Abstract
In froth flotation, the features of froth images are important information to predict the concentrate grade. However, the froth structure is influenced by multiple factors, such as air flowrate, slurry level, ore properties, reagents, etc., which leads to highly complex and dynamic changes in the image features. Additionally, issues such as the immeasurability of ore properties and measurement errors pose significant uncertainties including aleatoric uncertainty (intrinsic variability from ore fluctuations and sensor noise) and epistemic uncertainty (incomplete feature representation and local data heterogeneity) and generalization challenges for prediction models. This paper proposes an uncertainty quantification regression framework based on cross-modal interaction fusion, which integrates the complementary advantages of Selective Kernel Networks (SKNet) and Vision Transformers (ViT). By designing a cross-modal interaction module, the method achieves deep fusion of local and global features, reducing epistemic uncertainty caused by incomplete feature expression in single-models. Meanwhile, by combining adaptive calibrated quantile regression—using exponential moving average (EMA) to track real-time coverage and adjust parameters dynamically—the prediction interval coverage is optimized, addressing the inability of static quantile regression to adapt to aleatoric uncertainty. And through the localized conformal prediction module, sensitivity to local data distributions is enhanced, avoiding the limitation of global conformal methods in ignoring local heterogeneity. Experimental results demonstrate that this method significantly improves the robustness of uncertainty estimation while maintaining high prediction accuracy, providing strong support for intelligent optimization and decision-making in industrial flotation processes.
1. Introduction
Froth flotation is a critical process in mineral processing, which separates valuable minerals from gangue based on their physicochemical properties. Accurate and timely measurement of concentrate grade is paramount for optimization and control of the flotation process to enhance resource utilization [1]. However, complex on-site environment, high cost, and maintenance demand of the online analysis instruments mean that the industrial operations often rely on manual observation or offline laboratory analysis (e.g., X-ray fluorescence). These methods are subjective and introduce significant time lags (typically 1–2 h), which is inadequate for real-time closed-loop control [2]. Since froth flotation images contain a wealth of process state information, image-based grade soft sensing methods have become an active research focus.
Meanwhile, with the rapid development of deep learning and cumulative of process data, automatic feature extraction and representation methods, and prediction methods based on deep neural networks for flotation grade have been researched broadly [3]. Methodologically, most works rely on Convolutional Neural Networks (CNNs) because froth images carry rich cues. Wang et al. [4] proposed a two-step operating condition recognition strategy based on image sequences, where deep learning was used to classify the images to obtain the conditions of antimony flotation, and satisfactory classification results were achieved. Fu et al. [5,6] investigated several popular CNNs for classification of arsenic flotation conditions, and experiment results showed that the ResNet achieved the best classification results. Zarie et al. [7] developed a froth image classification method based on CNN for process monitoring. The study demonstrated that the CNN classifier effectively extracts froth features and its classification accuracy outperforms traditional artificial neural networks (ANNs). Jia et al. [8] proposed a CNN-based performance evaluation method with feature learning and expert feedback fusion, which improves robustness and accuracy under image distortions. Beyond purely spatial cues, sequence models capture temporal dynamics. Zhou et al. [9] proposed a domain-knowledge-embedded deep Long Short-Term Memory (LSTM) soft measurement framework (DKST-DLSTM), which significantly improved the prediction accuracy of key indicators such as concentrate grade by extracting spatio-temporal features in the flotation process. Pu et al. [10] used LSTM to predict iron and silicon waste concentrations by using industrial data, which outperforms random forests, and Zhang et al. [11] combined feed grade refined embedding (FGRE) and nonoverlapping patch encoding (NOPE) with RNNs to enhance dynamic monitoring accuracy. In addition, graph-based and attention models have been explored too. Wang et al. [12] proposed a sparse-attention spectral graph neural network (SASGNN) for state-variable prediction, while Lu et al. [13] developed a multimode performance assessment method using a deep embedded graph clustering network that integrates froth images and process variables via Bayesian fusion. Complementary to these architectures, Xie et al. [14] employed an mRMR plus multiswarm PSO-based sensitive feature selection with collaborative search, coupled with a self-adjusting RBF neural network, to further improve flotation prediction accuracy. Despite progress in deep learning for flotation grade prediction, most methods provide only point estimates without calibrated uncertainty. Uncertainty arises from two sources: aleatoric (intrinsic process variability such as changing ore conditions, operating fluctuations, and sensor noise) and epistemic (limited/delayed labels, unobserved variables, and covariate shift). Hence, soft sensors should output accurate predictions with reliable intervals under distributional change. While CNNs emphasize local details [15] and ViTs capture global context [16], a single model struggles to account for both local variability and global trends.
For modeling uncertainty in industrial processes, primary approaches include probabilistic distribution modeling [17], quantile regression [18], and conformal prediction [19]. While these methods provide interval estimates, they largely depend on global statistical characteristics, making it difficult to adapt in real-time to local distributional variations caused by raw material or process fluctuations in flotation operations. Moreover, static calibration may result in prediction intervals being either too wide or too narrow [20], thereby affecting reliability. Although research on uncertainty prediction for flotation processes is scarce, advanced techniques have emerged in other complex systems. For instance, in probabilistic distribution prediction, Dong et al. [21] proposed an uncertainty-guided graph neural network for air quality forecasting, Sun et al. [22] developed a multi-distribution ensemble framework, and Trapero et al. [23] combined kernel density estimation with forecast errors. In terms of hybrid modeling and interval estimation, Wang et al. [24] employed an integrated Empirical Mode Decomposition (EMD) and Relevance Vector Machine (RVM) model for photovoltaic power output, Khosravi et al. [25] proposed a neural network-based method for constructing prediction intervals, and Hou et al. [26] developed an uncertainty-aware deep learning framework for risk identification. Other methods, such as the non-parametric quantile approach by Bremnes et al. [27] or the fuzzy theory-based intervals by Pierre et al. [28], are often limited by linear structure assumptions or reliance on expert knowledge, respectively. Despite these advances, their direct application is challenged by the unique multi-modal data and dynamic, nonlinear behavior of flotation—even as effective multi-modal fusion strategies have been developed for other scenarios [29,30]. Therefore, how to integrate multi-modal deep features and achieve dynamic, locally sensitive uncertainty quantification remains an urgent and unresolved challenge.
