
A Diffusion Model Based on Network Intrusion Detection Method for Industrial Cyber-Physical Systems

Abstract
1. Introduction
- We use a diffusion model to equilibrate the rare class dataset. To the best of our knowledge, this is the first application of diffusion models to the study of ICPS network intrusion.
- We implemented network intrusion detection for ICPS using the BiLSTM model, which can accurately model and detects all types of network access traffic.
- We demonstrate the effectiveness of our approach for intrusion detection on imbalanced datasets through extensive experiments.
2. Related Work
2.1. Intrusion Detection
2.2. Diffusion Model
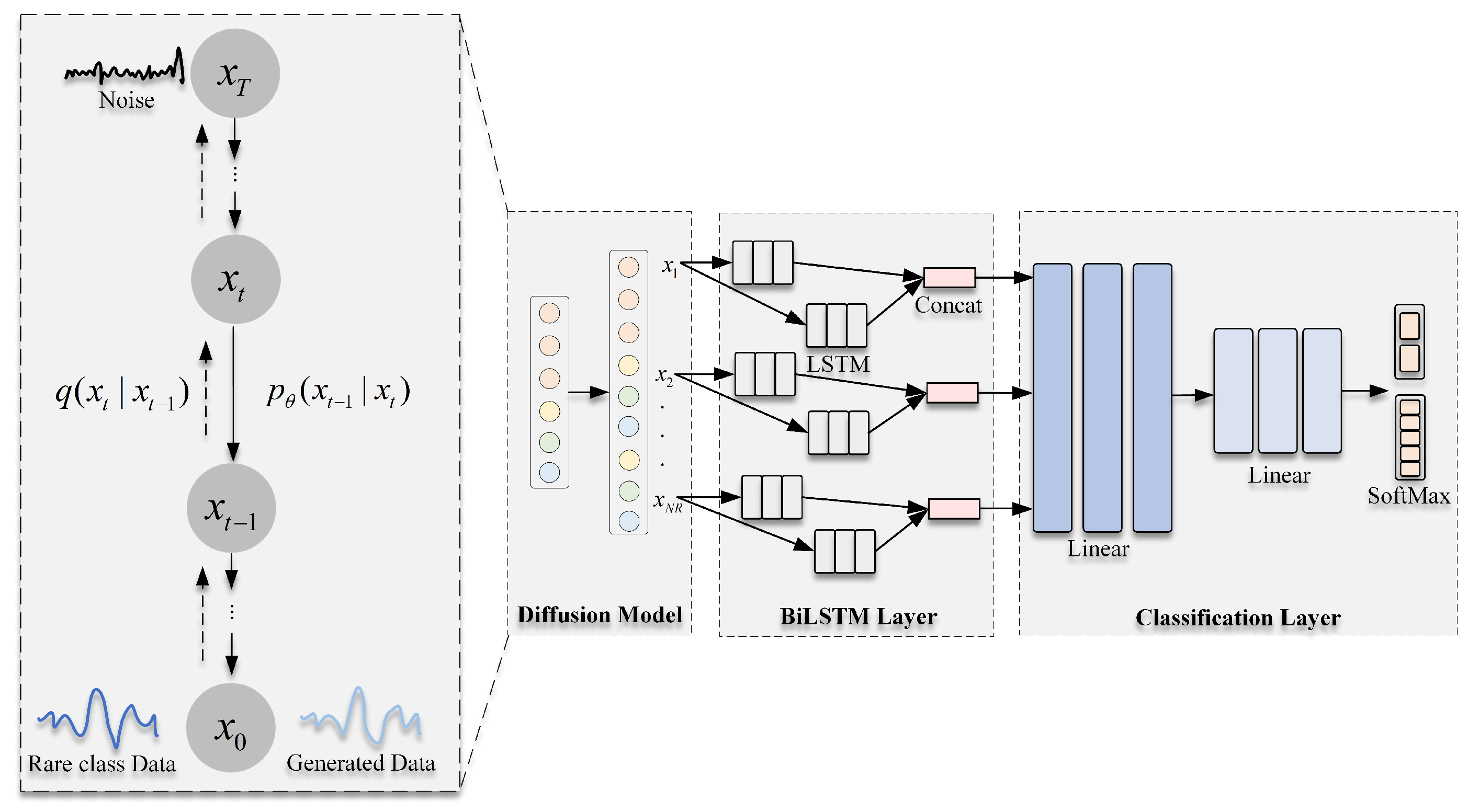
3. Method
3.1. Problem Description
3.2. Feature Representation
3.3. Data Generation Based on the Diffusion Model
3.3.1. Forward Diffusion Process
3.3.2. Reverse Diffusion Process
3.3.3. Parameter Training
3.4. Classification Network
4. Experiment and Results
4.1. Comparison Method
4.1.1. Generate Method
4.1.2. Classification Models
4.2. Evaluation Indicators
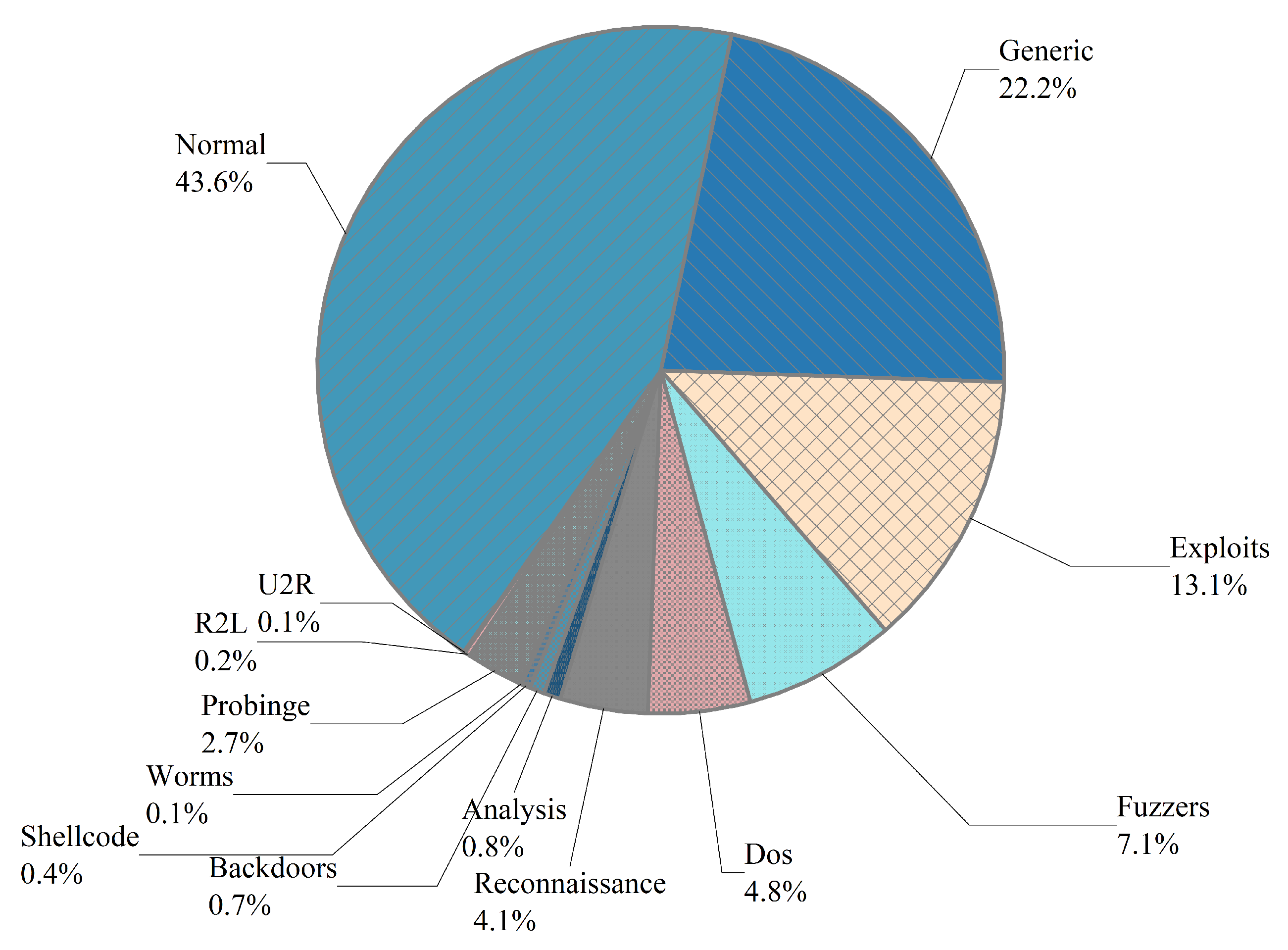
4.3. Dataset
4.3.1. Data Set Introduction
4.3.2. Data Pre-Processing
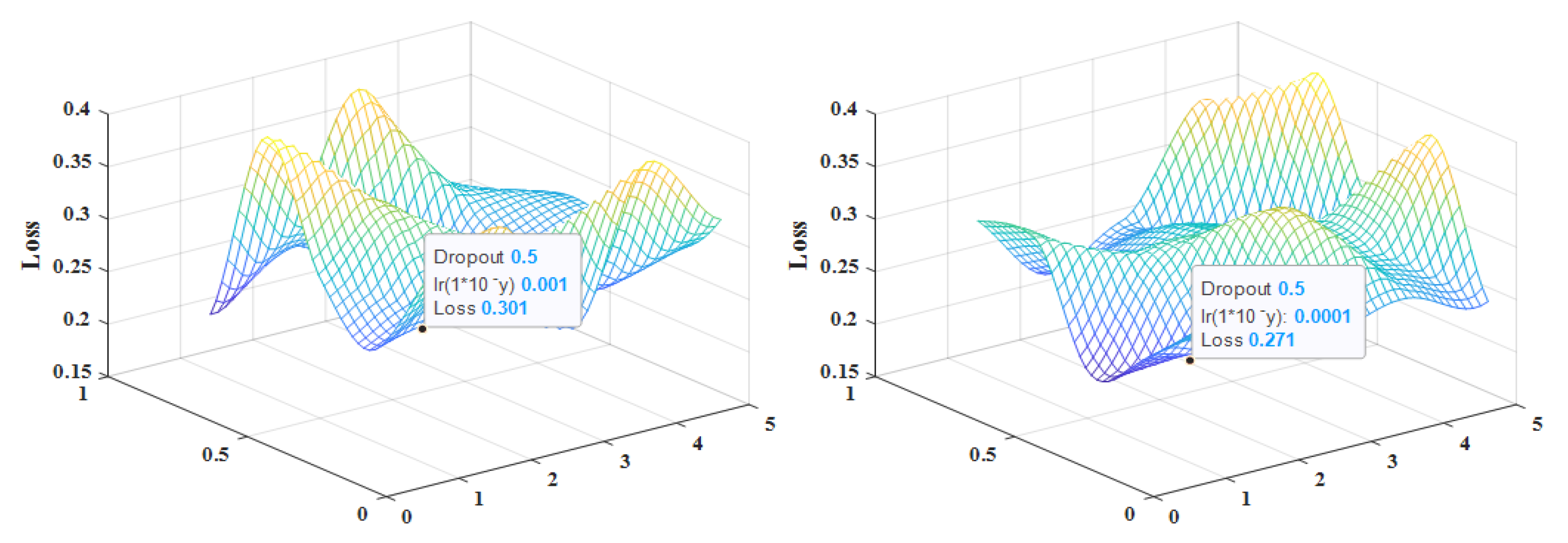
4.3.3. Parameter Setting
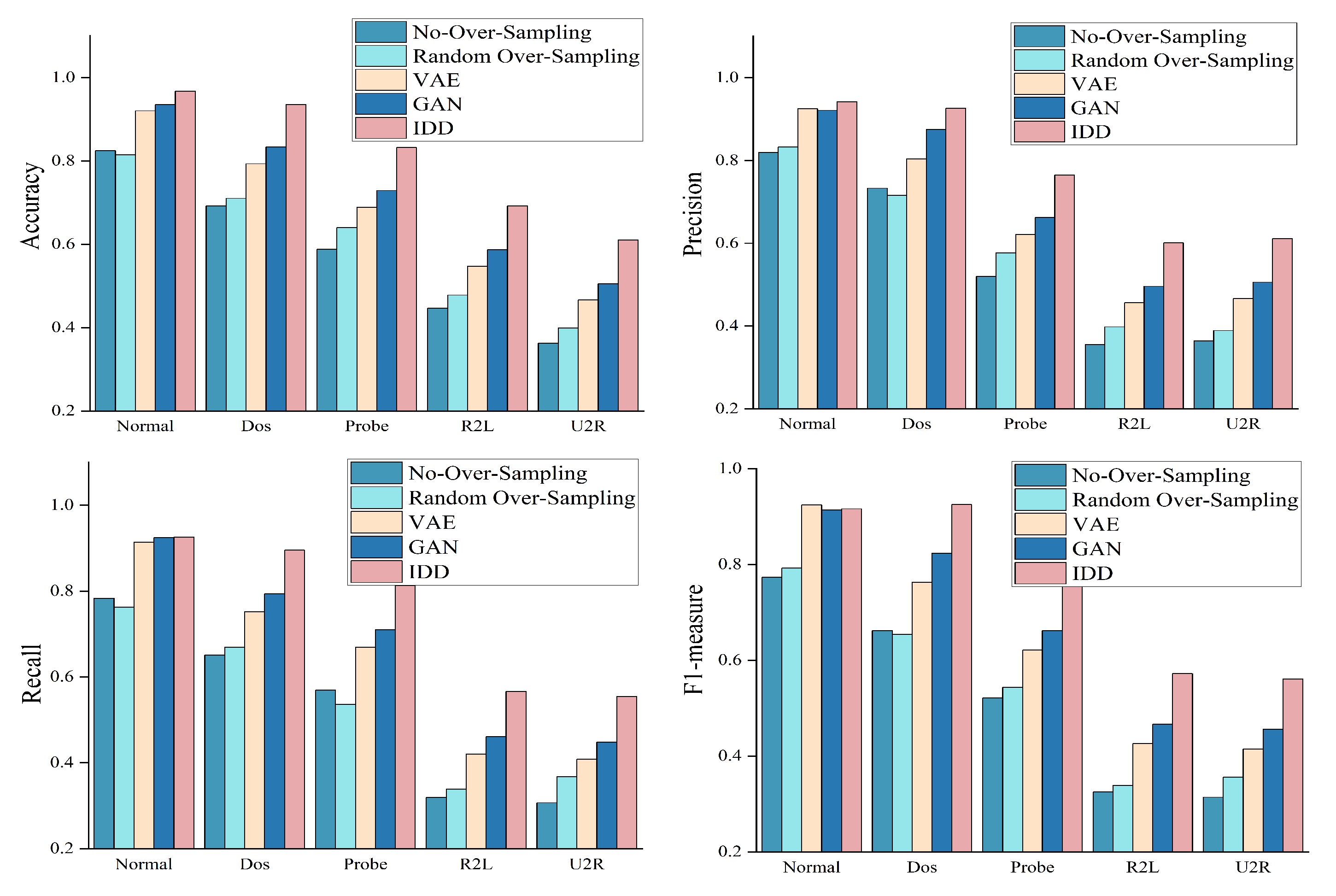
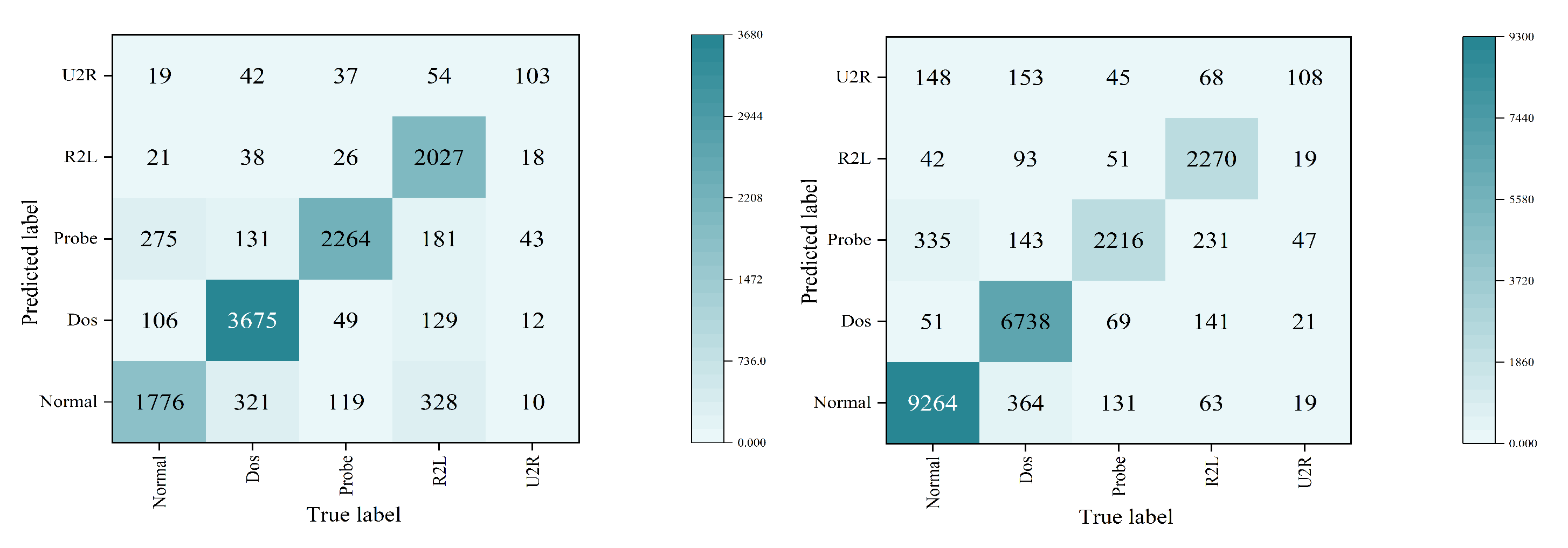
4.4. Results Comparison
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Garcia-Teodoro, P.; Diaz-Verdejo, J.; Macia-Fernandez, G.; Vazquez, E. Anomaly-based network intrusion detection: Techniques, systems and challenges. Comput. Secur. 2009, 28, 18–28. [Google Scholar] [CrossRef]
- Agrawal, S.; Agrawal, J. Survey on Anomaly Detection using Data Mining Techniques. Procedia Comput. Sci. 2015, 60, 708–713. [Google Scholar] [CrossRef]
