Abstract
Automatic Modulation Recognition (AMR) is a critical technology for intelligent wireless communication systems, but the deployment of high-performance deep learning models is often hindered by their substantial computational and memory requirements. To address this challenge, this paper proposes a multi-level knowledge distillation network, namely MLD-Net, for creating a lightweight and powerful AMR model. Our approach employs a large Transformer-based network as a teacher to guide the training of a compact and efficient Reformer-based student model. The knowledge contained in the large model is transferred across three distinct granularities: at the output level, to convey high-level predictive distributions; at the feature level, to align intermediate representations; and at the attention level, to propagate relational information about signal characteristics. This comprehensive distillation strategy empowers the student model to effectively emulate the teacher’s complex reasoning processes. Experimental results on the RML2016.10A benchmark dataset demonstrate that MLD-Net achieves state-of-the-art performance, outperforming other baseline models across a wide range of signal-to-noise ratios while requiring only a fraction of the parameters. Extensive ablation study further confirms the collaborative contribution of each distillation level, validating that the proposed MLD-Net is an effective solution for developing lightweight and efficient AMR networks for edge deployment.
1. Introduction
With the explosive growth of wireless devices and the increasing scarcity of spectrum resources, efficiently managing and optimizing limited wireless resources has become a critical challenge []. Automatic Modulation Recognition (AMR), as a core technology in wireless communication systems, aims to identify the modulation scheme of received signals under unknown channel conditions. AMR is a key component for applications such as spectrum monitoring, interference detection, and cognitive radio [].
However, traditional likelihood-based and feature-based AMR methods suffer from high computational complexity, strong reliance on prior knowledge, and limited feature representation capability, making it difficult to meet the dual demands of high accuracy and low latency in real-world scenarios [].
In recent years, the rapid development of deep learning has brought significant breakthroughs to AMR. Large-scale deep neural networks can automatically extract highly discriminative features from raw signals in an end-to-end manner, significantly improving modulation recognition performance under complex channels and low signal-to-noise ratio (SNR) conditions [,]. However, these large models usually come with substantial computational and storage costs, which severely limit their real-time deployment on resource-constrained devices.
Therefore, how to significantly reduce the computational and memory footprint of AMR models while maintaining high recognition accuracy has become a pressing research problem. To address this issue, Knowledge Distillation (KD) has emerged as an effective model compression technique. As illustrated in Figure 1, KD facilitates the transfer of knowledge from a large, high-performance “teacher” model (in our work, a standard Transformer encoder) to a lightweight “student” model (a compact Reformer). We specifically chose the Reformer architecture for its efficiency, as its core LSH (Locality-Sensitive Hashing) attention mechanism scales efficiently with sequence length ( complexity instead of ), making it ideal for resource-constrained edge deployment. This enables the compact student model to achieve strong model performance with much lower complexity, making it suitable for deployment on edge devices.
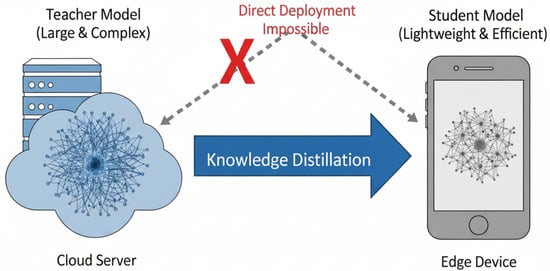
Figure 1.
Illustration of knowledge distillation: a large teacher model transfers knowledge to a lightweight student, overcoming the limitations of direct deployment on edge devices for AMR.
For AMR tasks, KD not only allows the student model to inherit the teacher’s ability to extract complex modulation features and global temporal–spectral dependencies but also improves the robustness of the student under noisy and dynamic channel conditions. Building upon the above background, this paper investigates the application of knowledge distillation to AMR. We present a knowledge distillation framework specifically designed for modulation recognition tasks, enabling efficient and robust performance under resource-constrained scenarios.
The main contributions of this study are summarized as follows:
- We propose a multi-level knowledge distillation network (MLD-Net) for AMR. By transferring knowledge simultaneously at the output, feature, and attention levels, MLD-Net enables a lightweight student model to learn not only the teacher’s predictive distribution but also its internal reasoning process regarding complex signal characteristics, significantly enhancing the student model’s performance and its robustness under diverse channel conditions.
- We design an efficient yet powerful student model. We demonstrate that a compact Reformer-based architecture, when guided by a larger Transformer teacher through our multi-level distillation, can achieve state-of-the-art accuracy with only a fraction of the computational and memory costs, making it ideal for edge deployment.
- Adequate comparative and ablation experiments on the RML2016.10A and RML2016.10B datasets validate that our proposed MLD-Net establishes a superior trade-off between efficiency and performance. It achieves state-of-the-art accuracy among lightweight models (e.g., 61.14% on 10A and 64.62% on 10B) with an approximately 131.9-fold parameter reduction compared to the teacher model.
