Abstract
Fifth-generation (5G) and beyond networks are expected to serve large numbers of user equipments (UEs). Grant-based random access (RA) protocols are efficient when serving human users, typically with large data volumes to transmit. The strongest user collision resolution (SUCRe) is the first protocol that effectively uses the many antennas at the 5G base station (BS) to improve connectivity performance. In this paper, our proposal involves substituting the retransmission rule of the SUCRe protocol with a neural network (NN) to enhance the identification of the strongest user and resolve collisions in a decentralized manner on the UEs’ side. The proposed NN-based procedure is trained offline, admitting different congestion levels of the system, aiming to obtain a single setup able to operate with different numbers of UEs. The numerical results indicate that our method attains substantial connectivity performance improvements compared to other protocols without requiring additional complexity or overhead. In addition, the proposed approach is robust regarding variations in the number of BS antennas and transmission power while improving energy efficiency by requiring fewer attempts on the RA stage.
1. Introduction
Fifth-generation (5G) and beyond (B5G) mobile communication networks should be ready to provide reliable and enhanced mobile broadband (eMBB) communications to an ever-increasing number of devices [1]. The limited availability of time and frequency resources makes pilot collisions prone to happen during the random access (RA) stage, particularly when the number of connected devices exceeds the number of available pilots. This, in turn, can adversely affect the network’s functionality. This problem is an important and challenging issue that future wireless networks must solve to provide reliable connections with the expected quality. Therefore, ensuring the implementation of reliable and effective RA protocols is crucial for the development of B5G networks.
Since its inception [2], massive multiple-input multiple-output (M-MIMO) systems have been evolving from a theoretical concept to a practical technology, becoming a key component of the current 5G standard [3]. Due to user mobility and channel delay spread, the limited channel coherence blocks make the reuse of pilots necessary, which, with a large number of BS antennas, gives rise to a beamformed interference known as pilot contamination [2,4,5,6,7,8,9]. Several different approaches have been proposed with the objective of mitigating this critical impairment of M-MIMO systems, including time-shifted pilots and data transmission between different users [10,11], power allocation [12,13], pilot assignment [13,14], and cell-free (CF)-based schemes [15]. In an RA context, pilot contamination also degrades the performance of crowded M-MIMO systems whenever two or more connected user equipments (UEs) choose the same pilot sequence, which is known as pilot collision [16].
There are multiple possible solutions for pilot collision in M-MIMO systems, such as the adoption of grant-free (GF) or grant-based (GB) protocols. One prominent GB approach is the strongest-user collision resolution (SUCRe) protocol [16], which is a four-step procedure that allows only the strongest contender to access the network resources. The motivation for the strongest-user retransmission criterion is that it will always have only one strongest user in a pilot collision, and it is possible to evaluate a decentralized test to let the user know if it is the strongest contender without additional signaling overhead. Despite being able to address up to 90% of all collisions, the SUCRe protocol still suffers from a significant number of false-negative cases, as highlighted in [17]. This is due to its inability to resolve pilot collisions where the strongest UE’s signal strength is lower than 50% of the sum of the signal strengths of contending UEs.
Some works propose variations on the SUCRe protocol, showing relatively good results. In [18], the UE receives a precoded downlink (DL) response from the BS. This response helps the UEs estimate the sum of the signal strengths of all the competing signals and provides information on idle pilots after the first RA round. Additionally, the response includes an access class barrier (ACB) factor to regulate access control. Hence, some UEs that failed to be granted access on the first attempt can try to access the network resources through previously unused pilot signals. A similar protocol is proposed in [19] in which the BS broadcasts no ACB factor to UEs; instead, a graph-based interference cancellation scheme is applied to maximize the number of UEs that can be admitted to the network. Although both works show better results than the SUCRe protocol, they introduce extra signaling overhead by informing idle pilots to the UEs, which increases latency and harms the system’s spectral efficiency.
Another variation of the SUCRe protocol is the access class barring with power control (ACBPC) RA protocol [20]. The proposed ACBPC protocol suggests implementing decentralized UL pilot transmit power control on the UEs’ end, resulting in a notable performance improvement compared to the SUCRe protocol. Additionally, the ACBPC protocol offers fair access to the UEs, regardless of their distance from the BS. A variation of the SUCRe protocol, known as softSUCRe and introduced in [21], incorporates a soft decision retransmission rule. The softSUCRe rule differs from the SUCRe protocol in that the UE decides to retransmit its pilot based on the probability of being the strongest user. While the softSUCRe protocol yields superior results to the original SUCRe protocol, it also requires additional information for the UE to make decision. Various studies, including [22,23], suggest different approaches to collision resolution protocols. However, Refs. [22,23] introduce additional overhead to the RA phase, increasing system complexity. In addition, other approaches for RA in extra-large MIMO (XL-MIMO) systems are proposed in [24,25].
Finally, the authors of [17] propose a GB RA protocol that employs statistical techniques to address collisions in a decentralized manner at the UE level. This protocol uses a Bayesian classifier (BC) to identify the strongest user and replaces the retransmission rule of the SUCRe protocol. This protocol also shows results superior to the SUCRe protocol without the need for extra overhead. However, as a statistical approach, the BC method has a maximum accuracy limited by the distribution of the considered classes.
With the development of artificial intelligence, a new approach to solving problems in communication systems has emerged, especially using neural networks (NNs) for pattern recognition [26,27]. In this work, we propose a decision-making methodology based on a multilayer perceptron (MLP) NN, which is applied to empirical simulation data of the SUCRe protocol. The proposed approach suggests replacing the retransmission rule of the original SUCRe protocol with an MLP, which can determine if the UE is the strongest contender or not, resolving pilot collisions in a decentralized manner. Our choice for employing offline training instead of online is because the method is evaluated on the UEs’ side since the RA scheme should run in a distributed way for scalability purposes. Thus, the online training should be carried out by the users and would incur additional latency, for they establish a connection to the network, making the approach less attractive. The performance results, which include the fraction of failed access attempts (FFAAs), average number of access attempts (ANAAs), throughput, latency, and energy consumption, indicate a significant improvement in the proposed method compared to other protocols available in the literature.
Thus, the contribution of this paper is threefold:
- (i)
- We propose a GB RA protocol for crowded M-MIMO systems applying an NN at the UEs’ side to assist in self-classification as the strongest competitor or not, allowing the UEs to resolve pilot collisions in a decentralized and uncoordinated manner;
- (ii)
- The offline training procedure of the NN to the RA problem is entirely characterized, including data collection, preprocessing, training, and validation steps. In addition, to avoid excessively complex processing at the devices’ side, we show that a simple MLP with only one hidden layer with five neurons is able to remarkably improve the connectivity performance;
- (iii)
- Extensive numerical results are provided corroborating the performance of the proposed approach, including the performance influence of certain key NN parameters and the robustness against the variation of some network parameters, like the number of BS antennas and transmit power.
