Abstract
Camouflaged Object Detection (COD) aims to identify objects that are intentionally concealed within their surroundings through appearance, texture, or pattern adaptations. Despite recent advances, extreme object–background similarity causes existing methods struggle with accurately capturing discriminative features and effectively modeling multiscale patterns while preserving fine details. To address these challenges, we propose Iterative Refinement Fusion Network (IRFNet), a novel framework that mimics human visual cognition through progressive feature enhancement and iterative optimization. Our approach incorporates the following: (1) a Hierarchical Feature Enhancement Module (HFEM) coupled with a dynamic channel-spatial attention mechanism, which enriches multiscale feature representations through bilateral and trilateral fusion pathways; and (2) a Context-guided Iterative Optimization Framework (CIOF) that combines transformer-based global context modeling with iterative refinement through dual-branch supervision. Extensive experiments on three challenging benchmark datasets (CAMO, COD10K, and NC4K) demonstrate that IRFNet consistently outperforms fourteen state-of-the-art methods, achieving improvements of 0.9–13.7% across key metrics. Comprehensive ablation studies validate the effectiveness of each proposed component and demonstrate how our iterative refinement strategy enables progressive improvement in detection accuracy.
1. Introduction
Camouflage is a widespread phenomenon in nature by which organisms evolve to blend with their surroundings through adaptation of appearance, coloration, or pattern [1,2,3]. This biological defense mechanism has evolved in response to harsh living environments, as exemplified by chameleons, cuttlefish, and flatfish. Camouflaged Object Detection (COD) aims to identify such concealed objects from their surroundings [4]. COD presents unique challenges compared to both traditional object detection tasks [5,6] and Salient Object Detection (SOD) [7,8,9], where targets typically stand out from their environment. Recently, COD has garnered increasing research interest due to its wide applicability in medical analysis (e.g., polyp segmentation [10,11,12]), agriculture [13], and industrial detection tasks [14].
The inherent challenges of COD stem from several factors: the extreme similarity between objects and backgrounds makes feature discrimination exceptionally difficult; in addition, camouflaged objects vary dramatically in size, shape, and appearance, ranging from tiny insects against complex textures to larger animals with disruptive coloration patterns. These objects often have boundaries that seamlessly blend with environmental elements, while partial occlusions and complex backgrounds further complicate accurate detection and segmentation.
Early COD approaches relied primarily on handcrafted features such as color, texture, and intensity; however, these traditional methods often struggled with complex scenes due to their limited semantic understanding capabilities. With the advent of deep learning, more advanced approaches have emerged, demonstrating superior detection accuracy and generalization ability. Nevertheless, existing deep learning-based methods still face limitations in distinguishing fine-grained features and perceiving subtle differences between objects and their surroundings, frequently producing incomplete or imprecise results when confronted with well-camouflaged targets.
When observing camouflaged objects in natural settings, the human visual system employs a sophisticated process of perception that relies on two key capabilities. First, highly discriminative feature perception allows humans to notice subtle discontinuities or peculiar patterns that reveal a camouflaged animal. Second, iterative observation refinement enables progressive analysis where initial observations might only capture partial features, which then activate prior knowledge to formulate recognition hypotheses. These hypotheses are progressively refined by focusing attention on potentially discriminative features until successful recognition occurs. Inspired by these cognitive processes, we propose an Iterative Refinement Fusion Network (IRFNet) that mimics such perceptual mechanisms. To enhance discriminative feature perception, we design a Hierarchical Feature Enhancement Module (HFEM) that employs bilateral and trilateral fusion pathways to establish cross-scale feature connections, complemented by a dynamic channel-spatial attention mechanism that adaptively emphasizes the most informative features in a similar way to how human attention shifts in response to discriminative cues. To emulate the iterative observation process, we develop a Context-guided Iterative Optimization Framework (CIOF) that enables each iteration’s predictions to inform subsequent feature processing, creating a feedback loop that steadily refines detection results through global context integration and targeted feature enhancement.
Our main contributions can be summarized as follows:
- We propose IRFNet, a novel iterative refinement framework for camouflaged object detection that mimics human visual cognition through progressive feature enhancement and feedback mechanisms.
- We design a hierarchical feature enhancement module that effectively integrates multiscale features through bilateral and trilateral fusion pathways. This is coupled with a dynamic channel-spatial attention mechanism for adaptive feature modulation.
- We develop a context-guided iterative optimization framework that combines global semantic guidance with iterative refinement, enabling comprehensive scene understanding and progressive prediction improvement through feedback integration and dual branch supervision.
- We conduct comprehensive comparisons with state-of-the-art methods and demonstrate consistent superiority across evaluation metrics on three challenging benchmark datasets. Additionally, our approach shows strong generalization capability when applied to medical polyp segmentation, confirming its practical value across different domains.
2. Related Work
2.1. Camouflaged Object Detection
Camouflaged object detection has evolved significantly, from early methods using hand-crafted features to modern deep learning approaches. Early works relied on low-level visual cues such as color [15], texture [16], and intensity [17], but often struggled with complex scenes. The introduction of large-scale datasets such as CAMO [18], COD10K [19], and NC4K [20] catalyzed the development of deep learning-based methods, significantly improving detection accuracy.
Recent deep learning approaches can be broadly categorized based on their key strategies. Multiscale feature integration approaches such as ZoomNet [21] and C2FNet [22] address the challenge of detecting camouflaged objects at varying scales by fusing features across different levels of feature hierarchies. Boundary-aware methods such as BGNet [23] and FEDER [24] incorporate explicit edge information to improve segmentation accuracy at object boundaries. Several methods leverage uncertainty modeling [25,26] to handle ambiguous regions, while others adopt graph-based reasoning [27] to capture complex relationships between image regions. Despite these advances, fully addressing the unique challenges of camouflaged object detection remains an open problem.
