Abstract
This paper proposes a novel Denoiser and Low-Frequency Enhancer Network (DLFE-Net) for Low-Light Image Enhancement (LLIE). The DLFE-Net addresses two key challenges: (1) overexposure and detail loss in local areas during enhancement, and (2) the effective removal of inherent noise in low-light images. Specifically, the input RGB image is first converted to the HVI color space. The intensity (I) and color (H, V) maps are then enhanced and denoised separately, i.e., preserving details and removing noise. For preserving details, the Low-Frequency Illumination Enhancer (LFIE) module isolates and processes the image’s low-frequency information. This targeted approach effectively mitigates local overexposure and preserves fine details during enhancement. For removing noise, the Multi-Scale Gated Denoiser (MSGD) module performs denoising through strong preservation after predicting image noise. Comprehensive experiments were conducted on three benchmark datasets (LOL, SICE, Sony-Total-Dark) and five unpaired datasets. Both qualitative and quantitative analyses demonstrated the superiority of DLFE-Net over state-of-the-art methods. Moreover, ablation studies demonstrated the effectiveness of each module in DLFE-Net.
1. Introduction
In low-light conditions, image sensors are susceptible to noise and have a limited dynamic range, which degrades image quality. Low-light Image Enhancement (LLIE) techniques address this by improving signal-to-noise ratio and dynamic range distribution, restoring lost details for clearer images and better performance in downstream tasks like object detection [,] and re-identification [,]. While traditional methods like adaptive histogram equalization [] and Retinex [] are widely used, they often introduce noise and overexposure, limiting their effectiveness. These issues not only compromise enhancement quality but also negatively impact downstream task performance.
In recent years, researchers have proposed different solutions to the above problems. Some methods [,] combine Retinex and deep learning to improve the problem of image detail loss, but there is a drawback of noise amplification when dealing with extremely low-light scenes. Some methods [,] integrate degraded representations from low-light images into diffusion models, using the diffusion process to gradually remove noise from the image while gradually restoring details. However, existing diffusion model-based methods for modeling noise are still limited to the assumption of additive Gaussian noise, making it difficult to handle complex noise mixture distributions in real scenes. There are also some methods [,,,] that use attention mechanisms to focus the model on low-light parts and areas with high noise distribution in the image. Although progress has been made in noise suppression, the global attention map constructed by them makes it difficult to accurately capture local degradation features under non-uniform lighting conditions.
Recently, the HSV color space has shown significant advantages in the LLIE field due to its ability to effectively separate color and brightness information from images [,]. By targeting the chromaticity and brightness channels separately, the HSV space can not only achieve more accurate denoising and enhancement operations but also effectively solve the common color distortion and detail loss problems of traditional methods in low-light environments. However, in HSV space, there are issues with red discontinuous noise and black plane noise. Yan et al. [] proposed polarizing HS into orthogonal HV (Horizontal/Vertical) components and introducing an adaptive intensity compression function , which effectively eliminates red discontinuous noise and black plane noise, laying an important theoretical foundation for our research.
We propose a Denoiser and Low-Frequency Enhancer Network (DLFE-Net) to address the difficulty in effectively removing noise in low-light images and the loss of image detail information and local exposure during the enhancement process. DLFE consists of Multi-Scale Gated Denoiser (MSGD) and Low-Frequency Illumination Enhancer (LFIE). As shown in Figure 1, in the HV color map, we can observe the high-frequency noise contained in low-light images. The intensity map mainly contains information on light distribution, which is usually manifested as low-frequency features that depend on long distances. Therefore, we use MSGD to denoise the HV color map while employing LFIE to enhance the illumination intensity map. On the one hand, the MSGD module first extracts noise features through multi-scale dilated convolution, then it fuses multi-scale features through channel attention, and it finally performs gate modulation denoising based on predicted noise maps. On the other hand, the LFIE module separates high-frequency and low-frequency information in the image, performs deep processing on low-frequency information, and weakens high-frequency information. This separation processing method can effectively improve the overall lighting distribution while preserving key texture features. The main contributions of this work are summarized as follows:
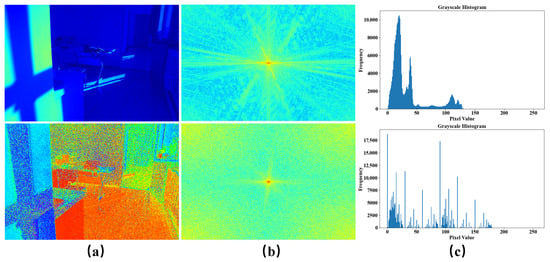
Figure 1.
Comparison of pixel frequency distribution histograms and spectrograms between intensity and HV color maps. Among them, (a) represents the intensity map (above) and the HV color map (below), (b) represents the spectrogram and corresponds one-to-one with (a), and (c) represents the histogram of pixel value frequency distribution and corresponds one-to-one with (a).
- We introduce the MSGD module in the HV branch, which first uses multi-scale dilated convolution to extract noise features and then achieves adaptive denoising through gate modulation, effectively eliminating the influence of noise in low-light images.
- We introduce the LFIE module in branch I, which first separates image information into low-frequency and high-frequency information, and then performs deep enhancement processing on the low-frequency information. This processing method effectively solves the problem of local overexposure in LLIE, while avoiding the possible loss of details during the enhancement process.
- A large number of experimental results on nine datasets demonstrate that our proposed DLFE method achieves state-of-the-art performance in LLIE tasks.
2. Related Work
2.1. Low-Light Image Enhancement
Traditional methods. Traditional LLIE methods, including histogram equalization [], gamma correction [], and Retinex methods [], can improve image contrast but often produce unnatural results. Histogram equalization may cause some regions to be overenhanced while leaving others underenhanced. Gamma correction leads to uneven brightness distribution and loss of image details. Retinex-based approaches suffer from halo artifacts and noise amplification because their Gaussian filtering cannot accurately separate illumination variations from object edges. These conventional methods struggle with complex illumination and often amplify noise during enhancement.
Deep learning methods. In recent years, many deep learning-based LLIE methods have been proposed. Some methods [,,,,,] focus on improving image brightness. For example, Brateanu et al. [] adopted a YUV channel separation strategy, using a CWD module for noise suppression and MHSA for illumination adjustment. Cai et al. [] proposed a single-stage Retinex framework and an illumination-guided Transformer architecture to simultaneously handle illumination adjustment and noise suppression. However, these methods often struggle to balance denoising and enhancement tasks in complex lighting environments. Other methods [,,,,] employ diffusion models to jointly accomplish denoising and enhancement, but their progressive recovery process leads to a significant increase in computational complexity, severely impacting the model’s inference efficiency. We decouple images into HV color maps and intensity maps based on the HVI space, enhancing the intensity map while denoising the HV color map. This enhancement strategy not only achieves specialized processing of denoising and enhancement tasks through a dual-branch network but also employs a single-iteration denoising module, significantly improving computational efficiency while ensuring performance.
