
Road and Railway Smart Mobility: A High-Definition Ground Truth Hybrid Dataset

 ,
,  , , and
, , and 
Abstract
:1. Introduction
- Object tracking [2],
- Mapping and localization: this represents the establishment of spatial relations between the vehicle and the static surrounding objects. The vehicle must know its position on the map.
- Detection and tracking of moving objects: the vehicle must be able to distinguish between static and dynamic objects, but it must also know its position to them at all times, and therefore follow, or even anticipate, their trajectories.
- The classification of objects (cars, buses, pedestrians, cyclists, etc.).
2. Related Work
2.1. Monomodal Dataset
2.2. Multimodal Dataset
2.2.1. Road Smart Mobility Dataset
2.2.2. Railway Smart Mobility Dataset
3. Virtual Multimodal Road and Railway Dataset
3.1. Introduction
3.2. Virtual Dataset Architecture
4. Real Multimodal Road and Railway Dataset
4.1. Introduction
- The realization of a new multimodal acquisition system composed of a camera and a LiDAR. This phase allows us to calibrate the sensor and to synchronize the camera-LiDAR data.
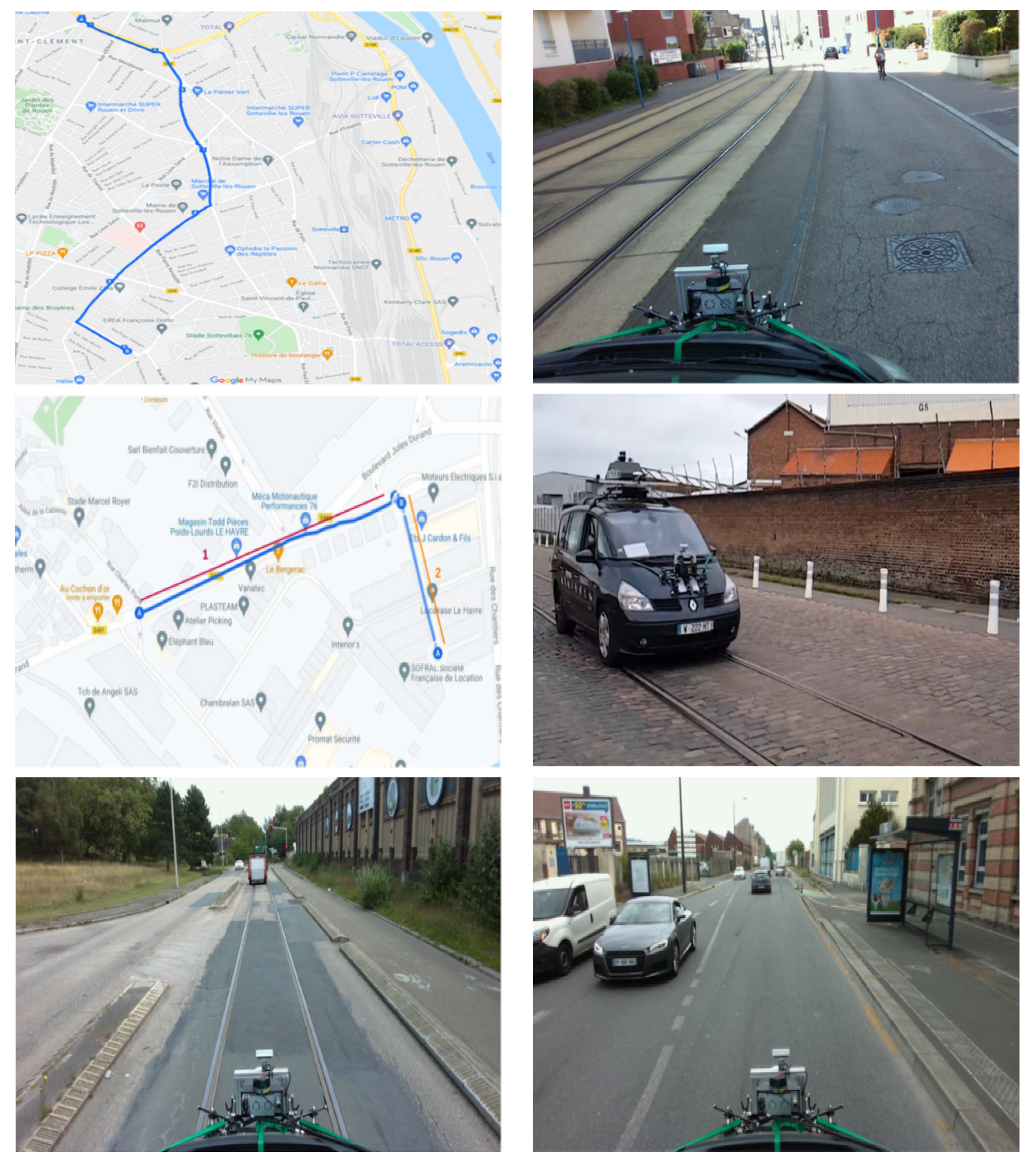
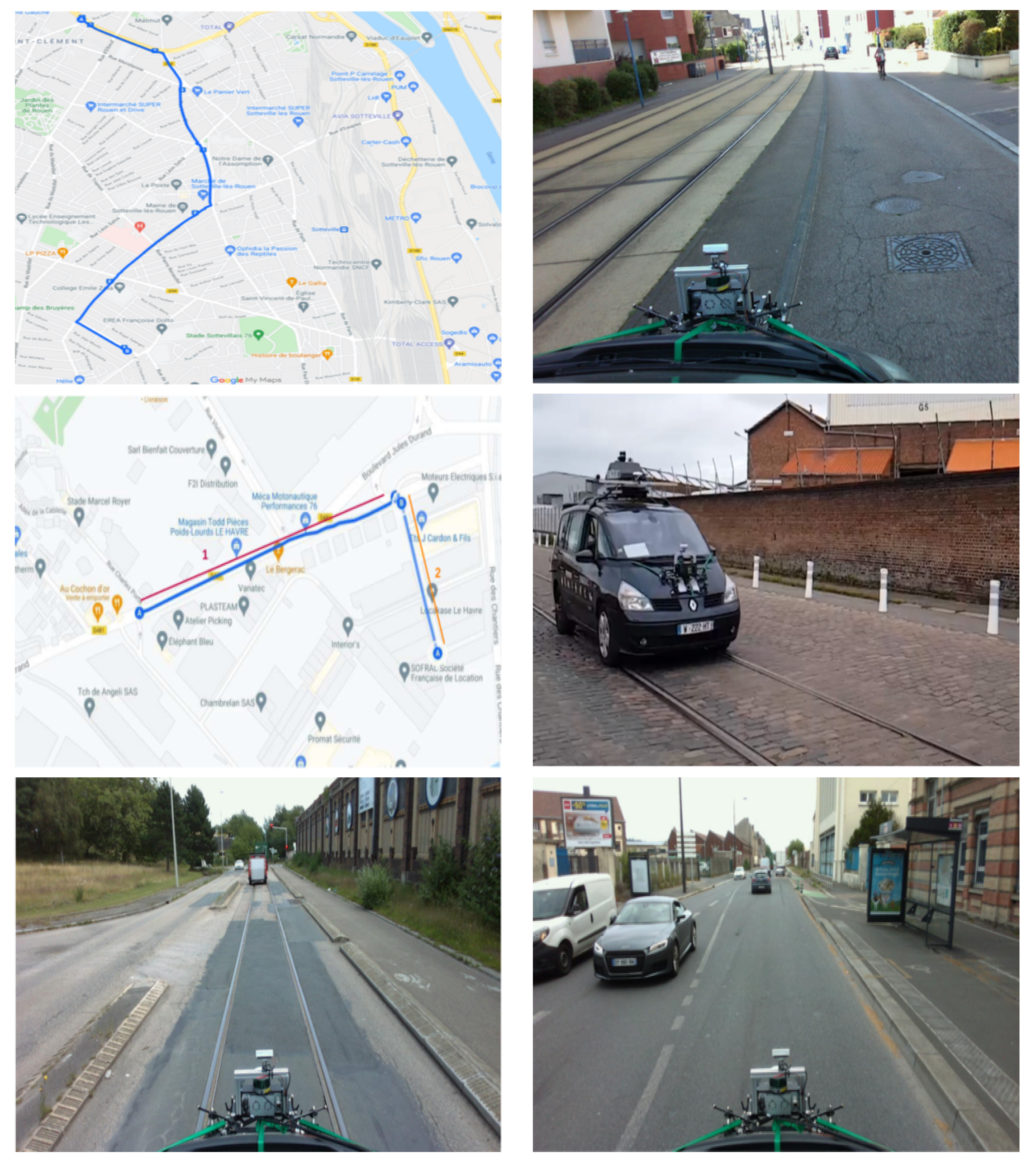
- Collection of road and rail data via images acquired with the stereoscopic camera as well as the depth of the objects recorded via the LiDAR. Two cities have been the subject of a data collection protocol: Rouen and Le Havre.
- The annotation of all the collected images. This allows us to constitute the ground truth and will allow us to validate the depth estimates issued during the protocol evaluation.
4.2. Architecture of the Acquisition System
- Stereoscopic Intel RealSense cameras (L515).
- GPS AsteRx (septentrio).
- Inertial Measurement Unit (IMU) LANDYN (IXblue) composed with an accelerometer, a magnetometer, and a gyroscope. The system also has a post processing software APPS.
- Odometer mounted on the right rear wheel.
- VLP16 LiDAR Velodyne type synchronized with the GPS.
- A real-time data acquisition system RTMAPS (Intempora).
