
Research on Design Pattern Detection Method Based on UML Model with Extended Image Information and Deep Learning

Abstract
:1. Introduction
2. Research Status of Design Pattern Detection
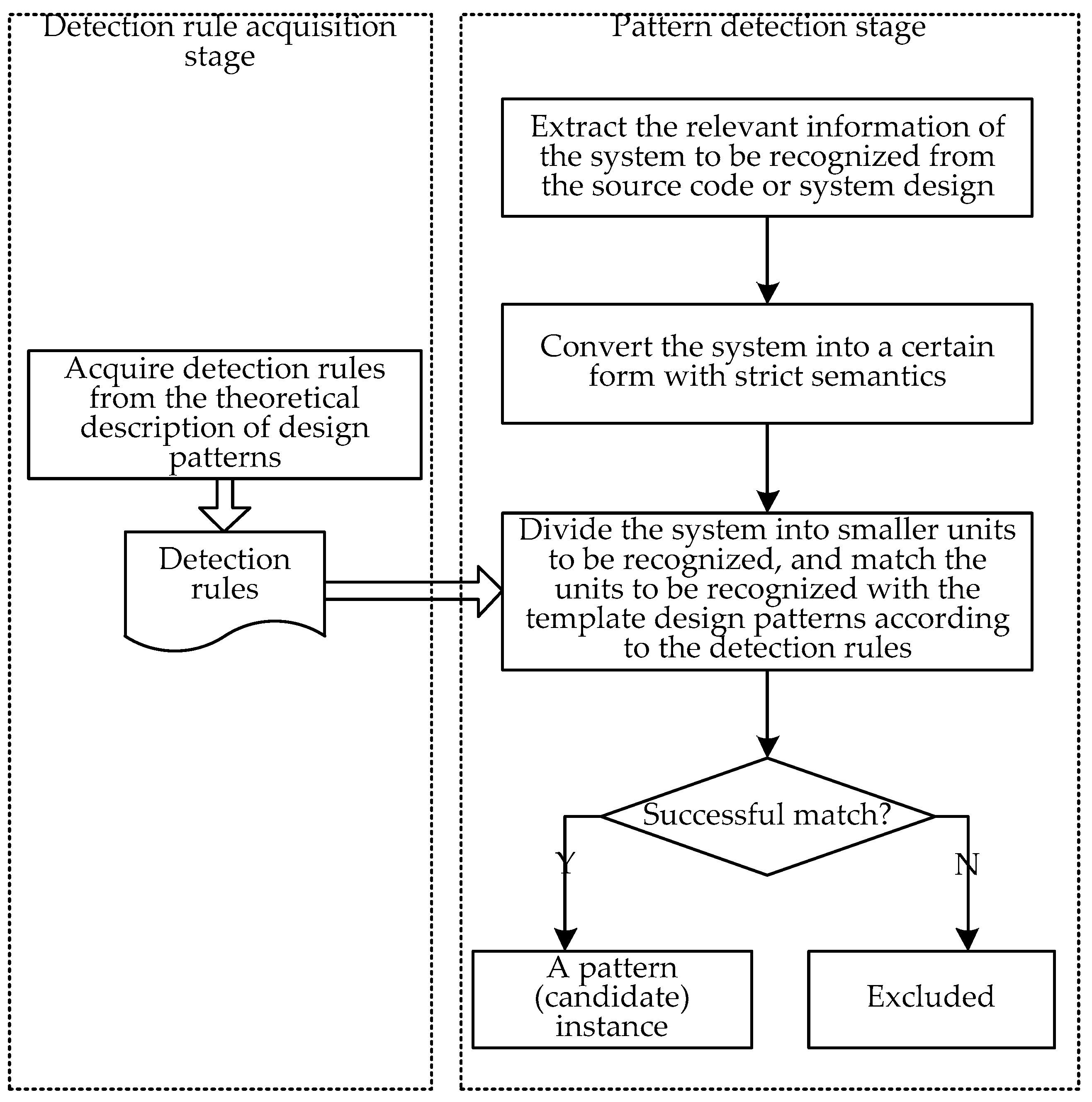
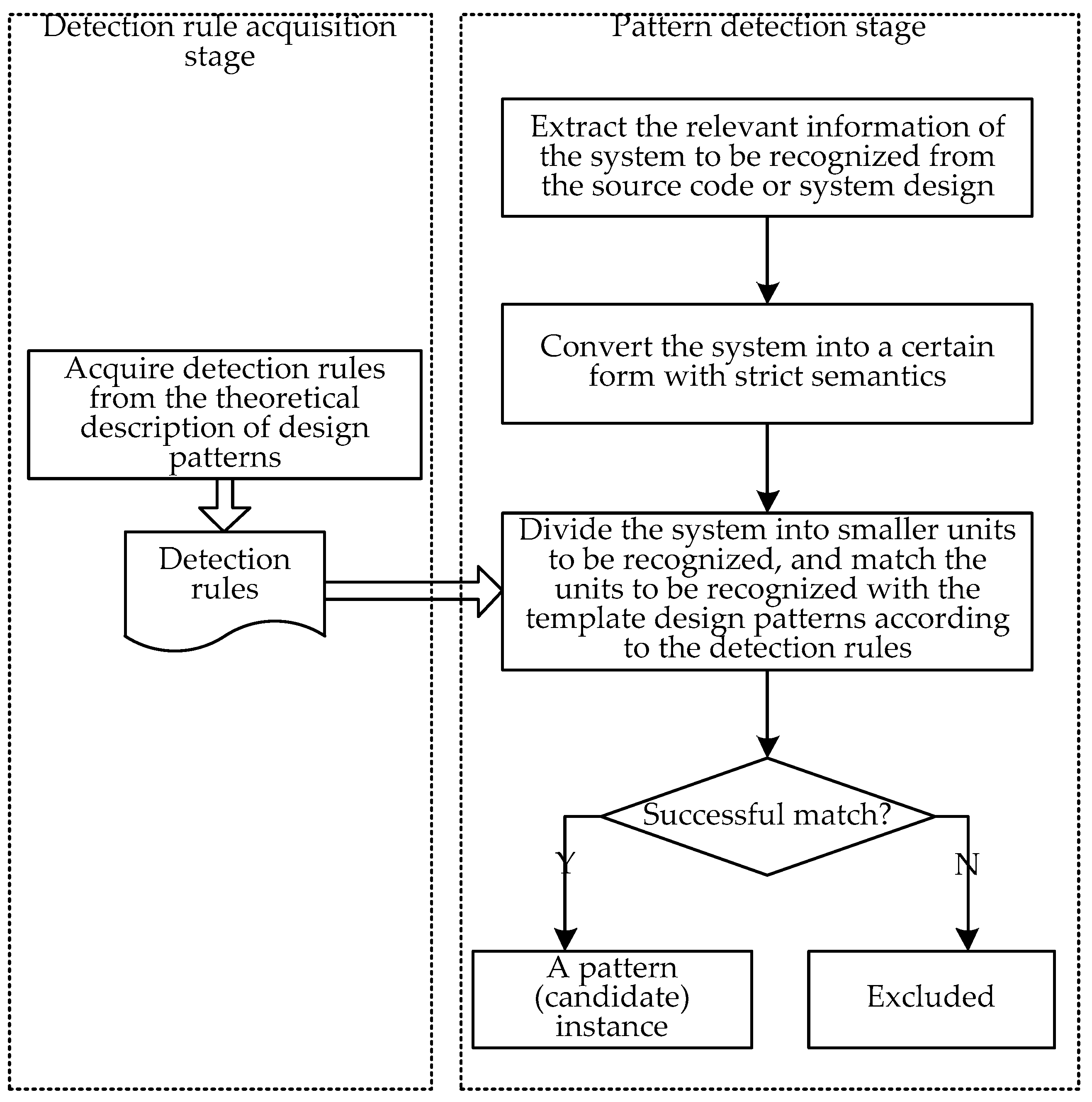
2.1. Non-Machine Learning Design Pattern Detection Methods
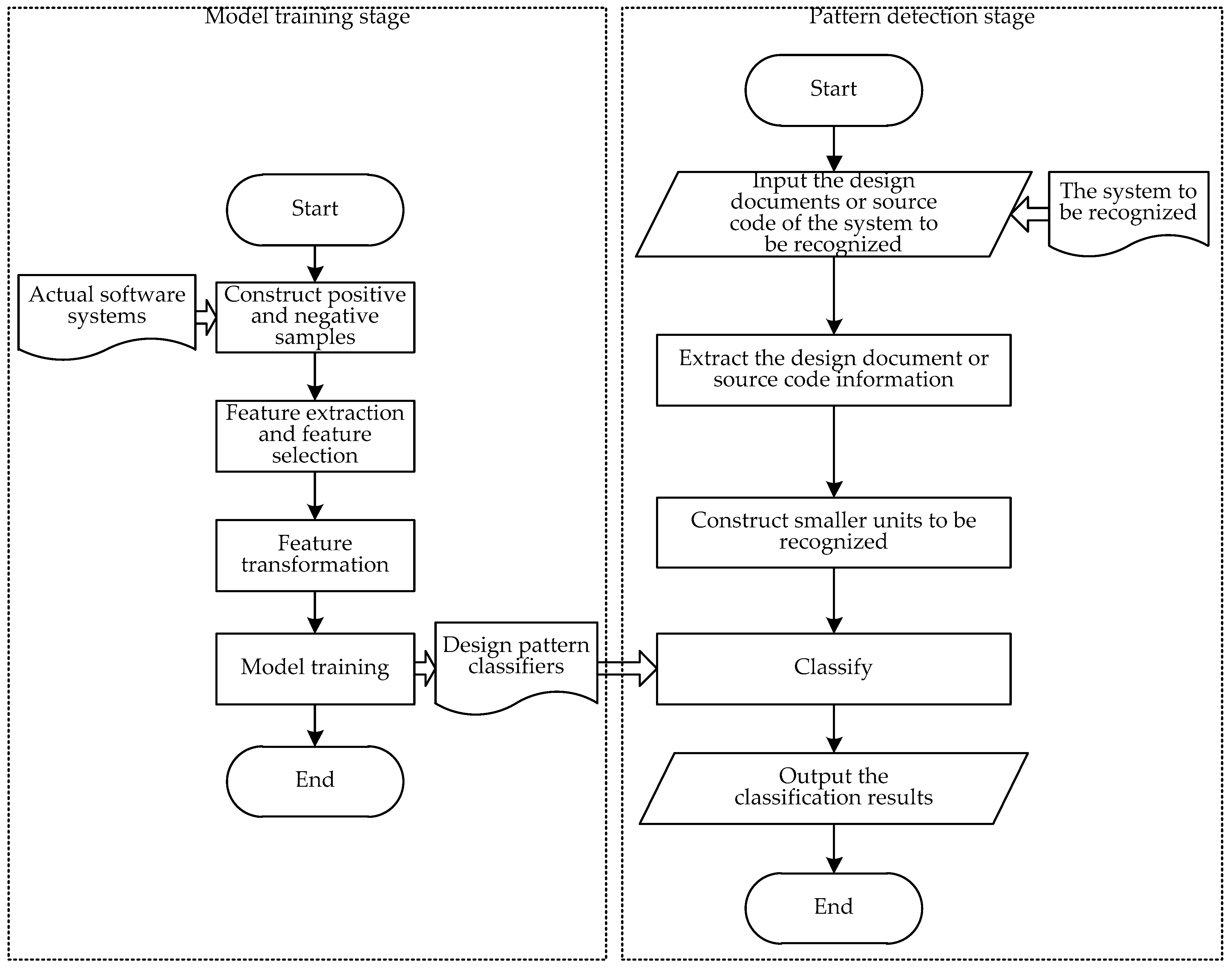
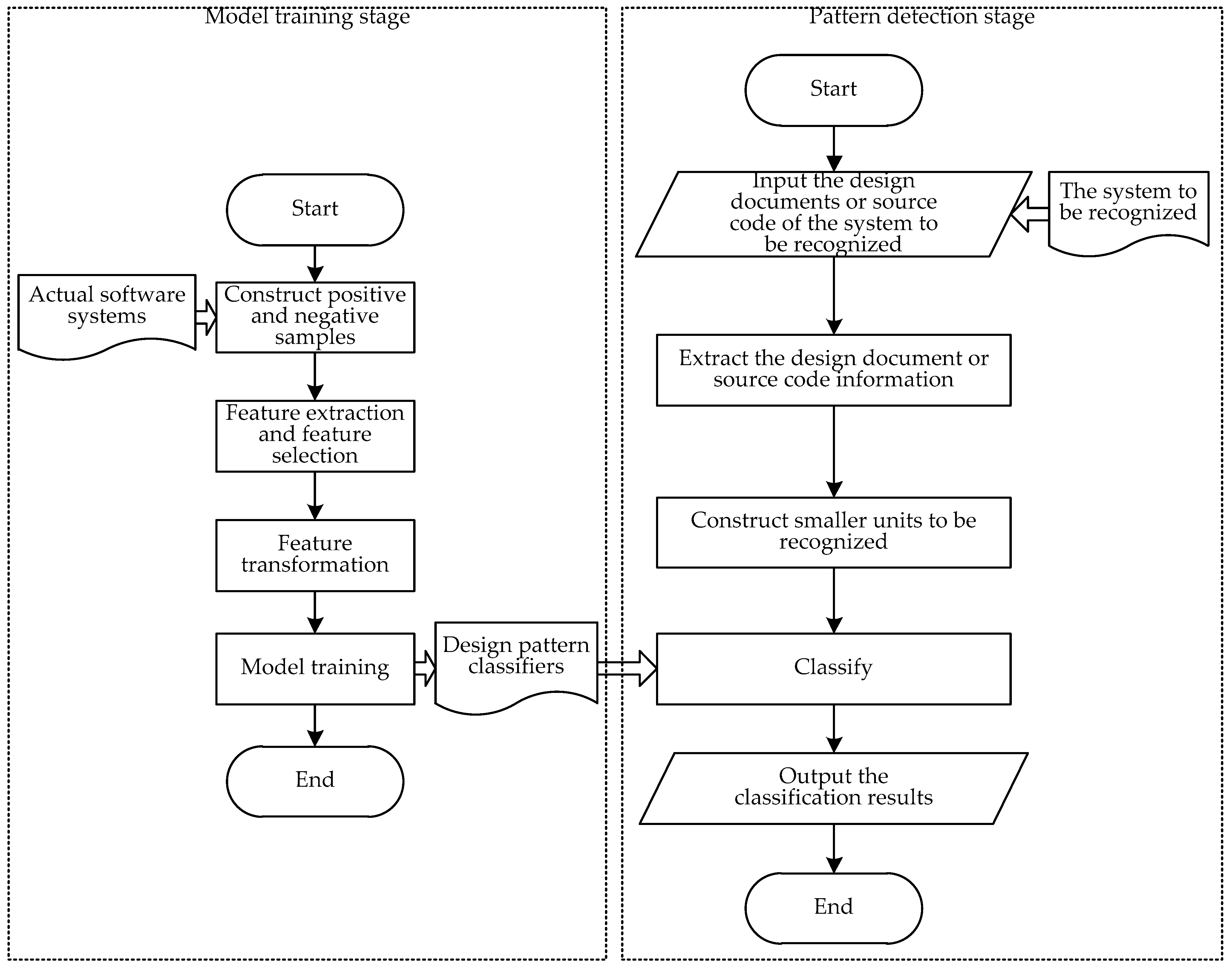
2.2. Machine Learning Design Pattern Detection Methods
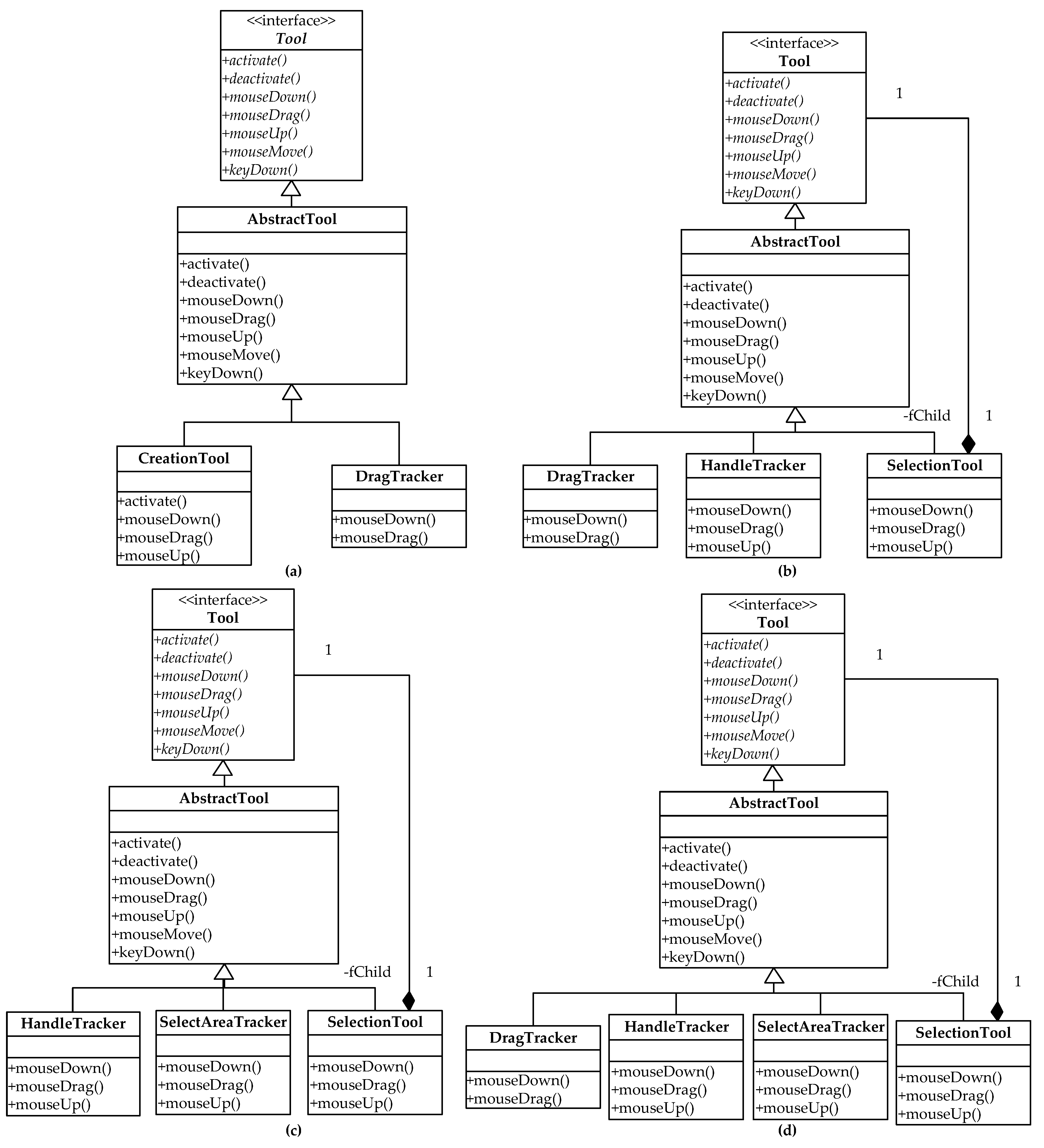
3. Extended UML Model with Graph Information—Colored UML
3.1. Extension of Traditional UML Class Diagram
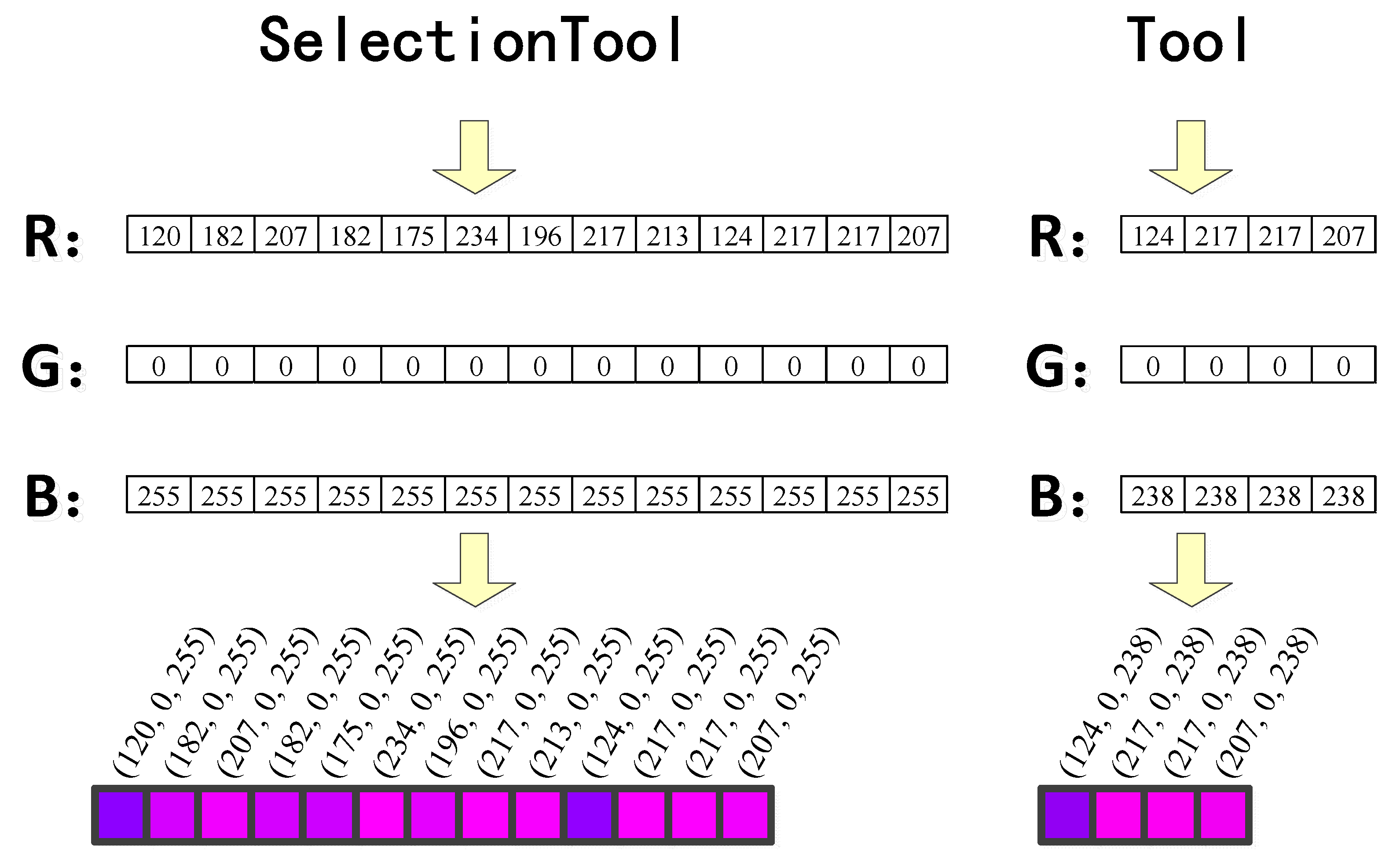
