
CINet: A Constraint- and Interaction-Based Network for Remote Sensing Change Detection

Abstract
1. Introduction
2. Related Work
2.1. Classical Change Detection Methods
2.2. Feature Interaction
2.3. Model Constraint
3. Materials and Methods
3.1. Notation and Preliminaries
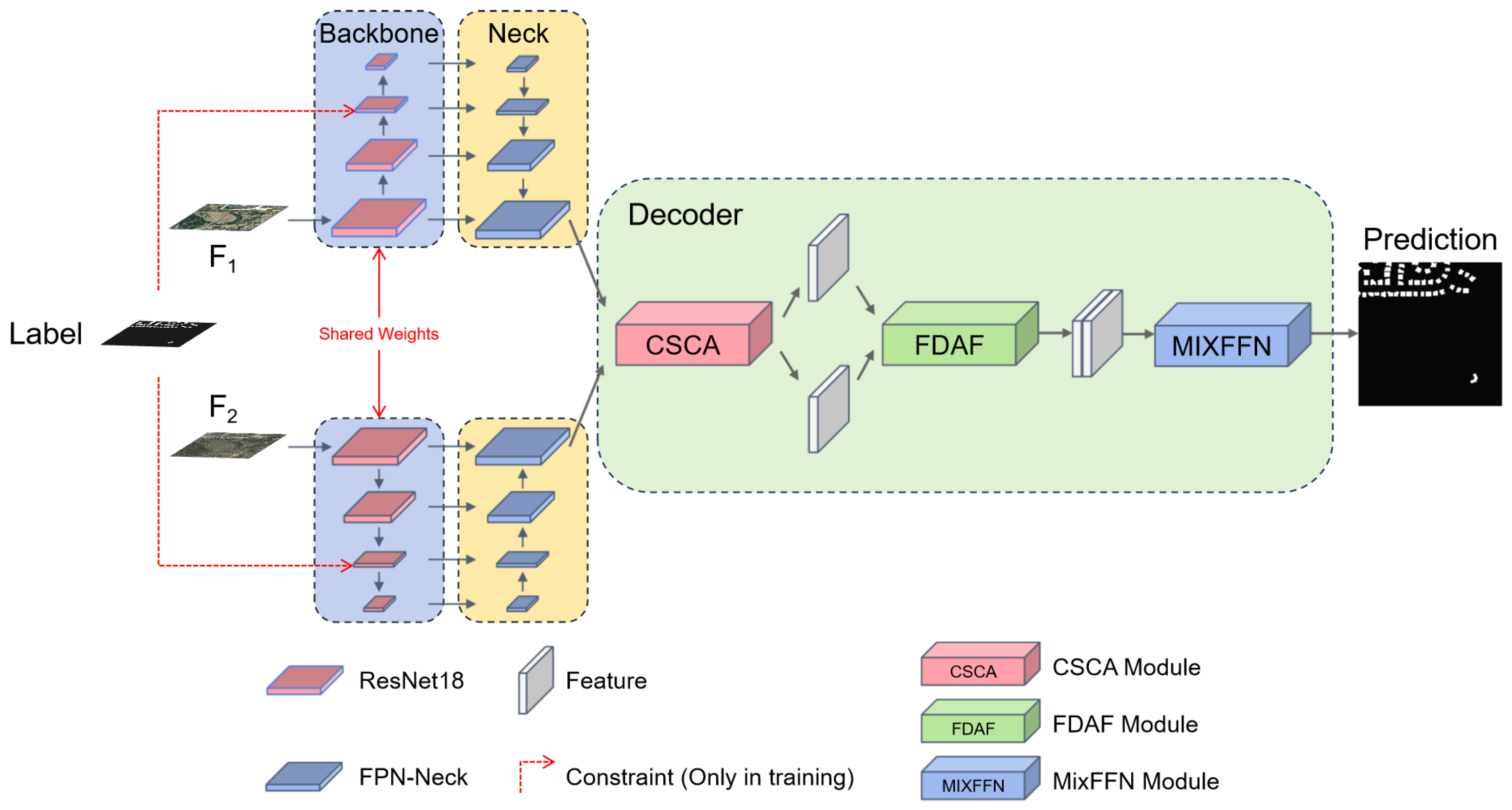
3.2. Overall Architecture
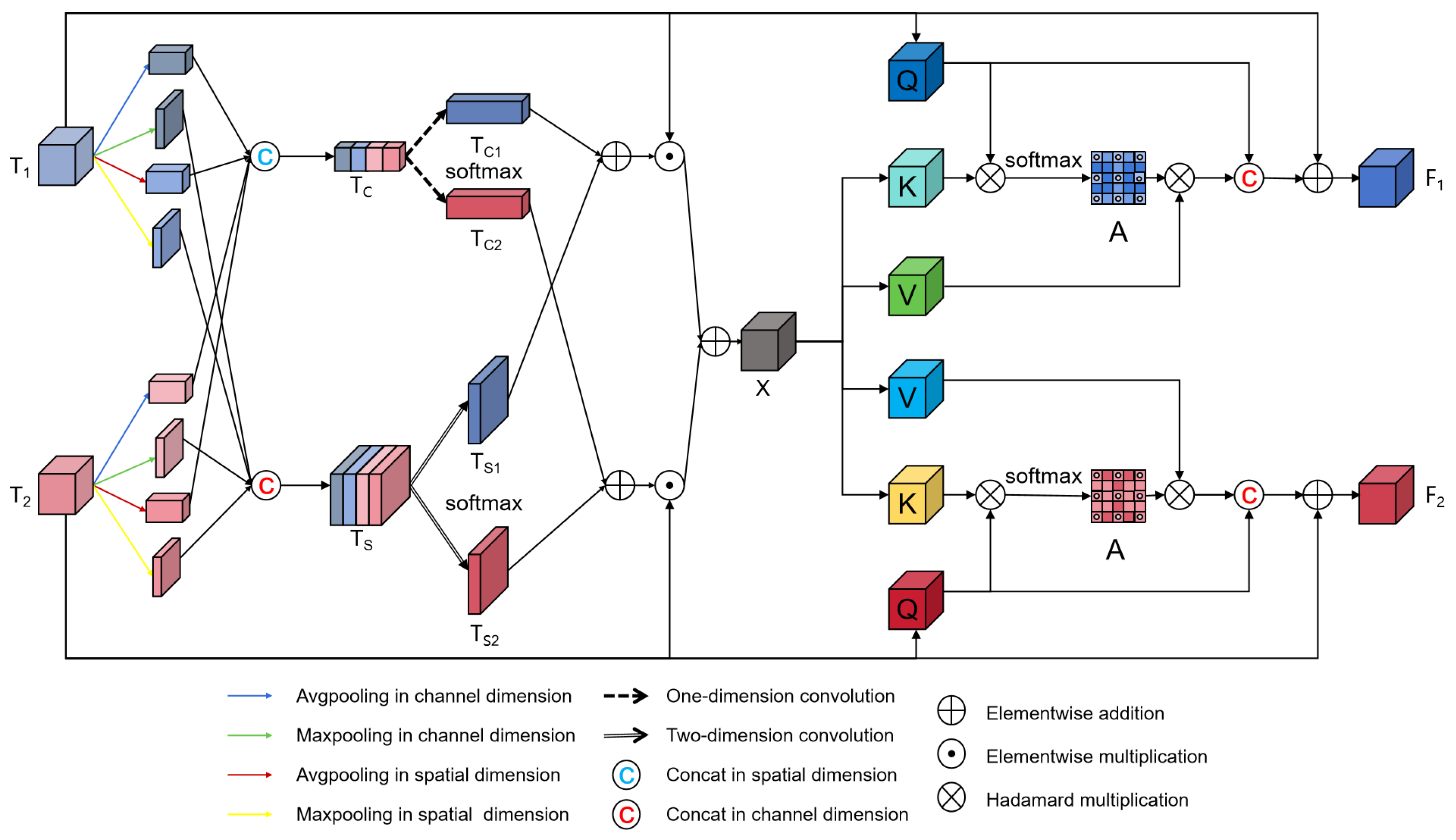
3.3. Cross-Spatial-Channel Attention Module
3.4. Change Constraint
3.4.1. Unchanged Area Constraint
3.4.2. Changed Area Constraint
3.4.3. All-Area Constraint
4. Experimental Results
4.1. Dataset
4.2. Evaluation Metrics
4.3. Implementation Detail
4.4. Main Results
4.5. Constraint Results
4.6. Ablation Studies
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Toker, A.; Kondmann, L.; Weber, M.; Eisenberger, M.; Camero, A.; Hu, J.; Hoderlein, A.P.; Şenaras, Ç.; Davis, T.; Cremers, D.; et al. DynamicEarthNet: Daily Multi-Spectral Satellite Dataset for Semantic Change Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 21158–21167. [Google Scholar]
- Shen, L.; Lu, Y.; Chen, H.; Wei, H.; Xie, D.; Yue, J.; Chen, R.; Lv, S.; Jiang, B. S2Looking: A satellite side-looking dataset for building change detection. Remote Sens. 2021, 13, 5094. [Google Scholar] [CrossRef]
- Verma, S.; Panigrahi, A.; Gupta, S. QFabric: Multi-task change detection dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1052–1061. [Google Scholar]
- Daudt, R.C.; Le Saux, B.; Boulch, A. Fully convolutional siamese networks for change detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 4063–4067. [Google Scholar]
- Chen, H.; Shi, Z. A spatial-temporal attention-based method and a new dataset for remote sensing image change detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Bandara, W.G.C.; Patel, V.M. A Transformer-Based Siamese Network for Change Detection. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Lumpur, Malaysia, 17–22 July 2022; pp. 207–210. [Google Scholar]
