Abstract
The large scale and shape variation in breast lesions make their segmentation extremely challenging. A breast ultrasound image segmentation model integrating Mamba-CNN and feature interaction is proposed for breast ultrasound images with a large amount of speckle noise and multiple artifacts. The model first uses the visual state space model (VSS) as an encoder for feature extraction to better capture its long-range dependencies. Second, a hybrid attention enhancement mechanism (HAEM) is designed at the bottleneck between the encoder and the decoder to provide fine-grained control of the feature map in both the channel and spatial dimensions, so that the network captures key features and regions more comprehensively. The decoder uses transposed convolution to upsample the feature map, gradually increasing the resolution and recovering its spatial information. Finally, the cross-fusion module (CFM) is constructed to simultaneously focus on the spatial information of the shallow feature map as well as the deep semantic information, which effectively reduces the interference of noise and artifacts. Experiments are carried out on BUSI and UDIAT datasets, and the Dice similarity coefficient and HD95 indexes reach 76.04% and 20.28 mm, respectively, which show that the algorithm can effectively solve the problems of noise and artifacts in ultrasound image segmentation, and the segmentation performance is improved compared with the existing algorithms.
1. Introduction
Breast cancer is currently one of the most common malignant tumors in women and has become a major killer of women’s health [1]. The latest data indicate that breast cancer has become the leading cause of cancer incidence among women [2]. Therefore, early diagnosis and treatment of breast cancer are crucial for patients. Ultrasound imaging technology has become one of the most common methods for early diagnosis of breast cancer due to its affordability, ease of operation, and noninvasiveness [3]. BUS (Breast Ultrasound Scan) images can be analyzed to well diagnose whether the breast is diseased and the extent of the lesion, and to better prevent the disease. However, manual segmentation is often time-consuming, laborious, and subjective, and breast ultrasound images have many inherent defects such as speckle noise, artifacts, low contrast, and low resolution, etc., all of which make the segmentation of breast ultrasound images very challenging. Therefore, the use of computer-aided diagnosis, through the automatic segmentation of breast ultrasound images, can accurately identify the breast ultrasound image of the skin, glands, and tumors and other tissue areas, to provide doctors with more accurate information about the lesions, so as to assist the doctor in carrying out more accurate diagnosis and treatment [4].
Breast ultrasound image segmentation belongs to an important branch of medical image segmentation, and its main methods can be categorized into those based on traditional image processing and those based on deep learning. The traditional image processing methods can be mainly categorized into region growing algorithms [5] and the threshold segmentation method [6]. However, methods based on traditional image processing are only suitable for simple image segmentation with high imaging quality, but the segmentation effect is poor for complex environments with high noise and many artifacts. Additionally, with the development of deep learning, various deep learning-based breast ultrasound image segmentation methods have been enthusiastic.
Convolutional Neural Networks (CNN) are an end-to-end deep learning method that can extract deep features well and have made amazing progress in breast ultrasound image segmentation [7]. Among the convolutional neural network models, Unet [8] proposed by Ronneberger et al. is the most classic. Unet is a deep learning network designed for medical image segmentation with a symmetric U-shaped structure as well as jump connections. Later on, a large number of CNN-based models emerged, such as U-net++ [9], FPN [10] and DeepLabv3+ [11]. Based on these approaches, Shareef et al. [12] used deterministic kernels to adapt breast segmentation structures and designed dual encoders to fuse information from different scales to segment small breast tumors. Yap et al. [13] investigated three CNN-based approaches for breast ultrasound lesion detection. Hu et al. [14] proposed to combine dilated convolutional networks with phase-based active contouring models to automatically segment breast lesion regions. Zhu et al. [15] developed a second-order subregion network for breast lesion segmentation by utilizing the second-order statistics of multiple feature subregions. All these CNN-based methods have some limitations, and the local operation of their convolution can make the network under- or over-segmented when performing breast ultrasound image segmentation.
Transformer [16] has a global dependency modeling capability to capture long-range dependencies through a self-attention mechanism, and its superior performance has achieved excellent performance in medical image segmentation. Chen et al. [17] combined the advantages of Transformer and Unet and used Transformer architecture as an encoder, which well improved the medical image segmentation task. Mo et al. [18] proposed Hover-trans network for breast tumor diagnosis in breast ultrasound images using Transformer. Cao et al. [19] proposed a pure Transformer network model with Unet architecture, which uses a hierarchical self-attention mechanism with a shift window, namely Swin Transformer, as encoder and decoder. However, Transformer has a better performance; it requires pre-training on many datasets, and its high computational complexity leads to a large overhead for training and inference.
Recent developments in the state space model (SSM), especially structured SSM (S4) [20] provide a very promising solution for dealing with long sequences. The Mamba model enhances the S4 model with selective mechanisms and hardware optimizations, which present excellent performance in dense data domains [21]. The introduction of the Cross-Scan Module (CSM) in Visual Mamba further enhances the applicability of Mamba to computer vision tasks by traversing the spatial domain and converting the visual images into an ordered sequence of patches [22]. Wang et al. [23] proposed the MambaUnet, which can synergize the capabilities of Unet and Mamba in medical image segmentation to improve the segmentation performance.