The remainder of this paper is organized as follows. The materials and methods are provided in Section 2, which describes the adopted crowded M-MIMO system model in Section 2.1 and proposes the NN-based RA protocol in Section 2.2. In Section 3, the numerical results of the proposed NN GB-RA protocol are presented. The main conclusions are offered in Section 4.
2. Materials and Methods
We present in this section our adopted system model for the crowded M-MIMO network under investigation. Then, we present in detail the proposed NN-based RA protocol, carefully describing the methodology for applying the NN to improve the random access performance of the system. In addition, we also evaluate the performance influence of certain key NN parameters, like the number of neurons in the hidden layer and learning rate. Then, in the next section, we numerically evaluate the robustness of the obtained NN regarding the variation of some network parameters, like transmit power and number of BS antennas.
2.1. System Model
Similar to the work presented in [16], our M-MIMO system model focus on a center hexagonal cell , surrounded by 6 neighboring cells with . All cells present a BS located at their centers and equipped with M antennas to serve a set of UEs, through a time-division duplex (TDD) scheme, with time and frequency resources divided into coherence blocks of T channel uses. Furthermore, we represent the set of all UEs inside cell j by , and the subset of of all active UEs by . Also, we consider that inactive UEs will try to become active with probability . Therefore, even in cells with , it is possible to consider a scenario where . This scenario allows the BS to temporarily make orthogonal payload data pilot (PDP) signals available to all active UEs during payload data transmission by employing a grant-based RA protocol.
Let denote the set of inactive UEs with cardinality in cell . The channel vector between BS and UE k is denoted by . The channel follows a complex Gaussian distribution , where is the large-scale fading coefficient, obtained as in [16]. The BS makes available a number of orthogonal RA pilot signals , where satisfies , . The available pilots are then shared by the inactive UEs. A particular UE that wants to become active firstly randomly chooses one pilot out of the RA pilot signals available and then makes an access attempt by transmitting with power , with . The UEs choosing the pilot are represented in the set , whose cardinality corresponds to the number of UEs contending for such a pilot, and follows a binomial distribution [16]:
Given this system model, in order to employ the SUCRe protocol, four steps are necessary, as illustrated in Figure 1.
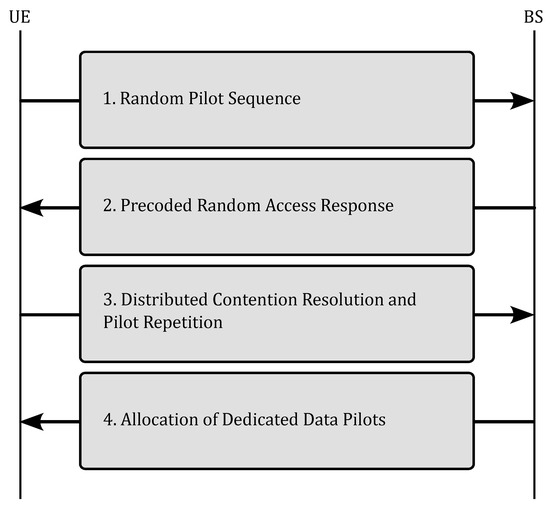
Figure 1.
SUCRe protocol diagram for crowded M-MIMO networks.
(i) Random pilot sequence: The first step of the SUCRe protocol consists of the UEs sending pilot sequences to the BS, which receives the signal from the sent pilots:
where is the noise matrix at the BS’s side. Each element of the noise matrix follows , with being the noise variance. represents the interference signals received by the BS from the adjacent cells, and is the transpose operation. The signal is then correlated with at the BS:
where represents the effective noise and has the distribution , with representing the conjugate operation.
(ii) Precoded random access: The second step involves the BS responding to all UEs that transmitted pilot signals by sending a precoded signal :
in which q is the BS transmit power per pilot. The k-th UE then receives the signal :
where is the inter-cell interference (ICI), and is noise, which follows . Next, the UE correlates with its chosen pilot , resulting in
where . We define as the sum of the signal strengths and inter-cell interference received by the BS during the first step of the protocol for each pilot t in (3) as
Then, as proposed in [16], the value of can be estimated at the k-th UE by :
where is the gamma function, and returns the real part of a complex number.
(iii) Distributed contention resolution and pilot repetition: In the third step, it is assumed that the k-th UE is aware of its average channel gain . Using this information along with the estimated value , the UE decides whether to retransmit the pilot signal or not. The primary aim of the SUCRe protocol is to allow only one UE (the strongest one) to retransmit the pilot signal at this step and establish a connection with the network to transmit payload data. Retransmission of the pilot signal occurs when the hypothesis test is true [16], and the pilot signal is not retransmitted when is true:
where is a bias parameter. It is worth noting that (9) and (10) mean that the UE only retransmits when its own signal strength is larger than half of the contending UEs’ signal strengths, which is a sufficient but not necessary condition for being the strongest contender [17]. In addition, the bias parameter can be calibrated to adjust the system behavior; for instance, to maximize the average number of resolved collisions, to minimize the occurrence of false positives (or negatives), or to ensure that at most one UE will transmit the pilot in the third step of the SUCRe protocol when for all k [16]. A suitable value of is proposed as in [16], where the factor multiplies the standard deviations of centered around its mean value and is the average UL interference, assumed to be known at the UE [16,17]. It is given by , where the expectation is computed with respect to user locations and shadow-fading realizations. The bias term’s influence on performance is also further investigated in [16].
(iv) Allocation of dedicated data pilots: In the fourth step, all UEs that successfully retransmitted their pilots (without collision in the third step) are granted access to exclusive network resources to become active and transmit payload data [28].
2.2. Neural Network Classifier
One of the most relevant features of artificial NNs is their capability to learn from the input data samples that express the system’s behavior. Hence, after the network has learned the relationship between inputs and outputs in a supervised way, it can generalize solutions, meaning that the network can produce an output close to the expected (or desired) output of any given input value.
This section presents a new approach to tackle the random access problem in crowded M-MIMO networks using an NN classifier specifically designed to resolve pilot collisions under the “strongest-user criterion”. To accomplish this, users are classified into two classes: for those who are not the strongest contenders for their selected pilots, and for the strongest users. The set of classes is defined as . Each user’s state k is denoted as and belongs to . To approximate the true class of each user, an MLP NN estimates a function that maps input values and to the state of the k-th UE. In essence, the objective is to obtain an approximation that accurately represents the UE’s true class. Furthermore, as the NN algorithm is evaluated on the devices’ side, we seek here the simplest NN topology able to achieve the desired performance improvements.
The steps to implement this method are the following: (a) database acquisition, (b) preprocessing, (c) neural network training, and (d) validation.
2.2.1. Database Acquisition
The first step is to acquire the NN’s training data. The database is generated from the simulation setup publicly shared by the authors of [16], where the values of , and their respective actual states , which serve as labels, are collected.
The numerical parameters for data collection in the SUCRe protocol simulation are shown in Table 1. In this work, we collected nearly labeled training data from the numerical simulation setup with different channel and system scenarios.

Table 1.
