1. Introduction
With the acceleration of urbanization, urban green spaces have been continuously encroached upon, placing increasing pressure on urban ecosystems. Urban green spaces play a critical role in mitigating the urban heat island effect, purifying the air, and improving the microclimate [
1,
2,
3,
4,
5,
6]. They also serve as a fundamental component for achieving sustainable urban development. Against the backdrop of promoting “green development” and building “livable cities”, the ability to efficiently and accurately obtain urban green space classification data has become a prerequisite for the refined management of ecological space and the systematic optimization of green infrastructure [
7,
8].
The rapid development of remote sensing technology has provided effective tools for urban green space classification. Early studies primarily relied on satellite imagery from platforms such as Landsat and Sentinel [
9,
10,
11,
12], which offer strong temporal and spatial coverage. However, their limited spatial resolution hinders the detection of fragmented green areas and transitional boundaries within urban environments, making them insufficient for fine-scale classification tasks. In contrast, high spatial resolution remote sensing imagery offers a solid foundation for detailed urban green space classification. Among these, GF-2 (Gaofen-2) satellite imagery, with its sub-meter spatial resolution, has become an important data source for high-precision green space mapping [
13,
14,
15]. Nevertheless, this also imposes higher demands on classification methodologies. Traditional remote sensing classification methods primarily include pixel-based and object-based approaches. Pixel-based methods are easy to implement and computationally efficient, and have been widely applied in early urban green space extraction tasks. However, when dealing with high-resolution imagery, these methods are prone to salt-and-pepper noise and discontinuities along object boundaries, which compromise classification consistency [
16]. While object-based methods can alleviate pixel-level noise to some extent in fine urban vegetation classification, they still face challenges in high-resolution remote sensing applications, such as difficulty in selecting appropriate segmentation algorithms, complex feature extraction, and potential loss of fine spatial details [
17,
18]. Therefore, there is an urgent need for efficient and intelligent automated methods for urban green space classification to enable rapid perception and dynamic monitoring of urban green space patterns.
In recent years, deep learning methods have been widely applied in the field of remote sensing image segmentation due to their superior feature extraction capabilities [
19,
20,
21,
22]. Currently, deep learning-based semantic segmentation models for remote sensing imagery can be broadly categorized into two groups. The first group consists of models based on traditional convolutional neural networks (CNNs), such as the Fully Convolutional Network (FCN) [
23], U-Net [
24], and the DeepLab series [
25,
26]. These models extract hierarchical semantic information through successive convolutional operations and have demonstrated excellent pixel-level classification accuracy and strong algorithmic robustness in various remote sensing tasks, including water body detection, object extraction, and land surface classification [
27,
28,
29]. Numerous enhancements have been proposed to further improve the performance of these CNN-based architectures. For instance, Shi et al. [
30] incorporated the CBAM attention module into the U-Net framework and developed a water body segmentation approach applicable to multi-source remote sensing data. Men et al. [
19] introduced CRAUNet by combining residual connections with a channel attention mechanism, which effectively improved segmentation accuracy in complex urban green space environments. Zhang and Zhao [
31] proposed an improved DeepLabV3+ architecture by optimizing the atrous spatial pyramid pooling (ASPP) module and introducing an attention-based feature fusion module (AFFM), resulting in better segmentation performance under complex background conditions. Among these approaches, DeepLabV3+ has demonstrated particularly strong performance in semantic segmentation tasks involving natural scenes. Its multi-scale feature extraction mechanism significantly enhances the ability to capture objects across varying spatial scales, while the encoder–decoder structure facilitates more effective reconstruction of spatial features [
32,
33,
34]. Nevertheless, most existing studies have concentrated on optimizing the encoder component, with limited emphasis on enhancing the capacity of the decoder to reconstruct high-dimensional features and recover fine spatial details [
35,
36]. This architectural imbalance constrains the potential for further advancements in fine-grained remote sensing classification.
The second category consists of semantic segmentation models based on the Transformer architecture, which fundamentally rely on the self-attention mechanism to capture global contextual relationships. The Vision Transformer (ViT) [
37] was the first to introduce the Transformer architecture into computer vision tasks and has demonstrated strong performance in image segmentation. For instance, Qin et al. [
38] proposed a ViT-based model for tunnel defect segmentation, enabling the unified detection of various defects such as cracks and water stains. Wang et al. [
39] developed a remote sensing classification approach that integrates ViT with self-supervised pretraining, resulting in significantly improved classification accuracy and validating the effectiveness of ViT in representing multi-scale features in remote sensing imagery. However, in high spatial resolution remote sensing applications, such models often suffer from high parameter complexity and elevated computational costs [
40]. To mitigate these limitations, a series of improved Transformer-based models have been proposed, including SegFormer [
41] and Swin Transformer [
42]. These models incorporate hierarchical feature pyramids and shifted window attention mechanisms, thereby enhancing multi-scale feature representation in remote sensing imagery and gaining popularity in semantic segmentation tasks. For example, Wang et al. [
43] introduced an enhanced SegFormer model combining a multi-scale feature fusion network (MSF-FFN) with CoordAttention to extract winter wheat planting regions. Wu and Zhang [
22] developed a hybrid framework, Swin-CFNet, which integrates Swin Transformer with convolutional layers for fine-scale urban green space classification, achieving an overall accuracy of 98.3% on high spatial resolution imagery. Despite notable improvements in segmentation performance, such models still require substantial computational resources, which limits their applicability in resource-constrained environments.
