Privacy-Preserving Process Mining in Healthcare †

 ,
, 

Abstract
1. Introduction
2. Related Work
2.1. Privacy-Preserving Data Mining
2.1.1. Generic Privacy-Preserving Data Transformation Approaches
2.1.2. Privacy Models
2.2. Privacy-Preserving Process Mining
3. Data Privacy and Utility Requirements: Healthcare
3.1. Healthcare Process Data
3.2. Legislative Requirements
3.3. Privacy Requirements for Healthcare Process Data
3.4. Data Requirements for Process Mining Approaches
- Process discovery techniques usually take as input a multi-set of traces (i.e., ordered sequences of activity labels) and do not require timestamps; however, timestamps are typically used to order events. Most academic process discovery algorithms (implemented in ProM) and some commercial process discovery tools (e.g., Celonis) can discover formal models with concurrency (represented using modeling notations with well-defined semantics, e.g., Petri nets). Such algorithms require that all events in the log refer to cases. On the other hand, most commercial process mining tools (as well as some ProM plugins) convert the log to Directly Follows Graphs (DFG) annotated with frequencies and times, which show how frequently different activities follow each other and average times between them. Such tools then use the annotated DFG to perform process discovery, conformance, and performance analysis. DFG-based tools do not require complete traces and only require that “directly-follows” relations between activities are preserved in the log.