Although intelligent methods have been extensively explored for uncertainty modeling in industrial processes [31], they often suffer from insufficient robustness and limited generalization capability when they face high-noise and highly dynamic of the input data, making it difficult to meet the practical demand for high-confidence interval prediction in production. Therefore, integrating multi-modal structures with stronger expressive power and theoretically guaranteed out-of-distribution uncertainty calibration has become a key breakthrough in current research.
In addition, traditional quantile regression and global conformal prediction methods also exhibit significant limitations in constructing prediction intervals. On one hand, these methods typically rely on the statistical characteristics of global data, making it difficult to adapt in real-time to local distributional differences in flotation processes caused by variations in ore properties or fluctuations of operating conditions. On the other hand, static calibration methods often produce prediction intervals that are either too wide or too narrow in the face of dynamically changing data distributions, thereby reducing the reliability of decision-making in practical applications.
To address the aforementioned challenges, this paper proposes a cross-modal interactive fusion-based uncertainty quantification regression framework for high-precision prediction and uncertainty quantification of concentrate grade in flotation. First, a hybrid architecture integrating SKNet and ViT is constructed, in which bidirectional information interaction is achieved through a cross-attention mechanism, so that local details and global features are effectively combined. Subsequently, we design an adaptive calibrated quantile regression method that introduces an exponential moving average (EMA) update strategy for coverage rate and an adaptive loss function, thereby enabling dynamic adjustment of calibration parameters and enhancing the coverage capability of prediction intervals under dynamic operating conditions. Finally, a conformal prediction module based on local data distribution is developed, which improves the model’s responsiveness to local data fluctuations and further enhances the reliability of prediction intervals by incorporating local neighborhood analysis and nonlinear interval width adjustment.
The main contributions of this paper can be summarized as follows:
- (1)
- A novel cross-modal feature fusion architecture is proposed, which is based on the integration of SKNet (convolutional features) and ViT (global structure) with cross-attention. By designing a cross-modal interaction module, complementary learning between different feature extractors is achieved. This approach enables simultaneous capture of local details and global information in flotation process data, significantly enhancing the model’s capacity to represent complex data patterns.
- (2)
- An adaptive calibrated quantile regression framework is developed, coupling an EMA-driven coverage-rate updater with a loss comprising quantile error and a calibration-penalty term, enabling real-time reweighting and improved interval coverage under nonstationary conditions.
- (3)
- A localized conformal prediction method based on local neighborhood analysis is proposed. By mining the local features of the calibration set and adjusting the interval width nonlinearly, the prediction intervals become highly sensitive to local data distributions. Automatic iterative optimization is used to effectively enhance the reliability of intervals for samples from different regions.
- (4)
- A complete end-to-end framework covering data preprocessing, feature fusion, model training, and uncertainty prediction interval evaluation is constructed. The method’s superior performance on real flotation datasets is systematically validated through multi-dimensional experiments and comprehensive metrics (MAE, MSE, coverage, interval width, etc.), providing technical support for industrial applications.
The structure of this paper is arranged as follows: Section 1 reviews the relevant theoretical foundations and research progress; Section 2 provides a detailed description of the proposed method and its implementation; Section 3 presents experimental design, result analysis, and discussion; and finally, Section 4 concludes the paper and discusses future research directions.
2. Methodology: Cross-Modal Modeling Method with Adaptive and Localized Uncertainty
The system begins by acquiring real-time flotation froth images, which undergo preprocessing to ensure high-quality inputs for subsequent feature extraction. The multi-scale feature extraction module employs both a multi-scale variable receptive field convolutional layer (SKNet) and Vision Transformer (ViT) to extract rich features at different scales. Positional embeddings and a transformer encoder further enhance the representation of spatial structures. In the cross-modal feature fusion stage, the multi-scale features extracted from the images are fused to leverage the correlations between different modalities, thereby enhancing the expressive power of the features. This results in a high-dimensional fused feature vector used for prediction. To address the uncertainty in grade prediction, the system incorporates an uncertainty modeling module. Specifically, we use quantile regression to generate interval predictions. This is combined with localized conformal prediction to quantify the uncertainty of the results while maintaining accuracy. An adaptive calibration mechanism further refines the confidence intervals to align with observed data, improving the model’s reliability in industrial settings. Finally, the system outputs not only the predicted grade value but also the corresponding prediction interval and an analysis of uncertainty, providing a scientific basis for intelligent process control and risk-informed decision-making. The overall architecture of the proposed grade prediction and uncertainty quantification framework is illustrated in Figure 1.
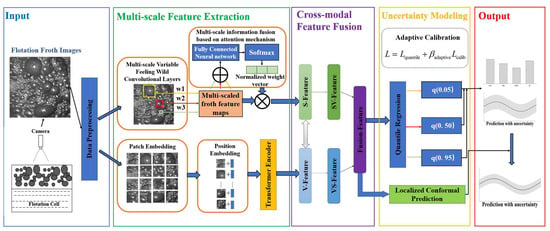
Figure 1.
The overall architecture of the proposed cross-modal grade prediction framework.
2.1. Feature Extraction Backbone: SKNet and ViT
Flotation froth images are characterized by complex local textures and global structural patterns. To simultaneously capture these multi-granular features, we construct a dual-branch backbone comprising a Selective Kernel Network (SKNet) and a Vision Transformer (ViT).
SKNet is employed to extract multi-scale local features. By dynamically adjusting the receptive fields of its convolutional kernels based on the input information, SKNet effectively captures fine-grained details of froth bubbles at varying scales [32]. Complementarily, ViT serves as the global feature extractor. Utilizing the multi-head self-attention mechanism, ViT models long-range dependencies and global semantic contexts across the entire image, compensating for the limited receptive field of traditional CNNs [33].
The detailed mathematical formulations and architectural specifications of both SKNet and ViT are provided in Appendix A.
