
Noise-Resistant Demosaicing with Deep Image Prior Network and Random RGBW Color Filter Array

Abstract
:1. Introduction
2. Related Works
2.1. Color Filter Arrays in Digital Imaging Systems
2.2. RGBW Color Filter Array
2.3. Deep-Image-Prior-Based Image Restoration
3. Proposed Method
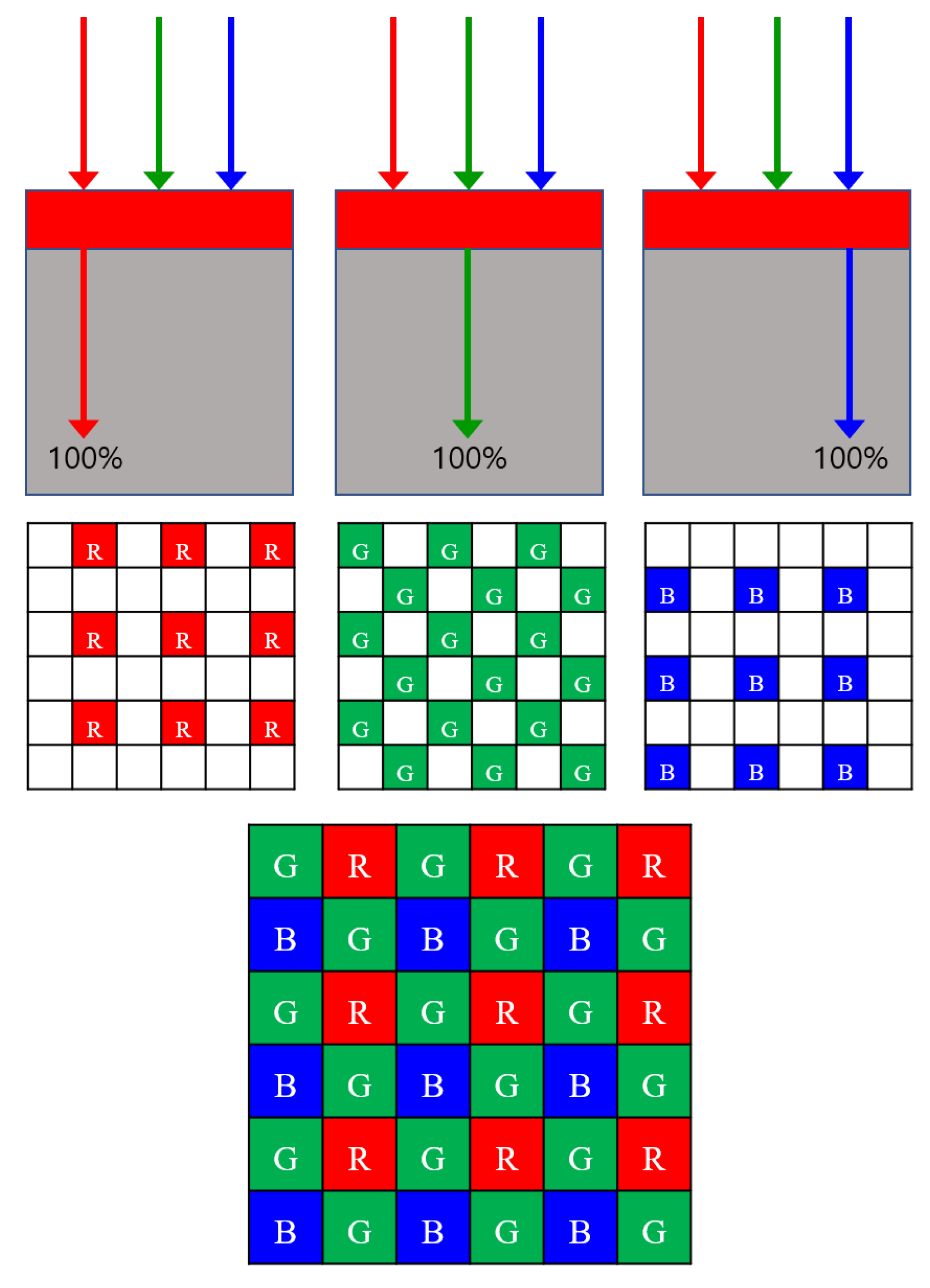
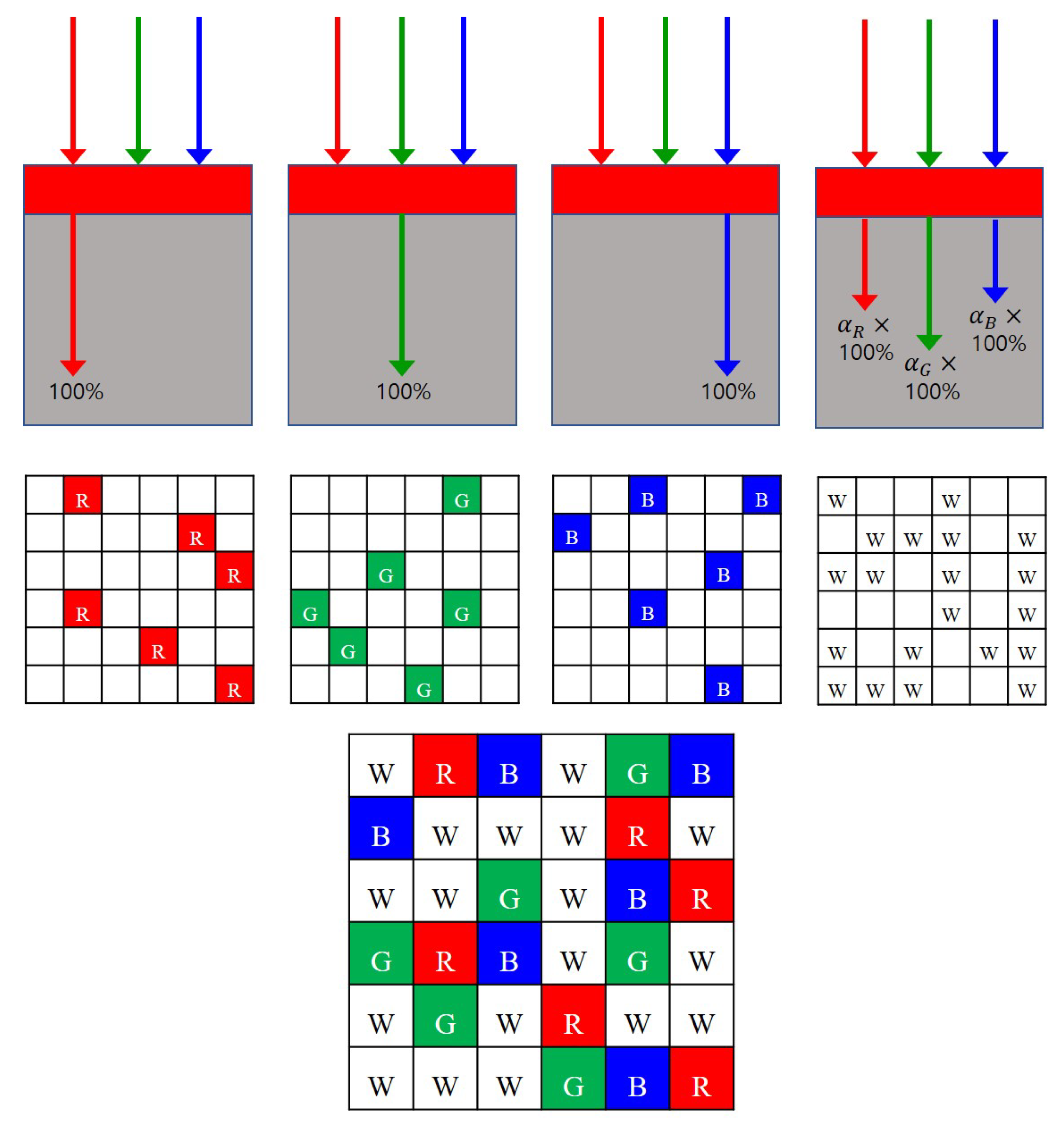
3.1. Random RGBW Color Filter Array
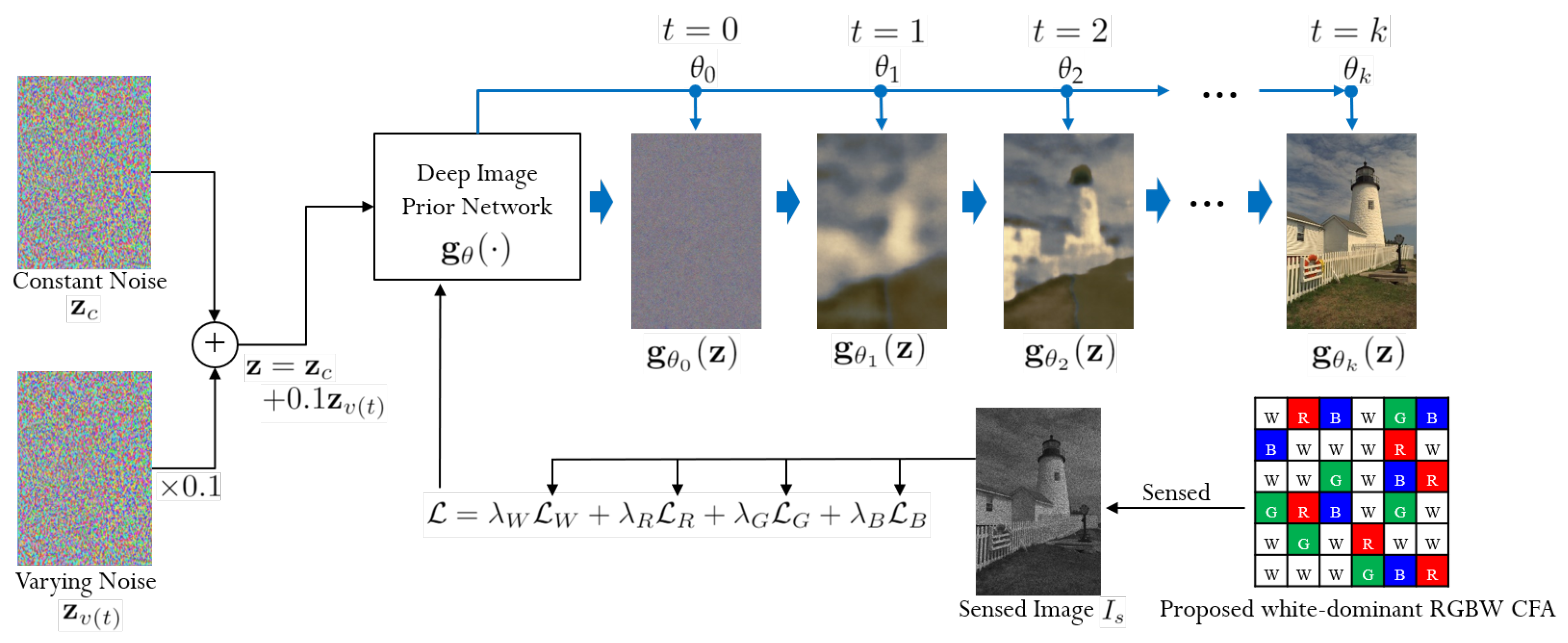
3.2. DIP-Based Demosaicing of the Random RGBW-CFA
4. Experiments and Discussion
4.1. Experimental Settings
4.2. Network Structure
4.3. Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Bayer, B. Color Imaging Array. U.S. Patent 3,971,065, 20 July 1976. [Google Scholar]
- Alleysson, D.; Susstrunk, S.; Herault, J. Linear demosaicing inspired by the human visual system. IEEE Trans. Image Process. 2005, 14, 439–449. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dubois, E. Frequency-domain methods for demosaicking of Bayer-sampled color images. IEEE Signal Process. Lett. 2005, 12, 847–850. [Google Scholar] [CrossRef]
- Gunturk, B.K.; Altunbasak, Y.; Mersereau, R.M. Color plane interpolation using alternating projections. IEEE Trans. Image Process. 2002, 11, 997–1013. [Google Scholar] [CrossRef] [PubMed]