- Most academic process conformance and performance analysis techniques (e.g., alignment-based approaches) use formal models and require that complete traces are recorded in the log; while most commercial tools work with Directly Follows Graphs.
- Organisational mining techniques require resource information to be recorded in the log (in addition to case IDs, activities, and timestamps). Moreover, resource and data attributes can also be required by conformance checking approaches that consider different process perspectives.
- Process variant analysis, which is concerned with comparing process behaviour and performance of different cohorts, often uses case data attributes to distinguish between cohorts.
4. Anonymising Healthcare Process Data
4.1. Anonymising Sensitive Attribute Values
4.2. Anonymising Atypical Process Behaviour
5. Evaluating the Impact of Anonymisation on Process Mining
5.1. Event Logs
5.2. Anonymisation
- Activity suppression was used to hide infrequent activities: for a given value of k (described below), we suppressed all activities that were not performed in at least k cases. Activity suppression targets an infrequent activity linkage threat (e.g., when an adversary with background knowledge of the process can identify a patient by a rare medical test or treatment that was performed in the case).
- Resource suppression was used to hide infrequent resources: for a given value of k, we suppressed all resources that were not involved in at least k cases. Resource suppression targets an infrequent resource linkage threat (e.g., when an adversary can identify a patient by the involvement in the patient’s case of a doctor who is only involved in exceptional cases).
- Data suppression was used to hide infrequent combinations of case data attributes: for a given value of k, we suppressed all combinations of case data attributes that were not associated with at least k cases. This anonymisation method targets infrequent case data linkage threat (e.g., when a patient can be identified by a unique combination of case data attributes, e.g., age, language and diagnosis).
- Generalisation was used to replace exact timestamp values with more general values (e.g., by only keeping the year of an event as we describe below). This anonymisation method targets timestamp linkage threat (e.g., when a patient can be identified by their admission time to the hospital).
5.3. Results
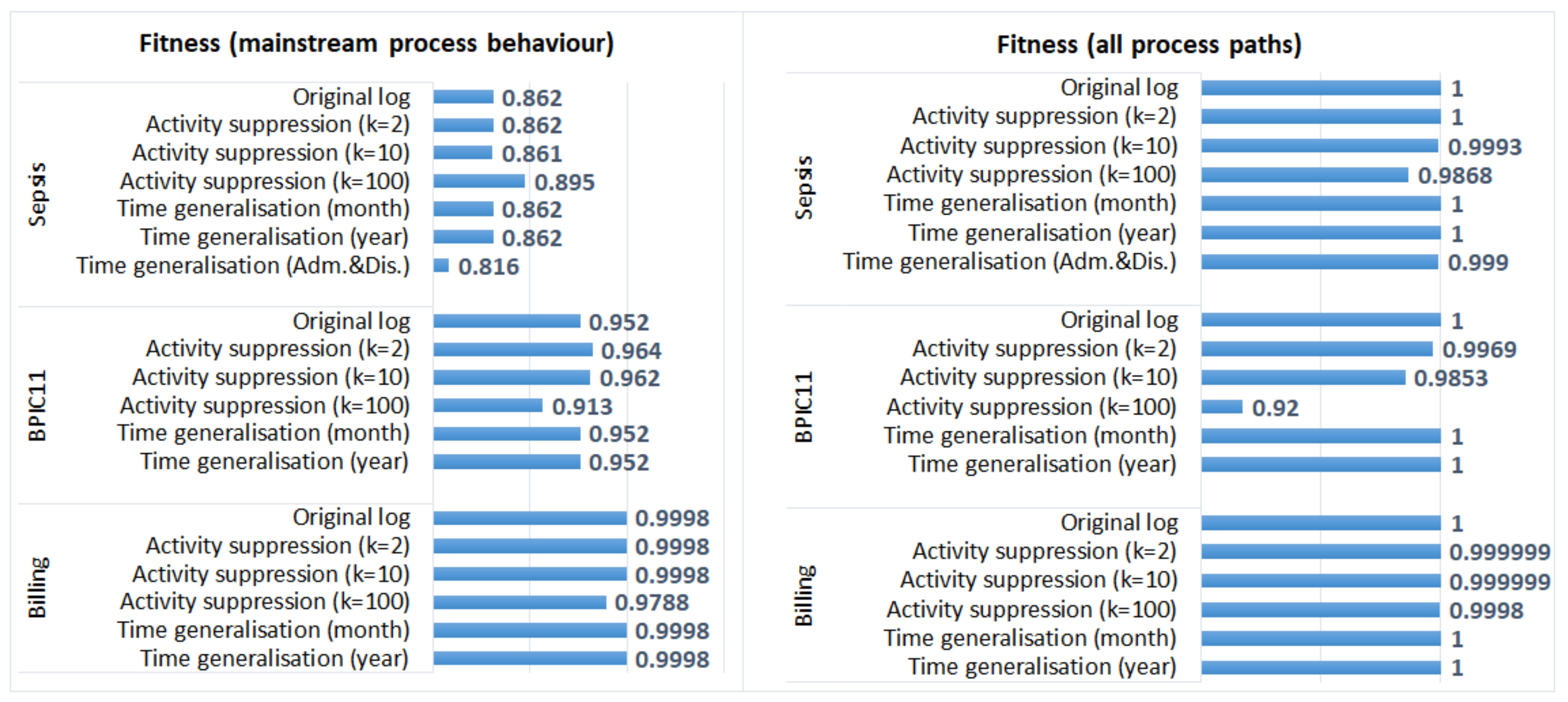
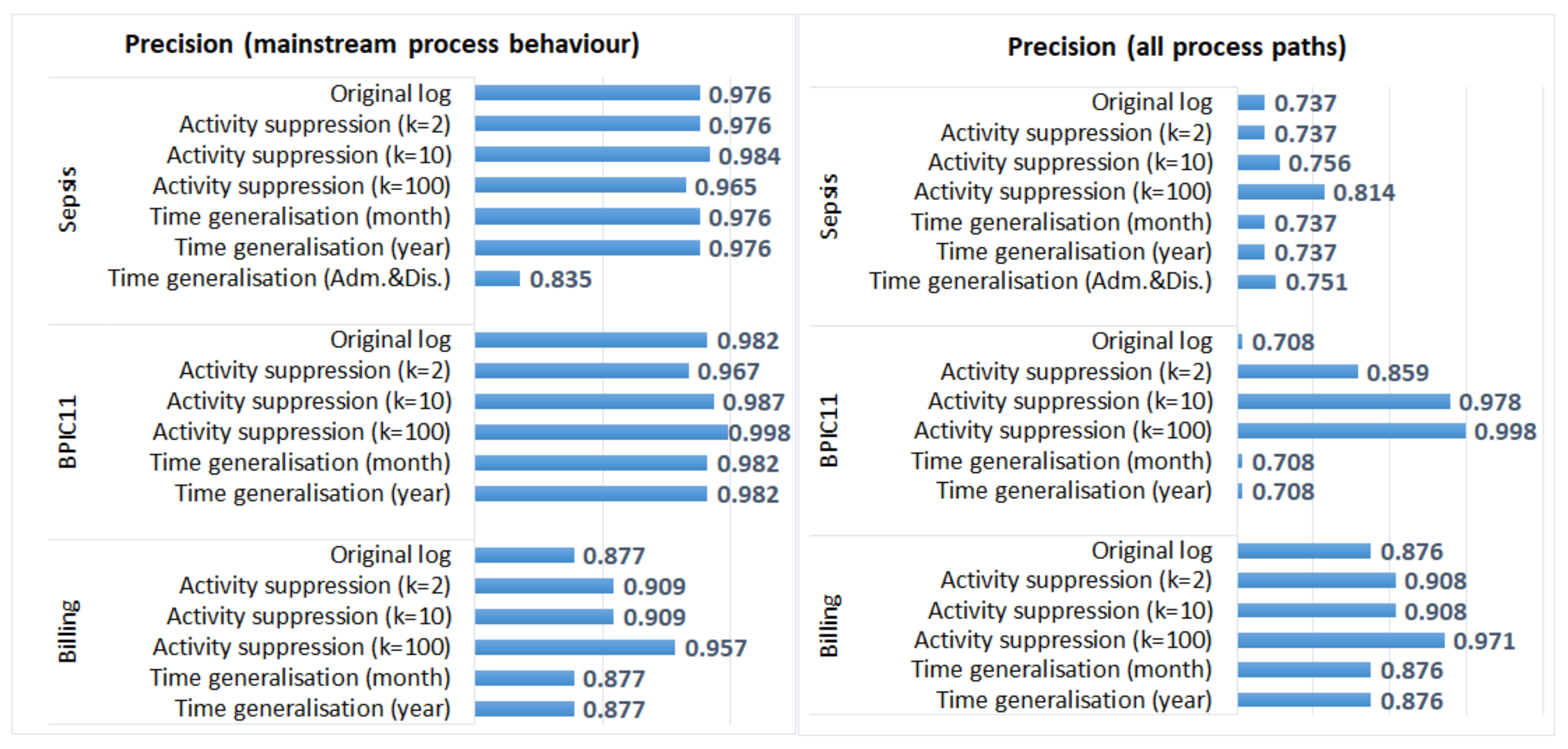
5.3.1. Process Discovery
