Abstract
Efficient cucumber detection in greenhouse environments is crucial for agricultural automation, yet challenges like background interference, target occlusion, and resource constraints of edge devices hinder existing solutions. This paper proposes LMS-Res-YOLO, a lightweight multi-scale cucumber detection model with three key innovations: (1) A plug-and-play HEU module (High-Efficiency Unit with residual blocks) that enhances multi-scale feature representation while reducing computational redundancy. (2) A DE-HEAD (Decoupled and Efficient detection HEAD) that reduces the number of model parameters, floating-point operations (FLOPs), and model size. (3) Integration of KernelWarehouse dynamic convolution (KWConv) to balance parameter efficiency and feature expression. Experimental results demonstrate that our model achieves 97.9% mAP@0.5 (0.7% improvement over benchmark model YOLOv8_n), 87.8% mAP@0.5:0.95 (2.3% improvement), and a 95.9% F1-score (0.7% improvement), while reducing FLOPs by 33.3% and parameters by 19.3%. The model shows superior performance in challenging cucumber detection scenarios, with potential applications in edge devices.
1. Introduction
Timely harvesting of mature cucumbers is essential to preserve their quality and maximize economic benefits, making automatic cucumber detection a core technology for intelligent harvesting robots. However, greenhouse cucumber detection faces significant challenges: cucumbers share similar colors with surrounding leaves and branches, grow in dense clusters with mutual occlusion, and exhibit shape variations across varieties and growth stages. Additionally, edge devices (e.g., embedded systems on harvesting robots) have limited computational resources, requiring models to balance accuracy and efficiency.
Traditional detection methods relying on handcrafted features (color, shape, texture) struggle in complex agricultural environments. Lighting changes easily distort color-based detection [1,2], while shallow features fail to capture the contextual information needed to distinguish occluded or small cucumbers [3]. These methods also suffer from high computational complexity and slow inference speeds, unable to meet real-time detection requirements [4]. Greenhouse cucumber detection technologies based on texture and color analysis have shown limited cost-effectiveness [5], further highlighting the need for improved solutions.
Deep learning has emerged as the mainstream paradigm for object detection, which can be categorized into two-stage detectors and one-stage detectors. Represented by R-CNN [6], two-stage object detectors encompass variants such as PV-RCNN [7], Sparse R-CNN [8], and other related models [9,10,11]. While these detectors deliver high accuracy, they demand substantial computational resources primarily due to the candidate region generation step. One-stage detectors like YOLO series address this trade-off, achieving better balance between speed and accuracy. YOLOv8_n [12], as a lightweight variant, is suitable for edge deployment but still has shortcomings in complex cucumber detection scenarios: its C2f module lacks effective multi-scale feature fusion, leading to suboptimal performance on occluded or small targets; the original detection head is redundant in parameters; and standard convolutions fail to balance parameter efficiency and feature representation. In this paper, we propose a lightweight cucumber detection model based on YOLOv8_n structure. The main innovations include:
- We propose a plug-and-play multi-branch convolutional residual module, which can be applied to the backbone, neck and detection heads of YOLO series models to improve detection accuracy and recall, especially for small object detection.
- We researched the detection model’s lightweight module design and further reduced the model’s parameters, FLOPs and size while maintaining its performance.
- We created an image dataset of greenhouse cucumbers, which is useful for studying automatic picking and yield analysis.
2. Related Work
The cucumber target detection task is distinct from other fruit target detection tasks. In terms of appearance, cucumbers may undergo significant changes between different varieties and growth stages. Some cucumbers are long and thin, while others are short and thick. Some cucumbers are straight, while others are curved. Diversity in appearance necessitates that object detection algorithms have great generalization performance and accurate detection capabilities so that they can identify cucumbers with different appearances. In terms of the spatial distribution of cucumbers, cucumber plants often grow very densely in complex situations where cucumbers are stacked on top of each other. This density and stacking characteristics also increase the difficulty of cucumber detection. Additionally, leaves, vines, or other objects may partially obscure cucumbers, leading to poor information integrity. This partial visibility may result in a limited amount of information that object detection algorithms can use, making it difficult to accurately locate and detect cucumbers. Therefore, the algorithm needs to be robust to such conditions and able to accurately detect targets in complex scenarios. And changes in light and shadow can affect the appearance of cucumbers, resulting in changes in the brightness of captured images, which further increases the accuracy requirements for target detection models.
