Abstract
This paper compares the finite sample performance of three non-parametric threshold estimators via the Monte Carlo method. Our results indicate that the finite sample performance of the three estimators is not robust to the position of the threshold level along the distribution of the threshold variable, especially when a structural change occurs at the tail part of the distribution.
Keywords:
difference kernel estimator; integrated difference kernel estimator; M-estimation; Monte Carlo; nonparametric threshold regression JEL Classification:
C14; C21
1. Introduction
Popularly used to describe structural changes in economic relationships, threshold models have seen many applications, especially in macro fields (e.g., Hansen 2011; Potter 1995). Typical examples include the nonlinearity in public debt to GDP ratio (e.g., Afonso and Jalles 2013; Caner et al. 2010; Cecchetti et al. 2011). A number of threshold estimators for threshold models have been proposed in the literature, and the asymptotic results of these estimators can be categorized into two groups based on different assumptions. The first group is based on the “fixed threshold effect” assumption. The second group imposes a “diminishing threshold effect” assumption introduced by Hansen (2000). For example, it is well known that, for the least-squares estimator, the threshold estimator is super-consistent with the convergence rate n under the “fixed threshold effect” assumption and under the “diminishing threshold effect” assumption, respectively, where measures the diminishing rate of the threshold effect.
The asymptotic theory and statistical inference have been well developed for the least-squares estimator exogenous regressors and exogenous threshold variable (e.g., Chan 1993; Hansen 2000; Seo and Linton 2007). Recently, there has been a growing interest in studying threshold models with endogenous regressors and/or a threshold variable. Extending the framework of Hansen (2000), Caner and Hansen (2004) applied the two-step least-squares method to estimate threshold models with endogenous slope regressors. In the spirit of the sample selection technique of Heckman (1979), imposing the joint normality assumption, Kourtellos et al. (2016) explored the case that both the threshold variable and slope regressors are endogenous. The work in Seo and Shin (2016) proposed a two-step GMM estimator for a dynamic panel threshold model with fixed effects, which allows endogeneity in both the slope regressors and threshold variable. It is worth noticing that the GMM method allows both a fixed and diminishing threshold effect, and the convergence rate for the GMM threshold estimator is not super-consistent. By relaxing the joint normality assumption of Kourtellos et al. (2016, 2017), a two-step least square estimator based on a nonparametric control function approach to correct the threshold endogeneity was proposed. The semiparametric threshold model separates the threshold effect into two parts, namely the exogenous threshold effect and endogenous threshold bias-correction term. Therefore, with a “small threshold” effect, the convergence rate for the threshold variable depends on diminishing rates of the threshold effect and the bias-correction term.
However, few studies have worked on the estimation and statistical inference of threshold estimators based on nonparametric estimation methods, which do not rely on the least square method. The work in Delgado and Hidalgo (2000) suggested a difference kernel estimator (or DKE), which depends on a chosen point. The convergence rate of Delgado and Hidalgo (2000) DKE is , which depends on both the bandwidth, h, and the dimensionality of regressors in their threshold model, . Built upon the method of Delgado and Hidalgo (2000), Yu et al. (2018) introduced an integrated difference kernel estimator (or IDKE). The work in Yu et al. (2018) argued that the IDKE can be applied to the case with the endogenous threshold variable. The convergence rate of the IDKE is not related to either the bandwidth or the dimensionality of regressors and is super-consistent with the rate n. Using recently-developed discrete smoothing methods, Henderson et al. (2017) introduced a semiparametric M-estimator of a nonparametric threshold regression model. The threshold estimator of Henderson et al. (2017) can be estimated at the rate (h is the bandwidth), which is faster than the parametric convergence rate of . One may notice that the aforementioned convergence rate is the same as that of the smoothed least squares estimator in Seo and Linton (2007). However, they are entirely different. The work in Henderson et al. (2017) focussed on the nonparametric threshold model, and their proposed estimator was based on a non-smooth objective function. On the contrary, Seo and Linton (2007) worked on a linear threshold model, and the proposed estimator was based on a smooth objective function with the indicator function replaced by a CDF-type smooth function.