4.3. Calibration and Synchronization of the Acquisition System
4.3.1. Sensors Calibration
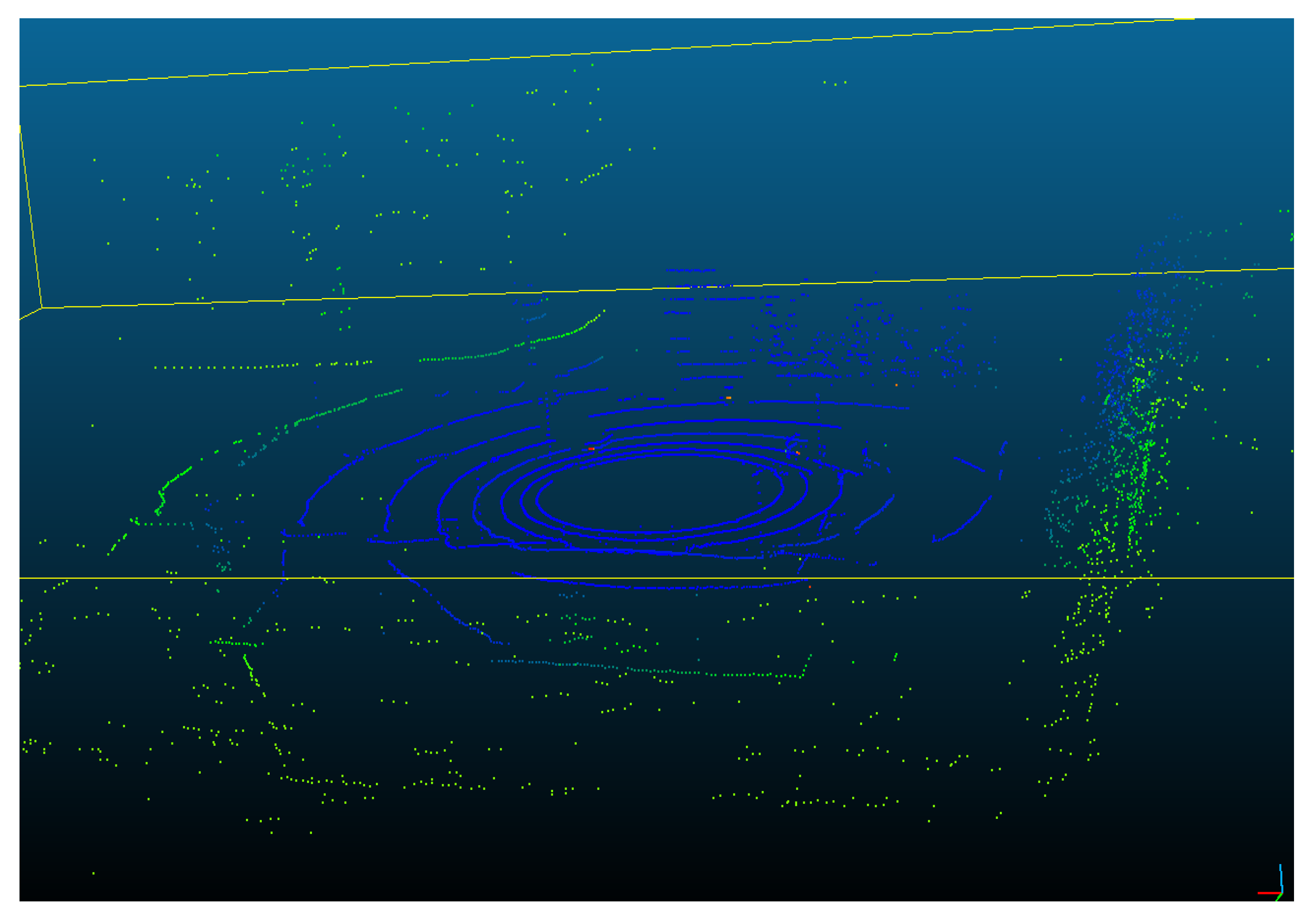
4.3.2. Projection of LiDAR Points on the 2D Image
4.3.3. Camera-LiDAR Synchronization
4.4. Data Collection
4.4.1. Route Selection for Data Collection
4.4.2. Data Recording Protocol
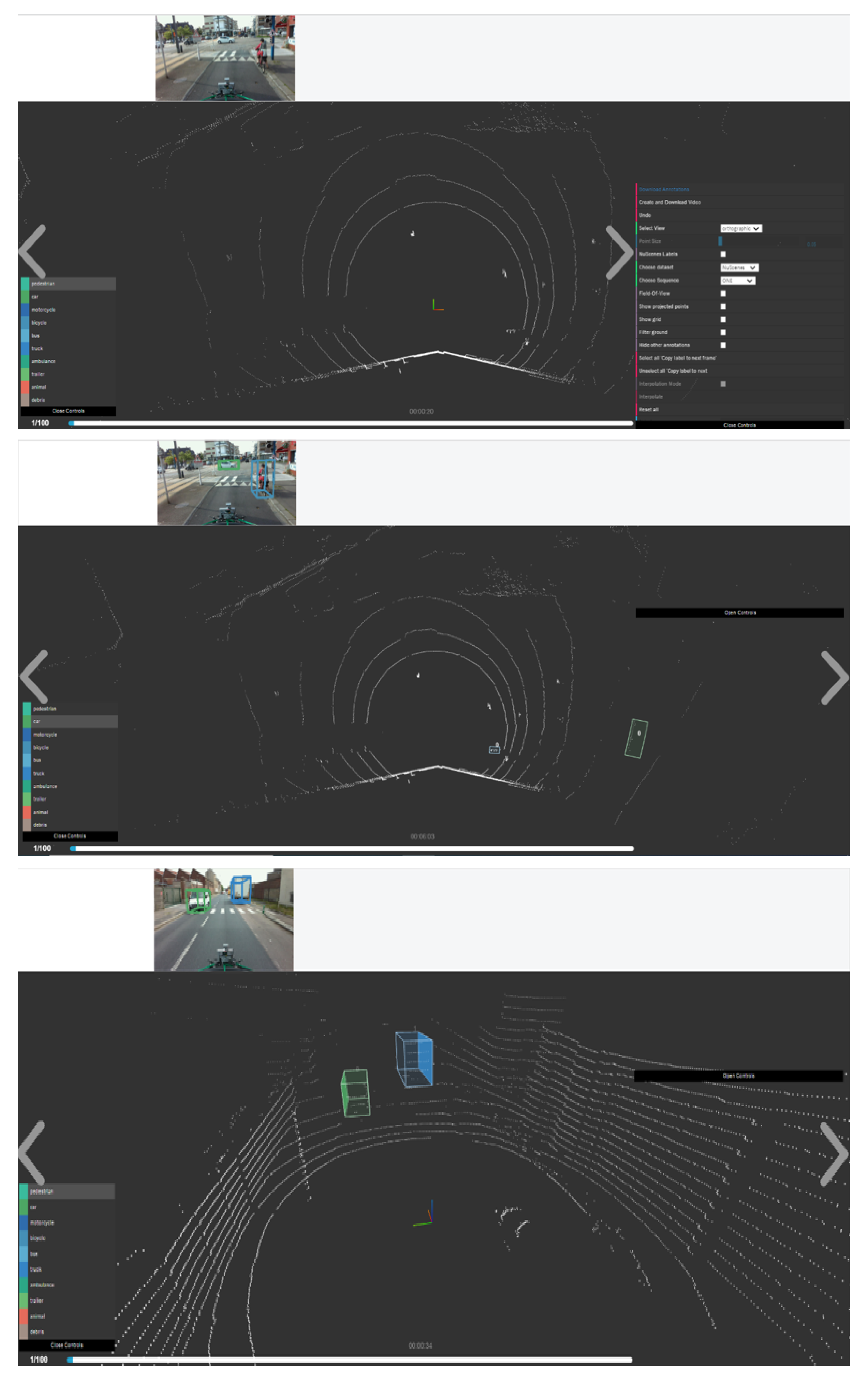
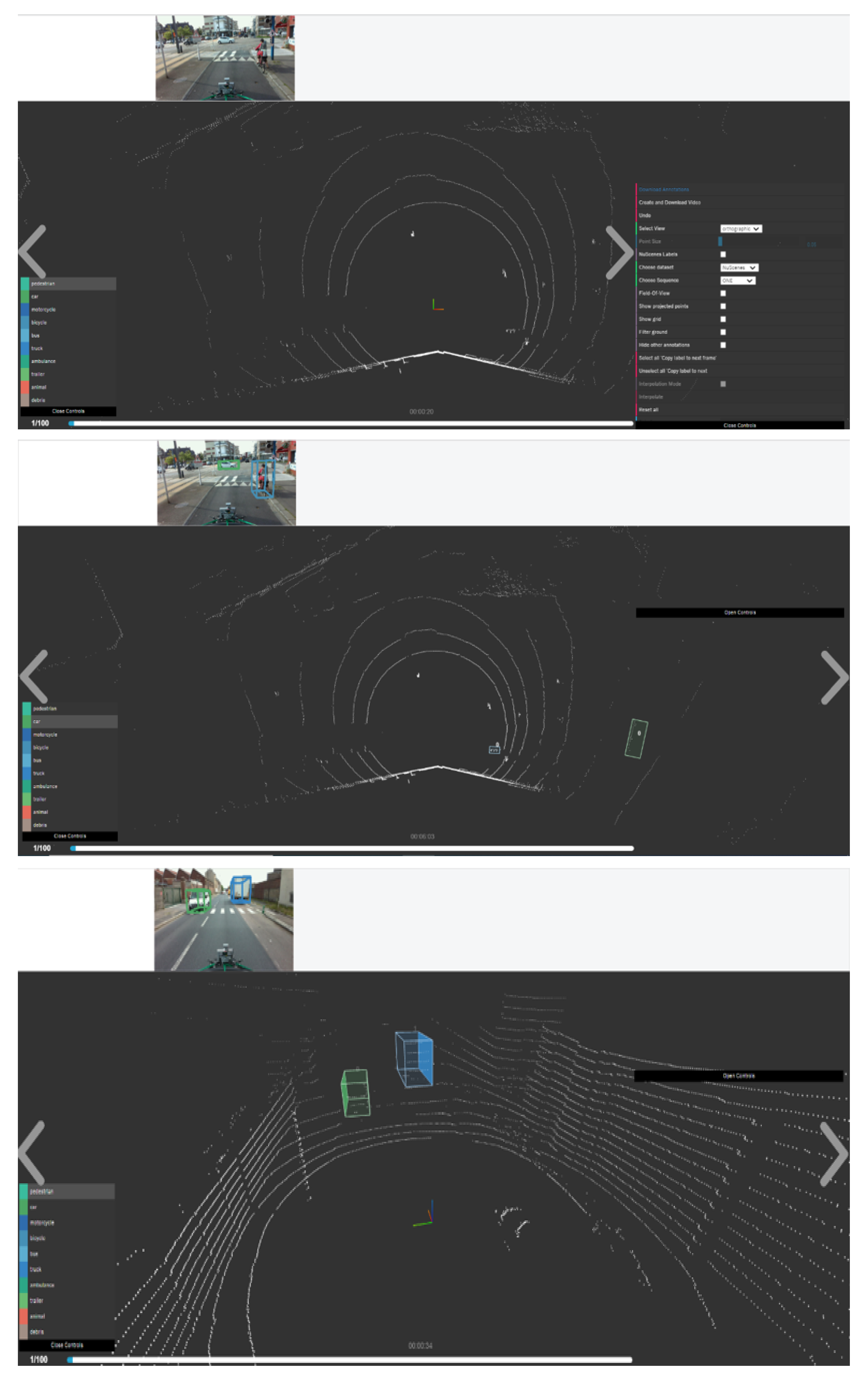
5. Dataset Annotation Process
5.1. Dataset Annotation Softwares
5.2. Road and Railway Dataset Annotation
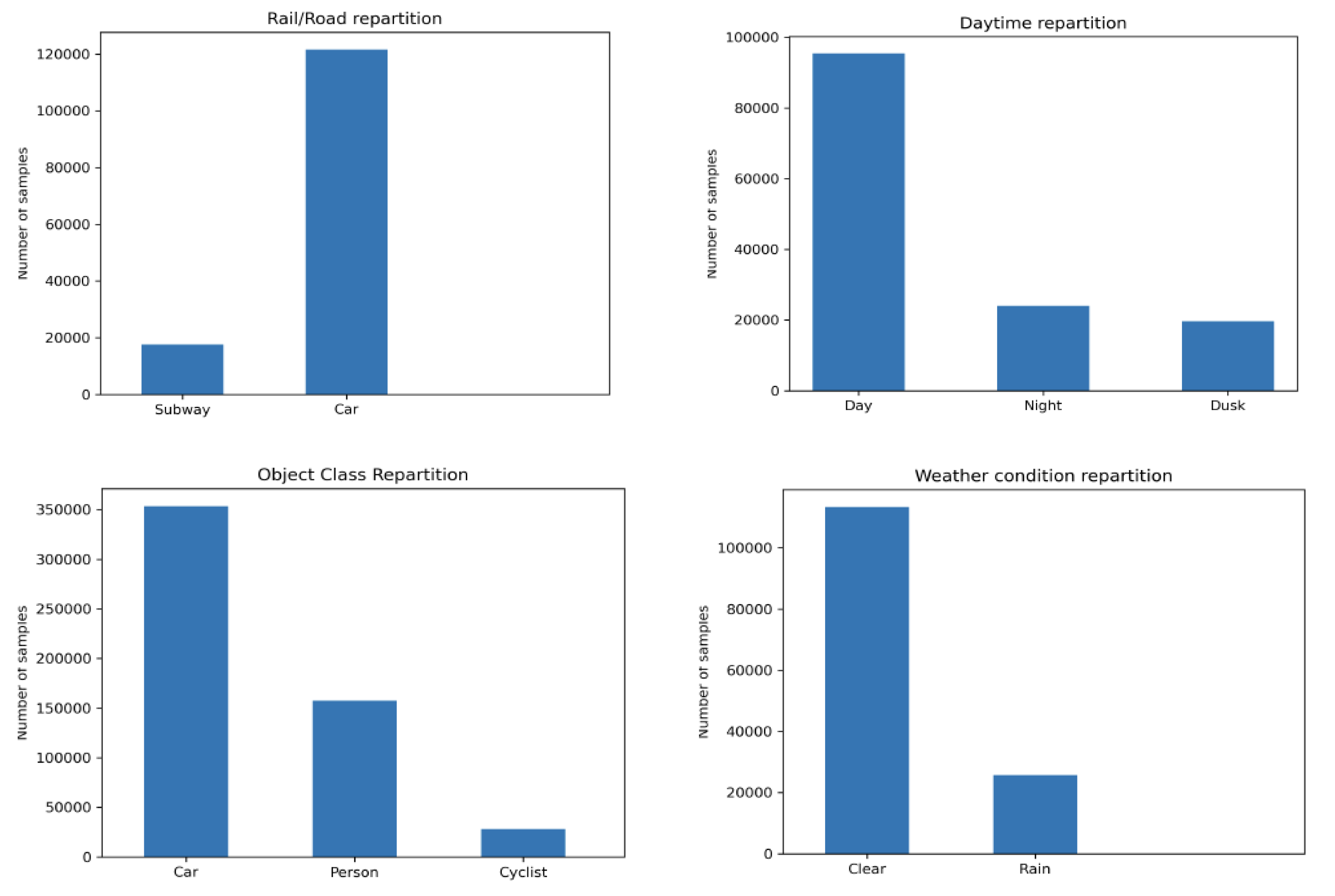
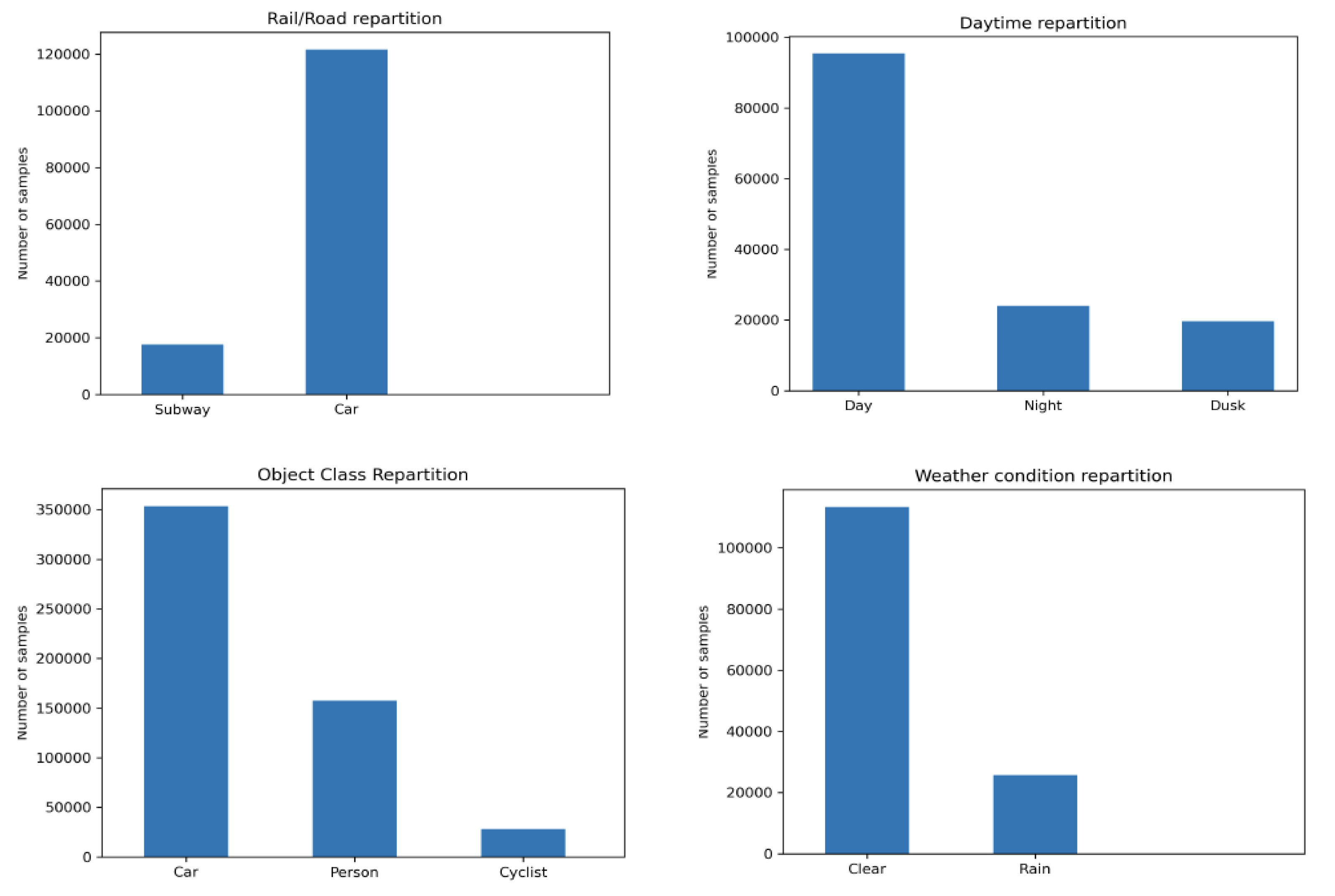
6. Experimental Results and Analysis
- ESRORAD is currently the only dataset, to our knowledge, dedicated not only to road smart mobility (autonomous car) but also to railway smart mobility (autonomous train).
- For the railway domain, there is only one dataset available in the literature(RailSem19 [50]), but it does not include ground truth data and therefore it does not allow one to qualify 3D object detection deep learning algorithms or distance estimation approaches.
- ESRORAD is the only dataset that combines road (80%) and rail (20%) scenes with virtual (220K images) and real (100k images) data.
- In the medium term:
- -
- ESRORAD aims to extend railway data outside cities to integrate rural landscapes such as in the case of long-distance trains.
- -
- Images and video quality will be improved through a new high-resolution LiDAR. This will allows us to make available high-quality HD datasets for more accuracy and safety.
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ESRORAD | Esigelec engineering high school and Segula technologies ROad and RAilway Dataset |
| ADAS | Advanced Driver Assistance System |
| ANL | Autonomous Navigation Laboratory |
| DL | Deep Learning |
| RGB | Red, Green, and Blue |
| GTAV | Grand Theft Auto V |
| CNN | Convolutional Neural Network |
| YOLOv3 | You Only Look Once |
