In order to comprehensively explore the specific roles played by the proposed HETMCL as a whole and its different internal modules within the framework, a series of ablation experiments were carried out. By gradually removing certain modules from the model or changing the settings of some modules and observing the changes in the model’s performance, it is possible to clearly and intuitively analyze the contribution of each module to the overall performance and thus determine the effectiveness of each module within the entire framework. All ablation experiments were conducted on the AID dataset, with the training rates set at 20% and 50%.
5.1. Effectiveness of AFFM
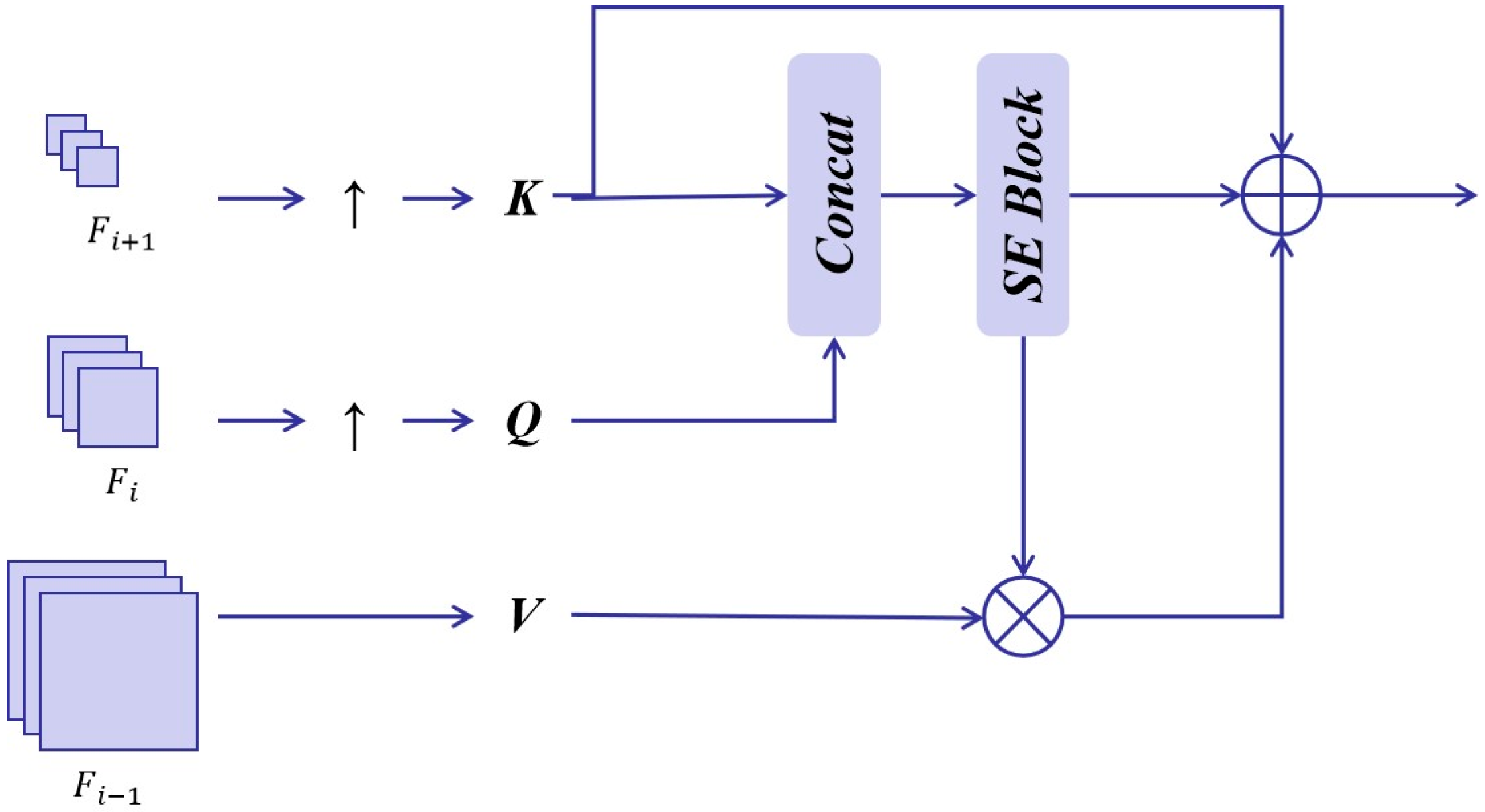
As described in
Section 2, our AFFM is designed to efficiently extract complementary multi-layered features from pretrained ResNet18. In total, the following three models were built for comparison:
- (1)
Net–0: HETMCL without AFFM: The AFFM is removed (features are upsampled to the same size, with simple additions).