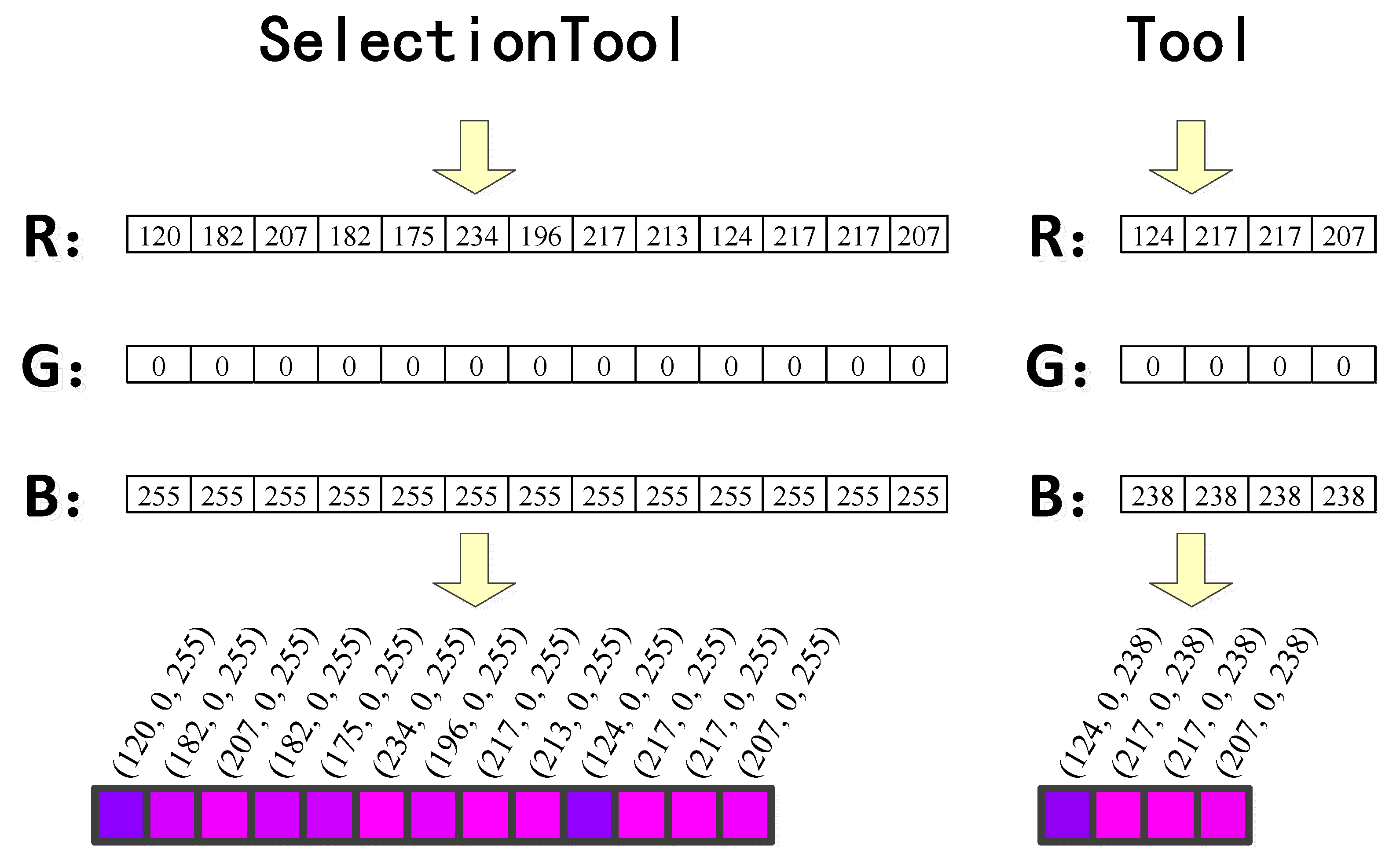
3.1.1. Representation of Classes in Colored UML
3.1.2. Representation of Classes in Colored UML
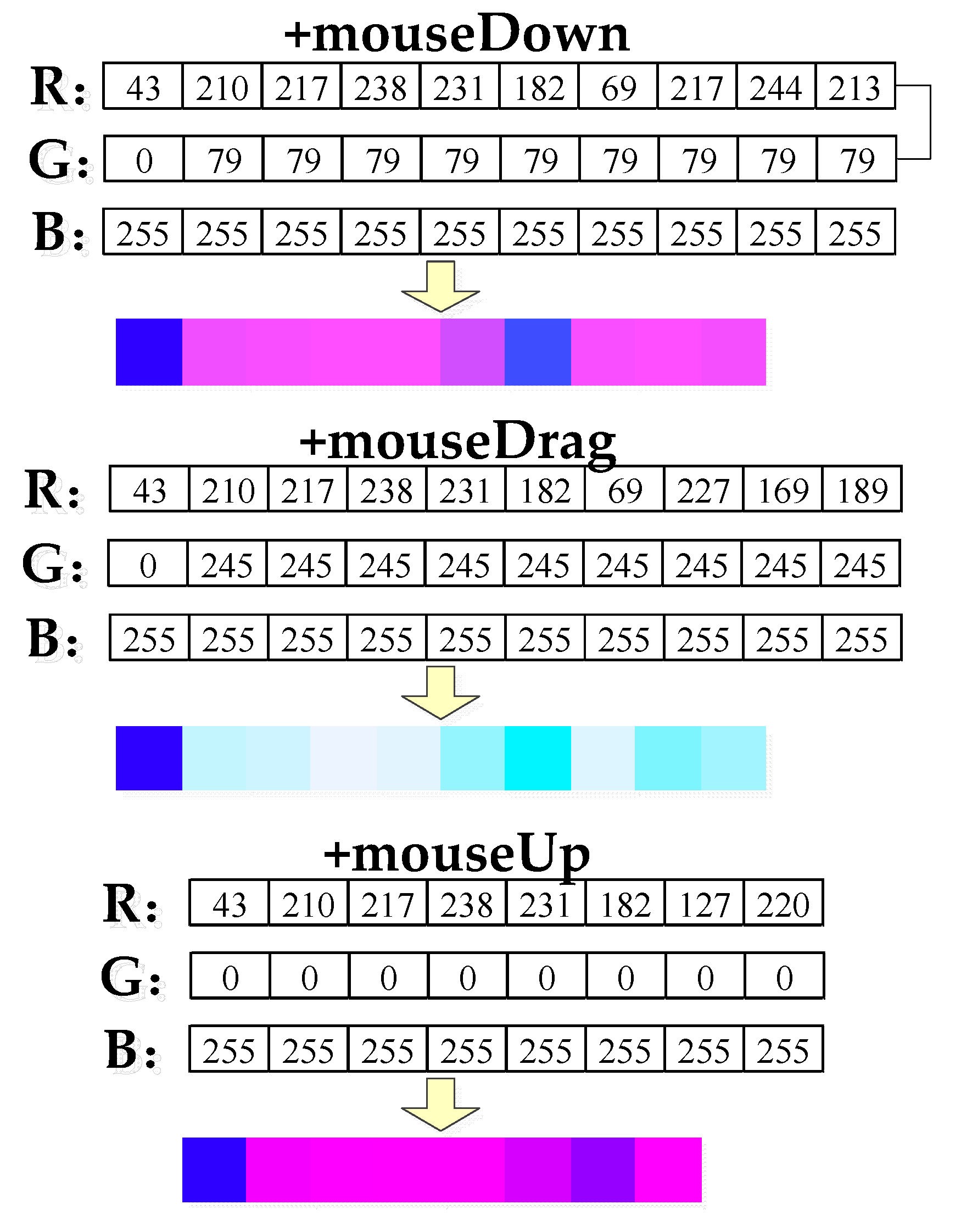
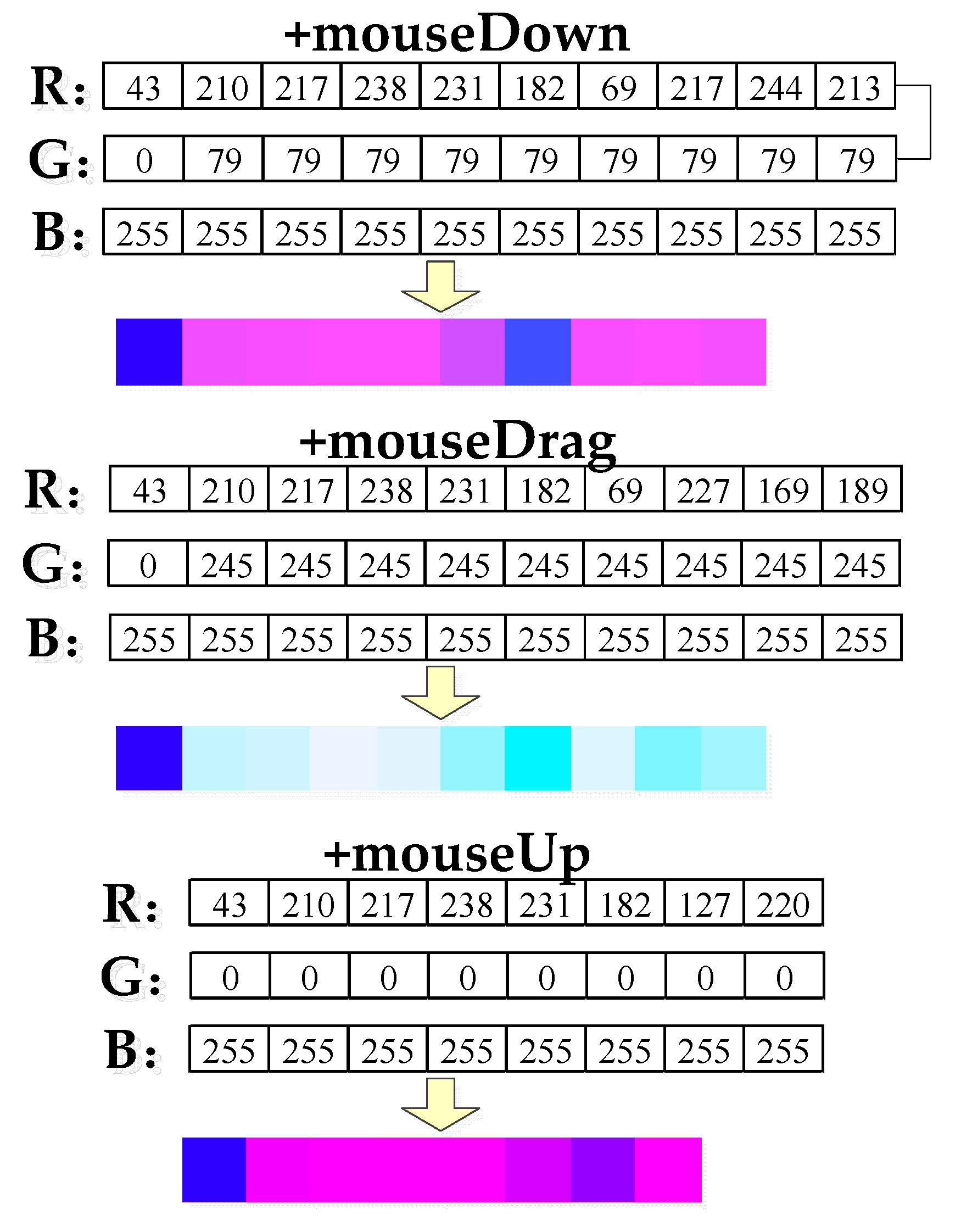
3.2. Expansion of Traditional UML Sequence Diagram
3.3. Expansion of Traditional UML Names
3.3.1. Representation of Class Names in Colored UML
3.3.2. Representation of Operation Names in Colored UML
4. Construction of the Sample Set
4.1. Acquisition of Positive and Negative Samples
- (1)
- Design pattern detection methods based on logical reasoning: we selected the method proposed by Hayashi et al. [6].
- (2)
- Design pattern detection methods based on XML matching: we selected the method proposed by Balanyi et al. [10].
- (3)
- Design pattern detection methods based on ontology technology: we selected the method proposed by Di Martino et al. [12].
- (4)
- Design pattern detection methods based on formal technologies: we selected the method proposed by Bernardi et al. [17].
- (5)
- Design pattern detection methods based on rules: we selected the method proposed by Aladib et al. [18].
- (6)
- Design pattern detection methods based on graph theory: we selected the method previously developed by the authors [24].
