1. Introduction
Recent advancements in neural networks have sparked exploration across various modalities, enabling more efficient feature extraction in fields such as Natural Language Processing (NLP), Computer Vision (CV), and Healthcare Diagnostics. Human–Robot Interaction (HRI) is a multifaceted research area that encompasses a wide range of information, including audio, visual, text, and signal, with a growing emphasis on applying machine learning methods to enhance the intelligence of these systems. A critical factor in improving HRI intelligence is granting social capabilities to the robots [
1], which classifies them as social robots. Social robots are designed to actively engage with humans to achieve their internal social aims [
2], necessitating accurate recognition of human behaviours. To achieve this, a fundamental requirement is the robot’s ability to understand, reason about human emotions [
3], and present emotional responses [
4]. Recent studies have highlighted that robots equipped with emotional HRI system (
Figure 1) capabilities can create a positive and sociable impression on humans [
5]. The integration of Large Language Models (LLMs) in robots has significantly advanced the development of humanized communication within emotional HRI [
6]. For instance, the framework proposed by the authors in [
7] introduces a multimodal emotional HRI system, which combines visual and auditory modalities to enhance the quality of human–robot companionship. In this system, the robot conveys emotions through facial expressions and language generated by GPT models. Furthermore, emotional HRI has been shown to play a central role in mental health care. Studies [
8,
9] indicate that interactions between humans and robots, such as storytelling and conversational robots based on LLMs, can provide valuable support for individuals in expressing their emotions, particularly those who face difficulties with emotional articulation.
A key challenge in achieving emotional interactions between humans and robots lies in accurately recognizing human emotions. Convolutional neural networks (CNNs) are widely used for inferring human emotions based on facial expressions, and this methodology has become prevalent in the development of emotional HRI [
7,
10,
11,
12]. Bath et al. [
12] demonstrated that CNNs with residual blocks can effectively recognize emotions from facial expressions. Additionally, Yu et al. [
13] incorporated Long Short-Term Memory (LSTM) networks into CNNs to further enhance the performance of emotion recognition systems. However, facial emotion recognition faces significant challenges under varying lighting conditions, head orientations, and facial occlusions [
14]. Additionally, processing facial images is computationally expensive, as the required resolution for accurate recognition demands large image sizes [
15]. While these issues can be mitigated by imposing constraints on human behaviour or controlling the ambient environment, such approaches compromise the sociability of the robot and the naturalness of HRI. To overcome these limitations, alternative affective modalities are necessary, with human gait emerging as a potential solution.
Gaits are composed of a series of skeleton graphs that record the coordinates of human joints during walking. Before the emergence of emotional gaits analysis, the research mainly focused on recognizing human emotion through facial expressions, speech intonation, and physiological signals [
16], as gaits lack both efficient affective feature learning methods and large-scale datasets. While gaits have not been widely studied in emotion recognition, it has played a crucial role in human action recognition, where the initial challenge of extracting representative features from gaits has been addressed. Influenced by the development of CNNs and graph convolutional networks (GCNs), Yan et al. [
17] introduced a model capable of capturing both temporal patterns and spatial connections between joints in gait graphs. Inspired by this novel approach to affective learning, Bhattacharya et al. [
18] released a large-scale emotional gait dataset, containing 2177 real gaits labelled with emotional information. This work addressed two major challenges in gait-based emotion recognition: effective feature extraction and dataset availability. As a result, various machine learning techniques have been developed, making gait a more popular affective modality. Current research has demonstrated that the utilization of gait offers advantages in terms of low acquisition cost [
19,
20] and the ability to be monitored from long distances [
21]. Although some studies have explored emotional gait in robots [
22,
23], the integration of human emotional gait perception with robot emotional gait responses remains an underexplored area.
