Abstract
Sparse Coding (SC) has been widely studied and shown its superiority in the fields of signal processing, statistics, and machine learning. However, due to the high computational cost of the optimization algorithms required to compute the sparse feature, the applicability of SC to real-time object recognition tasks is limited. Many deep neural networks have been constructed to low fast estimate the sparse feature with the help of a large number of training samples, which is not suitable for small-scale datasets. Therefore, this work presents a simple and efficient fast approximation method for SC, in which a special single-hidden-layer neural network (SLNNs) is constructed to perform the approximation task, and the optimal sparse features of training samples exactly computed by sparse coding algorithm are used as ground truth to train the SLNNs. After training, the proposed SLNNs can quickly estimate sparse features for testing samples. Ten benchmark data sets taken from UCI databases and two face image datasets are used for experiment, and the low root mean square error (RMSE) results between the approximated sparse features and the optimal ones have verified the approximation performance of this proposed method. Furthermore, the recognition results demonstrate that the proposed method can effectively reduce the computational time of testing process while maintaining the recognition performance, and outperforms several state-of-the-art fast approximation sparse coding methods, as well as the exact sparse coding algorithms.
1. Introduction
Object recognition is a fundamental problem in machine learning, and has been widely researched for many years. The performance of object recognition methods largely relies on feature representation. Traditional methods used handcrafted features to represent objects, i.e., scale-invariant feature transform (SIFT) [1], histograms of oriented gradients (HOG) [2], etc. Inspired by biological finding [3,4], learning sparse representation is more beneficial for object recognition, because mapping features from low-dimensional space to a high-dimensional space makes the features more likely to be linearly separable. Therefore, many sparse coding (SC) algorithms have been proposed to learn a good sparse representation for natural signals [5,6,7].
In general, SC is the problem of reconstructing input signal using a linear combination of an over-complete dictionary with sparse coefficients, i.e., for an observed signal an over-complete dictionary , SC aims to find a representation to reconstruct by using only a small number of atoms chosen from . The problem of SC is formulated as
where the -norm is defined as the number of non-zero elements of , and is the regularization factor. Several optimization algorithms have been proposed for the numerical solution of (1). However, the high computational cost induced by these optimization algorithms is a major drawback for real-time applications, especially when a large-sized dictionary is used.
To get rid of this problem, many works focusing on fast approximation for sparse coding have been proposed. Kavukcuoglu et al. [8] proposed a method named Predictive Sparse Decomposition (PSD) that used a non-linear regressor to approximate the sparse feature, and applied this method to objection recognition. However, the predictor is simplistic and produces crude approximation, and the regressor training procedure is somewhat time-consuming because of the gradient descent training method. Recently, deep learning showed its widespread success on many inference problems, which provides another way to design fast approximation methods for sparse coding algorithms. The idea is first proposed by Gegor et al. [9] who constructed two deep learning networks to approximate the iterative soft thresholding and coordinate descent algorithms, leading to the so-called LISTA and LCoD methods, respectively. LISTA showed its superiority on calculation and approximation, and many recent variants of LISTA have been proposed for miscellaneous applications, see [10,11] for some examples. Inspired by [9], many fast approximation sparse coding methods based on deep learning have been proposed and shown their effectiveness on unfolding the corresponding sparse coding algorithms, i.e., LAMP [12], LVAMP [12], etc.
Though these methods perform well in large-scale datasets, there are three defects. First, they are not suitable for small-scale datasets, in which the number of training samples is far less then ten thousand. The performance of deep neural network is sensitive to the scale of training data, when the number of training samples is small, the deep network model is over-parameterized and may result in over-fitting. Second, deep networks involve lots of hyper-parameters, whose training requires large computational and storage resources because of the gradient-based back-propagation method, and is easy to get stuck in a local optimal solution. Last but not least, each deep network architecture is designed only for the corresponding sparse coding algorithm that cannot be generalized to other algorithms. Therefore, the extendibility of these methods are limited.
To solve the problems mentioned above, a simple and effective fast approximation sparse coding method is proposed for small-scale datasets object recognition task in this paper. Differing from the deep learning-based methods, a special single-hidden-layer neural network (SLNNs) is constructed to perform the approximation task, and the training process of this SLNNs can be easily implemented by the least squared method. The proposed method includes two steps. In the first step, the optimal sparse features of training samples are exactly computed by sparse coding algorithm (in this paper, the homotopy iterative hard thresholding (HIHT) algorithm [13] is used), and in the second step the optimal sparse features are used as ground truth to train the especially constructed SLNNs. After training, the input layer and hidden layer of this SLNNs can be used to implement the nonlinear feature mapping from the input space to sparse feature space, which only involves simple inner product calculation with a non-linear activation function. Therefore, the sparse features of new samples can be estimated quickly. Ten benchmark datasets taken from UCI databases and two face image datasets are used to validate the proposed method, and the root mean square error (RMSE) results on testing data have verified the approximation performance of this proposed method. Furthermore, the approximated sparse features have been applied to object recognition task, and the recognition results demonstrate that this proposed approximation sparse coding method is beneficial for object recognition in terms of recognition accuracy and testing time.
The main contributions of this paper can be concluded as
- A fast approximation sparse coding method is proposed for small-scale datasets object recognition task, which can quickly estimate the sparse features for testing samples.