With many applications and simulations available for comparing the parametric threshold estimators in the literature, little guidance is available for researchers to apply as to the choice of nonparametric threshold estimators. Moreover, to avoid the boundary effect of the threshold estimator, most simulations are designed deliberately with the true threshold level chosen at the middle point of the threshold variable distribution, which can be highly doubted in reality. Therefore, the purpose of this paper is to carefully compare the three nonparametric threshold estimators mentioned above using the Monte Carlo method. More importantly, we consider the case that the true threshold level is not only at the middle, but also at the two tails of the threshold variable distribution.
The rest of the paper is organized as follows. In Section 2, we briefly review the estimation procedure of three nonparametric threshold estimators such as DKE, IDKE and the M-estimator, where threshold models have exogenous regressors and a threshold variable. In Section 3, we illustrate the possible theoretical reason for the conjecture of the poor finite sample performance of the difference kernel-type estimators. Section 4 presents the design of the Monte Carlo simulations. Section 5 reports the finite sample performance. Section 6 concludes.
2. Three Nonparametric Threshold Estimators
In this paper, we aim to compare the finite sample performance of three nonparametric threshold estimators: Henderson et al. (2017) the semiparametric M-estimator, Delgado and Hidalgo (2000) the difference kernel estimator (DKE) and Yu et al. (2018) the integrated difference kernel estimator (IDKE).
Following Henderson et al. (2017), we consider a generalized threshold regression model:
for , where is an unknown smooth function, is a vector of d regressors, is the threshold variable, is the threshold level, is the indicator function and measures the jump size of the regression function at . Furthermore, and are both exogenous and may have a common variable.
2.1. Semiparametric M-Estimator
If is known a priori, Model (1) is known as a partially linear model. The conventional method to estimate the unknown is minimizing the sum of squared errors, which can be iterated by the grid search. Therefore, Henderson et al. (2017) suggested the semi-parametric M-estimator of the nonparametric threshold model, which can be obtained in three steps.
In Step 1, given , Model (1) becomes a standard nonparametric model. Therefore, we can obtain the Nadaraya–Watson (NW) estimator of at an interior point, x, i.e.,
where , , , is a second order kernel function, h is the bandwidth and d is the dimension of x.
In Step 2, given , Model (1) becomes a partially linear model. Then, can be estimated as:
where works as the weighting function.
The work in Henderson et al. (2017) shows that has the following mathematical expression:
where we denote .
In Step 3, we can estimate the threshold level by solving the following optimization problem,
where is a weighting function and is application dependent.
As mentioned in Section 1, the convergence rate of the threshold estimator of Henderson et al. (2017) is , which explodes faster than the usual parametric rate. However, the unknown function and the jump size converge at standard nonparametric rates of and , respectively.
2.2. DKE and IDKE
Instead of using the absolute value of the weighted average of the sum of errors as the objective function, Delgado and Hidalgo (2000) considered using the difference between and as the objective function. Ideally, the closer approaches the true value, the larger the absolute value of the above difference should be. As a result, we are able to estimate the threshold level by choosing , which gives the most considerable gap between the two one-sided expectations. Therefore, the difference kernel estimator (DKE) can be obtained by:
where we have:
if is not part of , and
if is part of , i.e., , and . Furthermore, is the one-sided kernel function with:
and is a second order kernel function.
Obviously, it is reasonable to expect that the DKE estimator is sensitive to the choice of . Furthermore, the DKE suffers the curse of dimensionality problem as the convergence rate of the DKE, , depends on the dimension of the regressor. To fix these potential weaknesses, Yu et al. (2018) proposed an integrated difference kernel estimator, which allows not to rely on the single choice in , but the expectation of all X. The can be derived as follows:
where:
if is not part of , and
if is part of , i.e., , and . is defined the same as above.
The IDKE is super-consistent with convergence rate n. The work in Yu et al. (2018) showed that IDKE is consistent even if the threshold variable is endogenous. They explain that the role of the instruments of the endogenous regressors and the endogenous threshold variable is improving only the efficiency of the IDKE.