The remainder of this paper is organized as follows. Section 2 reviews related work in automatic modulation recognition and model compression techniques. Section 3 details our proposed MLD-Net, including the signal model, the teacher-student architecture, and the multi-level distillation strategy. Section 4 presents the experimental setup, results, and ablation studies. Finally, Section 5 concludes the paper and discusses future work.
2. Related Work
2.1. Automatic Modulation Recognition
Traditional AMR methods can be roughly categorized into two classes: likelihood-based (LB) and feature-based (FB) approaches [,]. LB methods formulate AMR as a hypothesis testing problem, requiring prior knowledge of channel parameters such as signal-to-noise ratio (SNR) and frequency offset [,]. Typical LB techniques include average likelihood ratio test, generalized likelihood ratio test, and hybrid likelihood ratio test, which achieve optimal classification in the Bayesian sense [,]. However, they are computationally intensive and depend heavily on accurate prior knowledge, making them impractical in dynamic real-world environments [].
In contrast, FB methods extract domain-specific features from signals, which are then fed into machine learning classifiers [,]. Classical examples include utilizing statistical features like high-order cumulants or cyclic spectral features, often classified by support vector machines [] or random forests []. In recent years, more advanced FB approaches have shown promising results. For instance, methods based on phase diagrams and their entropy have been used for robust recognition [,], while compressive sensing techniques have been applied to achieve classification from sub-Nyquist samples [,]. However, the performance of these FB methods, both classical and modern, still relies heavily on the quality of handcrafted features and expert knowledge, which may struggle in complex and dynamic channel environments [].
Recently, deep learning (DL) has shown strong feature learning capability in fields such as computer vision [] and wireless communications []. DL-based AMR frameworks can learn discriminative features directly from raw signals without handcrafted feature engineering []. For example, initial works by O’Shea et al. [] applied deep neural networks to raw IQ samples, while Peng et al. [] used AlexNet and GoogLeNet on constellation diagrams. Deeper architectures, such as residual networks (ResNet), were also designed to extract more intricate features [].
To better capture temporal and spatial relationships, subsequent research explored hybrid architectures. Prominent examples that combine CNNs for feature extraction and LSTMs for temporal modeling include the widely used CNN+LSTM [] and the deeper ResNet+LSTM []. Other powerful models include CNNIQ, a network designed for robustness under fading channels [], and CLDNN, which integrates CNN, LSTM, and fully connected layers []. An extension, MCLDNN, further enhances performance through a spatiotemporal multi-channel learning framework []. More recently, Transformer-based architectures have been introduced to model long-range dependencies in signals effectively [,,], setting a new benchmark for performance.
2.2. Model Pruning and Lightweight
With the growing adoption of deep learning in communication and other domains, the computational and memory overhead of large models has become a major bottleneck for real-time inference and deployment on edge devices. This is particularly critical in AMR tasks, which require fast and efficient models.
To address this, various lightweight techniques have been developed. For instance, quantization [] reduces model size by lowering the numerical precision of weights and activations, with quantization-aware training (QAT) often mitigating the performance degradation associated with post-training quantization (PTQ). Another common method is pruning [], which is based on the “lottery ticket hypothesis” and removes non-essential parameters. Pruning can be unstructured, by sparsifying weights, or structured, by removing entire components like channels or attention heads to achieve acceleration on general hardware.
Beyond adjusting parameters, architectural modifications also play a key role. Knowledge distillation transfers knowledge from a large teacher model to a compact student, enabling the student to learn rich representations, as demonstrated by TinyBERT [,]. Parameter sharing, as implemented in ALBERT, reuses weights across layers to achieve significant model compression [].
Furthermore, to address the quadratic complexity of self-attention on long sequences, efficient attention mechanisms have been proposed. Reformer [] leverages locality-sensitive hashing (LSH) to reduce complexity to and uses reversible residual layers to save memory. Similarly, Linformer [] approximates the attention matrix via low-rank projection, reducing complexity to . Overall, these techniques can be combined to compress model size, accelerate inference, and reduce energy consumption, providing practical solutions for deploying deep models in resource-constrained AMR scenarios.
2.3. Knowledge Distillation
Knowledge distillation (KD) has emerged as an effective technique for compressing and accelerating deep models by transferring knowledge from a large teacher model to a lightweight student model. In AMR tasks, KD enables student models to retain high recognition accuracy while meeting the computational and memory constraints of edge devices.
The concept of KD was first introduced by Hinton et al. [], who proposed that students should learn from the soft probability distribution output by the teacher, which encodes inter-class similarity and enhances generalization. Later, FitNets [] extended KD by guiding the student to also learn intermediate feature representations from the teacher, improving performance further. Zagoruyko and Komodakis [] proposed attention transfer, encouraging the student to focus on the same salient regions as the teacher.
To narrow the gap between teacher and student, more advanced strategies have been developed. Furlanello et al. [] explored multi-generation distillation, where students iteratively teach subsequent students. Kimura et al. [] introduced pseudo-samples to strengthen student training in few-shot scenarios. Park et al. [] proposed a relational knowledge distillation approach, constructing distance-wise and angle-wise distillation losses to transfer the interrelationships of instances from the teacher to the student. Liu et al. [] designed a method to preserve the inter-channel correlation of features during distillation.