- A special SLNNs architecture has been constructed to perform the approximation task, whose parameters can be optimized easily by the least squared method, avoiding the multifarious procedure induced by the gradient-based back-propagation training.
- Experiment results on ten benchmark UCI datasets and two face image datasets show that our approach is more effective than current state-of-the-art deep learning-based fast approximation sparse coding methods both in RMSE, recognition accuracy and testing time.
The remainder of this paper is organized as follows. Section 2 briefly reviews the sparse coding algorithms and fast approximation sparse coding methods. Section 3 details the proposed method. Section 4 describes implementation details and presents experimental results. Finally, conclusions are given in Section 5.
2. Related Work
2.1. Sparse Coding Algorithms
As described in Section 1, the problem of SC can be formulated as problem (1). However, problem (1) is NP-hard, which is difficult to be solved. There are three common methods for approximations/relaxations of this problem: (1) iterative greedy algorithms [14,15,16]; (2) -norm convex relaxation methods (which are called basis pursuit) [17]; (3) -norm () relaxation methods [18,19,20,21,22]. Among these methods, BP has been studied more widely, in which the norm is replaced by norm to make a convex relaxation for the problem (1), i.e.,
where the -norm is defined as the sum of absolute values of all elements of .
BP methods were proven to give the same solutions to (1) when the dictionary satisfies the Restricted Isometry Property (RIP) condition [23,24]. Many research works focusing on efficiently solving problem (2) have been proposed, [25] provides a comprehensive review of five representative algorithms, namely Gradient Projection (GP) [26,27], Homotopy [28,29], Iterative Soft Shrinkage-Thresholding Algorithm (ISTA) [30,31,32], Proximal Gradient (PG) [33,34], and Augmented Lagrange Multiplier (ALM) [35]. Among these algorithms, ISTA is the most popular algorithm, and lots of heuristic strategies have been proposed to reduce the computational time of ISTA, i.e., TwIST [36], FISTA [33], etc. Recently, a kind of pathwise coordinate optimization method called PICASSO [37,38,39] has been proposed to solve the () least squared problem, which showed superior empirical performance compared with other state-of-the-art sparse coding algorithms mentioned above.
Although satisfactory results can be achieved by using the approximation/relaxation methods, the -norm is more desirable from the sparsity perspective. In recent years, researchers have attempted to solve problem (1) directly, with iterative hard thresholding (IHT) [13,40,41] being the most popular method. The IHT methods have strong theoretical guarantees, and the extensive experimental results show that the IHT methods can improve the sparse representation reconstruction results.
2.2. Fast Approximation for Sparse Coding
The sparse coding algorithms mentioned in Section 2.1 involve a lot of iterative operations, which induces high computational cost and prohibits them from real-time applications. To get rid of this problem, some research focusing on fast approximation for sparse coding was proposed. Kavukcuoglu et al. [8] proposed the PSD method to approximate sparse coding algorithms using a non-linear regressor. In inspired by this, Chalasani et al. [42] extended PSD to estimate convolutional sparse features. However, the approximation performance of non-linear regressor is limited. As the development of deep learning, some researchers have constructed deep networks to solve the fast approximation sparse coding problem. Given a large set of training examples , a many-layer neural network is optimized to minimize the reconstruction mean squared error between network outputs and . After training, the approximation of sparse representation for a new signal can be quickly predicted by the deep network. The idea is first proposed by Gregor et al. [9] who constructed two deep learning networks to approximate the iterative soft thresholding and coordinate descent algorithms, leading to the so-called LISTA and LCoD methods, respectively. Inspired by [9], Xin et al. [43] translated the iterative hard thresholding algorithm into a deep learning framework. Borgerding et al. [12] proposed two deep neural-network architectures to unfold the approximate message passing (AMP) algorithm [44] and “vector AMP” (VAMP) algorithm [45] respectively, namely LAMP and LVAMP. In [46], the authors proposed a deep learning framework for the approximation of sparse representation of a signal with the aid of a correlated signal, the so-called side information. The learned deep networks perform steps similar to those implemented by corresponding sparse coding algorithms; however, the trained network can reduce the computational cost when calculating the sparse representation of new samples effectively, which is critical in large-scale data settings and real-time applications.
3. Materials and Methods
3.1. Homotopy Iterative Hard Thresholding Algorithm
The homotopy iterative hard thresholding (HIHT) [13] is an extension of IHT for the -norm regularized problem
where is a differentiable convex function, whose gradient satisfies the Lipschitz continuous condition with parameter . Therefore, can be approximately iteratively updated by the projected gradient method
where is a constant, which should satisfies the condition of .
Adding into both side of (4), the solution of (3) can be obtained by iteratively solving the subproblem
The optimization of (5) is the same as follows (by removing or adding some constant items which are independent on ):
If denote
then the closed form solution of is given by the following lemma.
Lemma 1.
In (8), the parameter L needs to be tuned. The upper bound on Lipschitz constant is unknown or may not be easily calculated, thus we use the line search method to search L as suggested in [41] until the objective value descends.