- Chen, H.; Qi, Z.; Shi, Z. Remote Sensing Image Change Detection with Transformers. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5607514. [Google Scholar] [CrossRef]
- Fang, S.; Li, K.; Li, Z. Changer: Feature Interaction is What You Need for Change Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5610111. [Google Scholar] [CrossRef]
- Hearst, M.; Dumais, S.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Their Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Abdi, H.; Williams, L.J. Principal component analysis. WIREs Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- Johnson, R.D.; Kasischke, E.S. Change vector analysis: A technique for the multispectral monitoring of land cover and condition. Int. J. Remote Sens. 1998, 19, 411–426. [Google Scholar] [CrossRef]
- Zheng, Z.; Ma, A.; Zhang, L.; Zhong, Y. Change is everywhere: Single-temporal supervised object change detection in remote sensing imagery. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 15193–15202. [Google Scholar]
- Fang, S.; Li, K.; Shao, J.; Li, Z. SNUNet-CD: A densely connected Siamese network for change detection of VHR images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 8007805. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhong, Y.; Tian, S.; Ma, A.; Zhang, L. ChangeMask: Deep multi-task encoder-transformer-decoder architecture for semantic change detection. ISPRS J. Photogramm. Remote Sens. 2022, 183, 228–239. [Google Scholar] [CrossRef]
- Chen, P.; Zhang, B.; Hong, D.; Chen, Z.; Yang, X.; Li, B. FCCDN: Feature constraint network for VHR image change detection. ISPRS J. Photogramm. Remote Sens. 2022, 187, 101–119. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Yeh, C.H.; Lin, M.H.; Chang, P.C.; Kang, L.W. Enhanced Visual Attention-Guided Deep Neural Networks for Image Classification. IEEE Access 2020, 8, 163447–163457. [Google Scholar] [CrossRef]