- Gunturk, B.K.; Glotzbach, J.; Altunbasak, Y.; Schafer, R. Demosaicking: Color filter array interpolation. Signal Process. Mag. IEEE 2005, 22, 44–54. [Google Scholar] [CrossRef]
- Kiku, D.; Monno, Y.; Masayuki, T.; Okutomi, M. Beyond Color Difference: Residual Interpolation for Color Image Demosaicking. IEEE Trans. Image Process. 2016, 25, 1288–1300. [Google Scholar] [CrossRef] [PubMed]
- Kimmel, R. Demosaicing: Image reconstruction from color CCD samples. IEEE Trans. Image Process. 1999, 8, 1221–1228. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Daniele, M.; Giancarlo, C. Color image demosaicking: An overview. Signal Process. Image Commun. 2011, 26, 518–533. [Google Scholar] [CrossRef]
- Pei, S.C.; Tam, I.K. Effective color interpolation in CCD color filter arrays using signal correlation. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 503–513. [Google Scholar] [CrossRef] [Green Version]
- Pekkucuksen, I.; Altunbasak, Y. Multiscale Gradients-Based Color Filter Array Interpolation. IEEE Trans. Image Process. 2013, 22, 157–165. [Google Scholar] [CrossRef]
- Lei, Z.; Xiaolin, W. Color demosaicking via directional linear minimum mean square-error estimation. IEEE Trans. Image Process. 2005, 14, 2167–2178. [Google Scholar] [CrossRef]