Homotopy Strategy: many works [13,26,39] have verified that the sparse coding approaches benefit from a good starting point. Therefore, we use a recursive process automatically tunes regularization factor . This process begins from a large initial value . At the end of each -tuning iterations indexed by k, an optimal solution is obtained given . Then is updated as , where , and is used as the initial solution for the next iteration . The process stops once is small enough (given a positive lower-bound target, the stop condition is ). An outline of HIHT algorithm is described as Algorithm 1.
| Algorithm 1 |
| (Input:) (Output:) ; initialize ; repeat ; ; ; repeat An L-tuning iteration indexed by i ; while do ; ; end while ; ; until ; . ; ; until ; . |
3.2. Proposed Method
Figure 1 illustrates the schematic diagram of this proposed method. As it can be seen, for the given training dataset and the over-complete dictionary , the HIHT algorithm described in Section 3.1 is used to calculate the optimal sparse features of training data in the first step. After that, these optimal sparse features are used to train the SLNNs in second step.
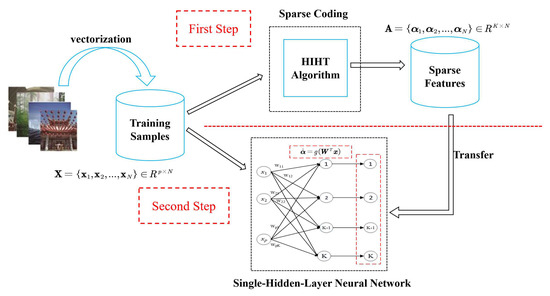
Figure 1.
The schematic diagram of this proposed method.
As Figure 1 shows, the architecture of the neural network consists of an input layer, a feature layer and an output layer. The number of hidden neurons is the same as that of output neurons, which is set as the dimension of the sparse feature. Each hidden neuron is only connected to its corresponding output neuron with weight 1. Our goal is to obtain a optimal input weights to make the outputs of hidden layer as equal to as possible, that is
where refers to a non-linear activation function.
There are two strategies to optimize the input weights :
(1) If the activation function is known, we chose tanh function as the activation function, where . We firstly calculate , and denote the result as , that is
then we formulate the objective function of the SLNNs as
where constant refers to the regularization factor used to control the trade-off between the smoothness of the mapping function and the closeness to .
By setting the derivative of (11) with respect to to zero and solve this equality, then the optimal solution of is obtained as follows:
In addition, the sparse feature of a testing sample can be quickly estimated as
(2) If the activation function is unknown, a kernel trick based on Mercer’s condition can be used to calculate the approximated sparse feature of testing data directly instead of training the weights ,
where and stands for the kernel function.
In this proposed method, Gaussian function is used as the kernel function :
where denotes the standard deviation of the Gaussian function.
4. Results and Discussion
4.1. Data Sets Description
Ten benchmark datasets taken from UCI Machine Learning Repository [47] and two image datasets: the Extended YaleB [48] and the AR dataset [49], are used to validate the proposed method. The ten UCI datasets include 5 binary-classification cases and 5 multi-classification cases. The details of these datasets are shown in Table 1. In this table, column “Random Perm” shows whether the training and testing data are randomly assigned or not. In the experiments, of samples per class are randomly selected for training, and the rest samples are responsible for testing if “Random Perm” is Yes.

Table 1.
UCI Data sets Used in Our Experiments.
The extended YaleB dataset [48] contains 38 different people with 2414 frontal face images, and each class has about 64 samples. This dataset is challenging from varying expressions and illumination conditions, see Figure 2 for some examples. The random face feature descriptor generated in [7] is used as raw feature, in which a cropped image with pixels was projected onto a 504-dimensional vector by a random normal distributed matrix. In the experiment, 50% of samples per class are randomly selected for training and the rest are responsible for testing.

Figure 2.
Extended YaleB.
The AR face dataset contains over 126 people with more than 4000 face images. There are 26 images per person taken during two different sessions. The images have large variations in terms of disguise, facial expressions, and illumination conditions. A few samples from the AR dataset are shown in Figure 3 for illustration. A subset of 2600 images pertaining to 50 males and 50 females objects are used for experiment. For each object, 20 samples are randomly chosen for training and the rest for testing. The images with pixels were projected onto a 540-dimensional vector by using a random projection matrix.

Figure 3.
AR Face.
4.2. Implementation Details
The experiments are mainly divided into two parts: (1) The RMSE between the approximated sparse features and the optimal features of testing data is calculated to verify the approximation performance of this proposed method, and the results of several state-of-the-art fast approximation sparse coding methods are also reported for comparison. (2) Classification experiments are implemented to validate the recognition performance of the approximated sparse features estimated by the proposed SLNNs. The compared methods can be categorized as follows: (a) Different representation learning methods: ELM [50] with random feature mapping, and ScELM [51] with optimal sparse features computed by HIHT; (b) Different fast approximation sparse coding methods: PSD [8], LISTA [9], LAMP [12], and LVAMP [12], detailed descriptions to these methods are provided in Section 2.
