Abstract
In this paper we introduce a deep learning method for pricing and hedging American-style options. It first computes a candidate optimal stopping policy. From there it derives a lower bound for the price. Then it calculates an upper bound, a point estimate and confidence intervals. Finally, it constructs an approximate dynamic hedging strategy. We test the approach on different specifications of a Bermudan max-call option. In all cases it produces highly accurate prices and dynamic hedging strategies with small replication errors.
1. Introduction
Early exercise options are notoriously difficult to value. For up to three underlying risk factors, tree based and classical PDE approximation methods usually yield good numerical results; see, e.g., Forsyth and Vetzal (2002); Hull (2003); Reisinger and Witte (2012) and the references therein. To treat higher-dimensional problems, various simulation based methods have been developed; see, e.g., Tilley (1993); Barraquand and Martineau (1995); Carriere (1996); Andersen (2000); Longstaff and Schwartz (2001); Tsitsiklis and Van Roy (2001); García (2003); Broadie and Glasserman (2004); Bally et al. (2005); Kolodko and Schoenmakers (2006); Egloff et al. (2007); Broadie and Cao (2008); Berridge and Schumacher (2008); Jain and Oosterlee (2015). Haugh and Kogan (2004) as well as Kohler et al. (2010) have already used shallow1 neural networks to estimate continuation values. More recently, in Sirignano and Spiliopoulos (2018) optimal stopping problems in continuous time have been solved by approximating the solutions of the corresponding free boundary PDEs with deep neural networks. In Becker et al. (2019a, 2019b), deep learning has been used to directly learn optimal stopping strategies. The main focus of these papers is to derive optimal stopping rules and accurate price estimates.
The goal of this article is to develop a deep learning method which learns the optimal exercise behavior, prices and hedging strategies from samples of the underlying risk factors. It first learns a candidate optimal stopping strategy by regressing continuation values on multilayer neural networks. Employing the learned stopping strategy on a new set of Monte Carlo samples gives a low-biased estimate of the price. Moreover, the candidate optimal stopping strategy can be used to construct an approximate solution to the dual martingale problem introduced by Rogers (2002) and Haugh and Kogan (2004), yielding a high-biased estimate and confidence intervals for the price. In the last step, our method learns a dynamic hedging strategy in the spirit of Han et al. (2018) and Buehler et al. (2019). However, here, the continuation value approximations learned during the construction of the optimal stopping strategy can be used to break the hedging problem down into a sequence of smaller problems that learn the hedging portfolio only from one possible exercise date to the next. Alternative ways of computing hedging strategies consist in calculating sensitivities of option prices (see, e.g., Bally et al. 2005; Bouchard and Warin 2012; Jain and Oosterlee 2015) or approximating a solution to the dual martingale problem (see, e.g., Rogers 2002, 2010).
Our work is related to the preprints Lapeyre and Lelong (2019) and Chen and Wan (2019). Lapeyre and Lelong (2019) also use neural network regression to estimate continuation values. However, the networks are slightly different. While they work with leaky ReLU activation functions, we use tanh activation. Moreover, Lapeyre and Lelong (2019) study the convergence of the pricing algorithm as the number of simulations and the size of the network go to infinity, whereas we calculate a posteriori guarantees for the prices and use the estimated continuation value functions to implement efficient hedging strategies. Chen and Wan (2019) propose an alternative way of calculating prices and hedging strategies for American-style options by solving BSDEs.
The rest of the paper is organized as follows. In Section 2 we describe our neural network version of the Longstaff–Schwartz algorithm to estimate continuation values and construct a candidate optimal stopping strategy. In Section 3 the latter is used to derive lower and upper bounds as well as confidence intervals for the price. Section 4 discusses two different ways of computing dynamic hedging strategies. In Section 5 the results of the paper are applied to price and hedge a Bermudan call option on the maximum of different underlying assets. Section 6 concludes.