2.2. Frequency Domain in Low-Light Image Enhancement
Recent research has found that by converting images from the spatial domain to the frequency domain and processing them in the frequency domain, this method exhibits significant performance improvements in LLIE. Liang et al. [] performed adaptive processing on high-frequency and low-frequency information in images, improving overall brightness while enhancing texture details and edge information. Huang et al. [] set up a dual-stream encoder to process information in both the spatial and frequency domains, thereby improving the brightness and contrast of the image. He et al. [] used a wavelet transform to separate the high and low-frequency information of images, and performed a Fourier transform in the low-frequency domain to obtain amplitude and phase information, thus compensating for the lack of illumination and structural information. These methods all process images in the frequency domain and have achieved remarkable results, laying a solid theoretical foundation for our research.
3. Methods
3.1. Network Architecture
As shown in Figure 2, we convert the RGB color space to the HVI color space and apply a denoising task to the HV branch and an enhancement task to the I branch. The input of the HV branch combines the intensity map and HV color map, as the brightness component of extremely low-light images also contains noise []. Furthermore, unlike CIDNet [], which lacks explicit denoising and enhancement modules, our approach achieves more refined processing through two key modules: the MSGD module performs denoising on the color branch in a strong-preservation manner, while the LFIE module enables targeted enhancement by decoupling the low- and high-frequency components of the illumination. The specific details of these modules are described in more detail below.
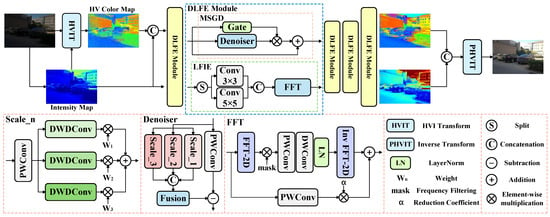
Figure 2.
The overall network of DLFE proposed by us. MSGD is applied to the HV branch, and LFIE is applied to the I branch. The self-attention module and feedforward network after the MSGD and LFIE modules have been omitted in the figure.
3.2. Multi-Scale Gated Denoiser
Images captured in low-light environments often contain noise, which can interfere with the color information of the image. Inspired by [], we propose a new MSGD module. The MSGD module consists of a noise estimation module and a noise modulation module. We discuss these two modules in detail below.
Noise Estimation Module. Unlike [], which estimates noise in images from both local and global perspectives, we adopt a multi-scale approach to estimate noise in low-light images. A three-level hierarchical perception structure is adopted at each scale . In the three-level hierarchical perception structure, we set three convolutions with different dilation rates and assign a learnable weight coefficient to each convolution. We then weigh and sum the noise features extracted from each convolution:
Specifically, we use small dilation convolutions designed to capture pixel-level high-frequency noise. We configure medium dilation convolutions at the mesoscale to focus on extracting noise patterns in local regions. At the macro scale, a large dilation convolution of is used specifically to capture the global noise distribution characteristics of the image. Afterward, multi-scale fusion is performed through the fusion module. Among them, is the concatenation of noise features according to channel dimensions, is a lightweight channel attention module designed to further fuse multi-scale noise features and suppress unreliable noise estimations, and is the estimated noise:
Noise Modulation Module. After estimating the noise distribution of low-light images, we dynamically adjust the fusion strength of denoising residuals through a gating mechanism, which is not present in []. Firstly, we input into and use a learnable linear transformation to map the input signal to a feature space that is more suitable for noise separation, resulting in a cleaner image with higher separability from noise in the projected space. The specific formula is as follows, where is a point-wise convolution, and is the residual for denoising:
However, the noise estimation module may mistakenly identify image details as noise. If the aforementioned denoising method is directly applied, it will lead to the loss of image detail information. Therefore, we introduce a gating mechanism to achieve a dynamic balance between noise removal and detail preservation:
First, in regions where the noise estimation module makes incorrect judgments, reducing the gating value effectively preserves detailed image information. Second, for correctly identified noise regions, increasing the gating value enhances denoising performance while maintaining feature integrity through residual connections. More detailed information is given in ‘Comparison of Different Denoising Methods’ in Section 4.4.
3.3. Low-Frequency Illumination Enhancer
Image detail loss and local exposure issues may occur in LLIE tasks. Inspired by [], we innovatively propose the LFIE module. The module decomposes the image into high- and low-frequency information, transforming the complex light optimization problem into a targeted enhancement of the low-frequency information. This approach enables the model to focus on modeling the global illumination distribution, thereby effectively avoiding local overexposure while preserving high-frequency details during the enhancement process. The LFIE module consists of a multi-scale spatial perception module and a low-frequency information enhancement module. We now discuss these two modules in detail.
Multi-scale Spatial Perception Module. To provide more comprehensive frequency-domain input for subsequent frequency-domain processing, we set up a multi-scale spatial perception module before the low-frequency information enhancement module. The module first decomposes the input features along the channel dimension and sends them to the and convolution branches for parallel processing. The convolution focuses on capturing high-frequency detail components, while the convolution focuses on extracting low-frequency lighting features. By concatenating features in the channel dimension, this multi-scale design ensures that the Fourier transform can synchronously process key information in different frequency bands:
Low-frequency Information Enhancement Module. Unlike [], we separate low-frequency and high-frequency information and process low-frequency information after converting images from the spatial domain to the frequency domain. Specifically, we first construct frequency-domain coordinates and convert the height and width of the image spatial domain into normalized frequency coordinates and through linear mapping. The vertical index i covers all spatial domain sampling points from 0 to , ensuring the completeness of the frequency-domain components. The normalized coordinates are used to center the zero frequency. The horizontal index j covers the non-redundant frequency-domain components of the real FFT output from 0 to , ensuring that the Nyquist frequency is correctly preserved at even widths. Simultaneously normalized coordinates :
Subsequently, based on the distance characteristics between the frequency coordinates and the frequency center, we designed a Gaussian mask . When the coordinate point is close to the frequency center, the mask value tends to 1 to enhance low-frequency information. To achieve adaptive control of different frequency bands, we introduce a learnable parameter to dynamically adjust the attenuation rate of the Gaussian mask, enabling the model to automatically adjust the frequency band division based on the frequency-domain characteristics of the input image:
Among them, is the base scaling factor, and is the learnable parameter.