4.2. Data Augmentation
4.3. Dataset Splitting
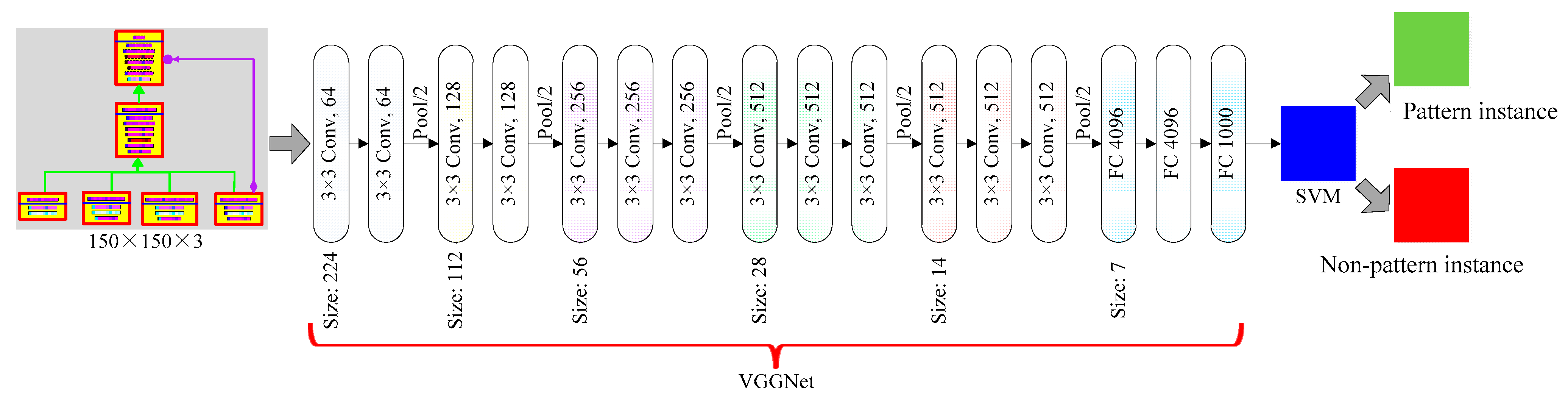
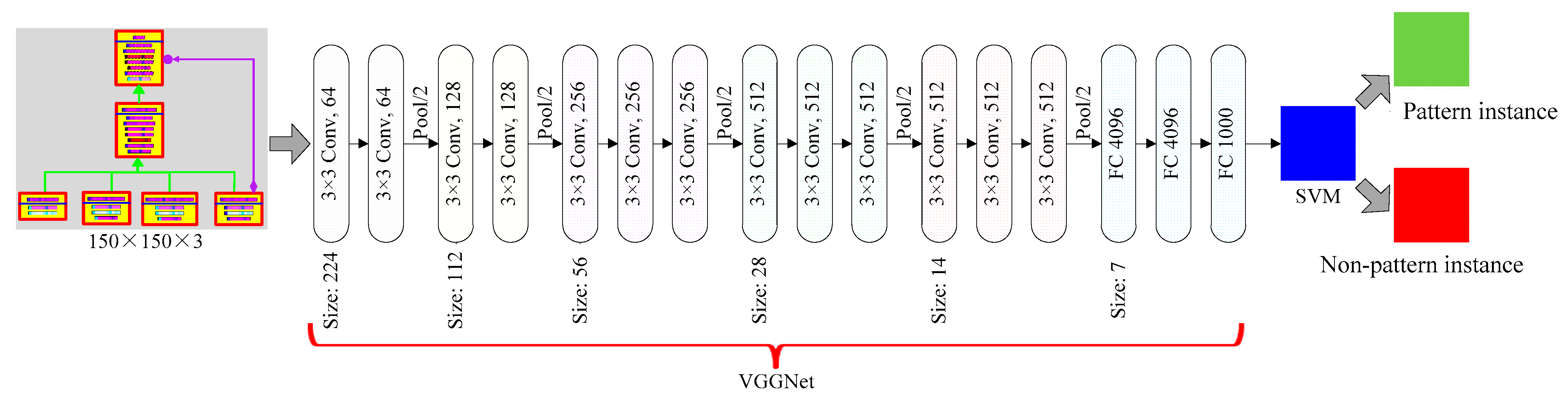
5. Deep Learning Model Combining VGGNet and SVM for Design Pattern Identification
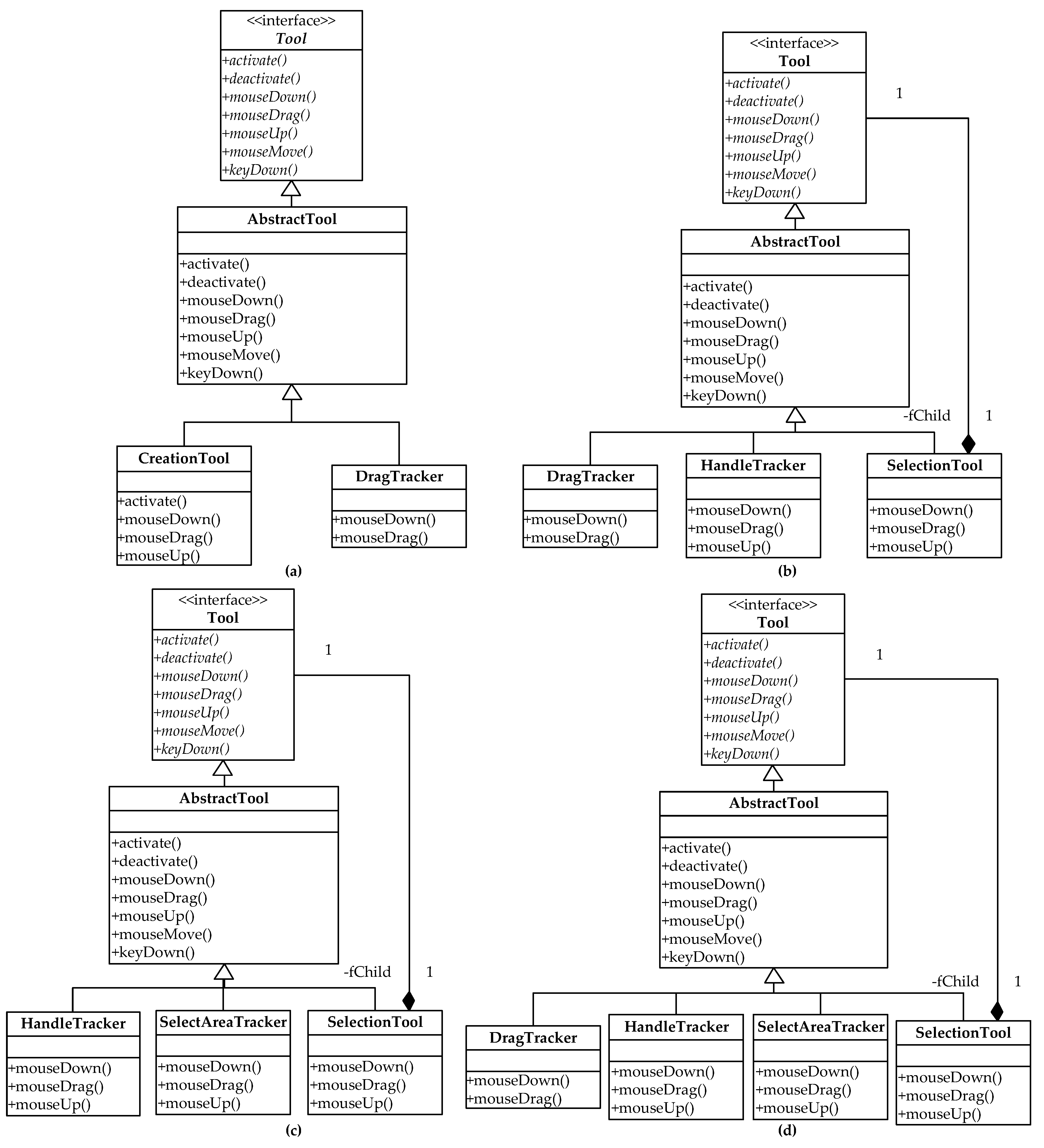
5.1. Model Design
5.2. Model Configuration
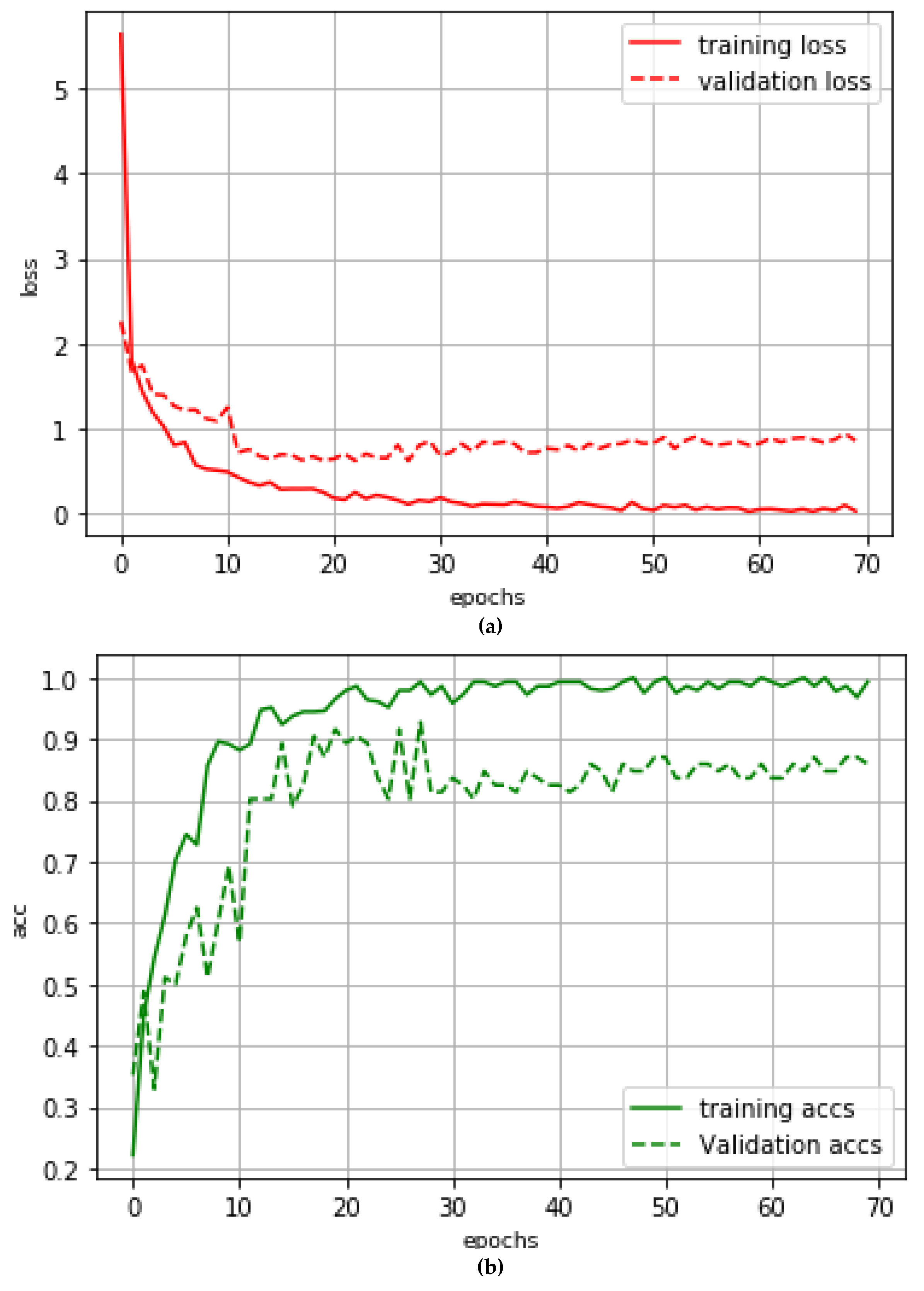
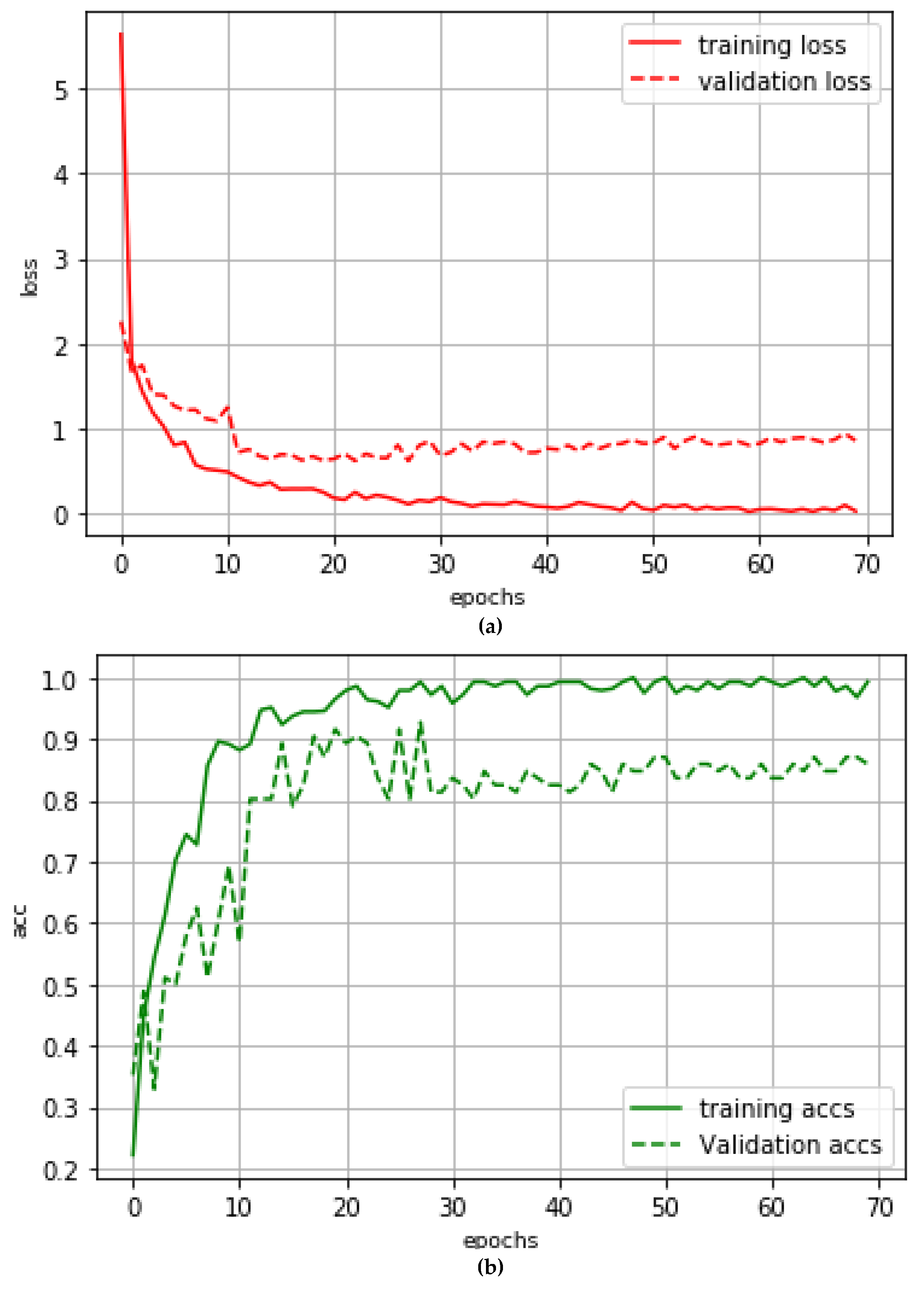
5.3. Model Training
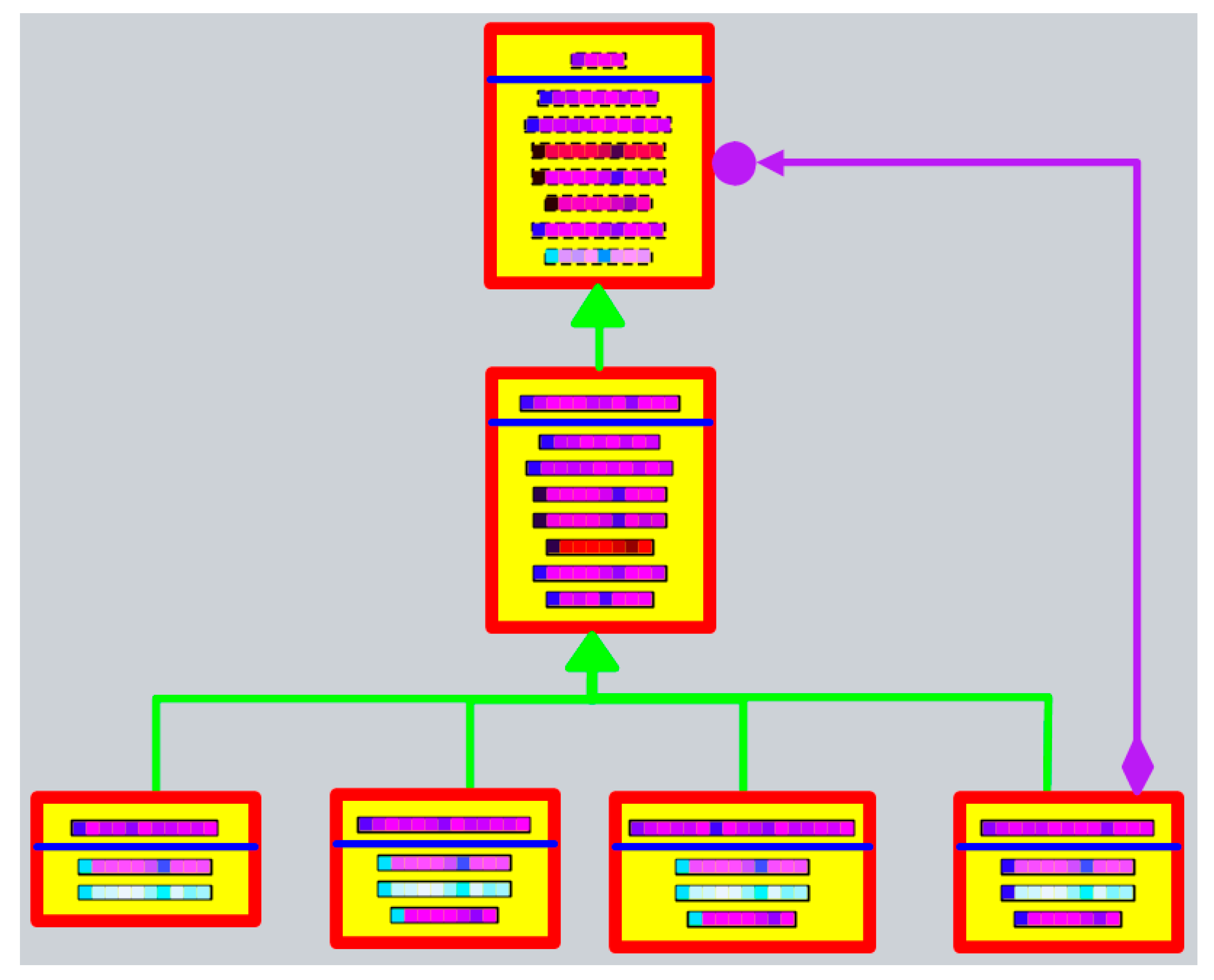
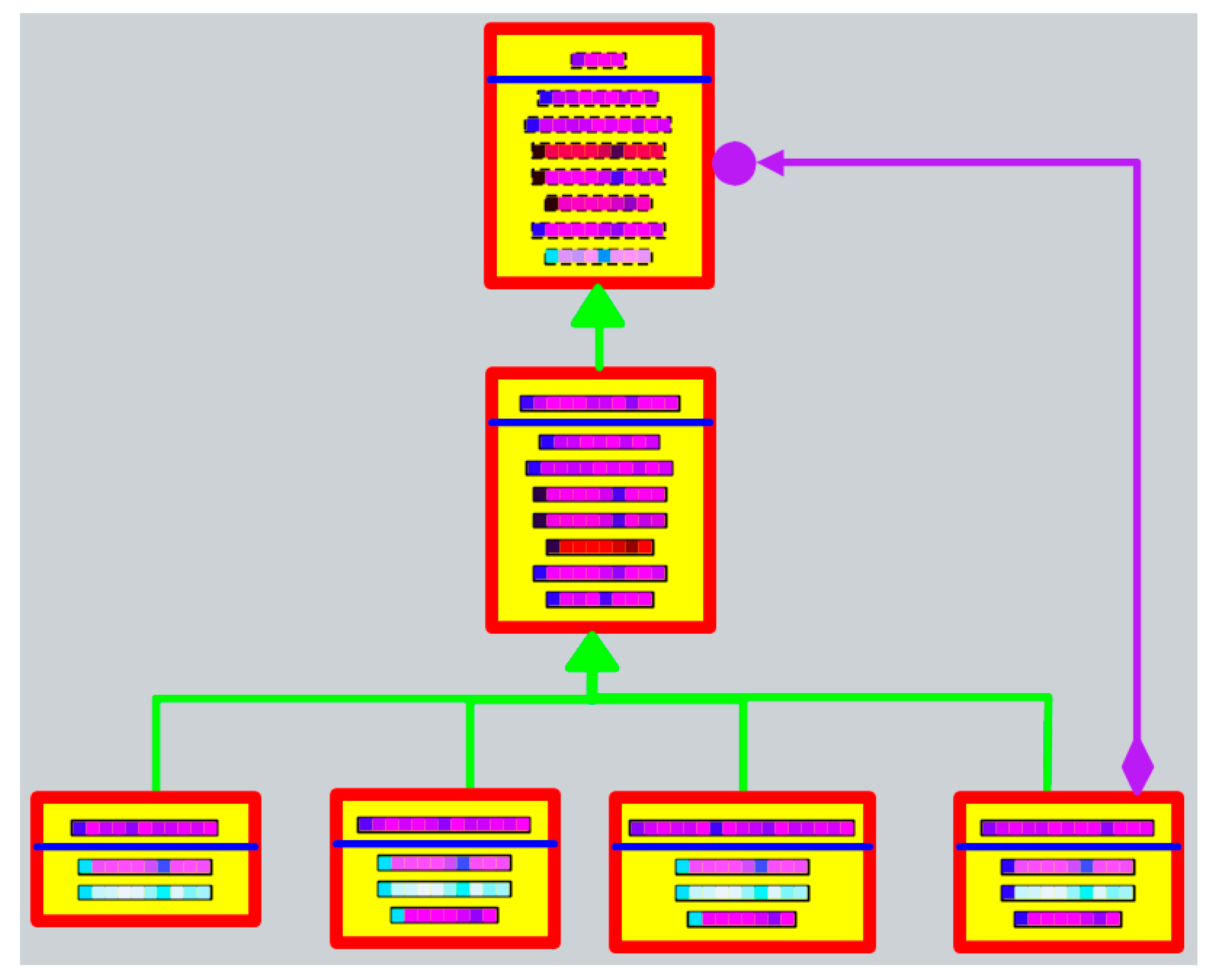
6. Extraction of System Information and Division of Subsystems and Second-Level Subsystems
6.1. Extraction of System Information
6.2. Division of Subsystems
6.3. Division of Second-Level Subsystems
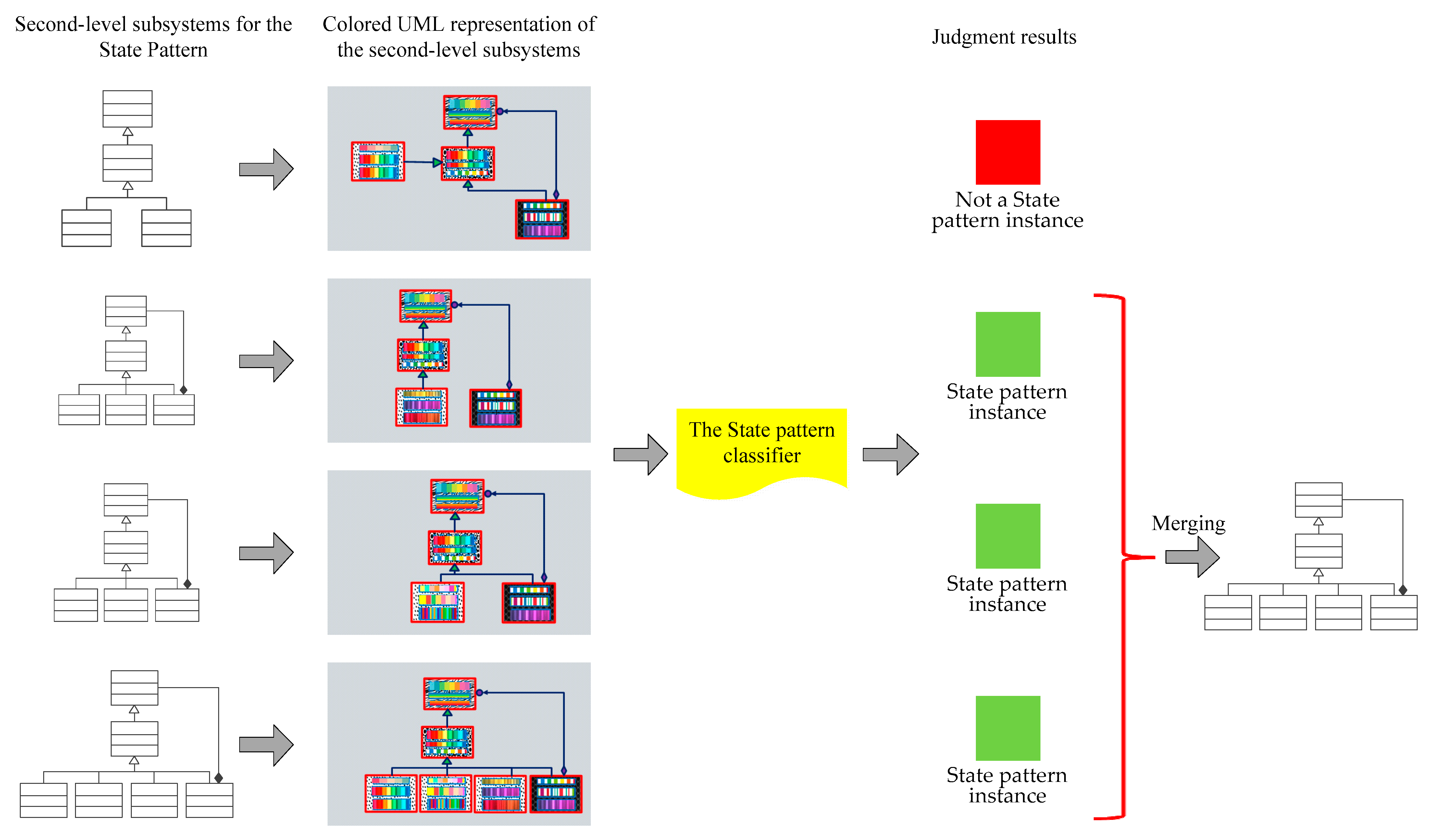
7. Pattern Instance Acquisition Based on Deep Learning Model
7.1. Image Resizing
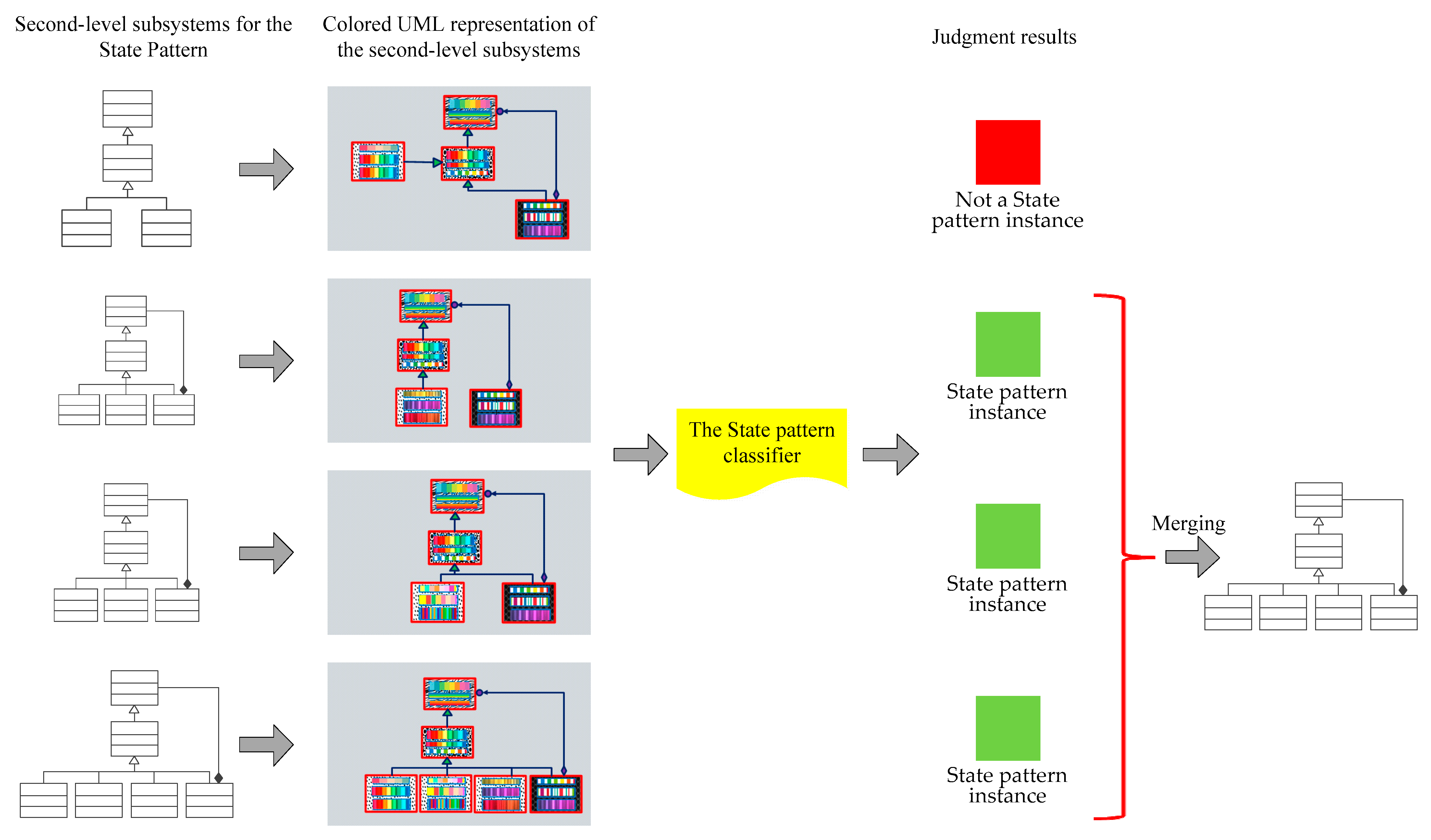
7.2. Judgment of Whether a Second-Level Subsystem Is a Pattern Instance
7.3. Merging of Judgment Results
8. Experiments and Result Analysis
8.1. Experimental Environment and Data
8.2. Evaluation Indexes
- (1)
- True positive (TP).
- (2)
- False positive (FP).
- (3)
- False negative (FN).
- (4)
- Precision.
- (5)
- Recall.
8.3. Result Analysis
9. Conclusions and Prospect
9.1. Conclusions
9.2. The Pros and Cons of Using Our Method
9.2.1. Pros
9.2.2. Cons and Limitations
9.3. Prospect
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
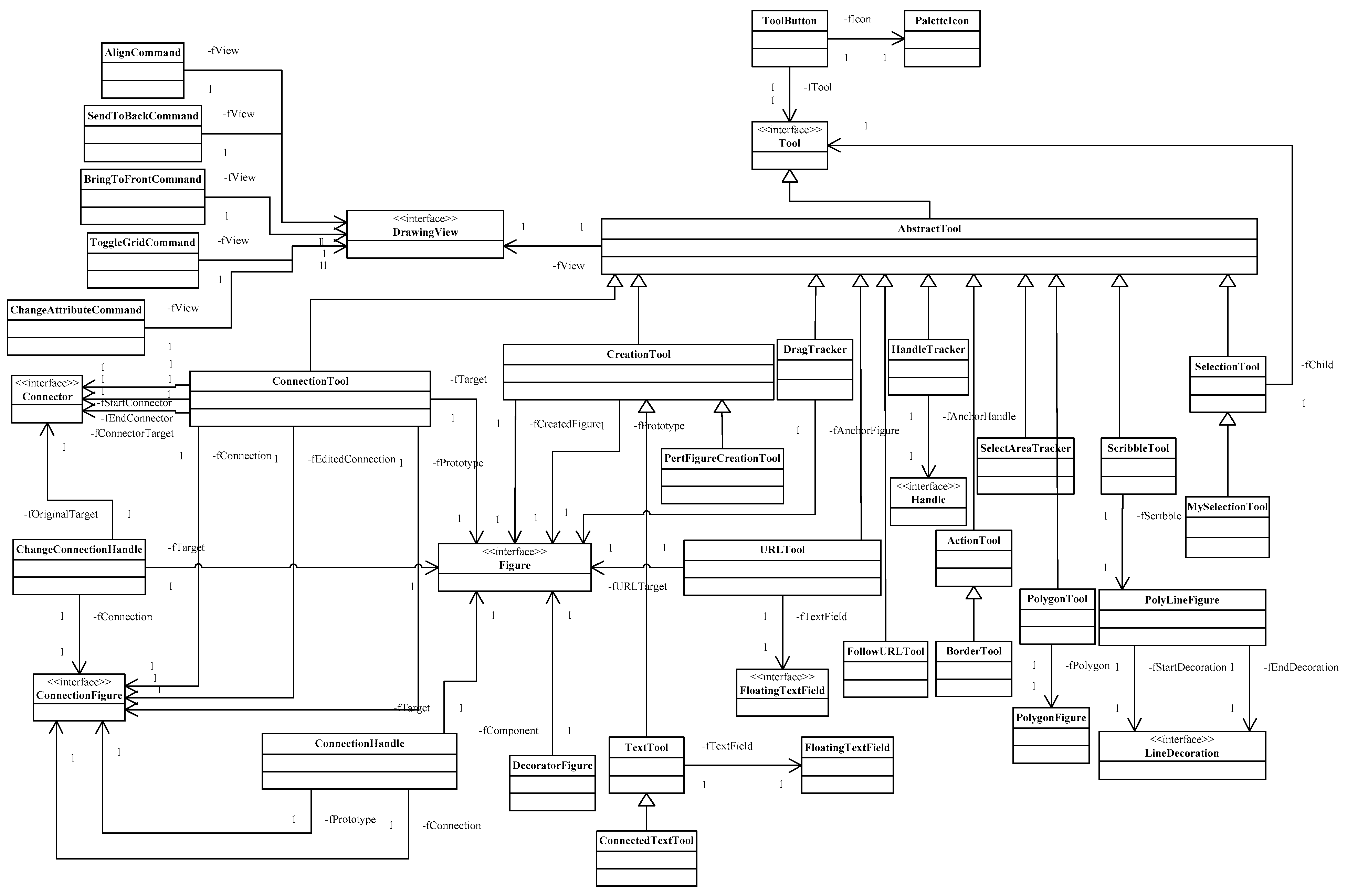
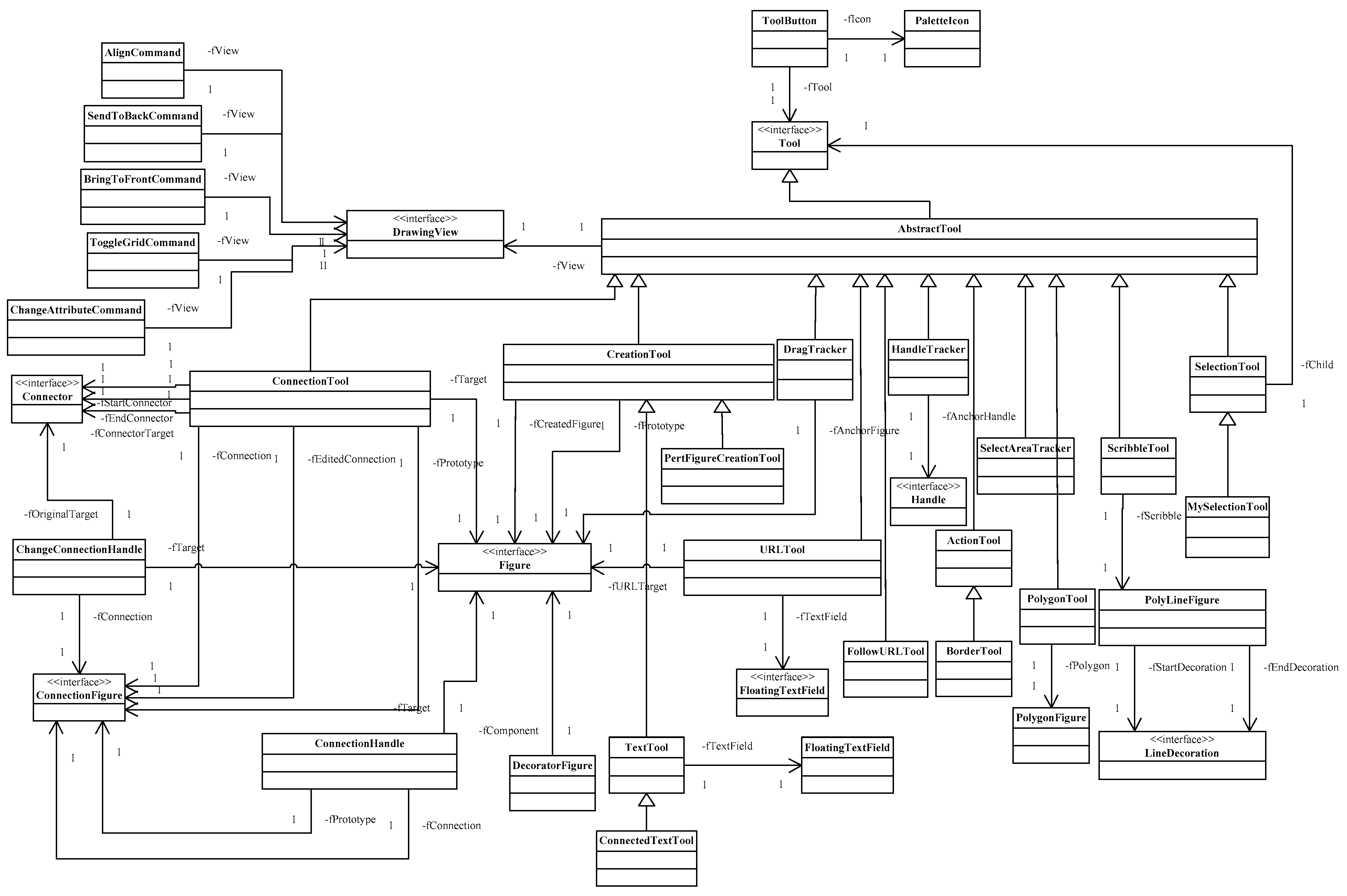
Appendix A
References
- Naghdipour, A.; Hasheminejad, S.; Keyvanpour, M.R. DPSA: A Brief Review for Design Pattern Selection Approaches. In Proceedings of the 2021 26th International Computer Conference: Computer Society of Iran (CSICC), Tehran, Iran, 3–4 March 2021; pp. 1–14. [Google Scholar]
- Ohstuki, M.; Kakeshita, T. Generating Relationship between Design Pattern and Source Code. In Proceedings of the 13th International Conference on Computer Supported Education, Prague, Czech Republic, 23–25 April 2021; pp. 288–293. [Google Scholar]
- Gamma, E.; Helm, R.; Johnson, R.; Vlissides, J. Design Patterns: Elements of Reusable Object-Oriented Software; Addison-Wesley: Boston, MA, USA, 1995. [Google Scholar]
- Yarahmadi, H.; Hasheminejad, S. Design pattern detection approaches: A systematic review of the literature. Artif. Intell. Rev. 2020, 53, 5789–5846. [Google Scholar] [CrossRef]
- Krämer, C.; Prechelt, L. Design recovery by automated search for structural design patterns in object-oriented software. In Proceedings of the Working Conference on Reverse Engineering, Monterey, CA, USA, 11–10 November 1996; pp. 1–9. [Google Scholar]
- Luitel, G.; Stephan, M.; Inclezan, D. Model level design pattern instance detection using answer set programming. In Proceedings of the International Workshop on Modeling in Software Engineering, Austin, TX, USA, 16–17 May 2016; pp. 13–19. [Google Scholar]
- Tsantalis, N.; Chatzigeorgiou, A.; Stephanides, G.; Halkidis, S.T. Design pattern detection using similarity scoring. IEEE Trans. Softw. Eng. 2006, 32, 896–909. [Google Scholar] [CrossRef]
- Yu, D.; Zhang, P.; Yang, J.; Chen, Z.; Liu, C.; Chen, J. Efficiently detecting structural design pattern instances based on ordered sequences. J. Syst. Softw. 2018, 142, 35–56. [Google Scholar] [CrossRef]
- Mayvan, B.B.; Rasoolzadegan, A. Design pattern detection based on the graph theory. Knowl.-Based Syst. 2017, 120, 211–225. [Google Scholar] [CrossRef]
- Fawareh, H.J.; Alshira’H, M. MDetection a design pattern through merge static and dynamic analysis using altova and lambdes tools. Int. J. Appl. Eng. Res. 2017, 12, 8518–8522. [Google Scholar]
- Zhang, P.; Yu, D.; Wang, J. A Degree-Driven Approach to Design Pattern Mining Based on Graph Matching. In Proceedings of the 2017 24th Asia-Pacific Software Engineering Conference (APSEC), Nanjing, China, 4–8 December 2017; pp. 179–188. [Google Scholar]