2. Calculating a Candidate Optimal Stopping Strategy
We consider an American-style option that can be exercised at any one of finitely2 many times . If exercised at time , it yields a discounted payoff given by a square-integrable random variable defined on a filtered probability space . We assume that describes the information available at time and is of the form for a measurable function and a d-dimensional -Markov process3 . We assume to be deterministic and to be the pricing measure. So that the value of the option at time 0 is given by
where is the set of all -stopping times . If the option has not been exercised before time , its discounted value at that time is
where is the set of all -stopping times satisfying .
Obviously, is optimal for . From there, one can recursively construct the stopping times
Clearly, belongs to , and it can be checked inductively that
In particular, is an optimizer of (1).
Recursion (2) is the theoretical basis of the Longstaff and Schwartz (2001) method. Its main computational challenge is the approximation of the conditional expectations . It is well known that is of the form , where minimizes the mean squared distance over all Borel measurable functions from to ; see, e.g., Bru and Heinich (1985). The Longstaff–Schwartz algorithm approximates by projecting on the linear span of finitely many basis functions. However, it is also possible to project on a different subset. If the subset is given by for a function family parametrized by , one can apply the following variant4 of the Longstaff–Schwartz algorithm:
- (i)
- Simulate5 paths , , of the underlying process .
- (ii)
- Set for all k.
- (iii)
- For , approximate with by minimizing the sum
- (iv)
- Set
- (v)
- Define , and set constantly equal to .
In this paper we specify as a feedforward neural network, which in general, is of the form
where
- denotes the depth and the numbers of nodes in the different layers;
- are affine functions;
- For , is of the form for a given activation function .
The components of the parameter consist of the entries of the matrices and vectors appearing in the representation of the affine functions , . So, lives in for . To minimize (3) we choose a network with and employ a stochastic gradient descent method.
3. Pricing
3.1. Lower Bound
Once have been determined, we set and define
This defines a valid -stopping time. Therefore, is a lower bound for the optimal value V. However, typically, it is not possible to calculate the expectation exactly. Therefore, we generate simulations of based on independent sample paths6 , , of and approximate L with the Monte Carlo average
Denote by the quantile of the standard normal distribution and consider the sample standard deviation
Then one obtains from the central limit theorem that
is an asymptotically valid confidence interval for L.
3.2. Upper Bound, Point Estimate and Confidence Intervals
Our derivation of an upper bound is based on the duality results of Rogers (2002); Haugh and Kogan (2004) and Becker et al. (2019a). By Rogers (2002) and Haugh and Kogan (2004), the optimal value V can be written as
where is the martingale part of the smallest -supermartingale dominating the payoff process . We approximate with the -martingale obtained from the stopping decisions implied by the trained continuation value functions , , as in Section 3.2 of Becker et al. (2019a). We know from Proposition 7 of Becker et al. (2019a) that if is a sequence of integrable random variables satisfying for all , then
is an upper bound for V. As in Becker et al. (2019a), we use nested simulation7 to generate realizations of along independent realizations , , of sampled independently of , , and estimate U as
Our point estimate of V is
The sample standard deviation of the estimator , given by
can be used together with the one-sided confidence interval (5) to construct the asymptotically valid two-sided confidence interval
for the true value V; see Section 3.3 of Becker et al. (2019a).
4. Hedging
We now consider a savings account together with financial securities as hedging instruments. We fix a positive integer M and introduce a time grid such that for all . We suppose that the information available at time is described by , where is a filtration satisfying for all n. If any of the financial securities pay dividends, they are immediately reinvested. We assume that the resulting discounted8 value processes are of the form for measurable functions and an -Markov process9 such that for all . A hedging strategy consists of a sequence of functions specifying the time- holdings in . As usual, money is dynamically deposited in or borrowed from the savings account to make the strategy self-financing. The resulting discounted gains at time are given by
4.1. Hedging Until the First Possible Exercise Date
For a typical Bermudan option, the time between two possible exercise dates might range between a week and several months. In case of an American option, we choose for a small amount of time such as a day. We assume does not stop at time 0. Otherwise, there is nothing to hedge. In a first step, we only compute the hedge until time . If the option is still alive at time , the hedge can then be computed until time and so on. To construct a hedge from time 0 to , we approximate the time- value of the option with for the function , where is the time- continuation value function estimated in Section 2. Then we search for hedging positions , , that minimize the mean squared error
To do that we approximate the functions with neural networks of the form (4) and try to find parameters that minimize
for independent realizations of , of . We train the networks together, again using a stochastic gradient descent method. Instead of (7), one could also minimize a different deviation measure. However, (7) has the advantage that it yields hedging strategies with an average hedging error close to zero10.
