
A Honeybee-Inspired Framework for a Smart City Free of Internet Scams

 ,
,  , ,
, ,  and
and
Abstract
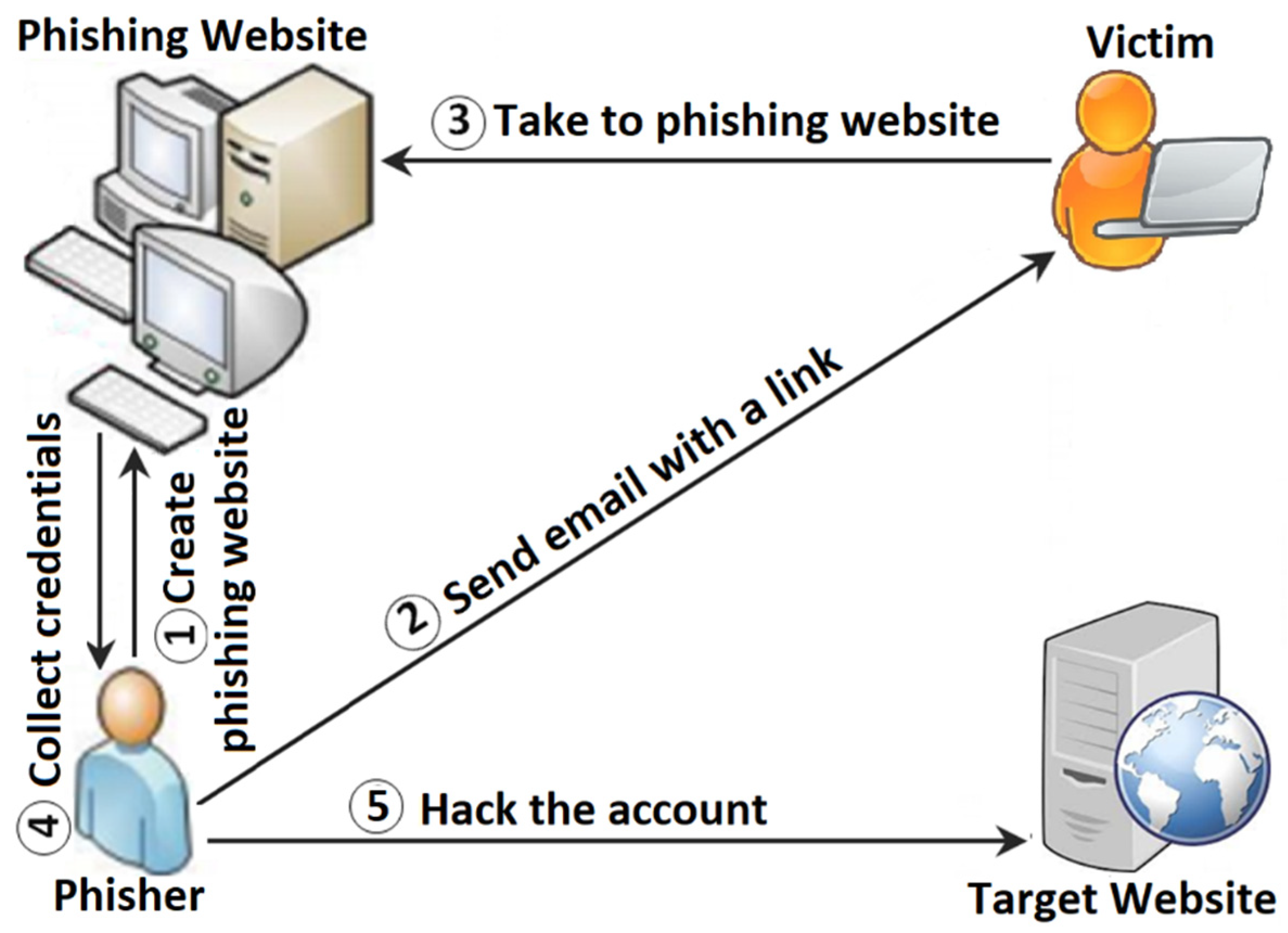
1. Introduction
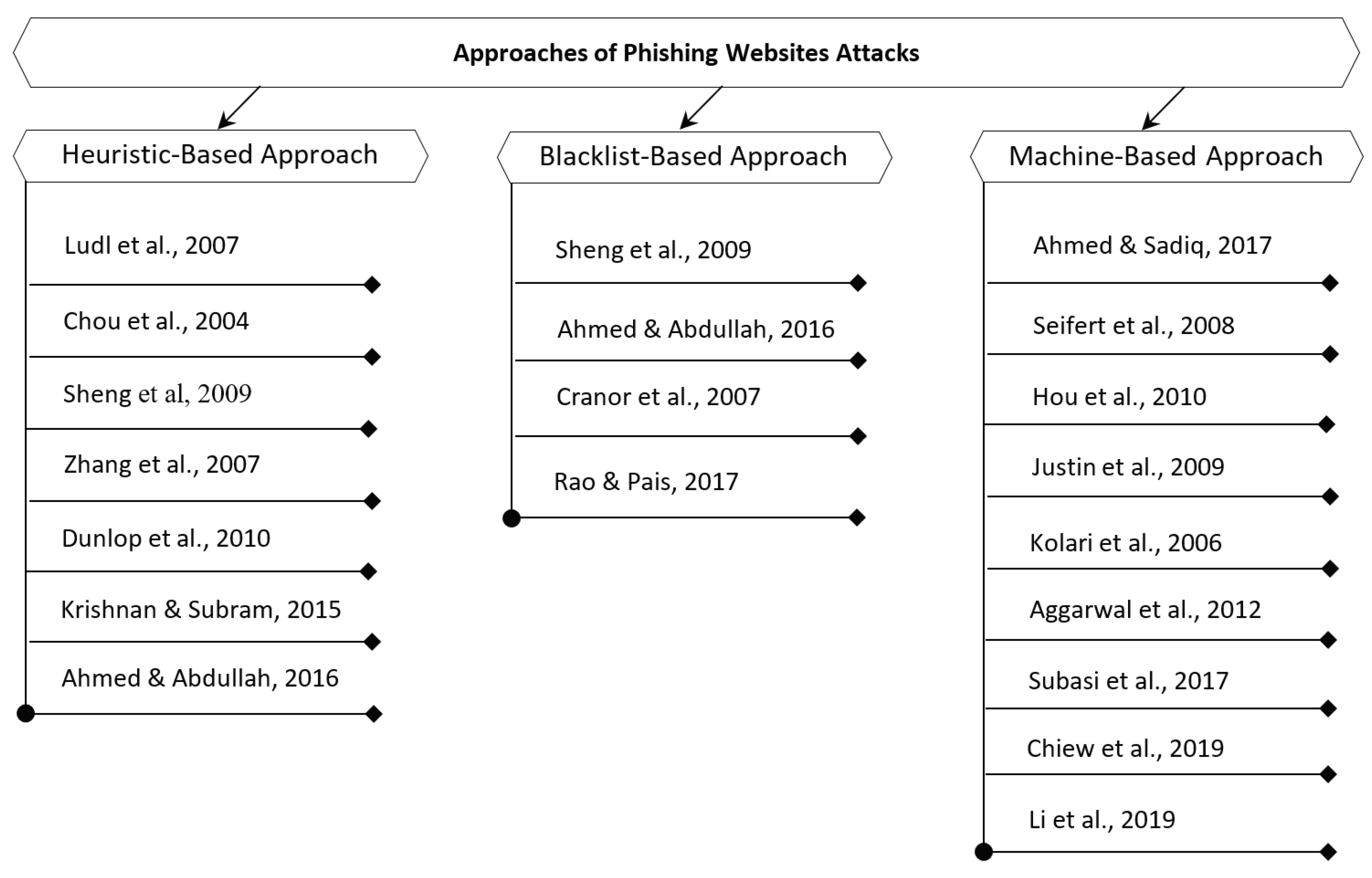
2. Related Works
2.1. Heuristic-Based Approach
2.2. Blacklist-Based Approach
2.3. Machine-Learning-Based Approach
