Abstract
To address the power constraints of the emerging Internet of Things (IoT) era, we propose a compression-efficient feature extraction method for a CMOS image sensor that can extract binary feature data. This sensor outputs six-channel binary feature data, comprising three channels of binarized luminance signals and three channels of horizontal edge signals, compressed via a run length encoding (RLE) method. This approach significantly reduces data transmission volume while maintaining image recognition accuracy. The simulation results obtained using a YOLOv7-based model designed for edge GPUs demonstrate that our approach achieves a large object recognition accuracy () of 60.7% on the COCO dataset while reducing the data size by 99.2% relative to conventional 8-bit RGB color images. Furthermore, the image classification results using MobileNetV3 tailored for mobile devices on the Visual Wake Words (VWW) dataset show that our approach reduces data size by 99.0% relative to conventional 8-bit RGB color images and achieves an image classification accuracy of 89.4%. These results are superior to the conventional trade-off between recognition accuracy and data size, thereby enabling the realization of low-power image recognition systems.
1. Introduction
In the present Internet of Things (IoT) era, big data from a vast number of sensors in the physical space is transmitted to cyberspace, where artificial intelligence (AI) processes it and provides feedback to the physical space [1]. To achieve high accuracy in image recognition, Deep Neural Network (DNN) models [2,3,4,5,6] trained with large-scale datasets [7,8,9,10,11] are widely utilized. However, for sustainability purposes, it is important to reduce the power consumption of image recognition systems composed of sensors and AI. In the field of image sensing, CMOS image sensors suitable for AI applications, known as sensing image sensors, have emerged as a promising solution. Conventional RGB color image sensors generate high-resolution photographic images for viewing. Since these images typically contain redundant data that AI removes during feature extraction, sensing image sensors capable of outputting lightweight feature data suitable for AI tasks offer a promising approach to reducing the power consumption of image recognition systems and the storage requirements for massive imaging data [12,13,14,15]. A log-gradient QVGA image sensor [12] outputs feature data in the form of histograms of oriented gradients (HOGs). However, as its readout circuitry is specifically designed for HOG extraction, it cannot produce conventional photographic images. A convolutional image sensor [13] can provide both photographic images and feature outputs; however, it requires in-pixel capacitors to perform multiply–accumulate (MAC) operations. This design results in larger pixel areas, which can degrade light sensitivity and increase fabrication costs. Event-based vision sensors (EVSs) [14,15] are designed to reduce spatial redundancy and enable high dynamic range imaging with compact feature representations. Nevertheless, they face challenges in capturing stationary objects because small luminance variations (those that fall below or rise above a preset threshold [16,17]) are ignored to avoid redundancy. Furthermore, the in-pixel circuits required to detect temporal variations lead to an increase in pixel size.
Our research group has proposed a CMOS image sensor capable of outputting both photographic RGB color images and lightweight feature data [18,19]. This feature-extractable CMOS image sensor is compatible with conventional RGB color image sensors utilizing small pixels. Figure 1 shows the framework of an image recognition system using the feature-extractable CMOS image sensor with a Bayer pixel array. A key feature of this system is its ability to switch operation modes according to computer vision tasks. In sensing mode, lightweight feature data is processed by a lightweight DNN on the edge device, significantly reducing overall power consumption by eliminating the need to transfer large volumes of image data to cyberspace. With aggressive quantization, the power consumed by ADC is also reduced [18]. When a target object is detected in the feature data as an event, the sensor switches to viewing mode to capture RGB color images for human observation or further analysis by a DNN in cyberspace.
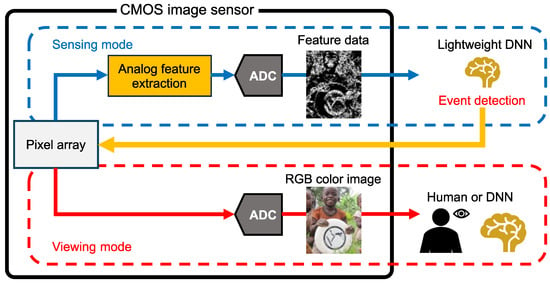
Figure 1.
Image recognition system with a feature-extractable CMOS image sensor [8].
Our research group has also verified an object detection system using binary feature data [20]. First, we developed a lightweight YOLOv7 model based on the YOLOv7 architecture [21], designed to process feature data, specifically horizontal edge information, with low power consumption. This model has approximately the same number of parameters and FLOPs as YOLOv7-tiny, and both models can be implemented on edge-AI devices such as the NVIDIA Jetson Nano. Notably, the object recognition accuracy for large objects () improved by 6.6%. Furthermore, we proposed a feature compression method that combines a feature binarization method and run length encoding (RLE) as an on-chip signal processing technique within a CMOS image sensor. We adopted a feature binarization method based on a given threshold, which was chosen considering recognition accuracy [20]. This threshold-based approach is similar to another work in which the threshold was chosen considering sensor performance and luminance environments [22,23]. The simulation results indicated that, compared with outputting color images, the proposed method reduced the output data size by 99.4%. However, compared with 8-bit edge signals, decreased by 17.7% because the binary edge signal is insensitive to contrast magnitude (it only indicates whether the absolute gradient is above or below a threshold).
In this paper, we propose a feature data format that combines multiple luminance and edge features, aiming to achieve both high recognition accuracy and high compression efficiency. Specifically, the primary objective is to verify an on-chip signal processing method for the proposed feature data format using large-scale datasets prior to the chip design phase. We also introduce an encoding method using RLE tailored to the feature data characteristics. The details of this on-chip compressed feature extraction method is detailed in Section 2. Section 3 presents the image recognition accuracy and data size, evaluating the proposed CMOS image sensor. Section 5 summarizes this paper.