- Lukac, R.; Plataniotis, K.N. Color filter arrays: Design and performance analysis. IEEE Trans. Consum. Electron. 2005, 51, 1260–1267. [Google Scholar] [CrossRef] [Green Version]
- Hirakawa, K.; Wolfe, P.J. Spatio-Spectral Color Filter Array Design for Optimal Image Recovery. IEEE Trans. Image Process. 2008, 17, 1876–1890. [Google Scholar] [CrossRef] [PubMed]
- Oh, P.; Lee, S.; Kang, M.G. Colorization-Based RGB-White Color Interpolation using Color Filter Array with Randomly Sampled Pattern. Sensors 2017, 17, 1523. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tachi, M. Image Processing Device, Image Processing Method, and Program Pertaining to Image Correction. U.S. Patent 8,314,863, 20 November 2012. [Google Scholar]
- Rafinazari, M.; Dubois, E. Demosaicking algorithms for RGBW color filter arrays. In SPIE Electronic Imaging 2016; Eschbach, R., Gabriel, G., Marcu, A.R., Eds.; Society for Imaging Science and Technology: Bellingham, WA, USA, 2015; Volume 9395, pp. 1–6. [Google Scholar] [CrossRef]
- RGBW Filter Spectral Responses of VEML6040 Sensor. Available online: http://www.vishay.com/docs/84276/veml6040.pdf (accessed on 19 January 2022).
