

A Novel Hybrid Multi-Modal Deep Learning for Detecting Hashtag Incongruity on Social Media


Abstract
1. Introduction
- We introduce a dataset for Instagram that consists of metadata, visual and textual information collected from different hashtags pertinent to brands and celebrities with additional generic features related to images and texts.
- We develop machine learning and deep learning models based on metadata, text and images for incongruity detection. We also propose a multimodal model by fusing text and image classifiers. Further, by comparing the experimental results of models, we show that our proposed multimodal models outperform other models.
- We apply object detection to the two categories of images. First, we use brand-related images to detect a brand’s logos. Second, we employ celebrity-related images to recognize the faces of the celebrity and other people who are somehow connected to them by performing clustering on their Instagram accounts and show the effectiveness of object detection to discriminate incongruent information from other relevant information.
- We conduct an explorative analysis and empirical study of our dataset from different perspectives to categorize the type of incongruity in posts and examine the characteristic of social media users who share such posts.
2. Related Works
2.1. Brand Marketing and Advertising on Social Media
2.2. Incongruent Content, Misinformation and Spam
2.3. Machine Learning, NLP and Computer Vision
3. Materials and Methods
3.1. Approach Overview
3.2. Data Collection
3.3. Data Annotation
3.4. Classification Module
3.4.1. Metadata Classification
3.4.2. Text Classification
3.4.3. Image Classification
3.4.4. Hybrid Multimodal Deep Learning Model
3.5. Object Detection Module
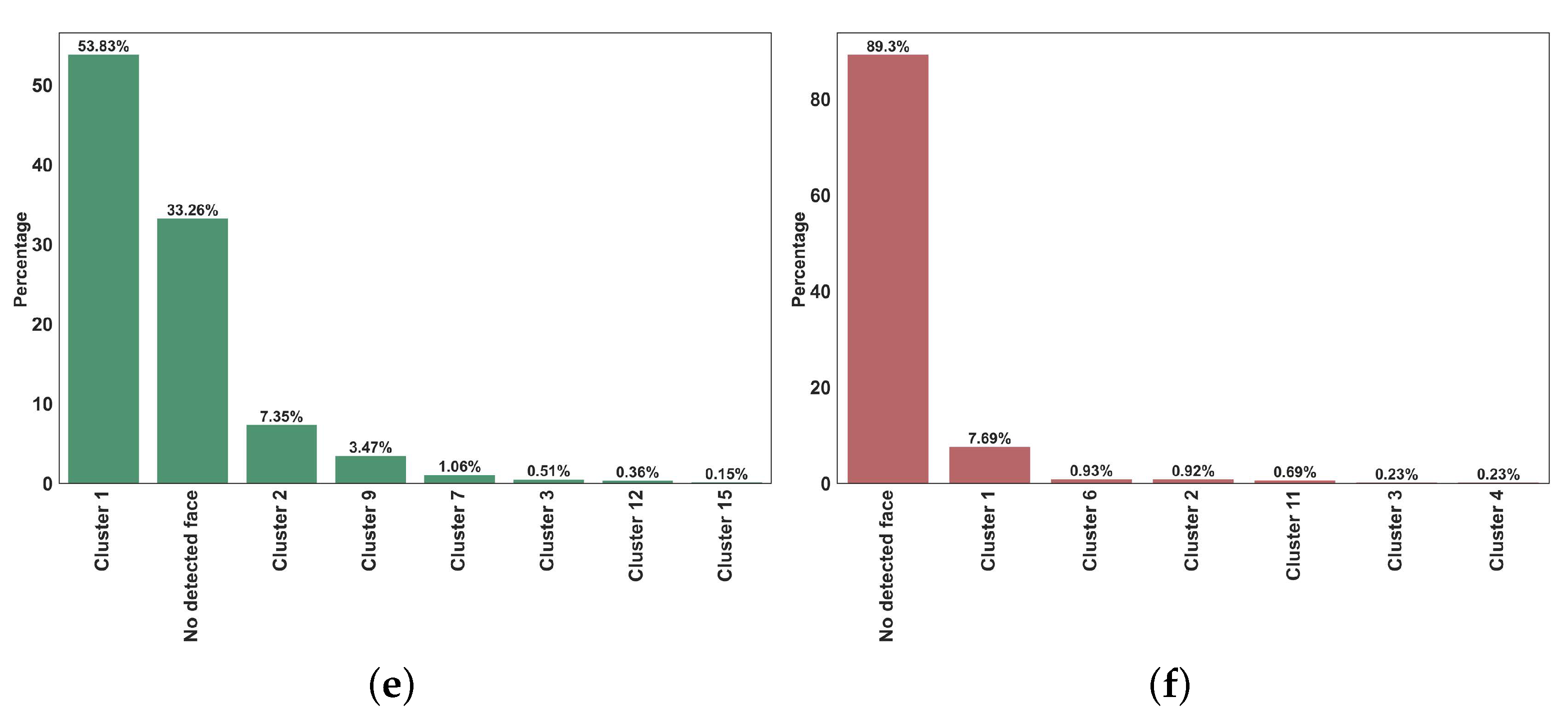
3.6. Face Recognition
3.7. Logo Detection
4. Experiment and Analysis
4.1. Data Analysis
4.1.1. Mismatch Topics
- Personal: selfies and photos of an individual or group without any relation to the hashtag.
- Art: painting, graphic art, musical instruments and artists.
- Sport: sports equipment, pictures of professional sports, athletes.
- Animal: all pictures of animals.
- Food: meals and beverages and simply everything edible and drinkable.
- Cosmetic: hairdressing, makeup, cosmetic treatments, even healthcare.
- Environment: photo of nature, building.
- Quote: images of quotes, memes, tweets, manuscripts.
- Screenshot: photos displayed on the screen of a computer or mobile phone.
- Ads: posters and flyers.
- Economy: images relating to bitcoin and other digital currencies.
- Shop: online sales and products related to other brands.
- Inappropriate: sensitive and sexual pictures that are not suitable for all users. Note that Instagram strictly handles this sort of content, so there is little of them.
- Other: the remaining images do not belong to mentioned topics.