While these two branches provide rich feature representations independently, simply concatenating them fails to exploit their semantic correlations. To address this, we introduce a cross-modal interaction fusion module in the following section to achieve deep bidirectional information integration.
2.2. Fusion of Cross-Modal Features
To fully leverage SKNet’s local detail perception and ViT’s global semantic understanding capabilities, we design a cross-modal interaction fusion module. This module achieves mutual enhancement of features through bidirectional attention mechanisms and generates unified feature representations through deep fusion. Unlike simple concatenation or summation used in standard CNN-transformer hybrids, our proposed cross-modal interaction module (Equations (1)–(4)) employs a bidirectional attention mechanism. This allows the local features from SKNet to modulate the global representations of ViT and vice versa, explicitly modeling the semantic alignment between texture details and global structural patterns.
2.2.1. Bidirectional Attention Modulation
Let the features extracted by SKNet and ViT be and , respectively. First, we calculate attention weights of local features on global features:
where is a learnable projection matrix, and is the sigmoid activation function.
This attention weight is then used to modulate global features:
Similarly, we calculate attention modulation of global features on local features:
2.2.2. Fusion of Multi-Level Features
Original features and interaction-modulated features are concatenated as,
Deep fusion is performed through multi-layer perceptron (MLP):
where are weight matrices.
This fusion strategy preserves unique information from each modality while enhancing feature representation through interaction.
2.3. Adaptive Quantile Regression Model
To quantify the uncertainty, we propose an adaptive calibrated quantile regression method which not only predicts multiple quantiles to construct prediction intervals but also ensures interval reliability through dynamic calibration mechanisms.
2.3.1. Quantile Regression Network
For fused features , K quantiles are predicted through independent fully connected networks:
where is the target quantile, and is the corresponding prediction network.
2.3.2. Pinball Loss Function
Quantile regression typically employs the Pinball loss function:
The total quantile loss is
2.3.3. Adaptive Calibration Mechanism
To ensure prediction interval coverage aligns with theoretical values, we introduce exponential moving average (EMA) tracking of coverage:
where is the momentum coefficient, and is the actual coverage of the t-th batch.
Target coverage is defined as
Calibration loss is defined as
Adaptive weight is calculated as
where is the base weight and is the adaptive strength coefficient.
The final total loss is
This adaptive mechanism ensures that when coverage deviation is large, the model automatically increases the weight of calibration loss, promoting rapid convergence of prediction intervals to target coverage.
2.3.4. Closed-Loop Calibration (Feedback) Mechanism
The proposed framework incorporates an explicit coverage-feedback loop to maintain reliable prediction intervals under nonstationary flotation conditions. First, during training of the quantile regression heads, the empirical coverage of each target quantile is computed on mini-batches and treated as a feedback signal. To suppress batch-to-batch fluctuations, an exponential moving average (EMA) is used to track the smoothed coverage trajectory. The deviation between EMA coverage and the theoretical target coverage is then converted into an adaptive gain to dynamically reweight the calibration penalty term (i.e., a larger deviation leads to a larger , thereby accelerating convergence of interval coverage while preserving point accuracy). This procedure corresponds to the EMA coverage update and adaptive weighting strategy in Equations (11)–(15) and is implemented in the training loss where EMA coverage is updated online and the calibration weight is increased when the coverage mismatch becomes large.
Second, at the interval construction stage, the localized conformal prediction module provides a second feedback loop: for each test sample, a local nonconformity radius is computed from its k-nearest calibration neighbors in the fused feature space, and a global width multiplier m is iteratively adjusted on the calibration set to meet the target coverage (Algorithm 1). In industrial deployment, this closed-loop calibration can be executed periodically using a sliding window of the most recent labeled samples (e.g., once per shift or every N assays), which enables continuous re-calibration under ore property drift and operating condition changes.
| Algorithm 1 Iterative optimization strategy |
| 1. Initialize width multiplier m = 1.2. |
| 2. Evaluate current coverage on calibration set. |
| 3. If , |
| Calculate the coverage gap: . |
| Update the Nonlinear multiplier: . |
| Repeat steps 2–3 for maximum T iterations. |
| The final prediction interval is |
| . |
2.4. Localized Conformal Prediction Module
While quantile regression can provide prediction intervals, it assumes uniform data distribution and struggles to adapt to local data heterogeneity. Therefore, we introduce localized conformal prediction methods that provide more precise prediction intervals by considering local neighborhood information of samples.
2.4.1. Calculation of the Nonconformity Score
During calibration, for each sample in the calibration set, its nonconformity score is calculated by,
where is the median prediction. The corresponding feature vector is also stored.
2.4.2. Construction of the Localized Prediction Interval
For test sample , first, its features are extracted, then, Euclidean distances to all samples are calculated in the calibration set:
Select k-nearest neighbors to obtain the local nonconformity score set as .
Based on significance level , the local calibration factor is calculated by,
where represents the quantile.
2.4.3. Optimization of the Adaptive Interval Width
To ensure that the prediction intervals can achieve target coverage, an iterative optimization strategy is designed. The algorithm is as shown in Algorithm 1.
This local neighbor-based strategy provides statistically guaranteed prediction intervals tailored to the local data distribution of specific test samples.
2.5. End-to-End Training Strategy
We adopt an end-to-end training strategy which optimizes the feature extractors and the uncertainty prediction modules simultaneously. The training procedure consists of three stages:
- Stage 1: Feature Extractor Pre-training
First, SKNet and ViT are pre-trained using standard mean squared error loss to learn capabilities of basic feature representation.
- Stage 2: Joint Training
Feature extractors are then jointly trained with the adaptive quantile regression module using Adam optimizer with learning rate of 0.001 and cosine annealing scheduling.
- Stage 3: Localized Calibration
Localized conformal calibration is performed on the validation set, determining optimal interval width multipliers through iterative optimization. The complete algorithm pseudocode is shown in Algorithm 2.
| Algorithm 2 Our method in this study |
|
3. Experimental Results and Analysis
3.1. Experimental Setup and Environment
In industrial flotation process, frequent shifts in ore properties, reagent dosages, and operating conditions make the process highly nonlinear and time varying. As a result, grade prediction models must deliver not only accurate point estimates but also reliable uncertainty to remain robust under noise, drift, and delays. Accurate point estimates are essential for process optimization, while reliable uncertainty quantification is critical for risk management, anomaly detection, and intelligent process control. Therefore, models must achieve both high prediction accuracy and robust, trustworthy uncertainty estimates to be applicable in real-world production environments.