- (2)
Net–1: HETMCL with FPN: The AFFM is replaced by FPN (without the global weight injecting operation).
- (3)
Net–2: HETMCL with AFFM.
The results are shown in
Table 5. The results show that both the Adjacent Layer Feature Fusion Module (AFFM) and the Feature Pyramid Network structure (FPN) have a positive impact on the classification performance. Among several network settings, Net-2 achieves better performance than Net-1 and Net-0, and Net-0 has the worst result. The root cause of Net-0’s poor performance lies in the aliasing effect caused by the upsampling operation. The aliasing effect refers to the phenomena of feature repetition, redundancy, or mutual interference that may occur during upsampling. The upsampling operation itself is aimed at changing the size of the feature map to meet the requirements of the feature scale in the subsequent processing stage. However, in this process, there inevitably emerges the problem that it is difficult to align the high-level semantic features with the shallow-level positioning detail features. High-level semantic features often contain more abstract and generalized information, which represents a high-level understanding of the overall content of the image at the semantic level, while the shallow-level positioning detail features focus on recording the local and detailed visual information in the image, such as edges, textures, etc.
Compared with Net-0, Net-1 has a better effect. After obtaining the additive features, FPN will use a 3 × 3 convolution to fuse the generated features. The 3 × 3 convolution plays a key role here. By re-combining and optimizing the features, it eliminates the overlapping effect brought about by the upsampling process and provides higher-quality and more relevant features for the subsequent classification operation.
In all cases, Net-2 performs the best. This demonstrates the effectiveness of the global weight injection operation adopted by AFFM in extracting and integrating multi-layer features. Specifically, the global weight injection operation can consider the internal connections and respective importance degrees of features at different levels from the macroscopic perspective of the entire model, avoiding the unreasonable utilization of features or information loss. In this way, it not only enhances the semantic expression ability of a single feature but also makes the integrated multi-layer features have stronger semantic representativeness as a whole and can provide more discriminative features for subsequent classification.
5.2. Effectiveness of HFIE
The HFIE is designed to perceive global pixels through frequency-domain analysis and supplement the high-frequency texture details lost in the spatial domain due to the convolution operation. To verify the effectiveness of the HFIE, we compared the performance of models that only use the high-frequency mixer, the low-frequency mixer, the global branch only, and the complete HFIE. The following networks were designed:
- (1)
Net–0: HETMCL without HFIE: The HFIE is removed.
- (2)
Net–1: HETMCL without HFIE Low–frequency Mixer
- (3)
Net–2: HETMCL without HFIE High–frequency Mixer
- (4)
Net–3: HETMCL with full HFIE
The results are depicted in
Table 6. Among these three networks, Net-0 has the weakest performance. After introducing the high-frequency mixer and low-frequency mixer proposed in this paper, Net-1 and Net-2 outperform Net-0 in all scenarios. This phenomenon fully demonstrates the positive roles played by these two mixer branches. The low-frequency mixer has a global receptive field, which can break through the limitations of the local scope and effectively capture the global low-frequency information from a global scale. It models the global context by calculating global self-attention, enabling the model to focus on the correlations between features, thus excavating the overall semantic and structural features.
