
Dynamic Selection Techniques for Detecting GPS Spoofing Attacks on UAVs




Abstract
:1. Introduction
- A one-stage ensemble feature selection technique to identify correlated and low importance features simultaneously.
- Two dynamic-based selection methods, MOD and WMOD, for efficient detection of spoofing signals.
- Performance comparison of the MOD and WMOD dynamic methods with bagging, boosting, and stacking-based ensemble models for validating the proposed techniques.
2. Related Work
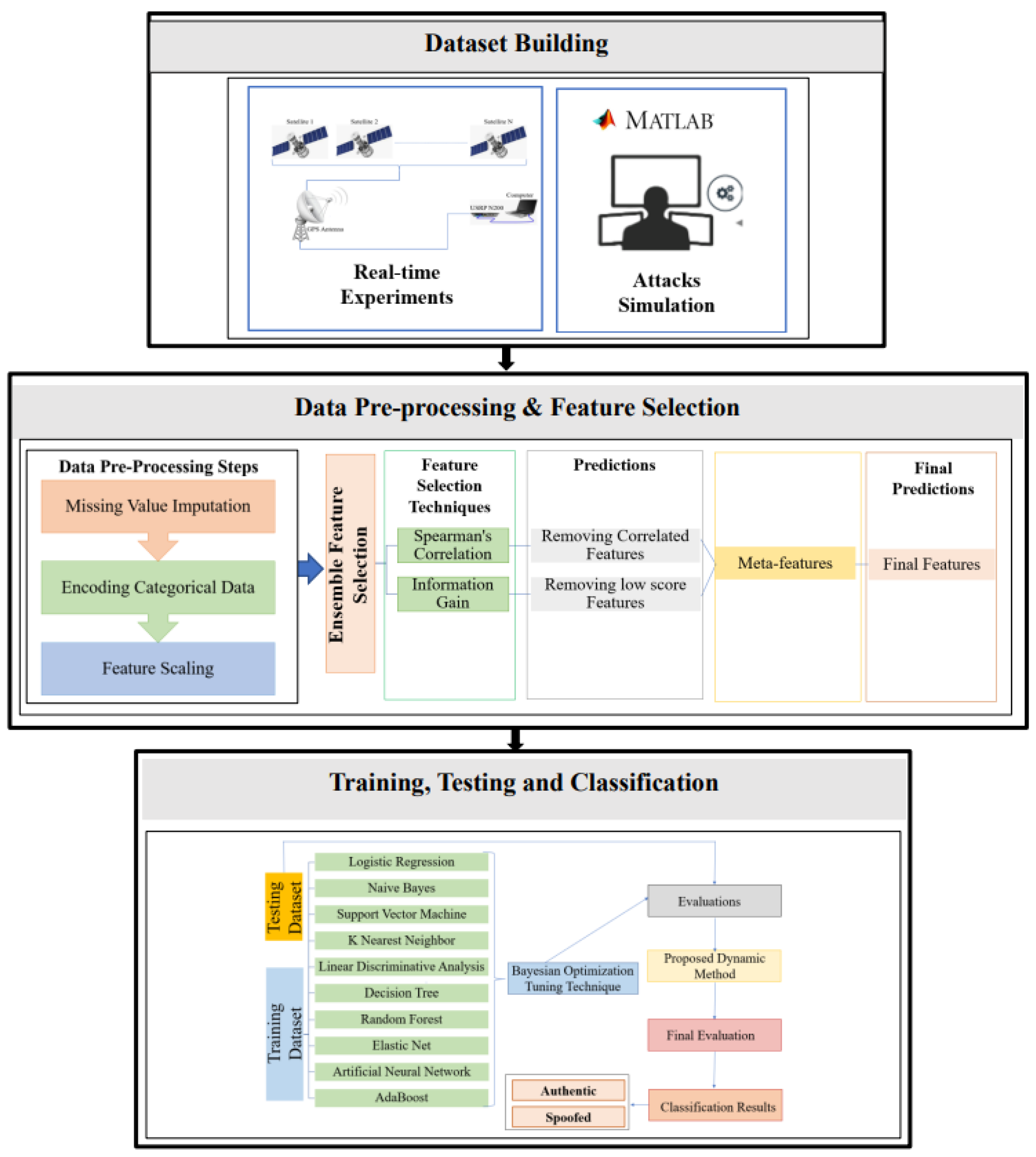
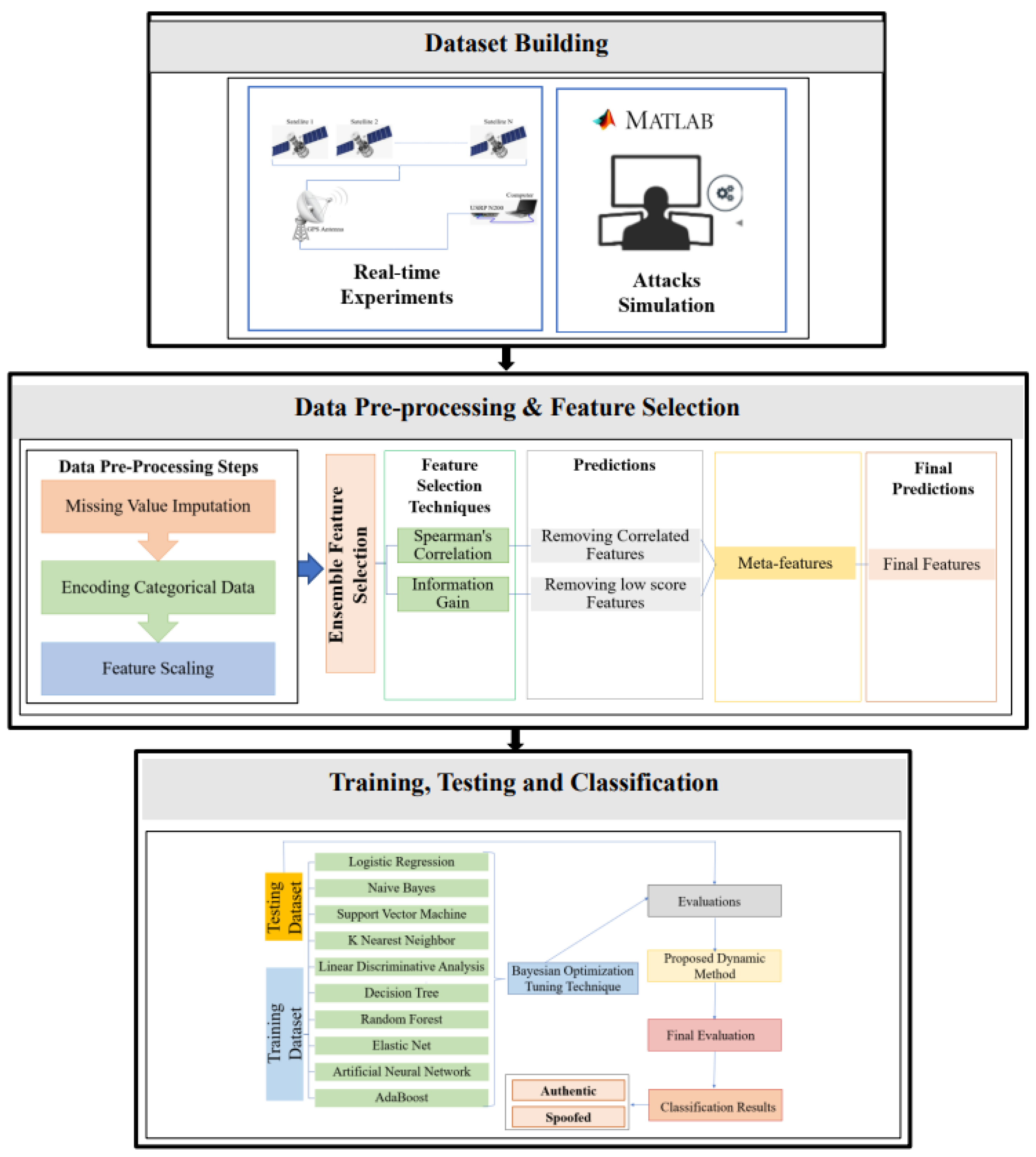
3. Proposed Architecture
4. Methodology
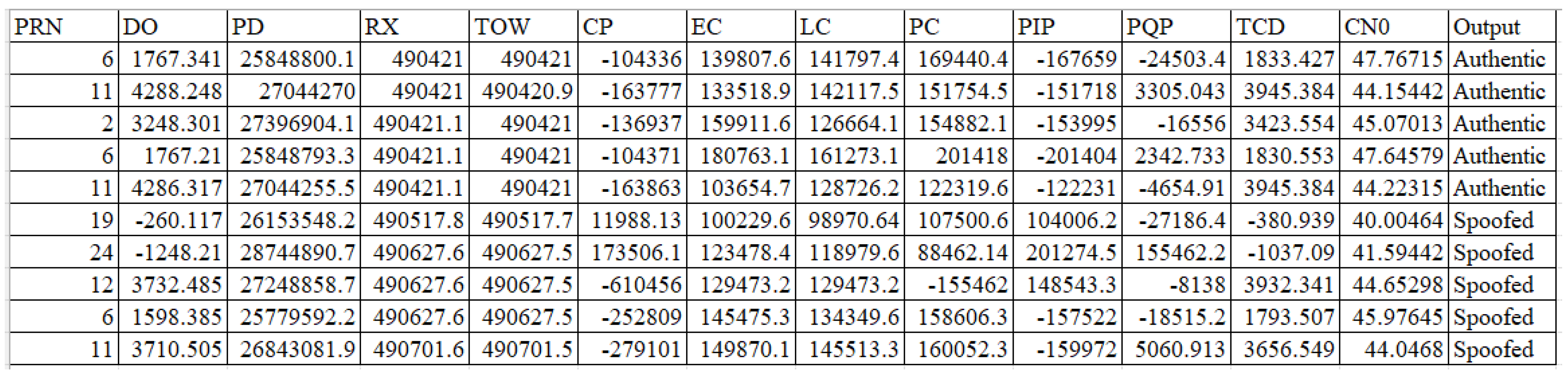
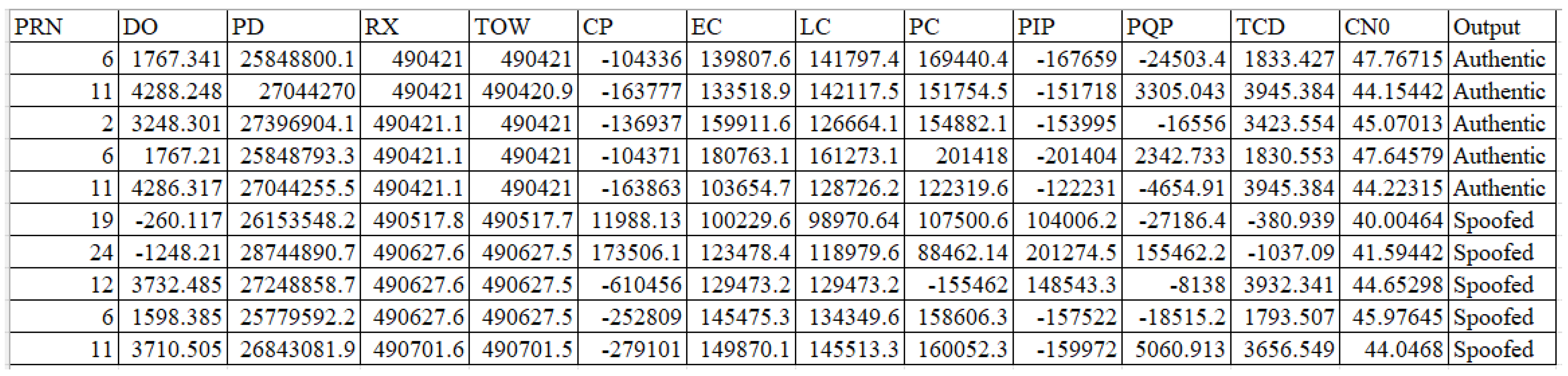
4.1. Dataset
4.2. Data Pre-Processing
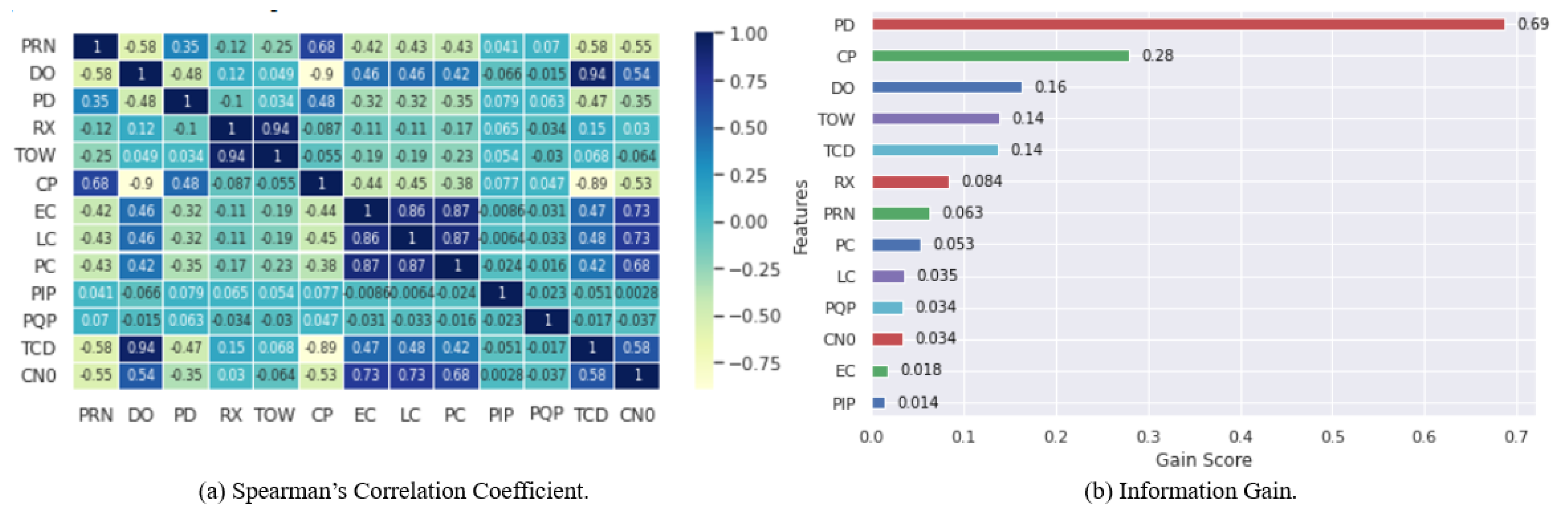
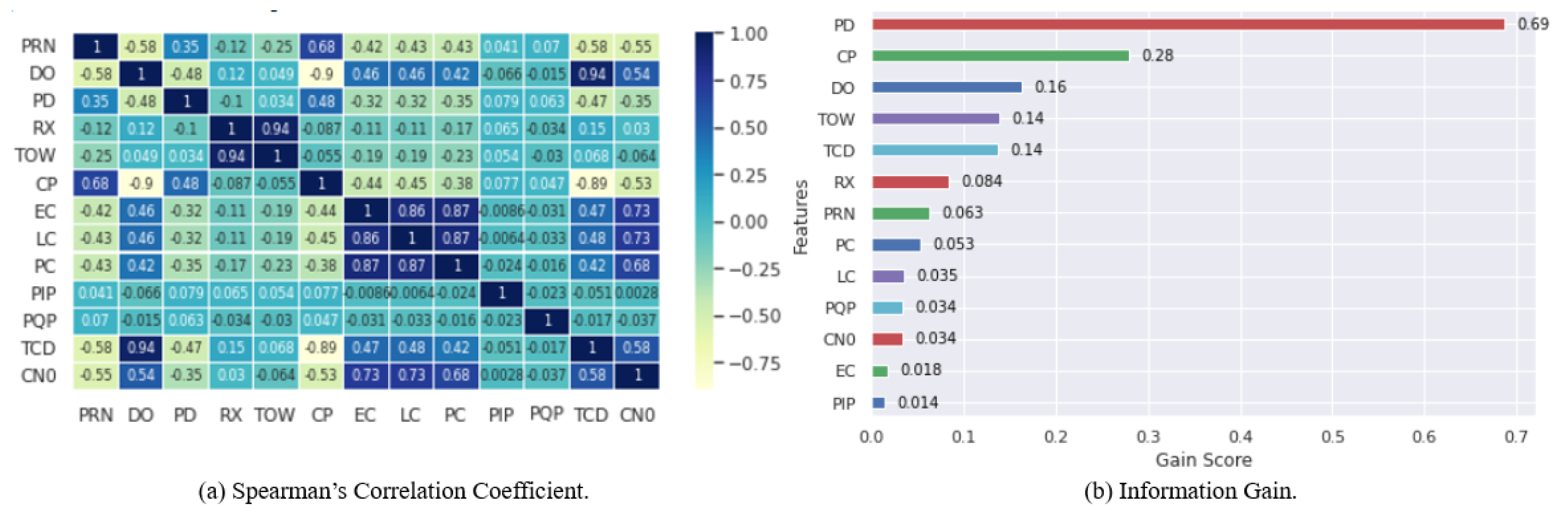
4.3. Feature Selection
