

Enhanced YOLOv5: An Efficient Road Object Detection Method

Abstract
:1. Introduction
2. Related Works
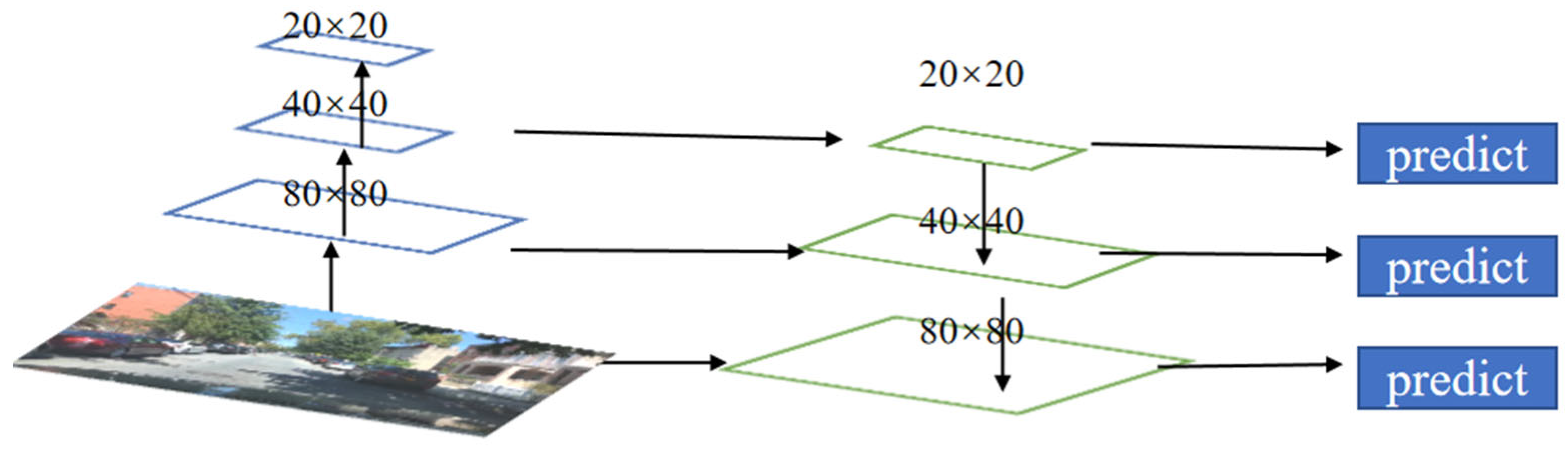
2.1. Multi-Scale Feature Fusion
2.2. Attention Mechanism
2.3. NMS
3. Benchmark Model and Proposed Methods
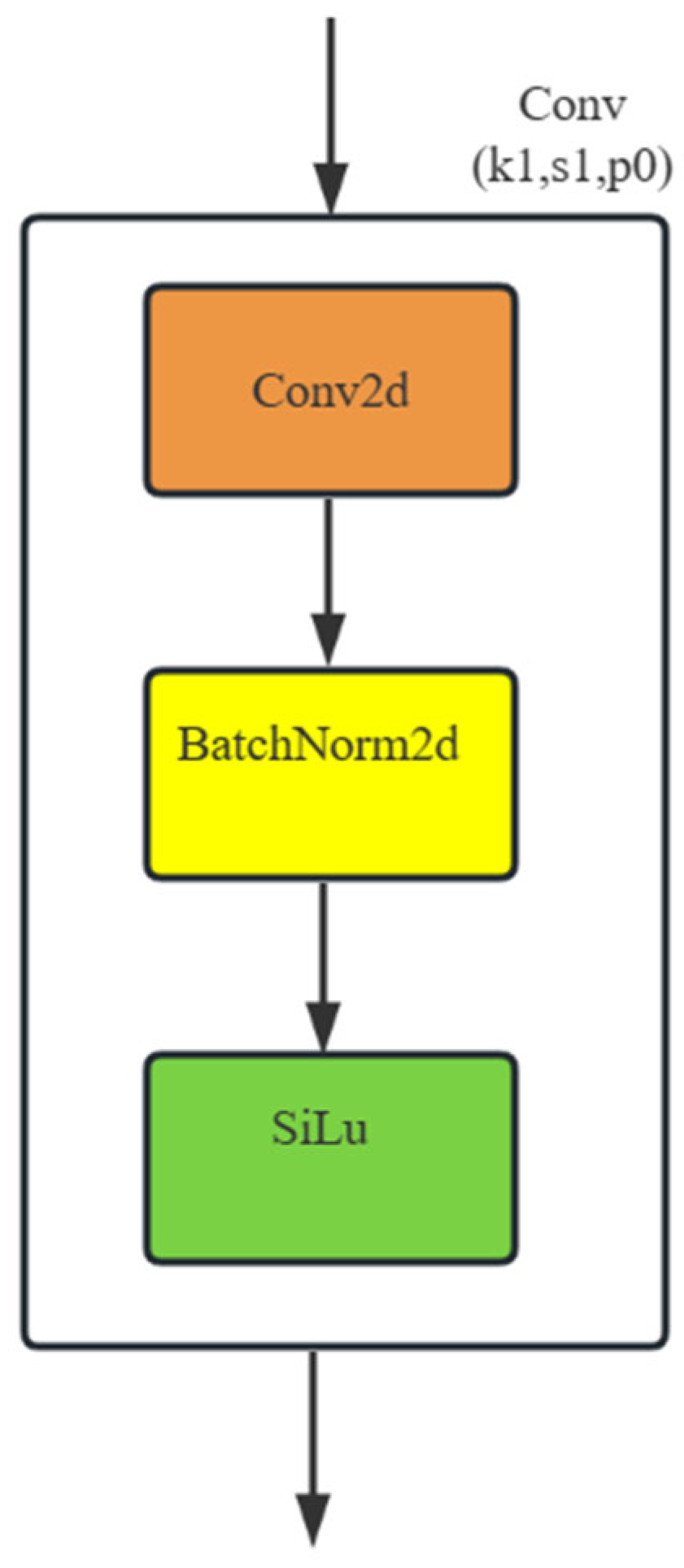
3.1. Benchmark Model
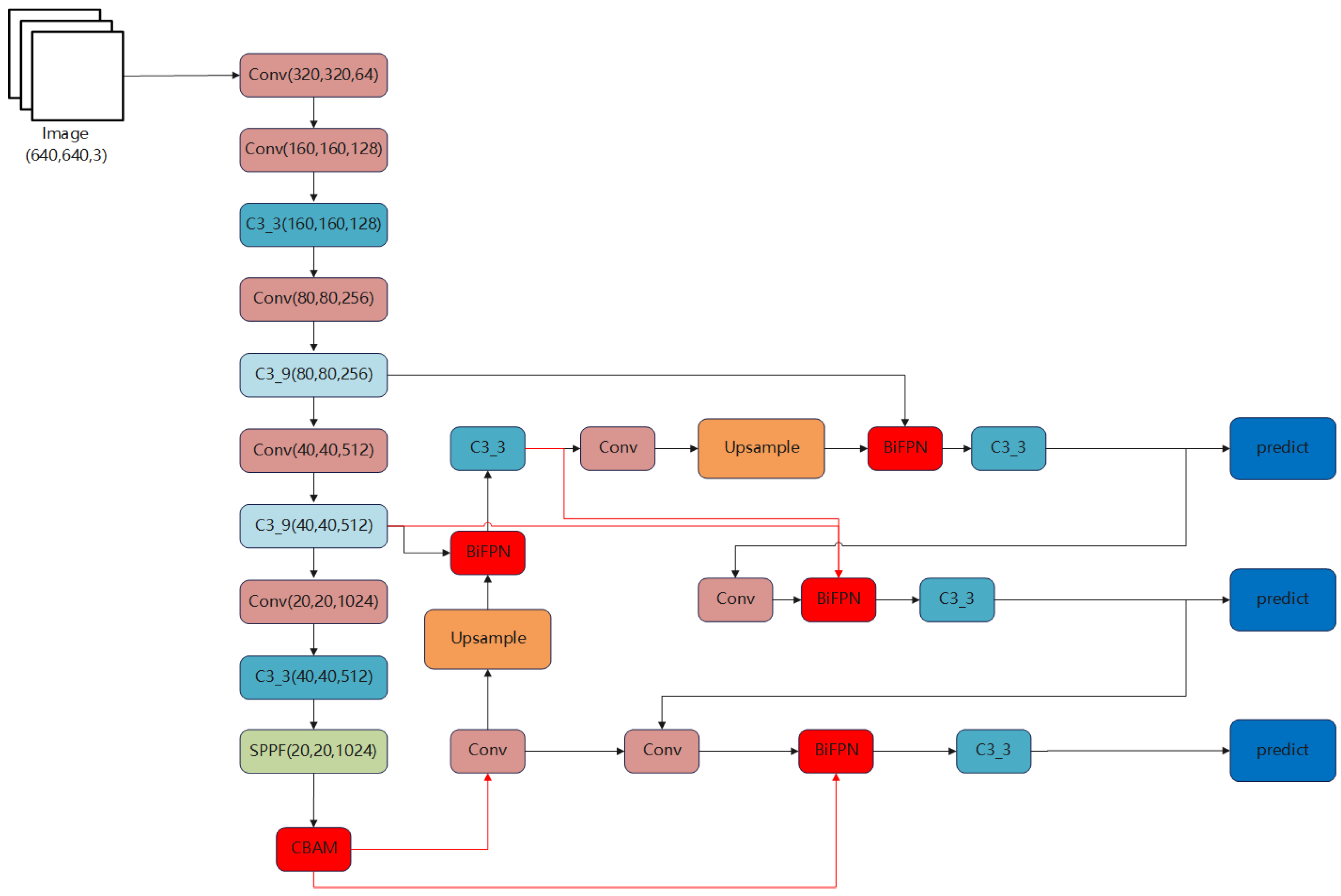
3.2. Proposed Methods
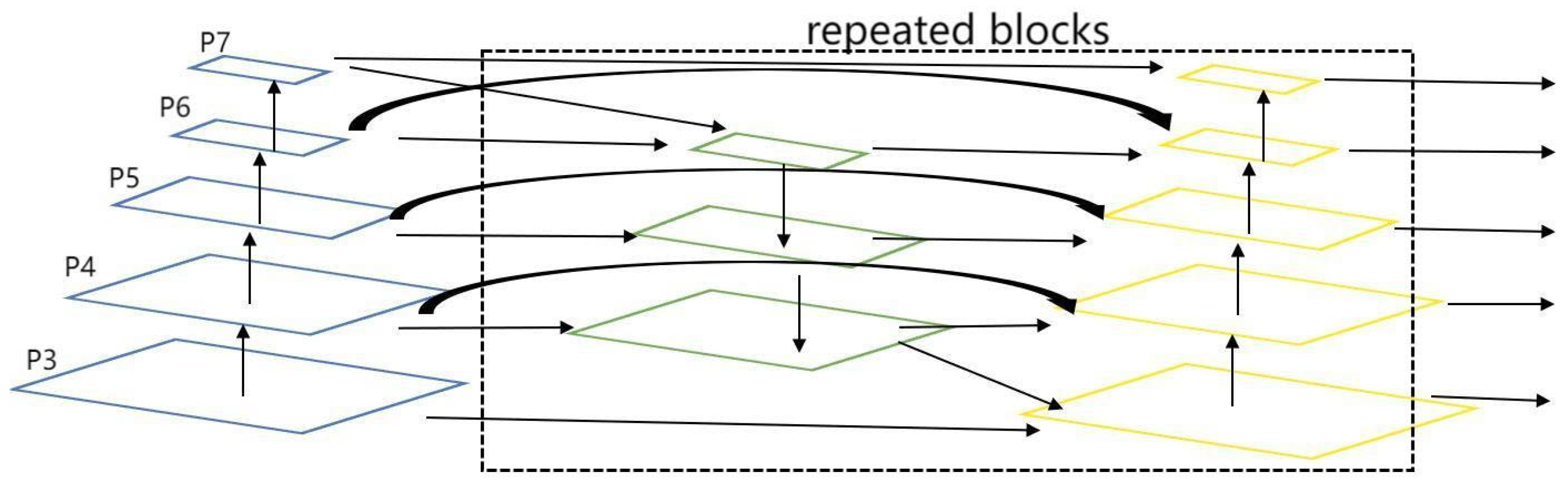
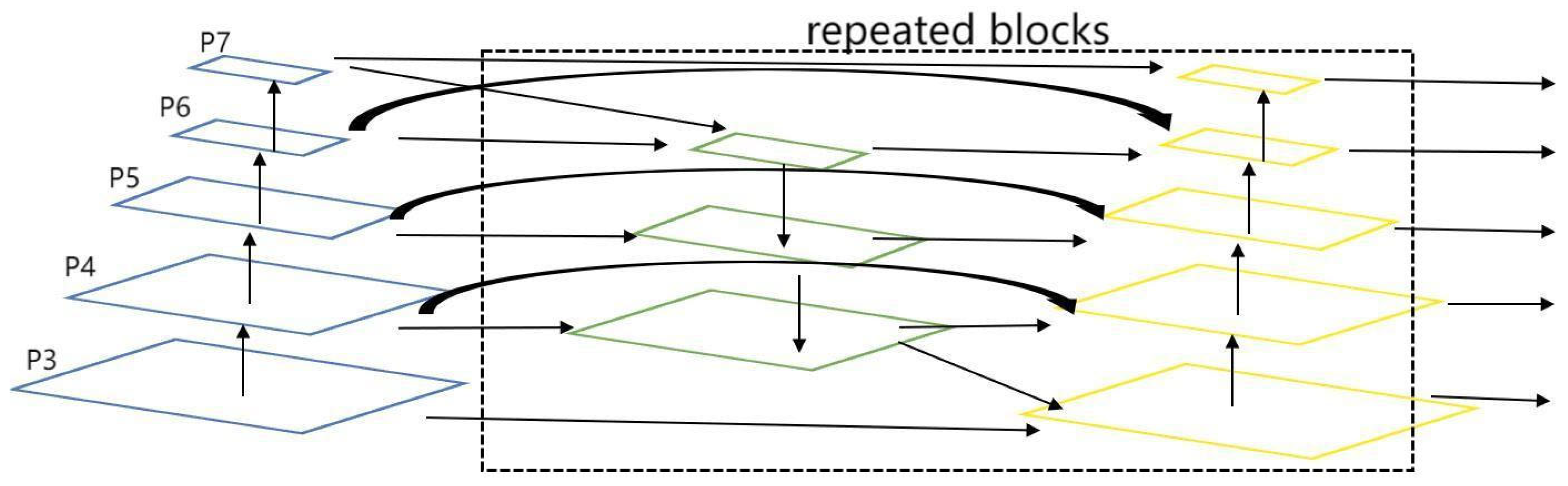
3.3. BiFPN
Weighted Feature Fusion

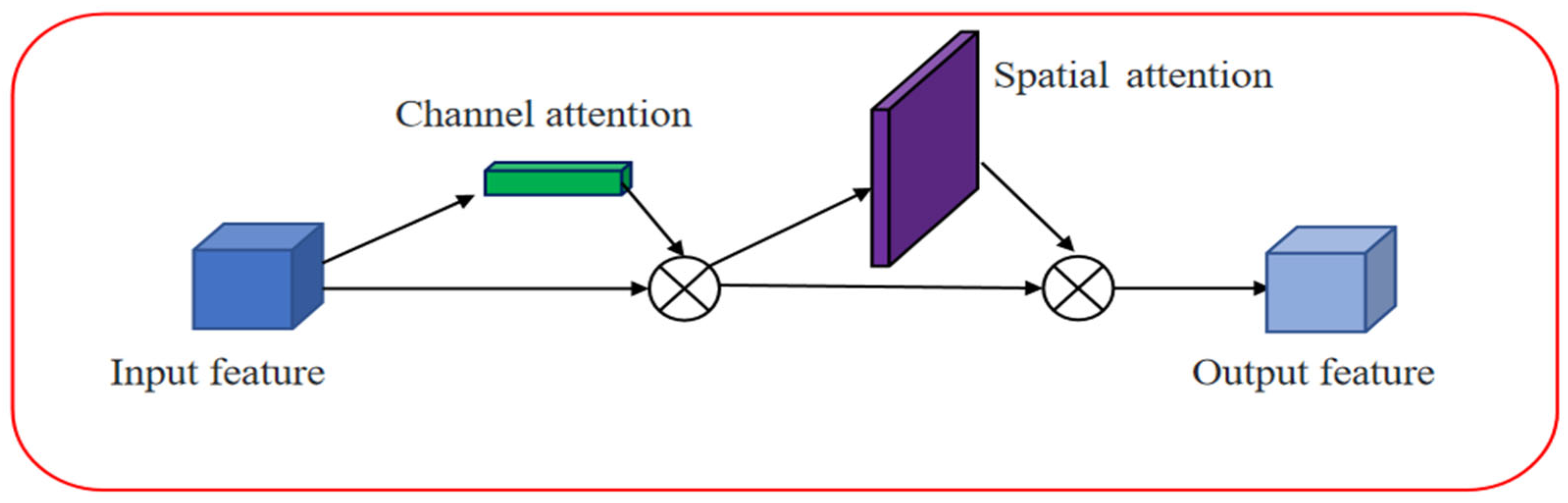
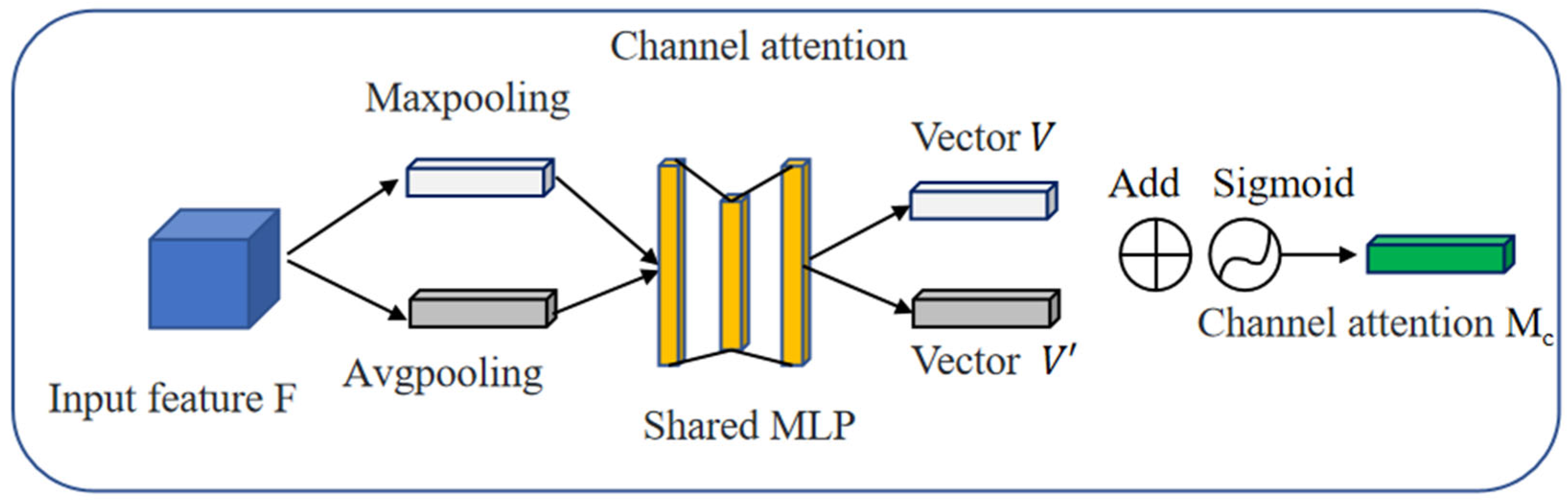
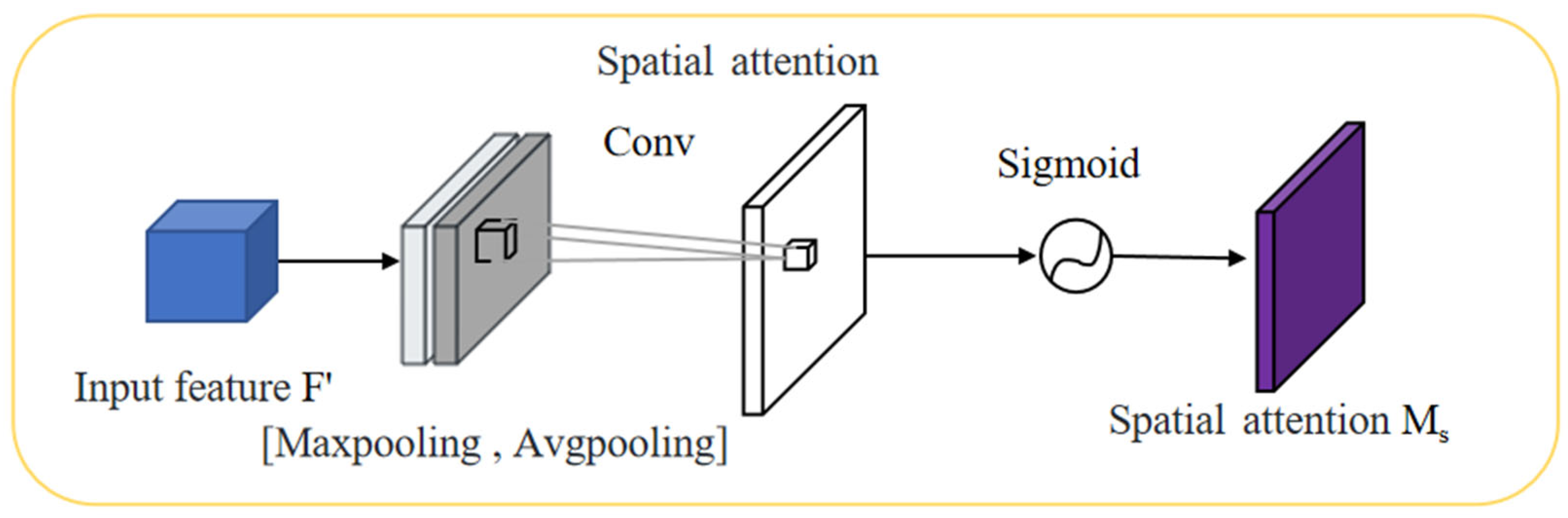
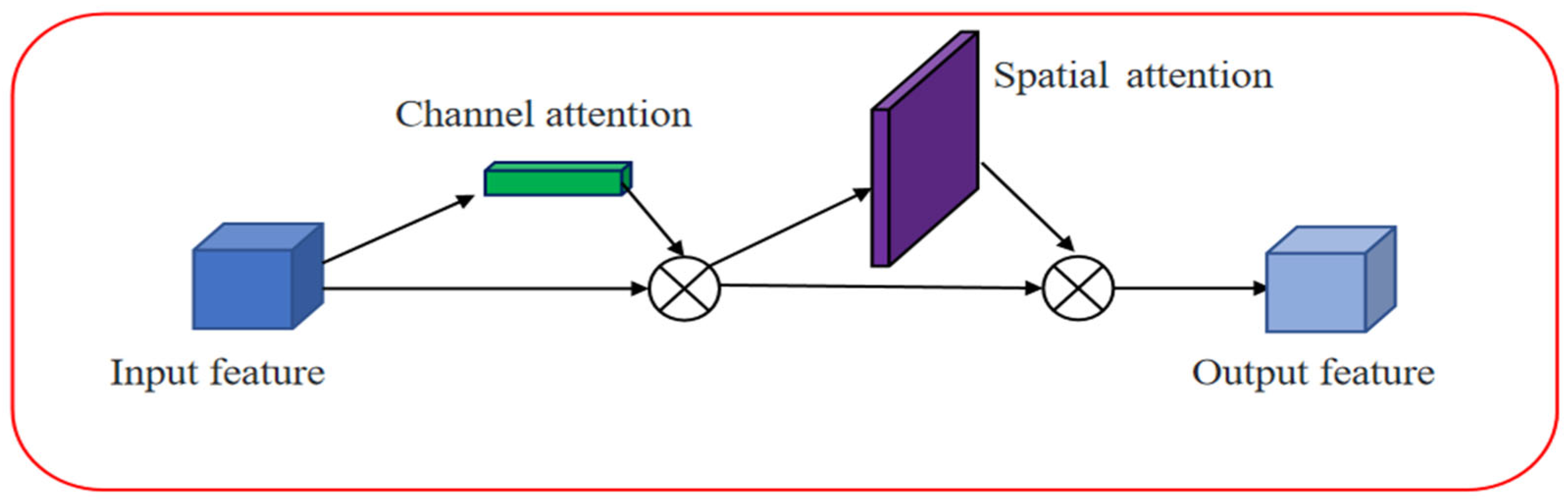
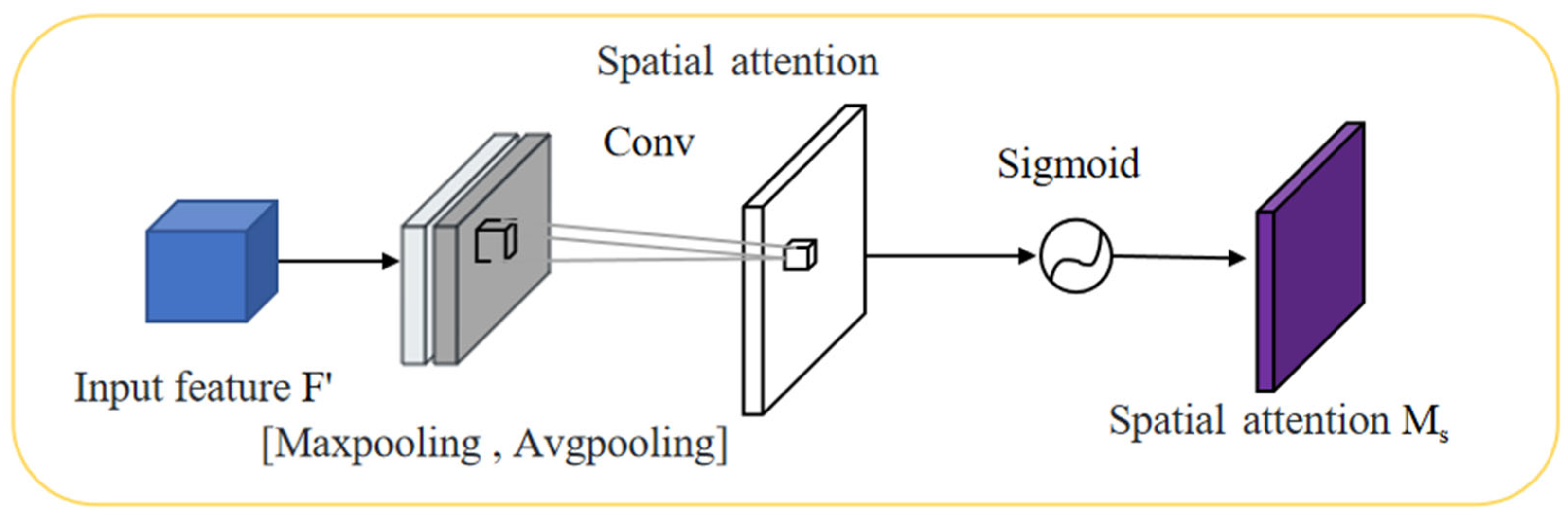
3.4. CBAM
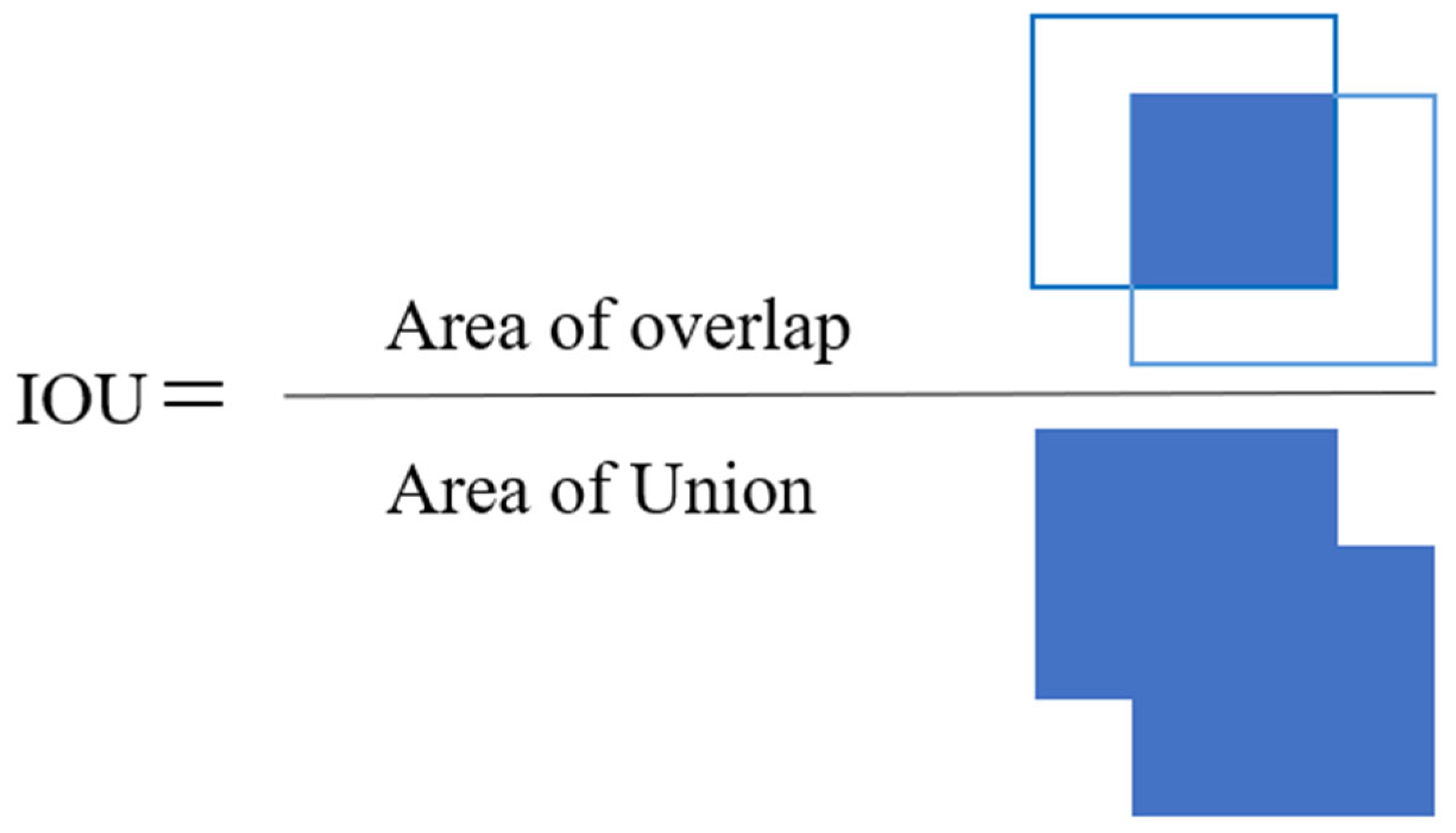
3.5. DIoU_NMS
4. Experimental Results and Analysis
4.1. Environment and Parameter Settings
4.2. Database
4.3. Performance Evaluation Metrics
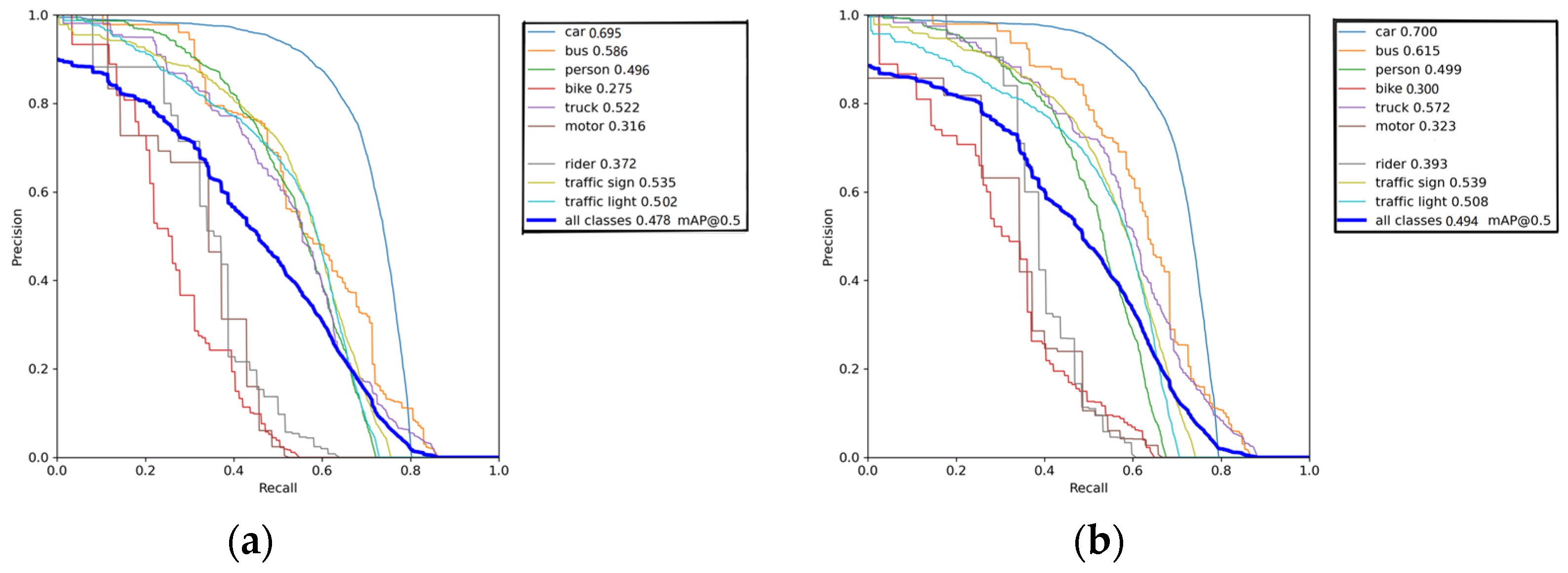
4.4. Experimental Results
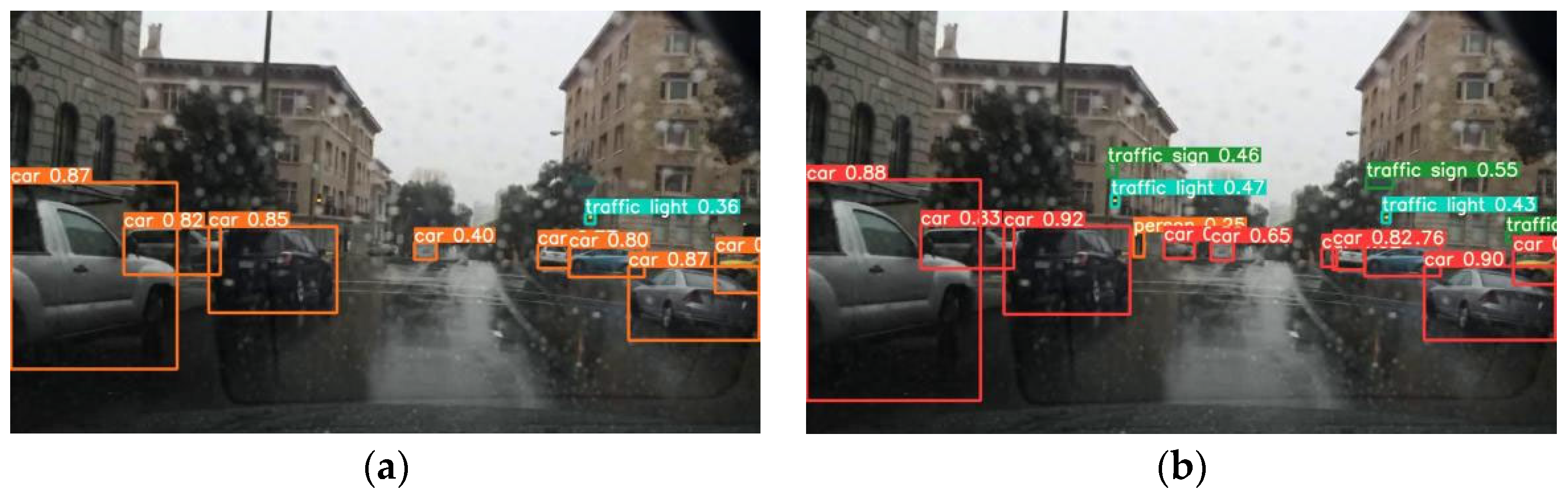