Numerical parameters for data collection in SUCRe protocol simulation.
2.2.2. Preprocessing
In the preprocessing step, the data are prepared for being used as input for the NN. This step, which includes data shuffling and normalization, is essential for ensuring the proper functioning of an NN. The data shuffling prevents overfitting, and normalization is important to ensure all input data have the same scale and fall within the range of the chosen activation function.
Given the skewed nature (the skewed nature of the data comes from the fact that the dataset has a number of data items labeled much larger than the ones labeled ) of the collected dataset (primary dataset), the input values are randomly shuffled using the MATLAB function randperm to ensure that a subset of the primary dataset with a sufficiently large number of elements will have members of both classes in a proportion near or equal to the one of the primary dataset. Next, data samples are taken from the shuffled dataset, from which are separated for the training set and for the validation set . Then, the input values and of both the training and validation data are normalized according to
and
The normalization procedures mathematically described above are divided into two steps. First, the natural logarithm of the input data is taken to smooth large numerical discrepancies (above six orders of magnitude) among the input data, improving the data resolution. Next, the resulting values are normalized to fit within the closed interval , matching the output range of the activation function in (16). Finally, both input values are grouped into a vector , where an input bias b is also appended:
2.2.3. Neural Network Training
The training process of an NN consists of applying the required ordinate steps for tuning the synaptic weights and thresholds of its neurons to generalize the solutions produced by its outputs. In the proposed method, the normalized data, , and the desired output value associated with each training sample are used as training data for an MLP NN with one hidden layer, as illustrated in Figure 2. It is noteworthy that our choice for a simple MLP NN with only one hidden layer is motivated by the fact that such an algorithm is carried out at the devices. Therefore, it is interesting to use the less complex scheme able to achieve the desired performance improvements.
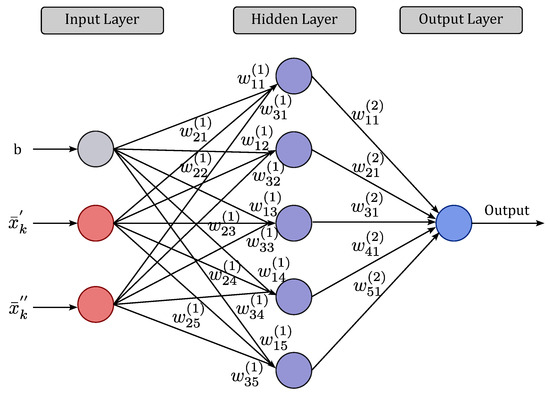
Figure 2.
MLP NN with one hidden layer, where is the synaptic weight between the i-th neuron of layer l and j-th neuron of layer .
The MLP NN consists of a set of linear combiners, called neurons, that control scalar product operations between input vectors, and sometimes an input bias b, with synaptic weights to generate a result by applying a given activation function. The input bias b counts as an additional input term for the hidden layer’s neurons. The training is carried out through the well-known backpropagation algorithm [29], which updates the set of weight matrices , the weight matrix between the input layer with neurons and the hidden layer with neurons, and , the weight matrix between the hidden layer with length neurons and output layer with neurons. Given a learning rate , the backpropagation algorithm proceeds iteratively by minimizing the mean square error (MSE) function between the desired outputs and the actual output at each i-th training epoch:
where is the MSE value at the i-th training epoch. The training is considered complete when a given precision value in consecutive training epochs, is achieved. Once trained, the MLP NN can be used to estimate the function as:
where is the activation sigmoid function:
Finally, the output is associated to one of the output classes in . Thus, forming the estimator :
2.2.4. Validation
Validation is a crucial step in demonstrating the ability of an NN to generalize its results over data that were not used during the training process. The validation in this work aims to support the choice of the architecture, topology, and the adopted hyperparameter values of the proposed NN binary classifier. The performance metrics recall, precision, F-measure, and accuracy are evaluated using the set of data reserved for testing.
The recall metric measures the proportion of actual instances of that were correctly classified as . Precision indicates the ratio of predictions that were actually to the total number of predictions. The F-measure is the harmonic mean of precision and recall, calculated as . Finally, accuracy represents the proportion of correct predictions made by the MLP NN over all predictions. The results in Table 2 and Table 3 are based on the classification of data generated from a simulation scenario with ICI. These tables show the NN binary classifier performance for different numbers of neurons in the hidden layer and different learning rates .
Table 2.
Number of neurons test.
Table 3.
Learning rate test.
In Table 2, the number of neurons in the hidden layer increases from 3 to 10 while the learning rate is fixed as and the precision is set to . The bias term is set to . It is noteworthy from Table 2 that there is no significant change in performance when varying from 3 to 10. Also, there is no indication of an increase in the overall accuracy metric. Nonetheless, there is a slight performance increase in the recall and the F-measure metrics. The F-measure is an important metric of performance for skewed data classification since it indicates that the precision and recall metrics are balanced out.
The learning rate in Table 3 ranges from to , with the hyperparameter fixed at 5, at and . As increases, the recall drops from to , but precision improves slightly from to . Despite these changes, the accuracy and F-measure do not present significant changes.
Figure 3 shows the convergence of the MSE function to its minimum value with the training parameters set to , , , and . The training is set up to stop when one of the two conditions occurs. The first stopping criterion is reached when the required precision value attains , and the second one is completed when a predetermined number of training epochs is attained, which is set to 1000. In Figure 3, the maximum number of epochs is achieved first, which stops the training at 1000 epochs of training. The MSE value achieved is , with a precision below .
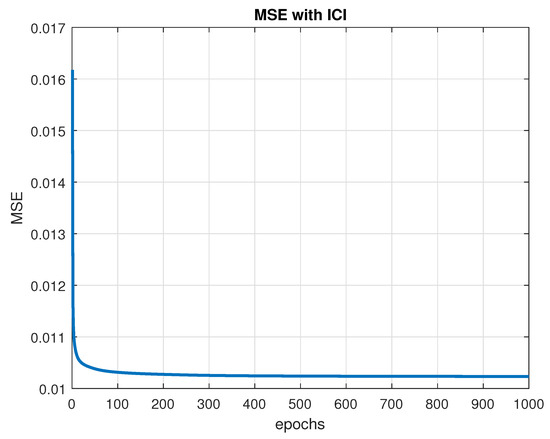
Figure 3.
MSE convergence with ICI.
In the following section, we evaluate the performance of our proposed NN-based RA protocol employing an MLP NN binary classifier with neuron in the output layer, neurons in the input layer, and neurons in the hidden layer. The NN is trained with the backpropagation algorithm with a learning rate . Two main training runs are carried out, the first with data collected in a scenario with ICI and the second with data collected in a scenario without ICI, yielding as the final result of the training process four weight matrices, two of them for the NN trained in the scenario with ICI and two of them for the NN trained in the scenario without ICI. The and values are chosen empirically among the tested values since their performance metrics do not show any significant difference. The value of is also kept relatively low, at 5, because adding more neurons to the NN introduces more complexity, making the algorithm computationally costly. For the same reason, a second hidden layer is not introduced. The bias term, b, is set to , similar to in [29].
