
Analysis of a Human Meta-Strategy for Agents with Active and Passive Strategies


Abstract
:1. Introduction
2. Background
3. Agent Model
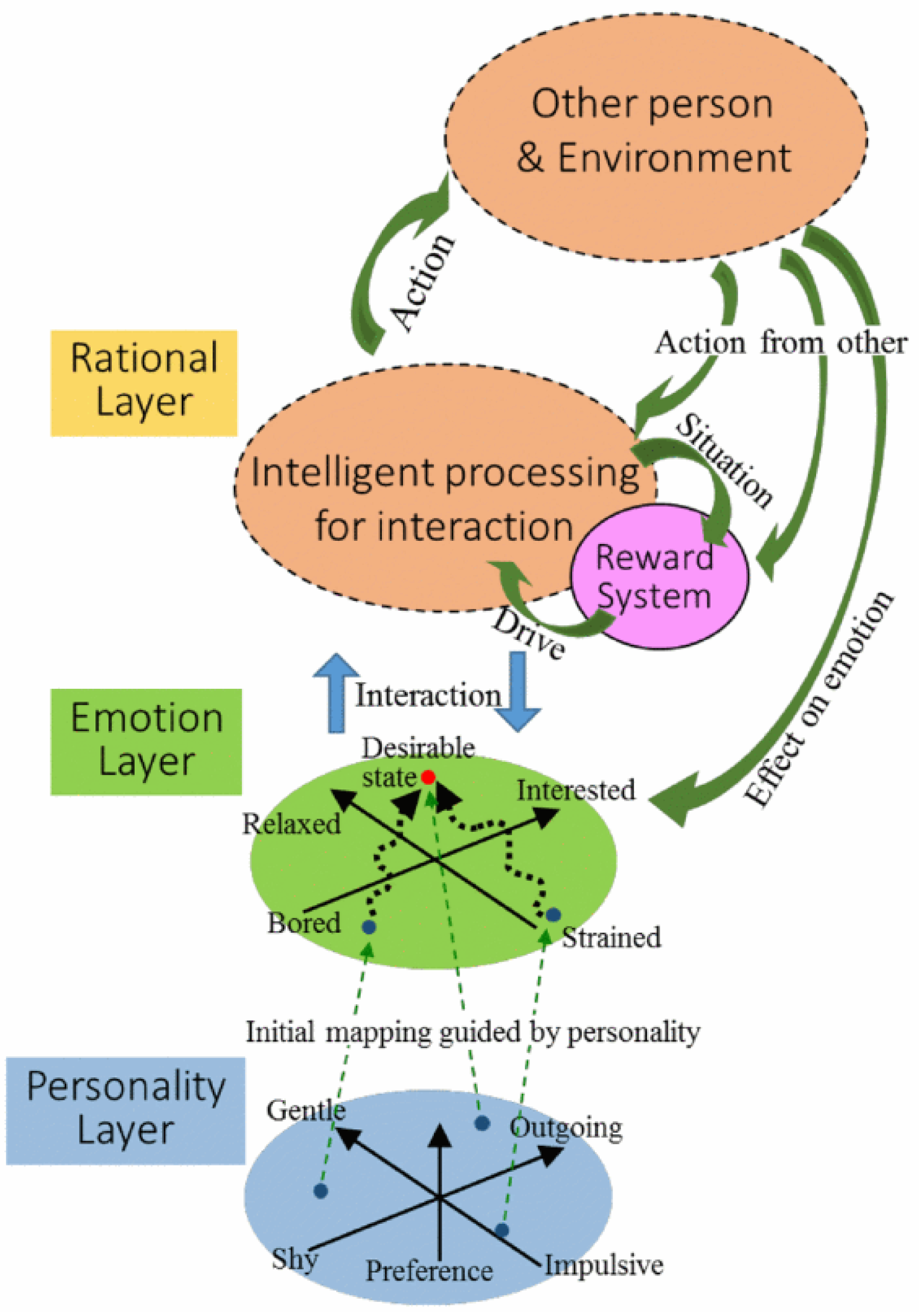
3.1. Agent Model with a Meta-Strategy
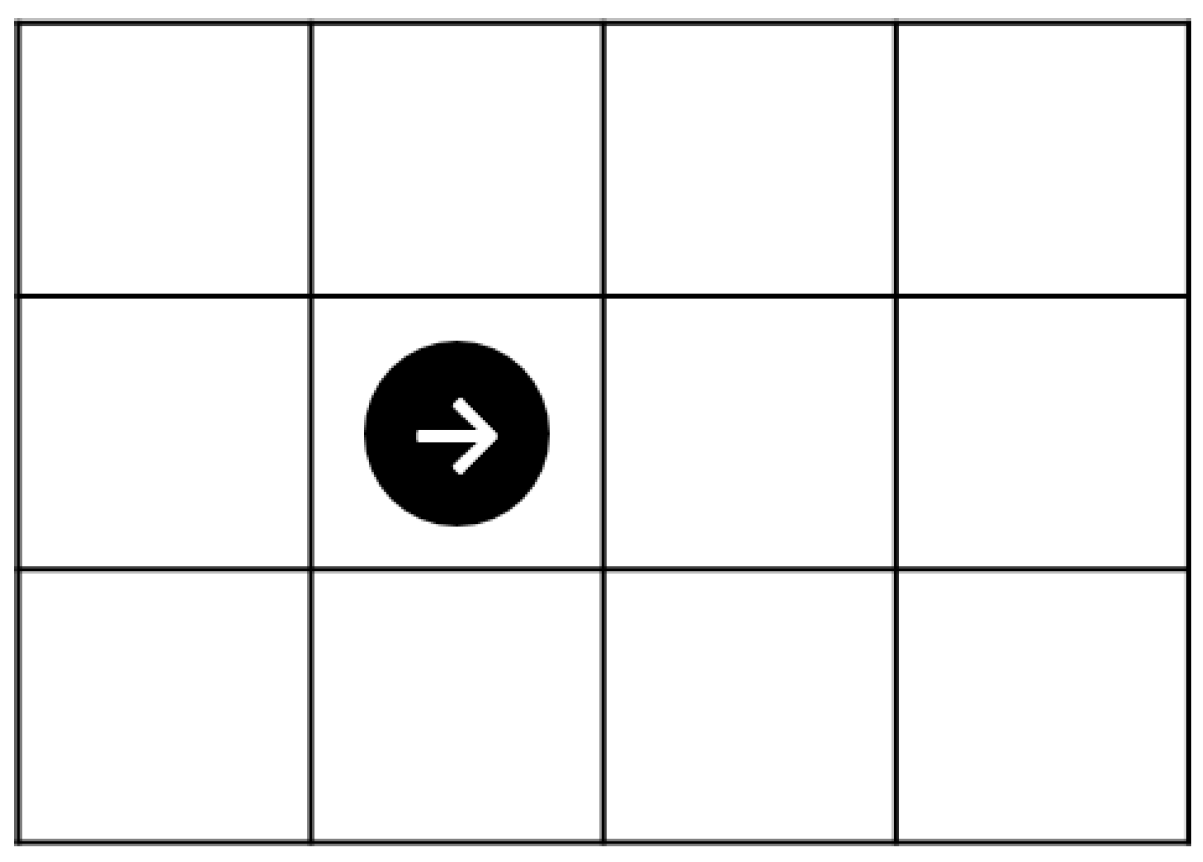
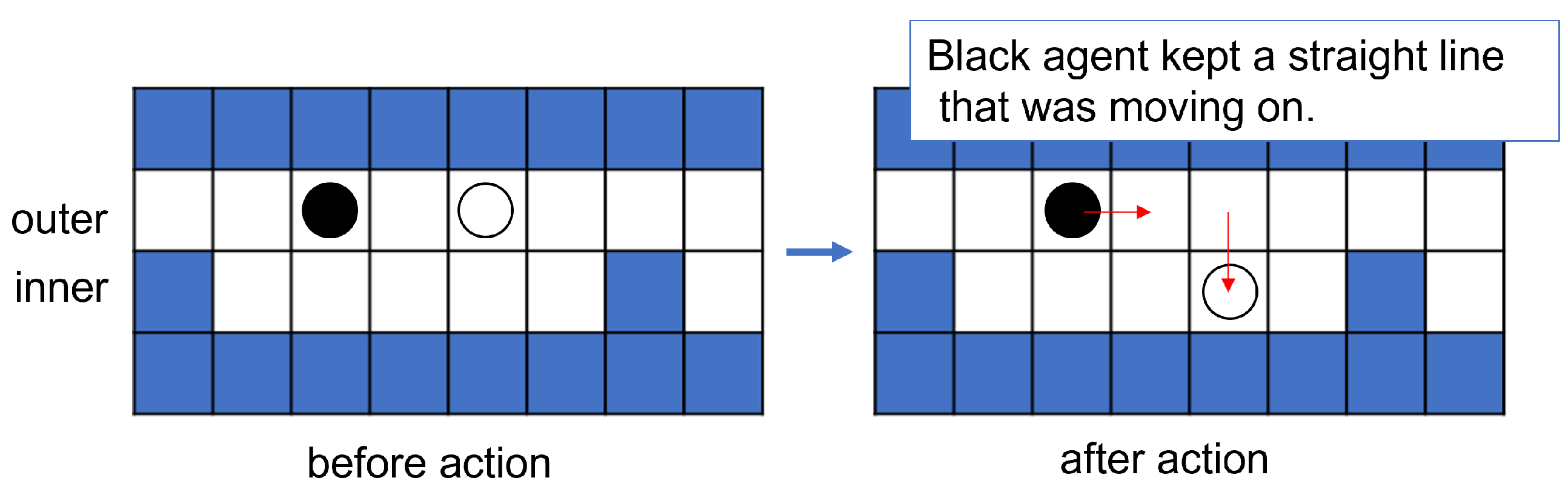
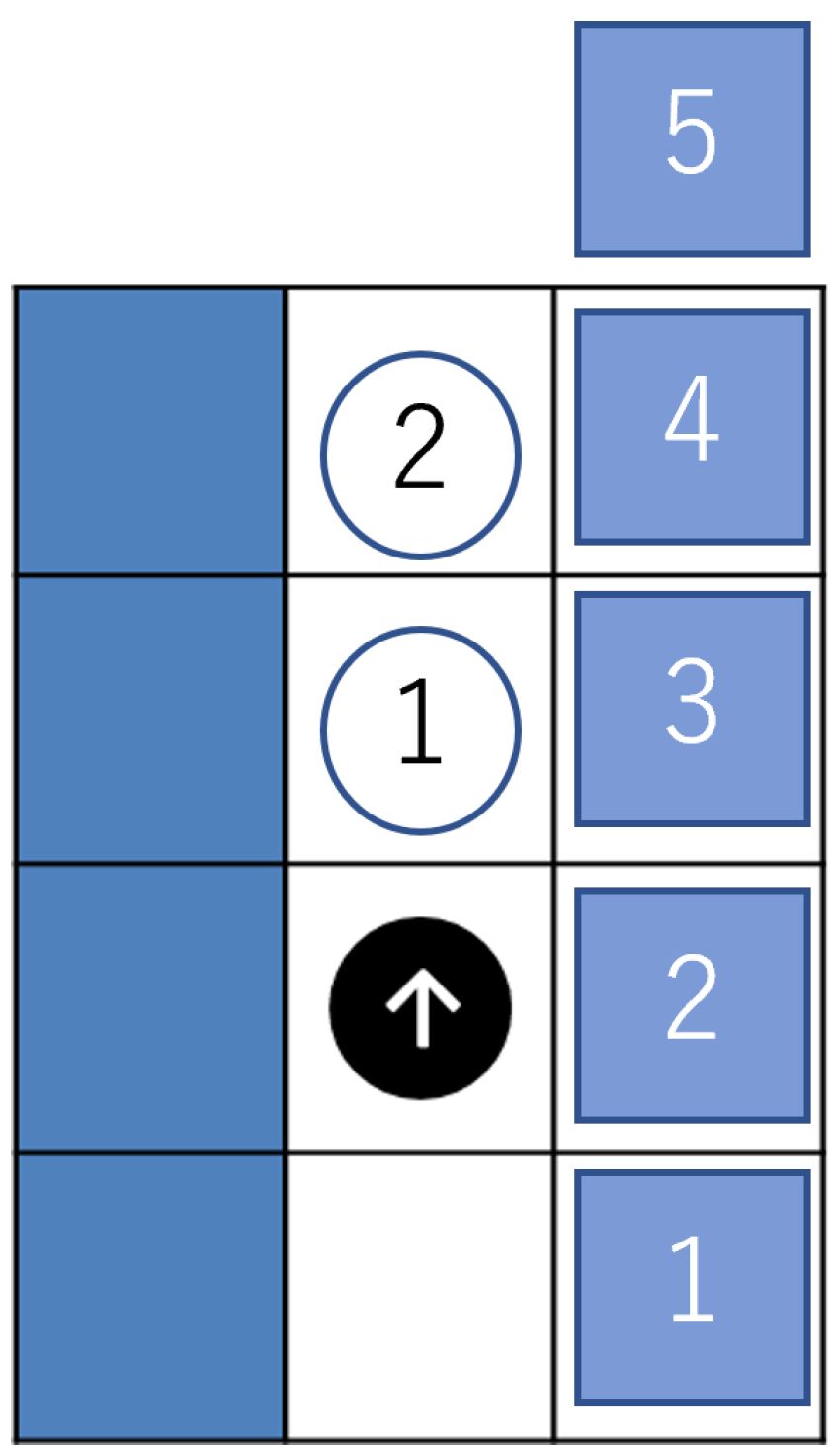
3.2. Behavioral Environment of the Agents
3.3. Learning in a One-to-One Interaction
4. Measurement Experiment on Human Actions in Collision Avoidance with an Agent
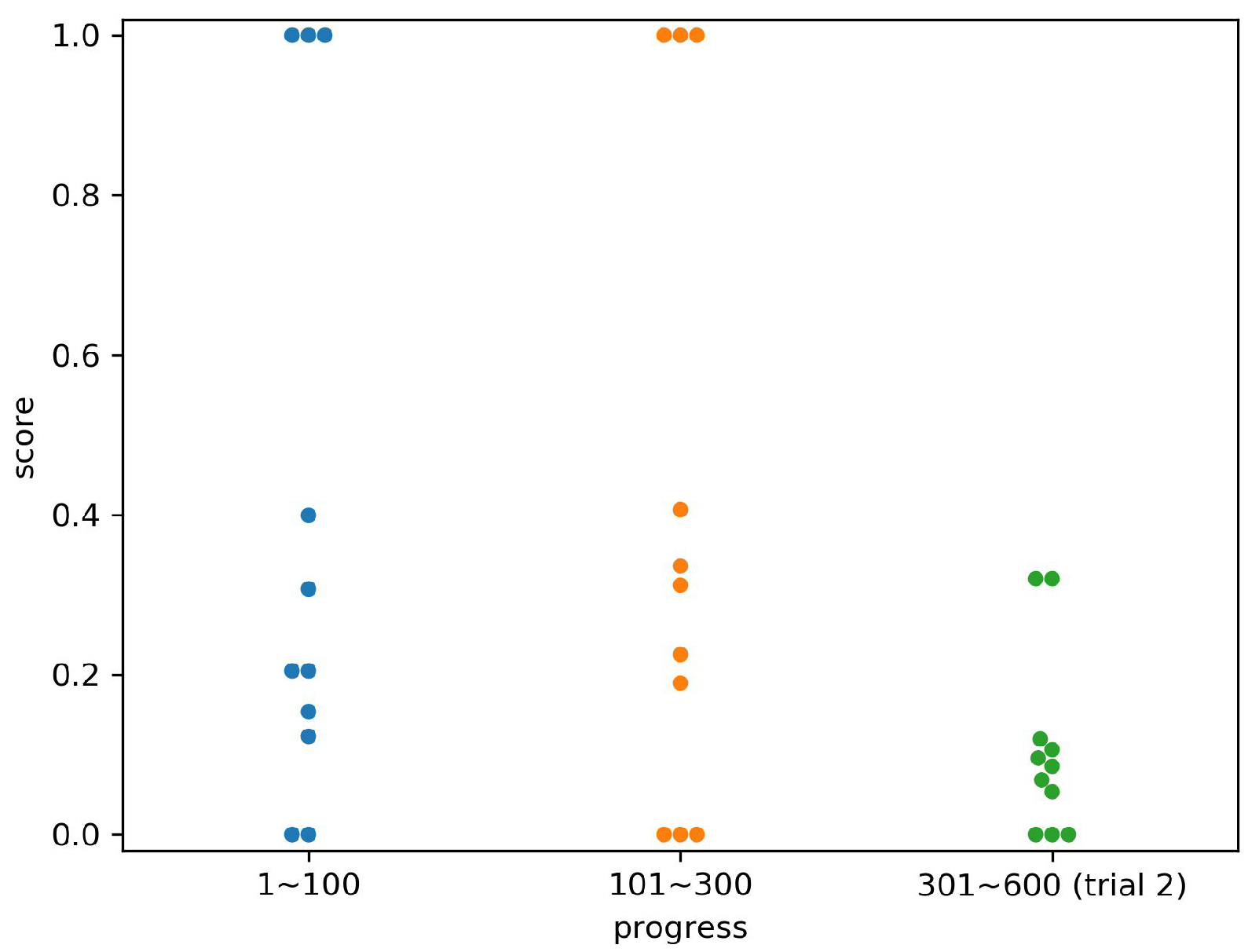
4.1. Experimental Objective
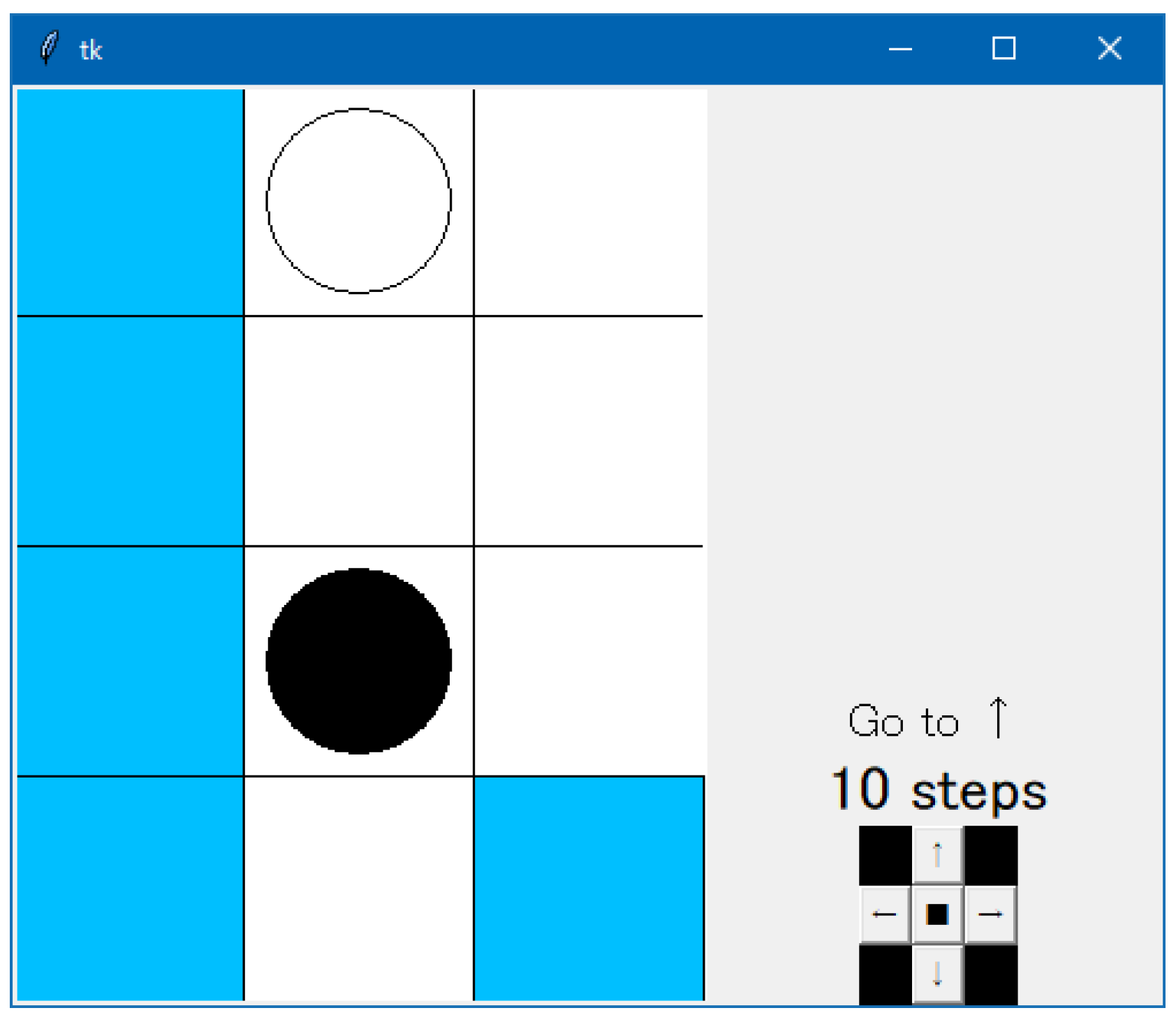
4.2. Methods
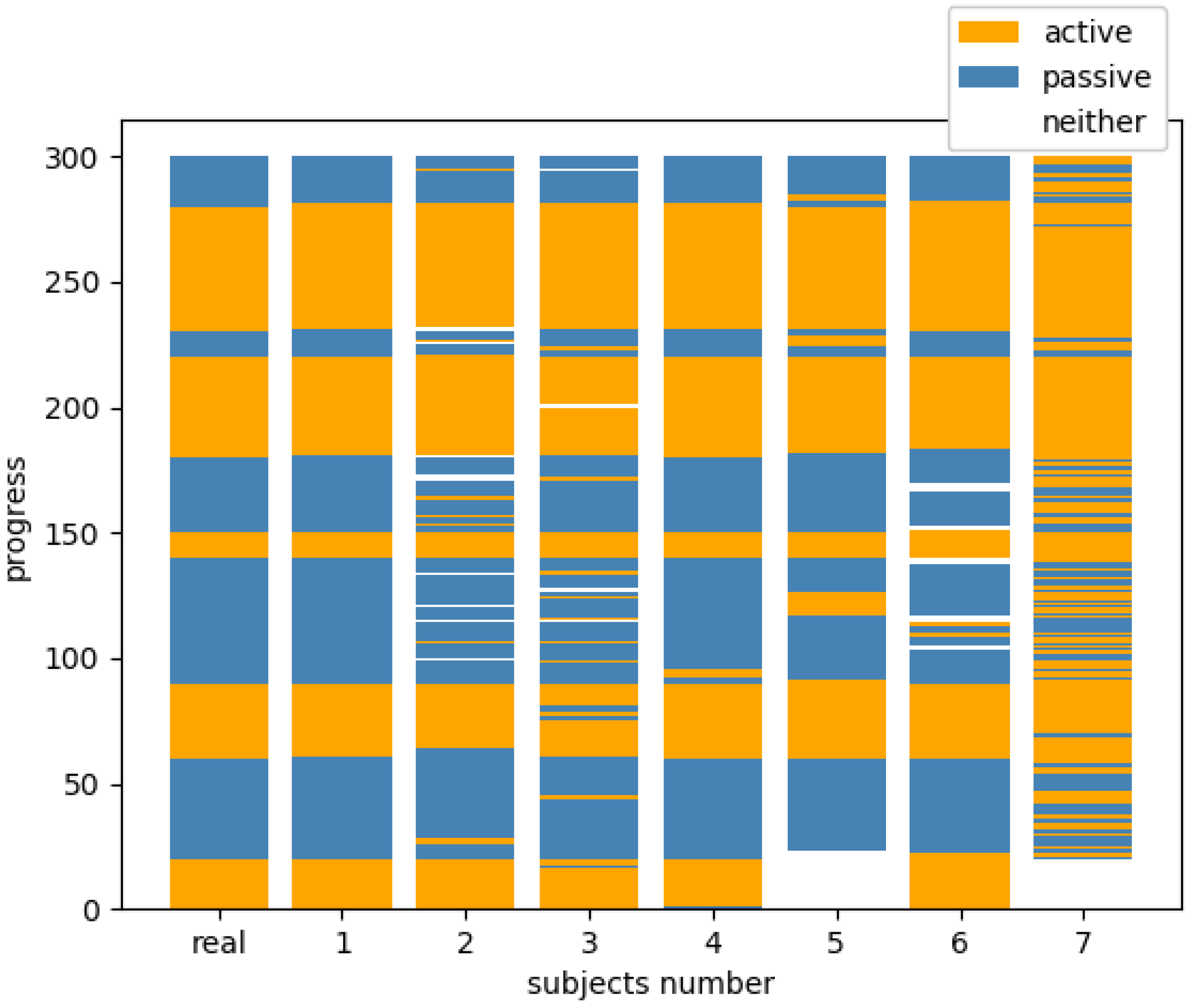
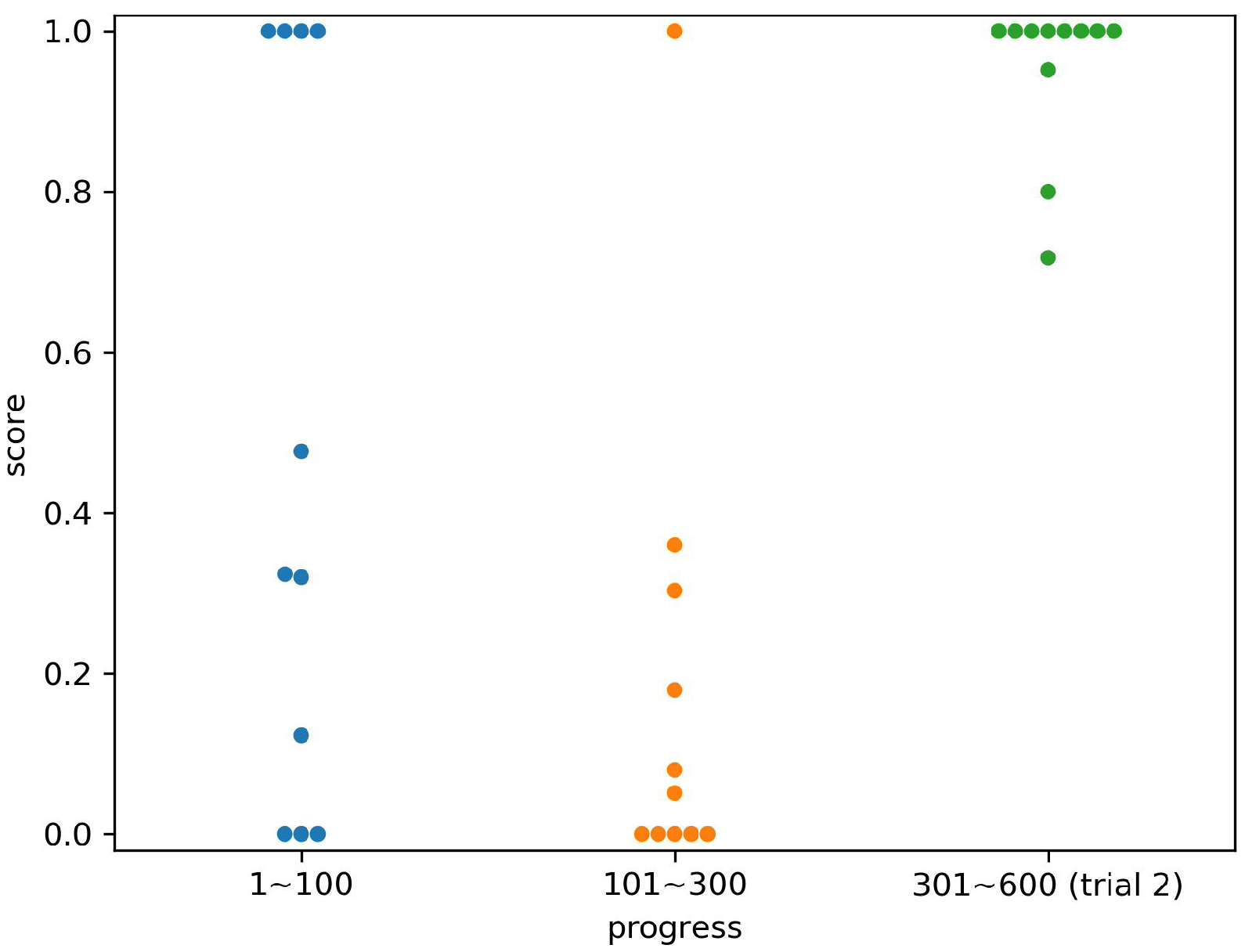
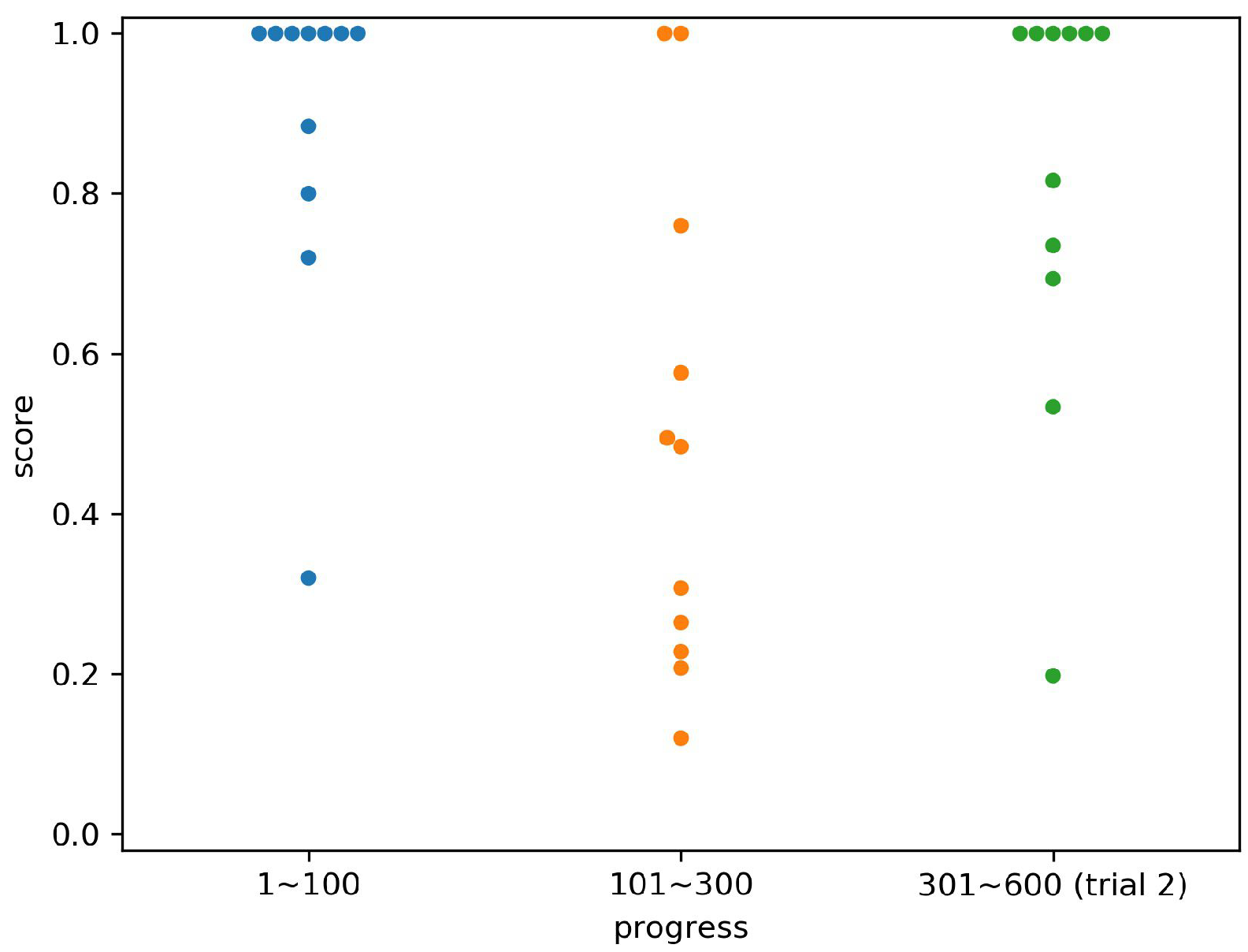
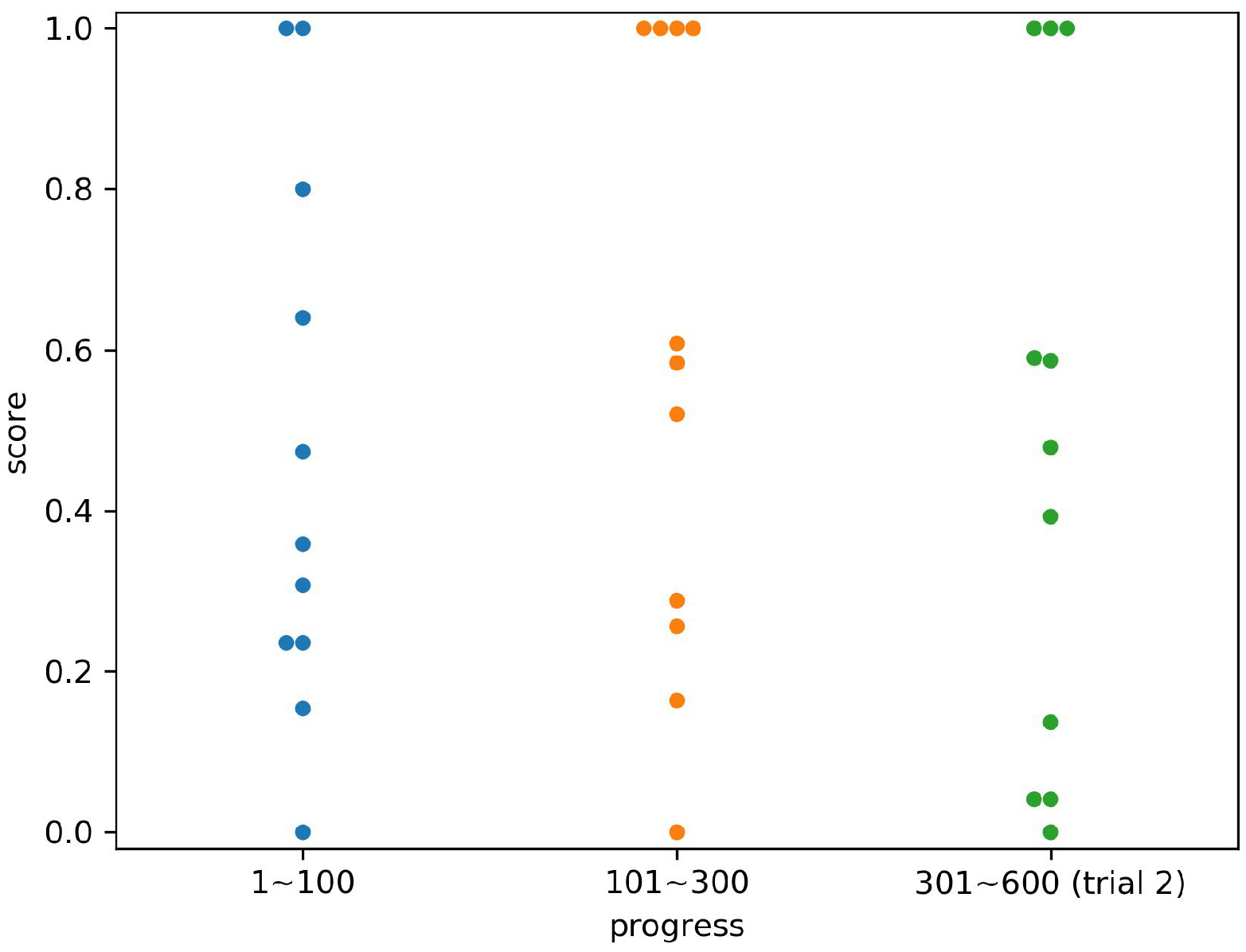
4.3. Result
4.4. Discussion
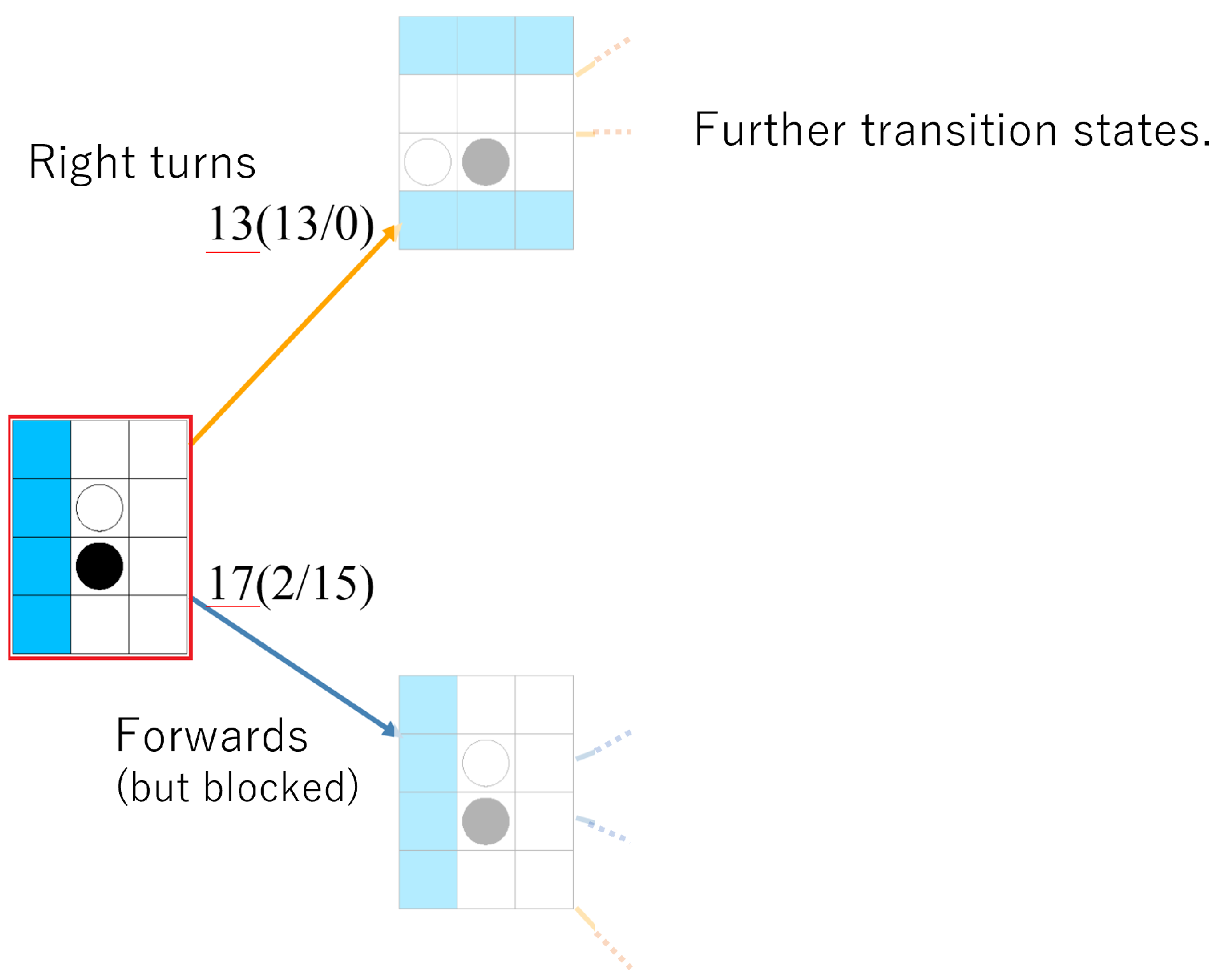