Inspired by the above, a breast ultrasound image segmentation model integrating Mamba-CNN and feature interaction is proposed to address the problems of speckle noise and many artifacts in breast ultrasound images. The main contributions of this paper are as follows: (1) a novel network is designed to capture long-range dependencies with linear time complexity using the Mamba module, and the feature maps are upsampled step by step using transposed convolution [24], which recovers the spatial information of the images while improving their resolution; (2) a hybrid attention enhancement mechanism, HAEM, is designed as the bottleneck module of the model, which is used for feature maps by spatial attention and channel attention for feature selection of the feature map, focusing on more critical regions and features for better information extraction; (3) A cross-fusion module, CFM, is constructed to interact the output of the encoder as well as the output of the decoder, which organically combines the semantic information of the shallow feature map as well as the spatial information of the deeper feature map to improve the segmentation capability effectively; (4) Compared with several mainstream medical segmentation models in the BUSI and UDIAT datasets shows better segmentation performance, which provides some application value for early diagnosis of breast tumors.
2. Materials and Methods
With the proposal of the state space model Mamba, more visual Mamba models have been used in the field of image processing. The Mamba model alleviates the modeling constraints of convolutional neural networks through global sensing field and dynamic weighting, and avoids the secondary computational complexity of Transformer while possessing the long sequence modeling capability of Transformer. The Mamba model effectively combines with CNN, which is very helpful to deal with the problems of blurred boundaries and severe noise in breast ultrasound image segmentation.
2.1. General Structure of the Network Model
To solve the problems of much speckle noise, serious artifacts, and blurred boundaries in breast ultrasound image segmentation, this paper proposes a breast ultrasound image segmentation algorithm that incorporates Mamba-CNN and feature interactions, and the overall structure of its network is shown in Figure 1.
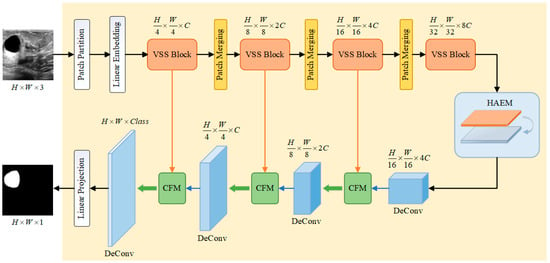
Figure 1.
Breast ultrasound image segmentation model integrating Mamba-CNN and feature interaction.
The main structure of the model is divided into four parts, i.e., encoder (Visual State Space model, VSS), HAEM, Transpose Convolution (Deconvolution) and CFM.
The input image of size is first grayscaled and decomposed into ViT-like patch blocks [25], which are then integrated into a one-dimensional sequence of size . Afterwards, the dimensions are scaled to an arbitrary size that can be represented by by means of a linear embedding layer, i.e., . These one-dimensional sequences are then processed through multiple VSS blocks and a patch merging layer [26] to create layered features. The VSS blocks focus on feature extraction and learning, while the Patch Merging layer downsamples the features and increases the channel dimensions. The output dimensions of each layer of the encoder are , , , and , respectively. The HAEM does not change the output dimension of the last layer of the encoder. The decoder section uses transposed convolution to upsample the feature map, which can maintain the same dimension as the encoder output, and undergoes CFM for feature interaction. Where the encoder part, i.e., VSS module, loads VMamba Tiny pre-trained weights.
2.2. Encoder Module VSS
The VSS block originated from the State Space Model (SSM). Specifically, in SSM, each channel of the input vector is mapped to the output vector and then transformed through a high-dimensional latent state . This process is jointly achieved by the projection process and the selection mechanism. This model can be described as:
where , , , , , , . , , , and are all weighting factors.
To integrate SSM into a deep learning model, the continuous time model SSM must be discretized, and given the time scale parameter , the discrete model of SSM can be obtained by transforming it with a zero-order holder:
where , . Approximating using a first-order Taylor series, i.e., .
The CSM is further introduced in the visual Mamba model, and then the convolution operations are integrated into the VSS block. The structure of the visual state space module VSS is shown in Figure 2, where LN denotes layer normalization, Linear denotes a linear layer, DWCNN denotes depth convolution, and SS2D is 2D selective scanning. In the VSS block, the input features are first layer normalized to the linear embedding layer and then forked into two branches into different layers. One of the branches undergoes deep convolution [27] and SiLU [28] activation, enters the SS2D block, undergoes layer normalization again, merges with the other branch after SiLU activation, and finally enters the linear layer as well as residual concatenation to obtain the output. Unlike a typical vision transformer, the VSS module avoids positional embedding and chooses a streamlined structure without MLP phases, achieving a denser stack of blocks within the same depth budget.
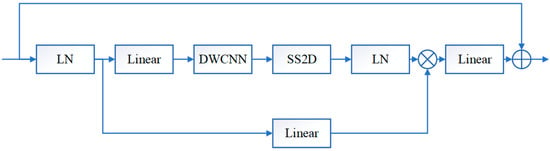
Figure 2.
Visual state space model VSS.
2.3. Hybrid Attention Enhancement Mechanism (HAEM)
The bottleneck of the network receives the output feature maps from the encoder, and it is difficult to capture the target accurately due to the many noise artifacts in breast ultrasound images, so this paper proposes a new module, HAEM, which receives the output features from the encoder, and through the organic combination of spatial attention [29] as well as channel attention [30], it captures and filters the more critical regions and features, which enhances the network’s ability to capture the target region and improves the accuracy of segmentation. HAEM contains two branches, channel attention and spatial attention, and the specific structure is shown in Figure 3.