4.5. Algorithm Verification
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS) 25, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Sifre, L. Rigid-Motion Scattering for Image Classifification. Ph.D. Thesis, École Polytechnique, Paris, France, 2014. [Google Scholar]
- Kim, H.; Lee, Y.; Yim, B.; Park, E.; Kim, H. On-road object detection using deep neural network. In Proceedings of the 2016 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), Seoul, South Korea, 26–28 October 2016. [Google Scholar]
- Roh, M.-C.; Lee, J.-Y. Refining faster-RCNN for accurate object detection. In Proceedings of the 2017 Fifteenth IAPR International Conference on Machine Vision Applications (MVA), Nagoya, Japan, 8–12 May 2017. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Juan, PR, USA, 17–19 June 1997. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning spatial fusion for single-shot object detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Cao, J.; Zhang, J.; Huang, W. Traffic sign detection and recognition using multi-scale fusion and prime sample attention. IEEE Access 2020, 9, 3579–3591. [Google Scholar] [CrossRef]
- Zhou, P.; Ni, B.; Geng, C.; Hu, J.; Xu, Y. Scale-transferrable object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 528–537. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. Nas-fpn: Learning scalable feature pyramid architecture for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Kim, S.W.; Kook, H.K.; Sun, J.Y.; Kang, M.C.; Ko, S.J. Parallel feature pyramid network for object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Lian, J.; Yin, Y.; Li, L.; Wang, Z.; Zhou, Y. Small Object Detection in Traffic Scenes Based on Attention Feature Fusion. Sensors 2021, 21, 3031. [Google Scholar] [CrossRef] [PubMed]
- Akyon, F.C.; Altinuc, S.O.; Temizel, A. Slicing Aided Hyper Inference and Fine-Tuning for Small Object Detection. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- He, Y.; Zhu, C.; Wang, J.; Savvides, M.; Zhang, X. Bounding Box Regression with Uncertainty for Accurate Object Detection. arXiv 2019, arXiv:1809.08545v3. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, J.; Chen, Y.; Dong, Z.; Gao, M. Improved YOLOv5 network for real-time multi-scale traffic sign detection. Neural Comput. Appl. 2023, 35, 7853–7865. [Google Scholar] [CrossRef]
- Terven, J.; Cordova-Esparza, D. A Comprehensive Review of YOLO: From YOLOv1 and Beyond. arXiv 2023, arXiv:2304.00501. [Google Scholar]
- Zha, W.; Hu, L.; Sun, Y.; Li, Y. ENGD-BiFPN: A remote sensing object detection model based on grouped deformable convolution for power transmission towers. Multimed. Tools Appl. 2023. [Google Scholar] [CrossRef]
- Lu, X.; Lu, X. An efficient network for multi-scale and overlapped wildlife detection. Signal Image Video Process. 2023, 17, 343–351. [Google Scholar] [CrossRef]
- Jiang, M.; Song, L.; Wang, Y.; Li, Z.; Song, H. Fusion of the YOLOv4 network model and visual attention mechanism to detect low-quality young apples in a complex environment. Precis. Agric. 2022, 23, 559–577. [Google Scholar] [CrossRef]
- Zagoruyko, S.; Komodakis, N. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. arXiv 2016, arXiv:1612.03928. [Google Scholar]
- Roy, A.G.; Conjeti, S.; Navab, N.; Wachinger, C. Concurrent spatial and channel squeeze & excitation in fully convolutional networks. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Granada, Spain, 16–20 September 2018; pp. 421–429. [Google Scholar]
- Cai, D.; Zhang, Z.; Zhang, Z. Corner-Point and Foreground-Area IoU Loss: Better Localization of Small Objects in Bounding Box Regression. Sensors 2023, 23, 4961. [Google Scholar] [CrossRef]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. BDD100K: A diverse driving dataset for heterogeneous multitask learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2633–2642. [Google Scholar]
