Abstract
As a biological characteristic, gait uses the posture characteristics of human walking for identification, which has the advantages of a long recognition distance and no requirement for the cooperation of subjects. This paper proposes a research method for recognising gait images at the frame level, even in cases of discontinuity, based on human keypoint extraction. In order to reduce the dependence of the network on the temporal characteristics of the image sequence during the training process, a discontinuous frame screening module is added to the front end of the gait feature extraction network, to restrict the image information input to the network. Gait feature extraction adds a cross-stage partial connection (CSP) structure to the spatial–temporal graph convolutional networks’ bottleneck structure in the ResGCN network, to effectively filter interference information. It also inserts XBNBlock, on the basis of the CSP structure, to reduce estimation caused by network layer deepening and small-batch-size training. The experimental results of our model on the gait dataset CASIA-B achieve an average recognition accuracy of 79.5%. The proposed method can also achieve 78.1% accuracy on the CASIA-B sample, after training with a limited number of image frames, which means that the model is more robust.
1. Introduction
Biometric technology utilizes the principles of biostatistics and combines them with modern technologies such as computers, optics, acoustics, and biosensors to use biometric information as a unique identifier for individual identification. It is currently widely applied in various areas of life, such as public safety and mobile payments. Biometric information can be divided into physiological information determined by an individual’s genes and behavioural information gradually formed by an individual’s experiences. Physiological information includes fingerprints [1], iris patterns [2], facial features [3], and DNA [4], while behavioural information includes human handwriting [5], gait [6], and so on.
Gait recognition is a new biometric recognition technology currently proposed, which aims to record and distinguish the movement trajectories of the trunk and limbs as the main identification information during the movement or walking of an individual [7]. Studies in related disciplines, such as medicine and psychology [8,9,10], have shown that human strength, tendon and bone length, bone density, visual acuity, coordination ability, experience, weight, centre of gravity, degree of muscle or bone damage, physiological conditions and personal walking style are maintained as an individual’s unique characteristics [11]; they are very distinctive, and these do not change easily.
Gait information can be captured by wearable sensors attached to the human body, including accelerometers [12], gyroscopes, pressure sensors [13], etc.; these can be analysed in series, using the principles of biostatistics. The non-wearable gait information acquisition method combines a computer and a camera; an ordinary 2 K camera is used to capture an uncontrolled pedestrian gait video of a crowd 50 m away in real-time. Further analysis is performed using computer technology. The process is called vision-based gait recognition. This identification method has the advantages of not requiring individual cooperation, and being difficult to deceive. It can also detect and measure in low resolution, allowing it to be used when facial or iris information cannot be recognized in high resolution. Visual gait recognition technology based on deep learning networks can autonomously extract gait motion features from image sequences without building a complex human body model, and its accuracy and robustness only depend on the design of the network structure and the training image library. It has promising applications in intelligent video surveillance, patient monitoring systems, virtual reality, intelligent security, athlete training assistance, and more.
The main characteristics of a pedestrian walking in a public place are small changes in the range of walking movements, but there are changeable walking angles and blocking by objects. In view of these characteristics, this paper proposes a research method of gait image recognition that leverages discontinuously the extraction of key points on the human skeleton.
The main contributions of our work are summarised below:
- (1)
- We attempt to extract gait features from discontinuous video images of walking, which have rarely been studied in gait recognition. We designed a discontinuous frame-level image extraction module, which filters and integrates image sequence information, and sends the relevant information obtained to the gait feature extraction network, to extract relevant features and identify pedestrians, improving the network’s gait characteristics for discontinuous time-series’ learning ability.
- (2)
- Compared with ResGCN, the improved gait recognition algorithm (based on ResGCN) uses a bottleneck for feature dimensionality reduction. It also reduces the number of layers of the feature map, reduces the amount of computation, increases the cross stage partial connection (CSP) structure and XBNBlock, and upgrades the spatial graph convolution (SCN) and temporal graph convolutional (TCN) network modules, with a bottleneck structure in the network. This maintains the same size of input and output, on the basis of reducing network parameters, so as to enhance the learning ability of the response module. It can also reduce memory consumption.
- (3)
- Our paper demonstrates the effectiveness of the improved network algorithm on the commonly used gait data set CASIA-B, and the recognition accuracy is better than other current model-based recognition methods, especially for pedestrian gait images influenced by a certain appearance. The effectiveness and generalization of the algorithm proposed in this paper were tested on both the CASIA-A dataset and a self-built small-scale real environment dataset.
2. Related Works
2.1. Human Keypoint Detection Research
Human keypoint detection [14] mainly detects the head, shoulder, elbow and other joint parts of the human body in an image. It outputs the relevant parameters and positional relationship of all or partial parts of the human body through keypoints, to describe information regarding the human body skeleton. The position and category of joints are the basis of research fields such as human behaviour recognition and gait recognition. In computer vision tasks, research on human keypoint detection using convolutional networks is divided into single-person and multi-person keypoint detection. Our paper mainly considers the use of a single-point detection network to extract the skeleton keypoint coordinate information.
The testing methods can be divided into two categories:
- (1)
- Regression-based keypoint detection, i.e., learning information from input images to the keypoints of human bones through an end-to-end network framework. DeepPose [15] applied the Deep Neural Network (DNN) to the problem of human keypoint detection for the first time, and proposed a cascaded regressor that can directly predict the coordinates of keypoints, using a complete image and a seven-layer general convolutional DNN as input. The detection works well on series datasets, with obvious changes and occlusions. The authors of [16] proposed a structure-aware regression method based on ResNet-50, using body structure information to design bone-based representations. Dual-source deep convolutional neural networks (DS-CNN) [17] used a holistic view to learn the appearance of local parts of the human body, and to detect and localise joints. The authors of [18] proposed a multi-task framework for joint 2D and 3D recognition of human skeleton keypoint detection from video sequences of still images. In [19], a 2D human pose estimation keypoint regression based on the subspace attention module (SAMKR), was proposed. Each keypoint was divided into an independent regression branch and its feature map equally divided into a specified number of feature map subspaces, deriving different attention maps for each feature map subspace.