Implementations of ELM, ScELM, PSD, and this proposed method are based on Matlab codes and others are based on Python. A random normal distributed matrix is used as the dictionary in each sparse coding algorithm, and the number of atoms or hidden nodes K is set to 100 if the dimension of dataset is less than 100, otherwise 1000. The parameter is searched for in the grid of , and the is searched for in . The number of hidden layers of LISTA, LAMP, and LVAMP are set as 6, 5, and 4, respectively, if not stated otherwise. Other parameters are default as the authors suggested. For the randomly training-testing assigned datasets, ten repeated trials are carried out in the following experiments, and the average result and standard deviation are recorded.
In object recognition experiments, the trained network of each method is used to compute the approximated sparse features for training and testing samples, and the approximated sparse features are used as the input of the classifier. The ridge regression model is used as the classifier in our experiments, whose objective function is
where is the label matrix of training data , and is the weights of the classifier model. For a testing sample , the predicted label for it is calculated as
The hyper-parameter of the classifier is searched for in the grid of , and a value with best validation accuracy is selected. We compare our method with others in terms of recognition accuracy and testing time, where the recognition accuracy is defined as the ratio of the number of correctly classified testing samples to that of all testing samples, and the testing time refers to the total spending time of testing samples’ feature calculation and classification.
A standard PC is used in our experiments and its hardware configuration as follows:
- CPU: Intel(R) Pentium(R) CPU G2030 @3.40GHz;
- Memory: 32.00GB;
- Graphics Processing Unit (GPU): None.
4.3. Root Mean Square Error Results
For testing data , whose optimal sparse features computing by sparse coding algorithm is denoted as , and the approximated sparse features computing by the fast approximation method is denoted as , the RMSE between and is defined as
where denotes the amount of testing samples.
Some UCI datasets are used in this experiment, and we reported the results of our method, LISTA, LAMP and LVAMP to compare their approximation performance, Table 2 shows the results. As it can be seen from this table, our approach can achieve a lower RMSE result than other methods on the most datasets, which indicates that the approximated sparse features estimated by our approach are more closer to the optimal ones than that estimated by the compared methods. For the Glass dataset, our method has achieved a significant improvement, and for LiverDisorders, though the result of our approach is not the best one, it is very close to the best one.
Table 2.
The root mean square error of compared methods on UCI datasets (bold one represents the best result).
4.4. Objection Recognition Results
4.4.1. The Evaluation of HIHT
The existing literature on sparse coding only compared different sparse coding algorithms in terms of reconstruction error and convergence speed, but did not compare their classification performance when applying these algorithms in object recognition. To show why this paper uses the HIHT algorithm to compute the optimal sparse features, we implemented some experiments to validate the superiority of HIHT compared with several state-of-the-art sparse coding algorithms when used in object recognition. The compared methods include IHT, homotopy GPSR (HGPSR) [26], PGH [34], and PICASSO [39].
(1) Effectiveness on Object Recognition: the binary-classification datasets listed in Table 1 are used in this experiment. Firstly, the sparse coding algorithms are used to compute sparse features for the experimental datasets using the same dictionary, and the measure of cross entropy is used to show how different the sparse features are between class 1 and class 2. A higher value means that the sparse features computed by corresponding algorithm are more discriminative and more beneficial for object recognition. The measure of cross entropy is estimated as follows: we accumulate a histogram along feature dimensions over all sparse features that belongs to the same class v, then normalize the histogram as the probability of class v, the cross entropy between class 1 and class 2 is estimated as
where is the element of the probability .
Table 3 shows the cross entropy results. It can be seen that the HIHT algorithm can achieve the best result on the most datasets than the other four algorithms. It indicated that the sparse features computed by HIHT can distinguish different classes more effectively, which is more useful for classification, especially when a simple linear classifier is used.
Table 3.
Cross entropy of sparse features between different classes.
Subsequently, we use these sparse coding algorithms to compute the optimal sparse features of training data to train the proposed SLNNs, and compare the final recognition results, which is shown in Table 4. From this table it can be seen that these sparse coding algorithms can achieve similar classification performance on most datasets when used in the proposed method, while HIHT outperforms the other three algorithms in some datasets (i.e., Glass and Vehicle) significantly. From the view of standard deviation, the results show that the optimal sparse features computed by HIHT are more robust to classification than other algorithms.
Table 4.
Recognition Results of the Proposed Method Using different sparse coding algorithms.
(2) Parameter Sensitivity: In HIHT algorithm, different values of the regularization factor and dictionary will product different sparse features, which will cause the proposed method to estimate different approximated sparse features and influence final recognition result. In this experiment, the sensitivities of and in final recognition performance are verified, and the two face image datasets are used for testing.
Firstly, the influence of is investigated. By fixing other parameters (i.e., dictionary, parameters of the classifier), is searched for in the grid of , and the corresponding recognition accuracy is recorded. From the results in Figure 4, we can conclude that the final recognition result is not very sensitive to the , so it is no need to spend much time turning when uses HIHT to compute the optimal sparse features in this proposed method.
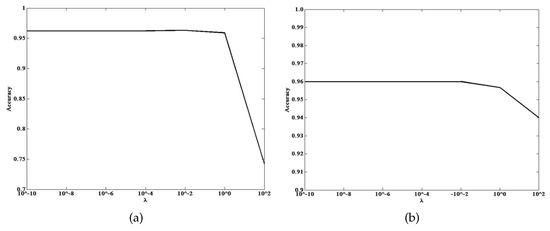
Figure 4.
