
A Multi-Angle Appearance-Based Approach for Vehicle Type and Brand Recognition Utilizing Faster Regional Convolution Neural Networks
Abstract
:1. Introduction
2. Data Construction
2.1. Data Construction
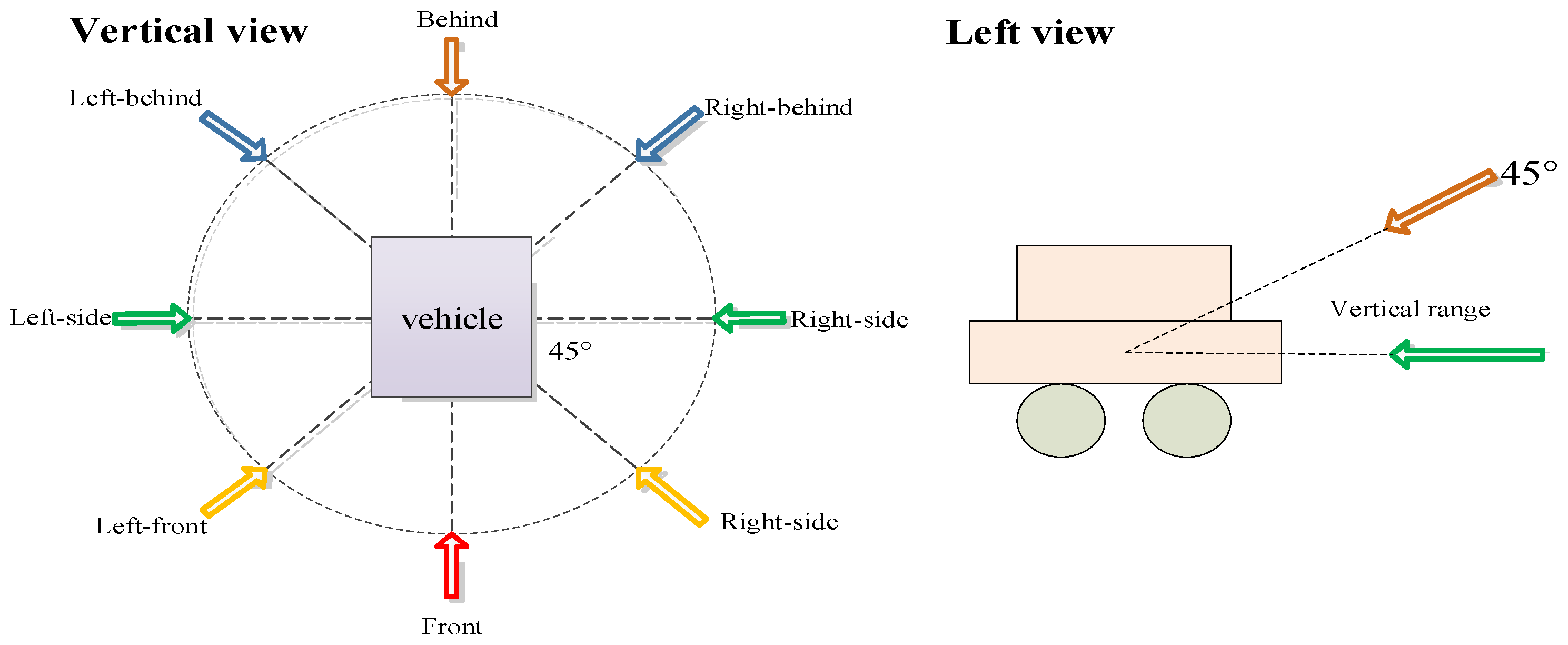
2.2. Data Annotation and Statistic
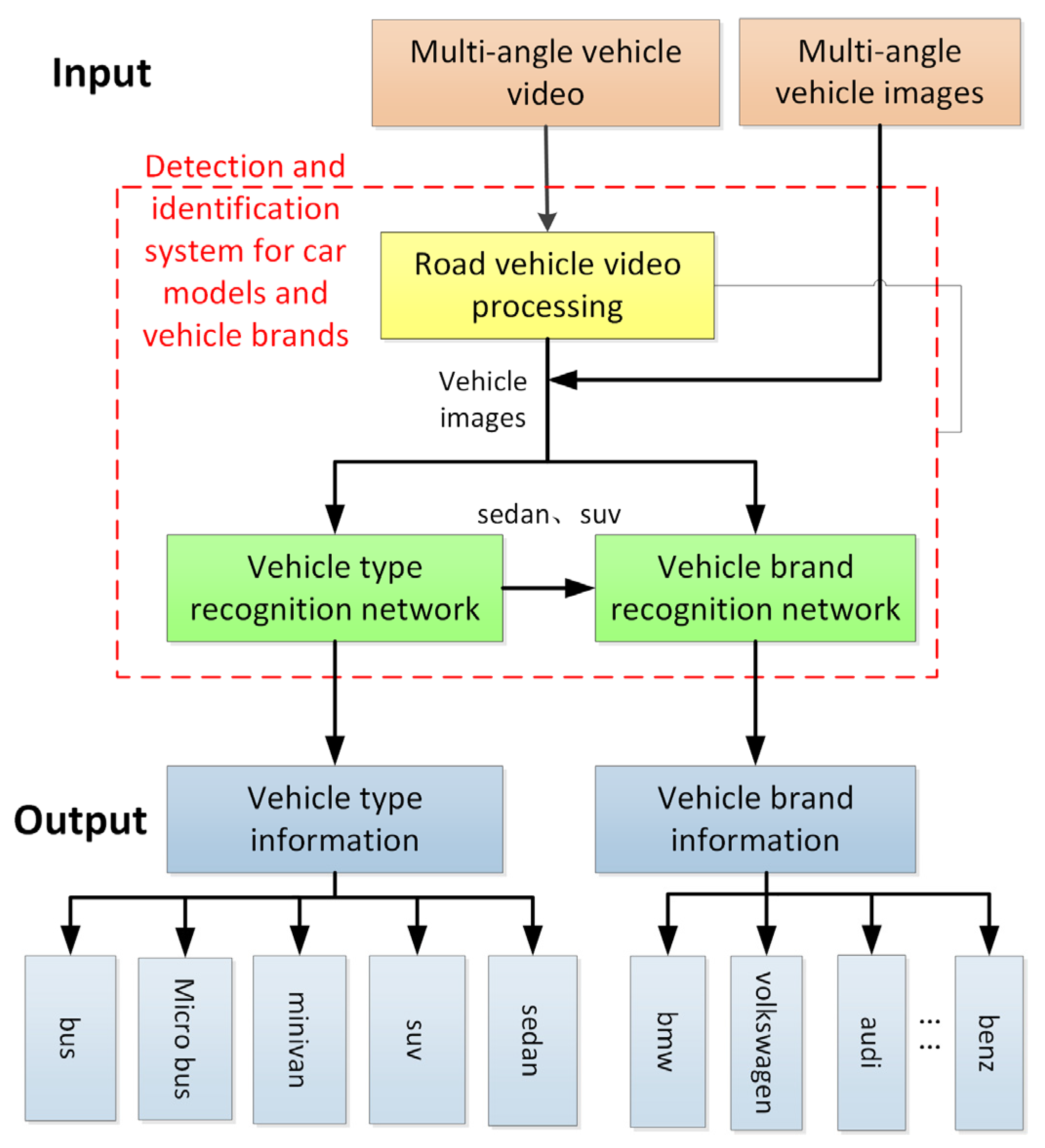
3. Vehicle Information Recognition Model
3.1. Video Processing Model
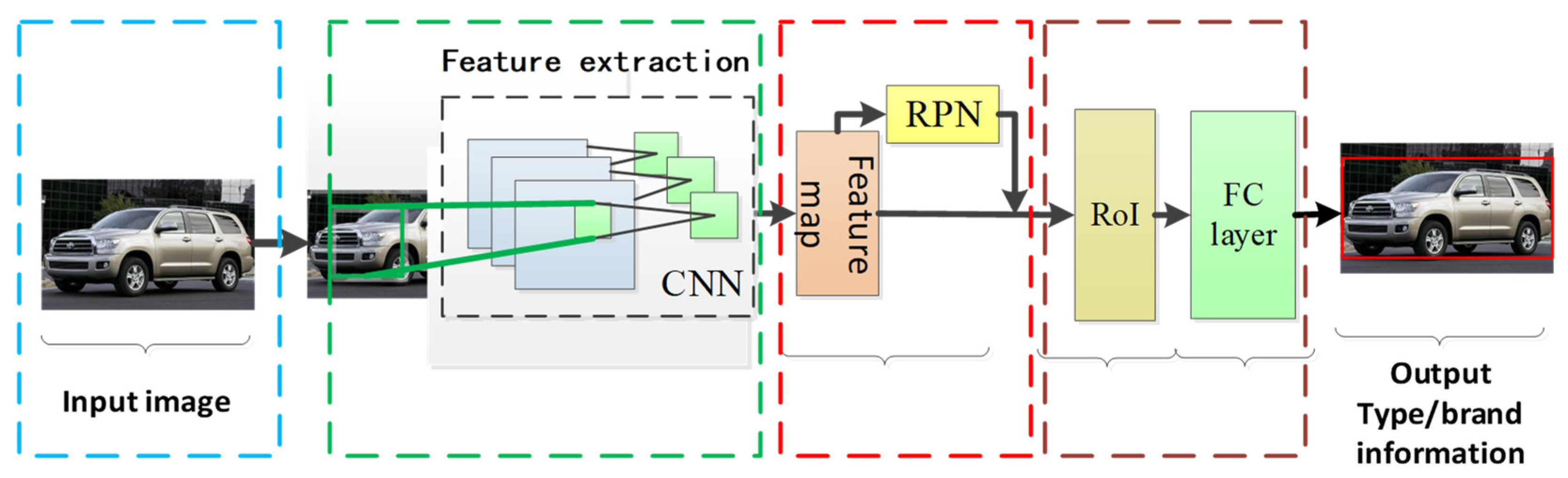
3.2. Vehicle Type and Brand Recognition Network
3.2.1. Network
3.2.2. Proposal Region Generation
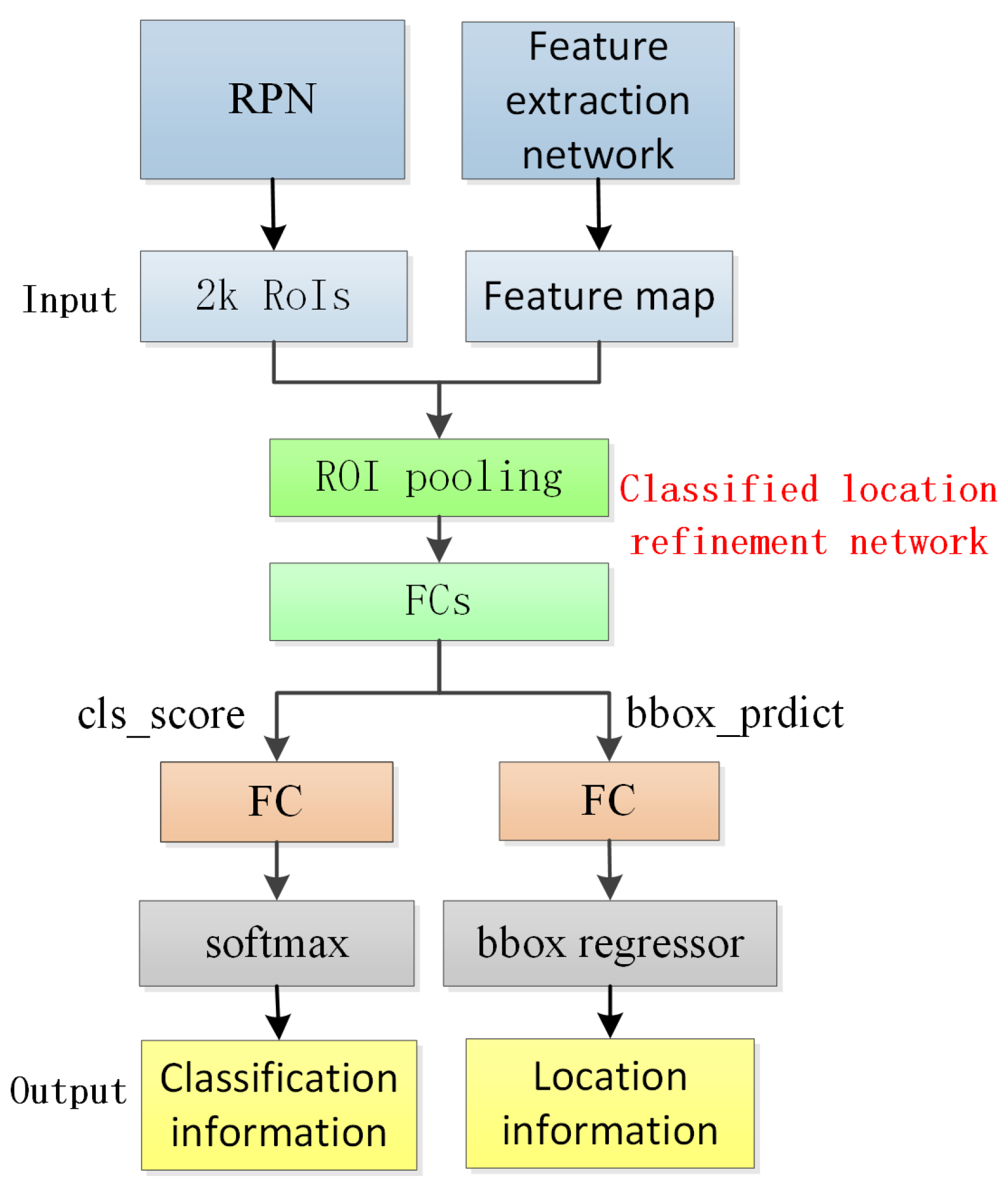
3.3. Classification Location Refinement Network
3.3.1. Classification Layer
3.3.2. Position Refinement Layer
4. Experimental Results Analysis
4.1. Experimental Results
4.2. Comparison of Single-Angle and Multi-Angle Models
4.3. Vehicle Type Recognition Results
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhou, H.; Yuan, Y.; Shi, C. Object tracking using SIFT features and mean shift. Comput. Vis. Image Underst. 2009, 113, 345–352. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; pp. 886–893. [Google Scholar] [CrossRef]
- Zhu, Q.; Yeh, M.-C.; Cheng, K.-T.; Avidan, S. Fast Human Detection Using a Cascade of Histograms of Oriented Gradients. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; Volume 2, pp. 1491–1498. [Google Scholar]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Bilik, S.; Horak, K. SIFT and SURF based feature extraction for the anomaly detection. arXiv 2022, arXiv:2203.13068. [Google Scholar]