Once have been determined, we assess the quality of the hedge by simulating new11 independent realizations , of and calculating the average hedging error
and the empirical hedging shortfall
over the time interval .
4.2. Hedging Until the Exercise Time
Alternatively, one can precompute the whole hedging strategy from time 0 to T and then use it until the option is exercised. In order to do that we introduce the functions
and hedge the difference on each of the time intervals , , separately. describes the approximate value of the option at time if it has not been exercised before, and the definition of takes into account that the true continuation values are non-negative due to the non-negativity of the payoff function g. The hedging strategy can be computed as in Section 4.1, except that we now have to simulate complete paths of , , and then for all , find parameters which minimize
Once the hedging strategy has been trained, we simulate independent samples , , of and denote the realization of along each sample path by . The corresponding average hedging error is given by
and the empirical hedging shortfall by
5. Example
In this section we study12 a Bermudan max-call option13 on d financial securities with risk-neutral price dynamics
for a risk-free interest rate , initial values , dividend yields , volatilities and a d-dimensional Brownian motion W with constant instantaneous correlations14 between different components and . The option has time-t payoff for a strike price and can be exercised at one of finitely many times . In addition, we suppose there is a savings account where money can be deposited and borrowed at rate r.
For notational simplicity, we assume in the following that for , and all assets have the same15 characteristics; that is, , and for all .
5.1. Pricing Results
Let us denote , . Then the price of the option is given by
where the supremum is over all stopping times with respect to the filtration generated by . The option payoff does not carry any information not already contained in . However, the training of the continuation values worked more efficiently when we used it as an additional feature. So instead of we simulated the extended state process for
to train the continuation value functions , . The network was chosen of the form (4) with depth (two hidden layers), nodes in each hidden layer and activation function . For training we used stochastic gradient descent with mini-batches of size 8192 and batch normalization (Ioffe and Szegedy 2015). At time we used Xavier (Glorot and Bengio 2010) initialization and performed 6000 Adam (Kingma and Ba 2015) updating steps16. For , we started the gradient descent from the trained network parameters and made 3500 Adam updating steps. To calculate we simulated 4,096,000 paths of . For we generated 2048 outer and 2048 × 2048 inner simulations.
Our results for , , and 95% confidence intervals for different specifications of the model parameters are reported in Table 1. To achieve a pricing accuracy comparable to the more direct methods of Becker et al. (2019a, 2019b), the networks used in the construction of the candidate optimal stopping strategy had to be trained for a longer time. But in exchange, the approach yields approximate continuation values that can be used to break down the hedging problem into a series of smaller problems.

Table 1.
Price estimates for max-call options on 5 and 10 symmetric assets for parameter values of , , , , , , . is the number of seconds it took to train and compute . is the computation time for in seconds. 95% CI is the 95% confidence interval (6). The last column lists the 95% confidence intervals computed in Becker et al. (2019a).
5.2. Hedging Results
Suppose the hedging portfolio can be rebalanced at the times , , for a positive integer M. We assume dividends paid by shares of held in the hedging portfolio are continuously reinvested in . This results in the adjusted discounted security prices
We set . To learn the hedging strategy, we trained neural networks , , of the form (4) with depth (two hidden layers), nodes in each hidden layer and activation function . As in Section 5.1, we used stochastic gradient descent with mini-batches of size 8192 and batch normalization (Ioffe and Szegedy 2015). For , we initialized the networks according to Xavier (Glorot and Bengio 2010) and performed 10,000 Adam (Kingma and Ba 2015) updating steps, whereas for , we started the gradient trajectories from the trained network parameters and made 3000 Adam updating steps.