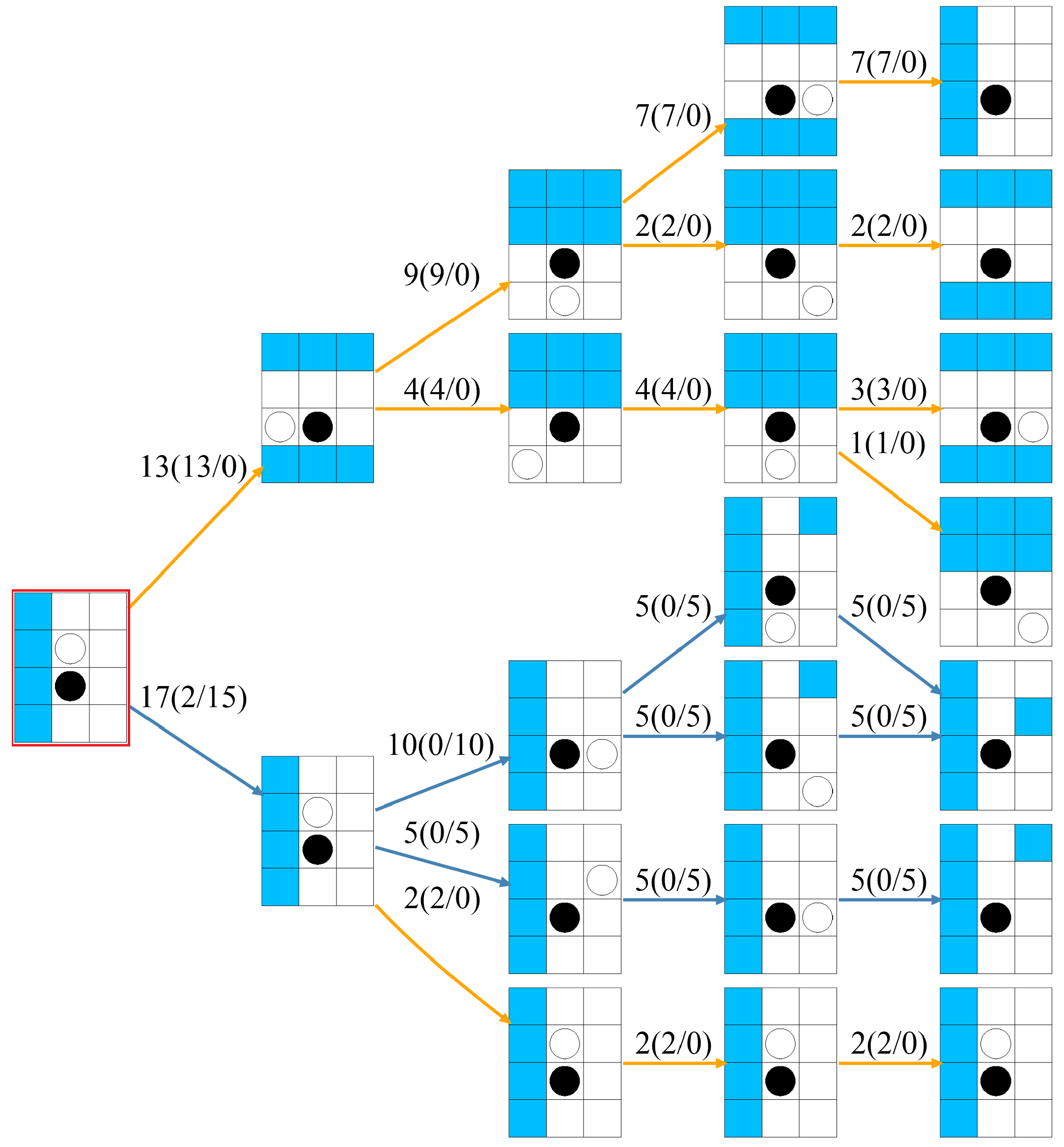
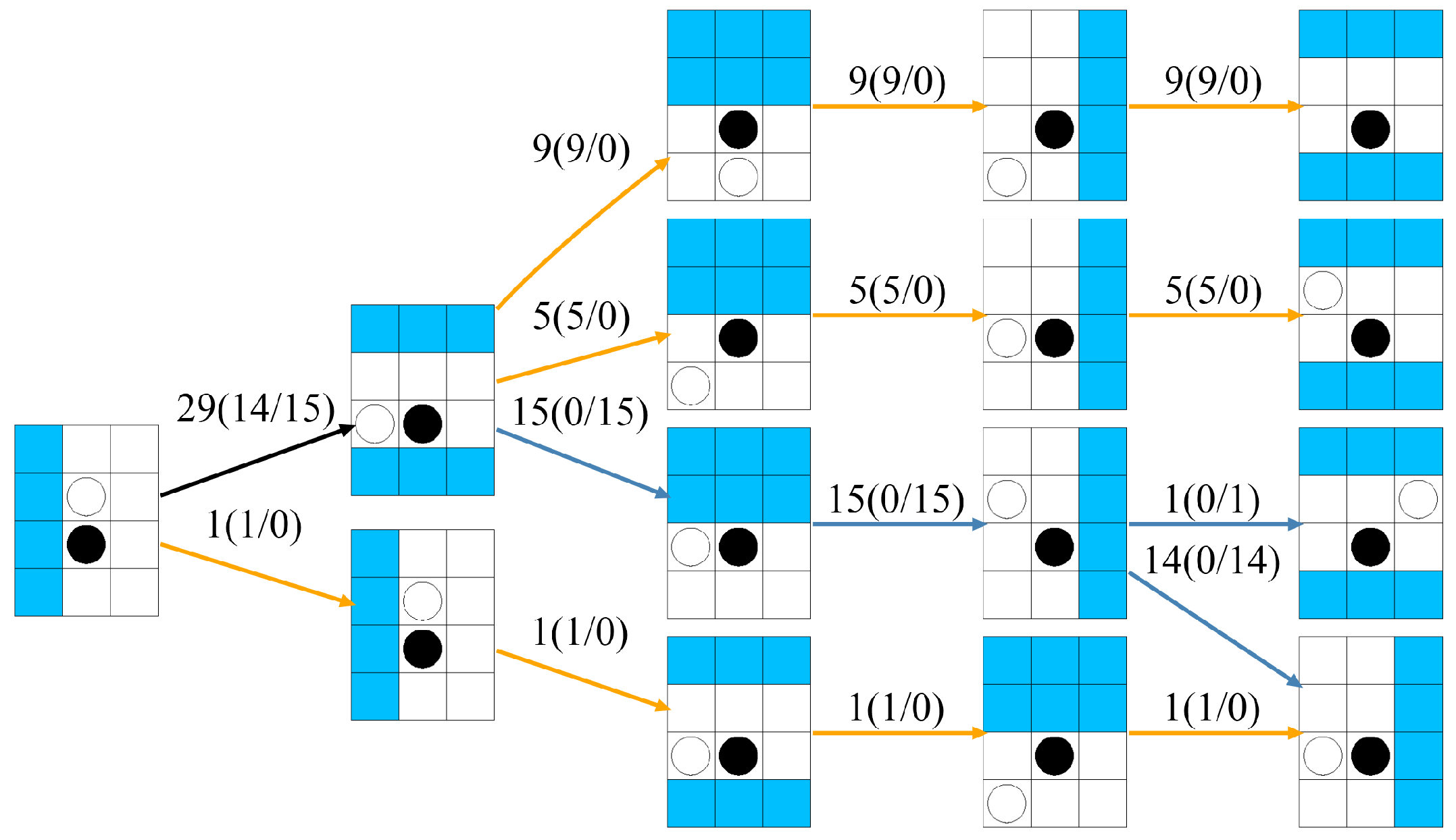
5. Behavior of Agents according to Human Meta-Strategy Characteristics
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Itoda, K.; Watanabe, N.; Takefuji, Y. Analyzing human decision making process with intention estimation using cooperative pattern task. In Proceedings of the 10th International Conference on Artificial General Intelligence (AGI 2017), Melbourne, Australia, 15–18 August 2017; pp. 249–258. [Google Scholar]
- Osawa, M.; Okuoka, K.; Sakamoto, T.; Ichikawa, J.; Imai, M. Other’s Mind Model Based on Cognitive Interaction Framework. In Proceedings of the Human-Agent Interaction Symposium 2020, online, 7–8 March 2020; p. 40. (In Japanese). [Google Scholar]
