Abstract
Efficient task offloading decision is a crucial technology in vehicular edge computing, which aims to fulfill the computational performance demands of complex vehicular tasks with respect to delay and energy consumption while minimizing network resource competition and consumption. Conventional distributed task offloading decisions rely solely on the local state of the vehicle, failing to optimize the utilization of the server’s resources to its fullest potential. In addition, the mobility aspect of vehicles is often neglected in these decisions. In this paper, a cloud-edge-vehicle three-tier vehicular edge computing (VEC) system is proposed, where vehicles partially offload their computing tasks to edge or cloud servers while keeping the remaining tasks local to the vehicle terminals. Under the restrictions of vehicle mobility and discrete variables, task scheduling and task offloading proportion are jointly optimized with the objective of minimizing the total system cost. Considering the non-convexity, high-dimensional complex state and continuous action space requirements of the optimization problem, we propose a task offloading decision-making algorithm based on deep deterministic policy gradient (TODM_DDPG). TODM_DDPG algorithm adopts the actor–critic framework in which the actor network outputs floating point numbers to represent deterministic policy, while the critic network evaluates the action output by the actor network, and adjusts the network evaluation policy according to the rewards with the environment to maximize the long-term reward. To explore the algorithm performance, this conduct parameter setting experiments to correct the algorithm core hyper-parameters and select the optimal combination of parameters. In addition, in order to verify algorithm performance, we also carry out a series of comparative experiments with baseline algorithms. The results demonstrate that in terms of reducing system costs, the proposed algorithm outperforms the compared baseline algorithm, such as the deep Q network (DQN) and the actor–critic (AC), and the performance is improved by about 13% on average.
1. Introduction
As 5G technology and artificial intelligence are rapidly developing, autonomous driving has become a hot topic in both academic and engineering fields, particularly in intelligent transportation [1]. By leveraging advanced environmental perception and precise vehicle control, autonomous driving technology offers convenience and improves driving efficiency [2]. However, the increasing volume of in-vehicle data poses challenges for intelligent transportation systems [3]. The Internet of Vehicles, as an integral part of the Internet of Things, plays a crucial role in Intelligent Transport Systems, integrating vehicles, communication networks, and cloud computing [4,5]. Through Vehicle Ad Hoc Networks and various communication modes like Vehicle-to-Everything, IoV aims to enhance traffic safety, reduce congestion, and improve the overall user experience [6,7,8,9]. However, the proliferation of intelligent vehicles results in a surge of data and complex computational tasks [10], posing challenges such as limited network bandwidth, high latency, and security concerns [11]. To address these challenges, mobile edge computing moves computing and storage functions to the network edge as the complement of cloud computing, and becomes a promising solution [12,13,14]. This approach, suitable for vehicular networking environments requiring latency and reliability needs, alleviates IoV limitations. Vehicular edge computing combines mobile edge computing and the Internet of Vehicles, enabling distributed edge servers to facilitate computing offloading and interaction between vehicle users and roadside units via wireless access networks [15,16]. While mobile edge computing effectively addresses the limited resources and real-time constraints of the Internet of Vehicles, it still faces challenges such as restricted computing, storage, and bandwidth resources compared to cloud servers [17,18]. Overloading edge servers leads to increased service delay and reduced user experience [19]. Moreover, in vehicular edge computing where vehicles are the main research object, their high-speed mobility results in dynamic changes in communication links within the computing offloading environment [20]. Therefore, some service requests from vehicle users still require execution in the cloud or locally to optimize the utilization of system resources. Consequently, it remains a challenge to maintain the efficient operation of a vehicular edge computing system by designing intelligent resource management and scheduling schemes that can dynamically adapt to the complex vehicular edge computing environment while considering the dynamic nature of system status and resource constraints.
In the face of the challenge, traditional optimization techniques such as convex or non-convex optimization are insufficient to address decision-making problems in the vehicular edge computing environment. We introduce Deep Reinforcement Learning as our solution. Deep Reinforcement Learning is a field within artificial intelligence that enables intelligent agents to learn optimal actions through iterative interactions with the environment, allowing them effective adaptation to dynamic environments [21,22]. Inspired by the aforementioned issues, we design a VEC system model about “cloud-edge-vehicle” three-tier architecture, which integrates system resources, vehicle mobility, and task offloading to develop a comprehensive offloading strategy that considers both user experience and system energy consumption. This strategy effectively reduces system costs by making decisions on the task offload destinations of vehicles and reasonably allocating the proportion of task offloading. We formulate the task offloading decision process in vehicular edge computing environments as a Markov decision process. To optimize system costs, we propose a novel deep reinforcement learning algorithm that considers dynamic communication conditions. This algorithm effectively allocates the task offloading proportion, resulting in improved efficiency and reduced system costs.
The main contributions of this article are as follows:
- This paper proposes a “cloud-edge-vehicle” collaborative vehicular edge computing system model aimed at minimizing system costs by considering both system energy consumption and user experience. Taking into account the dynamic state of the system, we jointly optimize vehicle scheduling, task offloading and resource allocation. The optimization process is formulated as a Markov decision process and corresponding parameters are set.
- Taking into account the complexity of vehicular edge computing environment and continuous action space requirement of computation offloading decisions, this paper proposes a task offloading decision-making algorithm based on deep deterministic policy gradient (TODM_DDPG). The algorithm employs DNN networks to approximate the policy and Q-functions, thereby preventing dimensional explosion and obtaining the optimal policy by jointly addressing task offloading and resource allocation.
- This paper also provides a detailed training and validation process of the TODM_DDPG algorithm and introduces a state normalization mechanism to pre-process the system state.
The remaining structure of this paper is as follows: Section 2 examines previous related work. The system model and problem descriptions are introduced in Section 3. The background information of deep reinforcement learning and the suggested TODM_DDPG algorithm are introduced in Section 4. Section 5 investigates the experiment results. The paper is finally summarized in Section 6.
2. Related Work
As autonomous driving technology continues to evolve and intelligent transportation systems (ITS) mature, the scale of vehicular data for new applications such as vision-based object detection, path planning, and in-vehicle entertainment is growing explosively [23]. To address the diverse service needs of vehicular users, it is urgent to design effective computation offloading schemes for vehicular tasks. Due to its ability to meet the time-sensitive requirements of ITS application services, in the subject of intelligent transportation, the combination of mobile edge computing with the Internet of Vehicles has drawn considerable attention [15]. Computation offloading, as a core technology of mobile edge computing, encompasses several key elements, including the offloading target and destination, offloading mode, offloading function, and evaluation criteria for decision-making. These aspects collectively contribute to the overall process of computation offloading, enabling efficient resource utilization and improved system performance.
