
Human Multi-Activities Classification Using mmWave Radar: Feature Fusion in Time-Domain and PCANet



Abstract
1. Introduction
- (1)
- The introduction of an original method for classifying fourteen types of human daily activities, leveraging statistical offset measures, range profiles, time–frequency analyses, and azimuth–range–time data.
- (2)
- Pioneering the use of the CNN-BiLSTM framework for fusing 3D range–azimuth–time information.
- (3)
- Recommendation of the Margenau–Hill Spectrogram (MHS) for optimal feature quality and minimal feature count, which has been validated by analysis of four time–frequency methods.
2. Related Work
3. Methodology
3.1. Radar Formula
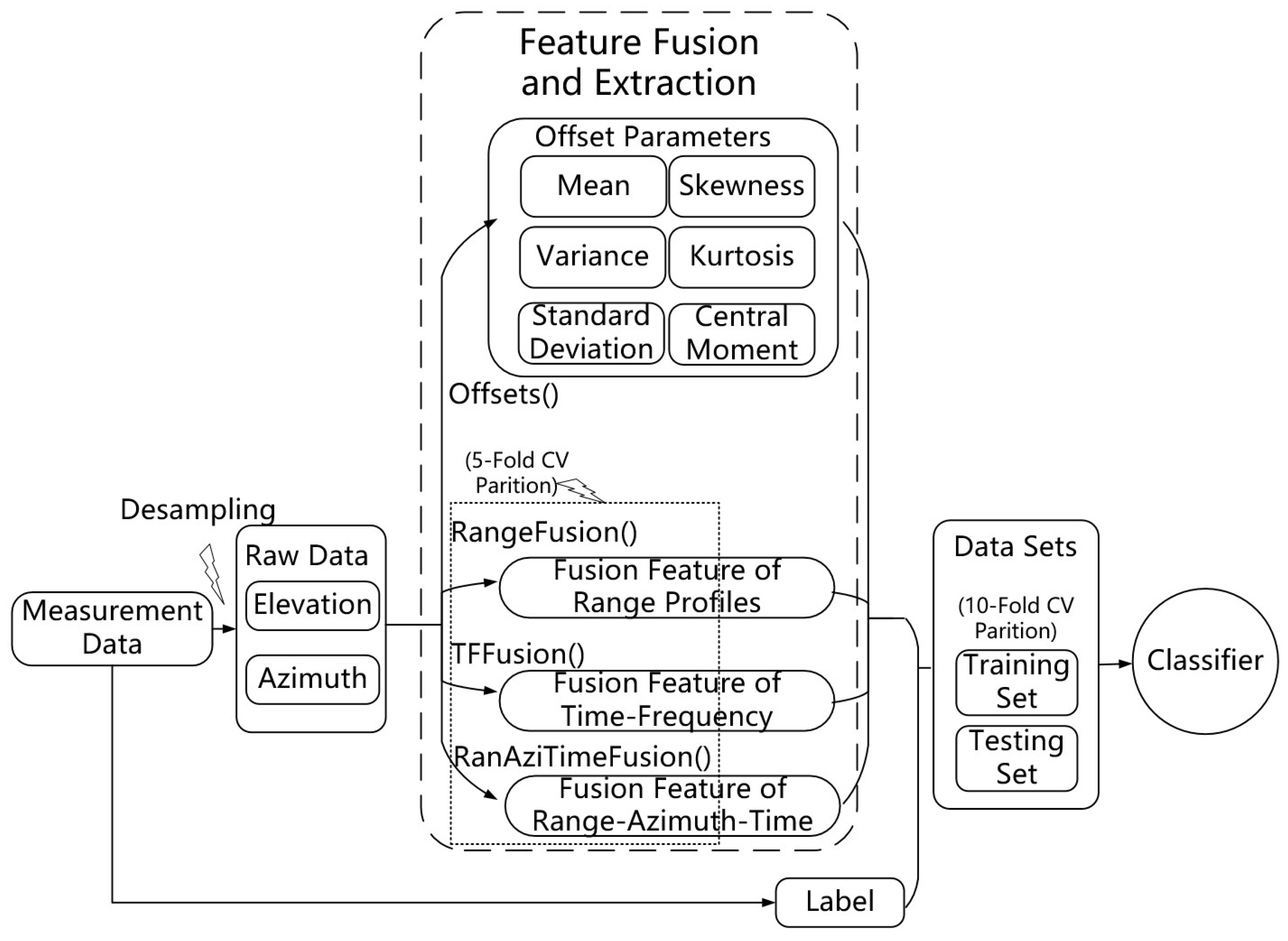
3.2. Feature Source
3.2.1. Offset Parameters
| Algorithm 1 Offsets() |
Input: Elevation, Azimuth Output: Offset Parameters · |
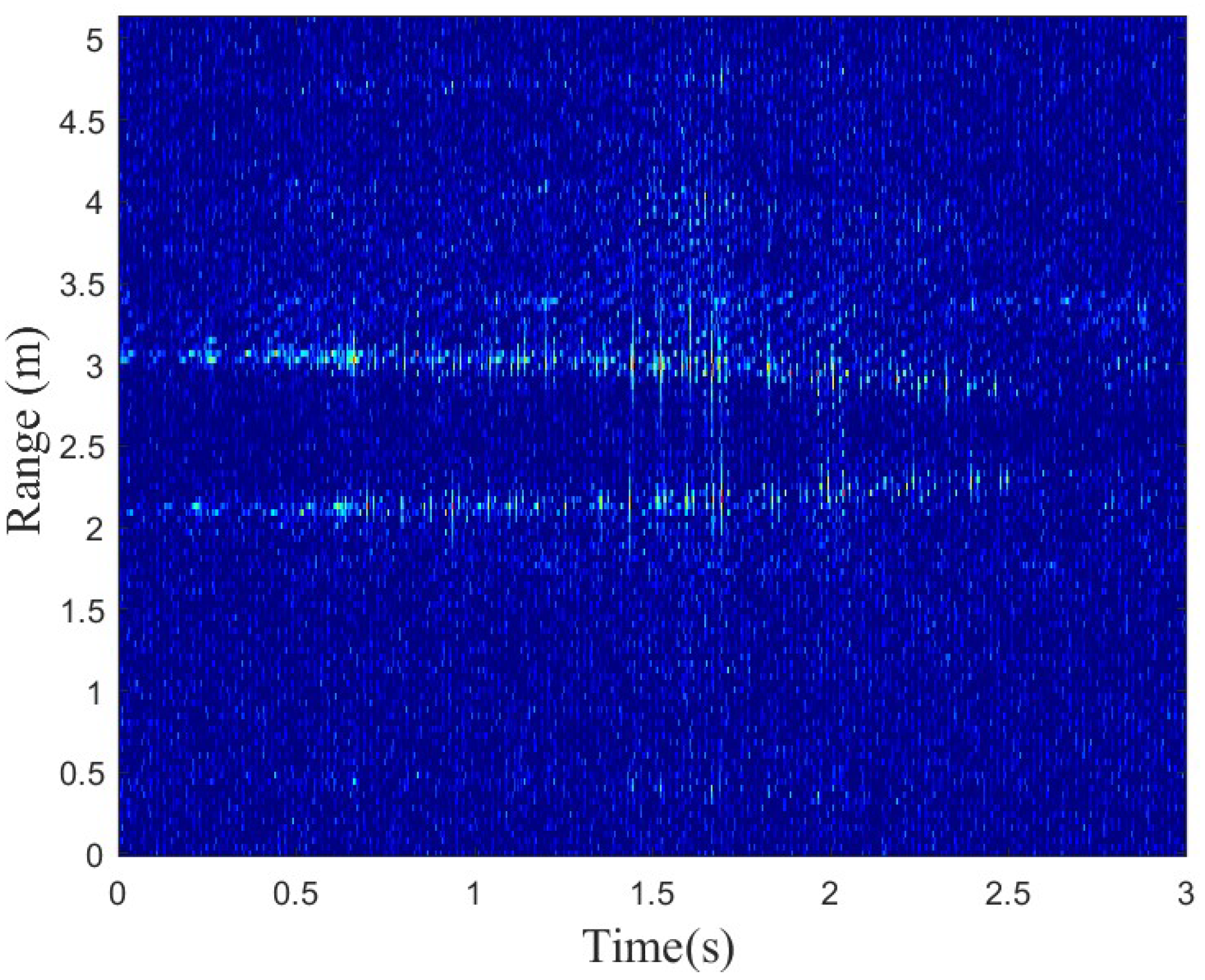
3.2.2. Range Profiles
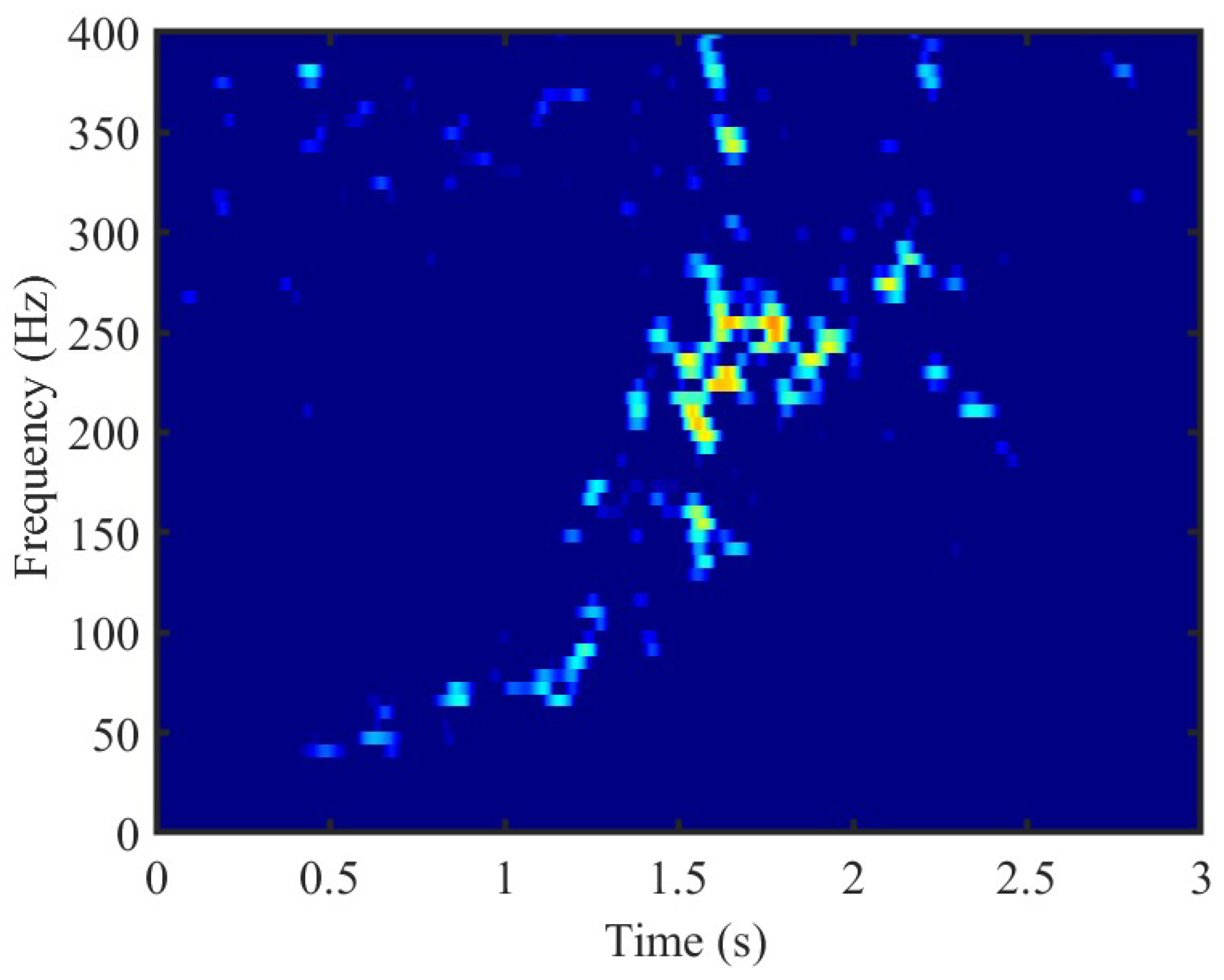
3.2.3. Time-Frequency
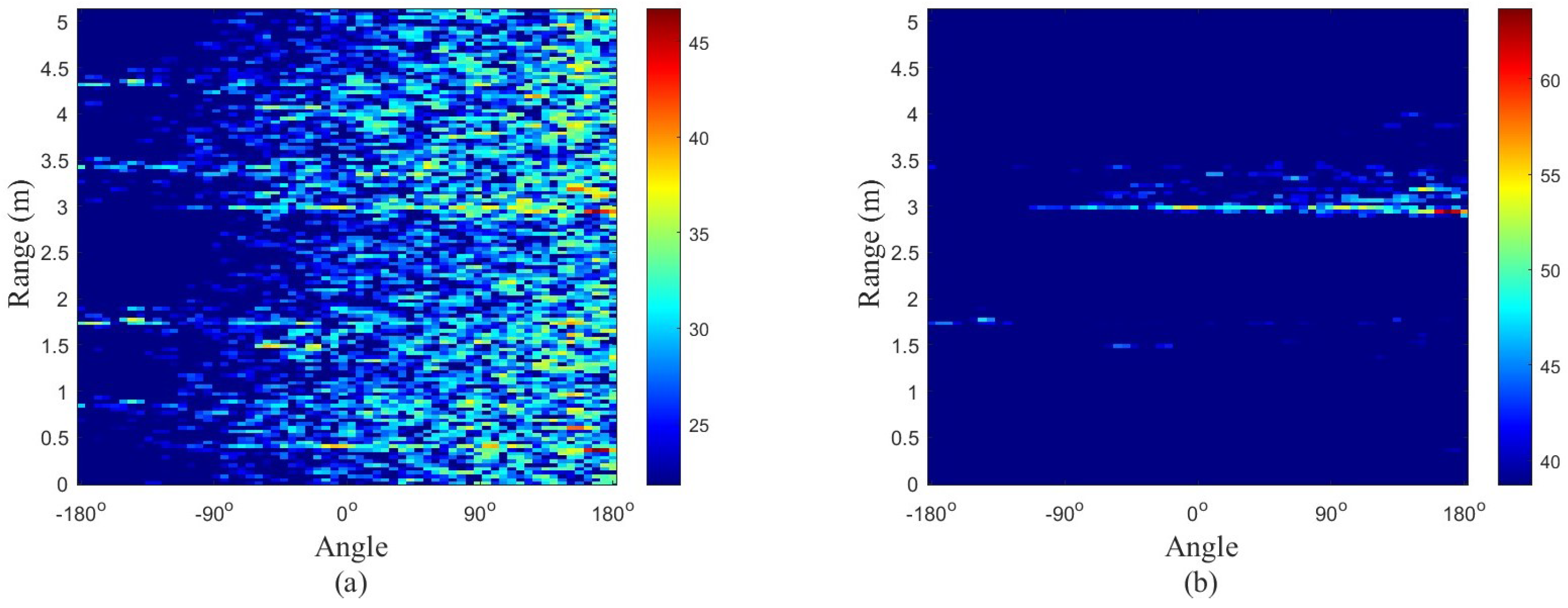