3. Results and Discussion
In this section, we report the results of our proposed NN-based RA method applied in an overcrowded M-MIMO scenario, similar to that of [16,17,20,21]. Our outcomes are presented in terms of confusion matrices, ANAAs, FFAAs, latencies, and throughputs. Our study focuses on a system that operates in the 5G sub-6 GHz band, where we consider a center cell named with a radius of 250 m [16,17,18,19,20,21,22,24,30]. To create a crowded access scenario, we vary the number of inactive UEs in from 100 to 30,000 in increments of 500. Although a broad range of values is evaluated, our main focus is on the overcrowded scenario because of the very high number of connections expected for B5G networks [1], and since it is a performance bottleneck of the investigated system. Moreover, we add six neighboring cells, where , each having a radius of 250 m and 10 active UEs. Unless specified otherwise, we adopt the parameters from Table 1 in the simulations. We first present the strongest-user classification accuracy of the schemes and then compare the RA performance of the protocols. Our motivation for the strongest-user retransmission criterion is that it will always have only one strongest user in a pilot collision, and our proposed method lets the user itself know if it is the strongest contender in a decentralized way without additional signaling overhead. In addition, since power control is not the focus of this paper, we assume for simplicity the same transmit power for all UEs, similar to in [16,17,18,21,24]. It is worth noting that this is a simple but challenging scenario, since a further elaborated power control mechanism can be employed to improve performance. For example, in [20], a power control mechanism is employed in the RA protocol to provide the same performance for all UEs independent of their distance to the BS at the expense of decreasing the performance of the closest UEs and enhancing the transmit power of the farthest ones to compensate for their severe path loss. Furthermore, we have assumed a transmit power per UE of 27 dBm, which is equal to the BS transmit power per pilot, i.e., , as in [16,17,18,19,20,21,22,24].
3.1. Classification Performance
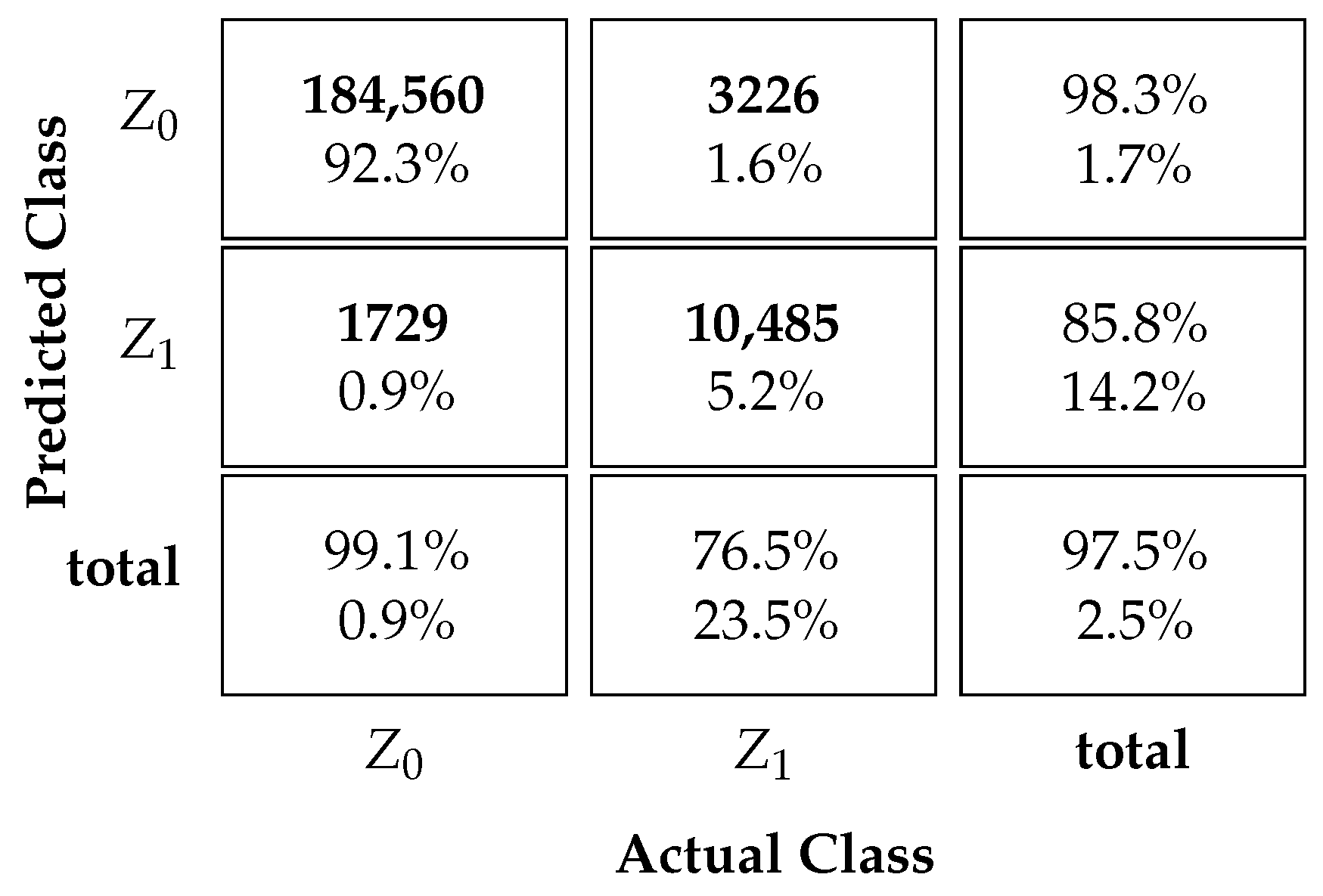
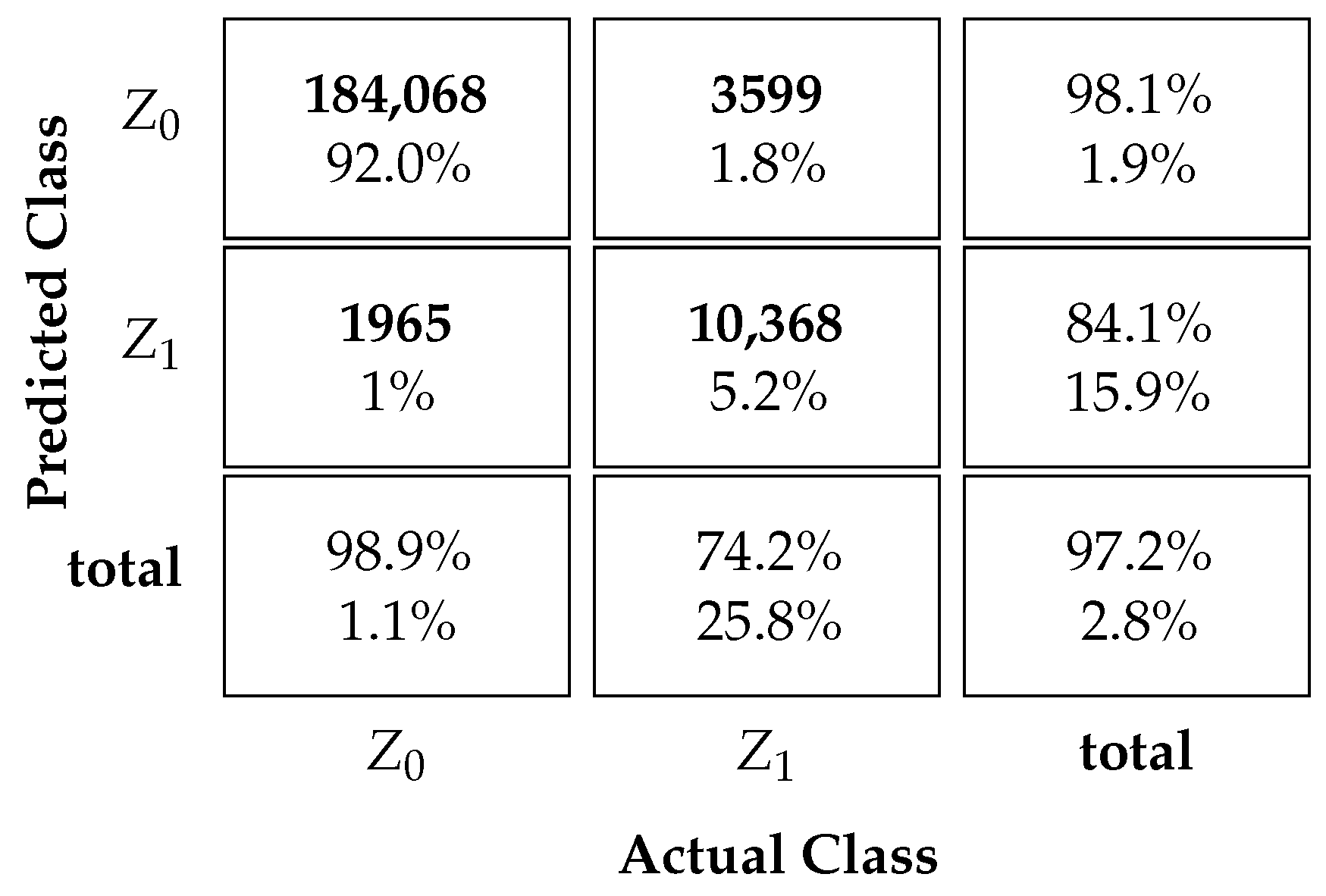
Table 4 and Table 5 display the proposed MLP NN-based protocol classification performance. The tables depict the confusion matrices for scenarios with and without ICI. The successful classification rates for each state are shown in the bottom row of the matrix. Additionally, the third column on the far right of the matrix indicates the precision of the predictions for . This represents the classifier’s accuracy for each output class or . The overall accuracy of the classifier is shown in the bottom right square of the matrix.
Table 4.
NN classifier without ICI.
Table 5.