3.1.1. Image Acquisition Setup
For the collection of froth images, a dedicated device was deployed in the plant’s production scene, as shown in Figure 2 (flotation froth picture acquisition device). Froth images were captured on-site using a Hikvision industrial camera mounted above the flotation column, pointing vertically downward to cover the region of interest on the froth surface. To ensure high-quality imaging, the camera was rigidly fixed to minimize vibration-induced motion blur, and a bar-shaped auxiliary light source was installed to provide stable illumination, thereby reducing the influence of ambient light variations. The camera operated in continuous acquisition mode, recording froth images in real-time at a fixed sampling interval.

Figure 2.
Schematic diagram of the flotation froth image acquisition device.
3.1.2. Label Alignment with Assay Measurements
For the acquisition of grade labels matching the froth samples, a standardized assay process was strictly executed—covering sampling, dehydration, drying, grinding into fine powder, and offline analysis with an XRF analyzer. The detailed workflow is presented in Figure 3 (flotation froth grade assay process). Concentrate grade labels were obtained from these offline assay measurements at approximately one-hour intervals. Since the assay label is inherently time-delayed relative to the instantaneous froth appearance, each label was aligned to the corresponding image samples by timestamp matching. Specifically, for each assay timestamp, the froth image closest in time was selected as the paired input to ensure temporal consistency between the visual features and the chemical analysis.

Figure 3.
Flotation Froth Grade Assay Process.
To further elucidate the data characteristics and the correlation between surface morphology and flotation performance, Figure 4 illustrates representative froth samples across different grade intervals. These visual variations are direct consequences of the fluctuating operating conditions (e.g., changes in air flow rate, pulp level, and reagent regime) inherent to the industrial process. As shown in the figure, the low-grade froth is characterized by large, irregular bubbles with a “watery” texture and poor stability, indicating low mineralization and significant gangue entrainment. Conversely, the high-grade froth manifests as a compact, fine-grained structure with uniform bubble size and a distinct luster, reflecting a high loading of hydrophobic valuable minerals and a stable froth layer. The middle-grade froth represents a transitional state with intermediate bubble size and viscosity. Incorporating such diverse visual patterns into the dataset is crucial for the model to learn robust feature representations that generalize well across the complex, nonlinear dynamics of the flotation process.

Figure 4.
Representative froth images corresponding to different concentrate grades (low, medium, and high).
To validate the effectiveness and practicality of our proposed method, we conducted systematic experimental validation using real industrial data. The data was collected from a tungsten flotation plant from January to June 2022, comprising 1800 froth images with corresponding grade labels. The dataset was split into training, validation, and test sets in an 8:1:1 ratio.
The configuration of the experimental environment is,
Hardware: NVIDIA RTX 3090 GPU (24 GB memory), 32GB RAM, AMD 5800X CPU.
Software: PyTorch 2.41, Python 3.12, CUDA 12.4.
Hyperparameters: Learning rate 0.001, batch size 16, training epochs 100.
The backbone network structure parameters are set based on the input size and computing power constraints; uncertainties and conformal related hyperparameters (such as α, k, width multiplier, etc.) are determined on the validation set through grid search/sensitivity analysis, with the criterion of “minimizing the interval width and error while satisfying the target coverage”.
The experimental workflow includes the following:
Data preprocessing: Each froth image was loaded using Python Imaging Library (PIL) and converted to RGB to ensure a consistent three-channel input. Images were then resized to 600 × 600 and converted to tensors. Finally, channel-wise normalization was applied using mean [0.485, 0.456, 0.406] and standard deviation [0.229, 0.224, 0.225]. Unless otherwise specified, no additional data augmentation was applied, so that the learned representations reflect real industrial imaging conditions without introducing artificial geometric or photometric distortions.
Model training: A total of 80% of the data was used for training, 10% for validation, and 10% for testing. Both quantile and calibration losses were monitored.
Performance evaluation: On the test set, we report MAE, RMSE, and R2 for point accuracy, and assess uncertainty with prediction-interval coverage (PICP) and mean interval width (MIW), for both the model’s quantile-based intervals and the localized conformal intervals.
3.2. Evaluation Metrics
To comprehensively assess both regression performance and uncertainty quantification for prediction of grade in froth flotation, a two-dimensional evaluation system was established, encompassing regression accuracy and prediction interval metrics.
3.2.1. Regression Accuracy Metrics
Regression accuracy metrics include Mean Absolute Error (MAE), Root Mean Squared Error (RMSE), and coefficient of determination (R2).
where and are the predicted and true values of the i-th sample, respectively, and is the mean of all the true values.
3.2.2. Prediction Interval Metrics
For quantifying model uncertainty characterization, the method was further evaluated from the perspective of prediction intervals by using the following metrics.
Coverage: Proportion of true values contained within the predicted intervals.
Mean Interval Width (MIW): Average width of the prediction intervals.
where and are the lower and upper bounds of the prediction interval for the i-th sample, and is the indicator function.
For LCP, k-nearest neighbor statistics were used to compute personalized intervals, and the same metrics were applied.
3.3. Baseline Model Design
A robust and representative baseline is essential for objectively evaluating the contributions of the proposed method. The baseline combined state-of-the-art components without integrating the core innovations introduced in this work. Specifically, it used a multi-modal feature extraction and quantile regression framework as follows.
At the feature extraction level, we construct a SKNet-ViT Fusion network combining SKNet’s convolutional attention mechanism with ViT’s self-attention mechanism. The SKNet branch captures local spatial features through selective kernel convolution, and the ViT branch extracts global semantic information through transformer blocks, where each branch outputs 128-dimensional feature vectors. These feature vectors are concatenated to form a 256-dimensional vector, which is then fused through a two-layer fully connected network (256 → 256 → 256). For uncertainty modeling, a standard quantile regression method is employed. Independent prediction heads are constructed for three preset quantiles (0.05, 0.5, 0.95). Each head consists of three fully connected layers and is trained with the standard quantile (pinball) loss.
