical Association 104: 572–85. [Google Scholar] [CrossRef] [Green Version]
- Ferraty, Frédéric, and Philippe Vieu. 2006. Nonparametric Functional Data Analysis: Theory and Practice. Berlin: Springer Science & Business Media. [Google Scholar]
- Gabrys, Robertas, Lajos Horváth, and Piotr Kokoszka. 2010. Tests for error correlation in the functional linear model. Journal of the American Statistical Association 105: 1113–25. [Google Scholar] [CrossRef]
- Gao, Yuan, Han Lin Shang, and Yanrong Yang. 2019. High-dimensional functional time series forecasting: An application to age-specific mortality rates. Journal of Multivariate Analysis 170: 232–43. [Google Scholar] [CrossRef] [Green Version]
- Gneiting, Tilmann, and Adrian E. Raftery. 2007. Strictly proper scoring rules, prediction, and estimation. Journal of the American Statistical Association 102: 359–78. [Google Scholar] [CrossRef]
- Hays, Spencer, Haipeng Shen, and Jianhua Z. Huang. 2012. Functional dynamic factor models with application to yield curve forecasting. The Annals of Applied Statistics 6: 870–94. [Google Scholar] [CrossRef]
- Hörmann, Siegfried, ukasz Kidziński, and Marc Hallin. 2015. Dynamic functional principal components. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 77: 319–48. [Google Scholar] [CrossRef]