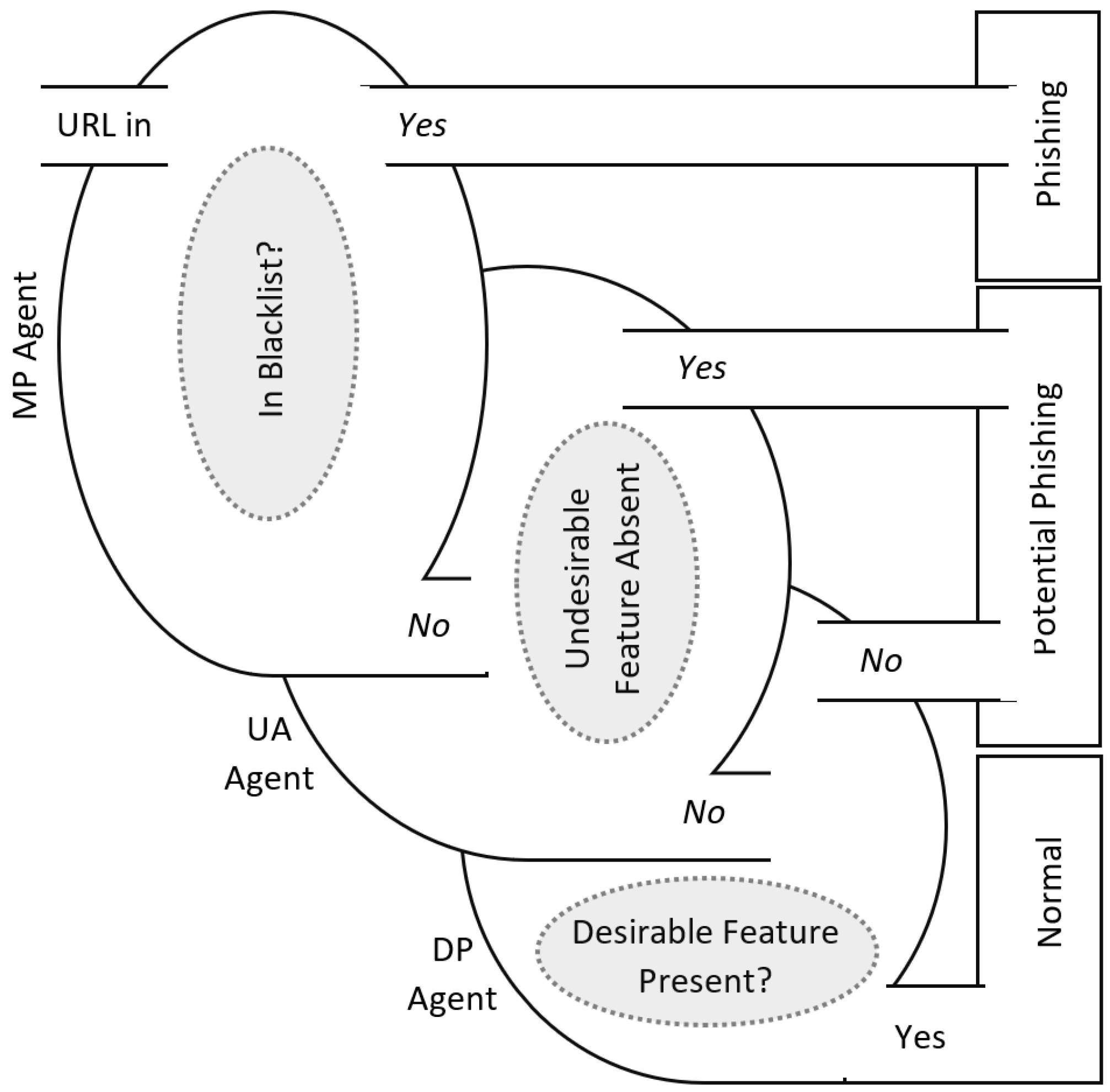
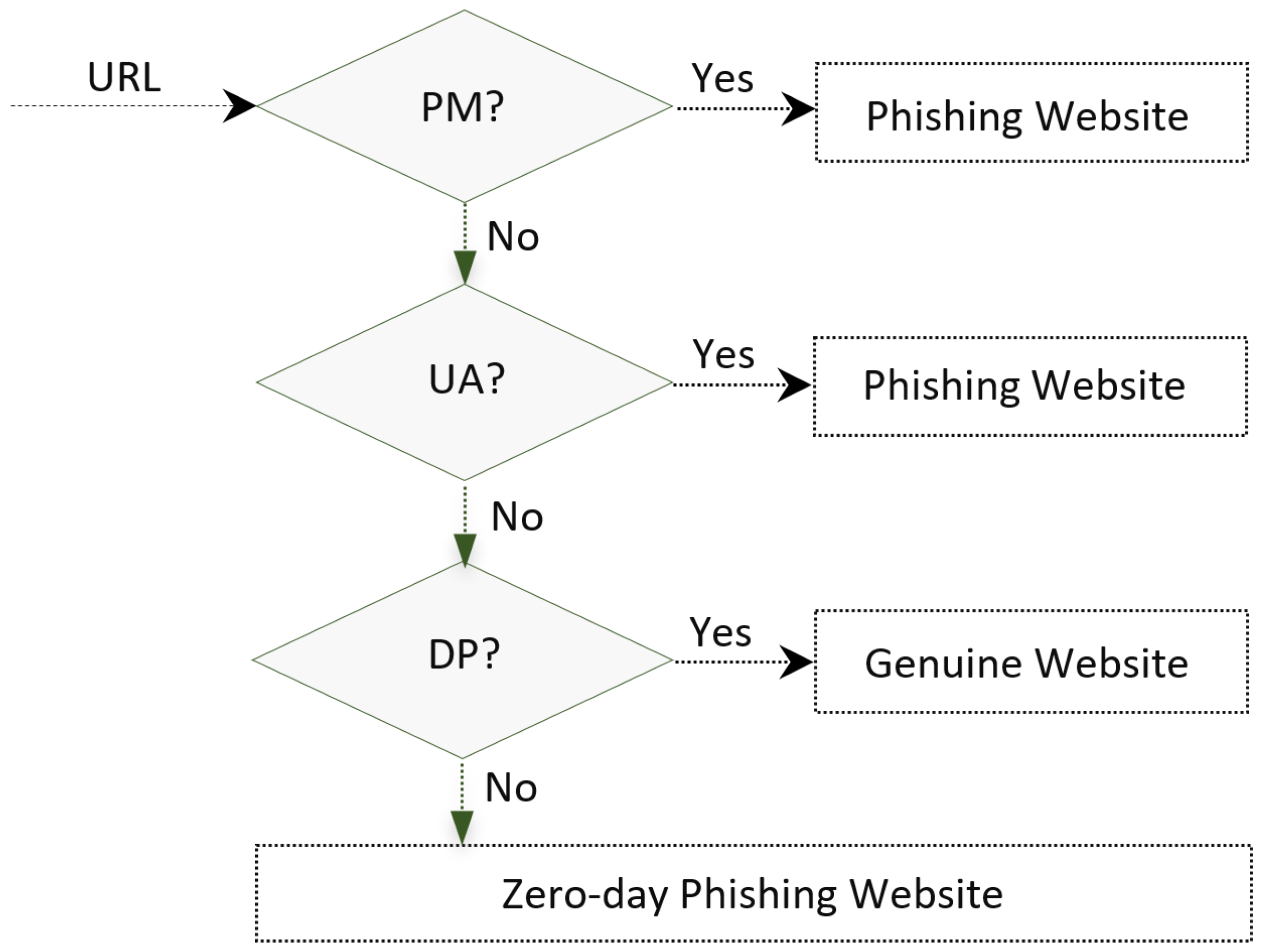
3. Proposed Model Phisfilter
3.1. PM Agent
3.2. UA Agent
3.3. DP Agent
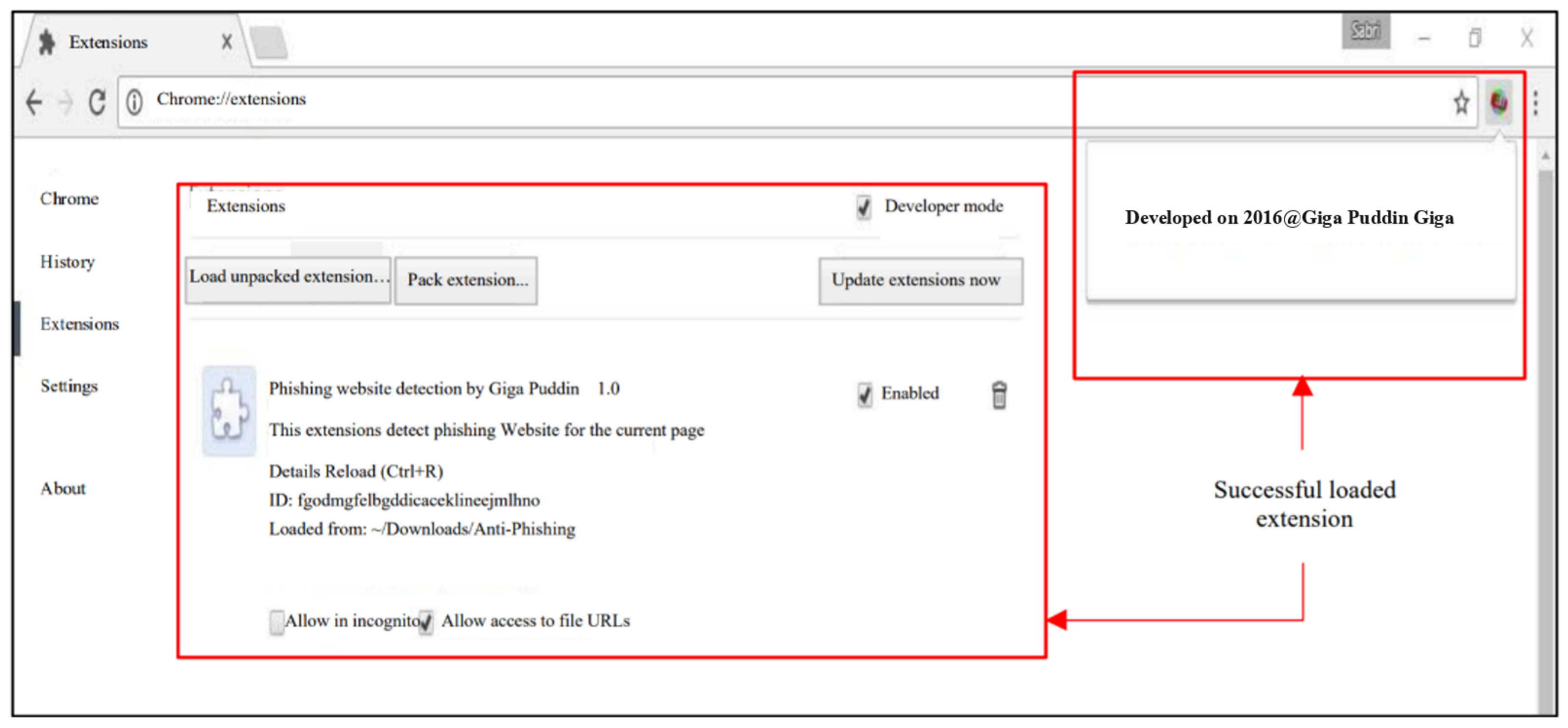
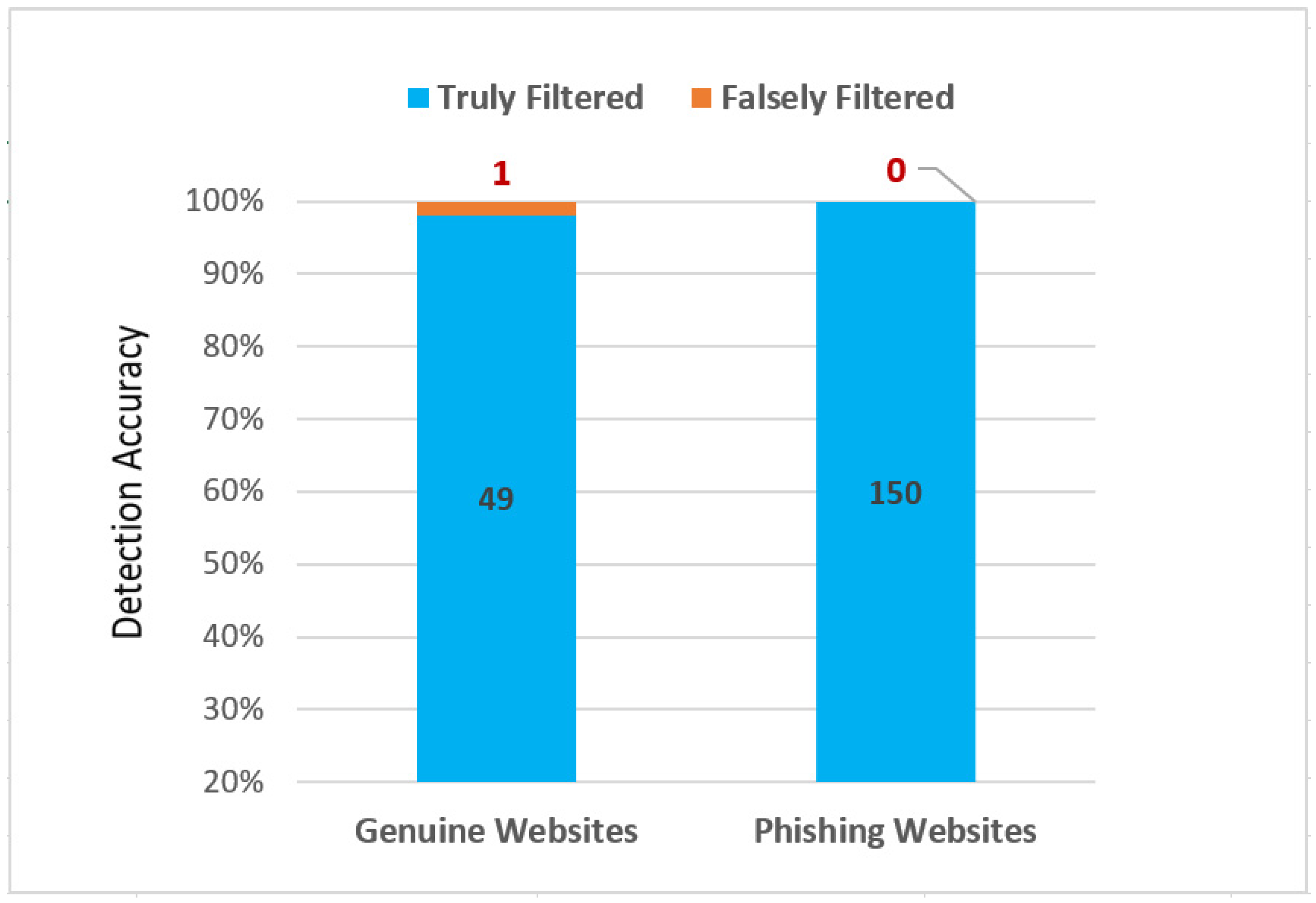
4. Implementation and Results
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ludl, C.; McAllister, S.; Kirda, E.; Kruegel, C. On the effectiveness of techniques to detect phishing sites. In Detection of Intrusions and Malware, and Vulnerability Assessment; Springer: Berlin/Heidelberg, Germany, 2007; pp. 20–39. [Google Scholar]
- Anti-Phishing Working Group Phishing, Anti-Phishing Working Group Phishing Trends Report. 2014. Available online: https://apwg.org/ (accessed on 30 March 2015).
- Alsharaiah, M.; Abu-Shareha, A.; Abualhaj, M.; Baniata, L.; Adwan, O.; Al-saaidah, A.; Oraiqat, M. A new phishing-website detection framework using ensemble classification and clustering. Int. J. Data Netw. Sci. 2023, 7, 857–864. [Google Scholar] [CrossRef]
- Intelligence, M.S. Microsoft Digital Defense Report. 2022. Available online: https://www.microsoft.com/en-us/security/business/microsoft-digital-defense-report-2022 (accessed on 20 February 2023).