Despite the issues related to capturing affective information having been solved by the spatial–temporal graph convolutional network (ST-GCN) in [
17,
18], current spatial–temporal approaches for extracting representative affective information have two key limitations: ignoring sequential dependency and lacking structural understanding of the graph. Current ST-GCN based methods rely on CNNs to extract temporal information. While CNNs can effectively capture global representative features over specific periods, they fail to account for the sequential dependencies between elements in the data. This type of temporal relationship, where each element is dependent on previous elements, is more effectively captured by Recurrent Neural Networks (RNNs). However, RNNs suffer from inefficient training due to their inability to parallelize computations [
24]. Another challenge arises from merely aggregating spatial information based on connections between nodes, which ignores the global position of nodes and the substructures within the graph. This can lead to nodes becoming indistinguishable after aggregation, thereby weakening the representational power of graph convolutional networks (GCNs) on the graph level [
25]. These issues become more pronounced in graphs with complicated structures. As there is a trend toward enhancing the performance of ST-GCNs in emotion prediction by introducing additional connections in the gait graphs, such as reconstructing them into fully connected graphs [
26], it is crucial to explore methods that strengthen the positional and structural representations in skeleton-based graphs.
To bridge the gap in emotional HRI research based on gait analysis, our study introduces a Gait-to-Gait Emotional HRI system. This system emphasizes human-gait emotion classification and the design of predefined robotic emotional gait responses. First, we capture videos of the walking person using the camera on the NAO robot and extract the human gaits. Our Trajectories- and Skeleton-Graph-Aware Spatial–Temporal Transformer (TS-ST) model then predicts the person’s emotion and transmits this predicted emotion to the NAO robot. Finally, the NAO expresses the same emotion through its preset gaits. Our TS-ST model is designed to address the challenges described above in extracting both temporal and spatial information. Inspired by the success of State Space Models (SSMs) in NLP [
27], which excel in capturing sequential dependencies, we applied the SSM to encode the trajectorial information in the gaits’ sequences, incorporating temporal attention to mitigate the limitations in representing temporal data. Our spatial transformer utilizes the Laplacian and Random Walk encodings to enhance the extraction of spatial information by comprising node positions and graph substructures in the gait graphs.
In summary, we propose a new emotional HRI approach based on human gaits, introducing the Gait-to-Gait Emotional HRI system utilizing the NAO robot. To the best of our knowledge, we are among the first to integrate both human emotional gait and robot emotional gait in emotional HRI.
We present a novel spatial–temporal transformer-based model that extracts affective representations by considering both sequential dependencies in the frames and positional, as well as structural, information in the graph. Our approach incorporates State Space Models (SSM) and Graph Transformers into gait-based emotion recognition.
3. Methodology
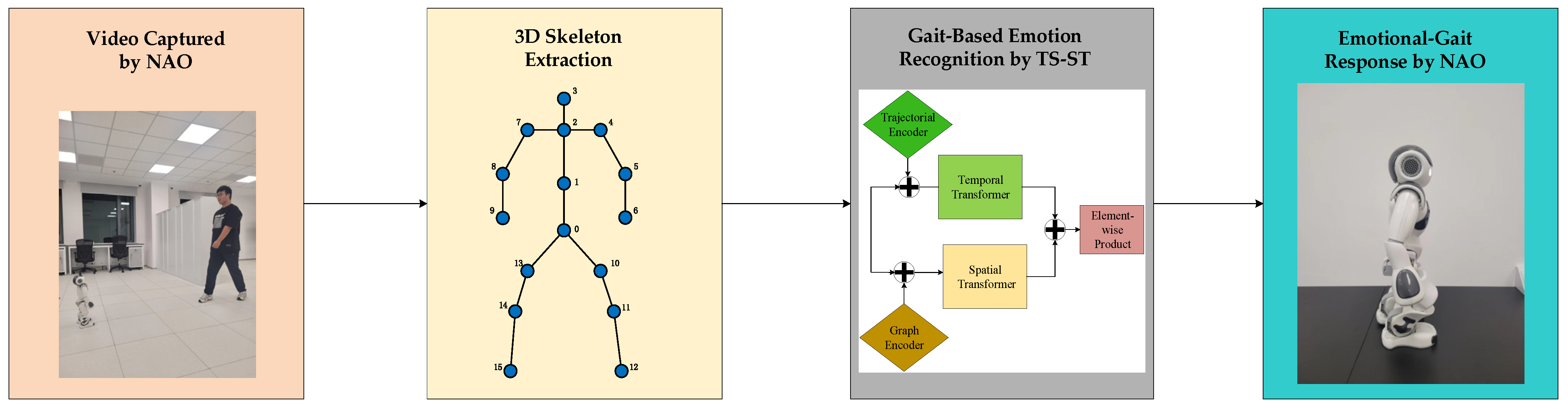
We propose a new emotion-driven gait-based emotional HRI system, named the “Gait-to-Gait Emotional HRI system”, recognizing human emotions from gaits and responding with predefined emotional gaits using the NAO robot. An overview of the entire system is illustrated in
Figure 2. Initially, human gaits are recorded using the camera on NAO’s head. A pretrained HoT model is then used to extract the 3D gait coordinates from the video data, with detailed information on the HoT model available in [
46]. The extracted gait data are subsequently fed into our novel gait emotion classifier, TS-ST, to infer the emotion of the observed human. Finally, the NAO robot expresses the predicted emotion through its predefined gaits, enabling emotional HRI.