In AMR, the modulation patterns are often buried in complex temporal, spectral, and amplitude variations, and subject to noise and interference. KD allows the student model to benefit from the teacher’s ability to extract robust and discriminative signal features. Combining KD with feature selection, multi-scale modeling, and attention mechanisms further enhances student performance under challenging conditions, making KD an indispensable approach for efficient AMR model design.
3. Methodology
In this section, we present our proposed lightweight automatic modulation recognition (AMR) framework based on multi-level knowledge distillation. We detail the signal model, the proposed teacher-student architecture, and the multi-level distillation strategy used for training.
3.1. Signal Model
In a typical wireless communication system, the transmitted signal is subjected to various channel impairments. To accurately model this process, we consider a complex baseband representation of the received signal. The channel model incorporates key distortions simulated in platforms like GNU Radio, such as multipath fading, carrier frequency offset (CFO), phase offset (PO), and additive white Gaussian noise (AWGN).
The received signal at the input of the receiver can be expressed as:
where is the complex baseband transmitted signal, the operator ∗ denotes convolution, and is the channel impulse response modeling the multipath effects. The term represents the impact of oscillator inaccuracies, with being the carrier frequency offset and the phase offset. Finally, is the complex additive white Gaussian noise. This signal is then sampled to obtain a sequence of in-phase (I) and quadrature (Q) components, which is formatted as a matrix for model input, where the sequence length .
3.2. Proposed Framework Architecture
Our proposed framework is built upon a teacher-student paradigm, as illustrated in Figure 2. The core idea is to transfer knowledge from a large, high-performance teacher model to a compact and efficient student model, which is based on the Reformer architecture. The teacher model is a standard Transformer encoder designed for maximum accuracy, while the student model is an efficient Reformer designed for lightweight deployment.
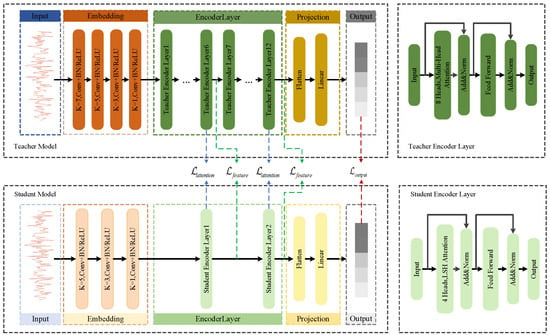
Figure 2.
The proposed multi-level knowledge distillation framework. It illustrates the teacher-student architecture with highlighted knowledge distillation paths (1) , (2) , and (3) . Detailed structures of the Teacher (Transformer) and Student (Reformer) Encoder Layers are provided on the right.
A key differentiator between the teacher and student models lies in their attention mechanisms. The teacher model employs standard Full Multi-Head Self-Attention, which computes attention scores between every pair of tokens in the input sequence. While powerful, this approach has a computational and memory complexity of with respect to the sequence length L, making it demanding for long sequences.
In contrast, the student model utilizes LSH (Locality-Sensitive Hashing) Attention, a core innovation of the Reformer architecture. Instead of performing a full comparison, LSH Attention uses hashing to group similar tokens together and computes attention only within these smaller, localized groups. This strategy significantly reduces the complexity to a much more manageable , enabling efficient processing of longer sequences with a smaller memory footprint.
To be specific, the student model is a 2-layer Reformer encoder, as detailed in Table 1 and visually depicted in Figure 2. It utilizes LSH Attention with 4 attention heads, 4 hashes, and a bucket size of 32 to approximate the full attention mechanism. The model dimension () is reduced to 128, and it does not use reversible residual layers to optimize for inference speed. This lightweight design is the key to its efficiency.

Table 1.
Architectural comparison of the Teacher and Student models.
The detailed architectural comparison, including layer counts, model dimensions, and attention types, is presented in Table 1. As shown, the student model achieves an approximately 131.9-fold reduction in parameters (from 38.27 M to 0.29 M), highlighting its suitability for resource-constrained environments. The intricate connections and distillation points are further illustrated in Figure 2.
3.3. Multi-Level Knowledge Distillation
To endow the compact Reformer student with the capabilities of the powerful teacher model, we employ a multi-level knowledge distillation strategy. This strategy transfers knowledge at three distinct granularities, compelling the student to mimic the teacher’s behavior from low-level feature extraction to high-level decision-making. The student model is subsequently trained by minimizing a composite loss function that synergizes a standard supervised loss with these multi-level distillation losses.
The first level is output-level distillation, which transfers the teacher’s class probability distribution to the student. This is achieved by minimizing the Kullback-Leibler (KL) divergence between the softened logits of the two models. Let and be the temperature-scaled probability distributions from the teacher and student, respectively, where is the softmax function. The loss is defined as:
where and are the logit vectors, C is the number of modulation classes, and T is a temperature hyperparameter. Following the original knowledge distillation framework [], we multiply the KL divergence loss by a factor of . This scaling is crucial because the gradients produced by the soft targets scale as . Including the term ensures that the relative contribution of the distillation loss and the standard cross-entropy loss remains roughly constant when the temperature is changed.