The influence of the target value of HIHT on the recognition performance. (a) Extended YaleB. (b) AR Face.
Subsequently, we investigate the influence of . An unsupervised learned dictionary by the Lagrangian dual method [52] is used to compare with a random dictionary generated by normal distribution. The number of iterations in dictionary learning is set as 5, and 10 times with random selection of training and testing data are repeated, the average accuracy is recorded for comparison. As Table 5 shows, the final recognition accuracy achieved by using learned dictionary are close to that by using random dictionary. However, the computational time of optimal sparse features calculation with dictionary learning is five times (equal to the number of iterations) that with the random dictionary. Thus, in the following experiments we use random dictionary to compute optimal sparse features in HIHT algorithm.
Table 5.
Comparison of final recognition performance with or without dictionary learning in HIHT algorithm.
4.4.2. Evaluation on UCI Datasets
The average recognition accuracies on UCI datasets are listed in Table 6 and Table 7 presents the testing time. From these two tables we can conclude that the proposed approach outperforms other methods in terms of accuracy and testing time simultaneously. For most datasets, the approximated sparse features estimated by our approach can obtain the highest accuracy, and is approximately 100 times faster than ScELM (exact sparse coding algorithm), especially in high-dimensional datasets. Compared with other approximation sparse coding methods, our approach can achieve higher recognition accuracy with simpler network training, and the testing time of the proposed method and PSD are much less than LISTA, LAMP and LVAMP. It is worth noting that the performances of activation function and kernel function of this approach are similar, but kernel function outperforms when the dataset is a litter complex, (i.e., Satimage, Madelon), which will be confirmed in next experiments.
Table 6.
The average accuracy of compared methods on UCI datasets (red is the best result and blue is the second one).
Table 7.
The testing time of compared methods on UCI datasets
Figure 5 (The Tanh and Kernel mean the version and kernel version of our method, respectively.) shows the confusion matrices obtained by this proposed method, PSD, LISTA, LAMP and LVAMP on Satimage dataset, in which the kernel version of this proposed method achieved a much better recognition result than others. It can be seen from this figure that all methods almost fail to correctly classify the test samples of class 4 except the kernel version of our method. It indicates that the features computed by this proposed method are more discriminative than that of other approximation methods. Figure 6 shows two examples of the receiver operating characteristic (ROC) curves of the approximation methods, where the red lines report the performance of our approach. It is clear that the Areas Under ROC curves (AUC) of our approach is much higher than others.
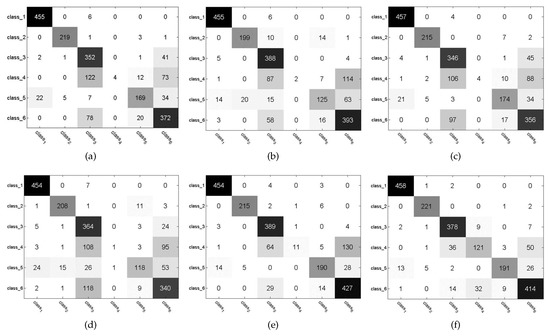
Figure 5.
Confusion matrices on Satimage dataset. (a) PSD. (b) LISTA. (c) LAMP. (d) LVAMP. (e) Tanh. (f) Kernel.
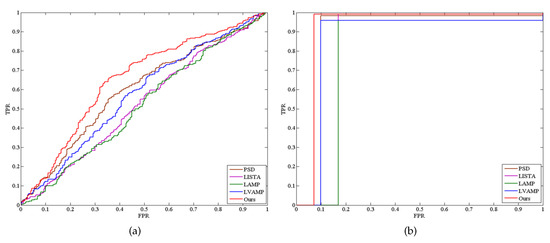
Figure 6.
The receiver operating characteristic (ROC) curves of the approximate methods. (a) Madelon. (b) Breast.
4.4.3. Evaluation on Extended YaleB Dataset
Table 8 lists the recognition accuracies and testing time on Extended YaleB dataset, in which the famous sparse representation-based face recognition algorithm SRC [53] and collaborative representation-based classification (CRC) [54] are also used for comparison. Furthermore, a result obtained by raw features is set as the error bar (denoted as Baseline), and we set different number of hidden layers (denoted as T) for LISTA to show its influence on object recognition performance. As Table 8 shows, all methods beat the Baseline, indicating the benefit of feature learning. The kernel version of this proposed method obtains the best result with the value of , and is higher than the second one. In testing process, the proposed method is approximately 21 times faster than the deep learning-based approximation methods, and 182 times faster than SRC, also much faster than CRC. For LISTA, if the number of layers is small (), the recognition performance will degrade much, and as the number of layers increases, the recognition results tend to be stable. Thus, the recognition performance is somewhat sensitive to the number of layers of deep network.
Table 8.
Average Recognition Accuracy with Random-Face Features on the Extended YaleB Database.
Figure 7 shows the patterns of confusion across classes obtained by this proposed method, in which coordinates in X-axis and Y-axis represent 38 face classes. Color at coordinates represents the number of test samples whose ground truth are x while machine’s output labels are y. From this figure it can be seen that our approach shows fewer points in the non-diagonal region (i.e., fewer false positives and false negatives), indicting that the proposed method can classify most testing samples correctly.
