
Enhanced Knowledge Distillation for Advanced Recognition of Chinese Herbal Medicine


Abstract
1. Introduction
- Proposing a dual-teacher supervised model to reorganize the predictive distribution of dual teachers to achieve more accurate and robust soft labeling, which improves the performance of the model.
- Dynamically adjusting the temperature parameter T and the weight distribution value λ between the teacher model and the real label to gradually reduce the influence of the teacher model in the training process, so that the student model can more flexibly balance the complexity and the model’s generalization ability in the training process.
- Adopting JS scatter with symmetry to replace the cross-entropy loss of the predicted values of the soft label and the student model to better capture the similarity between the distributions and prompt the student model to better inherit the knowledge of the tutor model.
- A lightweight MobileNet_v3 network-based herbal medicine recognition system is implemented, and by applying our proposed DTSD method to the MobileNet_v3_Small network, we improve the accuracy and robustness of herbal medicine recognition while maintaining a small model size.
2. Materials and Methods
2.1. Dataset Collection
2.2. Data Enhancement
2.2.1. Image Transformation Class
2.2.2. Image Cropping
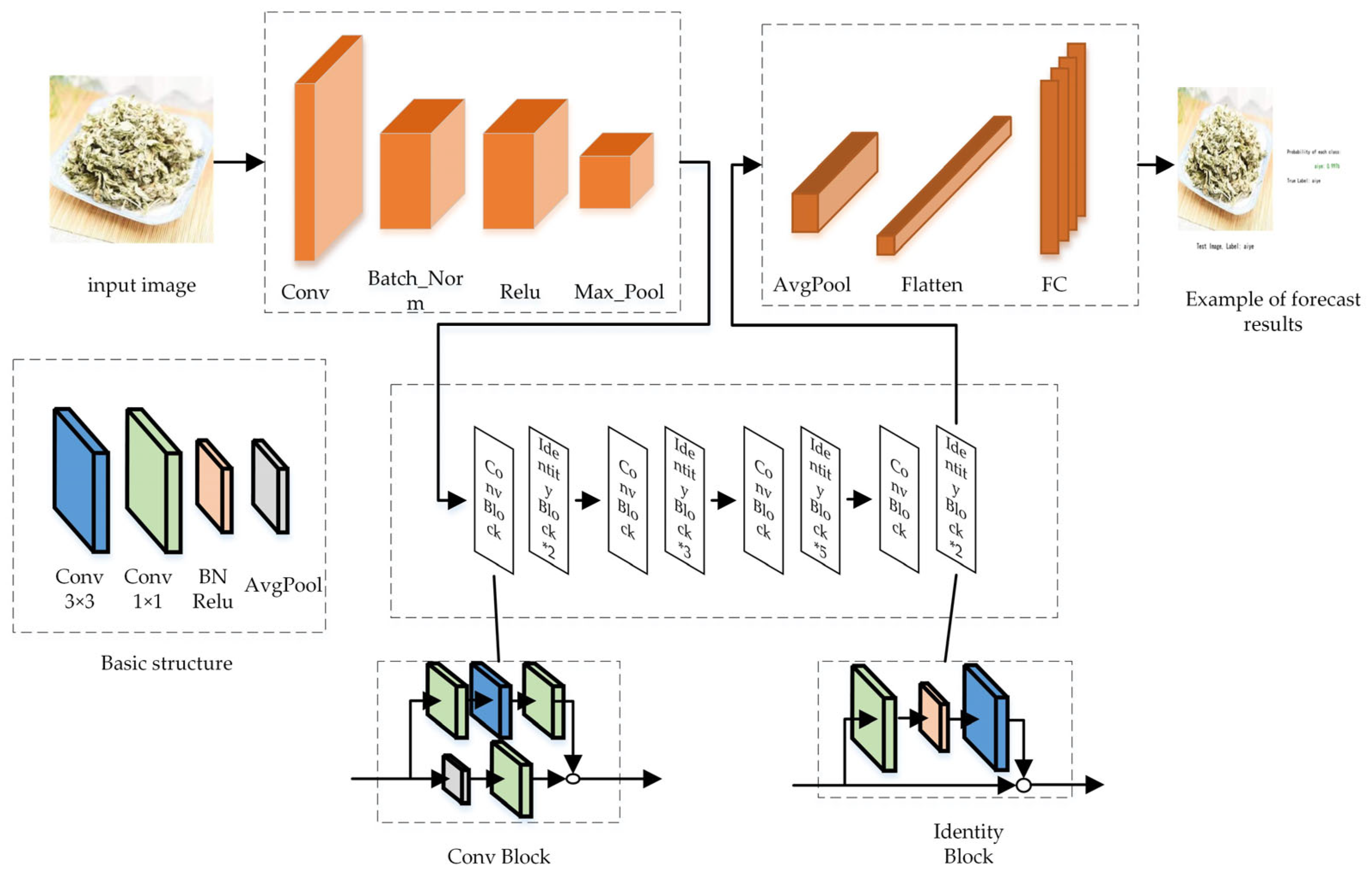
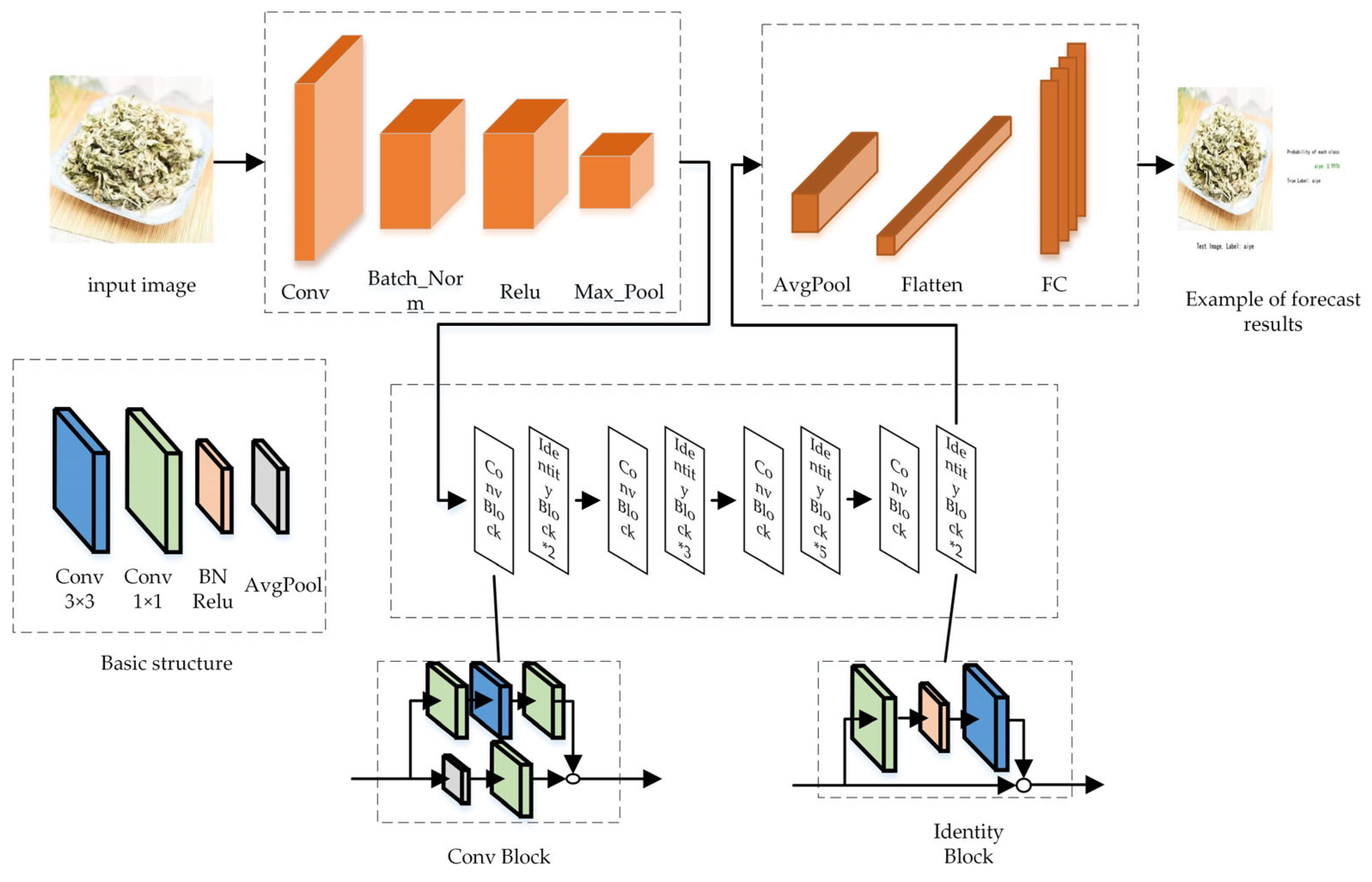