The main contributions of this study are as follows:
- We present a six-channel binary feature data format consisting of three channels of luminance signals and three channels of horizontal edge signals. This format effectively captures target features across various contrast levels, achieving a superior trade-off between object recognition accuracy and data size compared to previous edge-only methods.
- We propose an effective compression method using run length encoding (RLE) tailored to the six-channel binary feature data characteristics. By allocating an appropriate bit length to the binary values (0 and 1) for each feature channel, this approach significantly reduces data transmission volume while maintaining high accuracy for image recognition tasks.
2. Proposed Feature Data Format
In this section, we propose an on-chip signal processing method for a six-channel binary feature data format. Furthermore, we introduce a compression method using RLE tailored to the six-channel binary feature data characteristics.
2.1. Overview of Proposed Image Recognition System
Figure 2 shows a more detailed depiction of the system illustrated in Figure 1. The RGB color image is read out using a pixel-by-pixel architecture at an 8-bit resolution, similar to conventional RGB color image sensors. Feature extraction proceeds as follows: First, using its four-shared pixel structure, the sensor bins the RGGB Bayer pixel signal to convert it into a grayscale signal using the formula [24]. This simultaneous readout of photoelectrons from the Bayer array reduces the spatial resolution to one-fourth. Next, instead of performing correlated double-sampling on a single pixel, the horizontal edge is extracted by subtracting the signals from vertically adjacent Bayer cells. This subtraction is realized using a five-transistor (5T) pixel architecture [24,25], which incorporates a vertical binning transistor into the conventional four-transistor (4T) pixel structure. Besides the edge signal, the luminance signal is extracted from Bayer cells adjacent to the horizontal edge extraction cells. Horizontal edge extraction and luminance extraction reduce the spatial resolution to two-thirds, outputting two-channel analog feature data. The analog feature data, consisting of the luminance and horizontal edge signals, is quantized to 2-bit and 3-bit, respectively. We focus on horizontal edges rather than vertical edges because horizontal edge features can be extracted within the pixel array of our proposed CMOS image sensor [26]. Subsequently, the 2-bit luminance signal is separated into three channels of 1-bit luminance signals, representing the dark, middle, and bright regions, respectively. Similarly, the 3-bit horizontal edge signal is separated into three channels of 1-bit horizontal edge signals, representing the fine positive gradients, coarse gradients, and fine negative gradients, respectively. This separation reduces bit transitions within each channel, thereby improving compression efficiency. Quantization, separation, and binarization reduce the total bit resolution to six-eighths compared to the 8-bit RGB color image. Finally, the six-channel binary feature data is compressed using lossless RLE. These processing steps reduce the output data size from the sensor, thereby lowering power consumption [18]. The encoded binary feature data is then decoded and processed using the lightweight DNN model. The proposed on-chip signal compression method of the CMOS image sensor, including six-channel binary feature extraction and tailored RLE, is described in the following sub-sections.
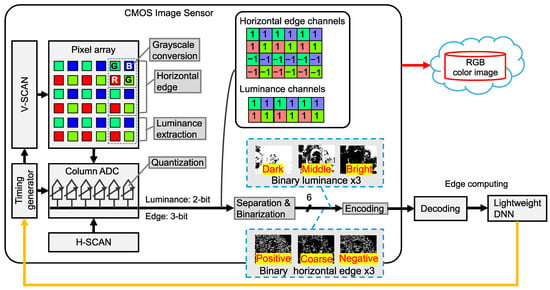
Figure 2.
Proposed feature data extraction on CMOS image sensor [8].
2.2. Six-Channel Binary Feature Separation and Binarization
Figure 3 shows the pipeline of the proposed six-channel binary feature separation and binarization. The analog feature data of the horizontal edge and luminance signals extracted from the pixel array are converted into the six-channel binary feature data through quantization by ADCs, followed by separation and binarization using logical operations. Specifically, the analog feature data are quantized by column-parallel ADCs in a row-by-row manner. The horizontal edge signal is quantized to 3 bits and the luminance signal to 2 bits, as described in Section 2.2.1. Subsequently, logical operations described in Section 2.2.2 are sequentially applied to the horizontal edge and luminance signals. For the three columns of 2-bit luminance signals, the -th, -th, and -th columns are converted into binary luminance signals representing the dark regions , the middle regions , and the bright regions , respectively. Similarly, the three columns of horizontal edge signals are converted into binary horizontal edge signals representing the fine positive gradients , the coarse gradients , and the fine negative gradients , respectively. Consequently, assuming a Bayer pixel array, each of the resulting feature channels consists of pixels.
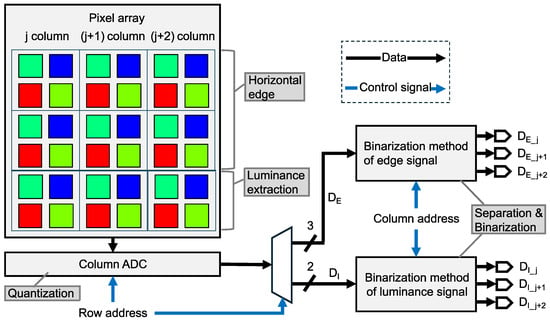
Figure 3.
Pipeline of the division and binarization process.