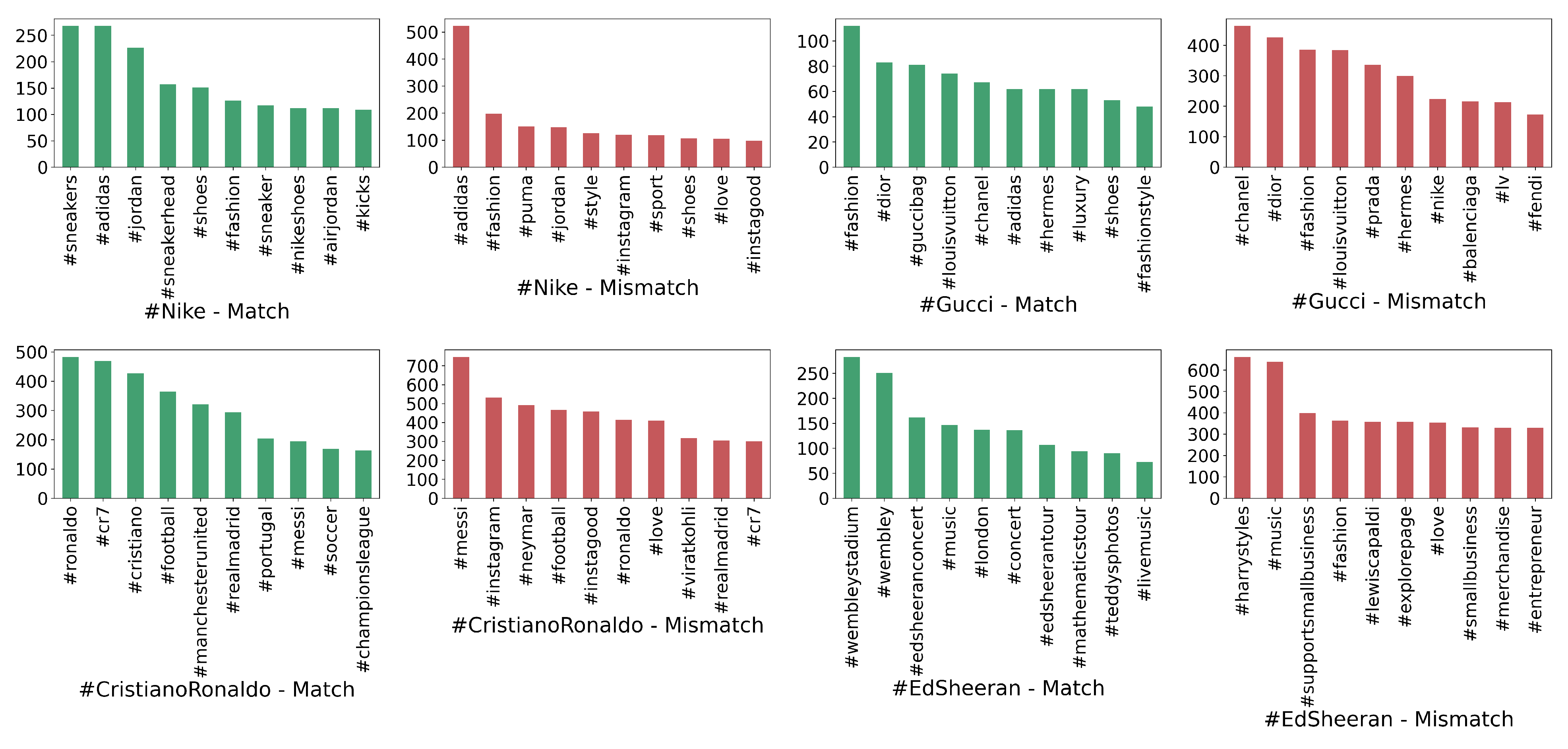
4.1.2. Hashtag Analysis
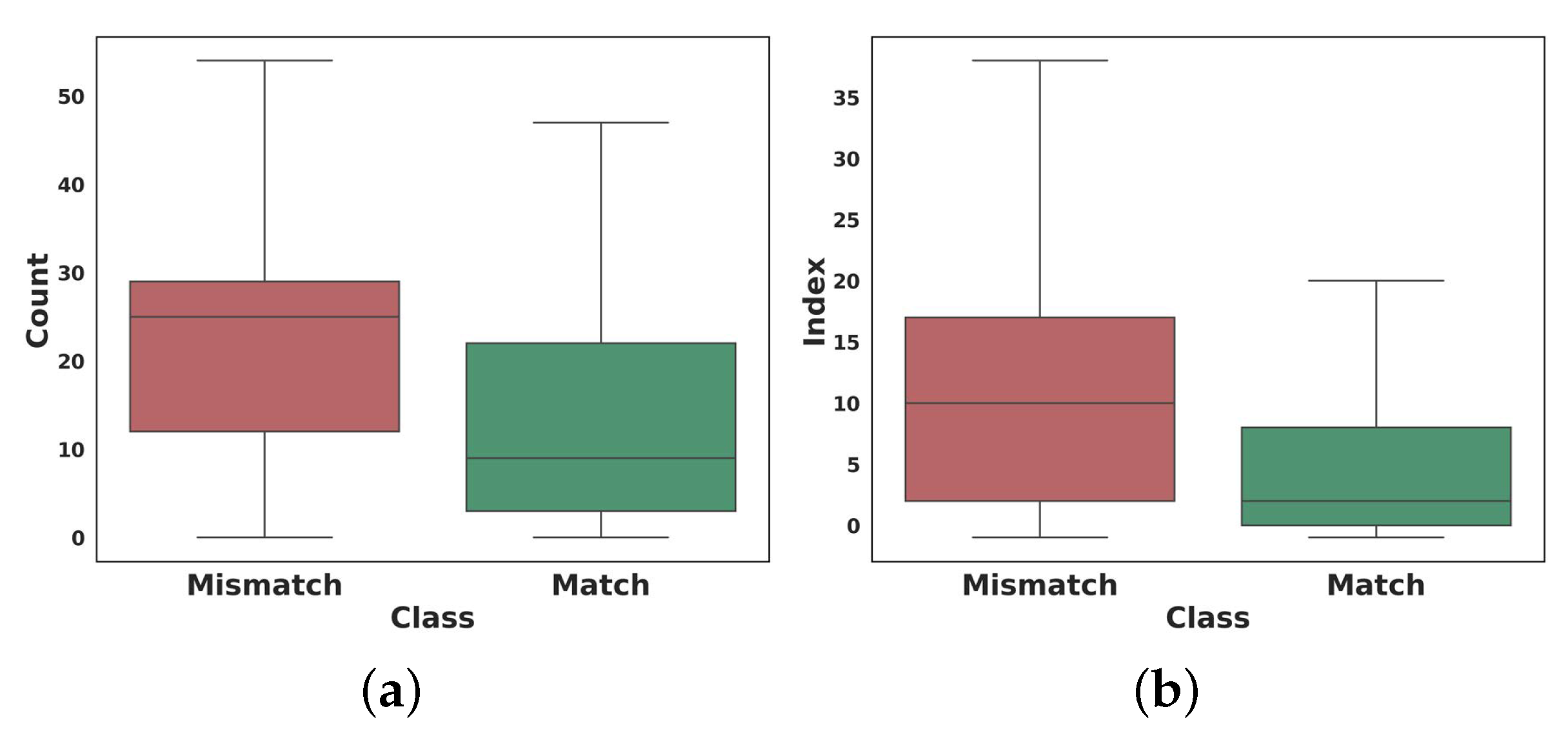
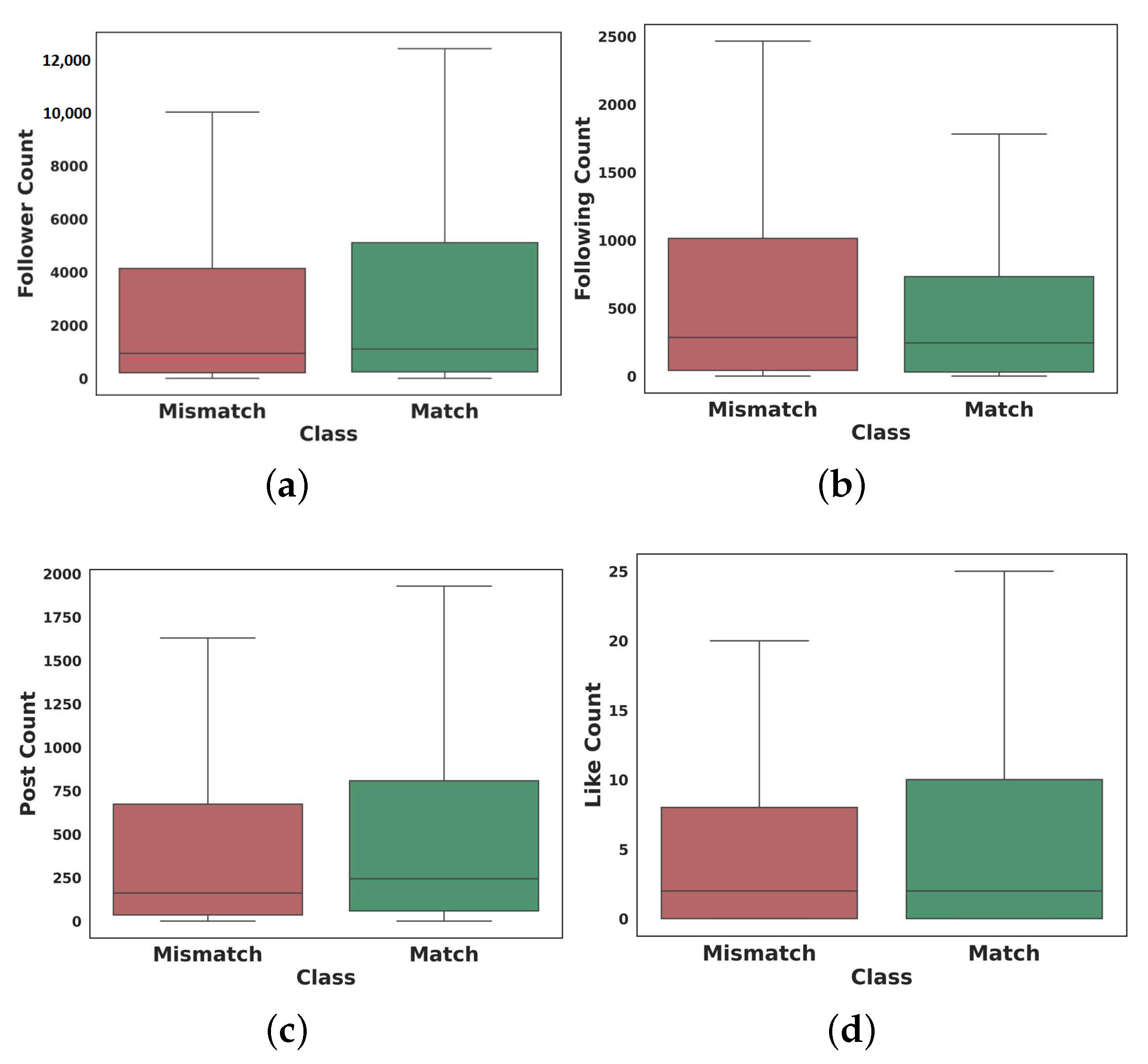
4.1.3. User Analysis
4.2. Experimental Results
4.2.1. Feature Selection
4.2.2. Classification Results
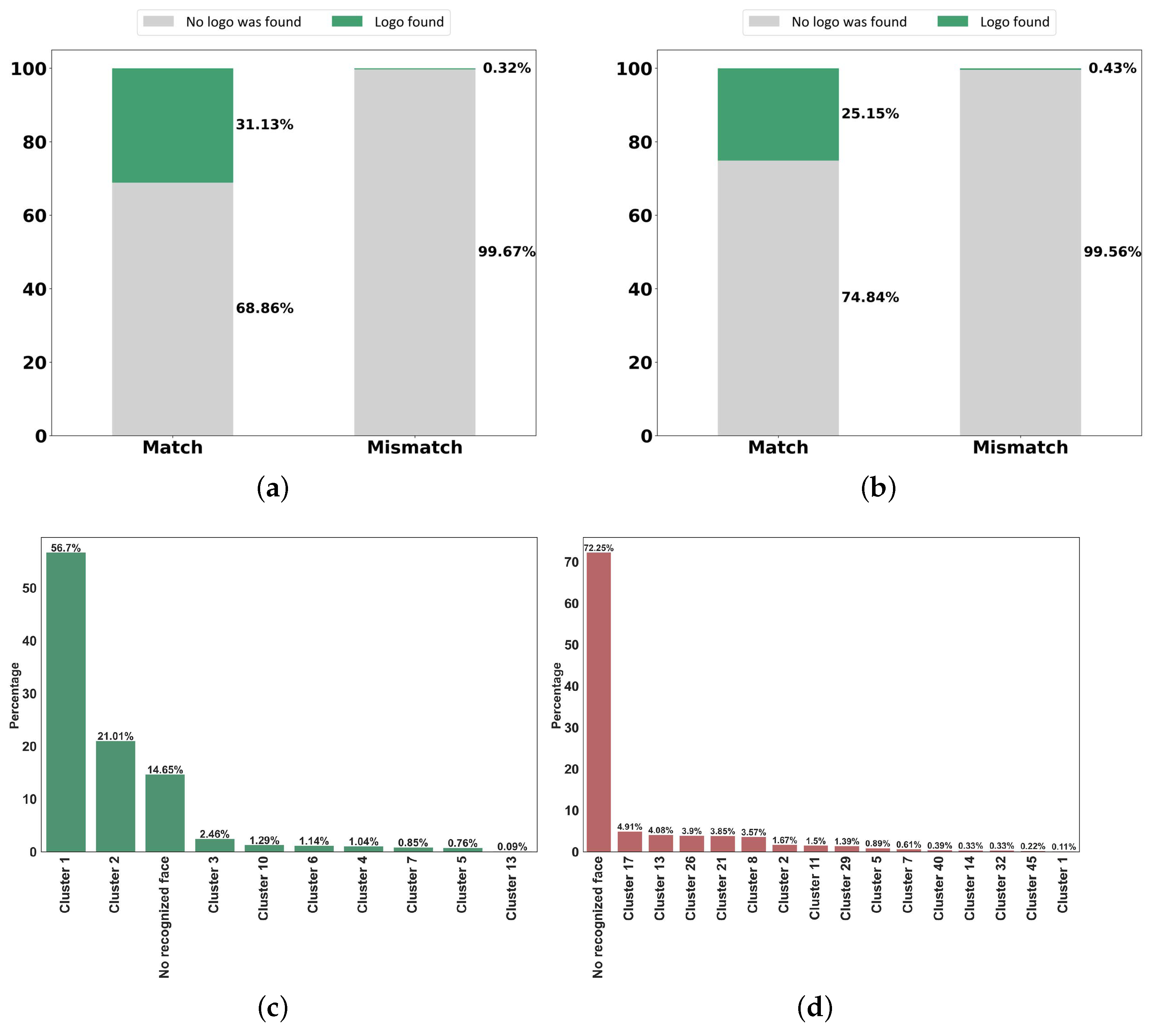
4.2.3. Object Detection Results
5. Limitations and Future Works
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| ML | Machine Learning |
| DL | Deep Learning |
| NLP | Natural Language Processing |
| CNN | Convolutional Neural Network |
| RNN | Recurrent Neural Network |
| LSTM | Long Short-Term Memory |
| GRU | Gated Recurrent Unit |
| SVM | Support Vector Machines |
| LR | Logistic Regression |
| DT | Decision Tree |
| NB | Naïve Bayes |
| RF | Random Forest |
| KNN | K-Nearest Neighbor |
| OCR | Optical Character Recognition |
| BERT | Bidirectional Encoder Representations from Transformers |
| ResNet | Residual neural network |
| MTCNN | Multi-task Cascaded Convolutional Networks |
| RFE | Recursive Feature Elimination |
| mAP | Mean Average Precision |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Models | Hyperparameters | Optimal Values |
|---|---|---|---|
| Metadata Classification | SVM | kernel = [linear, poly, rbf, sigmoid], C = [1, 10, 100, 1000] | kernel = rbf, C = 1 |
| Stacking Ensemble | estimators = [SVM, DT, XGBoost, NB, LR] | estimators = [SVM, DT, NB], final_estimator = LR | |
| RF | n_estimators = [10, 20, 50, 100, 200, 500], criterion = [gini, entropy, log_loss], max_depth = [None, 2, 5, 10], max_features = [sqrt, log2, None] | n_estimators = 10, criterion = gini, max_depth = None, max_features = sqrt | |
| XGBoost | loss = [log_loss, deviance, exponential], learning_rate = [0.01, 0.025, 0.05, 0.075, 0.1, 0.15, 0.2], max_depth = [3, 5, 8] | loss = log_loss, learning_rate = 0.15, max_depth = 3 | |
| Deep Dense layers | Optimizer = [SGD, RMSprop, Adagrad, Adadelta, Adam, Adamax, Nadam], Learning rate = [0.0001, 0.001, 0.01, 0.1], Dropout = [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9], Number of neurons (hidden layers) = [16, 32, 64, 128, 256], Activation functions = [softmax, softplus, softsign, relu, tanh, sigmoid, hard_sigmoid, linear] | optimizer = Adamax, learning_rate = 0.1, Dropout = 0, number of neurons (hidden layers) = [32, 32, 32], Activation functions = [linear, relu, relu] | |
| Text Classification | SVM | kernel = [linear, poly, rbf, sigmoid] C = [1, 10, 100, 1000] | kernel = rbf, C = 100 |
| Stacking Ensemble | estimators = [SVM, DT, XGBoost, NB, LR] | estimators = [SVM, XGBoost, NB], final_estimator = LR | |
| RF | n_estimators = [10, 20, 50, 100, 200, 500], criterion = [gini, entropy, log_loss], max_depth = [None, 2, 5, 10], max_features = [sqrt, log2, None] | n_estimators = 100, criterion = gini, max_depth = None, max_features = sqrt | |
| XGBoost | loss = [log_loss, deviance, exponential], learning_rate = [0.01, 0.025, 0.05, 0.075, 0.1, 0.15, 0.2], max_depth = [3, 5, 8] | loss = log_loss, learning_rate = 0.1, max_depth = 3 | |
| Fine-tuned BERT | Optimizer = [SGD, RMSprop, Adagrad, Adadelta, Adam, Adamax, Nadam], Learning rate = [0.0001, 0.001, 0.01, 0.1], Dropout = [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9], number of neurons (hidden layers) = [16, 32, 64, 128, 256], Activation functions = [softmax, softplus, softsign, relu, tanh, sigmoid, hard_sigmoid, linear] | Optimizer = Adam, Learning rate = 0.001, Dropout = 0.1, number of neurons (hidden layers) = [256, 32], Activation functions = [relu, relu] | |
| Image Classification | SVM | kernel = [linear, poly, rbf, sigmoid] C = [1, 10, 100, 1000] | kernel = rbf, C = 100 |
| Stacking Ensemble | estimators = [SVM, DT, XGBoost, NB, LR] | estimators = [SVM, XGBoost], final_estimator = LR | |
| RF | n_estimators = [10, 20, 50, 100, 200, 500], criterion = [gini, entropy, log_loss], max_depth = [None, 2, 5, 10], max_features = [sqrt, log2, None] | n_estimators = 100, criterion = gini, max_depth = None, max_features = sqrt | |
| XGBoost | loss = [log_loss, deviance, exponential], learning_rate = [0.01, 0.025, 0.05, 0.075, 0.1, 0.15, 0.2], max_depth = [3, 5, 8] | loss = deviance, learning_rate = 0.1, max_depth = 3 | |
| Fine-tuned VGG19 and Resnet50 | Optimizer = [SGD, RMSprop, Adagrad, Adadelta, Adam, Adamax, Nadam], Learning rate = [0.0001, 0.001, 0.01, 0.1], Dropout = [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9], number of neurons (hidden layers) = [16, 32, 64, 128, 256], Activation functions = [softmax, softplus, softsign, relu, tanh, sigmoid, hard_sigmoid, linear] | Optimizer = Adam, Learning rate = 0.001, Dropout = 0.2, number of neurons (hidden layers) = [256, 256, 16], Activation functions = [relu, relu, relu] |
References
- Maecker, O.; Barrot, C.; Becker, J.U. The effect of social media interactions on customer relationship management. Bus. Res. 2016, 9, 133–155. [Google Scholar] [CrossRef]
- Fatichah, C.; Lazuardi, W.F.; Navastara, D.A.; Suciati, N.; Munif, A. Image spam detection on Instagram using Convolutional Neural Network. In Intelligent and Interactive Computing; Springer: Berlin/Heidelberg, Germany, 2019; pp. 295–303. [Google Scholar]
- Sung, Y.; Kim, E.; Choi, S.M. # Me and brands: Understanding brand-selfie posters on social media. Int. J. Advert. 2018, 37, 14–28. [Google Scholar]