- Butun, I.; Morgera, S.D.; Sankar, R. A Survey of Intrusion Detection Systems in Wireless Sensor Networks. IEEE Commun. Surv. Tutor. 2014, 16, 266–282. [Google Scholar] [CrossRef]
- Hodo, E.; Bellekens, X.; Hamilton, A.; Tachtatzis, C.; Atkinson, R. Shallow and Deep Networks Intrusion Detection System: A Taxonomy and Survey. arXiv 2017, arXiv:1701.02145. [Google Scholar]
- Aminanto, M.E.; Kim, K. Improving Detection of Wi-Fi Impersonation by Fully Unsupervised Deep Learning. In Proceedings of the 18th International Conference on Information Security Applications, Jeju Island, Republic of Korea, 24–26 August 2017; pp. 212–223. [Google Scholar]
- Bi, J.; Zhang, C. An empirical comparison on state-of-the-art multi-class imbalance learning algorithms and a new diversified ensemble learning scheme. Knowl. Based Syst. 2018, 158, 81–93. [Google Scholar] [CrossRef]
- Vartouni, A.M.; Kashi, S.S.; Teshnehlab, M. An anomaly detection method to detect web attacks using Stacked Auto-Encoder. In Proceedings of the 6th Iranian Joint Congress on Fuzzy and Intelligent Systems, Kerman, Iran, 28 February–2 March 2018; pp. 131–134. [Google Scholar]
- Ni, G.; Ling, G.; Gao, Q.; Hai, W. An Intrusion Detection Model Based on Deep Belief Networks. In Proceedings of the Second International Conference on Advanced Cloud & Big Data, Huangshan, China, 20–22 November 2014; pp. 247–252. [Google Scholar]
- Abolhasanzadeh, B. Nonlinear dimensionality reduction for intrusion detection using auto-encoder bottleneck features. In Proceedings of the 7th Conference on Information and Knowledge Technology, Urmia, Iran, 26–28 May 2015; pp. 1–5. [Google Scholar]