2.3. Teacher Model: ResNet_vd
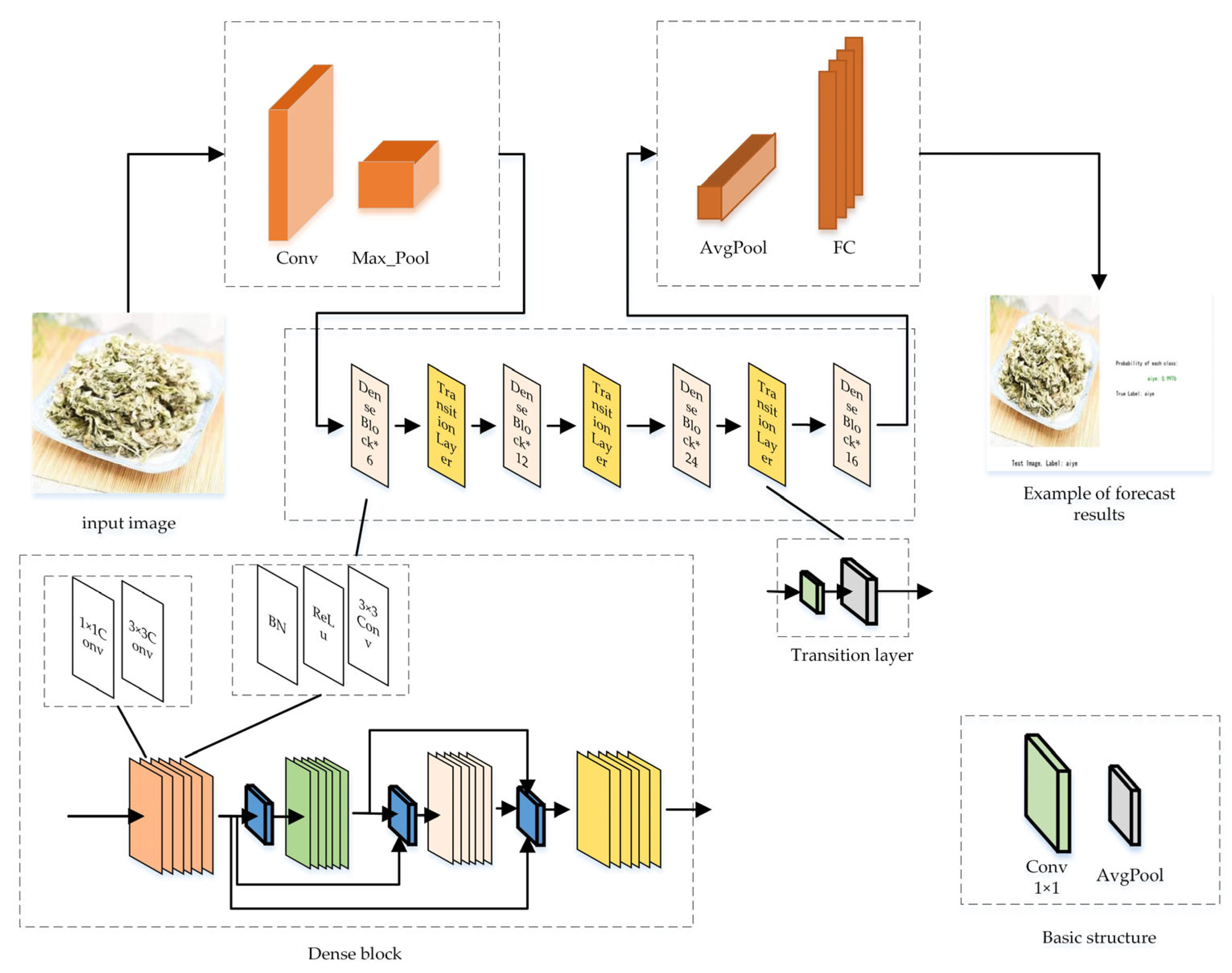
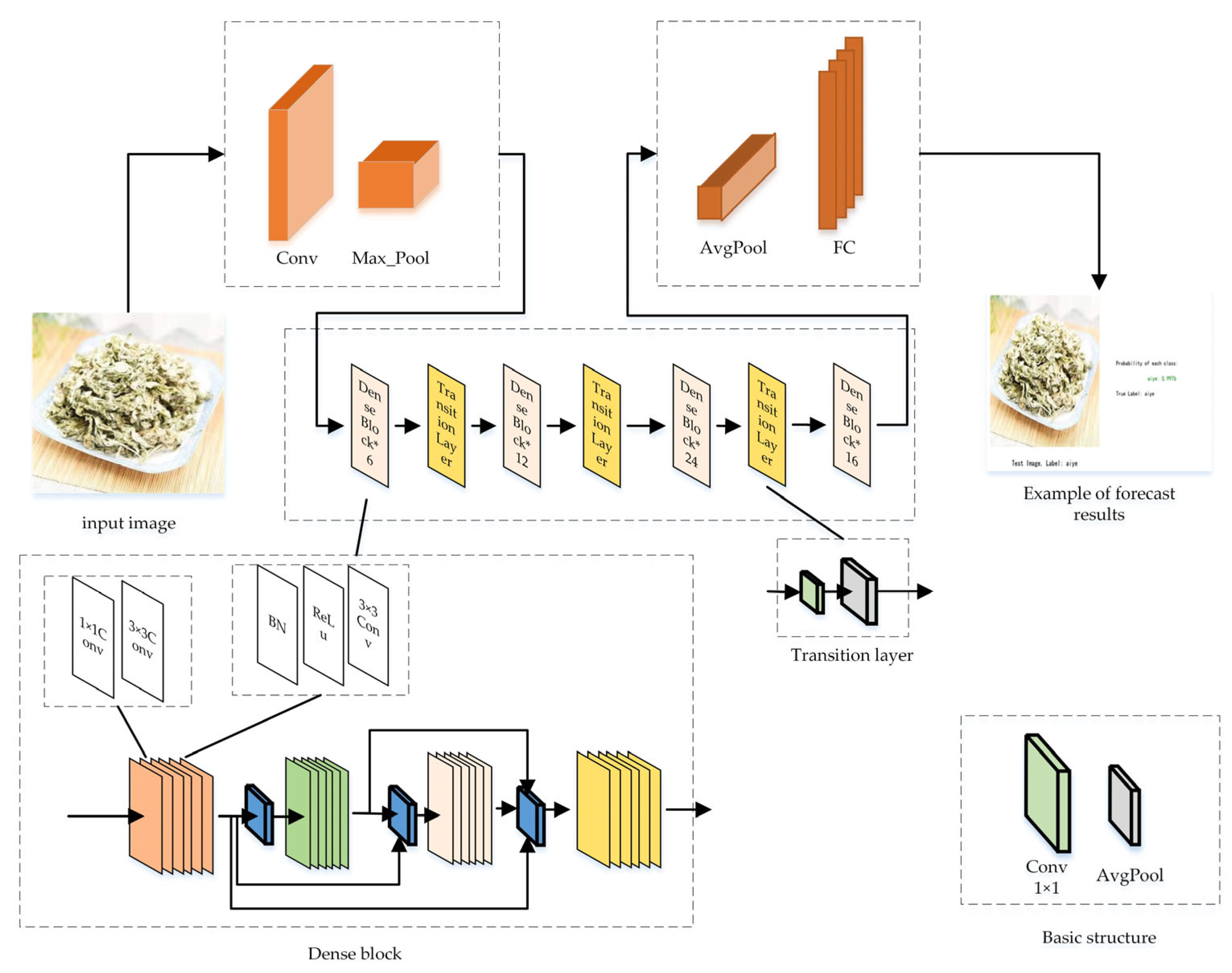
2.4. Teacher Model: DenseNet
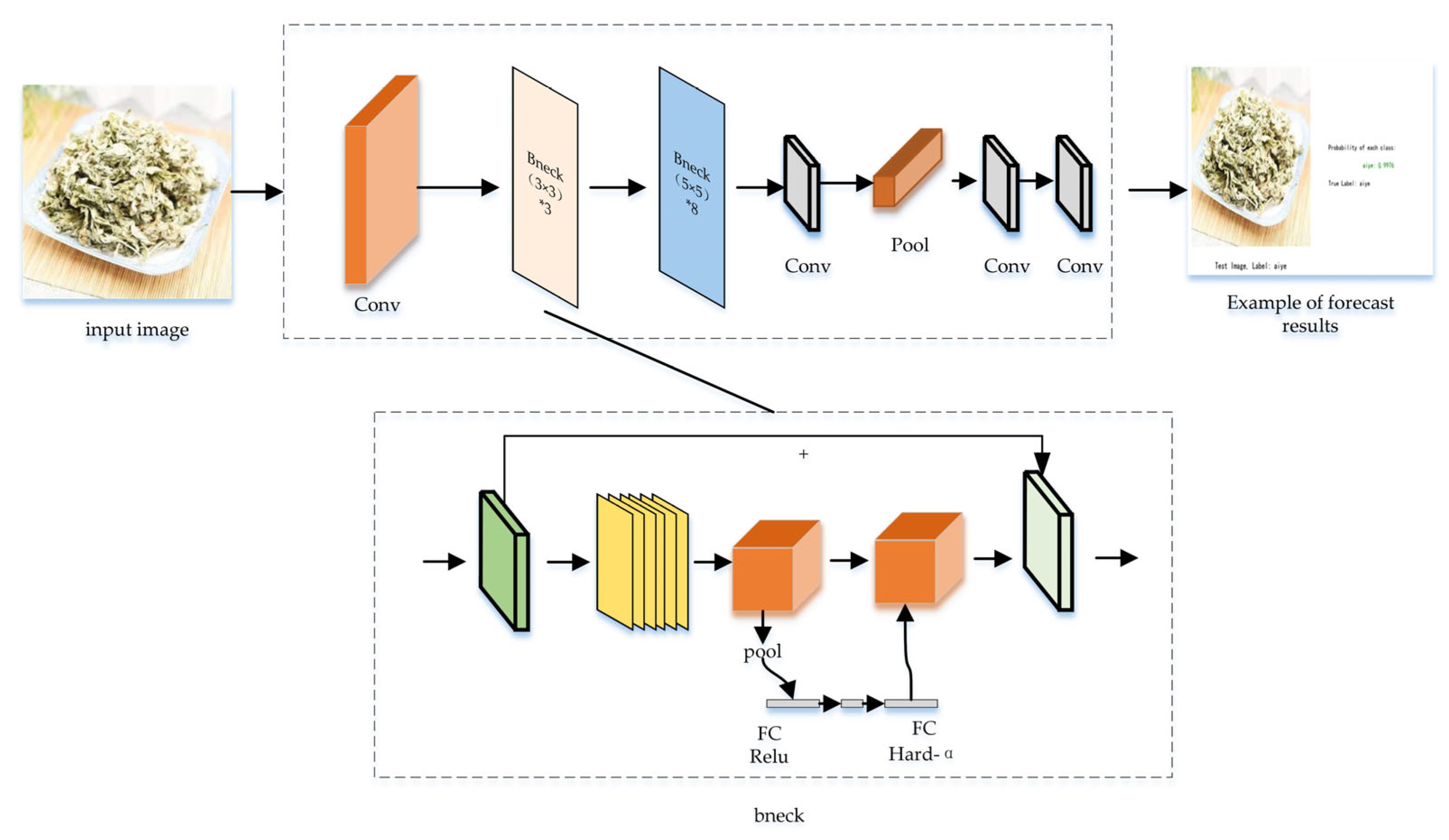
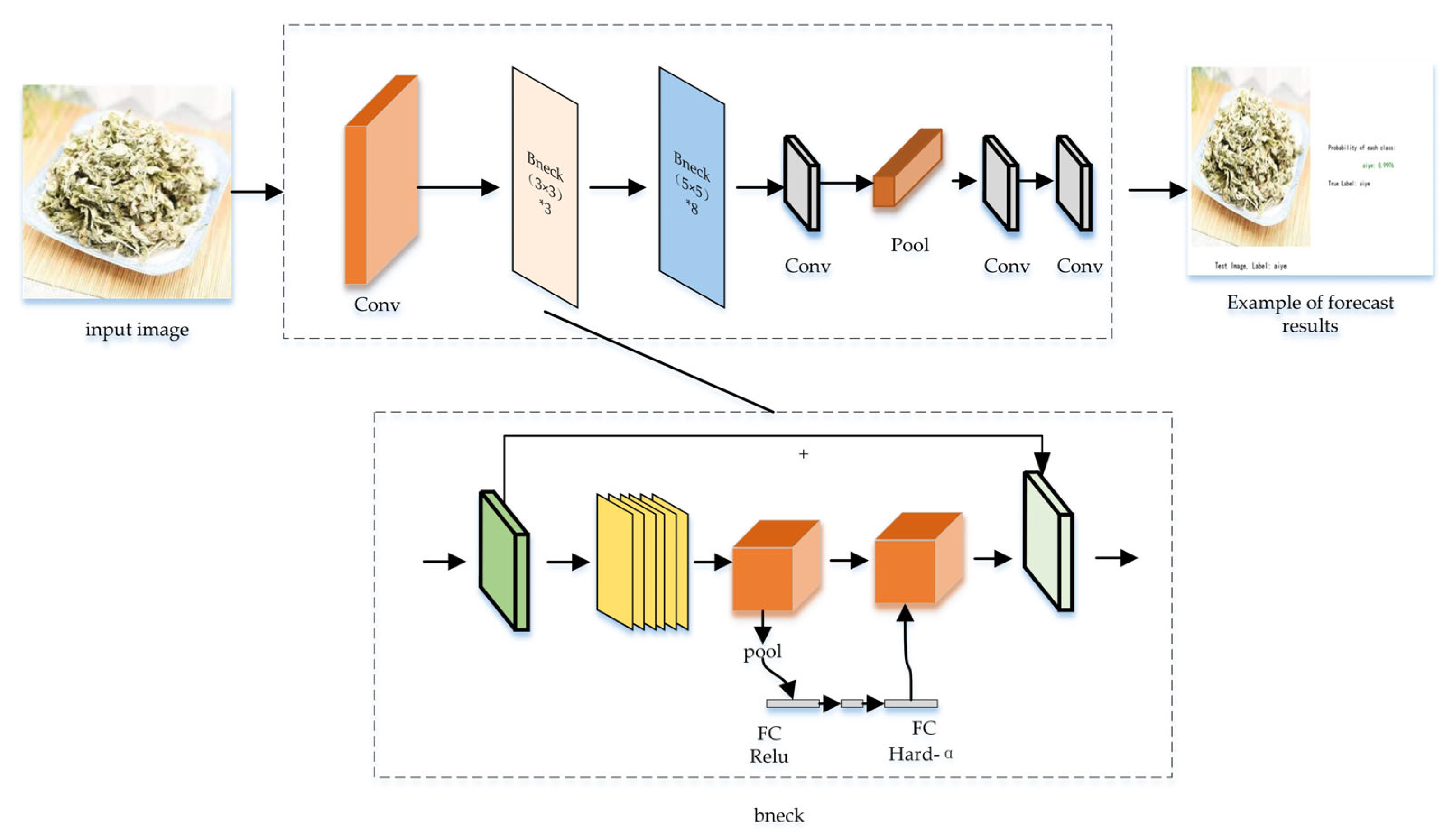
2.5. Student Model: MobileNet_v3_Small
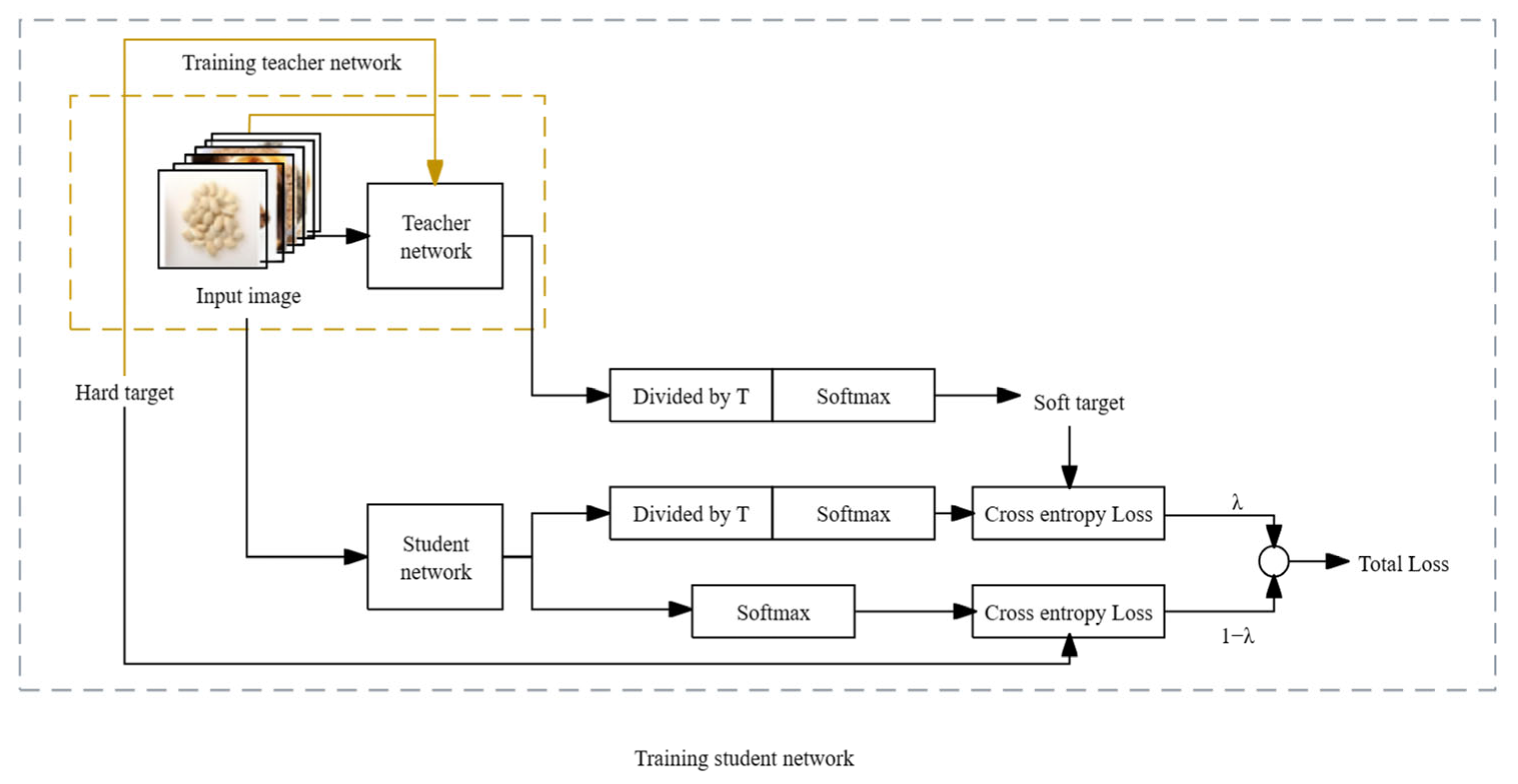
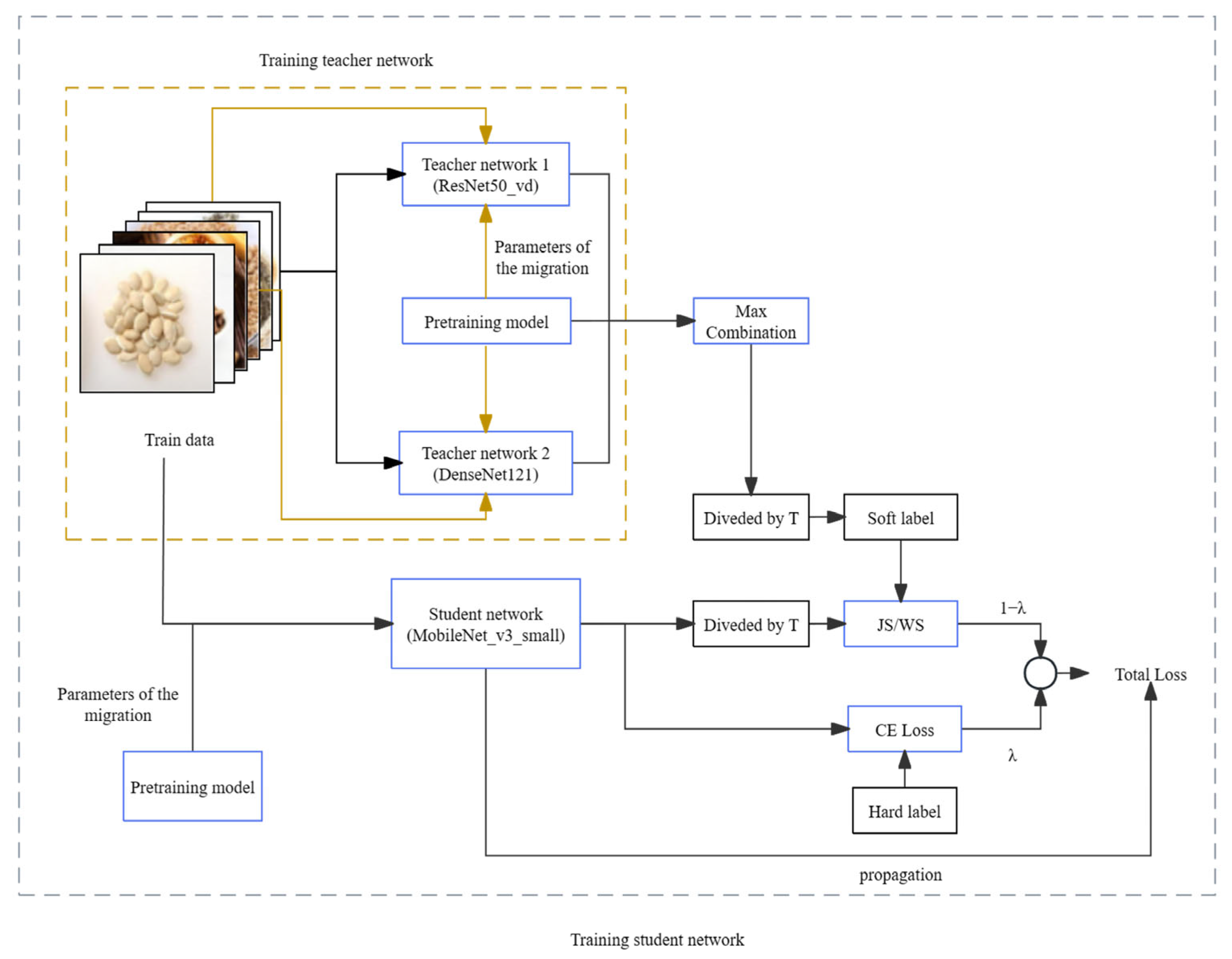
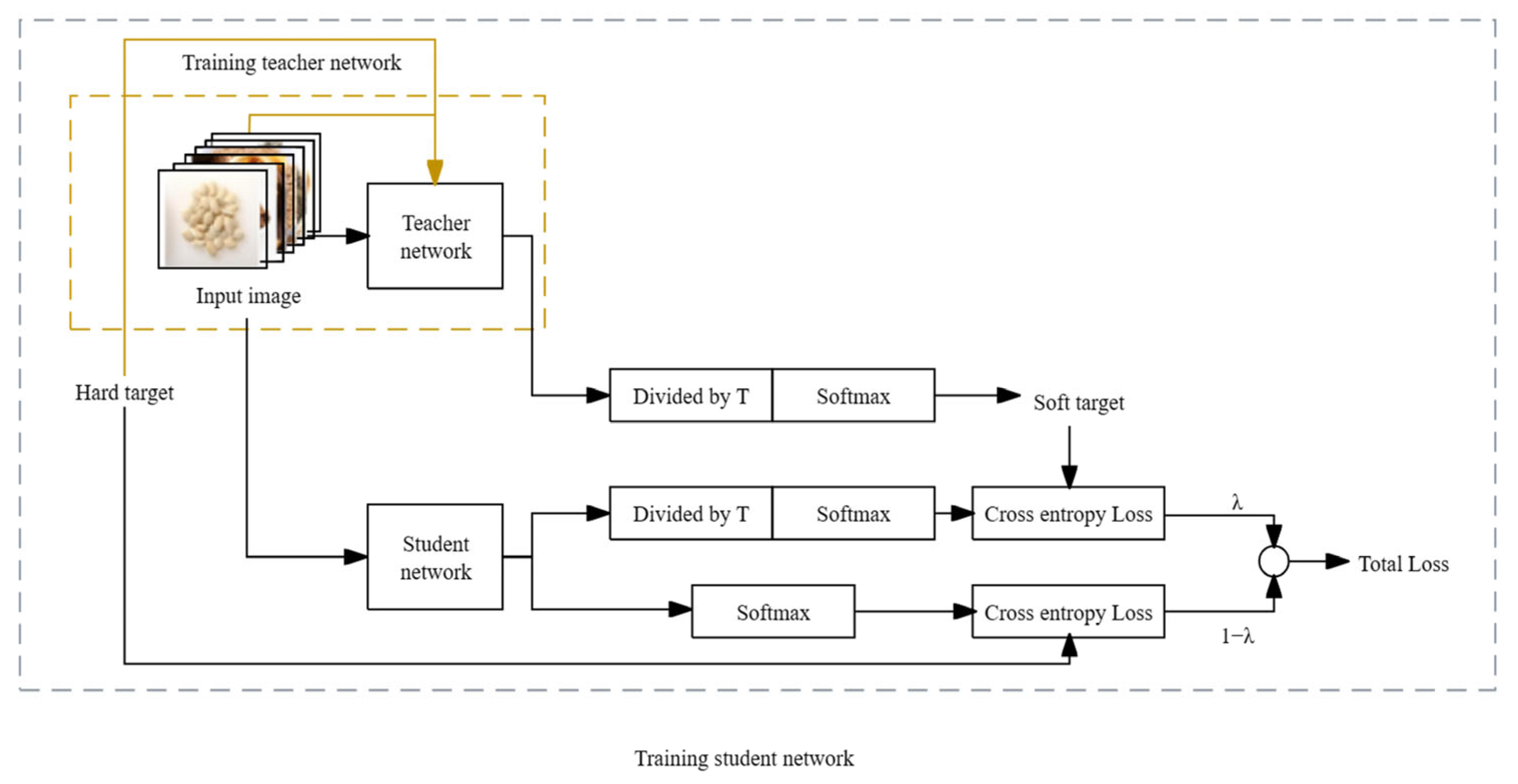
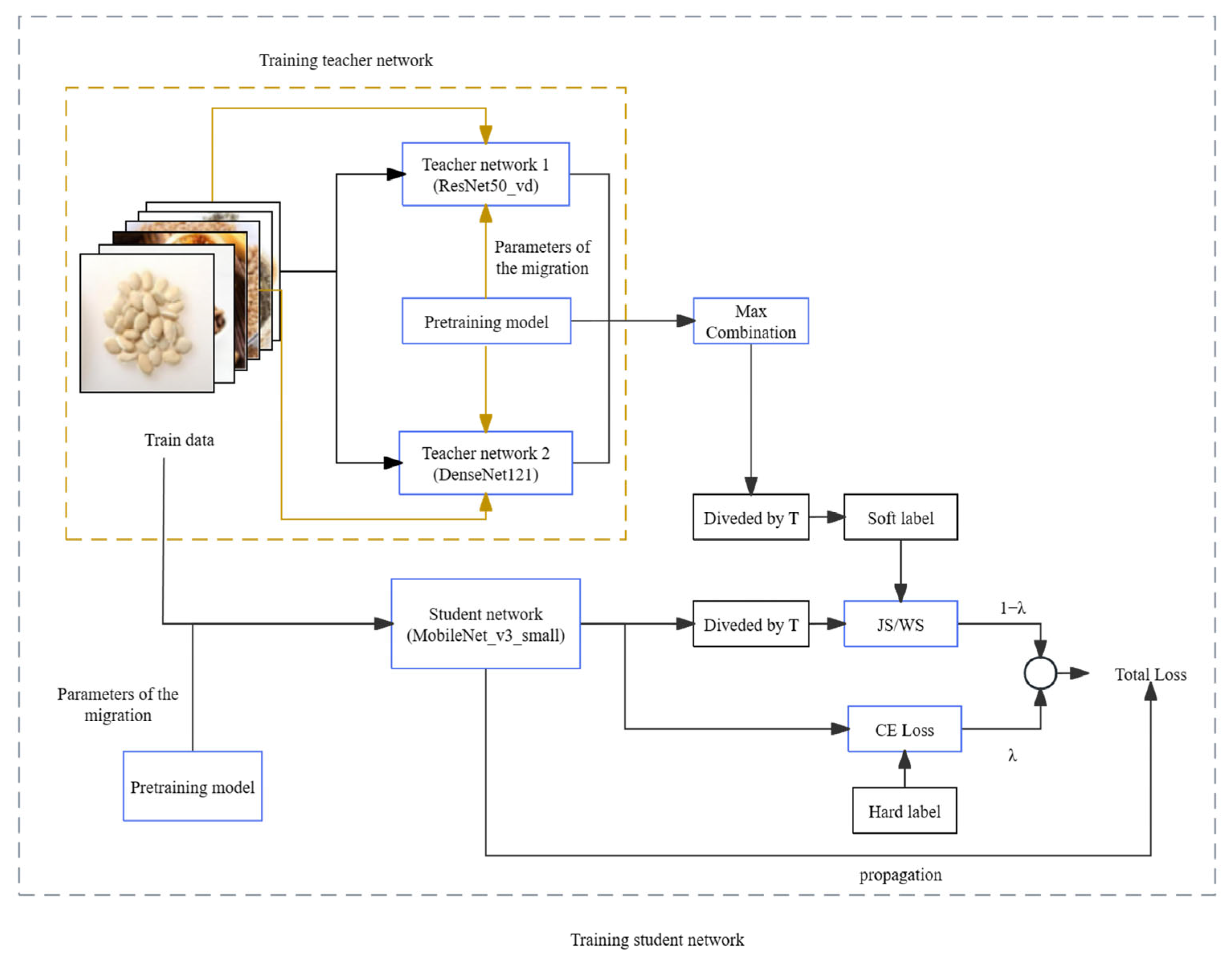
2.6. Knowledge Distillation Model with Dual-Teacher Supervised Decay
- The teacher network initially trains on hard targets. Once the model is trained, just before the network performs softmax normalization on the output, each term is divided by a fixed temperature, T. This process yields the soft targets used to guide the learning of the student network.
- During the training of the student network, the loss value employed for updating parameter weights during backpropagation is divided into two components. One part represents the cross-entropy loss computed on the true labels of the training dataset. The other part corresponds to the loss calculated on the soft output of the teacher network. Ultimately, these two losses are weighted and combined to generate the overall loss, which is then applied to the training of the student network model [25,26,27,28].