Lin et al. [13] constructed an efficient detection model (EFDet), which improved the detection performance of cucumber leaves in complex backgrounds by fusing feature maps at different levels. Li et al. [14] proposed an MTC-YOLOv5n method based on the YOLOv5 [15], which can effectively detect cucumber diseases in natural scenes. The model integrates Coordinate Attention (CA) and Transformer, which can reduce the interference of invalid information in the background and has strong robustness under dense fog, fine rain, and low light. Khan et al. [16] used pre-trained models VGG-19 and VGG-M for the detection and classification of cucumber leaf diseases and then extracted the most prominent features based on local standard deviation, local entropy, and local interquartile range method. They then input these refined features into multi-class support vector machines for disease recognition, as a result, five types of cucumber leaf diseases were classified. Chen et al. [17] suggested an improved YOLOv5 model for recognizing the top of a cucumber canopy, aiming to fix the issue of low accuracy in recognizing cucumber canopy vine top images. YOLOv8 [12] is a cutting-edge model that builds upon the success of previous YOLO versions, further enhancing performance and flexibility. Yang et al. [18] proposed a model based on YOLOv8, which uses deformable convolution and coordinate attention for fast cow detection, achieving mean Average Precision (mAP) of 72.9% at 62.5 frames per second (FPS). Recently, several lightweight YOLO variants have been proposed to improve efficiency for edge deployment. For instance, Light-YOLO [19] adopts channel pruning and depthwise separable convolutions to reduce model size but does not explicitly address multi-scale feature representation, limiting its effectiveness on small or occluded targets like greenhouse cucumbers. Similarly, PMDS-YOLO [20] enhances multi-scale detection through a modified PANet structure; however, its backbone still relies on conventional convolution blocks without residual multi-branch design, resulting in higher computational redundancy and weaker contextual modeling under cluttered agricultural scenes.
Multi-scale feature representation learning plays an important role in machine vision [21,22]. Object regions at different scales contain multiple levels of information. By utilizing multiscale representations, models can consider global contextual information while focusing on local details, thus generating richer and more diverse feature representations [23]. Multi-scale representations help to improve the model’s ability to understand the shape, texture, structure, and context of an object, which are prerequisites for efficient object detection. In object detection and localization tasks, multi-scale feature representations are important for detecting targets of different sizes and scales. By performing feature extraction and detection at different scales, the model is better able to capture and synthesize the target’s different scale features, which improves detection accuracy and robustness [24,25].
Most of the current research in the object detection field, including these mentioned above, focused on relatively large models, which contain large numbers of parameters and require more floating-point operations, resulting in a high computational burden. Due to the limitation of computing power and resources, these models are not suitable for application on mobile devices and systems, necessitating the development of more lightweight cucumber target detection models. Our work focuses on investigating light-weight object detection models and improving their learning efficiency so as to reach a satisfactory balance between the model size and performance.
3. Methodology
3.1. Cucumber Dataset
We collected the cucumber dataset in a greenhouse farm using an Intel RealSense D435 camera. We collected images with various conditions, including angles, orientations, heights, and brightness, to enhance the model’s generalization learning ability. During this process, we also ensured the balance of various types of samples to ensure sample diversity. After removing low-quality images, a total of 2000 valid images were obtained. We Randomly divide the cucumber dataset into a training dataset, a validation dataset, and a test dataset, with a ratio of 8:1:1, and then expanded the dataset to 8000 images by applying data augmentation methods like left and right flipping, up and down flipping, Gaussian noise, and salt and pepper noise. When annotating targets in each image, we make sure that the bounding box tightly encloses the cucumber target without any missing or excessive labeling, and we ignore particularly tiny cucumber targets. Figure 1 shows the diverse cucumber samples.

Figure 1.
Diverse cucumber samples. (a) The cucumber with one side is obstructed. (b) The cucumber heavily shaded in the middle. (c) The cucumber with a large amount of missing information. (d) Many cucumber targets. (e) The cucumber located at the edge of FOV (field of view). (f) Cucumbers with low-level lighting.
3.2. Benchmark Model YOLOv8_n
YOLOv8 is an advanced one-stage object detector that can achieve a good balance between detection speed and precision. It supports multiple tasks, such as image classification, object detection, and image segmentation. Building upon the success of previous YOLO versions, the performance and flexibility of YOLOv8 have been greatly improved. YOLOv8 consists of YOLOv8_n, YOLOv8_s, YOLOv8_m, YOLOv8_l, and YOLOv8_x models to meet various requirements in different scenarios. YOLOv8_n has a more lightweight design compared to some other versions. It employs a simplified network structure and optimized module design to reduce the number of parameters and computations. These enable YOLOv8_n to run efficiently on mobile devices and embedded systems with limited computational resources, making it the benchmark model.
The YOLOv8_n model mainly consists of the following four parts: the backbone network, feature fusion module, detection head, and loss function, as shown in Figure 2. In addition, it also has some auxiliary elements, such as pre-processing and post-processing steps, which involve tasks like image scaling, normalization, and non-maximum suppression. YOLOv8_n uses the backbone network as its primary feature extractor to extract deep semantic features from input images. The C3 structure of YOLOv5 has been replaced with the C2f structure, which can capture more detailed gradient flow information. This change has led to a significant improvement in model performance while also ensuring that the network is lightweight. The neck part constructs a feature pyramid using the PAFPN [26] structure, enhancing feature extraction and feature representation capabilities on the backbone network’s output feature maps.
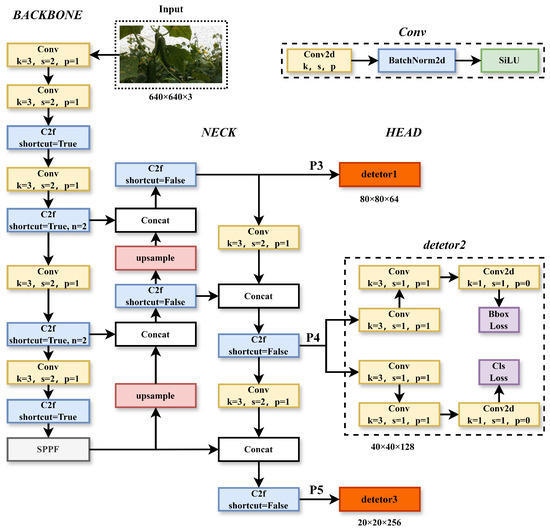
Figure 2.
