1. Introduction
The development of autonomous vehicles that can operate safely in highly unstructured environments, such as agricultural fields, proved to be a complex task. It requires an interdisciplinary approach [
1] and needs to address the challenges of natural variation and uncertainty [
2]. In order to meet the safety requirements, an autonomous agricultural vehicle needs to be equipped with robust obstacle detection algorithms that run in real time. In general, such an obstacle detection system relies on inputs from multiple sensor modalities in order to provide sufficient information about the surrounding environment and introduce necessary redundancy [
3]. A vehicle’s ability to perceive and understand its environment relies heavily on data from cameras. The success of deep learning architectures for image classification, semantic segmentation, and object detection, greatly benefited the application of deep learning in scene perception for autonomous vehicles [
4].
Agricultural fields are dynamic, unstructured and diverse environments. Supervised approaches to object detection and semantic segmentation are trained to detect objects from a predefined set of classes. Since these algorithms need substantial data for each class, they are usually limited to detection and classification of only the most common classes of objects that can be encountered in a field. While these approaches are essential for solving higher-level tasks such as scene understanding and autonomous navigation, they do not provide a complete solution for safe operation due to their inability to detect unknown objects. On the other hand, self-supervised approaches, such as autoencoders applied in anomaly detection, are trained to look for patterns that do not conform to normal operating conditions. Therefore, they are able to detect a wide range of objects in the field that pose a potential danger and need to be treated as obstacles. For these reasons, anomaly detection is crucial for developing safe and reliable perception systems for autonomous and semiautonomous agricultural vehicles.
In the agricultural context, all objects in the field that are a potential obstruction to the safe operation of a vehicle would be treated as anomalies. The anomalies include humans, animals, other vehicles, holes, standing water, buildings, and various other objects left in the field intentionally or unintentionally, e.g., different tools and equipment. Developing a system that can warn the machine operator when anomalies need their attention allows the operator to focus more on the other aspects of agricultural operation.
Autoencoders are commonly used in solving anomaly detection tasks and have applications in data compression and feature learning. An autoencoder is composed of two parts: encoder and decoder. The encoder network maps the input data to low-dimensional feature space, while the decoder attempts to reconstruct the data from the projected low-dimensional space [
5]. The encoder and decoder are trained together with reconstruction loss functions to minimize the reconstruction error between the input and reconstructions. Using normal data to train the autoencoder enables the model to learn to reconstruct normal data instances from low-dimensional feature spaces with low reconstruction error. Since anomalies deviate from normal data instances, they are much harder to reconstruct from the same low-dimensional feature space, resulting in greater reconstruction error. Therefore, reconstruction error can be used to identify anomalies and generate anomaly maps.
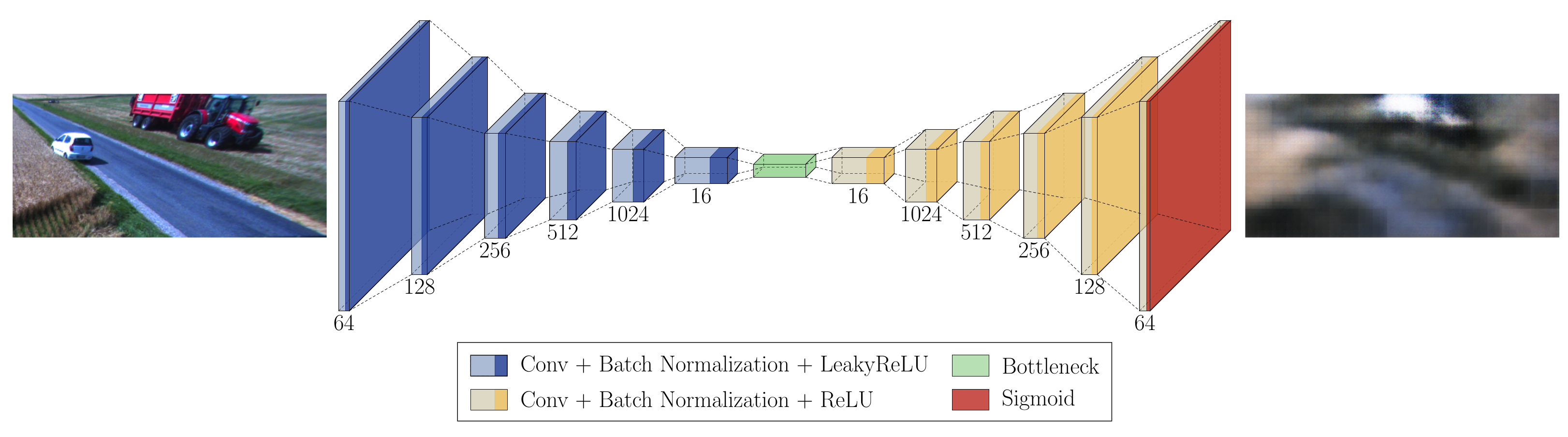
This paper investigates the application of different autoencoder variants for the detection of anomalies in an agricultural field. A semisupervised autoencoder (SSAE) trained with max-margin-inspired loss function applied to input image and reconstructed image at pixel level is proposed. The proposed approach is evaluated and shown to outperform the basic autoencoder (AE), the vector-quantized variational autoencoder (VQ-VAE) and the denoising autoencoder (DAE). The anomaly maps are generated using relative-perceptual-L1 loss [
6]. The overview of the autoencoder-based anomaly detection concept for all four models is shown in
Figure 1. The models are trained on a dataset collected by the front camera of an agricultural vehicle during summer harvest in Denmark. Finally, the performance of autoencoder architectures is compared with the performance of the baseline object detector model based on YOLOv5s [
7]. The object detector is trained to detect the classes of objects commonly found in a field during harvesting season.