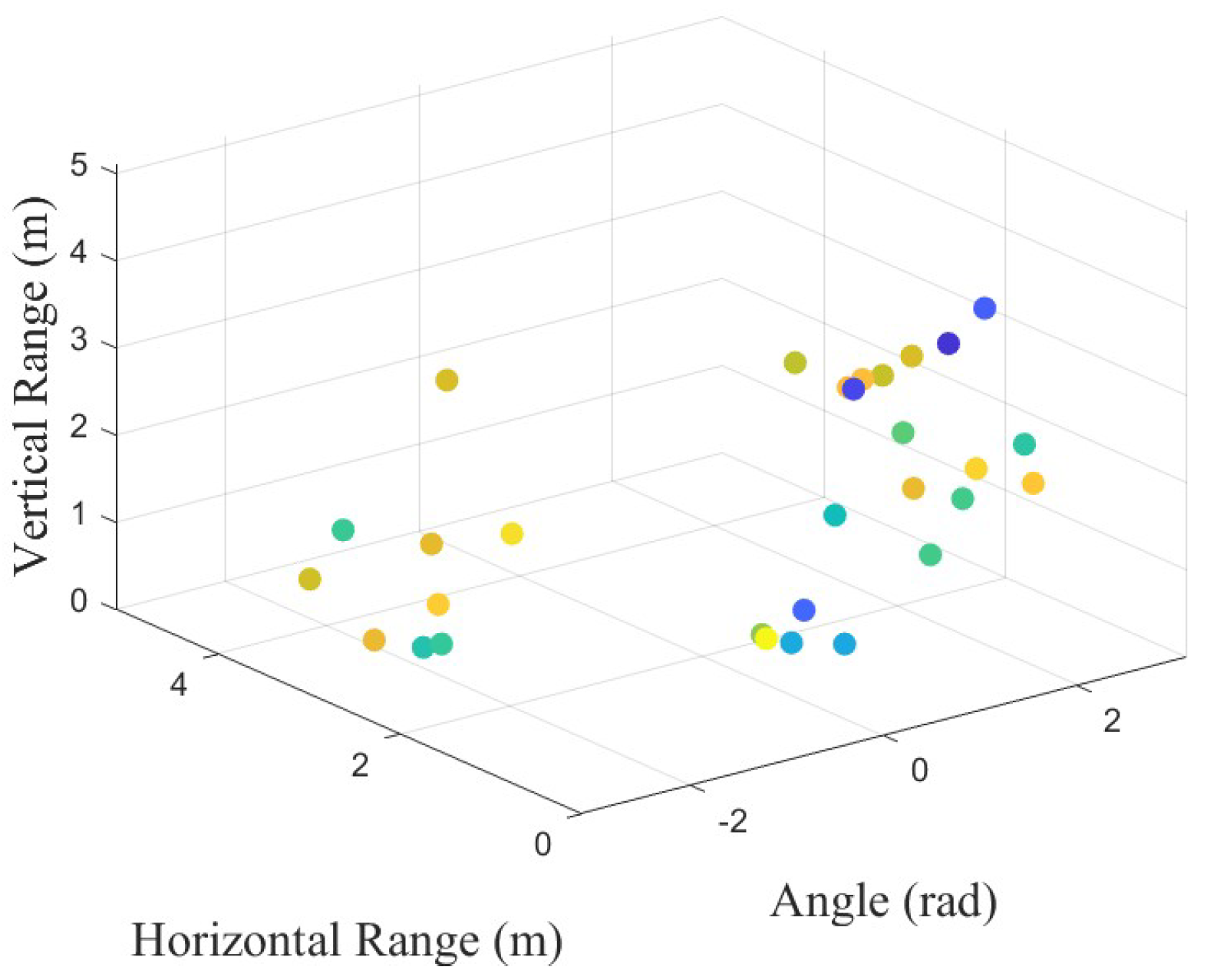
3.2.4. Range–Azimuth–Time
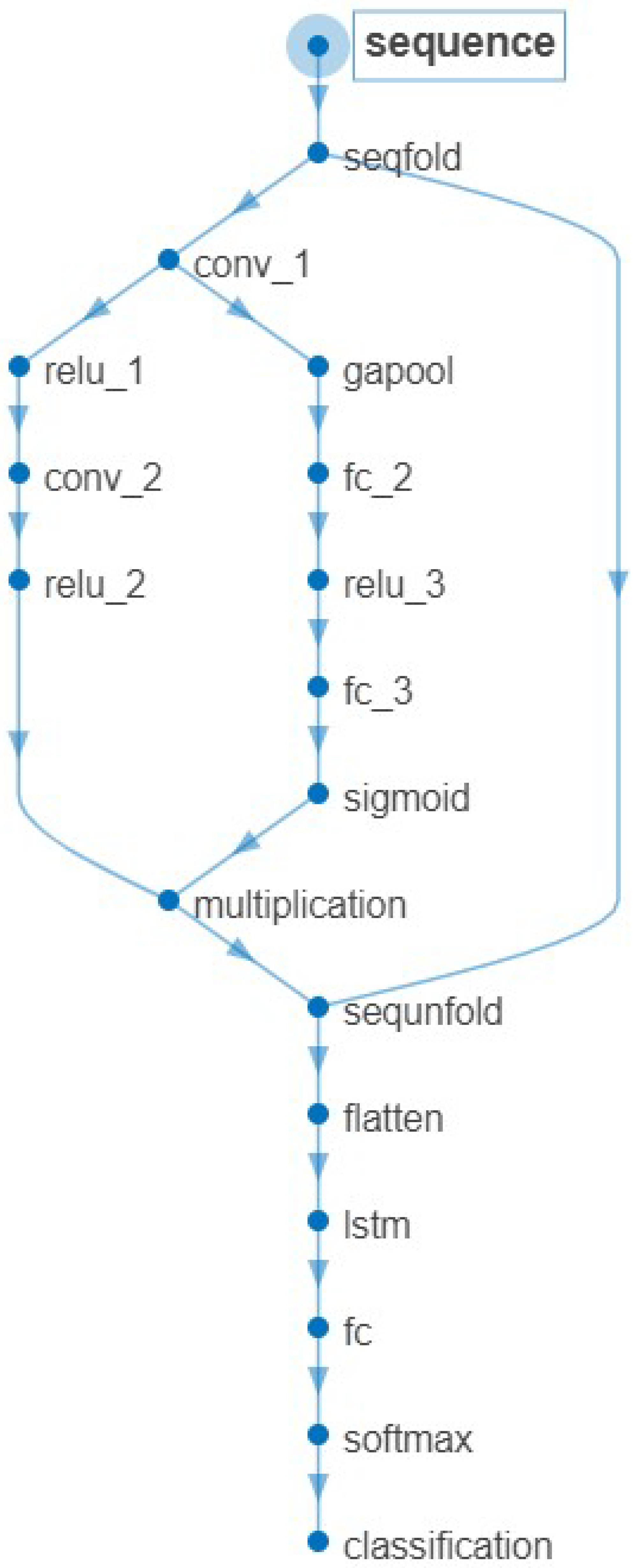
3.3. CNN-BiLSTM
| Algorithm 2 CNN-BiLSTM() |
Input: FusionInput, KFoldNum Output: Fusion Feature Create CNN-BiLSTM Layers. Set CNN-BiLSTM Options. ; for do ; ; ; ; ; for do ; ; ; ; ; ; ; end for ; ; ; end for for do ; ; for do ; end for for do ; end for ; end for ; |
3.4. Method Framework
| Algorithm 3 RangeFusion() |
Input: Elevation, Azimuth and Label of Sample Data, KFoldNum Output: Fusion Feature of Range Profiles of Samples Calculate Range Profiles of Elevation and Azimuth respectively. Calculate PCANet of Range Profiles of Samples via SVD. for do ; ; ; end for ; |
| Algorithm 4 TFFusion() |
Input: Elevation, Azimuth and Label of Sample Data, KFoldNum, Frebin, TFWin Output: Fusion Feature of TF image of Samples ; ; Calculate PCANet of Range Profiles of Samples via SVD. for do ; ; ; end for ; |
| Algorithm 5 RanAziTimeFusion() |