- Javaid, A.Y.; Niyaz, Q.; Sun, W.; Alam, M. A Deep Learning Approach for Network Intrusion Detection System. In Proceedings of the 9th EAI International Conference on Bio-Inspired Information and Communications Technologies, New York, NY, USA, 3–5 December2015; pp. 21–26. [Google Scholar]
- Alom, M.Z.; Taha, T.M. Network Intrusion Detection for Cyber Security using Unsupervised Deep Learning Approaches. In Proceedings of the National Aerospace & Electronics Conference, Dayton, OH, USA, 27–30 June 2017; pp. 63–69. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising Diffusion Probabilistic Models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Manikopoulos, C.; Papavassiliou, S. Network intrusion and fault detection: A statistical anomaly approach. IEEE Commun. Mag. 2002, 40, 76–82. [Google Scholar] [CrossRef]
- Caberera, J.; Ravichandran, B.; Mehra, R.K. Statistical traffic modeling for network intrusion detection. In Proceedings of the Analysis and Simulation of Computer and Telecommunication Systems, San Francisco, CA, USA, 29 August–1 September 2000; pp. 466–473. [Google Scholar]
- Stein, G.; Bing, C.; Wu, A.S.; Hua, K.A. Decision tree classifier for network intrusion detection with GA-based feature selection. In Proceedings of the Southeast Regional Conference, Kennesaw, GA, USA, 18–20 March 2005; pp. 136–141. [Google Scholar]
- Chitrakar, R.; Huang, C. Selection of Candidate Support Vectors in incremental SVM for network intrusion detection. Telecom Power Technol. 2014, 45, 231–241. [Google Scholar] [CrossRef]
- Sommer, R.; Paxson, V. Outside the Closed World: On Using Machine Learning for Network Intrusion Detection. In Proceedings of the 31th IEEE Symposium on Security and Privacy, Istanbul, Turkey, 8–9 June 2010; pp. 305–316. [Google Scholar]