NN classifier with ICI.
Table 4 presents the results of the proposed MLP NN-based classifier for a scenario without ICI. The table reveals that the successful classification rate of UEs belonging to class is 99.1%, while the successful classification rate among UEs is 76.5%. It is noteworthy that successful classification rates for are usually higher than for . This occurs because when the UE looks at the sum of the contending UEs’ signal strengths and its own signal strength, its decision is usually negatively biased. For example, with SUCRe, the UE only decides positively if its own signal gain is higher than half of the sum of the contending UEs’ signal strengths, which is a sufficient but not necessary condition, leading to high false negative rates. Our proposed NN classifier, on the other hand, improves the classification performance even for the UEs. These rates are higher than those achieved by the SUCRe protocol, 41.7%, and the BC method, 74.8%, as shown in [17]. Moreover, the precision of the and classifications are 98.3% and 85.8%, respectively. The overall accuracy of successful classifications is 97.5%, which is also higher than the values achieved by the SUCRe protocol and the BC method, which are 96% and 97.3%, respectively, in a scenario without ICI [17].
Table 5 presents the results for a scenario with ICI. The reported results indicate that the classification precision is for and for outputs. Furthermore, in the scenario with ICI, our method achieves a correct prediction rate of for class UEs and for class UEs. Overall, our method achieves an accuracy of in the scenario with ICI, superior to the SUCRe protocol and the BC method.
3.2. Connectivity Performance
Figure 4 and Figure 5 depict the numerical results of the ANAAs and FFAAs metrics, respectively, for the following algorithms: (a) The baseline, an ALOHA-based protocol described in [16], is represented by a black line and uses a technique where pilot collisions are exclusively addressed by retransmitting them in later RA blocks. (b) The results obtained from the original SUCRe protocol, as demonstrated in [16], are represented by red lines marked with “ ∘”. (c) The results of the ACBPC protocol [20] are represented by the cyan lines marked with the symbol “▹”. (d) The green lines marked with “x” indicate the results obtained with the softSUCRe protocol [21]. (e) The outcomes obtained from the BC method presented in [17] are indicated by the magenta lines marked with “⋄”. (f) Finally, the blue lines with the “□” marker indicate the MLP NN-based methodology proposed in this paper. The dotted lines show the results obtained for the cases without ICI, while the continuous lines refer to the results with ICI.
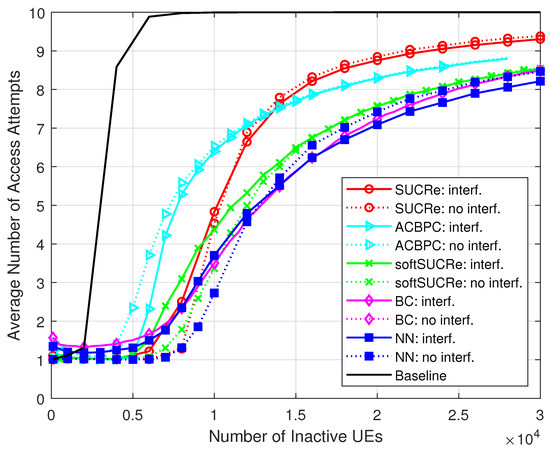
Figure 4.
ANAAs , for , , , and 0 dB of edge signal-to-noise ratio (SNR).
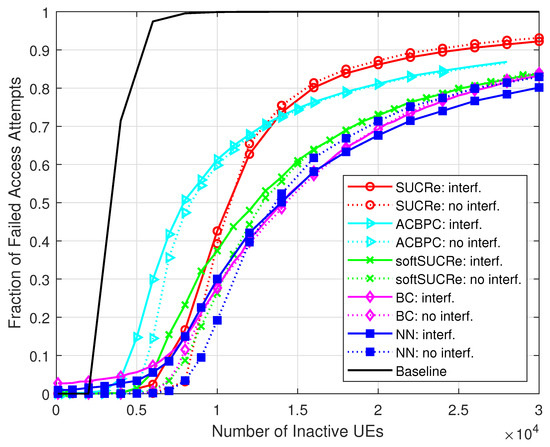
Figure 5.