2.2.1. Quantization for Feature Data
To decide the quantization strategy for the features, we examine the histogram distributions of feature data generated from RGB color images. Figure 4a,b shows high-contrast and low-contrast RGB color image samples from the COCO dataset, respectively. The histogram distributions of the simulated luminance signals in Figure 5a,c, which are derived from Figure 4a,b, respectively, are shown in Figure 5b,d. Similarly, the histogram distributions of the simulated horizontal edge signals in Figure 6a,c, derived from Figure 4a,b, respectively, are shown in Figure 6b,d. Regarding the luminance signals, the shape of pixel intensity distribution depends on the image scene. In contrast, pixel intensities of the horizontal edge signals exhibit a narrow, centered distribution that is largely independent of the scene, mainly due to the correlation between vertically adjacent Bayer cells. Therefore, while the quantized luminance signal represents the global scene characteristics, it tends to lose local detailed information. Conversely, the quantized horizontal edge signal preserves these local details, thereby complementing the quantized luminance signal. Consequently, both the luminance and horizontal edge signals are expected to be aggressively quantized while maintaining global and local features of the image scene.

Figure 4.
RGB color images [8].
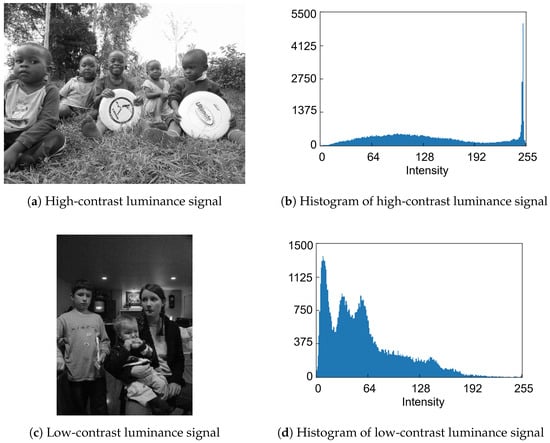
Figure 5.
Eight-bit luminance signals and histograms [8].
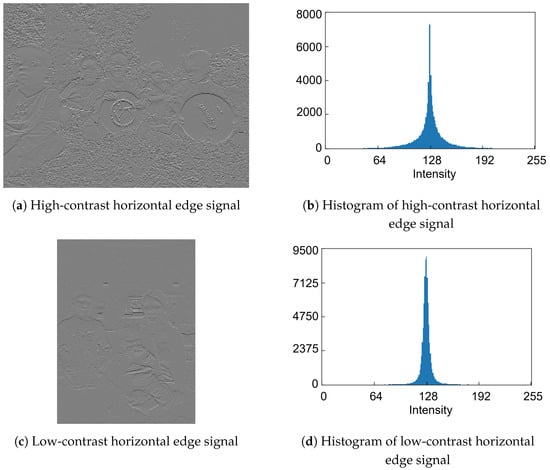
Figure 6.
Eight-bit horizontal edge signals and histograms [8].
Figure 7 shows the ADC-based quantization process for analog feature data, based on the histogram characteristics of the luminance and horizontal edge signals. As shown in Figure 7a, the analog luminance signal is converted into a 2-bit digital signal with a reference voltage range of , resulting in a quantization step of . Regarding the analog horizontal edge signal, since the distribution is concentrated around the center, the ADC reference voltage is set to a narrow range centered at 0 V, as shown in Figure 7b. Consequently, the analog edge signal is converted into a 3-bit digital signal . For instance, when the reference voltage is set to , two pixels with and are quantized into the same luminance value . However, the voltage difference is captured by the edge signal , representing a positive gradient. In this strategy, the edge signal resolves fine luminance variations that are indistinguishable using the luminance signal alone.
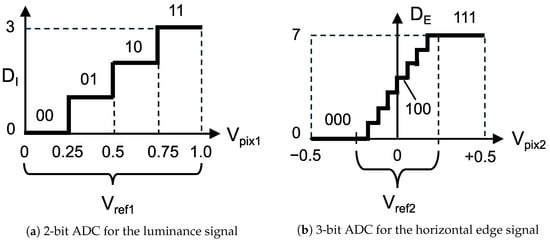
Figure 7.
Overview of quantization in a feature-extractable CMOS image sensor.
In this paper, we evaluate cases where the reference voltage for edge-signal quantization is set to and .
2.2.2. Separation and Binarization for Feature Data
Table 1 shows the truth of logical operations used for the separation and binarization of the luminance signal. In this process, , , and represent binary luminance features that extract the dark, middle, and bright regions, respectively. Since the 2-bit digital luminance signal is divided into 3 channels of 1-bit luminance signals, the data size temporarily increases. However, because bit transitions occur infrequently for gradual luminance variations in the image, the data volume is expected to decrease after compression. Similarly, Table 2 shows the truth of logical operations used for the separation and binarization of the horizontal edge signal. The analog horizontal edge signal intensities above denote a positive gradient, those below indicate a negative gradient, and an intensity of exactly represents no gradient. As the absolute value of the analog edge signal increases, random noise becomes more negligible; however, edges in low-contrast regions are lost. Considering these characteristics of the analog edge signal, , , and correspond to the fine positive gradients, coarse gradients, and fine negative gradients, respectively. Since the central codes of the 3-bit horizontal edge signal, specifically “011” and “100”, typically contain random noise, we convert these values to “0”, denoting no gradient. This process suppresses frequent bit transitions caused by noise, thereby improving compression efficiency. However, the magnitude of detectable edges varies depending on the value of used for edge-signal quantization. For example, when is small, small edges are more likely to be detected, whereas when is large, only coarse edges tend to be detected. Therefore, we evaluate two types of logical operations, named types 1 and 2, for the coarse gradients . The logical operation that converts the input codes “001” and “110” to 0 is defined as the “type 1” logical operation, while the logical operation that converts them to 1 is defined as the “type 2” logical operation.

Table 1.
The logical operations used for the division and binarization of the luminance signal.
Table 2.
The logical operations used for the division and binarization of the horizontal edge signal.