5.3.2. Process Conformance Analysis
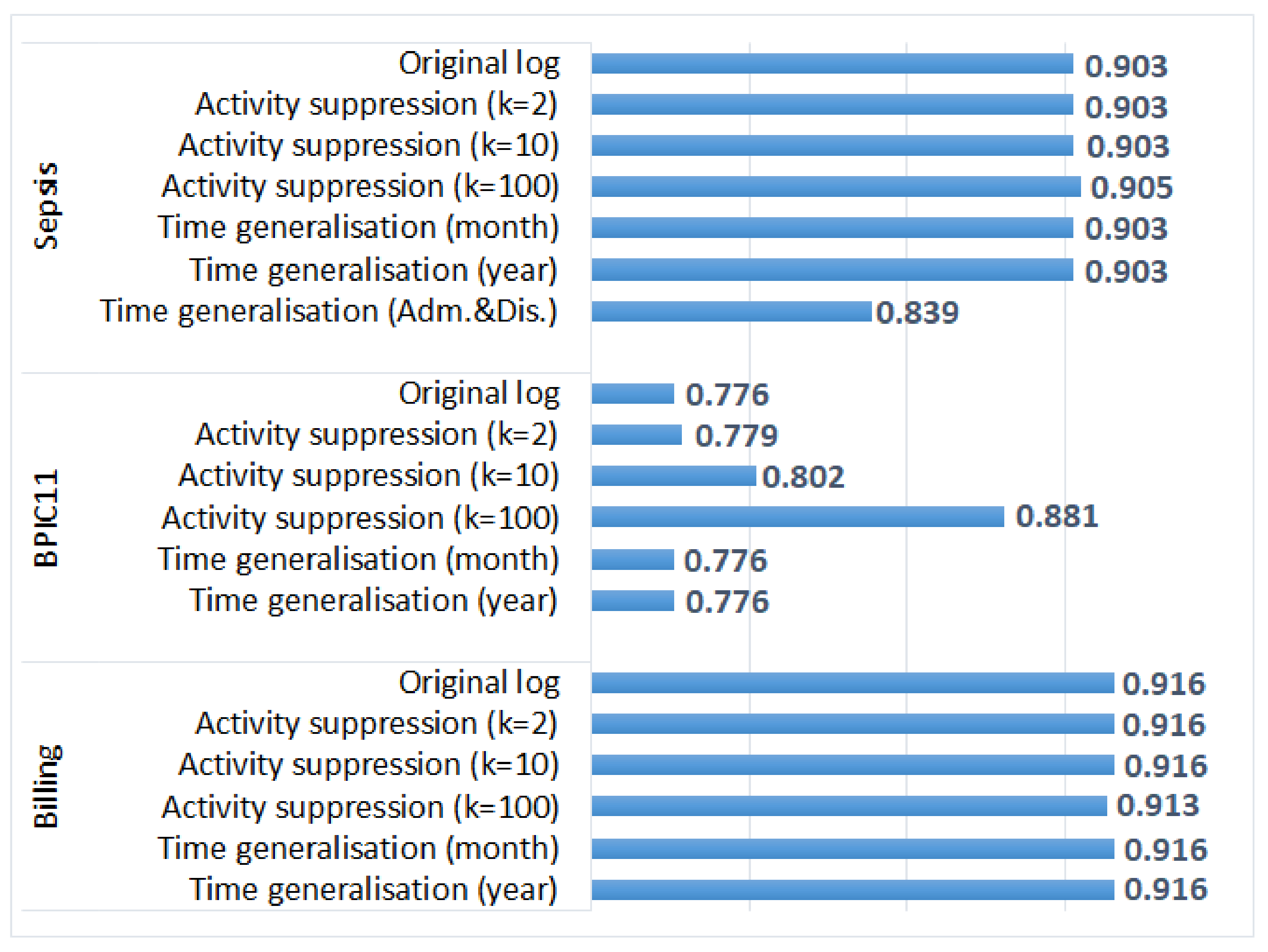
5.3.3. Process Performance Analysis
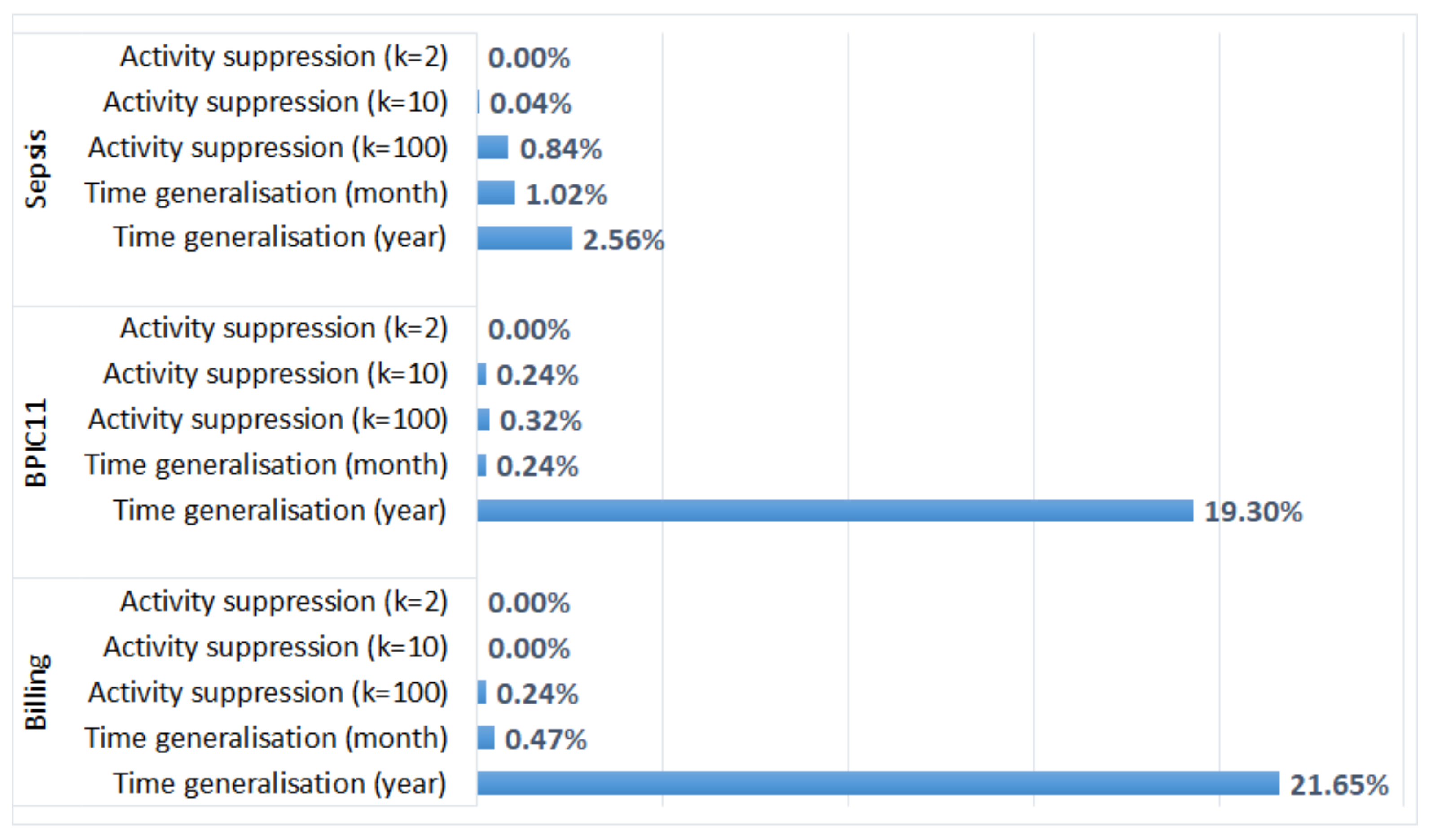
5.3.4. Organisational Mining
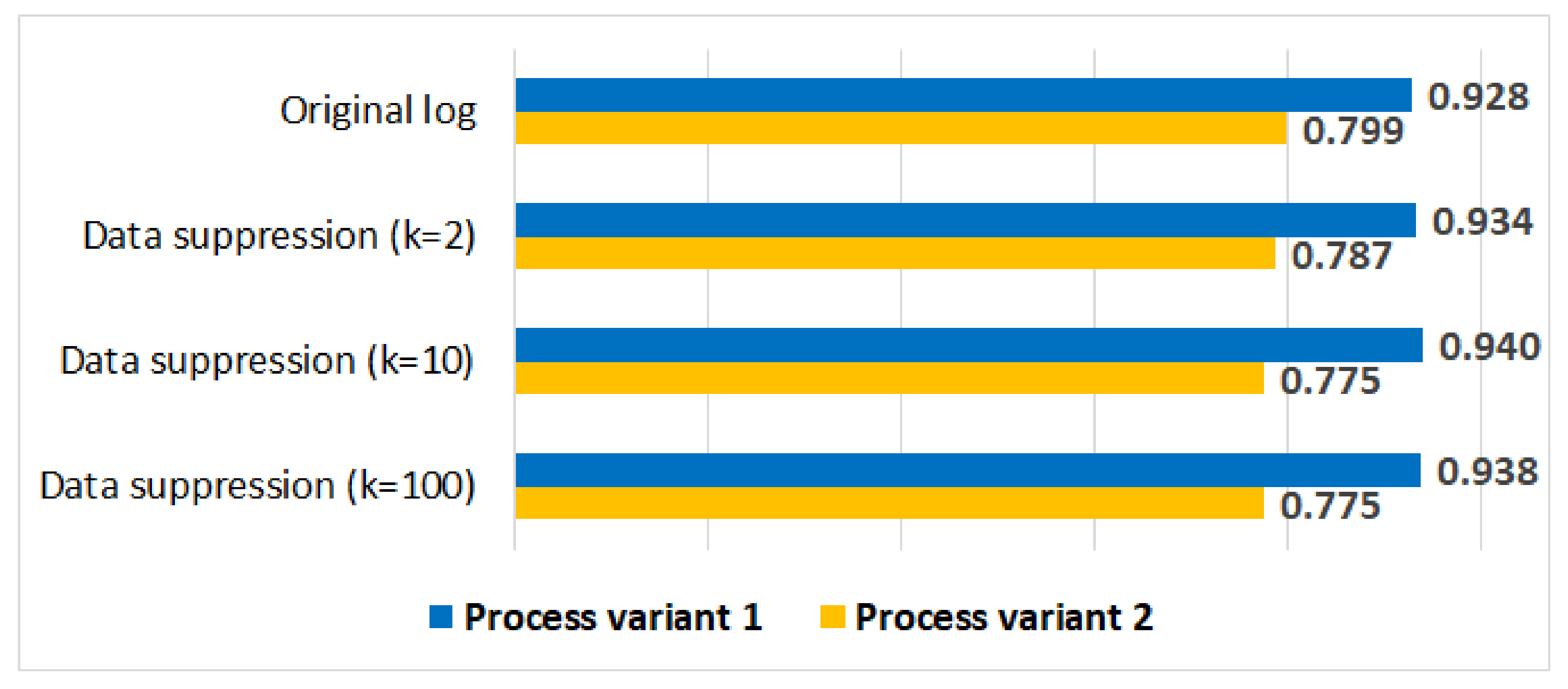
5.3.5. Process Variant Analysis
5.4. Discussion
- Generalisation of all timestamps (which did not change the order of events) did not have any effect on the results of process discovery and process conformance analysis plugins that take as input activity sequences (and do not require timestamps); however, it affected the results of process performance analysis;
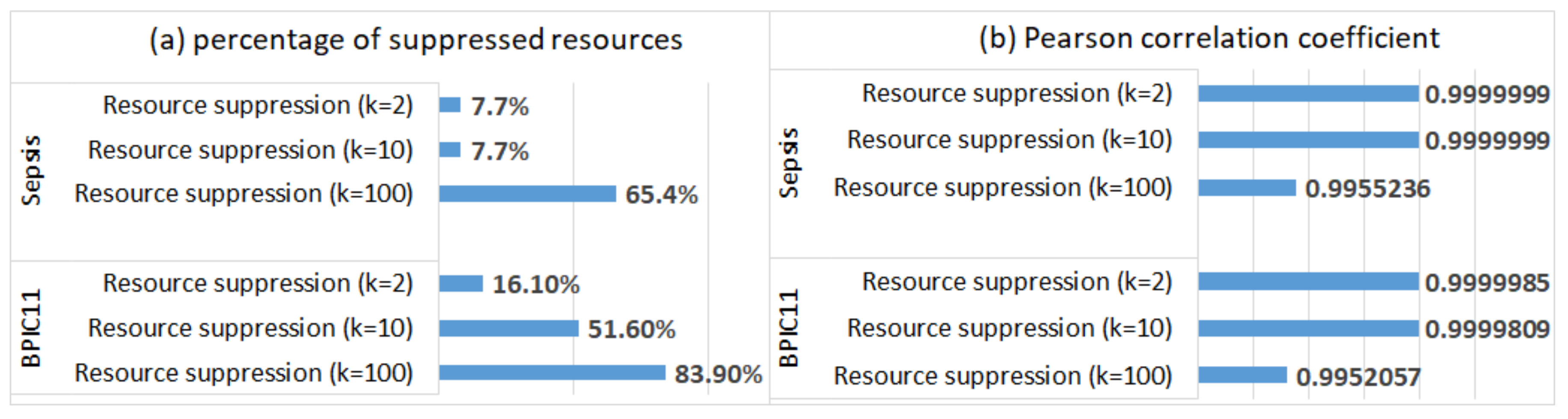
- Activity suppression, on the other hand, had a minimal effect on the average case throughput time (as start and end activities occur very frequently, and hence, are not suppressed); however, affected process discovery and conformance analysis results in some logs;
- Activity suppression affected many events in the BPIC11 log (which has many activity labels and few cases) and few events in the other logs (which have few labels and many cases);
- Smaller values of parameter k (used in suppression) had a minimal effect on process mining results, while larger values affected the results of some algorithms for some logs (e.g., the results of process conformance analysis for the BPIC11 log, Figure 5).