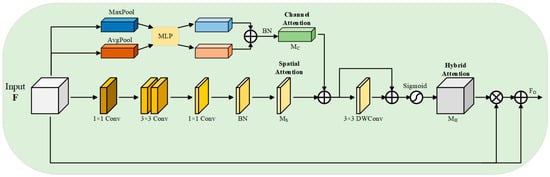
Figure 3.
Hybrid attention enhancement mechanism HAEM.
Given the input feature , a hybrid attention feature map is computed by HAEM, which is then weighted with the input features to obtain the final output feature map , which is computed as:
where denotes the element-by-element multiplication between matrices.
The hybrid attention feature map is formed by aggregating channel attention and spatial attention . The specific process can be expressed as follows:
where is the Sigmoid activation function, and DWConv is a depthwise convolution, which aims to enhance local relationships and cluster information.
In channel attention branching, each channel of the input features contains a specific feature response, and the relationship of each channel in the channel branching is fully utilized to aggregate the features in the channel. Firstly, global maximum pooling and global average pooling are performed on the input feature in spatial dimension, respectively, and two feature maps with a dimension of are obtained. Then the results of global maximum pooling and global average pooling are fed into a shared multilayer perceptron (MLP) for learning, respectively, to obtain two output feature maps of dimension . To reduce computational parameters, a dimensionality reduction operation is used in the MLP, the number of neurons in the first layer of the MLP is C/r, the activation function is ReLU, and the number of neurons in the second layer is C. Finally, the two outputs of the MLP are summed up, and then subjected to batch normalization (BN) to obtain the final channel attention map , the specific formula of the above process is:
where AvgPool denotes global average pooling, MaxPool denotes global maximum pooling, denotes the output feature of global average pooling, and denotes the output feature of global maximum pooling, , , , .
In the spatial attention branch, this paper employs Dilated Convolution (DC) [31] to reduce the computational effort while expanding its sensory field to construct a more efficient spatial feature map than standard convolution. Specifically, the input feature is first projected to a reduced dimension space using 1 × 1 standard convolution to facilitate the compression of the feature map in the channel dimension. Then the compressed feature map is convolved with two 3 × 3 dilated convolutions to effectively extract the context information. Finally, the feature map is again transformed into a feature map in dimension using 1 × 1 standard convolution, and a batch normalization operation is performed on it to obtain the final output spatial attention feature map , which is computed as:
After obtaining the required attention feature maps by channel attention branching and spatial attention branching, respectively, the spatial attention feature map and the channel attention feature map are summed up element by element, and then a deep convolution is performed to enhance the local relations, gather the more effective information, and construct the residual connections [32], and then activated by the Sigmoid function to obtain the hybrid attention features. Then, the hybrid attention features are element-wise multiplied with the input features to obtain an enhancement matrix, which is then added to the input features to obtain the output features of the HAEM at the bottleneck, i.e., the input features of the decoder.
2.4. Cross-Fusion Module (CFM)
Skip Connection is particularly important in medical segmentation, which not only facilitates information fusion but also improves the efficiency of gradient propagation while preserving the underlying information. Usually, the encoder partially reduces the resolution gradually by downsampling to extract features, but the downsampling operation will lead to the loss of spatial detail information of the target, which will affect the segmentation performance. Therefore, jump-joining is necessary in image segmentation. Since the boundary of the breast ultrasound image is blurred and the target region is difficult to be precisely localized, the simple jump connection cannot cope with this more complex environment. Therefore, in this paper, a new module, CFM is designed, which takes the shallow features output from the encoder and the deep features output from the decoder as inputs, and effectively fuses the spatial detail information at the bottom layer with the semantic information at the top layer, which can further improve the accuracy and robustness of the segmentation results of the model. The specific structure of the CFM is shown in Figure 4.
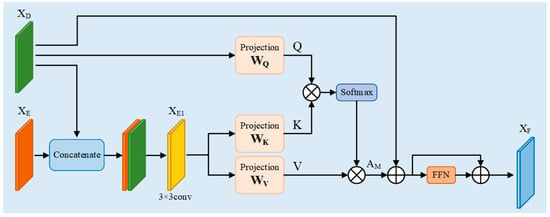
Figure 4.
Cross fusion module CFM.
The CFM first receives the same dimensional outputs , from the encoder and decoder, respectively. Then, the two are spliced in the channel direction to obtain a feature map containing spatial and semantic information with dimension . The number of channels is reduced to the original dimension by 3 × 3 convolution, and then the new feature map, i.e., , is obtained by the activation function ReLU as well as by normalization. The specific process is as follows:
After obtaining the new feature map that aggregates spatial and semantic information, it is fed into the linear projection layer for learning, along with the output feature of the decoder. is mapped to through the linear layer, and is mapped to and . Then , , and are used as inputs for the dot-product attention computation, which proceeds as follows:
where , and are the weight matrices of the linear layers, softmax is the activation function, and is a constant that serves to prevent the result of the dot product from being too large.
In order to capture richer contextual information, increase the generalization ability of the network, and improve its sparsity, the multi-head operation [16] is introduced into the dot product operation and its dimensions are transformed, keeping the input and output dimensions unchanged, which can be expressed as follows:
where concat is the concatenate operation and is the weight matrix, which is intended to keep the input and output constant throughout the attention computation process.