- Shen, J.; Chen, Y.; Liu, Y.; Zuo, X.; Fan, H.; Yang, W. ICAFusion: Iterative Cross-Attention Guided Feature Fusion for Multispectral Object Detection. Pattern Recognit. 2023, 145, 109913. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, Red Hook, NY, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Zhou, H.; Qi, L.; Wan, Z.; Huang, H.; Yang, X. RGB-D Co-attention Network for Semantic Segmentation. In Proceedings of the Computer Vision—ACCV 2020: 15th Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020; Revised Selected Papers, Part I. Springer: Berlin/Heidelberg, Germany, 2020; pp. 519–536. [Google Scholar]
- Antol, S.; Agrawal, A.; Lu, J.; Mitchell, M.; Batra, D.; Zitnick, C.L.; Parikh, D. VQA: Visual Question Answering. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2425–2433. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3141–3149. [Google Scholar]
- Chen, Q.; Wu, Q.; Wang, J.; Hu, Q.; Hu, T.; Ding, E.; Cheng, J.; Wang, J. MixFormer: Mixing Features across Windows and Dimensions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5249–5259. [Google Scholar]
- Cheng, G.; Huang, Y.; Li, X.; Lyu, S.; Xu, Z.; Zhao, H.; Zhao, Q.; Xiang, S. Change Detection Methods for Remote Sensing in the Last Decade: A Comprehensive Review. Remote Sens. 2024, 16, 2355. [Google Scholar] [CrossRef]
- Xu, Y.; Narayan, A.; Tran, H.; Webster, C.G. Analysis of the ratio of l1 and l2 norms in compressed sensing. Appl. Comput. Harmon. Anal. 2021, 55, 486–511. [Google Scholar] [CrossRef]
- Parekh, J.; Parekh, S.; Mozharovskyi, P.; Richard, G.; d’Alché Buc, F. Tackling Interpretability in Audio Classification Networks with Non-negative Matrix Factorization. IEEE/ACM Trans. Audio Speech Lang. Process. 2024, 32, 1392–1405. [Google Scholar] [CrossRef]