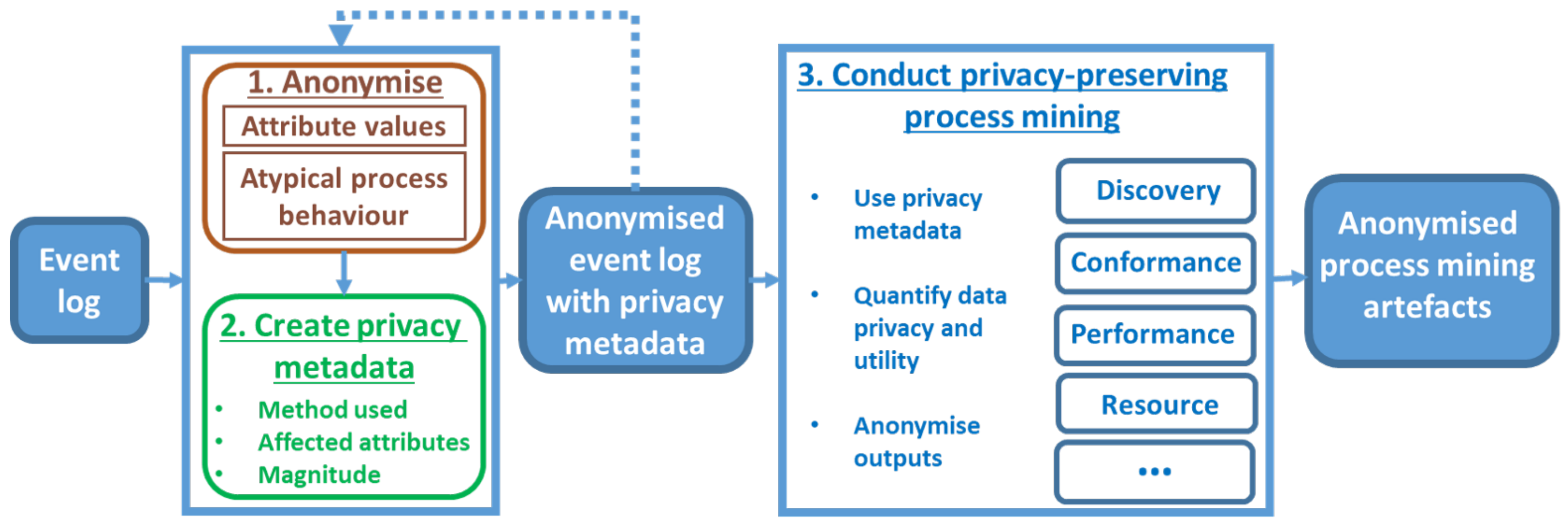
6. Privacy-Preserving Process Mining Framework
7. Privacy Metadata
- ID: the identifier of the anonymisation operation. For example, if one applies activity suppression to the log followed by resource generalisation, then all transformations recorded for the activity suppression will have one ID (e.g., “1”), and transformations recorded for the resource generalisation will have a different ID (e.g., “2”).
- level: the attribute is applicable on the log and the trace level and takes one of the two values: “event” (which indicates that the transformation was applied to event attributes) or “trace” (which indicates that the transformation was applied to trace attributes).
- method: the applied anonymisation method. Possible values include (but are not limited to): suppression, generalisation, micro-aggregation, swapping, noise addition, encryption.
- type: the attribute takes one of the three values: “UPDATE”, “DELETE”, or “INSERT”. Value “UPDATE” is used if the anonymisation method modifies an attribute value (e.g., by adding noise or generalising). Value “DELETE” is used if the anonymisation method removes an attribute value, an event, or a trace. Value “INSERT” is used if the anonymisation method adds a new event or a trace.
- attributes: a list of attributes affected by the transformation.