From the perspective of evaluation criteria for offloading decisions, most offloading decisions aim to optimize delay, energy consumption, system resources, combination of delay and energy consumption and maximize the quality of user experience or minimize the customized system cost. Luo et al. [24] aimed at minimizing offloading delay, proposed a multi-objective particle swarm optimization method using game theory analysis, which comprehensively considered communication, offloading decisions, and the allocation of computing resources. Simulation results show that this strategy is effective and feasible to solve the Pareto optimal solution. Based on the combination of a genetic algorithm and heuristic rules, Sun et al. [25] introduced a hybrid algorithm. Their approach aims to minimze delay and resource consumption by focusing on determining the execution location and the order of tasks. By leveraging the genetic algorithm and heuristic rules, their algorithm can effectively optimize task execution, resulting in reduced delays and efficient utilization of system resources. By introducing methods such as congestion degree and gravity reference point, literature [26] suggested an improved multi-objective whale optimization algorithm. A distributed computation offloading problem was presented in the senario of mobile device users by Chen et al. [27]. They presented a distributed technique that achieves the Nash equilibrium and formulated the problem as a game of multi-user computation offloading. Huang et al. [28] presented a cloud-edge server collaborative computation offloading method that leverages service orchestration. Their approach considers the delay and energy consumption and incorporates differentiated offloading decisions based on varying needs and delay sensitivities. By maximizing the distribution of processing tasks between cloud and edge servers, this technique successfully satisfies the demands of minimal latency and high dependability. In an effort to balance energy consumption and computation offloading delay, Cui et al. [29] suggested an enhancement to the NSGA-II method to discover the better solution to this constrained multi-objective optimization problem.
However, in the vehicular edge computing environment, the research object of computation offloading is the vehicle, while the mobility of the vehicle can lead to dynamic changes in the network topology. Traditional convex optimization or heuristic algorithms are not suitable for dynamic vehicular networks with vehicles, resources, and channel states. The majority of the aforementioned works, however, simply take into account the optimal or nearly optimal solution of the current system snapshot by offloading strategy, without considering the long-term impact of the current strategy on the environment. The decision-making process of computation offloading can be abstracted as a Markov decision process in the mobile edge computing context with dynamically changing network topology and computing resources [30]. With the help of repetitive interactions with the environment, reinforcement learning, a subfield of artificial intelligence, enables intelligent agents to learn the optimal action to maximize cumulative rewards. Reinforcement learning effectively addresses the Markov decision problem, permitting agents to learn through continuous trial and error [31]. A synchronous joint Q-learning (Sync-FQL) approach was introduced by Xiong et al. [32] that considers the probability of offloading failures in the vehicular edge computing environment while minimizing computation and communication costs. The algorithm optimizes the model to optimally utilize available resources by learning the Q-values from different parts. However, the performance of Q-learning algorithms in high-dimensional observation spaces is constrained because of the Q-table size constraint [33]. To overcome the shortcomings of conventional reinforcement learning algorithms in handling high-dimensional state and action spaces, the combination of deep learning with RL offers a potent strategy [21]. By leveraging the representation learning capabilities of deep neural networks, this combined approach enables effective learning and decision-making in complex environments. To improve computation offloading efficiency in vehicular networks, Zhao et al. [34] introduced an AHP-DQN-based computation offloading algorithm. This algorithm utilizes the Analytic Hierarchy Process (AHP) to appropriately allocate vehicle tasks and determines offloading decisions based on real-time channel gains. It addresses challenges such as limited terminal storage capacity and diverse network services in the process of computation offloading. In order to minimize user costs, Wang et al. [35] adopted the Double Deep Q-learning (DDQN) algorithm, treating the computational capacity of the mobile edge computing servers as the system state and improving resource utilization by learning offloading policies. For resource allocation and computation offloading, Khayyat et al. [36] introduced a DQN-based distributed learning algorithm. They approached the problem as a binary optimization challenge with the goal of minimizing the system’s overall time and energy costs. In order to meet the low latency requirements of vehicle-to-vehicle communication links and improve the throughput of vehicle-to-infrastructure links, Fu et al. [37] proposed the Double deep Q-learning (DDQN) algorithm, which effectively achieves the intelligent allocation of resources. While DQN-based algorithms effectively address dynamic computation offloading challenges, discretization methods used for continuous action spaces, such as resource allocation, can result in dimensionality explosion [38]. Regarding the computation offloading decision-making in continuous action spaces, research has been conducted recently. A mobile fog technique based on the DDPG algorithm, put forth by Chen et al. [39], effectively solves the state space explosion problem. Lu et al. [40] proposed an improved algorithm based on DDPG to solve the joint optimization problem of service delay, energy consumption and task success rate in the mobile edge computing environment, and effectively improved the quality of user experience.
3. System Model and Problem Description
As illustrated in Figure 1, the suggested system adopts a three-tier, region-based architecture for vehicular edge computing network. They are vehicle layer, edge layer and cloud layer. The vehicle layer comprises user vehicles on the road that are equipped with limited computing resources. Each vehicle can communicate with base stations and roadside units through 5G/LTE technology [41] and a dedicated wireless interface (IEEE 802.11p). The edge layer comprises roadside nodes that are deployed in different regions of the map. These roadside nodes include roadside units with limited signal coverage range and mobile edge computing servers connected to roadside units with computational and storage resources, and the signal ranges between them do not overlap. The cloud layer represents the cloud service layer, which includes high-performance computing resources connected to base stations through wired links to provide necessary resource support.
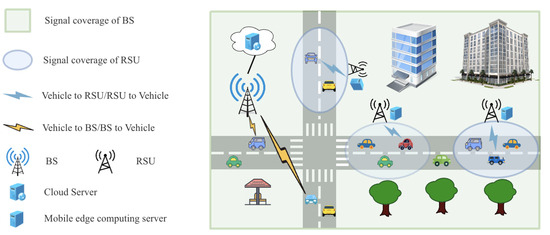
Figure 1.
Architecture of vehicular edge computing network.
The entire system operates in discrete time with equal time slot intervals [42]. In each time slot, the mobile edge computing servers can establish communication with vehicles within its coverage area. According to literature [14], in this paper, the base station signal coverage area is sufficiently large and that the cloud server can offer services to all vehicles. For vehicles outside the coverage area of the mobile edge computing servers, tasks need to be executed on the cloud. The set of RSUs is , and the set of vehicles can be represented by . Vehicles generate computational tasks at random for each time slot. Vehicle i’s task is denoted by . In this case, represents the task’s size, its computational complexity is denoted by , and the task’s maximum tolerated delay is denoted by . Table 1 gives the main symbols and their definitions.

Table 1.
The Meaning of the Main Symbols.
3.1. Communication Model
In the vehicular edge computing system, computational services are time-divisionallly allocated to vehicles [42]. Each vehicle is given a specific time slot for data transmission as the communication period is divided into T time slots. Using the Shannon formula, the data transmission rate from vehilcle i to the connected j within a given time slot t is given by
In the aforementioned equation, several parameters are involved. represents the total bandwidth available for the uplink channel of mobile edge computing server j. representes the number of tasks offloaded to mobile edge computing server during time slot t. While stands for the channel gain between vehicle and the mobile edge computing server j, refers to vehicle i’s transmission power. The communication channel’s noise power is represented by . Similarly, vehicles can also communicate with the cloud server via 5G/LTE technology. The transmission rate from vehicle i to the cloud server is given by
where is the channel gain between the vehicle and the cloud server, and denotes the bandwidth of the cloud server.