The paper’s main contributions are as follows:
Differentt autoencoder models and a baseline object detection model are compared in a difficult task of in-field anomaly detection for autonomous agricultural vehicles using image data. To the best of our knowledge, this is the first analysis of autoencoders applied in the agricultural domain to detect anomalies that pose a potential operational risk for agricultural vehicles.
The paper introduces a semisupervised anomaly detection strategy that leverages a small number of image samples with labeled anomalies and applies max-margin loss function to reinforce better discrimination of normal and abnormal pixels. The proposed approach outperforms the other investigated autoencoder models.
The results of the proposed autoencoder model and YOLOv5 model are compared. It is shown that the object detector is challenged in detecting unknown classes of objects as well as the trained classes of objects in some cases.
The remainder of the paper is structured as follows.
Section 2 reviews related work for anomaly detection using convolutional autoencoders and deep learning in the agricultural domain for anomaly detection.
Section 3 describes the dataset, autoencoder architectures as well as the object detector model. In
Section 4, the performance of the trained networks is evaluated. This is followed by the conclusion in
Section 5.
2. Related Work
Anomaly detection has been applied in several domains, such as fraud detection, medical imaging, Internet of Things (IoT), surveillance and monitoring and time series data analysis [
8]. In the agricultural domain, it has been mostly applied in precision farming [
9,
10,
11,
12,
13] and to a far lesser extent in navigation and obstacle detection [
14,
15].
Earlier work by Christiansen et al. [
14] exploited the homogeneous characteristics of an agricultural field and combined CNN and background subtraction algorithms. The work demonstrated successful use of background subtraction for a moving camera in agriculture, exploiting the fact that images taken from a front camera of an agricultural vehicle moving along rows in the field are similar. This approach is able to detect heavily occluded, distant and unknown objects. In addition, the approach showed better or comparable results with state-of-the-art object detectors in the agricultural context.
The image resynthesis methods focus on finding differences between the input image and the image resynthesized from the predicted semantic map. In the work presented by Lis et al. [
16], an exiting semantic segmentation algorithm generates the semantic map. Then, the approach utilizes generative adversarial network (GAN) to generate the resynthesized image. Finally, an anomaly map is yielded by a trained discrepancy network that takes the original image, resynthesized image and predicated semantic map as inputs. Ohgushi et al. [
17] addressed the detection of road obstacles in road scenes with a complex background where there is a risk of unknown objects that are not present in the training dataset. This study proposed a road obstacle detection method using an autoencoder consisting of modules for semantic segmentation and resynthesized image generation. First, the semantic segmentation network is trained with data from normal road scenes. Next, resynthesized images are created using a photographic image synthesis technique. The method then calculates the perceptual loss between the input and resynthesized images and multiplies it by the entropy for the semantic map to generate an anomaly map. Finally, the method localizes road obstacles and assigns obstacle scores at the superpixel level in the postprocessing step.
A new anomaly detection approach for high-resolution medical data, based on autoencoders with perceptual loss and progressive growing training, was introduced by Shvetsova et al. [
18]. Since anomalies in the medical images often resemble normal data, low-quality reconstructions from autoencoders may not capture the fine detail necessary for anomaly detection. This limitation is addressed by training the model with progressive growing technique where layers are added to the autoencoder and the depth of the features in perceptual loss is increased during training.
Van Den Oord et al. [
19] introduced a new generative model VQ-VAE. The model combines VAEs with vector quantization to obtain a discrete latent representation. The output of the encoder is mapped to the nearest embedding vector from the shared discrete embedding space. The corresponding embedding vector is used as the input to the decoder. The model parameters consist of encoder network, embedding space and decoder network. In order to avoid the unwanted reconstructions of anomalies, Wang et al. [
20] used a discrete probability model to estimate the latent space of the autoencoder and exclude the anomalous components of the latent space. More specifically, the VQ-VAE model is trained on normal data to obtain the discrete latent space of normal samples. Then, the deep autoregressive model PixelSNAIL [
21] is used to estimate the probability distribution of the latent space. The deviating components of the latent space are resampled from the distribution and decoded to yield a restored image.
Vincent et al. [
22] proposed a denoising autoencoder. The proposed training principle makes the learned representation robust to partial corruption. The input is first corrupted with noise, and the model is trained to reconstruct the original input from the corrupted one. Tun et al. [
23] used a convolutional autoencoder for denoising of outdoor facial images. The convolutional denoising autoencoder was used for efficient denoising of medical images by Gondara [
24]. The results showed that a small training dataset is sufficient for good denoising performance.
