Abstract
Rapid detection and precise segmentation of the weld seam region of interest (ROI) remain a core challenge in robotic intelligent grinding. To address this issue, this paper proposes a method for weld seam ROI detection and segmentation based on the fusion of active and passive vision. The proposed approach primarily consists of two stages: weld seam image instance segmentation and weld seam ROI point cloud segmentation. In the image segmentation stage, an enhanced segmentation network is constructed by integrating a convolutional attention module into YOLOv8n-seg, which effectively improves the localization accuracy and mask extraction quality of the weld seam region. In the point cloud segmentation stage, the 3D point cloud is first mapped onto a 2D pixel plane to achieve spatial alignment. Subsequently, a coarse screening of the projected point cloud is performed based on the bounding boxes output from the instance segmentation, eliminating a large amount of redundant data. Furthermore, a grayscale matrix is constructed based on the segmentation masks, enabling precise extraction of the weld seam ROI point cloud through point-wise discrimination. Experimental results demonstrate that the proposed method achieves high-quality segmentation of the weld seam region, providing a reliable foundation for robotic automated grinding.
1. Introduction
To ensure the mechanical properties of welded structural components, weld grinding has become a critical process in the equipment manufacturing industry. With the advancement of industrial technology, weld grinding has gradually evolved from traditional manual operations to robotic intelligent grinding [1]. Robotic intelligent grinding typically employs vision sensors to detect and segment the weld target region (ROI), followed by grinding trajectory planning to guide industrial robots in efficient operations. Among these, weld ROI detection and segmentation are considered the key and essential prerequisites for robotic intelligent grinding [2]. Compared to general objects such as tables, chairs, vehicles, or humans, welds exhibit smaller color differences from the background, making weld ROI detection and segmentation more sensitive to lighting conditions. Additionally, post-weld seams are characterized by irregular, diverse, and random shapes, which have made rapid weld ROI detection and precise segmentation persistent core challenges in robotic intelligent grinding.
In robotic grinding systems, visual sensors are generally categorized into passive and active vision [3]. Passive vision utilizes industrial CCD cameras to capture images of workpieces under natural light, followed by image processing to extract seam ROIs [4]. With the development of deep learning, some classic object detection and segmentation algorithms have been applied to weld seam ROI extraction. Li et al. [5] employed Mask R-CNN for instance segmentation of weld seams; Wang et al. [6] proposed an improved algorithm based on YOLOv5n for weld seam detection and trajectory extraction. Tung et al. [7] developed an automated robotic cleaning system by detecting and segmenting weld seam ROI using Mask R-CNN. Natan et al. [8] enhanced the U-Net model to segment welding points of workpieces by capturing image or video frames. Additionally, several studies [9,10,11,12,13] have utilized traditional object detection algorithms to detect weld seam boundaries, textures, and other features for seam ROI segmentation. However, 2D images lack depth information, resulting in extracted seam ROIs that do not accurately represent the true seam morphology for precise grinding path generation. These methods are generally suitable only for simple planar seam grinding scenarios or quality inspection tasks.
By projecting structural light or laser to the surface of the weld, active vision can stably capture the three-dimensional point cloud data of the weld, making up for the lack of depth information expression of two-dimensional images. Nevertheless, point clouds are typically disordered, sparse, and unevenly distributed, which severely affects the accuracy of feature extraction and target localization [14]. Therefore, early methods relied on manual processing of seam ROIs to construct precise 3D models of workpieces [15,16,17], followed by offline trajectory planning in programming environments.These approaches are inefficient, subjective, and limited to batch grinding tasks for standardized workpieces.To enhance weld ROI detection and segmentation efficiency, Ge et al. [18] developed weld tracking software and proposed and constructed an online automatic grinding system for welds based on laser vision sensors. In subsequent research [19], they utilized a model-based segmentation method for weld extraction, converting spatial point clouds into two-dimensional point clouds, and then performed weld segmentation based on the least squares method with threshold comparison, significantly improving processing speed and accuracy. Liu et al. [20] proposed a method for determining the cutting plane based on 3D projection and image binarization, which was used to extract weld feature points and automate the planning of grinding paths on the weld surface, thereby enhancing grinding efficiency. Meng et al. [21] proposed an improved B-spline curve weld grinding trajectory planning method integrating point cloud segmentation, feature point removal, point cloud light smoothing, and hole repair. However, these methods depend on the regular geometric features and statistical principles of workpieces, making them suitable for handling single-structured scenarios. They often struggle to adapt to complex and diverse seam types, resulting in suboptimal ROI extraction. In recent years, 3D point cloud instance segmentation based on deep learning has garnered widespread attention, enabling autonomous analysis and processing of captured point cloud data to accurately identify seam positions and shapes, achieving end-to-end output [22]. For example, Pandiyan et al. [23] utilized advanced network models and intelligent control systems to achieve automatic detection of weld endpoints during robotic belt grinding. Zhan et al. [24] proposed a weld instance segmentation method based on RGB-D level feature fusion, expanded the RGB-D-level feature fusion module based on the Mask R-CNN feature pyramid network (FPN), and added MaskGIoU Head to improve the segmentation accuracy of weld positioning. Dong et al. [25] introduced a 1D convolutional neural network for autonomous identification and segmentation of grinding points for weld grinding. Nonetheless, existing deep learning models face challenges in processing large-scale point cloud data, including long training times, high computational resource consumption, and limited generalization capabilities when dealing with complex or irregular weld morphologies.