The second level, feature-level distillation, transfers the rich intermediate representations learned within the teacher’s hidden layers. To align these representations, we define a formal mapping between specific layers of the student and teacher models. Let be the set of index pairs , where the i-th layer of the student model corresponds to the j-th layer of the teacher model. In our framework, which maps a 12-layer teacher to a 2-layer student, this set is defined as . This specific mapping was chosen to align the student’s layers with proportionally deep layers in the teacher. The student’s first layer (layer 1 of 2) is mapped to the teacher’s middle layer (layer 6 of 12) to learn robust, mid-level representations. The student’s final layer (layer 2 of 2) is mapped to the teacher’s final layer (layer 12 of 12) to capture the most abstract, high-level features and attention patterns just before the final projection. The feature distillation loss is then defined as the mean squared error between the corresponding feature maps, averaged over all mapped pairs and all samples in a batch:
where is the feature representation for the n-th sample from the i-th layer of the student, and is from the j-th layer of the teacher. N is the number of samples in the batch, and is the number of mapped layer pairs. As the feature dimensionalities may differ, a trainable linear projection layer, , is employed to match the student’s feature space to the teacher’s.
The third level is attention-level distillation, which transfers the relational knowledge encoded in the self-attention mechanisms. This relational knowledge is distinct from and complementary to the feature-level distillation. The feature-level loss, , is designed to align the student’s intermediate representations with the teacher’s. These representations typically provide a holistic summary of the signal’s learned characteristics, often pooled or summarized, teaching the student what high-level features to extract, regardless of their specific temporal positions. In contrast, the attention loss operates directly on the full self-attention matrices. These matrices explicitly model the temporal dependencies and token-to-token relationships within the sequence. This forces the student to mimic how the teacher model weighs the relative importance of different time steps in the I/Q sequence. For AMR, this distinction is crucial: ensures the student learns a robust set of features, while transfers the teacher’s complex temporal reasoning about which parts of the signal are most salient for classification. This is achieved by minimizing the KL divergence between the student’s and teacher’s attention distributions. The loss is calculated as the average over all samples in a batch and all mapped layer pairs. The loss function is defined as:
where and are the attention distributions for the n-th sample in the corresponding mapped layers. denotes the KL divergence, and is the Shannon entropy. The term is a hyperparameter that weights the entropy regularization on the teacher’s attention distribution, which encourages a smoother learning signal.
The training objective is also guided by the standard supervised learning loss, which is the cross-entropy loss () between the student model’s predictions and the ground-truth labels. This loss is defined as:
where is the one-hot encoded ground-truth label for the n-th sample and c-th class, and is the student’s predicted probability.
The final composite loss function is a weighted sum of the standard cross-entropy loss and the three aforementioned distillation losses:
where are scalar hyperparameters that balance the contribution of each loss component. In our experiments, these were empirically set to , , , and . This comprehensive loss function guides the student model to not only learn the correct classifications but also to internalize the intricate knowledge and reasoning process of the larger teacher model.
4. Experiments
4.1. Dataset and Experimental Setup
This study employs two publicly available datasets, RML2016.10A and RML2016.10B, as standard benchmarks for AMR research. Both datasets contain signals synthetically generated using the GNU Radio platform to emulate a real-world wireless communication environment, incorporating various channel impairments such as AWGN, multipath fading, clock synchronization errors, and carrier frequency offsets. All samples comprise 128 I/Q data points, generated at a nominal 8 samples-per-symbol, and span SNRs from −20 dB to +18 dB. The RML2016.10A dataset contains 220,000 samples across 11 modulation types, while RML2016.10B provides 1.2 million samples across 10 modulation types (excluding AM-SSB). For our experiments, each dataset was partitioned into training, validation, and testing sets using a 6:2:2 ratio.
All models were implemented using PyTorch (version 1.13.1) and trained on a single NVIDIA GeForce RTX 3060 GPU. The training process for MLD-Net was two-staged. First, the teacher model was trained from scratch until convergence using the Adam optimizer with a learning rate of and a weight decay of . Second, the student model was trained using the multi-level distillation framework with the pre-trained teacher model’s parameters frozen. All baseline models and the student model were trained using a learning rate of and a weight decay of .
For all training, a batch size of 128 was used. In the distillation stage, the temperature T was set to 3.0, and the loss weights were set to , , , and . The primary evaluation metric is the overall classification accuracy across all SNRs.
4.2. Results
In this section, we evaluate the performance of our proposed method, which we name MLD-Net. We first compare MLD-Net with several state-of-the-art AMR models in terms of both model efficiency and classification accuracy. Then, we conduct an ablation study to analyze the contribution of each component in our multi-level distillation framework.
4.2.1. Comparison with State-of-the-Art Methods
We compare our proposed MLD-Net against its un-distilled version (Student w/o KD), the large teacher model, and seven baseline models: CLDNN [], CNN+LSTM [], CNNIQ [], MCLDNN [], ResNet+LSTM [], MobileNet [], and ShuffleNet [].