2.2. Feature Fusion and Attention Mechanisms
Feature fusion architectures have been widely adopted in medical image segmentation and camouflaged object detection. U-Net-based architectures [28,29] employ skip connections to fuse low-level and high-level features. PraNet [11] introduces a parallel reverse attention mechanism using features from the last three stages while neglecting finer details from higher-resolution features. C2FNet [22] employs context-aware cross-level fusion with a combination of maximum pooling and point-wise convolutions, although its inter-layer fusion remains relatively simple and focuses primarily on high-level features.
In contrast to these approaches, our Hierarchical Feature Enhancement Module (HFEM) first fuses features through bilateral and trilateral pathways that establish connections between adjacent layers, then enhances these fused features using our proposed attention mechanism. Unlike existing attention mechanisms, our Dynamic Channel-Spatial Attention (DCSA) module incorporates multiple pooling operations (average, maximum, and mixed) with dynamic weighting in its channel attention component, significantly enhancing attention representation compared to single maximum pooling approaches. We further differentiate our approach through a spatial attention mechanism incorporating multiscale dilated convolutions that capture features at different receptive fields.
2.3. Iterative Refinement Strategies
Iterative refinement has shown promising results in various vision tasks by allowing progressive improvement through multiple processing passes. TPRNet [30] implements a progressive refinement approach based on the Res2Net [31] architecture, but lacks an explicit feedback mechanism, limiting its ability to learn from previous predictions. HitNet [32], built on PVT-v2 [33], introduces an iterative feedback mechanism, but primarily applies it to low-resolution features while maintaining separate processing streams for high and low-resolution features. This separation potentially limits the benefits of iterative refinement for fine-grained segmentation.
Departing from these designs, our approach implements a unified architecture across all feature levels and strategically places feedback at the highest-resolution layer, where fine-grained features are most beneficial for precise segmentation.
3. Materials and Methods
3.1. Network Architecture Overview
As shown in Figure 1, given an input image , we first employ PVT-v2-B2 [33] as the backbone to extract multiscale features with resolutions of . These features are then processed through a channel reduction module to obtain unified feature representations with channel dimension . To effectively leverage these multiscale features, we design two collaborative modules that work in an iterative manner: (1) a Hierarchical Feature Enhancement Module (HFEM) that enriches feature representations through multiscale fusion and dynamic attention at each iteration stage; (2) a Context-guided Iterative Optimization Framework (CIOF) that integrates global context through the Global Context Awareness Module (GCAM) before iteratively refining features through parallel prediction pathways, with one path focused on global semantic understanding and the other on refined local details. In addition, a feedback mechanism is incorporated to utilize previous iteration results for continuous improvement.
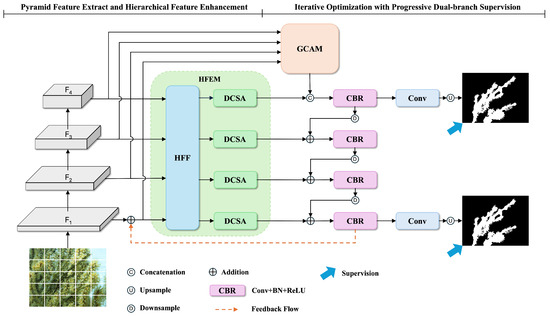
Figure 1.
Overview of our proposed network architecture.
3.2. Hierarchical Feature Enhancement Module
3.2.1. Hierarchical Feature Fusion
Given backbone features after channel reduction, we design a hierarchical feature fusion mechanism that combines both bilateral and trilateral fusion pathways to comprehensively capture cross-scale relationships, as illustrated in Figure 2.
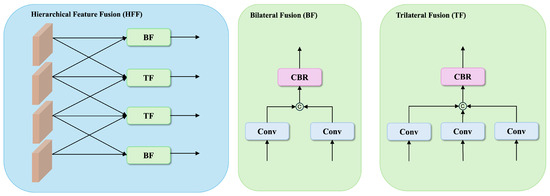
Figure 2.
Illustration of our proposed Hierarchical Feature Fusion (HFF) module.
For bilateral fusion, we establish connections between feature pairs
where denotes channel-wise concatenation, CBR represents a sequential combination of convolution, batch normalization, and ReLU activation, and both feature maps are aligned to the same spatial dimensions through bilinear interpolation when necessary. Specifically, we compute bilateral fusion features between two adjacent levels, resulting in and .
For trilateral fusion, we integrate features from three consecutive scales:
This results in two trilateral fusion features and , capturing multiscale contextual information at different semantic levels.
3.2.2. Dynamic Channel-Spatial Attention
To effectively capture both channelwise and spatial feature dependencies while maintaining adaptability to different scales of information, we propose the Dynamic Channel-Spatial Attention (DCSA) module to enhance the hierarchically fused features from HFF.
As illustrated in Figure 3, the DCSA consists of three key components: (1) Channel attention with dynamic pooling that adaptively integrates global average and maximum information, followed by Excitation modules consisting of two 1×1 convolution layers with a ReLU activation in between to capture channel dependencies; (2) Multi-scale dilated convolution (MSDC) that captures features at different scales through parallel dilated convolutions; (3) Spatial attention that emphasizes informative spatial regions. These components work together synergistically to enhance feature representations.
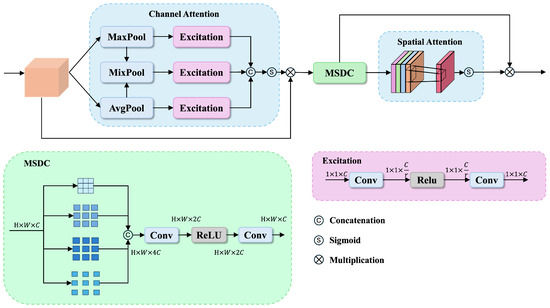
Figure 3.