3.2. Computation Model
We use a partial offloading strategy in our vehicular edge computing system, where for each time slot t, the computational task generated by the vehicle is divisible. is the offloading proportion of task , and is the proportion of the task to be executed at the local terminal.
The connection between vehicles and mobile edge computing servers is limited by the signal coverage range. The mobile edge computing server j in our vehicular edge computing system has a fixed location represented by a coordinate , with an signal coverage radius. In time slot t, represents vehicle i’s location. The position of vehicle i after a time interval of is , where is the vehicle’s speed and is the direction of movement, supposing that the vehicles in the same direction and speed during time slot t. For a time interval in time slot t, only when both and are less than , vehicle i is regarded as being inside mobile edge computing server j’s signal coverage. For vehicles located outside the mobile edge computing server’s signal coverage, their tasks needs to be on the cloud for execution.
3.2.1. Local Computational Model
In time slot t, the local task execution time of task for vehicle i is
where represents the computational complexity, and is the vehicle’s terminal execution capability. The local energy consumption is given by
where represents the local energy cost power of vehicle.
3.2.2. Mobile Edge Computing Computational Model
We assume that the feedback delay can be disregarded due to the fact that the resulting data size is significantly smaller than the task data itself [13]. Therefore, in time slot t, the transmission and execution delay on the mobile edge computing server are the two parts of the total delay of task . The transmission delay of task is given by
where denotes the offloading proportion, represents the task data size, and represents the transmission rate from vehicle i to the connected mobile edge computing server j, assuming the server has I cores with the same processing power indicated by for each core. When the offloaded tasks to mobile edge computing server are more than cores available at time slot t, the remaining tasks must be executed on the cloud. The execution delay for tasks offloaded to the mobile edge computing server is described as follows:
When a vehicle offloads a task to the MEC, the total delay and energy consumption is depicted as
where and are the MEC’s transmission and energy consumption powers, respectively.
3.2.3. Cloud Computational Model
The computational capabilities of the cloud server are specified as . For task excuted on the cloud, the execution time is marked as , while the transmission time is represented as . The transmission and execution delay are depicted as
When a vehicle offloads a task to the cloud, the total delay and energy consumption are depicted as
Overall, for the task offloaded part,
where indicates whether task is offloaded to mobile edge computing j, with a value of 1 if it is, otherwise 0. represents whether task is offloaded to the cloud. Therefore, for task ,
3.3. Problem Description
The weighted sum of the user service cost and system energy consumption is used in this paper to define the system’s overall cost. For time slot t, the user service cost is defined as the entire waiting time for all tasks to complete:
The system energy consumption is defined as
In this paper, the objective is to improve system efficiency by minimizing the system cost. According to the above model, we formulate the optimization problem:
where C1 is the delay constraint that means the task waiting time cannot exceed the maximum tolerant delay; C2 and C8 are the offloading constraints, which indicate the offloading destination of task ; C3 is the mobile edge computing server core constraint; C4 is the computational constraint, which mandates that all computation tasks be finished within the allotted time; C5 and C7 are weight coefficient constraints; and C6 is the offloading proportion constraint, which indicates the value range of offloading proportion.
4. Deep-Deterministic-Policy-Gradient-Based Task Offloading Decision-Making Algorithm
In this section, first, we suggest the vehicular edge computing system’s reinforcement learning framework, and elaborate the main elements of the Markov decision process. We also explain how to train an effective task offloading decision-making algorithm within the vehilce edge computing system. In detail, we introduce the normalization pre-processing of the states and illustrate the training and validation process of the algorithm.
4.1. Vehicular-Edge-Computing-Based Reinforcement Learning Framework
The reinforcement learning framework model of our vehicular edge computing system is shown in Figure 2. The described model represents how intelligent agent vehicles interact with environment. The agent observes the state and determines the appropriate action according to the trained policy . After the action is chosen, the environment’s state transitions from to . Then, the intelligent agent vehicles receive an instantaneous reward associated with the transition. This process can be abstracted and modeled as a Markov decision process, where actions and states follow the Markov property.
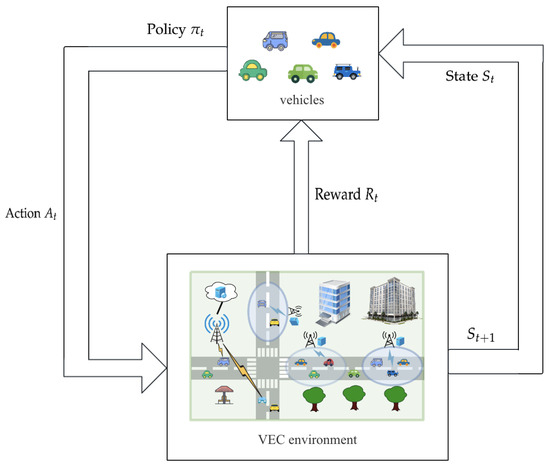
Figure 2.
Reinforcement learning framework model based on vehilce edge computing system.
The basic model of the Markov decison process is a five-tuple: . In this formulation, S represents the system’s state space, while A represents the action space. is the state transition function, which determines the probability of transitioning from state to when the agent performs action . determines the instantaneous reward obtained when optimal action is performed in state . , which ranges between zero and one, indicates the extent to which the present reward affects the future. The goal of the Markov decision process framework is to determine an optimal policy for each state that maximizes the expected cumulative long-term reward. This long-term reward is determined by the discounted sum of future rewards.
To assess the value of the current state in terms of long-term reward, value functions are utilized. There are two main types of value functions: the action value function and the state value function .
represents the expected cumulative reward of following policy starting from state . denotes the expected discounted return of the future of following policy and taking action , starting from state . and can also be represented by the Bellman equation, which indicates the relationship between the value of the current and the subsequent states.
The total number of potential future returns is estimated by variables and . As mentioned previously, the goal of the Markov decision process framework is to discover the optimal policy, and the effectiveness of the policy is assessed using its associated value function. The optimal value function is the one that reflects the best course of action. Specifically, there are two types of optimal value functions:
Then, the optimal policy is
For the optimal policy, the Bellman equation becomes the Bellman optimality equation:
4.2. Markov Decision Process Elements
Based on the above model, we consider all vehicles of the vehicular edge computing system as a centralized controlled agent that can make effective offloading decisions with global information and the system environment state. The definitions of the Markov decision process elements are as follows:
- (1)
- State space: At a time slot, the system state isThe coordinate location of the mobile edge computing server is , Here, represents the remaining task data size that the system needs to complete, and denotes the services that vehicles have requested. is the mobile edge computing server’s coordinate location, is the vehicle i’s coordinate location, indicates the task data size, and represents the computation complexity.
- (2)
- Action Space: A set of available actions for agents under centralized control within the given time period are represented by the action space. The actions performed by the agent can include selecting vehicles to request service, making offloading decisions, and determining offload proportion for vehicle tasks. The representation of the action isHere, indicates whether to offload to a mobile edge computing server or a cloud server, and the task offloading proportion is represented by
- (3)
- Reward: The optimization goal of the vehicular edge computing system’s reward function is to minimize system cost while training the reinforcement learning agent to maximize long-term rewards. Consequently, according to Formula (19), the agent’s reward function is
4.3. TODM_DDPG Architecture
In the VEC system, we utilize the actor–critic architecture-based deep reinforcement learning algorithm DDPG for our task offloading decision-making strategy. As shown in Figure 3, the algorithm iteratively trains the policy network (actor) and the Q network (critic) by interacting with the environment. By taking into account the system’s state and action space, this strategy enables the agent to learn optimal offloading decisions.