| LiDAR | Light Detection And Ranging |
| LiDARSeg | LiDAR semantic Segmentation) |
| ROAD | ROad event Awareness Dataset for autonomous driving |
| RADAR | Radio Detection And Ranging |
| KITTI | Karlsruhe Institute of Technology and Toyota technological Institute at chicago |
| RailSem19 | A Dataset for Semantic Rail Scene Understanding |
| FPS | Frame Per Seconde |
| EKF | Extended Kalman Filter |
| NUScenes | NuTonomy Scenes |
| INRIA | Institut National de Recherche en Sciences et Technologies du Numérique |
References
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef] [Green Version]
- Mauri, A.; Khemmar, R.; Decoux, B.; Ragot, N.; Rossi, R.; Trabelsi, R.; Boutteau, R.; Ertaud, J.Y.; Savatier, X. Deep Learning for Real-Time 3D Multi-Object Detection, Localisation, and Tracking: Application to Smart Mobility. Sensors 2020, 20, 532. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mauri, A.; Khemmar, R.; Decoux, B.; Haddad, M.; Boutteau, R. Real-time 3D multi-object detection and localization based on deep learning for road and railway smart mobility. J. Imaging 2021, 7, 145. [Google Scholar] [CrossRef] [PubMed]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Duerig, T.; et al. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. arXiv 2018, arXiv:1811.00982. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Cai, Z.; Fan, Q.; Feris, R.S.; Vasconcelos, N. A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection. arXiv 2016, arXiv:cs.CV/1607.07155. [Google Scholar]
- Wang, X.; Yin, W.; Kong, T.; Jiang, Y.; Li, L.; Shen, C. Task-Aware Monocular Depth Estimation for 3D Object Detection. arXiv 2019, arXiv:cs.CV/1909.07701. [Google Scholar] [CrossRef]
- Godard, C.; Mac Aodha, O.; Brostow, G.J. Unsupervised monocular depth estimation with left-right consistency. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 270–279. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Firman, M.; Brostow, G. Digging into self-supervised monocular depth estimation. arXiv 2018, arXiv:1806.01260. [Google Scholar]