The high-frequency mixer plays another key role in supplementing the lost high-frequency texture details. During the process of calculating the global self-attention, the operation of dividing the image into image patches will inevitably lead to the loss of some high-frequency texture details, and the high-frequency mixer can specifically make up for this deficiency. It is good at capturing texture and shape features. Supplementing the high-frequency texture details makes the feature information of the model more complete and further improves the classification accuracy.
Net-3 achieves the best results in all cases, and the main reason is that it realizes the effective fusion of high-frequency and low-frequency information. The detailed features, such as textures and shapes, that the high-frequency mixer is good at capturing form a good complementary relationship with the global modeling carried out by the low-frequency mixer. The low-frequency mixer grasps the global information from a macroscopic perspective and constructs the overall semantic and structural framework; the high-frequency mixer supplements the detailed features from a microscopic perspective, making the overall feature description more refined. Moreover, this collaborative method skillfully takes advantage of the sensitivity of CNNs to local features and the ability of Transformers to capture long-range dependencies. The advantages of the two are synergistically exerted through the fusion of high-frequency and low-frequency information, focusing the model’s attention on the important areas where the scene objects are located. Therefore, Net-3 can exhibit the best classification performance in various scenarios.
5.5. Analysis of HFIE
- (1)
Comparison with Other Architectures
In order to more fully demonstrate its performance advantages and competitiveness among similar methods, we selected multiple representative Vision Transformer architectures for comparison. These include the original Vision Transformer architecture, namely ViT [
14], as well as several improved Transformer architectures that have shown certain influence in related fields, including Pyramid Vision Transformer (PVT [
61]), Swin Transformer (Swin [
59]), and CMT [
15]. To ensure fairness, we only replaced the HFIE with ViT, PVT, Swin, and CMT, respectively, to construct new networks so as to observe the impact of the integration of different architectures on the performance of the entire model. The results are shown in
Table 9.
Judging from the tabular data, all models participating in the comparison showed acceptable overall performance on multiple performance metrics. Although there are differences in calculation quantity (GFLOPs), parameter quantity (Para (M)) and inference speed (FPS), the values of the key evaluation indicators are at a high level under the conditions of Tr = 20% and Tr = 50% (both above 95), which fully verifies the powerful context information learning ability of the transformer model.
In the comparative experiments of the HETMCL model with different Transformer architectures, the data further reveals performance differences. In terms of the comprehensive performance of computational complexity, parameter count, and inference speed, HETMCL models equipped with PVT, Swin, and CMT exhibit more significant advantages compared to HETMCL using ViT. Among them, although HETMCL based on the Swin architecture has a slightly lower inference speed than the ViT architecture (50.72 FPS vs. 52.96 FPS), it still demonstrates excellent performance indicators under the test conditions of Tr = 20% and Tr = 50%, indicating that this type of architecture can better balance computational resources and model performance. It is worth emphasizing that the proposed HETMCL method achieves optimal classification performance in all comparison scenarios. Taking HETMCL integrated with the HFIE module as an example, when Tr is 20% and 50%, its classification accuracies reach 95.91 and 97.32, respectively, which are significantly higher than those of other comparative models. In the quantitative comparison with ViT, Swin-T, and CMT, although HETMCL has slightly higher GFLOPs (12.28 vs. 10.36 for Swin-T), its parameter count (20.08M) remains competitive, and the FPS (50.23) is within 3% of Swin-T (51.72). In terms of classification accuracy, a critical performance indicator, HETMCL demonstrates significant improvements. Take HETMCL integrated with the HFIE module as an example: its classification accuracy reaches 97.32 at a test ratio (Tr) of 50%, significantly outperforming other comparative models. Such performance improvements typically come at the cost of increased computational load. However, when the practical value brought by accuracy improvements surpasses the computational cost, the increase in computational load becomes justifiable. Through evaluation, the increase in model computational complexity is still within an acceptable range, which indicates that while pursuing high performance, HETMCL does not lose its practical application feasibility due to the increase in computational volume.