- (2)
- Detection based on the heat map detection method, i.e., the heat map of K keypoints of the human body is detected first, and the probability that the key point is located at (x, y) is then represented by the heat map pixel value Li(x, y). The heat map of bone keypoints is generated by a two-dimensional Gaussian model [20] centred on the location of the real keypoint, and the bone keypoint detection network is then trained by minimising the difference between the predicted heat map and the real heat map. Heatmap-based detection methods can preserve more spatial location information and provide richer supervision information. A hybrid architecture [21], consisting of deep convolutional networks and Markov random fields, can be used to detect human skeleton keypoints in monocular images. In [22], the image was discretised into a logarithmic polar coordinate region, centred on the skeletal keypoint, and a VGG network was employed to predict the category confidence of each paired skeletal keypoint. According to the relative confidence scores, the final heatmap for each keypoint was generated by a deconvolutional network. HRNet [23] proposed a high-resolution network structure. This model was the first multi-layer network structure to maintain the initial resolution of the image, while increasing the feature receptive field. This structure continuously expands the features through multi-stage cascaded residual modules. Receptive fields, multi-network branches to extract feature information with different resolutions, and multi-scale feature information fusion, make the network more accurate in detecting the keypoints of human skeletons. Since the heat map representation is more robust than the coordinate representation, more current research is based on the heat map representation.
2.2. Gait Recognition Research Methods
According to the type of gait feature extraction, the current gait recognition methods can be roughly divided into human appearance-based [24] and model-based [25].
Appearance-based Method. The binarisation algorithm is used to extract the contour in the image and the optical flow method is used to extract gait features such as speed, leg angle, and gait cycle time in the contour. In [26], the Gaussian mapping principle was used to calculate the curvature of the human body contour boundary in the binary image as the recognition feature. The authors in [27,28] extracted pedestrians’ walking and moving contours from the background and calculated the similarity of gait images by calculating the temporal changes in the contours to represent gait features. The other method is to use gait energy images (GEI) [29], chrono gait images (CGI), or frame difference energy image (FDEI), etc., to aggregate the contours of the complete gait sequence into an image template, and use a recursive learning strategy and a neural network to learn temporal features of the sequence for recognition. GaitNet [30] proposed an end-to-end gait recognition network that could be trained simultaneously, consisting of two convolutional neural networks for gait segmentation and classification. GaitSet [31] used a convolutional network to extract frame-level features of gait contours, using horizontal pyramid mapping (HMP) to map them to set-level features, and finally using Euclidean distance to perform the difference between the object to be identified and the template. Gaitpart [32] used a frame-level part-feature extractor (FPFE) and multiple parallel micro-motion capture modules (MCMs) to extract the spatio-temporal features of the contours of different parts of the human body. Ref. [33] used 3D convolutions and 3D local convolutions [34] to capture global or local spatio-temporal features under multiple views for gait recognition. The model is relatively difficult to train. This type of gait recognition method has the problem of losing time and fine-grained spatial information during the pre-processing process, and it is difficult to train the network model.
Model-based Method. Refs. [35,36] abstracted various parts of the human body into a stick model to simulate the movement characteristics of the human body while walking. In [37], the rotation angles of the hip and knee joints were used to characterise the gait when a person walks. Ref. [38] tracked and fitted the movement of the lower limb joints of the human body during walking, to obtain dynamic changes of the lower-limb-joint rotation angle over time, as the gait feature. Traditional skeleton modelling methods usually rely on hand-crafted features or traversal rules, resulting in limited expressive power and difficult generalisations. The human skeleton can also use the depth camera in ‘Microsoft Kinect’ to capture the action [39] and the segmentation strategy to separate the person from the background, analysing the image of the pedestrian in motion to obtain the various parts of the body and further extract relevant features. However, using the depth camera in Kinect has certain limitations on the shooting space and distance. At present, the deep convolutional neural network is more widely used to directly evaluate and extract the features of the human body structure in the image. In [40,41], OpenPose [42] was used to extract the keypoints of the human skeleton; the PTSN network was constructed to obtain the temporal and spatial variation characteristics of the joint sequence, to realise cross-view recognition. GaitGraph [43] proposed a gait graph that combines human keypoint detection with graph convolutional networks (GCNs), to obtain a model-based approach to end-to-end gait recognition. SDHF-GCN [44] handled skeleton-based gait recognition tasks via natural connections, temporal correlations, and symmetric interactions.
In the past, appearance-based gait recognition methods were more popular. However, advancements in human keypoint detection algorithms have brought about more development opportunities for model-based gait recognition methods.
3. Cross-Gait Recognition Network for Keypoint Extraction
We used Gaitgraph [43] as the original network, with the aim of improving the algorithm and realising the gait image recognition that leverages discontinuously the keypoint extraction of human bones. GaitGraph uses a graph convolutional network on the human skeleton pose map for gait recognition. Compared with the extraction of human appearance and outline, the human-skeletal-keypoint coordinate information and feature extraction only involve the 2D coordinates of the major joints of the body. Since the skeletal sequence only captures motion information, inferring the keypoint coordinates of the human body through model inference allows for the avoid the influence of contextual interferences such as background changes and lighting variations. The implementation process inputs a set of gait images for the model, uses YOLOv3 to detect pedestrian targets in the images, uses HRNet [23] to extract keypoints of the human skeleton, and then uses ResGCN to independently extract frame-level features from the pre-processed skeleton images.