To provide a comprehensive evaluation, Table 2 summarizes the model complexity, including the number of parameters, FLOPs, and inference time, alongside the overall classification accuracy on both RML2016.10A and RML2016.10B datasets.
Table 2.
Comparison of model performance on two datasets (A: RML2016.10A, B: RML2016.10B).
The results clearly demonstrate the effectiveness of our knowledge distillation framework. The large teacher model, while achieving the highest accuracy, is computationally prohibitive in terms of both parameters (38.27 M) and computational cost (3.263 G FLOPs). Through our MLD-Net framework, the student model significantly improves its performance over the baseline: on RML2016.10A, accuracy increases from 59.06% to 61.14%, and on RML2016.10B, it increases from 61.80% to 64.62%.
This performance is achieved while maintaining an approximately 131.9-fold reduction in parameters compared to the teacher.
Furthermore, MLD-Net establishes a new state-of-the-art trade-off between efficiency and performance. A detailed analysis of Table 2 reveals the critical relationship between computational cost and model accuracy. In terms of FLOPs, our MLD-Net requires 35.899 M, which is a moderate cost. While ultra-lightweight models like ShuffleNet and MobileNet offer significantly lower FLOPs at 0.873 M and 2.812 M respectively, this extreme compression results in a clear performance deficit, as evidenced by their lower overall accuracy. This trade-off is also evident in the Inference Time. Models such as CNNIQ and CNN+LSTM achieve the fastest speeds, clocking in as low as 0.4754 ms. However, this speed comes at the cost of accuracy, with their performance lagging behind our model. Our MLD-Net, with inference times of 1.5674 ms on RML2016.10A and 1.1495 ms on RML2016.10B, makes a deliberate trade-off. It leverages a moderate computational and inference budget to achieve the highest accuracy among all non-teacher models on both datasets. Specifically, MLD-Net achieves 61.14% on dataset 10A and 64.62% on dataset 10B, nearly matching the performance of the full-sized teacher model. This highlights our model’s ability to establish a superior balance between a practical, real-time inference speed and state-of-the-art accuracy, making it highly suitable for deployment on edge devices.
The superior classification performance of MLD-Net is further detailed in Figure 3, which illustrates the accuracy of all models across the full range of SNRs from −20 dB to +18 dB on both the RML2016.10A and RML2016.10B datasets. It is evident that MLD-Net consistently outperforms all baseline models, particularly in the mid-to-high SNR region (0 dB to 18 dB) on both datasets. While all models exhibit similar performance at very low SNRs where noise dominates, our model’s accuracy curve rises more steeply and achieves a higher plateau, demonstrating its superior robustness and feature extraction capabilities inherited from the teacher model.
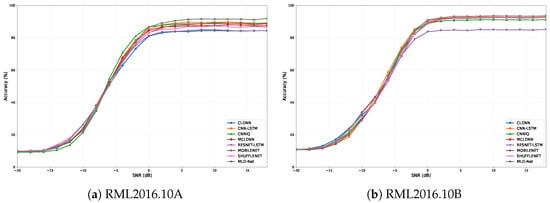
Figure 3.
Classification accuracy versus SNR for the proposed MLD-Net and baseline models on (a) RML2016.10A and (b) RML2016.10B.
To further analyze the classification performance, we present the confusion matrices for all models at an SNR of 10 dB on the RML2016.10A dataset in Figure 4. We selected 10 dB as it is a representative mid-to-high SNR where model differences are clearly visible. This point offers the most informative comparison of how each model handles challenging, spectrally similar classes, such as QAM16 and QAM64, once performance has stabilized from the low-SNR regime. A darker diagonal indicates higher accuracy for individual modulation types. The confusion matrix for our MLD-Net (h) shows a significantly more pronounced diagonal compared to the baselines. Notably, baseline models like CLDNN (a) and CNN+LSTM (b) exhibit considerable confusion between spectrally similar modulations, such as QAM16 and QAM64, or AM-SSB and WBFM. In contrast, our model demonstrates a marked improvement in discriminating these challenging classes, which validates the effectiveness of the transferred knowledge.
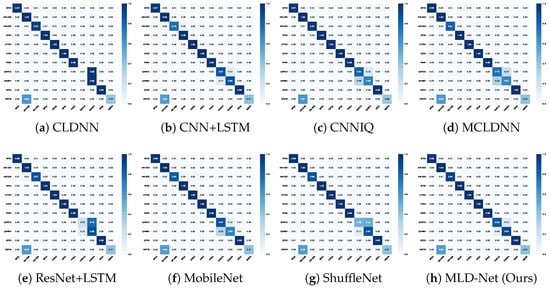
Figure 4.
Confusion matrices of different models at SNR = 10 dB on the RML2016.10A dataset.