In the subsequent subsections, we describe our approaches for emotion classification and gait-based robotic response in detail. We first introduce the skeletal representations of the emotional gaits, followed by a detailed discussion of the architecture of our TS-ST model and its modules. Finally, we demonstrate how the NAO’s gaits are employed to express different emotions.
3.1. Definition of Gait Skeletal Graph
A sequence of gait graphs
consists of skeletal graphs
extracted from
frames in the video, defined as
, where the skeletal graph at frame
is defined as
, with
. The set of nodes
in the graph represents the joints,
, of the human skeleton.
is the set of edges between node pairs, denoting the natural connections between joints in the human body. Here,
is the adjacency matrix of the skeletal graph, which indicates whether there is a connection between nodes
and
. The definition of
can be written as follows:
The node features of the skeletal graph
can be defined as
, where
coordinates of joint
in
dimensions.
Figure 3 presents the structure of the gaits utilized for emotion recognition in this paper. The skeletal graph consists of 16 joints, each represented by three-dimensional coordinates that record their locations during walking. The sequence length for gait sequences is set to 240 frames, while the gait sequences shorter than this length are extended by repeating frames to match the required length.
3.2. Emotion Classifier Based on Gaits: TS-ST
The overall structure of our gait-based emotion classifier, TS-ST, is illustrated in
Figure 4. The input gait graph sequence has the size of
, where
,
, and
. As described in the previous section, the input consists of
frames, with each frame representing a gait graph containing
joints. The position of each joint is defined by a three-dimensional coordinate (
x,
y,
z), corresponding to
C = 3 dimensions. Our TS-ST model is primarily composed of two parallel modules stacked in sequence: the Trajectories-Aware Temporal (TT) module and the Skeletal-Graph-Aware Spatial (SS) module. The TT module captures temporal representations by understanding sequence dependencies between frames, while the SS module extracts spatial representations by considering positional and structural information from the skeletal graph. The integration of these two modules, referred to as the TT-SS module, fuses the outputs of the TT and SS modules through an element-wise product operation. By stacking
TT-SS modules in sequence, the model generates affective representations that combine temporal and spatial information.
The resulting representations are averaged using 2D pooling across the and dimensions and are subsequently projected onto the emotion class space in the final dimension. Additionally, we incorporate spectral features of size to enhance the classifier’s performance. These spectral features serve as complementary inputs, augmenting the global temporal information and manually derived affective features.
In the following subsections, we describe the methods for capturing temporal information with sequence dependencies and extracting positional and structural information from the skeletal graph, followed by the architectures and algorithms used in the TT and SS modules.
3.2.1. State Space Models
State Space Models (SSMs) are extensively applied in estimating the output of a first-order differential system by mapping the sequence of continuous-time input 1-D signals
to response signals
, which depend on the latent states
[
27]. Equations (2) and (3) can be utilized to define SSMs, where
,
and
are continuous parameters. In this context,
denotes the length of the input sequence, while N is determined by the predefined sizes of the parameters of
,
, and
. When processing an input sequence of length
with D channels, SSMs are applied to each channel independently. For example, in the case of the gait sequence described in
Section 3.2,
corresponds to the number of frames, while
represents the number of dimensions in the joint coordinates.
While
is required to obtain the output sequence
computing
in a continuous-time system is challenging. We can discrete the sequence
, computing
using a discretization step size
to address this. The resulting discrete
and
can be described by following Equations (4) and (5), which provides the output from the discrete system.
The discrete parameters
,
, and
can be defined by following Equations (6)–(8).
It is evident that any discrete hidden state can be represented using discrete parameters and the discrete input sequence by setting the initial state
. Therefore, the output can be calculated through a discrete convolution between the input sequence and a discrete convolutional kernel, as shown in the following Equations (9) and (10).