Illustration of our proposed Dynamic Channel-Spatial Attention (DCSA) module.
Given an input feature map or from HFF module , we first apply three parallel pooling operations to capture different aspects of channelwise statistics:
where balances the contributions of different pooling strategies.
These pooled features are then processed through a shared two-layer network implemented with 1 × 1 convolutions
where the first reduces the channel dimension from C to (with r as the reduction ratio) and the second restores it back to C. The final channel attention map is computed as follows:
Following the channel attention, we employ a Multi-Scale Dilated Convolution (MSDC) module to capture multiscale contextual information. The MSDC module applies four parallel dilated convolutions with different dilation rates
where represents dilated convolution with kernel size 3 × 3 and dilation rate . The multiscale features are then concatenated and processed through the following dimension reduction operation:
For spatial attention, we exploit interchannel relationships by first computing the channel-wise statistics:
where represents the i-th channel of . The spatial attention map is then generated through
The final output of the DCSA module is computed as
The features enhanced by DCSA, that is, the output of the HFEM module, are then used for the top-down refinement path.
3.3. Context-Guided Iterative Optimization Framework
3.3.1. Global Context Awareness Module
As shown in Figure 4, given backbone features , we first downsample and concatenate them to obtain a unified feature representation
where Down represents downsampling operations that align features to the spatial dimensions of . The concatenated feature is then reshaped to a sequence of tokens for attention computation.

Figure 4.
Architecture of our Global Context Awareness Module (GCAM).
The GCAM processes these tokens through two main blocks. The first block applies multi-head attention as follows:
where LN denotes layer normalization and MHA represents multi-head attention.
The second block further processes the attention output through a multilayer perceptron:
where the MLP consists of two linear transformations with a GELU activation in between:
Finally, the processed features are reshaped back to the spatial domain to obtain the global context representation .
3.3.2. Iterative Optimization Mechanism
We design an iterative optimization mechanism that combines global semantic guidance with local detail enhancement. At each iteration t, our mechanism first enhances the initial feature representation by incorporating feedback from the previous iteration:
where is the high-resolution feature from the backbone, represents the refined feature from the previous iteration, and denotes the upsampling operation.
The enhanced feature together with other backbone features are processed by our previously described Hierarchical Feature Enhancement Module (HFEM) to obtain the enhanced multiscale representations .
We employ the GCAM to capture the global context, which is then utilized to enhance the highest-level features before starting the top-down refinement process:
The refinement pathway then progressively propagates semantic information while preserving fine details:
Finally, we generate predictions through two complementary branches:
Both prediction maps are upsampled to the input resolution for supervision.
3.3.3. Loss Function
To effectively supervise our network, we employ a structure-aware loss function combined with a progressive supervision strategy. For each prediction and ground truth mask , we compute
where denotes the weighted binary cross-entropy loss that emphasizes boundary regions and measures the weighted intersection over union between the prediction and ground truth.
To encourage progressive refinement through iterations, we define the total loss as
where controls the weights of different iterations, encouraging the network to continuously refine its predictions.
4. Experiments
4.1. Implementation Details
We implemented our model using PyTorch 2.5.1 and conducted all experiments on a single NVIDIA A40 GPU (48GB) with CUDA 12.4. Additional computational efficiency tests were performed on an NVIDIA RTX 4090 consumer-grade GPU. Our experiments were performed on a system with an AMD EPYC 7543 32-core processor running Ubuntu 22.04. For the backbone network, we employed PVT-v2-B2 [33] pretrained on ImageNet. During training, we employed an effective batch size of 16 and trained the model for 100 epochs. We used the AdamW optimizer with an initial learning rate of and weight decay of . The learning rate was adjusted using a step scheduler that decayed by a factor of 0.1 every 30 epochs. To prevent gradient explosion, we applied gradient clipping with a maximum norm of 0.5. For data preprocessing, input images were resized to a resolution of 704 × 704 pixels. During training, we employed standard data augmentation techniques to enhance model generalization, including random horizontal flipping, random rotation, and color jittering. No augmentation was applied during the testing phase. The complete training process took approximately 12 h, with each epoch requiring around 7 min.
4.2. Datasets
We evaluated our proposed IRFNet on three widely-used camouflaged object detection benchmark datasets:
CAMO [18] contains 1250 images across eight categories, including both natural and artificial camouflage examples. The dataset is split into 1000 training images and 250 testing images.
COD10K [19] features 5066 high-quality images across 78 categories, covering aquatic, terrestrial, flying animals, and artificial camouflage art, which are divided into 3040 training images and 2026 testing images with detailed annotations.
NC4K [20] comprises 4121 high-quality images with instance-level annotations, serving as the largest COD test dataset to evaluate model generalization.
Following established protocol [19], we used a combined training set of 4040 images (1000 from CAMO and 3040 from COD10K) and performed evaluation on all three test sets.
4.3. Evaluation Metrics
To comprehensively evaluate our model’s performance, we adopted four widely used metrics in camouflaged object detection: the structure measure () [34], mean absolute error (MAE) [35], enhanced-alignment measure () [36], and weighted F-measure () [37].
The structure measure evaluates the structural similarity between predictions and ground truth considering both region-aware and object-aware structural similarities. The MAE computes the average absolute pixel-wise difference between the predicted mask and ground truth, with lower values indicating better performance. The considers both local and global similarities; we report the mean E-measure (). The combines precision and recall with , which emphasizes precision over recall.
For all metrics except MAE, higher values indicate better performance. We follow standard evaluation protocols established in previous works in order to ensure fair comparison.