- Southwell, B.G.; Brennen, J.S.B.; Paquin, R.; Boudewyns, V.; Zeng, J. Defining and measuring scientific misinformation. Ann. Am. Acad. Political Soc. Sci. 2022, 700, 98–111. [Google Scholar] [CrossRef]
- El-Komy, A.; Shahin, O.R.; Abd El-Aziz, R.M.; Taloba, A.I. Integration of Computer Vision and natural language processing in multimedia robotics application. Inf. Sci. 2022, 7, 6. [Google Scholar]
- Lee, E.; Lee, J.A.; Moon, J.H.; Sung, Y. Pictures speak louder than words: Motivations for using Instagram. Cyberpsychol. Behav. Soc. Netw. 2015, 18, 552–556. [Google Scholar] [CrossRef]
- Selkie, E. Influence at the Intersection of Social Media and Celebrity. JAMA Netw. Open 2022, 5, e2143096. [Google Scholar] [CrossRef]
- Casas, A.; Williams, N.W. Images that matter: Online protests and the mobilizing role of pictures. Political Res. Q. 2019, 72, 360–375. [Google Scholar] [CrossRef]
- Jaulkar, M.; Virag, R.; Mohite, D.; Muktadevi, P. Impact of Advertisement on the Development of Brand Image. SSRN Electron. J. 2022, 1, 1–2. [Google Scholar] [CrossRef]
- Broeder, P.; Schouten, M. The Impact of Product Tagging on Trust and Purchase Intention: A cross-cultural perspective in visual e-commerce. CBR-Consum. Behav. Rev. 2022, 6, 250595. [Google Scholar] [CrossRef]
- Fu, L. A Brand Image Design Service Model Using the Visual Communication Technology under the Background of Internationalization. Wirel. Commun. Mob. Comput. 2022, 2022, 5922967. [Google Scholar] [CrossRef]
- Liu, L.; Dzyabura, D.; Mizik, N. Visual listening in: Extracting brand image portrayed on social media. Mark. Sci. 2020, 39, 669–686. [Google Scholar] [CrossRef]
- Paolanti, M.; Kaiser, C.; Schallner, R.; Frontoni, E.; Zingaretti, P. Visual and textual sentiment analysis of brand-related social media pictures using deep Convolutional Neural Networks. In Image Analysis and Processing—ICIAP 2017; Springer: Cham, Switzerland, 2017; pp. 402–413. [Google Scholar]
- Apostolova, E.; Tomuro, N. Combining visual and textual features for information extraction from online flyers. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1924–1929. [Google Scholar]
- Wijenayake, P.; Alahakoon, D.; De Silva, D.; Kirigeeganage, S. Deep LSTM for Generating Brand Personalities Using Social Media: A Case Study from Higher Education Institutions. Int. J. Comput. Commun. Eng. 2021, 10, 17–27. [Google Scholar] [CrossRef]
- Nakayama, A.; Baier, D. Predicting brand confusion in imagery markets based on deep learning of visual advertisement content. Adv. Data Anal. Classif. 2020, 14, 927–945. [Google Scholar] [CrossRef]
- Tous, R.; Gomez, M.; Poveda, J.; Cruz, L.; Wust, O.; Makni, M.; Ayguadé, E. Automated curation of brand-related social media images with deep learning. Multimed. Tools Appl. 2018, 77, 27123–27142. [Google Scholar] [CrossRef]
- Lee, S.S.; Chen, H.; Lee, Y.H. How endorser-product congruity and self-expressiveness affect Instagram micro-celebrities’ native advertising effectiveness. J. Prod. Brand Manag. 2021, 31, 149–162. [Google Scholar] [CrossRef]
- Argyris, Y.A.; Wang, Z.; Kim, Y.; Yin, Z. The effects of visual congruence on increasing consumers’ brand engagement: An empirical investigation of influencer marketing on Instagram using deep-learning algorithms for automatic image classification. Comput. Hum. Behav. 2020, 112, 106443. [Google Scholar] [CrossRef]
- Strycharz, J.; van Noort, G.; Smit, E.; Helberger, N. Consumer view on personalized advertising: Overview of self-reported benefits and concerns. In Advances in Advertising Research X; Springer Gabler: Wiesbaden, Germany, 2019; pp. 53–66. [Google Scholar]
- Hong, T.; Choi, J.A.; Lim, K.; Kim, P. Enhancing personalized ads using interest category classification of SNS users based on deep neural networks. Sensors 2020, 21, 199. [Google Scholar] [CrossRef]
- Ha, Y.; Park, K.; Kim, S.J.; Joo, J.; Cha, M. Automatically detecting image–text mismatch on Instagram with deep learning. J. Advert. 2020, 50, 52–62. [Google Scholar] [CrossRef]
- Sirija, M.; Jayashankari, R.; Kalpana, R.; Umamaheswari, B.; Shanthakumari, A. Characteristic based spam detection system to reveal the mock appraise in online social media. Aip Conf. Proc. 2022, 2393, 020134. [Google Scholar]
- Rogers, R. Visual media analysis for Instagram and other online platforms. Big Data Soc. 2021, 8, 20539517211022370. [Google Scholar] [CrossRef]
- Alorini, D.; Rawat, D.B. Automatic spam detection on gulf dialectical Arabic Tweets. In Proceedings of the 2019 International Conference on Computing, Networking and Communications (ICNC), Honolulu, HI, USA, 18–21 February 2019; pp. 448–452. [Google Scholar]
- Alsini, A.; Huynh, D.Q.; Datta, A. Hashtag Recommendation Methods for Twitter and Sina Weibo: A Review. Future Int. 2021, 13, 129. [Google Scholar] [CrossRef]
- Kumar, N.; Baskaran, E.; Konjengbam, A.; Singh, M. Hashtag recommendation for short social media texts using word-embeddings and external knowledge. Knowl. Inf. Syst. 2021, 63, 175–198. [Google Scholar] [CrossRef]
- Bhaskar, R.; Bansal, A. Implementing Prioritized-Breadth-First-Search for Instagram Hashtag Recommendation. In Proceedings of the 2022 12th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 27–28 January 2022; pp. 66–70. [Google Scholar]