- Mohammadi, S.; Namadchian, A. A new deep learning approach for anomaly base IDS using memetic classifier. Int. J. Comput. Commun. Control 2017, 12, 677–688. [Google Scholar] [CrossRef]
- Wang, Z.; Li, Z.; He, D.; Chan, S. A Lightweight Approach for Network Intrusion Detection in Industrial Cyber-Physical Systems Based on Knowledge Distillation and Deep Metric Learning. Expert Syst. Appl. 2022, 206, 117671. [Google Scholar] [CrossRef]
- Sheikhan, M.; Jadidi, Z.; Farrokhi, A. Intrusion detection using reduced-size RNN based on feature grouping. Neural Comput. Appl. 2012, 21, 1185–1190. [Google Scholar] [CrossRef]
- Kim, J.; Kim, J.; Thu, H.L.T.; Kim, H. Long short term memory recurrent neural network classifier for intrusion detection. In Proceedings of the 2016 International Conference on Platform Technology and Service, Jeju, Republic of Korea, 15–17 February 2016; pp. 1–5. [Google Scholar]
- Imrana, Y.; Xiang, Y.; Ali, L.; Abdul-Rauf, Z. A bidirectional LSTM deep learning approach for intrusion detection. Expert Syst. Appl. 2021, 185, 115524. [Google Scholar] [CrossRef]
- Batzolis, G.; Stanczuk, J.; Schönlieb, C.B.; Etmann, C. Conditional image generation with score-based diffusion models. arXiv 2021, arXiv:2111.13606. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Esser, P.; Rombach, R.; Ommer, B. Taming transformers for high-resolution image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12873–12883. [Google Scholar]
- Austin, J.; Johnson, D.D.; Ho, J.; Tarlow, D.; van den Berg, R. Structured denoising diffusion models in discrete state-spaces. Adv. Neural Inf. Process. Syst. 2021, 34, 17981–17993. [Google Scholar]