In summary, the efficient detection and accurate segmentation of weld ROI constitute a highly challenging 3D data understanding task, with the core difficulties lying in the fact that the weld morphology exhibits both diversity (varying forms under the same semantic label) and randomness (no clear geometric boundary with the base material). To address these challenges, this paper proposes a method for weld ROI detection and segmentation based on the fusion of active and passive vision. By integrating dual-modal data of point clouds and images, the method achieves comprehensive scene perception to compensate for the limitations of a single modality, realizes efficient pixel-level point cloud segmentation of weld ROI, and thus provides prerequisites and technical support for intelligent robotic grinding.
2. The Proposed Method
This paper utilizes a binocular structured-light camera to acquire two modal data types of the workpiece—2D images and 3D point clouds—and proposes a weld seam detection and segmentation method based on the fusion of active and passive vision. As illustrated in Figure 1, the proposed approach mainly consists of two steps: weld seam image instance segmentation and weld seam ROI point cloud segmentation. In the weld seam image instance segmentation stage, to enhance the localization accuracy of the weld seam region and the extraction quality of the mask map, an improved segmentation algorithm is designed by integrating the convolutional block attention module (CBAM) into the YOLOv8n-seg model. In the weld seam ROI point cloud segmentation stage, the 3D point cloud is first mapped onto the 2D pixel plane using a calibrated parameter matrix to achieve spatial alignment between point cloud coordinates and pixel coordinates. Subsequently, using the weld seam ROI bounding boxes output from the instance segmentation stage as boundaries, a coarse screening of the projected point cloud is performed to rapidly eliminate a large number of redundant point clouds in non-weld seam regions. Finally, a fine screening operation is executed: a grayscale matrix is constructed based on the high-precision mask maps generated by the instance segmentation, and point-wise discrimination is applied to the coarsely screened point cloud to further remove interfering points outside the mask region, ultimately achieving precise segmentation of the weld seam ROI point cloud.
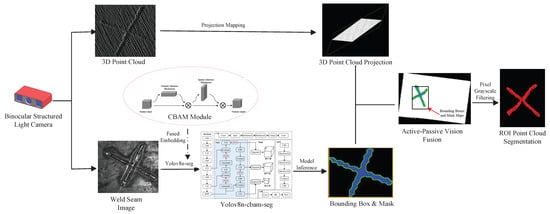
Figure 1.
Framework for weld seam ROI detection and segmentation method based on active–passive vision fusion.
2.1. Instance Segmentation of Weld Seam Images
YOLOv8, part of the YOLO model family, is designed for tasks such as object detection, instance segmentation, and classification. YOLOv8n-seg is the most “lightweight” model in this series for instance segmentation, requiring minimal parameters and computational resources. The network structure of the YOLOv8n-seg model [26] consists of the following components, as illustrated in Figure 2: input layer, backbone network, neck network, and output head. The backbone is composed of modules such as CBS convolution, C2f, and SPPF, arranged sequentially to extract multi-scale and multi-category instance features from images. The neck network adopts the classical PAFPN architecture [27] from YOLOv5, ensuring robust feature fusion across scales. The output head provides both object detection bounding boxes and segmentation mask information.
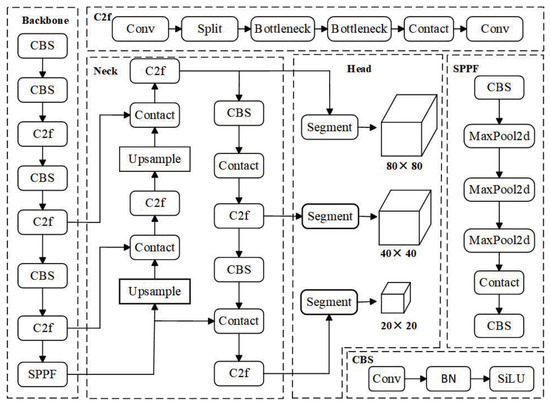
Figure 2.
YOLOv8n-seg network architecture.
Compared to previous YOLO series algorithms, YOLOv8n-seg demonstrates superior detection speed and accuracy. However, its segmentation performance still shows limitations when dealing with complex scenes where the target and background are highly similar. To address this challenge, this study introduces the convolutional block attention module (CBAM), which can automatically assign high weights to critical information while disregarding redundant data with lower weight, thereby enhancing the model’s sensitivity to the weld ROI. CBAM consists of two components, the channel attention mechanism and the spatial attention mechanism, as shown in Figure 3. These two mechanisms work in synergy; they not only strengthen the feature representation ability across different channels but also accurately highlight key information in spatial positions, achieving effective distinction and precise segmentation between the target and background.
