
HFR-Video-Based Stereo Correspondence Using High Synchronous Short-Term Velocities


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Related Works
2.1. Image Similarity Measurement
2.2. Matching Based on Motion
3. HFR Stereo Correspondence Based on High Synchronous Short-Term Velocities
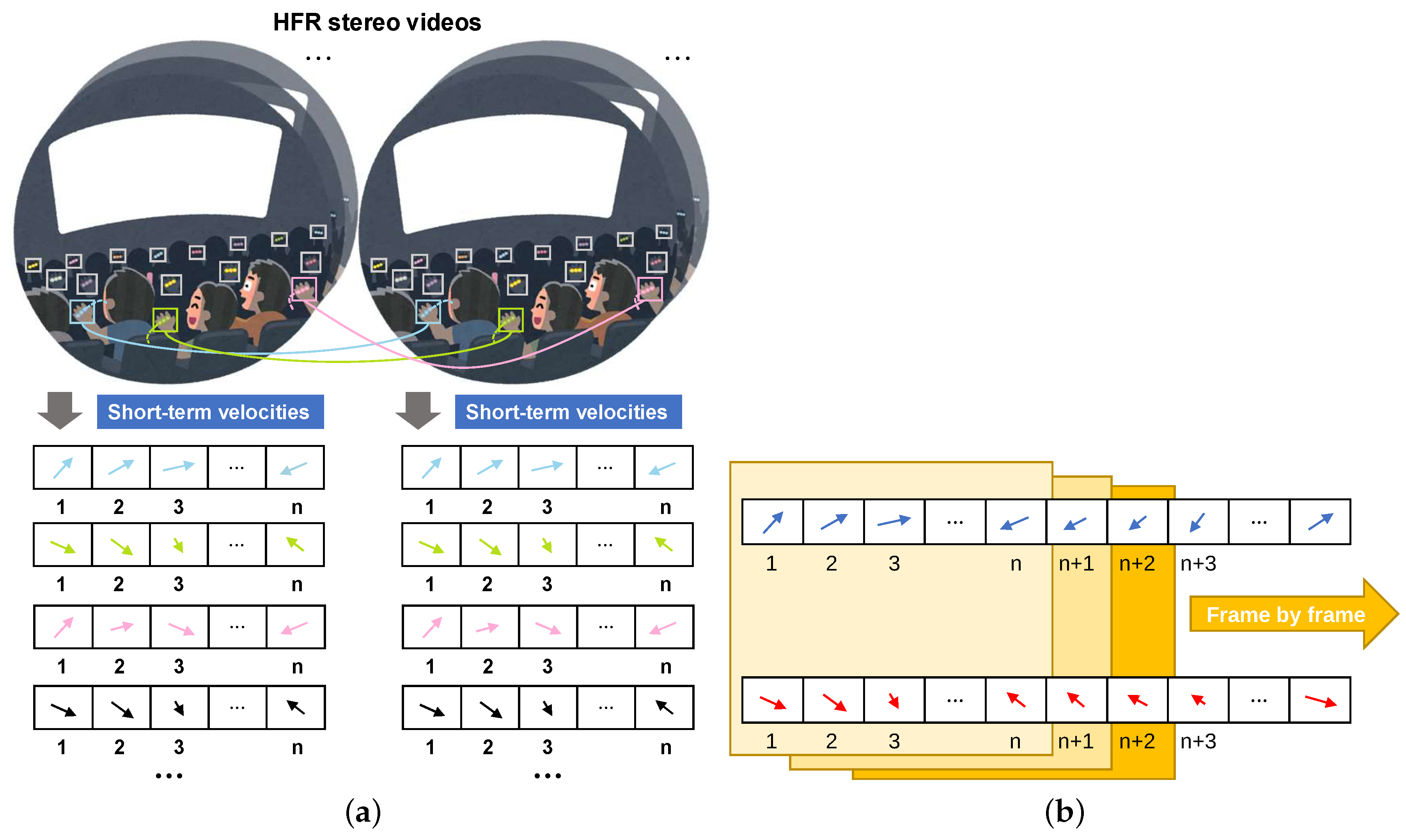
3.1. Concept
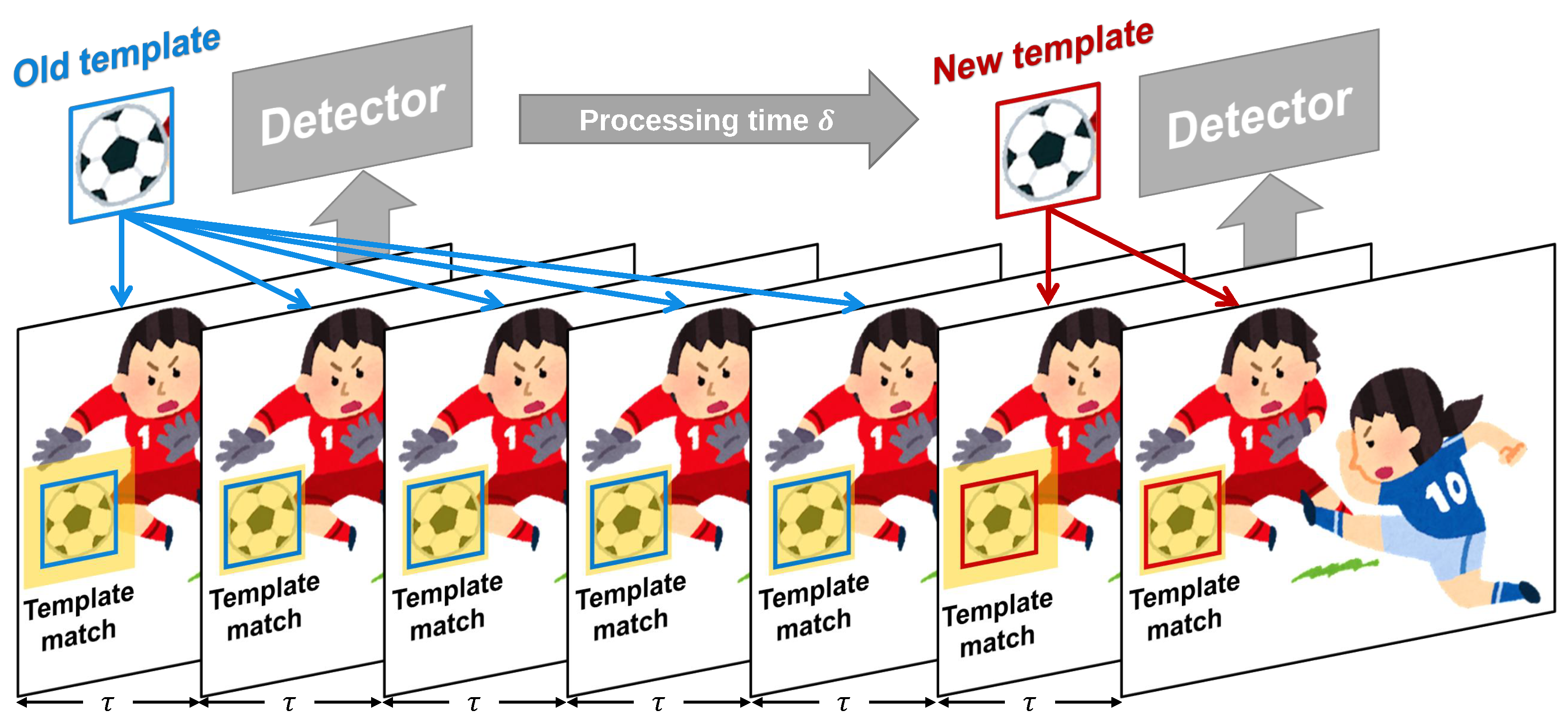
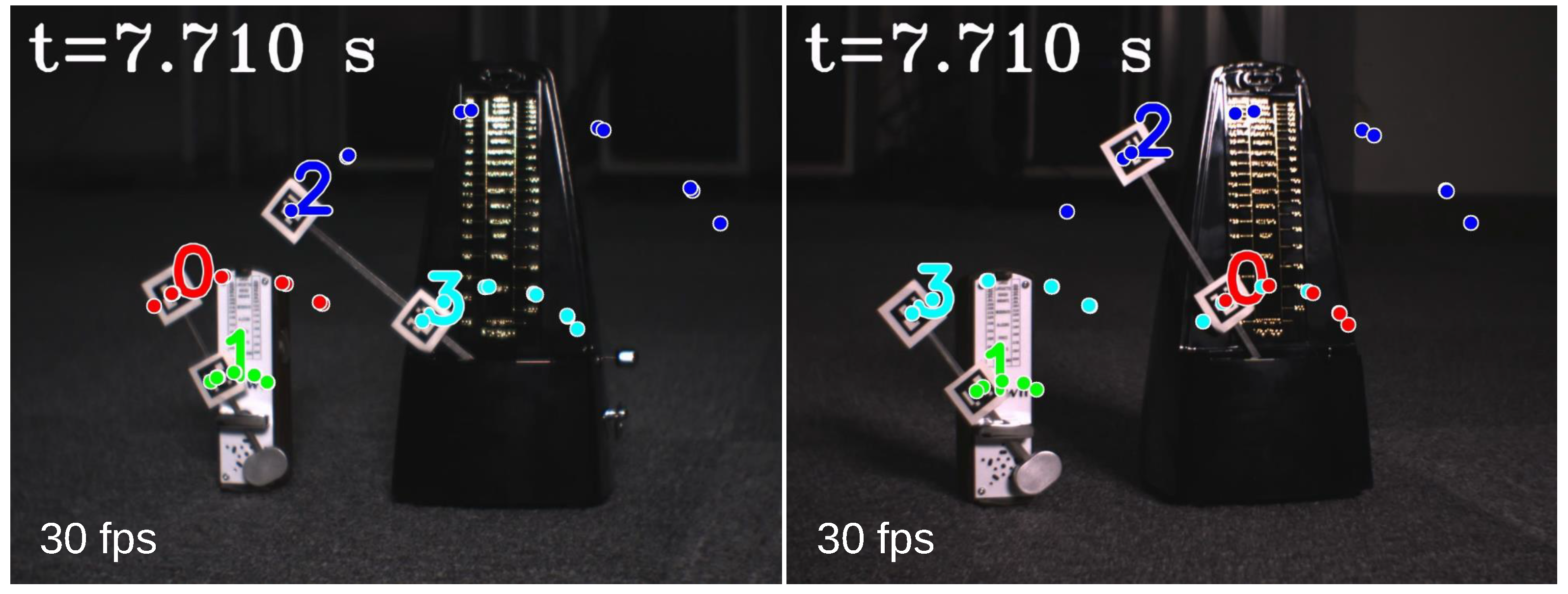
3.2. Independent Multiple-Object Tracking in HFR Stereoscopic Video
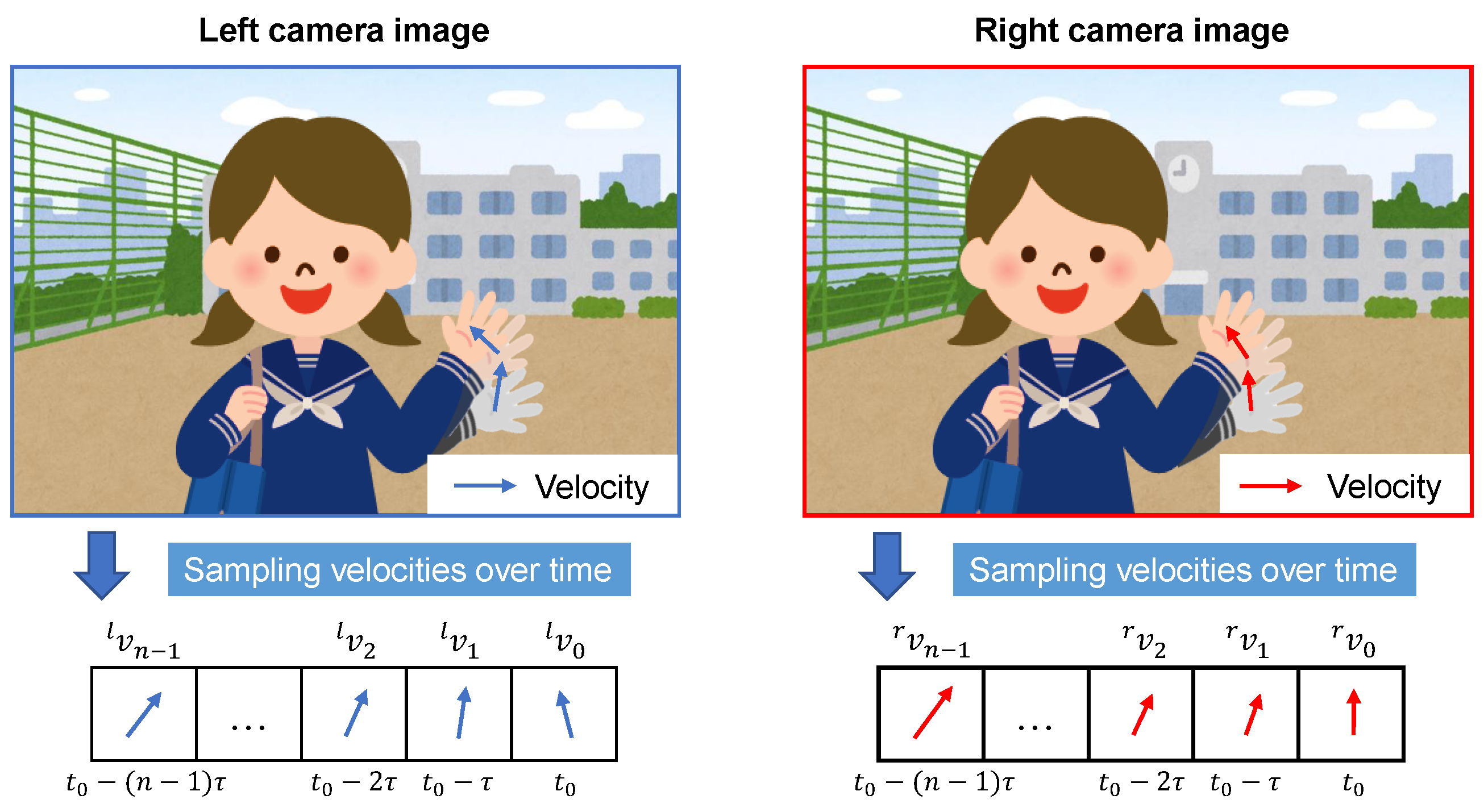
3.3. Correspondence Based on High Synchronous Velocities
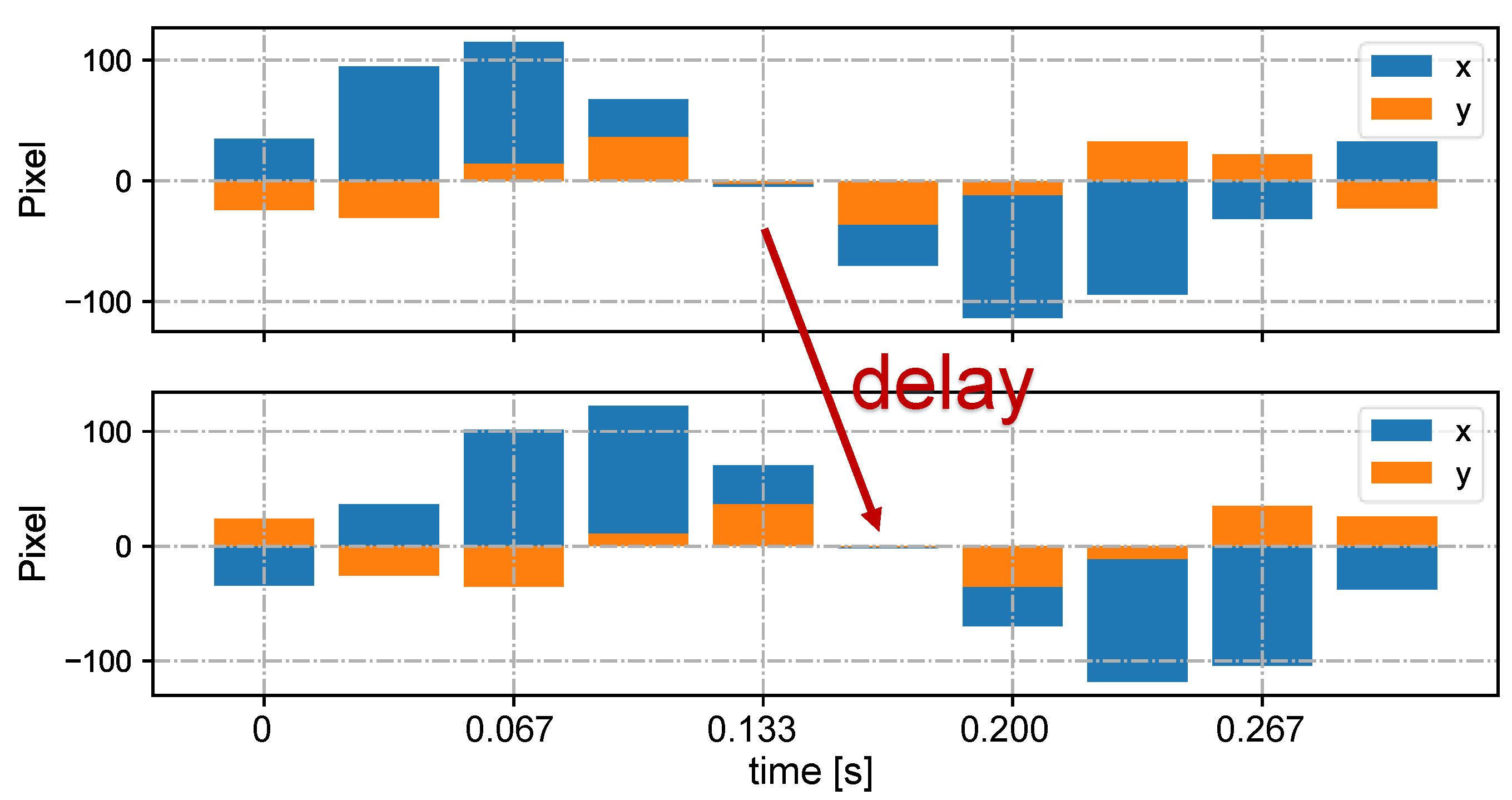
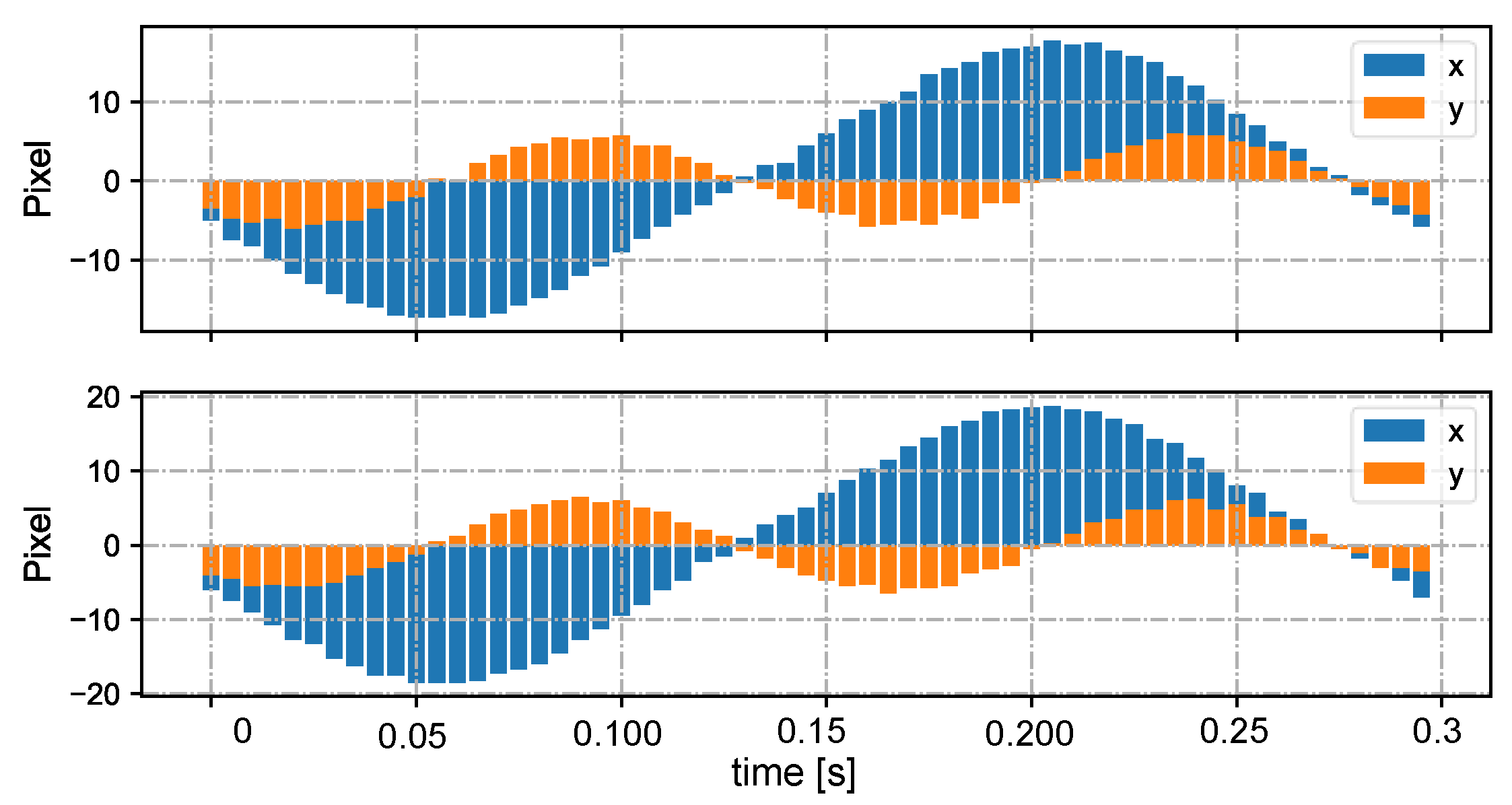
3.3.1. Velocity-Based Correspondence
3.3.2. Direction-Based Correspondence
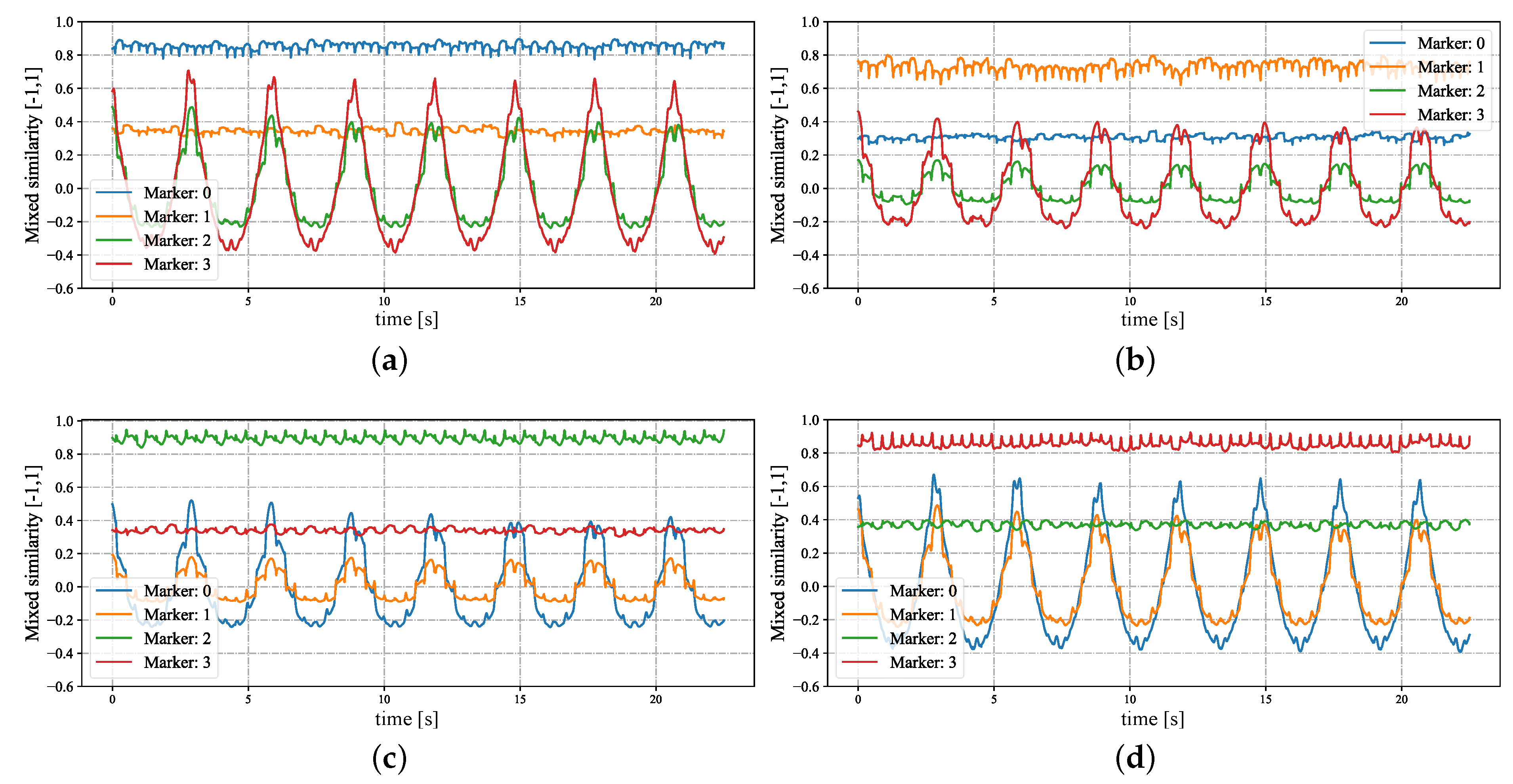
3.3.3. Mixed Correspondence
4. Experiment
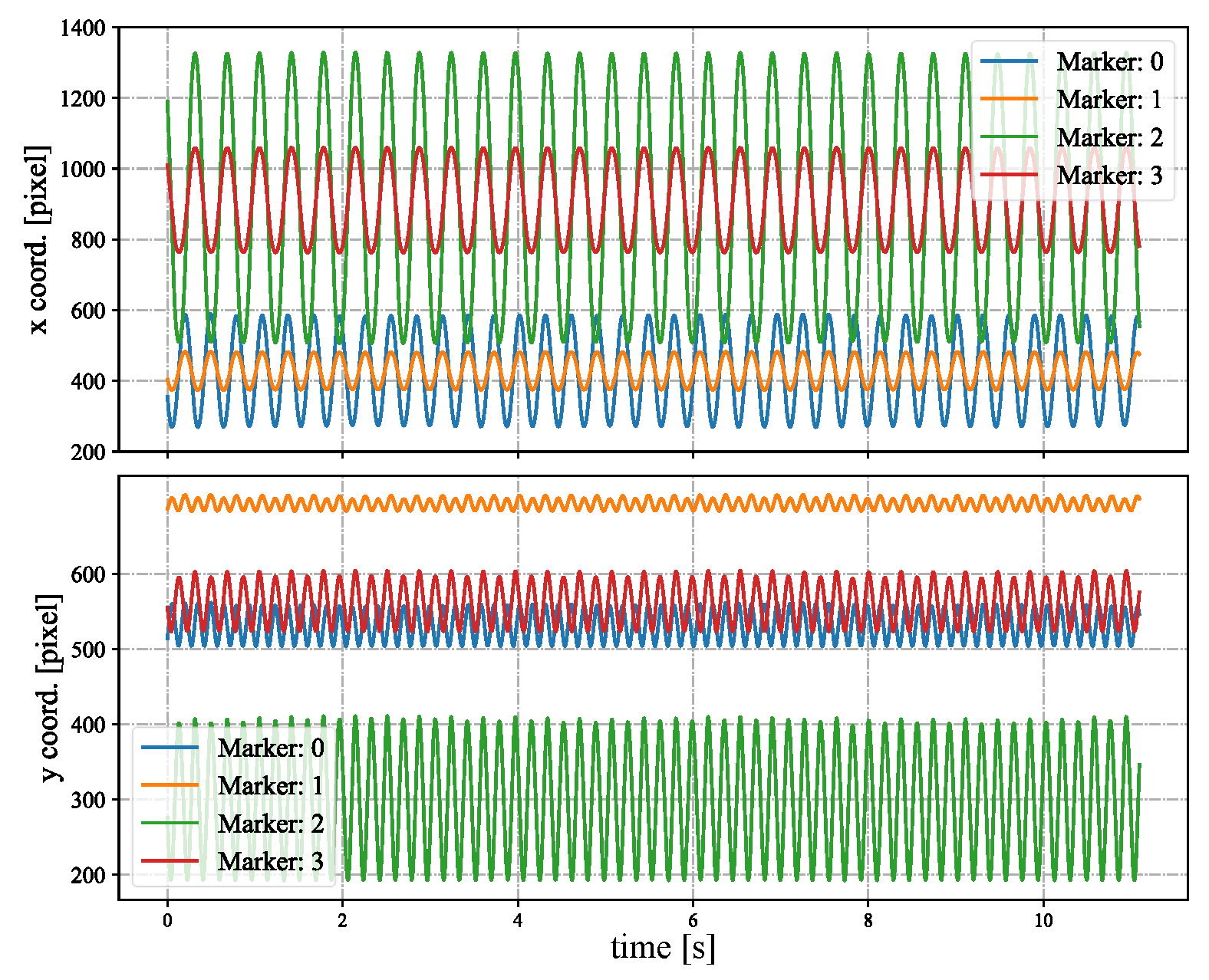
4.1. Stereo Correspondence Evaluation
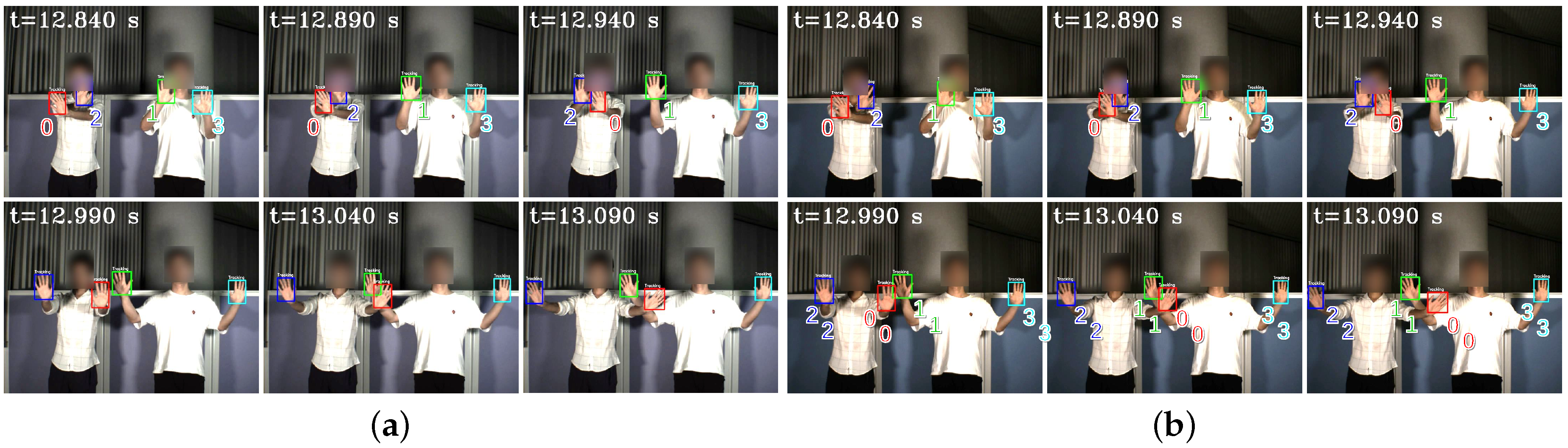
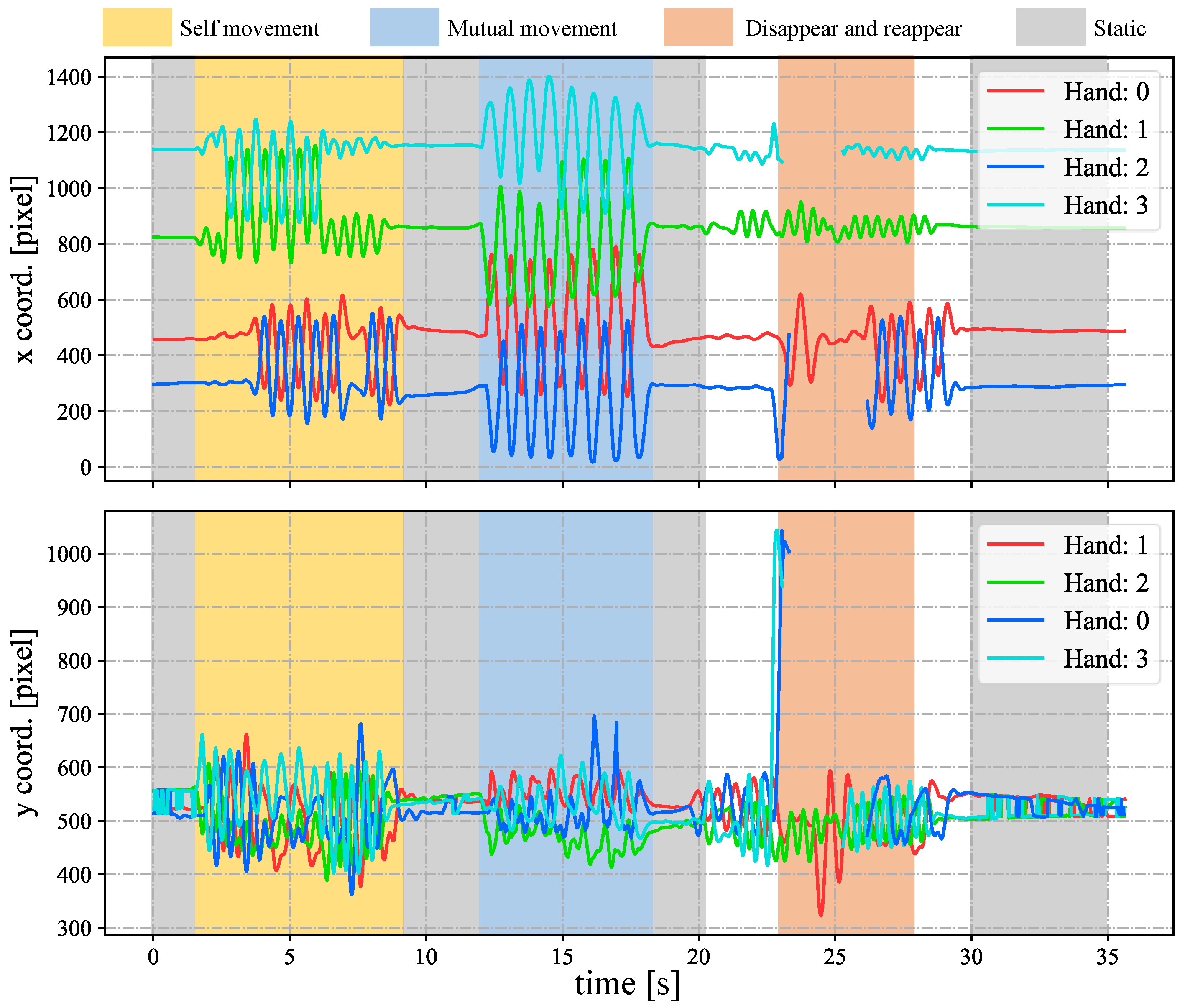
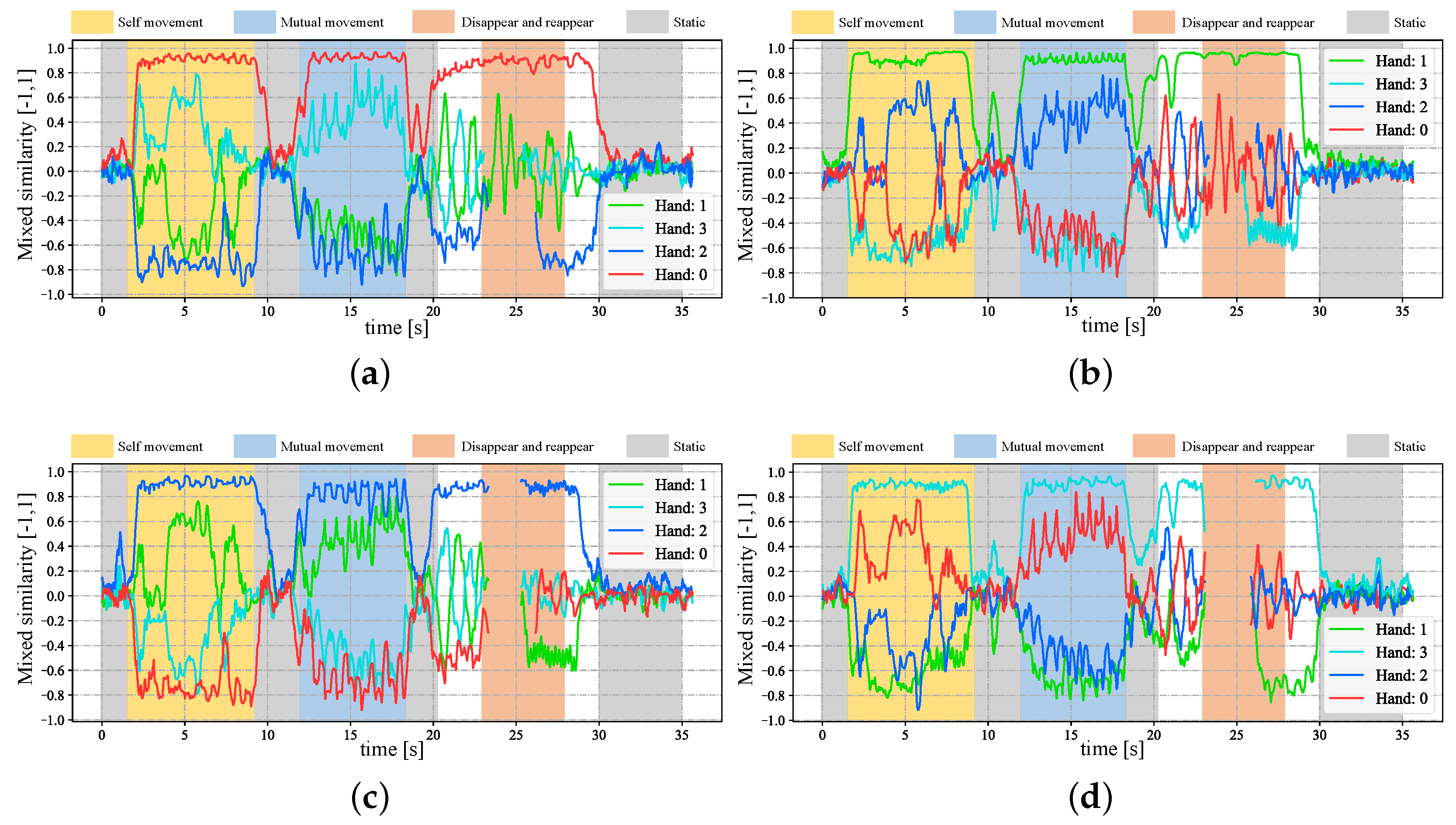
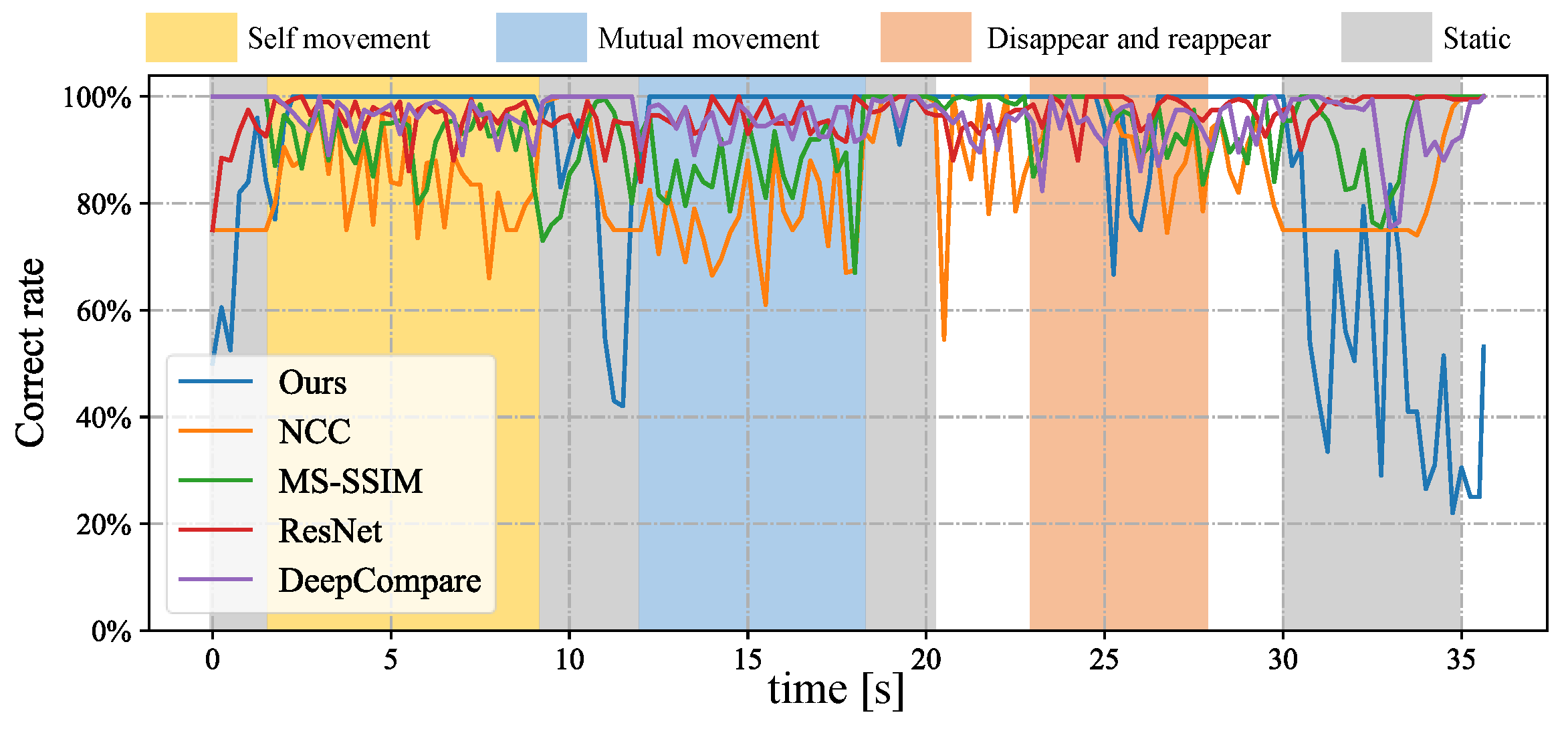
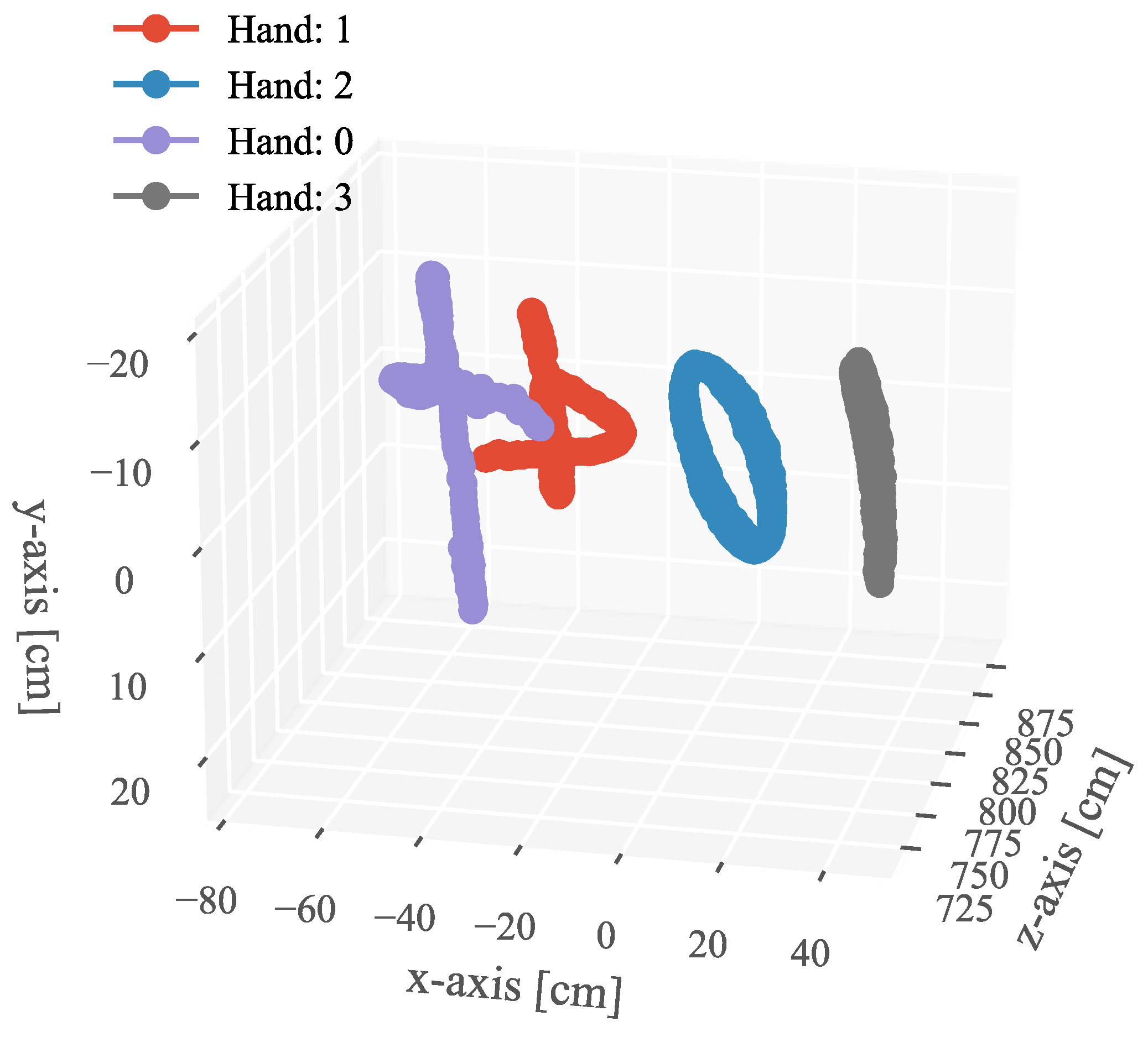
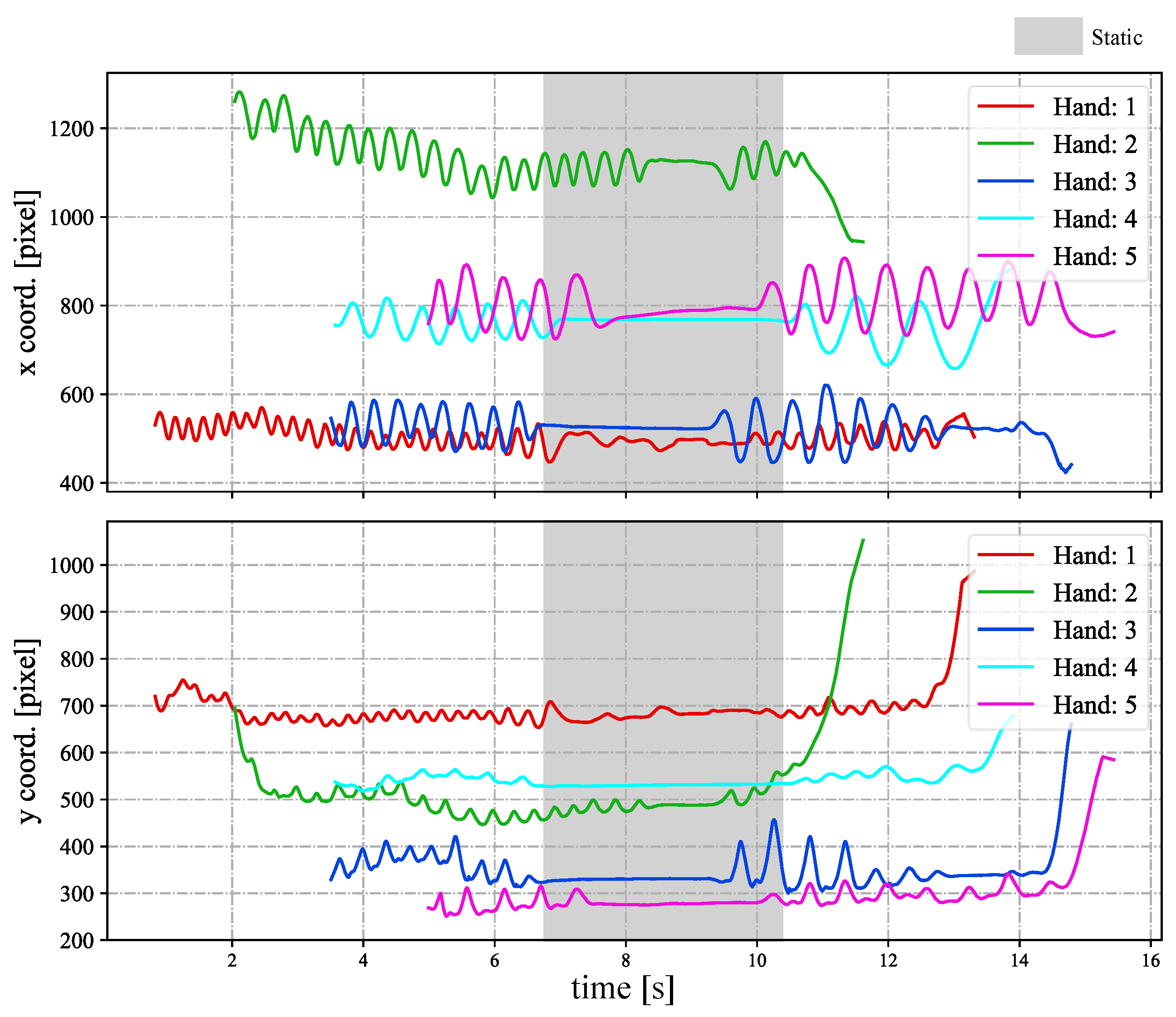
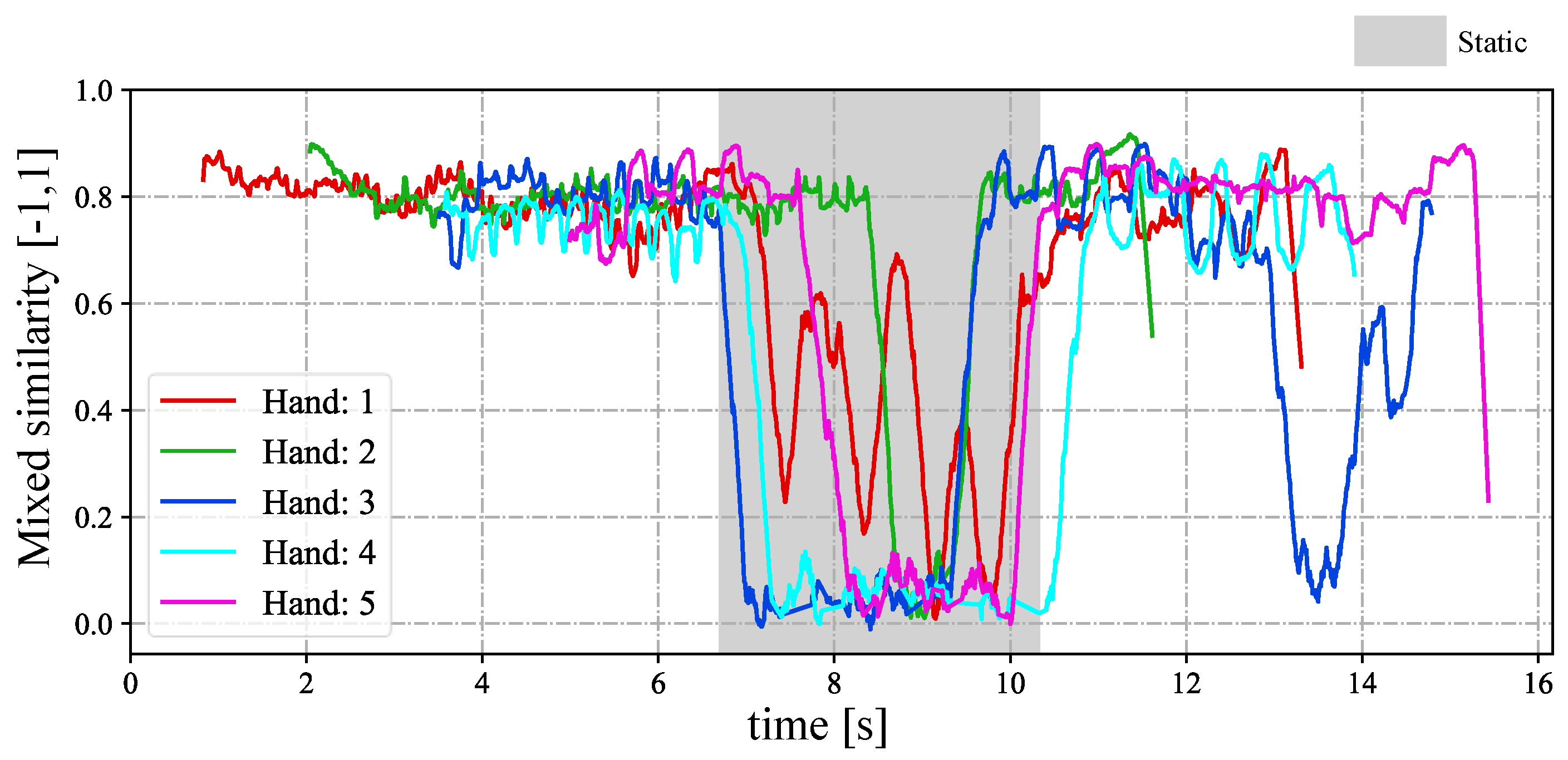
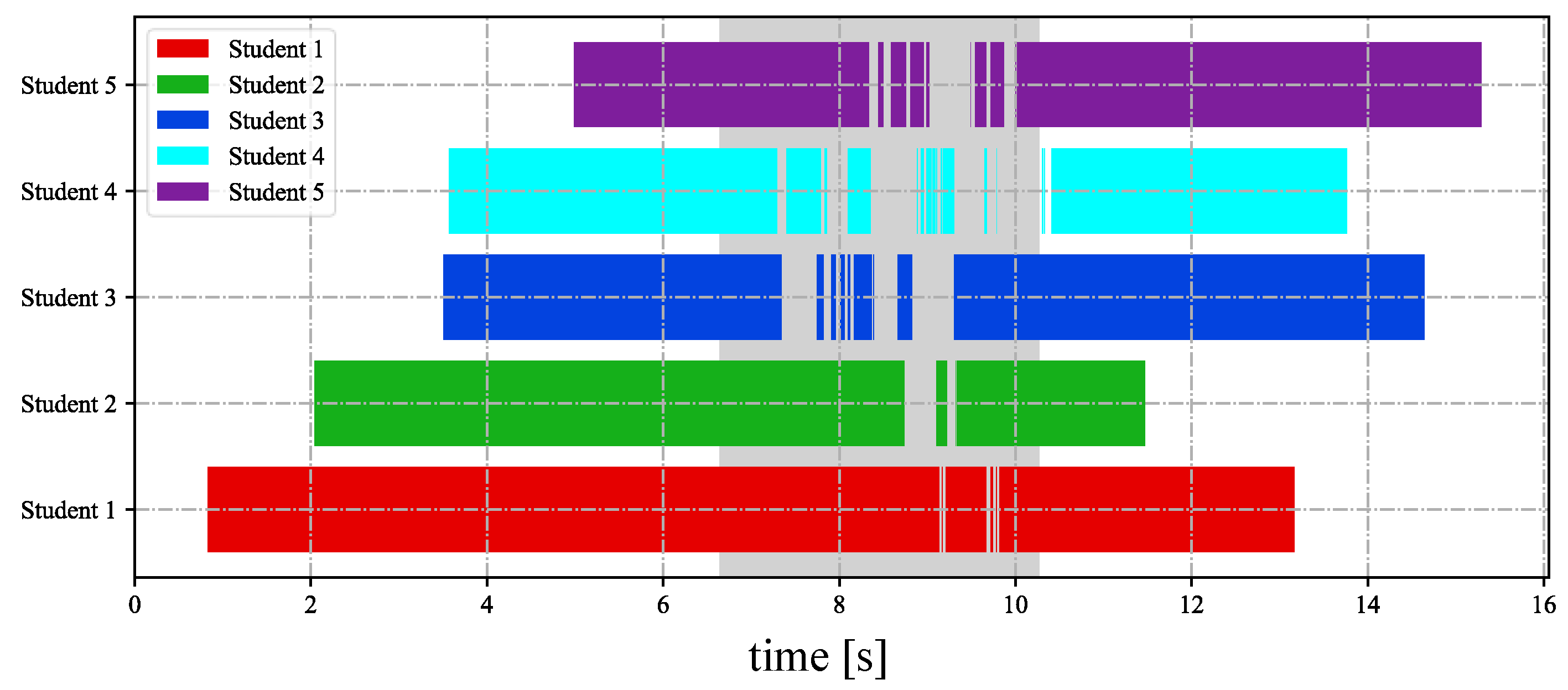
4.2. Stereo Correspondence of Hands with Complex Movements
4.3. Stereo Correspondence in the Meeting Room
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hamid, M.S.; Abd Manap, N.; Hamzah, R.A.; Kadmin, A.F. Stereo matching algorithm based on deep learning: A survey. J. King Saud-Univ.-Comput. Inf. Sci. 2022, 34, 1663–1673. [Google Scholar] [CrossRef]
- Oroko, J.A.; Nyakoe, G. Obstacle avoidance and path planning schemes for autonomous navigation of a mobile robot: A review. In Proceedings of the Sustainable Research and Innovation Conference, Nairobi, Kenya, 5–7 October 2022; pp. 314–318. [Google Scholar]