3. Estimation Difficulties in the Difference Kernel-Type Estimator with Near Boundary
In this section, we use a simple version of Model (1) to explain the estimation difficulties of the difference kernel-type estimators when lies at the tails of the threshold variable distribution. This estimation difficulty motivates us to investigate the position effect of the true threshold level on the finite sample performance. Specifically, we consider the true model as:
where is randomly drawn from a uniform distribution over the interval of for i.
The model above can be regarded as Model (1) with , , and for all . Therefore, the DKE is based on the objective function:
Letting and applying the change of variables, we have the probability limit of equal to:
where h is the bandwidth.
If , we obtain:
and:
where the positive sign follows for all for any second-order kernel function with a bell shape.
It is worth noting that as approaches from the left side, the difference between becomes smaller. As a result, for all , the above derivative goes to zero, which makes the objective function flat and leads to the estimation difficulty.
Similarly, if , we have:
and:
where the negative sign follows for all for any second-order kernel function with a bell shape.
Therefore, we observe that as approaches from the right side, for all , the difference between becomes smaller, which makes the derivative go to zero, and this results in a flat objective function.
In summary, the DKE is asymptotically consistent with . However, it is reasonable to suspect that DKE may have poor finite performance with the true threshold level lying at the tails of the threshold variable distribution due to the estimation difficulty of the flat objective function.
Next, we assume that there are additional covariates, , which are randomly drawn from uniform distribution over the interval of , for all , and and are independent. Therefore, the probability limit of the objective function of the IDKE is (with the same bandwidth):
where .
Note that:
Consequently, in this typical example, can be interpreted as a rescaled , which implies the IDKE will suffer the same boundary problem as the DKE estimator.
4. Monte Carlo Designs
To assess the finite sample performance of the three nonparametric threshold estimators, we consider seven data-generating mechanisms, which are similar to those studied in Henderson et al. (2017); Yu et al. (2018).
- DGP 1:
- DGP 2:
- DGP 3:
- DGP 4:
- DGP 5:
- DGP 6:
- DGP 7:
where is randomly drawn from a uniform distribution over the interval of for all ,1 and is randomly drawn from the distribution. All DGPs are based on the fixed threshold effect framework of Chan (1993) with both the exogenous threshold variable and exogenous regressors.
DGPs 1–4 are univariate threshold models. More specifically, DGPs 1–2 are typical linear threshold models. DGPs 3–4 are nonlinear threshold models modelling the periodicity and the quadraticity, respectively. DGPs 5–7 are multivariate threshold models. DGP 5 characterizes the multivariate linear threshold model. DGPs 6–7 are nonlinear threshold models extending DGPs 3–4 to multivariate specifications.
To examine the position effect of the true threshold level on the finite sample performance, we set at different segments of the threshold variable distribution. Specifically, we set the true threshold, , as the quantile of the threshold variable with , 50 and 75 to place the true threshold level to the left tail, middle and the right tail of the threshold variable distribution, respectively.
We set for the DKE estimate of Delgado and Hidalgo (2000), where is the data with the greatest empirical density among all generated ’s for each simulation of each DGP.2 We use the rule of thumb bandwidth, , where , d is the dimension of and is the sample standard deviation of . We use the Gaussian kernel function. As suggested by Yu et al. (2018), we use the one-sided rescaled Epanechnikov kernel with and to estimate the DKE and the IDKE.
We repeat 2000 times for each simulation.3 We set the sample size , 300 and 500. For each simulation, we report the average bias, mean squared error (or MSE) and the standard deviation (or stdev) of the threshold estimates. Table 1, Table 2, Table 3, Table 4, Table 5, Table 6 and Table 7 contain the details of the simulation results. Table 8 shows the realized convergence rate of the semi-parametric M-estimator of Henderson et al. (2017) and IDKE of Yu et al. (2018).

Table 1.
Simulation results of nonparametric threshold estimators, Data-generating Mechanism 1 (DGP 1). IDKE, integrated difference kernel estimator.
Table 2.
Simulation results of nonparametric threshold estimators, DGP 2.
Table 3.