- Tosi, F.; Aleotti, F.; Poggi, M.; Mattoccia, S. Learning monocular depth estimation infusing traditional stereo knowledge. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9799–9809. [Google Scholar]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised learning of depth and ego-motion from video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1851–1858. [Google Scholar]
- Aladem, M.; Chennupati, S.; El-Shair, Z.; Rawashdeh, S.A. A Comparative Study of Different CNN Encoders for Monocular Depth Prediction. In Proceedings of the 2019 IEEE National Aerospace and Electronics Conference (NAECON), Dayton, OH, USA, 15–19 July 2019; pp. 328–331. [Google Scholar]
- Praveen, S. Efficient Depth Estimation Using Sparse Stereo-Vision with Other Perception Techniques. In Advanced Image and Video Coding; IntechOpen: London, UK, 2019. [Google Scholar]
- Laga, H.; Jospin, L.V.; Boussaid, F.; Bennamoun, M. A Survey on Deep Learning Techniques for Stereo-based Depth Estimation. arXiv 2020, arXiv:2006.02535. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully Connected CRFs. arXiv 2016, arXiv:1606.00915. [Google Scholar] [CrossRef] [Green Version]
- Mukojima, H.; Deguchi, D.; Kawanishi, Y.; Ide, I.; Murase, H.; Ukai, M.; Nagamine, N.; Nakasone, R. Moving camera background-subtraction for obstacle detection on railway tracks. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3967–3971. [Google Scholar]
- Rodriguez, L.F.; Uribe, J.A.; Bonilla, J.V. Obstacle detection over rails using hough transform. In Proceedings of the 2012 XVII Symposium of Image, Signal Processing, and Artificial Vision (STSIVA), Medellin, Colombia, 12–14 September 2012; pp. 317–322. [Google Scholar]