- attribute: an attribute affected by the transformation. Value “ALL” indicates that all attributes were affected by the transformation.
- impact: the attribute is applicable on the log and on the trace level and specifies the number of traces or events (defined by attribute “level”) affected by the transformation.
- description: a list of properties which contain additional information about the transformation.
- property: a property with additional information about the transformation. For example, it may be used to specify more details about the anonymisation method (e.g., encryption type), a privacy risk targeted by the transformation (e.g., attribute disclosure) or privacy legislation.
| Listing 1. An example of log privacy attributes. |
 |
| Listing 2. An example of trace privacy attributes. |
 |
| Listing 3. An example of event privacy attributes. |
 |
8. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
Appendix A. Anonymisation Code and Anonymised Logs
- The anonymisation code (which is also available online (https://bitbucket.org/sbudiono/transformation-tools)) can generalise timestamps with a given level of granularity (e.g., a year or a month) and suppress infrequent values of a given attribute for a given value of k (code parameters and examples of usage are described in the `README’ file (https://bitbucket.org/sbudiono/transformation-tools/src/master/README.md)). Values of the parameters used in the experiments are described in Section 5.2.
Appendix B. Privacy Extension Definition
| Listing A1. The proposed privacy extension in XML format. |
  |
References
- van der Aalst, W.M.P. Process Mining: Data Science in Action; Springer: Berlin, Germany, 2016. [Google Scholar]
- Andrews, R.; Suriadi, S.; Wynn, M.T.; ter Hofstede, A.H.M. Healthcare process analysis. In Process Modelling and Management for HealthCare; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Erdogan, T.G.; Tarhan, A. Systematic Mapping of Process Mining Studies in Healthcare. IEEE Access 2018, 6, 24543–24567. [Google Scholar] [CrossRef]
- Mans, R.S.; van der Aalst, W.M.P.; Vanwersch, R.J. Process Mining in Healthcare: Evaluating and Exploiting Operational Healthcare Processes; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Partington, A.; Wynn, M.T.; Suriadi, S.; Ouyang, C.; Karnon, J. Process mining for clinical processes: A comparative analysis of four Australian hospitals. ACM (TMIS) 2015, 5, 19. [Google Scholar] [CrossRef]
- Rojas, E.; Sepúlveda, M.; Munoz-Gama, J.; Capurro, D.; Traver, V.; Fernandez-Llatas, C. Question-driven methodology for analyzing emergency room processes using process mining. Appl. Sci. 2017, 7, 302. [Google Scholar] [CrossRef]
- van der Aalst, W.M.P.; Adriansyah, A.; de Medeiros, A.K.A.; Arcieri, F.; Baier, T.; Blickle, T.; Bose, J.C.; van den Brand, P.; Brandtjen, R.; Buijs, J.; et al. Process Mining Manifesto. In BPM 2011 Workshops Proceedings; Springer: Berlin, Germany, 2011. [Google Scholar]
- Mannhardt, F.; Petersen, S.A.; Oliveira, M.F. Privacy challenges for process mining in human-centered industrial environments. In Proceedings of the 14th International Conference on Intelligent Environments (IE), Rome, Italy, 25–28 June 2018; pp. 64–71. [Google Scholar]
- Burattin, A.; Conti, M.; Turato, D. Toward an anonymous process mining. In Proceedings of the FiCloud 2015, Rome, Italy, 24–26 August 2015; pp. 58–63. [Google Scholar]
- Fahrenkrog-Petersen, S.A.; van der Aa, H.; Weidlich, M. PRETSA: Event log sanitization for privacy-aware process discovery. In Proceedings of the 2019 International Conference on Process Mining (ICPM), Aachen, Germany, 24–26 June 2019. [Google Scholar] [CrossRef]
- Liu, C.; Duan, H.; Qingtian, Z.; Zhou, M.; Lu, F.; Cheng, J. Towards comprehensive support for privacy preservation cross-organization business process mining. IEEE Trans. Serv. Comput. 2019, 12, 639–653. [Google Scholar] [CrossRef]
- Rafiei, M.; von Waldthausen, L.; van der Aalst, W. Ensuring Confidentiality in Process Mining. In Proceedings of the SIMPDA 2018, Seville, Spain, 13–14 December 2018. [Google Scholar]
- Aggarwal, C.C. Data Mining: The Textbook; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Toshniwal, D. Privacy Preserving Data Mining Techniques for Hiding Sensitive Data: A Step Towards Open Data. In Data Science Landscape; Springer: Singapore, 2018; pp. 205–212. [Google Scholar]