Input: Elevation, Azimuth and Label of Sample Data, KFoldNum Output: Fusion Feature of Range–Azimuth–Time Calculate Range–Azimuth–Time of Elevation and Azimuth, respectively. Calculate the PCANet of Range–Azimuth–Time. %PCAofRAT() for to do end for for to do end for |
4. Experimental Results and Analysis
4.1. Experiment Setup and Data Collection
4.2. Implement Details
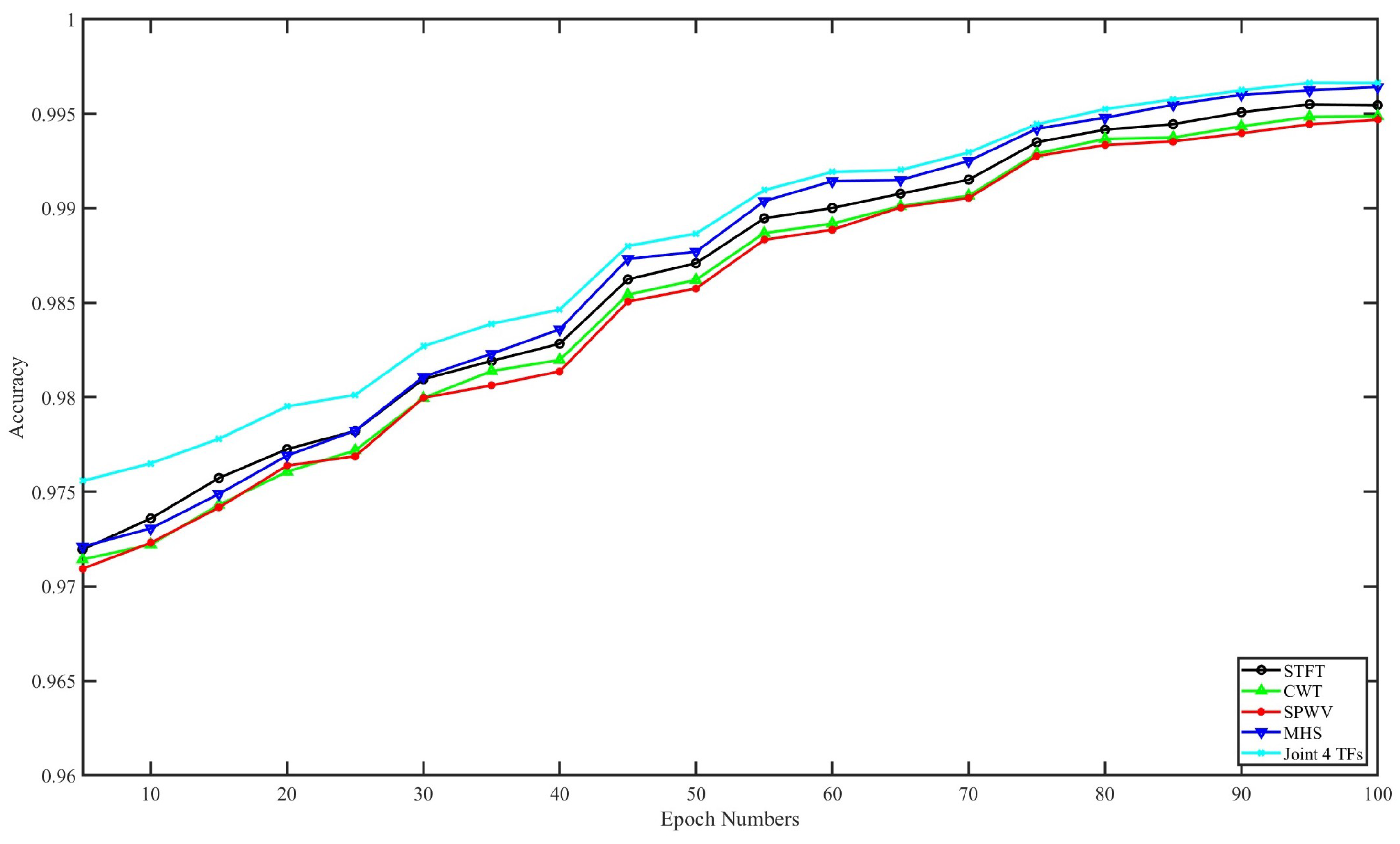
4.3. Performance Analysis
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ABLSTM | Attention-based Bidirectional Long Short-term Memory |
| BiLSTM | Bidirectional Long Short-term Memory |
| CPI | Coherent Processing Interval |
| CNN | Convolutional Neural Network |
| CNN-BiLSTM | Convolutional Neural Network with Bidirectional Long Short-term Memory |
| CW | Choi–Williams |
| DQDA | Diagonal Quadratic Discriminant Analysis |
| FFT | Fast Fourier Transform |
| FoV | Radar Field of View |
| GANs | Generative Adversarial Networks |
| GRU | Gated Recurrent Unit |
| LSTM | Long Short-term Memory |
| MHS | Margenau–Hill Spectrogram |
| mmWave | Millimeter Wave |
| MSRLSTMs | Residual and Long Short-term Memory Recurrent Networks |
| NB | Naïve Bayes |
| PCA | Principal Component Analysis |
| PCANet | Principal Component Analysis Network |
| PQDA | Pseudo Quadratic Discriminant Analysis |
| RF | Random Forest |
| RNN | Recurrent Neural Network |
| SNR | Signal-to-Noise Ratio |
| STFT | Short-Time Fourier Transform |
| SVD | Singular Value Decomposition |
| SVM | Support Vector Machine |
| TCN | Temporal Convolutional Neural Network |
| TF | Time–Frequency |
| TPN | Temporal Pyramid Recurrent Neural Network |
References
- WHO. Ageing. Available online: https://www.who.int/health-topics/ageing (accessed on 15 July 2024).
- WHO China. Ageing and Health in China. Available online: https://www.who.int/china/health-topics/ageing (accessed on 15 July 2024).
- Ageing and Health (AAH); Maternal, Newborn, Child & Adolescent Health & Ageing (MCA). WHO Global Report on Falls Prevention in Older Age. WHO. Available online: https://www.who.int/publications/i/item/9789241563536 (accessed on 15 July 2024).
