Abstract
The lack of labeled training samples restricts the improvement of Hyperspectral Remote Sensing Image (HRSI) classification accuracy based on deep learning methods. In order to improve the HRSI classification accuracy when there are few training samples, a Lightweight 3D Dense Autoencoder Network (L3DDAN) is proposed. Structurally, the L3DDAN is designed as a stacked autoencoder which consists of an encoder and a decoder. The encoder is a hybrid combination of 3D convolutional operations and 3D dense block for extracting deep features from raw data. The decoder composed of 3D deconvolution operations is designed to reconstruct data. The L3DDAN is trained by unsupervised learning without labeled samples and supervised learning with a small number of labeled samples, successively. The network composed of the fine-tuned encoder and trained classifier is used for classification tasks. The extensive comparative experiments on three benchmark HRSI datasets demonstrate that the proposed framework with fewer trainable parameters can maintain superior performance to the other eight state-of-the-art algorithms when there are only a few training samples. The proposed L3DDAN can be applied to HRSI classification tasks, such as vegetation classification. Future work mainly focuses on training time reduction and applications on more real-world datasets.
1. Introduction
Hyperspectral Remote Sensing Image (HRSI) contains abundant spectral and spatial information of ground objects, so it is widely used in land use and land cover [1,2], forestry [3,4], precision agriculture [5,6], environmental monitoring [7,8], and military surveillance [9,10], etc. In these applications, the task of classification of HRSI is a universal and significant process, whose purpose is to identify the class of ground object for every pixel, because the classification accuracy determines the effect of applications. Unfortunately, HRSI not only provides rich spectral and spatial features of ground objects, but also contains a large amount of redundant information, which increases the difficulty of feature extraction and reduces the classification accuracy. This is the so-called curse of dimensionality. In addition, it is expensive to specify the class of ground object for each pixel manually, so insufficient labeled pixels accelerate the difficulty of feature extraction. The difficulty in improving HRSI classification accuracy with insufficient labeled samples restricts these applications. In order to extract effective features and improve classification accuracy, a large number of algorithms have been proposed.
Early methods mainly reduced the spectral dimensionality by hand-designed features. Band selection aims to select partial bands to replace original data for features extraction through certain criteria, such as semantic information of bands [11], kernel similarity of discriminative information [12], and affinity propagation algorithm by unsupervised learning [13]. Although band selection methods can effectively reduce dimensionality of bands, the directly removed bands may contain more or less important information for classification, resulting in reduced classification accuracy.
More dimensionality reduction methods are based on Feature Extraction (FE), which maps the original spectral bands to a new feature domain by some algorithms. Based on Principal Component Analysis (PCA), which is a linear unsupervised statistical transformation, the Tensor PCA (TPCA) [14], Joint Group Sparse PCA (JGSPCA) [15], and Superpixelwise Kernel PCA (SuperKPCA) [16] are proposed for HRSI classification in the spectral domain. Morphological Attribute Profiles (MAP) [17] is another feature extraction method widely used in HRSI classification. Ye et al. [18] employed PCA and extended multiple attribute profiles (EMAP) to extract features. Liu et al. [19] combined MAP and deep random forest for small sample HRSI classification. Yan et al. [20] improved the 2D singular spectral analysis (2DSSA) for extracting global and local spectral features by fusing PCA and folded PCA (FPCA). Traditional FE methods can only extract shallow features. This makes it difficult to further improve the classification accuracy.
In recent years, Deep Learning (DL) has achieved significant success in image processing due to its powerful capabilities of deep feature extraction. Researchers are inspired to introduce DL methods into HRSI classification tasks and have achieved better classification results than traditional methods. Chen et al. [21] proposed a 1D autoencoder network to extract spatial features and spectral features, respectively. Mario et al. [22] employed 1D Stacked Autoencoders (SAE) with three layers of encoder and decoder for pixel-based classification. Bai et al. [23] proposed a two-stage multi-dimensional convolutional SAE for HRSI classification, which was composed of the SAE-1 sub-model based on 1D Convolutional Neural Network (CNN) and the SAE-2 sub-model based on 2D and 3D convolution operations. Zhao et al. [24] proposed a deep learning architecture by combining an SAE and 3D Deep Residual Network (3DDRN), where the SAE is designed for dimensionality reduction and the 3DDRN is used for extracting spatial–spectral joint features. Cheng et al. [25] proposed a Deep Two-stage Convolutional Sparse Coding Network (DTCSCNet) for HRSI classification without back propagation and a fine-tuning process. Although the models based on SAE can be trained without any labeled samples, the existence of the decoder restricts the increase in the number of layers in the encoder, as overfitting easily occurs when the depth of the SAE is too large. This constrains the improvement of feature extraction ability.
CNN is the most widely used model in HRSI classification [26]. Jacopo et al. [27] made a shallow 1D-CNN with only one hidden layer to achieve state-of-the-art performance by label-based data augmentation. Li et al. [28] proposed a DCNR composed of a deep cube 1D-CNN and a random forest classifier for extracting spectral and spatial information. From the perspective of kernel structure, 1D-CNNs are only suitable for extracting spectral features. If they are used to extract spatial features, the 2D spatial tensors must be converted into 1D vectors and this transformation will result in the loss of spatial information. In order to fully utilize the spatial information, 2D-CNNs are introduced for HRSI classification. Haque et al. [29] proposed multi-scale CNNs with three different sizes of 2D convolutional kernels to extract spectral and spatial features. Jia et al. [30] proposed an end-to-end deep 2D-CNN based on U-net which took the entire HSI as input instead of pixel patches. In 2D-CNNs, the spatial and spectral information are extracted separately. This ignores the fact that there is related information between spatial and spectral features. Gao et al. [31] proposed a lightweight spatial–spectral network which was composed of a 3D Multi-group Feature Extraction Module (MGFM) based on 3D-CNN and a 2D MGFM based on Depthwise Separable Convolution. Yu et al. [32] proposed a lightweight 2D-3D-CNN by combining 2D and 3D convolutional layers, which can extract the fused spatial and spectral features. Hueseyin et al. [33] proposed a 3D-CNN based on LeNet-5 model to extract spatial and spectral features from data processed by the PCA method. Due to the structural consistency between 3D convolutional kernels and 3D-cube HRSIs, 3D-CNNs can effectively extract spatial–spectral joint features. Unfortunately, the excellent feature extraction ability of 3D-CNNs requires sufficient labeled samples for training, but there is a high cost of labeling sample results in that there are insufficient labeled samples for training.
Recently, how to improve the feature extraction ability of 3D-CNNs with a small training sample size has become a research hotspot. Li et al. [34] proposed MMFN based on 3D-CNN, in which multi-scale architecture and residual blocks are introduced to fuse related information among different scale features and extract more discriminative features. Zhou et al. [35] proposed a Shallow-to-Deep Feature Enhancement (SDFE) model, which was composed of PCA, a shallow 3D-CNN (SSSFE), a channel attention residual 2D-CNN, and a Vision-Transformer network. Ma et al. [36] proposed a Multi-level Feature extraction Block (MFB) for spatial–spectral feature extraction and a spatial multi-scale interactive attention (SMIA) module for spatial feature enhancement. Paoletti et al. [37] proposed a pyramidal residual module architecture, which is used to build deep pyramidal residual networks for HRSI classification. In addition to residual structure, attention mechanism is also widely used to improve the feature extraction ability of CNNs. Zhu et al. [38] proposed a Residual Spectral–Spatial Attention Network (RSSAN) for HRSI classification. In this model, the raw data are sequentially processed through a spectral attention module, a spatial attention module, and a residual block. In the Cooperative Spectral–Spatial Attention Network (CS2ADN) [39], the spectral and spatial features are extracted by the independent spectral and spatial attention branches, respectively. Then, the fused features are further extracted by dense connection structure. Generally, there are two residual branches in a model, which are named the spatial residual branch and the spectral residual branch. Similarly, there are two attention branches named the spatial attention branch and the spectral attention branch, respectively, in a model based on attention mechanism. This structure composed of two independent branches cannot extract spatial–spectral joint features and increases the number of trainable parameters in the model. When the number of labeled samples is small, the trainable parameters of models cannot be fully trained and the classification accuracy will decrease.
To improve the HRSI classification accuracy-based deep learning models under a small number of labeled samples, a model with a small number of trainable parameters and robust deep feature extraction capability is necessary. Inspired by these studies, a Lightweight 3D Dense Autoencoder Network (L3DDAN) is proposed in this paper for HRSI classification. From the top-level architecture, the network is an SAE composed of an encoder for extracting features and a decoder for reconstructing data. First, the SAE is trained without any labeled samples through unsupervised learning. Then, all labeled samples are randomly divided into a training group, validating group and testing group. The fine-tuned encoder and trained classifier are completed with a small number of training groups and validating groups by supervised learning. Finally, the classification ability of the trained classifier is evaluated with the testing group. The experimental results indicate that the L3DDAN can extract deep spatial–spectral features with only a small number of labeled samples. Thanks to this, the high classification accuracy can still be achieved when there are insufficient labeled samples. The major contributions of this paper include the following:
- (1)
- A Lightweight 3D Dense Autoencoder Network (L3DDAN) is proposed for HRSI classification. The architecture of L3DDAN is an SAE based on 3D convolution operations and the Spectral–Spatial Joint Dense Block (S2DB) is introduced into the encoder to enhance the deep feature extraction ability. The high classification accuracy can be maintained when the number of training samples is small.
- (2)
- An SAE architecture is proposed to train the encoder by unsupervised learning. The encoder of the SAE composes 3D convolution operations and S2DB to extract deep features from HRSI. The decoder is implemented by 3D convolution operations. The SAE enables the L3DDAN to extract deep features from origin data without labeled samples.
- (3)
- The Spectral–Spatial Joint Dense Block (S2DB) is proposed to replace the traditional separated spatial residual branch and spectral residual branch. The S2DB not only avoids the loss of spectral–spatial joint features, but also reduces the number of trainable parameters in L3DDAN.