2.3. Run Length Encoding (RLE) for Feature Data
RLE compresses binary feature data by counting successive occurrences of 0s and 1s. In this paper, since the binary feature data consists solely of 0s and 1s, we adopt an encoding method that represents the run lengths of 0s and 1s using fixed-bit counters [20]. For instance, given the sentence “0000,0111”, the five consecutive 0s are encoded as “101” and the three consecutive 1s as “011”, assuming 3 bits are allocated to both 0s and 1s. Overflows occur when the number of consecutive 0s or 1s exceeds the capacity of the counter bits. For example, with a 3-bit counter, the sequence “0000,0000” is encoded as “111,000,001”, where the eight 0s are split into two segments (seven 0s and one 0s) to accommodate the overflow. Therefore, achieving high compression efficiency requires selecting a fixed bit width that is well-suited to the data characteristics. To compress the six channels of binary feature data efficiently, we apply the RLE method to each channel individually, selecting an appropriate fixed bit width for each.
Figure 8 shows the data flow diagram of RLE for the six-channel binary feature data to avoid expansion. The 2 Mpixel CMOS image sensor typically employs a -bit line memory for RGB color images. In the sensing mode, one row of feature data is divided into three channels of binary feature data through the logical operations. Each channel, consisting of -bit original data, is written to the line memory and then encoded using the proposed run length scheme. Note that one frame of one-channel feature data consists of pixels, supposing a Bayer pixel array. Since the characteristics of feature data differ by channel, we employ separate RLE compressors with distinct fixed-bit counters for each channel to improve the compression efficiency. For example, when a 3-bit length is allocated to the counters for 0s and 1s, the consecutive lengths of 0s and 1s are alternately written into the available space in the line memory. The encoded total bit length is simultaneously counted for each channel. If the counted length is less than 320, the compression rate is less than 100% and the encoded data is output along with a flag indicating successful compression. Conversely, if the compression rate exceeds 100%, that means data volume expansion is caused by frequent 0/1 transitions and overflows, and the original -bit data stored in the line memory is output without encoding. This selection process is performed independently for each channel to keep the compression rate below 100%.
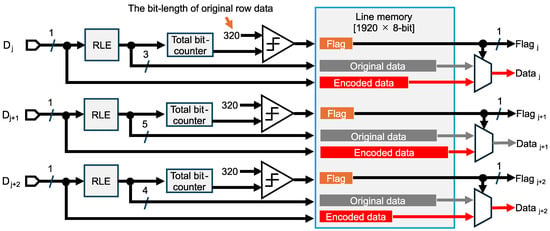
Figure 8.
Data flow diagram of run length encoding for the binary feature data to avoid expansion. Separated feature data in the j-th, (j+1)-th, and (j+2)-th columns are denoted as , , and , respectively.
3. Simulation Results
To evaluate object recognition accuracy with the proposed CMOS image sensor, we converted RGB color images from the COCO dataset [8] into the feature dataset, as shown in Figure 9. Since the majority of images in the COCO dataset have a resolution of pixels, the data were first resized to approximately 2 Mpixels to match the resolution required by the proposed CMOS image sensor. Furthermore, the three-channel RGB color image was masked to emulate the pixel output of a one-channel raw image, where each pixel value follows the Bayer pattern. The luminance signal was generated through grayscale conversion, and the horizontal edge signal was obtained by adding estimated pixel reset noise. This noise addition emulates the uncancelled Floating Diffusion (FD) reset noise caused by the dual reset pulsing scheme [19]. Subsequently, quantization, separation, and binarization processes were applied to the luminance and horizontal edge signals, resulting in the six-channel binary feature data. The feature dataset consists of 30,000 training images and 5000 validation images. To evaluate object recognition accuracy, we used the lightweight YOLOv7 model [20], with its input layer modified to accept six channels. The detailed model configuration, which is shown in Table 3, follows the architecture described in our previous work [20]. The model was trained from scratch without using pre-trained weights. The training hyperparameters are shown in Table A1.
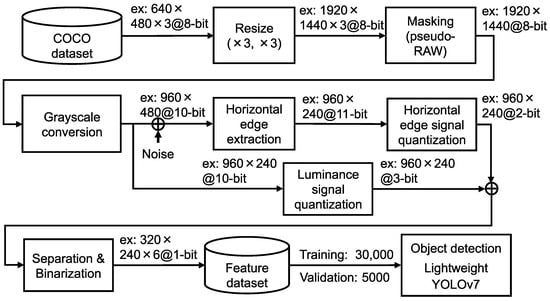
Figure 9.
Processing flow to generate six channels of binary feature data.
Table 3.
Comparison of model configurations.
3.1. Six-Channel Binary Feature Data
Figure 10 displays sample six-channel binary feature data. Figure 10a presents the original RGB color image. The simulated three-channel luminance signal and horizontal edge signal are visualized as three-channel images, as shown in Figure 10b,c, respectively. Since the luminance signals primarily capture global signal intensity, noise on the snow caused by fine gradients is largely absent in the luminance signal but appears in the horizontal edge signal. Conversely, the horizontal edge signal extracts local detailed information, rendering the outlines of the glasses, mouth, and head, which are indistinct in the luminance signal, clearly visible. Consequently, we expect that objects can be detected by utilizing the luminance signal as the primary feature for global scene characteristics and the horizontal edge signal for local details.

Figure 10.
Sample six-channel binary feature data [8].
Table 4 summarizes the impact of the reference voltage used for edge-signal quantization and of the logical operations used for separation and binarization on object recognition accuracy. Object recognition accuracy is quantified using AP50 (mean average precision at an IoU of 0.50) and (accuracy for large objects only). We focus on large objects because the proposed system assumes that if a given object is detected in the feature data, further analysis, such as detecting small objects, will be performed using the RGB color images. Comparing object detection accuracy across different logical operations reveals that when , the type 1 logical operation achieved a higher . In contrast, when , the type 2 logical operation yielded higher performance for both AP50 and . Therefore, in the following evaluations, we adopt the type 1 logical operation for and the type 2 logical operation for .