YOLOv8_n network structure. In the figure, k is the size of the convolution kernel, s is the stride, p is padding, and n is the number of repetitions of Bottleneck in C2f.
3.3. Our Improved Model
In complex natural environments, YOLOv8_n performs poorly in recognizing cucumbers. Based on YOLOv8_n, the LMS-Res-YOLO model has been developed, which is a lightweight and efficient cucumber object detection model that excels at accurately identifying cucumbers in near-colored backgrounds. LMS-Res-YOLO’s multi-layered network structure captures more detail in the input data by utilizing multiple layers of feature extractors. Figure 3 illustrates the network structure of the LMS-Res-YOLO model, and the main improvements over our proposed LMS-Res-YOLO include: (1) To replace the C2f with the HEU (High-Efficiency Unit with residual blocks) to enhance the multi-scale representation ability of features, improve the nonlinear modeling ability of the network for complex problems, and reduce information loss during network transmission. (2) To replace the detection head with the DE-HEAD (Decoupled and Efficient detection HEAD with the fusion of multi-scale features) in order to further reduce the model’s size without affecting its performance. (3) To replace the Conv of the backbone and neck with the KWConv (KernelWarehouse) [27], which was proposed by Intel in 2023. It can reduce the model’s size and better balance the relationship between parameter efficiency and representation ability.
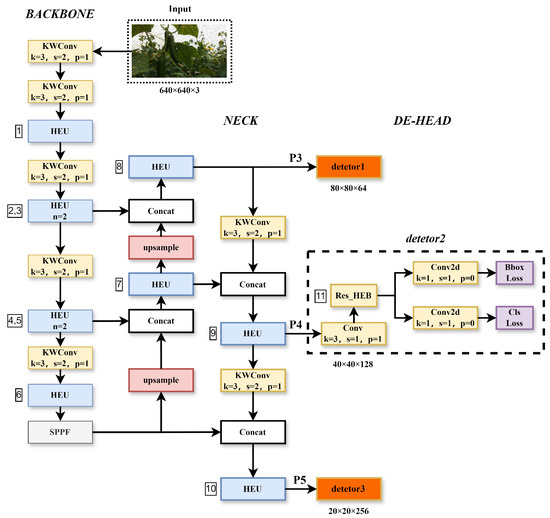
Figure 3.
LMS-Res-YOLO network structure. In the figure, k is the size of the convolution kernel, s is the stride, p is padding, and n is the number of repetitions of Res_HEB in HEU.
3.3.1. HEU Module
The C2f module has some shortcomings, such as its large number of parameters and high computational complexity. The newly designed HEU is more lightweight and has further improved performance. After replacing C2f with HEU alone, there is a slight improvement in mAP@0.5, and mAP@0.5:0.95 increases by 1%, which is very commendable. The HEU structure is shown in Figure 4. It is made up of the Conv, Split, Res_HEB (High-Efficiency Block with Residual blocks), and Concat modules. In Figure 5, the Res_HEB block takes full advantage of the multi-scale representation fusion, which can make models achieve invariance to scale changes. In practice, an object’s scale may change due to factors such as distance, viewing angle, or image resolution. By extracting features at different scales, the model can better adapt to objects of different sizes, leading to increased accuracy and stability. Feature fusion techniques frequently utilize multiscale representations to obtain more global and comprehensive feature representations [28,29]. For Res_HEB, the input feature maps have dimensions of . After the transition via a convolution, the dimension of the output feature maps becomes . Next, the output is divided into four parts in the channel dimension, which are denoted as split 1, split 2, split 3, and split 4. Subsequently, split 1 and split 2 execute the element-wise tensor addition operation, creating a new tensor known as X1, which maintains the same shape. X1 then undergoes depth-wise separable convolution with a kernel size of k1 while keeping the same input and output channel numbers. This process efficiently extracts features from multi-channels, preserves spatial information, requires few parameters, and maintains the number of channels unchanged. Z1 emerges from the element-wise tensor addition between X1 and Y1. This operation belongs to residual connections [30], which is crucial to our model, and experimental results show that our model cannot converge during training without it. Then, Z1 undergoes element-wise tensor addition with split 3. Following the same process as above, Z2 and Z3 are obtained. These feature maps from split1, Z1, Z2, and Z3 are concatenated as input to two convolutions to further obtain the cross-channel feature information.