We considered the design of the discontinuous frame extraction module of the gait video image after extracting the skeleton keypoint information, and selected the less-discontinuous image frame-level sequences (for example, 30 frames) from each group of skeleton keypoint information frames, to form a list. These were then sent to the gait feature network to extract gait-related features. The goal was to reduce the model’s reliance on temporal features of the images during the training process. The whole algorithm framework is shown in Figure 1.
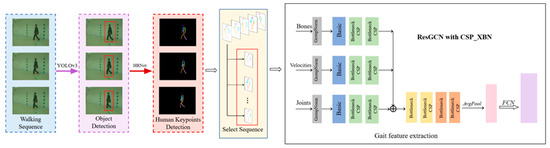
Figure 1.
Algorithm block diagram. Starting from the frame-level sequence of video images, YOLOv3 was used to detect pedestrian targets in the images, and body keypoints were extracted for each pedestrian. Discontinuous image sequences were selected for gait feature extraction by the improved ResGCN.
3.1. Human Keypoint Extraction Network
We followed the HRNet used in GaitGraph as a 2D human keypoint extractor. In general, 2D poses have certain advantages in extracting keypoints of the human body. In practical applications, the amount of calculation required to extract two-dimensional keypoints is small, and the requirements for equipment performance are not very high. Compared to traditional serially connected network structures, HRNet connects high-resolution and low-resolution subnetworks in parallel, always maintaining high resolution, which enhances the accuracy of spatial prediction. To address the issue of multi-scale feature fusion, HRNet employs multiple instances of the multi-scale fusion module, utilizing low-resolution features with the same depth and similar level to enhance high-resolution features. This approach ensures both high resolution and sufficient feature representation during skeleton extraction.
HRNet uses a convolutional network to detect pedestrians from top to bottom in an image of dimensions W × H × 3, and then detects the positions of 17 key parts of the human body (such as elbows, wrists, etc.). Our chosen network consisted of two-stride convolutions, forming a backbone aimed at reducing resolution, a subject outputting with its input feature map, and a regressor estimating selected keypoint locations and converting them to a full-resolution rate heatmap. Specifically, HRNet-W48 consists of four stages and four parallel subnetworks; the resolution is gradually reduced by half, and the width (number of channels) is increased by two times. This means that the width of the high-resolution subnetwork in the last three stages (C) is 48, and the widths of the other three parallel subnetworks are 96, 192, and 384, respectively. A total of eight cross-resolution information exchanges were performed to achieve multi-scale fusion. The keypoint connection diagram of the human skeleton, extracted from the gait data set CASIA-B using HRNet, is shown in Figure 2.
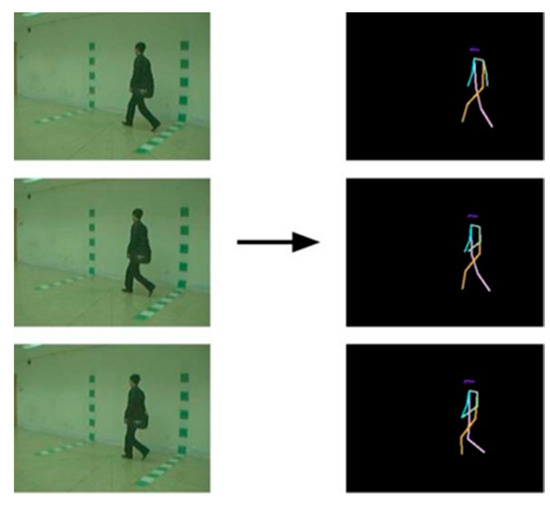
Figure 2.
HRNet to CASIA-B 2D skeleton pose extraction.
3.2. Gait Feature Extraction and Recognition
The gait feature extraction network consists of ResGCN blocks. The ResGCN block consists of SCN and TCN, with a bottleneck structure and residual connections. The network sequentially consists of multiple ResGCN blocks, followed by an average pooling layer and a fully connected layer producing feature vectors, using supervised contrast (SupCon) [45] as the loss function.
- (1)
- The spatial GCN operation of the graph convolutional network (GCN) for each frame t in the skeleton sequence is expressed as:
For temporal feature extraction, an L × 1 convolutional layer is designed to aggregate contextual features embedded in adjacent frames. L is a predefined hyperparameter which defines the length of the time window. The spatio-temporal convolution layer is followed by a batch normalisation (BN) layer and a ReLU layer, constructing a complete basic block.
- (2)
- A residual connection with a bottleneck structure: The bottleneck structure involves inserting two 1 × 1 convolutional layers before and after the shared convolutional layer. In this paper, the bottleneck structure is used to replace a set of temporal and spatial convolutions in the ResGCN architecture. The structures of SCN and TCN with the bottleneck structure are shown in Figure 3 and Figure 4, respectively. The lower half of the structures in the figures is added to the upper half to achieve residual connections, allowing a reduction in the number of feature channels during convolution computations using a channel reduction rate r.
 Figure 3. SCN module structure diagram. The SGC in the figure is a spatial graph convolution.
Figure 3. SCN module structure diagram. The SGC in the figure is a spatial graph convolution. Figure 4. TCN module structure diagram. The TGC in the figure is a temporal graph convolution.
Figure 4. TCN module structure diagram. The TGC in the figure is a temporal graph convolution.
- (3)
- The fully connected (FC) layer that generates feature vectors takes the residual matrix R as input. Each output of the FC layer corresponds to the attention weights of each GCN layer.
