
Machine Learning-Based Software Defect Prediction for Mobile Applications: A Systematic Literature Review



Abstract
:1. Introduction
2. Background and Related Work
2.1. Mobile Fault Prediction and Machine Learning
2.2. Software Metrics
2.3. Related Work
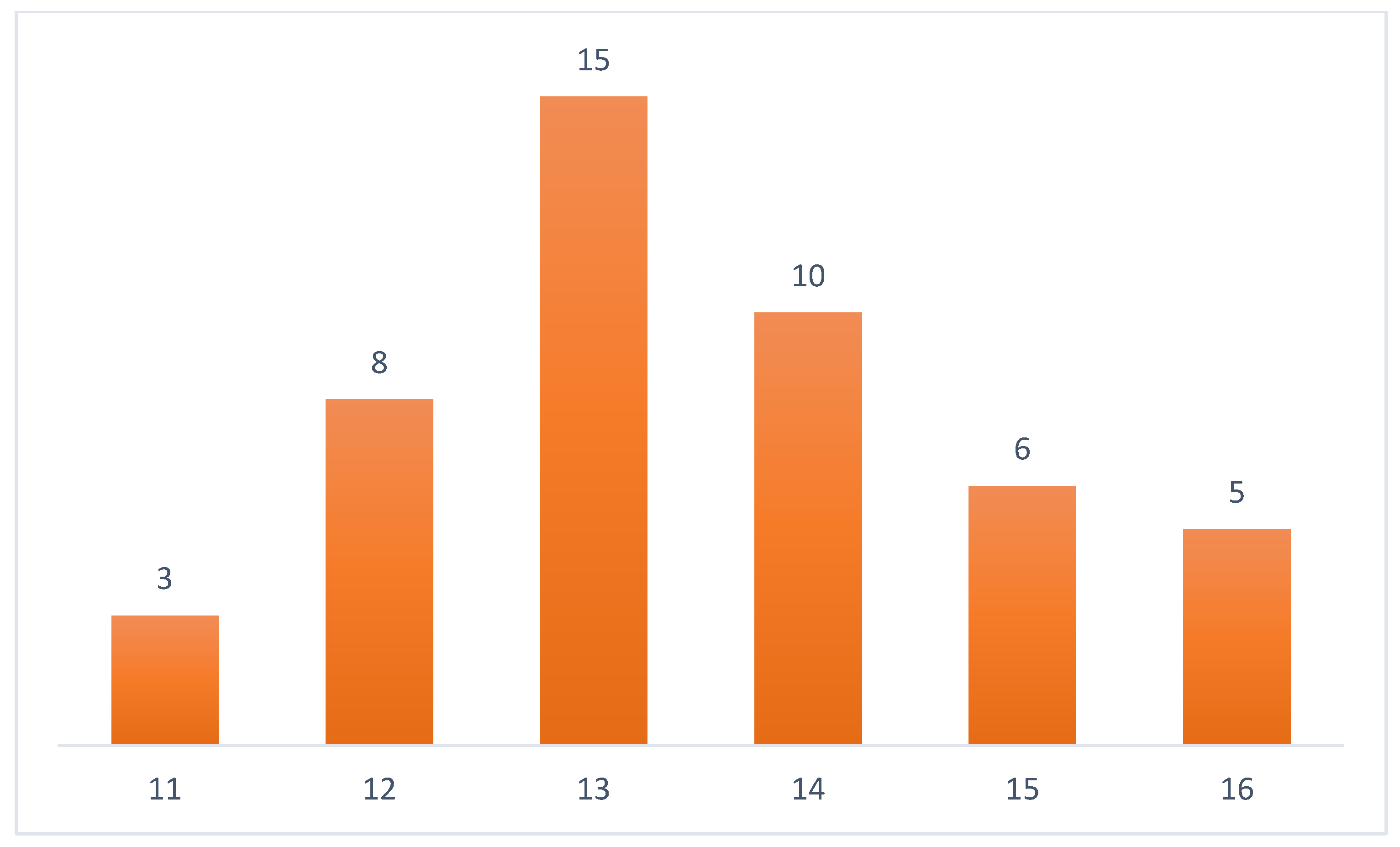
3. Research Methodology
4. Results
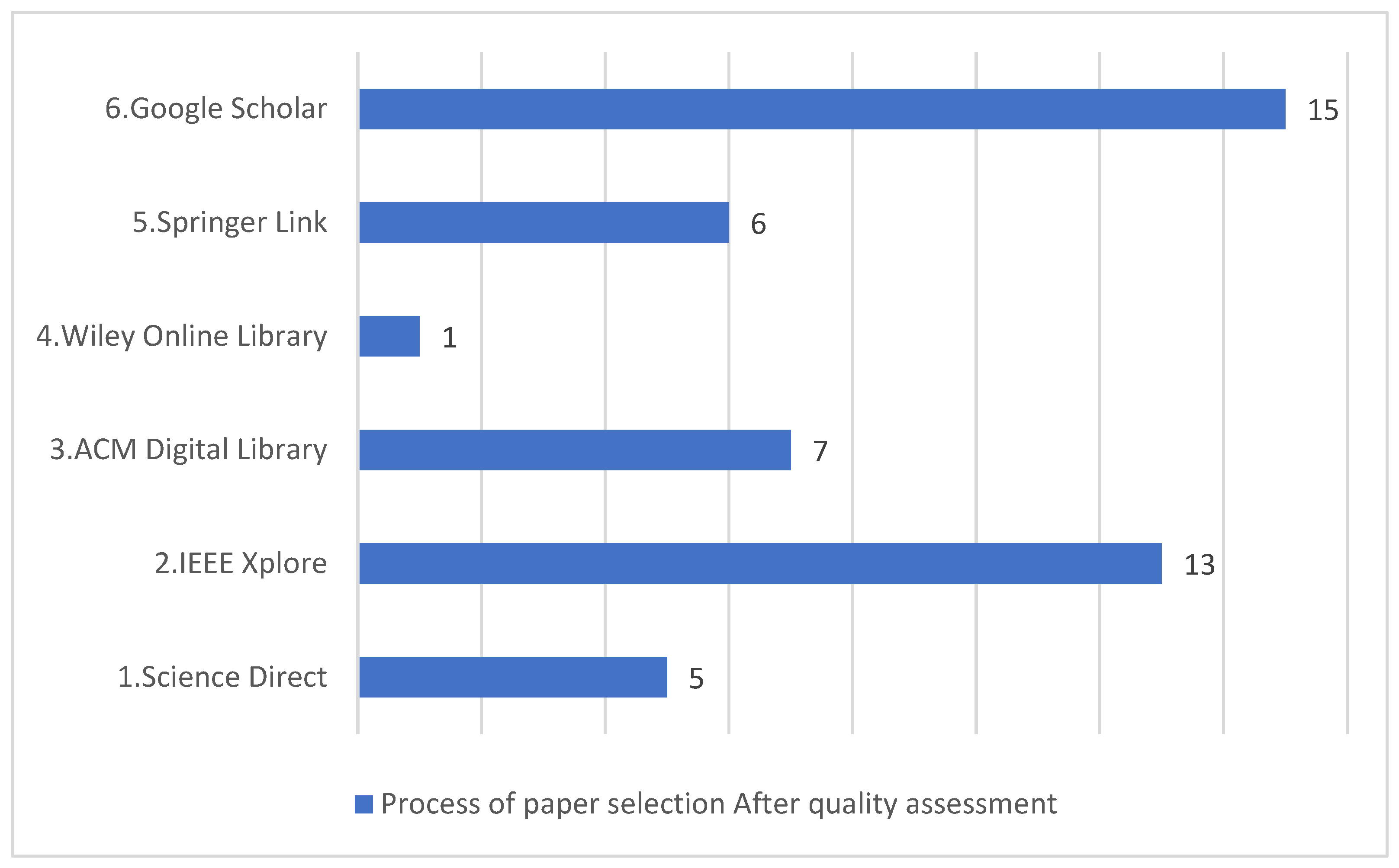
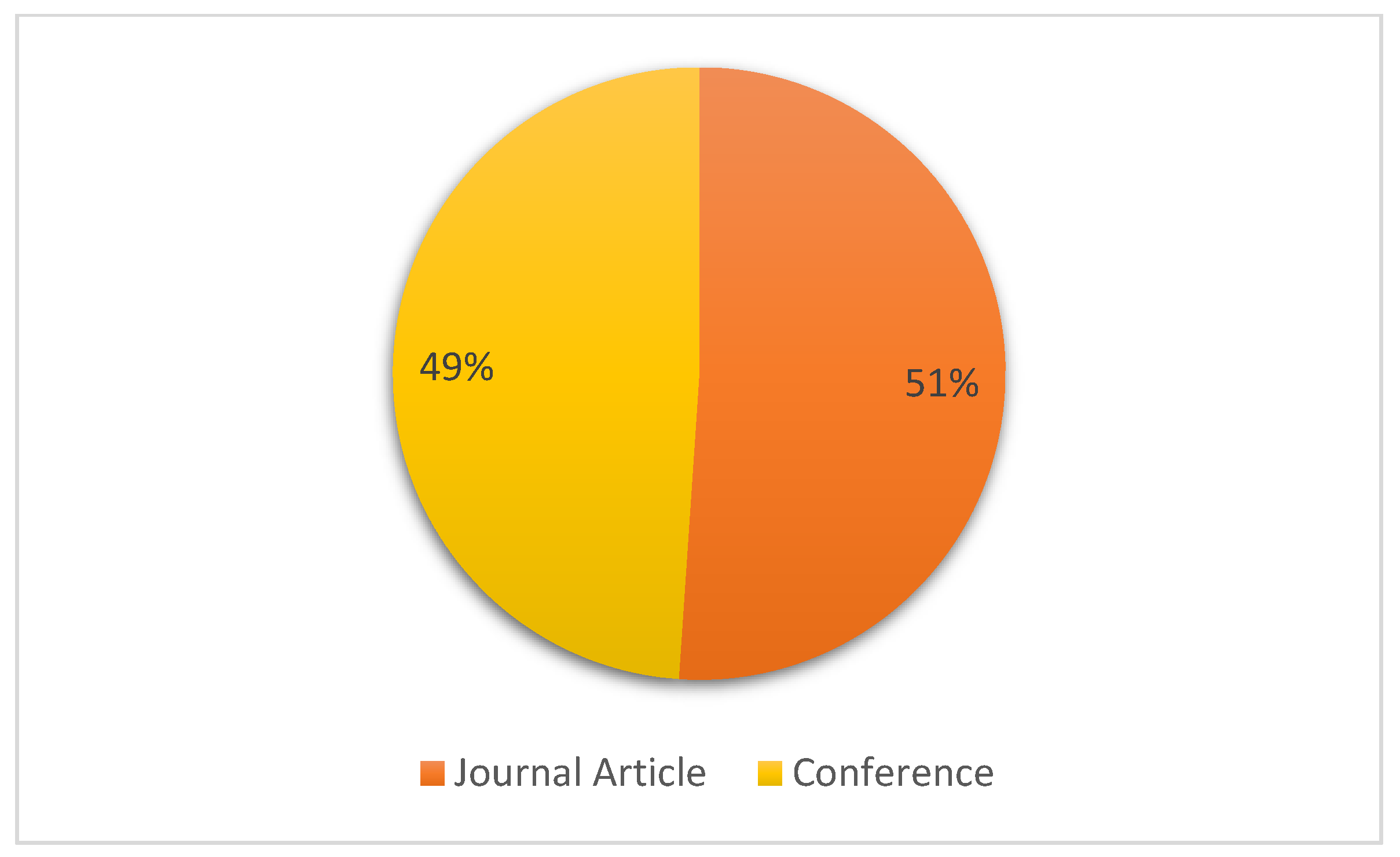
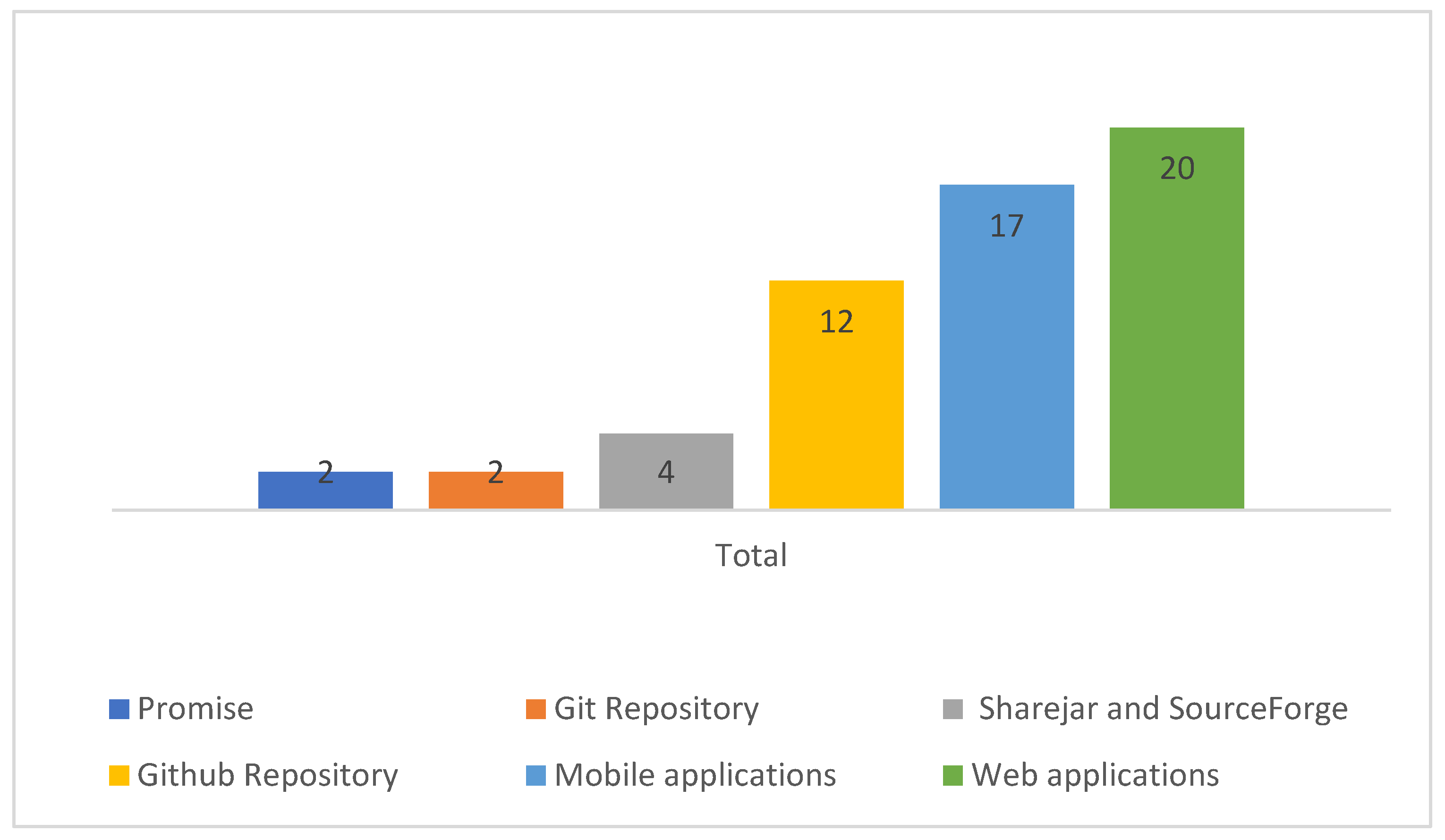
4.1. RQ-1: Platforms
4.2. RQ-2: Datasets
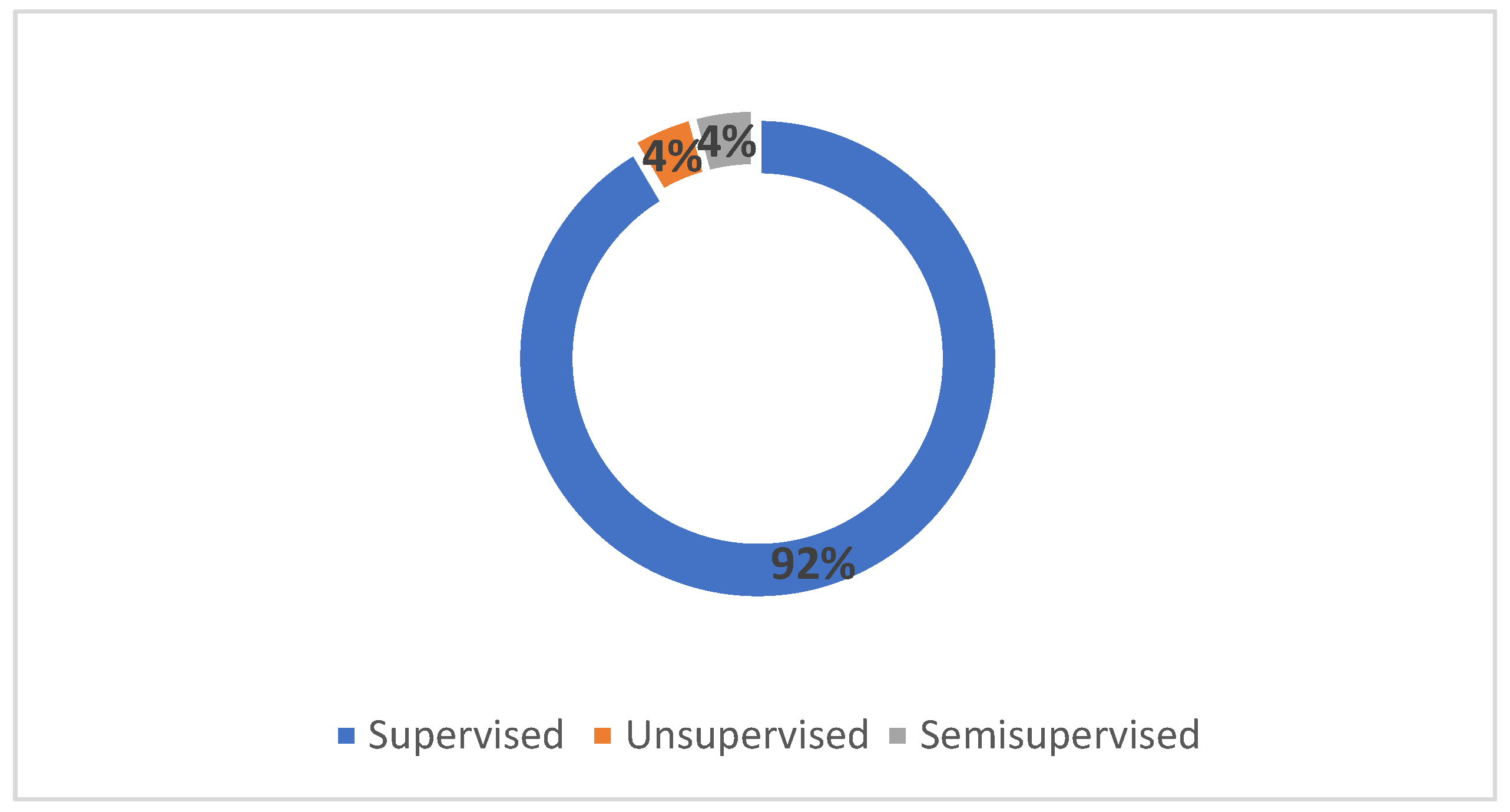
4.3. RQ-3: Machine Learning Types
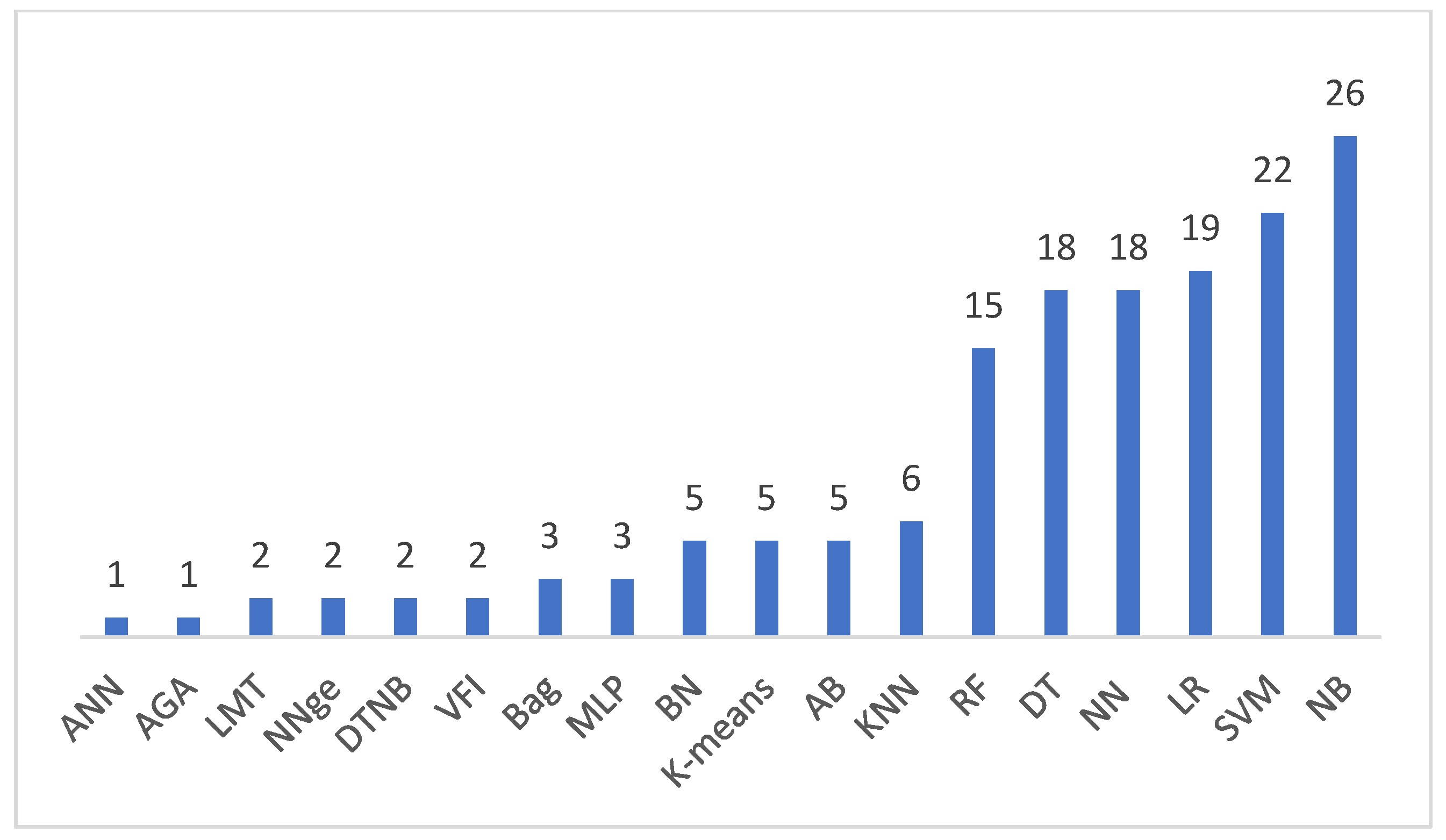
4.4. RQ-4: Machine Learning Algorithms
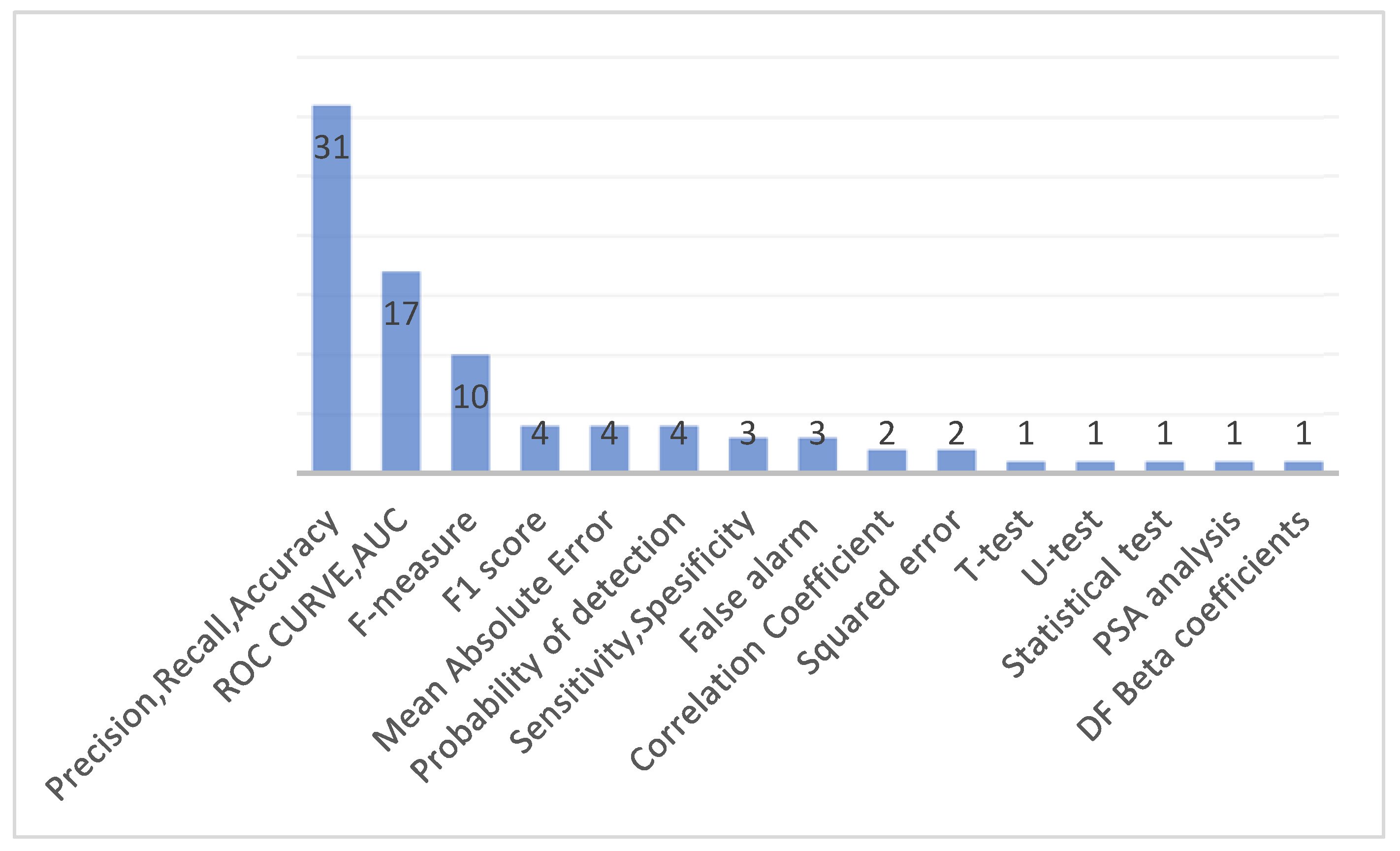
4.5. RQ-5: Evaluation Metrics
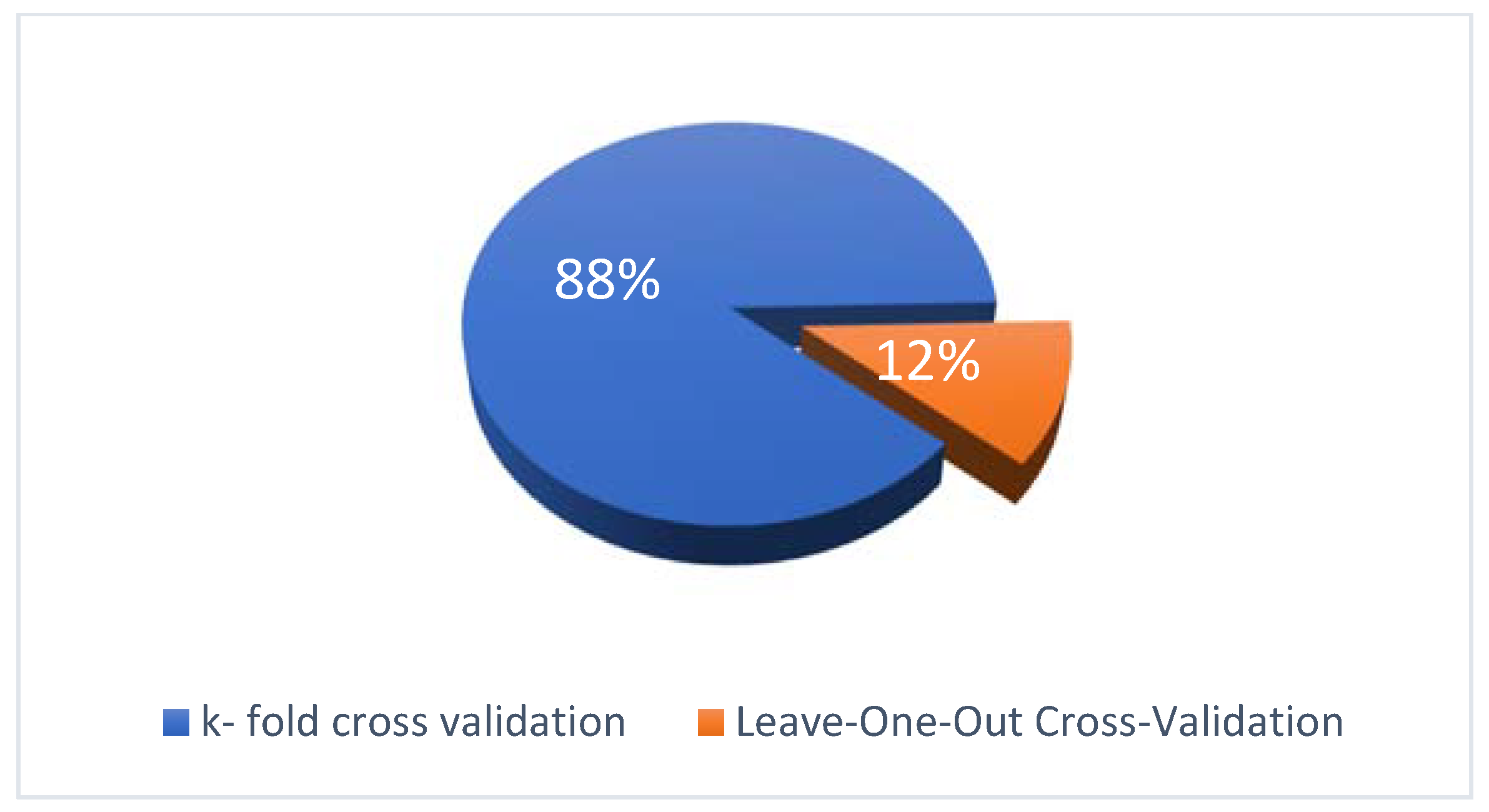
4.6. RQ-6: Validation Approaches
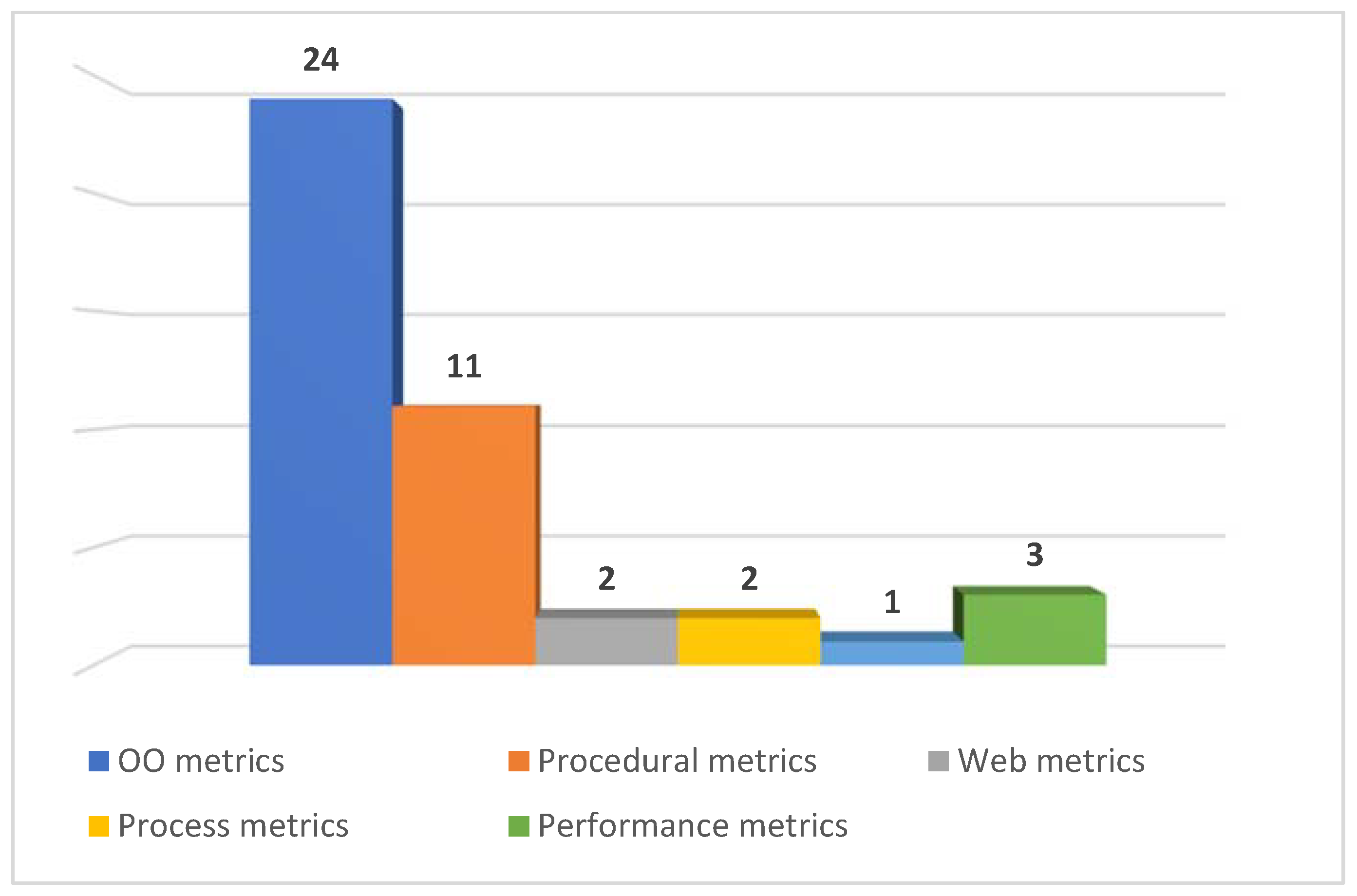
4.7. RQ-7: Software Metrics
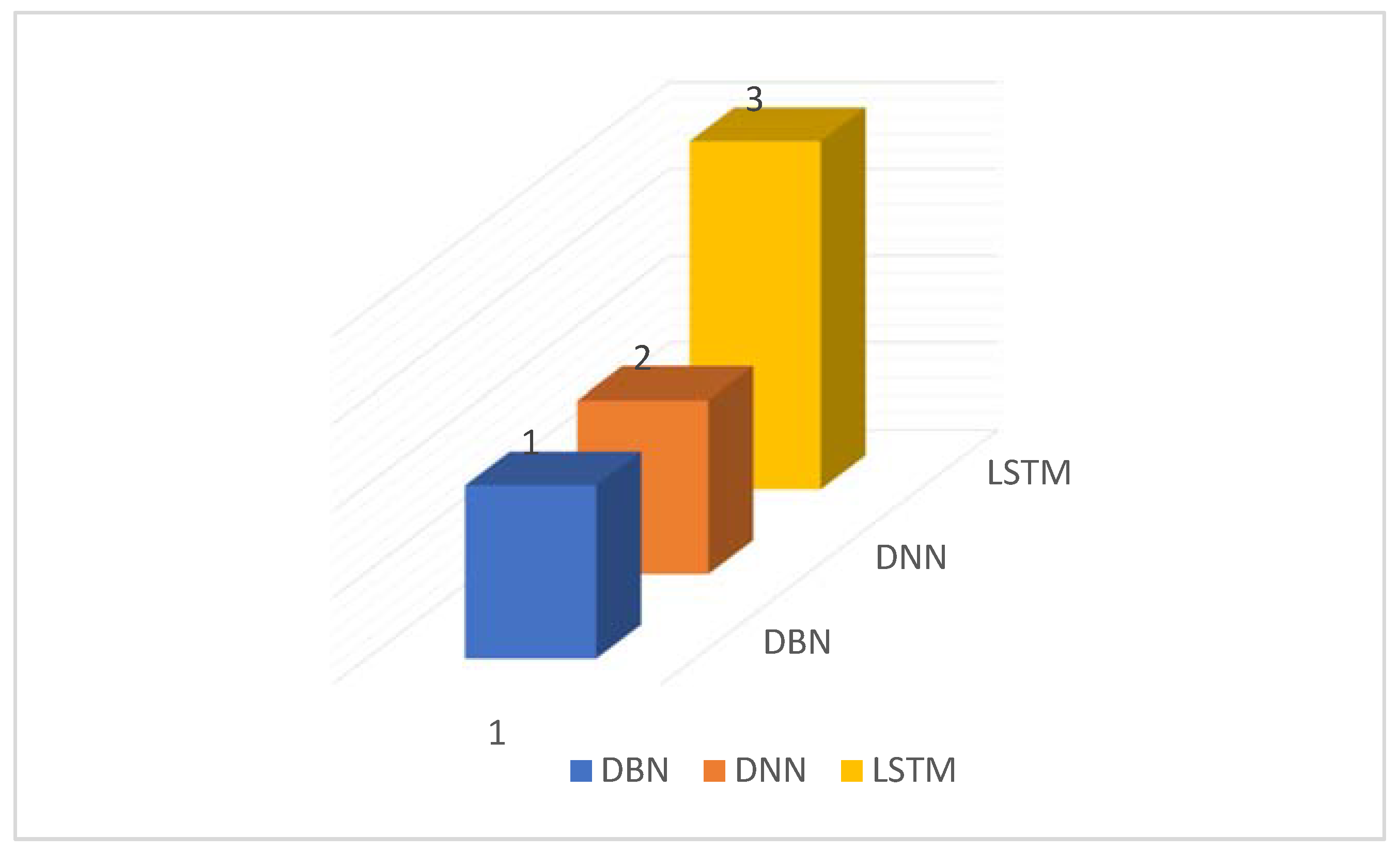
4.8. RQ-8: The Best Algorithm
4.9. RQ-9: Challenges
5. Discussion
5.1. General Discussion
5.2. Threats to Validity
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kaur, A.; Kaur, K. An investigation of the accuracy of code and process metrics for defect prediction of mobile applications. In Proceedings of the 2015 4th International Conference on Reliability, Infocom Technologies and Optimization (ICRITO) (Trends and Future Directions), Noida, India, 2–4 September 2015. [Google Scholar]
- Kha1id, H.E.; Shihab, M. What do mobile app users complain about? a study on free ios apps. IEEE Softw. 2015, 32, 222. [Google Scholar]
- Harman, M.; Jia, Y.; Zhang, Y. App store mining and analysis: MSR for app stores. In Proceedings of the 2012 9th IEEE Working Conference on Mining Software Repositories (MSR), Zurich, Switzerland, 2–3 June 2012; pp. 108–111. [Google Scholar]
- Xia, X.; Shihab, E.; Kamei, Y.; Lo, D.; Wang, X. Predicting crashing releases of mobile applications. In Proceedings of the 10th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement, Ciudad Real, Spain, 8–9 September 2016; pp. 1–10. [Google Scholar]