Table 4.
Object recognition accuracy after six-channel feature extraction.
3.2. Compression Rate of Tailored RLE
Table 5 shows the compression rates for bit allocation applying the proposed tailored RLE method to the six-channel binary feature data. The table presents the best compression rate among all possible bit allocation patterns, evaluated using 25,000 samples of the six-channel binary feature data. Detailed compression rates for each channel with respect to bit allocation are shown in Figure 11, Figure 12 and Figure 13.
Table 5.
Compression rates and fixed-bit allocation obtained using the proposed lossless RLE method for the feature data after division and binarization.
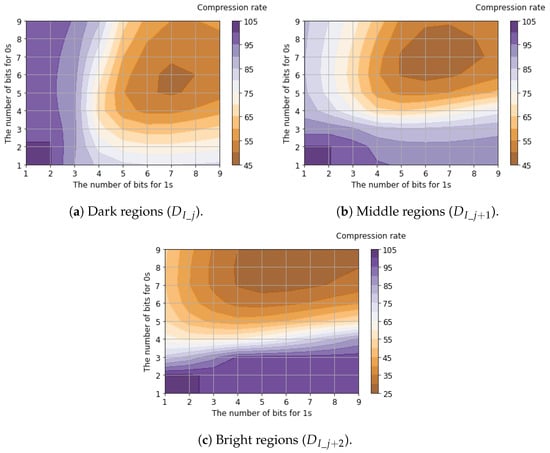
Figure 11.
Compression rates of luminance signals with respect to bit allocation.
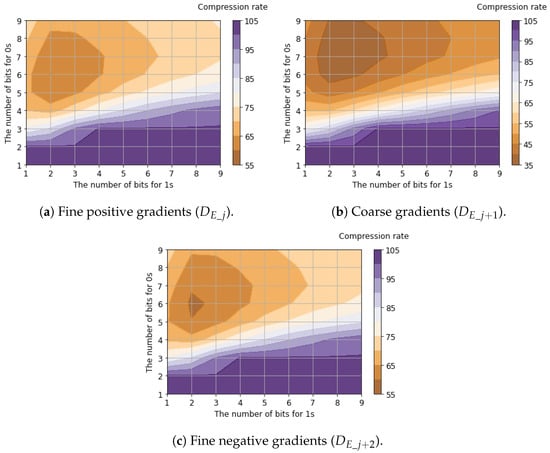
Figure 12.
Compression rates of horizontal edge signals () with respect to bit allocation.
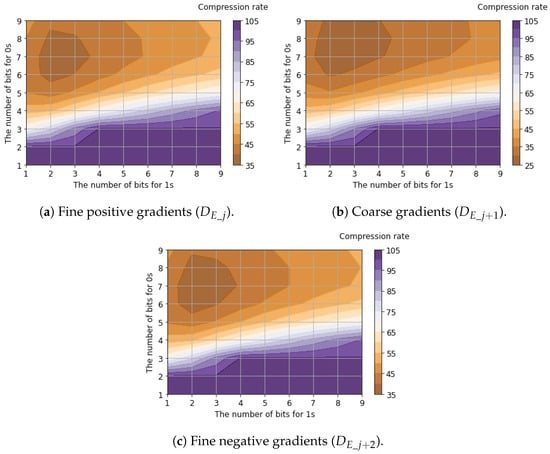
Figure 13.
Compression rates of horizontal edge signals () with respect to bit allocation.
Regarding luminance signals, we found that allocating balanced fixed-bit counters for 0s and 1s yields the minimum compression rates. This is because luminance signals capture the global signal intensity where bit transitions are suppressed due to the spatial correlation between horizontally adjacent pixels. In contrast, the compression rates of horizontal edge signals are minimized when allocating a larger bit width for 0s (denoting the absence of an edge gradient) compared to 1s (denoting the presence of an edge gradient). This occurs because horizontal edge signals capture local intensity changes. Since these changes appear sparsely, and the run length of 1s is significantly shorter than that of 0s. Compared to the case where , improved compression efficiency (a lower compression ratio) was achieved when . This improvement occurred because increasing reduces sensitivity to small edges, thereby increasing the proportion of consecutive 0s that represent the absence of a gradient. As a result, the average compression rates for all six channels of binary feature data were calculated to be 46.5% for and 37.5% for .
3.3. Data Size and Object Detection Accuracy
Figure 14 shows the object recognition accuracy () and data sizes for our lightweight YOLOv7 model trained on feature data [20]. For reference, the accuracy of the YOLOv7 and YOLOv7-tiny models trained on RGB color images is also plotted. The feature data includes six-channel binary feature data generated by the proposed method and edge-only signals from our previous works [19,20]. The input layer resolution of all models was matched to the resolution of the proposed sensor output feature data. For the six-channel binary feature data, the plotted data size reflects the size after compression using the tailored RLE method. The results indicate that the six-channel binary feature data achieved a superior trade-off between recognition accuracy and data size. Detailed numerical results are provided in Table 6, Table 7 and Table 8. The COCO dataset with 80 object categories is utilized for validation. Compared to the 3-bit edge signal, the size of the six-channel binary feature data with was reduced by 58.7%, and object recognition accuracy was improved by 3.7% (). Furthermore, compared to conventional 8-bit RGB color images and YOLOv7-tiny, the feature data with improved object recognition accuracy by 2.0% () while reducing the data size by 99.2%. Notably, our lightweight YOLOv7 model trained on six-channel features has approximately the same number of parameters as YOLOv7-tiny, with a reduction of 0.3 M. In addition, the FLOPs are reduced by 8.3 G () compared to YOLOv7-tiny, primarily due to the difference in the spatial resolution between the RGB color image and feature data.