- (4)
- Supervised contrastive (SupCon) loss function: For the experimental dataset, the data is processed in batches. The pre-divided dataset is sequentially input to the training network, and two augmented copies of the batch data are obtained through data augmentation. Both augmented samples undergo forward propagation using the encoder network to obtain normalized embeddings of dimension 2048. During training, the feature representations are propagated forward through the projection network, and the supervised contrastive loss function is computed on the output of the projection network. The formula for calculating the SupCon loss is as follows:
We improved and optimised the ResGCN network structure, and its position is presented in Table 1.

Table 1.
Overview of the improved ResGCN-N39-R8 network architecture for poses with 17 joints.
3.2.1. CSP Structure
CSP [46] structure can optimise the problem of repeated gradient information in the network; the structure is shown in Figure 5. The CSP structure of the SCN and TCN is optimised with a bottleneck structure in ResGCN, to achieve richer gradient combinations and reduce network calculations. The main idea of CSP is to spread the gradient flow through different network paths by splitting the gradient flow, and to further respect the variability of the gradient by integrating the feature maps at the beginning and end of the network stage. The specific method is to divide the feature map of the base layer into two parts. One branch passes through multiple residual structures, and the other branch directly performs convolution; the two branches performing are concatenated to realise that the characteristics of CSP are consistent with the number of output channels. The model learns more features.
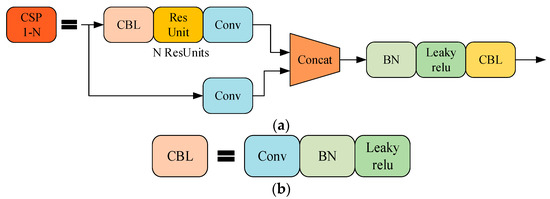
Figure 5.
Structure diagram: (a) CSP; (b) CBL module in CSP.
3.2.2. XBNBlock
Due to the stacking effect of batch normalisation (BN), the estimation bias is accumulated, affecting test performance. The limitation of BN is that the errors increase rapidly as the batch size becomes smaller. Batch-free normalisation (BFN) prevents the accumulation of such estimated offsets, hence the introduction of XBNBlock [47], a module that replaces a BN with a BFN in ResGCN, making it more robust to distributed offsets.
BFN avoids normalisation along the batch dimension, effectively avoiding the problem of statistic estimation. This paper replaces the second BN in the bottleneck layer with group normalisation (GN) [48]. The calculation of GN is independent of the batch size and can be used for tasks that occupy a large amount of video memory, such as image segmentation, in order to solve the problem of BN having a poor effect on small mini-batch sizes.
GN divides the channels into groups and computes, within each group, the mean and standard deviation (std) for normalisation.
The feature normalisation method performs the following computation:
Here, x is the feature computed by a layer and i is an index. In the case of 2D images, i = (iN, iC, iH, iW) is a 4D vector, indexing the features in (N, C, H, W) order, where N is the batch axis, C is the channel axis, and H and W are the spatial height and width axes, respectively.
The specific method is as follows: GN divides the channels of each sample feature map into G groups (each group will have C/G channels), and calculates the mean (μ) and standard deviation (σ) of the elements in these channels along the (H, W) axis and a set of C/G channels. Each group of channels is independently normalised with its corresponding normalisation parameter.
μ and σ in Equations (4) and (5) are computed by:
G is a pre-defined hyper-parameter (G = 32 by default), .

Figure 6.
TCN module structure improvement diagram.

Figure 7.
SCN module structure improvement diagram.
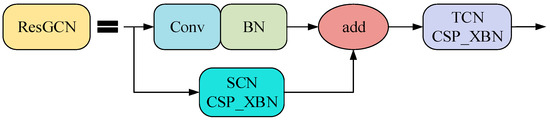
Figure 8.
Diagram of the improved ResGCN structure.
4. Experiments
This section provides a concise and precise description of the experimental results, their interpretation, and the experimental conclusions that can be drawn.
4.1. Computer Configuration
All experiments in this paper were conducted on a workstation with an NVIDIA RTX 2080Ti GPU. CUDA, cuDNN, OpenCv, and Pytorch were used to realize the detection model. The details of computer configuration are shown in Table 2.
Table 2.
Computer environment for the experiments.
4.2. Dataset and Training Details
CASIA-B [49] is a widely used large-scale multi-view single-person gait database. It was proposed by the Institute of Automation, Chinese Academy of Sciences in January 2005, according to the training and testing requirements of the gait recognition network. A total of 124 subjects, individual RGB images are provided, taking into account the three variations of viewing angle, clothing, and carrying-condition variations. The method uses 11 cameras to collect data from 11 viewing angles of each subject at an interval of 18°, from 0° to 180°, at the same time, and each subject in each viewing angle takes ten gait sequences; these include three different states, namely six gait sequences, NM#1–6, in the normal dressing state, two gait sequences, BG#1–2, with different backpacks, and two gait sequences with different coats, CL#1–2. Since the research for this data set focuses on the influence of factors other than human detection or segmentation, a simple background and indoor environment are used for video acquisition.
We selected CASIA-A [48], which can also provide RGB images, as a small-scale gait data test sample. It included walking videos of 20 people, and each person had 12 image sequences, containing 3 walking angles of view (0°, 45°, and 90°), with 4 image sequences for each direction.
At testing, the distance between the gallery and probe was defined as the Euclidean distance of the corresponding feature vectors. Besides this, we fed the original and a flipped order sequence into the network, and took the average of two feature vectors.
5. Experimental Results and Discussion
5.1. Basic Experiment
Figure 9 shows that, under the same training strategy, our modified model outperforms the baseline in both recognition accuracy and loss curve. The improved model has a more stable rise in recognition accuracy during testing. After training for 400 Epochs, the loss curve no longer declines significantly, and our model is more robust.