Simulation results of nonparametric threshold estimators, DGP 3.
Table 4.
Simulation results of nonparametric threshold estimators, DGP 4.
Table 5.
Simulation results of nonparametric threshold estimators, DGP 5.
Table 6.
Simulation results of nonparametric threshold estimators, DGP 6.
Table 7.
Simulation results of nonparametric threshold estimators, DGP 7.
Table 8.
Estimated convergence rate of the nonparametric threshold estimators.
5. Monte Carlo Results
For the semi-parametric M-estimator introduced by Henderson et al. (2017), our results show that the performance was slightly affected by the position of the true threshold level. Meanwhile, as the sample size increased, this position effect gradually vanished.4 In addition, we observed that the bias was smaller for multivariate models than univariate models. Using the bandwidth as defined in Section 4, which behaved roughly as for univariate models and for multivariate models, the theoretical convergence rates were and accordingly. From Table 8, the super-consistency was confirmed with the estimated convergence rate of . Consistent with the theory, the realized convergence rate decreased as the dimension increased. It is quite interesting that, for almost all univariate models, the realized convergence rate of was faster when was at the left- and right-tail position than when was at the median position. However, for multivariate models, the realized rates seemed to be stable with the position of .
For the DKE, as we conjectured, it was severely affected by the position of the true threshold value for all DGPs, which may result from the estimation difficulties, as we argued in Section 3. Furthermore, even with the middle-positioned , the bias still showed a non-decreasing pattern with the increasing sample size under some multivariate specifications.5 Intuitively, this may result from the choice of , which distorts the result by providing useless information. According to the comment in the Supplementary Material of Yu et al. (2018), the choice of is crucial in identifying the DKE estimator. On the one hand, the optimal should make as large as possible. On the other hand, one needs the conditional density to be large enough to provide sufficient information. Therefore, theoretically, with a uniform distribution and univariate linear threshold model as in DGP2, the ideal should be at the middle of its distribution with the value of zero. However, in the simulation, we set equal to the value with the largest empirical density, which may appear at the two tails. This may lead to approaching zero. Moreover, with the multivariate and nonlinear specification, we can expect more distortion involved. As a result, the DKE performs the worst among all three competitors for all DGPs.
For the IDKE, our results reveal several features. Firstly, the IDKE was affected by the position of the actual threshold value. The influence was not as substantial as the DKE. Indeed, the integration allowed more local information to be used and alleviated the possible distortion due to the choice of . Surprisingly, unlike the DKE, this position effect seemed to be asymmetric for the IDKE. For most of the DGPs, we observed that the absolute value of the average bias and MSE was larger with the left-tailed than the right-tailed . The theoretical convergence rate of the IDKE estimator, n, is not related to either the bandwidth or the dimension, which is faster than the semi-parametric M-estimator of Henderson et al. (2017). This is consistent with our realized convergence rates, which are shown in Table 8. Moreover, for all DGPs, the realized convergence rates were faster with two-sided tailed than the median .
In summary, the simulation results give some evidence that the finite sample performances were affected by the position of the true threshold level for all three nonparametric threshold estimators. However, this effect was heterogeneous. The position effect least influenced the semi-M estimator of Henderson et al. (2017). Meanwhile, the difference kernel-type estimators were severely distorted by the tailed , which confirms our conjecture made in Section 3. Furthermore, our results show that the position of the true threshold level also affects the realized convergence rate. We also found, for the semi-M estimator of Henderson et al. (2017) and the IDKE estimator, the tail distortion tended to be reduced in multivariate models.
As a robustness check of our findings, Figure 1, Figure 2, Figure 3 and Figure 4 show the simulation results of DGP 2 and DGP 5 with taking different positions along the threshold variable distribution. It is obvious that, for all figures, semi-M had lower average bias in absolute value than difference kernel-type estimators with tail . Furthermore, we found the gap between the average bias of the semi-M estimator and the average bias of the difference kernel-type estimators to drop greatly with approaching the middle position of the threshold variable distribution.