Finally, to visualize the learned feature representations, we use the t-SNE technique to project the high-dimensional features from the models’ final hidden layer into a 2D space. As shown in Figure 5 (for the RML2016.10A dataset), the feature clusters produced by MLD-Net (h) are significantly more compact and well-separated compared to the baseline models. This visual evidence confirms that our multi-level distillation approach enables the lightweight student model to learn highly discriminative features, leading to improved classification performance.
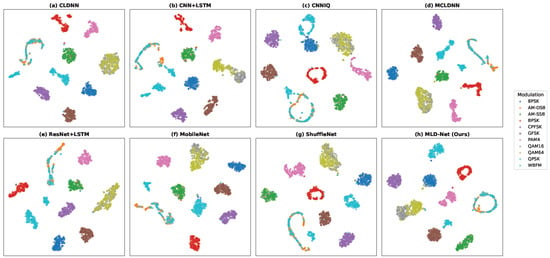
Figure 5.
t-SNE visualization of feature distributions from different models at SNR = 10 dB on the RML2016.10A dataset.
4.2.2. Ablation Study
To validate the effectiveness and complementarity of each component within our proposed MLD-Net, we conduct a comprehensive ablation study, as requested by Reviewer 1. We compare the performance of our full model with several variants on both the RML2016.10A (A) and RML2016.10B (B) datasets. The experimental configurations are as follows:
- Student w/o KD: The baseline Reformer student model trained from scratch using only the cross-entropy loss ().
- +Output KD: Student trained with .
- +Feature KD: Student trained with .
- +Attention KD: Student trained with .
- +Output + Feature: Student trained with the two corresponding distillation losses.
- +Output + Attention: Student trained with the two corresponding distillation losses.
- +Feature + Attention: Student trained with the two corresponding distillation losses.
- MLD-Net (Ours): The full proposed model trained with all four loss components.
The results of the ablation study are summarized in Table 3. The baseline student model (Student w/o KD) achieves a modest accuracy on both datasets. The addition of any single distillation component (Output, Feature, or Attention KD) brings a noticeable performance improvement, confirming their individual effectiveness.
Table 3.
Ablation study on RML2016.10A (A) and RML2016.10B (B) datasets.
More importantly, the results demonstrate a clear synergistic effect. Combining pairs of distillation methods (e.g., +Output + Feature) yields superior results compared to any single method alone. Our full MLD-Net, which leverages all three distillation losses simultaneously, achieves the highest accuracy on both datasets (61.14% on 10A and 64.62% on 10B). This validates our core hypothesis: the different knowledge types are complementary, and a multi-level approach that transfers output distributions, feature representations, and relational attention patterns is essential for maximizing the performance of the lightweight student model.
5. Conclusions
In this paper, we proposed MLD-Net, a novel multi-level knowledge distillation framework designed to produce a lightweight yet high-performance model for Automatic Modulation Recognition. By leveraging a large Transformer-based teacher model, we successfully transferred comprehensive knowledge to a compact Reformer-based student model. Our approach goes beyond traditional output-level distillation by incorporating feature-level and attention-level distillation, which compels the student to mimic the teacher’s internal feature representations and relational reasoning patterns. This multi-faceted knowledge transfer enables the student model to achieve significant performance gains that would be unattainable through standard training alone. Experimental results on the public RML2016.10A and RML2016.10b datasets demonstrate the superiority of our MLD-Net. It achieves state-of-the-art accuracy (61.14% on 10a and 64.62% on 10b) among lightweight models. With an approximately 131.9-fold parameter reduction, our model consistently outperforms several state-of-the-art AMR baselines across a wide range of SNRs. Our work provides a robust and effective solution for deploying advanced AMR capabilities on resource-constrained edge devices.
We acknowledge, however, some limitations. Our positive results are demonstrated on the widely used RML synthetic datasets. While these datasets include channel impairments, real-world deployment on edge devices will present further challenges, such as hardware-specific nonlinearities and unseen co-channel interference. Nonetheless, the MLD-Net’s drastically reduced parameter count (0.29 M) and fast inference time (approx. 1.1–1.6 ms/sample) make it a strong and viable candidate for implementation in real-time systems, where these additional challenges can be addressed.
Future work could explore the application of MLD-Net to more complex and diverse signal datasets, as well as investigate the integration of other model compression techniques, such as quantization and pruning, to further optimize the model for real-world deployment.
Author Contributions
Conceptualization, X.Z. and M.Z.; methodology, L.Z. and Z.Z.; software, L.Z., Z.Z. and X.S.; validation, L.Z., Z.Z. and F.Z.; investigation, X.Z. and M.Z.; data curation, X.Z. and Z.Z.; writing—original draft preparation, X.Z., L.Z., M.Z., Z.Z., X.S. and F.Z.; funding acquisition, Z.Z. Writing—review & editing, P.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Natural Science Foundation of China under grant numbers 62401429, 62401445, 62501437, 62531020, U2541202, and 62425113, in part by the Postdoctoral Fellowship Program of CPSF under grant numbers GZC20241332, GZC20232048, and GZC20251207, in part by the China Postdoctoral Science Foundation under grant numbers 2024M761178 and 2025M771739, in part by the Fundamental Research Funds for the Central Universities under grant number ZYTS25144, and in part by the Seed Funding Project of Sichuan Aerospace Electronics Research Institute under grant number of ZZJJ202402-01.