For prediction interval construction, basic split conformal prediction method is implemented by using absolute errors of median predictions on the validation set as nonconformity scores. We construct prediction intervals with 90% coverage by applying statistical calibration. The baseline SKNet–ViT fusion architecture and the corresponding uncertainty estimation pipeline are shown in Figure 5.

Figure 5.
Baseline Model Architecture.
Figure 6 shows the prediction results of the baseline method on the test set, including comparison curves between predicted values and actual values and coverage of prediction intervals. It can be observed that while the method can reasonably match the true grades in some samples, the prediction intervals are often too wide or too narrow, with significant fluctuations in coverage and interval width. This indicates that the standard quantile regression and global conformal methods have significant limitations in complex scenarios. This means that improvement to the calibration and conformal prediction is necessary.

Figure 6.
Prediction results of Baseline method.
3.4. Results and Discussion
Building on the unified baseline, we adopt a three-step incremental optimization that targets the key modules without re-stating architectural details: (1) feature fusion, where progressively more interactive schemes are compared and the cross-modal interaction variant is selected; (2) uncertainty loss design, where formulations that promote calibration and quantile ordering are assessed and the EMA-based adaptive calibration is chosen; and (3) interval construction, where personalized conformal variants are evaluated and localized conformal prediction is adopted. Each ablation swaps a single component while keeping all other settings fixed and is evaluated with MAE/RMSE/R2 and interval metrics (PICP/MIW). The best choices from the three ablations are then integrated into the final model, yielding consistent gains over the baseline in both point accuracy and calibrated sharpness.
Table 1 lists the parameter settings for each main model in detail, including SKNet’s input size, convolution kernel size, branch parameters, and feature channel count, as well as ViT’s patch size, embedding dimension, multi-head attention count, number of layers, and so on. A clear parameter table lays the foundation for method reproducibility and fair comparison, while also reflecting the trade-offs between model scale and complexity.

Table 1.
Detailed parameter settings for the SKNet and ViT backbone networks.
Table 2 provides a detailed overview of the uncertainty modeling strategies employed by each comparison method, including quantile settings, network head structures, loss function forms, and key parameters. This table clearly illustrates the similarities and differences between the methods in terms of uncertainty quantification design for experimental comparisons.
Table 2.
Comparison of different uncertainty quantification methods and their configurations.
3.4.1. Feature Fusion Strategies
Feature quality is a key factor in determining the upper limit of model performance. SKNet excels at capturing local texture details, while ViT focuses on global structure modeling. Effectively integrating these two complementary feature representations is the primary issue to be addressed. This section compares three different fusion strategies: attention-weighted fusion learns adaptive weights to balance the contributions of different features, cross-modal interaction fusion enhances feature expression through bidirectional information exchange, and adaptive feature selection fusion uses a gating mechanism to perform content-aware feature selection.
Three fusion mechanisms were compared:
- (1).
- Attention-weighted fusion: Adaptive attention weights are learned to balance the contributions of SKNet and ViT features, dynamically assigning more weight to the most relevant features per sample.
- (2).
- Cross-modal interaction fusion: bidirectional attention modules are employed to facilitate mutual guidance and deep feature interaction between SKNet and ViT, enhancing expressiveness and complementarity.
- (3).
- Adaptive feature selection fusion: a gating mechanism is used to adaptively select and combine features at a granular level, complemented by residual connections to preserve feature diversity.
Cross-modal interaction fusion achieved the best trade-off between regression accuracy and prediction interval metrics, highlighting the value of deep bidirectional feature integration.
Table 3 shows the comparison results of the three feature fusion strategies in terms of various indicators, and the corresponding prediction results are visualized in Figure 7, Figure 8 and Figure 9, respectively. It can be seen that cross-modal interaction fusion outperforms the other two methods in terms of accuracy indicators such as MAE, RMSE, and R2, and also performs more evenly in terms of interval coverage and width. This result verifies that the bidirectional attention mechanism can effectively improve feature expression capabilities, further supporting the rationality of the design of the method in this paper.
Table 3.
Comparison of experimental results under different feature fusion strategies.

Figure 7.
Prediction results on the test set using the attention-weighted fusion strategy.

Figure 8.
Prediction results on the test set using the cross-modal interaction fusion strategy.

Figure 9.
Prediction results on the test set using the adaptive feature selection fusion strategy.
3.4.2. Uncertainty Modeling with Multiple Loss Functions
Accurate quantification of uncertainty is a core requirement for industrial applications. While traditional quantile regression can provide prediction intervals, it often suffers from issues such as unstable coverage and overlapping intervals. This section explores three improved loss function designs: the hybrid uncertainty model combines the advantages of quantile and distribution modeling, the ranking consistency model ensures the reasonableness of prediction intervals, and the adaptive calibration model achieves precise control of coverage through dynamic adjustment. These methods improve the quality of uncertainty modeling from different perspectives.
Three advanced uncertainty modeling strategies were explored:
- (1).
- Hybrid Uncertainty Model (HUM)
The HUM combines quantile regression with Gaussian distribution modeling. It optimizes a composite objective that balances quantile loss, negative log-likelihood, and a consistency loss, thereby aligning quantile-based and distributional predictions.
- (2).
- Rank Consistency Model (RCM)
The RCM enforces monotonicity among predicted quantiles. By ensuring that larger prediction errors correspond to wider intervals, it prevents quantile crossing and maintains coherent interval ordering.
- (3).
- Adaptive Calibration Model (ACM)
The ACM dynamically adjusts calibration weights using an exponential moving average (EMA) of coverage rates. This mechanism steers the model toward the target coverage level without manual hyperparameter tuning.