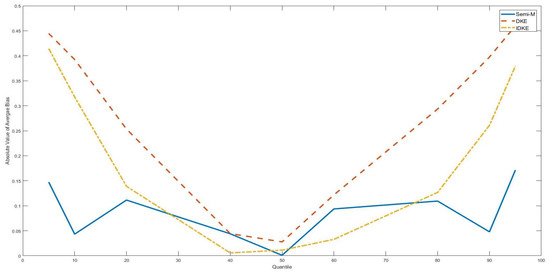
Figure 1.
Average bias with as various quantiles of the threshold variable, DGP 2, n = 100. This figure shows absolute values of the average bias with the true threshold level being several quantiles of the threshold variable (5th, 10th, 20th, 40th, 50th, 60th, 80th, 90th, 95th). The simulation is based on DGP 2. The sample size is 100.
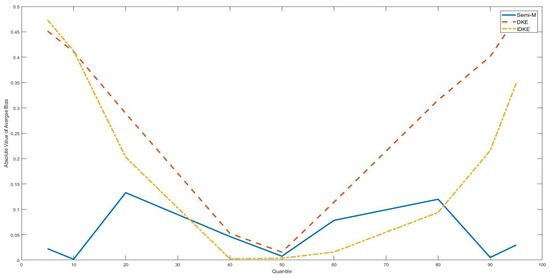
Figure 2.
Average bias with as various quantiles of the threshold variable, DGP 2, n = 300. This figure shows absolute values of the average bias with the true threshold level being several quantiles of the threshold variable (5th, 10th, 20th, 40th, 50th, 60th, 80th, 90th, 95th). The simulation is based on DGP 2. The sample size is 300.
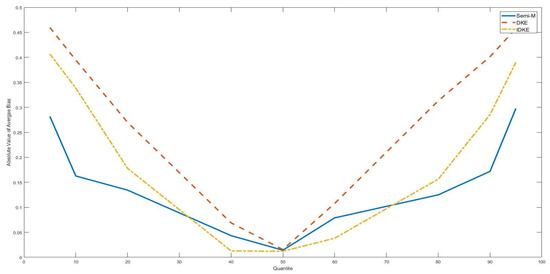
Figure 3.
Average bias with as various quantiles of the threshold variable, DGP 5, n = 100. This figure shows absolute values of the average bias with the true threshold level being several quantiles of the threshold variable (5th, 10th, 20th, 40th, 50th, 60th, 80th, 90th, 95th). The simulation is based on DGP 5. The sample size is 100.
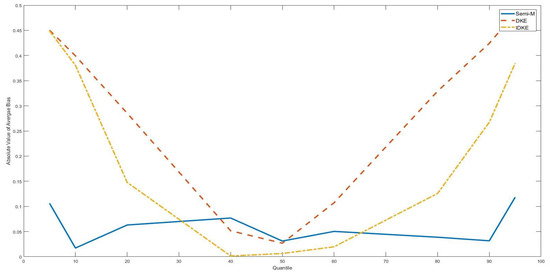
Figure 4.
Average bias with as various quantiles of the threshold variable, DGP 5, n = 300. This figure shows absolute values of the average bias with the true threshold level being several quantiles of the threshold variable (5th, 10th, 20th, 40th, 50th, 60th, 80th, 90th, 95th). The simulation is based on DGP 5. The sample size is 300.
6. Conclusions
In this paper, we evaluated the finite sample performance of three non-parametric threshold estimators and identified the relationship between the performances of different estimators and the position of the true threshold level with Monte Carlo methods.
The study shows, with all three estimators affected by the tail position of the true threshold value, that the semi-M estimator of Henderson et al. (2017) outperformed DKE and IDKE for roughly all DGPs considered in the paper. Interestingly, there appears to be some evidence that the distortion can be reduced if there are other covariates besides the threshold variable for the semi-M estimator and the IDKE. Consistent with the theory, we find that the realized convergence rates support the super-consistency in the threshold estimate for all three estimators. However, we find that the realized convergence rates are also affected by the position of the true threshold value. We therefore conclude that, in applied works, using the difference kernel-type estimation, researchers must be careful when the threshold estimate is at the left-tail or the right-tail of the threshold variable distribution.