- Hörmann, Siegfried, and Piotr Kokoszka. 2012. Functional time series. In Handbook of Statistics. Edited by Tata Subba Rao, Suhasini Subba Rao and Calyampudi Radhakrishna Rao. Amsterdam: Elsevier, vol. 30, pp. 157–86. [Google Scholar]
- Horváth, Lajos, and Piotr Kokoszka. 2012. Inference For Functional Data with Applications. New York: Springer Science & Business Media. [Google Scholar]
- Hyndman, Rob J., and Han Lin Shang. 2009. Forecasting functional time series. Journal of the Korean Statistical Society 38: 199–211. [Google Scholar] [CrossRef]
- Hyndman, Rob J., and Han Lin Shang. 2010. Rainbow plots, bagplots, and boxplots for functional data. Journal of Computational and Graphical Statistics 19: 29–45. [Google Scholar] [CrossRef] [Green Version]
- Jungbacker, Borus, Siem Jan Koopman, and Michel Van Der Wel. 2014. Smooth dynamic factor analysis with application to the US term structure of interest rates. Journal of Applied Econometrics 29: 65–90. [Google Scholar] [CrossRef]
- Kokoszka, Piotr, Hong Miao, and Xi Zhang. 2015. Functional dynamic factor model for intraday price curves. Journal of Financial Econometrics 13: 456–77. [Google Scholar] [CrossRef] [Green Version]
- Kokoszka, Piotr, and Matthew Reimherr. 2017. Introduction to Functional Data Analysis. Cleveland: CRC press. [Google Scholar]