After obtaining the attention matrix , residual concatenation is performed with the decoder output to obtain a new output . This is then passed through the feed-forward network FFN [16] and the residual concatenation is used again to finally obtain the final output of the cross-fusion module . The specific process can be expressed as follows:
where , which is consistent with the input feature dimensions. FFN is a feed-forward neural network, i.e., it is a linear layer, and the input and output dimensions are kept constant, which can be expressed as follows:
In the model of this paper, the output dimensions of each level of the encoder are , , , and , respectively, and the dimensions of each level of the decoder are , , and , respectively. Each CFM receives the encoder outputs and decoder outputs with matching dimensions, respectively, and calculates the new feature through CFM, and then uses it as an input into the decoder module of the next level, and so on to achieve the final outputs, and then goes through the linear projection layer to achieve the final segmentation result map.
2.5. Loss Function
In breast ultrasound image segmentation, foreground as well as background need to be predicted, which is a pixel-by-pixel classification problem; the most common loss function is the cross-entropy loss function; in this paper, we use a weighted binary cross-entropy loss function, which can be expressed as:
The cross-entropy loss function calculates the loss of each pixel equally, when the number of pixels in the foreground is much smaller than that of the background pixels, the loss of the background will be dominant, which leads to the model focusing too much on the background and ignoring the foreground; therefore, this paper combines the cross-entropy loss function as well as Dice loss function, which will effectively overcome the phenomenon of category imbalance, and also improve the spatial consistency. Dice loss function specifically can be expressed as:
where is the total number of pixels, is the number of categories, denotes the predicted value, denotes the true value of the mask, and is the value of the weights assigned.
The final total loss is obtained by weighing the cross-entropy loss as well as the Dice loss, which is:
The Dice loss enhances the model’s inference for contiguous regions, while the cross-entropy loss ensures per-pixel classification accuracy. The combination of the two can improve the spatial consistency between the predicted regions while ensuring the classification accuracy at the pixel level.
3. Experiments
3.1. Material Preparation
3.1.1. Environment Configuration
The experiments in this paper were conducted on Windows 11 operating system with Inter(R) Core (TM) i9-9900 CPU (Intel Corporation, Chandler, AZ, USA), NVIDIA GeForce RTX 2070 SUPER graphics card, and 8GB of GPU memory. The platform for model compilation was PyCharm 2023.3.4, and the framework used for model training was Pytorch 2.5.0 and CUDA 12.4 for acceleration. During the training process, the input size of the image is uniformly set to 224 × 224, and some hyperparameters of the model are set: the initial learning rate is 0.01, the momentum is 0.9, the training batch size is 8, the number of iterations is 300, and the optimizer is SGD.
The learning rate decay curve, as well as the loss function change curve, during the training process are shown in Figure 5 and Figure 6, respectively, and the total loss, as well as the learning rate, is recorded once for each batch trained. The orange curve represents the proposed model, while the blue curve is the baseline model of Mamba. The horizontal coordinate step in Figure 5 and Figure 6 is the number of batches; the vertical coordinates, respectively, represent the learning rate and loss value of each batch of the model. As the model iterates, the model starts to converge when Step is 75k, i.e., about 250 training rounds.
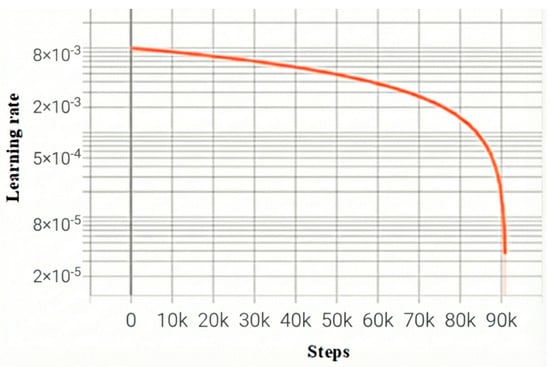
Figure 5.
Model learning rate decay curve.
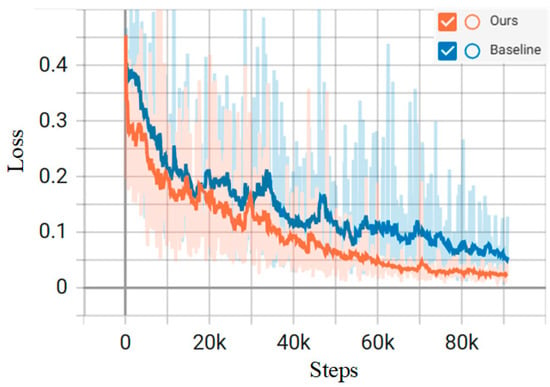
Figure 6.
Model training loss function variation curve.
Table 1 shows the comparison of the parameter counts and FLOPs between our model and several baselines, where the optimal results are bolded. As shown in the table, our model achieves optimal performance in terms of parameter count and computational complexity, with 21.76 million parameters and 39.19 GFLOPS, respectively. Compared to CNN- and Transformer-based models, we have reduced the parameter count while improving segmentation accuracy. In terms of computational complexity, our model is slightly higher than HCTNet and MambaUnet. This may be attributed to the incorporation of attention modules, which introduce quadratic computational complexity, resulting in a marginally higher computational load. Overall, our algorithm balances parameter counts and computational complexity while improving segmentation accuracy, demonstrating the model’s robust segmentation prediction performance and practical applicability.

Table 1.
Model complexity comparison.