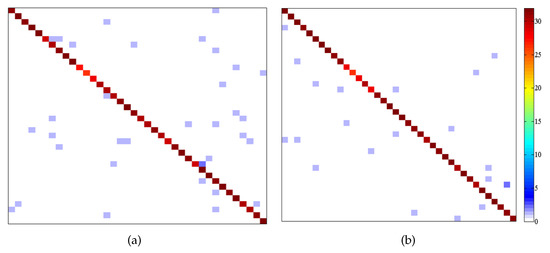
Figure 7.
Patterns of confusion on Extended YaleB. (a) Tanh. (b) Kernel.
4.4.4. Evaluation on AR Dataset
For the AR dataset, a protocol (e.g., only five training samples per class or all training samples are used) is established in our experiments, and the corresponding results are list in Table 9. As we can see, the kernel version of this proposed method achieves the best result in both cases. In addition, the version of this method gets comparable result with LAMP and ELM, but still better than SRC when all training samples were used. In terms of testing time, the proposed method is approximately 12 times faster than the deep learning-based approximation methods, 300 times faster than SRC, and 24 times faster than CRC. It is worth noting that the computational speed of kernel version is a little slower than that of version, since it needs to compute the kernel matrix between testing samples and training samples, while it is still much faster than the deep learning-based approximation methods.
Table 9.
Average Recognition Accuracy with Random-Face Features on the AR Face Database. The four column is the result when only 5 training samples per class are used.
We use a confusion matrix to give the detailed evaluation at the class-level. Figure 8 shows the results, in which coordinates in x- and y-axis denote 100 face classes. Red point with coordinates represents the misclassified test samples. It can be seen from this figure that this proposed method shows rare points in the non-diagonal region than other methods, indicating that this proposed method performs better than other methods in object recognition.
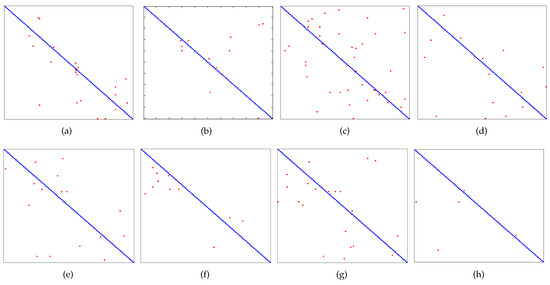
Figure 8.
Patterns of confusion on AR dataset. (a) SRC. (b) CRC. (c) ScELM. (d) PSD. (e) LISTA. (f) LAMP. (g) LVAMP. (h) Kernel.
To give an intuitive illustration, Figure 9 shows all misclassified images obtained by LAMP method (which achieves the second best result) and this proposed method (kernel version). It can be seen that images with exaggerated facial expressions is the main reason causing misclassification for both methods. Another interesting point can be seen that most images with facial “disguises” are misclassified by LAMP method while they are correctly recognized by this proposed method. It indicates that the approximate sparse features estimated by this proposed method is robustness to facial occlusion or corruption than LAMP.

Figure 9.
All misclassified images produced by (a) LAMP and (b) Kernel.
5. Conclusions
This paper proposes a simple fast approximation sparse coding method for small-scale datasets object recognition task, in which the optimal sparse features of training data computed by HIHT algorithm are used as ground truth to train a succinct and special SLNNs, thus make the representation learning in object recognition task more practical and efficient. Extensive experimental results on publicly available datasets show that this approach outperforms the compared approximation methods in terms of approximation performance, recognition accuracy and computational time. The high recognition and computational efficiency makes the proposed method very promising for real-time applications. Moreover, experimental results have demonstrated that this proposed method is robust to parameters on recognition performance, that make it more practical. Future work includes supervised sparse coding algorithms and autonomously finding an over-complete dictionary.