- Lei, K.; Fu, Q.; Yang, M.; Liang, Y. Tag recommendation by text classification with attention-based capsule network. Neurocomputing 2020, 391, 65–73. [Google Scholar] [CrossRef]
- Hachaj, T.; Miazga, J. Image hashtag recommendations using a voting deep neural network and associative rules mining approach. Entropy 2020, 22, 1351. [Google Scholar] [CrossRef]
- Zhao, F.; Zhu, Y.; Jin, H.; Yang, L.T. A personalized hashtag recommendation approach using LDA-based topic model in microblog environment. Future Gener. Comput. Syst. 2016, 65, 196–206. [Google Scholar] [CrossRef]
- Alsini, A.; Datta, A.; Huynh, D.Q. On utilizing communities detected from social networks in hashtag recommendation. IEEE Trans. Comput. Soc. Syst. 2020, 7, 971–982. [Google Scholar] [CrossRef]
- Bansal, S.; Gowda, K.; Kumar, N. A Hybrid Deep Neural Network for Multimodal Personalized Hashtag Recommendation. IEEE Trans. Comput. Soc. Syst. 2022. [Google Scholar] [CrossRef]
- Fatma, T.; Yüksel, E. Brand Analysis in Social Networks Using Deep Learning Techniques. Avrupa Bilim Teknol. Derg. 2021, 27, 386–391. [Google Scholar]
- Erisen, C.; Redlawsk, D.P.; Erisen, E. Complex thinking as a result of incongruent information exposure. Am. Politics Res. 2018, 46, 217–245. [Google Scholar] [CrossRef]
- Belanche, D.; Casaló, L.V.; Flavián, M.; Ibáñez-Sánchez, S. Building influencers’ credibility on Instagram: Effects on followers’ attitudes and behavioral responses toward the influencer. J. Retail. Consum. Serv. 2021, 61, 102585. [Google Scholar] [CrossRef]
- De Cicco, R.; Iacobucci, S.; Pagliaro, S. The effect of influencer–product fit on advertising recognition and the role of an enhanced disclosure in increasing sponsorship transparency. Int. J. Advert. 2021, 40, 733–759. [Google Scholar] [CrossRef]
- Tousignant, J.P.; Hall, D.; Loftus, E.F. Discrepancy detection and vulnerability to misleading postevent information. Mem. Cogn. 1986, 14, 329–338. [Google Scholar] [CrossRef]
- Deepak, S.; Chitturi, B. Deep neural approach to Fake-News identification. Procedia Comput. Sci. 2020, 167, 2236–2243. [Google Scholar]
- Park, K.; Kim, T.; Yoon, S.; Cha, M.; Jung, K. BaitWatcher: A lightweight web interface for the detection of incongruent news headlines. In Disinformation, Misinformation and Fake News in Social Media; Springer: Cham, Switzerland, 2020; pp. 229–252. [Google Scholar]
- Jang, J.; Cho, Y.S.; Kim, M.; Kim, M. Detecting incongruent news headlines with auxiliary textual information. Expert Syst. Appl. 2022, 199, 116866. [Google Scholar] [CrossRef]
- Mishra, R.; Yadav, P.; Calizzano, R.; Leippold, M. MuSeM: Detecting incongruent news headlines using mutual attentive semantic matching. In Proceedings of the 2020 19th IEEE International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 14–17 December 2020; pp. 709–716. [Google Scholar]
- Zannettou, S.; Sirivianos, M.; Blackburn, J.; Kourtellis, N. The web of false information: Rumors, fake news, hoaxes, clickbait, and various other shenanigans. J. Data Inf. Qual. (JDIQ) 2019, 11, 1–37. [Google Scholar] [CrossRef]
- Ahmed, M.; Bachmann, S.; Martin, C.; Walker, T.; Rooyen, J.; Barkat, A. False Information as a Threat to Modern Society: A Systematic Review of False Information, Its Impact on Society and Current Remedies. J. Inf. Warf. 2022, 21, 105–120. [Google Scholar]
- Mena, P.; Barbe, D.; Chan-Olmsted, S. Misinformation on Instagram: The impact of trusted endorsements on message credibility. Soc. Media+ Soc. 2020, 6, 2056305120935102. [Google Scholar] [CrossRef]
- Shahzad, H.F.; Rustam, F.; Flores, E.S.; Luís Vidal Mazón, J.; de la Torre Diez, I.; Ashraf, I. A Review of Image Processing Techniques for Deepfakes. Sensors 2022, 22, 4556. [Google Scholar] [CrossRef]
- Han, B.; Han, X.; Zhang, H.; Li, J.; Cao, X. Fighting fake news: Two stream network for deepfake detection via learnable SRM. IEEE Trans. Biom. Behav. Identity Sci. 2021, 3, 320–331. [Google Scholar] [CrossRef]
- Xarhoulacos, C.G.; Anagnostopoulou, A.; Stergiopoulos, G.; Gritzalis, D. Misinformation vs. Situational Awareness: The Art of Deception and the Need for Cross-Domain Detection. Sensors 2021, 21, 5496. [Google Scholar] [CrossRef]
- Wang, Z.; Yin, Z.; Argyris, Y.A. Detecting medical misinformation on social media using multimodal deep learning. IEEE J. Biomed. Health Inform. 2020, 25, 2193–2203. [Google Scholar] [CrossRef]
- Miró-Llinares, F.; Aguerri, J.C. Misinformation about fake news: A systematic critical review of empirical studies on the phenomenon and its status as a ‘threat’. Eur. J. Criminol. 2021, 1–19. [Google Scholar] [CrossRef]
- Sheikhi, S. An Efficient Method for Detection of Fake Accounts on the Instagram Platform. Rev. D’Intell. Artif. 2020, 34, 429–436. [Google Scholar] [CrossRef]
- Akyon, F.C.; Kalfaoglu, M.E. Instagram fake and automated account detection. In Proceedings of the 2019 Innovations in Intelligent Systems and Applications Conference (ASYU), Izmir, Turkey, 31 October–2 November 2019; pp. 1–7. [Google Scholar]
- Di Domenico, G.; Sit, J.; Ishizaka, A.; Nunan, D. Fake news, social media and marketing: A systematic review. J. Bus. Res. 2021, 124, 329–341. [Google Scholar] [CrossRef]
- Vidanagama, D.U.; Silva, T.P.; Karunananda, A.S. Deceptive consumer review detection: A survey. Artif. Intell. Rev. 2020, 53, 1323–1352. [Google Scholar] [CrossRef]