4.4. Comparison with State-of-the-Art Methods
To demonstrate the effectiveness of our proposed IRFNet, we conducted comprehensive comparisons with fourteen state-of-the-art (SOTA) COD models, including SINet [19], TINet [38], C2FNet [22], PFNet [39], SegMaR [40], BGNet [23], PreyNet [41], SINetV2 [42], ZoomNet [21], HitNet [32], FEDER [24], CFANet [43], PopNet [44], and VSCode [45]. For fair comparison, all models were evaluated on the same benchmark datasets using identical evaluation metrics.
Quantitative Results. As shown in Table 1, our proposed IRFNet consistently outperforms existing methods across all datasets. Compared to HitNet [32], IRFNet achieves average improvements of 13.7% in MAE, 1.8% in , 0.9% in , and 1.8% in across all three datasets. When compared to the recent VSCode [45], our method demonstrates even more significant improvements, with average gains of 22.0% in MAE, 3.3% in , 2.5% in , and 7.3% in . The precision–recall curves in Figure 5 further illustrate our method’s superior detection performance, consistently maintaining higher precision across varying recall values. These substantial improvements across different metrics and datasets validate the effectiveness of our proposed approach.

Table 1.
Quantitative comparison with state-of-the-art methods. The best and second-best results are highlighted in bold and underline, respectively; ↑ indicates higher is better; ↓ indicates lower is better.
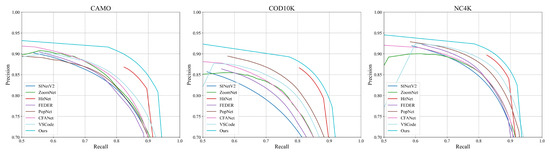
Figure 5.
Comparison of precision–recall curves on three benchmark datasets.
Qualitative Results. The visual comparisons in Figure 6 demonstrate IRFNet’s superior performance across challenging scenarios. For extremely fine-grained objects with minimal spatial extent (rows 1–3), our method successfully identifies targets that competing approaches struggle with. In cases of elongated structures such as snakes (rows 2–3), IRFNet accurately captures subtle occlusions and fine tail details that methods like ZoomNet [21] fail to detect. For medium-sized targets (rows 4–5), where other approaches mistakenly incorporate background leaves as part of the insect objects, our network maintains precise object boundaries. For larger objects such as the fish in row 6, it can be seen that existing methods only detect partial body segments, while our approach captures the complete structure. The bottom rows (7–9) showcase IRFNet’s capability in handling complex occlusion scenarios, where existing methods either misclassify occluding elements as part of the target or segment only portions of the object due to intermediate occlusions.

Figure 6.
Visual comparison with state-of-the-art methods. Our proposed IRFNet generates more accurate and complete segmentation maps across various challenging scenarios.
Computational Efficiency. We evaluated IRFNet’s computational efficiency against recent state-of-the-art methods, with the results shown in Table 2. All measurements were conducted on an NVIDIA RTX 4090 GPU. Compared to recent methods such as HitNet [32], FEDER [24], and PopNet [44], our approach maintains a balanced profile of parameters, computational complexity, inference speed, and memory consumption. While our iterative refinement introduces some computational overhead compared to single-pass methods such as CFANet [43], IRFNet still achieves competitive efficiency metrics while delivering superior detection accuracy. This balance between efficiency and performance makes IRFNet particularly suitable for applications where detection quality is prioritized, such as medical analysis and precision inspection systems.
Table 2.
Comparison of computational efficiency with state-of-the-art methods.
4.5. Ablation Study
Effectiveness of Proposed Modules. To comprehensively evaluate the contributions of each module, we conducted ablation studies by examining three variants: removing the HFEM, removing CIOF, and removing both modules to form the basic model. As shown in Table 3, removing CIOF causes significant performance degradation, with average increases of 27.3% in MAE, 2.5% in , 2.3% in , and 4.6% in across all datasets. In contrast, removing the HFEM leads to relatively milder degradation, with average increases of 12.1% in MAE, 0.8% in , 0.5% in , and 1.3% in . When both modules are removed the performance drops substantially, with average degradation of 36.0% in MAE, 6.5% in , 7.2% in , and 11.4% in . The qualitative comparisons in Figure 7 further validate these findings. Without the HFEM, the predictions exhibit a slight degradation in detail preservation, while removing CIOF leads to more severe performance drops in the form of blurred prediction maps due to failed object localization and increased prediction uncertainty. Notably, while both components contribute positively to the overall performance, the more significant performance degradation observed when removing the CIOF module indicates its particularly crucial role in accurate camouflaged object detection.
Table 3.
Ablation study on different components of IRFNet. ↑ indicates higher is better; ↓ indicates lower is better; ✓ indicates the component is included; Bold values represent the best performance.

Figure 7.
Qualitative comparison of different model variants.
Effectiveness of HFEM Components. To evaluate the contribution of the individual components within the HFEM, we conducted ablation experiments on the Hierarchical Multiscale Module (HMM) and Dynamic Channel-Spatial Attention (DCSA). As shown in Table 4, removing the DCSA module leads to average performance degradation of 7.7% in MAE, 0.5% in , 0.3% in , and 0.7% in across all datasets. Similarly, removing the HMM causes average degradation of 6.2% in MAE, 0.4% in , 0.4% in , and 0.7% in . The visual comparisons in Figure 8 reveal distinct failure patterns; removing DCSA leads to more diffused predictions with uncertain boundaries, while absence of the HMM tends to cause over-smoothed results. These patterns align with our design intuition, as DCSA dynamically modulates features, while the HMM enables multiscale integration. Notably, while removing individual components can cause specific types of detection errors, their combination works synergistically to produce surprisingly robust predictions, demonstrating the effectiveness of their coordinated feature enhancement.
Table 4.
Ablation study on different components of the HFEM. ↑ indicates higher is better; ↓ indicates lower is better; Bold values represent the best performance.