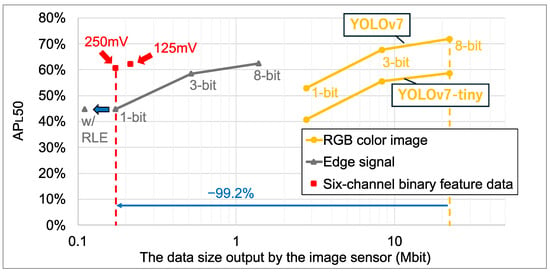
Figure 14.
Data size and object recognition accuracy.
Table 6.
Object recognition accuracy and data size in quantized RGB color images and YOLOv7-tiny.
Table 7.
Object recognition accuracy and data size in quantized horizontal edge feature data.
Table 8.
Object recognition accuracy and data size in six-channel binary feature data.
3.4. Evaluation on Image Classification
To examine the robustness of the proposed feature data format for different image recognition tasks in the sensing mode, we converted RGB color images from the Visual Wake Words (VWW) dataset [11] into the six-channel binary feature dataset, assuming a binary classification task to detect the presence of a person. Since the VWW dataset filters labels into “person” and “not-person” categories based on the COCO dataset, six-channel binary feature data based on the VWW dataset were generated using the same method shown in Figure 9. The images containing a “person” are labeled as 1 only when the bounding box is “Large” and “Medium” according to the COCO dataset definition. To evaluate image classification accuracy, we used the MobileNetV3-Large 1.0 model [27] tailored for mobile devices, with its input layer modified to accept six channels. The model was trained from scratch without using pretrained weights. For evaluation, in addition to the standard VWW validation set, we employed the Wake Vision (WV) dataset [28]. While the VWW dataset is widely used, it contains label errors that can affect evaluation reliability. The WV dataset cleans these labels, providing a more rigorous benchmark [28].
Figure 15 shows the image classification accuracy and data size for the MobileNetV3 model trained on quantized RGB color images and feature data generated from the VWW dataset. The feature data include six-channel binary feature data generated by the proposed method and edge-only signals from our previous works. Since image classification typically requires lower resolution than object detection, all image data were resized to pixels instead of using the raw sensor output resolution. For the six-channel binary feature data and the previous 1-bit edge signal, the plotted data size reflects the size after compression using the tailored RLE method. The training process and learning curves for each data format are detailed in Appendix B. Detailed numerical results are provided in Table 9 and Table 10. The simulation results show that the six-channel binary feature data yielded superior image classification accuracy, similar to the object detection task using the YOLOv7 models and the COCO dataset. Compared to the 8-bit edge signal, six-channel binary feature data with reduced the feature data size by 84.5%, and image classification accuracy improved by 0.5%. Furthermore, compared to conventional 8-bit RGB color images, the six-channel binary feature data reduced the data size by 99.0% at the cost of a 3.4% accuracy degradation. Evaluation on the WV dataset showed similar trends, confirming the robustness of the proposed features against label noise.
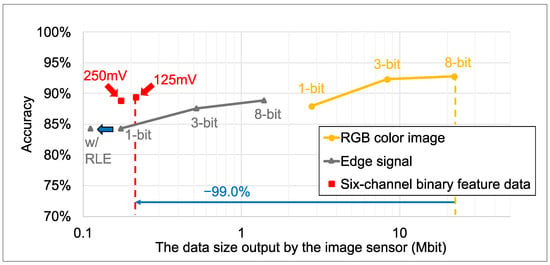
Figure 15.
Data size and image classification accuracy.
Table 9.
Image classification accuracy and data size in quantized RGB color images.
Table 10.
Image classification accuracy and data size in feature data.
4. Discussion
For both the large object detection and binary person classification tasks assumed in sensing mode, the proposed method demonstrated a superior trade-off between recognition accuracy and data size, compared to the RGB color image. These results demonstrate that our image recognition system can detect target objects in an energy-efficient manner; these objects serve as triggers to switch the operation mode of the CMOS image sensor from the sensing mode to the viewing mode, thereby realizing a low-power image recognition system.
Table 11 compares the proposed method with other feature extraction sensors. First, our method does not utilize in-pixel capacitors, making it well suited for low-cost CMOS image sensors with small pixels. Second, our sensor can output both RGB color images and feature data. This capability enables a flexible image recognition system configuration. Finally, the proposed method has been validated using large-scale datasets. While other methods are often validated on limited scenarios such as face or hand detection, our method has been verified using standard benchmarks (COCO, VWW, and WV), demonstrating its applicability to realistic scenarios.
Table 11.
Comparison of the proposed method with other feature extraction sensors.
5. Conclusions and Future Work
To realize an energy-efficient image recognition system, we proposed a compression-efficient feature extraction method for a CMOS image sensor capable of extracting binary feature data and present simulation results regarding recognition accuracy and compression efficiency. The compressed feature data is extracted via six-channel feature extraction and encoded using run length encoding with an appropriate bit length to binary values (0 and 1) for each feature channel. The simulation results obtained using our lightweight YOLOv7 model demonstrate that our approach improved the by 2.0% on the COCO dataset and reduced the data size by 99.2%, relative to conventional 8-bit RGB color images and the YOLOv7-tiny model. Furthermore, the image classification results obtained using MobileNetV3 show that our approach reduced the data size by 99.0% at the cost of a 3.4% accuracy degradation relative to conventional 8-bit RGB color images. These results indicate that the proposed method offers a superior trade-off between recognition accuracy and data size, thereby realizing a low-power image recognition system.