In addition to a large unlabeled dataset of normal data, weakly supervised anomaly detection uses a small labeled dataset during training to improve detection. Ruff et al. [
25] introduced an end-to-end deep methodology for semisupervised anomaly detection called deep semisupervised anomaly detection (DeepSAD). Zhou et al. [
26] leveraged unsupervised anomaly detection based on an autoencoder to extract feature representations of normal data. The extracted feature representation is used for weakly supervised anomaly detection.
An essential step in anomaly localization in image data is the visualization of detected anomalies. Baur et al. [
27] generated an anomaly map by computing the pixelwise L1-distance between an input image and image reconstruction by autoencoder. Then, the resulting residual is thresholded to obtain a binary segmentation. On the other hand, Lis et al. [
16] relied on a discrepancy network trained to detect significant image discrepancies. The discrepancy network uses the original image, the predicted semantic labels and the resynthesized image as inputs. A pretrained VGG [
28] network is used to extract features from the input image and resynthesized image, while a custom CNN network is used to extract features from predicted semantic labels. The features of all the streams are concatenated and fused using 1 × 1 convolutions at each level of the feature pyramid. The final discrepancy map is generated by passing features and their correlations through the decoder network.
Although different anomaly detection approaches have been successfully applied in various domains, very little research has been conducted on anomaly detection for autonomous agricultural vehicles. Moreover, the current research does not indicate which autoencoder architecture performs the best for this use case scenario. Hence, the focus of this paper is to investigate and compare several autoencoder models.