The convolutional results can be efficiently computed employing Fast Fourier Transforms (FFTs), as the convolution kernel can be precomputed from the discrete parameters. According to the algorithm of SSMs, representative features can be extracted while accounting for sequence dependencies between inputs. This allows SSMs to replace RNNs by utilizing convolution-based computations, which are more efficient than the recurrent operations used in RNNs.
3.2.2. Laplacian Positional Encoding and Random-Walk Structural Encoding
In this paper, we utilize Laplacian Positional Encoding (LapPE) and Random-Walk Structural Encoding (RWSE) to assist the spatial transformer in understanding the skeletal graph topology.
LapPE provides global positions of nodes within the graph, where nodes are considered closer if their LapPEs are more similar. LapPE is based on the eigenvectors and eigenvalues of Laplacian. The Laplacian of an undirected skeletal graph is computed using the degree matrix
and the adjacency matrix
, as presented in the following Equation (11). In this context,
L represents the resulting graph Laplacian.
Thereby, eigenvectors
can be obtained through solving the following Equation (12), where
are the eigenvectors and
are the eigenvalues.
The calculated eigenvectors are denoted as
, having the size of
, and eigenvalues,
, having the size of
, where
is the number of nodes in the skeletal graph (16 in this paper) and
is the number of eigenvectors. Following the approaches outlined in [
41], the
is expanded to match the size of
, and subsequently, concatenated with
. The concatenated
and
are then processed by a multi-layer perceptron (MLP) and linearly projected to the encoding dimension, resulting in the final LapPE.
RWSE incorporates the substructures of the nodes to which the nodes belong, based on the diagonal of the m-steps random-walk matrix of the graph. This can be defined by the following Equations (13) and (14).
The diagonal of the random-walk matrix represents the probabilities of node returning to itself after steps. The original RWSE process only involves a linear projection of these probabilities to the encoding dimension.
3.2.3. Trajectories-Aware Temporal (TT) Module
In the TT module, the skeletal graph feature, tensor
, is permuted into
. All subsequent operations within the temporal module are performed on the temporal features of each joint, so we redefine the
into a sequence as follows in Equation (15):
where
.
Trajectorial Encoding
In the TT module, a trajectory encoder is first applied to the temporal feature tensor
. The trajectories of the joints are sequences of coordinates with significant sequence dependencies between consecutive frames. To capture these sequence-based relationships, we employ the SSM as described in [
47] to encode trajectorial information in
along each dimension
. Specifically, we utilize two SSMs with kernel sizes of 5 and 10 to extract trajectorial information at short and long dependencies, resulting in
and
. We then concatenate
and
and apply a linear projection to obtain a fused trajectorial encoding
. Finally, the temporal feature tensor
is concatenated with
to form a tensor
, which contains both temporal features and trajectorial information. The entire process of trajectorial encoding is illustrated in
Figure 5.
3.2.4. Skeleton-Graph-Aware Spatial (SS) Module
In the SS module, the skeletal graph features
is permuted into
. All subsequent operations within the spatial module are performed on the spatial graph features for each frame, so we redefine the
into sequences:
where
.
It is important to note that only the first SS module expands dimension of from 3 to 32 through projection to enhance the capacity of the spatial module.
Skeletal Graph Encoder
Following the approaches described in
Section 3.2.2, the LapPE and 17-step RWSE are computed initially, defined as
and
, where the encoding dimension
is set to 32. Since the skeletal graph topology described in
Section 3.1 remains consistent across all gaits, we calculate
and
in advance at the beginning of the TS-ST model to avoid redundant calculation in the SS module. The precomputed
and
are then concatenated to form the graph encoding
, which is utilized in the skeletal graph encoder.
The architecture of the skeletal graph encoder is straightforward, consisting solely of a linear layer that projects to match the same dimension as . The projected graph encoding is defined as and is subsequently concatenated with to form .
3.2.5. Classification Module and Loss Function
As shown in
Figure 4, the TT module and the SS module operate in parallel. To fuse the output
from the TT module and
from the SS module, the element-wise product operation is performed between the outputs of two the modules, resulting in the fused output
. The fused output
is then utilized as the input for both the TT module and the SS module in the subsequent TT-SS module. The TS-ST model is composed of N TT-SS modules in sequence, with the final fused output from the last TT-SS module denoted as
.