In future work, we plan to carry out hardware implementation to validate the system’s practical performance. Building on our previous chip-level studies on pixels and ADCs [24,26], we aim to fabricate a prototype chip to validate the system’s practical performance and power efficiency in real-world environments.
Author Contributions
Conceptualization, S.O.; methodology, K.K., R.I. and K.Y.; software, K.K. and Y.O.; validation, K.K.; writing—original draft preparation, K.K.; writing—review and editing, K.K. and S.O.; supervision, R.U. and S.O.; project administration, H.S. and S.O. All authors have read and agreed to the published version of the manuscript.
Funding
This work was partly supported by JSPS KAKENHI, grant number JP24K15001.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in this study are included in this article. Further inquiries can be directed to the corresponding authors.
Conflicts of Interest
Authors Ryuichi Ujiie and Hideki Shima are employed by Nisshinbo Micro Devices Inc. The remaining authors declare that this research was conducted without any commercial or financial relationships that could be viewed as potential conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| CMOS | Complementary Metal–Oxide Semiconductor |
| RGB | Red, Green, and Blue |
| QVGA | Quarter Video Graphics Array |
| ADC | Analog-to-Digital Converter |
| FLOPs | Floating Point Operations per Second |
| IoU | Intersection over Union |
Appendix A. Training Hyperparameters
To ensure the reproducibility of our simulation results, the detailed training hyperparameters used for our lightweight YOLOv7 model are listed in Table A1. We strictly followed the settings of the original YOLOv7 model [21]. The model was trained using the SGD optimizer for 400 epochs. We performed a warm-up for 3 epochs, updating only the bias during this stage. Subsequently, the learning rate was linearly decayed from an initial value of 0.01 to a final value of 0.001. The detailed data augmentation settings are also provided in the table.
Table A1.
Hyperparameter settings for the lightweight YOLOv7 model [20].
Table A1.
Hyperparameter settings for the lightweight YOLOv7 model [20].
| Hyperparameter | Value |
|---|---|
| Epochs | 400 |
| Optimizer | SGD |
| Initial learning rate | 0.01 |
| Final learning rate | 0.001 |
| Momentum | 0.937 |
| Weight decay | 0.0005 |
| Warm-up | |
| Warm-up epochs | 3 |
| Warm-up momentum | 0.8 |
| Warm-up bias learning rate | 0.1 |
| Loss Gains | |
| Box loss gain | 0.05 |
| Class loss gain | 0.3 |
| Obj loss gain | 0.7 |
| Data Augmentation | |
| HSV hue | 0.015 |
| HSV saturation | 0.7 |
| HSV value | 0.4 |
| Translation | 0.2 |
| Scale | 0.9 |
| Horizontal flip | 0.5 |
| Mosaic | 1.0 |
| MixUp | 0.15 |
| Copy & Paste | 0.15 |
Note: SGD denotes Stochastic Gradient Descent. HSV stands for Hue, Saturation, and Value.
Appendix B. Learning Curves
Figure A1 shows the learning curves (training and validation accuracy versus epochs) when the model is trained using the VWW dataset across different data formats. The learning curves demonstrate that the validation accuracy converges stably alongside the training accuracy. Therefore, we conclude that our models have successfully learned features from the VWW dataset to evaluate our feature extraction method compared to the RGB color image.

Figure A1.
Epochs and accuracy during training on the VWW dataset.
Figure A1.
Epochs and accuracy during training on the VWW dataset.

References
- Government of Japan; Cabinet Office. Society 5.0. Available online: https://www8.cao.go.jp/cstp/english/society5_0/index.html (accessed on 5 November 2023).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; PMLR: Cambridge, MA, USA, 2019; pp. 6105–6114. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: New York, NY, USA, 2009; pp. 248–255. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Kolesnikov, A.; et al. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. Int. J. Comput. Vis. 2020, 128, 1956–1981. [Google Scholar] [CrossRef]
- Chowdhery, A.; Warden, P.; Shlens, J.; Howard, A.; Rhodes, R. Visual wake words dataset. arXiv 2019, arXiv:1906.05721. [Google Scholar] [CrossRef]
- Young, C.; Omid-Zohoor, A.; Lajevardi, P.; Murmann, B. A data-compressive 1.5/2.75-bit log-gradient QVGA image sensor with multi-scale readout for always-on object detection. IEEE J. Solid-State Circuits 2019, 54, 2932–2946. [Google Scholar] [CrossRef]
- Yoneda, S.; Negoro, Y.; Kobayashi, H.; Nei, K.; Takeuchi, T.; Oota, M.; Kawata, T.; Ikeda, T.; Yamazaki, S. Image Sensor Capable of Analog Convolution for Real-time Image Recognition System Using Crystalline Oxide Semiconductor FET. In Proceedings of the 2019 International Image Sensor Workshop (IISW 2019), Snowbird, UT, USA, 23–27 June 2019; pp. 322–325. [Google Scholar]