4.4. Hyperparameter Tuning
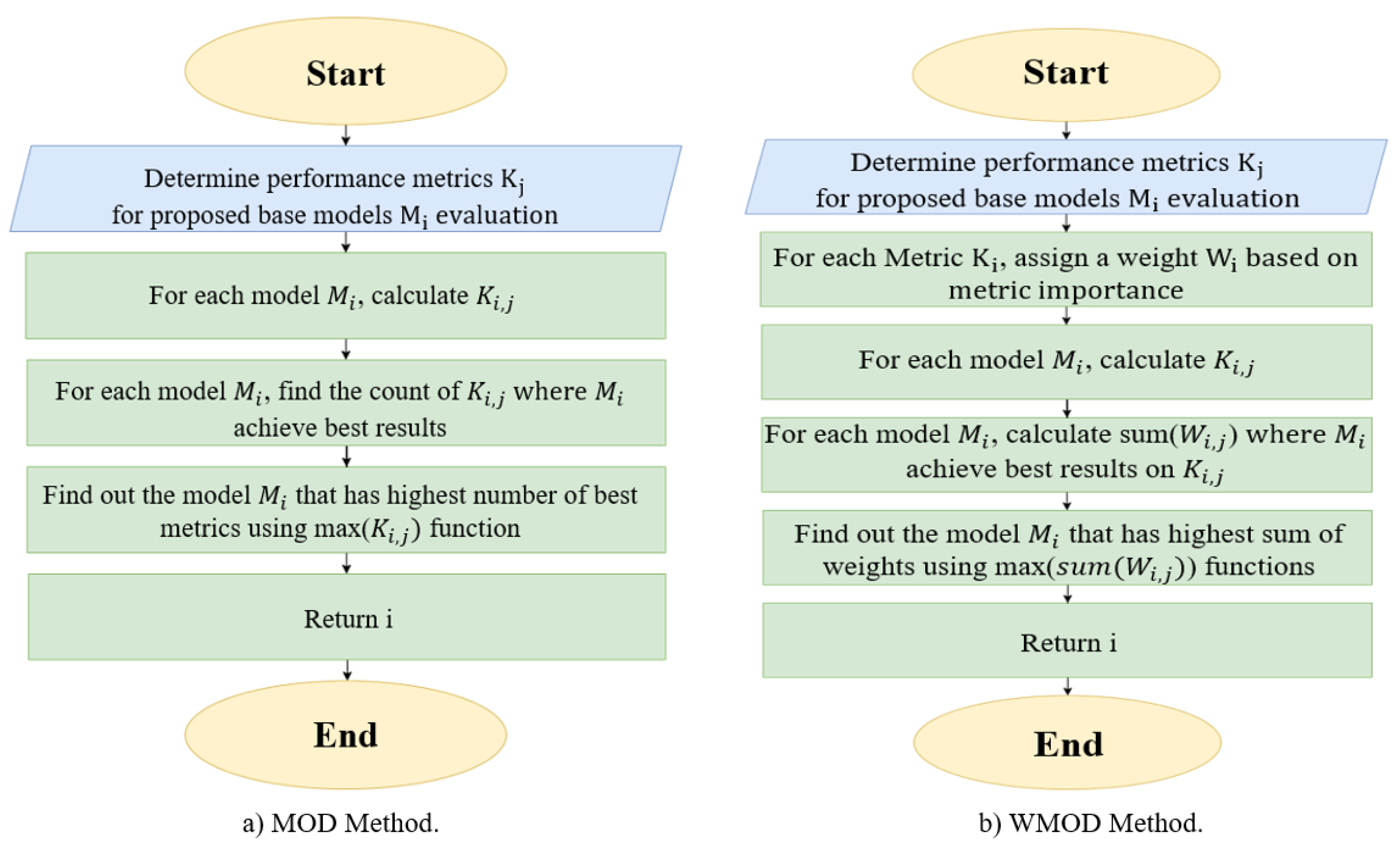
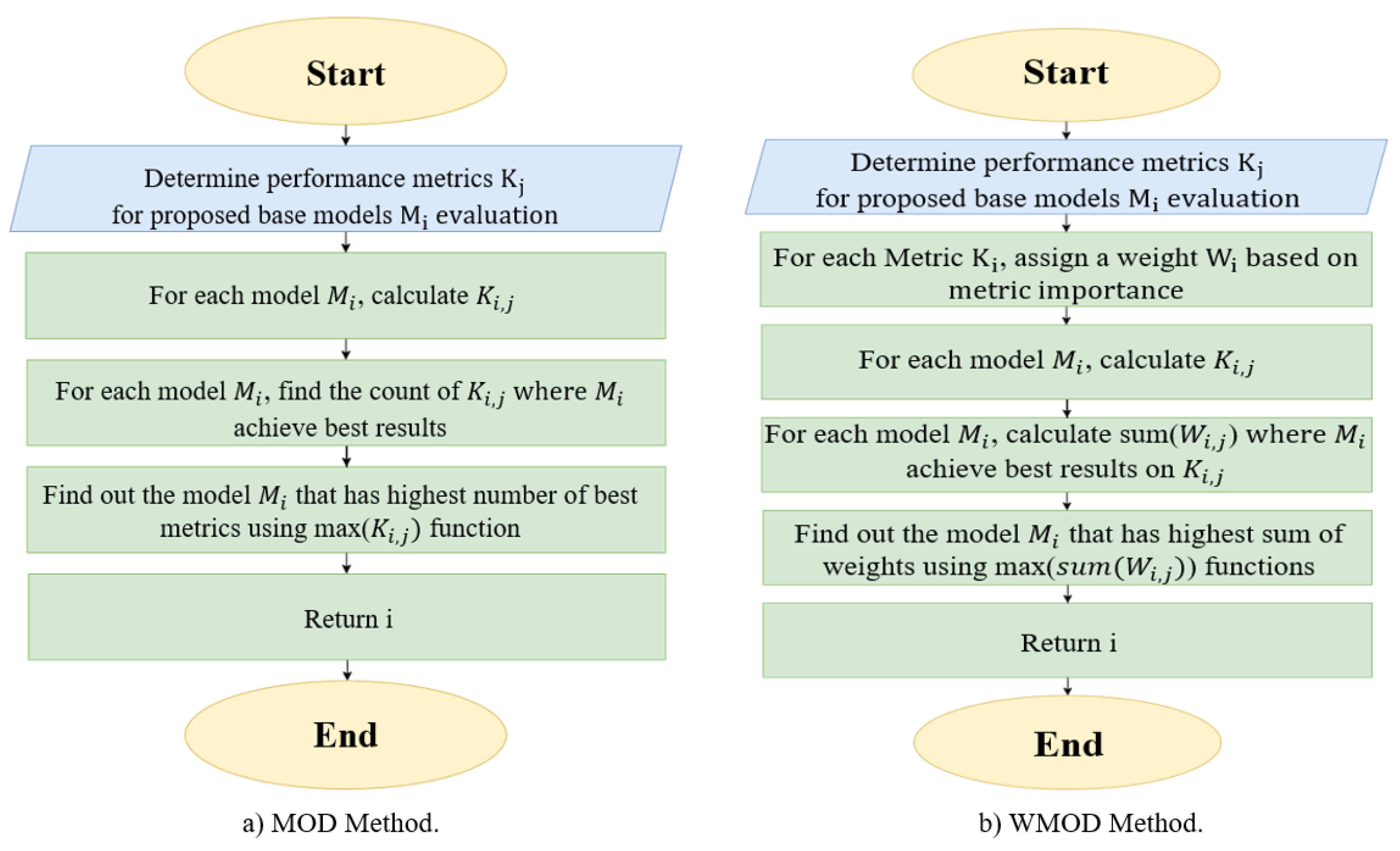
4.5. Description of the Proposed Methods
5. Results
- Ensemble feature selection removes the correlated and low importance features and decreases computational power and time.
- MOD and WMOD methods dynamically select one best classifier between the implemented ML models.