Average pooling is applied on the
dimensions of
to obtain the spatial–temporal representation
. A multilayer perceptron (MLP), consisting of two fully connected layers with a SoftMax function, is used to classify emotions. The result of the SoftMax,
, represents the predicted probabilities of
emotions. The entire process is indicated in Equations (27) and (28).
The cross-entropy function is used to calculate the loss of the TS-ST model, which can be computed as follows:
where
is the true probabilities distribution of each emotion. As this paper focuses on single-label emotion recognition, only the probability corresponding to the true emotion is set to 1, while the probabilities for other emotions are set to 0.
3.2.6. Spectral Information
Due to the parallel architecture of the TT module and the SS module, it is important to note that the SS module cannot access the temporal information among the gait sequence until the first element-wise product fusion between outputs of the TT and SS modules. Consequently, the temporal information is not incorporated in the first SS module. To address this limitation and complement the temporal information, handcrafted spectral information is concatenated with the spatial features at the outset of the first SS module.
To extract these spectral features, the Fast Fourier Transform (FFT) is applied to the sequence of skeletal graph features , obtaining the frequency spectrum . The frequency spectrum represents the discrete frequency components along dimension and the corresponding amplitudes along dimension . Instead of using the entire frequency spectrum, our focus is placed on the amplitude of the low-frequency components.
Figure 8 illustrates the frequency spectrums across
coordinate axes (
x,
y, and
z) of the right hand, corresponding to the expression of four emotions. It is notable that the zero-frequency component has been excluded. Due to limitations in figure size and clarity, the frequency spectrums for all joints are not presented; instead, the frequency spectrums of the right hand are shown as a representative example.
As illustrated in
Figure 8, high amplitudes are concentrated in the low-frequency components, highlighting the significance of low-frequency components in the gait sequence. Additionally, the peak amplitudes vary across different frequency spectra when expressing different emotions. By sorting the highest amplitudes along the
x axis from high to low, the emotion rankings are identified as follows: anger, happiness, neutral, and sadness. Moreover, the peak amplitudes in the low-frequency components for anger and happiness are significantly higher than those for neutral and sad expressions. This suggests that the variation in amplitude within the low-frequency components can be leveraged for emotion classification.
As a result, we only use the maximum amplitude among the first 20 frequency components to represent the entire spectrum, defining it as , where and retain the same values as in the original skeletal graph features, specifically, 16 and 3. In summary, the spectral features not only complement the temporal information overlooked by the TT module but also serve as affective features that enhance emotion classification.
3.3. Emotional Gait Response for Robot
In our research, we used the NAO robot to realize the predefined emotional gait response. The robot stands at a height of 57.4 cm and weighs 5.4 kg. It features a total of 25 degrees of freedom (DOF), with 2 DOF in the head, 5 DOF in each arm, 1 DOF in each hand, and 6 DOF in each leg. These DOF provide a broad range of motion, enabling natural movements. Additionally, the NAO robot is equipped with cameras, ultrasonic sensors, touch sensors, and an inertial unit for environmental perception. For interactions withhumans, microphones and speakers are placed in the robot.
To enable the NAO robot to express emotions through gait, we have defined four walking patterns corresponding to the observed human emotions, as presented in
Figure 9. When expressing anger, the NAO robot lowers its head slightly and walks at the fastest speed, taking the largest steps among the four emotional responses. To convey a neutral emotion, the NAO walks at a medium speed without bending its torso or lowering its head. In contrast, to express happiness, the NAO raises its head, bends its back, and walks at a high speed with a large step length. To express sadness, the NAO lowers its head significantly, bends its torso forward, and walks at the lowest speed with the smallest step length. The detailed parameters for these four emotional expressions are presented in
Table 1.
4. Experiments and Results
4.1. Emotion-Gait Dataset and Robot Platform
In this paper, we utilize the Emotion-Gait dataset provided by [
18], which consists of 2177 3D emotional gait sequences categorized into four emotions, angry, neutral, happy, and sad. The dataset includes 1835 gaits from the Edinburgh Locomotion Mocap Database (ELMD) and an additional 342 sequences collected by the authors of [
18]. The skeletal graphs in the Emotion-Gait dataset consist of 16 joints, and the maximum sequence length is 240 frames.