2. Methodology
2.1. 3D Convolution Operation
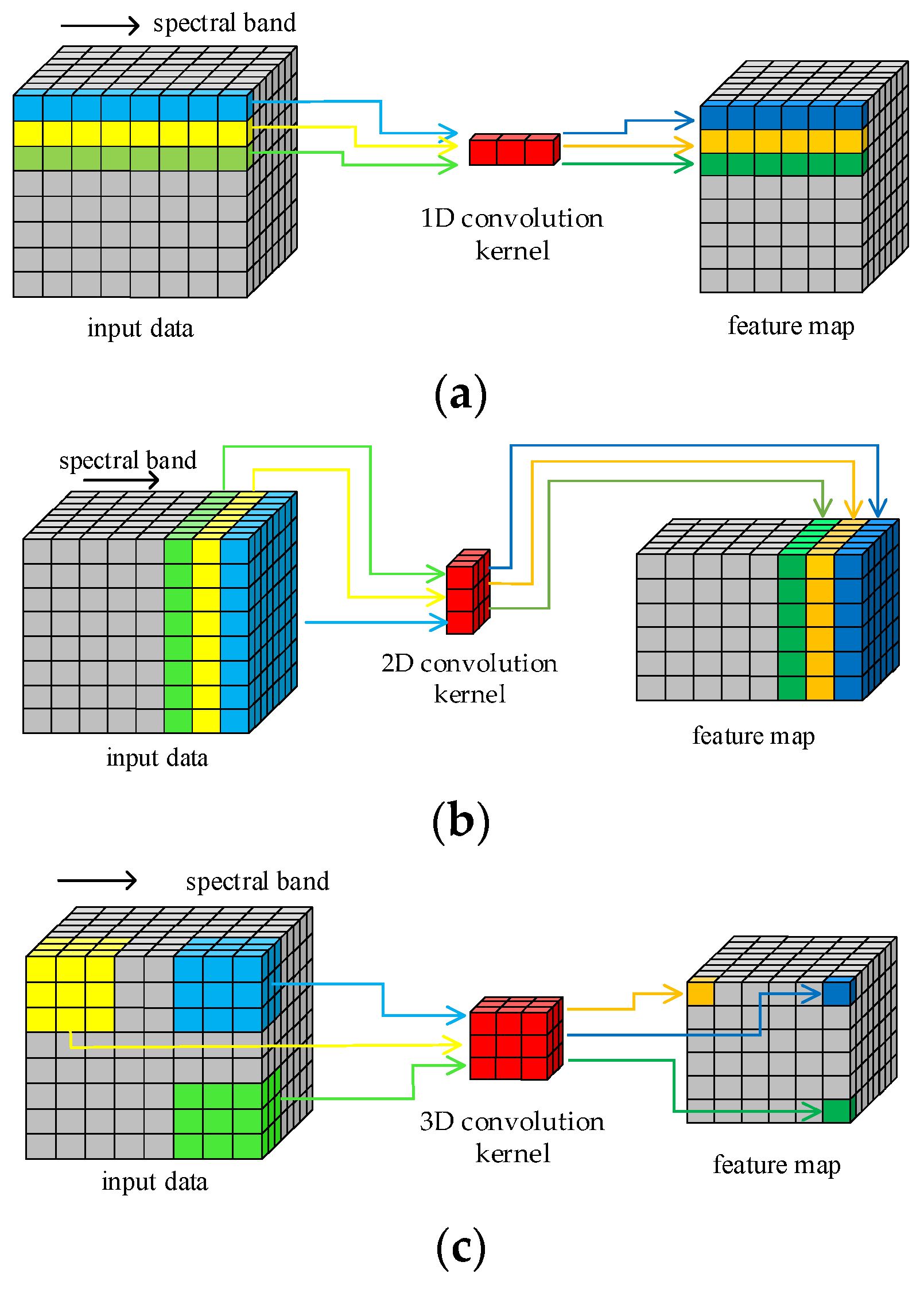
The structure of HRSI data is a 3D cube that contains both spatial and spectral features. Figure 1 illustrates the principle of HRSI feature extraction by 1D, 2D, and 3D convolution operations, respectively. The 1D kernels in 1D-CNN can only extract spectral features and cannot extract spatial features. Similarly, only the spatial information in HRSIs can be extracted by the 2D convolution kernels. Only the 3D convolution kernels can extract both spatial and spectral features simultaneously, as they are structurally consistent with the 3D cube HRSI data. In order to improve the feature extraction ability of proposed model in this paper, all required convolution operations are implemented by 3D convolution kernels. This design enables the traditional separated spatial and spectral feature extraction branches to be replaced by just one block.
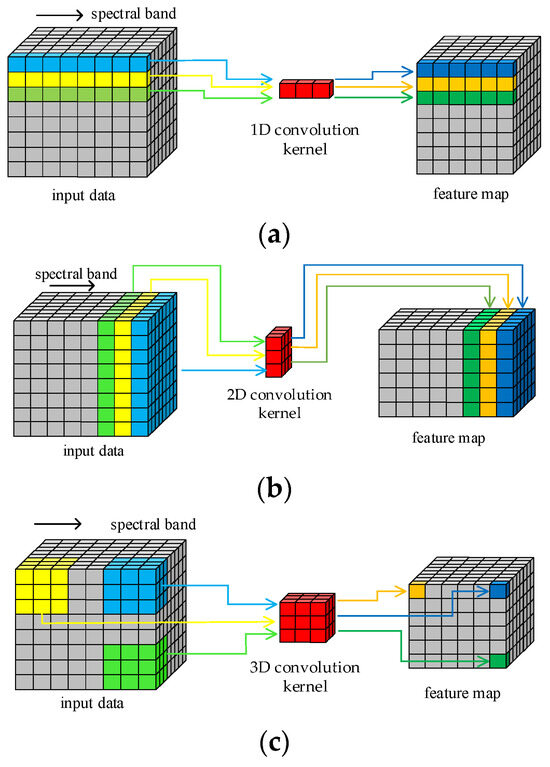
Figure 1.
Convolution operations: (a) 1D; (b) 2D; (c) 3D.
The 3D convolution operation can be formulated as follows:
where indicates the activation value at position in the jth feature map in the ith layer, is the index of feature maps in the th layer, is the value of the kernel at position connected to the th feature map in the preceding layer, is the bias and is the activation function, the , and is the height, width, and spectral dimension size of the kernel, respectively.
In the L3DDAN, all convolution operations are implemented by 3D convolution kernels to avoid the loss of spatial–spectral joint features as much as possible. In addition, 3D convolution operations are used for spectral dimensionality reduction. This design makes the hyperspectral data without any preprocess to be directly used as the input of L3DDAN.
2.2. Spectral–Spatial Joint Dense Block
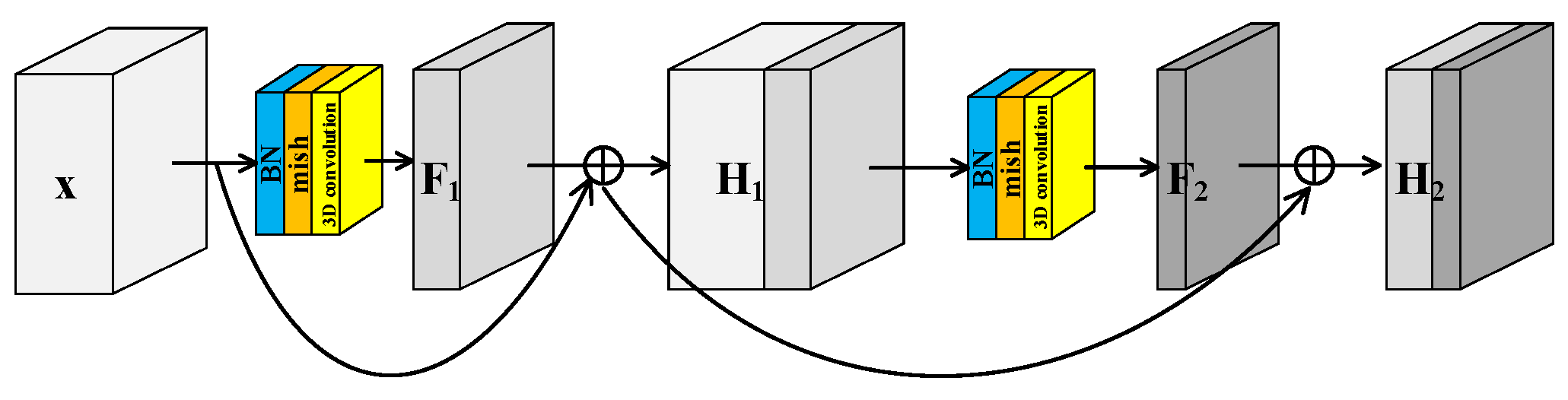
He et al. [40] proposed the residual structure to solve the degradation problem of deep neural networks and make feature extraction easier without adding any learnable parameters. Many models [41] for HRSI classification have been proposed inspired by residual block. Generally there are two independent residual blocks in these models to extract spectral and spatial features, respectively. This structure of two separated branches not only fails to extract spectral–spatial joint features, but also increases the number of trainable parameters. In this paper, a Spectral–Spatial Joint Residual Block (S2RB) based on 3D convolution operations was proposed. In the S2RB shown in Figure 2, the input hyperspectral data cube extracts features by 3D convolution operations to form output feature map . The spatial dimensions of and are equal, and the spectral dimension is reduced from to . The introduction of a skip connection changes the mapping from to .
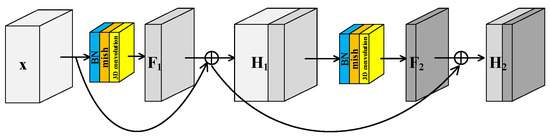
Figure 2.
Spectral–spatial joint residual block.