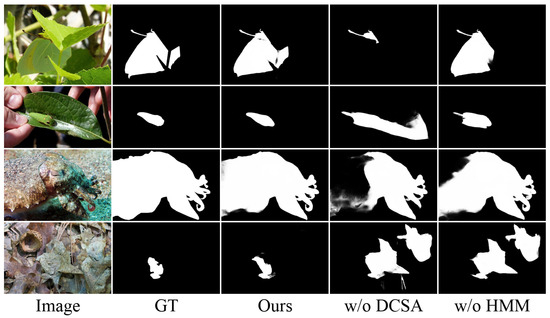
Figure 8.
Qualitative comparison of HFEM variants.
Effectiveness of CIOF Components. The results of our ablation studies reveal the distinct contributions of the GCAM and IOM within CIOF. As shown in Table 5, the IOM proves to be the more critical component, with its removal causing average performance drops of 25.2% in MAE, 2.2% in , 1.9% in , and 4.3% in across all datasets. This degradation is particularly pronounced on the CAMO dataset, where the MAE increases from 0.047 to 0.059 and drops from 0.830 to 0.796. The GCAM’s contribution, while still significant, shows more moderate impact; its removal leads to average degradation of 5.6% in MAE, 0.4% in , 0.2% in , and 0.6% in . These quantitative findings align with our qualitative observations in Figure 9 in that absence of the GCAM manifests primarily in incomplete object detection, as the global context is crucial in this regard, while removing the IOM leads to more fundamental issues including incorrect object localization, imprecise boundaries, and poor object-background separation.
Table 5.
Ablation study on different components of CIOF. ↑ indicates higher is better; ↓ indicates lower is better; Bold values represent the best performance.

Figure 9.
Qualitative comparison of CIOF components.
Effect of Different Backbone Networks. To investigate the impact of different backbone architectures, we evaluated our framework using various networks: ResNet-50 [46], Res2Net-50 [31], ConvNeXt-Base [47], Swin Transformer-Small [48], and PVT-v2-B2 [33]. As shown in Table 6, modern transformer-based architectures consistently outperform traditional CNN backbones across all datasets. While ConvNeXt-Base, Swin-S, and PVT-v2-B2 achieve comparable detection accuracy, PVT-v2-B2 offers a significantly better efficiency–performance tradeoff, requiring fewer FLOPs and maintaining a moderate parameter count. This favorable balance influenced our selection of PVT-v2-B2 as the default backbone.
Table 6.
Ablation study on different backbone architectures. The best and second-best results are highlighted in bold and underline, respectively;↑ indicates higher is better; ↓ indicates lower is better.
Ablation of Iteration Numbers. As shown in Table 7, we conducted experiments with varying iteration counts (1–5). Our results clearly demonstrate that three iterations achieves optimal performance compared to other total iteration numbers. For example, on the CAMO dataset, the MAE decreases from 0.054 to 0.047 when increasing from one to three iterations, then increases to 0.054 and 0.056 with four and five iterations, respectively. This pattern appears consistently across all datasets, indicating that excessive iterations may lead to overfitting or error accumulation rather than continued improvement.
Table 7.
Ablation study on different numbers of total iterations. ↑ indicates higher is better; ↓ indicates lower is better; Bold values represent the best performance.
Given this finding, we further analyzed the progressive improvement within the three iterations of our optimal model. Table 8 shows the detailed progression of metrics through iterations, revealing consistent improvements across all datasets. For example, the MAE decreases from 0.053 to 0.047 on CAMO, 0.025 to 0.020 on COD10K, and 0.038 to 0.032 on NC4K. Figure 10 visualizes these improvements for all evaluation metrics, while Figure 11 provides qualitative examples showing how the prediction quality improves during iterations.
Table 8.
Detailed performance metrics for each iteration in our optimal three-iteration model. ↑ indicates higher is better; ↓ indicates lower is better; Bold values represent the best performance.
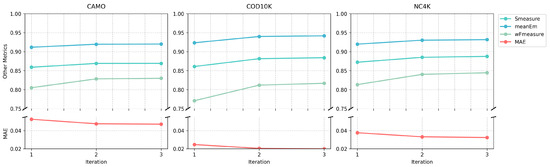
Figure 10.
Evolution of performance metrics during the iterations in our optimal three-iteration model on the CAMO, COD10K, and NC4K datasets. The plots demonstrate consistent improvement across iterations, with MAE decreasing and other metrics increasing.

Figure 11.
Visualization of the iterative refinement process in our optimal three-iteration model. From left to right: input image, ground truth (GT), and prediction after first iteration (Iter 1), second iteration (Iter 2), and third iteration (Iter 3). The prediction quality progressively improves with each iteration.
Effectiveness of Dual-Branch Supervision Strategy. We compared three approaches for supervision: using only the refined branch prediction, combining both branch predictions before supervision, and using our proposed approach of supervising both branches separately. As shown in Table 9, single-branch supervision achieves reasonable but limited results, with an MAE of 0.055 on CAMO and 0.021 on COD10K. While the combined branch approach shows improvements in , our dual-branch strategy achieves the best overall performance, with lower MAE, higher , and higher across all datasets. These results demonstrate that separately supervising the global and refined predictions enables both more effective learning of semantic understanding and finer detail preservation.
Table 9.
Ablation study on different supervision strategies. ↑ indicates higher is better; ↓ indicates lower is better; Bold values represent the best performance.
4.6. Application to Polyp Segmentation
To demonstrate the generalizability of our proposed IRFNet beyond natural camouflage scenarios, we evaluated its performance on a medical image segmentation task, specifically, polyp segmentation. Polyps are a precursor to colorectal cancer, and exhibit high visual similarity to the surrounding normal colonic mucosa. Their early detection through accurate segmentation in colonoscopy images is crucial for preventive care.