- Liu, C.; Xing, C.; Hu, Q.; Wang, S.; Zhao, S.; Gao, M. Stereoscopic hyperspectral remote sensing of the atmospheric environment: Innovation and prospects. Earth-Sci. Rev. 2022, 226, 103958. [Google Scholar] [CrossRef]
- Schlinkmann, N.; Khakhar, R.; Picht, T.; Piper, S.K.; Fekonja, L.S.; Vajkoczy, P.; Acker, G. Does stereoscopic imaging improve the memorization of medical imaging by neurosurgeons? Experience of a single institution. Neurosurg. Rev. 2022, 45, 1371–1381. [Google Scholar] [CrossRef] [PubMed]
- Macario Barros, A.; Michel, M.; Moline, Y.; Corre, G.; Carrel, F. A comprehensive survey of visual slam algorithms. Robotics 2022, 11, 24. [Google Scholar] [CrossRef]
- Shabanian, H.; Balasubramanian, M. A novel factor graph-based optimization technique for stereo correspondence estimation. Sci. Rep. 2022, 12, 15613. [Google Scholar] [CrossRef]
- Hamzah, R.A.; Azali, M.N.Z.; Noh, Z.M.; Zahari, M.; Herman, A.I. Development of depth map from stereo images using sum of absolute differences and edge filters. Indones. J. Electr. Eng. Comput. Sci. 2022, 25, 875–883. [Google Scholar] [CrossRef]
- Chang, Q.; Zha, A.; Wang, W.; Liu, X.; Onishi, M.; Lei, L.; Er, M.J.; Maruyama, T. Efficient stereo matching on embedded GPUs with zero-means cross correlation. J. Syst. Archit. 2022, 123, 102366. [Google Scholar] [CrossRef]
- Wang, F.; Ding, L. Object recognition and localization based on binocular stereo vision. In Proceedings of the 2022 2nd International Conference on Control and Intelligent Robotics, Nanjing, China, 24–26 June 2022; pp. 196–201. [Google Scholar]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.; Tardós, J.D. Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Zbontar, J.; LeCun, Y. Computing the stereo matching cost with a convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1592–1599. [Google Scholar]