- Rosten, E.; Drummond, T. Machine Learning for High-Speed Corner Detection. Comput. Vis. 2006, 3951, 430–443. [Google Scholar]
- Zhang, S.; Peng, Q.; Li, X.; Zhu, G.; Liao, J. A Multi-Features Fusion Method Based on Convolutional Neural Network for Vehicle Recognition. In Proceedings of the 2018 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation, Guangzhou, China, 8–12 October 2018; pp. 946–953. [Google Scholar]
- Zhang, H.; Li, H.; Ma, S.; Wang, F. Vehicle brand and model recognition based on discrete particle swarm optimization. Comput. Simul. 2016, 1, 177–180. [Google Scholar]
- Ouyang, W.; Wang, X. Joint Deep Learning for Pedestrian Detection. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2056–2063. [Google Scholar]
- LeCun, Y.; Kavukcuoglu, K.; Farabet, C. Convolutional networks and applications in vision. In Proceedings of the 2010 IEEE International Symposium on Circuits and Systems, Paris, France, 30 May–2 June 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 253–256. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Deng, J.; Krause, J.; Fei-Fei, L. Fine-Grained Crowdsourcing for Fine-Grained Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland OR, USA, 22–23 June 2013; pp. 580–587. [Google Scholar]
- Dong, Z.; Wu, Y.; Pei, M.; Jia, Y. Vehicle Type Classification Using a Semisupervised Convolutional Neural Network. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2247–2256. [Google Scholar] [CrossRef]
- Huttunen, H.; Yancheshmeh, F.S.; Chen, K. Car type recognition with Deep Neural Networks. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Gothenburg, Sweden, 19–22 June 2016; pp. 1115–1120. [Google Scholar]
- Azam, S.; Munir, F.; Rafique, M.A.; Sheri, A.M.; Hussain, M.I.; Jeon, M. N2C: Neural network controller design using be-havioral cloning. IEEE Trans. Intell. Transp. Syst. 2021, 22, 4744–4756. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, Z.; Xiao, F. A fast coarse-to-fine vehicle logo detection and recognition method. In Proceedings of the IEEE International Conference on Robotics and Biomimetics (ROBIO ’07), Sanya, China, 15–18 December 2007; pp. 691–696. [Google Scholar]
- Socher, R.; Lin, C.C.; Manning, C.; Ng, A.Y. Parsing natural scenes and natural language with recursive neural networks. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Bellevue, WA, USA, 28 June–2 July 2011; pp. 129–136. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015; Volume 28, pp. 91–99. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Network | Maximum Iterations | Accuracy of Partial Vehicle | mAP | ||||
|---|---|---|---|---|---|---|---|