- The proposed dynamic methods can choose the best metric among the implemented models based on the considered metrics, which means such methods can be easily extended to include additional metrics that can significantly enhance the selection criteria.
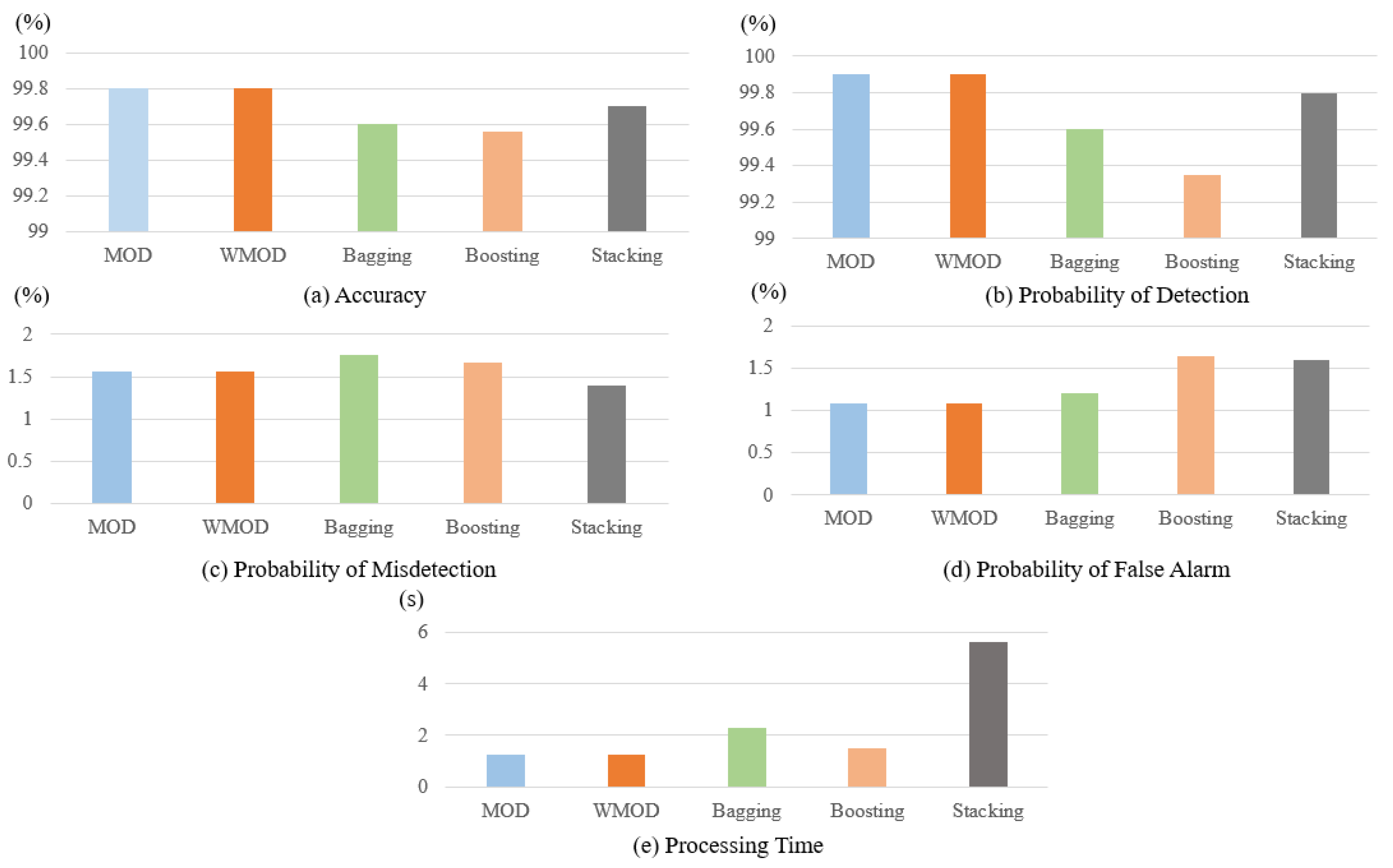
- Comparison of the ensemble models with the proposed dynamic methods shows that the two dynamic methods can achieve good results in detecting GPS spoofing attacks on UAVs.