FFAAs , for , , , and 0 dB of edge SNR.
The superiority of the proposed method is noteworthy. Comparing the FFAAs results with those of the BC method, for example, the proposed MLP NN-based method achieves better performance when inactive UEs in the cases with ICI, as highlighted in Figure 6, where varies from up to inactive users with probability of activation in a grant-based network operating under pilot sequences. For example, the proposed NN RA protocol reduces the FFAAs in comparison with the BC method with UEs in the ICI scenario. The proposed NN-based RA protocol also outperforms the BC method in the scenario without ICI, although with a less visible performance gain.
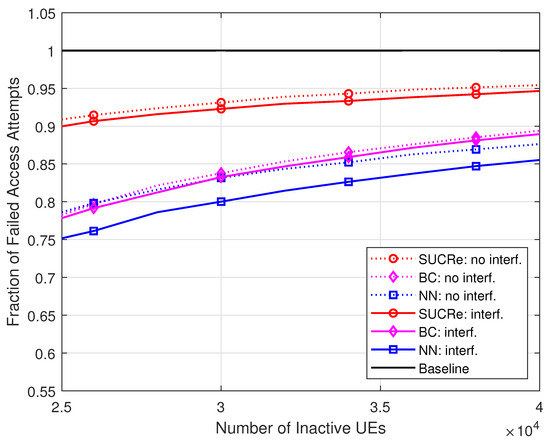
Figure 6.
FFAAs , for , , , 0 dB of edge SNR, and .
Figure 7 shows the FFAAs results when the number of BS antennas varies from to in steps of 2. Even though the NN-based method is trained with antennas, the proposed method shows robustness under the variation in the number of BS antennas M, where a number of antennas is revealed to be sufficient to provide superior results than the SUCRe and BC methods in the scenarios with or without ICI.
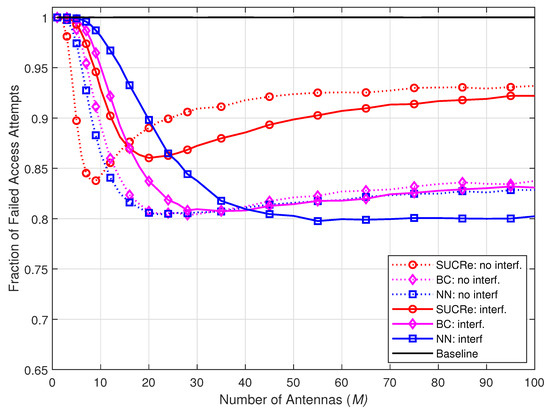
Figure 7.
FFAAs performance with M variation, considering , , , and 0 dB of edge SNR.
In Figure 8, we present the performance results with edge variations in dB (), defined as and , with being the large-scale fading of a UE at the cell edge without shadowing and , varying from dB to dB. The The FFAAs results are taken for a fixed number of antennas and UEs. One can see that the performance of the NN-based method, in both scenarios with and without ICI, is superior to the performance of the SUCRe protocol in the whole considered edge SNR range. Compared to the BC method, the proposed NN-based method presents a superior performance in the ICI scenario from ≈−6 dB to ≈+6 dB, and in the cases without ICI, from 0 dB to 8 dB. In addition, although FFAAs results are shown in Figure 7 and Figure 8, it is worth noting that the ANAAs results present a similar behavior, as can be seen from Figure 4 and Figure 5.
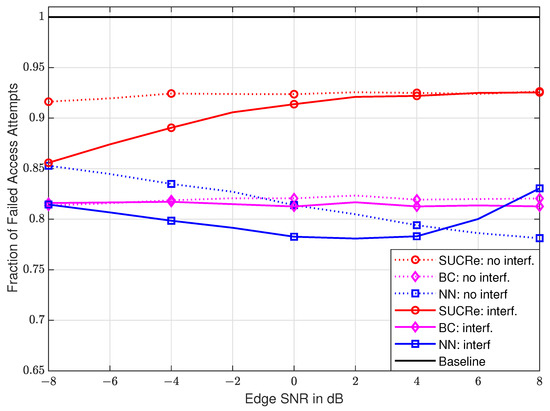
Figure 8.
FFAAs performance with edge SNR variation in dB, considering and .
In Figure 9, we evaluate the performance of the investigated schemes in terms of average throughput, defined as the number of UEs succeeding in a given RA opportunity divided by the number of RA pilots, . As one can see, the proposed NN RA protocol achieves the highest average throughput in the case without ICI, achieving a throughput of with UEs. On the other hand, in the case of ICI, the proposed method achieves the best average throughput with a high number of UEs, i.e., with UEs. One can see that the throughput performance of the NN RA protocol in this scenario saturates with ≈0.577, indicating that this ratio of pilot sequences is effectively used in the RA stage independent of the number of UEs. In addition, the proposed method outperforms the state-of-the-art BC protocol in most parts of the values.
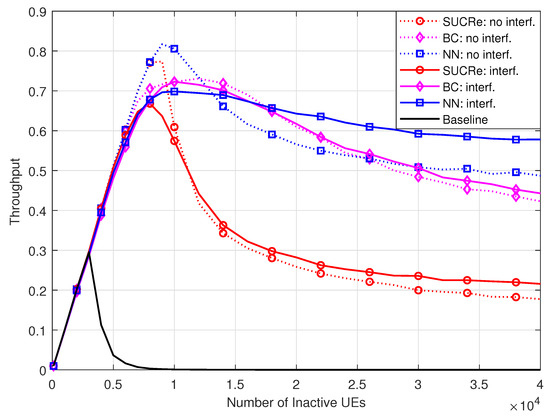
Figure 9.
Throughput , for , , , and 0 dB of edge SNR.
Figure 10 depicts the average latency performance of the investigated methods, defined as the average time that a UE stays in the RA procedure, i.e., between wanting to become active until succeeding or failing in the RA stage. For this simulation, we have assumed that each RA opportunity takes 1 ms, in the same way as in [24], and that after the first attempt, the UEs decide to try again in each RA opportunity with probability 0.5 [16,17,20,21]. In general, the curves maintain the same shapes as the ones in Figure 4, but scaled by two since, on average, the UEs make an attempt at each two RA opportunities. One can see that the proposed NN RA protocol usually achieves the lowest latencies, allowing the UEs to carry out the RA stage in 12 ms for UEs in the ICI scenario.