- Laga, H.; Jospin, L.V.; Boussaid, F.; Bennamoun, M. A survey on deep learning techniques for stereo-based depth estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1738–1764. [Google Scholar] [CrossRef]
- Kaya, M.; Bilge, H.Ş. Deep metric learning: A survey. Symmetry 2019, 11, 1066. [Google Scholar] [CrossRef]
- Köhl, P.; Specker, A.; Schumann, A.; Beyerer, J. The MTA Dataset for Multi Target Multi Camera Pedestrian Tracking by Weighted Distance Aggregation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 4489–4498. [Google Scholar] [CrossRef]
- Li, P.; Zhang, J.; Zhu, Z.; Li, Y.; Jiang, L.; Huang, G. State-aware re-identification feature for multi-target multi-camera tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- He, Y.; Wei, X.; Hong, X.; Shi, W.; Gong, Y. Multi-target multi-camera tracking by tracklet-to-target assignment. IEEE Trans. Image Process. 2020, 29, 5191–5205. [Google Scholar] [CrossRef]
- Magdy, N.; Sakr, M.A.; Mostafa, T.; El-Bahnasy, K. Review on Trajectory Similarity Measures; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2016; pp. 613–619. [Google Scholar] [CrossRef]
- Li, Q.; Chen, M.; Gu, Q.; Ishii, I. A Flexible Calibration Algorithm for High-speed Bionic Vision System based on Galvanometer. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; pp. 4222–4227. [Google Scholar]
- Gu, Q.Y.; Ishii, I. Review of some advances and applications in real-time high-speed vision: Our views and experiences. Int. J. Autom. Comput. 2016, 13, 305–318. [Google Scholar] [CrossRef]