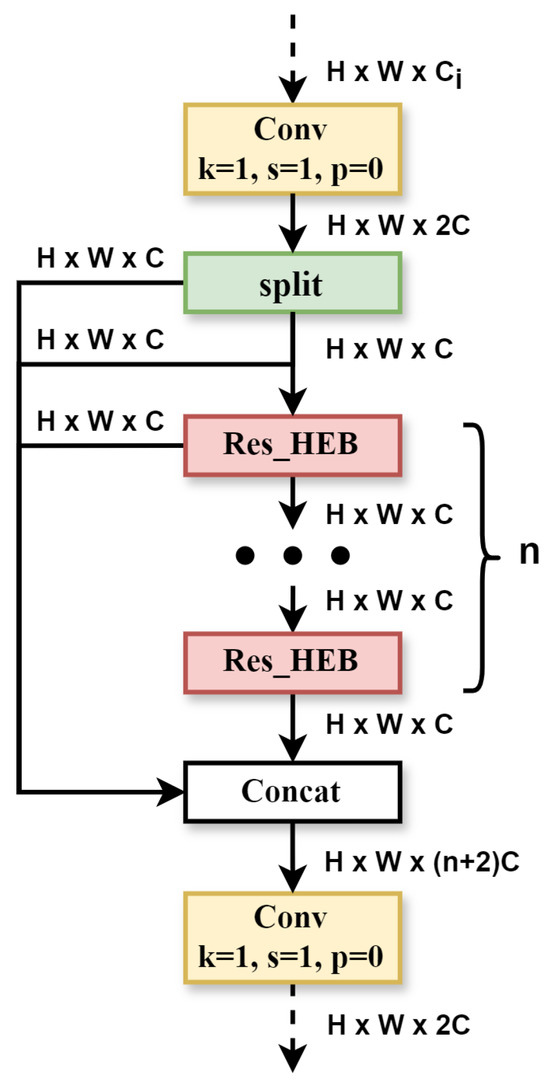
Figure 4.
HEU module.
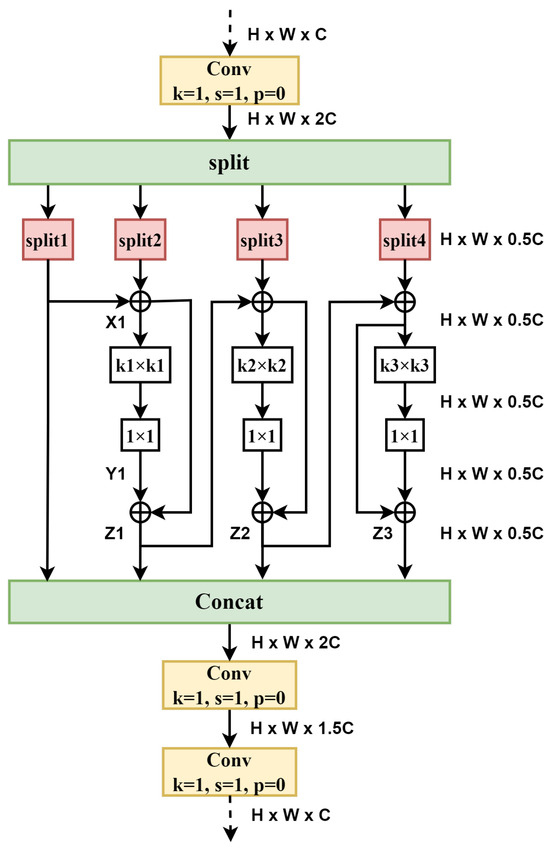
Figure 5.
Res_HEB block.
Our LMS-Res-YOLO network uses total 13 Res_HEB blocks in the backbone, neck and detector, and the parameters of each Res_HEB are shown in Table 1, in which indexes 1 to 6 are used in the backbone and indexes 7 to 10 are used in the neck. The Res_HEB block uses a large convolutional kernel size of k1, which can capture more contextual information, share parameters over a wider receptive field, and improve the model’s generalization ability.

Table 1.
Parameters of each Res_HEB in LMS-Res-YOLO.
3.3.2. DE-HEAD
The original YOLOv8 head is a type of decoupled detection head that needs separate network branches to predict the object’s category and position. This makes the model more complicated and increases the number of parameters. As shown in Figure 3, we constructed the DE-HEAD to replace the original head, reducing the head’s parameters and further making the model lightweight. Our DE-HEAD caused the learnable parameters and FLOPs (floating-point operations per second) of the model to decrease by more than 10%, while the other performance remained stable. After extracting features through the backbone network and neck network, we obtain a set of feature maps denoted as P3, P4, P5 at different scales. Then P3, P4, and P5, respectively, pass through the DE-HEAD detector. First, DE-HEAD adjusts the number of channels in the input feature maps using a convolution. Subsequently, the adjusted feature maps are fed into a Res_HEB block, which uses the index 11 parameters in Table 1 to fuse information on different scales, thereby enhancing the representation ability of features and the model’s robustness to scale changes. Finally, feature maps go through a convolutional layer to adjust the number of channels and then compute the loss function.
3.3.3. KWConv
To further reduce the model’s FLOPs, KernelWarehouse [27], denoted as KWConv, is introduced in the positions of the backbone network and neck network. It can reduce FLOPs by 15% with constant parameter amounts. Ordinary convolutions perform poorly in terms of parameter efficiency and representation ability, while KWConv can keep a favorable balance between them. The purpose of KWConv is to significantly increase the number of kernels while reducing their dimensions. Kernel partitioning and warehouse sharing are powerful tools in KWConv. It can enhance the relationship within the same layer and across consecutive layers to improve the dependency relationship of convolutional parameters. Firstly, KWConv divided the convolution kernel into m disjoint kernel units, which have the same dimensions. Then, calculate the linear mixture of each kernel unit based on a predefined “warehouse” containing n kernel units. This warehouse is shared across multiple adjacent convolutional layers, improving parameter sharing. Finally, the corresponding m mixtures are assembled in sequence, providing higher flexibility while maintaining a lightweight design.