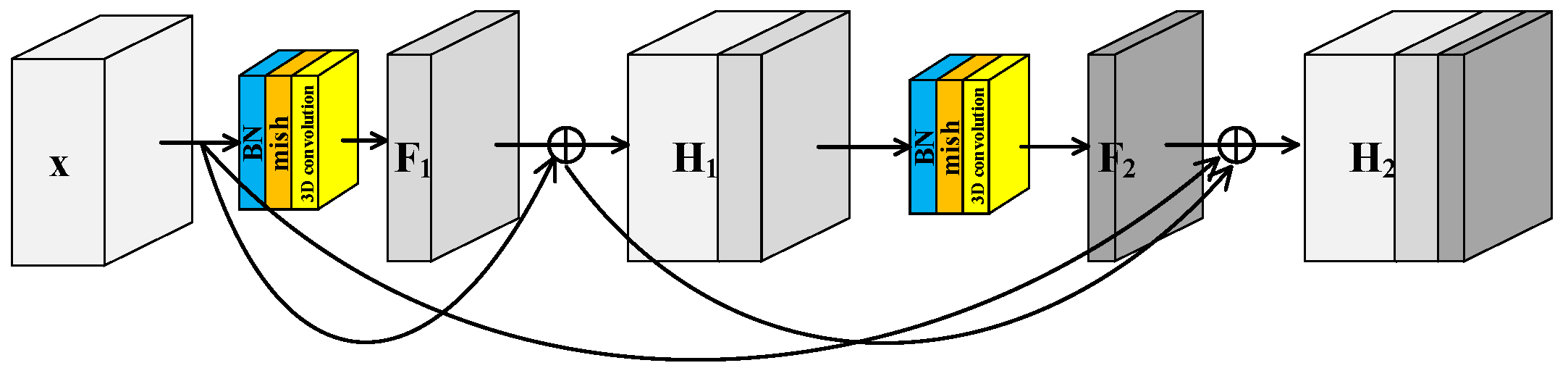
To further improve the feature extraction ability of model, a Spectral–Spatial Joint Dense Block (S2DB) is proposed inspired by Dense Convolutional Network [42]. Different from S2RB, there are skip connections between each layer and all preceding layers in S2DB as shown in Figure 3. Consequently, the output feature maps of the first layer are formulated as . This is the same as the output feature maps of S2RB. But for the second layer, the output feature maps of S2DB are formulated as . Compared to the H2 of S2RB, there is an additional term x in the H2 of S2DB.
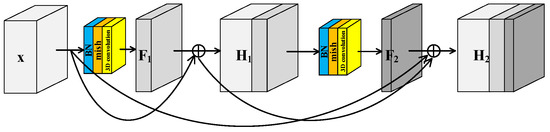
Figure 3.
Spectral–spatial joint dense block.
Previous models typically are composed of two separate branches for extracting spectral and spatial features, respectively. Because both S2RB and S2DB can extract spatial–spectral joint features, single branch structure can be adopted in the L3DDAN.
2.3. Proposed Framework
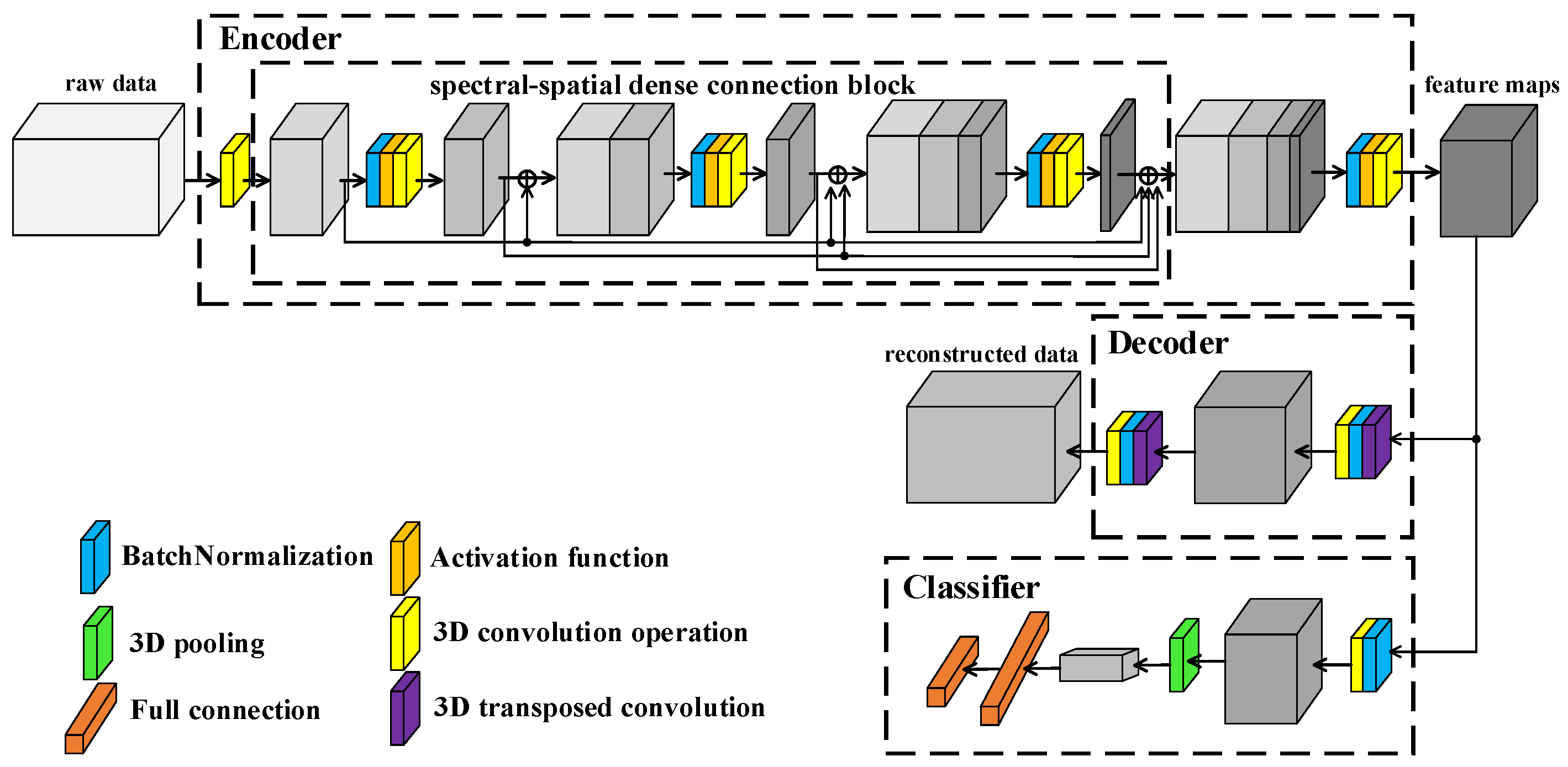
The framework of proposed L3DDAN is shown in Figure 4. Structurally, the model consists of an encoder, decoder, and classifier. The training and testing process is as follows: (1) The SAE composed of the encoder and decoder is first trained by unsupervised learning without any labeled samples. The purposes of encoder and decoder are to extract deep features from unpreprocessed data and reconstruct input data according to the feature maps, respectively. (2) After the training of SAE, the output feature maps from encoder are fed into the classifier. The fine-tuning for trained encoder and the training for classifier are completed simultaneously through supervised learning with small number of labeled samples. The decoder, which function is only to complete the training of the encoder, is not involved in this step. (3) The model composed of encoder and classifier can perform classification tasks on the test dataset.
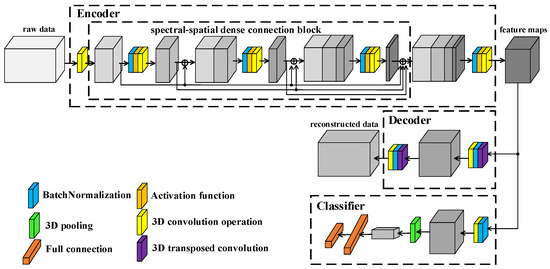
Figure 4.
Framework of L3DDAN.
The encoder of SAE is composed of 3D convolution operations and S2DB. The input data of L3DDAN are the patches of raw data without any preprocess. The spectral dimensionality of input data is reduced by the first 3D convolution layer. The S2DB is used to extract spatial–spectral joint features from the output data of previous layer. The deep features of raw data are obtained from the output feature maps of S2DB by the final 3D convolution layer of encoder. The output features maps of encoder are reconstructed by the decoder of SAE which composes two 3D deconvolution layers. In the classifier, the feature maps from encoder are classified by full connection layer after the last 3D convolution operation. Table 1 lists the detailed structure of the L3DDAN.

Table 1.
Network structure of L3DDAN.
3. Results and Discussion
3.1. Datasets Description
Three benchmark datasets were selected to validate the performance of the proposed L3DDAN for HRSI classification. The first dataset Indian Pines (IP) was acquired by the Airborne Visible Infrared Imaging Spectrometer (AVIRIS) instrument over a mixed vegetation site in northwestern Indiana, USA. It contains 16 cover types and pixels with 220 bands covering from to . The noise-affected 20 bands (104–108, 150–163, 220) were removed and the retaining 200 bands were utilized for experiments. The labeled pixels of IP are randomly divided into training (3%), validation (3%), and testing (94%) groups. The second dataset University of Pavia (UP) was gathered by the Reflective Optics System Imaging Spectrometer (ROSIS) over the urban area of Pavia, northern Italy. It contains pixels with 1.3 m spatial resolution and 103 spectral bands covering from to . All labeled pixels were divided into nine cover types. The third dataset Salinas Valley (SV) was captured over the Salinas Valley, CA, USA. It contains pixels with 3.7 m/pixel spatial resolution and 204 bands in the wavelength ranging from to . The labeled pixels of UP and KSC are randomly divided into training (1%), validation (1%), and testing (98%) groups. The minimum number of samples per group is three for three datasets. The pseudocolor images and the ground-truth maps of three datasets are shown in Figure 5. The categories and pixel count for each dataset are listed in Table 2, Table 3 and Table 4.

Figure 5.
The pseudocolor images and ground-truth: (a) IP; (b) UP; (c) SV.
Table 2.
The number of training, validation, and test samples in IP dataset.
Table 3.
The number of training, validation, and test samples in UP dataset.
Table 4.
The number of training, validation, and test samples in SV dataset.
3.2. Parameter Analysis
In the stage of SAE training, all samples were used for unsupervised learning without any labels. Then, all labeled samples are randomly divided into training group, validation group, and testing group. The training group was used for fine-tuning of encoder and training of classifier. The validation and testing groups were used to monitor the training process and evaluate the classification performance of L3DDAN, respectively. In the experiments, the overall accuracy (OA), average accuracy (AA), and Kappa coefficient [43] are used to quantitatively evaluate the classification performance. The proposed model was implemented by the Pytorch 1.10 framework (open source). All experiments were conducted on a PC (Lenovo, Shanghai, China) with Intel(R) Core i7-CPU, Nvidia Geforce GTX 3090 GPU and 64 GB RAM.