3.1.2. Datasets
The datasets used in the proposed model are two breast ultrasound image segmentation datasets, BUSI [33] and UDIAT [13], as shown in Figure 7. The BUSI dataset contains 780 breast ultrasound images of female patients, which are classified into three categories: normal, benign tumors, and malignant tumors, and the datasets all contain segmentation mask maps for tumor cells. The UDIAT dataset contains 163 breast ultrasound images with detailed annotations, of which 53 are malignant tumors, and the remaining 110 are benign tumors.
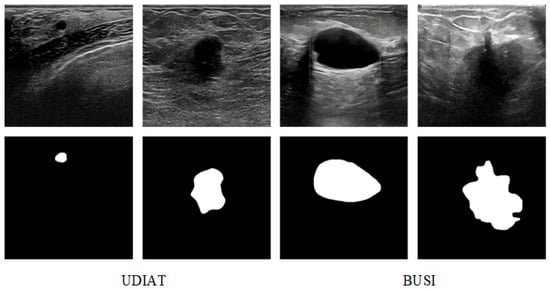
Figure 7.
Examples of BUSI and UDIAT.
The mixed BUSI and UDIAT dataset is firstly divided into training and test sets in the ratio of 8:2. In order to expand the dataset samples to cope with more complex environments and to improve the robustness of the model, data enhancement was performed on the training set and test set using flipping, random cropping, and other methods, respectively, to obtain the new experimental dataset, as shown in Figure 8. The new experimental dataset contains 3028 ultrasound images as well as 3028 segmentation mask images. This not only solves the problem of insufficient training data but also simulates the complexity in many breast ultrasound images, improves the segmentation performance of the network, and improves the generalization ability of the model.
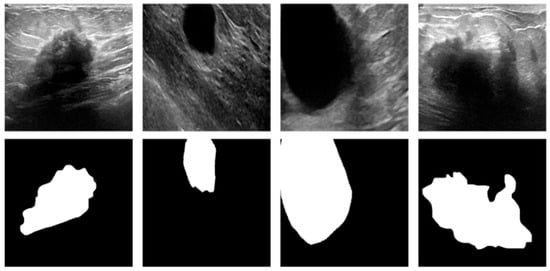
Figure 8.
Examples of experimental datasets.
3.1.3. Evaluation Metrics
To objectively evaluate the segmentation performance of the network model, we use the more common performance metrics in the field of medical image segmentation, which include the Dice Similarity Coefficient (Dice), the Hausdorff Distance (HD), the Precision (Pre), and the Recall (Rec).
Dice evaluates the similarity between two sets by calculating the ratio of their intersection and concatenation, which is an important performance evaluation index in segmentation tasks, and can objectively reflect the segmentation effect of the model on the target region; the higher the value, means that the segmentation result is more accurate. HD is a metric describing the degree of similarity between the two sets of points, which is used to measure segmentation accuracy at the boundary, and the lower the value, means that the segmentation effect is better. Pre refers to the proportion of correctly predicted positive samples among all predicted positive samples, and the higher the value, the higher the segmentation accuracy; Rec refers to the ratio of correctly predicted positive samples to the total number of real positive samples, and the higher the value, the better the segmentation effect. The formulas for the above indicators are, respectively:
(True Positive) means that the model determines the same results as the true label, which are all positive samples. (True Negative) means that the model determines the same results as the true label, which are all negative samples. (False Positive) indicates that the model’s judgment result is a positive sample, while the true label is a negative sample. (False Negative) indicates that the model’s judgment result is a negative sample, while the true label is a positive sample. For the Hausdorff distance, the maximum distance is generally not selected. Instead, the distances are sorted from smallest to largest, and the top 5% are extracted as the target. The purpose is also to exclude some unreasonable distances and maintain the stability of the data. Therefore, the Hausdorff distance is also abbreviated as HD95.
3.2. Experimental Results
3.2.1. Module Control Experiment
To investigate the rationality and effectiveness of the HAEM designed in this paper, controlled experiments are conducted with other attention modules on the experimental dataset.
The HAEM proposed in this paper is an effective aggregation of channel attention and spatial attention mechanisms, and local feature enhancement by deep convolution. Controlled experiments are conducted between HAEM and the spatial attention module (SAM), CAM, and the bottleneck attention module (BAM) [34] under the same base model, and the experimental results are shown in Table 2, where the optimal results are bolded.
Table 2.
Comparison of results from different attention modules.
As can be seen from Table 2, when only SAM or CAM is inserted at the bottleneck of the base model, the segmentation performance of the model performs poorly, with the lowest Dice coefficients and high HD95 indexes, which also indicates that it is totally insufficient to pay attention to and capture the features in only one dimension. The BAM combines spatial attention and channel attention to pay attention to the features in multiple dimensions at the same time, which has a better improvement, and the Dice coefficient and HD95 metrics reach sub-optimal. HAEM combines channel attention and spatial attention more effectively, and enhances the local relationship of features through deep convolution and residual connection, so that the segmentation performance of the model reaches its best, and both the Dice coefficient and the HD95 index reach their optimal, which are 73.89% and 23.21 mm, respectively. Thus, it can be shown that the HAEM proposed in this paper is reasonable and more effective than other attention mechanisms.
3.2.2. Comparison of Different Algorithms
In order to verify the effectiveness of the proposed algorithm on breast ultrasound image segmentation, under the premise of using the same dataset, training equipment, and training strategy, this algorithm is compared with the mainstream medical segmentation algorithms of the present time, including the classical CNN-based medical image segmentation networks, Unet [8], FPN [10], and DeepLabv3+ [11], Transformer-based segmentation models, Transunet [17], Swin-unet [19], and HCTNet [35], and the Mamba-based segmentation models VMamba [22], MambaUNet [23].