- Lam, Clifford, and Qiwei Yao. 2012. Factor modeling for high-dimensional time series: Inference for the number of factors. The Annals of Statistics 40: 694–726. [Google Scholar] [CrossRef] [Green Version]
- Lam, Clifford, Qiwei Yao, and Neil Bathia. 2011. Estimation of latent factors for high-dimensional time series. Biometrika 98: 901–18. [Google Scholar] [CrossRef]
- Liebl, Dominik. 2013. Modeling and forecasting electricity spot prices: A functional data perspective. The Annals of Applied Statistics 7: 1562–92. [Google Scholar] [CrossRef] [Green Version]
- Liu, Xialu, and Rong Chen. 2016. Regime-switching factor models for high-dimensional time series. Statistica Sinica 26: 1427–51. [Google Scholar] [CrossRef]
- Martínez-Hernández, Israel, Jesús Gonzalo, and Graciela González-Farías. 2020. Nonparametric estimation of functional dynamic factor model. arXiv arXiv:2011.01831. [Google Scholar]
- Pan, Jiazhu, and Qiwei Yao. 2008. Modelling multiple time series via common factors. Biometrika 95: 365–79. [Google Scholar] [CrossRef] [Green Version]
- Panaretos, Victor M., and Shahin Tavakoli. 2013. Cramér–karhunen–loève representation and harmonic principal component analysis of functional time series. Stochastic Processes and their Applications 123: 2779–807. [Google Scholar] [CrossRef]
- Ramsay, James O., and Bernard W. Silverman. 2006. Functional Data Analysis. New York: Springer Science & Business Media. [Google Scholar]