- Belpaeme, T.; Baxter, P.; Wood, R.; Cuayáhuitl, H.; Kiefer, B.; Racioppa, S.; Kruijff-Korbayová, I.; Athanasopoulos, G.; Enescu, V.; Looije, R.; et al. Mutlimodal child-robot interaction, Building social bonds. J. Hum.-Robot. Interact. 2013, 1, 33–53. [Google Scholar] [CrossRef]
- Yokoyama, A.; Omori, T. Modeling of human intention estimation process in social interaction scene. In Proceedings of the 2010 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Barcelona, Spain, 18–23 July 2010; pp. 1–6. [Google Scholar]
- Miyamoto, K.; Watanabe, N.; Takefuji, Y. Adaptation to Other Agent’s Behavior Using Meta-Strategy Learning by Collision Avoidance Simulation. Appl. Sci. 2021, 11, 1786. [Google Scholar] [CrossRef]
- Omori, T.; Shimotomai, T.; Abe, K.; Nagai, T. Model of strategic behavior for interaction that guide others internal state. In Proceedings of the 2015 24th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), Kobe, Japan, 31 August–4 September 2015; pp. 101–105. [Google Scholar] [CrossRef]
- Abe, K.; Hamada, Y.; Nagai, T.; Shiomi, M.; Omori, T. Estimation of child personality for child-robot interaction. In Proceedings of the 2017 26th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), Lisbon, Portugal, 28 August–1 September 2017; pp. 910–915. [Google Scholar] [CrossRef]
- Hieida, C.; Abe, K.; Nagai, T.; Omori, T. Walking Hand-in-Hand Helps Relationship Building Between Child and Robot. J. Robot. Mechatron. 2020, 32, 8–20. [Google Scholar] [CrossRef]
- Sugahara, R.; Katagami, D. Proposal of discommunication robot. In Proceedings of the First International Conference on Human-Agent Interaction, Sapporo, Japan, 7–9 August 2013. [Google Scholar]
- Katagami, D.; Tanaka, Y. Change of impression resulting fromvoice in Discommunication motion of baby robot. In Proceedings of the HAI Symposium, Copenhagen, Denmark, 28–30 May 2015; pp. 171–176. (In Japanese). [Google Scholar]