- Hazan, H.; Manevitz, L.M. Topological constraints and robustness in liquid state machines. Expert Syst. Appl. 2012, 39, 1597–1606. [Google Scholar] [CrossRef]
- Wang, Z.; Zhou, X.; Xu, C.; Gao, F. Geometrically Constrained Trajectory Optimization for Multicopters. IEEE Trans. Robot. 2022, 38, 3259–3278. [Google Scholar] [CrossRef]
- Zhao, S.; Zhang, X.; Xiao, P.; He, G. Exchanging Dual-Encoder–Decoder: A New Strategy for Change Detection with Semantic Guidance and Spatial Localization. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–16. [Google Scholar] [CrossRef]
- Kirillov, A.; Girshick, R.; He, K.; Dollar, P. Panoptic Feature Pyramid Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Ji, S.; Wei, S.; Lu, M. Fully Convolutional Networks for Multisource Building Extraction From an Open Aerial and Satellite Imagery Data Set. IEEE Trans. Geosci. Remote Sens. 2019, 57, 574–586. [Google Scholar] [CrossRef]
- Shi, Q.; Liu, M.; Li, S.; Liu, X.; Wang, F.; Zhang, L. A Deeply Supervised Attention Metric-Based Network and an Open Aerial Image Dataset for Remote Sensing Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5604816. [Google Scholar] [CrossRef]
- Zhang, J.; Shao, Z.; Ding, Q.; Huang, X.; Wang, Y.; Zhou, X.; Li, D. AERNet: An Attention-Guided Edge Refinement Network and a Dataset for Remote Sensing Building Change Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5617116. [Google Scholar] [CrossRef]
- Zhang, C.; Yue, P.; Tapete, D.; Jiang, L.; Shangguan, B.; Huang, L.; Liu, G. A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 166, 183–200. [Google Scholar] [CrossRef]
- Li, K.; Jiang, J.; Codegoni, A.; Han, C.; Deng, Y.; Chen, K.; Zheng, Z.; Chen, H.; Zou, Z.; Shi, Z.; et al. Open-CD: A Comprehensive Toolbox for Change Detection. arXiv 2024, arXiv:2407.15317. [Google Scholar]
- Contributors, M. MMCV: OpenMMLab Computer Vision Foundation. 2018. Available online: https://github.com/open-mmlab/mmcv (accessed on 1 September 2024).