- Rice, Gregory, and Han Lin Shang. 2017. A plug-in bandwidth selection procedure for long-run covariance estimation with stationary functional time series. Journal of Time Series Analysis 38: 591–609. [Google Scholar] [CrossRef] [Green Version]
- Shang, Han Lin. 2017. Forecasting intraday s&p 500 index returns: A functional time series approach. Journal of Forecasting 36: 741–55. [Google Scholar]
- Shang, Han Lin. 2018. Bootstrap methods for stationary functional time series. Statistics and Computing 28: 1–10. [Google Scholar] [CrossRef] [Green Version]
- Shang, Han Lin, Yang Yang, and Fearghal Kearney. 2019. Intraday forecasts of a volatility index: Functional time series methods with dynamic updating. Annals of Operations Research 282: 331–54. [Google Scholar] [CrossRef] [Green Version]
- Wang, Dong, Xialu Liu, and Rong Chen. 2019. Factor models for matrix-valued high-dimensional time series. Journal of Econometrics 208: 231–48. [Google Scholar] [CrossRef] [Green Version]
- Wang, Jane-Ling, Jeng-Min Chiou, and Hans-Georg Müller. 2016. Functional data analysis. Annual Review of Statistics and Its Application 3: 257–95. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Jin-Ting, and Jianwei Chen. 2007. Statistical inferences for functional data. The Annals of Statistics 35: 1052–79. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Xiaoke, and Jane-Ling Wang. 2016. From sparse to dense functional data and beyond. The Annals of Statistics 44: 2281–321. [Google Scholar] [CrossRef]