- Wu, J.; Han, C.; Naim, D. A Voxelization Algorithm for Reconstructing mmWave Radar Point Cloud and an Application on Posture Classification for Low Energy Consumption Platform. Sustainability 2023, 15, 3342. [Google Scholar] [CrossRef]
- Luwe, Y.J.; Lee, C.O.; Lim, K.M. Wearable Sensor-based Human Activity Recognition with Hybrid Deep Learning Model. Informatics 2022, 9, 56. [Google Scholar] [CrossRef]
- Ullah, H.; Munir, A. Human Activity Recognition Using Cascaded Dual Attention CNN and Bi-Directional GRU Framework. J. Imaging 2023, 9, 130. [Google Scholar] [CrossRef]
- Chetty, K.; Smith, G.E.; Woodbridge, K. Through-the-Wall Sensing of Personnel using Passive Bistatic WiFi Radar at Standoff Distances. IEEE Trans. Geosci. Remote Sens. 2012, 50, 1218–1226. [Google Scholar] [CrossRef]
- Kilaru, V.; Amin, M.; Ahmad, F.; Sévigny, P.; DiFilippo, D. Gaussian Mixture Modeling Approach for Stationary Human Identification in Through-the-wall Radar Imagery. J. Electron. Imaging 2015, 24, 013028. [Google Scholar] [CrossRef]
- Lin, Y.; Le Kernec, J.; Yang, S.; Fioranelli, F.; Romain, O.; Zhao, Z. Human Activity Classification with Radar: Optimization and Noise Robustness with Iterative Convolutional Neural Networks Followed With Random Forests. IEEE Sens. J. 2018, 18, 9669–9681. [Google Scholar] [CrossRef]
- Lin, Y.; Yang, F. IQ-Data-Based WiFi Signal Classification Algorithm Using the Choi-Williams and Margenau-Hill-Spectrogram Features: A Case in Human Activity Recognition. Electronics 2021, 10, 2368. [Google Scholar] [CrossRef]
- Sengupta, A.; Jin, F.; Zhang, R.; Cao, S. mm-Pose: Real-Time Human Skeletal Posture Estimation using mmWave Radars and CNNs. IEEE Sens. J. 2020, 20, 10032–10044. [Google Scholar] [CrossRef]
- An, S.; Ogras, U.Y. MARS: MmWave-based Assistive Rehabilitation System for Smart Healthcare. ACM Trans. Embed. Comput. Syst. 2021, 20, 1–22. [Google Scholar] [CrossRef]
- An, S.; Li, Y.; Ogras, U.Y. mRI: Multi-modal 3D Human Pose Estimation Dataset using mmWave, RGB-D, and Inertial Sensors. arXiv 2022, arXiv:2210.08394. [Google Scholar] [CrossRef]
- Pearce, A.; Zhang, J.A.; Xu, R.; Wu, K. Multi-Object Tracking with mmWave Radar: A Review. Electronics 2023, 12, 308. [Google Scholar] [CrossRef]
- Zhang, J.; Xi, R.; He, Y.; Sun, Y.; Guo, X.; Wang, W.; Na, X.; Liu, Y.; Shi, Z.; Gu, T. A Survey of mmWave-based Human Sensing: Technology, Platforms and Applications. IEEE Commun. Surv. Tutor. 2023, 25, 2052–2087. [Google Scholar] [CrossRef]
- Mafukidze, H.D.; Mishra, A.K.; Pidanic, J.; Francois, S.W.P. Scattering Centers to Point Clouds: A Review of mmWave Radars for Non-Radar-Engineers. IEEE Access 2022, 10, 110992–111021. [Google Scholar] [CrossRef]
- Muaaz, M.; Waqar, S.; Pätzold, M. Orientation-Independent Human Activity Recognition using Complementary Radio Frequency Sensing. Sensors 2023, 13, 5810. [Google Scholar] [CrossRef]
- Cardillo, E.; Li, C.; Caddemi, A. Heating, Ventilation, and Air Conditioning Control by Range-Doppler and Micro-Doppler Radar Sensor. In Proceedings of the 18th European Radar Conference (EuRAD), London, UK, 5–7 April 2022; pp. 21–24. [Google Scholar] [CrossRef]
- Wang, Z.; Jiang, D.; Sun, B.; Wang, Y. A Data Augmentation Method for Human Activity Recognition based on mmWave Radar Point Cloud. IEEE Sens. Lett. 2023, 7, 1–4. [Google Scholar] [CrossRef]
- Taylor, W.; Dashtipour, K.; Shah, S.A.; Hussain, A.; Abbasi, Q.H.; Imran, M.A. Radar Sensing for Activity Classification in Elderly People Exploiting Micro-Doppler Signatures using Machine Learning. Sensors 2021, 11, 3881. [Google Scholar] [CrossRef]
- Kurtoğlu, E.; Gurbuz, A.C.; Malaia, E.A.; Griffin, D.; Crawford, C.; Gurbuz, S.Z. ASL Trigger Recognition in Mixed Activity/Signing Sequences for RF Sensor-Based User Interfaces. IEEE Trans. Hum. Mach. Syst. 2022, 52, 699–712. [Google Scholar] [CrossRef]
- Jin, F.; Sengupta, A.; Cao, S. mmFall: Fall Detection Using 4-D mmWave Radar and a Hybrid Variational RNN AutoEncoder. IEEE Trans. Autom. Sci. Eng. 2022, 19, 1245–1257. [Google Scholar] [CrossRef]
- Mehta, R.; Sharifzadeh, S.; Palade, V.; Tan, B.; Daneshkhah, A.; Karayaneva, Y. Deep Learning Techniques for Radar-based Continuous Human Activity Recognition. Mach. Learn. Knowl. Extr. 2023, 5, 1493–1518. [Google Scholar] [CrossRef]
- Alhazmi, A.K.; Mubarak, A.A.; Alshehry, H.A.; Alshahry, S.M.; Jaszek, J.; Djukic, C.; Brown, A.; Jackson, K.; Chodavarapu, V.P. Intelligent Millimeter-Wave System for Human Activity Monitoring for Telemedicine. Sensors 2024, 24, 268. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, H.; Cui, K.; Zhou, A.; Li, W.; Ma, H. m-Activity: Accurate and Real-Time Human Activity Recognition via Millimeter Wave Radar. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2021), Toronto, ON, Canada, 6–11 June 2021; pp. 8298–8302. [Google Scholar] [CrossRef]
- Lee, G.; Kim, J. Improving Human Activity Recognition for Sparse Radar Point Clouds: A Graph Neural Network Model with Pre-trained 3D Human-joint Coordinates. Appl. Sci. 2022, 12, 2168. [Google Scholar] [CrossRef]