Data Availability Statement
The RML2016.10A and RML2016.10B datasets presented in this study are publicly available from DeepSig Inc. at https://www.deepsig.ai/datasets (accessed on 19 November 2025).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Nahum, C.V.; Lopes, V.H.L.; Dreifuerst, R.M.; Batista, P.; Correa, I.; Cardoso, K.V.; Klautau, A.; Heath, R.W. Intent-aware radio resource scheduling in a ran slicing scenario using reinforcement learning. IEEE Trans. Wirel. Commun. 2023, 23, 2253–2267. [Google Scholar] [CrossRef]
- Lin, Y.; Tu, Y.; Dou, Z. An improved neural network pruning technology for automatic modulation classification in edge devices. IEEE Trans. Veh. Technol. 2020, 69, 5703–5706. [Google Scholar] [CrossRef]
- Hazza, A.; Shoaib, M.; Alshebeili, S.A.; Fahad, A. An overview of feature-based methods for digital modulation classification. In Proceedings of the 2013 1st International Conference on Communications, Signal Processing, and Their Applications (ICCSPA), Sharjah, United Arab Emirates, 12–14 February 2013; pp. 1–6. [Google Scholar]
- O’shea, T.; Hoydis, J. An introduction to deep learning for the physical layer. IEEE Trans. Cogn. Commun. Netw. 2017, 3, 563–575. [Google Scholar] [CrossRef]
- Zhang, H.; Yuan, L.; Wu, G.; Zhou, F.; Wu, Q. Automatic modulation classification using involution enabled residual networks. IEEE Wirel. Commun. Lett. 2021, 10, 2417–2420. [Google Scholar] [CrossRef]
- Sills, J.A. Maximum-likelihood modulation classification for PSK/QAM. In Proceedings of the MILCOM 1999, IEEE Military Communications. Conference Proceedings (Cat. No. 99CH36341), Atlantic City, NJ, USA, 31 October–3 November 1999; Volume 1, pp. 217–220. [Google Scholar]
- Wei, W.; Mendel, J.M. Maximum-likelihood classification for digital amplitude-phase modulations. IEEE Trans. Commun. 2000, 48, 189–193. [Google Scholar] [CrossRef]
- Hameed, F.; Dobre, O.A.; Popescu, D.C. On the likelihood-based approach to modulation classification. IEEE Trans. Wirel. Commun. 2009, 8, 5884–5892. [Google Scholar] [CrossRef]
- Xu, J.L.; Su, W.; Zhou, M. Likelihood-ratio approaches to automatic modulation classification. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2010, 41, 455–469. [Google Scholar] [CrossRef]
- Hong, L.; Ho, K. Identification of digital modulation types using the wavelet transform. In Proceedings of the MILCOM 1999, IEEE Military Communications. Conference Proceedings (Cat. No. 99CH36341), Atlantic City, NJ, USA, 31 October–3 November 1999; Volume 1, pp. 427–431. [Google Scholar]
- Liu, L.; Xu, J. A novel modulation classification method based on high order cumulants. In Proceedings of the 2006 International Conference on Wireless Communications, Networking and Mobile Computing, Wuhan, China, 22–24 September 2006; pp. 1–5. [Google Scholar]
- Park, C.S.; Choi, J.H.; Nah, S.P.; Jang, W.; Kim, D.Y. Automatic modulation recognition of digital signals using wavelet features and SVM. In Proceedings of the 2008 10th International Conference on Advanced Communication Technology, Gangwon, Republic of Korea, 17–20 February 2008; Volume 1, pp. 387–390. [Google Scholar]
- Zhang, Z.; Li, Y.; Zhu, X.; Lin, Y. A method for modulation recognition based on entropy features and random forest. In Proceedings of the 2017 IEEE International Conference on Software Quality, Reliability and Security Companion (QRS-C), Prague, Czech Republic, 25–29 July 2017; pp. 243–246. [Google Scholar]
- Stanescu, D.; Digulescu, A.; Ioana, C.; Serbanescu, A. Modulation recognition of underwater acoustic communication signals based on phase diagram entropy. In Proceedings of the OCEANS 2022, Hampton Roads, VA, USA, 17–20 October 2022; pp. 1–7. [Google Scholar]
- Stanescu, D.; Digulescu, A.; Ioana, C.; Serbanescu, A. Spread spectrum modulation recognition based on phase diagram entropy. Front. Signal Process. 2023, 3, 1197619. [Google Scholar]
- Sun, Z.; Wang, S.; Chen, X. Feature-Based Digital Modulation Recognition Using Compressive Sampling. Mob. Inf. Syst. 2016, 2016, 9754162. [Google Scholar] [CrossRef]
- Sun, X.; Su, S.; Zuo, Z.; Guo, X.; Tan, X. Modulation classification using compressed sensing and decision tree–support vector machine in cognitive radio system. Sensors 2020, 20, 1438. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Hong, X. Recent progresses on object detection: A brief review. Multimed. Tools Appl. 2019, 78, 27809–27847. [Google Scholar] [CrossRef]