3.2.1. Effect Analysis of the S2DB
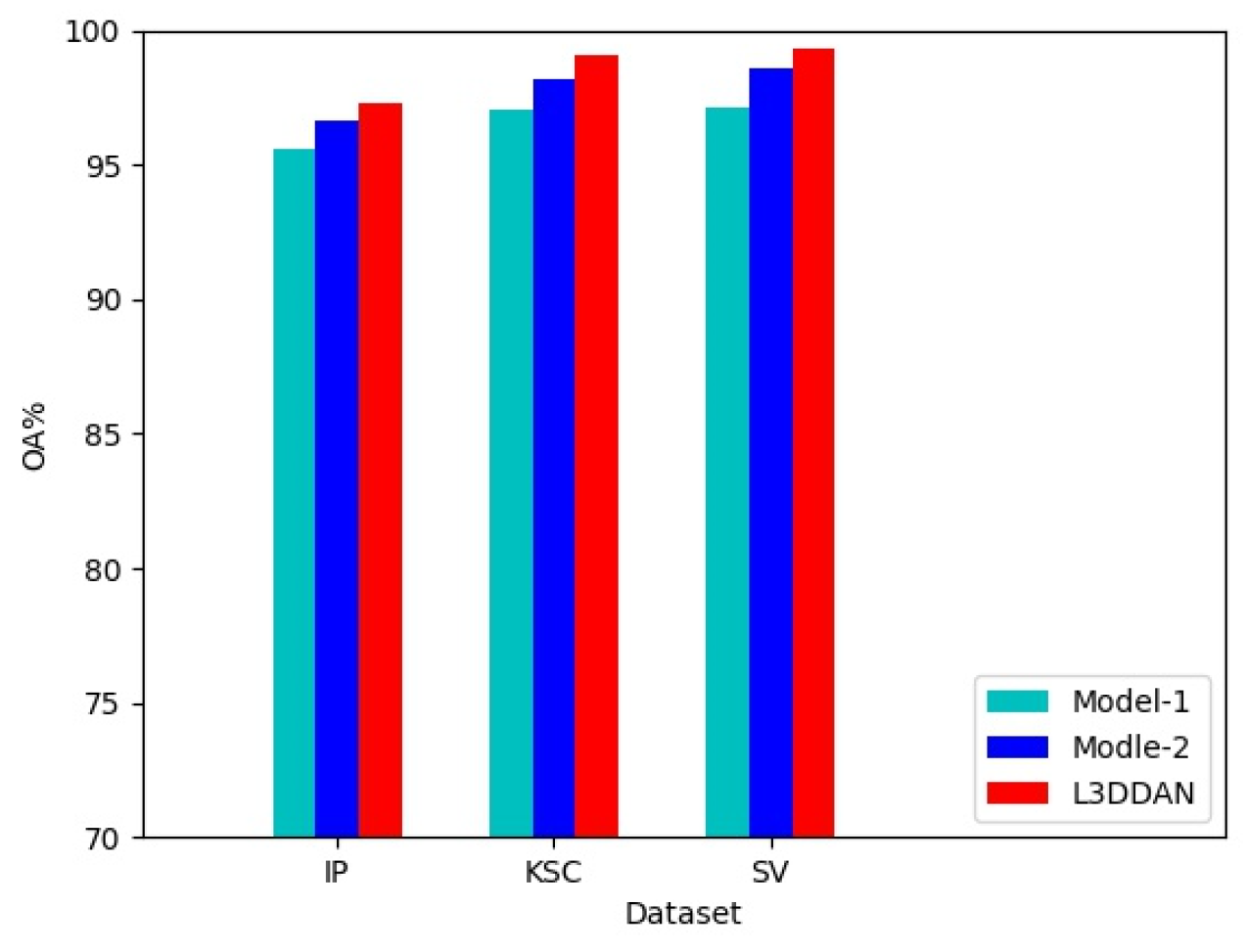
To evaluate the effectiveness of the S2DB in L3DDAN, two comparative networks named Model-1 and Model-2 were constructed. The Model-1 and Model-2 networks were constructed by replacing the S2DB in L3DDAN with normal 3D convolution operations and S2RB, respectively. The three networks are identical except for the above difference. Comparative experiments were conducted under identical parameters and the experimental results are shown in Figure 6. It can be seen that the highest classification accuracies were achieved on all three datasets by L3DDAN, followed by the Model-2. This indicates that the dense connection structure further improves the feature extraction ability of the network compared to residual skip connection.
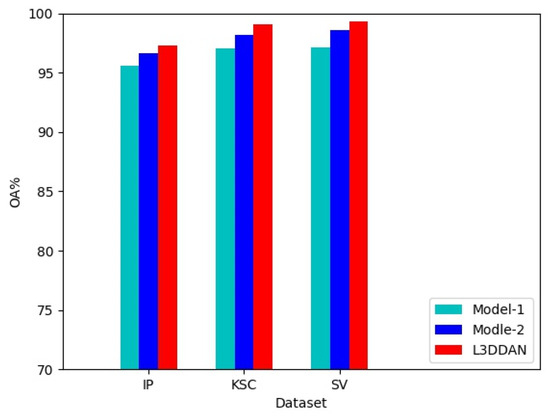
Figure 6.
Effectiveness experiment of the S2DB.
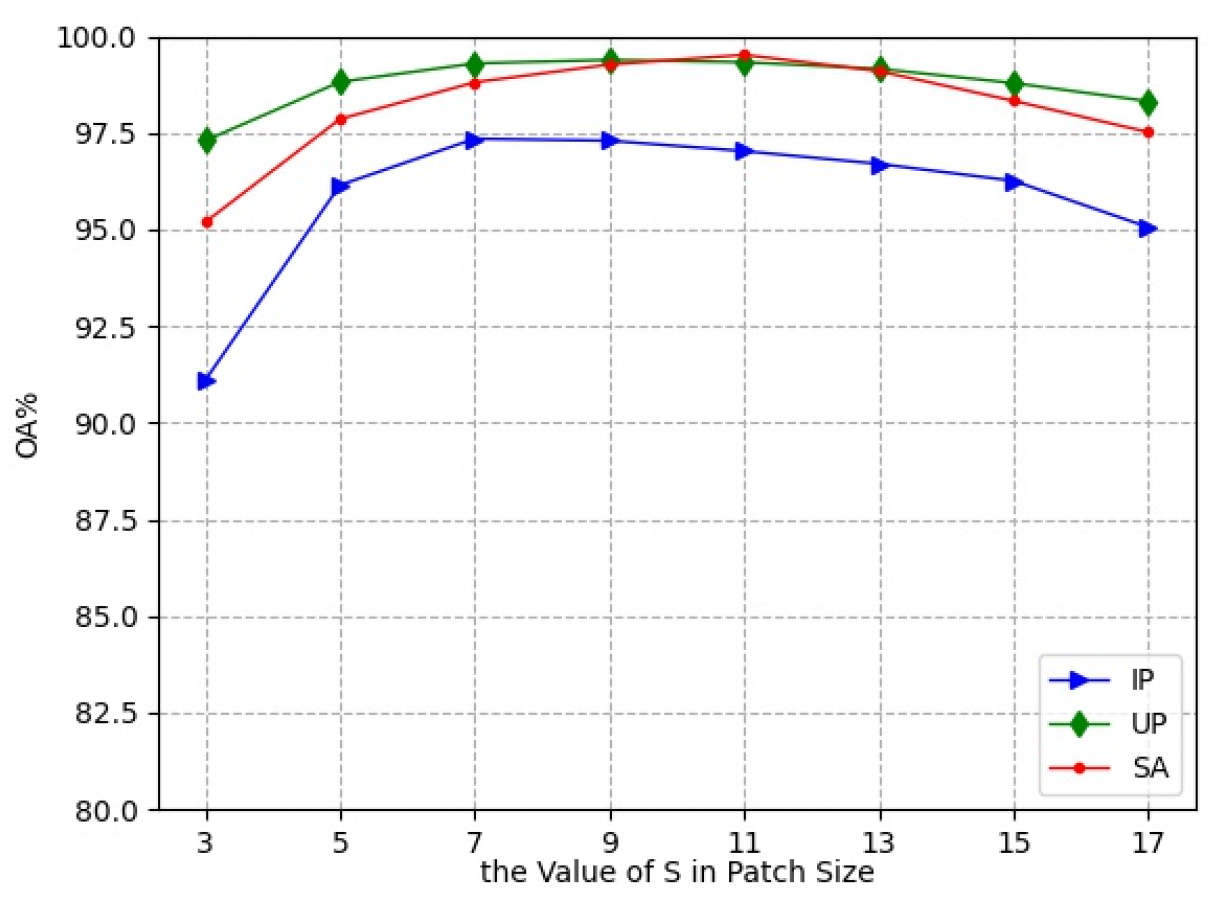
3.2.2. Effect of the Patch Size
In the experiments, the small 3D neighboring patches divided from HRSI data cube were used as the input of L3DDAN. The is the number of pixels in spatial dimension and the L is the number of spectral bands. In this section, a series of comparative experiments were conducted to determine the value of S. The experimental results are shown in Figure 7.
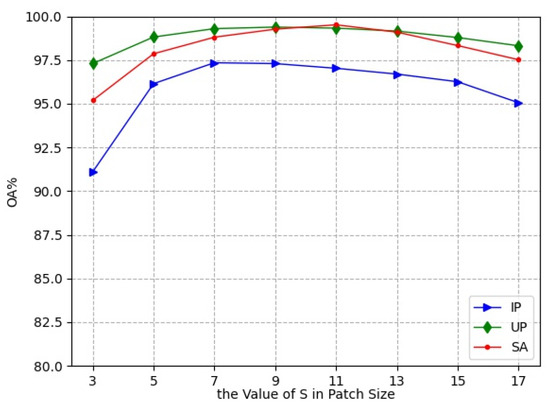
Figure 7.
Classification accuracies with different patch size.
As the spatial size increases from to , the classification accuracies first increase and then decrease. The OA reached the maximum value when the spatial size of patches was , and for the IP, UP, and SA datasets, respectively. This indicates that increasing the patch size appropriately can bring more spatial information, but oversize introduces noise and reduces the classification accuracy. The patch sizes , and were the optimal selections for the three datasets in the proposed network.