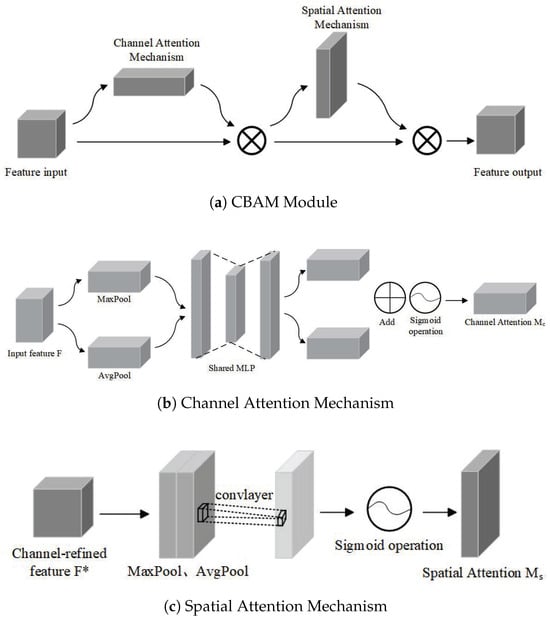
Figure 3.
Schematic diagram of the convolutional block attention module (CBAM) structure.
The channel attention mechanism (CAM) initially performs max pooling and average pooling operations on the input feature map, then feeds them into a multiLayer perceptron (MLP) to learn the feature weights of each channel, which are then summed. The channel attention feature weight matrix is then output via a sigmoid activation function. The MLP consists of two linear layers and a ReLU activation function. The channel attention mechanism can be formulated as follows:
where is the input feature map; MLP denotes the multilayer perceptron operation; AvgPool and MaxPool represent the global max pooling and global average pooling operations on the channel dimension for , respectively; and represents the Sigmoid activation function.
The spatial attention mechanism (SAM) first performs channel-based global max pooling and average pooling operations, followed by concatenation along the channel dimension. A 7 × 7 convolution operation is then applied to the concatenated feature map for further processing, generating a feature map with a channel dimension of 1. Finally, the Sigmoid activation function generates the spatial attention feature weight matrix . The spatial attention mechanism can be formulated as follows:
where is a convolution operation that is performed.
To enhance the model’s capability in perceiving and distinguishing weld seam features within complex industrial scenarios, this study integrates the convolutional block attention module (CBAM) into the neck component (comprising the feature pyramid network and path aggregation network) of the YOLOv8n-seg architecture. As illustrated in Figure 4, within the neck structure, the CBAM modules are incorporated following each C2f module and are interactively coupled with operations such as Upsample and Concat. This design enables the model to refine multi-scale feature representations during the feature fusion process in the neck, thereby directing subsequent feature processing to focus more effectively on critical weld seam characteristics. Consequently, this enhancement improves the accuracy of subsequent object detection and instance segmentation tasks. The modified model is designated as YOLOv8n-cbam-seg.
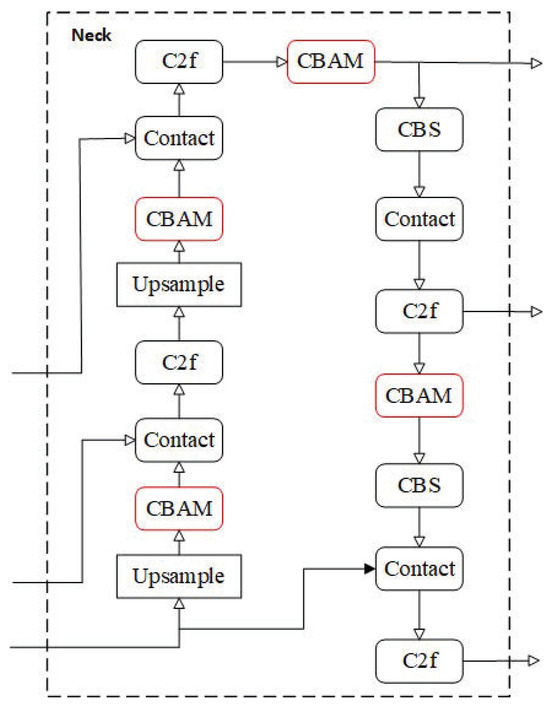
Figure 4.
Neck architecture in YOLOv8n-cbam-seg.