- Elhawary, H.M.; Suddamalla, U.; Shapiai, M.I.; Wong, A.; Zamzuri, H. Real-Time Attribute Based Deep Learning Network for Traffic Sign Detection. In Proceedings of the 14th International Conference on Information Technology and Electrical Engineering (ICITEE), Yogyakarta, Indonesia, 18–19 October 2022. [Google Scholar]
- Li, S.; Wang, S.; Wang, P. A Small Object Detection Algorithm for Traffic Signs Based on Improved YOLOv7. Sensors 2023, 23, 7145. [Google Scholar]
- Ogunrinde, I.; Bernadin, S. Deep Camera–Radar Fusion with an Attention Framework for Autonomous Vehicle Vision in Foggy Weather Conditions. Sensors 2023, 23, 6255. [Google Scholar] [PubMed]
- Hou, X.; Sun, K.; Shen, L.; Qiu, G. Improving variational autoencoder with deep feature consistent and generative adversarial training. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017. [Google Scholar]
- Küppers, F.; Haselhoff, A.; Kronenberger, J.; Schneider, J. Confidence Calibration for Object Detection and Segmentation. In Deep Neural Networks and Data for Automated Driving: Robustness, Uncertainty Quantification, and Insights Towards Safety; Springer: Cham, Switzerland, 2022; pp. 225–250. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class Name | Train Numbers | Test Numbers |