4. Results and Discussion
Results are divided into two subsections. The first section shows experimental results for determining the optimal threshold
for the objective function of SSAE. The second section presents a performance evaluation of trained models followed by qualitative examples comparing the performance of the autoencoders and the object detector. The training hyperparameters for all models are listed in
Table 3.
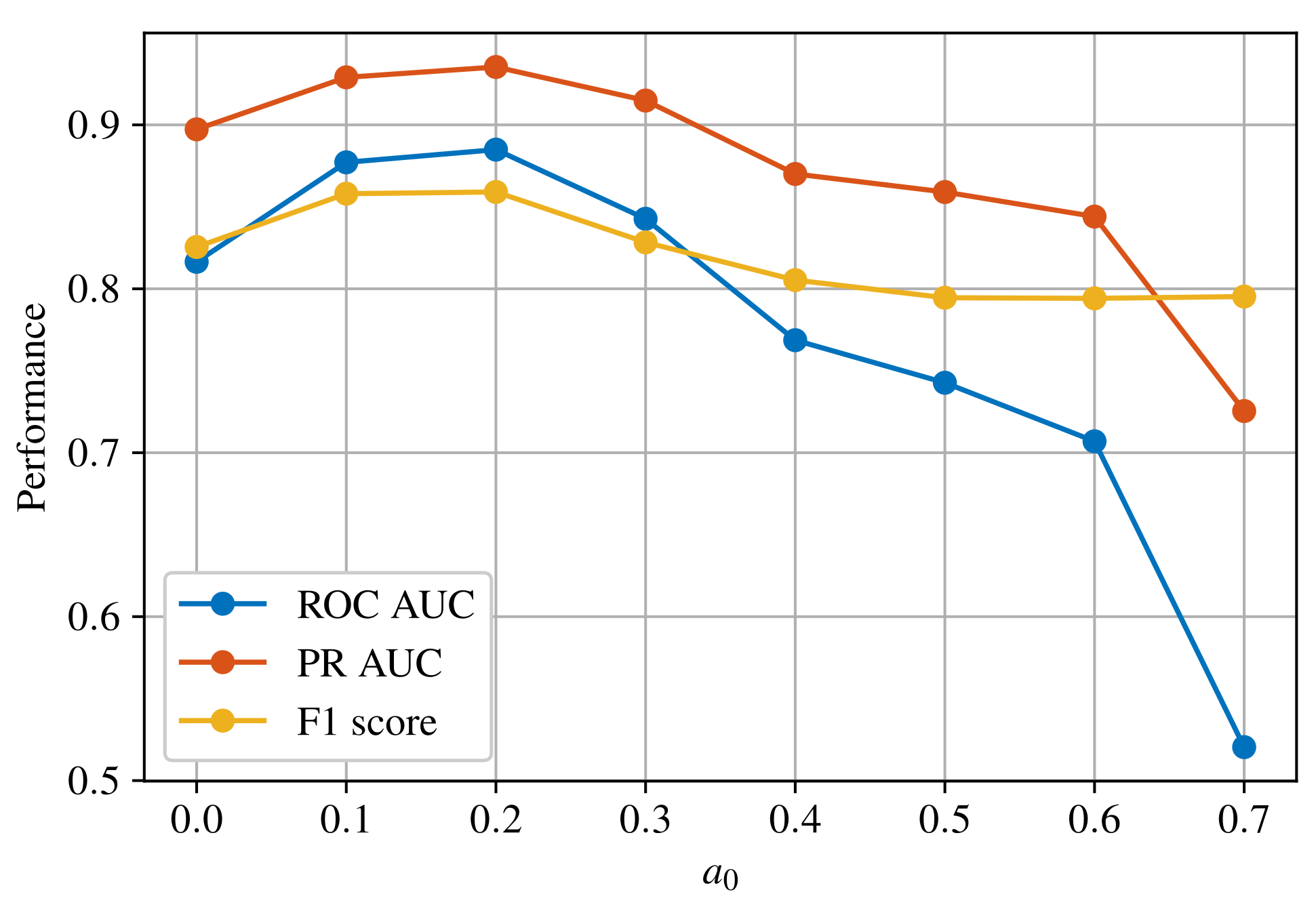
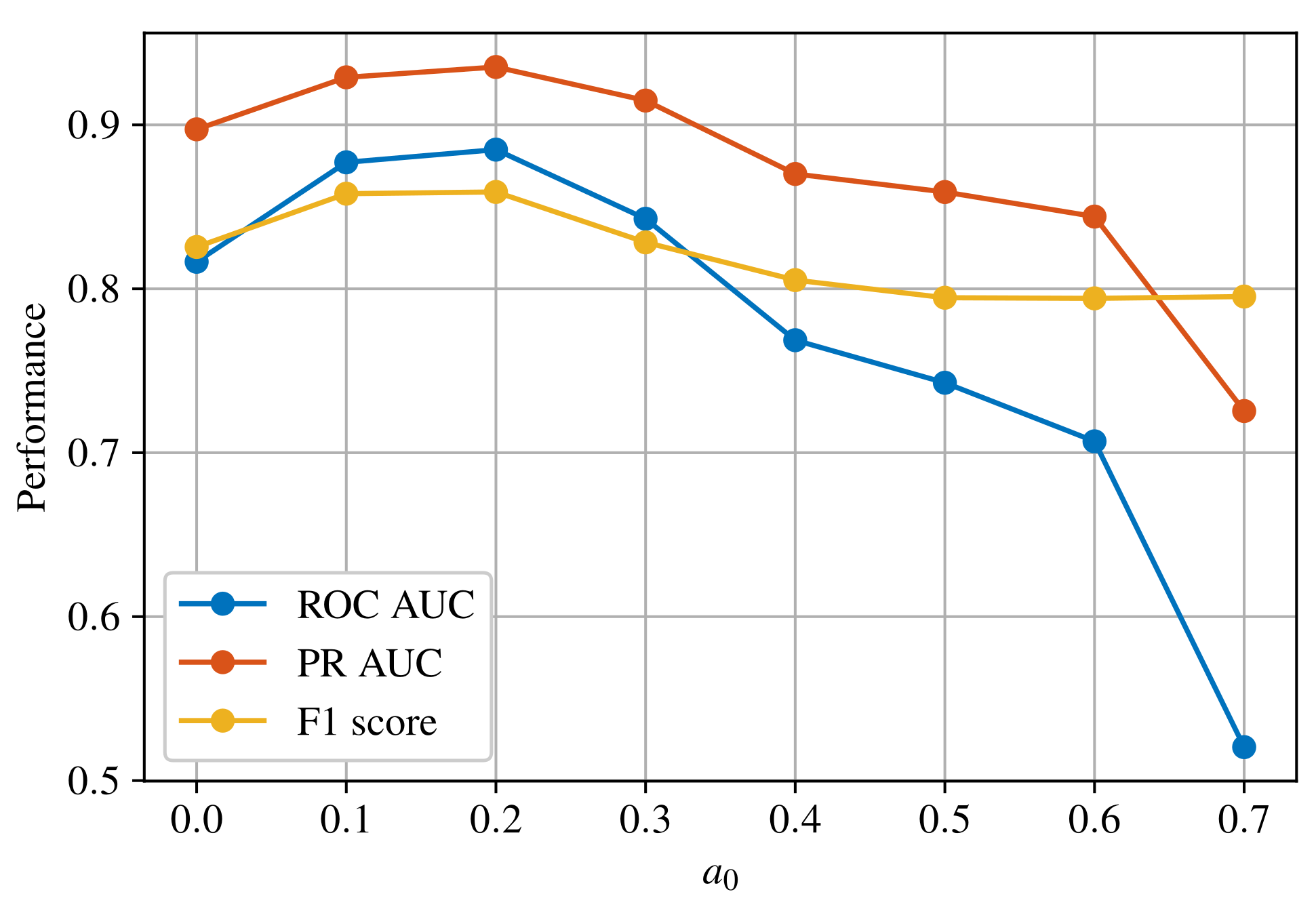
4.1. Experimental Results for Threshold
Threshold
represents the margin that separates normal and abnormal pixels in the training set. Setting this threshold to a low value prevents the model from discriminating between normal and abnormal samples. On the other hand, setting this threshold to a large value makes the optimization task very difficult, and the model’s performance might start to deteriorate. Therefore, the model is trained for different values of
and the optimal one is determined based on the results.
Figure 3 shows the performance comparison for three different metrics.
With a basis in
Figure 3, the optimal threshold is found to be
for the proposed semisupervised autoencoder model.
4.2. Performance Evaluation of Models
Due to the inconsistent outputs of the models, each model is evaluated against the annotated dataset according to its ability to classify an image as anomalous or not. For autoencoders, anomaly scores are computed for each image, and images are classified according to Equation (
4) for various thresholds. For the baseline model, if objects are detected in an image, the image is classified as anomalous.