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kumar, K.; Kumar, S.; Kaiwartya, O.; Sikandar, A.; Kharel, R.; Mauri, J.L. Internet of unmanned aerial vehicles: QoS provisioning in aerial ad-hoc networks. Sensors 2020, 20, 3160. [Google Scholar] [CrossRef]
- Manesh, M.R.; Kenney, J.; Hu, W.C.; Devabhaktuni, V.K.; Kaabouch, N. Detection of GPS Spoofing Attacks on Unmanned Aerial Systems. In Proceedings of the 2019 16th IEEE Annual Consumer Communications and Networking Conference, CCNC 2019, Las Vegas, NV, USA, 11–14 January 2019. [Google Scholar] [CrossRef]
- Wang, S.; Wang, J.; Su, C.; Ma, X. Intelligent detection algorithm against Uavs’ GPS spoofing attack. In Proceedings of the International Conference on Parallel and Distributed Systems—ICPADS, Hong Kong, China, 2–4 December 2020; pp. 382–389. [Google Scholar] [CrossRef]
- Sheet, D.K.; Kaiwartya, O.; Abdullah, A.H.; Cao, Y.; Hassan, A.N.; Kumar, S. Location information verification using transferable belief model for geographic routing in vehicular ad hoc networks. IET Intell. Transp. Syst. 2017, 11, 53–60. [Google Scholar] [CrossRef]
- Manickam, S. GPS Signal Authentication Using INS-A Comparative Study and Analysis. Master’s Thesis, University of Calgary, Calgary, AB, Canada, 2016. [Google Scholar]
- Jiang, P.; Wu, H.; Xin, C. DeepPOSE: Detecting GPS spoofing attack via deep recurrent neural network. Digit. Commun. Netw. 2021, in press. [Google Scholar]
- Kwon, K.C.; Shim, D.S. Performance analysis of direct GPS spoofing detection method with AHRS/Accelerometer. Sensors 2020, 20, 954. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Narain, S.; Ranganathan, A.; Noubir, G. Security of GPS/INS based on-road location tracking systems. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–22 May 2019; pp. 587–601. [Google Scholar]
- Feng, Z.; Guan, N.; Lv, M.; Liu, W.; Deng, Q.; Liu, X.; Yi, W. Efficient drone hijacking detection using two-step GA-XGBoost. J. Syst. Archit. 2020, 103, 101694. [Google Scholar] [CrossRef]
- Aissou, G.; Ould Slimane, H.; Benouadah, S.; Kaabouch, N. Tree-Based Supervised Machine Learning Models for Detecting GPS Spoofing Attacks on UAS. In Proceedings of the 2021 IEEE 12th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 1–4 December 2021; 2021. [Google Scholar]
- Khoei, T.T.; Ismail, S.; Kaabouch, N. Boosting Models with Tree-Structured Parzen Estimator Optimization to Detect Intrusion Attacks on Smart Grid. In Proceedings of the 2021 IEEE 12th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 1–4 December 2021. [Google Scholar]
- Khoei, T.T.; Aissou, G.; Hu, W.C.; Kaabouch, N. Ensemble learning methods for anomaly intrusion detection system in smart grid. In Proceedings of the 2021 IEEE International Conference on Electro Information Technology (EIT), Mt. Pleasant, MI, USA, 13–15 May 2021. [Google Scholar]
- Cruz, R.M.; Sabourin, R.; Cavalcanti, G.D. Dynamic classifier selection: Recent advances and perspectives. Inf. Fusion 2018, 41, 195–216. [Google Scholar] [CrossRef]
- Meng, L.; Yang, L.; Ren, S.; Tang, G.; Zhang, L.; Yang, F.; Yang, W. An Approach of Linear Regression-Based UAV GPS Spoofing Detection. Wirel. Commun. Mob. Comput. 2021, 2021, 5517500. [Google Scholar] [CrossRef]
- Qiao, Y.; Zhang, Y.; Du, X. A Vision-Based GPS-Spoofing Detection Method for Small UAVs. In Proceedings of the 13th International Conference on Computational Intelligence and Security, CIS 2017, Hong Kong, China, 15–18 December 2017; pp. 312–316. [Google Scholar] [CrossRef]
- Varshosaz, M.; Afary, A.; Mojaradi, B.; Saadatseresht, M.; Parmehr, E.G. Spoofing detection of civilian UAVs using visual odometry. ISPRS Int. J. Geo-Inf. 2019, 9, 6. [Google Scholar] [CrossRef] [Green Version]
- Liang, C.; Miao, M.; Ma, J.; Yan, H.; Zhang, Q.; Li, X.; Li, T. Detection of GPS spoofing attack on unmanned aerial vehicle system. In Proceedings of the International Conference on Machine Learning for Cyber Security, Xi’an, China, 19–22 September 2019; pp. 123–139. [Google Scholar]