Finally, we perform the Fourier transform on the input feature and multiply the obtained frequency-domain representation element by element with a Gaussian mask to extract low-frequency components. The processed low-frequency information is fused with the appropriately attenuated original features through residual connections. This design aims to effectively enhance lighting information while fully preserving the key detail features of the image:
Among them, represents a series of convolution operations, and is the decay parameter.
3.4. Loss Function
In order to integrate the advantages of RGB space and HVI space, we convert the RGB space of the normal-light image to HVI space and constrain it with the output HVI image, and at the same time convert the output HVI image to RGB space and constrain it with the normal-light image. Where is set to 1 in the experiment, and other hyperparameter settings are specified in the experimental section:
4. Experiments
4.1. Datasets and Evaluation Metrics
We evaluate using nine commonly used LLIE benchmark datasets, including LOLv1 [], LOLv2 [], DICM [], LIME [], MEF [], NPE [], VV [], SICE [], and Sony-Total-Dark. For paired datasets, we evaluate using the Peak Signal-to-Noise Ratio (PSNR), the Structural Similarity (SSIM) [], and the Learned Perceptual Image Patch Similarity (LPIPS) [] evaluation metrics, while for unpaired datasets, we evaluate using the Natural Image Quality Evaluator (NIQE) [] evaluation metrics.
LOL. The LOL dataset includes two main variants: LOLv1 [] and LOLv2 []. In LOLv1, there are 485 paired training images along with 15 test pairs. LOLv2 is further divided into LOLv2-real and LOLv2-synthetic: the former comprises 689 training pairs and 100 test pairs of real-captured images, while the latter contains 900 synthetic training pairs and 100 synthetic test pairs. During training, we process LOLv1 and LOLv2-real by extracting 400 × 400 patches from each image, followed by model optimization over 1500 epochs using a batch size of 8. For LOLv2-synthetic, we adopt a slightly different approach, cropping images into 384 × 384 patches and training for 500 epochs with a batch size of 1.
Unpaired Datasets. For unpaired datasets, such as DICM [], LIME [], MEF [], NPE [], VV [], we test the model trained on the LOLv2-synthetic dataset to evaluate its generalization ability.
SICE. The SICE dataset [] includes 4803 training images captured in varying lighting conditions, including low-light and overexposed scenarios. For testing, we employ two subsets SICE-Mix and SICE-Grad [] totaling 589 evaluation images. During training, images are divided into 160 × 160 patches, and the model is optimized over 1000 epochs using a batch size of 10.
Sony-Total-Dark. This dataset was modified and constructed based on a subset of the SID [], where the training set contains 1866 images captured by sensors under extremely low-light conditions, and the test set consists of 598 images captured at different exposure times, covering various lighting conditions from short-exposure low-light to long-exposure normal-light. To increase the complexity of the task, we processed the raw images by converting them to sRGB format without applying gamma correction, producing significantly darker outputs. We cropped the training images into 256 × 256 patches and trained the model for 1000 epochs with a batch size of 4.
4.2. Implementation Details
We trained our U-net-based [] DLFE-Net using a single RTX 4090 GPU. In terms of the optimizer, we chose the Adam optimizer [] and set the learning rate to . Then, during the training process, we gradually reduced it to through a cosine annealing scheme []. In terms of weight setting for the loss function, for the LOLv1 and LOLv2-synthetic datasets, we set weights of 1.00, 200.00, and 0.01 for SSIM loss [], edge loss [], and perceptual loss [], respectively. For the LOLv2-real and Sony-Total-Dark datasets, we only set weights of 0.01 for perceptual loss. For the SICE dataset, we set weights of 50.00 and 0.01 for edge loss and perceptual loss, respectively. In addition, we used gamma correction to train the model on the SICE dataset. As shown in Figure 3, we provide the variation of model performance with the number of training rounds on the LOLv1, LOLv2-synthetic, and Sony-Total-Dark datasets.
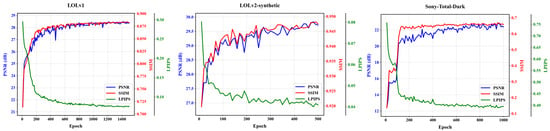
Figure 3.
Model performance curve with the number of training rounds.
4.3. Comparisons with States of the Art
Results on LOL Datasets. As shown in Table 1, our method achieves optimal results in PSNR and LPIPS metrics. This is because the MSGD module effectively suppresses noise in low-light images, significantly reducing pixel-level errors and achieving optimal PSNR performance. At the same time, the LFIE module focuses on low-frequency information processing, avoiding local overexposure issues during image enhancement, and achieving lighting adjustments that are more in line with human perception. Therefore, the LPIPS performance is optimal. As shown in Figure 4, in the first line, our method targets low-light images with uneven lighting distribution, effectively avoiding the problem of local overexposure during the enhancement process and solving the problem of detail loss during image enhancement. In the second line, compared to other methods, our approach not only effectively suppresses noise but also better preserves key details in the image. In the third line, facing the interference of high-brightness areas in low-light images, our method avoids the overall brightness decrease problem that occurs with other methods. In the fourth line, our method successfully solves the problem of overexposure or insufficient enhancement that other methods have in local areas. In the fifth line, compared to the color distortion caused by other methods, our method maintains accurate color reproduction when enhancing the detailed areas of the image.

Table 1.
Quantitative comparison of different methods on the LOLv1 and LOLv2 datasets. The best and second-best results are highlighted in red and blue, respectively. “↑” (or “↓”) means that the larger (or smaller) the better. The FLOPs was tested on a single 256 × 256 image. Please note that we obtained these results from corresponding papers or by running pre-trained models published by the authors.

Figure 4.
Visual comparisons of enhancement results by using different methods: SNR-Aware [], RetinexFormer [], GSAD [], CIDNet [], and LYT-Net [] on the LOLv1, LOLv2-real, and LOLv2-synthetic datasets.
Results on SICE and Sony-Total-Dark. To validate the performance of our model under extreme low-light conditions and mixed low-light and exposure conditions, we tested the model on the SICE and Sony-Total-Dark datasets. As shown in Table 2, the test results on the SICE dataset indicate that our model can better adapt to different lighting distributions, owing to the LFIE module’s focused processing of low-frequency information in images. In addition, each image in the SICE-Mix and SICE-Grad datasets is mixed with three conditions: low-light, normal-light, and exposure. The test results of the model on these two datasets further demonstrate its excellent generalization ability and adaptability to extreme conditions. The test results on the Sony Total Dark dataset show that our model not only performs best under extreme low-light conditions but also effectively suppresses the noise generated by the sensor in extreme low-light environments.
Table 2.
Quantitative comparison of different methods on SICE and Sony-Total-Dark datasets. The best and second-best results are highlighted in red and blue, respectively. “↑” (or “↓”) means that the larger (or smaller) the better. Please note that we obtained these results from corresponding papers or by running pre-trained models published by the authors.