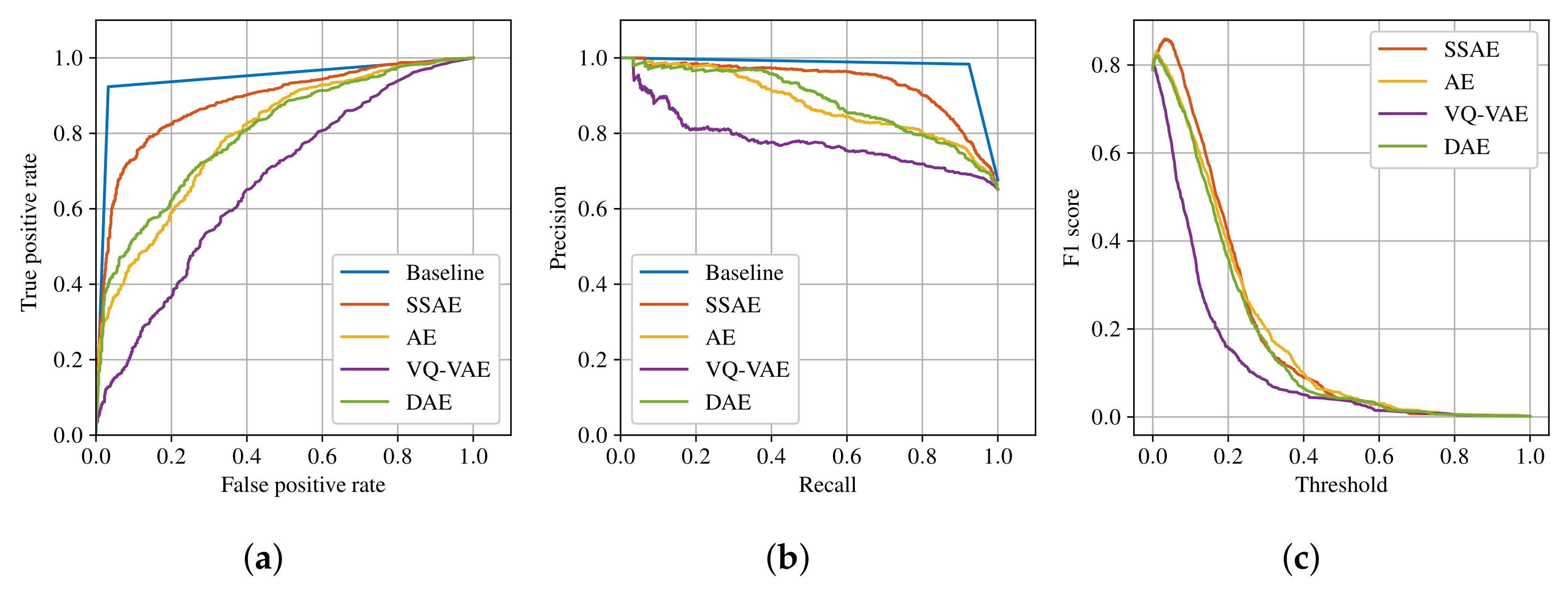
A receiver operating characteristic (ROC) curve, precision/recall curve and F1 score are generated for each model in
Figure 4. Furthermore, the models’ performances are measured using the maximum F1 score, the area under the curve for ROC curve (ROC AUC) and the area under the curve for precision/recall curve (PR AUC). ROC is one of the most commonly used evaluation metrics for classification tasks and it is insensitive to class imbalance [
30]. Since the test dataset is imbalanced, PR metrics are also computed, which provide a more informative measure in the case of imbalanced data [
31].
The results can be seen in
Table 4. The baseline model has the highest performance scores on all three metrics. The proposed SSAE has the highest performance scores from the autoencoder models, followed by AE and DAE with similar performances and VQ-VAE with the worst performance of the autoencoder models.
The generated ROC curves and precision/recall curves are shown in
Figure 4a,b, respectively. For the autoencoder models, the generated F1 score curves with normalized thresholds are also shown in
Figure 4c. The ROC curve and precision/recall curve show that SSAE has the best performance compared with the other autoencoder models.