Table 4 shows the impact of different loss functions on the model performance. The adaptive calibration model performs best, achieving the narrowest model prediction interval while maintaining high prediction accuracy. Although its model coverage appears low, this precisely highlights the method’s advantage: it shifts the coverage guarantee to the subsequent conformal prediction stage, thereby avoiding overly conservative interval estimates. The key innovations are the following: (1) the EMA mechanism smooths coverage fluctuations between batches, providing a stable calibration signal; (2) adaptive weights are dynamically adjusted based on deviation, accelerating convergence; and (3) the optimization objectives of point prediction accuracy and interval coverage are separated. In contrast, the mixed uncertainty model suffers from performance trade-offs due to attempting to optimize multiple objectives simultaneously; while ordering consistency addresses interval overlap issues, it fails to effectively control coverage. The training curves in Figure 10, Figure 11 and Figure 12 show that the adaptive calibration model exhibits more stable loss convergence, with coverage gradually approaching the target value.
Table 4.
Comparison of experimental results under different loss functions.

Figure 10.
Prediction results on the test set using the hybrid uncertainty model.
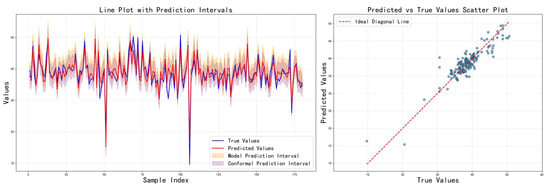
Figure 11.
Prediction results on the test set using the rank consistency model.

Figure 12.
Prediction results on the test set using the adaptive calibration model.
3.4.3. Improved Conformal Prediction Methods
Conformal prediction provides prediction intervals with theoretical guarantees, but traditional global calibration methods ignore the local characteristics of the data. In the flotation process, the difficulty of prediction varies significantly under different operating conditions, and a unified calibration strategy is difficult to adapt to this heterogeneity. This section compares three personalized conformal prediction methods: conditional CP achieves adaptive interval adjustment through error prediction, quantile regression CP fully utilizes existing quantile information, and localized CP performs fine-tuned calibration based on similarity in the feature space.
Traditional global conformal calibration may fail under non-uniform or complex data distributions. To address this, we evaluate three personalized conformal prediction methods:
- (1).
- Conditional Conformal Prediction (CCP)
CCP trains an auxiliary model to estimate the sample-wise expected absolute error and adjusts the prediction interval width for each instance accordingly, enabling individualized interval allocation.
- (2).
- Quantile Regression Conformal Prediction (QR-CP)
QR-CP exploits quantile forecasts to calibrate the lower and upper bounds separately, improving interval sharpness and coverage, particularly for asymmetric target distributions.
- (3).
- Localized Conformal Prediction (LCP)
LCP performs k-nearest-neighbor-based local calibration: for each test instance, it uses only the most similar calibration samples in the feature space, allowing the intervals to adapt to local data complexity. The results of three different conformal prediction methods are shown in Table 5. In terms of metrics, localized CP achieves a better balance between interval width and coverage, especially when dealing with complex, non-uniform data distributions. This shows that feature-space-based localized calibration can provide more personalized and reliable prediction intervals for each test sample, which is an effective means of improving practicality in industrial scenarios.
Table 5.
Experimental results by using different conformal prediction methods.
It is important to note that the regression accuracy metrics remain identical across all three methods in Table 5. This uniformity arises because conformal prediction functions as a post hoc calibration technique applied to the same underlying pre-trained base regressor. Consequently, while the point predictions and their associated errors remain unchanged, the distinct calibration strategies result in significant variations in interval widths and coverage rates.
Among the evaluated strategies, localized CP achieves the most favorable balance, yielding a reasonable mean interval width of 7.942 while maintaining a robust coverage rate of 92.2%. This superior performance is primarily attributed to the k-nearest neighbor strategy, which identifies similar samples in the feature space to provide customized calibration for each test point. Unlike global methods, these local statistics more accurately reflect the prediction difficulty inherent to specific regions of the data distribution. Conversely, although the quantile regression CP produces the narrowest intervals of 6.336, its coverage rate of 85.1% falls short of the theoretical 90% target, a deficiency likely caused by the bias inherent in direct quantile estimation. Similarly, while conditional CP offers theoretical flexibility, the requirement for an additional error prediction model introduces further uncertainty, leading to suboptimal performance compared to the localized approach. These findings collectively validate the effectiveness of personalized calibration rooted in local information.
Although the localized conformal prediction module involves k-nearest neighbor search, its computational overhead is fully controllable. The module consists of two phases: (1) the calibration phase is a one-time offline process that takes about 10 s, and (2) the online prediction phase, in which reasoning on a single image takes about 50–55 ms, with the k-nearest-neighbor search (180 × 256 distance calculations and sorting) accounting for only 3 ms. Considering that the time interval for grade prediction in real industrial applications is at least 3 min, the reasoning time is very low and has rich time surplus. The memory footprint of the module is about 50–55 MB, of which only a few hundred KB are needed for calibration data. k-nearest neighbor search is therefore not a system performance bottleneck, and the proposed method has good industrial deployability.
After module-wise validation, we assembled the final system using cross-modal interaction for feature extraction, adaptive calibration for uncertainty estimation, and localized conformal prediction for interval construction. We subsequently assessed performance with a suite of quantitative metrics and complementary visual analyses. To validate the effectiveness of the proposed method, this paper selects three mainstream uncertainty quantification methods for comparative experiments. MC Dropout maintains activated Dropout layers during inference and performs multiple stochastic forward passes, utilizing the mean and standard deviation of prediction results to estimate epistemic uncertainty, with prediction intervals constructed through quantiles of the standard normal distribution. Deep Ensemble employs an ensemble model composed of multiple independently trained neural networks, where each member network simultaneously outputs prediction means and variance, quantifying model uncertainty by ensembling the predictive distributions of all members, with the total variance comprising the mean of member prediction variances (aleatoric uncertainty) and the variance of member prediction means (epistemic uncertainty). DKL-GP (Deep Kernel Learning with Gaussian Process) combines the feature extraction capability of deep learning with the uncertainty modeling advantages of Gaussian processes, mapping inputs to a latent space through neural networks and then leveraging local neighborhood information and residual statistics of training samples to estimate predictive uncertainty, with prediction intervals comprehensively considering base variance, distance uncertainty, and neighborhood residual standard deviation. These three methods, respectively, represent uncertainty quantification paradigms based on stochastic inference, model ensembling, and kernel methods, providing comprehensive comparison benchmarks for the proposed method.
