
Ancient Chinese Character Recognition with Improved Swin-Transformer and Flexible Data Enhancement Strategies





Abstract
1. Introduction
- We collect various forms of each ancient script to comprehensively showcase the diversity of ancient Chinese characters and construct the first large-scale Chinese ancient script dataset, comprising 9233 classes and over 970,000 instances.
- This paper proposes an improved Swin-Transformer model for feature extraction and adopts a data augmentation strategy to solve the problem of long tail distribution in ancient Chinese characters.
- According to the latest research findings, this work is the first to apply deep learning models to recognize ancient Chinese characters on a large dataset. The primary goal of this work is to develop a deep learning network to analyze the inherent commonalities of ancient Chinese characters.
2. Related Works
2.1. Ancient Chinese Script Recognition
2.2. Image Classification Based on Convolutional Neural Networks
2.3. Vision Transformer
3. Methodology
3.1. Preliminaries
3.1.1. Swin-Transformer
3.1.2. Swin-Transformer Block
3.1.3. Shifted Window-Based Self-Attention
3.2. Model Structure
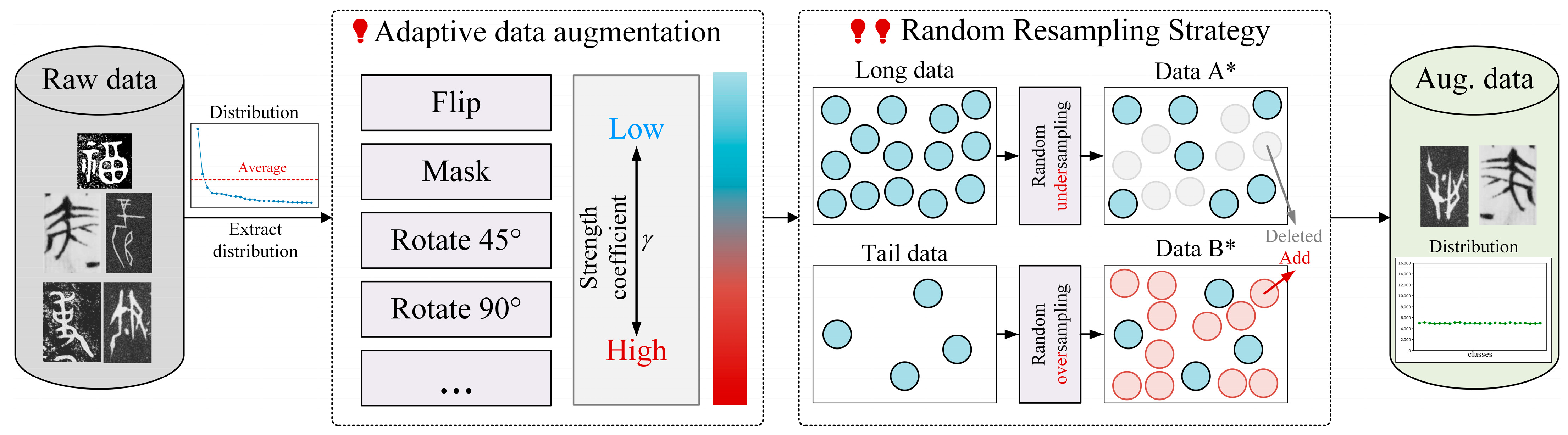
3.3. Ancient Chinese Data Enhancement Strategy
4. Experiments, Analysis, and Discussion
4.1. Datasets
4.1.1. Dataset of Sample Acquisition
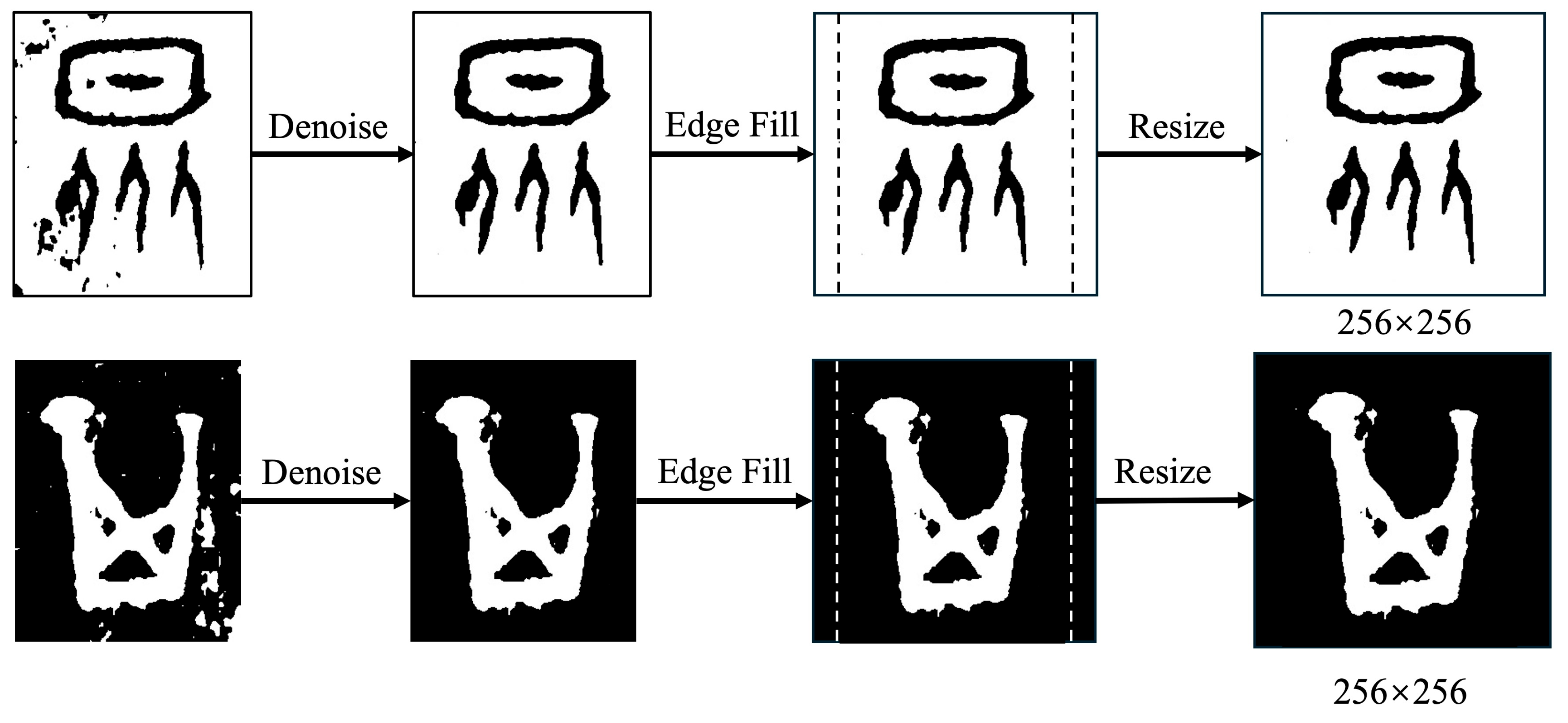
4.1.2. Data Preprocessing
- Denoising: In the raw images of ancient Chinese characters, there is a significant amount of “salt and pepper noise”. We first employed a median filter to remove noise. This method sorts all pixel values around each pixel in the image and assigns the middle value (i.e., the median) to the central pixel, effectively eliminating noise. This approach is particularly suitable for removing salt and pepper noise as it preserves image edges effectively without causing blurring.
- Size standardization: We standardized the image size to 256 × 256 pixels while preserving the original aspect ratio. For non-square images, we first padded the edges with white or black pixels and then adjusted them to the desired size.