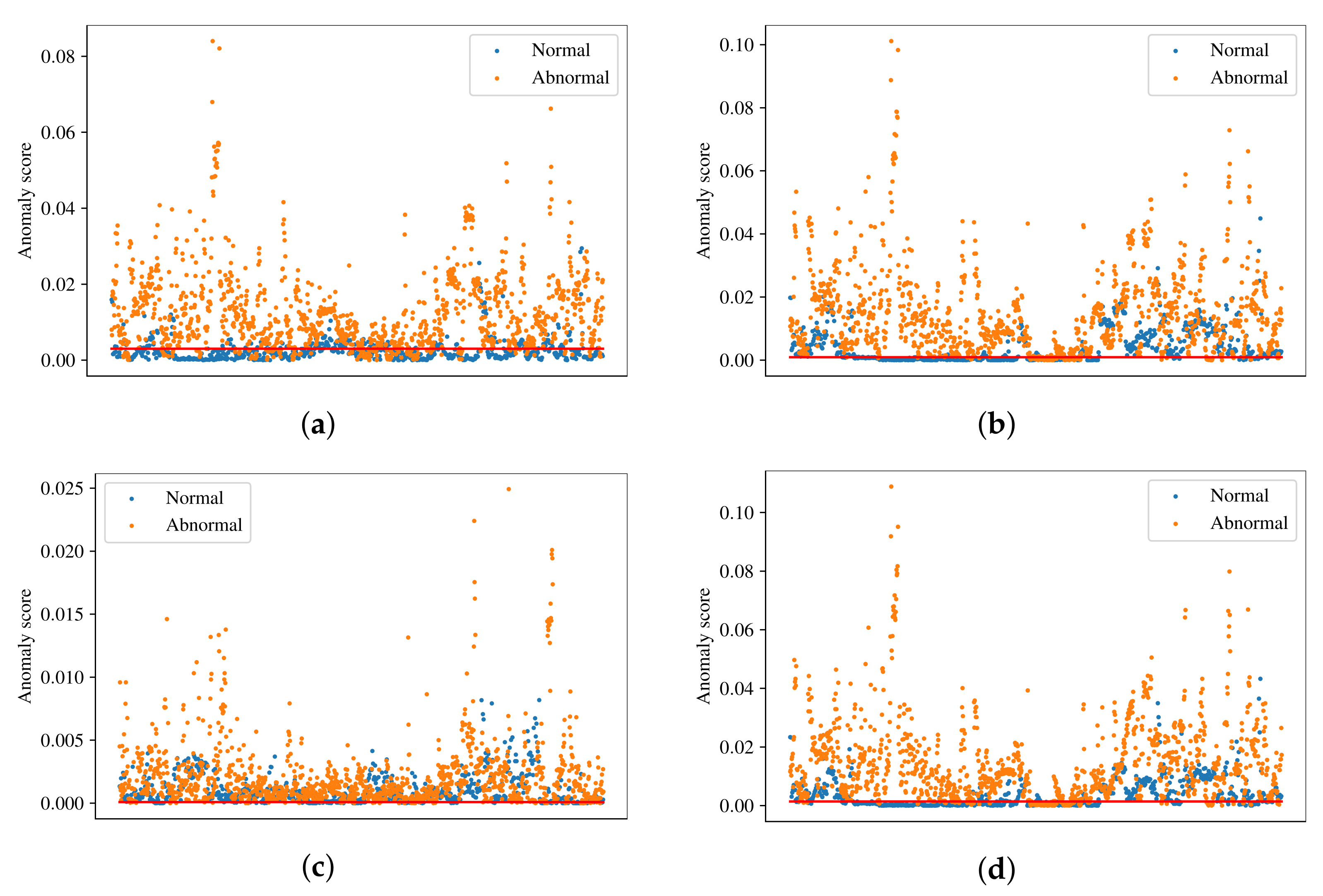
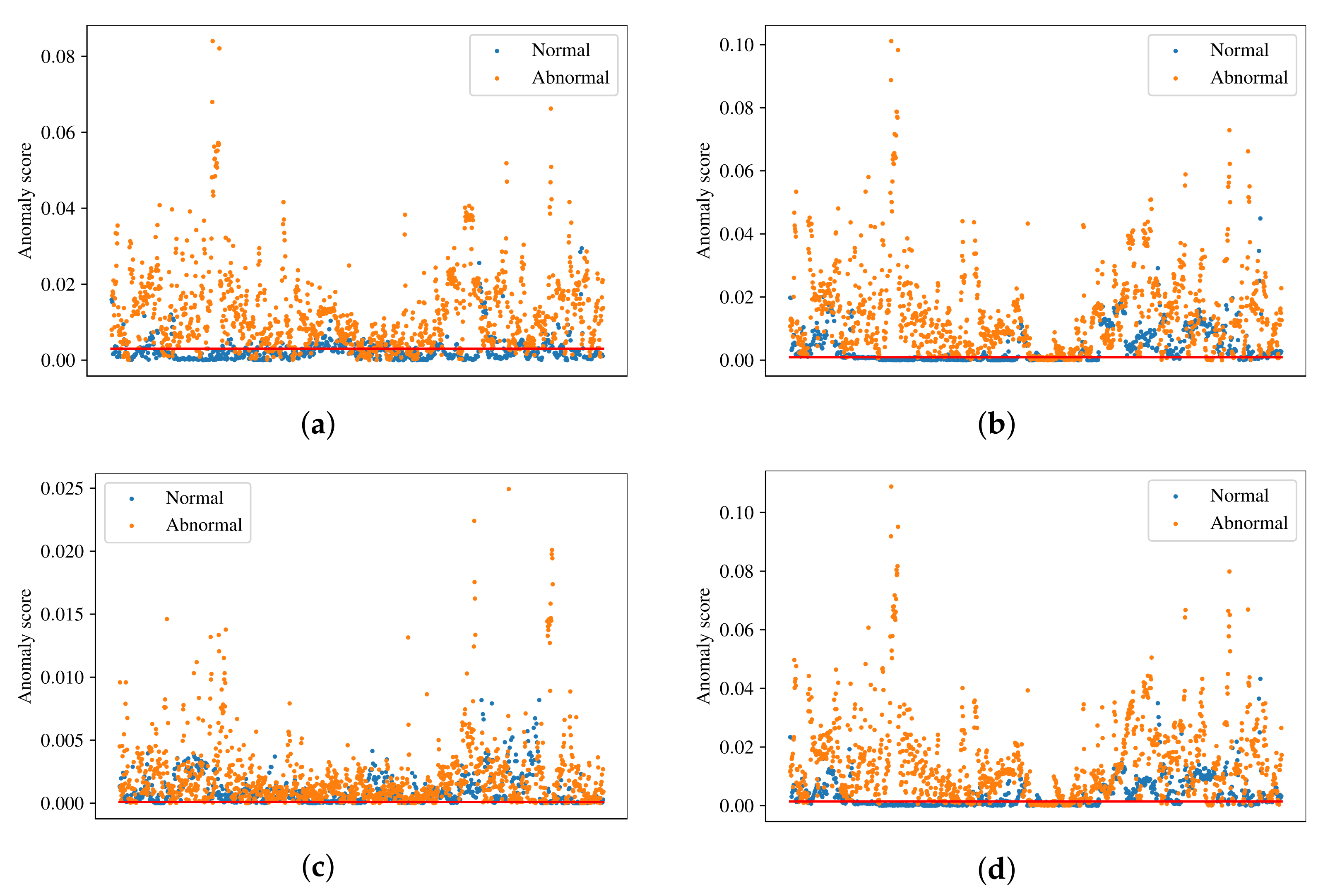
The distribution of normal and abnormal samples in the test dataset is shown in
Figure 5. In the figure, blue dots correspond to normal samples, orange dots correspond to abnormal samples and red lines represent the thresholds found by optimizing the F1 score. For a good anomaly detector, normal samples should be placed below the threshold line and abnormal samples above the threshold line. The results in
Figure 5 support the performance results stated earlier. It can be clearly seen in
Figure 5c that VQ-VAE has trouble classifying normal and abnormal samples, since the anomaly scores of a significant number of those samples fall within the same range. However, abnormal samples have higher anomalies scores in general. On the other hand,
Figure 5b,d shows that AE and DAE have a good ability of distinguishing between normal and abnormal samples. The SSAE has the best ability to distinguish between the samples, where the majority of normal samples is below threshold and the majority of abnormal samples is above threshold.