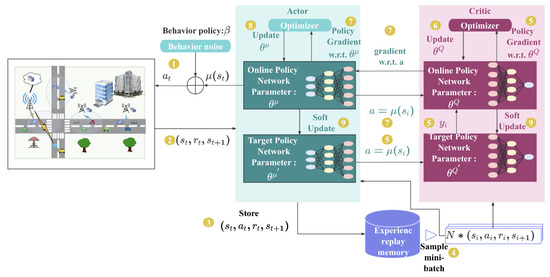
Figure 3.
Diagram of TODM_DDPG.
In the TODM_DDPG algorithm, the actor network consists of a target policy network in addition to an online policy network. Action that maximizes relevant action value based on state is produced by the online policy network. The actor network aims to learn actions with higher Q values, indicating better performance.
The critic network comprises online and target Q network. The state-action pair ’s action value is estimated by the online Q network as . The goal is to train the critic network to produce more accurate Q values, indicating better estimation.
To ensure training stability, the TODM_DDPG algorithm employs a delayed update technique called soft update. By combining them with the weights of the respective online networks, the target policy network and target Q network’s weights progressively update.
The TODM_DDPG algorithm’s training process can be outlined in the following way:
- (1)
- On the basis of the behavior policy , the actor network first chooses action and sends it to the vehicular edge computing environment for execution.Here, behavior policy guides the environment to perform an action in the training phase. By introducing noise into the decision mechanism of action, it takes into account both exploration and exploitation to explore potentially superior policy. The online policy network generated policy in the previous stage, while is the parameter. is Gaussian noise with mean and variance .
- (2)
- The agent of vehicular edge computing environment executes action and returns instantaneous reward and new environment state .
- (3)
- To train the online network, the actor network records the state transition process as the dataset.
- (4)
- N transition data is randomly sampled as mini-batch training data from replay memory buffer R for the online network.
- (5)
- Based on actions generated by the target policy network and the transition data, the target Q network first calculates label value .Gradient is then calculated by the online Q network using the back-propagation method in the neural network and loss function :
- (6)
- Online Q network’s parameters are updated.
- (7)
- Firstly, according to action , the online Q network computes gradient . Then, the online policy network calculates the policy gradient:
- (8)
- The online policy network’s parameters are updated.
- (9)
- Using the sliding mean approach, the target policy and Q network parameters and are softly updated:Here, .
4.4. State Normalization
Based on the aforementioned TODM_DDPG algorithm’s training process, two different DNN networks are utilized to to fit the value and policy function of the actor and critic networks, respectively, as illustrated in Figure 3. Taking the actor network as an example, we can observe that it takes as input and outputs action . However, the distribution of activation input values of the DNN network changes during the training process, gradually approaching the top and lower boundaries of the range of nonlinear function values [43]. This leads to the disappearance of gradients in the lower layers during the back-propagation process, resulting in slow convergence. To better train the neural network, in addition to using the Relu activation function, based on batch normalization [44,45], Algorithm 1 is proposed to normalize input states with different ranges.
| Algorithm 1: State Normalization |
|
Input: State parameters: , , , , ; Scale factors: , ; Min–Max value: , , , ; Output: Normalized State parameters: , , , , ;
|
This paper normalizes the state parameters with different ranges separately. and are scaling factors used to normalize the remaining total data size and coordinate information, respectively. The task data size and complexity are normalized using the min–max normalization method. The top and lower boundaries of the task data volume and complexity for each time slot are denoted by variables , , , and , respectively.
4.5. TODM_DDPG Training and Validating Algorithm
We propose the training algorithm, which is depicted in Algorithm 2, based on the aforementioned TODM_DDPG algorithm and state normalization method. By iteratively adjusting the online policy network parameters and online Q network parameters through interactions with the environment, actor, and critic networks throughout the training phase, the algorithm seeks to maximize the long-term reward and returns the optimal online policy network parameter after training. Algorithm 3 describes the validation algorithm for computing the offloading strategy, which utilizes trained optimal parameters . It performs the offloading decision-making process and obtains the system cost based on the output policy of the training algorithm.
| Algorithm 2: TODM_DDPG training algorithm |
 |
| Algorithm 3: TODM_DDPG validating algorithm |
 |
5. Experimental Analysis
5.1. Parameter Setting
We evaluate the algorithm in the Python development environment based on the Tensorflow platform in order to assess the efficiency and operational performance of the algorithm model in this research. In the vehicular edge computing test system, the simulation scenario is a three-tier structure of cloud-edge-vehicle consisting of one cloud server, one edge server and several vehicle users. Among them, a two-dimensional square area covered by the base station signals is considered, and within the area, the mobile edge computing servers are distributed on the road side, and their signal coverage is a circular area. Within the base station’s coverage area, vehicles move at random along the road. We use TensorFlow to initialize an instance of the deep reinforcement learning agent function acccording to the settings of Markov decision elements in Section 4.2. Table 2 displays the environmental parameters as well as the neural network’s parameters.
Table 2.
Experimental parameters.
5.2. Result and Analysis
5.2.1. Parameter Analysis
Since the selection of different hyperparameters impacts the effectiveness, convergence, and stability of the algorithm, the significance of hyperparameter setting should be considered. In order to obtain the ideal values for the hyperparameters used in the TODM_DDPG algorithm, we conducted a series of experiments.
Figure 4 demonstrates the impact of different learning rates on the convergence and stability of the algorithm. Since the actor network is updated by the critic network, we assumed that the learning rate of the critic network is greater than that of the actor network. Two combinations of learning rates were compared: and , and and . The algorithm converges in both cases, but the solution obtained with and is superior to the one with and . The latter converges to a local optimum instead of the global optimum. This is because the larger update rates for both the critic and actor networks allow for larger update steps, enabling convergence to the local optimum. Alternatively, using smaller learning rates like and maintains stability but leads to poor optimization performance. The lower learning rate slows down the network’s update speed, requiring more iterations to converge. Consequently, it fails to reach the optimal solution. Based on the experiment, the optimal network learning rate selected was and .
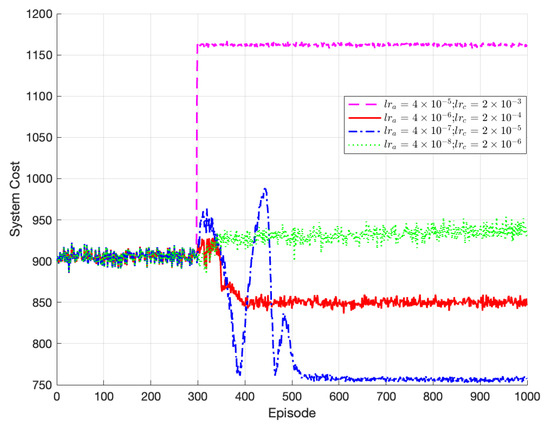
Figure 4.