- AlDairi, A. Cyber security attacks on smart cities and associated mobile technologies. Procedia Comput. Sci. 2017, 109, 1086–1091. [Google Scholar] [CrossRef]
- Ijaz, S.; Shah, M.A.; Khan, A.; Ahmed, M. Smart cities: A survey on security concerns. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 612–625. [Google Scholar] [CrossRef]
- Eric, C.-T.; Loretta, J.S. Phishing for profit. In Handbook on Crime and Technology; Edward Elgar Publishing: Cheltenham, UK, 2023; pp. 54–71. [Google Scholar]
- Fadhil, H.S. Social Engineering Attacks Techniques. Int. J. Progress. Res. Eng. Manag. Sci. IJPREMS 2023, 3, 18–20. [Google Scholar]
- Jagatic, T.N.; Johnson, N.A.; Jakobsson, M.; Menczer, F. Social phishing. Commun. ACM 2007, 50, 94–100. [Google Scholar] [CrossRef]
- Why HTTPS and SSL Are Not Secure as You Think. Available online: http://scottiestech.info/2014/03/12/why-https-and-ssl-are-not-as-secure-as-you-think (accessed on 12 March 2014).
- Ahmed, A.A.; Sadiq, A.S. PhishSys: A Honey Bee Inspired Intelligent System for Phishing Websites Detection. J. Eng. Appl. Sci. 2017, 12, 8088–8094. [Google Scholar]
- PhishTank | Join the Fight against Phishing. (N.D.). Available online: https://www.phishtank.com/ (accessed on 3 March 2022).
- Chou, N.; Ledesma, R.; Teraguchi, Y.; Mitchell, J.C. Client-Side Defense Against Web-Based Identity Theft. In Proceedings of the NDSS 2004, San Diego, CA, USA, 5 February 2004. [Google Scholar]
- Sheng, S.; Wardman, B.; Warner, G.; Cranor, L.F.; Hong, J.; Zhang, C. An empirical analysis of phishing blacklists. In Proceedings of the International Conference on Email and Anti-Spam, Mountain View, CA, USA, 16–17 July 2009. [Google Scholar]
- Zhang, Y.; Hong, J.I.; Cranor, L.F. Cantina: A content-based approach to detecting phishing web sites. In Proceedings of the 16th International Conference on World Wide Web, New York, NY, USA, 8–12 May 2007; pp. 639–648. [Google Scholar]
- Dunlop, M.; Groat, S.; Shelly, D. Goldphish: Using images for content-based phishing analysis. In Proceedings of the Internet Monitoring and Protection (ICIMP), 2010 Fifth International Conference on Internet Monitoring and Protection, Barcelona, Spain, 9–15 May 2010; pp. 123–128. [Google Scholar]
- Krishnan, D.; Subramaniyaswamy, V. Phishing website detection system based on enhanced itree classifier. ARPN J. Eng. Appl. Sci. 2015, 10, 5688–5699. [Google Scholar]
- Ahmed, A.A.; Abdullah, N.A. Real time detection of phishing websites. In Proceedings of the Information Technology, Electronics and Mobile Communication Conference (IEMCON), 2016 IEEE 7th Annual, Vancouver, BC, Canada, 13–15 October 2016; pp. 1–6. [Google Scholar]
- Cranor, L.F.; Egelman, S.; Hong, J.I.; Zhang, Y. Phinding Phish: An Evaluation of Anti-Phishing Toolbars. In Proceedings of the NDSS Symposium 2007, San Diego, CA, USA, 28 February–2 March 2007; pp. 1–19. [Google Scholar]
- Rao, R.S.; Pais, A.R. An enhanced blacklist method to detect phishing websites. In Proceedings of the Information Systems Security: 13th International Conference, ICISS, Mumbai, India, 16–20 December 2017; pp. 323–333. [Google Scholar]
- Chen, Y.; Zheng, R.; Zhou, A.; Liao, S.; Liu, L. Automatic detection of pornographic and gambling websites based on visual and textual content using a decision mechanism. Sensors 2020, 20, 3989. [Google Scholar] [CrossRef]
- Seifert, C.; Welch, I.; Komisarczuk, P. Identification of malicious web pages with static heuristics. In Proceedings of the 2008 Australasian Telecommunication Networks and Applications Conference, Adelaide, Australia, 7–10 December 2008; pp. 91–96. [Google Scholar]
- Hou, Y.-T.; Chang, Y.; Chen, T.; Laih, C.-S.; Chen, C.-M. Malicious web content detection by machine learning. Expert Syst. Appl. 2010, 37, 55–60. [Google Scholar] [CrossRef]
- Justin, M.; Lawrence, K.; Saul, S.S.; Geoffrey, M.V. Beyond blacklists: Learning to detect malicious web sites from suspicious URLs. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 1245–1254. [Google Scholar]
- Kolari, P.; Tim, F.; Anupam, J. SVMs for the blogosphere: Blog identification and splog detection. In Proceedings of the AAAI Spring Symposium on Computational Approaches to Analysing Weblogs, Stanford, CA, USA, 27–29 March 2006. [Google Scholar]
- Aggarwal, A.; Rajadesingan, A.; Kumaraguru, P. PhishAri: Automatic realtime phishing detection on twitter. In Proceedings of the 2012 eCrime Researchers Summit, Las Croabas, PR, USA, 23–24 October 2012; pp. 1–12. [Google Scholar]