- Avizienis, A.; Laprie, J.-C.; Randell, B.; Landwehr, C. Basic concepts and taxonomy of dependable and secure computing. IEEE Trans. Dependable Secur. Comput. 2004, 1, 11–33. [Google Scholar] [CrossRef] [Green Version]
- Malhotra, R. An empirical framework for defect prediction using machine learning techniques with Android software. Appl. Soft Comput. 2016, 49, 1034–1050. [Google Scholar] [CrossRef]
- Hall, T.; Beecham, S.; Bowes, D.; Gray, D.; Counsell, S. systematic literature review on fault prediction performance in software engineering. IEEE Trans. Softw. Eng. 2011, 38, 1276–1304. [Google Scholar] [CrossRef]
- Mishra, A.; Shatnawi, R.; Catal, C.; Akbulut, A. Techniques for Calculating Software Product Metrics Threshold Values: A Systematic Mapping Study. Appl. Sci. 2021, 11, 11377. [Google Scholar] [CrossRef]
- Catal, C.; Diri, B. A systematic review of software fault prediction studies. Expert Syst. Appl. 2009, 36, 7346–7354. [Google Scholar] [CrossRef]
- Malhotra, R.; Jain, A. Software fault prediction for object-oriented systems: A systematic literature review. ACMSIGSOFT Softw. Eng. 2011, 36, 1–6. [Google Scholar] [CrossRef]
- Malhotra, R. A systematic review of machine learning techniques for software fault prediction. Appl. Soft Comput. 2015, 27, 504–518. [Google Scholar] [CrossRef]
- Radjenovic, D.; Heriko, M. Software fault prediction metrics: A systematic literature review. Inf. Softw. Technol. 2013, 55, 1397–1418. [Google Scholar] [CrossRef]
- Misirli, A.T.; Bener, A.B. A mapping study on Bayesian networks for software quality prediction. In Proceedings of the 3rd International Workshop on Realizing Artificial Intelligence Synergies in Software Engineering, Hyderabad, India, 3 June 2014; pp. 7–11. [Google Scholar]
- Murillo-Morera, J.; Quesada-López, C.; Jenkins, M. Software Fault Prediction: A Systematic Mapping Study; CIbSE: London, UK, 2015; p. 446. [Google Scholar]