Performance of TODM_DDPG algorithm under different learning rates.
Figure 5 compares the algorithm’s performance for experience replay buffers of different sizes, denoted by R. When R = 5000, the algorithm reaches a local optimum around episode 70. However, due to the small size of the experience replay buffer, it fails to extract sufficient data feature information, leading to an inability to learn the optimal strategy. When R = 50,000, the algorithm converges to the global optimum at around episode 520. When R = 500,000, the algorithm fails to converge due to the excessively large experience replay buffer, resulting in a longer training time and insufficient data updates. Therefore, the optimal size of the experience replay buffer chosen in this paper is 50,000.
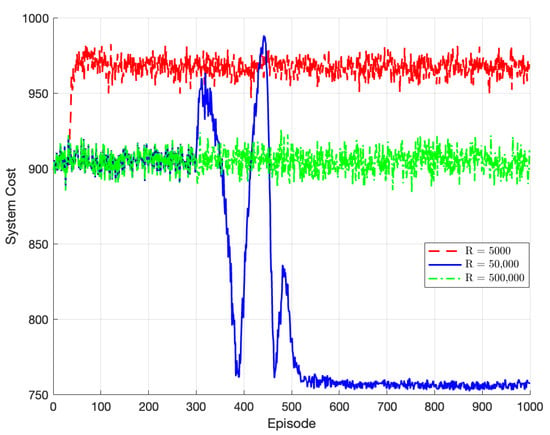
Figure 5.
Performance of TODM_DDPG algorithm under different experience replay buffer sizes.
Figure 6 presents the comparison of the algorithm’s performance for various discount factors . The algorithm achieves the fastest convergence and best performance when = 0.01. This is attributed to the dynamic nature of the vehicular edge computing system, where environmental conditions change over time. Considering long-term returns over the entire duration does not accurately represent long-term behavior, resulting in significant variations in data across different time periods and an inability to capture comprehensive data features. Therefore, this paper adopts = 0.01 as the optimal discount factor.
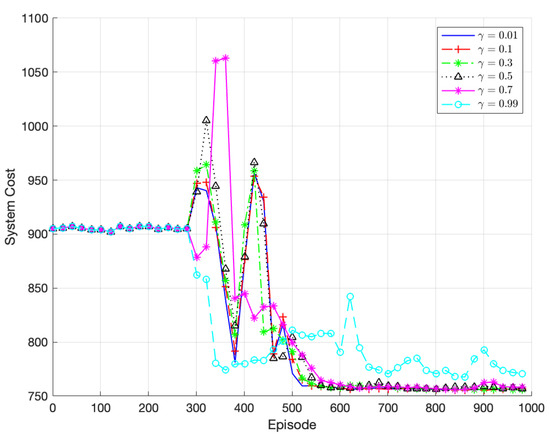
Figure 6.
Performance of TODM_DDPG algorithm under different discount factors.
Figure 7 illustrates the comparison of the algorithm’s performance for different exploration parameters , which represents the exploration noise in the TODM_DDPG algorithm. Since the policy network outputs deterministic actions, exploration in TODM_DDPG relies on adding noise to the action space. In this case, the noise is represented by the variance parameter . When is set to 0.01, the algorithm eventually converges to the best result. Notably, as increases, the algorithm explores a larger action space, leading to faster convergence but a potentially larger noise distribution space. As shown in the figure, when is set to 0.2, the algorithm exhibits fluctuations around a system cost of approximately 820. When is set to 0.001, the exploration parameter is too small, resulting in a narrow range of generated action space, which can lead to convergence to local optima or an inability to converge. Therefore, the optimal exploration parameter chosen in this paper is = 0.01.
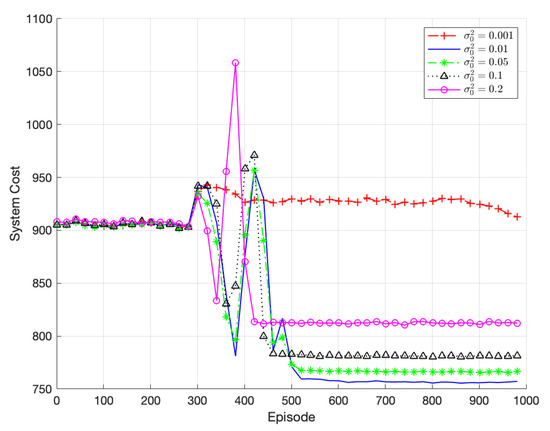
Figure 7.
Performance of TODM_DDPG algorithm under different exploration parameters.
Figure 8 presents the comparison of the algorithm’s performance with the influence of state normalization and behavior noise during training. As we mentioned in Section 4.3, the DDPG training process executed by introducing noise into the decision-making mechanism of actions considers both exploration and exploitation to explore potentially superior policies. In the figure, the algorithm’s convergence speed slows down when behavior noise is not used during policy training. Furthermore, the presence of state normalization has a more significant effect than that of behavioral noise. As mentioned before, TODM_DPPG utilizes two different deep neural network networks to fit the value and policy function of actor and critic networks, respectively. Taking the actor network as an example, we can observed that it takes the state as input and outputs policy actions. However, the distribution of the activation input values of the deep neural network changes during the training process, gradually approaching the upper and lower bounds of the non-linear function value range. This causes gradients in lower layers to vanish during the backpropagation process, leading to slow convergence. Therefore, for the characteristics of the deep neural network, we propose Algorithm 1, which incorporates normalization of the state values using scaling factors and the min–max method. Training the algorithm without state normalization, large state parameters can cause slow convergence of the deep neural network, rendering the training process ineffective, and the algorithm approximate to be greedy.

Figure 8.
Performance of TODM_DDPG algorithm with state normalization or behavior noise.
5.2.2. Performance Comparison
The comparison of performance of different algorithms is shown in Figure 9. We compare five different algorithms in this experiment: the AC algorithm, the TODM_DDPG algorithm, the DQN algorithm, the local offloading algorithm, and the cloud offloading algorithm. For the three reinforcement learning algorithms, the training iterations are set to 1000. It is evident from the figure that the three reinforcement learning algorithms implement significantly lower system costs compared to the local offloading and cloud offloading algorithms. However, the AC algorithm fails to converge during the training process due to the interaction between the actor and critic. This is because the action of the actor relies on the critic’s value, and updating both networks simultaneously when the critic’s value is challenging to converge may leads to instability. On the other hand, both the TODM_DDPG and DQN algorithms, with their dual network structures, effectively overcome this issue by breaking the correlation among training data and achieving convergence. However, the DQN algorithm fails to converge to the minimum system cost. This is mainly due to the fact that the DQN algorithm discretizes the action space of continuous actions, resulting in an inability to find the optimal offloading strategy accurately. In comparison, the TODM_DDPG algorithm performs best. Its ability to explore continuous action spaces enables it to find optimal solutions more effectively. Therefore, the TODM_DDPG algorithm demonstrates superior performance in terms of minimizing system cost.