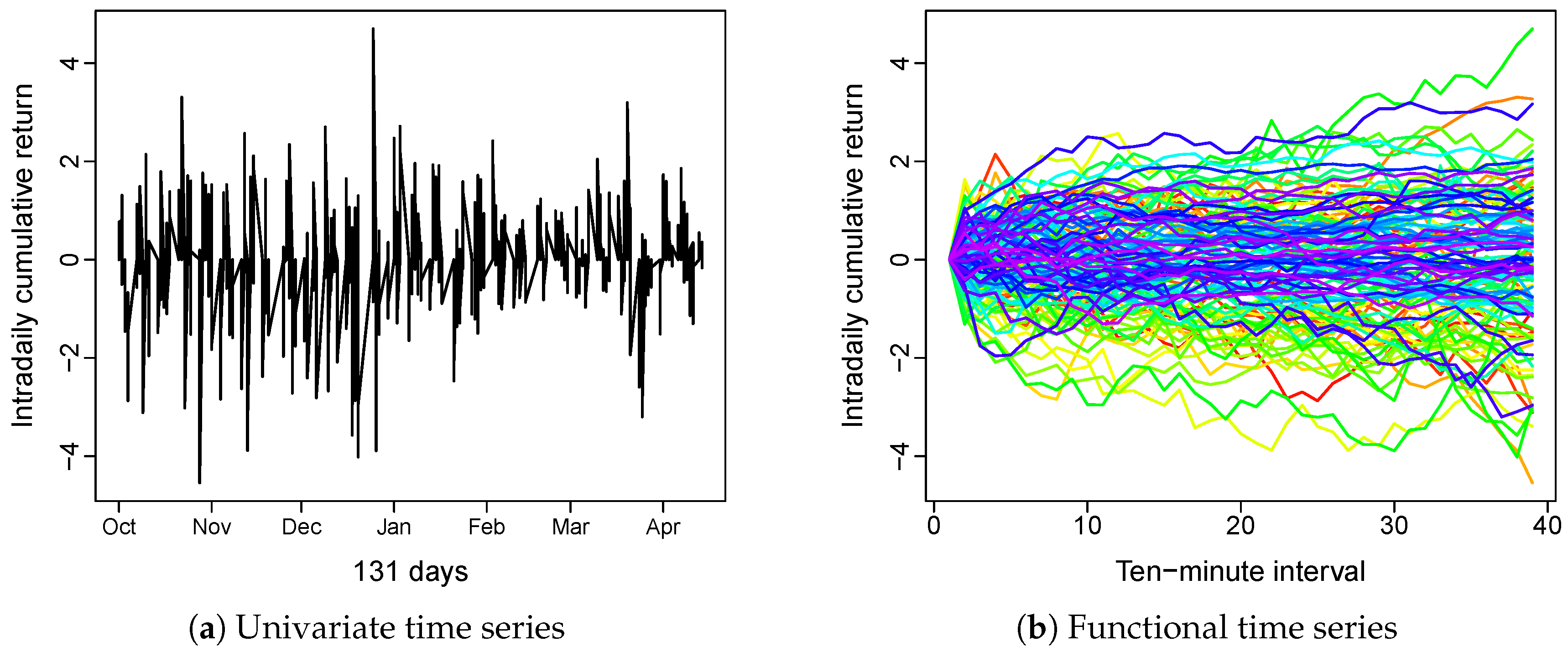

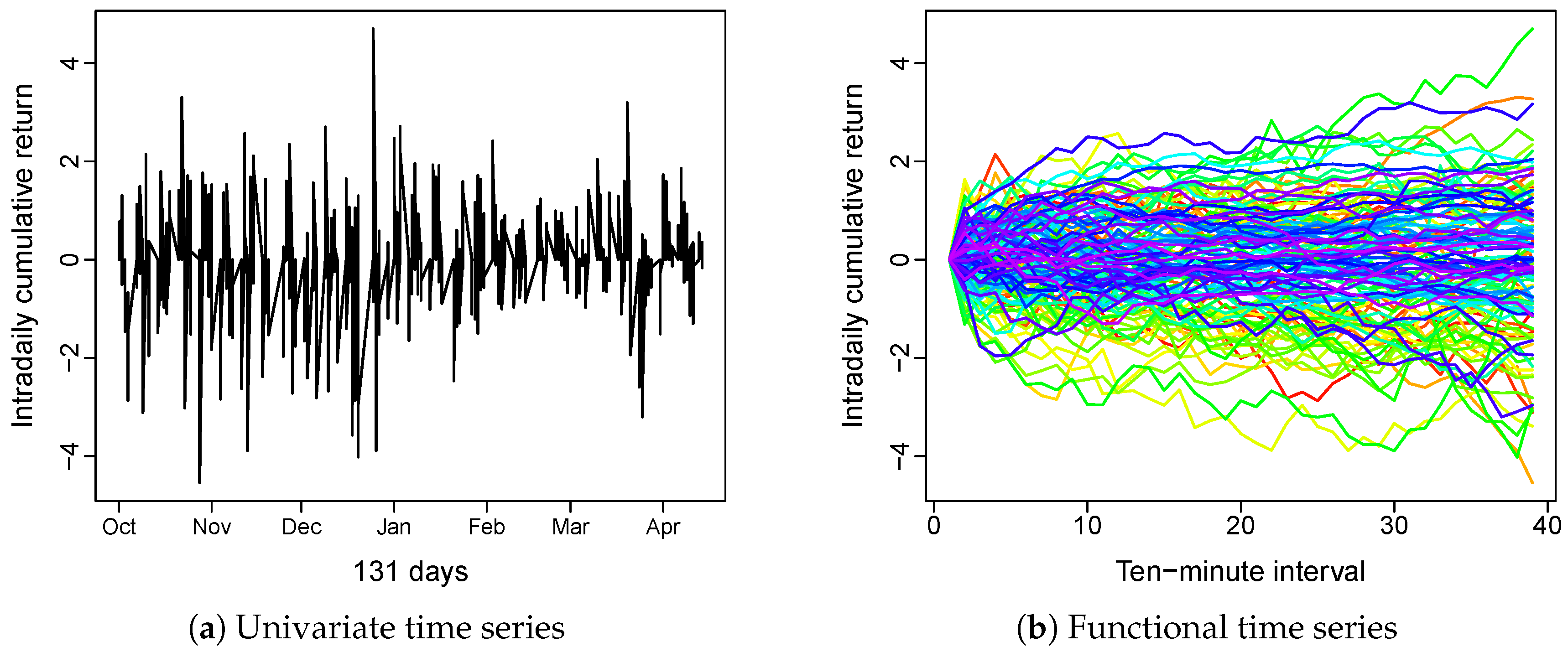{kind=link}
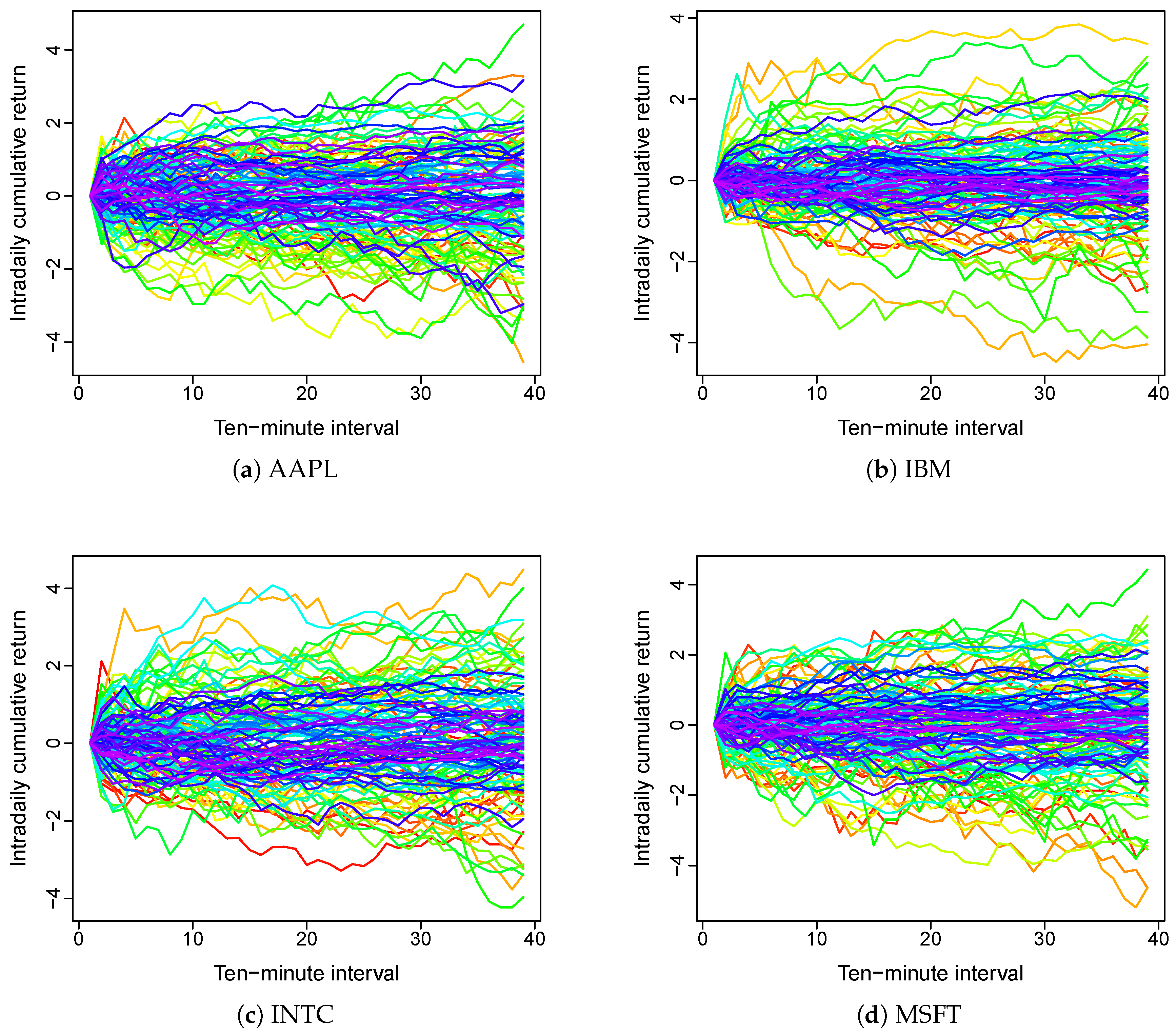
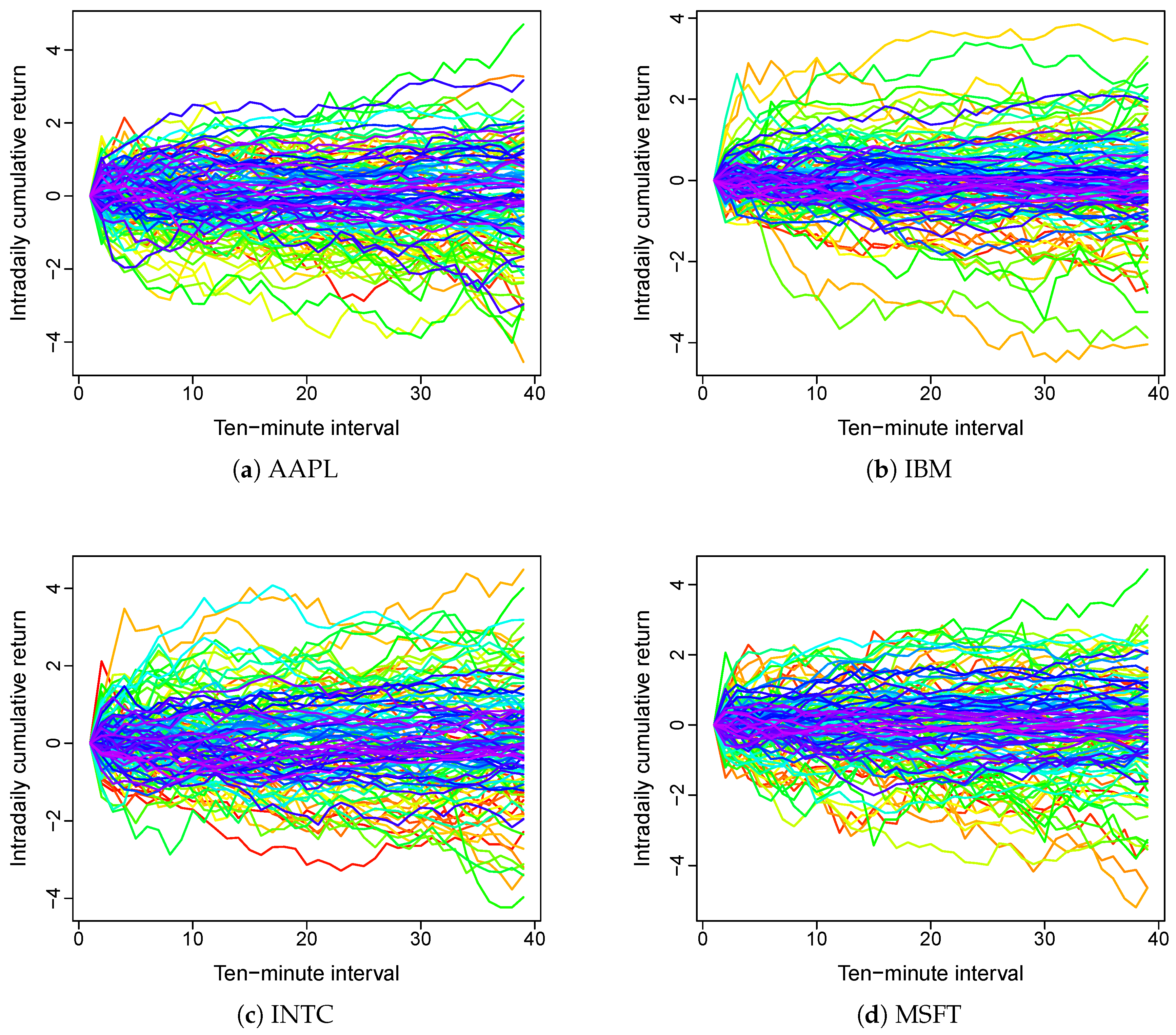{kind=link}
| Company Name | Symbol |
|---|---|
| Apple Inc. | AAPL |
| American Express | AXP |
| The Boeing Company | BA |
| Caterpillar Inc. | CAT |
| Cisco Systems, Inc. | CSCO |
| Chevron Corporation | CVX |
| The Walt Disney Company | DIS |
| The Goldman Sachs Group, Inc. | GS |
| The Home Depot, Inc. | HD |
| International Business Machines Corporation | IBM |
| Intel Corporation | INTC |
| Johnson & Johnson | JNJ |
| JPMorgan Chase & Co. | JPM |
| The Coca-Cola Company | KO |
| McDonald’s Corporation | MCD |
| 3M Company | MMM |
| Merck & Co., Inc. | MRK |
| Microsoft Corporation | MSFT |
| NIKE, Inc. | NKE |
| Pfizer Inc. | PFE |
| The Procter & Gamble Company | PG |
| The Travelers Companies, Inc. | TRV |
| UnitedHealth Group Incorporated | UNH |
| United Technologies Corporation | UTX |
| Visa Inc. | V |
| Verizon Communications Inc. | VZ |
| Walgreens Boots Alliance, Inc. | WBA |
| Walmart Inc. | WMT |
| Exxon Mobil Corporation | XOM |
| Averaged RMSFE | Averaged Interval Score | |||||
|---|---|---|---|---|---|---|