4. Experiments
4.1. Evaluation Metrics
We use mAP@0.5, mAP@0.5:0.95, Params, FLOPs, Precision (P), Recall (R), F1-score (F1), and Model Size as evaluation metrics in our experiments to comprehensively and objectively assess the performance of the LMS-Res-YOLO object detection model. (1) mAP@0.5 represents the average accuracy at an Intersection over Union (IoU) of 0.5 and is a commonly used evaluation metric in object detection tasks to measure the accuracy of the model in detecting targets. (2) mAP@0.5:0.95 is Similar to mAP@0.5, it takes into account a range of IoU thresholds from 0.5 to 0.95, at a step of 0.05, providing a more comprehensive evaluation of model performance by considering a series of overlap levels between predicted bounding boxes and ground truth boxes. Compared to mAP@0.5, mAP@0.5:0.95 is a more stringent evaluation metric. (3) Params refers to the number of parameters in a model, usually measured in millions (M), which represent the model’s complexity and memory requirements. In general, a larger number of parameters indicates a more complex model. (4) FLOPs represent the number of floating-point operations per inference, indicating a model’s computational workload. Lower FLOPs values often indicate lower computational complexity. (5) Precision (P) is defined as detection precision, which measures a model’s predictive accuracy, with higher values indicating greater accuracy. It is equal to the ratio of the number of correctly detected cucumber targets to the total number of detected targets in this experiment. (6) Recall (R) is defined as the ratio of the correctly detected number of cucumber targets to the ground truth number. Higher values indicate higher sensitivity. (7) F1-score (F1) is the harmonic mean of Precision and Recall, it provides a balanced measure of a model’s performance by considering both precision and recall, with a higher value indicating a better balance between the two metrics. (8) Model Size refers to the file size of the model, including model’s structure and weights.
4.2. Ablation Experiments
The experimental configuration is shown in Table 2.
Table 2.
Experiment hardware and software system.
In order to evaluate the impact of the three improvements on the overall performance of the network structure, a series of ablation experiments were conducted in this experiment. The above improvements were combined to verify reliability and effectiveness, providing guidance for model design and optimization. The results of the ablation experiments are shown in Table 3. The symbol ✓ refers to the use of the improved module. If there is no ✓ for the three improvement measures, it is the baseline model, YOLOv8_n. To ensure the objectivity of the experiment, all training processes were conducted from scratch with exactly the same hyperparameters as the baseline model YOLOv8_n.
Table 3.
Ablation experiments results.
When the three improved modules work independently, they all bring improvements to mAP@0.5 and mAP@0.5:0.95, with HEU performing the best. In terms of making the model lightweight, HEU reduced Params and FLOPs by 9% and 3.7%, respectively, but increased the model size slightly. KWconv decreased FLOPs by 14.8%, but increased Params and Model Size slightly. DE-HEAD has the most significant effect on lightweight, reducing Params, FLOPs, and Model Size by 11.3%, 14.8%, and 8%, respectively. Combining all three modules leads to improvements in all evaluation indicators, with mAP@0.5, mAP@0.5:0.95, Params, Precision, Recall, F1-score, and Model Size achieving improvement effects of 0.7%, 2.7%, 19.3%, 0.3%, 1.2%, 0.7% and 5.5%. FLOPs achieved the most significant improvement at 33.3%. The ablation experiment results demonstrate that our improvement modules can improve the original YOLOv8_n’s performance while also making it lighter-weight.
4.3. Comparison Experiment with Advanced Models
To further verify the effectiveness of our LMS-Res-YOLO, comparative experiments were conducted with current advanced object detection models in the YOLO series, including YOLOv5 [15], YOLOv6 [31], YOLOv7 [32], YOLOv8 [12], YOLOX [33], and YOLOv10 [34]. The experiments results are presented in Table 4 and Table 5. It is evident that in terms of accuracy, YOLOv5_s, YOLOX_m, YOLOv8_s, and YOLOv10_s achieve slightly higher performance on mAP@0.5; only YOLOv8_s and YOLOv10_s outperform LMS-Res-YOLO at mAP@0.5:0.95. However, YOLOv5_s, YOLOv8_s, and YOLOv10_s are relatively large-scale models. Compared with the proposed LMS-Res-YOLO, their Params increase by 188.5%, 358%, and 230.9%, FLOPs by 192.6%, 425.9%, and 300%, and Model Size by 143%, 280%, and 179.5%, respectively. In contrast, LMS-Res-YOLO exhibits outstanding overall performance when compared with models of similar scale (i.e., YOLOv5_n, YOLOv6_n, YOLOv8_n, and YOLOv10_n), achieving the highest accuracy in mAP@0.5, mAP@0.5:0.95, Precision, Recall, and F1-score. While YOLOv5_n has a parameter advantage (1.76 M vs. 2.43 M), our LMS-Res-YOLO demonstrates superior overall performance. Specifically, it achieves 97.9% mAP@0.5 (vs. 97.1%), a 95.9% F1-score (vs. 94.3%), and, more importantly, 87.8% mAP@0.5:0.95 (vs 80.4%)—a substantial 7.4% improvement in the more rigorous metric.