- Özakıncı, R.; Tarhan, A. Early software defect prediction: A systematic map and review. J. Syst. Softw. 2018, 144, 216–239. [Google Scholar] [CrossRef]
- Son, L.H.; Pritam, N.; Khari, M.; Kumar, R.; Phuong, P.T.M.; Thong, P.H. Empirical Study of Software Defect Prediction: A Systematic Mapping. Symmetry 2019, 11, 212. [Google Scholar] [CrossRef] [Green Version]
- Najm, A.; Zakrani, A.; Marzak, A. Decision Trees Based Software Development Effort Estimation: A Systematic Mapping Study. In Proceedings of the 2019 International Conference of Computer Science and Renewable Energies (ICCSRE), Agadir, Morocco, 22–24 July 2019. [Google Scholar]
- Alsolai, H.; Roper, M. A systematic literature review of machine learning techniques for software maintainability prediction. Inf. Softw. Technol. 2020, 119, 106214. [Google Scholar] [CrossRef]
- Auch, M.; Weber, M.; Mandl, P.; Wolff, C. Similarity-based analyses on software applications: A systematic literature review. J. Syst. Softw. 2020, 168, 110669. [Google Scholar] [CrossRef]
- Degu, A. Android application memory and energy performance: Systematic literature review. IOSR J. Comput. Eng. 2019, 21, 20–32. [Google Scholar]
- Kaur, A.; Kaur, K. Systematic literature review of mobile application development and testing effort estimation. J. King Saud Univ.Comput. Inf. Sci. 2018, 34, 1–15. [Google Scholar] [CrossRef]
- Del Carpio, A.F.; Angarita, L.B. Trends in Software Engineering Processes using Deep Learning: A Systematic Literature Review. In Proceedings of the 2020 46th Euromicro Conference on Software Engineering and Advanced Applications (SEAA), Portorož, Slovenia, 26–28 August 2020; pp. 445–454. [Google Scholar]
- Kaur, A. A Systematic Literature Review on Empirical Analysis of the Relationship between Code Smells and Software Quality Attributes. Arch. Comput. Methods Eng. 2019, 27, 61267–61296. [Google Scholar] [CrossRef]