- Lee, G.; Kim, J. MTGEA: A Multimodal Two-Stream GNN Framework for Efficient Point Cloud and Skeleton Data Alignment. Sensors 2023, 5, 2787. [Google Scholar] [CrossRef]
- Kittiyanpunya, C.; Chomdee, P.; Boonpoonga, A.; Torrungrueng, D. Millimeter-Wave Radar-Based Elderly Fall Detection Fed by One-Dimensional Point Cloud and Doppler. IEEE Access 2023, 11, 76269–76283. [Google Scholar] [CrossRef]
- Rezaei, A.; Mascheroni, A.; Stevens, M.C.; Argha, R.; Papandrea, M.; Puiatti, A.; Lovell, N.H. Unobtrusive Human Fall Detection System Using mmWave Radar and Data Driven Methods. IEEE Sens. J. 2023, 23, 7968–7976. [Google Scholar] [CrossRef]
- Khunteta, S.; Saikrishna, P.; Agrawal, A.; Kumar, A.; Chavva, A.K.R. RF-Sensing: A New Way to Observe Surroundings. IEEE Access 2022, 10, 129653–129665. [Google Scholar] [CrossRef]
- Singh, A.D.; Sandha, S.S.; Garcia, L.; Srivastava, M. Human Activity Recognition from Point Clouds Generated through a Millimeter-wave Radar. In Proceedings of the 3rd ACM Workshop on Millimeter-Wave Networks and Sensing Systems, Los Cabos, Mexico, 25 October 2019; pp. 51–56. [Google Scholar] [CrossRef]
- Yu, C.; Xu, Z.; Yan, K.; Chien, Y.R.; Fang, S.H.; Wu, H.C. Noninvasive Human Activity Recognition using Millimeter-Wave Radar. IEEE Syst. J. 2022, 7, 3036–3047. [Google Scholar] [CrossRef]
- Ma, C.; Liu, Z. A Novel Spatial–temporal Network for Gait Recognition using Millimeter-wave Radar Point Cloud Videos. Electronics 2023, 12, 4785. [Google Scholar] [CrossRef]
- Li, J.; Li, X.; Li, Y.; Zhang, Y.; Yang, X.; Xu, P. A New Method of Tractor Engine State Identification based on Vibration Characteristics. Processes 2023, 11, 303. [Google Scholar] [CrossRef]
- Hippel, P.T.V. Mean, Median, and Skew: Correcting a Textbook Rule. J. Stat. Educ. 2005, 13. [Google Scholar] [CrossRef]
- Asfour, M.; Menon, C.; Jiang, X. A Machine Learning Processing Pipeline for Relikely Hand Gesture Classification of FMG Signals with Stochastic Variance. Sensors 2021, 21, 1504. [Google Scholar] [CrossRef]
- Gurland, J.; Tripathi, R.C. A Simple Approximation for Unbiased Estimation of the Standard Deviation. Am. Stat. 1971, 25, 30–32. [Google Scholar] [CrossRef]
- Moors, J.J.A. The Meaning of Kurtosis: Darlington Reexamined. Am. Stat. 1986, 40, 283–284. [Google Scholar] [CrossRef]
- Doane, D.P.; Seward, L.E. Measuring Skewness: A Forgotten Statistic? J. Stat. Educ. 2011, 19, 1–18. [Google Scholar] [CrossRef]
- Clarenz, U.; Rumpf, M.; Telea, A. Robust Feature Detection and Local Classification for Surfaces based on Moment Analysis. IEEE Trans. Vis. Comput. Graph. 2004, 10, 516–524. [Google Scholar] [CrossRef]
- Hippenstiel, R.; Oliviera, P.D. Time-varying Spectral Estimation using the Instantaneous Power Spectrum (IPS). IEEE Trans. Acoust. Speech Signal Process. 1990, 38, 1752–1759. [Google Scholar] [CrossRef]
- Choi, H.; Williams, W. Improved Time-Frequency Representation of Multicomponent Signals using Exponential kernels. IEEE Trans. Acoust. Speech Signal Process. 1989, 37, 862–871. [Google Scholar] [CrossRef]
- Loza, A.; Canagarajah, N.; Bull, D. A Simple Scheme for Enhanced Reassignment of the SPWV Representation of Noisy Signals. IEEE Int. Symp. Image Signal Process. Anal. ISPA2003 2003, 2, 630–633. [Google Scholar] [CrossRef]
- Zhang, A.; Nowruzi, F.E.; Laganiere, R. RADDet: Range-Azimuth-Doppler based Radar Object Detection for Dynamic Road Users. arXiv 2021. [Google Scholar] [CrossRef]
- Qing, Y.; Liu, W. Hyperspectral Image Classification based on Multi-scale Residual Network with Attention Mechanism. Remote Sens. 2021, 13, 335. [Google Scholar] [CrossRef]
- Gao, L.; Hong, D.; Yao, J.; Zhang, B.; Gamba, P.; Chanussot, J. Spectral Superresolution of Multispectral Imagery with joint Sparse and Low-rank Learning. IEEE Trans. Geosci. Remote Sens. 2020, 59, 2269–2280. [Google Scholar] [CrossRef]
- Yin, X.; Liu, Z.; Liu, D.; Ren, X. A Novel CNN-based Bi-LSTM Parallel Model with Attention Mechanism for Human Activity Recognition with Noisy Data. Sci. Rep. 2022, 12, 7878. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Bian, S.; Lei, M.; Zhao, C.; Liu, Y.; Zhao, Z. Feature Extraction and Classification of Load Dynamic Characteristics based on Lifting Wavelet Packet Transform in Power System Load Modeling. Int. J. Electr. Power Energy Syst. 2023, 62, 353–363. [Google Scholar] [CrossRef]
- Auger, F.; Flandrin, P.; Gonçalvès, P.; Lemoine, O. Time-Frequency Toolbox For Use with MATLAB. Tftb-Info 2008, 7, 465–468. Available online: http://tftb.nongnu.org/ (accessed on 15 July 2024).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Optimizer | Parameters |
|---|---|
| Optimization | adam |
| Initial Learn Rate | 0.001 |
| regularization | 1 × 10 |
| Learn Rate Schedule | piecewise |
| Learn Rate Drop Factor | 0.5 |
| Learn Rate Drop Period | 400 |
| Shuffle | every epoch |
| Name | Type | Activations | Learnable Properties |
|---|---|---|---|
| sequence | Sequence Input | 256(S) × 1(S) × 1(C) × 1(B) × 1(T) | - |
| seqfold | Sequence Folding | out 256(S) × 1(S) × 1(C) × 1(B) | - |
| miniBatchSize 1(C) × 1(U) | |||
| conv_1 | 2D Convolution | 254(S) × 1(S) × 32(C) × 1(B) | Weights 3 × 1 × 1 × 32 |