- Yanan, S.; Hui, Z.; Li, L.; Hang, Z. Rail Surface Defect Detection Method Based on YOLOv3 Deep Learning Networks. In Proceedings of the 2018 Chinese Automation Congress (CAC), Xi’an, China, 30 November–2 December 2018; pp. 1563–1568. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016, European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Mauri, A.; Khemmar, R.; Decoux, B.; Haddad, M.; Boutteau, R. Lightweight convolutional neural network for real-time 3D object detection in road and railway environments. J. Real-Time Image Processing 2022. [Google Scholar] [CrossRef]
- Singh, G.; Akrigg, S.; Di Maio, M.; Fontana, V.; Alitappeh, R.J.; Saha, S.; Jeddisaravi, K.; Yousefi, F.; Culley, J.; Nicholson, T.; et al. Road: The road event awareness dataset for autonomous driving. arXiv 2021, arXiv:2102.11585. [Google Scholar] [CrossRef] [PubMed]
- Brostow, G.J.; Shotton, J.; Fauqueur, J.; Cipolla, R. Segmentation and recognition using structure from motion point clouds. In Proceedings of the Computer Vision—ECCV 2016, European Conference on Computer Vision, Marseille, France, 12–18 October 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 44–57. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Scharwächter, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset. In Proceedings of the CVPR Workshop on the Future of Datasets in Vision, Boston, MA, USA, 11 June 2015; Volume 2. [Google Scholar]
- Huang, X.; Wang, P.; Cheng, X.; Zhou, D.; Geng, Q.; Yang, R. The apolloscape open dataset for autonomous driving and its application. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2702–2719. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Che, Z.; Li, G.; Li, T.; Jiang, B.; Shi, X.; Zhang, X.; Lu, Y.; Wu, G.; Liu, Y.; Ye, J. D2-City: A Large-Scale Dashcam Video Dataset of Diverse Traffic Scenarios. arXiv 2019, arXiv:1904.01975. [Google Scholar]