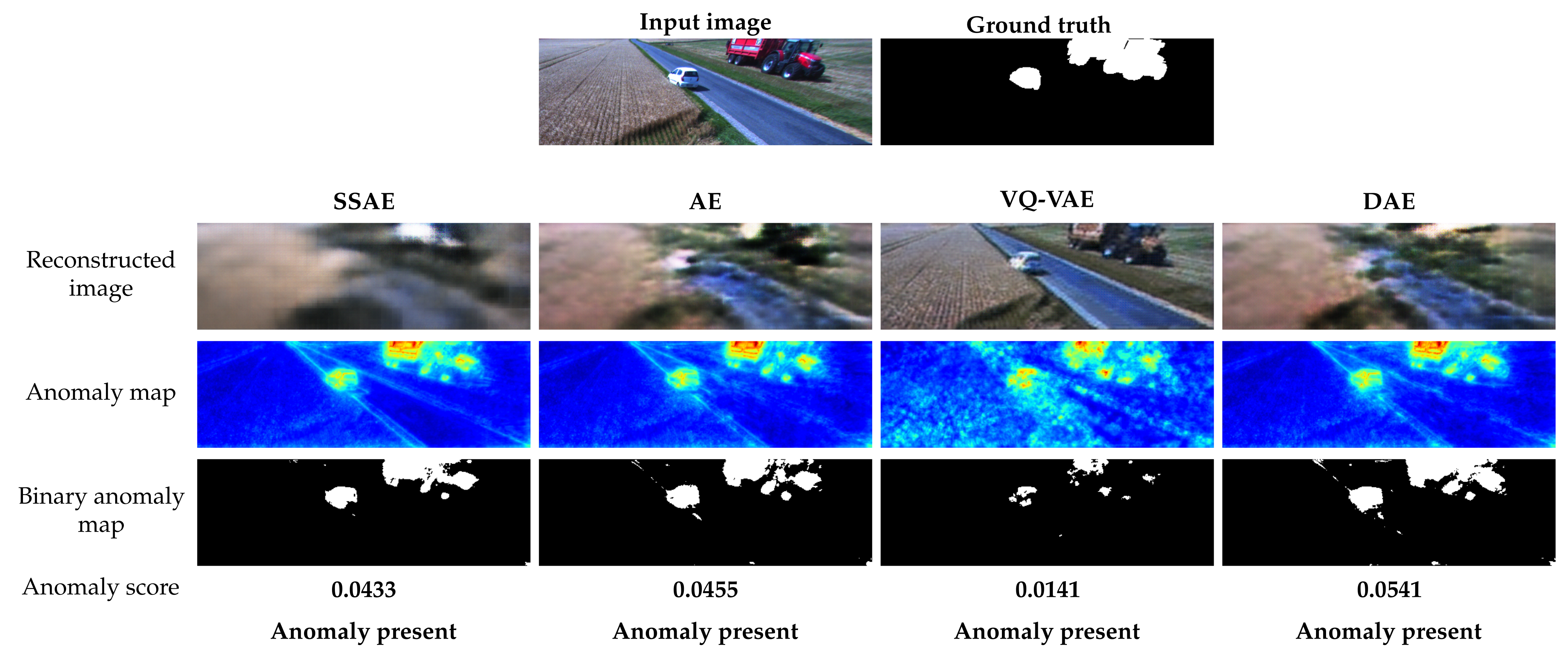
The qualitative performance of the autoencoder models is presented in
Figure 6. The example image is captured by the front camera of the combine harvester during field operation. In this scenario, the tractor with a trailer and the car are potential obstacles in the harvester’s path and should be detected as anomalies. The reconstruction images show that the different autoencoders are reconstructing the images as expected. For SSAE, there is significant difference in the reconstruction of normal and abnormal areas. The AE and VQ-VAE models are reconstructing anomalies poorly, while DAE is able to remove the anomalies from the image. The anomaly maps of SSAE, AE and DAE show the anomalies clearly. However, the anomaly map produced by SSAE has smoother normal areas. The anomaly map generated by VQ-VAE has significantly more noise in areas without anomalies. The anomaly scores are above the threshold for all four autoencoders, indicating that the image would be correctly classified as anomalous in all cases.