- Kaya, A.; Keceli, A.S.; Catal, C.; Tekinerdogan, B. Model analytics for defect prediction based on design-level metrics and sampling techniques. In Model Management and Analytics for Large Scale Systems; Academic Press: Cambridge, MA. USA, 2020; pp. 125–139. [Google Scholar]
- Kaur, A.; Kaur, K.; Kaur, H. Application of machine learning on process metrics for defect prediction in mobile application. In Information Systems Design and Intelligent Applications; Springer: New Delhi, India, 2016; pp. 81–98. [Google Scholar]
- Zhao, K.; Xu, Z.; Yan, M.; Tang, Y.; Fan, M.; Catolino, G. Just-in-time defect prediction for Android apps via imbalanced deep learning model. In Proceedings of the 36th Annual ACM Symposium on Applied Computing, Online, 22–26 March 2021; pp. 1447–1454. [Google Scholar]
- Sewak, M.; Sahay, S.K.; Rathore, H. Assessment of the Relative Importance of different hyper-parameters of LSTM for an IDS. In Proceedings of the 2020 IEEE REGION 10 CONFERENCE (TENCON), Osaka, Japan, 16-19 November 2020; pp. 414–419. [Google Scholar]
- Pandey, S.K.; Mishra, R.B.; Tripathi, A.K. Machine learning based methods for software fault prediction: A survey. Expert Syst. Appl. 2021, 172, 114595. [Google Scholar] [CrossRef]
- Bhavana, K.; Nekkanti, V.; Jayapandian, N. Internet of things enabled device fault prediction system using machine learning. In International Conference on Inventive Computation Technologies; Springer: Cham, Switzerland, 2019; pp. 920–927. [Google Scholar]
- Pandey, S.K.; Tripathi, A.K. DNNAttention: A deep neural network and attention based architecture for cross project defect number prediction. Knowl. Based Syst. 2021, 233, 107541. [Google Scholar] [CrossRef]
- Kitchenham, B.; Brereton, O.P.; Budgen, D.; Turner, M.; Bailey, J.; Linkman, S. Systematic literature reviews in software engineering—A systematic literature review. Inf. Softw. Technol. 2009, 51, 7–15. [Google Scholar] [CrossRef]
- Kang, Z.; Catal, C.; Tekinerdogan, B. Machine learning applications in production lines: A systematic literature review. Comput. Ind. Eng. 2020, 149, 106773. [Google Scholar] [CrossRef]