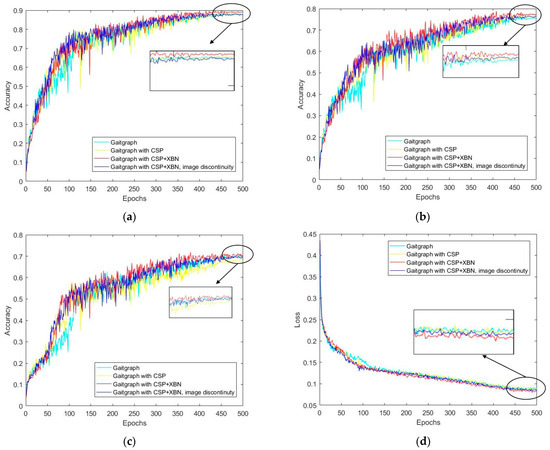
Figure 9.
Accuracy of models with different modifications and loss curves: (a) NM#5–6; (b) BG#1–2; (c) CL#1–2. (d) Comparison of loss curves.
Table 3 shows the comparison between the improved-gait-recognition algorithm network and the baseline. For the photographed pedestrians walking normally, the network before and after the improvement has its own advantages and disadvantages in the recognition process of each angle, and the final average detection accuracy rate increases by 2.3%. For the photographed pedestrian carrying a backpacks and wearing a jacket, the improved gait recognition network in this paper shows better improvement in the recognition accuracy of each angle; its average accuracy is increased by 3.1% and 4.2%, respectively. Specific to each angle, in the case of the lowest recognition accuracy of 180°, the recognition accuracy of the photographed pedestrians carrying backpacks and wearing coats also increased, by 2.4% and 10.5%, respectively. This indicates that, after adding the CSP structure and XBNBlock, the extraction of gait features is more accurate, which effectively improves the defects of the original network in relation to identification in these two cases. The last row in the table shows the recognition accuracy after training on non-continuous frame-level images. Compared with the baseline, the final average detection accuracy of the photographed pedestrians walking normally is increased by 0.5%. For the photographed pedestrians carrying backpacks and wearing coats, the average recognition accuracy of 11 different viewing angles increased by 1.8% and 3.3%, respectively, indicating the effectiveness of the improved network in reducing the dependence on temporal features.
Table 3.
Averaged rank-1 accuracies in percent on CASIA-B per probe angle, compared with the baseline model GaitGraph, excluding identical-view cases. Image discontinuity study. Control Condition: interrupt the input sequence at train/test phase. Results are rank-1 accuracies on CASIA-B, averaged in percent.
In order to prove the contribution of the three modules added in the improved model and to select the most suitable statistical function for image dimensionality reduction, an ablation experiment was designed, and the experimental results are shown in Table 4. It can be seen from the table that, after increasing the modules sequentially, the recognition accuracy gradually increases.
Table 4.
Ablation experiments conducted on CASIA-B using setting ‘LT’. Results are rank-1 accuracies averaged in percent on all 11 views, excluding identical-view cases.
The comparison of recognition accuracy of eleven walking angles in three different walking states in the ablation experiment is shown in Figure 10. The three figures show that, whether or not the input gait image is restricted to discontinuous frames, the overall recognition accuracy of the improved network is higher than that of the baseline network. Figure 10b is in the knapsack state, and the improvement in recognition is more obvious. As can be seen from the line graph of the comparison of the state of wearing a jacket in Figure 10c, adding different modules has a greater impact on the recognition of different angles.
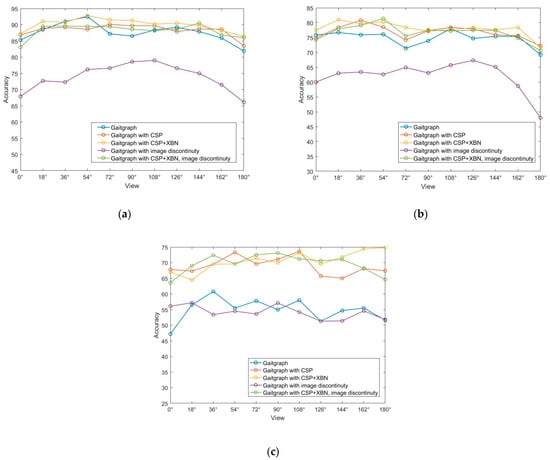
Figure 10.
Ablation experiment comparison line chart: (a) NM#5–6; (b) BG#1–2; (c) CL#1–2.
5.2. Multipart Figures
At present, there are many gait recognition algorithms based on the CASIA-B dataset. The current best-performing model is based on contour features. This paper compares both appearance-based and model-based methods with this improved model; the specific comparison values are shown in Table 5.
Table 5.
Averaged rank-1 accuracies, in percent on CASIA-B: comparison with other methods.
3DLocal is the best gait-image-recognition algorithm based on human appearance contours in the table, with an average recognition accuracy of 88.8%. In the gait recognition network based on human skeleton keypoints, the best recognition accuracy of the improved network in this paper is 79.5%. Although there is a certain gap between the accuracy of the algorithm based on human appearance contour recognition, it is worth noting that the accuracy of the skeleton keypoint information and discontinuous frame-level image information used in this paper can be the same as that of the GaitNet network recognition.