- Majidi, M.; Erfanian, A.; Khaloozadeh, H. Prediction-discrepancy based on innovative particle filter for estimating UAV true position in the presence of the GPS spoofing attacks. IET Radar Sonar Navig. 2020, 14, 887–897. [Google Scholar] [CrossRef]
- Schmidt, E.; Gatsis, N.; Akopian, D. A GPS spoofing detection and classification correlator-based technique using the LASSO. IEEE Trans. Aerosp. Electron. Syst. 2020, 56, 4224–4237. [Google Scholar] [CrossRef]
- Shafique, A.; Mehmood, A.; Elhadef, M. Detecting Signal Spoofing Attack in UAVs Using Machine Learning Models. IEEE Access 2021, 9, 93803–93815. [Google Scholar] [CrossRef]
- Feng, Z.; Guan, N.; Lv, M.; Liu, W.; Deng, Q.; Liu, X.; Yi, W. Efficient drone hijacking detection using onboard motion sensors. In Proceedings of the Design, Automation Test in Europe Conference Exhibition (DATE) 2017, Lausanne, Switzerland, 27–31 March 2017; pp. 1414–1419. [Google Scholar] [CrossRef]
- Yoon, H.J.; Wan, W.; Kim, H.; Hovakimyan, N.; Sha, L.; Voulgaris, P.G. Towards Resilient UAV: Escape Time in GPS Denied Environment with Sensor Drift. IFAC-PapersOnLine 2019, 52, 423–428. [Google Scholar] [CrossRef]
- Panice, G.; Luongo, S.; Gigante, G.; Pascarella, D.; Di Benedetto, C.; Vozella, A.; Pescapè, A. A SVM-based detection approach for GPS spoofing attacks to UAV. In Proceedings of the 2017 23rd International Conference on Automation and Computing (ICAC), Huddersfield, UK, 7–8 September 2017; pp. 1–11. [Google Scholar]
- Dang, Y.; Benzaïd, C.; Shen, Y.; Taleb, T. GPS Spoofing Detector with Adaptive Trustable Residence Area for Cellular based-UAVs. In Proceedings of the GLOBECOM 2020–2020 IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar]
- Liu, R.; Liu, E.; Yang, J.; Li, M.; Wang, F. Optimizing the Hyper-Parameters for SVM. Intell. Control. Autom. 2006, 344, 712–721. [Google Scholar]
- Rajadurai, H.; Gandhi, U.D. A stacked ensemble learning model for intrusion detection in wireless network. Neural Comput. Appl. 2020, 1–9. [Google Scholar] [CrossRef]
- Goudos, S.K.; Athanasiadou, G. Application of an ensemble method to UAV power modeling for cellular communications. IEEE Antennas Wirel. Propag. Lett. 2019, 18, 2340–2344. [Google Scholar] [CrossRef]
- Ben Brahim, A.; Limam, M. Ensemble feature selection for high dimensional data: A new method and a comparative study. Adv. Data Anal. Classif. 2018, 12, 937–952. [Google Scholar] [CrossRef]
- Hoque, N.; Singh, M.; Bhattacharyya, D.K. EFS-MI: An ensemble feature selection method for classification. Complex Intell. Syst. 2018, 4, 105–118. [Google Scholar] [CrossRef]
- Ismail, S.; Khoei, T.T.; Marsh, R.; Kaabouch, N. A Comparative Study of Machine Learning Models for Cyber-attacks Detection in Wireless Sensor Networks. In Proceedings of the 2021 IEEE 12th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 1–4 December 2021. [Google Scholar]
- Reading, F.; Aspects, M. Spearman Rank Correlation Coefficient. Concise Encycl. Stat 2008, 502–505. [Google Scholar]
- Kent, J.T. Information gain and a general measure of correlation. Biometrika 1983, 70, 163–173. [Google Scholar] [CrossRef]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical Bayesian optimization of machine learning algorithms. Adv. Neural Inf. Process. Syst. 2012, 4, 2951–2959. [Google Scholar]
- Joy, T.T.; Rana, S.; Gupta, S.; Venkatesh, S. Fast hyperparameter tuning using Bayesian optimization with directional derivatives. Knowl. Based Syst. 2020, 205, 106247. [Google Scholar] [CrossRef]
- Shahriari, B.; Swersky, K.; Wang, Z.; Adams, R.P.; De Freitas, N. Taking the human out of the loop: A review of Bayesian optimization. Proc. IEEE 2016, 104, 148–175. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, V. Bayesian optimization for accelerating hyper-parameter tuning. In Proceedings of the IEEE 2nd International Conference on Artificial Intelligence and Knowledge Engineering, AIKE 2019, Sardinia, Italy, 3–5 June 2019; pp. 302–305. [Google Scholar] [CrossRef]