- Kozima, H.; Michalowski, M.P.; Nakagawa, C. Keepon: A playful robot for research, therapy, and entertainment. Int. J. Soc. Robot. 2009, 1, 3–18. [Google Scholar] [CrossRef]
- Sato, T. Emergence of robust cooperative states by Iterative internalizations of opponents’ personalized values in minority game. J. Inf. Commun. Eng. 2017, 3, 157–166. [Google Scholar]
- Okamura, K.; Yamada, S. Empirical Evaluations of Framework for Adaptive Trust Calibration in Human-AI Cooperation. IEEE Access 2020, 8, 220335–220351. [Google Scholar] [CrossRef]
- Yamada, K.; Takano, S.; Watanabe, S. Reinforcement Learning Approaches for Acquiring Conflict Avoidance Behaviors in Multi-Agent Systems. In Proceedings of the 2011 IEEE/SICE International Symposium on System Integration, Kyoto, Japan, 20–22 December 2011; pp. 679–684. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Abe, K.; Hieida, C.; Attamimi, M.; Nagai, T.; Shimotomai, T.; Omori, T.; Oka, N. Toward playmate robots that can play with children considering personality. In Proceedings of the Second International Conference on Human-Agent Interaction (HAI ’14), New York, NY, USA, 29–31 October 2014; pp. 165–168. [Google Scholar]
- Koga, H. A construction of revised machiavellianism scale. Rikkyo Psychol. Res. 2000, 42, 83–92. (In Japanese) [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subject 1 | Subject 2 | Subject 3 | Subject 4 | Subject 5 | Subject 6 | Subject 7 | |
|---|---|---|---|---|---|---|---|
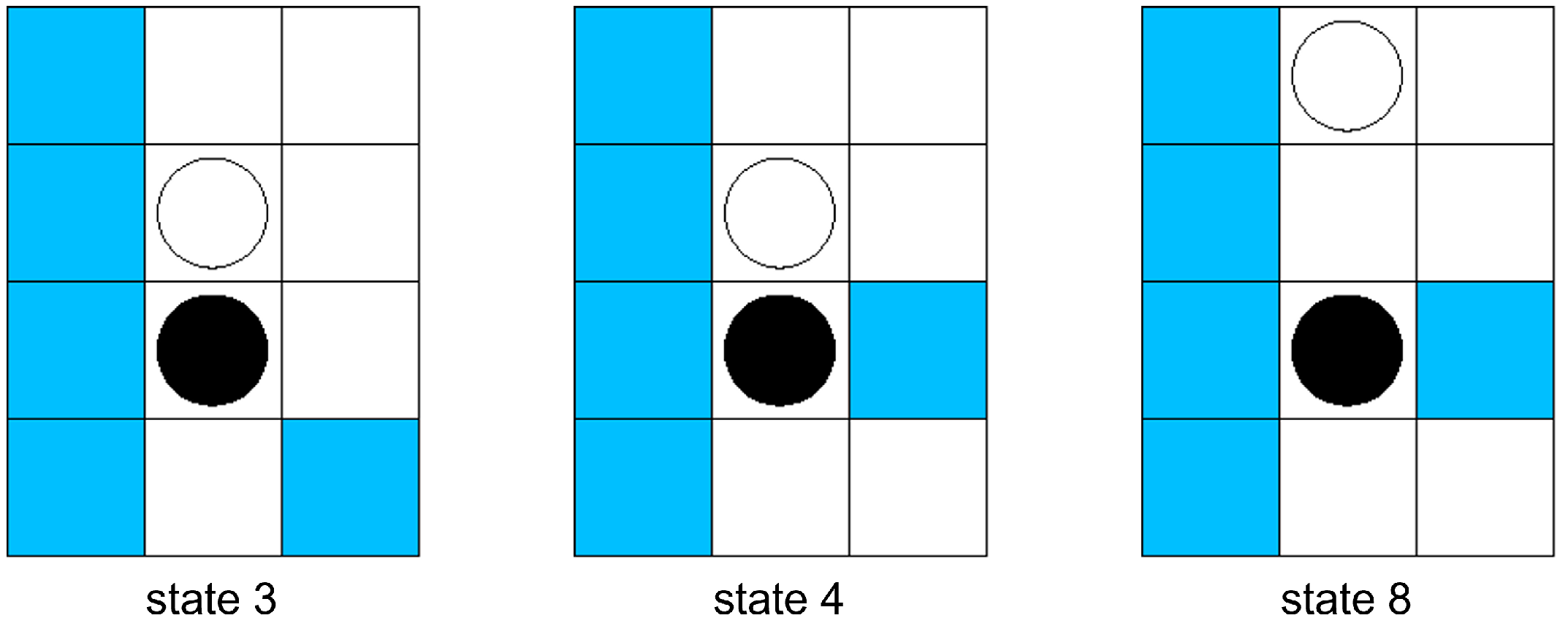
| state 1 | 1.00 | 1.00 | 1.00 | 0.59 | 0.77 | 0.32 | 0.00 |
| state 2 | 1.00 | 1.00 | 1.00 | 1.00 | 0.75 | 0.32 | 0.00 |
| state 3 | 1.00 | 1.00 | 1.00 | 1.00 | 0.80 | 0.00 | 0.00 |