- Kitchenham, B.; Charters, S. Guidelines for Performing Systematic Literature Reviews in Software Engineering; Technical Report; EBSE: Goyang-si, Korea, 2007. [Google Scholar]
- Catal, C.; Sevim, U.; Diri, B. Metrics-driven software quality prediction without prior fault data. In Electronic Engineering and Computing Technology; Springer: Dordrecht; The Netherlands, 2010; pp. 189–199. [Google Scholar]
- Catal, C. A Comparison of Semi-Supervised Classification Approaches for Software Defect Prediction. J. Intell. Syst. 2014, 23, 75–82. [Google Scholar] [CrossRef]
- Alan, O.; Catal, C. Thresholds based outlier detection approach for mining class outliers: An empirical case study on software measurement datasets. Expert Syst. Appl. 2011, 38, 3440–3445. [Google Scholar] [CrossRef]
- Ricky, M.Y.; Purnomo, F.; Yulianto, B. Mobile application software defect prediction. In Proceedings of the 2016 IEEE Symposium on Service-Oriented System Engineering (SOSE), Oxford, UK, 29 March–2 April 2016; pp. 307–313. [Google Scholar]
- Biçer, M.S.; Diri, B. Predicting defect-prone modules in web applications. In International Conference on Information and Software Technologies; Springer: Cham, Switzerland, 2015; pp. 577–591. [Google Scholar]
- Malhotra, R.; Sharma, A. Empirical assessment of feature selection techniques in defect prediction models using web applications. J. Intell. Fuzzy Syst. 2019, 36, 6567–6578. [Google Scholar] [CrossRef]
- Ramakrishnan, R.; Kaur, A. An empirical comparison of predictive models for web page performance. Inf. Softw. Technol. 2020, 123, 106307. [Google Scholar] [CrossRef]
- Kang, D.; Bae, D.H. Software fault prediction models for web applications. In Proceedings of the 2010 IEEE 34th Annual Computer Software and Applications Conference Workshops, Seoul, Korea, 19–23 July 2010; pp. 51–56. [Google Scholar]