| h | UFTS | HDFTS | MFMTS | UFTS | HDFTS | MFMTS |
| 1 | 0.7570 | 0.7502 | 0.7312 | 2.5381 | 2.5489 | 2.5296 |
| 2 | 0.7535 | 0.7483 | 0.7283 | 2.8369 | 2.8199 | 2.7830 |
| 3 | 0.7541 | 0.7452 | 0.7305 | 3.1635 | 3.1614 | 3.1495 |
| 4 | 0.7702 | 0.7581 | 0.7421 | 3.2891 | 3.2150 | 3.2054 |
| 5 | 0.7579 | 0.7500 | 0.7330 | 2.3043 | 2.3278 | 2.2883 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, C.; Shi, Y. Forecasting High-Dimensional Financial Functional Time Series: An Application to Constituent Stocks in Dow Jones Index. J. Risk Financial Manag. 2021, 14, 343. https://doi.org/10.3390/jrfm14080343
Tang C, Shi Y. Forecasting High-Dimensional Financial Functional Time Series: An Application to Constituent Stocks in Dow Jones Index. Journal of Risk and Financial Management. 2021; 14(8):343. https://doi.org/10.3390/jrfm14080343
Chicago/Turabian StyleTang, Chen, and Yanlin Shi. 2021. "Forecasting High-Dimensional Financial Functional Time Series: An Application to Constituent Stocks in Dow Jones Index" Journal of Risk and Financial Management 14, no. 8: 343. https://doi.org/10.3390/jrfm14080343
APA StyleTang, C., & Shi, Y. (2021). Forecasting High-Dimensional Financial Functional Time Series: An Application to Constituent Stocks in Dow Jones Index. Journal of Risk and Financial Management, 14(8), 343. https://doi.org/10.3390/jrfm14080343