Table 4.
Experimental comparison results with relatively large models.
Table 5.
Experimental comparison results with similar scale models.
These comparative experiments confirm that LMS-Res-YOLO can effectively balance the complexity and performance of an object detection model. It requires fewer computational resources and less storage space for operation, which is critical for its application in resource-constrained devices such as mobile devices, embedded systems, and edge devices.
4.4. Visualization Comparison Experiments
Figure 6 presents the mAP curve during training, demonstrating that after approximately 50 training epochs, the mAP results of LMS-Res-YOLO outperform those of the benchmark model YOLOv8_n. To further validate the model’s performance, additional challenging experiments were conducted between LMS-Res-YOLO and YOLOv8_n. As illustrated in Figure 7, LMS-Res-YOLO exhibits superior detection performance on occluded and overlapping cucumbers. Specifically, it can accurately detect cucumbers in scenarios such as partial overlap (e.g., Figure 7a,c) and heavy occlusion by adjacent leaves (e.g., Figure 7b). Figure 8 further highlights the advantage of LMS-Res-YOLO in small target detection: unlike YOLOv8_n, which misses some small targets, LMS-Res-YOLO achieves accurate detection of such objects, including obscured small cucumbers (e.g., Figure 8a,b) and small cucumbers growing laterally near the edge of the field of view (FOV) (e.g., Figure 8c).
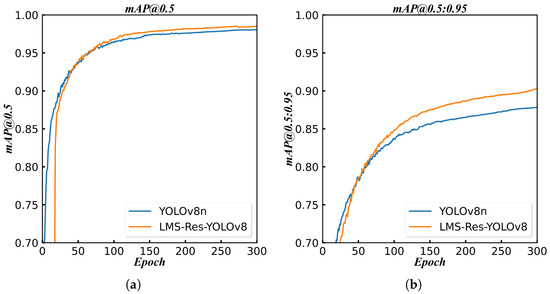
Figure 6.
Training curve of mAP on YOLOv8_n and LMS-Res-YOLO. (a) Training curve of mAP@0.5. (b) Training curve of mAP@0.5:0.95.

Figure 7.
Comparison of detection results on obscured cucumbers between YOLOv8_n and LMS-Res-YOLO. The first row shows the detection results of YOLOv8_n, and the second row shows the detection results of LMS-Res-YOLO. (a) Overlapping cucumber. (b) Heavily obscured cucumber. (c) Obscured cucumber.

Figure 8.
Comparison of detection results on small cucumbers between YOLOv8_n and LMS-Res-YOLO. The first row shows the detection results of YOLOv8_n, and the second row shows the detection results of LMS-Res-YOLO. (a) Small cucumbers at the edge of FOV and occluded small cucumbers. (b) Occluded small cucumbers. (c) Small cucumbers at the edge of FOV.
Features at different scales contain semantic and detailed information at varying levels, which facilitates distinguishing cucumber targets from backgrounds or other objects. The experimental results demonstrate that our LMS-Res-YOLO exhibits stronger and more robust detection performance than YOLOv8_n. This advantage is mainly attributed to three factors: First, the HEU module’s multi-scale design enables effective feature extraction at different receptive fields, crucial for handling scale variation. Second, the Res_HEB residual blocks facilitate gradient flow, improving training stability and convergence. Third, the integration of KernelWarehouse convolution (KWConv) optimizes parameter efficiency and representation capacity through its kernel partitioning and warehouse sharing mechanism. Consequently, LMS-Res-YOLO not only improves the accuracy and comprehensiveness of cucumber detection but also enhances the ability to detect occluded targets and FOV edge targets.
5. Conclusions
This study intends to develop a lightweight object detection model with potential applications for cucumber detection on edge devices. First, we designed the HEU module to replace the C2f module in YOLOv8_n; this module enhances the ability of multi-scale feature representation, thereby improving detection accuracy. Second, we proposed the DE-HEAD, which effectively reduces the model’s parameters, FLOPs, and size while ensuring the stability of detection accuracy. Third, we replaced the standard convolutions in the network’s backbone and neck components with KWConv, which further enhances detection accuracy without increasing FLOPs. The experimental results indicate that the proposed LMS-Res-YOLO model outperforms the benchmark model YOLOv8_n in challenging cucumber detection scenarios. Additionally, we also demonstrated that our model has strong generalization performance on public datasets, as shown in Appendix A. Future work will focus on real-time deployment optimization on mobile terminals.
Author Contributions
Conceptualization, B.L. and G.Z.; methodology, B.L. and G.Z.; software, G.Z.; validation, B.L. and G.Z.; formal analysis, W.K.; investigation, W.K.; resources, B.L.; data curation, B.L.; writing—original draft preparation, B.L.; writing—review and editing, W.K.; visualization, B.L.; supervision, W.K.; project administration, B.L.; funding acquisition, B.L. and W.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by Macao Polytechnic University (s/c fca.f9e4.21d5.f), and the Zhongshan City social public science and technology research project under Grant No. 2023B2007.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The datasets used and analyzed during the current study are available from the corresponding author upon request.