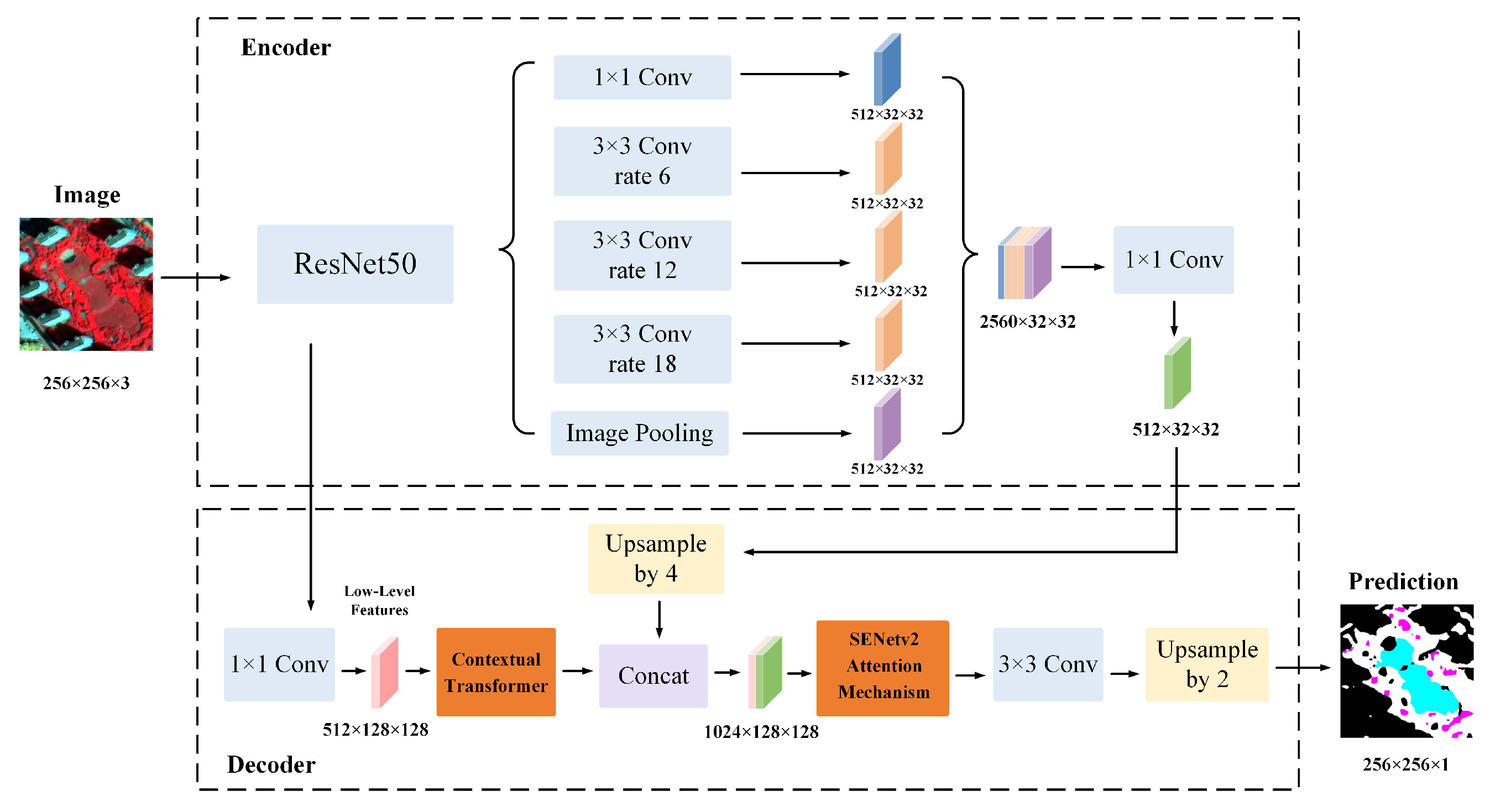
In summary, CNN-based models are limited by their constrained receptive fields, while Transformer-based approaches typically involve high computational complexity. To address the practical needs of high spatial resolution urban green space classification, a tailored GF-2-based dataset was constructed in this study, and an improved model—CTSA-DeepLabV3+—was proposed by incorporating a Contextual Transformer [
44] module and the SENetv2 attention mechanism [
45]. The main contributions of this study are summarized as follows:
A high spatial resolution urban green space dataset was constructed based on GF-2 satellite imagery and manually annotated, providing a reliable basis for training and evaluation.
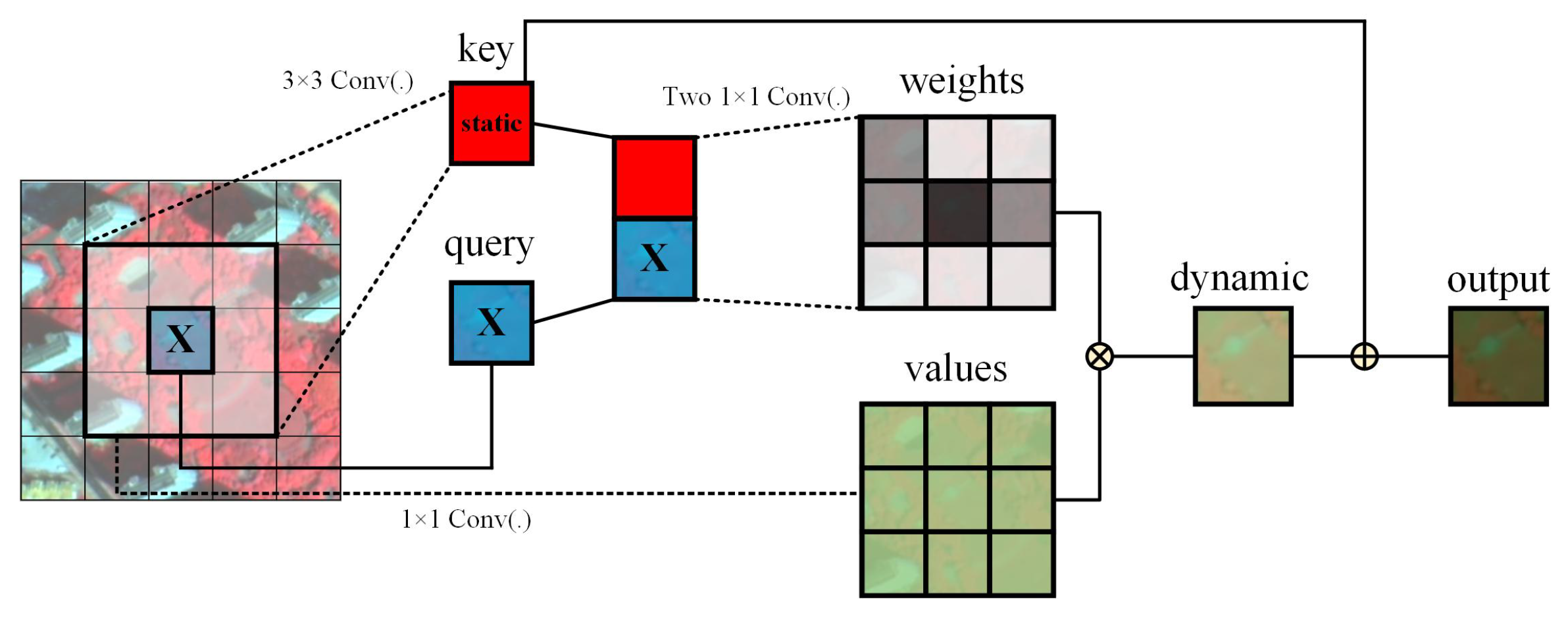
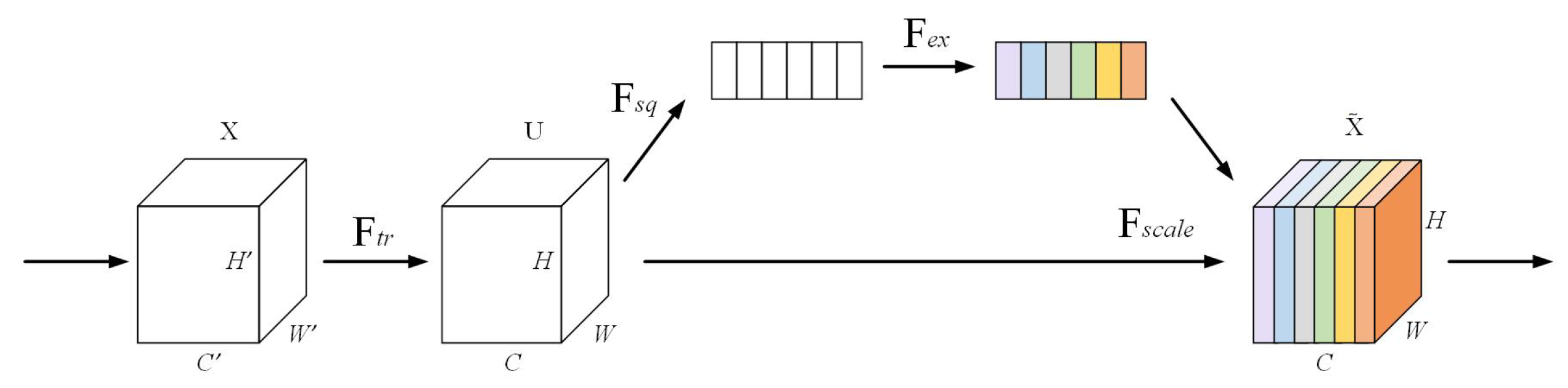
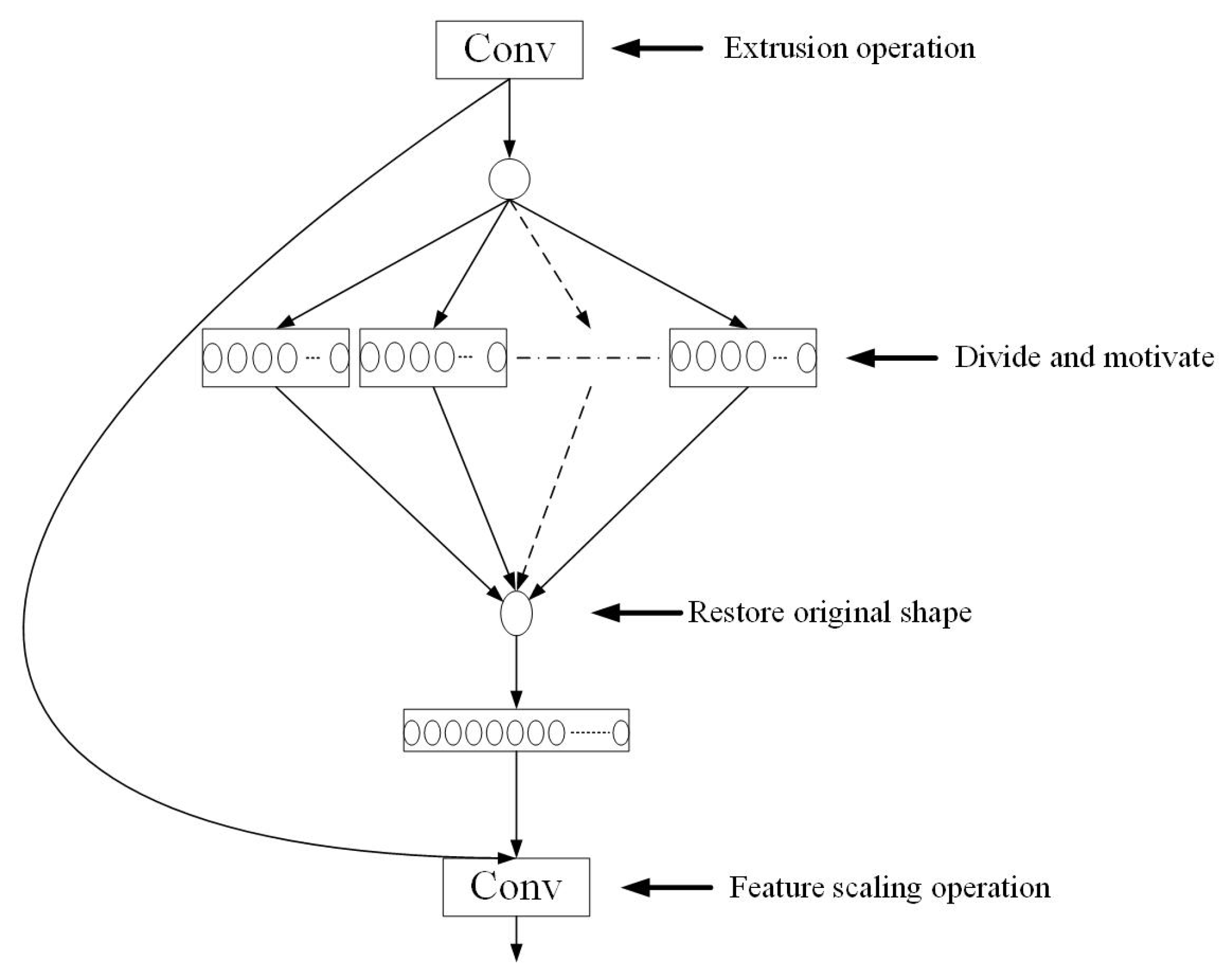
A Contextual Transformer module was introduced into the decoder of DeepLabV3+ to enhance the capacity for capturing complex spatial structures and delineating fine-scale object boundaries. Meanwhile, SENetv2 was integrated to strengthen channel-level feature discrimination and suppress irrelevant responses, thereby improving classification precision.