- Liu, Y.; Pang, C.; Zhan, Z.; Zhang, X.; Yang, X. Building change detection for remote sensing images using a dual-task constrained deep siamese convolutional network model. IEEE Geosci. Remote Sens. Lett. 2020, 18, 811–815. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Chen, H.; Li, W.; Shi, Z. Adversarial instance augmentation for building change detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5603216. [Google Scholar] [CrossRef]
- Han, C.; Wu, C.; Du, B. HCGMNet: A Hierarchical Change Guiding Map Network for Change Detection. In Proceedings of the IGARSS 2023—2023 IEEE International Geoscience and Remote Sensing Symposium, Pasadena, CA, USA, 16–21 July 2023; pp. 5511–5514. [Google Scholar]
- Wu, P.; He, X.; Tang, M.; Lv, Y.; Liu, J. HANet: Hierarchical Alignment Networks for Video-Text Retrieval. In Proceedings of the 29th ACM International Conference on Multimedia, Online, 20–24 October 2021; pp. 1–12. [Google Scholar]
- Guo, Q.; Zhang, J.; Zhu, S.; Zhong, C.; Zhang, Y. Deep Multiscale Siamese Network with Parallel Convolutional Structure and Self-Attention for Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5406512. [Google Scholar] [CrossRef]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified Perceptual Parsing for Scene Understanding. In Proceedings of the Computer Vision—ECCV 2018: 15th European Conference, Munich, Germany, 8–14 September 2018; Proceedings, Part V. Springer: Berlin/Heidelberg, Germany, 2018; pp. 432–448. [Google Scholar]
- Wu, T.; Tang, S.; Zhang, R.; Zhang, Y. CGNet: A Light-weight Context Guided Network for Semantic Segmentation. IEEE Trans. Image Process. 2019, 30, 1169–1179. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Peng, D.; Bruzzone, L.; Zhang, Y.; Guan, H.; He, P. SCDNET: A novel convolutional network for semantic change detection in high resolution optical remote sensing imagery. Int. J. Appl. Earth Obs. Geoinf. 2021, 103, 102465. [Google Scholar] [CrossRef]
- Ji, D.; Gao, S.; Tao, M.; Lu, H.; Zhao, F. Changenet: Multi-Temporal Asymmetric Change Detection Dataset. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 2725–2729. [Google Scholar]
- Lei, T.; Wang, J.; Ning, H.; Wang, X.; Xue, D.; Wang, Q.; Nandi, A.K. Difference Enhancement and Spatial–Spectral Nonlocal Network for Change Detection in VHR Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4507013. [Google Scholar] [CrossRef]
- Wang, J.; Yao, L.; Wang, Y. IFNet: An Interactive Frequency Convolutional Neural Network for Enhancing Motor Imagery Decoding From EEG. IEEE Trans. Neural Syst. Rehabil. Eng. 2023, 31, 1900–1911. [Google Scholar] [CrossRef]
- Li, S.; Liu, F. SVNet: A Single View Network for 3D Shape Recognition. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–23 July 2019; pp. 1648–1653. [Google Scholar]