- Costa, L.d.F. Comparing cross correlation-based similarities. arXiv 2021, arXiv:2111.08513. [Google Scholar]
- Sara, U.; Akter, M.; Uddin, M.S. Image quality assessment through FSIM, SSIM, MSE and PSNR—a comparative study. J. Comput. Commun. 2019, 7, 8–18. [Google Scholar] [CrossRef]
- Zhao, S.; Wang, Y.; Yang, Z.; Cai, D. Region mutual information loss for semantic segmentation. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar] [CrossRef]
- Ye, Y.; Bruzzone, L.; Shan, J.; Bovolo, F.; Zhu, Q. Fast and robust matching for multimodal remote sensing image registration. IEEE Trans. Geosci. Remote. Sens. 2019, 57, 9059–9070. [Google Scholar] [CrossRef]
- Zermi, N.; Khaldi, A.; Kafi, R.; Kahlessenane, F.; Euschi, S. A DWT-SVD based robust digital watermarking for medical image security. Forensic Sci. Int. 2021, 320, 110691. [Google Scholar] [CrossRef]
- Yang, L.; Su, H.; Zhong, C.; Meng, Z.; Luo, H.; Li, X.; Tang, Y.Y.; Lu, Y. Hyperspectral image classification using wavelet transform-based smooth ordering. Int. J. Wavelets, Multiresolut. Inf. Process. 2019, 17, 1950050. [Google Scholar] [CrossRef]
- Pautrat, R.; Larsson, V.; Oswald, M.R.; Pollefeys, M. Online invariance selection for local feature descriptors. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Lecture Notes in Computer Science. Springer: Cham, Switzerland; Volume 12347, pp. 707–724. [Google Scholar]
- Gupta, S.; Thakur, K.; Kumar, M. 2D-human face recognition using SIFT and SURF descriptors of face’s feature regions. Vis. Comput. 2021, 37, 447–456. [Google Scholar] [CrossRef]
- Pang, Y.; Li, A. An improved ORB feature point image matching method based on PSO. In Proceedings of the Tenth International Conference on Graphics and Image Processing (ICGIP 2018), Chengdu, China, 12–14 December 2018; SPIE: Bellingham, WA, USA, 2019; Volume 11069, pp. 224–232. [Google Scholar]