Data augmentation is applied to datasets to simulate complex real-world scenarios such as image blurring and occlusion, thereby enhancing model robustness. Prior to this, we conducted comparative experiments using selected models on the original datasets (BUSI-only and UDIAT-only).
Table 3 and Table 4 present the comparison results of selected models on the BUSI and UDIAT datasets, respectively, with the optimal metrics highlighted in bold. As shown in the table, our model demonstrates outstanding performance across all metrics, with the Dice coefficient achieving optimal results. Due to the small sample size and inherent randomness of the original dataset, coupled with its clear images and minimal environmental influences, we applied data augmentation to expand the sample size while simulating complex environments. We then conducted experiments on the model using this new experimental dataset.
Table 3.
Comparison results of various models on BUSI.
Table 4.
Comparison Results of Various Models on UDIAT.
Table 5 gives the evaluation results of the proposed method with eight other segmentation methods on the experimental dataset consisting of BUSI and UDIAT, where the optimal metrics are bolded.
Table 5.
Comparison of results from different segmentation algorithms.
In Table 5, our proposed model is optimal in Dice, HD95, and Rec metrics, while the Pre reaches the second. Dice and Rec are higher than the suboptimal model by 0.85% and 1.40%, respectively, while the HD95 is lower than the suboptimal model by 1.76 mm. Specifically, the CNN-based segmentation models Unet and FPN perform poorly in terms of performance metrics, with poor segmentation results on the BUSI and UDIAT datasets. For Unet, its model complexity is low, and it is difficult to capture the detailed information of the image; it is also less capable of coping with complex environments. The FPN model adopts a feature pyramid structure, which may lose the feature information of the highest pyramid in the process of downsampling, and the FPN may reduce the multiscale expression ability when fusing features of different levels due to the semantic divide between different layers. The Deeplabv3+ has a great improvement in performance compared with Unet and FPN models, but due to its insufficient processing of boundary detail recovery and long-distance dependence of CNN, the performance of this model is not optimal.
The performance of the three major Transformer-based segmentation networks, Transunet, Swin-unet, and HCTNet, is significantly improved over the traditional CNN medical segmentation networks, and considerable progress has been achieved in the experimental dataset in various metrics, but there are still shortcomings. Combined with the advantages of CNN and Transformer, the Transunet model has more advantages in long-term modeling. However, Transunet does not further process image details, so it is difficult for this model to deal with complex environments with blurred boundaries. Swin-unet introduces a shift window mechanism based on the Transformer, which enhances the interaction between features and slightly improves various performance indicators. However, as this algorithm is a pure Transformer architecture, its computational quadratic complexity is high, and its ability to capture edge details is insufficient, resulting in its segmentation performance indicators not achieving the best. HCTNet, combined with a residual network and a Transformer, pays attention to the global and local characteristics of the model at the same time, which greatly improves the segmentation performance of the network, and various performance indicators rank among the top three. However, when dealing with a complex environment, the model can only roughly segment the lesion area, and there is still room for improvement in the boundary details.
The Mamba-based medical segmentation model considers the long-range dependent modeling capability while reducing the computational quadratic complexity, which significantly improves the accuracy of breast ultrasound image segmentation in all performance metrics. The VMamba model, as the underlying visual Mamba model, has a simpler structure; therefore, the segmentation capability is not outstanding. MambaUnet uses VMamba as the encoder and decoder and adopts a symmetric structure and skip connection, such as Unet; its performance indicators Dice and HD95 reached 75.19% and 22.04 mm, respectively, placing it in the second position. All the performance indexes of our proposed model have reached the top two, among which the most important performance indexes, Dice and HD95, are the best.
Figure 9 shows the visualization of the segmentation results of eight different medical image segmentation models compared with the proposed model on the experimental dataset. Six images from the experimental dataset consisting of BUSI and UDIAT are selected, which include benign and malignant tumor images. The first column is the input breast ultrasound image, the second column is the real mask label, and the third column to the tenth column are the segmentation results of Unet, FPN, Deeplabv3+, Transunet, Swin-unet, HCTNet, VMamba, and MambaUnet models in turn. The last column shows the segmentation results of our proposed model.

Figure 9.
Visualization of breast ultrasound image segmentation results of different models.
Of course, as shown in the figure, our model also has some limitations. For particularly slender or curved lesions, segmentation may exhibit discontinuities or breaks. Although SSM theoretically excels at handling long sequences, inadequate capture of complex 2D geometric relationships in the scanning order or field-of-view design within 2D images may lead to insufficient modeling of continuous structures. In a small number of cases, boundary segmentation is inaccurate (either overly smooth or jagged), particularly when lesions of varying sizes coexist. Small lesions may be overlooked, or fine details of large lesion boundaries may be lost. In a small number of cases, boundary segmentation is inaccurate (either overly smooth or jagged), particularly when lesions of varying sizes coexist. Smaller lesions may be overlooked, while larger lesions may lose boundary details. Cross-attention may fail to optimally fuse the encoder (detail) and decoder (semantic) features. This could stem from Q/K/V projections failing to align key features, or the fusion process losing fine-grained spatial information. These findings clearly indicate that future work will focus on enhancing the model’s ability to represent complex structures and exploring more robust feature fusion strategies.