Compared with other methods, HETMCL innovatively introduces a High-Frequency and Low-Frequency Feature Interaction Module (HFIE). By fusing feature information of different frequencies, this module can more efficiently capture the detailed textures and global structures in remote sensing images. In contrast, PVT adopts a progressive pyramid structure to enhance multi-scale feature representation, and Swin introduces a hierarchical windowing mechanism, dividing the input image into several overlapping local windows, and applies Transformer operations within these windows. CMT replaces the self-attention mechanism with convolution. None of these models involve explicit processing of frequency features, while the HFIE module of HETMCL fills this gap and provides a brand-new idea for the design of hybrid models.
- (2)
The Influence of the Number of HFIE
In the High-Frequency Information Enhancement (HFIE) component, the number of HLFTM modules significantly influences model behavior. Stacking multiple HLFTMs enhances the model’s capacity to learn complex data representations through hierarchical feature abstraction. However, excessive module accumulation introduces challenges: overfitting risks escalate as redundant components may overemphasize training data noise and trivial details, undermining the model’s generalization to unseen samples. Concurrently, deep stacking of HLFTMs may induce gradient instability issues, such as vanishing or exploding gradients, during backpropagation.
To systematically analyze the impact of HLFTM count on model performance, we instantiated a series of HETMCL variants with varying module configurations: we used one HLFTM to construct HETMCL-T, two HLFTMs to construct HETMCL-S, three HLFTMs to construct HETMCL-B, and four HLFTMs to construct HETMCL-L. In this way, we can intuitively observe the specific change trend of the model performance as the number of HLFTMs changes. From the performance results of different models shown in
Figure 14, we found that the performance of HETMCL under different parameter values k (that is, different numbers of HLFTMs) is relatively similar. This phenomenon indicates that our HETMCL is not sensitive to the selection of the parameter k; that is, the model can adapt to changes in the number of HLFTMs to a certain extent without significant fluctuations in performance. Although there is a slight upward trend in performance as the number of HLFTMs increases, considering the balance between computational complexity and performance in practical applications, an excessive number of HLFTMs will increase the consumption of computational resources and the computation time, while the performance improvement is not significant. Therefore, after a comprehensive trade-off, we finally chose to use only one HLFTM to construct HETMCL. In this way, it can not only ensure that the model has a certain performance level but also maintain a good balance in terms of computational resources and time costs.
- (3)
Spectral Analysis
Through performing a two-dimensional Fourier transform (2D-FFT) on visualized feature maps, the spectral distribution of features can be characterized. The 2D-FFT enables the conversion of images from the spatial domain to the frequency domain, where frequency components at distinct positions encode feature information across different scales and orientations. Specifically, the central region of the frequency spectrum represents low-frequency components corresponding to global image characteristics such as general contours and smooth regions, while peripheral regions denote high-frequency components associated with local details, including edges, textures, and fine structures.
During the spectral analysis, we conducted an in-depth investigation of feature maps from three hierarchical levels of HFIE modules within HETMCL. Taking the second-level HFIE as an illustrative case, we compared two critical feature maps: one constructed using only the low-frequency mixer and the other employing the full HFIE architecture integrating both low-frequency and high-frequency mixers. The comparative results are visualized in
Figure 15.