- Park, S.W.; Lee, K.; Kwon, J. Neural Markov Controlled SDE: Stochastic Optimization for Continuous-Time Data. In Proceedings of the 10th International Conference on Learning Representations, Online, 25–29 April 2022. [Google Scholar]
- Tashiro, Y.; Song, J.; Song, Y.; Ermon, S. CSDI: Conditional score-based diffusion models for probabilistic time series imputation. Adv. Neural Inf. Process. Syst. 2021, 34, 24804–24816. [Google Scholar]
- Graves, A. Long short-term memory. Supervised Seq. Label. Recurr. Neural Netw. 2012, 385, 37–45. [Google Scholar]
- Zhu, X.; Sobihani, P.; Guo, H. Long short-term memory over recursive structures. In Proceedings of the International Conference on Machine Learning, Miami, FL, USA, 9–11 December 2015; pp. 1604–1612. [Google Scholar]
- Wan, L.; Zeiler, M.; Zhang, S.; Le Cun, Y.; Fergus, R. Regularization of neural networks using dropconnect. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1058–1066. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Jeatrakul, P.; Wong, K.W.; Fung, C.C. Classification of imbalanced data by combining the complementary neural network and SMOTE algorithm. In Proceedings of the International Conference on Neural Information Processing, Sydney, Australia, 22–25 November 2010; pp. 152–159. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Anani, W.; Samarabandu, J. Comparison of recurrent neural network algorithms for intrusion detection based on predicting packet sequences. In Proceedings of the 2018 IEEE Canadian Conference on Electrical & Computer Engineering, Quebec, QC, Canada, 13–16 May 2018; pp. 1–4. [Google Scholar]