Table 2 reports the average hedging errors (8) and (10) together with the empirical hedging shortfalls (9) and (11) for different numbers M of rebalancing times between two consecutive exercise dates and . They were computed using 4,096,000 simulations of .
Table 2.
Average hedging errors and empirical hedging shortfalls for 5 and 10 underlying assets and different numbers M of rehedging times between consecutive exercise times and . The values of the parameters r, , , , K, T and N were chosen as in Table 1. IHE is the intermediate average hedging error (8), IHS the intermediate hedging shortfall (9), HE the total average hedging error (10) and HS the total hedging shortfall (11). is our price estimate from Table 1. T1 is the computation time in seconds for training the hedging strategy from time 0 to . T2 is the number of seconds it took to train the complete hedging strategy from time 0 to T.
Figure 1 shows histograms of the total hedging errors
for and .
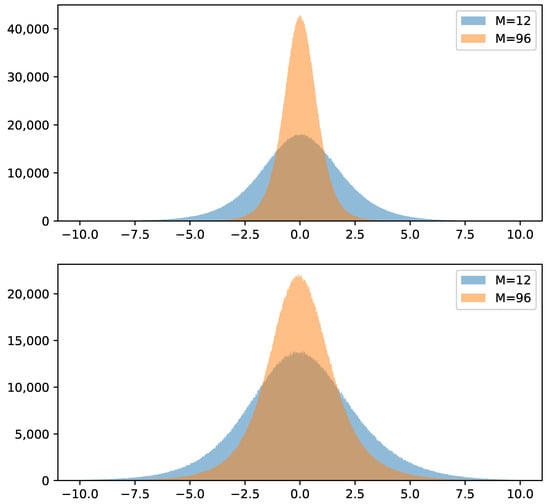
6. Conclusions
In this article, we used deep learning to price and hedge American-style options. In a first step our method employs a neural network version of the Longstaff–Schwartz algorithm to estimate continuation values and derive a candidate optimal stopping rule. The learned stopping rule immediately yields a low-biased estimate of the price. In addition, it can be used to construct an approximate solution of the dual martingale problem of Rogers (2002) and Haugh and Kogan (2004). This gives a high-biased estimate and confidence intervals for the price. To achieve the same pricing accuracy as the more direct approaches of Becker et al. (2019a, 2019b), we had to train the neural network approximations of the continuation values for a longer time. However, computing approximate continuation values has the advantage that they can be used to break the hedging problem into a sequence of subproblems that compute the hedge only from one possible exercise date to the next.
Author Contributions
S.B., P.C. and A.J. have contributed equally to this work. All authors have read and agreed to the published version of the manuscript.
Funding
A.J. acknowledges support from the DFG through Germany’s Excellence Strategy EXC 2044-390685587, Mathematics Münster: Dynamics - Geometry - Structure.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Andersen, Leif. 2000. A simple approach to the pricing of Bermudan swaptions in the multifactor LIBOR market model. The Journal of Computational Finance 3: 5–32. [Google Scholar] [CrossRef]
- Bally, Vlad, Gilles Pagès, and Jacques Printems. 2005. A quantization tree method for pricing and hedging multidimensional American options. Mathematical Finance 15: 119–68. [Google Scholar] [CrossRef]
- Barraquand, Jérôme, and Didier Martineau. 1995. Numerical valuation of high dimensional multivariate American securities. The Journal of Financial and Quantitative Analysis 30: 383–405. [Google Scholar] [CrossRef]
- Becker, Sebastian, Patrick Cheridito, and Arnulf Jentzen. 2019a. Deep optimal stopping. Journal of Machine Learning Research 20: 1–25. [Google Scholar]
- Becker, Sebastian, Patrick Cheridito, Arnulf Jentzen, and Timo Welti. 2019b. Solving high-dimensional optimal stopping problems using deep learning. arXiv arXiv:1908.01602. [Google Scholar]
- Berridge, Steffan J., and Johannes M. Schumacher. 2008. An irregular grid approach for pricing high-dimensional American options. Journal of Computational and Applied Mathematics 222: 94–111. [Google Scholar] [CrossRef]
- Bouchard, Bruno, and Xavier Warin. 2012. Monte-Carlo valuation of American options: Facts and new algorithms to improve existing methods. In Numerical Methods in Finance. Berlin and Heidelberg: Springer, pp. 215–255. [Google Scholar]