From the comparison of the frequency spectrum diagrams, it is clear that there are significant differences in the frequency components of the feature maps constructed by the two methods. The central bright spots in both diagrams represent low-frequency components. The central bright spot in
Figure 15a is brighter than that in the left-hand diagram, and the surrounding green area is larger and brighter. This indicates that the low-frequency components in the corresponding feature map have stronger energy and a larger proportion, meaning that it contains more information about the global structure of the image. The high-frequency region is relatively dim, suggesting that the high-frequency components in the feature map corresponding to the spectrum of the feature map constructed only with a low-frequency mixer have relatively lower energy. The low-frequency components dominate, which means that this method performs outstandingly in obtaining the macroscopic and overall information of the image. For example, a remote-sensing image can better capture the general outline of the terrain and the overall distribution of urban areas. However, due to the relatively low energy of the high-frequency components, its ability to capture detailed information, such as the fine structure of buildings and the texture of roads in the image, is relatively limited. In
Figure 15b, the high-frequency region away from the center is relatively more prominent, with brighter points distributed around. The high-frequency components in the corresponding feature map have relatively stronger energy and contain more information about details and edges. This enables it to keenly capture the detailed features in the image, such as the edge trends of rivers and the texture differences of vegetation in remote-sensing images. By combining the low-frequency and high-frequency mixers, the complete HFIE structure can extract and retain high-frequency information and performs well in capturing both the macroscopic features and local details of the image.
To analyze the proportions of each frequency, we performed a Power Spectral Density (PSD) calculation, and the results are as follows in
Table 10:
This metric quantifies the relative emphasis on high-frequency details. As shown in
Figure 15, the full HFIE architecture exhibits a 46% increase in EPI compared to the low-frequency-only variant, indicating enhanced retention of fine-grained features. Spectral entropy analysis further reveals that the full HFIE achieves a 12.7% higher entropy value (3.21 vs. 2.85 nats), demonstrating a more balanced distribution of information across frequency bands. Specifically, the central luminance in
Figure 15a exhibits a 37.2% higher pixel intensity (measured via region-of-interest analysis) compared to
Figure 15b, with the surrounding green area (indicating intermediate frequencies) expanding by 29.5% in radius and 41.8% in integrated brightness. These metrics indicate that the low-frequency mixer-only approach retains stronger energy in global structural features, accounting for 83.2±1.7% of total spectral power.
5.6. Visual Analysis
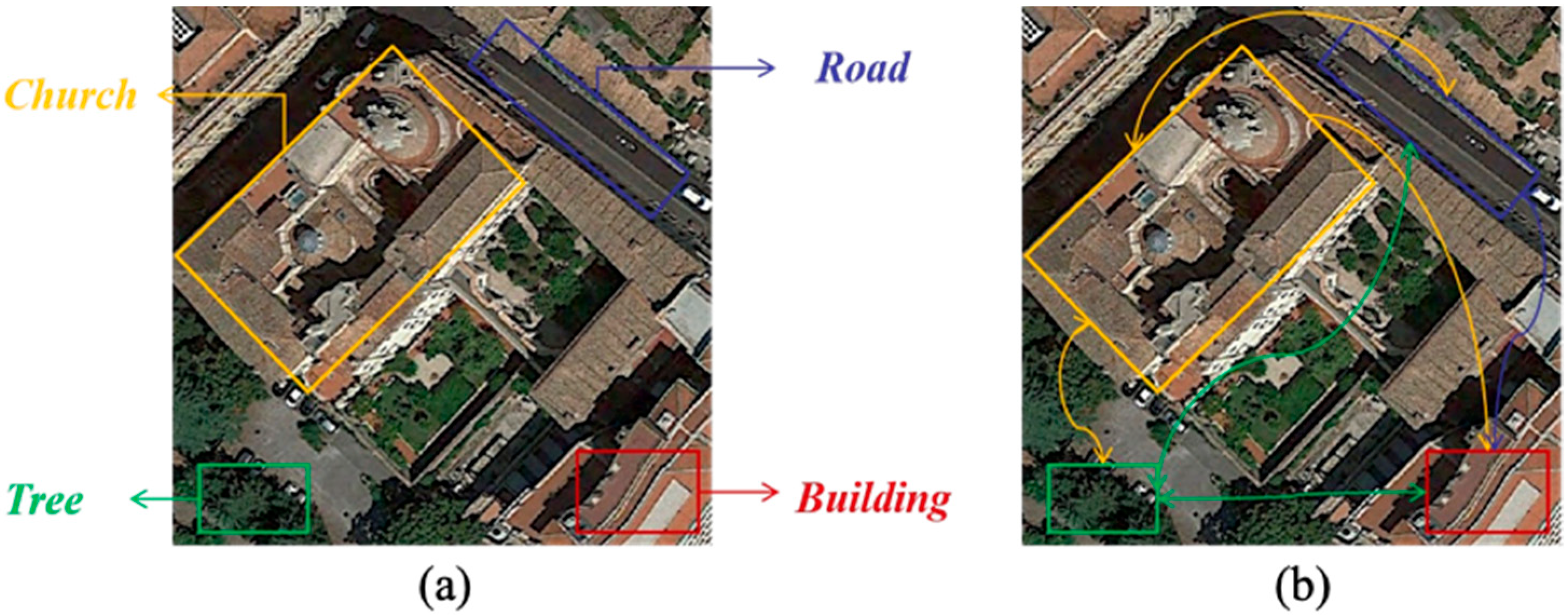