| Bias 1 × 1 × 32 | |||
| relu_1 | ReLU | 254(S) × 1(S) × 32(C) × 1(B) | - |
| conv_2 | 2D Convolution | 252(S) × 1(S) × 64(C) × 1(B) | Weights 3 × 1 × 32 × 64 |
| Bias 1 × 1 × 64 | |||
| relu_2 | ReLU | 252(S) × 1(S) × 64(C) × 1(B) | - |
| gapool | 2D Global | 1(S) × 1(S) × 32(C) × 1(B) | - |
| Average Pooling | |||
| fc_2 | Fully Connected | 1(S) × 1(S) × 16(C) × 1(B) | Weights 16 × 32 |
| Bias 16 × 1 | |||
| relu_3 | ReLU | 1(S) × 1(S) × 16(C) × 1(B) | - |
| fc_3 | Fully Connected | 1(S) × 1(S) × 64(C) × 1(B) | Weights 64 × 16 |
| Bias 64 × 1 | |||
| sigmoid | Sigmoid | 1(S) × 1(S) × 64(C) × 1(B) | - |
| multiplication | Elementwise | 252(S) × 1(S) × 64 (C) × 1(B) | - |
| Multiplication | |||
| sequnfold | Sequence | 252(S) × 1(S) × 64(C) × 1(B) × 1(T) | - |
| Unfolding | |||
| flatten | Flatten | 16,128(C) × 1(B) × 1(T) | - |
| lstm | BiLSTM | 12(C) × 1(B) | InputWeights 48 × 16,128 |
| RecurrentWeights 48 × 6 | |||
| Bias 48 × 1 | |||
| fc | Fully Connected | 14(C) × 1(B) | Weights 14 × 12 |
| Bias 14 × 1 | |||
| softmax | Softmax | 14(C) × 1(B) | - |
| classification | Classification | 14(C) × 1(B) | - |
| Output |
| Parameters | Value |
|---|---|
| Radar Name | AWR2243 |
| Frequency Range | 76–81 GHz |
| Carrier Frequency | 77 GHz |
| Number of Receivers | 4 |
| Number of Transmitters | 3 |
| Number of Samples per Chirp | 256 |
| Number of Chirps per Frame | 128 |
| Bandwidth | 4 GHz |
| Range Resolution | 4 cm |
| ADC Sampling Rate (max) | 45 Msps |
| MIMO Modulation Scheme | TDM |
| Interface Type | MIPI-CSI2, SPI |
| Rating | Automotive |
| Operating Temperature Range | −40 to 140 C |
| TI Functional Safety Category | Functional Safety Compliant |
| Power Supply Solution | LP87745-Q1 |
| Evaluation Module | DCA1000 |
| Participant ID | Gender | Height (cm) | Age |
|---|---|---|---|
| Participant 1 | Male | 172 | 25 |
| Participant 2 | Male | 167 | 23 |
| Participant 3 | Male | 165 | 24 |
| Participant 4 | Male | 177 | 22 |
| Participant 5 | Male | 174 | 26 |
| Participant 6 | Male | 180 | 23 |
| Participant 7 | Male | 185 | 25 |
| Participant 8 | Male | 183 | 24 |
| Participant 9 | Male | 188 | 22 |
| Participant 10 | Female | 157 | 25 |
| Participant 11 | Female | 155 | 23 |
| Participant 12 | Female | 159 | 24 |
| Participant 13 | Female | 167 | 22 |
| Participant 14 | Female | 165 | 26 |
| Participant 15 | Female | 170 | 23 |
| Participant 16 | Female | 175 | 25 |
| Participant 17 | Female | 173 | 24 |
| Participant 18 | Female | 177 | 22 |
| Sensitivity | STFT | MHS | CW | SPWV | Joint 4TFs |
|---|---|---|---|---|---|
| NB | 0.7380 | 0.7710 | 0.7449 | 0.7460 | 0.8066 |
| PQDA | 0.7926 | 0.8063 | 0.7889 | 0.7950 | 0.8376 |
| DQDA | 0.7414 | 0.7717 | 0.7458 | 0.7454 | 0.8062 |
| KNN (k = 3) | 0.5877 | 0.5875 | 0.5880 | 0.5861 | 0.5920 |
| Boosting | 0.4861 | 0.4863 | 0.4858 | 0.4862 | 0.4862 |
| Bagging | 0.9473 | 0.9595 | 0.9401 | 0.9424 | 0.9594 |
| Random Forest | 0.9771 | 0.9825 | 0.9754 | 0.9746 | 0.9840 |
| SVM | 0.9547 | 0.9651 | 0.9545 | 0.9550 | 0.9682 |
| Precision | STFT | MHS | CW | SPWV | Joint 4TFs |
| NB | 0.7663 | 0.7929 | 0.7691 | 0.7692 | 0.8176 |
| PQDA | 0.8127 | 0.8232 | 0.8105 | 0.8163 | 0.8503 |
| DQDA | 0.7691 | 0.7934 | 0.7700 | 0.7699 | 0.8170 |
| KNN (k = 3) | 0.5954 | 0.5952 | 0.5958 | 0.5938 | 0.5995 |
| Boosting | 0.3257 | 0.3399 | 0.3647 | 0.3970 | 0.3764 |
| Bagging | 0.9479 | 0.9598 | 0.9409 | 0.9429 | 0.9597 |
| Random Forest | 0.9772 | 0.9825 | 0.9755 | 0.9747 | 0.9841 |
| SVM | 0.9552 | 0.9655 | 0.9549 | 0.9554 | 0.9684 |
| F1 | STFT | MHS | CW | SPWV | Joint 4TFs |
| NB | 0.7058 | 0.7453 | 0.7127 | 0.7140 | 0.7884 |
| PQDA | 0.7701 | 0.7879 | 0.7652 | 0.7712 | 0.8235 |
| DQDA | 0.7101 | 0.7459 | 0.7144 | 0.7139 | 0.7873 |
| KNN (k = 3) | 0.5859 | 0.5854 | 0.5861 | 0.5843 | 0.5900 |
| Boosting | 0.3570 | 0.3577 | 0.3748 | 0.3765 | 0.3681 |
| Bagging | 0.9471 | 0.9594 | 0.9399 | 0.9422 | 0.9594 |
| Random Forest | 0.9772 | 0.9825 | 0.9754 | 0.9746 | 0.9841 |
| SVM | 0.9548 | 0.9651 | 0.9546 | 0.9551 | 0.9682 |
| Accuracy | STFT | MHS | CW | SPWV | Joint 4TFs |
| NB | 0.9798 | 0.9824 | 0.9804 | 0.9805 | 0.9851 |
| PQDA | 0.9840 | 0.9851 | 0.9838 | 0.9842 | 0.9875 |
| DQDA | 0.9801 | 0.9824 | 0.9804 | 0.9804 | 0.9851 |
| KNN (k = 3) | 0.9683 | 0.9683 | 0.9683 | 0.9682 | 0.9686 |
| Boosting | 0.9605 | 0.9605 | 0.9604 | 0.9605 | 0.9605 |
| Bagging | 0.9959 | 0.9969 | 0.9954 | 0.9956 | 0.9969 |
| Random Forest | 0.9982 | 0.9987 | 0.9981 | 0.9980 | 0.9988 |
| SVM | 0.9965 | 0.9973 | 0.9965 | 0.9965 | 0.9976 |
| Specificity | STFT | MHS | CW | SPWV | Joint 4TFs |
| NB | 0.9626 | 0.9673 | 0.9636 | 0.9637 | 0.9724 |
| PQDA | 0.9704 | 0.9723 | 0.9698 | 0.9707 | 0.9768 |
| DQDA | 0.9631 | 0.9674 | 0.9637 | 0.9636 | 0.9723 |
| KNN (k = 3) | 0.9411 | 0.9411 | 0.9411 | 0.9409 | 0.9417 |
| Boosting | 0.9266 | 0.9266 | 0.9265 | 0.9266 | 0.9266 |
| Bagging | 0.9925 | 0.9942 | 0.9914 | 0.9918 | 0.9942 |
| Random Forest | 0.9967 | 0.9975 | 0.9965 | 0.9964 | 0.9977 |
| SVM | 0.9935 | 0.9950 | 0.9935 | 0.9936 | 0.9955 |
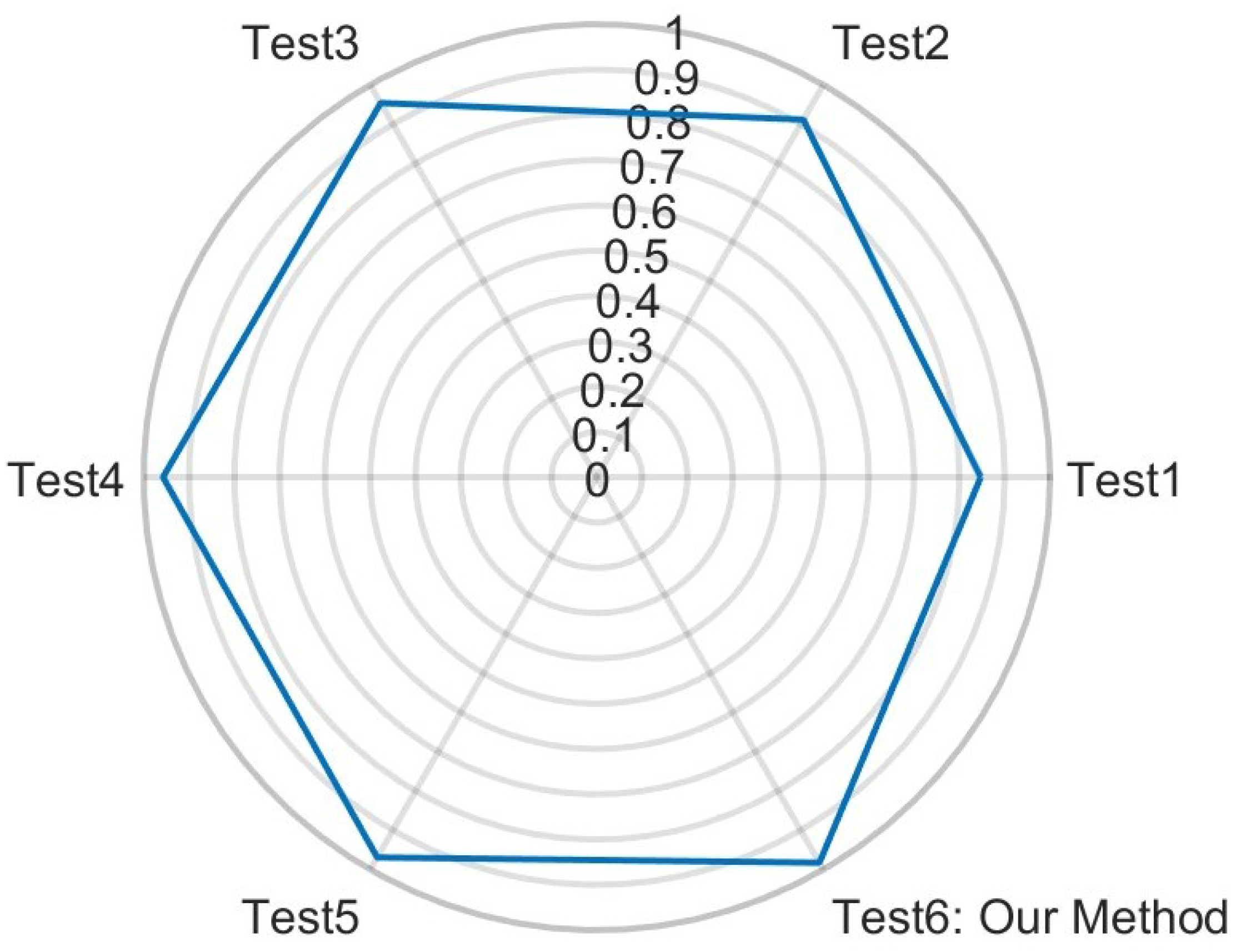