- Di Martino, B.; Esposito, A. A rule-based procedure for automatic recognition of design patterns in UML diagrams. Softw. Pract. Exp. 2016, 46, 983–1007. [Google Scholar] [CrossRef]
- Al-Obeidallah, M.; Petridis, M.; Kapetanakis, S. MLDA: A Multiple Levels Detection Approach for Design Patterns Recovery. In Proceedings of the International Conference on Compute and Data Analysis, Lakeland, Florida, 19–23 May 2017; pp. 33–40. [Google Scholar]
- Shi, N.; Olsson, R.A. Reverse Engineering of Design Patterns from Java Source Code. In Proceedings of the 21st IEEE/ACM International Conference on Automated Software Engineering (ASE 2006), Tokyo, Japan, 18–22 September 2006; pp. 123–134. [Google Scholar]
- Panich, A.; Vatanawood, W. Detection of design patterns from class diagram and sequence diagrams using ontology. In Proceedings of the IEEE/ACIS International Conference on Computer & Information Science, Okayama, Japan, 26–29 June 2016; pp. 1–6. [Google Scholar]
- Chaturvedi, A.; Gupta, M.; Kumar, S. Design Pattern Detection using Genetic Algorithm for Sub-graph Isomorphism to Enhance Software Reusability. Int. J. Comput. Appl. 2016, 135, 33–36. [Google Scholar] [CrossRef]
- Bernardi, M.L.; Cimitile, M.; de Ruvo, G.D.; di Lucca, G.A.; Santone, A. Model checking to improve precision of design pattern instances identification in OO systems. In Proceedings of the International Joint Conference on Software Technologies, Lisbon, France, 20–22 July 2015; pp. 53–63. [Google Scholar]
- Aladib, L.; Lee, S.P. Pattern detection and design rationale traceability: An integrated approach to software design quality. IET Softw. 2019, 13, 249–259. [Google Scholar] [CrossRef]
- Al-Obeidallah, M.G.; Petridis, M.; Kapetanakis, S. A Structural Rule-Based Approach for Design Patterns Recovery. In Proceedings of the International Conference on Software Engineering Research, Management and Applications, London, UK, 7–9 June 2017; pp. 107–124. [Google Scholar]
- Xiao, Z.Y.; He, P. Multistage relaxing detection method for variants of design pattern. J. Huazhong Univ. Sci. Technol. (Nat. Sci. Ed.) 2018, 46, 26–31. [Google Scholar]
- Chan, E.P. Artificial Intelligence Techniques; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2017. [Google Scholar]
- Wang, L. Design Pattern Detection Based on Similarity Scoring, FSM and Machine Learning. Ph.D. Thesis, China University of Mining and Technology (Beijing), Beijing, China, 20 June 2019. [Google Scholar]
- Wang, L. Automatic Design Pattern Detection—Principles, Methods and Tools; Hans Publishing House: Wuhan, China, 2020. [Google Scholar]
- Wang, L.; Wang, W.-F.; Song, H.-N.; Zhang, S. Design Pattern Detection Based on Similarity Scoring and Secondary Subsystems. Comput. Eng. 2022. online. [Google Scholar]
- Dong, J.; Sun, Y.; Zhao, Y. Compound record clustering algorithm for design pattern detection by decision tree learning. In Proceedings of the 2008 IEEE International Conference on Information Reuse and Integration, Las Vegas, NV, USA, 13–15 July 2018; pp. 1–6. [Google Scholar]
- Zanoni, M.; Fontana, F.A.; Stella, F. On applying machine learning techniques for design pattern detection. J. Syst. Softw. 2015, 88, 102–117. [Google Scholar] [CrossRef]
- Lu, R.-Z.; Zhang, H.-P. Research on Design Pattern Mining Based on Machine Learning. Comput. Eng. Appl. 2019, 55, 119–125. [Google Scholar]
- Chihada, A.; Jalili, S.; Hasheminejad, S.M.H.; Zangooei, M.H. Source code and design conformance, design pattern detection from source code by classification approach. Appl. Soft Comput. J. 2015, 26, 357–367. [Google Scholar] [CrossRef]
- Chaturvedi, S.; Chaturvedi, A.; Tiwari, A.; Agarwal, S. Design Pattern Detection using Machine Learning Techniques. In Proceedings of the 2018 7th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 29–31 August 2018; pp. 1–6. [Google Scholar]