- Broadie, Mark, and Menghui Cao. 2008. Improved lower and upper bound algorithms for pricing American options by simulation. Quantitative Finance 8: 845–61. [Google Scholar] [CrossRef]
- Broadie, Mark, and Paul Glasserman. 2004. A stochastic mesh method for pricing high-dimensional American options. Journal of Computational Finance 7: 35–72. [Google Scholar] [CrossRef]
- Bru, Bernard, and Henri Heinich. 1985. Meilleures approximations et médianes conditionnelles. Annales de l’I.H.P. Probabilités et Statistiques 21: 197–224. [Google Scholar]
- Buehler, Hans, Lukas Gonon, Josef Teichmann, and Ben Wood. 2019. Deep hedging. Quantitative Finance 19: 1271–91. [Google Scholar] [CrossRef]
- Carriere, Jacques F. 1996. Valuation of the early-exercise price for options using simulations and nonparametric regression. Insurance: Mathematics and Economics 19: 19–30. [Google Scholar] [CrossRef]
- Chen, Yangang, and Justin W.L. Wan. 2019. Deep neural network framework based on backward stochastic differential equations for pricing and hedging American options in high dimensions. arXiv arXiv:1909.11532. [Google Scholar]
- Egloff, Daniel, Michael Kohler, and Nebojsa Todorovic. 2007. A dynamic look-ahead Monte Carlo algorithm for pricing Bermudan options. Annals of Applied Probability 17: 1138–71. [Google Scholar] [CrossRef]
- Forsyth, Peter A., and Ken R. Vetzal. 2002. Quadratic convergence for valuing American options using a penalty method. SIAM Journal on Scientific Computing 23: 2095–122. [Google Scholar] [CrossRef]
- García, Diego. 2003. Convergence and biases of Monte Carlo estimates of American option prices using a parametric exercise rule. Journal of Economic Dynamics and Control 27: 1855–79. [Google Scholar] [CrossRef]
- Glorot, Xavier, and Yoshua Bengio. 2010. Understanding the difficulty of training deep feedforward neural networks. Paper Presented at Thirteenth International Conference on Artificial Intelligence and Statistics, PMLR, Sardinia, Italy, May 13–15, vol. 9, pp. 249–256. [Google Scholar]
- Han, Jiequn, Arnulf Jentzen, and Weinan E. 2018. Solving high-dimensional partial differential equations using deep learning. Proceedings of the National Academy of Sciences of the United States of America 115: 8505–10. [Google Scholar] [CrossRef]
- Haugh, Martin B., and Leonid Kogan. 2004. Pricing American options: a duality approach. Operations Research 52: 258–70. [Google Scholar] [CrossRef]
- Hull, John C. 2003. Options, Futures and Other Derivatives. London: Pearson. Upper Saddle River: Prentice Hall. [Google Scholar]
- Ioffe, Sergey, and Christian Szegedy. 2015. Batch normalization: accelerating deep network training by reducing internal covariate shift. Paper presented at 32nd International Conference on Machine Learning, ICML 2015, Lille, France, July 6–11, vol. 37, pp. 448–456. [Google Scholar]
- Jain, Shashi, and Cornelis W. Oosterlee. 2015. The stochastic grid bundling method: efficient pricing of Bermudan options and their Greeks. Applied Mathematics and Computation 269: 412–31. [Google Scholar] [CrossRef]
- Kingma, Diederik P., and Jimmy Ba. 2015. Adam: A method for stochastic optimization. Paper Presented at International Conference on Learning Representations, San Diego, CA, USA, May 7–9. [Google Scholar]
- Kohler, Michael, Adam Krzyżak, and Nebojsa Todorovic. 2010. Pricing of high-dimensional American options by neural networks. Mathematical Finance 20: 383–410. [Google Scholar] [CrossRef]
- Kolodko, Anastasia, and John Schoenmakers. 2006. Iterative construction of the optimal Bermudan stopping time. Finance and Stochastics 10: 27–49. [Google Scholar] [CrossRef]
- Lapeyre, Bernard, and Jérôme Lelong. 2019. Neural network regression for Bermudan option pricing. arXiv arXiv:1907.06474. [Google Scholar]