- Catolino, G.; Di Nucci, D.; Ferrucci, F. Cross-project just-in-time bug prediction for mobile apps: An empirical assessment. In Proceedings of the 2019 IEEE/ACM 6th International Conference on Mobile Software Engineering and Systems (MOBILESoft), Montreal, QC, Canada, 25–26 May 2019; pp. 99–110. [Google Scholar]
- Kumar, A.; Chugh, R.; Girdhar, R.; Aggarwal, S. Classification of faults in Web applications using machine learning. In Proceedings of the 2017 International Conference on Intelligent Systems, Metaheuristics & Swarm Intelligence, Hong Kong, China, 25–27 March 2017; pp. 62–67. [Google Scholar]
- Bhandari, G.P.; Gupta, R. Fault Prediction in SOA-Based Systems Using Deep Learning Techniques. Int. J. Web Serv. Res. 2020, 17, 1–19. [Google Scholar] [CrossRef]
- Cui, J.; Wang, L.; Zhao, X.; Zhang, H. Towards predictive analysis of android vulnerability using statistical codes and machine learning for IoT applications. Comput. Commun. 2020, 155, 125–131. [Google Scholar] [CrossRef]
- Shar, L.K.; Briand, L.C.; Tan, H.B.K. Web Application Vulnerability Prediction Using Hybrid Program Analysis and Machine Learning. IEEE Trans. Dependable Secur. Comput. 2014, 12, 688–707. [Google Scholar] [CrossRef]
- Malhotra, R.; Khurana, A. Analysis of evolutionary algorithms to improve software defect prediction. In Proceedings of the 2017 6th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 20–22 September 2017; pp. 301–305. [Google Scholar]
- Pang, Y.; Xue, X.; Wang, H. Predicting vulnerable software components through the deep neural network. In Proceedings of the 2017 International Conference on Deep Learning Technologies, Chengdu, China, 2–4 June 2017; pp. 6–10. [Google Scholar]
- Dehkordi, M.R.; Seifzadeh, H.; Beydoun, G.; Nadimi-Shahraki, M.H. Success prediction of android applications in a novel repository using neural networks. Complex Intell. Syst. 2020, 6, 573–590. [Google Scholar] [CrossRef]
- Padhy, N.; Satapathy, S.C.; Mohanty, J.; Panigrahi, R. Software reusability metrics prediction by using evolutionary algorithms: The interactive mobile learning application RozGaar. Int. J. Knowl.-Based Intell. Eng. Syst. 2018, 22, 261–276. [Google Scholar] [CrossRef]