Results on Unpaired Datasets. We use the NIQE evaluation metric [] to assess the visual quality of unpaired images after enhancement. As shown in Table 3, our method achieves optimal performance on the DICM, LIME, and MEF datasets, and suboptimal performance on the NPE datasets. This indicates that our enhancement results have advantages in naturalness and visual realism, avoiding the problem of local exposure in images caused by excessive processing. As shown in Figure 5, our method exhibits significant advantages in low-light image enhancement, especially when dealing with images with uneven lighting distribution. In the first four lines of the example, our method avoids the problem of local overexposure during low-light image enhancement. For the fifth line, compared with the LLFlow method, our method enhances the image while fully preserving the cloud details in the background, while the comparative method shows a significant loss of details.
Table 3.
Quantitative comparison of different methods on DICM, LIME, MEF, NPE, and VV datasets. The best and second-best results are highlighted in red and blue, respectively. Please note that we obtained these results from corresponding papers or by running pre-trained models published by the authors.

Figure 5.
Visual comparisons of enhancement results by using different methods: LLFlow [], GSAD [], QuadPrior [], and CIDNet [] on the DICM, LIME, MEF, NPE, and VV datasets.
4.4. Ablation Studies
Comparison between Various Modules. We conducted four quantitative ablation experiments on the LOLv1 dataset to validate the feasibility of each module. As shown in Table 4, firstly, Experiment 2 and Experiment 3 are higher than Experiment 1 in all evaluation indicators, which directly reflects the feasibility of each module. Secondly, Experiment 2 achieves significant improvements in PSNR and SSIM metrics compared to Experiment 1, mainly due to LFIE’s focus on processing the low-frequency components of intensity maps. By optimizing and adjusting low-frequency information, the model can effectively improve the overall brightness distribution of the image, allowing darker areas to receive more enhancement while brighter areas remain relatively stable. This processing method makes the enhanced image closer to the real image in terms of brightness distribution, thereby directly reducing the pixel difference between the two, which is the main reason for the improvement of PSNR. At the same time, due to the improvement of brightness distribution, the similarity of the image structure is also enhanced, so the SSIM index is correspondingly improved. Finally, Experiment 3 achieves a more significant improvement in PSNR compared to Experiment 2. This is because MSGD directly acts on the HV color map, which can more accurately estimate the noise in the image and, thus, perform targeted denoising. As shown in Figure 6, we compare an image on the LOLv1 test set. Experiment 2 achieves better restoration of details outside the left window compared to Experiments 1 and 3 under the lighting optimization effect of the LFIE module. At the same time, Experiment 3 shows superior noise suppression performance in the middle area of the image, with its noise reduction performance significantly surpassing that of Experiments 1 and 2. In addition, as shown in Table 5, we tested the computational complexity of each module to provide more detailed information about each module.
Table 4.
Quantitative assessment results for (a) MSGD and (b) LFIE on the LOLv1 dataset. The assessment metrics used in the experiment are PSNR, SSIM, and LPIPS. “↑” (or “↓”) means that the larger (or smaller) the better. ✓ and × represent whether the module is used or not. The best results are highlighted in red.
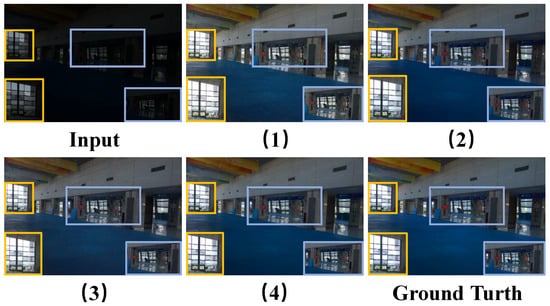
Figure 6.
Visual comparisons of enhancement results by using four ablation experiments on the LOLv1 dataset. Among them, (1), (2), (3), and (4) correspond one-to-one with Table 4.
Table 5.
The computational complexity of different modules. We tested the MSGD, LFIE, and DLFE modules on a single RTX 4090 GPU and recorded the FLOPs, parameters, and inference time on the GPU. Among them, Resolutions represents the shape of the image we used for testing.
Feasibility Study Focusing on Low-Frequency Processing. In the intensity map, the information of light distribution mainly exists in the low-frequency components. Based on this characteristic, we adopted a frequency-domain separation method to decompose the image into high- and low-frequency components and process the low-frequency information in a targeted manner to optimize the global illumination distribution and solve the problem of local overexposure during the enhancement process. To verify the above theory, we conducted four quantitative experiments. The first experiment extracted high-frequency information for independent processing, the second experiment fully segregated both high and low frequencies and processed them separately, the third experiment processed high and low frequencies jointly without any separation, and the fourth experiment isolated low-frequency information for dedicated processing. As shown in Table 6, the low-frequency emphasis method performs the best in all evaluation indicators. This method achieves dual advantages by separating low-frequency information and processing it specifically to adjust illumination uniformity, while using a reduction coefficient to control the contribution of original features. It effectively addresses the issue of local overexposure while avoiding the loss of high-frequency information and the amplification of noise. In contrast, the high-frequency emphasis method has obvious shortcomings. Because the high-frequency region in the illumination intensity map contains fewer effective details and noise [], enhancing the high-frequency component will significantly amplify the noise and cannot improve the problem of uneven low-frequency illumination. Although the high- and low-frequency complete separation method performs well in some indicators, it significantly deteriorates the LPIPS index due to the destruction of the natural correlation between frequency bands, reflecting a decrease in perceptual quality. Although the method of not separating high and low frequencies is superior to the high-frequency focused method, due to the lack of band-specific processing, it cannot differentiate and optimize low-frequency lighting and high-frequency details, and it still enhances high-frequency noise. The overall comparison shows that the low-frequency emphasis method exhibits the most comprehensive and optimal performance due to its targeted frequency band processing strategy.
Table 6.
Quantitative evaluation results of different frequency treatments on the LOLv1 dataset. Among them, (1) high-frequency emphasis, (2) high- and low-frequency complete separation, (3) no frequency separation, and (4) low-frequency emphasis. “↑” (or “↓”) means that the larger (or smaller) the better. The best results are highlighted in red.
Residual Contribution Ratio. As shown in Figure 2, in the LFIE module, we set a reduction coefficient to control the contribution of the residual part. By changing this value, the model can achieve different effects. As shown in Figure 7, as the residual contribution ratio increases, the values of all evaluation indicators first become better and then worse. This is because the residual part contains a lot of high-frequency information, which includes texture features, edge details, and noise in the intensity map []. If the residual is appropriately introduced, it can effectively compensate for the loss of image details after low-frequency separation. However, if the residual is excessively introduced, on the one hand, it will amplify the noise of the image, and on the other hand, it will suppress the processed low-frequency information with high-frequency information. At the same time, if the residual part is completely discarded, it is equivalent to losing some of the detailed information of the image, and the evaluation index will also significantly decrease. After considering all evaluation indicators comprehensively, we chose 0.1 as the reduction coefficient.