- Peng, S.; Jiang, H.; Wang, H.; Alwageed, H.; Zhou, Y.; Sebdani, M.M.; Yao, Y.D. Modulation classification based on signal constellation diagrams and deep learning. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 718–727. [Google Scholar] [CrossRef]
- O’Shea, T.J.; Roy, T.; Clancy, T.C. Over-the-air deep learning based radio signal classification. IEEE J. Sel. Top. Signal Process. 2018, 12, 168–179. [Google Scholar] [CrossRef]
- Zhao, J.; Mao, X.; Chen, L. Speech emotion recognition using deep 1D & 2D CNN LSTM networks. Biomed. Signal Process. Control 2019, 47, 312–323. [Google Scholar]
- Elsagheer, M.M.; Ramzy, S.M. A hybrid model for automatic modulation classification based on residual neural networks and long short term memory. Alex. Eng. J. 2023, 67, 117–128. [Google Scholar] [CrossRef]
- Tekbıyık, K.; Ekti, A.R.; Görçin, A.; Kurt, G.K.; Keçeci, C. Robust and fast automatic modulation classification with CNN under multipath fading channels. In Proceedings of the 2020 IEEE 91st Vehicular Technology Conference (VTC2020-Spring), Antwerp, Belgium, 25–28 May 2020; pp. 1–6. [Google Scholar]
- Sainath, T.N.; Vinyals, O.; Senior, A.; Sak, H. Convolutional, long short-term memory, fully connected deep neural networks. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; pp. 4580–4584. [Google Scholar]
- Xu, J.; Luo, C.; Parr, G.; Luo, Y. A spatiotemporal multi-channel learning framework for automatic modulation recognition. IEEE Wirel. Commun. Lett. 2020, 9, 1629–1632. [Google Scholar] [CrossRef]
- Kong, W.; Jiao, X.; Xu, Y.; Zhang, B.; Yang, Q. A transformer-based contrastive semi-supervised learning framework for automatic modulation recognition. IEEE Trans. Cogn. Commun. Netw. 2023, 9, 950–962. [Google Scholar] [CrossRef]
- Cai, J.; Gan, F.; Cao, X.; Liu, W. Signal modulation classification based on the transformer network. IEEE Trans. Cogn. Commun. Netw. 2022, 8, 1348–1357. [Google Scholar] [CrossRef]
- Zhai, L.; Li, Y.; Feng, Z.; Yang, S.; Tan, H. Learning Cross-Domain Features with Dual-Path Signal Transformer. IEEE Trans. Neural Netw. Learn. Syst. 2025, 36, 3863–3869. [Google Scholar] [CrossRef]
- Zafrir, O.; Boudoukh, G.; Izsak, P.; Wasserblat, M. Q8bert: Quantized 8bit bert. In Proceedings of the 2019 Fifth Workshop on Energy Efficient Machine Learning and Cognitive Computing-NeurIPS Edition (EMC2-NIPS), Vancouver, BC, Canada, 13 December 2019; pp. 36–39. [Google Scholar]
- Liu, Z.; Sun, M.; Zhou, T.; Huang, G.; Darrell, T. Rethinking the value of network pruning. arXiv 2018, arXiv:1810.05270. [Google Scholar]
- Jiao, X.; Yin, Y.; Shang, L.; Jiang, X.; Chen, X.; Li, L.; Wang, F.; Liu, Q. Tinybert: Distilling bert for natural language understanding. arXiv 2019, arXiv:1909.10351. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar] [CrossRef]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Kitaev, N.; Kaiser, Ł.; Levskaya, A. Reformer: The efficient transformer. arXiv 2020, arXiv:2001.04451. [Google Scholar] [CrossRef]
- Wang, S.; Li, B.Z.; Khabsa, M.; Fang, H.; Ma, H. Linformer: Self-attention with linear complexity. arXiv 2020, arXiv:2006.04768. [Google Scholar] [CrossRef]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. Fitnets: Hints for thin deep nets. arXiv 2014, arXiv:1412.6550. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. arXiv 2016, arXiv:1612.03928. [Google Scholar]
- Furlanello, T.; Lipton, Z.; Tschannen, M.; Itti, L.; Anandkumar, A. Born again neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 1607–1616. [Google Scholar]
- Kimura, A.; Ghahramani, Z.; Takeuchi, K.; Iwata, T.; Ueda, N. Few-shot learning of neural networks from scratch by pseudo example optimization. arXiv 2018, arXiv:1802.03039. [Google Scholar] [CrossRef]
- Park, W.; Kim, D.; Lu, Y.; Cho, M. Relational knowledge distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3967–3976. [Google Scholar]
- Liu, L.; Huang, Q.; Lin, S.; Xie, H.; Wang, B.; Chang, X.; Liang, X. Exploring inter-channel correlation for diversity-preserved knowledge distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 8271–8280. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).