Comparing anomaly detectors with the baseline YOLOv5 model, it can be seen from
Figure 4 and
Table 4 that SSAE has the closest performance to the baseline model. One major difference between the anomaly detectors and object detector is that anomaly detectors do not provide class labels for the detected objects. Another major difference is the requirements for the training dataset. For example, AE and VQ-VAE require only normal data that does not need to be annotated. On the other hand, SSAE requires a small number of annotated samples. Furthermore, DAE requires annotated masks for objects, which can be time-consuming. Although object detectors provide class labels for anomalous objects, they require a large amount of data for each object class. Given that the agricultural fields are highly unstructured environments, it is unrealistic to collect enough data for each object that could potentially be found in a field. For example,
Figure 7c shows a header trailer that was not included as a class for annotation. YOLOv5s cannot detect it as an object, but SSAE can detect it as an anomaly. Moreover,
Figure 7b shows a scenario where YOLOv5s fails to detect a person because of their body position. In the same scenario, SSAE is able to detect a person as an anomaly successfully.
4.3. Potential Applications
The proposed anomaly detection can be integrated with agricultural vehicles at several levels of driving automation.
As a first step towards autonomy, the proposed anomaly detection can be integrated with current agricultural vehicles as an assisted tool. The current generation of agricultural vehicles use commercially available products, such as autosteering and tractor-guidance systems, to navigate automatically and more efficiently. However, the human operator is still responsible for obstacle detection and the safety of local navigation. Moreover, the operator monitors the parameters related to the specific agricultural operation and ensures optimal performance. The proposed anomaly detection can be integrated as an assisted tool which provides visual feedback and/or an audio warning to the operator if an anomaly is detected near the vehicle. By providing assistance in detecting objects that may cause a collision, the system relieves the operators of some responsibility and enables them to focus more on monitoring process-related performance.
In the future, the proposed system can be integrated with a fully autonomous agricultural vehicle. According to the functional architecture of the autonomous driving system outlined in [
32], the proposed system would be integrated as part of the perception functional block. In general, the perception block receives data from multiple sources and generates a representation of the vehicle’s environment. This information is passed to the planning and decision block for navigation planning as well as reactive behavior. The motion and vehicle control block includes execution of the planned trajectory with movement commands and control of the actuators. The overall robustness of such a complex system and its ability to be certified for autonomous operation depend on the performance of numerous components.
On the environment perception part, and more specifically the processing of image data and object detection, the robustness of the system can be improved by combining multiple approaches to object detection. For example, the proposed anomaly detection would be applied to detect a wide range of potential obstacles without providing any additional information about them, such as their class. On the other hand, an object detector could classify a limited number of those detected obstacles depending on how extensive the training dataset is. Together, the two algorithms would provide the planning and decision system with more complete information about the objects in the vehicle’s environment.
5. Conclusions and Future Work
This work presented the application of different autoencoder architectures for anomaly detection in agricultural fields. A Semisupervised autoencoder (SSAE), basic autoencoder (AE), vector-quantized variational autoencoder (VQ-VAE) and denoising autoencoder (DAE) were successfully implemented and evaluated. The performance of the autoencoders was compared with the baseline object detector model trained on an agricultural dataset. SSAE showed performance close to the object detector with a PR AUC of 0.9353 compared with 0.9794 for the object detector. AE and DAE showed lower performance with a PR AUC of 0.8786 and 0.8861, respectively. VQ-VAE had the worst performance with a PR AUC of 0.7797. Even though an object detector can provide valuable information for the object class, examples showed that it could fail in critical cases. In those scenarios, the autoencoder successfully detected objects as anomalies.
The potential applications for the above-mentioned anomaly detection technologies in the agricultural industry are broad. Agricultural vehicles such as combines, forage harvesters, sprayers and tractors with implements such as cultivators, sprayers, seeders and spreaders will, with the current labor shortage, move towards more autonomous operation in the upcoming years. The automated ability to detect abnormal conditions in the forward-moving direction and after field processing is a building block in enabling such future autonomous operating systems.
Future work will investigate the possibility of including temporal information and leveraging anomaly detection from previous image frames for better performance. The work could be further expanded by including domain-specific knowledge such as the type of crop and season and weather conditions. This would ensure a better definition of boundary conditions for a specific model and help identify when it is necessary to collect more data.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}