- Quality of guidance from the teacher model: Sometimes, the complex model might not predict perfectly. This is like a chef giving slightly incorrect cooking instructions to an apprentice. When these predictions, or guidance, are enhanced to make them more detailed for the student model (akin to increasing the “temperature” to make the lessons more intense), it can introduce errors or “noise”. This may lead the student model to learn incorrectly, like an apprentice learning flawed cooking techniques.
- Adjusting the intensity of teaching (temperature): In past research, the intensity or detail in the teacher’s guidance was often set at a fixed level, usually moderate. But it is now understood that this should vary throughout the training, much like adjusting teaching methods for students as they progress. The “temperature”, or level of detail and complexity in the teacher’s guidance, needs to be adaptable, increasing or decreasing at different stages of the student model’s learning.
- Balancing real data vs. teacher’s predictions (loss weighting λ): In traditional teaching methods, the balance between real-world data (hard labels) and the teacher’s predictions (soft labels) is constant. However, it is more effective if this balance changes over time. As the student model learns, the emphasis should gradually shift from what the teacher model predicts to what is actually observed in real-world data, allowing the student model to become more adept at handling real situations independently.
- The combination of soft labels: In standard knowledge distillation, we expand the teacher model from a single teacher to dual teachers to obtain multiple prediction distributions. To maintain the accuracy of the prediction distributions while acquiring more dark knowledge, we recombine the prediction distributions of the two teacher models. This is done by taking the maximum value of the predictions from the two teacher models in each dimension as the category classification result for that dimension, thereby obtaining a soft label with greater accuracy and richer dark knowledge. The formula is shown as Formula (1). Here, p and q represent the predicted labels given by the two teacher models, respectively. Through this formula, we generate a new probability distribution composed of the maximum values from two different probability distributions in each dimension.
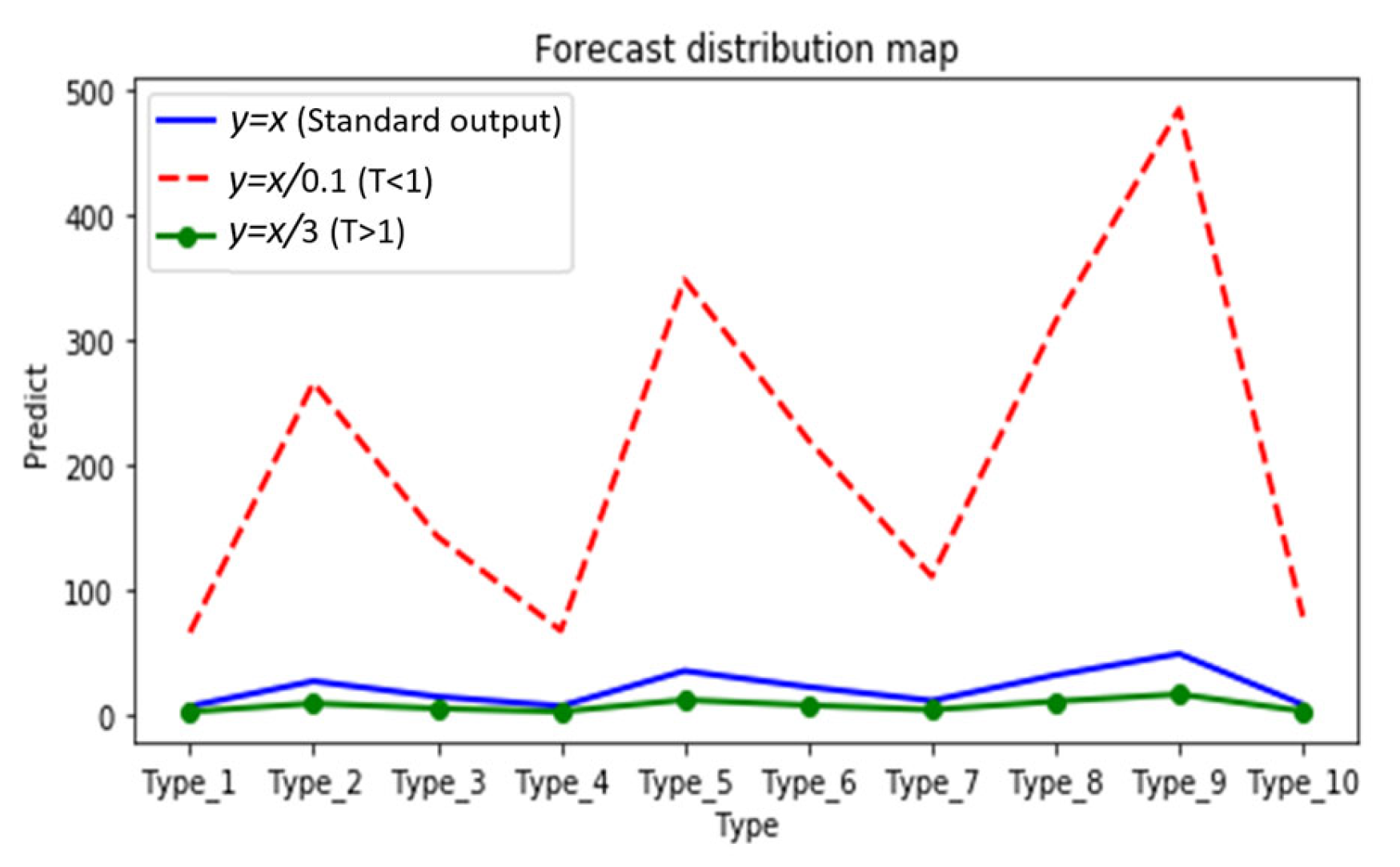
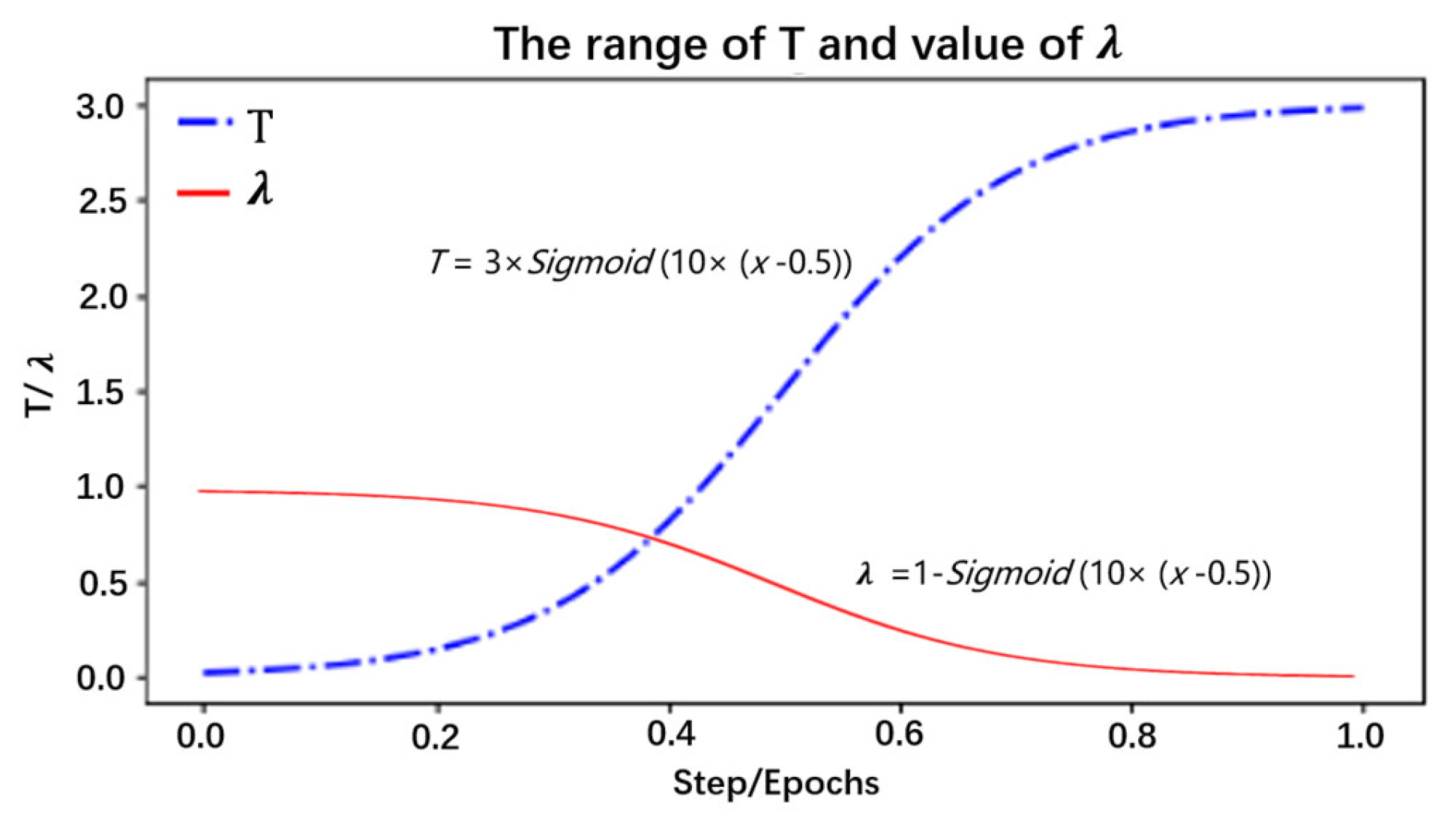
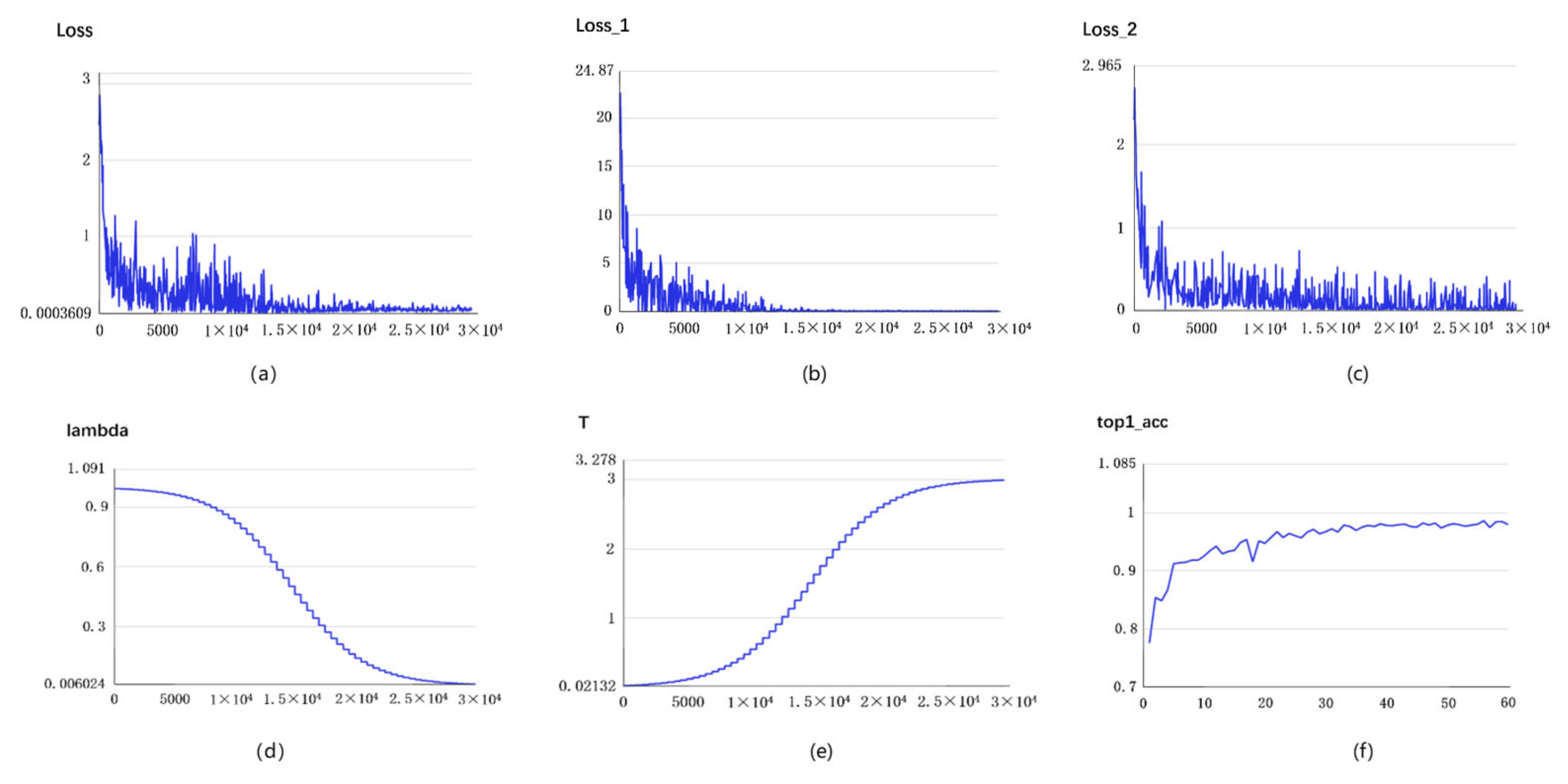
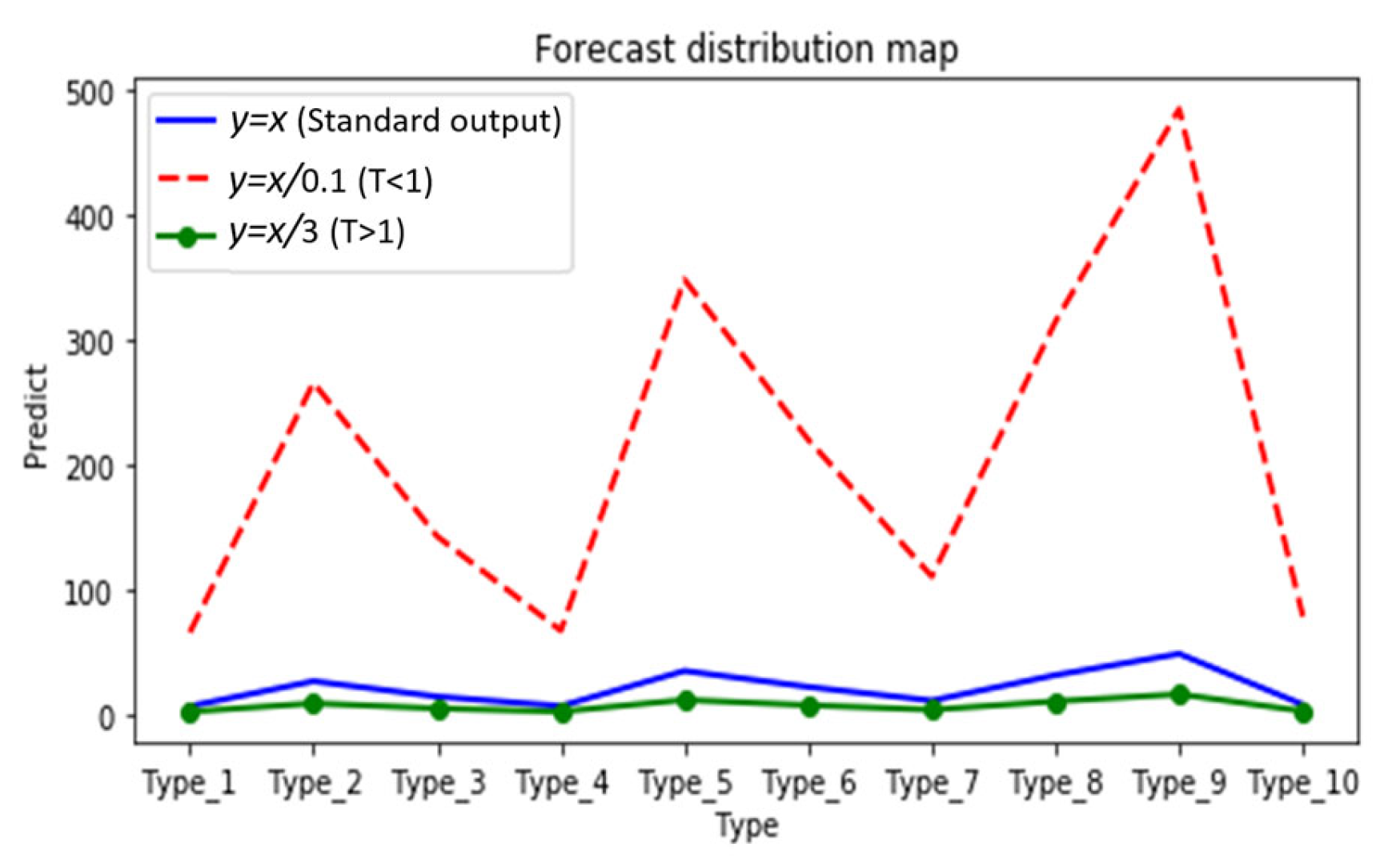
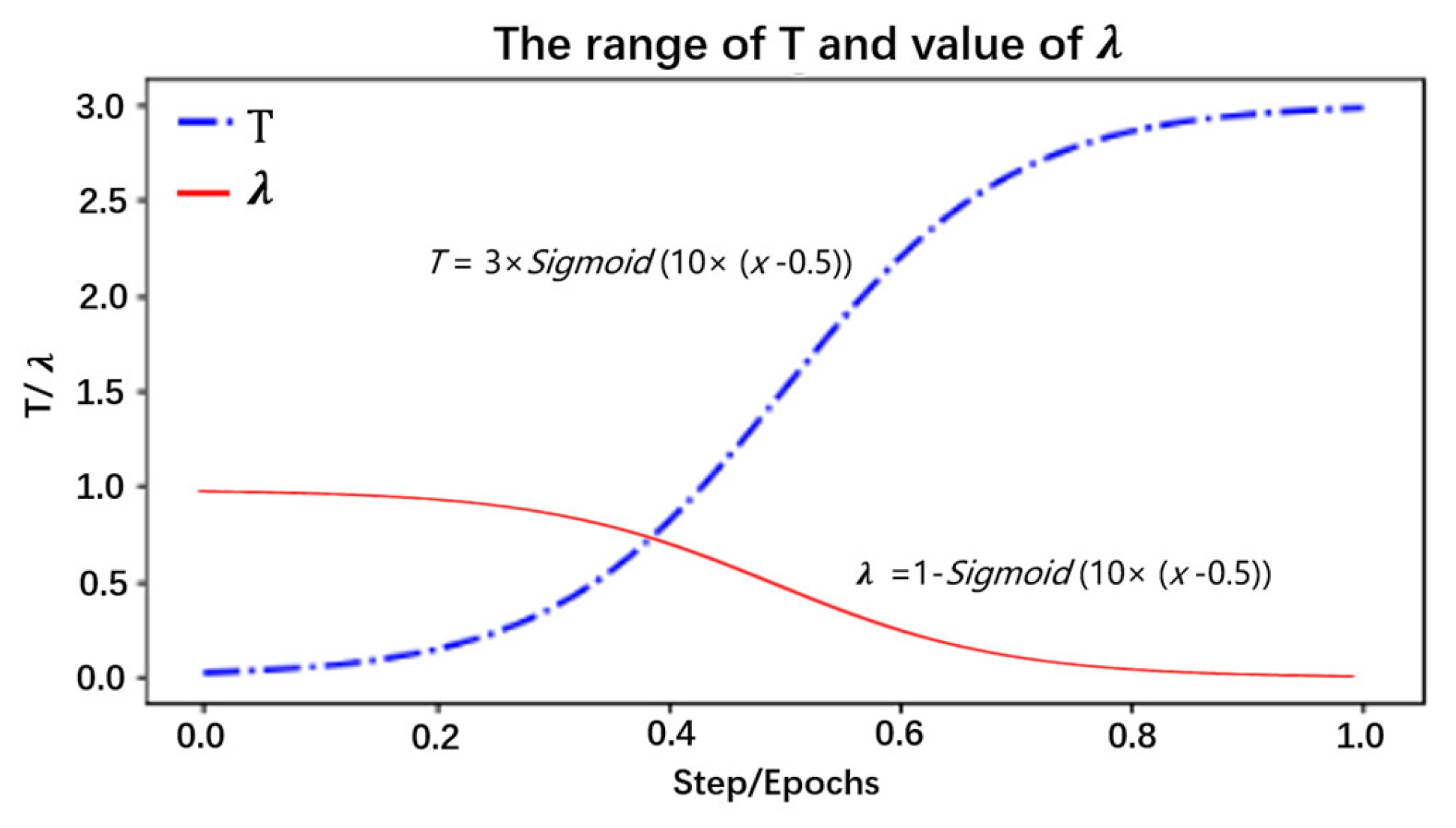
- Selection of T: By analyzing the distillation distribution of the model output probability for different T cases, as shown in Figure 7, the different types are 10 classifications for herbal recognition, and the standard output is the blue solid line. When the value of T is smaller than 1 (the red dotted line), the gap between the true prediction value and the dark knowledge is enlarged, that is, the proportion of the true prediction increases. When the value of T is greater than 1 (green dotted line), the total prediction distribution is smoother, which means the proportion of dark knowledge is increased. Therefore, in the early stage of training, T is set to a value smaller than 1, so that the student model can quickly find the basic proper parameters in the early stage. With the deepening of training and the expansion of the proportion of dark knowledge, the student model with high accuracy further learns the dark knowledge part of the correct prediction distribution given by the teacher model, so as to improve its accuracy. Thus, the value of T is set to the value of the function that grows with the training epochs. As illustrated in Formula (2) x is the training metric; through this function, the temperature T changes with the x in an S-shaped curve and is defined as the deepening of the experiment (step/epochs), increasing in an S-shaped curve, and the main value range is [0–3], so that the student model can learn different degrees of dark knowledge in different epochs. This is shown in Figure 8. The student model in the early stage as a low weight; as the model training process continues to rise, the relationship is well reflected as a sigmoid function, that is, an “S” curve. We have adjusted the parameters of the sigmoid function so as to be more in line with the whole training process of the model.