- Chengtao, C.; Mengqun, L. Tire pattern similarity detection based on template matching and LBP. In Proceedings of the 2019 3rd International Conference on Electronic Information Technology and Computer Engineering (EITCE), Xiamen, China, 18–20 October 2019; pp. 419–423. [Google Scholar]
- Venkataramanan, A.K.; Wu, C.; Bovik, A.C.; Katsavounidis, I.; Shahid, Z. A hitchhiker’s guide to structural similarity. IEEE Access 2021, 9, 28872–28896. [Google Scholar] [CrossRef]
- Targ, S.; Almeida, D.; Lyman, K. Resnet in resnet: Generalizing residual architectures. arXiv 2016, arXiv:1603.08029. [Google Scholar]
- Sengupta, A.; Ye, Y.; Wang, R.; Liu, C.; Roy, K. Going deeper in spiking neural networks: VGG and residual architectures. Front. Neurosci. 2019, 13, 95. [Google Scholar] [CrossRef] [PubMed]
- Hernandez-Diaz, K.; Alonso-Fernandez, F.; Bigun, J. Cross Spectral Periocular Matching using ResNet Features. In Proceedings of the 2019 International Conference on Biometrics (ICB), Crete, Greece, 4–7 June 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Agarwal, R.; Verma, O.P. An efficient copy move forgery detection using deep learning feature extraction and matching algorithm. Multimed. Tools Appl. 2020, 79, 7355–7376. [Google Scholar] [CrossRef]
- Han, X.; Leung, T.; Jia, Y.; Sukthankar, R.; Berg, A.C. Matchnet: Unifying feature and metric learning for patch-based matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3279–3286. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Learning to compare image patches via convolutional neural networks. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4353–4361. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Yang, T.Y.; Hsu, J.H.; Lin, Y.Y.; Chuang, Y.Y. DeepCD: Learning Deep Complementary Descriptors for Patch Representations. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3334–3342. [Google Scholar] [CrossRef]