- Farahnakian, F.; Heikkonen, J. A deep auto-encoder based approach for intrusion detection system. In Proceedings of the 20th International Conference on Advanced Communication Technology, Chuncheon, Republic of Korea, 11–14 February 2018; pp. 178–183. [Google Scholar]
- Alom, M.Z.; Bontupalli, V.; Taha, T.M. Intrusion detection using deep belief networks. In Proceedings of the 2015 National Aerospace and Electronics Conference, Dayton, OH, USA, 15–19 June 2015; pp. 339–344. [Google Scholar]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the IEEE International Conference on Computational Intelligence for Security & Defense Applications, Ottawa, IL, USA, 8–10 July 2009; pp. 1–6. [Google Scholar]
- Moustafa, N.; Slay, J. UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In Proceedings of the Military Communications and Information Systems Conference, Cracow, Poland, 18–19 May 2015; pp. 1–6. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Paul Smolley, S. Least squares generative adversarial networks. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2794–2802. [Google Scholar]
- Huang, H.; Li, Z.; He, R.; Sun, Z.; Tan, T. Introvae: Introspective variational autoencoders for photographic image synthesis. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Yang, L.; Zhang, Z.; Song, Y.; Hong, S.; Xu, R.; Zhao, Y.; Shao, Y.; Zhang, W.; Cui, B.; Yang, M.H. Diffusion models: A comprehensive survey of methods and applications. arXiv 2022, arXiv:2209.00796. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Name | Description | Value Type | Ranges |
|---|---|---|---|
| Protocol Type | Protocol used in the connection | Textual | |
| Num Failed Logins | Count of failed login attempts | Numerical | 0–4 |
| Root Shell | 1 if root shell is obtained; 0 otherwise | Numerical | 0, 1 |