- Menzies, T.; Greenwald, J.; Frank, A. Data Mining Static Code Attributes to Learn Defect Predictors. IEEE Trans. Softw. Eng. 2006, 33, 2–13. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RQ | Research Questions |
|---|---|
| RQ1 | Which platforms are addressed in mobile defect prediction? |
| RQ2 | Which datasets are used in mobile defect prediction studies? |
| RQ3 | Which machine learning types are used in mobile defect prediction studies? |
| RQ4 | Which machine learning algorithms are applied in mobile defect prediction? |
| RQ5 | Which evaluation metrics are used in mobile defect prediction? |
| RQ6 | Which validation approaches were used in mobile defect prediction? |
| RQ7 | Which software metrics were adopted in mobile defect prediction? |
| RQ8 | Which ML algorithm works best for mobile defect prediction? |
| RQ9 | What are the challenges and research gaps in mobile defect prediction? |
| ID | Exclusion Criteria |
|---|---|
| 1. | The paper includes only an abstract (this criterion is not about the accessibility of the paper, we included both open access and subscription basis papers) |
| 2. | The paper is not written in English |
| 3. | The article is not a primary study paper |
| 4. | The content does not provide any experimental results |
| 5. | The study does not describe in detail how machine learning is applied |
| ID | Questions |
|---|---|
| Q1 | Are the aims of the study clearly declared? |
| Q2 | Are the scope and context of the study clearly defined? |
| Q3 | Is the proposed solution clearly explained and validated by an empirical study? |
| Q4 | Are the variables used in the study likely to be valid and reliable? |
| Q5 | Is the research process documented adequately? |
| Q6 | Are all study questions answered? |
| Q7 | Are the negative findings presented? |
| Q8 | Are the main findings stated clearly in terms of credibility, validity, and reliability? |