As shown in Figure 13 and Table 6, experimental results show that the proposed method not only achieves low error in point predictions but also effectively covers most real observations with its prediction intervals, demonstrating good convergence in interval width, thereby intuitively showcasing the model’s reliability and practicality. Specifically, cross-modal fusion fully exploits local and global information, the adaptive calibration mechanism effectively controls the coverage of prediction intervals, and localized conformal prediction targets personalized feature distributions to enhance the accuracy of confidence intervals. Overall, the proposed method performs exceptionally well in quantifying uncertainty, providing robust data support and reference for industrial decision-making.

Figure 13.
Prediction results of proposed method.
Table 6.
Performance comparison between the proposed method and other approaches.
4. Conclusions
In this paper, we proposed a novel method for flotation grade prediction with uncertainty quantification, based on cross-modal feature fusion and adaptive calibration. By designing a network that fuses multi-scale information from froth images, an adaptive mechanism that ensures accurate interval coverage, and a localized conformal prediction module that provides theoretically guaranteed uncertainty estimates, our method effectively addresses key challenges in industrial process modeling.
Overall, our method demonstrates significant potential in fusing multi-modal information, performing robust uncertainty quantification, and generating localized predictions. It offers new insights and a powerful framework for regression and interval estimation tasks in complex industrial processes.
Future work will focus on incorporating temporal information to better handle process drifts and exploring semi-supervised learning to leverage unlabeled data, further enhancing the model’s adaptability in dynamic industrial environments.
Author Contributions
Methodology and writing—review and editing: F.L. and X.W.; Guidance: W.G.; Programming: X.W. Methodology and writing—review: Y.W. and J.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Major Program of the National Natural Science Foundation of China [Grant No. 62394340] and the Kunming Academician Workstation [Grant No. YSZJGZZ-2023011].
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
No new data were created or analyzed in this study.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Mathematical Details of Feature Extractors
Appendix A.1. Multi-Scale Local Feature Extraction with SKNet
SKNet enhances a model’s ability to capture information at different spatial scales through an adaptive combination of convolutional kernels [32]. To extract the rich, local, multi-scale features from flotation froth images, we employ the Selective Kernel (SK) module. The SK module processes the input feature map through multiple parallel convolutional branches, with a different dilation rate and kernel size for each branch. It then uses global information to adaptively assign weights to each branch.
For input flotation froth image , SKNet first extracts features at different scales through M parallel branches:
where Convdi(⋅) is a convolution operation with a specific dilation rate , denotes batch normalization, and ReLU is the activation function.
Different dilation rates provide branches with different receptive fields, capturing multi-scale information.
Subsequently, unified representation is obtained through feature aggregation:
To achieve adaptive feature selection, SKNet generates attention weights from global information. First, Global Average Pooling (GAP) is used to compress spatial information:
Next, a two-layer fully connected network generates channel-wise attention weights:
where FC1 maps the GAP vector to a lower-dimensional vector , followed by a pointwise nonlinearity (e.g., ReLU). FC2 expands to a higher-dimensional vector , which is then reshaped into a matrix is the reduced feature dimension, is the reduction ratio, and is the minimum dimension threshold.
The selection weights for each branch are computed using a softmax function:
Finally, the output of the SKNet module is a weighted sum of the features from each branch:
where ⊙ denotes element-wise multiplication.
This adaptive mechanism enables the network to dynamically adjust the importance of features at different scales based on input content.
Appendix A.2. Global Feature Extraction with ViT
To capture global dependencies and long-range interactions within the froth images, we introduce a ViT as a global feature extractor. ViT models the relationships between image patches using a self-attention mechanism, effectively complementing the local focus of SKNet.
Appendix A.2.1. Image Patch Embedding and Position Encoding
Given input image , it is first divided into non-overlapping patches. With patch size , the image is divided into patches. Each patch is mapped to d-dimensional embedding space through linear projection:
where is a learnable classification token, is the patch embedding matrix, and is position encoding.
Appendix A.2.2. Multi-Head Self-Attention Mechanism
The core of the transformer encoder is the multi-head self-attention (MHSA) mechanism [33]. For input sequence , MHSA is calculated as:
where query matrix , key matrix , value matrix , and is the dimension per attention head.
Multi-head attention captures different representation subspaces by computing h attention heads in parallel:
where .
Appendix A.2.3. Transformer Encoder Block
Each transformer block contains MHSA and feed-forward network (FFN), enhanced with residual connections and layer normalization for training stability:
where denotes layer normalization, and is a two-layer fully connected network which is,
where GELU denotes the Gaussian Error Linear Unit activation function.