| Same Srv Rate | The percentage of connections that have activated the flag REJ | Numerical | 0, 1 |
| Class | Classification of the traffic input | Textual | |
| Difficulty Level | Difficulty level | Numerical | 0–21 |
| Type | Train_Original | Test | Train_Generated | |||
|---|---|---|---|---|---|---|
| Records | Percentage | Records | Percentage | Records | Percentage | |
| Normal | 13,449 | 53.38% | 9711 | 43.07% | 13,449 | 39.07% |
| Dos | 9234 | 16.65% | 7458 | 33.08% | 9234 | 26.82% |
| Prob | 2289 | 9.08% | 2421 | 10.73% | 2936 | 8.53% |
| R2L | 209 | 0.83% | 2754 | 12.21% | 2936 | 8.53% |
| U2R | 11 | 0.04% | 200 | 0.89% | 2936 | 8.53% |
| Total | 25,192 | 22,544 | 34,427 | |||
| BiLSTM Model | Classification Model | ||||
|---|---|---|---|---|---|
| Layer | Type | Output Shape | Layer | Type | Output Shape |
| 1 | Embedding | # | 8 | Linear | 128, 64 |
| 2 | BiLSTM | #, 64 | 9 | Relu | 64, 64 |
| 3 | Relu | 64, 64 | 10 | Dropout | 64, 64 |
| 4 | Dropout | 64, 64 | 11 | Linear | 64, 32 |
| 5 | BiLSTM | 64, 128 | 12 | Relu | 32, 32 |
| 6 | Relu | 128, 128 | 13 | Dropout | 32, 32 |
| 7 | Dropout | 128, 128 | 14 | Full connect | 32, * |
| Dataset | Model | Accuracy | Precision | Recall | F1-measures |
|---|---|---|---|---|---|
| NSL-KDD | CNN | 0.739 | 0.866 | 0.784 | 0.790 |
| DBN | 0.763 | 0.879 | 0.806 | 0.811 | |
| LSTM | 0.812 | 0.903 | 0.813 | 0.836 | |
| BiLSTM | 0.866 | 0.922 | 0.832 | 0.877 | |
| Ours | 0.896 | 0.931 | 0.853 | 0.894 | |
| UNSW-NB15 | CNN | 0.746 | 0.857 | 0.776 | 0.781 |
| DBN | 0.771 | 0.871 | 0.797 | 0.802 | |
| LSTM | 0.820 | 0.893 | 0.804 | 0.826 | |
| BiLSTM | 0.874 | 0.912 | 0.823 | 0.867 | |
| Ours | 0.904 | 0.921 | 0.843 | 0.884 |