4.6.1. Experimental Settings
Following established protocols, we trained IRFNet using 1450 images from the Kvasir [49] and CVC-ClinicDB [50] datasets. We then evaluated its performance on five test sets consisting of the remaining 100 images from Kvasir, and four independent datasets: CVC-300 [51] (60 images), CVC-ClinicDB (553 images), CVC-ColonDB [52] (380 images), and ETIS-LaribPolypDB [53] (196 images). During training, images were resized to 352 × 352 pixels with standard augmentation techniques (random rotation and flipping). The model was trained for 60 epochs with a learning rate of and weight decay of using the AdamW optimizer, which it completed in approximately one hour.
4.6.2. Comparison with State-of-the-Art Methods
Table 10 presents a comprehensive comparison between our proposed IRFNet and five state-of-the-art polyp segmentation methods: UNet [28], UNet++ [29], SFA [10], PraNet [11], and CFANet [12]. Our approach demonstrates superior performance across all datasets and metrics, with particularly significant improvements on challenging cases in ETIS-LaribPolypDB and CVC-ColonDB. Specifically, compared to the second-best performer (CFANet), IRFNet achieves improvements of 3.5% in , 2.4% in , and 8.8% in on ETIS-LaribPolypDB and 4.5% in , 5.3% in , and 9.5% in on CVC-ColonDB.
Table 10.
Quantitative comparison of polyp segmentation performance. The best and second-best results are highlighted in bold and underline, respectively;↑ indicates higher is better; ↓ indicates lower is better.
Figure 12 presents visual comparisons across various challenging polyp segmentation scenarios. IRFNet demonstrates superior performance in three critical aspects: (1) accurately delineating boundaries between polyps and surrounding tissue, (2) effectively detecting small polyps that are missed or oversegmented by other methods, and (3) maintaining robust performance under varying lighting conditions. The consistent improvements across different polyp sizes and appearances demonstrate that the hierarchical feature enhancement and iterative refinement mechanisms in IRFNet effectively generalize to medical imaging contexts where target–background similarity poses significant challenges.
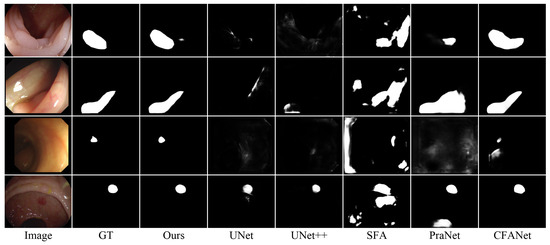
Figure 12.
Visual comparison of polyp segmentation results.
These results validate the conclusion that our proposed cognitive-inspired iterative refinement approach effectively addresses the fundamental challenge of distinguishing visually similar structures in natural camouflage as well as in medical imaging contexts, confirming the broader applicability of our method beyond its original design domain.
5. Conclusions
This paper proposes IRFNet, a novel framework for camouflaged object detection that effectively addresses the challenges of detecting objects intentionally hidden within their surroundings. Our framework’s key components consist of a Hierarchical Feature Enhancement Module (HFEM) and a Context-guided Iterative Optimization Framework (CIOF), which work together synergistically to enrich multiscale feature representations and progressively refine predictions through global context and local detail integration. Through extensive experiments on three challenging benchmark datasets (CAMO, COD10K, and NC4K), our results demonstrate that IRFNet consistently outperforms state-of-the-art methods, demonstrating high effectiveness.
While achieving superior detection accuracy, our iterative refinement mechanism requires additional computational resources compared to single-forward-pass methods. Nevertheless, IRFNet maintains competitive efficiency on modern hardware. This balance between efficiency and accuracy could be further improved through future research on lightweight attention mechanisms and model compression techniques. Moreover, as GPU hardware continues to advance, the computational demands of iterative approaches will become increasingly manageable.
Looking forward, promising research directions include developing adaptive iteration mechanisms that dynamically determine refinement steps based on image complexity, similar to how large language models adjust reasoning depth according to task difficulty. Another direction involves exploring backtracking mechanisms inspired by cognitive processes that can re-evaluate decisions made in previous iterations. Additionally, extending our approach to emerging tasks such as Referring Camouflaged Object Detection (Ref-COD) [54] represents a valuable future direction. Such an approach would enable precise identification of specific camouflaged targets through reference image matching, which is particularly valuable in ecological monitoring, medical diagnosis, and other domains requiring targeted detection in complex environments. Such targeted approaches may also reduce dependency on extensive general training datasets while maintaining robust detection performance.