2.2. Weld ROI Point Cloud Segmentation
To achieve spatial alignment between 3D point clouds and 2D images while establishing a unified coordinate system for subsequent weld seam point cloud segmentation, this paper proposes an active–passive vision fusion approach. Specifically, based on the calibration parameters of the binocular structured-light camera, a projective mapping model is established. As shown in Equation (3), this model projects 3D point clouds from the world coordinate system onto a 2D pixel plane:
where represents the coordinates of any point in the point cloud, is the coordinate normalization coefficient, and are the camera’s intrinsic and extrinsic parameter matrices, and denotes the pixel coordinates of point , where is the point index.
Let the set of transformed point cloud pixels be denoted as , and the set of weld ROI mask contours output by YOLOv8n-cbam-seg be denoted as . For a point , its pixel coordinates are . If is inside , then belongs to the weld ROI point cloud; otherwise, it does not. In a two-dimensional plane, the “ray casting method” [28] is typically used to determine the relationship between a point and a region. However, this method requires traversing all pixel points in and performing complex geometric computations to find the intersection of the “ray” with the contour , which leads to slow segmentation efficiency for weld seam ROI point clouds. To address this issue, this paper proposes a new pixel grayscale filtering method, which is mainly divided into three steps:
1. Coarse filtering. Based on the weld detection bounding box information output by YOLOv8n-cbam-seg, where is the top-left pixel coordinate and is the bottom-right pixel coordinate, the pixels in that are covered by the detection box are filtered out and denoted as , as shown in Figure 5a.
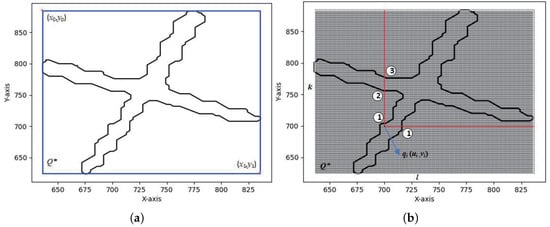
Figure 5.
ROI point selection. (a) Coarse Screening of Detection Boxes; (b) Fine Screening by Pixel Intensity.
2. Grayscale matrix construction. Based on the detection box , a pixel grayscale matrix is constructed. The length and width of the matrix are determined as follows:
where ⌈⌉ denotes the ceiling operator, and and are the pixel dimensions in the X and Y directions respectively. The elements of the matrix are initialized with a default value of 255. Denoting the set of mask contours output by YOLOv8n-cbam-seg as S, where the coordinates of any mask point are given by , its corresponding position in the matrix is determined by the following equation:
Thus, the point is located at row and column in the matrix, and the grayscale value at this position is updated to 0.
3. Fine filtering. For any pixel point in , the corresponding position in the matrix is calculated as follows:
From the position , a ray is drawn in both the horizontal and vertical directions. The number of pixels with a grayscale value of 0 in each ray within the matrix is recorded as . According to the ray-casting method, if is odd for any ray, the pixel point corresponds to a point that belongs to the weld seam ROI region; otherwise, it does not, as shown in Figure 5b.
By iterating through all pixel points in using the aforementioned procedure, pixel-level precise screening of the weld seam ROI point cloud can be achieved.
3. Experimental Analysis
3.1. Data Collection and Processing
This study employs an Elson binocular line-scan structured-light camera with a baseline distance of 200 mm and a resolution of 1920 × 1200 pixels. System calibration was performed using Zhang’s calibration method in conjunction with a standard checkerboard, achieving a mean reprojection error of 0.15 ± 0.03 pixels. Data were acquired at a typical working distance of 600 mm, with the system covering a field of view of 640 × 400 mm. As shown in Figure 6, four types of small-target overlay weld specimens were designed—I-shaped, X-shaped, L-shaped, and three-segment discontinuous D-shaped—yielding a total of 40 randomly combined weld seam samples. Each scanned dataset includes a 2D image and its corresponding 3D point cloud. Diverse data were obtained by varying lighting conditions, shooting distance, angle, workpiece type, and position to simulate complex industrial scenarios. The initially collected 300 weld seam images were augmented to 1800 via flipping, affine transformation, brightness adjustment, blurring, and Gaussian noise injection. All images were pixel-wise mask-annotated by experienced engineers using the LabelMe tool, with contours strictly traced along the weld seams to ensure consistency.

Figure 6.
Experimental weld specimens.
The experimental platform operated on Ubuntu 18.04.6 LTS, with a 13th Gen Intel® Core™ i5-13400F CPU (Intel, Santa Clara, CA, USA), an NVIDIA GeForce RTX 3060Ti GPU, and 32 GB of RAM (NVIDIA, Santa Clara, CA, USA). The deep learning framework was built on PyTorch 1.12, compatible with Python 3.8.16, utilizing CUDA version 11.3 and cuDNN version 8.9.2 for GPU acceleration. The dataset of 1800 images was pre-divided into training, validation, and test sets in a 6:2:2 ratio. To ensure unbiased evaluation, data augmentation techniques—such as flipping and brightness adjustment—were applied exclusively to the training set, thereby preserving the purity of the validation and test sets and preventing data leakage. After augmentation, the training, validation, and test sets comprised 1080, 360, and 360 images, respectively. Detailed hyperparameter configurations for model training are summarized in Table 1.