Author Contributions
The two authors both contribute to the project formulation and paper preparation.
Funding
This research received no external funding.
Acknowledgments
We thank three anonymous referees for their helpful and constructive comments.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Afonso, Antonio, and Joao Tovar Jalles. 2013. Growth and productivity: The role of government debt. International Review of Economics and Finance 25: 384–407. [Google Scholar] [CrossRef]
- Caner, Mehmet, and Bruce Hansen. 2004. Instrumental variable estimation of a threshold model. Econometric Theory 20: 813–43. [Google Scholar] [CrossRef]
- Caner, Mehmet, Thomas J. Grennes, and Friederike N. Koehler-Geib. 2010. Finding the Tipping Point—When Sovereign Debt Turns Bad. Policy Research WP, No. 5391. New Delhi: Policy Research, pp. 1–13. [Google Scholar]
- Cecchetti, Stephen G., Madhusudan Mohanty, and Fabrizio Zampolli. 2011. The Real Effects of Debt. Working paper. Basel, Switzerland: Bank for International Settlements. [Google Scholar]
- Chan, Kung-Sik. 1993. Consistency and Limiting Distribution of the Least Squares Estimator of a Threshold Autoregressive Model. Annals of Statistics 21: 520–33. [Google Scholar] [CrossRef]
- Delgado, Miguel A., and Javier Hidalgo. 2000. Nonparametric inference on structural breaks. Journal of Econometrics 96: 113–44. [Google Scholar] [CrossRef]
- Hansen, Bruce E. 2000. Sample splitting and threshold estimation. Econometrica 68: 575–603. [Google Scholar] [CrossRef]
- Hansen, Bruce E. 2011. Threshold Autoregression in Economics. Statistics and Its Interface 4: 123–27. [Google Scholar] [CrossRef]
- Heckman, James J. 1979. Sample Selection Bias as a Specification Error. Econometrica 47: 153–61. [Google Scholar] [CrossRef]
- Henderson, Daniel J., Christopher F. Parmeter, and Liangjun Su. 2017. Nonparametric Threshold Regression: Estimation and Inference. Working paper. Singapore: Research Collection School of Economics. [Google Scholar]
- Kourtellos, Andros, Thanasis Stengos, and Chih Ming Tan. 2016. Structural Threshold Regression. Econometric Theory 32: 827–60. [Google Scholar] [CrossRef]
- Kourtellos, Andros, Thanasis Stengos, and Yiguo Sun. 2017. Endogeneity in Semiparametric Threshold Regression. Working paper. Guelph, ON, Canada: University of Cyprus and University of Guelph. [Google Scholar]
- Potter, Simon M. 1995. A Nonlinear Approach to US GNP. Journal of Applied Econometrics 10: 109–25. [Google Scholar] [CrossRef]
- Seo, Myung Hwan, and Oliver Linton. 2007. A smoothed least squares estimator for threshold regression models. Journal of Econometrics 141: 704–35. [Google Scholar] [CrossRef]
- Seo, Myung Hwan, and Yongcheol Shin. 2016. Dynamic Panels with Threshold Effect and Endogeneity. Journal of Econometrics 195: 169–86. [Google Scholar] [CrossRef]
- Yu, Ping, and Peter C. B. Phillips. 2018. Threshold Regression with Endogeneity. Journal of Econometrics 203: 50–68. [Google Scholar] [CrossRef]
| 1. | With the uniform distribution, the intensity of the Poisson process would not change with the change in the true threshold location. Therefore, the limiting distribution of both the DKE and the IDKE is not affected given is not on the boundary of . |
| 2. | The theoretical density should be the same for all x due to the uniform distribution. The reason we use the data-driven choice of is because we do not know the true density in reality. |
| 3. | All programming is finished in Matlab. |
| 4. | With n = 100, the bias, MSE and standard deviation were larger with placed at two tails and placed at the median point. However, with n = 500, there was no apparent difference between tail position estimation and the median position estimation. |
| 5. | For example, in Table 6, the bias monotonically increases with the in sample size. |




© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).