Author Contributions
Conceptualization, G.L.; methodology, G.L.; validation, G.L., J.W. (Jingxin Wang) and J.W. (Jianming Wei); formal analysis, G.L. and J.W. (Jingxin Wang); investigation, G.L.; resources, J.W. (Jianming Wei); data curation, G.L.; writing—original draft preparation, G.L.; writing—review and editing, G.L., J.W. (Jingxin Wang), J.W. (Jianming Wei) and Z.X.; visualization, G.L.; supervision, J.W. (Jianming Wei) and Z.X.; project administration, J.W. (Jianming Wei); funding acquisition, Z.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Youth Innovation Promotion Association of the Chinese Academy of Sciences, grant number 2021289.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The training datasets are publicly available at https://github.com/DengPingFan/SINet, accessed on 1 March 2025. The test datasets can be found at https://drive.google.com/file/d/1QEGnP9O7HbN_2tH999O3HRIsErIVYalx/view, accessed on 1 March 2025 and https://drive.google.com/file/d/1kzpX_U3gbgO9MuwZIWTuRVpiB7V6yrAQ/view, accessed on 1 March 2025. All additional data used in this study, including images and source code, are available upon reasonable request from the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Merilaita, S.; Scott-Samuel, N.E.; Cuthill, I.C. How camouflage works. Philos. Trans. R. Soc. Biol. Sci. 2017, 372, 20160341. [Google Scholar] [CrossRef] [PubMed]
- Stevens, M.; Merilaita, S. Animal camouflage: Current issues and new perspectives. Philos. Trans. R. Soc. Biol. Sci. 2009, 364, 423–427. [Google Scholar] [CrossRef] [PubMed]
- Troscianko, T.; Benton, C.P.; Lovell, P.G.; Tolhurst, D.J.; Pizlo, Z. Camouflage and visual perception. Philos. Trans. R. Soc. Biol. Sci. 2009, 364, 449–461. [Google Scholar] [CrossRef] [PubMed]
- Mondal, A. Camouflaged object detection and tracking: A survey. Int. J. Image Graph. 2020, 20, 2050028. [Google Scholar] [CrossRef]
- Goferman, S.; Zelnik-Manor, L.; Tal, A. Context-aware saliency detection. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 1915–1926. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Pang, Y.; Zhao, X.; Zhang, L.; Lu, H. Multi-scale interactive network for salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 9413–9422. [Google Scholar]
- Wang, F.; Pan, J.; Xu, S.; Tang, J. Learning discriminative cross-modality features for RGB-D saliency detection. IEEE Trans. Image Process. 2022, 31, 1285–1297. [Google Scholar] [CrossRef]
- Tang, H.; Li, Z.; Zhang, D.; He, S.; Tang, J. Divide-and-Conquer: Confluent Triple-Flow Network for RGB-T Salient Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 47, 1958–1974. [Google Scholar] [CrossRef]
- Fang, Y.; Chen, C.; Yuan, Y.; Tong, K.Y. Selective feature aggregation network with area-boundary constraints for polyp segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2019: 22nd International Conference, Shenzhen, China, 13–17 October 2019; pp. 302–310. [Google Scholar]
- Fan, D.P.; Ji, G.P.; Zhou, T.; Chen, G.; Fu, H.; Shen, J.; Shao, L. Pranet: Parallel reverse attention network for polyp segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Lima, Peru, 4–8 October 2020; pp. 263–273. [Google Scholar]
- Zhou, T.; Zhou, Y.; He, K.; Gong, C.; Yang, J.; Fu, H.; Shen, D. Cross-level feature aggregation network for polyp segmentation. Pattern Recognit. 2023, 140, 109555. [Google Scholar] [CrossRef]
- Wang, L.; Yang, J.; Zhang, Y.; Wang, F.; Zheng, F. Depth-Aware Concealed Crop Detection in Dense Agricultural Scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–18 June 2024; pp. 17201–17211. [Google Scholar]
- Fang, F.; Li, L.; Gu, Y.; Zhu, H.; Lim, J.H. A novel hybrid approach for crack detection. Pattern Recognit. 2020, 107, 107474. [Google Scholar] [CrossRef]
- Zhang, X.; Zhu, C.; Wang, S.; Liu, Y.; Ye, M. A Bayesian approach to camouflaged moving object detection. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 2001–2013. [Google Scholar] [CrossRef]
- Galun, M.; Sharon, E.; Basri, R.; Brandt, A. Texture segmentation by multiscale aggregation of filter responses and shape elements. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; pp. 716–723. [Google Scholar]
- Li, S.; Florencio, D.; Li, W.; Zhao, Y.; Cook, C. A fusion framework for camouflaged moving foreground detection in the wavelet domain. IEEE Trans. Image Process. 2018, 27, 3918–3930. [Google Scholar] [CrossRef]
- Le, T.N.; Nguyen, T.V.; Nie, Z.; Tran, M.T.; Sugimoto, A. Anabranch network for camouflaged object segmentation. Comput. Vis. Image Underst. 2019, 184, 45–56. [Google Scholar] [CrossRef]
- Fan, D.P.; Ji, G.P.; Sun, G.; Cheng, M.M.; Shen, J.; Shao, L. Camouflaged object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2777–2787. [Google Scholar]
- Lv, Y.; Zhang, J.; Dai, Y.; Li, A.; Liu, B.; Barnes, N.; Fan, D.P. Simultaneously localize, segment and rank the camouflaged objects. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 11591–11601. [Google Scholar]
- Pang, Y.; Zhao, X.; Xiang, T.Z.; Zhang, L.; Lu, H. Zoom in and out: A mixed-scale triplet network for camouflaged object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2160–2170. [Google Scholar]
- Sun, Y.; Chen, G.; Zhou, T.; Zhang, Y.; Liu, N. Context-aware Cross-level Fusion Network for Camouflaged Object Detection. In Proceedings of the 30th International Joint Conference on Artificial Intelligence, IJCAI 2021, Montreal, QC, Canada, 19–27 August 2021; pp. 1025–1031. [Google Scholar]
- Sun, Y.; Wang, S.; Chen, C.; Xiang, T.Z. Boundary-Guided Camouflaged Object Detection. In Proceedings of the 31st International Joint Conference on Artificial Intelligence, IJCAI 2022, Vienna, Austria, 23–29 July 2022; pp. 1335–1341. [Google Scholar]