| BMW | Benz | BYD | Nissan | Land Rover | |||
| ZFNet | 240,000 | 0.9035 | 0.8495 | 0.8757 | 0.8788 | 0.8559 | 0.8614 |
| ZFNet | 360,000 | 0.9296 | 0.8611 | 0.8905 | 0.8798 | 0.9037 | 0.9240 |
| VGG16 | 240,000 | 0.9561 | 0.8935 | 0.8950 | 0.8736 | 0.9434 | 0.9392 |
| VGG16 | 360,000 | 0.9552 | 0.9174 | 0.9075 | 0.8806 | 0.9470 | 0.9403 |
| Feature Network | Maximum Iterations | Accuracy | mAP | |||||
|---|---|---|---|---|---|---|---|---|
| Sedan | SUV | Bus | Minivan | Microbus | Truck | |||
| ZFNet | 240,000 | 0.9335 | 0.9128 | 0.9775 | 0.9258 | 0.9567 | 0.9810 | 0.9478 |
| ZFNet | 360,000 | 0.9407 | 0.9286 | 0.9856 | 0.9279 | 0.9537 | 0.9857 | 0.9612 |
| VGG16 | 240,000 | 0.9725 | 0.9432 | 0.9834 | 0.9707 | 0.9689 | 0.9846 | 0.9705 |
| VGG16 | 360,000 | 0.9764 | 0.9459 | 0.9886 | 0.9772 | 0.9735 | 0.9956 | 0.9762 |
| Model | f | b | rf | lf | ls | rs | rb | lb | All Angles |
|---|---|---|---|---|---|---|---|---|---|
| Vehicle brand | 0.8874 | 0.8650 | 0.8995 | 0.8863 | 0.8724 | 0.8955 | 0.8795 | 0.8720 | 0.9303 |
| Vehicle type | 0.9209 | 0.8922 | 0.9267 | 0.9345 | 0.8905 | 0.8562 | 0.9295 | 0.9059 | 0.9762 |
| mAP | 0.9042 | 0.8786 | 0.9131 | 0.9104 | 0.8815 | 0.8759 | 0.9045 | 0.8890 | 0.9533 |
| Vehicle Model | Car5_48 | Stanford Cars Dataset | BIT-Vehicle Dataset | mAP1 |
|---|---|---|---|---|
| Sedan | 0.9764 | 0.9000 | 0.9500 | 0.9500 |