- Pika, A.; Wynn, M.T.; Budiono, S.; ter Hofstede, A.H.M.; van der Aalst, W.M.P.; Reijers, H.A. Towards Privacy-Preserving Process Mining in Healthcare. In Business Process Management Workshops, Proceedings of the International Workshop on Process-Oriented Data Science for Healthcare Vienna, Austria, 1–6 September 2019; Springer: Cham, Switzerland, 2019; Volume LNBIP 362, pp. 483–495. [Google Scholar]
- Fienberg, S.E.; McIntyre, J. Data Swapping: Variations on a Theme by Dalenius and Reiss. In International Workshop on PSD; Springer: Berlin/Heidelberg, Germany, 2004; pp. 14–29. [Google Scholar]
- Domingo-Ferrer, J.; Torra, V. A critique of k-anonymity and some of its enhancements. In Proceedings of the 2008 Third International Conference on Availability, Reliability and Security, Barcelona, Spain, 4–7 March 2008; pp. 990–993. [Google Scholar]
- Templ, M. Statistical Disclosure Control for Microdata; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Sánchez, D.; Batet, M. Toward sensitive document release with privacy guarantees. Eng. Appl. Artif. Intell. 2017, 59, 23–34. [Google Scholar] [CrossRef]
- Aggarwal, C.C.; Philip, S.Y. Privacy-Preserving Data Mining: Models and Algorithms; Springer Science & Business Media: New York, NY, USA, 2008. [Google Scholar]
- Zhang, Q.; Yang, L.T.; Castiglione, A.; Chen, Z.; Li, P. Secure weighted possibilistic c-means algorithm on cloud for clustering big data. Inf. Sci. 2019, 479, 515–525. [Google Scholar] [CrossRef]
- Giggins, H.; Brankovic, L. VICUS: A noise addition technique for categorical data. In Proceedings of the Tenth Australasian Data Mining Conference, Sydney, Australia, 5–7 December 2012; Volume 134, pp. 139–148. [Google Scholar]
- Domingo-Ferrer, J.; Mateo-Sanz, J.M. Practical data-oriented microaggregation for statistical disclosure control. IEEE Trans. Knowl. Data Eng. 2002, 14, 189–201. [Google Scholar] [CrossRef]
- Abidi, B.; Yahia, S.B.; Perera, C. Hybrid microaggregation for privacy preserving data mining. J. Ambient Intell. Hum. Comput. 2020, 11, 23–38. [Google Scholar] [CrossRef]
- Dwork, C. Differential privacy: A survey of results. In Theory and Applications of Models of Computation; Springer: Berlin/Heidelberg, Germany, 2008; pp. 1–19. [Google Scholar]
- Dwork, C.; Smith, A. Differential privacy for statistics: What we know and what we want to learn. J. Privacy Confid. 2010, 1. [Google Scholar] [CrossRef]
- Tillem, G.; Erkin, Z.; Lagendijk, R.L. Privacy-Preserving Alpha Algorithm for Software Analysis. In Proceedings of the 37th WIC Symposium on Information Theory in the Benelux/6th WIC/IEEE SP Symposium on Information Theory and Signal Processing in the Benelux, Benelux, 19–20 May 2016. [Google Scholar]
- Tillem, G.; Erkin, Z.; Lagendijk, R.L. Mining Sequential Patterns from Outsourced Data via Encryption Switching. In Proceedings of the 16th Annual Conference on Privacy, Security and Trust (PST), Belfast, UK, 28–30 August 2018; pp. 1–10. [Google Scholar]
- Michael, J.; Koschmider, A.; Mannhardt, F.; Baracaldo, N.; Rumpe, B. User-Centered and Privacy-Driven Process Mining System Design for IoT. In Proceedings of the International Conference on Advanced Information Systems Engineering, Rome, Italy, 3–7 June 2019; pp. 194–206. [Google Scholar]
- Mannhardt, F.; Koschmider, A.; Baracaldo, N.; Weidlich, M.; Michael, J. Privacy-preserving Process Mining: Differential Privacy for Event Logs. Informatik Spektrum 2019, 42, 349–351. [Google Scholar] [CrossRef]
- Rafiei, M.; van der Aalst, W.M. Mining roles from event logs while preserving privacy. In Proceedings of the International Conference on Business Process Management, Vienna, Austria, 1–6 September 2019; pp. 676–689. [Google Scholar]
- Leemans, S.J.; Fahland, D.; van der Aalst, W.M.P. Process and Deviation Exploration with Inductive Visual Miner. BPM (Demos) 2014, 1295, 8. [Google Scholar]
- Leemans, S.J.; Fahland, D.; van der Aalst, W.M.P. Scalable process discovery and conformance checking. Softw. Syst. Model. 2018, 17, 599–631. [Google Scholar] [CrossRef] [PubMed]
- van der Aalst, W.M.P.; Adriansyah, A.; van Dongen, B. Replaying history on process models for conformance checking and performance analysis. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2012, 2, 182–192. [Google Scholar] [CrossRef]