After L transformer blocks, the feature corresponding to the classification token is extracted as global representation:
References
- Wills, B.A.; Finch, J.A. Wills’ Mineral Processing Technology; Butterworth-Heinemann: Oxford, UK, 2015. [Google Scholar]
- Aldrich, C.; Marais, C.; Shean, B.; Cilliers, J. Online monitoring and control of froth flotation systems with machine vision: A review. Int. J. Miner. Process. 2010, 96, 1–13. [Google Scholar] [CrossRef]
- Fu, Y.; Aldrich, C. Deep learning in mining and mineral processing operations: A review. IFAC-Papersonline 2020, 53, 11920–11925. [Google Scholar] [CrossRef]
- Wang, X.; Song, C.; Yang, C.; Xie, Y. Process working condition recognition based on the fusion of morphological and pixel set features of froth for froth flotation. Miner. Eng. 2018, 128, 17–26. [Google Scholar] [CrossRef]
- Fu, Y.; Aldrich, C. Froth image analysis by use of transfer learning and convolutional neural networks. Miner. Eng. 2018, 115, 68–78. [Google Scholar] [CrossRef]
- Fu, Y.; Aldrich, C. Flotation froth image recognition with convolutional neural networks. Miner. Eng. 2019, 132, 183–190. [Google Scholar] [CrossRef]
- Zarie, M.; Jahedsaravani, A.; Massinaei, M. Flotation froth image classification using convolutional neural networks. Miner. Eng. 2020, 155, 6443–6456. [Google Scholar] [CrossRef]
- Jia, R.; Ren, M.; Wang, J.; Yu, F.; He, D. Robust operating performance assessment of flotation processes using convolutional neural networks and feature learning. Adv. Eng. Inform. 2025, 64, 103087. [Google Scholar] [CrossRef]
- Zhou, J.Y.; Yang, C.-H.; Wang, X.-L.; Cao, S.-Y. A soft sensor modeling framework embedded with domain knowledge based on spatio-temporal deep LSTM for process industry. Eng. Appl. Artif. Intell. 2023, 126, 106847. [Google Scholar] [CrossRef]
- Pu, Y.; Szmigiel, A.; Apel, D.B. Purities prediction in a manufacturing froth flotation plant: The deep learning techniques. Neural Comput. Appl. 2020, 32, 13639–13649. [Google Scholar] [CrossRef]
- Zhang, H.; Yang, M.; Tang, Z.; Xie, Y.; Zheng, Z.; Gui, W. Flotation grade monitoring using feed grade refined embedding and nonoverlapped patch encoding. IEEE Trans. Ind. Inform. 2025, 21, 8779–8790. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, X.; Zhou, J.; Yang, C.; Yang, Y. Long sequence multivariate time-series forecasting for industrial processes using sasgnn. IEEE Trans. Ind. Inform. 2024, 20, 12407–12417. [Google Scholar] [CrossRef]
- Lu, D.; Wang, F.; Wang, S.; Bu, K.; Li, K.; Ma, X. Multimode froth flotation process operating performance assessment based on deep embedded graph clustering network. IEEE Trans. Ind. Inform. 2024, 20, 9445–9454. [Google Scholar] [CrossRef]
- Xie, S.; Yu, Y.; Xie, Y.; Tang, Z. Sensitive feature selection for industrial flotation process soft sensor based on multiswarm PSO with collaborative search. IEEE Sens. J. 2024, 24, 17159–17168. [Google Scholar] [CrossRef]
- Lu, F.; Gui, W.; Qin, L.; Wang, X.; Zhou, J. A novel semi-supervised prediction modeling method based on deep learning for flotation process with large drift of working conditions. Adv. Eng. Inform. 2024, 62, 102934. [Google Scholar] [CrossRef]
- Liu, X.; Aldrich, C. Flotation Froth Image Recognition Using Vision Transformers. IFAC PapersOnLine 2023, 56, 2329–2334. [Google Scholar] [CrossRef]
- Zhang, B.; Shin, Y.C. A probabilistic neural network for uncertainty prediction with applications to manufacturing process monitoring. Appl. Soft Comput. 2022, 124, 108995. [Google Scholar] [CrossRef]
- Mehdiyev, N.; Majlatow, M.; Fettke, P. Quantifying and explaining machine learning uncertainty in predictive process monitoring: An operations research perspective. Ann. Oper. Res. 2024, 347, 991–1030. [Google Scholar] [CrossRef]
- Shen, C.; Liu, Y. Conformal Segmentation in Industrial Surface Defect Detection with Statistical Guarantees. Mathematics 2025, 13, 2430. [Google Scholar] [CrossRef]
- Perrin, G. Adaptive calibration of a computer code with time-series output. Reliab. Eng. Syst. Saf. 2020, 196, 106728. [Google Scholar] [CrossRef]
- Dong, M.; Sun, Y.; Jin, Y.; Song, C.; Zhang, X.; Luo, X. Uncertainty graph convolution recurrent neural network for air quality forecasting. Adv. Eng. Inform. 2024, 62, 102651. [Google Scholar] [CrossRef]
- Sun, M.C.; Feng, C.; Zhang, J. Multi-distribution ensemble probabilistic wind power forecasting. Renew. Energy 2020, 148, 135–149. [Google Scholar] [CrossRef]
- Trapero, J.R. Calculation of solar irradiation prediction intervals combining volatility and kernel density estimates. Energy 2016, 114, 266–274. [Google Scholar] [CrossRef]
- Wang, S.; Sun, Y.H.; Zhou, Y.; Jamil Mahfoud, R.; Hou, D. A new hybrid short-term interval forecasting of PV output power based on EEMD-SE-RVM. Energies 2020, 13, 87. [Google Scholar] [CrossRef]
- Khosravi, A.; Nahavandi, S.; Creighton, D. A prediction interval-based approach to determine optimal structures of neural network metamodels. Expert Syst. Appl. 2010, 37, 2377–2387. [Google Scholar] [CrossRef]
- Hou, Z.; Wang, H.; Xiong, M.; Zhou, C.; Yue, Y. Towards trustworthy civil aviation hazards identification: An uncertainty-aware deep learning framework. Adv. Eng. Inform. 2025, 65, 103280. [Google Scholar] [CrossRef]
- Bremnes, J.B. Probabilistic wind power forecasts using local quantile regression. Wind Energy 2004, 7, 47–54. [Google Scholar] [CrossRef]
- Pinson, P.; Kariniotakis, G. Conditional prediction intervals of wind power generation. IEEE Trans. Power Syst. 2010, 25, 1845–1856. [Google Scholar] [CrossRef]
- Biehler, M.; Jing, L.; Shi, J. FUSION3D: Multimodal data fusion for 3D shape reconstruction: A soft-sensing approach. IISE Trans. 2025, 57, 101–105. [Google Scholar] [CrossRef]
- Wang, J.; Xu, H. Cross-modal deep learning framework for 3D reconstruction and information integration of Zhejiang wood carving heritage. Sci. Rep. 2025, 15, 2025. [Google Scholar] [CrossRef]
- García-Díaz, J.C.; Gozalvez-Zafrilla, J.M. Uncertainty and sensitive analysis of environmental model for risk assessments: An industrial case study. Reliab. Eng. Syst. Safety 2012, 107, 16–22. [Google Scholar] [CrossRef]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.