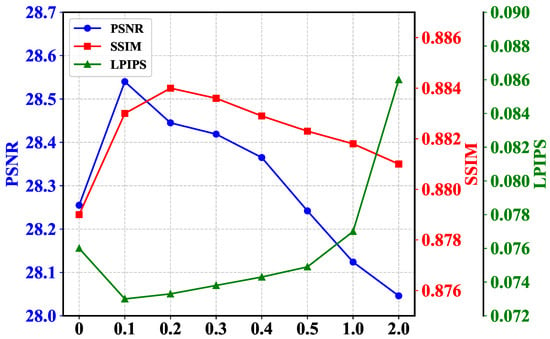
Figure 7.
Comparison of quantitative test results for different residual contribution rates on the LOLv1 dataset. The horizontal axis represents the residual ratio, and the vertical axis represents the size of the test indicators.
Comparison of Different Denoising Methods. We use a gate-controlled weighting mechanism to process the denoised features and then perform residual connections with the original features, aiming to effectively preserve the detailed information of the image during the denoising process. To verify the effectiveness of this method, we designed three sets of quantitative experiments. The first group weights the estimated noise through a gating weighting mechanism and directly denoises it, which is called direct denoising. The second group balances the original features and denoised features through a gating weighting mechanism, which is called weak preservation denoising. The third group uses a gate-weighted mechanism to process the denoised features, which is called strong preservation denoising. The following shows the specific formulas for three denoising methods, and the group numbers after the formulas correspond one-to-one with the group numbers in Table 7:
Table 7.
Quantitative evaluation results of different denoising methods on different evaluation indicators. (1) Direct denoising method, (2) weak preservation denoising method, (3) strong preservation denoising method. “↑” (or “↓”) means that the larger (or smaller) the better. The best results are highlighted in red.
As shown in Table 7, the third group of experiments achieved the best performance in terms of the four evaluation indicators. For direct denoising, subtracting the weighted noise from the original features can effectively suppress noise, but it will excessively smooth the image, resulting in texture and edge loss. Compared to direct denoising, weak preservation denoising may seem to compromise denoising and detail preservation. However, if the gating value is small, the original features are amplified while the noise is not sufficiently suppressed. If the gating value is large, this method is equivalent to direct denoising, which will result in the loss of details. Finally, for strong preservation denoising, we model the original features as . When the gate value approaches 1, it indicates that the estimated noise is approaching the true noise. Therefore, the denoising formula becomes
Although residual connections are used to introduce noise from the original features, the clean image portion is doubled in size. Through the layer-by-layer denoising of the UNet network’s encoder and decoder, the clean portion can be gradually enlarged while gradually reducing noise, achieving the goal of denoising while preserving image details. As shown in Figure 8, under extremely low-light conditions, both direct denoising and weak preservation denoising methods will smooth out the detailed features of the image to some extent, leading to color distortion problems. In contrast, strong preservation denoising methods not only effectively denoise, but also better preserve image details and features. Therefore, we choose this method to denoise the HV color map branches.

Figure 8.
Visual comparisons of enhancement results by using different denoising methods on the Sony-Total-Dark dataset. Among them, (1), (2), and (3) correspond one-to-one with Table 7.
Comparison of different dilation rates. In the noise estimation module, we adopt a multi-scale approach with a three-level hierarchical perception structure at each scale to estimate noise in low-light images. We test various dilation rate combinations to evaluate their impact on model performance. As shown in Table 8, the progressive dilation rate combination demonstrates the best performance, which benefits from its ability to capture local details hierarchically, mid-range correlations, and globally distributed noise patterns, thereby achieving comprehensive noise modeling. In contrast, single global or local dilation rates each have significant drawbacks: global captures large-scale noise distributions but misses local details, while local preserves high-frequency information but fails to capture global structures. This confirms the necessity of multi-scale feature fusion in noise estimation. Additionally, although the skip dilation rate combination attempts to expand the receptive field range, the lack of continuity between dilation rates disrupts the correlation between local and global noise patterns, adversely affecting feature fusion. Without dilated convolutions, this case preserves high-frequency noise better but only captures pixel-level features, lacking contextual image information for accurate noise estimation. As shown in Figure 9, the heatmap analysis provides more intuitive insights into the performance differences among various dilation rate combinations. For the global dilation rate combination, the heatmap shows that the model applies uniform attention across the image, failing to distinguish intensity variations in noisy regions, which hinders accurate identification of critical noise areas. The large gaps between dilation rates in the skip dilation combination weaken the correlation between local and global noise patterns, causing the model’s focus to deviate from actual noise distributions. As for the case without dilation rates, the heatmap shows that its attention scope is overly limited, capturing only pixel-level local noise features. Finally, while both local and progressive dilation rate combinations effectively focus on noise-dense regions, the latter exhibits clearer multi-scale attention in the heatmap: small dilation rates capture fine details, medium ones cover regional patterns, and large ones establish global correlations. This hierarchical attention pattern aligns well with the actual distribution characteristics of noise, leading us to ultimately select the progressive dilation rate strategy as the optimal solution.
Table 8.
Quantitative evaluation results of different expansion rates on the LOLv1 dataset. Among them, Scalen represents the combination of dilation rates contained in each scale. “↑” (or “↓”) means that the larger (or smaller) the better. The best results are highlighted in red.
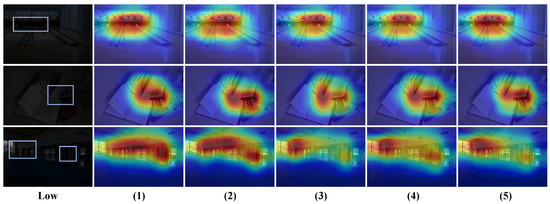
Figure 9.
Comparison of heatmaps with different dilation rates on the LOLv1 dataset. Among them, (1), (2), (3), (4), and (5) correspond one-to-one with Table 8. In addition, the areas marked with boxes in low-light images are the key areas that the model should focus on.