- Chen, J.; Yuan, Z.; Peng, J.; Chen, L.; Huang, H.; Zhu, J.; Liu, Y.; Li, H. DASNet: Dual Attentive Fully Convolutional Siamese Networks for Change Detection in High-Resolution Satellite Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 1194–1206. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | LEVIR-CD [5] | S2Looking [2] | WHU-CD [33] | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1 | Precision | Recall | F1 | Precision | Recall | F1 | ||
| FC-EF [4] | - | 86.91 | 80.17 | 83.40 | 81.36 | 8.95 | 7.65 | 77.24 | 68.88 | 72.82 |
| FC-Siam-Conc [4] | - | 91.99 | 76.77 | 83.69 | 68.27 | 18.52 | 13.54 | 76.94 | 69.74 | 73.17 |
| FC-Siam-Diff [4] | - | 89.53 | 83.31 | 86.31 | 83.29 | 15.76 | 13.19 | 71.61 | 73.40 | 72.49 |
| DTCDSCN [39] | SE-Res34 [21] | 88.53 | 86.83 | 87.67 | 68.58 | 49.16 | 57.27 | 90.15 | 89.35 | 89.75 |
| STANet-Base [5] | ResNet18 [40] | 79.20 | 89.10 | 83.90 | 25.75 | 56.29 | 35.34 | - | - | - |
| STANet-BAM [5] | ResNet18 [40] | 81.50 | 90.40 | 85.70 | 31.19 | 52.91 | 39.24 | - | - | - |
| STANet-PAM [5] | ResNet18 [40] | 83.81 | 91.00 | 87.26 | 38.75 | 56.49 | 45.97 | 90.62 | 86.26 | 88.38 |
| CDNet [41] | ResNet18 [40] | 91.60 | 86.50 | 89.00 | 67.48 | 54.93 | 60.56 | 89.80 | 83.30 | 86.4 |
| BiT [7] | ResNet18 [40] | 89.24 | 89.37 | 89.31 | 72.64 | 53.85 | 61.85 | 89.40 | 90.03 | 89.72 |
| ChangeFormer [6] | MiT-b1 [17] | 92.59 | 89.68 | 91.11 | 72.82 | 56.13 | 63.39 | 92.70 | 82.28 | 87.97 |
| ChangerAlign [8] | ResNet18 [40] | 93.30 | 89.59 | 91.41 | 71.62 | 60.06 | 65.33 | 90.20 | 89.58 | 89.89 |
| ChangerEx [8] | ResNet18 [40] | 92.97 | 90.61 | 91.77 | 73.59 | 60.15 | 66.20 | 89.71 | 88.94 | 89.32 |
| Ours | ResNet18 [40] | 93.07 | 90.96 | 92.00 | 71.78 | 61.86 | 66.45 | 91.46 | 89.77 | 90.61 |
| Method | SYSU-CD [34] | ||
|---|---|---|---|
| Precision | Recall | F1 | |
| FC-EF [4] | 75.27 | 62.35 | 68.20 |
| FC-Siam-Conc [4] | 81.57 | 66.69 | 73.38 |
| FC-Siam-Diff [4] | 91.27 | 55.61 | 69.11 |
| STANet-PAM [5] | 77.60 | 78.10 | 77.80 |
| HCGMNet [42] | 84.31 | 75.07 | 79.42 |
| HANet [43] | 78.71 | 76.14 | 77.41 |
| MSPSNet [44] | 77.29 | 76.29 | 76.79 |
| UPerNet [45] | 81.13 | 74.38 | 77.61 |
| BiT [7] | 75.15 | 71.58 | 73.32 |
| ChangeFormer [6] | 70.84 | 59.40 | 64.62 |
| RSP-BiT [7] | 86.29 | 71.61 | 78.26 |
| CGNet [46] | 86.37 | 74.37 | 79.92 |
| Ours | 85.12 | 75.9 | 80.25 |
| Method | HRCUS-CD [35] | ||
|---|---|---|---|
| Precision | Recall | F1 | |
| FC-EF [4] | 72.75 | 50.30 | 59.48 |
| FC-Siam-Conc [4] | 53.95 | 66.95 | 59.75 |
| FC-Siam-Diff [4] | 64.29 | 67.76 | 65.98 |
| U-Net [47] | 60.87 | 69.75 | 65.01 |
| SCDNet [48] | 55.74 | 67.95 | 61.24 |
| ChangeNet [49] | 55.24 | 69.09 | 60.59 |
| DSIFN [36] | 59.42 | 74.76 | 66.21 |