- Shende, S.; Gillman, A.; Yoo, D.; Buskohl, P.; Vemaganti, K. Bayesian topology optimization for efficient design of origami folding structures. Struct. Multidiscip. Optim. 2021, 63, 1907–1926. [Google Scholar] [CrossRef]
- Britto, A.S.; Sabourin, R.; Oliveira, L.E. Dynamic selection of classifiers—A comprehensive review. Pattern Recognit. 2014, 47, 3665–3680. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Approach | Advantages | Limitations |
|---|---|---|---|
| External UAV characteristics | Acceleration error [7] | • Uses magnitude acceleration error to provide better performance | • Depends on accelerator error. • Pre-defined probability of false alarm. |
| IMU-based [9] | • Provides a detection rate of 96.3% and 100% in hijacked and non-hijacked cases. | • Only detects attacks with similar behaviors during training. | |
| IMU-based [25] | • In best cases, detection rate of 98.6%,within 8 s when the system is under attack. • Provides a precision of 97%, a recall of 97%, and F1-score of 97%. | • In worse cases, the detection of GPS spoofing attacks can table over 28 s after the UAV started its mission. | |
| Gyroscopes measurement-based [21] | • Easy to be implemented in any drone. | • Needs motion sensors (gyro-scopes and accelerators for detection. These are power hungry. | |
| Artificial Intelligence Method | Artificial Neural Network-based [2] | • Provides an accuracy of 98.3%, a probability of detection of 99.2%, a probability of misdetection of 2.6%, and probability of false alarm of 0.8%. | • Uses a dataset with only 5 features and very limited samples. |
| Linear regression-based and long short term memory [14] | • Works effectively in a case of UAV flying along the specified rout. | • Lack of optimization methods from the perspective of UAV sensor integrated navigation and UAV attitude control. | |
| Prediction-discrepancy based [18] | • Reduces the effects of GPS spoofing errors and estimates the true position of the UAV in the presence of GPS spoofing attacks. | • Evaluated only based on accuracy and redundancy. | |
| Least Absolute Shrinkage and Selection Operator [19] | • Provides a 0.3% detection error rate for a spoofing attack in nominal signal-to-noise ratio conditions and an authentic-over-spoofer power of 3 dB. | • Uses a public old dataset, namely, Texas spoofing test battery as benchmark. • Lack of using common evaluation metrics, such as the probability of misdetection. | |
| K-learning based [20] | • Provides an accuracy of 99%, a precision of 98%, a recall of 99%, and F-score of 98%. | • Uses only Shimmer and Jitter as features in the dataset. | |
| Resilient State Estimation [22] | • Addresses the sensor drift problem. | • Evaluated only based on estimated error, and statistics of attacks. | |
| Support Vector machine [23] | • Improves the performance in case of using magnetometer sensors. | • Performance degradation during long attacks. | |
| 5G-assisted position monitoring [24] | • A detection rate of 95%, and F1-score of 88%. | • Lacks of several evaluation metrics. | |
| Long-Short Term Memory [3] | • A comprehensive comparison with encryption-based detection techniques in terms of detection rate and time cost. | • Detection rate of 78% and a time cost of 3s. • Detection rate is high when the flight trajectory is not complicated. | |
| Signal Processing | Vision-based [15] | • Detects spoofing attacks with an average of 5s based on several parameters. | • Only applied when the attacker is visible. |
| Vision-based [16] | • Detects spoofing in the long-range UAV flights when the changes in UAV flight direction is larger than 3° and in the incremental UAV spoofing with the redirection rate of 1°. | • Only applied when the attacker is visible. |
| Feature | Abbreviation | Description |
|---|---|---|
| Satellite Vehicle Number | PRN | Identifying uniquely each satellite in orbit. |
| Doppler Shift Measurement | DO | Difference in the frequency of a GPS receiver moving relatively to its source. Difference in the frequency of a GPS receiver moving relatively to its source. |