- Selection of λ: In knowledge distillation, when the student model is at distinct training phases, the combined weights of the teacher model and the true label are likewise diverse. In the early stage of training, transfer learning and real labels are mainly mixed for learning and fitting, which guarantees that the high accuracy based on the pretrained model can be acquired in the whole model training. Nevertheless, with the deepening of the training epochs, since the student model has reached a successful convergence situation through self-study, the accuracy cannot be further improved. Therefore, by increasing the proportion of the teacher model on and on, the student model learns the dark knowledge distribution from the teacher model prediction distribution, thereby improving the model performance. The change in λ is shown in Figure 8 and Formula (3), where x indicates the training times. By this function, λ decreases in an S-curve with the deepening of the training process.
- Calculation of the loss:
- (a)
- In the loss calculation of the soft label and the student model, the Jensen–Shannon divergence with symmetry is utilized to replace the cross-entropy loss as the similarity measure metrics of two prediction distributions, as shown in Formula (5).
- (b)
- In view of the one-hot characteristic of the hard label, the loss between the hard label and the student model is still computed via the cross-entropy loss, as shown in Formula (6).
- (c)
- The total loss is derived from Formulas (7)–(12).
3. Results and Discussion
3.1. Experimental Setting
3.2. Experimental Design
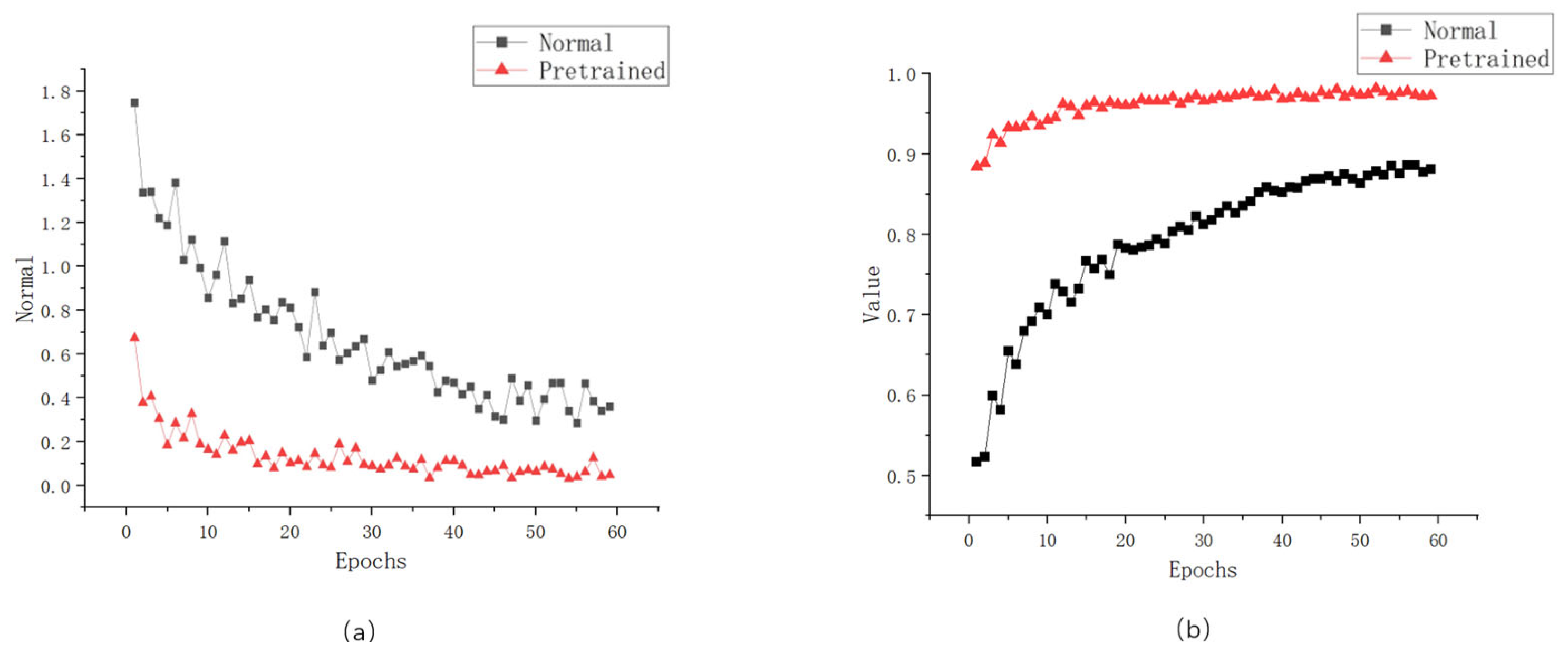
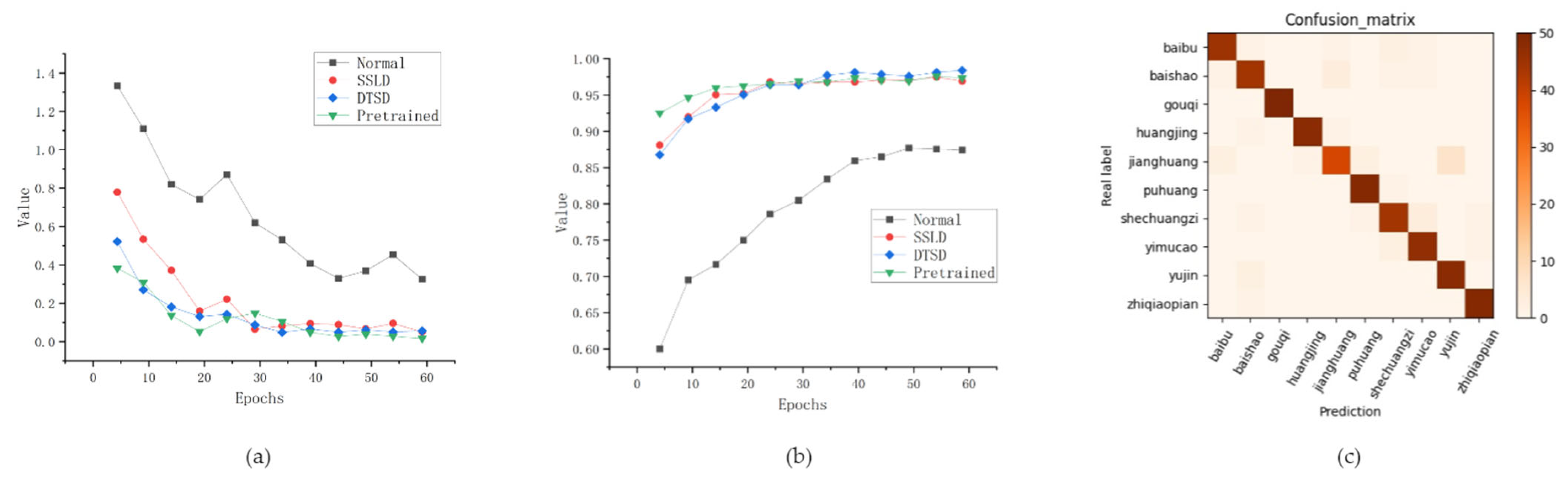
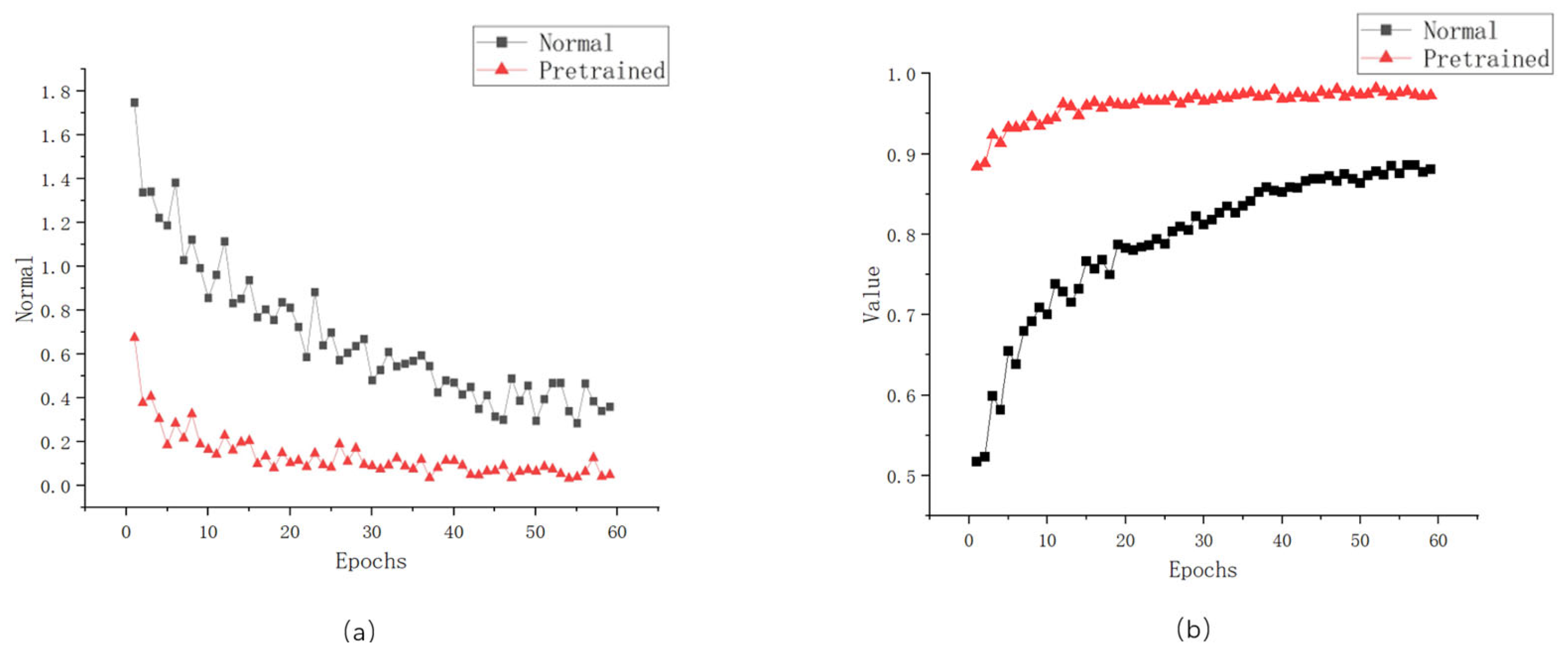
3.3. Experiments on Boosting Training with Pretrained Models
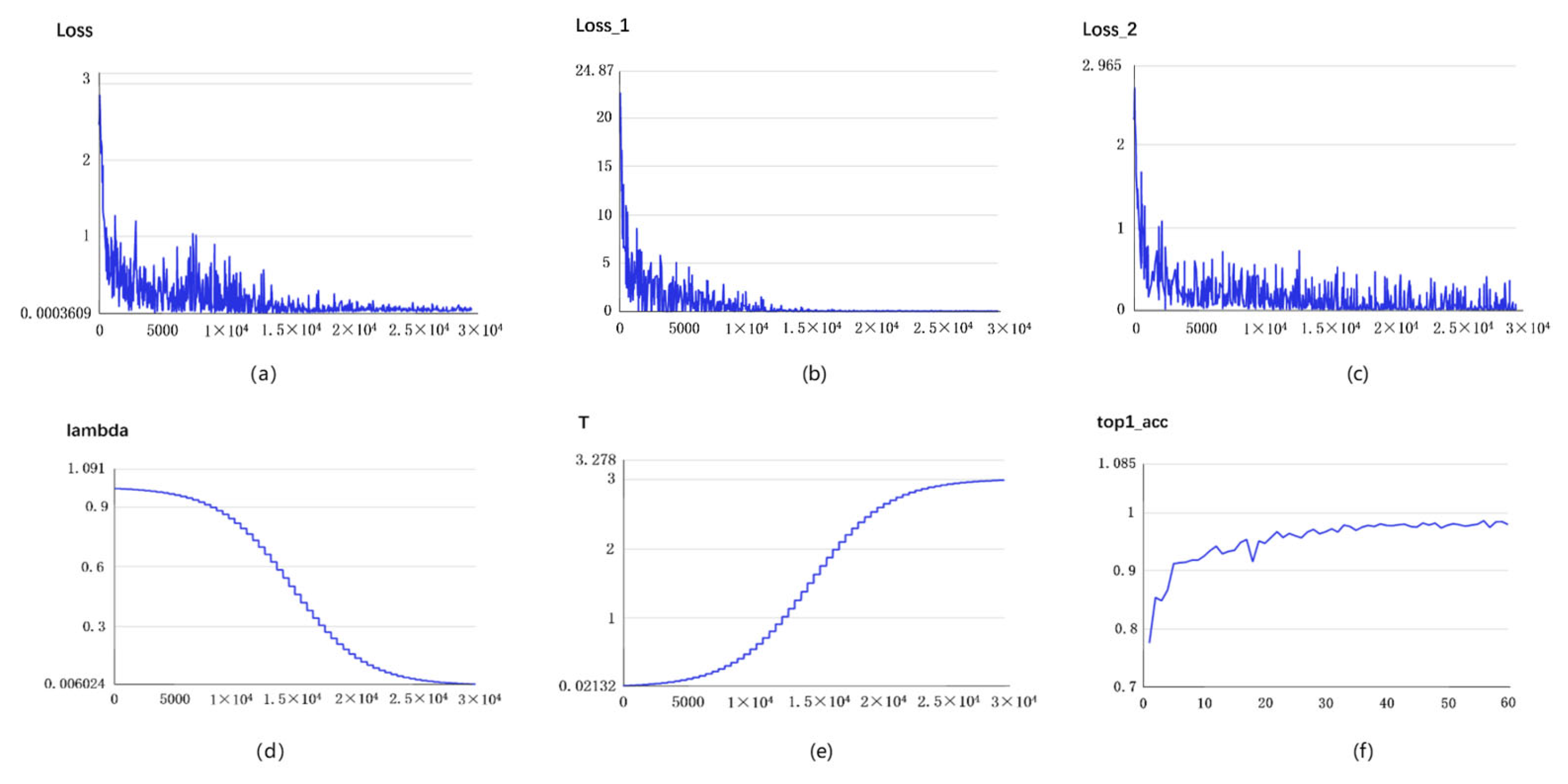
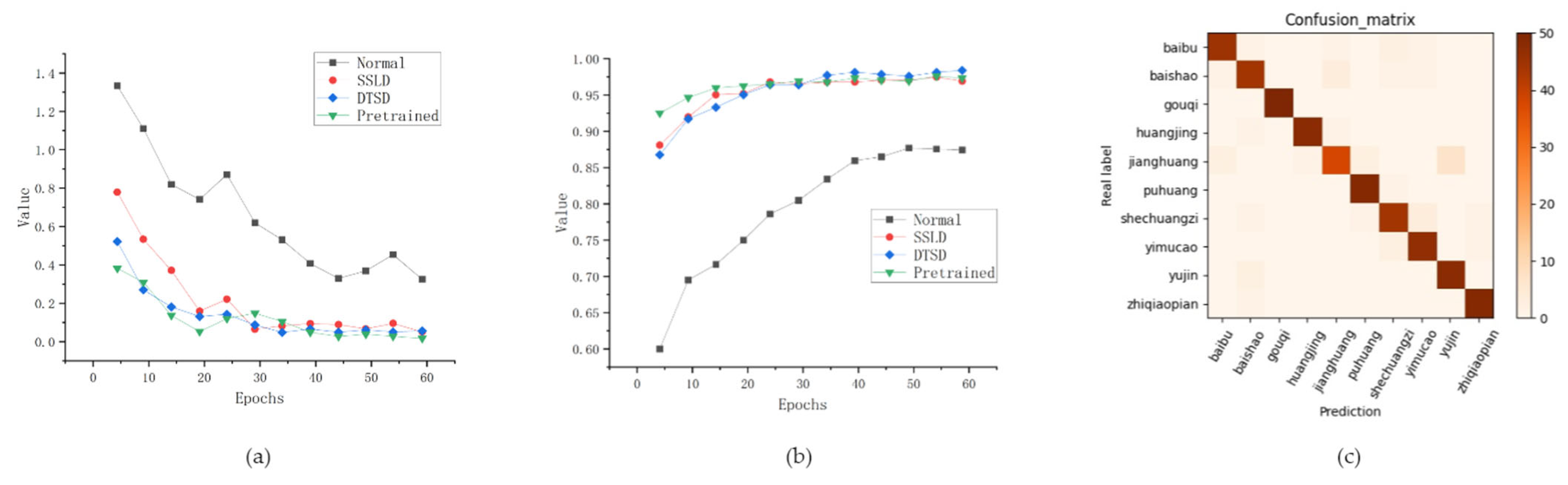
3.4. Improved Model Verification
3.5. Comparative Experiments with Similar Models
3.6. Experimental Comparisons with Other Models
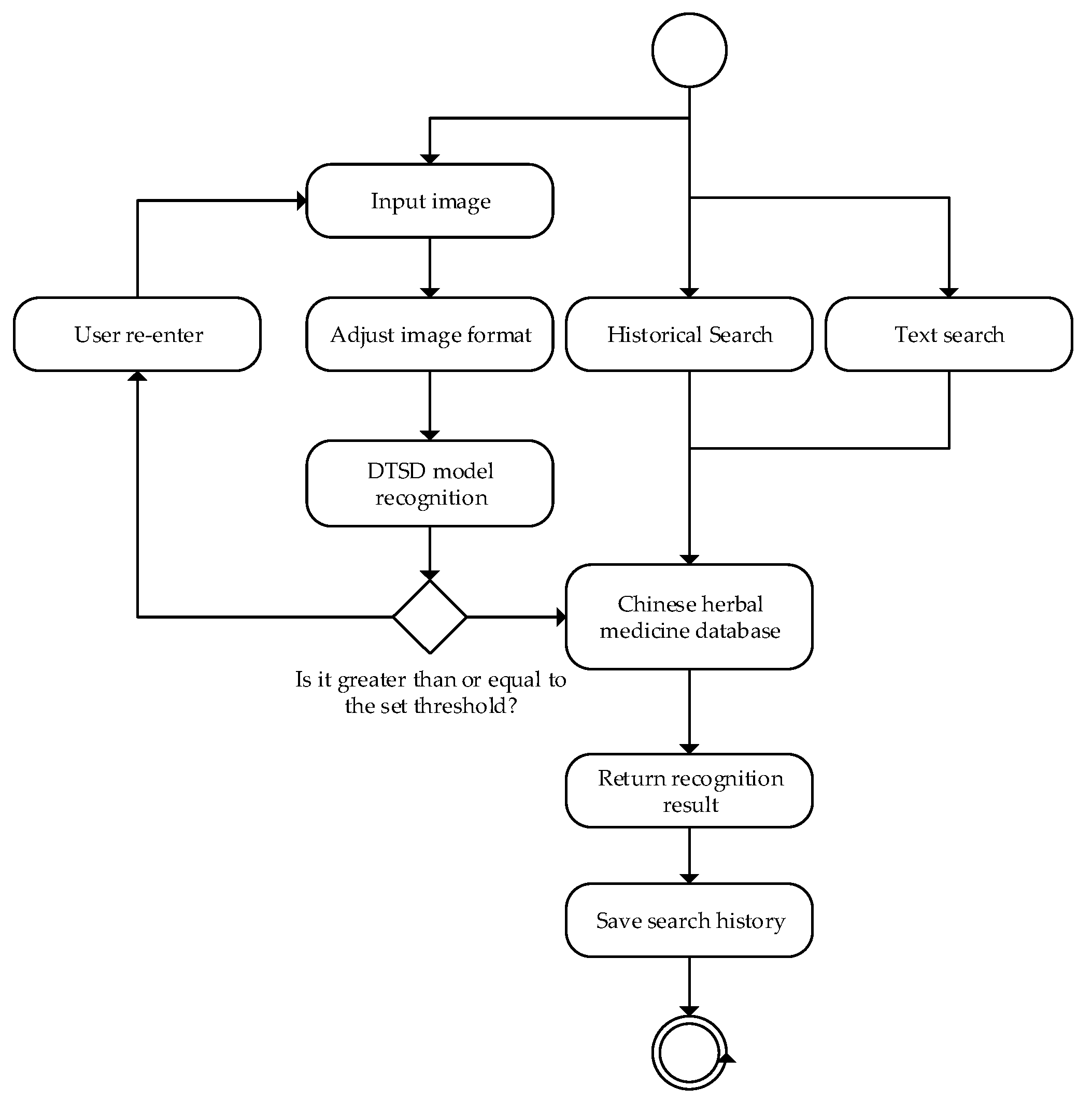
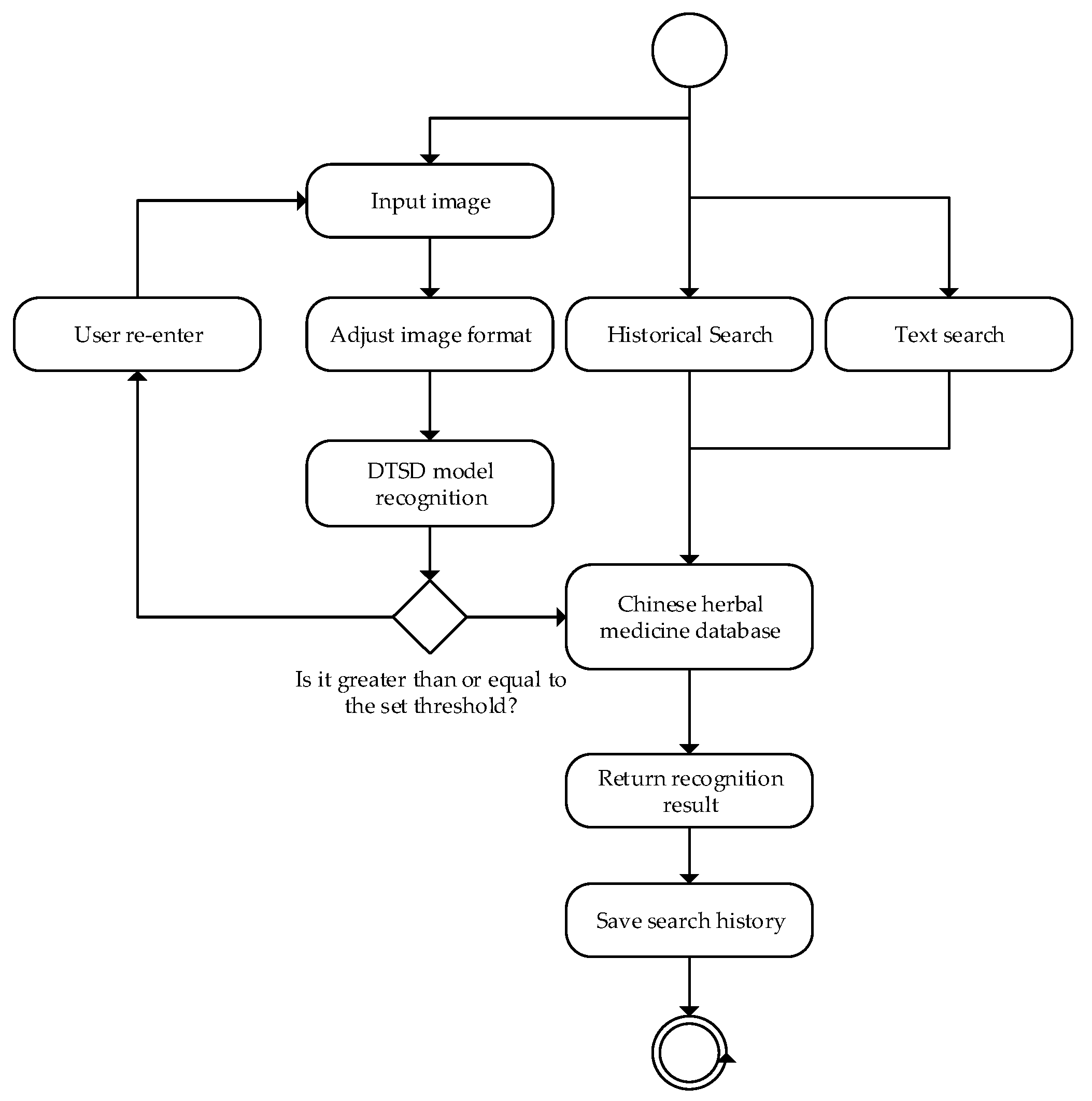
3.7. Application
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Huang, F.; Yu, L.; Shen, T. Research and implementation of Chinese herbal medicine plant image classification based on alexnet deep learning model. J. Qilu Univ. Technol. 2020, 34, 44–49. [Google Scholar]
- Gao, H.; Gao, X.; Feng, Q. Natural grassland plant species identification method based on deep learning. Grassl. Sci. 2020, 37, 1931–1939. [Google Scholar]
- Zhang, W.; Zhang, Q.; Pan, J. Classification and recognition of Chinese herbal medicine based on deep learning. Smart Health 2020, 6, 1–4+13. [Google Scholar]
- Wang, Y.; Sun, W.; Zhou, X. Research on Chinese herbal medicine plant image recognition method based on deep learning. Inf. Tradit. Chin. Med. 2020, 37, 21–25. [Google Scholar]