- Hsu, H.M.; Cai, J.; Wang, Y.; Hwang, J.N.; Kim, K.J. Multi-target multi-camera tracking of vehicles using metadata-aided re-id and trajectory-based camera link model. IEEE Trans. Image Process. 2021, 30, 5198–5210. [Google Scholar] [CrossRef]
- Gou, M.; Karanam, S.; Liu, W.; Camps, O.; Radke, R.J. Dukemtmc4reid: A large-scale multi-camera person re-identification dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 10–19. [Google Scholar]
- Xiu, Y.; Li, J.; Wang, H.; Fang, Y.; Lu, C. Pose Flow: Efficient online pose tracking. arXiv 2018, arXiv:1802.00977. [Google Scholar]
- Su, H.; Liu, S.; Zheng, B.; Zhou, X.; Zheng, K. A survey of trajectory distance measures and performance evaluation. VLDB J. 2020, 29, 3–32. [Google Scholar] [CrossRef]
- Zhao, L.; Shi, G. A novel similarity measure for clustering vessel trajectories based on dynamic time warping. J. Navig. 2019, 72, 290–306. [Google Scholar] [CrossRef]
- Maergner, P.; Pondenkandath, V.; Alberti, M.; Liwicki, M.; Riesen, K.; Ingold, R.; Fischer, A. Combining graph edit distance and triplet networks for offline signature verification. Pattern Recognit. Lett. 2019, 125, 527–533. [Google Scholar] [CrossRef]
- Rubinstein, A.; Song, Z. Reducing approximate longest common subsequence to approximate edit distance. In Proceedings of the Fourteenth Annual ACM-SIAM Symposium on Discrete Algorithms, SIAM, PA, United States, 5–8 January 2020; pp. 1591–1600. [Google Scholar]