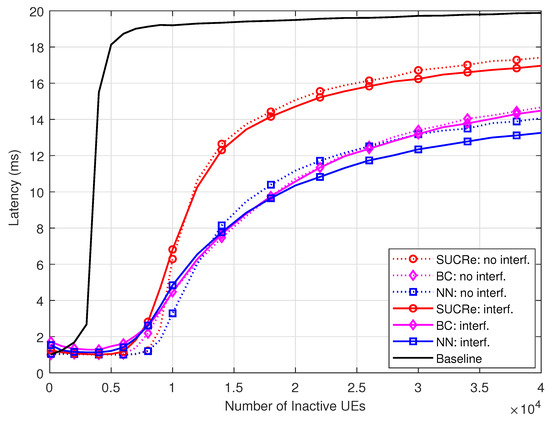
Figure 10.
Latency , for , , , and 0 dB of edge SNR.
In addition, to evaluate how the users’ performance depends on their distance to the BS, Figure 11 presents the FFAAs according to the users’ distance to the BS. As one can see, the proposed NN-based RA protocol remarkably improves the performance of the closest UEs, while the performance of the users farther than ≈152 m from the BS becomes nearly the same as the softSUCRe and BC methods and slightly better than the SUCRe performance. On the other hand, the ACBPC protocol of [20] applies UL power control to provide an equal performance for all users, independent of their distance from the BS, and thus provides slightly better performance to the users close to the cell edge. The price to pay for this is significantly decreasing the performance of the closest UEs and increasing the transmit power of the farthest ones to compensate for the severe path loss. It is worth noting that we do not exploit UL power control in the proposed protocol, while assuming a constant UL transmit power for all UEs for simplicity purposes. Nevertheless, if improving the performance of the farthest UEs is an important objective, one can combine a UL power control policy with the proposed protocol, similar to in [20]. However, this is outside the scope of this paper but is suggested as a promising topic for future works.
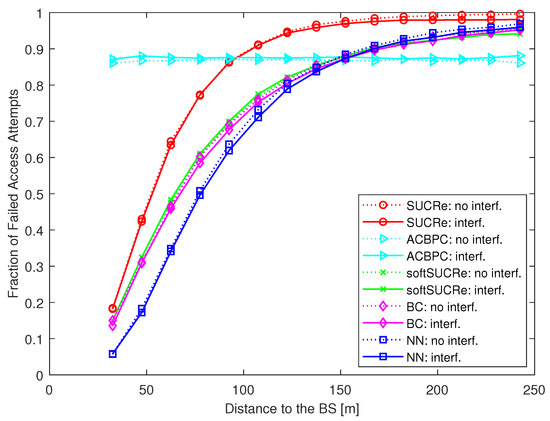
Figure 11.
FFAAs according to the users’ distance to the BS, for , , , , and 0 dB of edge SNR.
Finally, it is worth highlighting some insights about the energy consumption during the RA stage. Since the transmit powers are the same for all the investigated schemes, as well as the intervals of each protocol step, we can assume the same energy expenditure per RA attempt for all RA protocols. Therefore, the overall energy expenditure in the RA stage is proportional to the ANAAs, as depicted in Figure 4. One can thus see that the proposed NN RA protocol is the most energy efficient in the scenario without ICI, and in the ICI scenario with UEs. In the latter scenario, the proposed method achieves a ≈24% energy reduction compared with SUCRe, and ≈7% compared to the BC protocol with UEs. Consequently, the proposed approach demonstrates itself as a viable GB RA protocol option for B5G systems, outperforming the state-of-the-art BC protocol in the most relevant investigated scenarios.
4. Conclusions
In this work, we have proposed a GB RA protocol for crowded M-MIMO systems by implementing an NN on the UEs side to allow their classification under the strongest-user criterion, thus resolving pilot collisions in a non-centralized manner. Based on extensive numerical results, it is possible to conclude that the proposed NN-based method achieves significantly superior performance in comparison with the SUCRe protocol for both scenarios with or without inter-cell interference and without the necessity of extra overhead. We have shown how the proposed method is superior to other state-of-the-art protocols, especially in an overcrowded scenario, i.e., (in scenarios with and ). Finally, we have also evaluated the robustness of our proposed approach concerning the number of BS antennas and transmit power levels, as well as throughput, latency, and energy efficiency performances. Our results demonstrate that our method is a promising solution for implementing a GB RA protocol in crowded B5G systems.
Author Contributions
Conceptualization, F.A.D.B., P.R.S. and T.A.; data curation, F.A.D.B. and C.F.Y.; funding acquisition, T.A.; investigation, F.A.D.B. and C.F.Y.; methodology, C.F.Y., P.R.S., T.A. and J.C.M.; project administration, J.C.M.; software, F.A.D.B. and J.C.M.; supervision, J.C.M.; validation, C.F.Y., P.R.S. and T.A.; visualization, C.F.Y. and P.R.S.; writing—original draft, F.A.D.B.; writing—review and editing, P.R.S., T.A. and J.C.M. All authors have read and agreed to the published version of the manuscript.
Funding
This work was partly supported by the National Council for Scientific and Technological Development (CNPq) of Brazil under Grants 405301/2021-9 and 405760/2021-3.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
All test data mentioned in this paper will be made available on request to the corresponding author’s email with appropriate justification.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| 5G | Fifth-generation |
| UE | User equipment |
| RA | Random access |
| SUCRe | Strongest-user collision resolution |
| BS | Base station |
| NN | Neural network |
| B5G | Beyond fifth-generation |
| eMBB | Enhanced mobile broadband |
| M-MIMO | Massive multiple-input multiple-output |
| CF | Cell-free |
| GF | Grant-free |
| GB | Grant-based |
| DL | Downlink |
| UL | Uplink |
| ACB | Access class barrier |
| ACBPC | Access class barring with power control |
| XL-MIMO | Extra-large MIMO |
| BC | Bayesian classifier |
| NN | Neural network |
| MLP | Multilayer perceptron |
| FFAAs | Fraction of failed access attempts |
| ANAAs | Average number of access attempts |
| TDD | Time-division duplex |
| PDP | Payload data pilot |
| ICI | Inter-cell interference |
| MSE | Mean square error |
| SNR | Signal-to-noise ratio |
References
- Chen, X.; Ng, D.W.K.; Yu, W.; Larsson, E.G.; Al-Dhahir, N.; Schober, R. Massive Access for 5G and Beyond. IEEE J. Sel. Areas Commun. 2021, 39, 615–637. [Google Scholar] [CrossRef]
- Marzetta, T.L. Noncooperative Cellular Wireless with Unlimited Numbers of Base Station Antennas. IEEE Trans. Wirel. Commun. 2010, 9, 3590–3600. [Google Scholar] [CrossRef]