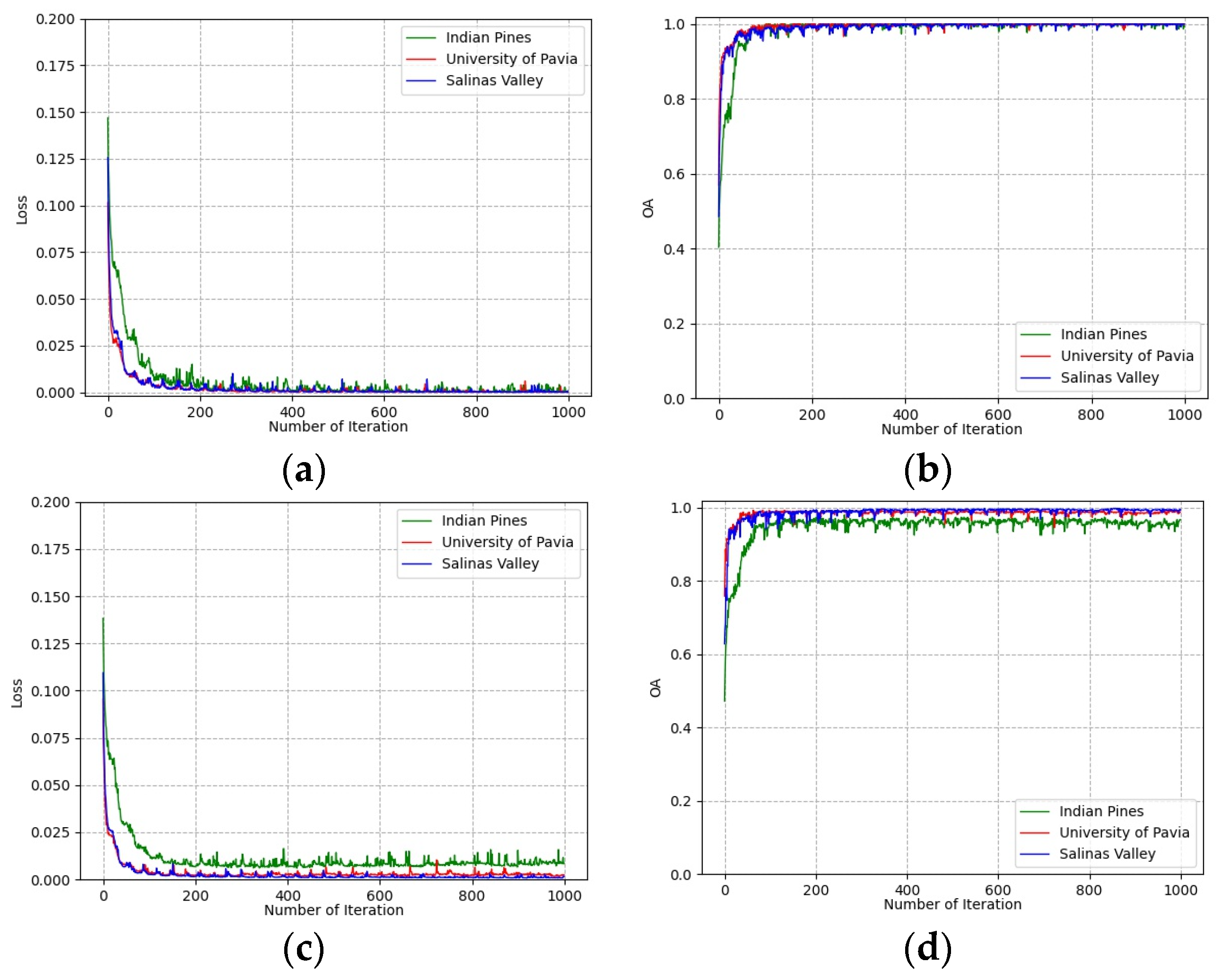
3.2.3. Impact of the Number of Training Epochs
To determine the number of training epochs, the loss and classification accuracies of training and validation groups vary with the number of training epochs on all three datasets shown in Figure 8. It can be seen that all curves converge after 500 epochs on the training group and validation group. This indicates that the deep features extracted from the training group are effective for the classification of the validation group. The number of training epochs was determined to be 500 for all experiments.
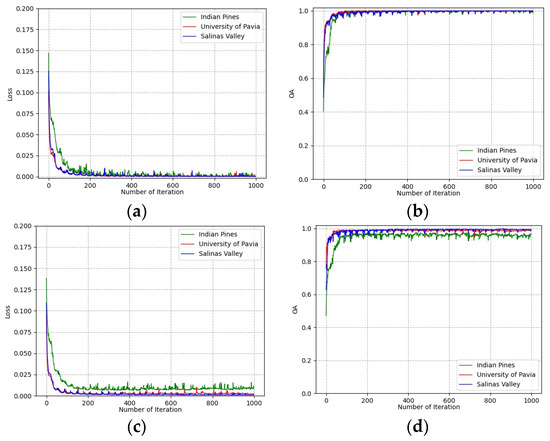
Figure 8.
Loss and accuracy convergence versus epochs: (a) loss of training group; (b) accuracies of training group; (c) loss of validation group; (d) accuracies of validation group.
3.3. Performance Evaluation
3.3.1. Comparison of Classification Results
In this section, the proposed L3DDAN was compared with eight state-of-the-art algorithms including 1D-CNN [44], 2D-CNN [45], 3D-CNN [46], 3D-CAE [47], DBDA [48], DBMA [49], DSGSF [50], and AMGCFN [51]. These methods cover unsupervised learning and supervised learning algorithms with different architectures, such as 1D-CNN, 2D-CNN, 3D-CNN, autoencoder, and attention mechanism network. The architectures and hyperparameters of the above-mentioned comparative models are described in the corresponding published papers.
The classification results of the IP dataset are demonstrated in Table 5. From Table 5, it can be seen that the 1D-CNN achieves the worst results with only 75.67% OA. The main reason is considered that the spatial information is not utilized for classification. Compared with the 1D-CNN, the 2D-CNN, 3D-CNN, and 3D-CAE improve the OA to 83.48%, 84.08%, and 82.27%, respectively, because they consider both spectral and spatial information simultaneously. The accuracies of DBDA and DBMA are improved further by introducing attention mechanism and dense structure. For L3DDAN, the highest classification accuracy is achieved thanks to the autoencoder structure and spectral–spatial joint dense block.
Table 5.
Classification results (%) for IP dataset with 3% training samples.
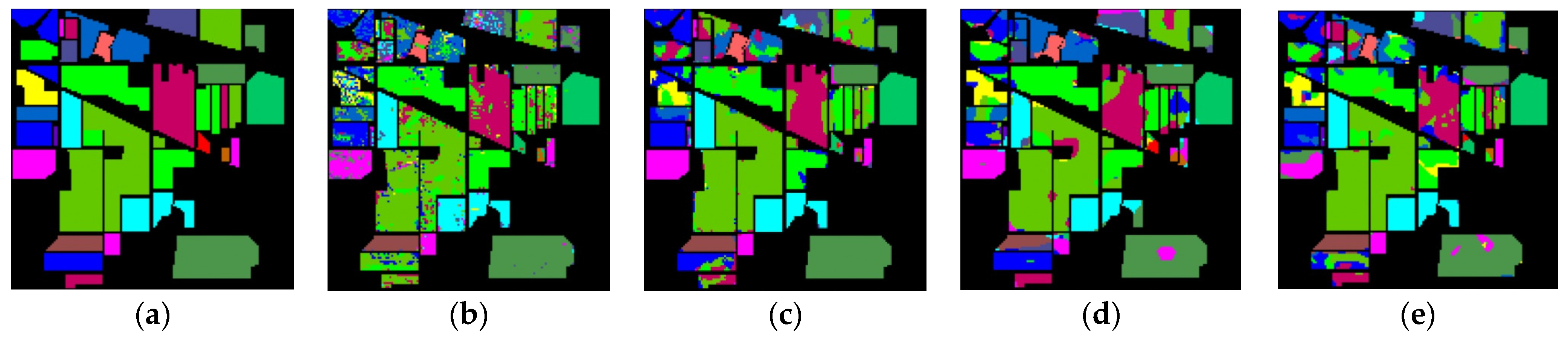
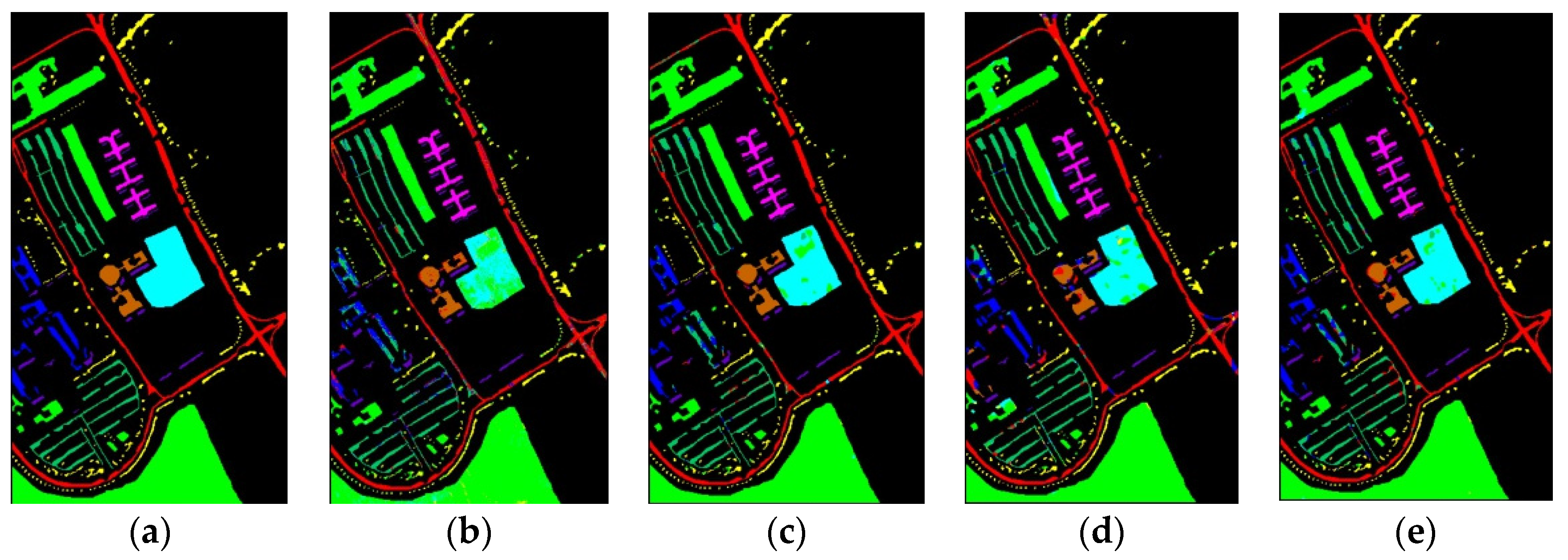
The classification maps of different methods for IP datasets are shown in Figure 9. It can be observed that there are a large amount of misclassified pixels in (b), (c), (d) of Figure 9. In contrast, the classification map of L3DDAN is the most similar to the ground-truth.