- Ying, L.; Li, Z.; Xiang-mo, Z.; Ke, C. Effectiveness of trajectory similarity measures based on truck GPS data. China J. Highw. Transp. 2020, 33, 146. [Google Scholar]
- Gong, L.; Chen, B.; Xu, W.; Liu, C.; Li, X.; Zhao, Z.; Zhao, L. Motion similarity evaluation between human and a tri-co robot during real-time imitation with a trajectory dynamic time warping model. Sensors 2022, 22, 1968. [Google Scholar] [CrossRef] [PubMed]
- Zhu, C.; Yang, J.; Shao, Z.; Liu, C. Vision based hand gesture recognition using 3D shape context. IEEE/CAA J. Autom. Sin. 2019, 8, 1600–1613. [Google Scholar] [CrossRef]
- Patel, C.I.; Labana, D.; Pandya, S.; Modi, K.; Ghayvat, H.; Awais, M. Histogram of oriented gradient-based fusion of features for human action recognition in action video sequences. Sensors 2020, 20, 7299. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Rao, Y.; Cai, J.; Ma, W. Abnormal trajectory detection based on a sparse subgraph. IEEE Access 2020, 8, 29987–30000. [Google Scholar] [CrossRef]
- Liang, X.; Zhang, H.B.; Zhang, Y.X.; Huang, J.L. JTCR: Joint Trajectory Character Recognition for human action recognition. In Proceedings of the 2019 IEEE Eurasia Conference on IOT, Communication and Engineering (ECICE), Yunlin, Taiwan, 3–6 October 2019; pp. 350–353. [Google Scholar] [CrossRef]
- Cao, J.; Liang, M.; Li, Y.; Chen, J.; Li, H.; Liu, R.W.; Liu, J. PCA-based hierarchical clustering of AIS trajectories with automatic extraction of clusters. In Proceedings of the 2018 IEEE 3rd International Conference on Big Data Analysis (ICBDA), Shanghai, China, 9–12 March 2018; pp. 448–452. [Google Scholar]
- Xiao, Z.; Wang, Y.; Fu, K.; Wu, F. Identifying Different Transportation Modes from Trajectory Data Using Tree-Based Ensemble Classifiers. ISPRS Int. J. -Geo-Inf. 2017, 6, 57. [Google Scholar] [CrossRef]