| Platforms | Total |
|---|---|
| Android | 21 |
| Windows Phone | 1 |
| Web Applications | 20 |
| Mobile Applications | 5 |
| Challenges | Proposed Solutions | Reference |
|---|---|---|
| Metric selection limitations for mobile software | Use alternate code and process metrics | [3,18] |
| Faults in Android data | Remove faults | [9] |
| Limited mobile app repository | Use of public repository | [11,27,28,36] |
| Repeated data/code in the project | Domain Adaptation | [26] |
| Small dataset problem | Not mentioned | [22] |
| Different programming language problem | Defect prediction only GIT open-source Android, Java, and C++ uncertain | [8,10,26] |
| Modeling problem | Not mentioned | [4,11,30] |
| Different platforms and languages | Not mentioned | [18,21] |
| Extensive datasets | Not mentioned | [16] |
| Not fully automated | Manually code, log, bug, and review control | [11] |
| Imbalance Class problem | Sampling methods, Under sampling methods | [7,12,22] |
| Manual feature engineering | Not mentioned | [26] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jorayeva, M.; Akbulut, A.; Catal, C.; Mishra, A. Machine Learning-Based Software Defect Prediction for Mobile Applications: A Systematic Literature Review. Sensors 2022, 22, 2551. https://doi.org/10.3390/s22072551
Jorayeva M, Akbulut A, Catal C, Mishra A. Machine Learning-Based Software Defect Prediction for Mobile Applications: A Systematic Literature Review. Sensors. 2022; 22(7):2551. https://doi.org/10.3390/s22072551
Chicago/Turabian StyleJorayeva, Manzura, Akhan Akbulut, Cagatay Catal, and Alok Mishra. 2022. "Machine Learning-Based Software Defect Prediction for Mobile Applications: A Systematic Literature Review" Sensors 22, no. 7: 2551. https://doi.org/10.3390/s22072551
APA StyleJorayeva, M., Akbulut, A., Catal, C., & Mishra, A. (2022). Machine Learning-Based Software Defect Prediction for Mobile Applications: A Systematic Literature Review. Sensors, 22(7), 2551. https://doi.org/10.3390/s22072551