From Figure 9, it can be clearly seen that our proposed model is not only able to locate the lesion region more accurately, but also the model has a stronger ability to extract the edge detail features, and there are fewer cases of misclassification of the lesion region. Due to the lack of global context learning when processing local information, other segmentation models will be difficult to accurately find the lesion area in the segmentation results, and there is a high possibility of misjudgment in complex environments. Therefore, it can be considered that the segmentation algorithm proposed in this paper has more accurate segmentation results and stronger performance than other algorithms.
3.2.3. Ablation Study
We propose HAEM and CFM, which can improve the segmentation performance of breast ultrasound images in complex environments such as blurred boundaries and more artifacts, by paying special attention to the critical regions and effectively fusing shallow and deep features. To further verify the validity of each module of the proposed segmentation algorithm, an ablation experiment was conducted on the experimental dataset. The control variable method was used in the ablation experiment, and the experiments were conducted in the case of the baseline network, adding only the hybrid attention enhancement mechanism, adding only the cross-fusion module, and the complete model, respectively. To investigate the impact of each layer of CFM on model performance, the CFM was inserted into the deepest layer (CFM-1) and the skip connections of each layer (CFM-3), respectively, for testing. The experimental results are shown in Table 6, in which the optimal results are bolded.
Table 6.
Ablation test results.
In Table 6, algorithm A represents the baseline network model composed of Mamba and CNN, algorithm B represents that only HAEM is introduced into the baseline model, algorithm C represents that CFM-1 is introduced into the baseline model, algorithm D represents that both HAEM and CFM-1 are introduced into the baseline model, and the complete model is that HAEM and CFM-3 are introduced into the baseline model. As can be seen in Table 6, Algorithm A performs the lowest in both Dice and Pre performance metrics, and HD95 also performs the highest. Compared with the basic network A, the Dice and Pre indicators of algorithm B are improved, while HD95 and Rec are slightly decreased. Compared with basic network A, network C is optimized in the other three performance indicators except for Rec. The Dice, Pre, and Rec performance indicators of network D are improved, and HD95 is reduced; the overall performance is suboptimal. The three performance indicators of the complete model, Dice, HD95, and Rec, are all optimal, and the Pre index is suboptimal. The segmentation effect of the complete model is the best, which is greatly improved compared with the baseline model.
Figure 10 demonstrates a comparison of the visualization results of some ablation experiments on the dataset, where the green boxes mark the inaccurate regions. The baseline network A can only roughly localize the lesion region, and the misclassification range is large. While the lesion region localization is more accurate after adding the hybrid attention enhancement mechanism, the boundary contour of the segmentation target is not accurately grasped. After further adding the cross-fusion module, the model can not only accurately localize the lesion region but also control the details of the boundary more accurately, and the segmentation effect is optimized.
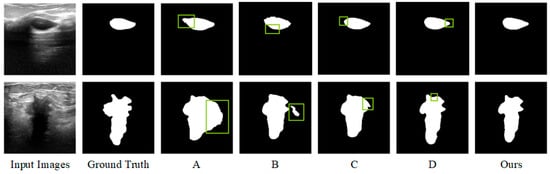
Figure 10.
Visualization of ablation test results.
4. Conclusions
We propose a breast ultrasound image segmentation algorithm integrating Mamba-CNN and feature interaction, which effectively solves the problems caused by the complex environment, such as blurred boundaries and more artifacts in breast ultrasound images, and achieves better segmentation results; the Dice similarity coefficient and HD95 reach 76.04% and 20.28 mm, respectively. The proposed model effectively combines Mamba and CNN to refine local features while having excellent long-range modeling capabilities. We propose the HAEM, which enhances the attention to key regions of the features in the spatial and channel dimensions, filters out the effective information, excludes the redundant information, and effectively mitigates the artifact interference. Additionally, we design the CFM to effectively fuse the deep semantic information with the shallow spatial detail information through the interaction between the encoder and the decoder output features, to enhance the model’s grasp of the details of the boundary contour, and to effectively improve the segmentation accuracy of the model in the case of blurring of the image boundary. Comparison with other mainstream algorithms also validates the effectiveness of the proposed model. In future work, we will consider the lightweight research of the model to reduce the complexity of the model and improve the efficiency of segmentation while ensuring its segmentation accuracy.
Author Contributions
Conceptualization, Y.Z. and H.Y.; methodology, G.Y. and Y.Z.; software, G.Y. and Y.Z.; validation, G.Y., Y.Z. and H.Y.; formal analysis, H.Y.; investigation, Y.Z. and H.Y.; resources, G.Y.; data curation, H.Y.; writing—original draft preparation, G.Y. and Y.Z.; writing—review and editing, G.Y.; visualization, Y.Z.; supervision, G.Y.; project administration, Y.Z. and H.Y.; funding acquisition, G.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Science and Technology Program of Jiangxi Provincial Department, GJJ210861.