- Parkvall, S.; Dahlman, E.; Furuskar, A.; Frenne, M. NR: The New 5G Radio Access Technology. IEEE Commun. Stand. Mag. 2017, 1, 24–30. [Google Scholar] [CrossRef]
- Hoydis, J.; ten Brink, S.; Debbah, M. Massive MIMO in the UL/DL of Cellular Networks: How Many Antennas Do We Need? IEEE J. Sel. Areas Commun. 2013, 31, 160–171. [Google Scholar] [CrossRef]
- Rusek, F.; Persson, D.; Lau, B.K.; Larsson, E.G.; Marzetta, T.L.; Edfors, O.; Tufvesson, F. Scaling Up MIMO: Opportunities and Challenges with Very Large Arrays. IEEE Signal Process. Mag. 2013, 30, 40–60. [Google Scholar] [CrossRef]
- Larsson, E.G.; Edfors, O.; Tufvesson, F.; Marzetta, T.L. Massive MIMO for next generation wireless systems. IEEE Commun. Mag. 2014, 52, 186–195. [Google Scholar] [CrossRef]
- Lu, L.; Li, G.Y.; Swindlehurst, A.L.; Ashikhmin, A.; Zhang, R. An Overview of Massive MIMO: Benefits and Challenges. IEEE J. Sel. Top. Signal Process. 2014, 8, 742–758. [Google Scholar] [CrossRef]
- Björnson, E.; Sanguinetti, L.; Hoydis, J.; Debbah, M. Optimal Design of Energy-Efficient Multi-User MIMO Systems: Is Massive MIMO the Answer? IEEE Trans. Wirel. Commun. 2015, 14, 3059–3075. [Google Scholar] [CrossRef]
- Björnson, E.; Larsson, E.G.; Marzetta, T.L. Massive MIMO: Ten myths and one critical question. IEEE Commun. Mag. 2016, 54, 114–123. [Google Scholar] [CrossRef]
- Fernandes, F.; Ashikhmin, A.; Marzetta, T.L. Inter-Cell Interference in Noncooperative TDD Large Scale Antenna Systems. IEEE J. Sel. Areas Commun. 2013, 31, 192–201. [Google Scholar] [CrossRef]
- Jin, S.; Wang, X.; Li, Z.; Wong, K.K.; Huang, Y.; Tang, X. On Massive MIMO Zero-Forcing Transceiver Using Time-Shifted Pilots. IEEE Trans. Veh. Technol. 2016, 65, 59–74. [Google Scholar] [CrossRef]
- Van Chien, T.; Björnson, E.; Larsson, E.G. Joint Pilot Design and Uplink Power Allocation in Multi-Cell Massive MIMO Systems. IEEE Trans. Wirel. Commun. 2018, 17, 2000–2015. [Google Scholar] [CrossRef]
- Xu, H.; Huang, N.; Yang, Z.; Shi, J.; Wu, B.; Chen, M. Pilot Allocation and Power Control in D2D Underlay Massive MIMO Systems. IEEE Commun. Lett. 2017, 21, 112–115. [Google Scholar] [CrossRef]
- Zhu, X.; Wang, Z.; Dai, L.; Qian, C. Smart Pilot Assignment for Massive MIMO. IEEE Commun. Lett. 2015, 19, 1644–1647. [Google Scholar] [CrossRef]
- Polegre, A.A.; Sanguinetti, L.; Armada, A.G. Pilot Decontamination Processing in Cell-Free Massive MIMO. IEEE Commun. Lett. 2021, 25, 3990–3994. [Google Scholar] [CrossRef]
- Björnson, E.; de Carvalho, E.; Sørensen, J.H.; Larsson, E.G.; Popovski, P. A Random Access Protocol for Pilot Allocation in Crowded Massive MIMO Systems. IEEE Trans. Wirel. Commun. 2017, 16, 2220–2234. [Google Scholar] [CrossRef]
- Bueno, F.A.D.; Yamamura, C.F.; Goedtel, A.; Marinello Filho, J.C. A Random Access Protocol for Crowded Massive MIMO Systems Based on a Bayesian Classifier. IEEE Wirel. Commun. Lett. 2022, 11, 2455–2459. [Google Scholar] [CrossRef]
- Han, H.; Guo, X.; Li, Y. A High Throughput Pilot Allocation for M2M Communication in Crowded Massive MIMO Systems. IEEE Trans. Veh. Technol. 2017, 66, 9572–9576. [Google Scholar] [CrossRef]
- Han, H.; Li, Y.; Guo, X. A Graph-Based Random Access Protocol for Crowded Massive MIMO Systems. IEEE Trans. Wirel. Commun. 2017, 16, 7348–7361. [Google Scholar] [CrossRef]
- Marinello, J.C.; Abrão, T.; Souza, R.D.; de Carvalho, E.; Popovski, P. Achieving Fair Random Access Performance in Massive MIMO Crowded Machine-Type Networks. IEEE Wirel. Commun. Lett. 2020, 9, 503–507. [Google Scholar] [CrossRef]
- Marinello, J.C.; Abrão, T. Collision Resolution Protocol via Soft Decision Retransmission Criterion. IEEE Trans. Veh. Technol. 2019, 68, 4094–4097. [Google Scholar] [CrossRef]
- Han, H.; Li, Y.; Guo, X. User Identity-Aided Pilot Access Scheme for Massive MIMO-IDMA System. IEEE Trans. Veh. Technol. 2019, 68, 6197–6201. [Google Scholar] [CrossRef]
- Han, H.; Fang, L.; Lu, W.; Chi, K.; Zhai, W.; Zhao, J. A Novel Grant-Based Pilot Access Scheme for Crowded Massive MIMO Systems. IEEE Trans. Veh. Technol. 2021, 70, 11111–11115. [Google Scholar] [CrossRef]
- Marinello Filho, J.C.; Brante, G.; Souza, R.D.; Abrão, T. Exploring the Non-Overlapping Visibility Regions in XL-MIMO Random Access and Scheduling. IEEE Trans. Wirel. Commun. 2022, 21, 6597–6610. [Google Scholar] [CrossRef]
- Iimori, H.; Takahashi, T.; Ishibashi, K.; de Abreu, G.T.F.; González G., D.; Gonsa, O. Joint Activity and Channel Estimation for Extra-Large MIMO Systems. IEEE Trans. Wirel. Commun. 2022, 21, 7253–7270. [Google Scholar] [CrossRef]
- Tao, J.; Chen, J.; Xing, J.; Fu, S.; Xie, J. Autoencoder Neural Network Based Intelligent Hybrid Beamforming Design for mmWave Massive MIMO Systems. IEEE Trans. Cogn. Commun. Netw. 2020, 6, 1019–1030. [Google Scholar] [CrossRef]
- Yang, P.; Zhu, J.; Xiao, Y.; Chen, Z. Antenna selection for MIMO system based on pattern recognition. Digit. Commun. Networks 2019, 5, 34–39. [Google Scholar] [CrossRef]
- 3GPP TS 38.321-1; Medium Access Control (MAC) Protocol Specification (Release 16). ETSI: Sophia Antipolis, France, 2020; 3rd Generation Partnership Project (3GPP); Version 16.1.0.
- da Silva, I.; Spatti, D.; Flauzino, R.; Liboni, L.; dos Reis Alves, S. Artificial Neural Networks: A Practical Course; Springer International Publishing: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- 3GPP TR 38.901; Study on Channel Model for Frequencies from 0.5 to 100 GHz. ETSI: Sophia Antipolis, France, 2020; 3rd Generation Partnership Project (3GPP); Version 16.1.0.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).