We utilize the NAO robot, supported by Softbank Robotics China (Shanghai, China), for our research. The robot interactions are managed through the NAOqi operating system, developed by Softbank Robotics.
4.2. Implementation Details and Training Configurations
Our TS-ST model is composed of two TT-SS modules. The transformer architecture in both the TT and SS modules follows similar settings. In the first module, both the dimension and the dimension are set to 32, while in the second module, and are set to 32 and 64, respectively. For all transformers, the output projection dimension is consistent with the dimension . Additionally, in the two fully connected layers within MLP, the input and output dimensions are 64 and 32 and 32 and 4, respectively.
In accordance with the method outlined in [
18], the only preprocessing step involves transforming all gaits to match the viewpoint of the first gait in the dataset. The preprocessed dataset is then split into training and test sets with a 9:1 ratio and batched into sets of eight.
We train the model using an NVIDIA RTX 4080 GPU (Dell (China) Co., Ltd., Xiamen, China), implemented in the PyTorch 2.3.1 framework. The training optimizer is RMSprop with a learning rate of 1E-4, momentum of 0.5, and weight decay of . The training runs for 200 epochs, and we apply learning rate annealing with a decay ratio of 0.5 every 50 epochs after the initial 75 epochs.
The TS-ST model contains 0.14 M parameters, and its computational cost, measured in FLOPs, is 3.70 G when using a batch size of eight. Due to the limitations imposed by the Python version supported by the NAOqi operating system and the computational power of the NAO robot, emotion prediction operations are performed on an external computer. The computer receives gait image sequences captured by the NAO robot, processes them, and sends the predicted results back to the robot.
4.3. Comparison with State-of-the-Art Approaches
We utilize accuracy as the metric to evaluate the performance of our model on the Emotion-Gait dataset. The accuracy is defined as Equation (30), where
and
are the numbers of true positive samples and true negative samples, respectively, and
is the total number of samples in the test set.
The results are presented in
Table 2, where we compare our TS-ST model with state-of-the-art gait-based emotion classification methods. ST-GCN [
17] employs spatial graph convolutional networks to extract graph-aware spatial features from human skeleton data and utilizes convolutional neural networks to capture temporal features. In contrast, STEP [
18] reduces the number of layers in the ST-GCN architecture, demonstrating improved performance in gait-based emotion recognition. Both TT-GCN and G-GCSN are variants of the ST-GCN framework. TT-GCN [
36] introduces casual temporal convolution networks, capturing dependencies between steps in the gait sequence, while G-GCSN [
49] incorporates global links in spatial graph convolutional neural networks to capture spatial features with the global context. These approaches are categorized as graph-based methods, as summarized in
Table 3. TNTC [
37] encodes the gait sequence into two image streams processed by ResNet and then fuses the features from both streams using a transformer model. Similarly, ProxEmo [
5], encodes the gait sequence into images, from which emotion representations are extracted using group convolutional networks.
The results from other gait-based emotion classification methods are extracted from the original papers and evaluated using the Emotion-Gait dataset, with a train-test split ratio of 9:1. The methods are classified into three categories: robot-based, graph-based, and transformer-based approaches, as indicated in the table. It is evident that our TS-ST model outperforms other graph-based and transformer-based methods in terms of accuracy, achieving notably better performance than the most advanced robot-based approach for gait emotion recognition.
4.4. Performance Analysis
To further evaluate the performance of our TS-ST model across each emotion, we utilize precision, recall, and F1-score as evaluation metrics. These metrics are computed using the following equations.
The results are presented in
Table 4, where our TS-ST model demonstrates strong performance in classifying the emotion of anger, achieving both high precision and recall, which results in a high F1-score of 0.9610. Based on the F1-scores, our TS-ST model also performs effectively in classifying the emotions of neutrality and happiness, with scores of 0.8000 and 0.8182, respectively. However, there is a noticeable disparity between the precision and recall for the classification of neutrality, suggesting frequent misclassification of other emotions as neutral. In contrast, the model’s performance in predicting sad emotions is relatively poor, with a low F1-score of 0.5625, indicating a less accurate classification compared to other emotions.