| Test 1 | Test 2 | Test 3 | Test 4 | Test 5 | Test 6 | |
|---|---|---|---|---|---|---|
| Statistical Offsets | 6 | 6 | 6 | 6 | 0 | 6 |
| Range Features | 1 | 10 | 1 | 1 | 1 | 1 |
| TF Features | 1 | 10 | 1 | 1 | 1 | 1 |
| Range–Azimuth–Time | 0 | 0 | 0 | 0 | 1 | 1 |
| Total Features | 8 | 26 | 8 | 8 | 3 | 9 |
| Sensitivity | 0.8477 | 0.9115 | 0.9535 | 0.9569 | 0.9691 | 0.9825 |
| Precision | 0.8472 | 0.9114 | 0.9538 | 0.9572 | 0.9692 | 0.9825 |
| F1 | 0.8469 | 0.9112 | 0.9535 | 0.9570 | 0.9691 | 0.9825 |
| Specificity | 0.9883 | 0.9932 | 0.9964 | 0.9967 | 0.9976 | 0.9987 |
| Accuracy | 0.9782 | 0.9874 | 0.9934 | 0.9938 | 0.9956 | 0.9975 |
| Single Feature Type | Feature Vectors | Sensitivity | Precision | F1 | Specificity | Accuracy |
|---|---|---|---|---|---|---|
| Mean | 1 | 0.0699 | 0.0701 | 0.0697 | 0.9285 | 0.8671 |
| Variance | 1 | 0.2605 | 0.2585 | 0.2588 | 0.9431 | 0.8944 |
| Standard Deviation | 1 | 0.2596 | 0.2576 | 0.2578 | 0.9430 | 0.8942 |
| Kurtosis | 1 | 0.2058 | 0.2055 | 0.2050 | 0.9389 | 0.8865 |
| Skewness | 1 | 0.1664 | 0.1670 | 0.1661 | 0.9359 | 0.8809 |
| Central Moment | 1 | 0.2485 | 0.2470 | 0.2471 | 0.9422 | 0.8926 |
| Offset Parameters | 6 | 0.2769 | 0.2763 | 0.2758 | 0.9444 | 0.8967 |
| PCA of Range Profiles | 1 | 0.2769 | 0.2763 | 0.2758 | 0.9444 | 0.8967 |
| PCA of Range Profiles | 10 | 0.7675 | 0.7706 | 0.7663 | 0.9821 | 0.9668 |
| PCANet Fusion of Range Profiles | 1 | 0.6758 | 0.7048 | 0.6707 | 0.9751 | 0.9537 |
| PCA of TF Image | 1 | 0.3555 | 0.3551 | 0.3545 | 0.9504 | 0.9079 |
| PCA of TF Image | 10 | 0.7910 | 0.7960 | 0.7907 | 0.9839 | 0.9701 |
| PCANet Fusion of TF Image | 1 | 0.8937 | 0.8975 | 0.8941 | 0.9918 | 0.9848 |
| Fusion of Range–Azimuth–Time | 1 | 0.9253 | 0.9286 | 0.9251 | 0.9943 | 0.9893 |
| Action Combinations | ID | I | II | III | IV | V | VI | VII | VIII | IX | X | XI | XII | XIII | XIV |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Bend and Bend | I | 1465 | 33 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Squat and Bend | II | 13 | 1448 | 18 | 1 | 1 | 11 | 4 | 0 | 0 | 4 | 0 | 0 | 0 | 0 |
| Stand and Bend | III | 1 | 21 | 1468 | 0 | 0 | 6 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Walk and Bend | IV | 0 | 0 | 0 | 1475 | 15 | 0 | 0 | 2 | 5 | 0 | 3 | 0 | 0 | 0 |
| Fall and Bend | V | 0 | 0 | 0 | 4 | 1470 | 19 | 0 | 6 | 0 | 0 | 1 | 0 | 0 | 0 |
| Squat and Squat | VI | 1 | 9 | 1 | 1 | 12 | 1450 | 15 | 7 | 0 | 4 | 0 | 0 | 0 | 0 |
| Stand and Squat | VII | 0 | 1 | 1 | 0 | 0 | 16 | 1475 | 4 | 0 | 3 | 0 | 0 | 0 | 0 |
| Fall and Squat | VIII | 0 | 1 | 0 | 0 | 6 | 6 | 17 | 1455 | 9 | 1 | 3 | 2 | 0 | 0 |
| Walk and Squat | IX | 0 | 0 | 0 | 4 | 1 | 0 | 0 | 20 | 1469 | 1 | 4 | 1 | 0 | 0 |
| Stand and Stand | X | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 2 | 0 | 1494 | 0 | 0 | 0 | 0 |
| Walk and Stand | XI | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 9 | 0 | 1485 | 4 | 0 | 0 |
| Fall and Stand | XII | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 4 | 1 | 1 | 4 | 1488 | 0 | 0 |
| Walk and Walk | XIII | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 1497 | 0 |
| Fall and Walk | XIV | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 5 | 2 | 1493 |
| Action Combinations | Sensitivity | Precision | F1 | Specificity | Accuracy |
|---|---|---|---|---|---|
| Bend and Bend | 0.9767 | 0.9899 | 0.9832 | 0.9992 | 0.9976 |
| Squat and Bend | 0.9653 | 0.9564 | 0.9608 | 0.9966 | 0.9944 |
| Stand and Bend | 0.9787 | 0.9846 | 0.9816 | 0.9988 | 0.9974 |
| Walk and Bend | 0.9833 | 0.9933 | 0.9883 | 0.9995 | 0.9983 |
| Fall and Bend | 0.9800 | 0.9767 | 0.9784 | 0.9982 | 0.9969 |
| Squat and Squat | 0.9667 | 0.9603 | 0.9635 | 0.9969 | 0.9948 |
| Stand and Squat | 0.9833 | 0.9723 | 0.9778 | 0.9978 | 0.9968 |
| Fall and Squat | 0.9700 | 0.9687 | 0.9694 | 0.9976 | 0.9956 |
| Walk and Squat | 0.9793 | 0.9839 | 0.9816 | 0.9988 | 0.9974 |
| Stand and Stand | 0.9960 | 0.9907 | 0.9934 | 0.9993 | 0.9990 |
| Walk and Stand | 0.9900 | 0.9900 | 0.9900 | 0.9992 | 0.9986 |
| Fall and Stand | 0.9920 | 0.9900 | 0.9910 | 0.9992 | 0.9987 |
| Walk and Walk | 0.9980 | 0.9987 | 0.9983 | 0.9999 | 0.9998 |
| Fall and Walk | 0.9953 | 1.0000 | 0.9977 | 1.0000 | 0.9997 |
| Average Performance | 0.9825 | 0.9825 | 0.9825 | 0.9987 | 0.9975 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, Y.; Li, H.; Faccio, D. Human Multi-Activities Classification Using mmWave Radar: Feature Fusion in Time-Domain and PCANet. Sensors 2024, 24, 5450. https://doi.org/10.3390/s24165450
Lin Y, Li H, Faccio D. Human Multi-Activities Classification Using mmWave Radar: Feature Fusion in Time-Domain and PCANet. Sensors. 2024; 24(16):5450. https://doi.org/10.3390/s24165450
Chicago/Turabian StyleLin, Yier, Haobo Li, and Daniele Faccio. 2024. "Human Multi-Activities Classification Using mmWave Radar: Feature Fusion in Time-Domain and PCANet" Sensors 24, no. 16: 5450. https://doi.org/10.3390/s24165450
APA StyleLin, Y., Li, H., & Faccio, D. (2024). Human Multi-Activities Classification Using mmWave Radar: Feature Fusion in Time-Domain and PCANet. Sensors, 24(16), 5450. https://doi.org/10.3390/s24165450