To address the class imbalance problem, a dual-loss strategy combining cross-entropy loss and Dice loss was employed, which enhances the segmentation performance of minority classes and improves overall robustness and generalization.
The remainder of this paper is organized as follows:
Section 2 presents the dataset construction and preprocessing procedures;
Section 3 describes the architecture and components of the proposed model;
Section 4 outlines the experimental setup and performance evaluation;
Section 5 discusses the main findings and their implications; and
Section 6 concludes the study and suggests directions for future work.
4. Results Analysis
4.1. Training Setup of the Model
The experiments were conducted using the PyTorch (PyTorch 1.10.0+cu113) deep learning framework. The computer hardware consisted of an Intel(R) Core(TM) i7-12700H processor (Intel(R): Santa Clara, CA, USA) and an NVIDIA GeForce RTX 3060 graphics card (NVIDIA: Santa Clara, CA, USA). The environment was based on Python 3.8 and CUDA 11.0, meeting the training requirements for semantic segmentation models. The Adam optimizer was selected, with the batch size set to 16. The maximum number of training epochs was set to 10,000, the initial learning rate was set to , and the learning rate adjustment strategy adopted a polynomial decay (poly policy) with a decay exponent of 0.9 and a minimum learning rate (min_lr) of . The learning rate was dynamically adjusted based on the number of iterations to ensure convergence and optimal final performance during training.
4.2. Model Performance Evaluation
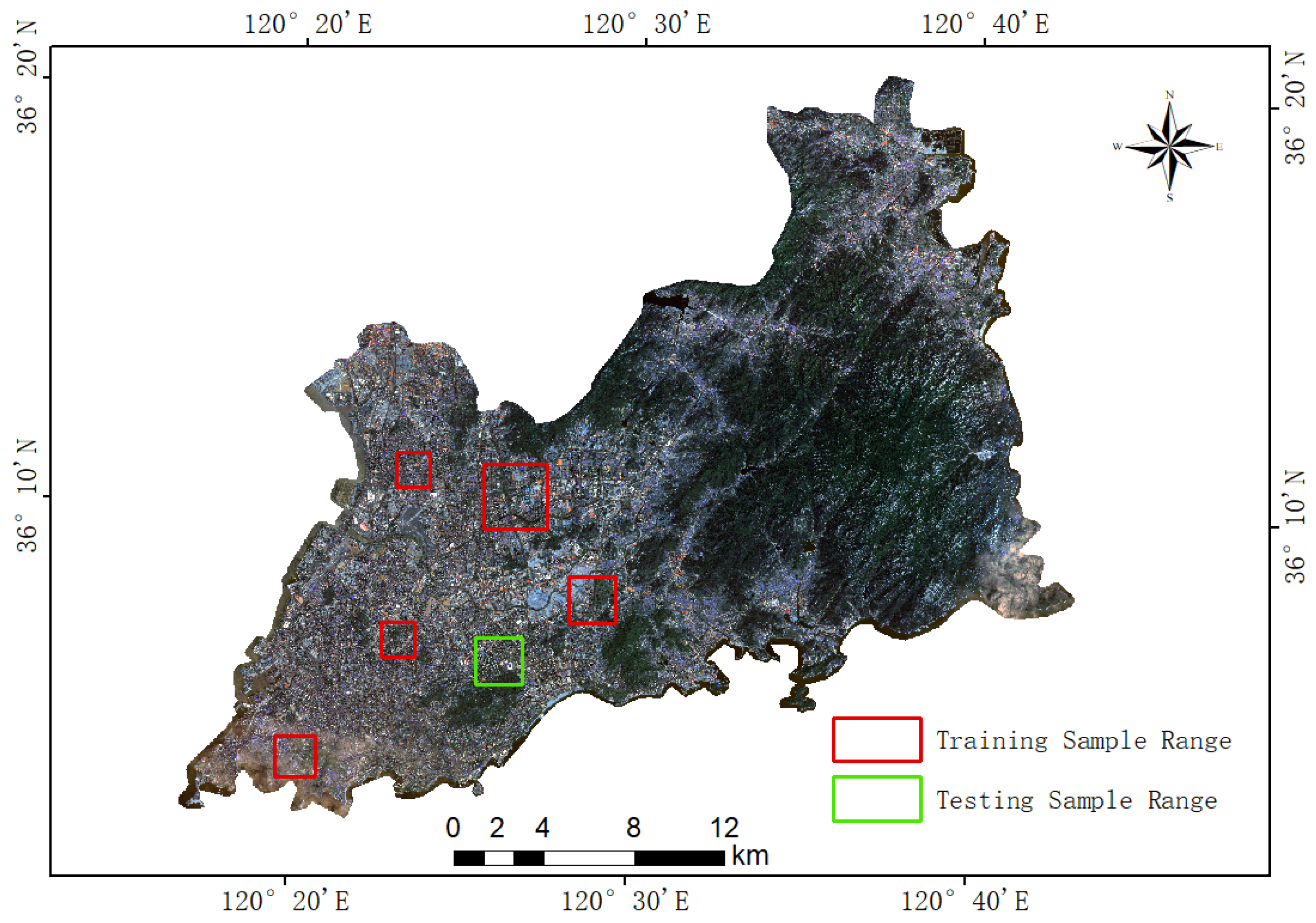
To verify the effectiveness of the CTSA-DeepLabV3+ model for urban green space classification, comparative experiments were conducted between it and several mainstream semantic segmentation models in the paper. Five models—FCN, UNet, PSPNet, DeepLabv3+, and UperNet-Swin Transformer—were selected as baselines to comprehensively evaluate classification accuracy, result quality, computational efficiency, and automation level. To facilitate visual comparison, local features from five typical areas were extracted for analysis (
Table 2). The results demonstrated that FCN, UNet, PSPNet, UperNet-Swin Transformer, and the original DeepLabv3+ models exhibited notable limitations in green space classification. Although these models distinguished urban green spaces from non-green spaces, omissions and misclassifications were frequently observed in green space type classification, such as evergreen trees being misclassified as deciduous trees, inaccurate edge segmentation, and jagged boundaries, particularly in detail-rich and complex scenes. Specifically, FCN struggled to distinguish complex green space types due to resolution degradation and feature loss from multiple subsampling. UNet, despite strong local feature extraction capability, failed to capture sufficient global context, leading to blurred boundaries in textured scenes. PSPNet, while enhancing contextual information via multi-scale feature fusion, produced overly smooth edges and lacked detailed classification accuracy. UperNet-Swin Transformer suffered from limited local feature representation in complex scenes, resulting in significant discrepancies from ground truth labels. The original DeepLabv3+ model showed weak boundary detail extraction, with boundary blurring and missing features. In contrast, the CTSA-DeepLabV3+ model enhanced contextual expression through the CoT module, effectively captured fine details, and reduced feature loss and misclassification. Moreover, the integration of the SENetv2 attention mechanism optimized boundary processing, mitigated blurring and jaggedness, and clarified boundaries between green spaces and other categories, resulting in significant overall improvement.