In this section, we use the Grad-CAM (Gradient-weighted Class Activation Mapping) technique to generate visual explanations. The core objective is to highlight the regions in the image that play a crucial role in predicting the corresponding objects. In this way, we can intuitively understand which parts of the image the model mainly focuses on when making classification decisions. In the class activation map, the shade of color represents the weight level. The darker the color, the higher the attention of the model to that region.The results are shown at
Figure 16.
Target Region Recognition Accuracy: On the AID dataset, HETMCL outperforms ResNet18 in remote sensing scene classification. ResNet18 roughly identifies target areas but lacks detail, with diffuse activation (e.g., scattered across airport edges). HETMCL without HFIE focuses more on core regions (e.g., airport buildings/runways) but still has scattered activations. In contrast, full HETMCL concentrates attention tightly on classification-relevant areas, enabling precise localization.
Widely Distributed Target Recognition: For playground images, ResNet18’s activation scatters across sports fields and surroundings, indicating interference and incomplete target coverage. The HFIE-free model focuses on lawns and runways but retains edge activations. HETMCL comprehensively covers core sports areas, suppresses irrelevant edges, and extracts features more accurately for superior classification.
The visualization results reveal the internal mechanism of the model’s classification from the perspective of feature-focused regions. Subsequently, we used OA and Kappa to further demonstrate the classification performance of the model on different datasets from a quantitative perspective.The results are shown at
Table 11.
On the UCM dataset, the OA and Kappa coefficients under both division ratios are extremely high, indicating that the model has very good classification accuracy and consistency on this dataset. The classification results of the algorithm have a strong consistency with the real situation, and the influence of random factors on the classification results is minimal, showing excellent algorithm performance.
On the AID dataset, both the OA and Kappa coefficients are relatively high, indicating that the classification results of the algorithm have good consistency with the real situation. As the ratio of the training set to the test set changes, the performance of the model also improves. The indicators under the (5:5) division are higher than those under the (2:8) division, suggesting that a more balanced data division is conducive to the model’s learning, thereby improving classification accuracy and consistency.
On the NWPU dataset, although the OA and Kappa are relatively lower compared to the other two datasets as a whole, the performance of the algorithm also improves as the proportion of the training set increases. The indicators under the (2:8) division are higher than those under the (1:9) division, also indicating that increasing the proportion of the training set can improve the classification performance of the model.
Combining the results of visualization and quantitative analysis, the HETMCL model demonstrates unique advantages. At the visualization level, it can accurately focus on the key features of the target area, intuitively reflecting its ability to capture core information. In terms of quantitative indicators, although its performance varies across different datasets, the overall trend is positive, highlighting the model’s adaptability to data structures.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}