We also evaluate the performance of the TS-ST model with varying numbers of TT-SS (Trajectories-Aware Temporal and Skeleton-Graph-Aware Spatial Module in parallel) modules under the metric of accuracy. In this evaluation, the number of the TT-SS module with 32
and 32
is modified. The results are shown in
Table 5 with implementation details of
and
in each TT-SS module’s transformer. The results indicate that the TS-ST model with two TT-SS modules yields the highest performance. The accuracy of the model with a single TT-SS module is slightly lower (approximately 0.5%) compared to the two-module configuration, suggesting that affective representations are not fully captured with just one TT-SS module. In contrast, the performance of the model with more than two TT-SS modules shows a significant decline, indicating overfitting to the training data and incorrect extraction of affective representations.
Additionally, the performance of the TS-ST model, which integrates spectral information with the Trajectories-Aware Temporal (TT) module and the Skeleton-Graph-Aware Spatial (SS) module, is evaluated. The spectral information is concatenated with the input to the first SS module, following the methodology described in
Section 3.2.6. The accuracy results are presented in
Table 6, where concatenating spectral information with the input of the first SS module presents the highest performance, achieving an accuracy of 84.15%. In contrast, concatenating spectral information with the input to the TT module results in significantly lower performance, with an accuracy of 77.91%. This decrease in performance can be attributed to the distortion of local temporal information caused by the inclusion of spectral information during trajectory encoding, which primarily focuses on local temporal features. The distortion also affects the model’s performance when spectral information is concatenated with the inputs of both the TT and SS modules, with an accuracy of 83.67%.
4.5. Ablation Study
To verify the effectiveness of our trajectorial encoding (TE), graph encoding (GE), and spectral information, we train the model with only one type of encoding and without spectral information, evaluating the performance on the test data using accuracy and average precision (AP) metrics. The average precision is calculated from Equation (34), where
is the number of thresholds,
is the recall at the
threshold, and
is the precision at the
.
In the actual calculation, the thresholds are determined dynamically based on the data and are linearly spaced to values. The precision–recall curves are generated to obtain precisions and recalls at different thresholds.
We compared the performances of different models with the base model, which only includes the spatial transformer and the temporal transformer described in the methodology section, and excludes the TE, GE and spectral information. The results are presented in
Table 7, with the Mean Average Precision (MAP) being the mean of the average precision of each class.
The results show that the accuracy of models using any type of encoding exceeds that of the base model by more than 3%, indicating that TE and GE contribute significantly to capturing temporal and spatial features in the skeletal graph sequences, respectively. This verifies the significance of sequence dependencies between frames, as well as the positional and structural information within the graph. According to the average precision results, TE improves performance in predicting neutral and angry emotions, while GE significantly enhances performance in predicting sad emotions. Furthermore, the model with both TE and GE shows better performance compared to models using either encoding individually, demonstrating the complementary effect between TE and GE, especially for the classification of sad emotion, which is evident from the improvement in average precision. Finally, there is a clear improvement in the model with spectral information, as the average precision for each emotion increases significantly compared to the base model. This is because spectral information provides global temporal information to the SS module, addressing the lack of temporal representations in the early stages of the spatial stream. This allows our spatial model to aggregate features from the joints on the same skeletal graph while being aware of the differences in joints in the temporal domain in the initial spatial module.
5. Conclusions and Future Works
In this paper, we present a new Gait-to-Gait Emotional HRI system, implemented on the NAO robot, to address the gap between human gait-based emotion recognition and robot emotional-gait response, applying it to the NAO robot. To overcome challenges in capturing both temporal and spatial information, we propose a new gait-emotion classification model, TS-ST, which can effectively extract sequence dependencies across frames and encode positional and structural information from skeletal graphs, by incorporating the space state model and the graph transformer. Our TS-ST can recognize four human emotions: anger, neutrality, happiness, and sadness. Moreover, the NAO robot is capable of walking with corresponding preset emotional gait responses to predicted human emotions, completing an emotional interaction. The evaluation of the Emotion-Gait dataset shows that our TS-ST model outperforms the state-of-the-art robot-based gait-emotion classification model.
In future work, we plan to integrate the affective features of gaits alongside joint coordinates to enhance our model’s performance. Specifically, we will use regression prediction to constrain the representation of gait emotion with these affective features. Additionally, we will explore efficient methods for extracting temporal representations to significantly reduce the computational cost of our model. Our current research is limited to the Emotion-Gait dataset. Consequently, we will investigate the generalizability of the model on other gait-emotion datasets.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}