- Zhang, W.; Deng, Y.; Ma, J.; Lam, W. AnswerFact: Fact checking in product question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 2407–2417. [Google Scholar]
- Tainter, J.A.; Taylor, T.G.; Brain, R.; Lobo, J. Emerging Trends in the Social and Behavioral Sciences: An Interdisciplinary, Searchable and Linkable Resource; John Wiley & Sons: Hoboken, NI, USA, 2015. [Google Scholar]
- Geerthik, S. Survey on internet spam: Classification and analysis. Int. J. Comput. Technol. Appl. 2013, 4, 384. [Google Scholar]
- Ahmed, N.; Amin, R.; Aldabbas, H.; Koundal, D.; Alouffi, B.; Shah, T. Machine learning techniques for spam detection in email and IoT platforms: Analysis and research challenges. Secur. Commun. Net. 2022, 2022, 1862888. [Google Scholar] [CrossRef]
- Ruskanda, F.Z. Study on the effect of preprocessing methods for spam email detection. Indones. J. Comput. (Indo-JC) 2019, 4, 109–118. [Google Scholar] [CrossRef]
- Shang, E.X.; Zhang, H.G. Image spam classification based on Convolutional Neural Network. In Proceedings of the 2016 International Conference on Machine Learning and Cybernetics (ICMLC), Jeju, Korea, 10–13 July 2016; Volume 1, pp. 398–403. [Google Scholar]
- Abuzaid, N.N.; Abuhammad, H.Z. Image SPAM Detection Using ML and DL Techniques. Int. J. Adv. Soft. Compu. Appl. 2022, 14, 226–243. [Google Scholar] [CrossRef]
- Gargiulo, F.; Sansone, C. Combining visual and textual features for filtering spam emails. In Proceedings of the 2008 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar]
- Kumaresan, T.; Saravanakumar, S.; Balamurugan, R. Visual and textual features based email spam classification using S-Cuckoo search and hybrid kernel Support Vector Machine. Clust. Comput. 2019, 22, 33–46. [Google Scholar] [CrossRef]
- Seth, S.; Biswas, S. Multimodal spam classification using deep learning techniques. In Proceedings of the 2017 13th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), Jaipur, India, 4–7 December 2017; pp. 346–349. [Google Scholar]
- Chrismanto, A.R.; Sari, K.; Suyanto, Y. Critical evaluation on spam content detection in social media. J. Theor. Appl. Inf. Technol. 2022, 100, 2642–2667. [Google Scholar]
- Haqimi, N.A.; Rokhman, N.; Priyanta, S. Detection of Spam Comments on Instagram Using Complementary Naïve Bayes. IJCCS (Indones. J. Comput. Cybern. Syst.) 2019, 13, 263–272. [Google Scholar] [CrossRef]
- Yaseen, Y.K.; Abbas, A.K.; Sana, A.M. Image spam detection using machine learning and natural language processing. J. Southwest Jiaotong Univ. 2020, 55, 1–9. [Google Scholar] [CrossRef]
- Raza, T.; Afsar, S.; Jameel, J.; Mateen, A.; Khalid, A.; Naeem, H. Execution Assessment of Machine Learning Algorithms for Spam Profile Detection on Instagram. Int. J. 2021, 10, 1889–1894. [Google Scholar]
- Fahfouh, A.; Riffi, J.; Mahraz, M.A.; Yahyaouy, A.; Tairi, H. A Contextual Relationship Model for Deceptive Opinion Spam Detection. IEEE Trans. Neural Net. Learn. Syst. 2022, 1–12. [Google Scholar] [CrossRef]
- Mahesh, B. Machine learning algorithms-a review. Int. J. Sci. Res. (IJSR) 2020, 9, 381–386. [Google Scholar]
- Lai, Y. A comparison of traditional machine learning and deep learning in image recognition. J. Phys. 2019, 1314, 012148. [Google Scholar] [CrossRef]
- Zhang, H.; Peng, Y. Image clustering: An unsupervised approach to categorize visual data in social science research. Sociol. Methods Res. 2021, 00491241221082603. [Google Scholar] [CrossRef]
- Mredula, M.S.; Dey, N.; Rahman, M.S.; Mahmud, I.; Cho, Y.-Z. A Review on the Trends in Event Detection by Analyzing Social Media Platforms’ Data. Sensors 2022, 22, 4531. [Google Scholar] [CrossRef]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A survey of Convolutional Neural Networks: Analysis, applications, and prospects. IEEE Trans. Neural Net. Learn. Syst. 2021, 33, 6999–7019. [Google Scholar] [CrossRef]
- Van Houdt, G.; Mosquera, C.; Nápoles, G. A review on the long short-term memory model. Artif. Intell. Rev. 2020, 53, 5929–5955. [Google Scholar] [CrossRef]
- Kang, Y.; Cai, Z.; Tan, C.W.; Huang, Q.; Liu, H. Natural language processing (NLP) in management research: A literature review. J. Manag. Anal. 2020, 7, 139–172. [Google Scholar] [CrossRef]
- Hossain, M.Z.; Sohel, F.; Shiratuddin, M.F.; Laga, H. A comprehensive survey of deep learning for image captioning. ACM Comput. Surv. (CsUR) 2019, 51, 1–36. [Google Scholar] [CrossRef]
- Bakkali, S.; Ming, Z.; Coustaty, M.; Rusiñol, M. Visual and textual deep feature fusion for document image classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 562–563. [Google Scholar]
- Kafle, K.; Kanan, C. Visual question answering: Datasets, algorithms and future challenges. Comput. Vis. Image Underst. 2017, 163, 3–20. [Google Scholar] [CrossRef]
- Seeland, M.; Mäder, P. Multi-view classification with Convolutional Neural Networks. PLoS ONE 2021, 16, e0245230. [Google Scholar] [CrossRef] [PubMed]
- Guarino, A.; Lettieri, N.; Malandrino, D.; Zaccagnino, R.; Capo, C. Adam or Eve? Automatic users’ gender classification via gestures analysis on touch devices. Neural Comput. Appl. 2022, 34, 18473–18495. [Google Scholar] [CrossRef]
- Subyantoro, S.; Apriyanto, S. Impoliteness in Indonesian language hate speech on social media contained in the Instagram account. J. Adv. Linguist. 2020, 11, 36–46. [Google Scholar] [CrossRef]