Table 1.
Model training parameter settings.
3.2. Data Collection and Processing
3.2.1. Model Training Results
Figure 7 shows the loss function convergence curves during the training process for both YOLOv8n-seg and YOLOv8n-cbam-seg networks. Here, box_loss represents the bounding box loss, seg_loss represents the segmentation loss, cls_loss represents the classification loss, and dfl_loss represents the distribution focal loss. The x-axis represents the number of epochs, indicating the number of times the samples have been traversed. As shown in Figure 7a,b, during the initial training phase, the values of all loss functions decrease rapidly, indicating that the model is quickly fitting the training data. YOLOv8n-seg begins to converge after 100 epochs, while YOLOv8n-cbam-seg demonstrates better convergence after just 50 epochs. Figure 7c plots the sum of the loss values of each of the two models, showing that the YOLOv8n-cbam-seg network has a smaller loss value, indicating a better fit to the data.
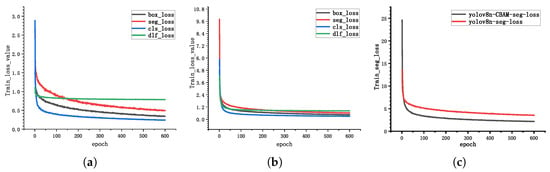
Figure 7.
A comparison of training loss curves between YOLOv8n-seg and the proposed YOLOv8n-cbam-seg model. (a) YOLOv8n-seg network training loss value; (b) YOLOv8n-cbam-seg network training loss value; (c) The comprehensive loss value of each model.
Figure 8 presents the mean average precision (mAP) metrics for both YOLOv8n-seg and YOLOv8n-cbam-seg networks at different intersection over union (IoU) thresholds, used to evaluate the overall performance of the models. Specifically, mAP0.5(B) and mAP0.5(M) represent the average precision of bounding boxes (B) and instance segmentation masks (M) at IoU = 0.5, respectively, while mAP0.5:0.95(B) and mAP0.5:0.95(M) provide a more comprehensive assessment of model localization and segmentation performance across multiple IoU thresholds. Experimental results show that compared to YOLOv8n-seg, YOLOv8n-cbam-seg demonstrates faster convergence in all four metrics and achieves higher precision in mAP0.5:0.95(B) and mAP0.5:0.95(M). The precision in mAP0.5(B) and mAP0.5(M) for both models is comparable. The results validate that the introduction of CBAM enhances both detection speed and segmentation accuracy in the YOLOv8n-cbam-seg network.
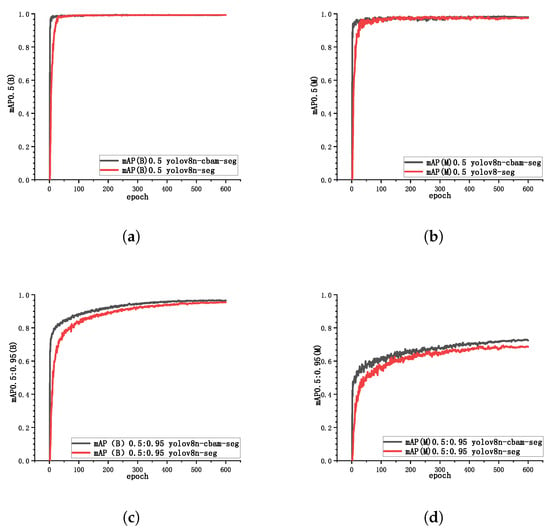
Figure 8.
Variation curves of mAP values for different categories. (a) mAP0.5(B) value; (b) mAP0.5(M) value; (c) mAP0.5:0.95(B) value; (d) mAP0.5:0.95(M) value.
To further analyze model performance across different decision thresholds, Figure 9 presents the precision–recall (PR) curves of both models. It can be observed that the PR curve of YOLOv8n-CBAM-seg lies closer to the upper-right corner of the coordinate plane and exhibits a larger area under the curve (AUC) across all categories, indicating its ability to maintain a superior balance between precision and recall under varying confidence thresholds. Notably, for the D-shaped weld seams—characterized by complex geometry and high segmentation difficulty—the proposed model achieves a 16.9% improvement in average precision (AP) compared to the baseline. This enhancement, coupled with the capability of the PR curve to sustain high precision at high recall rates, is particularly critical for industrial applications such as weld inspection where missed detections are unacceptable. It demonstrates that the model ensures the identification of all actual weld seams while effectively reducing the risk of false positives.
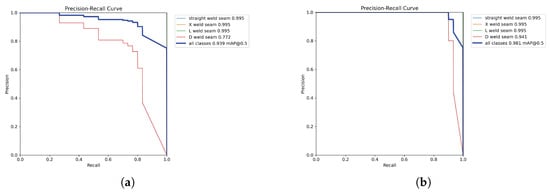
Figure 9.