4.1.3. Data Enhancement
4.2. Experimental Setup
4.3. Comparison Experiments
4.4. Ablation Experiments
4.5. Visual Analysis
4.6. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Coulmas, F. The Writing Systems of the World; Basil Blackwell: Oxford, UK, 1989. [Google Scholar]
- Creel, H.G. Chinese Writing; American Council on Education: Washington, DC, USA, 1943. [Google Scholar]
- Fu, X.; Yang, Z.; Zeng, Z.; Zhang, Y.; Zhou, Q. Improvement of Oracle Bone Inscription Recognition Accuracy: A Deep Learning Perspective. ISPRS Int. J. Geo-Inf. 2022, 11, 45. [Google Scholar] [CrossRef]
- Guo, Z.; Zhou, Z.; Liu, B.; Li, L.; Jiao, Q.; Huang, C.; Zhang, J. An Improved Neural Network Model Based on Inception-v3 for Oracle Bone Inscription Character Recognition. Sci. Program. 2022, 2022, e7490363. [Google Scholar] [CrossRef]
- Wang, M.; Deng, W.; Liu, C.-L. Unsupervised Structure-Texture Separation Network for Oracle Character Recognition. IEEE Trans. Image Process. 2022, 31, 3137–3150. [Google Scholar] [CrossRef] [PubMed]
- Qiu, X. Chinese Writing; Institute of East Asian Studies University of California Berkeley: Berkeley, CA, USA, 2000. [Google Scholar]
- Huang, S.; Wang, H.; Liu, Y.; Shi, X.; Jin, L. OBC306: A Large-Scale Oracle Bone Character Recognition Dataset. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 681–688. [Google Scholar]
- Li, J.; Wang, Q.-F.; Huang, K.; Yang, X.; Zhang, R.; Goulermas, J.Y. Towards Better Long-Tailed Oracle Character Recognition with Adversarial Data Augmentation. Pattern Recognit. 2023, 140, 109534. [Google Scholar] [CrossRef]
- Ji, X.; Lai, C.S.; Zhou, G.; Dong, Z.; Qi, D.; Lai, L.L. A Flexible Memristor Model With Electronic Resistive Switching Memory Behavior and Its Application in Spiking Neural Network. IEEE Trans. NanoBiosci. 2023, 22, 52–62. [Google Scholar] [CrossRef] [PubMed]
- Meng, L. Recognition of Oracle Bone Inscriptions by Extracting Line Features on Image Processing. In Proceedings of the 6th International Conference on Pattern Recognition Applications and Methods—ICPRAM, Porto, Portugal, 24–26 February 2017; SciTePress: Setúbal, Portugal, 2017; pp. 606–611. [Google Scholar]
- Zhao, R.; Wang, H.; Wang, K.; Wang, Z.; Liu, W. Recognition of Bronze Inscriptions Image Based on Mixed Features of Histogram of Oriented Gradient and Gray Level Co-Occurrence Matrix. Laser Optoelectron. Prog. 2020, 57, 98–104. [Google Scholar]
- Chen, B.; Wang, Z.; Xia, R.; Chen, M. Text image recognition algorithm of Qin bamboo slips based on lightweight AlexNet network. J. Cent. South Univ. (Sci. Technol.) 2023, 54, 3506–3517. [Google Scholar]
- Gao, J.; Liang, X. Distinguishing Oracle Variants Based on the Isomorphism and Symmetry Invariances of Oracle-Bone Inscriptions. IEEE Access 2020, 8, 152258–152275. [Google Scholar] [CrossRef]
- Ji, X.; Dong, Z.; Han, Y.; Lai, C.S.; Zhou, G.; Qi, D. EMSN: An Energy-Efficient Memristive Sequencer Network for Human Emotion Classification in Mental Health Monitoring. IEEE Trans. Consum. Electron. 2023, 69, 1005–1016. [Google Scholar] [CrossRef]
- Meng, L.; Kamitoku, N.; Yamazaki, K. Recognition of Oracle Bone Inscriptions Using Deep Learning Based on Data Augmentation. In Proceedings of the 2018 Metrology for Archaeology and Cultural Heritage (MetroArchaeo), Cassino, Italy, 22–24 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 33–38. [Google Scholar]