- Alhusain, S.; Coupland, S.; John, R.; Kavanagh, M. Towards machine learning based design pattern recognition. In Proceedings of the The 13th Annual UK Workshop on Computational Intelligence, Guildford, UK, 9–11 September 2013; pp. 244–251. [Google Scholar]
- Uchiyama, S.; Kubo, A.; Washizaki, H.; Fukazawa, Y. Design Pattern Detection using Software Metrics and Machine Learning. In Proceedings of the First International Workshop on Model-Driven Software Migration, Oldenburg, Germany, 1–4 March 2011; pp. 38–47. [Google Scholar]
- Uchiyama, S.; Kubo, A.; Washizaki, H.; Fukazawa, Y. Detecting design patterns in object-oriented program source code by using metrics and machine learning. J. Softw. Eng. Appl. 2014, 7, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Barbudo, R.; Ramírez, A.; Servant, F.; Romero, J.R. GEML: A grammar-based evolutionary machine learning approach for design-pattern detection. J. Syst. Softw. 2021, 175, 110919. [Google Scholar] [CrossRef]
- Thaller, H.; Linsbauer, L.; Egyed, A. Feature Maps: A Comprehensible Software Representation for Design Pattern Detection. In Proceedings of the 2019 IEEE 26th International Conference on Software Analysis, Evolution and Reengineering (SANER), Hangzhou, China, 24–27 February 2019; pp. 207–217. [Google Scholar]
- Mhawish, M.Y.; Gupta, M. Software Metrics and tree-based machine learning algorithms for distinguishing and detecting similar structure design patterns. SN Appl. Sci. 2020, 2, 2–11. [Google Scholar] [CrossRef]
- Feng, T.; Jin, L.; Zhang, J.-C.; Wang, H.-Y. Design Pattern Detection Approach Based on Stacked Generalization. J. Softw. 2020, 31, 1703–1722. [Google Scholar]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Pouyanfar, S.; Sadiq, S.; Yan, Y.; Tian, H.; Tao, Y.; Reyes, M.P.; Shyu, M.-L.; Chen, S.-C.; Iyengar, S.S. A Survey on Deep Learning: Algorithms, Techniques, and Applications. ACM Comput. Surv. 2019, 51, 1–36. [Google Scholar]
- Wang, H.-Y.; Wang, H.-Y.; Zhu, X.-J.; Song, L.-M.; Guo, Q.-H.; Dong, F. Three-Dimensional Reconstruction of Dilute Bubbly Flow Field with Light-Field Images Based on Deep Learning Method. IEEE Sens. J. 2021, 21, 13417–13429. [Google Scholar] [CrossRef]
- Shi, J.Y.; Wang, X.-D.; Ding, G.Y.; Dong, Z.; Han, J.; Guan, Z.-H.; Ma, L.-J.; Zheng, Y.-X.; Zhang, L.; Yu, G.-Z.; et al. Exploring prognostic indicators in the pathological images of hepatocellular carcinoma based on deep learning. Gut 2020, 70, 951–961. [Google Scholar] [CrossRef] [PubMed]
- Francese, R.; Frasca, M.; Risi, M.; Tortora, G. A mobile augmented reality application for supporting real-time skin lesion analysis based on deep learning. J. Real-Time Image Processing 2021, 18, 1247–1259. [Google Scholar] [CrossRef]
- Zhu, H. Weibo Text Sentiment Analysis Based on BERT and Deep Learning. Appl. Sci. 2021, 11, 10774–10791. [Google Scholar]
- Ali, M.N.Y.; Rahman, M.L.; Chaki, J.; Dey, N.; Santosh, K.C. Machine translation using deep learning for universal networking language based on their structure. Int. J. Mach. Learn. Cybern. 2021, 12, 2365–2376. [Google Scholar] [CrossRef]
- Yang, S.; Wang, Y.; Chu, X. A Survey of Deep Learning Techniques for Neural Machine Translation. arXiv 2002, arXiv:2002.07526. [Google Scholar]
- Cui, H.; Zhao, Y.; Dong, W. Research on life prediction method of rolling bearing based on deep learning and voice interaction technology. Int. J. Speech Technol. 2021. online. [Google Scholar] [CrossRef]
- Wahengbam, K.; Singh, M.P.; Nongmeikapam, K.; Singh, A.D. A Group Decision Optimization Analogy based Deep Learning architecture for multiclass pathology classification in a voice signal. IEEE Sens. J. 2021, 21, 8100–8116. [Google Scholar] [CrossRef]
- Faris, H. Toward an Automatic Quality Assessment of Voice-Based Telemedicine Consultations: A Deep Learning Approach. Sensors 2021, 21, 3279–3305. [Google Scholar]
- Wang, X.; Zhang, T.; Xin, W.; Hou, C.-Y. Source Code Defect Detection Based on Deep Learning. Trans. Beijing Inst. Technol. 2019, 39, 1155–1159. [Google Scholar]