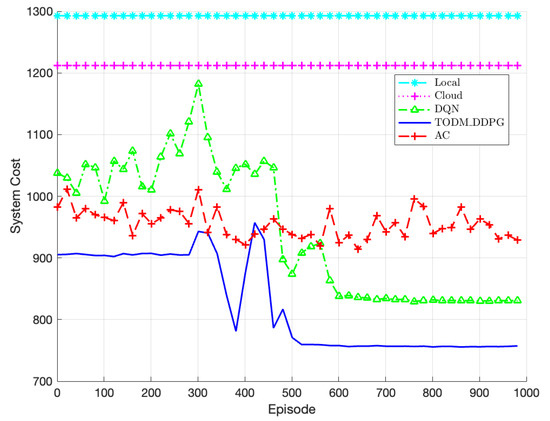
Figure 9.
Performance of system cost of different algorithm under different episodes.
Figure 10 illustrates the comparison of performence of the algorithms under different task size ranges. The system costs of all algorithms increase as the task size increases, showing a positive correlation. Within a given task data size range, the TODM_DDPG algorithm’s system cost is significantly lower compared to those of local or cloud offloading algorithms, as these offloading algorithms fail to fully utilize system resources. Furthermore, from the figure, we can observe that the TODM_DDPG algorithm’s advantage over other methods in terms of system cost becomes more obvious as the task data size increases. Overall, the TODM_DDPG algorithm consistently converges to the minimum system cost.
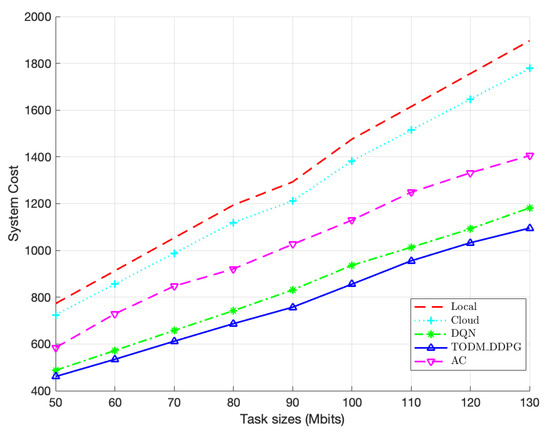
Figure 10.
Performance of system cost of different algorithm under different different task size ranges.
Figure 11 depicts the performance comparison of the proposed solution (DQN and TODM_DDPG) in terms of system cost and offloading proportion under different vehicle computing capacities. Figure 11a shows the convergence performance comparison between TODM_DDPG and DQN approaches under different vehicle computing capacities. The AC algorithm is not compared because of its lack of convergence. It can be observed that when the vehicle’s computing capacity is relatively low, i.e., = 9 × 10, both optimization approaches result in higher system costs compared to when the vehicle’s computing capacity is = 12 × 10 and = 15 × 10. On the other hand, as shown in Figure 11b, when the vehicle’s computing capacity is larger, the offloading proportion in the system is smaller. Therefore, as the vehicle’s computing capacity increases, the vehicles tend to execute tasks locally. Smaller computing capacities result in slower data processing speeds in the system at a given time, leading to larger maximum delays between local execution and offloading, i.e., higher offloading rates.
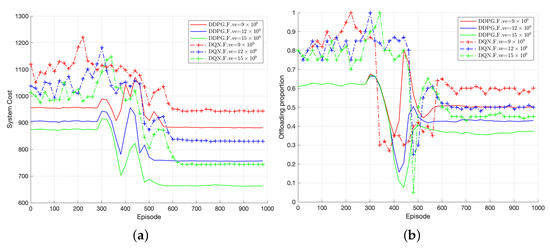
Figure 11.
(a) Performance of system cost of TODM_DDPG and DQN under different vehicle computing capacity. (b) Performance of offloading proportion of TODM_DDPG and DQN.
Additionally, since DQN algorithms are suitable for discrete action spaces, the offloading proportion level of DQN is set to in this paper. Based on Figure 11a, we can find that the TODM_DDPG scheme achieves lower system cost compared with the DQN scheme under different vehicle computing capabilities. Also, in Figure 11b, we can see that the DQN algorithm can only output a limited discrete action set for offloading proportion, while TODM_DDPG is capable of continuous action output. This is because TODM_DDPG outputs the value of the action by adding a layer of policy network on the basis of the DQN algorithm instead of directly outputting the maximum Q value like DQN, and thus expands to the control space of continuous actions. Hence, for the same vehicle computing capacity, the TODM_DDPG algorithm exhibits lower system costs compared to the DQN algorithm, as shown in Figure 11a.
Figure 12a represents the performance comparison of different algorithms under different energy consumption weights. The figure shows that the TODM_DDPG algorithm always achieves the lowest system cost, regardless of the weight coefficients. Additionally, we can find that with the increase in the energy weight coefficient, the system cost of the cloud offloading algorithm decreases significantly, and the system costs of DQN and TODM_DDPG algorithms gradually approach that of the cloud offloading algorithm. The reason for this is that when the energy weight is larger, the advantage of offloading tasks to the cloud in terms of system cost becomes more significant compared to local offloading. Therefore, the DQN and TODM_DDPG algorithms tend to offload tasks to the cloud or teh edge for executing. As for the AC algorithm, due to its lack of convergence, the optimization effect is not significant as the energy consumption weight increases. Figure 12b demonstrates the performance comparison of different algorithms under different numbers of vehicles. In this case, we assume that in regard to the MEC processing capacity, MEC cores I are equal to seven, and under different numbers of vehicles, the total task size to be completed in whole time period is the same. In the figure, we can find that as the number of vehicles increases, and when the number of vehicles is less than 25, the average system cost of all schemes is almost constant, and when the number of vehicles is greater than 25, the system costs of the three reinforcement learning algorithm schemes begin to increase. This is because, as the number of vehicles increases, the amount of offloaded tasks also increases, and the MEC cores are limited, which leads to redundant tasks being offloaded to the cloud server for processing and increases the system cost. In addition, it can be concluded from the figure that the system cost of the proposed TODM_DDPG algorithm is less than those of the other four algorithms, because the TODM_DDPG algorithm can find the optimal value in the continuous action space and obtain the optimal offloading proportion.
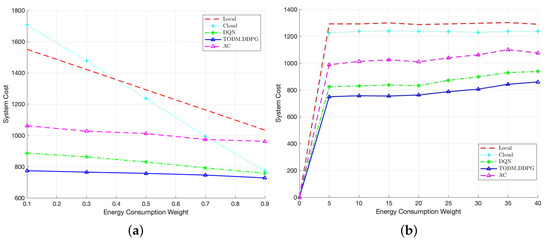
Figure 12.
(a) Performance of system cost of different algorithms under different energy consumption weights. (b) Performance of system cost of different algorithms under different number of vehicles.