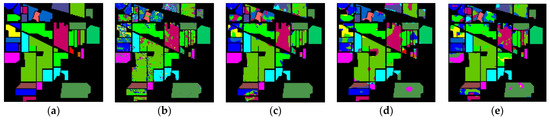

Figure 9.
Classification maps of different methods for the IP: (a) ground-truth; (b) 1D-CNN; (c) 2D-CNN; (d) 3D-CNN; (e) 3D-CAE; (f) DBDA; (g) DBMA; (h) DSGSF; (i) AMGCFN; (j) L3DDAN.
The classification results of the UP dataset are reported in Table 6. From Table 6, it can be seen that the L3DDAN achieved the best performance on OA (99.31%), AA (98.67%), Kappa (0.9908), and 6 of 9 specific classes. The worst result is achieved by 1D-CNN and the results of DBDA and DBMA are similar.
Table 6.
Classification results (%) for UP dataset with 1% training samples.
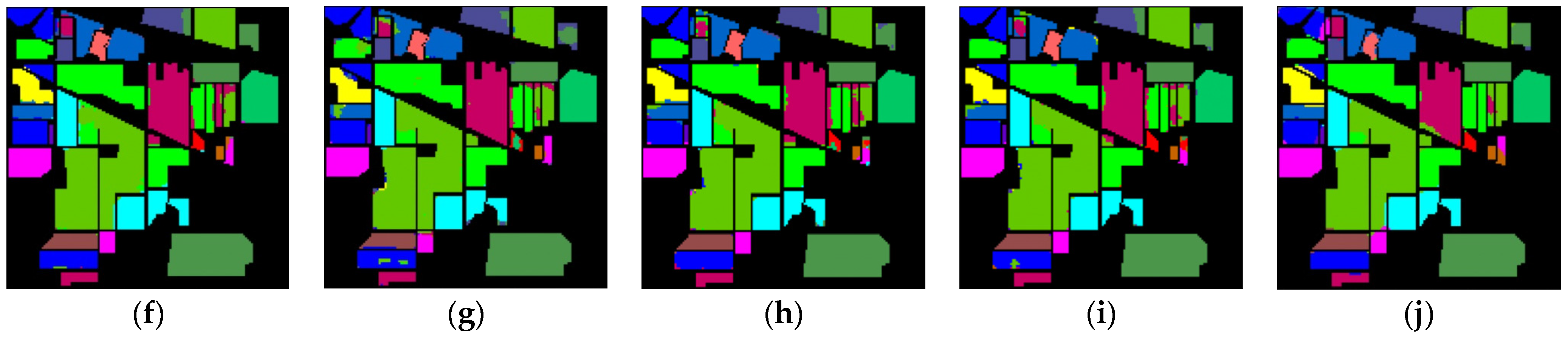
Figure 10 shows classification maps of different methods for the UP dataset. More misclassified pixels appear in some classes with few labeled pixels such as Gravel and Bare Soil.
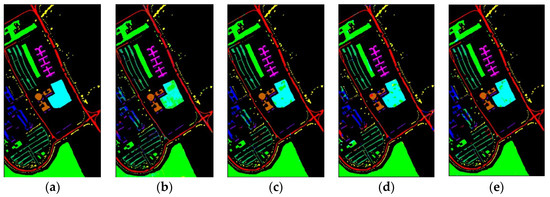
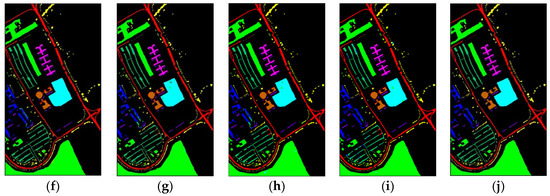
Figure 10.
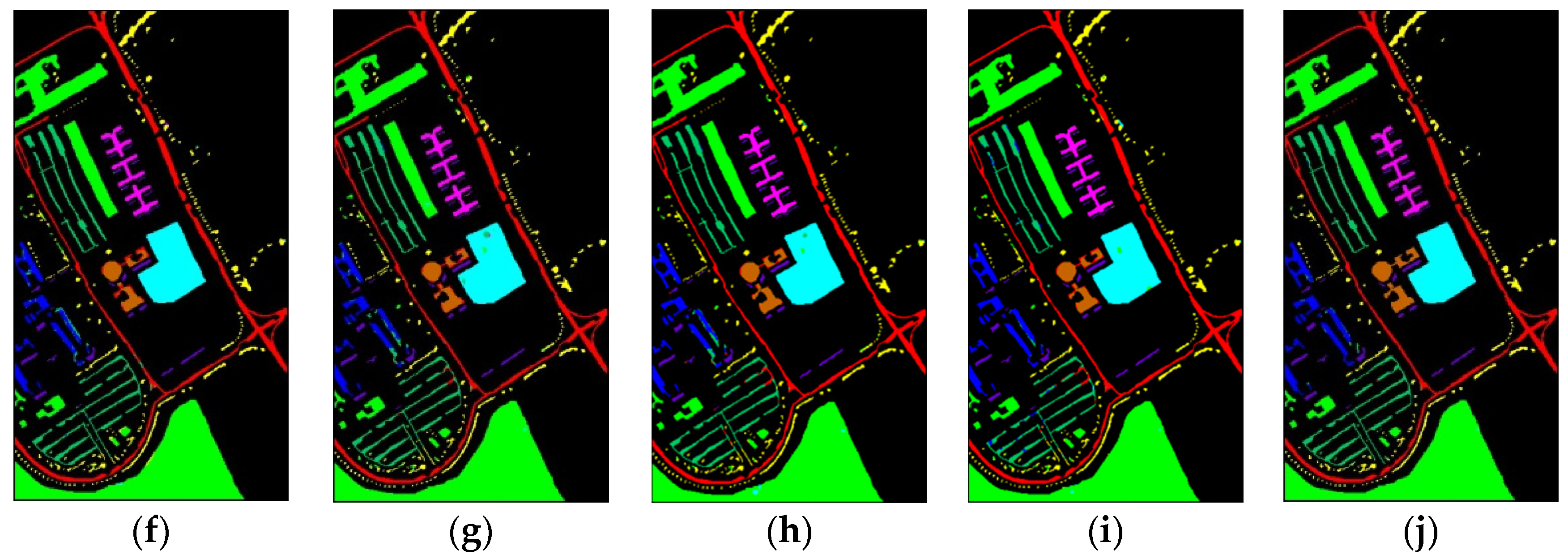
Classification maps of different methods for the UP: (a) ground-truth; (b) 1D-CNN; (c) 2D-CNN; (d) 3D-CNN; (e) 3D-CAE; (f) DBDA; (g) DBMA; (h) DSGSF; (i) AMGCFN; (j) L3DDAN.
The categorized results for SV dataset are demonstrated in Table 7. From Table 7, it can be seen that the L3DDAN obtains the best results with 99.64% OA, 99.69% AA, and 0.9960 Kappa.
Table 7.
Classification results (%) for SV dataset with 1% training samples.
The classification maps for SV dataset are shown in Figure 11. There are obvious mislabeled pixels in areas of Vineyard—untrained and Grapes—untrained in classification maps of 1D-CNN, 2D-CNN, and DBMA. The classification map of the proposed method shows less mislabeled pixels than other methods.

Figure 11.
Classification maps of different methods for the SV: (a) ground-truth; (b) 1D-CNN; (c) 2D-CNN; (d) 3D-CNN; (e) 3D-CAE; (f) DBDA; (g) DBMA; (h) DSGSF; (i) AMGCFN; (j) L3DDAN.
3.3.2. Impact of Training Sample Size
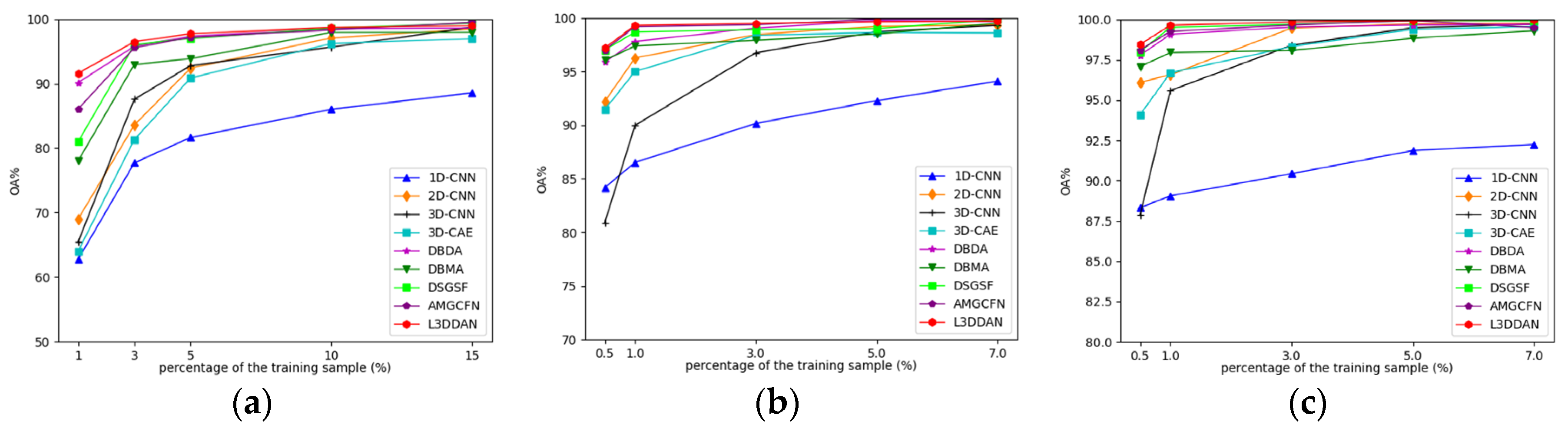
Due to the limited number of HRSI labeled samples, the classification performance with a small number of training samples becomes particularly important. A series of experiments were conducted to explore the OA variations with different proportions of training samples for all methods. For the IP dataset, the training samples proportion is set to 1%, 3%, 5%, 10%, and 15%, and for the UP and SV datasets, they are set to 0.5%, 1%, 3%, 5%, and 7%. The experimental results are shown in Figure 12.