Comparison of different color spaces. In order to justify the choice of HVI color space, we performed multiple color space transformations on the RGB images and decoupled them into illumination components and color components, which were processed using the same network architecture. As shown in Table 9, although the LAB color space is designed to take into account the perceptual characteristics of the human eye on color change, so that its color difference calculation is more in line with human visual perception, the a-axis and b-axis obtained from its decoupling have the problem of difficult color adjustment during model processing, especially in the low-illumination region that is prone to the color bias phenomenon. While the YUV color space was originally designed for video transmission, the chromaticity downsampling technique it adopts effectively reduces the amount of data but inevitably causes the loss of color information. As shown in Figure 10, in the HSV color space, the calculation of the Saturation depends on the Value. When the luminance decreases, the maximum effective saturation of the color will show a nonlinear decay characteristic, which leads to color distortion. Through the comprehensive analysis above, compared to other color spaces, HVI shows superior performance.
Table 9.
Quantitative test results for different color spaces on the LOLv2-real dataset. Here, the RGB images were converted to different color spaces and decoupled into luminance and color components, and processed using the same network. “↑” (or “↓”) means that the larger (or smaller) the better. The best results are highlighted in red.

Figure 10.
Visualization results for different color spaces on the LOLv2-real dataset. The HSV and LAB color spaces show color deviation problems marked with blue boxes.
4.5. Inference Time on Device
To comprehensively evaluate the model’s practical deployment performance, we conducted systematic testing on both the 13th Gen Intel(R) Core(TM) i7-13650HX CPU and RTX 4060 GPU platforms. Our evaluation focused on two key metrics: CPU/GPU utilization and inference latency. As shown in Table 10, we performed repeated experiments across multiple test sets from different datasets, collecting multiple measurements to calculate mean values and standard deviations, thereby ensuring the reliability and statistical significance of our experimental results.
Table 10.
The results of the inference performance of the model on different datasets. Among them, the first row shows the number of images in the test set of each dataset, and the second row indicates the image resolution. The CPU/GPU utilization rate is measured multiple times to obtain the mean and standard deviation, while the inference time is measured multiple times to obtain the average value.
4.6. Analysis of Failure Cases
In order to fully evaluate the performance of DLFE-Net, we provide some failure cases and analyze them. As shown in Figure 11, our method exhibits issues of localized detail blurring and color deviation when processing extremely low-light regions in images. Specifically, when dealing with extremely low-light areas where brightness is nearly completely absent, although the noise modulation module in MSGD can preserve some image detail information during denoising, the degradation in these regions is so severe that the model struggles to extract authentic image features. This makes it difficult for the model to accurately distinguish between noise and structural image information, leading to excessive denoising in these areas and ultimately resulting in edge smoothing. Regarding color deviation, this issue stems from the inherent limitations of the HSV and HVI color spaces. In the HSV space, the Value component is calculated based on the maximum RGB theory. However, noise interference in low-light images can excessively amplify the Value component, thereby widening the gap between the maximum and minimum channel values. This not only weakens the chrominance signal but also affects the accurate calculation of the Saturation, ultimately leading to color distortion. More critically, excessive noise interference can even alter the relative magnitudes of RGB channel values, causing a fundamental shift in the dominant hue. This phenomenon is particularly evident in the Sony-Total-Dark dataset. Since the H and V components in the HVI space are calculated from the Hue and Saturation in HSV, the aforementioned issue exists not only in HSV but also in HVI.

Figure 11.
Comparison chart of failure case results. Among them, from left to right are the low-light image, the enhanced image, and the label image in that order.
5. Conclusions
This paper proposes DLFE-Net, a novel network addressing critical challenges in low-light image enhancement (LLIE): local overexposure with detail loss and persistent noise suppression. Specifically, DLFE-Net contains two modules: Low-Frequency Illumination Enhancement (LFIE) and Multi-Scale Gated Denoising (MSGD) modules. The RGB images are transformed into the HVI color space, enabling independent enhancement and denoising of the intensity (I) and color (H, V) components. The LFIE module selectively processes low-frequency illumination information, effectively mitigating localized over-enhancement and preserving intricate details. The MSGD module adopts noise estimation and strong preservation denoising methods to preserve high-frequency details of the image during the denoising process. Extensive evaluations on diverse datasets (LOL, SICE-Mix, SICE-Grad, Sony-Total-Dark, and five unpaired datasets) demonstrate DLFE-Net’s superior performance and robust generalization: (i) LFIE excels in optimizing illumination distribution, particularly under mixed lighting conditions (validated on SICE-Mix/SICE-Grad); (ii) MSGD exhibits exceptional sensor noise suppression capability, even in extreme low-light environments (validated on Sony-Total-Dark). While DLFE-Net achieves significant performance gains, it incurs higher computational complexity. Future work will focus on developing a content-adaptive frequency processing mechanism to dynamically allocate computational resources. This aims to substantially improve inference speed while preserving the model’s performance advantages, thereby enhancing its practical application scenarios.
Author Contributions