- Al-Rakhami, M.S.; Al-Amri, A.M. Lies kill, facts save: Detecting COVID-19 misinformation in Twitter. IEEE Access 2020, 8, 155961–155970. [Google Scholar] [CrossRef]
- Liang, G.; He, W.; Xu, C.; Chen, L.; Zeng, J. Rumor identification in microblogging systems based on users’ behavior. IEEE Trans. Comput. Soc. Syst. 2015, 2, 99–108. [Google Scholar] [CrossRef]
- Chen, C.; Zhang, J.; Xie, Y.; Xiang, Y.; Zhou, W.; Hassan, M.M.; AlElaiwi, A.; Alrubaian, M. A performance evaluation of machine learning-based streaming spam tweets detection. IEEE Trans. Comput. Soc. Syst. 2015, 2, 65–76. [Google Scholar] [CrossRef]
- Awel, M.A.; Abidi, A.I. Review on optical character recognition. Int. Res. J. Eng. Technol. (IRJET) 2019, 6, 3666–3669. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Rawat, W.; Wang, Z. Deep Convolutional Neural Networks for image classification: A comprehensive review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef]
- Mascarenhas, S.; Agarwal, M. A comparison between VGG16, VGG19 and ResNet50 architecture frameworks for Image Classification. In Proceedings of the 2021 International Conference on Disruptive Technologies for Multi-Disciplinary Research and Applications (CENTCON), Bengaluru, India, 19–21 November 2021; Volume 1, pp. 96–99. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Kruk, J.; Lubin, J.; Sikka, K.; Lin, X.; Jurafsky, D.; Divakaran, A. Integrating text and image: Determining multimodal document intent in Instagram posts. arXiv 2019, arXiv:1904.09073. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NA, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 15 October 2015; pp. 815–823. [Google Scholar]
- Ward, J. A content analysis of celebrity Instagram posts and parasocial interaction. Elon J. Undergrad. Res. Commun. 2016, 7, 1–4. [Google Scholar]
- Kelly, M. Analysing the complex relationship between logo and brand. Place Brand. Public Dipl. 2017, 13, 18–33. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Wolpert, D.H. Stacked generalization. Neural Net. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Neshat, M.; Nezhad, M.M.; Sergiienko, N.Y.; Mirjalili, S.; Piras, G.; Garcia, D.A. Wave power forecasting using an effective decomposition-based convolutional Bi-directional model with equilibrium Nelder-Mead optimiser. Energy 2022, 256, 124623. [Google Scholar] [CrossRef]
- Neshat, M.; Nezhad, M.M.; Mirjalili, S.; Piras, G.; Garcia, D.A. Quaternion convolutional long short-term memory neural model with an adaptive decomposition method for wind speed forecasting: North aegean islands case studies. Energy Convers. Manag. 2022, 259, 115590. [Google Scholar] [CrossRef]














| Ref. | Year | Task | Source of Information | Dataset | Data Type | Models | Main Focus |
|---|---|---|---|---|---|---|---|
| [22] | 2020 | Mismatch Detection | 7769 labeled posts and 444,491 unlabeled posts | Textual, Visual, Metadata | LR, SVM, RF | Detecting brand-irrelevant posts in brand-relevant hashtags | |
| [40] | 2020 | News-Headlines Incongruent Detection | News | 1.7 million news articles | Textual | SVM, DL | Introducing a web interface for predicting the incongruence between news-headline |
| [41] | 2022 | News-Headlines Incongruent Detection | News | Incongruent News Headline Dataset | Textual | Deep Learning (GRU) | Proposing a method to detect incongruence of news headlines using the lexical and contextual connection between news body and its headline |
| [42] | 2020 | News Headlines Incongruent Detection | News | NELA17: 91,042 news, Clickbait Challenge: 21,033 social media posts | Textual | SVM, LSTM | Incongruence detection using inter-mutual attention-based semantic matching |
| [27] | 2021 | Hashtag Recommendation | 30 million news tweets | Textual | SVM | Proposing a novel method to recommend hashtags of tweets using lexical, topical, semantic and user influence features | |
| [29] | 2020 | Hashtag Recommendation | - | Two public datasets: 18,464 articles with five tags and 127,600 articles with four tags | Textual | AdaBoost, RF, LSTM, Bi-LSTM, CNN | An approach to recommend hashtags using text classification. |
| [30] | 2020 | Hashtag Recommendation | HARRISON dataset: 57,383 multi-labeled images | Visual | Voting Deep Neural Network with Associative Rules Mining | Recommending one to ten hashtags for images | |
| [31] | 2016 | Hashtag Recommendation | 1,674,789 tweets with 28,526 hashtags | Textual | Latent Dirichlet Allocation (LDA) | Hashtag recommendation using the latent relationship between words and hashtags | |
| [32] | 2020 | Hashtag Recommendation | Dataset-UDI-TwitterCrawl-Aug2012 | Textual | Clique percolation method (CPM) | A community-based approach to recommend hashtags using tweet similarity | |
| [33] | 2022 | Hashtag Recommendation | Social media | - | Textual, Visual, User information | Hybrid deep neural network | Proposing a multimodal personalized hashtag recommendation |
| [49] | 2020 | Misinformation Detection | 30,000 posts | Textual, Visual | LSTM, GRU, VGG16, VGG19, ResNet50, ResNet101, DenseNet121, DenseNet169, Ensemble model | Detecting medical misinformation with semantic level and task-level attention to focus on important contents | |
| [39] | 2020 | Fake News Detection | - | George McIntires dataset: 10,558 texts | Textual | LSTM, FNN | Fake news detection using NLP and deep learning by including auxiliary features from live data mining |