- Liu, M.; Liu, G.; Liu, Y.; Jiao, Q. Oracle Bone Inscriptions Recognition Based on Deep Convolutional Neural Network. J. Image Graph. 2020, 8, 114–119. [Google Scholar] [CrossRef]
- Wu, X.; Wang, Z.; Ren, P. CNN-Based Bronze Inscriptions Character Recognition. In Proceedings of the 2022 5th International Conference on Advanced Electronic Materials, Computers and Software Engineering (AEMCSE), Wuhan, China, 22–24 April 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 514–519. [Google Scholar]
- He, J. Research on Classification Algorithm of Ancient Chinese Characters Based on “Long Tail Distribution”. Master’s Thesis, East China Normal University, Shanghai, China, 2022. [Google Scholar]
- Zheng, Y.; Yan, Y.; Qi, D. Bronze Inscription Recognition with Distribution Calibration Based on Few-Shot Learning. In Proceedings of the 4th International Conference on Informatics Engineering & Information Science (ICIEIS2021), Tianjin, China, 19–21 November 2021; SPIE: Bellingham, WA, USA, 2022; Volume 12161, pp. 150–158. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Siem Reap, Cambodia, 13–16 December 2018; Curran Associates Inc.: Red Hook, NY, USA, 2012; Volume 1, pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Dong, Z.; Ji, X.; Lai, C.S.; Qi, D. Design and Implementation of a Flexible Neuromorphic Computing System for Affective Communication via Memristive Circuits. IEEE Commun. Mag. 2023, 61, 74–80. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; AAAI Press: Palo Alto, CA, USA, 2017; pp. 4278–4284. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Ji, X.; Dong, Z.; Lai, C.S.; Zhou, G.; Qi, D. A Physics-oriented Memristor Model with the Coexistence of NDR Effect and RS Memory Behavior for Bio-inspired Computing. Mater. Today Adv. 2022, 16, 100293. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers; Springer International Publishing: Cham, Switzerland, 2020. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jegou, H. Training Data-Efficient Image Transformers & Distillation through Attention. In Proceedings of the 38th International Conference on Machine Learning, Online Event, 18–24 July 2021; Meila, M., Zhang, T., Eds.; PMLR: Cambridge, MA, USA, 2021; Volume 139, pp. 10347–10357. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.S.; et al. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 6877–6886. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.-P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 548–558. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 9992–10002. [Google Scholar]
- Xu, Z. Jiǎgǔwén ZìDiǎn [Oracle Bone Inscriptions Dictionary]; Sichuan Publishing Group & Sichuan Lexicographical Publishing House: Chengdu, China, 2006. [Google Scholar]
- Li, Z. Jiǎgǔ Wénzìbiān [Oracle Bone Inscriptions Compilation]; Zhonghua Book Company: Beijing, China, 2012. [Google Scholar]
- Liu, Z.; Hong, Y.; Zhou, Z.; Zhang, C.; Li, S.; Ren, P.; Gao, Y. (Eds.) Xīn Jiǎgǔwén Biān (Zengdingben) [New Compilation of Oracle Bone Inscriptions (Expanded and Revised Edition)]; The Straits Publishing & Distributing Group & Fujian People’s Publishing House: Fuzhou, China, 2014. [Google Scholar]
- Gao, M.; Tu, B. Gǔwénzì Lèi Biān [Compilation of Categorized Ancient Characters]; Shanghai Chinese Classics Publishing House: Shanghai, China, 2008. [Google Scholar]