- Guéhéneuc, Y.-G. P-MARt: Pattern-like Micro Architecture Repository. In Proceedings of the lst EuroPLoP Focus Group on Pattern Repositories, Irsee, Germany, 4–8 July 2007; pp. 1–3. [Google Scholar]
- Fontana, F.A.; Caracciolo, A.; Zanoni, M. DPB: A benchmark for design pattern detection tools. In Proceedings of the Proc. of the 16th European Conf. on Software Maintenance and Reengineering (CSMR), Szeged, Hungary, 27–30 March 2012; pp. 235–244. [Google Scholar]
- Ampatzoglou, A.; Michou, O.; Stamelos, I. Building and mining a repository of design pattern instances: Practical and research benefits. Entertain. Comput. 2013, 4, 131–142. [Google Scholar] [CrossRef]
- Nazar, N.; Aleti, A. Feature-Based Software Design Pattern Detection. J. Syst. Softw. 2021, 185, 111179. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Bi, R.; Sun, G.-F.; Zhou, X.-Y.; Liu, W.-W. Hands-On Deep Learning from Scratch; Tsinghua University Press: Beijing, China, 2020. [Google Scholar]
- Liu, X.-L.; Yang, Q.-H.; Hu, X.-G.; Yu, D.-H.; Bai, H.-J. Deep Learning by PaddlePaddle; Machinery Industry Press: Beijing, China, 2020. [Google Scholar]
- Zangooei, M.H.; Jalili, S. PSSP with dynamic weighted kernel fusion based on SVM-PHGS. Knowl.-Based Syst. 2012, 27, 424–442. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Batch_Size | Accuracy Rate of Validation Set |
|---|---|
| 100 | 90.56% |
| 200 | 91.23% |
| 300 | 91.78% |
| 400 | 92.79% |
| 500 | 91.93% |
| Design Pattern | Mayvan et al.’s Method | Tsantalis et al.’s Method | Luitel et al.’s Method | Our Method | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TP | FP | FN | TP | FP | FN | TP | FP | FN | TP | FP | FN | |
| Adapter | 9 | 0 | 9 | 18 | 3 | 0 | 15 | 3 | 3 | 17 | 1 | 1 |
| Command | ||||||||||||
| Composite | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 0 |
| Decorator | 3 | 0 | 0 | 3 | 1 | 0 | 3 | 2 | 0 | 3 | 1 | 0 |
| Factory method | 3 | 0 | 0 | 2 | 0 | 1 | 1 | 0 | 2 | 2 | 0 | 1 |
| Observer | 3 | 0 | 2 | 5 | 2 | 0 | 5 | 3 | 0 | 4 | 1 | 1 |
| Prototype | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| Singleton | 2 | 0 | 0 | 2 | 1 | 0 | 1 | 0 | 1 | 2 | 0 | 0 |
| State | 22 | 0 | 1 | 22 | 3 | 1 | 21 | 2 | 2 | 23 | 2 | 0 |
| Strategy | ||||||||||||
| Template Method | 5 | 0 | 0 | 5 | 3 | 0 | 4 | 4 | 1 | 5 | 0 | 0 |
| Visitor | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 2 | 0 | 1 | 0 | 0 |
| Average | ||||||||||||
| Design Pattern | Mayvan et al.’s Method | Tsantalis et al.’s Method | Luitel et al.’s Method | Our Method | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TP | FP | FN | TP | FP | FN | TP | FP | FN | TP | FP | FN | |
| Adapter | 4 | 0 | 3 | 7 | 2 | 0 | 6 | 2 | 1 | 6 | 1 | 1 |
| Command | ||||||||||||
| Decorator | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 |
| Factory method | 3 | 0 | 1 | 1 | 0 | 3 | 2 | 1 | 2 | 2 | 0 | 2 |
| Singleton | 9 | 0 | 3 | 12 | 2 | 0 | 10 | 1 | 2 | 12 | 1 | 0 |
| State | 11 | 0 | 1 | 11 | 5 | 1 | 10 | 4 | 2 | 11 | 0 | 1 |
| Strategy | ||||||||||||
| Template Method | 17 | 3 | 0 | 17 | 13 | 0 | 16 | 6 | 1 | 17 | 2 | 0 |
| Visitor | 2 | 0 | 0 | 2 | 1 | 0 | 1 | 2 | 1 | 2 | 1 | 0 |
| Average | ||||||||||||
| Design Pattern | Mayvan et al.’s Method | Tsantalis et al.’s Method | Luitel et al.’s Method | Our Method | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TP | FP | FN | TP | FP | FN | TP | FP | FN | TP | FP | FN | |
| Adapter | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 0 |
| Command | ||||||||||||
| Composite | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| Decorator | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 0 |
| Observer | 3 | 0 | 1 | 4 | 2 | 0 | 3 | 1 | 1 | 4 | 2 | 0 |
| State | 3 | 0 | 0 | 3 | 2 | 0 | 2 | 1 | 1 | 3 | 1 | 0 |
| Strategy | ||||||||||||
| Template Method | 1 | 0 | 0 | 1 | 2 | 0 | 1 | 3 | 0 | 1 | 0 | 0 |
| Average | ||||||||||||