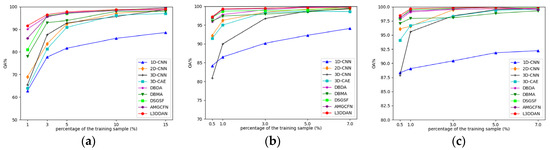
Figure 12.
The impact of training samples proportions on classification accuracy for all datasets: (a) IP; (b) UP; (c) SV.
From Figure 12, the classification accuracy of 1D-CNN is the lowest in most cases and the increase in training sample number only improves limited OA. The reason is considered that the spatial features are discarded and the feature extraction capability of 1D-CNN is insufficient. The classification accuracies of other methods are close when the proportion of training samples is greater than 10% for the IP dataset and 3% for the UP and SV datasets. As the training samples proportion decreased, declines of all classification accuracies with different levels occurred. The proposed L3DDAN maintains the highest classification accuracies for all datasets. It indicates that the L3DDAN can extract more distinguishable features from limited training samples for classification.
3.3.3. Comparison of Parameter Quantity
The number of trainable parameters is an important indicator for evaluating the model. Table 8 lists the numbers of trainable parameters for all methods.
Table 8.
The number of trainable parameters for all methods.
For all datasets, the number of trainable parameters of proposed L3DDAN is the second smallest. For the IP dataset, the trainable parameter number in L3DDAN has been reduced to 4.2%, 0.6%, 30.3%, 44.5%, 27.9%, 38.97%, and 46.23% of those in 2D-CNN, 3D-CNN, 3D-CAE, DBDA, DBMA, DSGSF, and AMGCFN, respectively. For the UP and SV datasets, the trainable parameter numbers of L3DDAN also have been significantly reduced.
3.4. Discussion
Based on the results in Table 5, Table 6 and Table 7, it is evident that the classification results of 1D-CNN (75.67% for IP, 86.25% for UP, and 89.19% for SV) are the lowest on all datasets. This indicates that the feature extraction ability of 1D convolution kernels is insufficient for HRSI, because it can only extract spectral features. By introduction of spatial features, the classification accuracies of 2D-CNN (83.48% for IP, 95.31% for UP, and 97.17% for SV) and 3D-CNN models (92.26% for IP, 92.26% for UP, and 94.42% for SV) have been significantly improved. It is notable that the classification results of 3D-CNN are lower than those of 2D-CNN on all datasets. This indicates that the feature extraction ability of models based on convolution operations for HRSI classification not only relates to the kernel type, but also to the model architecture. The classification accuracies of 3D-CAE (95.20% for UP and 96.12% for SV) are further improved by introducing the SAE into 3D-CNN. This indicates that the deep features can be learned by unlabeled data. Other compared methods significantly improved feature extraction capabilities by introducing a multi-branch structure. In DBDA and DBMA, both spatial and spectral branches are based on the attention mechanism. The difference between the two models is that the two branches are parallel in DBDA and serial in DBMA. In proposed L3DDAN, the two separated branches are replaced by a spatial–spectral joint branch to extract deep spatial–spectral joint features in HRSI. The classification accuracies of L3DDAN (97.65% for IP, 99.31% for UP, and 99.64% for SV) are higher than those of DBDA (94.97% for IP, 98.65% for UP, and 98.35% for SV) and DBMA (94.76% for IP, 98.62% for UP, and 97.57% for SV).
The experimental results of Figure 12 indicate that all methods except 1D-CNN can achieve satisfactory classification accuracies when there are sufficient training samples. As the training sample proportion decreases, the classification accuracies of 2D-CNN, 3D-CNN, and 3D-CAE decrease more significantly, even below that of 1D-CNN for UP and SV. Based on Table 8, the main reason for the above-mentioned results is that there are too many trainable parameters in 2D-CNN (4,013,386) and 3D-CNN (30,536,176) than 1D-CNN (72,216). The trainable parameter numbers of DBDA (382,326), DBMA (609,791), DUGS (436,791), and AMGCFN (368,217) are far fewer than 2D-CNN and 3D-CNN and these models can achieve better classification accuracies. The number of trainable parameters in L3DDAN is further reduced by the introduction of the spatial–spectral joint branch and it maintains the highest classification accuracies with the minimum number of training samples.
4. Conclusions
In this paper, a Lightweight 3D Dense Autoencoder Network is proposed for HRSI classification. The framework of L3DDAN is designed as an SAE to utilize unlabeled samples by unsupervised learning. In addition, the Spatial–Spectral Joint Dense Block is introduced to replace the traditional separated spatial and spectral feature extraction blocks. This architecture not only improves the spatial–spectral joint features extraction ability of L3DDAN, but also reduces the number of trainable parameters. Extensive experiments’ results demonstrate that the L3DDAN surpasses eight different framework state-of-the-art methods in the classification accuracies with a small number of training samples. In addition, the L3DDAN can still maintain excellent deep feature extraction ability when the number of training samples is decreased. This is extremely important for HRSI classification with limited labeled samples.
However, the introduction of SAE makes a significant increase in training time, because all samples are used for the training of the encoder and decoder. The training time of the proposed L3DDAN is greater than other methods except 3D-CAE. This process consumes significant computational resources. In addition, the generalizability of L3DDAN on more HRSI datasets still needs to be verified. The future directions of our work mainly focus on the above-mentioned two limitations: (1) The architecture of SAE will be optimized to reduce the time consumption; (2) The parameters will be optimized to make L3DDAN exhibit state-of-the-art performance on more datasets for application.
Author Contributions
Y.B.: Conceptualization, methodology, investigation, validation, formal analysis, visualization, writing—original draft. X.S.: Conceptualization, investigation, funding acquisition. Y.J.: Conceptualization, investigation, funding acquisition. W.F.: Resources, software, visualization, writing—review and editing. X.D.: Investigation, validation, formal analysis, visualization, writing—review and editing. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Guangxi Key Laboratory of Precision Navigation Technology and Application, Guilin University of Electronic Technology (No. DH202208, No. DH202215), the Project for Enhancing Young and Middle-aged Teacher’s Research Basic Ability in Colleges of Guangxi (2023KY0198) and the Science and Technology Major Project of Guangxi (No. AD22080061).
Institutional Review Board Statement
No applicable.
Informed Consent Statement
No applicable.
Data Availability Statement
All datasets used in this research are open accessible online (http://www.ehu.eus/ccwintco/index.php?title=Hyperspectral_Remote_Sensing_Scenes, accessed on 15 October 2023).