Data Availability Statement
The original dataset BUSI can be accessed via the following link: https://doi.org/10.1016/j.dib.2019.104863.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Wang, Z.; Xiao, Y.; Jiang, Y.; Shao, Z. Advances in fundamental and translational breast cancer research in 2022. China Oncol. 2023, 33, 95–102. [Google Scholar]
- Siegel, R.L.; Kratzer, T.B.; Giaquinto, A.N.; Sung, H.; Jemal, A. Cancer statistics, 2025. CA Cancer J. Clin. 2025, 75, 10. [Google Scholar] [CrossRef] [PubMed]
- Dong, F. Clinical applications of contrast-enhanced ultrasound in diagnosis of breast diseases: Present situation and prospect. Chin. J. Med. Ultrasound 2020, 17, 1151–1154. [Google Scholar]
- Almajalid, R.; Shan, J.; Du, Y.; Zhang, M. Development of a deep-learning-based method for breast ultrasound image segmentation. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 1103–1108. [Google Scholar]
- Szénási, S. Distributed region growing algorithm for medical image segmentation. Int. J. Circuits Syst. Signal Process. 2014, 8, 173–181. [Google Scholar]
- Li, Y.; Zhu, R.; Mi, L.; Cao, Y.; Yao, D. Segmentation of white blood cell from acute lymphoblastic leukemia images using dual-threshold method. Comput. Math. Methods Med. 2016, 2016, 9514707. [Google Scholar] [CrossRef]
- Kayalibay, B.; Jensen, G.; van der Smagt, P. CNN-based segmentation of medical imaging data. arXiv 2017, arXiv:1701.03056. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18, 2015. pp. 234–241. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 20 September 2018; Proceedings 4, 2018. pp. 3–11. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Shareef, B.; Vakanski, A.; Freer, P.E.; Xian, M. Estan: Enhanced small tumor-aware network for breast ultrasound image segmentation. Healthcare 2022, 10, 2262. [Google Scholar] [CrossRef]
- Yap, M.H.; Pons, G.; Marti, J.; Ganau, S.; Sentis, M.; Zwiggelaar, R.; Davison, A.K.; Marti, R. Automated breast ultrasound lesions detection using convolutional neural networks. IEEE J. Biomed. Health Inform. 2017, 22, 1218–1226. [Google Scholar] [CrossRef]
- Hu, Y.; Guo, Y.; Wang, Y.; Yu, J.; Li, J.; Zhou, S.; Chang, C. Automatic tumor segmentation in breast ultrasound images using a dilated fully convolutional network combined with an active contour model. Med. Phys. 2019, 46, 215–228. [Google Scholar] [CrossRef]
- Zhu, L.; Chen, R.; Fu, H.; Xie, C.; Wang, L.; Wan, L.; Heng, P.-A. A second-order subregion pooling network for breast lesion segmentation in ultrasound. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2020: 23rd International Conference, Lima, Peru, 4–8 October 2020; Proceedings, Part VI 23, 2020. pp. 160–170. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar] [CrossRef]
- Mo, Y.; Han, C.; Liu, Y.; Liu, M.; Shi, Z.; Lin, J.; Zhao, B.; Huang, C.; Qiu, B.; Cui, Y. Hover-trans: Anatomy-aware hover-transformer for roi-free breast cancer diagnosis in ultrasound images. IEEE Trans. Med. Imaging 2023, 42, 1696–1706. [Google Scholar] [CrossRef] [PubMed]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 205–218. [Google Scholar]
- Gu, A.; Goel, K.; Ré, C. Efficiently modeling long sequences with structured state spaces. arXiv 2021, arXiv:2111.00396. [Google Scholar]
- Gu, A.; Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv 2023, arXiv:2312.00752. [Google Scholar] [CrossRef]
- Liu, Y.; Tian, Y.; Zhao, Y.; Yu, H.; Xie, L.; Wang, Y.; Ye, Q.; Jiao, J.; Liu, Y. Vmamba: Visual state space model. Adv. Neural Inf. Process. Syst. 2024, 37, 103031–103063. [Google Scholar]
- Wang, Z.; Zheng, J.-Q.; Zhang, Y.; Cui, G.; Li, L. Mamba-unet: Unet-like pure visual mamba for medical image segmentation. arXiv 2024, arXiv:2402.05079. [Google Scholar]
- Gao, H.; Yuan, H.; Wang, Z.; Ji, S. Pixel transposed convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1218–1227. [Google Scholar] [CrossRef]
- Yuan, L.; Chen, Y.; Wang, T.; Yu, W.; Shi, Y.; Jiang, Z.-H.; Tay, F.E.; Feng, J.; Yan, S. Tokens-to-token vit: Training vision transformers from scratch on imagenet. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 558–567. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Shazeer, N. Glu variants improve transformer. arXiv 2020, arXiv:2002.05202. [Google Scholar] [CrossRef]
- Zhu, X.; Cheng, D.; Zhang, Z.; Lin, S.; Dai, J. An empirical study of spatial attention mechanisms in deep networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6688–6697. [Google Scholar]
- Qin, Z.; Zhang, P.; Wu, F.; Li, X. Fcanet: Frequency channel attention networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 783–792. [Google Scholar]
- Yu, F.; Koltun, V.; Funkhouser, T. Dilated residual networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 472–480. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Al-Dhabyani, W.; Gomaa, M.; Khaled, H.; Fahmy, A. Dataset of Breast Ultrasound Images. Data Brief 2019, 28, 104863. [Google Scholar] [CrossRef]
- Park, J.; Woo, S.; Lee, J.-Y.; Kweon, I.S. Bam: Bottleneck attention module. arXiv 2018, arXiv:1807.06514. [Google Scholar] [CrossRef]
- He, Q.; Yang, Q.; Xie, M. HCTNet: A hybrid CNN-transformer network for breast ultrasound image segmentation. Comput. Biol. Med. 2023, 155, 106629. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.