Comparison of precision–recall curves. (a) Mask-PR Curve of YOLOv8n-seg; (b) Mask-PR Curve of YOLOv8n-cbam-seg.
3.2.2. Ablation Studies and Analysis
To quantitatively evaluate the contribution of the introduced CBAM module and its individual components to model performance, we designed systematic ablation studies. All experiments were conducted under the same dataset and training configuration described in Section 3.1 to ensure fair comparability. We first compared the computational efficiency between the baseline model and the enhanced model, with results summarized in Table 2. Although the incorporation of CBAM introduces a modest increase in parameters and computational load, the resulting performance gains substantially outweigh this minor computational cost.
Table 2.
Comparison of model computational complexity.
The results of the ablation studies are presented in Table 3. Using the standard YOLOv8n-seg as the baseline (A), we sequentially integrated the channel attention module (CAM) and spatial attention module (SAM) into the architecture.
Table 3.
Ablation study on CBAM.
The experimental results demonstrate the following: (1) The individual integration of either attention module consistently improves performance: both Model B (with CAM only) and Model C (with SAM only) surpass the baseline (Model A) across all evaluation metrics. This confirms the effectiveness of feature recalibration in either channel or spatial dimensions. (2) Spatial attention exhibits more pronounced contributions: Model C generally achieves higher performance gains than Model B, potentially because the local textural and structural differences between weld seams and background regions are more critical than overall channel-wise distribution disparities. (3) Synergistic effect of CBAM: The final model (Model D), integrating both CAM and SAM, achieves optimal performance across all metrics. This verifies the complementary nature of channel and spatial attention mechanisms, where their coordinated operation comprehensively enhances feature representation, thereby yielding the most accurate results for both object detection and instance segmentation tasks.
3.3. Weld ROI Point Cloud Segmentation Results
In this study, three experimental workpieces were used for weld seam ROI point cloud segmentation. The input data consisted of 2D images and 3D point clouds obtained from a binocular line-scan structured light camera. Following the proposed method in this paper, the YOLOv8n-cbam-seg network, trained in the previous section, was used for weld seam ROI image segmentation. The segmentation results are shown in Figure 10. As seen in the figure, YOLOv8n-cbam-seg accurately identified the weld seam detection boxes and segmentation masks.
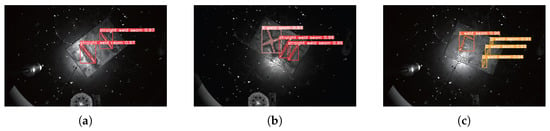
Figure 10.
Weld seam ROI image segmentation results based on YOLOv8n-cbam-seg. (a) Experimental Specimen 1; (b) Experimental Specimen 2; (c) Experimental Specimen 3.
The 3D point cloud is projected onto the pixel plane to achieve main passive vision fusion, followed by point cloud segmentation based on the weld seam ROI mask. The segmentation results are shown in Figure 11. The upper row shows the active and passive visual fusion results, where the white dots represent the point cloud projected onto the pixel plane and the colored dots represent the weld ROI mask segmented by the instance. The lower line is the result of weld ROI point cloud segmentation. The experimental results demonstrate that the proposed method effectively identifies and segments the weld seam ROI point clouds across all three workpieces.
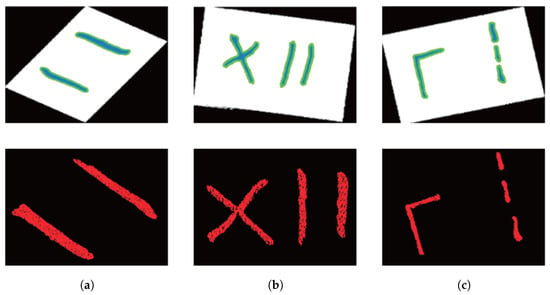
Figure 11.
Weld seam ROI point cloud segmentation results based on pixel grayscale screening. (a) Experimental Specimen 1; (b) Experimental Specimen 2; (c) Experimental Specimen 3.
3.4. Robot Weld Grinding Experiment
This study established an integrated weld seam grinding experimental platform comprising an ABB IRB2600-20/165 robot, a binocular line-structured-light camera, and an end-effector force-controlled grinding head. The vision system was configured in an “eye-in-hand” arrangement (Figure 12a). Based on the accurately segmented weld seam ROI point cloud obtained through the proposed method, grinding trajectories were generated using the slicing method [29] (Figure 12b). Under the process parameters of spindle speed 12,000 rpm, normal force 15 N, and feed rate 60 mm/s (Figure 12c), quantitative evaluation demonstrated that the average deviation between the actual grinding trajectory and the planned path was 0.32 mm; the surface roughness Ra of the weld seam was reduced from 12.5 μm before grinding to 3.2 μm; and the total cycle time for a single operational task from perception to grinding completion was 48 s. These results fully validate the capability of the proposed method to achieve autonomous weld seam identification and precision grinding, effectively enhancing the intelligence level of robotic grinding operations.