6. Conclusions
In this paper, the computation offloading problem of vehicular edge computing environment is studied, and a vehicular edge computing system based on three-layer cloud edge vehicle architecture is proposed. Based on the deep deterministic policy gradient, this paper suggests a task offloading decision-making algorithm, namely TODM_DDPG. We provide a comprehensive description of the algorithm’s training and testing processes, effectively addressing the challenge of high-dimensional continuous action space. Furthermore, we introduce a state normalization method to enhance the algorithm’s convergence and stability. Subsequently, we conduct experiments to examine the effects of several fundamental hyperparameters on the algorithm’s performance, and the results are contrasted with those obtained from baseline algorithms. The testing results prove the effectiveness of our suggested approach in reducing system costs. The algorithm evaluation considers the joint optimization of delay and energy, and points out the effectiveness of the strategy under different task sizes and vehicle computing capabilities. The TODM_DDPG algorithm is superior to the other four schemes and obtains lower system cost and more accurate task offloading rate, which shows its effectiveness in optimizing task offloading for vehicular edge computing. Moreover, for a scalable and long-term vehicular edge computing system, the proposed scheme shows high reliability even under different energy consumption and delay weights and the number of vehicles.
In future research, we plan to explore additional aspects such as task types that consider dependencies and mobile edge computing server offloading request forwarding and channel resource allocation, aiming to simulate real-world scenarios more accurately. For this dependency-aware task offloading, the problem of task offloading is transformed into two sub-problems of offloading decision and resource allocation. Firstly, the offloading positions of subtasks are determined according to the dependencies between subtasks. Secondly, the resource allocation optimization process is formulated as a Markov decision process. Based on this, our goal is to design a hybrid computational offloading strategy for resource allocation and task allocation using a collaborative mechanism, taking into account both task offloading and resource allocation, so that sub-tasks can be executed in parallel and the optimal fine-grained offload strategy can be obtained.
Author Contributions
Conceptualization, W.S. and L.C.; methodology, W.S.; validation, W.S.; formal analysis, W.S. and L.C.; resources, W.S. and L.C.; data curation, W.S. and L.C.; writing—original draft preparation, W.S.; writing—review and editing, L.C. and X.Z.; funding acquisition, L.C. and X.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Key Research and Development Program of China grant number 2022YFB3305500, the National Natural Science Foundation of China grant number 62273089 and 62102080, Natural Science Foundation of Jiangsu Province grant number BK20210204.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ma, Y.; Wang, Z.; Yang, H.; Yang, L. Artificial intelligence applications in the development of autonomous vehicles: A survey. IEEE/CAA J. Autom. Sin. 2020, 7, 315–329. [Google Scholar] [CrossRef]
- Ni, J.; Shen, K.; Chen, Y.; Cao, W.; Yang, S.X. An Improved Deep Network-Based Scene Classification Method for Self-Driving Cars. IEEE Trans. Instrum. Meas. 2022, 71, 1–14. [Google Scholar] [CrossRef]
- Jameel, F.; Chang, Z.; Huang, J.; Ristaniemi, T. Internet of Autonomous Vehicles: Architecture, Features, and Socio-Technological Challenges. IEEE Wirel. Commun. 2019, 26, 21–29. [Google Scholar] [CrossRef]
- Heidari, A.; Navimipour, N.J.; Unal, M. Applications of ML/DL in the management of smart cities and societies based on new trends in information technologies: A systematic literature review. Sustain. Cities Soc. 2022, 85, 104089. [Google Scholar] [CrossRef]
- Cao, B.; Sun, Z.; Zhang, J.; Gu, Y. Resource Allocation in 5G IoV Architecture Based on SDN and Fog-Cloud Computing. IEEE Trans. Intell. Transp. Syst. 2021, 22, 3832–3840. [Google Scholar] [CrossRef]
- Guan, K.; He, D.; Ai, B.; Matolak, D.W.; Wang, Q.; Zhong, Z.; Kürner, T. 5-GHz Obstructed Vehicle-to-Vehicle Channel Characterization for Internet of Intelligent Vehicles. IEEE Internet Things J. 2019, 6, 100–110. [Google Scholar] [CrossRef]
- Zheng, Q.; Zheng, K.; Chatzimisios, P.; Long, H.; Liu, F. A novel link allocation method for vehicle-to-vehicle-based relaying networks. Trans. Emerg. Telecommun. Technol. 2016, 27, 64–73. [Google Scholar] [CrossRef]
- Sewalkar, P.; Seitz, J. Vehicle-to-Pedestrian Communication for Vulnerable Road Users: Survey, Design Considerations, and Challenges. Sensors 2019, 19, 358. [Google Scholar] [CrossRef]
- Liu, X.; Li, Y.; Xiao, L.; Wang, J. Performance Analysis and Power Control for Multi-Antenna V2V Underlay Massive MIMO. IEEE Trans. Wirel. Commun. 2018, 17, 4374–4387. [Google Scholar] [CrossRef]
- Chen, C.; Wang, C.; Qiu, T.; Atiquzzaman, M.; Wu, D.O. Caching in Vehicular Named Data Networking: Architecture, Schemes and Future Directions. IEEE Commun. Surv. Tutor. 2020, 22, 2378–2407. [Google Scholar] [CrossRef]
- Hou, X.; Ren, Z.; Wang, J.; Cheng, W.; Ren, Y.; Chen, K.C.; Zhang, H. Reliable Computation Offloading for Edge-Computing-Enabled Software-Defined IoV. IEEE Internet Things J. 2020, 7, 7097–7111. [Google Scholar] [CrossRef]
- Tran, T.X.; Hajisami, A.; Pandey, P.; Pompili, D. Collaborative Mobile Edge Computing in 5G Networks: New Paradigms, Scenarios, and Challenges. IEEE Commun. Mag. 2017, 55, 54–61. [Google Scholar] [CrossRef]
- Huang, L.; Bi, S.; Zhang, Y.J.A. Deep Reinforcement Learning for Online Computation Offloading in Wireless Powered Mobile-Edge Computing Networks. IEEE Trans. Mob. Comput. 2020, 19, 2581–2593. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, F.; Chen, X.; Wu, Y. Efficient Multi-Vehicle Task Offloading for Mobile Edge Computing in 6G Networks. IEEE Trans. Veh. Technol. 2022, 71, 4584–4595. [Google Scholar] [CrossRef]
- Zhang, J.; Letaief, K.B. Mobile Edge Intelligence and Computing for the Internet of Vehicles. Proc. IEEE 2020, 108, 246–261. [Google Scholar] [CrossRef]