- Bagheri, M.A.; Gao, Q.; Escalera, S. Support vector machines with time series distance kernels for action classification. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–7. [Google Scholar]
- Yao, D.; Zhang, C.; Zhu, Z.; Huang, J.; Bi, J. Trajectory clustering via deep representation learning. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 3880–3887. [Google Scholar]
- Zhang, R.; Xie, P.; Jiang, H.; Xiao, Z.; Wang, C.; Liu, L. Clustering noisy trajectories via robust deep attention auto-encoders. In Proceedings of the 2019 20th IEEE International Conference on Mobile Data Management (MDM), Hong Kong, China, 10–13 June 2019; pp. 63–71. [Google Scholar]
- Liang, M.; Liu, R.W.; Li, S.; Xiao, Z.; Liu, X.; Lu, F. An unsupervised learning method with convolutional auto-encoder for vessel trajectory similarity computation. Ocean. Eng. 2021, 225, 108803. [Google Scholar] [CrossRef]





















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Q.; Hu, S.; Shimasaki, K.; Ishii, I. HFR-Video-Based Stereo Correspondence Using High Synchronous Short-Term Velocities. Sensors 2023, 23, 4285. https://doi.org/10.3390/s23094285
Li Q, Hu S, Shimasaki K, Ishii I. HFR-Video-Based Stereo Correspondence Using High Synchronous Short-Term Velocities. Sensors. 2023; 23(9):4285. https://doi.org/10.3390/s23094285
Chicago/Turabian StyleLi, Qing, Shaopeng Hu, Kohei Shimasaki, and Idaku Ishii. 2023. "HFR-Video-Based Stereo Correspondence Using High Synchronous Short-Term Velocities" Sensors 23, no. 9: 4285. https://doi.org/10.3390/s23094285
APA StyleLi, Q., Hu, S., Shimasaki, K., & Ishii, I. (2023). HFR-Video-Based Stereo Correspondence Using High Synchronous Short-Term Velocities. Sensors, 23(9), 4285. https://doi.org/10.3390/s23094285