Table 6 uses the average accuracy rate, detection and recognition time per frame and file weight as network performance evaluation parameters, and compares the data of the algorithms after adding each network module. It can be seen from the table that, when the improved algorithm model does not limit the number of frames extracted for image training, the average recognition accuracy improves overall. The average detection time can be shortened by up to 0.0346 ms, and the average detection time weight of the improved model file size is reduced by 0.3 MB. After limiting the number of input image frame series during training, the average detection accuracy of the gait-recognition-algorithm models, before and after the improvement, decreases, and the average detection time increases; the file size weight did not change significantly.
Table 6.
Comparison of related parameters in the improved network experiment with the baseline.
5.3. Tests in CASIA-A
The experimental results of the test in CASIA-A are shown in Table 7. We followed the same training and testing protocol as the baseline model GaitGraph [43] method for fair comparison, and also tested discontinuous gait frame-level images. From the test results, it can be observed that our improved model achieves higher recognition accuracy than the baseline model across all three angles. The average recognition accuracy of the improved model is 5.9% higher than that of the baseline model. Even in the case of testing with non-consecutive frame-level gait images, the average recognition accuracy can still reach 89%.
Table 7.
Results are rank-1 accuracies (%) of the proposed method on CASIA-A under 3 probe views, excluding identical-view cases.
5.4. Real-Scene Gait Image Test
In order to further verify the effectiveness of the algorithm proposed in this paper, we collected gait images in real scenes. We collected three walking states of six volunteers: normal walking (NM), backpack walking (BG) and wearing a coat (CL). Three walking angles of view (36°, 108° and 162°) and two image sequences for each state (#1–2) were used. Some of the data images are shown in Figure 11. In the test, NM#1–2 is used as the gallery and BG#1–2 and CL#1–2 are used as probes; the experimental results are shown in Table 8.

Figure 11.
Gait images of three variations in real scenes.
Table 8.
Results are rank-1 accuracies (%) of the proposed method on real-scene gait images, excluding identical-view cases.
Since the image data of the self-built gait dataset is relatively limited, the data range for testing is narrowed down, so the recognition accuracy is slightly better than the test results in the public dataset. From the test results in Table 8, it can be observed that the average recognition accuracy of the algorithm in real-gait images reaches 82.3%, which is a good performance. When limiting the number of input image frames during the test, the average recognition accuracy is 79%. The overall recognition accuracy is not significantly affected by the reduction in the number of image frames, especially for the state recognition effects of pedestrians carrying backpacks and wearing coats, which only decrease by 0.6% and 1%.
6. Conclusions
We propose a gait-image-recognition method that leverages discontinuous human skeleton keypoint extraction, which can effectively improve the influence of various appearance changes, such as clothing and items, on the accuracy of gait recognition. The experimental results on the CSASIA-B data set have verified that using HRNet, which has a good effect in extracting keypoints of the human body at this stage, aggregates the information of independent branches and introduces multi-resolution interaction to improve the extraction accuracy of keypoints of the human body. Using the modified ResGCN network, gait features containing effective identity information can also be extracted, based on discontinuous picture information, which significantly improves recognition compared with other existing methods. The effectiveness of the algorithm proposed in this paper is also verified by testing the CASIA-A gait dataset and the gait images in real scenes.
However, the work we have undertaken to date is far from being enough. The experiment only uses public data sets, which are small in scale, and with simple scenarios; the recognition accuracy needs to be further improved.
Future research directions can be pursued in the following areas:
- (1)
- Due to the differences between the gait dataset used in the experiment and the real-world environment, the next step for the work involves testing the algorithm on videos collected in real environments, considering more walking views, and different walking conditions and lighting conditions. This is necessary to achieve pedestrian recognition with algorithm adaptability to the diversity of the database.
- (2)
- The various algorithm modules selected in the framework of this paper are continuously being upgraded and iterated with the development of deep learning theory. In future research work, we can consider to replacing the pedestrian object-detection network with a network that provides better detection results. For the human skeleton keypoint-detection network, it is advisable to use a multi-person skeleton keypoint-detection network to address pedestrian gait recognition in crowded places and other scenarios.
Author Contributions
Methodology and writing—original draft, X.L.; writing—review and editing, K.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