|---|---|---|
| Person | 10,614 | 1199 |
| Rider | 512 | 59 |
| Car | 81,881 | 10,425 |
| Bus | 1258 | 167 |
| Truck | 3374 | 420 |
| Bike | 797 | 92 |
| Motor | 364 | 44 |
| Traffic sign | 28,182 | 3331 |
| Traffic light | 21,370 | 2701 |
| Model | Precision (%) | Recall (%) | mAP@0.5 (%) |
|---|---|---|---|
| YOLOv5s | 66.7 | 39.7 | 47.8 |
| YOLOv5s + BiFPN | 69.4 | 40.5 | 48.6 |
| YOLOv5s + BiFPN + CBAM | 70.5 | 41.6 | 49.1 |
| YOLOv5s + BiFPN + CBAM + DIOU_NMS | 72 | 42.1 | 49.4 |
| Algorithm | AP(%) | mAP@0.5(%) | P(%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Car | Bus | Person | Bike | Truck | Motor | Rider | Traffic Sign | Traffic Light | |||
| Faster R-CNN | 57.4 | 46.2 | 30.5 | 19.7 | 43.7 | 19.2 | 27.4 | 20.9 | 8.5 | 30.4 | 39.5 |
| SSD | 47.3 | 38.2 | 18.9 | 19.6 | 36.2 | 18.2 | 13.7 | 12 | 7.4 | 23.5 | 67.8 |