Acknowledgments
We acknowledge Macao Polytechnic University (s/c fca.f9e4.21d5.f) and Zhongshan Municipal Bureau of Science and Technology for the financial support.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this paper:
| YOLO | You Only Look Once |
| PAFPN | Path Aggregation Feature Pyramid Network |
| HEU | High-Efficiency Unit |
| Res_HEB | High Efficiency Block with Residual blocks |
| DE-HEAD | Decoupled and Efficient detection HEAD |
| KWConv | KernelWarehouse convolution |
| FLOPs | Floating-point operations per inference |
| mAP | mean Average Precision |
| FOV | field of view |
Appendix A
To evaluate the generalization performance of our detection model, we conducted experiments on the public datasets include PASCAL VOC2007&2012 [35], MS-COCO2017 [36] and VisDrone2019 [37]. It is worth emphasizing that MS-COCO2017 and VisDrone2019 are characterized by a large proportion of small-scale objects, which poses significant challenges to the detection ability of most existing models. All models involved in the experiments were trained from scratch to ensure the fairness and reliability of the comparison, and subsequent testing was performed under consistent evaluation settings. The experimental results from Table A1, Table A2 and Table A3 prove that our model has more advantages in the evalutation metic of mAP, especially in the more stringent mAP@0.5:0.95 compared to benchmark models with similar model sizes. Notably, this superiority is more pronounced in the small-target-rich scenarios of MS-COCO2017 and VisDrone2019, fully verifying the effectiveness of our model in addressing small object detection challenges.
Table A1.
Comparison experiment results on VOC2007&2012 dataset.
Table A1.
Comparison experiment results on VOC2007&2012 dataset.
| Detection Model | mAP@0.5 | mAP@0.5:0.95 | Params (M) | FLOPs (G) | P | R | F1 |
|---|---|---|---|---|---|---|---|
| YOLOv8_n | 0.807 | 0.604 | 3.01 | 8.1 | 0.819 | 0.718 | 0.765 |
| YOLOv10_n | 0.805 | 0.607 | 2.30 | 6.7 | 0.815 | 0.723 | 0.767 |
| LMS-Res-YOLO(our) | 0.802 | 0.616 | 2.43 | 5.4 | 0.800 | 0.726 | 0.761 |
Table A2.
Comparison experiment results on MS-COCO2017 dataset.
Table A2.
Comparison experiment results on MS-COCO2017 dataset.
| Detection Model | mAP@0.5 | mAP@0.5:0.95 | Params (M) | FLOPs (G) | P | R | F1 |
|---|---|---|---|---|---|---|---|
| YOLOv8_n | 0.517 | 0.369 | 3.01 | 8.7 | 0.631 | 0.476 | 0.543 |
| YOLOv10_n | 0.536 | 0.388 | 2.30 | 6.7 | 0.643 | 0.492 | 0.558 |
| LMS-Res-YOLO(our) | 0.540 | 0.394 | 2.43 | 5.4 | 0.652 | 0.492 | 0.563 |
| Detection Model | mAP@0.5:0.95 (Small) | mAP@0.5:0.95 (Medium) | mAP@0.5:0.95 (Large) | ||||
| YOLOv8_n | 0.182 | 0.405 | 0.527 | ||||
| YOLOv10_n | 0.184 | 0.424 | 0.558 | ||||
| LMS-Res-YOLO(our) | 0.195 | 0.434 | 0.570 | ||||
Table A3.
Comparison experiment results on VisDrone2019 dataset.
Table A3.
Comparison experiment results on VisDrone2019 dataset.
| Detection Model | mAP@0.5 | mAP@0.5:0.95 | Params (M) | FLOPs (G) | P | R | F1 |
|---|---|---|---|---|---|---|---|
| YOLOv8_n | 0.341 | 0.195 | 3.01 | 8.1 | 0.455 | 0.343 | 0.391 |
| YOLOv10_n | 0.341 | 0.199 | 2.30 | 6.7 | 0.477 | 0.333 | 0.396 |
| LMS-Res-YOLO(our) | 0.343 | 0.200 | 2.43 | 5.4 | 0.479 | 0.339 | 0.399 |
References
- Bao, G.; Cai, S.; Qi, L.; Xun, Y.; Zhang, L.; Yang, Q. Multi-template matching algorithm for cucumber recognition in natural environment. Comput. Electron. Agric. 2016, 127, 754–762. [Google Scholar] [CrossRef]
- Wang, J.; Li, B.; Li, Z.; Zubrycki, I.; Granosik, G. Grasping behavior of the human hand during tomato picking. Comput. Electron. Agric. 2021, 180, 105901. [Google Scholar] [CrossRef]
- Zheng, C.; Chen, P.; Pang, J.; Yang, X.; Chen, C.; Tu, S.; Xue, Y. A mango picking vision algorithm on instance segmentation and key point detection from RGB images in an open orchard. Biosyst. Eng. 2021, 206, 32–54. [Google Scholar] [CrossRef]
- Omer, S.M.; Ghafoor, K.Z.; Askar, S.K. Lightweight improved yolov5 model for cucumber leaf disease and pest detection based on deep learning. Signal Image Video Process. 2024, 18, 1329–1342. [Google Scholar] [CrossRef]
- Sun, Y.; Zhang, J.; Wang, H.; Wang, L.; Li, H. Identifying optimal water and nitrogen inputs for high efficiency and low environment impacts of a greenhouse summer cucumber with a model method. Agric. Water Manag. 2019, 212, 23–34. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. Pv-rcnn: Point-voxel feature set abstraction for 3d object detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10529–10538. [Google Scholar]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Luo, P. Sparse r-cnn: End-to-end object detection with learnable proposals. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 14454–14463. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the 2015 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 27–30 June 2016; pp. 1440–1448. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2961–2969. [Google Scholar]
- Ultralytics YOLO. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 15 October 2025).