- Klatzer, T.; Hammernik, K.; Knobelreiter, P.; Pock, T. Learning joint demosaicing and denoising based on sequential energy minimization. In Proceedings of the 2016 IEEE International Conference on Computational Photography (ICCP), Evanston, IL, USA, 13–15 May 2016; pp. 1–11. [Google Scholar] [CrossRef]
- Gharbi, M.; Chaurasia, G.; Paris, S.; Durand, F. Deep joint demosaicking and denoising. ACM Trans. Graph. 2016, 35, 1–12. [Google Scholar] [CrossRef]
- Huang, T.; Wu, F.F.; Dong, W.; Shi, G.; Li, X. Lightweight Deep Residue Learning for Joint Color Image Demosaicking and Denoising. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 127–132. [Google Scholar] [CrossRef]
- Dmitry, U.; Andrea, V.; Victor, L. Deep Image Prior. Int. J. Comput. Vis. 2020, 128, 1867–1888. [Google Scholar] [CrossRef]
- Park, S.W.; Kang, M.G. Generalized color interpolation scheme based on intermediate quincuncial pattern. J. Electron. Imaging 2014, 23, 030501. [Google Scholar] [CrossRef]
- The Kodak Color Image Dataset. Available online: http://r0k.us/graphics/kodak/ (accessed on 19 January 2022).
- Zhang, L.; Wu, X.; Buades, A.; Li, X. Color demosaicking by local directional interpolation and nonlocal adaptive thresholding. J. Electron. Imaging 2011, 20, 023016. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Method | CPSNR | SSIM | FSIMc |
|---|---|---|---|---|
| SEM [18] | 30.39 | 0.9961 | 0.9792 | |
| DNet [19] | 28.79 | 0.9540 | 0.9743 | |
| LCNN [20] | 29.00 | 0.9948 | 0.9932 | |
| Kodak | RI [6] | 28.69 | 0.9517 | 0.9448 |
| Sony [15] | 29.17 | 0.9615 | 0.9502 | |
| Paul et al. [14] | 30.72 | 0.9794 | 0.9566 | |
| Proposed | 30.80 | 0.9964 | 0.9953 | |
| SEM [18] | 29.26 | 0.9940 | 0.9773 | |
| DNet [19] | 28.88 | 0.9579 | 0.9756 | |
| LCNN [20] | 28.94 | 0.9943 | 0.9922 | |
| McMaster | RI [6] | 28.59 | 0.9563 | 0.9456 |
| Sony [15] | 28.80 | 0.9641 | 0.9515 | |
| Paul et al. [14] | 27.79 | 0.9715 | 0.9571 | |
| Proposed | 31.61 | 0.9963 | 0.9936 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kurniawan, E.; Park, Y.; Lee, S. Noise-Resistant Demosaicing with Deep Image Prior Network and Random RGBW Color Filter Array. Sensors 2022, 22, 1767. https://doi.org/10.3390/s22051767
Kurniawan E, Park Y, Lee S. Noise-Resistant Demosaicing with Deep Image Prior Network and Random RGBW Color Filter Array. Sensors. 2022; 22(5):1767. https://doi.org/10.3390/s22051767
Chicago/Turabian StyleKurniawan, Edwin, Yunjin Park, and Sukho Lee. 2022. "Noise-Resistant Demosaicing with Deep Image Prior Network and Random RGBW Color Filter Array" Sensors 22, no. 5: 1767. https://doi.org/10.3390/s22051767
APA StyleKurniawan, E., Park, Y., & Lee, S. (2022). Noise-Resistant Demosaicing with Deep Image Prior Network and Random RGBW Color Filter Array. Sensors, 22(5), 1767. https://doi.org/10.3390/s22051767