- Yan, Z. Shāng Jīnwén Biān [Compilation of Shang Dynasty Bronze Inscriptions]; China Social Sciences Press: Beijing, China, 2016. [Google Scholar]
- Zhang, J. Xī Zhōu Jīnwén Zìbiān [Compilation of Western Zhou Bronze Inscriptions]; Shanghai Chinese Classics Publishing House: Shanghai, China, 2018. [Google Scholar]
- Zhang, Z. Qí Lǔ Wénzì Biān [Compilation of Characters in the States of Qi and Lu]; Xueyuan Publishing House: Beijing, China, 2014. [Google Scholar]
- Wang, H.; Yang, Z.; Peng, W.; Jiang, W. (Eds.) Qín Wénzì Biān [Compilation of Qin State Characters]; Zhonghua Book Company: Beijing, China, 2015. [Google Scholar]
- Tang, Z. Sān Jìn Wénzì Biān [Compilation of Characters from the Three Jin]; The Writers Publishing House Co., Ltd: Beijing, China, 2013. [Google Scholar]
- Wang, A. Yān Wénzì Biān [Word’s Character Study Volumes of Yan]. Master’s Dissertation, Jilin University, Changchun, China, 2010. [Google Scholar]
- Li, S. Chǔ Wénzì Biān [Compilation of Characters from the State of Chu]; East China Normal University Press: Shanghai, China, 2003. [Google Scholar]
- Li, S.; Jia, L.; Ma, N. Bāoshān Chǔmù Wénzì Quán Biān [Complete Compilation of Characters from Chu Tombs at Baoshan]; Shanghai Chinese Classics Publishing House: Shanghai, China, 2012. [Google Scholar]
- Jiang, W. Lǐyē Qínjiǎn Wénzì Biān [Compilation of Characters on Bamboo Slips from Liye]; Xueyuan Publishing House: Beijing, China, 2018. [Google Scholar]
- Chen, S. Mǎwángduī Jiǎnbó Wénzì Biān [Compilation of Characters on Bamboo and Silk from the Ma Wang Dui Tombs]; Cultural Relies Press: Beijing, China, 2001. [Google Scholar]
- Peng, Z.; Huang, W.; Gu, S.; Xie, L.; Wang, Y.; Jiao, J.; Ye, Q. Conformer: Local Features Coupling Global Representations for Visual Recognition. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 357–366. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.-Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Dong, Z.; He, Y.; Hu, X.; Qi, D.; Duan, S. Flexible memristor-based LUC and its network integration for Boolean logic implementation. IET Nanodielectrics 2019, 2, 61–69. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. RepVGG: Making VGG-Style ConvNets Great Again. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13728–13737. [Google Scholar]
- Gao, S.-H.; Cheng, M.-M.; Zhao, K.; Zhang, X.-Y.; Yang, M.-H.; Torr, P. Res2Net: A New Multi-Scale Backbone Architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 652–662. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Lin, H.; Zhang, Z.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R.; et al. ResNeSt: Split-Attention Networks. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), New Orleans, LA, USA, 19–20 June 2022; pp. 2735–2745. [Google Scholar]
- Xie, S.; Girshick, R.; Dollar, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UH, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Dong, Z.; Li, C.; Qi, D.; Luo, L.; Duan, S. Multiple Memristor Circuit Parametric Fault Diagnosis Using Feedback-Control Doublet Generator. IEEE Access. 2016, 4, 2604–2614. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations From Deep Networks via Gradient-Based Localization. In Proceedings of the IEEE International Conference on Computer Vision, (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Representative Script Types | Period | 马 | 牛 | 明 | 走 |
|---|---|---|---|---|---|