No new data were created or analysed in this study. Data sharing is not applicable to this article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Shuping, N.; Feng, W. The research on fingerprint recognition algorithm fused with deep learning. In Proceeding of the 2020 IEEE International Conference on Information Technology, Big Data and Artificial Intelligence (ICIBA), Chongqing, China, 6–8 November 2020; pp. 1044–1047. [Google Scholar] [CrossRef]
- Danlami, M.; Jamel, S.; Ramli, S.N.; Azahari, S.R.M. Comparing the Legendre Wavelet filter and the Gabor Wavelet filter For Feature Extraction based on Iris Recognition System. In Proceedings of the 2020 IEEE 6th International Conference on Optimisation and Applications (ICOA), Beni Mellal, Morocco, 20–21 April 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Chen, H.T.; Peng, G.Y.; Chang, K.C.; Lin, J.Y.; Chen, Y.H.; Lin, Y.K.; Huang, C.Y.; Chen, J.C. Enhance Face Recognition Using Time-series Face Images. In Proceedings of the 2021 IEEE International Conference on Consumer Electronics-Taiwan (ICCE-TW), Penghu, Taiwan, 15–17 September 2021; pp. 1–2. [Google Scholar] [CrossRef]
- Katsanis, S.H.; Claes, K.; Doerr, M.; Cook-Deegan, R.; Tenenbaum, J.D.; Evans, B.J.; Lee, M.K.; Anderton, J.; Weinberg, S.M.; Wagner, J.K. U.S. Adult Perspectives on Facial Images, DNA, and Other Biometrics. IEEE Trans. Technol. Soc. 2022, 3, 9–15. [Google Scholar] [CrossRef] [PubMed]
- Ghali, N.S.; Haldankar, D.D.; Sonkar, R.K. Human Personality Identification Based on Handwriting Analysis. In Proceedings of the 2022 5th International Conference on Advances in Science and Technology (ICAST), Mumbai, India, 2–3 December 2022; pp. 393–398. [Google Scholar] [CrossRef]
- Wang, L.; Hong, B.; Deng, Y.; Jia, H. Identity Recognition System based on Walking Posture. In Proceeding of the 2020 Chinese Automation Congress (CAC), Shanghai, China, 6–8 November 2020; pp. 3406–3411. [Google Scholar] [CrossRef]
- Nixon, M.S.; Carter, J.N. Automatic Recognition by Gait. Proc. IEEE 2006, 94, 2013–2024. [Google Scholar] [CrossRef]
- Sun, J.; Wu, P.Q.; Shen, Y.; Yang, Z.X. Relationship between personality and gait: Predicting personality with gait features. In Proceedings of the 2018 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Madrid, Spain, 3–6 December 2018; pp. 1227–1231. [Google Scholar] [CrossRef]
- Killane, I.; Donoghue, O.A.; Savva, G.M.; Cronin, H.; Kenny, R.A.; Reilly, R.B. Variance between walking speed and neuropsychological test scores during three gait tasks across the Irish longitudinal study on aging (TILDA) dataset. In Proceedings of the 2013 35th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Osaka, Japan, 3–7 July 2013; pp. 6921–6924. [Google Scholar] [CrossRef]
- Stevenage, S.V.; Nixon, M.S.; Vince, K. Visual analysis of gait as a cue to identity. Appl. Cogn. Psychol. 1999, 13, 513–526. [Google Scholar] [CrossRef]
- Nixon, M.S.; Carter, J.N. On gait as a biometric: Progress and prospects. In Proceedings of the 2004 12th European Signal Processing Conference, Vienna, Austria, 6–10 September 2004; pp. 1401–1404. [Google Scholar]
- Xia, Y.; Ma, J.; Yu, C.; Ren, X.; Antonovich, B.A.; Tsviatkou, V.Y. Recognition System of Human Activities Based on Time-Frequency Features of Accelerometer Data. In Proceedings of the 2022 International Conference on Intelligent Systems and Computer Vision (ISCV), Fez, Morocco, 18–20 May 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Verma, A.; Merchant, R.A.; Seetharaman, S.; Yu, H. An intelligent technique for posture and fall detection using multiscale entropy analysis and fuzzy logic. In Proceedings of the 2016 IEEE Region 10 Conference (TENCON), Singapore, 22–25 November 2016; pp. 2479–2482. [Google Scholar] [CrossRef]
- Munea, T.L.; Jembre, Y.Z.; Weldegebriel, H.T.; Chen, L.; Huang, C.; Yang, C. The Progress of Human Pose Estimation: A Survey and Taxonomy of Models Applied in 2D Human Pose Estimation. IEEE Access 2020, 8, 133330–133348. [Google Scholar] [CrossRef]
- Toshev, A.; Szegedy, C. DeepPose: Human Pose Estimation via Deep Neural Networks. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1653–1660. [Google Scholar] [CrossRef]
- Sun, X.; Shang, J.; Liang, S.; Wei, Y. Compositional Human Pose Regression. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2621–2630. [Google Scholar] [CrossRef]
- Fan, X.; Zheng, K.; Lin, Y.; Wang, S. Combining local appearance and holistic view: Dual-Source Deep Neural Networks for human pose estimation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1347–1355. [Google Scholar] [CrossRef]
- Luvizon, D.C.; Picard, D.; Tabia, H. 2D/3D Pose Estimation and Action Recognition Using Multitask Deep Learning. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA; 2018; pp. 5137–5146. [Google Scholar] [CrossRef]
- Chen, L.; Zhou, D.; Liu, R.; Zhang, Q. SAMKR: Bottom-up Keypoint Regression Pose Estimation Method Based on Subspace Attention Module. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–9. [Google Scholar] [CrossRef]
- Tompson, J.; Goroshin, R.; Jain, A.; LeCun, Y.; Bregler, C. Efficient object localisation using Convolutional Networks. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 9 June 2015; pp. 648–656. [Google Scholar] [CrossRef]
- Tompson, J.; Jain, A.; LeCun, Y.; Bregler, C. Joint training of a convolutional network and a graphical model for human pose estimation. In Advances in Neural Information Processing Systems; IEEE: New York, NY, USA, 17 September 2014; pp. 152–167. [Google Scholar]
- Lifshitz, I.; Fetaya, E.; Ullman, S. Human Pose Estimation Using Deep Consensus Voting. In Proceedings of the Computer Vision–ECCV Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science. Springer: Cham, Swizterland, 2016; Volume 9906. [Google Scholar] [CrossRef]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5686–5696. [Google Scholar] [CrossRef]
- Lam, T.H.W.; Cheung, K.H.; Liu, J. Gait flow image: A silhouette-based gait representation for human identification. Pattern Recognit. 2011, 44, 973–987. [Google Scholar] [CrossRef]