| SUV | 0.9459 | 0.8500 | 0.9500 | 0.9000 |
| Bus | 0.9886 | - | 0.9670 | 0.9830 |
| Minivan | 0.9772 | - | 0.9330 | 0.9330 |
| Microbus | 0.9735 | 0.9000 | 0.9000 | 0.9160 |
| Truck | 0.9956 | - | 0.9750 | 0.9850 |
| mAP2 | 0.9762 | 0.8830 | 0.9410 | 0.9340 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Li, X.; Yuan, H.; Liang, H.; Wang, Y.; Song, S. A Multi-Angle Appearance-Based Approach for Vehicle Type and Brand Recognition Utilizing Faster Regional Convolution Neural Networks. Sensors 2023, 23, 9569. https://doi.org/10.3390/s23239569
Zhang H, Li X, Yuan H, Liang H, Wang Y, Song S. A Multi-Angle Appearance-Based Approach for Vehicle Type and Brand Recognition Utilizing Faster Regional Convolution Neural Networks. Sensors. 2023; 23(23):9569. https://doi.org/10.3390/s23239569
Chicago/Turabian StyleZhang, Hongying, Xusheng Li, Huazhi Yuan, Huagang Liang, Yaru Wang, and Siyan Song. 2023. "A Multi-Angle Appearance-Based Approach for Vehicle Type and Brand Recognition Utilizing Faster Regional Convolution Neural Networks" Sensors 23, no. 23: 9569. https://doi.org/10.3390/s23239569
APA StyleZhang, H., Li, X., Yuan, H., Liang, H., Wang, Y., & Song, S. (2023). A Multi-Angle Appearance-Based Approach for Vehicle Type and Brand Recognition Utilizing Faster Regional Convolution Neural Networks. Sensors, 23(23), 9569. https://doi.org/10.3390/s23239569