Conceptualization, Z.H., X.Y., and G.H.; methodology, Z.H. and X.Y.; software, Z.H. and W.W.; validation, Z.H., X.Y., and G.H.; formal analysis, X.Y.; investigation, Z.H. and W.W.; resources, Z.H.; data curation, Z.H.; writing—original draft preparation, Z.H. and X.Y.; writing—review and editing, Z.H. and X.Y.; visualization, Z.H. and W.W.; supervision, X.Y.; project administration, Z.H. and X.Y.; funding acquisition, X.Y. and G.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was financially supported by funds from Nature Science Foundation of Hubei Province (No. 2025AFB056), Key Project of the Science Research Plan of the Hubei Provincial Department of Education (No. D20241103), Hubei Province Key Laboratory of Intelligent Information Processing and Real-time Industrial System (Wuhan University of Science and Technology) (No. ZNXX2023QNO3), Fund of Hubei Key Laboratory of Inland Shipping Technology and Innovation (NO. NHHY2023004), Key Laboratory of Social Computing and Cognitive Intelligence (Dalian University of Technology), Ministry of Education (No. SCCI2024YB02), Research Project of Hubei Provincial Department of Science and Technology (No. 2024CSA075), College Students’ Innovation and Entrepreneurship Training Program of Hubei Province (No. S202410488120), and Entrepreneurship Fund for Graduate Students of Wuhan University of Science and Technology (No. JCX2023049, JCX2023160).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The LOLv1 dataset can be found using this link: https://daooshee.github.io/BMVC2018website/. The LOLv2 dataset can be accessed through the following link: https://github.com/flyywh/CVPR-2020-Semi-Low-Light. The DICM, LIME, MEF, NPE, and VV datasets can be accessed through the following link: https://1drv.ms/f/s!AoPRJmiD24UphBNGBbsDmSwppNPf?e=2yGImv. The SICE dataset can be accessed through the following link: https://1drv.ms/u/s!AoPRJmiD24UphAlaTIekdMLwLZnA?e=WxrfOa. The Sony-Total-Dark dataset can be accessed through the following link: https://1drv.ms/u/s!AoPRJmiD24UphAie9l0DuMN20PB7?e=Zc5DcA. The passwords above are all “yixu”.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Zang, Y.; Li, W.; Han, J.; Zhou, K.; Loy, C.C. Contextual Object Detection with Multimodal Large Language Models. Int. J. Comput. Vis. 2025, 133, 825–843. [Google Scholar] [CrossRef]
- Yang, K.; Wang, X.; Wang, W.; Yuan, X.; Xu, X. SEANet: Semantic Enhancement and Amplification for Underwater Object Detection in Complex Visual Scenarios. Sensors 2025, 25, 3078. [Google Scholar] [CrossRef] [PubMed]
- Xu, X.; Yuan, X.; Wang, Z.; Zhang, K.; Hu, R. Rank-in-Rank Loss for Person Re-identification. ACM Trans. Multimed. Comput. Commun. Appl. 2022, 18, 1–21. [Google Scholar] [CrossRef]
- Yuan, X.; He, Y.; Hao, G. Identity Hides in Darkness: Learning Feature Discovery Transformer for Nighttime Person Re-Identification. Sensors 2025, 25, 862. [Google Scholar] [CrossRef] [PubMed]
- Rao, B.S. Dynamic histogram equalization for contrast enhancement for digital images. Appl. Soft Comput. 2020, 89, 106114. [Google Scholar] [CrossRef]
- McCann, J. Retinex theory. In Encyclopedia of Color Science and Technology; Springer: Berlin/Heidelberg, Germany, 2023; pp. 1384–1392. [Google Scholar] [CrossRef]
- Cai, Y.; Bian, H.; Lin, J.; Wang, H.; Timofte, R.; Zhang, Y. Retinexformer: One-stage Retinex-based Transformer for Low-light Image Enhancement. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 12504–12513. [Google Scholar] [CrossRef]
- Bai, J.; Yin, Y.; He, Q.; Li, Y.; Zhang, X. Retinexmamba: Retinex-Based Mamba for Low-Light Image Enhancement. In Proceedings of the International Conference on Neural Information Processing, Okinawa, Japan, 20–24 November 2025; pp. 427–442. [Google Scholar] [CrossRef]
- Wang, T.; Zhang, K.; Zhang, Y.; Luo, W.; Stenger, B.; Lu, T.; Kim, T.K.; Liu, W. LLDiffusion: Learning degradation representations in diffusion models for low-light image enhancement. Pattern Recognit. 2025, 166, 111628. [Google Scholar] [CrossRef]
- Hou, J.; Zhu, Z.; Hou, J.; Liu, H.; Zeng, H.; Yuan, H. Global Structure-Aware Diffusion Process for Low-Light Image Enhancement. Adv. Neural Inf. Process. Syst. 2024, 36, 79734–79747. [Google Scholar] [CrossRef]
- Xu, X.; Wang, R.; Fu, C.W.; Jia, J. SNR-Aware Low-light Image Enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17714–17724. [Google Scholar] [CrossRef]
- Xu, X.; Wang, R.; Lu, J. Low-Light Image Enhancement via Structure Modeling and Guidance. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 9893–9903. [Google Scholar] [CrossRef]
- Ruan, Y.; Ma, H.; Li, W.; Wang, X. ECAFormer: Low-light Image Enhancement using Cross Attention. arXiv 2024, arXiv:2406.13281. [Google Scholar] [CrossRef]
- Fang, X.; Gao, X.; Li, B.; Zhai, F.; Qin, Y.; Meng, Z.; Lu, J.; Xiao, C. A non-uniform low-light image enhancement method with multi-scale attention transformer and luminance consistency loss. Vis. Comput. 2025, 41, 1591–1608. [Google Scholar] [CrossRef]
- Zhou, L.; Chen, X.; Ye, B.; Jiang, X.; Zou, S.; Ji, L.; Yu, Z.; Wei, J.; Zhao, Y.; Wang, T. A low-light image enhancement method based on HSV space. Imaging Sci. J. 2025, 73, 16–29. [Google Scholar] [CrossRef]
- Du, X.; Yang, M.; Lei, T.; Zhang, X.; Wang, Y.; Nandi, A.K. HSVFormer: Robust and Unsupervised HSV-based Transformer Framework for Low-Light Image Enhancement. In Proceedings of the 2024 IEEE International Conference on Multimedia and Expo, Niagara Falls, ON, Canada, 15–19 July 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Yan, Q.; Feng, Y.; Zhang, C.; Pang, G.; Shi, K.; Wu, P.; Dong, W.; Sun, J.; Zhang, Y. HVI: A New Color Space for Low-light Image Enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 11–15 June 2025; pp. 5678–5687. [Google Scholar] [CrossRef]
- Acharya, A.; Giri, A.V. Contrast improvement using local gamma correction. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems, Coimbatore, India, 6–7 March 2020; pp. 110–114. [Google Scholar] [CrossRef]
- Brateanu, A.; Balmez, R.; Avram, A.; Orhei, C.; Ancuti, C. LYT-NET: Lightweight YUV Transformer-based Network for Low-light Image Enhancement. IEEE Signal Process. Lett. 2025, 32, 2065–2069. [Google Scholar] [CrossRef]
- In, H.; Kweon, J.; Moon, C. Squeeze-EnGAN: Memory Efficient and Unsupervised Low-Light Image Enhancement for Intelligent Vehicles. Sensors 2025, 25, 1825. [Google Scholar] [CrossRef]
- Brateanu, A.; Balmez, R.; Orhei, C.; Ancuti, C.; Ancuti, C. Enhancing Low-Light Images with Kolmogorov–Arnold Networks in Transformer Attention. Sensors 2025, 25, 327. [Google Scholar] [CrossRef]
- Balmez, R.; Brateanu, A.; Orhei, C.; Ancuti, C.O.; Ancuti, C. DepthLux: Employing Depthwise Separable Convolutions for Low-Light Image Enhancement. Sensors 2025, 25, 1530. [Google Scholar] [CrossRef]
- He, J.; Palaiahnakote, S.; Ning, A.; Xue, M. Zero-Shot Low-Light Image Enhancement via Joint Frequency Domain Priors Guided Diffusion. arXiv 2024, arXiv:2411.13961. [Google Scholar] [CrossRef]