| Oracle bone inscriptions; bronze inscriptions | Shang Dynasty (about 1700 B.C.E.—1100 B.C.E) |  |  |  |  |
| Bronze inscriptions | West Zhou Dynasty (about 1100 B.C.E.—770 B.C.E) |  |  |  |  |
| Bronze inscriptions; stone inscriptions; pottery inscriptions; bamboo slip, wooden tablet, and silk manuscript texts | Spring and Autumn Period (about 770 B.C.E.—476 B.C.E) |  |  |  |  |
| Bronze inscriptions; seal inscriptions; coin inscriptions; bamboo slip and silk manuscript texts | Warring States Period (about 476 B.C.E.—221 B.C.E) |  |  |  |  |
| Modern Chinese Characters | Qin | Chu | Qi | Yan | Jin |
|---|---|---|---|---|---|
| 者 zhě |  |  |  |  |  |
| 市 shì |  |  |  |  |  |
| Source Materials of Ancient Chinese Characters | Literature | Example | |||
|---|---|---|---|---|---|
| Oracle bone inscriptions | [35,36,37,38] |  |  |  |  |
| Bronze inscriptions | [38,39,40,41,42,43,44,45] |  |  |  |  |
| Seal inscriptions | [38,42,44,45] |  |  |  |  |
| Coin inscriptions | [38,41,42,43,44,45] |  |  |  |  |
| Pottery inscriptions | [38,41,42,43,44,45] |  |  |  |  |
| Bamboo slip and silk manuscript texts | [38,45,46,47,48] |  |  |  |  |
| Models | Backbone | Image Size | Top-1 Accuracy | Top-5 Accuracy |
|---|---|---|---|---|
| ResNet101 [23] | ResNet101 | 224 × 224 | 84.1283 | 94.6614 |
| ResNet101 [23] | ResNet101 | 256 × 256 | 83.0917 | 94.1338 |
| SwinT-v2 [34] | SwinTv2-small | 256 × 256 | 85.7395 | 94.8672 |
| Conformer [49] | Conformer-base | 256 × 256 | 82.1387 | 93.3345 |
| Convnext [50] | Convnext-base | 256 × 256 | 81.2875 | 92.8199 |
| DenseNet [24] | DenseNet121 | 256 × 256 | 76.6406 | 90.3361 |
| EfficentNet [26] | EfficientNet-b3 | 224 × 224 | 77.4249 | 91.1524 |
| Poolformer [51] | Poolformer-s24 | 224 × 224 | 78.4632 | 90.9764 |
| RepVGG [52] | Repvgg-A0 | 224 × 224 | 80.1162 | 92.2734 |
| Res2Net [53] | Res2Net-101 | 224 × 224 | 77.3113 | 90.8053 |
| ResNeSt [54] | ResNeSt-101 | 256 × 256 | 83.1570 | 94.0690 |
| ResNeXt [55] | ResNeXt-101 | 224 × 224 | 74.0102 | 88.8082 |
| SeResNet [56] | SeResNet-101 | 224 × 224 | 71.7029 | 86.5144 |
| ShuffleNet-v2 [57] | ShuffleNet-v2 | 224 × 224 | 79.4450 | 91.7922 |
| Ours | Ours-backbone | 224 × 224 | 86.6273 | 95.1640 |
| Ours | Ours-backbone | 256 × 256 | 87.2469 | 95.8088 |
| +Enhancement Strategy | +CoT Block | Top-1 Accuracy | Top-5 Accuracy |
|---|---|---|---|
| 85.7395 | 94.8672 | ||
| √ | 86.2664 | 95.2735 | |
| √ | 86.6730 | 95.7355 | |
| √ | √ | 87.2469 | 95.8088 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, Y.; Chen, Y.; Wang, X.; Qi, D.; Yan, Y. Ancient Chinese Character Recognition with Improved Swin-Transformer and Flexible Data Enhancement Strategies. Sensors 2024, 24, 2182. https://doi.org/10.3390/s24072182
Zheng Y, Chen Y, Wang X, Qi D, Yan Y. Ancient Chinese Character Recognition with Improved Swin-Transformer and Flexible Data Enhancement Strategies. Sensors. 2024; 24(7):2182. https://doi.org/10.3390/s24072182
Chicago/Turabian StyleZheng, Yi, Yi Chen, Xianbo Wang, Donglian Qi, and Yunfeng Yan. 2024. "Ancient Chinese Character Recognition with Improved Swin-Transformer and Flexible Data Enhancement Strategies" Sensors 24, no. 7: 2182. https://doi.org/10.3390/s24072182
APA StyleZheng, Y., Chen, Y., Wang, X., Qi, D., & Yan, Y. (2024). Ancient Chinese Character Recognition with Improved Swin-Transformer and Flexible Data Enhancement Strategies. Sensors, 24(7), 2182. https://doi.org/10.3390/s24072182