- Subasi, A.; Molah, E.; Almkallawi, F.; Chaudhery, T.J. Intelligent phishing website detection using random forest classifier. In Proceedings of the 2017 International Conference on Electrical and Computing Technologies and Applications (ICECTA), Ras Al Khaimah, United Arab Emirates, 21–23 November 2017; pp. 1–5. [Google Scholar]
- Chiew, K.L.; Tan, C.L.; Wong, K.; Yong, K.S.; Tiong, W.K. A new hybrid ensemble feature selection framework for machine learning-based phishing detection system. Inf. Sci. 2019, 484, 153–166. [Google Scholar] [CrossRef]
- Li, Y.; Yang, Z.; Chen, X.; Yuan, H.; Liu, W. A stacking model using URL and HTML features for phishing webpage detection. Future Gener. Comput. Syst. 2019, 94, 27–39. [Google Scholar] [CrossRef]
- Ahmed, A.A.; Jantan, A.; Wan, T.-C. SLA-based complementary approach for network intrusion detection. Comput. Commun. 2011, 34, 1738–1749. [Google Scholar] [CrossRef]
- Rains, G.C.; Tomberlin, J.K.; Kulasiri, D. Using insect sniffing devices for detection. Trends Biotechnol. 2008, 26, 288–294. [Google Scholar] [CrossRef] [PubMed]
- Srinoy, S. Intrusion Detection Model Based On Particle Swarm Optimization and Support Vector Machine. In Computational Intelligence in Security and Defense Applications, Proceedings of the CISDA 2007, Honolulu, HA, USA, 1–5 April 2007; IEEE Computer Society Press: Los Alamitos, CA, USA, 2007; pp. 186–192. [Google Scholar]
- Jantan, A.; Abdulghani, A.A. Honeybee Protection System for Detecting and Preventing Network Attacks. J. Theor. Appl. Inf. Technol. 2014, 64, 38–47. [Google Scholar]
- Jantan, A.; Abdulghani, A.A. Honey Bee Intelligent Model for Network Zero Day Attack Detection. Int. J. Digit. Content Technol. Its Appl. 2014, 8, 45. [Google Scholar]
- Couvillon, M.J.; Robinson, E.J.; Atkinson, B.; Child, L.; Dent, K.R.; Ratnieks, F.L. En garde: Rapid shifts in honeybee, Apis mellifera, guarding behaviour are triggered by onslaught of conspecific intruders. Anim. Behav. 2008, 76, 1653–1658. [Google Scholar] [CrossRef]
- Free, J.; Butler, C. The behaviour of worker honeybees at the hive entrance. Behaviour 1952, 4, 263–291. [Google Scholar]
- Stabentheiner, A.; Kovac, H.; Schmaranzer, S. Honeybee nestmate recognition: The thermal behaviour of guards and their examinees. J. Exp. Biol. 2002, 205, 2637–2642. [Google Scholar] [CrossRef]
- Liu, C.; Guan, Z.; Liu, J.; Lv, X. Phishing website detection based on machine learning algorithm. J. Ambient. Intell. Humaniz. Comput. 2020, 11, 873–884. [Google Scholar]
- Garera, S.; Provos, N.; Chew, M.; Rubin, A.D. A framework for detection and measurement of phishing attacks. In Proceedings of the 2007 ACM Workshop on Recurring Malcode, Alexandria, VA, USA, 2 November 2007; pp. 1–8. [Google Scholar]
- Ahmed, A.A.; Jantan, A.; Wan, T.-C. Filtration model for the detection of malicious traffic in large-scale networks. Comput. Commun. 2016, 82, 59–70. [Google Scholar] [CrossRef]
- Osareh, A.; Shadgar, B. Intrusion detection in computer networks based on machine learning algorithms. Int. J. Comput. Sci. Netw. Secur. 2008, 8, 15–23. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pros | Cons |
|---|---|
| Can be more effective at detecting phishing websites that may not have been added to blacklists or other databases. | May generate false positives, flagging legitimate websites as phishing sites and causing inconvenience and frustration for users. |
| Can analyze various features of the website, such as the domain name, URL structure, and content, to identify phishing patterns and indicators. | May not be able to detect some sophisticated phishing attacks that employ advanced techniques to evade detection. |
| It is somewhat flexible and responsive to new threats and emerging trends related to phishing attacks. | May require significant computational resources and can be slower than other detection methods due to the delay in exploring webpages. |
| URL-based methods have limited information and cannot entirely depict the attributes of the illicit websites. |
| Pros | Cons |
|---|---|
| Effective at blocking known phishing websites that have been added to the blacklist. | Less effective in detecting new or unknown phishing websites that have not yet been added to the blacklist. |
| Can be updated frequently to add new phishing websites to the blacklist. | It can generate false negatives, failing to detect some phishing websites that are not on the blacklist. |