- Liu, C.; Zhu, H.; Guo, W.; Han, X.; Chen, C.; Wu, H. EFDet: An efficient detection method for cucumber disease under natural complex environments. Comput. Electron. Agric. 2021, 189, 106378. [Google Scholar] [CrossRef]
- Li, S.; Li, K.; Qiao, Y.; Zhang, L. A multi-scale cucumber disease detection method in natural scenes based on YOLOv5. Comput. Electron. Agric. 2022, 202, 107363. [Google Scholar] [CrossRef]
- Ultralytics YOLOv5. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 15 October 2025).
- Khan, M.A.; Akram, T.; Sharif, M.; Javed, K.; Raza, M.; Saba, T. An automated system for cucumber leaf diseased spot detection and classification using improved saliency method and deep features selection. Multimed. Tools Appl. 2020, 79, 18627–18656. [Google Scholar] [CrossRef]
- Chen, M.; Lang, X.; Zhai, X.; Li, T.; Shi, Y. Intelligent recognition of greenhouse cucumber canopy vine top with deep learning model. Comput. Electron. Agric. 2023, 213, 108219. [Google Scholar] [CrossRef]
- Yang, W.; Wu, J.; Zhang, J.; Gao, K.; Du, R.; Wu, Z.; Firkat, E.; Li, D. Deformable convolution and coordinate attention for fast cattle detection. Comput. Electron. Agric. 2023, 211, 108006. [Google Scholar] [CrossRef]
- Zhong, Z.; Yun, L.; Cheng, F.; Chen, Z.; Zhang, C. Light-YOLO: A lightweight and efficient YOLO-based deep learning model for mango detection. Agriculture 2024, 14, 140. [Google Scholar] [CrossRef]
- Xu, X.; Xie, Z.; Wang, N.; Yan, P.; Shao, C.; Shu, X.; Zhang, J. PMDS-YOLO: A lightweight multi-scale detector for efficient aquatic product detection. Agriculture 2025, 612, 743210. [Google Scholar] [CrossRef]
- Gui, Z.; Peng, D.; Wu, H.; Long, X. MSGC: Multi-scale grid clustering by fusing analytical granularity and visual cognition for detecting hierarchical spatial patterns. Future Gener. Comput. Syst. 2020, 112, 1038–1056. [Google Scholar] [CrossRef]
- Khan, S.I.; Shahrior, A.; Karim, R.; Hasan, M.; Rahman, A. MultiNet: A deep neural network approach for detecting breast cancer through multi-scale feature fusion. J. King Saud-Univ.-Comput. Inf. Sci. 2022, 34, 6217–6228. [Google Scholar] [CrossRef]
- Karnati, M.; Seal, A.; Sahu, G.; Yazidi, A.; Krejcar, O. A novel multi-scale based deep convolutional neural network for detecting COVID-19 from X-rays. Appl. Soft Comput. 2022, 125, 109109. [Google Scholar] [CrossRef] [PubMed]
- Hu, X.; Li, X.; Huang, Z.; Chen, Q.; Lin, S. Detecting tea tree pests in complex backgrounds using a hybrid architecture guided by transformers and multi-scale attention mechanism. J. Sci. Food Agric. 2024, 104, 3570–3584. [Google Scholar] [CrossRef]
- Chen, Y.; Yuan, X.; Wang, J.; Wu, R.; Li, X.; Hou, Q.; Cheng, M.M. YOLO-MS: Rethinking multi-scale representation learning for real-time object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2025, 47, 4240–4252. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Li, C.; Yao, A. KernelWarehouse: Towards parameter-efficient dynamic convolution. arXiv 2023, arXiv:2308.08361. [Google Scholar]
- Guo, Q.; Geng, L.; Xiao, Z.; Zhang, F.; Liu, Y. Mifanet: Multi-scale information fusion attention network for determining hatching eggs activity via detecting PPG signals. Neural Comput. Appl. 2023, 35, 22637–22649. [Google Scholar] [CrossRef]
- Yang, J.; Li, A.; Xiao, S.; Lu, W.; Gao, X. MTD-Net: Learning to detect deepfakes images by multi-scale texture difference. IEEE Trans. Inf. Forensics Secur. 2021, 16, 4234–4245. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar] [CrossRef]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J. Yolov10: Real-time end-to-end object detection. In Proceedings of the 38th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 10–15 December 2024; pp. 107984–108011. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the 2014 European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Zhu, P.; Wen, L.; Du, D.; Bian, X.; Fan, H.; Hu, Q.; Ling, H. Detection and tracking meet drones challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 7380–7399. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).