| Pseudo Range | PD | Difference between the transmission and the reception time. |
| Receiver Time | RX | Time of transmission of the navigation messages. |
| Decoded Time Information | TOW | Information regarding the reception time of a subframe. |
| Carrier Phase Shift | CP | Beat frequency difference between the received carrier and a receiver-generated carrier replica. |
| Prompt Correlator | PC | Happens when the replica signal generated from the receiver is compatible with the incoming signals. |
| Late Correlator Output | LC | Occurrs at the 1/2 chip spacing after the prompt correlator. |
| Early Correlator Output | EC | Happens at the 1/2 chip spacing before the prompt correlator. |
| Prompt In-phase Prompt | PIP | In-phase component of the Prompt correlator amplitude. |
| Prompt Quadrature Prompt | PQP | Quadrature component of the prompt correlator amplitude. |
| Carrier Loop Doppler Measurements | TCD | Doppler shift that is measured during the correlation stage. |
| Signal to Noise Ratio | CN0 | Doppler shift that is measured during the correlation stage. Ratio of the power signal to noise. |
| Model | Parameter Setting | Best Parameters |
|---|---|---|
| SVM | C = [0.1, 1, 10, 100], | C = 10, |
| degree = [1, 2, 3, 4, 5], | degree = 5, | |
| gamma = [1, 0.1, 0.01, 0.001, 0.0001]. | gamma = 0.1. | |
| NB | var_smoothing = [1e-2, 1e-3, 1e-4, 1e-5, 1e-6, 1e-7, 1e-8, 1e-9, 1e-10, 1e-11, 1e-12, 1e-13, 1e-14, 1e-15]. | var_smoothing = 1e-3. |
| DT | Criterion = [‘gini’, ‘entropy’], | criterion = ‘entropy’, |
| Splitter = [‘best’, ‘random’], | splitter = ‘best’, | |
| max_features = [‘auto’, ‘sqrt’, ‘log2’], | max_features = ‘auto’, | |
| max_depth = range (1, 32). | max_depth = 26.0. | |
| RF | n_estimators = [10, 100, 1000, 10,000], | n_estimators = 1000, |
| max_depth = range (10, 200), | max depth = 110, | |
| min_samples_split = range (2, 10). | min_samples_split = 2. | |
| KNN | n_neighbors = range (1, 20), | n_neighbors = 6, |
| p = range (1, 10). | p = 1.0. | |
| LDA | Solver = [‘svd’,‘lsqr’]. | solver = ‘lsqr’. |
| NN | Activation = [‘identity’, ‘logistic’, ‘tanh’, ‘relu’], | activation = ‘tanh’, |
| Solver = [‘lbfgs’, ‘sgd’, ‘adam’], | solver = ‘lbfgs’ | |
| Alpha = linspace(0.0001, 0.5, num = 50). | alpha = 0.0409, | |
| LR | l1_ratio = linspace(0.0001, 1, num = 50), | l1_ratio = 0.0001, |
| C = [0.1, 1, 10, 100], | C = 100.0, | |
| Solver = [‘newton-cg’, ‘sag’, ‘lbfgs’]. | solver = ‘lbfgs’. | |
| EN | l1_ratio = linspace(0.0001, 1, num = 50), | l1_ratio = 0.190, |
| alpha = linspace(0.0001, 2, num = 50), | alpha = 0.1409, | |
| selection = [“random", “cyclic"]. | selection = ‘cyclic’. | |
| AD | n_estimators = [10, 100, 1000, 10,000]. | n_estimators = 100. |
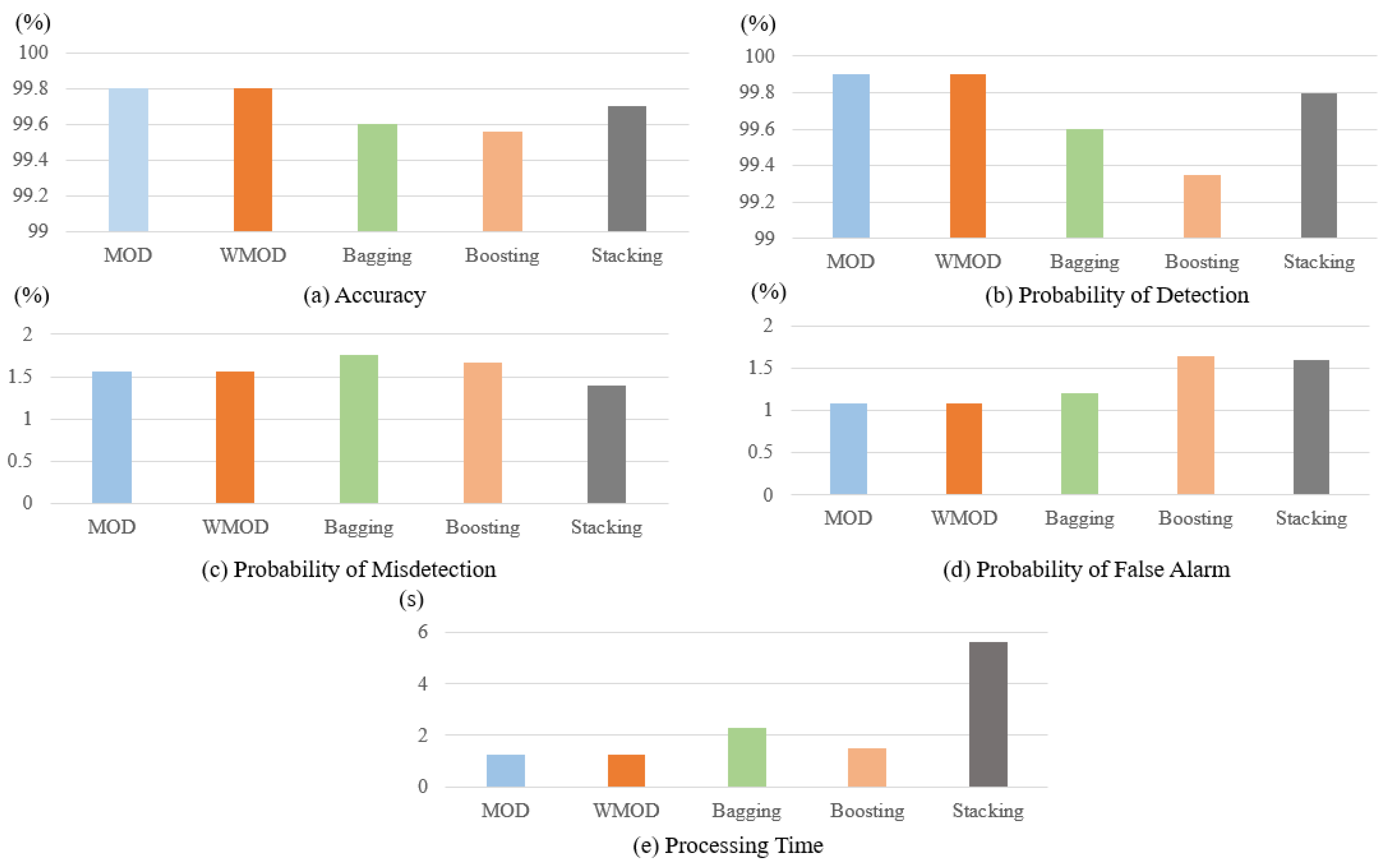
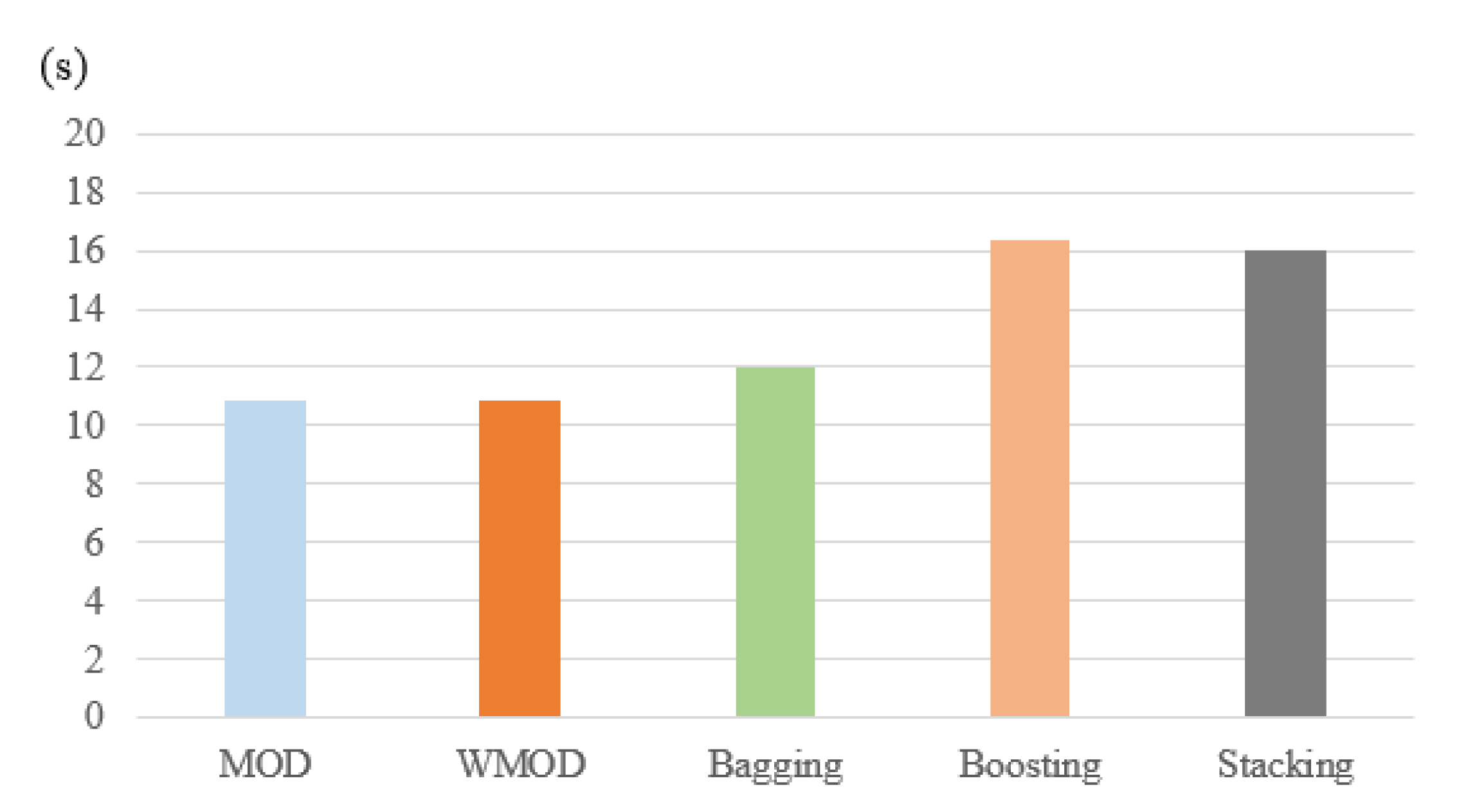
| Methods | Metrics | |||||
|---|---|---|---|---|---|---|
| ACC (%) | (%) | (%) | (%) | Processing Time (s) | (s) | |
| MOD | 99.8 | 99.9 | 1.56 | 1.09 | 1.24 | 10.9 |
| WMOD | 99.8 | 99.9 | 1.56 | 1.09 | 1.24 | 10.9 |
| Bagging | 99.6 | 99.6 | 1.76 | 1.2 | 2.321 | 12 |
| Boosting | 99.56 | 99.35 | 1.67 | 1.64 | 1.511 | 16.4 |
| Stacking | 99.7 | 99.8 | 1.4 | 1.6 | 5.65 | 16 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Talaei Khoei, T.; Ismail, S.; Kaabouch, N. Dynamic Selection Techniques for Detecting GPS Spoofing Attacks on UAVs. Sensors 2022, 22, 662. https://doi.org/10.3390/s22020662
Talaei Khoei T, Ismail S, Kaabouch N. Dynamic Selection Techniques for Detecting GPS Spoofing Attacks on UAVs. Sensors. 2022; 22(2):662. https://doi.org/10.3390/s22020662
Chicago/Turabian StyleTalaei Khoei, Tala, Shereen Ismail, and Naima Kaabouch. 2022. "Dynamic Selection Techniques for Detecting GPS Spoofing Attacks on UAVs" Sensors 22, no. 2: 662. https://doi.org/10.3390/s22020662
APA StyleTalaei Khoei, T., Ismail, S., & Kaabouch, N. (2022). Dynamic Selection Techniques for Detecting GPS Spoofing Attacks on UAVs. Sensors, 22(2), 662. https://doi.org/10.3390/s22020662