| state 4 | 0.00 | 1.00 | 0.20 | 0.14 | 0.00 | 0.09 | 0.00 |
| state 5 | 1.00 | 1.00 | 1.00 | 0.04 | 0.00 | 0.00 | 0.00 |
| state 6 | 1.00 | 1.00 | 0.69 | 0.39 | 0.14 | 0.07 | 0.00 |
| state 7 | 1.00 | 0.72 | 0.73 | 1.00 | 0.14 | 0.05 | 0.00 |
| state 8 | 0.53 | 0.8 | 0.53 | 0.59 | 1.00 | 0.12 | 0.00 |
| state 9 | 1.00 | 1.00 | 1.00 | 0.04 | 0.00 | 0.10 | 0.00 |
| state 10 | 1.00 | 1.00 | 1.00 | 0.00 | 0.09 | 0.00 | 0.00 |
| average | 0.85 | 0.95 | 0.82 | 0.48 | 0.37 | 0.11 | 0.00 |
| variance | 0.11 | 0.01 | 0.08 | 0.18 | 0.16 | 0.01 | 0.00 |
| Subject 1 | Subject 2 | Subject 3 | Subject 4 | Subject 5 | Subject 6 | Subject 7 | Average | Variance |
|---|---|---|---|---|---|---|---|---|
| 20.891 | 19.036 | 21.183 | 19.207 | 14.472 | 21.292 | 18.943 | 19.289 | 5.593 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Miyamoto, K.; Watanabe, N.; Nakamura, O.; Takefuji, Y. Analysis of a Human Meta-Strategy for Agents with Active and Passive Strategies. Appl. Sci. 2022, 12, 8720. https://doi.org/10.3390/app12178720
Miyamoto K, Watanabe N, Nakamura O, Takefuji Y. Analysis of a Human Meta-Strategy for Agents with Active and Passive Strategies. Applied Sciences. 2022; 12(17):8720. https://doi.org/10.3390/app12178720
Chicago/Turabian StyleMiyamoto, Kensuke, Norifumi Watanabe, Osamu Nakamura, and Yoshiyasu Takefuji. 2022. "Analysis of a Human Meta-Strategy for Agents with Active and Passive Strategies" Applied Sciences 12, no. 17: 8720. https://doi.org/10.3390/app12178720
APA StyleMiyamoto, K., Watanabe, N., Nakamura, O., & Takefuji, Y. (2022). Analysis of a Human Meta-Strategy for Agents with Active and Passive Strategies. Applied Sciences, 12(17), 8720. https://doi.org/10.3390/app12178720