| YOLOv3 | 55.4 | 44.3 | 28.9 | 15.9 | 42.6 | 21.6 | 17.5 | 29 | 25.6 | 31.1 | 58.9 |
| YOLOv4 | 60 | 40.5 | 50.2 | 19.2 | 52 | 30.4 | 12.1 | 48.3 | 45.5 | 39.8 | 41.3 |
| YOLOv5s | 69.5 | 58.6 | 49.6 | 27.5 | 52.2 | 31.6 | 37.2 | 53.5 | 50.2 | 47.8 | 66.7 |
| TheProposed | 70 | 61.5 | 49.9 | 30 | 57.2 | 32.3 | 39.3 | 53.9 | 50.8 | 49.4 | 72 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Chen, Z.; Yu, H. Enhanced YOLOv5: An Efficient Road Object Detection Method. Sensors 2023, 23, 8355. https://doi.org/10.3390/s23208355
Chen H, Chen Z, Yu H. Enhanced YOLOv5: An Efficient Road Object Detection Method. Sensors. 2023; 23(20):8355. https://doi.org/10.3390/s23208355
Chicago/Turabian StyleChen, Hao, Zhan Chen, and Hang Yu. 2023. "Enhanced YOLOv5: An Efficient Road Object Detection Method" Sensors 23, no. 20: 8355. https://doi.org/10.3390/s23208355
APA StyleChen, H., Chen, Z., & Yu, H. (2023). Enhanced YOLOv5: An Efficient Road Object Detection Method. Sensors, 23(20), 8355. https://doi.org/10.3390/s23208355