Figure 12.
Robotic weld grinding. (a) Grinding Experimental Platform; (b) Grinding Trajectory; (c) Weld Grinding.
4. Conclusions
This paper addresses the challenge of rapid detection and precise segmentation of multi-type weld seams in robotic intelligent grinding by proposing an active–passive vision fusion-based method for weld seam ROI detection and point cloud segmentation. The core of this approach lies in integrating 2D image and 3D point cloud data to establish an integrated processing pipeline from visual perception to trajectory planning for weld seam grinding. The main contributions can be summarized as follows: (1) An improved YOLOv8n-CBAM-seg instance segmentation network is proposed, where the incorporation of the convolutional block attention module (CBAM) effectively enhances the model’s capability to represent weld seam features and improves segmentation accuracy under complex backgrounds. (2) An efficient active vision fusion processing method is designed, achieving accurate identification and rapid segmentation from 2D weld seam ROI masks to 3D point clouds, thereby reducing the complexity associated with direct 3D point cloud processing. (3) A comprehensive robotic intelligent grinding system is constructed, and multiple quantitative metrics—including trajectory deviation, surface roughness, and operational cycle time—collectively demonstrate the method’s effectiveness, precision, and efficiency in practical applications. However, this study currently focuses primarily on planar and simple geometric weld seams, and its generalizability to complex curved configurations (such as saddle-shaped and circular welds) requires systematic validation. Future work will aim to expand the scale and diversity of the dataset by incorporating more weld seam types in complex 3D spaces, and further explore network architectures and segmentation strategies with enhanced robustness to complex geometries, thereby improving the method’s universality and industrial application potential.
Author Contributions
Methodology, M.H.; Validation, M.H.; Resources, X.H.; Writing—original draft, M.H.; Writing—review & editing, X.H., J.Z. and H.Z.; Project administration, X.H.; Funding acquisition, X.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China, grant number 52175210 and The Dream Chasing Fund of Jianghuai Frontier Technology Collaborative Innovation Center, grant number 2023-ZM01Z009.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
The data that support the findings of this study are available upon reasonable request from the corresponding author. However, the data are not publicly available due to privacy or ethical restrictions.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Huynh, H.N.; Assadi, H.; Rivière-Lorphèvre, E.; Verlinden, O.; Ahmadi, K. Modelling the dynamics of industrial robots for milling operations. Robot. Comput.-Integr. Manuf. 2020, 61, 101852. [Google Scholar] [CrossRef]
- Guo, W.; Huang, X.; Qi, B.; Ren, X.; Chen, H.; Chen, X. Vision-guided path planning and joint configuration optimization for robot grinding of spatial surface weld beads via point cloud. Adv. Eng. Inform. 2024, 61, 102465. [Google Scholar] [CrossRef]
- Wang, N.; Zhong, K.; Shi, X.; Zhang, X. A robust weld seam recognition method under heavy noise based on structured-light vision. Robot. Comput. Integr. Manuf. 2020, 61, 101821–101829. [Google Scholar] [CrossRef]
- Huang, K.; Dong, Z.; Wang, J.; Fei, Y. Weld bead segmentation using RealSense depth camera based on 3D global features and texture features of subregions. Signal Image Video Process. 2023, 17, 2369–2383. [Google Scholar] [CrossRef]
- Li, J.; Li, B.; Dong, L.; Wang, X.; Tian, M. Weld seam identification and tracking of inspection robot based on deep learning network. Drones 2022, 6, 216. [Google Scholar] [CrossRef]
- Wang, J.; Yao, J.; Liu, X.; Du, Y.; Liu, M.; Su, Y.; Lu, D. Weld Detection and Tracking Algorithm for Inspection Robot Based on Deep Learning. In Proceedings of the 2024 International Conference on Electronic Engineering and Information Systems (EEISS), Chania, Greece, 29–31 May 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 85–92. [Google Scholar]
- Tung, T.-J.; Al-Hussein, M.; Martinez, P. Vision-Based Guiding System for Autonomous Robotic Corner Cleaning of Window Frames. Buildings 2023, 13, 2990. [Google Scholar] [CrossRef]
- Natan, O.; Putri, D.U.K.; Dharmawan, A. Deep learning-based weld spot segmentation using modified UNet with various convolutional blocks. ICIC Express Lett. Part B Appl. 2021, 12, 1169–1176. [Google Scholar]