Table 3 shows the accuracy comparison between the paper’s method and the other five deep learning models for urban green space classification. It can be seen that the CTSA-DeepLabV3+ model achieves significant improvement in all evaluation indexes, which is significantly higher than the other models. Specifically, the MIoU, OA, precision, recall, and F1-score of the CTSA-DeepLabV3+ model reach 89.22%, 96.21%, 92.56%, 90.12%, and 91.23%, respectively, which is the best performance among all the methods. Compared with FCN, UNet, PSPNet, UperNet-Swin Transformer, and the original DeepLabV3+ model, the overall accuracy of this model improved by 1.32%, 1.18%, 1.68%, 1.85%, and 1.08%, respectively. The CTSA-DeepLabV3+ model not only achieves a significant increase in the overall classification accuracy of the MIoU, precision, recall, and F1-score and other accuracy evaluation metrics are also significantly better than the comparison model, which indicates that it has stronger robustness and accuracy in complex scenarios and multi-category classification tasks.
To evaluate computational efficiency and performance in urban green space classification, the computational complexity (FLOPs), parameter count (Parameters), and average inference time (Inference Time) of different models were compared in this paper, as shown in
Table 4. On 256 × 256 pixel test images, the CTSA-DeepLabV3+ model has the highest computational complexity, with 123.02 G FLOPs, 118.94 M parameters, and 153.31 ms inference time. In comparison, DeepLabV3+ (44.06 G, 41.22 M, 61.20 ms) and PSPNet (44.66 G, 46.61 M, 61.13 ms) offer better computational efficiency, while FCN (72.31 G, 3.73 M, 81.60 ms) has higher computational demand but fewer parameters. UperNet-Swin Transformer (59.65 G, 58.94 M, 74.39 ms) has higher computational complexity due to its Transformer structure, but it enhances long-range dependency modeling. UNet has the lowest computational complexity, with only 1.94 G FLOPs, 1.87 M parameters, and the fastest inference time (6.02 ms), but its smaller parameter size and shallow network structure may limit its classification accuracy on high spatial resolution remote sensing images.
Despite the moderate increase in computational overhead, the CTSA-DeepLabV3+ model demonstrated superior classification accuracy, fine-grained feature extraction, and improved boundary delineation, attributed to the CoT module’s global context modeling and the SENetv2 module’s feature enhancement. These improvements significantly enhanced the generalization ability and robustness of the model, making it well-suited for tasks requiring fine classification, such as high-precision remote sensing interpretation and urban ecological monitoring.
4.3. Ablation Experiment
The improvement of the DeepLabV3+ model in the paper focused on two aspects: the introduction of a CoT module and the SENetv2 attention mechanism. The improvement effect of the CoT module and SENetv2 attention mechanism on urban green space remote sensing classification is verified by ablation experiments on the CTSA-DeepLabV3+ model, and the experimental results are shown in
Table 5. The experimental results show that all evaluation indexes of the original DeepLabV3+ model are low. By introducing the CoT module or the SENetv2 attention mechanism, respectively, the model is significantly improved in terms of classification accuracy and detail processing ability. When the CoT module was introduced, the OA, MioU, precision, recall, and F1-score of the model were improved by 0.49%, 1.22%, 0.92%, 0.93%, and 0.97%, respectively. When the SENetv2 attention mechanism is introduced, the accuracy of the model is further improved by 0.51% and 1.5% for OA and MIoU, and 1.43%, 1.17%, and 1.27% for precision, recall, and F1-score, respectively. When the CoT module and SENetv2 attention mechanisms were used jointly, all the evaluation metrics of the model reached a high level, with OA and MIoU improving by 1.08% and 3.02%, and precision, recall, and F1-score improving by 3.29%, 2.38%, and 2.84%, respectively. This indicates that the synergy between the CoT module and the SENetv2 attention mechanism further enhances the model performance, which effectively improves the classification of urban green spaces in complex scenes.