| Design Pattern | Mayvan et al.’s Method | Tsantalis et al.’s Method | Luitel et al.’s Method | Our Method | ||||
|---|---|---|---|---|---|---|---|---|
| Precision | Recall | Precision | Recall | Precision | Recall | Precision | Recall | |
| Adapter | 100.0% | 50.0% | 85.7% | 100.0% | 83.3% | 83.3% | 94.4% | 94.4% |
| Command | ||||||||
| Composite | 100.0% | 100.0% | 50.0% | 100.0% | 50.0% | 100.0% | 100.0% | 100.0% |
| Decorator | 100.0% | 100.0% | 75.0% | 100.0% | 60.0% | 100.0% | 75.0% | 100.0% |
| Factory method | 100.0% | 100.0% | 100.0% | 66.7% | 100.0% | 33.3% | 100.0% | 66.7% |
| Observer | 100.0% | 60.0% | 71.4% | 100.0% | 62.5% | 100.0% | 80.0% | 80.0% |
| Prototype | 100.0% | 100.0% | 100.0% | 100.0% | 100.0% | 100.0% | 100.0% | 100.0% |
| Singleton | 100.0% | 100.0% | 66.7% | 100.0% | 100.0% | 50.0% | 100.0% | 100.0% |
| State | 100.0% | 95.7% | 88.0% | 95.7% | 91.3% | 91.3% | 92.0% | 100.0% |
| Strategy | ||||||||
| Template Method | 100.0% | 100.0% | 62.5% | 100.0% | 50.0% | 80.0% | 100.0% | 100.0% |
| Visitor | 0.0% | 50.0% | 100.0% | 33.3% | 100.0% | 100.0% | 100.0% | |
| Average | 90.0% | 80.6% | 74.9% | 96.2% | 73.0% | 83.8% | 94.1% | 94.1% |
| Design Pattern | Mayvan et al.’s Method | Tsantalis et al.’s Method | Luitel et al.’s Method | Our Method | ||||
|---|---|---|---|---|---|---|---|---|
| Precision | Recall | Precision | Recall | Precision | Recall | Precision | Recall | |
| Adapter | 100.0% | 57.1% | 77.8% | 100.0% | 75.0% | 85.7% | 85.7% | 85.7% |
| Command | ||||||||
| Decorator | 0.0% | 100.0% | 100.0% | 0.0% | 100.0% | 100.0% | ||
| Factory method | 100.0% | 75.0% | 100.0% | 25.0% | 66.7% | 50.0% | 100.0% | 50.0% |
| Singleton | 100.0% | 75.0% | 85.7% | 100.0% | 90.9% | 83.3% | 92.3% | 100.0% |
| State | 100.0% | 91.7% | 68.8% | 91.7% | 71.4% | 83.3% | 100.0% | 91.7% |
| Strategy | ||||||||
| Template Method | 85.0% | 100.0% | 56.7% | 100.0% | 72.7% | 94.1% | 89.5% | 100.0% |
| Visitor | 100.0% | 100.0% | 66.7% | 100.0% | 33.3% | 50.0% | 66.7% | 100.0% |
| Average | 83.6% | 71.3% | 79.4% | 88.1% | 58.6% | 63.8% | 90.6% | 89.6% |
| Design Pattern | Mayvan et al.’s Method | Tsantalis et al.’s Method | Luitel et al.’s Method | Our Method | ||||
|---|---|---|---|---|---|---|---|---|
| Precision | Recall | Precision | Recall | Precision | Recall | Precision | Recall | |
| Adapter | 100.0% | 100.0% | 50.0% | 100.0% | 50.0% | 100.0% | 100.0% | 100.0% |
| Command | ||||||||
| Composite | 100.0% | 100.0% | 100.0% | 100.0% | 100.0% | 100.0% | 100.0% | 100.0% |
| Decorator | 100.0% | 100.0% | 50.0% | 100.0% | 50.0% | 100.0% | 100.0% | 100.0% |
| Observer | 100.0% | 75.0% | 66.7% | 100.0% | 75.0% | 75.0% | 66.7% | 100.0% |
| State | 100.0% | 100.0% | 60.0% | 100.0% | 66.7% | 66.7% | 75.0% | 100.0% |
| Strategy | ||||||||
| Template Method | 100.0% | 100.0% | 33.3% | 100.0% | 25.0% | 100.0% | 100.0% | 100.0% |
| Average | 100.0% | 95.8% | 60.0% | 100.0% | 61.1% | 90.3% | 90.3% | 100.0% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Song, T.; Song, H.-N.; Zhang, S. Research on Design Pattern Detection Method Based on UML Model with Extended Image Information and Deep Learning. Appl. Sci. 2022, 12, 8718. https://doi.org/10.3390/app12178718
Wang L, Song T, Song H-N, Zhang S. Research on Design Pattern Detection Method Based on UML Model with Extended Image Information and Deep Learning. Applied Sciences. 2022; 12(17):8718. https://doi.org/10.3390/app12178718
Chicago/Turabian StyleWang, Lei, Tian Song, Hui-Na Song, and Shuai Zhang. 2022. "Research on Design Pattern Detection Method Based on UML Model with Extended Image Information and Deep Learning" Applied Sciences 12, no. 17: 8718. https://doi.org/10.3390/app12178718
APA StyleWang, L., Song, T., Song, H.-N., & Zhang, S. (2022). Research on Design Pattern Detection Method Based on UML Model with Extended Image Information and Deep Learning. Applied Sciences, 12(17), 8718. https://doi.org/10.3390/app12178718