- Haffner, O.; Kučera, E.; Kozák, Š. Weld segmentation for diagnostic and evaluation method. In Proceedings of the 2016 Cybernetics & Informatics (K&I), Levoca, Slovakia, 2–5 February 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–6. [Google Scholar]
- Malarvel, M.; Sethumadhavan, G.; Bhagi, P.C.R.; Kar, S.; Thangavel, S. An improved version of Otsu’s method for segmentation of weld defects on X-radiography images. Optik 2017, 142, 109–118. [Google Scholar] [CrossRef]
- Wang, X.; Yang, Y.; Kong, J.; Shi, Y. Image Binarization Method of Equal-thickness Butt Welds Based on Regional Optimization. China Mech. Eng. 2019, 30, 1756. [Google Scholar]
- Li, X.; Li, X.; Ge, S.S.; Khyam, M.O.; Luo, C. Automatic welding seam tracking and identification. IEEE Trans. Ind. Electron. 2017, 64, 7261–7271. [Google Scholar] [CrossRef]
- Golodov, V.A.; Maltseva, A.A. Approach to weld segmentation and defect classification in radiographic images of pipe welds. NDT E Int. 2022, 127, 102597. [Google Scholar] [CrossRef]
- Fei, B.; Yang, W.; Chen, W.-M.; Li, Z.; Li, Y.; Ma, T.; Hu, X.; Ma, L. Comprehensive review of deep learning-based 3d point cloud completion processing and analysis. IEEE Trans. Intell. Transp. Syst. 2022, 23, 22862–22883. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, X.; Ren, X.; Li, L.; Feng, H.; He, Y.; Chen, H.; Chen, X. Point cloud 3D parent surface reconstruction and weld seam feature extraction for robotic grinding path planning. Int. J. Adv. Manuf. Technol. 2020, 107, 827–841. [Google Scholar] [CrossRef]
- Jing, O.; Lai, Z.; Qinghong, W.; Xin, L.; Yingjie, L. Weld-seam identification and model reconstruction of remanufacturing blade based on three-dimensional vision. Adv. Eng. Inform. 2021, 49, 101300. [Google Scholar] [CrossRef]
- Wilson, J.M.; Piya, C.; Shin, Y.C.; Zhao, F.; Ramani, K. Remanufacturing of turbine blades by laser direct deposition with its energy and environmental impact analysis. J. Clean. Prod. 2014, 80, 170–178. [Google Scholar] [CrossRef]
- Ge, J.; Deng, Z.; Li, Z.; Li, W.; Lv, L.; Liu, T. Robot welding seam online grinding system based on laser vision guidance. Int. J. Adv. Manuf. Technol. 2021, 116, 1737–1749. [Google Scholar] [CrossRef]
- Ge, J.; Deng, Z.; Li, Z.; Li, W.; Liu, T.; Zhang, H.; Nie, J. An efficient system based on model segmentation for weld seam grinding robot. Int. J. Adv. Manuf. Technol. 2022, 121, 7627–7641. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, S.; Tang, Q.; Tian, X. A novel path planning method of robotic grinding for free-form weld seam based on 3D point cloud. Int. J. Adv. Manuf. Technol. 2024, 131, 5155–5176. [Google Scholar] [CrossRef]
- Meng, Y.; Jiang, Y.; Li, Y.; Pang, G.; Tong, Q. Research on point cloud processing and grinding trajectory planning of steel helmet based on 3D scanner. IEEE Access 2023, 11, 123456–123467. [Google Scholar] [CrossRef]
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep learning for 3d point clouds: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4338–4364. [Google Scholar] [CrossRef]
- Song, Y.; Yang, H.; Lv, H. Intelligent control for a robot belt grinding system. IEEE Trans. Control Syst. Technol. 2012, 21, 716–724. [Google Scholar]
- Zhan, S.; Qian, K.; Liu, Y.; Gong, Y. Weld Seam Segmentation in RGB-D Data using Attention-based Hierarchical Feature Fusion. In Proceedings of the 2022 China Automation Congress (CAC), Xiamen, China, 25–27 November 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1337–1342. [Google Scholar]
- Dong, C.; Shi, T.; Zhao, Q.; Huang, X.; Liu, C. 1D Segmentation Network for 3D Seam Weld Grinding. J. Phys. Conf. Ser. 2021, 1924, 012002. [Google Scholar] [CrossRef]
- Varghese, R.; Sambath, M. YOLOv8: A Novel Object Detection Algorithm with Enhanced Performance and Robustness. In Proceedings of the 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS), Chennai, India, 18–19 April 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–6. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; Kwon, Y.; Michael, K.; Fang, J.; Wong, C.; Yifu, Z.; Montes, D.; et al. ultralytics/yolov5: V6. 2-yolov5 classification models, apple m1, reproducibility, clearml and deci. ai integrations. Zenodo 2022, 10, 5281. [Google Scholar]
- Wang, W.C.; Wu, E.H. A New Method for Deciding Whether a Point is in a Polygon or a Polyhedron. J. Softw. 2000, 11, 1614–1619. [Google Scholar]
- Chen, W.; Li, X.; Ge, H.; Wang, L.; Zhang, Y. Trajectory planning for spray painting robot based on point cloud slicing technique. Electronics 2020, 9, 908. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).