- Ding, L.; Terwilliger, J.; Sherony, R.; Reimer, B.; Fridman, L. MIT DriveSeg (Manual) Dataset for Dynamic Driving Scene Segmentation; Technical Report; Massachusetts Institute of Technology: Cambridge, MA, USA, 2020. [Google Scholar]
- Everingham, M.; Eslami, S.A.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Wojek, C.; Walk, S.; Schiele, B. Multi-cue onboard pedestrian detection. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 794–801. [Google Scholar]
- Neumann, L.; Karg, M.; Zhang, S.; Scharfenberger, C.; Piegert, E.; Mistr, S.; Prokofyeva, O.; Thiel, R.; Vedaldi, A.; Zisserman, A.; et al. Nightowls: A pedestrians at night dataset. In Proceedings of the Computer Vision–ACCV 2018, Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; Springer: Cham, Switzerland, 2018; pp. 691–705. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Mayer, N.; Ilg, E.; Hausser, P.; Fischer, P.; Cremers, D.; Dosovitskiy, A.; Brox, T. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4040–4048. [Google Scholar]
- Ciaparrone, G.; Sánchez, F.L.; Tabik, S.; Troiano, L.; Tagliaferri, R.; Herrera, F. Deep Learning in Video Multi-Object Tracking: A Survey. Neurocomputing 2019, 381, 61–88. [Google Scholar] [CrossRef] [Green Version]
- Bernardin, K.; Stiefelhagen, R. Evaluating Multiple Object Tracking Performance: The CLEAR MOT Metrics. EURASIP J. Image Video Process. 2008, 2008, 246309. [Google Scholar] [CrossRef] [Green Version]
- Yang, S.; Baum, M. Extended Kalman filter for extended object tracking. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Orleans, LA, USA, 5–9 March 2017; pp. 4386–4390. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar]
- Wilson, B.; Qi, W.; Agarwal, T.; Lambert, J.; Singh, J.; Khandelwal, S.; Pan, B.; Kumar, R.; Hartnett, A.; Pontes, J.K.; et al. Argoverse 2: Next Generation Datasets for Self-Driving Perception and Forecasting. 2021. Available online: https://openreview.net/forum?id=vKQGe36av4k (accessed on 21 April 2022).