- Finateu, T.; Niwa, A.; Matolin, D.; Tsuchimoto, K.; Mascheroni, A.; Reynaud, E.; Mostafalu, P.; Brady, F.; Chotard, L.; LeGoff, F.; et al. 5.10 A 1280× 720 back-illuminated stacked temporal contrast event-based vision sensor with 4.86 μm pixels, 1.066 GEPS readout, programmable event-rate controller and compressive data-formatting pipeline. In Proceedings of the 2020 IEEE International Solid-State Circuits Conference-(ISSCC), San Francisco, CA, USA, 16–20 February 2020; IEEE: New York, NY, USA, 2020; pp. 112–114. [Google Scholar]
- Suh, Y.; Choi, S.; Ito, M.; Kim, J.; Lee, Y.; Seo, J.; Jung, H.; Yeo, D.H.; Namgung, S.; Bong, J.; et al. A 1280× 960 dynamic vision sensor with a 4.95-μm pixel pitch and motion artifact minimization. In Proceedings of the 2020 IEEE international symposium on circuits and systems (ISCAS), Sevilla, Spain, 10–21 October 2020; IEEE: New York, NY, USA, 2020; pp. 1–5. [Google Scholar]
- Lichtsteiner, P.; Posch, C.; Delbruck, T. A 128 x 128 120db 30mw asynchronous vision sensor that responds to relative intensity change. In Proceedings of the 2006 IEEE International Solid State Circuits Conference-Digest of Technical Papers, San Francisco, CA, USA, 6–9 February 2006; IEEE: New York, NY, USA, 2006; pp. 2060–2069. [Google Scholar]
- Son, B.; Suh, Y.; Kim, S.; Jung, H.; Kim, J.S.; Shin, C.W.; Park, K.; Lee, K.; Park, J.M.; Woo, J.; et al. 4.1 A 640×480 dynamic vision sensor with a 9µm pixel and 300Meps address-event representation. In Proceedings of the 2017 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 5–9 February 2017; pp. 66–67. [Google Scholar]
- Okura, S.; Otani, A.; Itsuki, K.; Kitazawa, Y.; Yamamoto, K.; Osuka, Y.; Morikaku, Y.; Yoshida, K. A study on a feature extractable CMOS image sensor for low-power image classification system. In Proceedings of the 2023 International Image Sensor Workshop, Crieff, UK, 21–25 May, 2023. [Google Scholar]
- Morikaku, Y.; Ujiie, R.; Morikawa, D.; Shima, H.; Yoshida, K.; Okura, S. On-Chip Data Reduction and Object Detection for a Feature-Extractable CMOS Image Sensor. Electronics 2024, 13, 4295. [Google Scholar] [CrossRef]
- Kuroda, K.; Morikaku, Y.; Osuka, Y.; Iegaki, R.; Ujiie, R.; Shima, H.; Yoshida, K.; Okura, S. [Paper] Lightweight Object Detection Model for a CMOS Image Sensor with Binary Feature Extraction. ITE Trans. Media Technol. Appl. 2026, 14, 102–109. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Sato, M.; Akebono, S.; Yasuoka, K.; Kato, E.; Tsuruta, M.; Takano, C.; Ota, K.; Haraguchi, K.; Watanabe, M.; Fujii, G.; et al. A 0.8 μm 32Mpixel Always-On CMOS Image Sensor with Windmill-Pattern Edge Extraction and On-Chip DNN. IEEE Solid-State Circuits Lett. 2025, 8, 353–356. [Google Scholar] [CrossRef]
- Lee, S.; Yun, Y.C.; Heu, S.M.; Lee, K.H.; Lee, S.J.; Lee, K.; Moon, J.; Lim, H.; Jang, T.; Song, M.; et al. The Design of a Computer Vision Sensor Based on a Low-Power Edge Detection Circuit. Sensors 2025, 25, 3219. [Google Scholar] [CrossRef] [PubMed]
- Okumura, S.; Morikaku, Y.; Osuka, Y.; Ujiie, R.; Morikawa, D.; Shima, H.; Okura, S. Feature Extractable CMOS Image Sensor Pixel with RGB to Grayscale Conversion. In Proceedings of the 2023 IEEE International Meeting for Future of Electron Devices, Kansai (IMFEDK), Kyoto, Japan, 16–17 November 2023; IEEE: New York, NY, USA, 2023; pp. 1–2. [Google Scholar]
- Takayanagi, I.; Yoshimura, N.; Mori, K.; Matsuo, S.; Tanaka, S.; Abe, H.; Yasuda, N.; Ishikawa, K.; Okura, S.; Ohsawa, S.; et al. An over 90 dB intra-scene single-exposure dynamic range CMOS image sensor using a 3.0 μm triple-gain pixel fabricated in a standard BSI process. Sensors 2018, 18, 203. [Google Scholar] [CrossRef] [PubMed]
- Matsubara, I.; Ujiie, R.; Morikawa, D.; Shima, H.; Okura, S. A Scalable Single-Slope ADC for a Feature-Extractable CMOS Image Sensor. In Proceedings of the 2025 International Technical Conference on Circuits/Systems, Computers, and Communications (ITC-CSCC), Seoul, Republic of Korea, 7–10 July 2025; IEEE: New York, NY, USA, 2025; pp. 1–4. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the EEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 1314–1324. [Google Scholar]
- Banbury, C.; Njor, E.; Garavagno, A.M.; Mazumder, M.; Stewart, M.; Warden, P.; Kudlur, M.; Jeffries, N.; Fafoutis, X.; Reddi, V.J. Wake vision: A tailored dataset and benchmark suite for tinyml computer vision applications. arXiv 2024, arXiv:2405.00892. [Google Scholar]
- Verdant, A.; Guicquero, W.; Coriat, D.; Moritz, G.; Royer, N.; Thuries, S.; Mollard, A.; Teil, V.; Desprez, Y.; Monnot, G.; et al. A 450μW@ 50fps Wake-Up Module Featuring Auto-Bracketed 3-Scale Log-Corrected Pattern Recognition and Motion Detection in a 1.5 Mpix 8T Global Shutter Imager. In Proceedings of the 2024 IEEE Symposium on VLSI Technology and Circuits (VLSI Technology and Circuits), Honolulu, HI, USA, 16–20 June 2024; IEEE: New York, NY, USA, 2024; pp. 1–2. [Google Scholar]
- Omid-Zohoor, A.; Ta, D.; Murmann, B. PASCALRAW: Raw image database for object detection. Stanf. Digit. Repos. 2014, 2, 4. [Google Scholar]















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.