- He, C.; Li, K.; Zhang, Y.; Tang, L.; Zhang, Y.; Guo, Z.; Li, X. Camouflaged object detection with feature decomposition and edge reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 22046–22055. [Google Scholar]
- Li, A.; Zhang, J.; Lv, Y.; Liu, B.; Zhang, T.; Dai, Y. Uncertainty-aware joint salient object and camouflaged object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 10071–10081. [Google Scholar]
- Yang, F.; Zhai, Q.; Li, X.; Huang, R.; Luo, A.; Cheng, H.; Fan, D.P. Uncertainty-guided transformer reasoning for camouflaged object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 4146–4155. [Google Scholar]
- Zhai, Q.; Li, X.; Yang, F.; Chen, C.; Cheng, H.; Fan, D.P. Mutual graph learning for camouflaged object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 12997–13007. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. Unet++: Redesigning skip connections to exploit multiscale features in image segmentation. IEEE Trans. Med. Imaging 2019, 39, 1856–1867. [Google Scholar] [CrossRef]
- Zhang, Q.; Ge, Y.; Zhang, C.; Bi, H. Tprnet: Camouflaged object detection via transformer-induced progressive refinement network. Vis. Comput. 2023, 39, 4593–4607. [Google Scholar] [CrossRef]
- Gao, S.H.; Cheng, M.M.; Zhao, K.; Zhang, X.Y.; Yang, M.H.; Torr, P. Res2net: A new multi-scale backbone architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 652–662. [Google Scholar] [CrossRef] [PubMed]
- Hu, X.; Wang, S.; Qin, X.; Dai, H.; Ren, W.; Luo, D.; Tai, Y.; Shao, L. High-resolution iterative feedback network for camouflaged object detection. AAAI Conf. Artif. Intell. 2023, 37, 881–889. [Google Scholar] [CrossRef]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pvt v2: Improved baselines with pyramid vision transformer. Comput. Vis. Media 2022, 8, 415–424. [Google Scholar] [CrossRef]
- Fan, D.P.; Cheng, M.M.; Liu, Y.; Li, T.; Borji, A. Structure-measure: A new way to evaluate foreground maps. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4548–4557. [Google Scholar]
- Perazzi, F.; Krähenbühl, P.; Pritch, Y.; Hornung, A. Saliency filters: Contrast based filtering for salient region detection. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 733–740. [Google Scholar]
- Fan, D.P.; Gong, C.; Cao, Y.; Ren, B.; Cheng, M.M.; Borji, A. Enhanced-alignment measure for binary foreground map evaluation. arXiv 2018, arXiv:1805.10421. [Google Scholar]
- Borji, A.; Cheng, M.M.; Jiang, H.; Li, J. Salient object detection: A benchmark. IEEE Trans. Image Process. 2015, 24, 5706–5722. [Google Scholar] [CrossRef]
- Zhu, J.; Zhang, X.; Zhang, S.; Liu, J. Inferring camouflaged objects by texture-aware interactive guidance network. AAAI Conf. Artif. Intell. 2021, 35, 3599–3607. [Google Scholar] [CrossRef]
- Mei, H.; Ji, G.P.; Wei, Z.; Yang, X.; Wei, X.; Fan, D.P. Camouflaged object segmentation with distraction mining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 8772–8781. [Google Scholar]
- Jia, Q.; Yao, S.; Liu, Y.; Fan, X.; Liu, R.; Luo, Z. Segment, magnify and reiterate: Detecting camouflaged objects the hard way. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4713–4722. [Google Scholar]
- Zhang, M.; Xu, S.; Piao, Y.; Shi, D.; Lin, S.; Lu, H. Preynet: Preying on camouflaged objects. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 5323–5332. [Google Scholar]
- Fan, D.P.; Ji, G.P.; Cheng, M.M.; Shao, L. Concealed Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 6024–6042. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.; Yan, W. CFANet: A cross-layer feature aggregation network for camouflaged object detection. In Proceedings of the 2023 IEEE International Conference on Multimedia and Expo (ICME), Brisbane, Australia, 10–14 July 2023; pp. 2441–2446. [Google Scholar]
- Wu, Z.; Paudel, D.P.; Fan, D.P.; Wang, J.; Wang, S.; Demonceaux, C.; Timofte, R.; Van Gool, L. Source-free depth for object pop-out. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 4–6 October 2023; pp. 1032–1042. [Google Scholar]
- Luo, Z.; Liu, N.; Zhao, W.; Yang, X.; Zhang, D.; Fan, D.P.; Khan, F.; Han, J. VSCode: General Visual Salient and Camouflaged Object Detection with 2D Prompt Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 17169–17180. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Jha, D.; Smedsrud, P.H.; Riegler, M.A.; Halvorsen, P.; De Lange, T.; Johansen, D.; Johansen, H.D. Kvasir-seg: A segmented polyp dataset. In Proceedings of the MultiMedia Modeling: 26th International Conference, MMM 2020, Daejeon, Republic of Korea, 5–8 January 2020; pp. 451–462. [Google Scholar]
- Bernal, J.; Sánchez, F.J.; Fernández-Esparrach, G.; Gil, D.; Rodríguez, C.; Vilariño, F. WM-DOVA maps for accurate polyp highlighting in colonoscopy: Validation vs. saliency maps from physicians. Comput. Med. Imaging Graph. 2015, 43, 99–111. [Google Scholar] [CrossRef] [PubMed]
- Vázquez, D.; Bernal, J.; Sánchez, F.J.; Fernández-Esparrach, G.; López, A.M.; Romero, A.; Drozdzal, M.; Courville, A. A benchmark for endoluminal scene segmentation of colonoscopy images. J. Healthc. Eng. 2017, 2017, 4037190. [Google Scholar] [CrossRef] [PubMed]
- Tajbakhsh, N.; Gurudu, S.R.; Liang, J. Automatic polyp detection in colonoscopy videos using an ensemble of convolutional neural networks. In Proceedings of the 2015 IEEE 12th International Symposium on Biomedical Imaging (ISBI), Bridge, NY, USA, 16–19 April 2015; pp. 79–83. [Google Scholar]
- Silva, J.; Histace, A.; Romain, O.; Dray, X.; Granado, B. Toward embedded detection of polyps in wce images for early diagnosis of colorectal cancer. Int. J. Comput. Assist. Radiol. Surg. 2014, 9, 283–293. [Google Scholar] [CrossRef]
- Zhang, X.; Yin, B.; Lin, Z.; Hou, Q.; Fan, D.P.; Cheng, M.M. Referring camouflaged object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2025. early access. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).