Author Contributions
Conceptualization, Z.S. and Y.Y.; methodology, Z.S.and Y.Y.; validation, Z.S.; data curation, Z.S.; writing—original draft preparation, Z.S.; writing—review and editing, Z.S. and Y.Y.; funding acquisition, Y.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (NSFC) under Grant No. 61873067.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Publicly available datasets were analyzed in this study. These datasets can be found here: http://archive.ics.uci.edu/ml/index.php.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Key-points. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diegol, CA, USA, 20–26 June 2005. [Google Scholar] [CrossRef]
- Hubel, D.; Wiesel, T. Receptive fields of signal neurons in the cat’s striate cortex. J. Physiol. 1959, 148, 574–591. [Google Scholar] [CrossRef] [PubMed]
- Roll, E.; Tovee, M. Sparseness of the neuronal representation of stmuli in the primate temporal visual cortex. J. Neurophysiol. 1992, 173, 713–726. [Google Scholar] [CrossRef]
- Mairal, J.; Bach, F.; Ponce, J.; Sapiro, G.; Zisserman, A. Discriminative learned dictionaries for local image analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008. [Google Scholar] [CrossRef]
- Wang, J.; Yang, J.; Yu, K.; Lv, F.; Huang, T.; Gong, Y. Locality-constrained Linear Coding for image classification. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3360–3367. [Google Scholar] [CrossRef]
- Jiang, Z.; Lin, Z.; Davis, L. Label consistent K-SVD: Learning a discriminative dictionary for recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2651–2663. [Google Scholar] [CrossRef]
- Kavukcuoglu, K.; Ranzato, M.; LeCun, Y. Fast Inference in Sparse Coding Algorithms with Applications to Object Recognition. In Technical Report CBLL-TR-2008-12-01, Computational and Biological Learning Lab, Courant Institude, NYU; New York University: New York, NY, USA, 2008. [Google Scholar]
- Gregor, K.; LeCun, Y. Learning fast approximations of sparse coding. In Proceedings of the International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Deng, X.; Dragotti, P.L. Deep Coupled ISTA Network for Multi-Modal Image Super-Resolution. IEEE Trans. Image Process. 2020, 29, 1683–1698. [Google Scholar] [CrossRef]
- Qian, Y.; Xiong, F.; Qian, Q.; Zhou, J. Spectral Mixture Model Inspired Network Architectures for Hyperspectral Unmixing. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7418–7434. [Google Scholar] [CrossRef]
- Borgerding, M.; Schniter, P.; Rangan, S. Amp-inspired deep networks for sparse linear inverse problem. IEEE Trans. Signal Process. 2017, 65, 4293–4348. [Google Scholar] [CrossRef]
- Dong, Z.; Zhu, W. Homotopy methods based on l0-norm for compressed sensing. IEEE Trans. Neural Networks Learn. Syst. 2018, 29, 1132–1146. [Google Scholar] [CrossRef]
- Mallat, S.; Zhang, Z. Matching pursuits with time-frequency dictionaries. IEEE Trans. Signal Process. 1993, 41, 3397–3415. [Google Scholar] [CrossRef]
- Pati, Y.; Rezaiifar, R.; Krishnaprasad, P. Orthogonal matching pursuit: recursive function approximation with applications to wavelet decomposition. In Proceedings of the IEEE International Conference on Signal, Systems and Computers, Pacific Grove, CA, USA, 1–3 November 1993; pp. 40–44. [Google Scholar] [CrossRef]
- Loza, C. RobOMP: Robust variants of Orthogonal Matching Pursuit for sparse representations. PeerJ Comput. Sci. 2019, 5, e192. [Google Scholar] [CrossRef]
- Chen, S.; Donoho, D.; Saunders, M. Atomic decomposition by basis pursuit. SIAM Rev. 2001, 43, 129–159. [Google Scholar] [CrossRef]
- Chartrand, R. Exact Reconstruction of Sparse Signals via Nonconvex Minimization. IEEE Signal Process. Lett. 2007, 14, 707–710. [Google Scholar] [CrossRef]
- Xu, Z.; Chang, X.; Xu, F.; Zhang, H. L1/2 regularization: A thresholding representation theory and a fast solver. IEEE Trans. Neural Networks Learn. Syst. 2012, 23, 1013–1027. [Google Scholar] [CrossRef]
- Chen, X.; Ng, M.K.; Zhang, C. Non-Lipschitz łp-Regularization and Box Constrained Model for Image Restoration. IEEE Trans. Image Process. 2012, 21, 4709–4721. [Google Scholar] [CrossRef] [PubMed]
- Qin, L.; Lin, Z.C.; She, Y.; Chao, Z. A comparison of typical Lp minimization algorithms. Neurocomputing 2013, 119, 413–424. [Google Scholar] [CrossRef]
- Qiu, Y.; Jiang, H.; Ching, W.; Ng, M.K. On predicting epithelial mesenchymal transition by integrating RNA-binding proteins and correlation data via L1/2-regularization method. Artif. Intell. Med. 2019, 95, 96–103. [Google Scholar] [CrossRef]
- Donoho, D.; Elad, M. Optimally sparse representation in general (nonorthogonal) dictionaries via l1 minimization. Proc. Natl. Acad. Sci. USA 2003, 100, 2197–2202. [Google Scholar] [CrossRef]
- Candes, E.J.; Tao, T. Near-Optimal Signal Recovery From Random Projections: Universal Encoding Strategies? IEEE Trans. Inf. Theory 2006, 52, 5406–5425. [Google Scholar] [CrossRef]
- Yang, A.; Ganesh, A.; Zhou, Z.; Sastry, S.; Ma, Y. A Review of Fast l1 -Minimization Algorithm for Robust Face Recognition. In Proceedings of the International Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 12–15 July 2010; pp. 1–36. [Google Scholar]