- Chang, M.F.; Lambert, J.; Sangkloy, P.; Singh, J.; Bak, S.; Hartnett, A.; Wang, D.; Carr, P.; Lucey, S.; Ramanan, D.; et al. Argoverse: 3d tracking and forecasting with rich maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–19 June 2019; pp. 8748–8757. [Google Scholar]
- Kesten, R.; Usman, M.; Houston, J.; Pandya, T.; Nadhamuni, K.; Ferreira, A.; Yuan, M.; Low, B.; Jain, A.; Ondruska, P.; et al. Lyft Level 5 av Dataset 2019. Available online: https://level-5.global/data/ (accessed on 21 April 2022).
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2446–2454. [Google Scholar]
- Malla, S.; Dariush, B.; Choi, C. Titan: Future forecast using action priors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11186–11196. [Google Scholar]
- Gählert, N.; Jourdan, N.; Cordts, M.; Franke, U.; Denzler, J. Cityscapes 3d: Dataset and benchmark for 9 dof vehicle detection. arXiv 2020, arXiv:2006.07864. [Google Scholar]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An Open Urban Driving Simulator. In Proceedings of the 1st Annual Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017; pp. 1–16. [Google Scholar]
- Ros, G.; Sellart, L.; Materzynska, J.; Vazquez, D.; Lopez, A.M. The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3234–3243. [Google Scholar]
- Richter, S.R.; Vineet, V.; Roth, S.; Koltun, V. Playing for data: Ground truth from computer games. In Proceedings of the Computer VisioECCV 2016, European Conference on Computer Vision, Amsterdam, The Netherlandws, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 102–118. [Google Scholar]
- Zendel, O.; Murschitz, M.; Zeilinger, M.; Steininger, D.; Abbasi, S.; Beleznai, C. RailSem19: A Dataset for Semantic Rail Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Harb, J.; Rébéna, N.; Chosidow, R.; Roblin, G.; Potarusov, R.; Hajri, H. FRSign: A Large-Scale Traffic Light Dataset for Autonomous Trains. arXiv 2020, arXiv:abs/2002.05665. [Google Scholar]
- Hu, H.N.; Cai, Q.Z.; Wang, D.; Lin, J.; Sun, M.; Krähenbühl, P.; Darrell, T.; Yu, F. Joint Monocular 3D Vehicle Detection and Tracking. arXiv 2019, arXiv:cs.CV/1811.10742. [Google Scholar]
- Kalman, R.E. A New Approach to Linear Filtering and Prediction Problems. J. Basic Eng. Mar. 1960, 82, 35–45. [Google Scholar] [CrossRef] [Green Version]
- Juarez-Salazar, R.; Zheng, J.; Diaz-Ramirez, V.H. Distorted pinhole camera modeling and calibration. Appl. Opt. 2020, 59, 11310–11318. [Google Scholar] [CrossRef] [PubMed]
- Berger, M.O. Calibrage d’Une Caméra, 2014. Available online: https://members.loria.fr/moberger/Enseignement/Image/calibration.2014.pdf (accessed on 21 April 2022).
- Supervisely Homepage. Available online: https://supervise.ly/lidar-3d-cloud/ (accessed on 6 April 2022).
- Scale Homepage. Available online: https://scale.com/ (accessed on 6 April 2022).
- Zimmer, W.; Rangesh, A.; Trivedi, M. 3d bat: A semi-automatic, web-based 3d annotation toolbox for full-surround, multi-modal data streams. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 1816–1821. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khemmar, R.; Mauri, A.; Dulompont, C.; Gajula, J.; Vauchey, V.; Haddad, M.; Boutteau, R. Road and Railway Smart Mobility: A High-Definition Ground Truth Hybrid Dataset. Sensors 2022, 22, 3922. https://doi.org/10.3390/s22103922
Khemmar R, Mauri A, Dulompont C, Gajula J, Vauchey V, Haddad M, Boutteau R. Road and Railway Smart Mobility: A High-Definition Ground Truth Hybrid Dataset. Sensors. 2022; 22(10):3922. https://doi.org/10.3390/s22103922
Chicago/Turabian StyleKhemmar, Redouane, Antoine Mauri, Camille Dulompont, Jayadeep Gajula, Vincent Vauchey, Madjid Haddad, and Rémi Boutteau. 2022. "Road and Railway Smart Mobility: A High-Definition Ground Truth Hybrid Dataset" Sensors 22, no. 10: 3922. https://doi.org/10.3390/s22103922
APA StyleKhemmar, R., Mauri, A., Dulompont, C., Gajula, J., Vauchey, V., Haddad, M., & Boutteau, R. (2022). Road and Railway Smart Mobility: A High-Definition Ground Truth Hybrid Dataset. Sensors, 22(10), 3922. https://doi.org/10.3390/s22103922