| Easy to implement and do not require significant computational resources. | May result in over-blocking [21], flagging legitimate websites as phishing sites and causing inconvenience and frustration for users who are prevented from accessing legitimate websites. This can undermine the effectiveness of the detection method if users start to ignore warnings or disable the detection altogether. |
| Pros | Cons |
|---|---|
| Capable of detecting phishing websites with an accuracy rate that exceeds 98.3% [29,38]. | Overfitting can occur when machine learning algorithms are trained on a limited set of data, leading to poor performance on predicting future observations. |
| Machine-learning-based methods can quickly analyze large amounts of data to detect characteristics of phishing websites. | Some machine learning algorithms are difficult to interpret, making it challenging to understand why a certain decision was made. |
| Can adapt to changing environments and update their algorithms to detect new threats. This can help to reduce the number of false positives and false negatives over time. | Machine learning models rely on historical data to identify patterns and anomalies, which may lead to less effectiveness in detecting new phishing attacks. |
| Can be trained on large datasets, making them scalable and able to check the visited website against a large number of website requests. | Datasets should be large enough for the system to train on, and they should represent the types of phishing attacks it may encounter. Obtaining and labelling these datasets can be time-consuming and resource-intensive. |
| Attackers can intentionally try to manipulate machine learning models by feeding them malicious data that has been designed to evade detection. |
| Criteria | Description |
|---|---|
| Accuracy | A measure of the method’s ability to discern legitimate websites from phishing websites. |
| False Positive Rate () | A percentage of legitimate websites that are incorrectly classified as phishing websites. A low FPR is desirable to prevent legitimate websites from being blocked. |
| False Negative Rate (ὲ) | A percentage of phishing websites that are not detected by the system. A low FNR is desirable to minimize the risk of successful phishing attacks. |
| Speed | A measure of how quickly incoming website requests can be analyzed and classified. |
| Scalability | A method’s ability to handle the growing number of website requests; it is important for web browsers that experience a rapid growth in user traffic. |
| Robustness | Refers to the methods’ ability to continue functioning under different types of attacks. |
| Usability | Refers to how easy it is for users to interact with the system. |
| Comparison Metrics | Accuracy | False Positive | False Negative | Speed | Scalability | Robustness | Usability |
|---|---|---|---|---|---|---|---|
| [1] | + | − | − | + | + | − | * |
| [13] | + | − | − | + | + | − | * |
| [14] | + | − | − | + | + | − | * |
| [15] | + | − | − | + | + | − | * |
| [16] | + | − | − | + | + | − | * |
| [17] | + | − | − | + | + | − | * |
| [18] | + | − | − | + | + | − | * |
| [19] | + | − | − | + | + | − | * |
| [20] | + | − | − | + | + | − | * |
| [11] | * | + | * | + | + | * | − |
| [22] | * | + | * | + | + | * | − |
| [23] | * | + | * | + | + | * | − |
| [24] | * | + | * | + | + | * | − |
| [25] | * | + | * | + | + | * | − |
| [26] | * | + | * | + | + | * | − |
| [27] | * | + | * | + | + | * | − |
| [28] | * | + | * | + | + | * | − |
| [29] | * | + | * | + | + | * | − |
| Honeybee framework | * | + | * | + | + | * | − |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmed, A.A.; Al-Bayatti, A.; Saif, M.; Jabbar, W.A.; Rassem, T.H. A Honeybee-Inspired Framework for a Smart City Free of Internet Scams. Sensors 2023, 23, 4284. https://doi.org/10.3390/s23094284
Ahmed AA, Al-Bayatti A, Saif M, Jabbar WA, Rassem TH. A Honeybee-Inspired Framework for a Smart City Free of Internet Scams. Sensors. 2023; 23(9):4284. https://doi.org/10.3390/s23094284
Chicago/Turabian StyleAhmed, Abdulghani Ali, Ali Al-Bayatti, Mubarak Saif, Waheb A. Jabbar, and Taha H. Rassem. 2023. "A Honeybee-Inspired Framework for a Smart City Free of Internet Scams" Sensors 23, no. 9: 4284. https://doi.org/10.3390/s23094284
APA StyleAhmed, A. A., Al-Bayatti, A., Saif, M., Jabbar, W. A., & Rassem, T. H. (2023). A Honeybee-Inspired Framework for a Smart City Free of Internet Scams. Sensors, 23(9), 4284. https://doi.org/10.3390/s23094284