- Hu, K. Research and Implementation of Fritillaria Classification Algorithm Based on Deep Learning. Master’s Thesis, Chengdu University, Chengdu, China, 2020. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 702–703. [Google Scholar]
- He, K.; Zhang, X.; Ren, S. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef]
- He, T.; Zhang, Z.; Zhang, H. Bag of Tricks for Image Classification with Convolutional Neural Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Huang, G.; Geoff, P.; Laurens, V.; Kilian, W. Convolutional Networks with Dense Connectivity. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 44, 8704–8716. [Google Scholar] [CrossRef]
- Guo, X.; Fan, T.; Shu, X. Tomato leaf diseases recognition based on improved multi-scale AlexNet. Trans. Chin. Soc. Agric. Eng. 2019, 35, 162–169. [Google Scholar]
- Fang, Z.; Ren, J.; Marshall, S.; Zhao, H.; Wang, S.; Li, X. Topological optimization of the DenseNet with pretrained-weights inheritance and genetic channel selection. Pattern Recognit. 2021, 109, 107608. [Google Scholar] [CrossRef]
- Koonce, B. MobileNetV3. In Convolutional Neural Networks with Swift for Tensorflow; Apress: Berkeley, CA, USA, 2021; Volume 1, pp. 125–144. [Google Scholar] [CrossRef]
- Rosebrock, A. Deep Learning for Computer Vision with Python-Starter Bundle; PyImageSearch: Baltimore, MD, USA, 2017; pp. 189–190. [Google Scholar]
- Gao, A.; Geng, A.; Song, Y.; Ren, L.; Zhang, Y.; Han, X. Detection of maize leaf diseases using improved MobileNet V3-small. Int. J. Agric. Biol. Eng. 2023, 16, 225–232. [Google Scholar] [CrossRef]
- Chen, W.; Tong, J.; He, R. An easy method for identifying 315 categories of commonly-used Chinese herbal medicines based on automated image recognition using AutoML platforms. Inform. Med. Unlocked 2021, 25, 100607. [Google Scholar] [CrossRef]
- Chen, J.; Wang, W.; Zhang, D. Attention embedded lightweight network for maize disease recognition. Plant Pathol. 2021, 70, 630–642. [Google Scholar] [CrossRef]
- Bi, S.; Gao, F.; Chen, J. Detection method of citrus based on deep convolution neural network. Trans. Chin. Soc. Agric. Mach. 2019, 50, 181–186. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Zhuang, F.; Luo, P.; He, Q. Survey on transfer learning research. J. Softw. 2015, 26, 26–39. [Google Scholar]
- Li, Y.; Hao, Z.; Lei, H. Survey of convolutional neural network. J. Comput. Appl. 2016, 36, 2508–2515, 2565. [Google Scholar]
- Ma, J.; Du, K.; Zheng, F.; Zhang, L.; Sun, Z. Disease recognition system for greenhouse cucumbers based on deep convolutional neural network. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2018, 34, 186–192. [Google Scholar]
- Jabir, B.; Falih, N. Deep learning-based decision support system for weeds detection in wheat fields. Int. J. Electr. Comput. Eng. 2022, 12, 816. [Google Scholar] [CrossRef]
- Khan, S.; Rahmani, H.; Shah, S.A. A guide to convolutional neural networks for computer vision. Synth. Lect. Comput. Vis. 2018, 8, 1–207. [Google Scholar]