Table 6 shows the urban green space classification results of typical regional ablation experiments. From the visualization effects, significant contributions were observed from the CoT module and SENetv2 attention mechanism in enhancing global feature capture and detail extraction capabilities of the model. The CoT module captures the dynamic and local detail information of the neighboring keys through the context encoding mechanism, optimizes the learning of the attention matrix, and strengthens the visual recognition ability of the model, especially in processing complex boundary regions and texture details, thereby enabling accurate capture of boundary features and improving the overall classification accuracy. The SENetv2 attention mechanism realizes adaptive weighting of channel features through the multi-branch fully connected layer, effectively highlighting key channel information and weakening redundant interference. When it acts on deep and shallow layer feature fusion, it significantly optimizes the feature synergy ability, makes the boundary segmentation smoother, the detail classification more accurate, and reduces the phenomenon of omission and misclassification. The classification results are further improved when the CoT module and SENetv2 attention mechanism are used jointly, and the two significantly enhance the adaptability and robustness of the model in complex greenfield scenes through the synergy of global context modeling and channel feature aggregation. The improved model performs well in classifying highly textured regions and complex boundaries with smooth boundaries. This suggests that the combination of the CoT and SENetv2 attention mechanism effectively improves the segmentation details and overall performance of the urban green space classification task.
4.4. Urban Green Space Classification Results
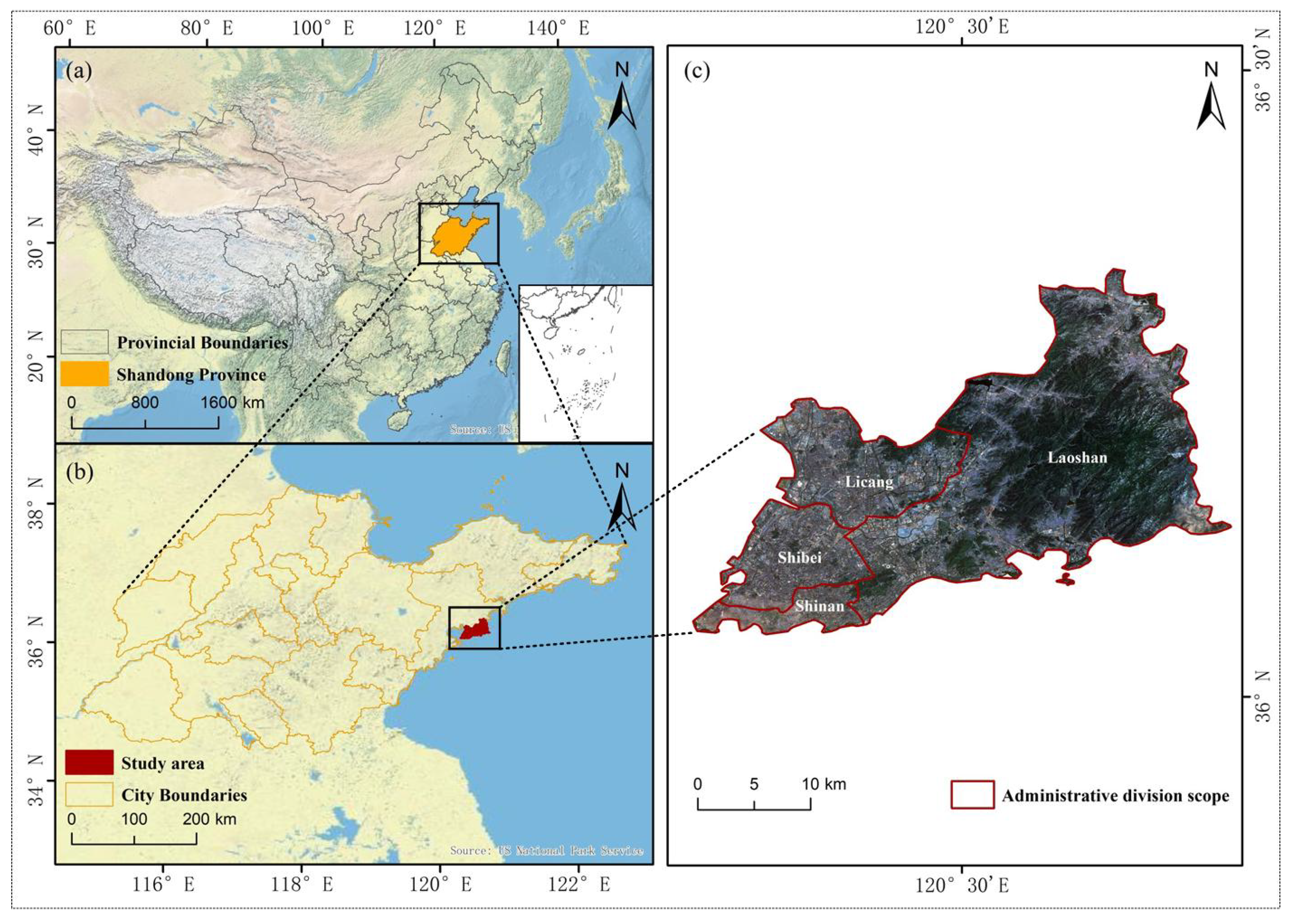
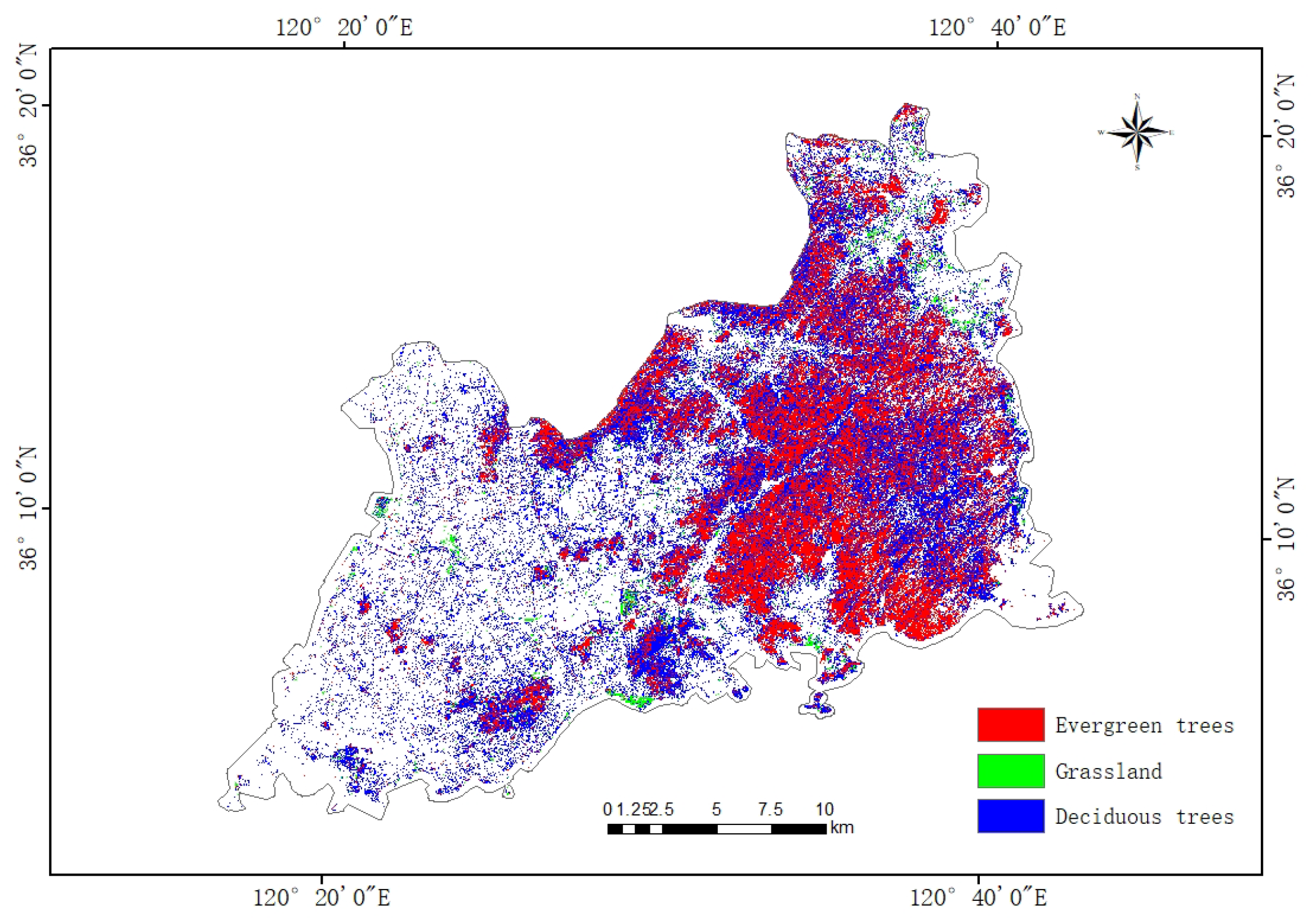
Through the above experiments, it is proved that the CTSA-DeepLabV3+ model proposed in this paper has a good classification effect on urban green space classification of high spatial resolution remote sensing images, and at the same time, it shows good model generalization ability and migration learning potential. On this basis, the paper’s urban vegetation classification system is adopted to classify the urban green space in the main urban area of Qingdao city. Its spatial distribution is shown in