- Wu, Y.; Wu, J.; Chen, L.; Yan, J.; Luo, Y. Efficient task scheduling for servers with dynamic states in vehicular edge computing. Comput. Commun. 2020, 150, 245–253. [Google Scholar] [CrossRef]
- Wang, H.; Lv, T.; Lin, Z.; Zeng, J. Energy-Delay Minimization of Task Migration Based on Game Theory in MEC-Assisted Vehicular Networks. IEEE Trans. Veh. Technol. 2022, 71, 8175–8188. [Google Scholar] [CrossRef]
- Nguyen, T.D.T.; Nguyen, V.; Pham, V.N.; Huynh, L.N.T.; Hossain, M.D.; Huh, E.N. Modeling Data Redundancy and Cost-Aware Task Allocation in MEC-Enabled Internet-of-Vehicles Applications. IEEE Internet Things J. 2021, 8, 1687–1701. [Google Scholar] [CrossRef]
- He, X.; Lu, H.; Du, M.; Mao, Y.; Wang, K. QoE-Based Task Offloading With Deep Reinforcement Learning in Edge-Enabled Internet of Vehicles. IEEE Trans. Intell. Transp. Syst. 2021, 22, 2252–2261. [Google Scholar] [CrossRef]
- Liu, W.; Shoji, Y. Edge-Assisted Vehicle Mobility Prediction to Support V2X Communications. IEEE Trans. Veh. Technol. 2019, 68, 10227–10238. [Google Scholar] [CrossRef]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Sallab, A.A.A.; Yogamani, S.; Pérez, P. Deep Reinforcement Learning for Autonomous Driving: A Survey. IEEE Trans. Intell. Transp. Syst. 2022, 23, 4909–4926. [Google Scholar] [CrossRef]
- Song, I.; Tam, P.; Kang, S.; Ros, S.; Kim, S. DRL-Based Backbone SDN Control Methods in UAV-Assisted Networks for Computational Resource Efficiency. Electronics 2023, 12, 2984. [Google Scholar] [CrossRef]
- Zhu, L.; Yu, F.R.; Wang, Y.; Ning, B.; Tang, T. Big Data Analytics in Intelligent Transportation Systems: A Survey. IEEE Trans. Intell. Transp. Syst. 2019, 20, 383–398. [Google Scholar] [CrossRef]
- Luo, Q.; Li, C.; Luan, T.H.; Shi, W. Minimizing the Delay and Cost of Computation Offloading for Vehicular Edge Computing. IEEE Trans. Serv. Comput. 2022, 15, 2897–2909. [Google Scholar] [CrossRef]
- Sun, J.; Gu, Q.; Zheng, T.; Dong, P.; Valera, A.; Qin, Y. Joint Optimization of Computation Offloading and Task Scheduling in Vehicular Edge Computing Networks. IEEE Access 2020, 8, 10466–10477. [Google Scholar] [CrossRef]
- Huang, M.; Zhai, Q.; Chen, Y.; Feng, S.; Shu, F. Multi-Objective Whale Optimization Algorithm for Computation Offloading Optimization in Mobile Edge Computing. Sensors 2021, 21, 2628. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Jiao, L.; Li, W.; Fu, X. Efficient Multi-User Computation Offloading for Mobile-Edge Cloud Computing. IEEE/ACM Trans. Netw. 2016, 24, 2795–2808. [Google Scholar] [CrossRef]
- Huang, M.; Liu, W.; Wang, T.; Liu, A.; Zhang, S. A Cloud–MEC Collaborative Task Offloading Scheme With Service Orchestration. IEEE Internet Things J. 2020, 7, 5792–5805. [Google Scholar] [CrossRef]
- Cui, L.; Xu, C.; Yang, S.; Huang, J.Z.; Li, J.; Wang, X.; Ming, Z.; Lu, N. Joint Optimization of Energy Consumption and Latency in Mobile Edge Computing for Internet of Things. IEEE Internet Things J. 2019, 6, 4791–4803. [Google Scholar] [CrossRef]
- Yang, G.; Hou, L.; He, X.; He, D.; Chan, S.; Guizani, M. Offloading Time Optimization via Markov Decision Process in Mobile-Edge Computing. IEEE Internet Things J. 2021, 8, 2483–2493. [Google Scholar] [CrossRef]
- Luong, N.C.; Hoang, D.T.; Gong, S.; Niyato, D.; Wang, P.; Liang, Y.C.; Kim, D.I. Applications of Deep Reinforcement Learning in Communications and Networking: A Survey. IEEE Commun. Surv. Tutor. 2019, 21, 3133–3174. [Google Scholar] [CrossRef]
- Xiong, K.; Leng, S.; Huang, C.; Yuen, C.; Guan, Y.L. Intelligent Task Offloading for Heterogeneous V2X Communications. IEEE Trans. Intell. Transp. Syst. 2021, 22, 2226–2238. [Google Scholar] [CrossRef]
- Huang, L.; Feng, X.; Zhang, C.; Qian, L.; Wu, Y. Deep reinforcement learning-based joint task offloading and bandwidth allocation for multi-user mobile edge computing. Digit. Commun. Netw. 2019, 5, 10–17. [Google Scholar] [CrossRef]
- Zhao, H.; Zhang, T.; Chen, Y.; Zhao, H.; Zhu, H. Task distribution offloading algorithm of vehicle edge network based on DQN. J. Commun. 2020, 41, 172–178. [Google Scholar]
- Wang, K.; Wang, X.; Liu, X.; Jolfaei, A. Task Offloading Strategy Based on Reinforcement Learning Computing in Edge Computing Architecture of Internet of Vehicles. IEEE Access 2020, 8, 173779–173789. [Google Scholar] [CrossRef]
- Khayyat, M.; Elgendy, I.A.; Muthanna, A.; Alshahrani, A.S.; Alharbi, S.; Koucheryavy, A. Advanced Deep Learning-Based Computational Offloading for Multilevel Vehicular Edge-Cloud Computing Networks. IEEE Access 2020, 8, 137052–137062. [Google Scholar] [CrossRef]
- Fu, J.; Qin, X.; Huang, Y.; Tang, L.; Liu, Y. Deep Reinforcement Learning-Based Resource Allocation for Cellular Vehicular Network Mode 3 with Underlay Approach. Sensors 2022, 22, 1874. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Zhang, Y.; Shen, R.; Xu, Y.; Zheng, F.C. DRL-Based Energy-Efficient Resource Allocation Frameworks for Uplink NOMA Systems. IEEE Internet Things J. 2020, 7, 7279–7294. [Google Scholar] [CrossRef]
- Chen, M.; Wang, T.; Zhang, S.; Liu, A. Deep reinforcement learning for computation offloading in mobile edge computing environment. Comput. Commun. 2021, 175, 1–12. [Google Scholar] [CrossRef]
- Lu, H.; He, X.; Du, M.; Ruan, X.; Sun, Y.; Wang, K. Edge QoE: Computation Offloading With Deep Reinforcement Learning for Internet of Things. IEEE Internet Things J. 2020, 7, 9255–9265. [Google Scholar] [CrossRef]
- Ning, Z.; Dong, P.; Wang, X.; Rodrigues, J.J.P.C.; Xia, F. Deep Reinforcement Learning for Vehicular Edge Computing: An Intelligent Offloading System. ACM Trans. Intell. Syst. Technol. 2019, 10, 60. [Google Scholar] [CrossRef]
- Wang, J.; Ke, H.; Liu, X.; Wang, H. Optimization for computational offloading in multi-access edge computing: A deep reinforcement learning scheme. Comput. Netw. 2022, 204, 108690. [Google Scholar] [CrossRef]
- Shrestha, A.; Mahmood, A. Review of Deep Learning Algorithms and Architectures. IEEE Access 2019, 7, 53040–53065. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Qiu, C.; Hu, Y.; Chen, Y.; Zeng, B. Deep Deterministic Policy Gradient (DDPG)-Based Energy Harvesting Wireless Communications. IEEE Internet Things J. 2019, 6, 8577–8588. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).