- Longstaff, Francis A., and Eduardo S. Schwartz. 2001. Valuing American options by simulation: a simple least-squares approach. The Review of Financial Studies 14: 113–47. [Google Scholar] [CrossRef]
- Reisinger, Christoph, and Jan H. Witte. 2012. On the use of policy iteration as an easy way of pricing American options. SIAM J. Financial Math. 3: 459–78. [Google Scholar] [CrossRef]
- Rogers, Chris. 2002. Monte Carlo valuation of American options. Mathematical Finance 12: 271–86. [Google Scholar] [CrossRef]
- Rogers, Chris. 2010. Dual valuation and hedging of Bermudan options. SIAM Journal on Financial Mathematics 1: 604–8. [Google Scholar] [CrossRef]
- Sirignano, Justin, and Konstantinos Spiliopoulos. 2018. DGM: A deep learning algorithm for solving partial differential equations. Journal of Computational Physics 375: 1339–64. [Google Scholar] [CrossRef]
- Tilley, James A. 1993. Valuing American options in a path simulation model. Transactions of the Society of Actuaries 45: 83–104. [Google Scholar]
- Tsitsiklis, John N., and Benjamin Van Roy. 2001. Regression methods for pricing complex American-style options. IEEE Transactions on Neural Networks 12: 694–703. [Google Scholar] [CrossRef]
| 1. | Meaning feedforward networks with a single hidden layer. |
| 2. | This covers Bermudan options as well as American options that can only be exercised at a given time each day. Continuously exercisable options must be approximated by discretizing time. |
| 3. | That is, is -measurable, and for all and every measurable function such that is integrable. |
| 4. | The main difference between this algorithm and the one of Longstaff and Schwartz (2001) is the use of neural networks instead of linear combinations of basis functions. In addition, the sum in (3) is over all simulated paths, whereas in Longstaff and Schwartz (2001), only in-the-money paths are considered to save computational effort. While it is enough to use in-the-money paths to determine a candidate optimal stopping rule, we need accurate approximate continuation values for all to construct good hedging strategies in Section 4. |
| 5. | As usual, we simulate the paths , , independently of each other. |
| 6. | Generated independently of , |
| 7. | The use of nested simulation ensures that are unbiased estimates of , which is crucial for the validity of the upper bound. In particular, we do not directly approximate with the estimated continuation value functions . |
| 8. | Discounting is done with respect to the savings account. Then, the discounted value of money invested in the savings account stays constant. |
| 9. | That is, is -measurable and for all and every measurable function such that is integrable. |
| 10. | |
| 11. | Independent of , . |
| 12. | The computations were performed on a NVIDIA GeForce RTX 2080 Ti GPU. The underlying system was an AMD Ryzen 9 3950X CPU with 64 GB DDR4 memory running Tensorflow 2.1 on Ubuntu 19.10. |
| 13. | Bermudan max-call options are a benchmark example in the literature on numerical methods for high-dimensional American-style options; see, e.g., Longstaff and Schwartz (2001); Rogers (2002); García (2003); Broadie and Glasserman (2004); Haugh and Kogan (2004); Broadie and Cao (2008); Berridge and Schumacher (2008); Jain and Oosterlee (2015); Becker et al. (2019a, 2019b). |
| 14. | That is, for all and . |
| 15. | Simulation based methods work for any price dynamics that can efficiently be simulated. Prices of max-call options on underlying assets with different price dynamics were calculated in Broadie and Cao (2008) and Becker et al. (2019a). |
| 16. | The hyperparamters were chosen as in Kingma and Ba (2015). The stepsize was specified as , , and according to a deterministic schedule. |

© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).