- Song, M.; van der Aalst, W.M.P. Towards comprehensive support for organizational mining. Decis. Support Syst. 2008, 46, 300–317. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
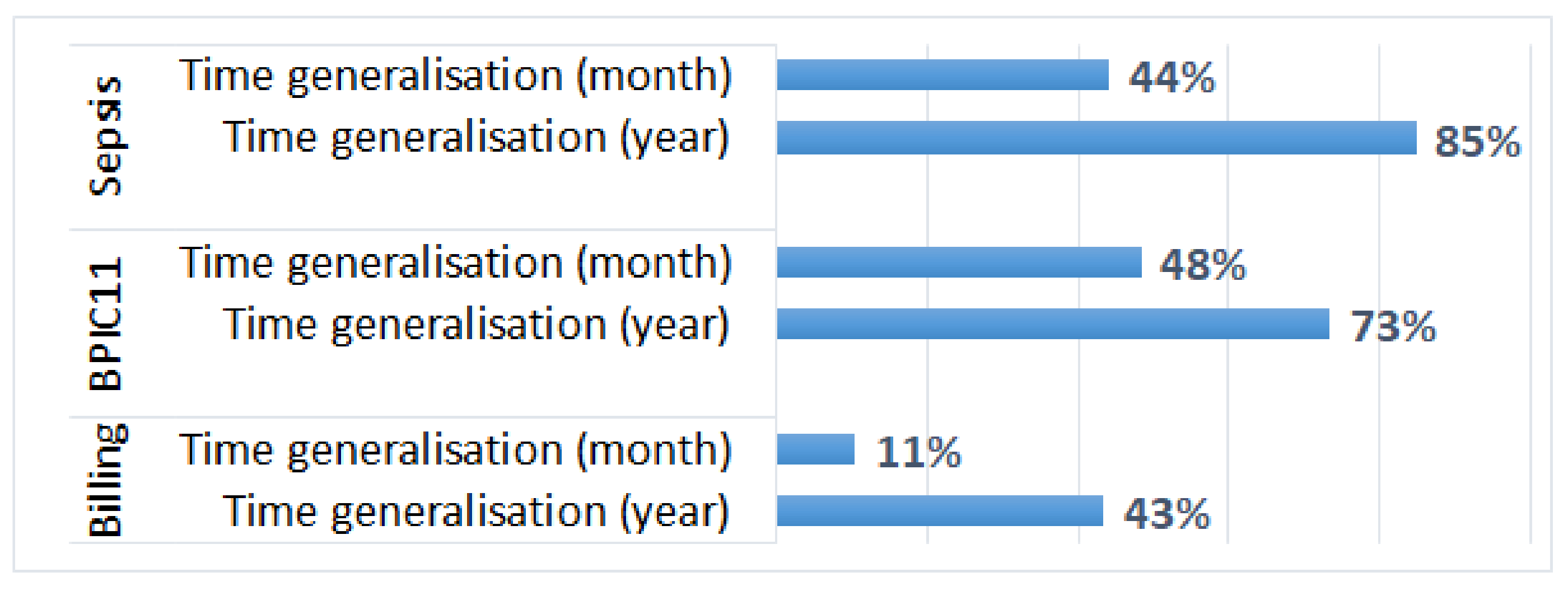{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Case ID | Activity | Time | Resource | Data | |
|---|---|---|---|---|---|
| Encryption (deterministic) | + | + | +/− | + | +/− |
| Swapping | + | − | − | − | − |
| Noise addition | − | − | − | − | − |
| Value suppression | NA | +/− | +/− | +/− | +/− |
| Generalisation/micro-aggregation | NA | +/− | +/− | +/− | +/− |
| Event Log | Events | Activities | Cases | Process Variants | Cases Per Variant | Log Duration |
|---|---|---|---|---|---|---|
| Sepsis | 15,214 | 16 | 1050 | 846 | 1.2 | 1 year & 210 days |
| BPIC11 | 27,065 | 333 | 220 | 192 | 1.1 | 2 years & 88 days |
| Billing | 451,359 | 18 | 100,000 | 1020 | 98 | 3 years & 37 days |
| Sepsis | BPIC11 | Billing | ||||
|---|---|---|---|---|---|---|
| Anonymisation Method | Events Affected | Cases Affected | Events Affected | Cases Affected | Events Affected | Cases Affected |
| Activity suppression () | 0% | 0% | 0.6% | 22% | 0.0002% | 0.001% |
| Activity suppression () | 0.04% | 0.6% | 3% | 58% | 0.0002% | 0.001% |
| Activity suppression () | 0.7% | 10.6% | 32% | 76% | 0.1% | 0.2% |
| Time generalisation, all (month & year) | 100% | 100% | 100% | 100% | 100% | 100% |
| Time generalisation, Adm.&Dis. (year) | 21% | 100% | NA | NA | NA | NA |
| Sepsis | BPIC11 | |||
|---|---|---|---|---|
| Anonymisation Method | Events Affected | Cases Affected | Events Affected | Cases Affected |
| Resource suppression () | 0.01% | 0.2% | 0.03% | 2.3% |
| Resource suppression () | 0.01% | 0.2% | 0.33% | 10.5% |
| Resource suppression () | 5.5% | 48.2% | 8.3% | 65.5% |
| Data suppression () | 1% | 15% | NA | NA |
| Data suppression () | 2.7% | 39% | NA | NA |
| Data suppression () | 5.2% | 75% | NA | NA |
| Level | Key | Type | Description |
|---|---|---|---|
| Log, trace, event | transformations | list | A list of applied privacy-preserving transformations. |
| meta | transformation | container | A container attribute which contains information about each transformation stored in attributes shown below. |
| meta | ID | int | The identifier of the anonymisation operation. |
| meta | level | string | Possible values: “trace” or “event” (applicable on the log and on the trace level). |
| meta | method | string | The applied anonymisation method (e.g., suppression, generalisation, swapping, noise addition, encryption). |
| meta | type | string | Possible values: “DELETE”, “UPDATE”, or "INSERT". |
| meta | attributes | list | A list of affected attributes. |
| meta | attribute | string | An affected attribute; value ‘ALL’ if the transformation affected all attributes. |
| meta | impact | int | The number of affected items (i.e., traces or events); applicable on the log and on the trace level. |
| meta | description | list | A list of additional properties of the transformation. |
| meta | property | string | An additional property of the transformation; for example, encryption type or privacy risk (e.g., identity disclosure). |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pika, A.; Wynn, M.T.; Budiono, S.; ter Hofstede, A.H.M.; van der Aalst, W.M.P.; Reijers, H.A. Privacy-Preserving Process Mining in Healthcare. Int. J. Environ. Res. Public Health 2020, 17, 1612. https://doi.org/10.3390/ijerph17051612
Pika A, Wynn MT, Budiono S, ter Hofstede AHM, van der Aalst WMP, Reijers HA. Privacy-Preserving Process Mining in Healthcare. International Journal of Environmental Research and Public Health. 2020; 17(5):1612. https://doi.org/10.3390/ijerph17051612
Chicago/Turabian StylePika, Anastasiia, Moe T. Wynn, Stephanus Budiono, Arthur H.M. ter Hofstede, Wil M.P. van der Aalst, and Hajo A. Reijers. 2020. "Privacy-Preserving Process Mining in Healthcare" International Journal of Environmental Research and Public Health 17, no. 5: 1612. https://doi.org/10.3390/ijerph17051612
APA StylePika, A., Wynn, M. T., Budiono, S., ter Hofstede, A. H. M., van der Aalst, W. M. P., & Reijers, H. A. (2020). Privacy-Preserving Process Mining in Healthcare. International Journal of Environmental Research and Public Health, 17(5), 1612. https://doi.org/10.3390/ijerph17051612