| [51] | 2020 | Fake account Detection | 10,000 accounts | Metadata | SVM, RF, NB, DT, MLP | Introducing a method to identify fake accounts efficiently | |
| [52] | 2019 | Fake Account Detection | Two datasets: 1002 real and 201 fake accounts; 700 real and 700 automated accounts | Metadata | NB, LR, SVM, NN | Detecting fake and automated accounts | |
| [55] | 2020 | Fact-Checking | Product Q&A forums on Amazon | 60,864 answer claims about products | Textual | CNN, LSTM, AVER (proposed model) | Proposing AVER, a model to predict the veracity of answers based on evidence |
| [25] | 2019 | Spam Detection | 2000 Dialectical Arabic tweets | Textual | SVM, NB | Detecting malicious and spam content on Twitter written in Dialectical Arabic | |
| [59] | 2019 | Spam Detection | 962 emails | Textual | NB, SVM | Effect of preprocessing of text on the performance of models | |
| [60] | 2016 | Spam Detection | 52,934 images in 7 categories | Visual | CNN and SVM instead of the Softmax layer | Classifying spam images into seven categories | |
| [61] | 2022 | Spam Detection | 1,725,928 spam images extracted from real spam emails | Visual | RF, DT, KNN, SVM, NB, CNN | Classifying spam images and analyzing the performance of ML models | |
| [62] | 2008 | Spam Detection | 14,723 emails | Textual, Visual | DT | Proposing a system to filter out spam emails using different sets of features | |
| [63] | 2019 | Spam Detection | Text dataset: 2893 message, Image dataset: 2359 images | Textual, Visual | SVM | Propose a method to improve spam classification using a dataset with a small number of data | |
| [64] | 2017 | Spam Detection | 1251 spam images from emails, Enron Spam Dataset: 33,645 texts | Textual, Visual | CNN | Detecting spam emails with hybrid architecture | |
| [2] | 2019 | Spam Detection | 8000 images | Visual | CNN | Detecting spam images and comparing five different CNN architectures | |
| [66] | 2019 | Spam Detection | 2600 comments | Textual | SVM, Complementary NB | Detecting spam using a balanced and an imbalanced dataset | |
| [67] | 2020 | Spam Detection | - | Mark Dredze spam images: 10,000 images | Textual, Visual | DL | Extracting text from images using OCR to improve spam classification |
| [68] | 2021 | Spam Profile Detection | 916 user profiles | Metadata | MLP, RF, KNN, SVM | Detecting spammers by extracting additional features | |
| [12] | 2020 | Image Classification | Flickr, Instagram | 13 features about color, shape, and texture from 16,368 images | Visual | SVM, CNN | Measuring how brands are portrayed on social media |
| [19] | 2020 | Image Classification | More than 45,000 images | Visual | CNN | Classifying images’ themes and analyzing to reveal the hidden relationship between visual content and brand engagement | |
| [17] | 2018 | Image Recognition, Object Detection | Instagram, Twitter | More than 50,000 images in 100 categories | Visual | CNN | Minimizing manual curation of brand-related images |
| [34] | 2021 | Image Recognition, Object Detection | Starbucks Instagram images | Visual | Mask R-CNN, Faster R-CNN, YOLO, SSD | Proposing a model to recognize the identity of a brand using object detection | |
| [72] | 2021 | Image Clustering | Chinese social media, Instagram | Images of protests, images related to climate change | Visual | K-means, Deep-Cluster | Developing three image clustering algorithms on two datasets |
| [13] | 2017 | Sentiment Analysis | GfK Verein Dataset: 4200 positive, negative and neutral images | Textual, Visual | Deep CNN, KNN, SVM, DT, RF, NB, ANN | Estimate the overall sentiment of brand-related pictures from social media. | |
| [21] | 2020 | User Interest Classification | Instagram, Twitter, Facebook, Flickr, Google | 33,647 images and 21,022 texts | Textual, Visual | CNN, RNN | Improving personalized advertising based on users’ interests |
| [14] | 2014 | Named Entity Recognition (NER) | Online sources | 1920 online flyers | Textual, Visual | SVM | Recognizing 12 types of named entities in online marketing materials |
| [16] | 2020 | Predicting Brand Confusion | All channels | Image and video advertising | Visual | CNN | Proposed an approach to predict the uniqueness of brand positionings |
| [15] | 2021 | Generate Brand Personalities | Social media data | 1.2 million posts | Textual | Deep LSTM | Investigating how users’ opinions can be used to generate and monitor brand personalities |
| Type | Hashtag | Total Number of Posts | No. of Collected Posts | No. of Matches | No. of Mismatches | No. of Users |
|---|---|---|---|---|---|---|
| Brands | #Nike | 125.6 million | 3151 | 1531 | 1620 | 2266 |
| #Gucci | 69.4 million | 3343 | 1039 | 2304 | 1940 | |
| Celebrities | #CristianoRonaldo | 12.7 million | 3481 | 1024 | 2457 | 2405 |
| #EdSheeran | 5.6 million | 2144 | 1134 | 1010 | 1403 |
| Type | Feature | Description |
|---|---|---|
| User | user_follower_count | Number of followers |
| user_following_count | Number of followings | |
| user_post_count | Number of posts published by the user | |
| user_business_category | Type of accounts business | |
| user_is_business_account | Type of the account | |
| user_is_verified | Whether the user is verified by Instagram | |
| Post | like_count | Number of the post’s like |