| DESSN [50] | 62.18 | 72.53 | 66.95 |
| BiT [7] | 73.29 | 67.18 | 70.11 |
| ChangeFormer [6] | 67.68 | 64.45 | 66.55 |
| Ours | 78.47 | 78.55 | 70.47 |
| Method | DSIFN-CD [36] | ||
|---|---|---|---|
| Precision | Recall | F1 | |
| FC-EF [4] | 61.80 | 57.75 | 59.71 |
| FC-Siam-Conc [4] | 59.08 | 62.80 | 60.88 |
| FC-Siam-Diff [4] | 68.44 | 58.27 | 62.95 |
| STANet [5] | 51.48 | 36.40 | 42.65 |
| IFNet [51] | 63.75 | 55.36 | 59.26 |
| SNVNet [52] | 64.15 | 57.09 | 60.41 |
| BiT [7] | 56.36 | 62.79 | 59.40 |
| DASNet [53] | 60.10 | 56.53 | 58.26 |
| Ours | 56.01 | 72.42 | 63.17 |
| P | R | (P, R) | F1 | |
|---|---|---|---|---|
| best | 1 | 3 | Top one: 1, (1, 1) | 6 |
| 2nd best | 2 | 2 | Top two: 3, (1, 1) (1, 2), (2, 1) | 0 |
| 3rd best | 0 | 0 | Top three: 3, (1, 1) (1, 2), (2, 1) | 0 |
| Others | 3 | 1 | 3 | 0 |
| Precision | Recall | F1 | |
|---|---|---|---|
| U-Constraint-1 | 93.73 | 89.48 | 91.56 |
| U-Constraint-2 | 93.31 | 90.11 | 91.68 |
| U-Constraint-3 | 93.59 | 89.89 | 91.70 |
| U-Constraint-4 | 93.28 | 90.09 | 91.65 |
| Precision | Recall | F1 | |
|---|---|---|---|
| C-Constraint-1 | 93.83 | 89.29 | 91.50 |
| C-Constraint-2 | 93.31 | 89.95 | 91.60 |
| C-Constraint-3 | 93.61 | 89.52 | 91.52 |
| C-Constraint-4 | 93.38 | 89.68 | 91.49 |
| Precision | Recall | F1 | |
|---|---|---|---|
| A-Constraint-1 | 93.48 | 89.73 | 91.68 |
| A-Constraint-2 | 93.43 | 89.96 | 91.66 |
| A-Constraint-3 | 93.70 | 89.91 | 91.77 |
| A-Constraint-4 | 93.48 | 89.86 | 91.63 |
| Baseline | Precision | Recall | F1 | ||
|---|---|---|---|---|---|
| FPN-Neck | A-Constraint | CSCA | |||
| 93.30 | 89.59 | 91.41 | |||
| ✓ | 93.37 | 90.27 | 91.61 | ||
| ✓ | 93.70 | 89.91 | 91.77 | ||
| ✓ | 93.41 | 90.58 | 91.97 | ||
| ✓ | ✓ | 93.37 | 90.27 | 91.79 | |
| ✓ | ✓ | 93.08 | 90.93 | 91.99 | |
| ✓ | ✓ | 92.78 | 91.01 | 91.89 | |
| ✓ | ✓ | ✓ | 93.07 | 90.96 | 92.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, G.; Shi, B.; Wang, C.; Wang, J.; Zhu, X. CINet: A Constraint- and Interaction-Based Network for Remote Sensing Change Detection. Sensors 2025, 25, 103. https://doi.org/10.3390/s25010103
Wei G, Shi B, Wang C, Wang J, Zhu X. CINet: A Constraint- and Interaction-Based Network for Remote Sensing Change Detection. Sensors. 2025; 25(1):103. https://doi.org/10.3390/s25010103
Chicago/Turabian StyleWei, Geng, Bingxian Shi, Cheng Wang, Junbo Wang, and Xiaolin Zhu. 2025. "CINet: A Constraint- and Interaction-Based Network for Remote Sensing Change Detection" Sensors 25, no. 1: 103. https://doi.org/10.3390/s25010103
APA StyleWei, G., Shi, B., Wang, C., Wang, J., & Zhu, X. (2025). CINet: A Constraint- and Interaction-Based Network for Remote Sensing Change Detection. Sensors, 25(1), 103. https://doi.org/10.3390/s25010103