- Li, Z.; Guo, R.; Li, M. A review of computer vision technologies for plant phenotyping. Comput. Electron. Agric. 2020, 176, 105672. [Google Scholar] [CrossRef]
- Li, K.; Zou, C.; Bu, S. Multi-modal feature fusion for geographic image annotation. Pattern Recognit. 2017, 73, 1–14. [Google Scholar] [CrossRef]
- Kolhar, S.; Jagtap, J. Plant trait estimation and classification studies in plant phenotyping using machine vision—A review. Inf. Process. Agric. 2023, 10, 114–135. [Google Scholar] [CrossRef]
- Cao, X.; Li, R.; Wen, L. Deep multiple feature fusion for hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3880–3891. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | Pretraining Model | Accuracy (%) |
|---|---|---|
| ResNet50_vd | × | 86.10 |
| √ | 98.50 | |
| DenseNet121 | × | 91.05 |
| √ | 98.40 | |
| MobileNet_v3_Small | × | 88.35 |
| √ | 97.85 |
| Student Model | Teacher Model | Acc Of Teacher Model (%) | Learning Rate Decline Strategy | Accuracy (%) |
|---|---|---|---|---|
| MobileNet_v3_Small | ResNet50_vd | 98.90 | Piecewise | 97.80 |
| DensNet121 | 98.70 | |||
| MobileNet_v3_Small | ReNet50_vd | 98.90 | Cosine | 98.15 |
| DenseNet121 | 98.70 | |||
| MobileNet_v3_Small | ResNet50_vd | 98.90 | Exponential warmup | 98.60 |
| DenseNet121 | 98.70 |
| Learning Rate Decline Strategy | Batch Size | Accuracy |
|---|---|---|
| MobileNet_v3_Small | 16 | 86.45 |
| MobileNet_v3_Small_PRE | 16 | 97.25 |
| MobileNet_v3_Small_SSLD | 16 | 97.10 |
| MobileNet_v3_Small_DTSD | 16 | 98.60 |
| Parameter | Batch Size | Basic Learning Rate | Learning Rate Decline Strategy | Epochs | Pretraining Model |
|---|---|---|---|---|---|
| Parameter value | 16 | 0.0037 | Warmup | 60 | √ |
| Network | Accuracy (%) | Model Volume (MB) | Prediction Time (s) |
|---|---|---|---|
| DenseNet121 | 97.10 | 29.30 | 0.0186 |
| ResNet50_vd | 97.35 | 90.90 | 0.0237 |
| Xception65 | 97.65 | 131 | 0.0198 |
| EfficientNetB1 | 98.95 | 27.5 | 0.0233 |
| MobileNet_v3_Small_DTSD | 98.60 | 10 | 0.0172 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, L.; Long, W.; Yi, J.; Liu, L.; Xu, K. Enhanced Knowledge Distillation for Advanced Recognition of Chinese Herbal Medicine. Sensors 2024, 24, 1559. https://doi.org/10.3390/s24051559
Zheng L, Long W, Yi J, Liu L, Xu K. Enhanced Knowledge Distillation for Advanced Recognition of Chinese Herbal Medicine. Sensors. 2024; 24(5):1559. https://doi.org/10.3390/s24051559
Chicago/Turabian StyleZheng, Lu, Wenhan Long, Junchao Yi, Lu Liu, and Ke Xu. 2024. "Enhanced Knowledge Distillation for Advanced Recognition of Chinese Herbal Medicine" Sensors 24, no. 5: 1559. https://doi.org/10.3390/s24051559
APA StyleZheng, L., Long, W., Yi, J., Liu, L., & Xu, K. (2024). Enhanced Knowledge Distillation for Advanced Recognition of Chinese Herbal Medicine. Sensors, 24(5), 1559. https://doi.org/10.3390/s24051559