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| HRSI | Hyperspectral Remote Sensing Image |
| PCA | Principal Component Analysis |
| MAP | Morphological Attribute Profiles |
| DL | Deep Learning |
| SAE | Stacked Autoencoder |
| 3DDRN | 3D Deep Residual Network |
| CNN | Convolutional Neural Network |
| CS2ADN | Cooperative Spectral–Spatial Attention Network |
| L3DDAN | Lightweight 3D Dense Autoencoder Network |
| S2DB | Spectral–Spatial Joint Dense Block |
| S2RB | Spectral–Spatial Joint Residual Block |
| IP | Indian Pines |
| AVIRIS | Airborne Visible Infrared Imaging Spectrometer |
| UP | University of Pavia |
| ROSIS | Reflective Optics System Imaging Spectrometer |
| SV | Salinas Valley |
| OA | Overall Accuracy |
| AA | Average Accuracy |
| FE | Feature Extraction |
References
- Tan, X.; Xue, Z. Spectral-spatial multi-layer perceptron network for hyperspectral image land cover classification. Eur. J. Remote Sens. 2022, 55, 409–419. [Google Scholar] [CrossRef]
- Moharram, M.A.; Sundaram, D.M. Land use and land cover classification with hyperspectral data: A comprehensive review of methods, challenges and future directions. Neurocomputing 2023, 536, 90–113. [Google Scholar] [CrossRef]
- Zhang, B.; Zhao, L.; Zhang, X. Three-dimensional convolutional neural network model for tree species classification using airborne hyperspectral images. Remote Sens. Environ. 2020, 247, 111938. [Google Scholar] [CrossRef]
- Tong, F.; Zhang, Y. Spectral-Spatial and Cascaded Multilayer Random Forests for Tree Species Classification in Airborne Hyperspectral Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 21764773. [Google Scholar] [CrossRef]
- Sethy, P.K.; Pandey, C.; Sahu, Y.K.; Behera, S.K. Hyperspectral imagery applications for precision agriculture—A systemic survey. Multimed. Tools Appl. 2022, 81, 3005–3038. [Google Scholar] [CrossRef]
- Lu, B.; Dao, P.D.; Liu, J.; He, Y.; Shang, J. Recent Advances of Hyperspectral Imaging Technology and Applications in Agriculture. Remote Sens. 2020, 12, 2569. [Google Scholar] [CrossRef]
- Stuart, M.B.; McGonigle, A.J.S.; Willmott, J.R. Hyperspectral Imaging in Environmental Monitoring: A Review of Recent Developments and Technological Advances in Compact Field Deployable Systems. Sensors 2019, 19, 3071. [Google Scholar] [CrossRef]
- Stuart, M.B.; Davies, M.; Hobbs, M.J.; Pering, T.D.; McGonigle, A.J.S.; Willmott, J.R. High-Resolution Hyperspectral Imaging Using Low-Cost Components: Application within Environmental Monitoring Scenarios. Sensors 2022, 22, 4652. [Google Scholar] [CrossRef] [PubMed]
- Shimoni, M.; Haelterman, R.; Perneel, C. Hyperspectral Imaging for Military and Security Applications Combining myriad processing and sensing techniques. IEEE Geosci. Remote Sens. Mag. 2019, 7, 101–117. [Google Scholar] [CrossRef]
- Gross, W.; Queck, F.; Voegtli, M.; Schreiner, S.; Kuester, J.; Boehler, J.; Mispelhorn, J.; Kneubuehler, M.; Middelmann, W. A Multi-Temporal Hyperspectral Target Detection Experiment—Evaluation of Military Setups. In Target and Background Signatures VII; Electr Network; SPIE: Bellingham, WA, USA, 2021. [Google Scholar]
- Sellami, A.; Farah, M.; Farah, I.R.; Solaiman, B. Hyperspectral Imagery Semantic Interpretation Based on Adaptive Constrained Band Selection and Knowledge Extraction Techniques. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2018, 11, 1337–1347. [Google Scholar] [CrossRef]
- Feng, J.; Jiao, L.; Sun, T.; Liu, H.; Zhang, X. Multiple Kernel Learning Based on Discriminative Kernel Clustering for Hyperspectral Band Selection. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6516–6530. [Google Scholar] [CrossRef]
- Jia, S.; Ji, Z.; Qian, Y.; Shen, L. Unsupervised Band Selection for Hyperspectral Imagery Classification Without Manual Band Removal. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2012, 5, 531–543. [Google Scholar] [CrossRef]
- Ren, Y.; Liao, L.; Maybank, S.J.; Zhang, Y.; Liu, X. Hyperspectral Image Spectral-Spatial Feature Extraction via Tensor Principal Component Analysis. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1431–1435. [Google Scholar] [CrossRef]
- Khan, Z.; Shafait, F.; Mian, A. Joint Group Sparse PCA for Compressed Hyperspectral Imaging. IEEE Trans. Image Process. 2015, 24, 4934–4942. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Su, H.; Shen, J. Hyperspectral Dimensionality Reduction Based on Multiscale Superpixelwise Kernel Principal Component Analysis. Remote Sens. 2019, 11, 1219. [Google Scholar] [CrossRef]
- Ghamisi, P.; Dalla Mura, M.; Benediktsson, J.A. A Survey on Spectral-Spatial Classification Techniques Based on Attribute Profiles. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2335–2353. [Google Scholar] [CrossRef]
- Ye, Z.; Yan, Y.; Bai, L.; Hui, M. Feature Extraction Based on Morphological Attribute Profiles for Classification of Hyperspectral Image. In Proceedings of the Tenth International Conference on Digital Image Processing (ICDIP 2018), Shanghai, China, 11–14 May 2018; SPIE: Bellingham, WA, USA, 2018; Volume 10806. [Google Scholar]
- Liu, B.; Guo, W.; Chen, X.; Gao, K.; Zuo, X.; Wang, R.; Yu, A. Morphological Attribute Profile Cube and Deep Random Forest for Small Sample Classification of Hyperspectral Image. IEEE Access. 2020, 8, 117096–117108. [Google Scholar] [CrossRef]
- Yan, Y.; Ren, J.; Liu, Q.; Zhao, H.; Sun, H.; Zabalza, J. PCA-Domain Fused Singular Spectral Analysis for Fast and Noise-Robust Spectral-Spatial Feature Mining in Hyperspectral Classification. IEEE Geosci. Remote Sens. Lett. 2023, 20, 5505405. [Google Scholar] [CrossRef]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep Learning-Based Classification of Hyperspectral Data. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Jijón-Palma, M.E.; Kern, J.; Amisse, C.; Centeno, J.A.S. Improving stacked-autoencoders with 1D convolutional-nets for hyperspectral image land-cover classification. J. Appl. Remote Sens. 2021, 15, 26506. [Google Scholar] [CrossRef]
- Bai, Y.; Sun, X.; Ji, Y.; Fu, W.; Zhang, J. Two-stage multi-dimensional convolutional stacked autoencoder network model for hyperspectral images classification. Multimed. Tools Appl. 2023. [Google Scholar] [CrossRef]
- Zhao, J.; Hu, L.; Dong, Y.; Huang, L.; Weng, S.; Zhang, D. A combination method of stacked autoencoder and 3D deep residual network for hyperspectral image classification. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102459. [Google Scholar] [CrossRef]
- Cheng, C.; Peng, J.; Cui, W. A Two-Stage Convolutional Sparse Coding Network for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2023, 20, 5501905. [Google Scholar] [CrossRef]
- Bai, Y.; Sun, X.; Ji, Y.; Huang, J.; Fu, W.; Shi, H. Bibliometric and visualized analysis of deep learning in remote sensing. Int. J. Remote Sens. 2022, 43, 5534–5571. [Google Scholar] [CrossRef]
- Jacopo, A.; Elena, M.; Lutgarde, M.C.B.; Thanh, T.; Twan, V.L. Spectral-Spatial Classification of Hyperspectral Images: Three Tricks and a New Learning Setting. Remote Sens. 2018, 10, 1156. [Google Scholar]
- Li, T.; Leng, J.; Kong, L.; Guo, S.; Bai, G.; Wang, K. DCNR: Deep cube CNN with random forest for hyperspectral image classification. Multimed. Tools Appl. 2019, 78, 3411–3433. [Google Scholar] [CrossRef]
- Haque, M.R.; Mishu, S.Z. Spectral-Spatial Feature Extraction Using PCA and Multi-Scale Deep Convolutional Neural Network for Hyperspectral Image Classification. In Proceedings of the 2019 22nd International Conference on Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 18–20 December 2019; pp. 1–6. [Google Scholar]
- Jia, Z.; Lu, W. An End-to-End Hyperspectral Image Classification Method Using Deep Convolutional Neural Network With Spatial Constraint. IEEE Geosci. Remote Sens. Lett. 2021, 18, 1786–1790. [Google Scholar] [CrossRef]
- Gao, H.; Zhu, M.; Wang, X.; Li, C.; Xu, S. Lightweight Spatial-Spectral Network Based on 3D-2D Multi-Group Feature Extraction Module for Hyperspectral Image Classification. Int. J. Remote Sens. 2023, 44, 3607–3634. [Google Scholar] [CrossRef]
- Yu, C.Y.; Han, R.; Song, M.P.; Liu, C.Y.; Chang, C.I. A Simplified 2D-3D CNN Architecture for Hyperspectral Image Classification Based on Spatial-Spectral Fusion. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2020, 13, 2485–2501. [Google Scholar] [CrossRef]
- Firat, H.; Asker, M.E.; Bayindir, M.I.; Hanbay, D. Spatial-spectral classification of hyperspectral remote sensing images using 3D CNN based LeNet-5 architecture. Infrared Phys. Technol. 2022, 127, 104470. [Google Scholar] [CrossRef]
- Li, Z.; Huang, L.; He, J. A Multiscale Deep Middle-level Feature Fusion Network for Hyperspectral Classification. Remote Sens. 2019, 11, 695. [Google Scholar] [CrossRef]
- Zhou, L.; Ma, X.; Wang, X.; Hao, S.; Ye, Y.; Zhao, K. Shallow-to-Deep Spatial-Spectral Feature Enhancement for Hyperspectral Image Classification. Remote Sens. 2023, 15, 261. [Google Scholar] [CrossRef]
- Ma, Y.; Wang, S.; Du, W.; Cheng, X. An Improved 3D-2D Convolutional Neural Network Based on Feature Optimization for Hyperspectral Image Classification. IEEE Access. 2023, 11, 28263–28279. [Google Scholar] [CrossRef]
- Paoletti, M.E.; Mario Haut, J.; Fernandez-Beltran, R.; Plaza, J.; Plaza, A.J.; Pla, F. Deep Pyramidal Residual Networks for Spectral-Spatial Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 740–754. [Google Scholar] [CrossRef]
- Zhu, M.; Jiao, L.; Liu, F.; Yang, S.; Wang, J. Residual Spectral-Spatial Attention Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 449–462. [Google Scholar] [CrossRef]
- Dong, Z.; Cai, Y.; Cai, Z.; Liu, X.; Yang, Z.; Zhuge, M. Cooperative Spectral-Spatial Attention Dense Network for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2021, 18, 866–870. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral-Spatial Residual Network for Hyperspectral Image Classification: A 3-D Deep Learning Framework. IEEE Trans. Geosci. Remote Sens. 2018, 56, 847–858. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Sun, H.; Zheng, X.; Lu, X.; Wu, S. Spectral-Spatial Attention Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3232–3245. [Google Scholar] [CrossRef]
- Wei, H.; Yangyu, H.; Li, W.; Fan, Z.; Hengchao, L.; Tianfu, W. Deep Convolutional Neural Networks for Hyperspectral Image Classification. J. Sens. 2015, 2015, 258619. [Google Scholar]
- Tun, N.L.; Gavrilov, A.; Tun, N.M.; Trieu, D.M.; Aung, H. Hyperspectral Remote Sensing Images Classification Using Fully Convolutional Neural Network. In Proceedings of the 2021 IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (ElConRus), St. Petersburg, Russia, 26–29 January 2021; pp. 2166–2170. [Google Scholar]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef]
- Sun, Q.; Liu, X.; Bourennane, S. Unsupervised Multi-Level Feature Extraction for Improvement of Hyperspectral Classification. Remote Sens. 2021, 13, 1602. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Duan, C.; Yang, Y.; Wang, X. Classification of Hyperspectral Image Based on Double-Branch Dual-Attention Mechanism Network. Remote Sens. 2020, 12, 582. [Google Scholar] [CrossRef]
- Ma, W.; Yang, Q.; Wu, Y.; Zhao, W.; Zhang, X. Double-Branch Multi-Attention Mechanism Network for Hyperspectral Image Classification. Remote Sens. 2019, 11, 1307. [Google Scholar] [CrossRef]
- Guo, T.; Wang, R.; Luo, F.; Gong, X.; Zhang, L.; Gao, X. Dual-View Spectral and Global Spatial Feature Fusion Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5512913. [Google Scholar] [CrossRef]
- Zhou, H.; Luo, F.; Zhuang, H.; Weng, Z.; Gong, X.; Lin, Z. Attention Multihop Graph and Multiscale Convolutional Fusion Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5508614. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).