Figure 8. The area of different urban green space categories was calculated using the ArcGIS platform, and the statistical results are shown in
Table 7.
The classification results show that the urban green space in the main urban area of Qingdao presents obvious spatial heterogeneity characteristics. Deciduous trees are mainly distributed in the central area of the city, covering the largest area of about 154.41 km2, indicating that seasonal vegetation dominates the urban green space system. Evergreen trees cover an area of 120.20 km2, mainly concentrated in the southern and southeastern regions, which is important for maintaining the city’s perennial greening and ecological stability. In contrast, the area of grassland is only 7.50 km2, which accounts for a relatively small proportion of the total green space in the city and is mainly distributed in the form of scattered patches.
The above results show that deciduous trees dominate the urban greening structure in the main urban area of Qingdao and are widely distributed. The spatial clustering characteristics of different green space types not only reflect the urban greening planning preferences but also are influenced by topographic conditions, land use history, and microclimate environment. The model proposed in this paper can accurately depict the spatial distribution of various types of green space in complex urban environments, better reflecting the distribution characteristics of urban green space in Qingdao’s main urban area, which is a blend of “mountain-sea-city”, and provides a reliable data basis for subsequent urban ecological assessment and green space system planning.
5. Discussion
5.1. Generalization Capability of the Improved Model in Handling Complex Images
To systematically assess the classification capability of CTSA-DeepLabV3+ across varying levels of scene complexity, this paper selected representative regions with distinct characteristics from the GF-2 dataset. These regions covered simple scenarios (such as large, homogeneous green areas), moderately complex scenarios (such as areas with interspersed vegetation and buildings), and highly complex scenarios (such as fragmented green spaces intersected by roads and areas significantly affected by shadow occlusion). Comparative analysis across these scene types confirmed the robustness and adaptability of CTSA-DeepLabV3+ in handling diverse urban environments, as detailed in
Table 8.