| comment_count | Number of comments | |
| has_location | Whether the location has been specified by the user in the post | |
| mention_num | Number of mentions (@) | |
| hashtags_num | Number of hashtags (#) | |
| Text | sentiment | Sentiment of captions |
| text_word_count | Number of words in captions | |
| capital_char_num | Number of capital characters | |
| digit_num | Number of digits | |
| hashtag_sequence_num | Index of a target hashtag in a sequence of hashtags | |
| is_comment_hashtags | Whether hashtags are used in the caption or comments | |
| mention_target_account | Whether the user also mentions the target account | |
| hashtag_other_related_brands | Whether the user tagged other famous brands | |
| tag_other_related_brands | Whether the user mentions other famous brands | |
| is_bio_related_brand | Whether the bio of the account relates to the target account | |
| is_username_related_brand | Whether the username relates to the target account | |
| Image | dominant_color | The dominant color of the image |
| image_original_size | Size of the image |
| Type | Models | #Nike | #Gucci | #CristianoRonaldo | #EdSheeran | All Hashtags |
|---|---|---|---|---|---|---|
| Metadata Classification | SVM | 0.6518 | 0.6956 | 0.7106 | 0.7558 | 0.7112 |
| Stacking Ensemble | 0.6518 | 0.6895 | 0.7220 | 0.7883 | 0.7194 | |
| RF | 0.6993 | 0.7492 | 0.7841 | 0.7868 | 0.7568 | |
| XGBoost | 0.7267 | 0.7522 | 0.7965 | 0.7930 | 0.7582 | |
| Deep Dense layers | 0.6990 | 0.7019 | 0.7177 | 0.7341 | 0.7417 | |
| Text Classification (Without OCR) | SVM | 0.6307 | 0.6542 | 0.6760 | 0.6832 | - |
| Stacking Ensemble | 0.6174 | 0.6412 | 0.6497 | 0.7037 | - | |
| RF | 0.6234 | 0.6955 | 0.6607 | 0.7204 | - | |
| XGBoost | 0.6429 | 0.7004 | 0.6946 | 0.6981 | - | |
| Fine-tuned BERT | 0.7358 | 0.7448 | 0.8142 | 0.8096 | - | |
| Text Classification (With OCR) | SVM | 0.6317 | 0.6483 | 0.6814 | 0.6722 | - |
| Stacking Ensemble | 0.6192 | 0.6559 | 0.6507 | 0.7305 | - | |
| RF | 0.6344 | 0.6784 | 0.6637 | 0.7253 | - | |
| XGBoost | 0.6830 | 0.7067 | 0.6911 | 0.7629 | - | |
| Fine-tuned BERT | 0.7509 | 0.7640 | 0.8172 | 0.8342 | - | |
| Image Classification | SVM | 0.5889 | 0.5972 | 0.6175 | 0.6487 | - |
| Stacking Ensemble | 0.6137 | 0.6214 | 0.6432 | 0.6663 | - | |
| RF | 0.6964 | 0.6811 | 0.7139 | 0.7100 | - | |
| XGBoost | 0.7320 | 0.7274 | 0.7548 | 0.7413 | - | |
| Fine-tuned VGG19 | 0.7632 | 0.7119 | 0.8295 | 0.8444 | - | |
| Fine-tuned Resnet50 | 0.7849 | 0.7988 | 0.8412 | 0.8785 | - | |
| Image–Text Multimodal Model | BERT + Resnet50 | 0.8363 | 0.8536 | 0.8762 | 0.9218 | - |
| Type | Models | #Nike | #Gucci | #CristianoRonaldo | #EdSheeran | All Hashtags |
|---|---|---|---|---|---|---|
| Metadata Classification | SVM | 0.6867 | 0.7104 | 0.7191 | 0.7532 | 0.6864 |
| Stacking Ensemble | 0.6550 | 0.7045 | 0.7265 | 0.7569 | 0.7208 | |
| RF | 0.7079 | 0.7103 | 0.7528 | 0.7697 | 0.7528 | |
| XGBoost | 0.7282 | 0.7564 | 0.7779 | 0.7638 | 0.7408 | |
| Deep Dense layers | 0.6987 | 0.6827 | 0.7211 | 0.7258 | 0.7169 | |
| Text Classification (Without OCR) | SVM | 0.6395 | 0.6499 | 0.6993 | 0.6798 | - |
| Stacking Ensemble | 0.6313 | 0.6238 | 0.6807 | 0.6968 | - | |
| RF | 0.5986 | 0.6704 | 0.6914 | 0.6835 | - | |
| XGBoost | 0.6250 | 0.6858 | 0.6851 | 0.7058 | - | |
| Fine-tuned BERT | 0.7460 | 0.7410 | 0.8155 | 0.8372 | - | |
| Text Classification (With OCR) | SVM | 0.6493 | 0.6746 | 0.6858 | 0.6930 | - |
| Stacking Ensemble | 0.6234 | 0.6432 | 0.6776 | 0.6625 | - | |
| RF | 0.6059 | 0.6807 | 0.6411 | 0.7167 | - | |
| XGBoost | 0.6955 | 0.6873 | 0.6798 | 0.7024 | - | |
| Fine-tuned BERT | 0.7547 | 0.7639 | 0.8317 | 0.8558 | - | |
| Image Classification | SVM | 0.5275 | 0.5664 | 0.5721 | 0.5917 | - |
| Stacking Ensemble | 0.5985 | 0.6067 | 0.6779 | 0.6776 | - | |
| RF | 0.6552 | 0.6775 | 0.7075 | 0.6922 | - | |
| XGBoost | 0.7082 | 0.7295 | 0.7633 | 0.7096 | - | |
| Fine-tuned VGG19 | 0.7249 | 0.7198 | 0.8458 | 0.8513 | - | |
| Fine-tuned Resnet50 | 0.7592 | 0.7743 | 0.8507 | 0.8627 | - | |
| Image–Text Multimodal Model | BERT + Resnet50 | 0.8104 | 0.8359 | 0.8860 | 0.9106 | - |
| Hashtag | @CristianoRonaldo | @EdSheeran |
|---|---|---|
| Number of account images | 2271 | 3095 |
| Number of faces | 8481 | 11,353 |
| Number of clusters | 65 | 24 |
| Clusters with the highest number of members | 1742 (20.54%) | 1213 (12.30%) |
| Number of poor-quality faces | 2778 (32.75%) | 4206 (42.66%) |
| Number of faces in unknown clusters | 1375 (16.21%) | 5652 (57.33%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dadgar, S.; Neshat, M. A Novel Hybrid Multi-Modal Deep Learning for Detecting Hashtag Incongruity on Social Media. Sensors 2022, 22, 9870. https://doi.org/10.3390/s22249870
Dadgar S, Neshat M. A Novel Hybrid Multi-Modal Deep Learning for Detecting Hashtag Incongruity on Social Media. Sensors. 2022; 22(24):9870. https://doi.org/10.3390/s22249870
Chicago/Turabian StyleDadgar, Sajad, and Mehdi Neshat. 2022. "A Novel Hybrid Multi-Modal Deep Learning for Detecting Hashtag Incongruity on Social Media" Sensors 22, no. 24: 9870. https://doi.org/10.3390/s22249870
APA StyleDadgar, S., & Neshat, M. (2022). A Novel Hybrid Multi-Modal Deep Learning for Detecting Hashtag Incongruity on Social Media. Sensors, 22(24), 9870. https://doi.org/10.3390/s22249870