| Datasets | Type | Accuracy | Precision | Recall | F1-measure | ||||
|---|---|---|---|---|---|---|---|---|---|
| v | p-v | v | p-v | v | p-v | V | p-v | ||
| NSL-KDD | Normal | 0.937 | p < 0.5 | 0.942 | p < 0.5 | 0.926 | p < 0.5 | 0.916 | p < 0.5 |
| Dos | 0.935 | 0.926 | 0.895 | 0.925 | |||||
| Probe | 0.832 | 0.765 | 0.813 | 0.765 | |||||
| R2L | 0.692 | 0.601 | 0.566 | 0.572 | |||||
| U2R | 0.610 | 0.611 | 0.554 | 0.561 | |||||
| UNSW-NB15 | Normal | 0.943 | p < 0.5 | 0.938 | p < 0.5 | 0.933 | p < 0.5 | 0.932 | p < 0.5 |
| Generic | 0.974 | 0.963 | 0.912 | 0.912 | |||||
| Exploits | 0.873 | 0.885 | 0.869 | 0.845 | |||||
| Fuzzers | 0.824 | 0.794 | 0.839 | 0.827 | |||||
| Dos | 0.778 | 0.698 | 0.761 | 0.753 | |||||
| Backdoors | 0.696 | 0.703 | 0.747 | 0.689 | |||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, B.; Lu, Y.; Li, Q.; Bai, Y.; Yu, J.; Yu, X. A Diffusion Model Based on Network Intrusion Detection Method for Industrial Cyber-Physical Systems. Sensors 2023, 23, 1141. https://doi.org/10.3390/s23031141
Tang B, Lu Y, Li Q, Bai Y, Yu J, Yu X. A Diffusion Model Based on Network Intrusion Detection Method for Industrial Cyber-Physical Systems. Sensors. 2023; 23(3):1141. https://doi.org/10.3390/s23031141
Chicago/Turabian StyleTang, Bin, Yan Lu, Qi Li, Yueying Bai, Jie Yu, and Xu Yu. 2023. "A Diffusion Model Based on Network Intrusion Detection Method for Industrial Cyber-Physical Systems" Sensors 23, no. 3: 1141. https://doi.org/10.3390/s23031141
APA StyleTang, B., Lu, Y., Li, Q., Bai, Y., Yu, J., & Yu, X. (2023). A Diffusion Model Based on Network Intrusion Detection Method for Industrial Cyber-Physical Systems. Sensors, 23(3), 1141. https://doi.org/10.3390/s23031141