In simple scenarios, all models were able to accurately identify large, continuous green spaces. However, CTSA-DeepLabV3+ achieved superior performance in handling boundary details, producing clearer and more precise segmentation along edges. Due to the homogeneous texture and singular targets in such scenes, the model effectively leveraged the global context modeling capability of the CoT module, combined with the optimized spectral feature selection enabled by the SENetv2 attention mechanism, to achieve high-precision classification.
In moderately complex scenes, classification results showed frequent confusion between evergreen and deciduous trees, indicating that the model’s ability to distinguish vegetation with similar spectral characteristics still requires further improvement. In highly complex scenarios—such as those characterized by fragmented green patches, mixed distributions of vegetation, buildings, and roads, and severe shadow occlusion—the classification task proved most challenging. Although the model exhibited more frequent misclassifications in such environments, it significantly reduced issues related to blurred boundaries and segmentation fragmentation compared to baseline models. Further analysis revealed that the CoT module effectively captured the spatial distribution patterns of fragmented green spaces through dynamic contextual encoding, while the SENetv2 attention mechanism successfully suppressed interference from non-vegetation features such as building shadows.
These experimental findings demonstrate that CTSA-DeepLabV3+ approaches near-optimal performance in simple scenarios. However, its accuracy moderately declines in more complex environments as a result of increased target diversity and background interference. This degradation is primarily caused by spectral confusion induced by mixed pixels in high-resolution imagery, as well as greater morphological variability in small-scale green spaces, both of which increase the difficulty of feature representation and learning. Despite these challenges, the model exhibits enhanced robustness through several mechanisms: (i) multi-scale context fusion in the CoT module mitigates detail loss at complex boundaries; (ii) channel reweighting in SENetv2 improves inter-class feature discrimination; and (iii) the combined use of cross-entropy and Dice loss functions helps address class imbalance issues during training.
5.2. Generalization Capability of the Improved Model Across Different Geographic Regions
To further evaluate the generalization capability of the model under varying geographic conditions, this study selected several urban areas in Nanjing—characterized by distinct spatial structures of urban green spaces and different geographic locations—as test regions. The model was directly transferred to GF-2 imagery of Nanjing without retraining, and its performance was systematically assessed in terms of classification accuracy and boundary delineation quality. This experiment aimed to validate the model’s generalizability across urban environments with diverse regional characteristics, see
Figure 9.
The test results indicate that the improved model exhibits good generalization capability in classifying green space types in the urban areas of Nanjing. Overall, the spatial distribution patterns of the three green space categories are clearly delineated. In particular, the model accurately identified green boundaries and effectively distinguished between vegetation types in areas such as urban parks, residential green spaces, and institutional green areas. Evergreen trees were mainly concentrated in park core zones and along certain roadside green belts. The model achieved stable segmentation performance for this class, with strong edge continuity and well-defined boundary contours. Deciduous trees, which had a wider spatial distribution, were effectively segmented into streets, residential areas, and open green zones. The model successfully differentiated them from adjacent grasslands and evergreen vegetation. Grasslands were primarily located in open urban spaces and along riverfront landscapes. The segmentation results were largely consistent with the actual spatial layout, and the classification boundaries showed smooth transitions, reflecting a high degree of spatial coherence.
However, some confusion between deciduous and evergreen trees persisted in shadow-covered areas of high-density urban blocks, especially in zones with densely interlaced green belts, likely due to spectral mixing effects that caused boundary ambiguity. In addition, misclassification between grass and deciduous trees occasionally occurred in regions with exposed soil or low-stature herbaceous vegetation, indicating that the model still encounters challenges in fine-grained classification when applied to cross-regional samples.
These findings confirm that the proposed model demonstrates strong transferability and high classification accuracy in the Nanjing region. It effectively adapts to variations in urban green space structures and spectral characteristics across different geographic contexts, underscoring its robust regional generalization performance.
6. Conclusions
A high spatial resolution urban green space sample dataset was constructed based on GF-2 remote sensing images, and the CTSA-DeepLabV3+ model was proposed by improving the traditional DeepLabV3+ structure to achieve more efficient, accurate, and intelligent urban green space classification. In the improved model, the CoT module and SENetv2 attention mechanism were integrated into the decoder, alleviating the mismatch between the encoder and decoder structures, capturing global contextual information, optimizing channel feature representation, and enhancing classification performance.
Experimental results show that the CTSA-DeepLabV3+ model achieved an overall accuracy (OA) of 96.21%, a mean intersection over union (MIoU) of 89.22%, and precision, recall, and F1 scores of 92.56%, 90.12%, and 91.23%, respectively. Compared with five representative baseline models (FCN, U-Net, PSPNet, DeepLabV3+, and UperNet-Swin Transformer), the proposed model consistently outperformed them in all accuracy metrics. Moreover, the model demonstrated strong capability in classifying complex and heterogeneous urban green spaces, accurately distinguishing between multiple vegetation types such as evergreen trees, deciduous trees, and grasslands, thus substantially improving multi-class discrimination. Although the introduction of attention modules led to a slight increase in computational complexity and inference time, this trade-off resulted in better classification accuracy, stronger fine-grained feature extraction, and improved boundary delineation, while still maintaining relatively high inference efficiency. These advantages make the model well-suited for high-resolution remote sensing image analysis. Furthermore, validation in a geographically distinct test area—urban Nanjing—confirmed that the model retained high classification accuracy and boundary recovery performance, further demonstrating its strong regional generalization ability.
However, the current model remains sensitive to the quality of remote sensing imagery, and low-quality inputs may adversely affect classification accuracy. Future research will consider integrating multi-source remote sensing data to enhance the model’s robustness under varying data conditions. In addition, incorporating richer auxiliary feature information into the deep learning framework is planned to further advance urban green space classification toward greater precision and intelligence.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}