- Ariyanto, G.; Nixon, M.S. Model-based 3D gait biometrics. In Proceedings of the 2011 International Joint Conference on Biometrics (IJCB), Washington, DC, USA, 11–13 October 2011; pp. 1–7. [Google Scholar] [CrossRef]
- El-Alfy, H.; Mitsugami, I.; Yagi, Y. Gait Recognition Based on Normal Distance Maps. IEEE Trans. Cybern. 2018, 48, 1526–1539. [Google Scholar] [CrossRef] [PubMed]
- Martin-Félez, R.; Mollineda, R.A.; Sánchez, J.S. Towards a More Realistic Appearance-Based Gait Representation for Gender Recognition. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 3810–3813. [Google Scholar] [CrossRef]
- Hirose, Y.; Nakamura, K.; Nitta, N.; Babaguchi, N. Anonymization of Human Gait in Video Based on Silhouette Deformation and Texture Transfer. IEEE Trans. Inf. Forensics Secur. 2022, 17, 3375–3390. [Google Scholar] [CrossRef]
- An, W.; Yu, S.; Makihara, Y.; Wu, X.; Xu, C.; Yu, Y.; Liao, R.; Yagi, Y. Performance Evaluation of Model-Based Gait on Multi-View Very Large Population Database with Pose Sequences. IEEE Trans. Biom. Behav. Identity Sci. 2020, 2, 421–430. [Google Scholar] [CrossRef]
- Song, C.; Huang, Y.; Huang, Y.; Ning, J.; Liang, W. GaitNet: An end-to-end network for gait based human identification. Pattern Recognit. 2019, 96, 106988. [Google Scholar] [CrossRef]
- Chao, H.; He, Y.; Zhang, J.; He, Y.; Feng, J. GaitSet: Regarding Gait as a Set for Cross-View Gait Recognition. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 12 December 2018. [Google Scholar] [CrossRef]
- Fan, C.; Peng, Y.; Cao, C.; Liu, X.; Hou, S.; Chi, J.; Huang, Y.; Li, Q.; He, Z. GaitPart: Temporal Part-Based Model for Gait Recognition. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 14213–14221. [Google Scholar] [CrossRef]
- Wolf, T.; Babaee, M.; Rigoll, G. Multi-view gait recognition using 3d convolutional neural networks. In Proceedings of the ICIP 2016, Phoenix, AZ, USA, 25–28 September 2016; pp. 4165–4169. [Google Scholar]
- Huang, Z.; Xue, D.; Shen, X.; Tian, X.; Li, H.; Huang, J.; Hua, X.S. 3D Local Convolutional Neural Networks for Gait Recognition. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 14900–14909. [Google Scholar] [CrossRef]
- Chen, K.; Wu, S.; Li, Z. Gait Recognition Based on GFHI and Combined Hidden Markov Model. In Proceedings of the 2020 13th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Chengdu, China, 17–19 October 2020; pp. 287–292. [Google Scholar] [CrossRef]
- Etoh, H.; Omura, Y.; Kaminishi, K.; Chiba, R.; Takakusaki, K.; Ota, J. Proposal of a Neuromusculoskeletal Model Considering Muscle Tone in Human Gait. In Proceedings of the 2021 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Melbourne, Australia, 17–20 October 2021; pp. 289–294. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, X.; Zhu, K.; Niu, H. Thigh Skin Strain Model for Human Gait Movement. In Proceedings of the 2021 IEEE Asia Conference on Information Engineering (ACIE), Sanya, China, 29–31 January 2021; pp. 27–31. [Google Scholar] [CrossRef]
- Tanawongsuwan, R.; Bobick, A. Gait recognition from time-normalised joint-angle trajectories in the walking plane. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. CVPR 2001, Kauai, HI, USA, 8–14 December 2001; pp. II–II. [Google Scholar] [CrossRef]
- Zhen, H.; Deng, M.; Lin, P.; Wang, C. Human gait recognition based on deterministic learning and Kinect sensor. In Proceedings of the 2018 Chinese Control and Decision Conference (CCDC), Shenyang, China, 9–11 June 2018; pp. 1842–1847. [Google Scholar] [CrossRef]
- Liao, R.; Cao, C.; Garcia, E.B.; Yu, S.; Huang, Y. Pose-Based Temporal-Spatial Network (PTSN) for Gait Recognition with Carrying and Clothing Variations. In Biometric Recognition, Proceedings of the 12th Chinese Conference, CCBR 2017, Shenzhen, China, 28–29 October 2017; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2017; Volume 10568, p. 10568. [Google Scholar] [CrossRef]
- Liao, R.; Yu, S.; An, W.; Huang, Y. A Model-based Gait Recognition Method with Body Pose and Human Prior Knowledge. Pattern Recognit. 2019, 98, 107069. [Google Scholar] [CrossRef]
- Zhe, C.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime Multi-person 2D Pose Estimation Using Part Affinity Fields. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 14 April 2017. [Google Scholar]
- Teepe, T.; Khan, A.; Gilg, J.; Herzog, F.; Hörmann, S.; Rigoll, G. Gaitgraph: Graph Convolutional Network for Skeleton-Based Gait Recognition. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 2314–2318. [Google Scholar] [CrossRef]
- Liu, X.; You, Z.; He, Y.; Bi, S.; Wang, J. Symmetry-Driven hyper feature GCN for skeleton-based gait recognition. Pattern Recognit. J. Pattern Recognit. Soc. 2022, 125, 125. [Google Scholar] [CrossRef]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised Contrastive Learning. arXiv 2020, arXiv:2004.11362. [Google Scholar]
- Wang, C.; Liao, H.M.; Wu, Y.; Chen, P.; Hsieh, J.; Yeh, I. Cspnet: A new backbone that can enhance learning capability of cnn. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 20 November 2020; pp. 390–391. [Google Scholar]
- Huang, L.; Zhou, Y.; Wang, T.; Luo, J.; Liu, X. Delving into the Estimation Shift of Batch Normalisation in a Network. In Proceedings of the 2022 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 21 March 2022. [Google Scholar]
- Wu, Y.; He, K. Group Normalisation; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Yu, S.; Tan, D.; Tan, T. A framework for evaluating the effect of view angle, clothing and carrying condition on gait recognition. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR'06), 20–24 August 2006. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).