- Yi, X.; Xu, H.; Zhang, H.; Tang, L.; Ma, J. Diff-Retinex: Rethinking Low-light Image Enhancement with A Generative Diffusion Model. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 12302–12311. [Google Scholar] [CrossRef]
- Wang, W.; Yang, H.; Fu, J.; Liu, J. Zero-Reference Low-Light Enhancement via Physical Quadruple Priors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 26057–26066. [Google Scholar] [CrossRef]
- Liang, X.; Chen, X.; Ren, K.; Miao, X.; Chen, Z.; Jin, Y. Low-light image enhancement via adaptive frequency decomposition network. Sci. Rep. 2023, 13, 14107. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.; Tu, X.; Fu, G.; Liu, T.; Liu, B.; Yang, M.; Feng, Z. Low-Light Image Enhancement by Learning Contrastive Representations in Spatial and Frequency Domains. In Proceedings of the 2023 IEEE International Conference on Multimedia and Expo, Brisbane, Australia, 10–14 July 2023; pp. 1307–1312. [Google Scholar] [CrossRef]
- Brateanu, A.; Balmez, R.; Avram, A.; Orhei, C. AKDT: Adaptive Kernel Dilation Transformer for Effective Image Denoising. In Proceedings of the 20th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications—Volume 3: VISAPP, Porto, Portugal, 26–28 February 2025; pp. 418–425. [Google Scholar] [CrossRef]
- Gao, N.; Jiang, X.; Zhang, X.; Deng, Y. Efficient Frequency-Domain Image Deraining with Contrastive Regularization. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; pp. 240–257. [Google Scholar] [CrossRef]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep Retinex Decomposition for Low-Light Enhancement. arXiv 2018, arXiv:1808.04560. [Google Scholar] [CrossRef]
- Yang, W.; Wang, W.; Huang, H.; Wang, S.; Liu, J. Sparse Gradient Regularized Deep Retinex Network for Robust Low-Light Image Enhancement. IEEE Trans. Image Process. 2021, 30, 2072–2086. [Google Scholar] [CrossRef] [PubMed]
- Lee, C.; Lee, C.; Kim, C.S. Contrast Enhancement Based on Layered Difference Representation of 2D Histograms. IEEE Trans. Image Process. 2013, 22, 5372–5384. [Google Scholar] [CrossRef] [PubMed]
- Guo, X.; Li, Y.; Ling, H. LIME: Low-Light Image Enhancement via Illumination Map Estimation. IEEE Trans. Image Process. 2016, 26, 982–993. [Google Scholar] [CrossRef] [PubMed]
- Ma, K.; Zeng, K.; Wang, Z. Perceptual Quality Assessment for Multi-Exposure Image Fusion. IEEE Trans. Image Process. 2015, 24, 3345–3356. [Google Scholar] [CrossRef]
- Wang, S.; Zheng, J.; Hu, H.M.; Li, B. Naturalness Preserved Enhancement Algorithm for Non-Uniform Illumination Images. IEEE Trans. Image Process. 2013, 22, 3538–3548. [Google Scholar] [CrossRef] [PubMed]
- Vonikakis, V.; Kouskouridas, R.; Gasteratos, A. On the evaluation of illumination compensation algorithms. Multimed. Tools Appl. 2018, 77, 9211–9231. [Google Scholar] [CrossRef]
- Cai, J.; Gu, S.; Zhang, L. Learning a Deep Single Image Contrast Enhancer from Multi-Exposure Images. IEEE Trans. Image Process. 2018, 27, 2049–2062. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar] [CrossRef]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “Completely Blind” Image Quality Analyzer. IEEE Signal Process. Lett. 2012, 20, 209–212. [Google Scholar] [CrossRef]
- Zheng, S.; Ma, Y.; Pan, J.; Lu, C.; Gupta, G. Low-Light Image and Video Enhancement: A Comprehensive Survey and Beyond. arXiv 2022, arXiv:2212.10772. [Google Scholar] [CrossRef]
- Chen, C.; Chen, Q.; Xu, J.; Koltun, V. Learning to See in the Dark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3291–3300. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Kingma, D.P. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic Gradient Descent with Warm Restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar] [CrossRef]
- Seif, G.; Androutsos, D. Edge-Based Loss Function for Single Image Super-Resolution. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing, Calgary, AB, Canada, 15–20 April 2018; pp. 1468–1472. [Google Scholar] [CrossRef]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 694–711. [Google Scholar] [CrossRef]
- Guo, C.; Li, C.; Guo, J.; Loy, C.C.; Hou, J.; Kwong, S.; Cong, R. Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1780–1789. [Google Scholar] [CrossRef]
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. EnlightenGAN: Deep Light Enhancement Without Paired Supervision. IEEE Trans. Image Process. 2021, 30, 2340–2349. [Google Scholar] [CrossRef]
- Yang, W.; Wang, S.; Fang, Y.; Wang, Y.; Liu, J. From Fidelity to Perceptual Quality: A Semi-Supervised Approach for Low-Light Image Enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3063–3072. [Google Scholar] [CrossRef]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H.; Shao, L. Learning Enriched Features for Fast Image Restoration and Enhancement. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1934–1948. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Wan, R.; Yang, W.; Li, H.; Chau, L.P.; Kot, A. Low-Light Image Enhancement with Normalizing Flow. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 2604–2612. [Google Scholar] [CrossRef]
- Qu, J.; Liu, R.W.; Gao, Y.; Guo, Y.; Zhu, F.; Wang, F.Y. Double domain guided real-time low-light image enhancement for ultra-high-definition transportation surveillance. IEEE Trans. Intell. Transp. Syst. 2024, 25, 9550–9562. [Google Scholar] [CrossRef]
- Adhikarla, E.; Zhang, K.; Nicholson, J.; Davison, B.D. ExpoMamba: Exploiting Frequency SSM Blocks for Efficient and Effective Image Enhancement. arXiv 2024, arXiv:2408.09650. [Google Scholar] [CrossRef]
- Wang, T.; Zhang, K.; Shen, T.; Luo, W.; Stenger, B.; Lu, T. Ultra-High-Definition Low-Light Image Enhancement: A Benchmark and Transformer-Based Method. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 2654–2662. [Google Scholar] [CrossRef]
- Wu, W.; Weng, J.; Zhang, P.; Wang, X.; Yang, W.; Jiang, J. URetinex-Net: Retinex-based Deep Unfolding Network for Low-light Image Enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5901–5910. [Google Scholar] [CrossRef]
- Liu, R.; Ma, L.; Zhang, J.; Fan, X.; Luo, Z. Retinex-inspired Unrolling with Cooperative Prior Architecture Search for Low-light Image Enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10561–10570. [Google Scholar] [CrossRef]
- Zhou, S.; Li, C.; Change Loy, C. LEDNet: Joint Low-Light Enhancement and Deblurring in the Dark. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 573–589. [Google Scholar] [CrossRef]
- Fu, Z.; Yang, Y.; Tu, X.; Huang, Y.; Ding, X.; Ma, K.K. Learning a Simple Low-Light Image Enhancer from Paired Low-Light Instances. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 22252–22261. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).