- Figueiredo, M.; Nowak, R.; Wright, S. Gradient Projection for Sparse Reconstruction: Application to Compressed Sensing and other Inverse Problems. IEEE J. Sel. Top. Signal Process. 2007, 1, 586–597. [Google Scholar] [CrossRef]
- Kim, S.J.; Koh, K.; Boyd, S. An Interior-Point Method for Large-Scale l1 -Regularized Least Squares. IEEE J. Sel. Top. Signal Process. 2007, 1, 606–617. [Google Scholar] [CrossRef]
- Osborne, M.R.; Presnell, B.; Turlach, B.A. A new approach to variable selection in least squares problems. IMA J. Numer. Anal. 2000, 20, 389–404. [Google Scholar] [CrossRef]
- Malioutov, D.M.; Cetin, M.; Willsky, A.S. Homotopy continuation for sparse signal representation. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Philadelphia, PA, USA, 18–23 March 2005. [Google Scholar] [CrossRef]
- Combettes, P.; Wajs, V. Signal recovery by proximal forward-backward splitting. SIAM Multiscale Model. Simul. 2005, 4, 1168–1200. [Google Scholar] [CrossRef]
- Hale, E.; Yin, W.; Zhang, Y. A Fixed-Point Continuation Method for l1-Regularized Minimization with Applications to Compressed Sensing; CAAM Tech Report TR07-07; Rice University: Houston, TX, USA, 7 July 2007; pp. 1–45. [Google Scholar] [CrossRef]
- Wright, S.J.; Nowak, R.D.; Figueiredo, M.A. Sparse reconstruction by separable approximation. IEEE Trans. Signal Process. 2009, 57, 2479–2493. [Google Scholar] [CrossRef]
- Beck, A.; Teboulle, M. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imaging Sci. 2009, 2, 183–202. [Google Scholar] [CrossRef]
- Lin, X.; Tong, Z. A proximal-gradient homotopy method for the sparse least-squares problem. SIAM J. Optim. 2013, 23, 1062–1091. [Google Scholar] [CrossRef]
- Yang, J.; Zhang, Y. Alternating direction algorithms for l1-problems inbcompressive sensing. SIAM J. Sci. Comput. 2011, 31, 250–278. [Google Scholar] [CrossRef]
- Bioucas-Dias, J.M.; Figueiredo, M.A.T. A New TwIST: Two-Step Iterative Shrinkage/Thresholding Algorithms for Image Restoration. IEEE Trans. Image Process. 2007, 16, 2992–3004. [Google Scholar] [CrossRef]
- Li, X.G.; Ge, J.; Jiang, H.M.; Wang, M.D.; Hong, M.Y.; Zhao, T. Boosting Pathwise Coordinate Optimization in High Dimensions: Sequential Screening and Proximal Sub-Sampled Newton Algorithm; Technical Report; Georgia Tech: Atlanta, GA, USA, 2017. [Google Scholar]
- Zhao, T.; Liu, H.; Zhang, T. Pathwise coordinate optimization for nonconvex sparse learning: Algorithm and theory. Ann. Stat. 2018, 46, 180–218. [Google Scholar] [CrossRef]
- Ge, J.; Li, X.; Jiang, H.; Liu, H.; Zhang, T.; Wang, M.; Zhao, T. Picasso: A sparse learning library for high dimensional data analysis in R and Python. J. Mach. Learn. Res. 2019, 20, 1–5. [Google Scholar]
- Blumensath, T.; Davies, M. Iterative thresholding for sparse approximations. Fourier Anal. Appl. 2008, 14, 629–654. [Google Scholar] [CrossRef]
- Lu, Z. Iterative hard thresholding methods for l0 regularized convex cone programming. Math. Program. 2014, 147, 125–154. [Google Scholar] [CrossRef]
- Chalasani, R.; Principe, J.C.; Ramakrishnan, N. A fast proximal method for convolutional sparse coding. In Proceedings of the 2013 International Joint Conference on Neural Networks (IJCNN), Dallas, TX, USA, 4–9 August 2013; pp. 1–5. [Google Scholar] [CrossRef]
- Xin, B.; Wang, Y.; Gao, W.; Wipf, D.; Wang, B. Maximal sparsity with deep networks? In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2016; pp. 4340–4348. [Google Scholar]
- Donoho, D.L.; Maleki, A.; Montanari, A. Message passing algorithms for compressed sensing. Proc. Natl. Acad. Sci. USA 2009, 106, 18914–18919. [Google Scholar] [CrossRef]
- Rangan, S.; Schniter, P.; Fletche, A.K. Vector approximate message passing. arXiv 2016, arXiv:1610.03082. [Google Scholar]
- Tsiligianni, E.; Deligiannis, N. Deep coupled-representation learning for sparse linear inverse problems with side information. IEEE Signal Process. Lett. 2019, 26, 1768–1772. [Google Scholar] [CrossRef]
- Dua, D. and Graff, C. UCI Machine Learning Repository; University of California: Oakland, CA, USA, 2017. [Google Scholar]
- Georghiades, A.; Belhumeur, P.; Kriegman, D. From few to many: Illumination cone models for face recognition under variable lighting and pose. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 643–660. [Google Scholar] [CrossRef]
- Martinez, A.; Benavente, R. The AR Face Database; Tech. Rep; Comput. Vis. Center, Purdue University: West Lafayette, IN, USA, 1998. [Google Scholar]
- Huang, G.; Zhou, H.; Ding, X.; Zhang, R. Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. Man, Cybern. Part Cybern. 2012, 42, 513–529. [Google Scholar] [CrossRef]
- Yu, Y.; Sun, Z. Sparse coding extreme learning machine for classification. Neurocomputing 2017, 261, 50–56. [Google Scholar] [CrossRef]
- Lee, H.; Battle, A.; Raina, R.; Ng, A. Efficient sparse coding algorithm. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Vancouver, BC, Canada, 2006; pp. 801–808. [Google Scholar]
- Wright, J.; Yang, A.; Ganesh, A.; Sastry, S.; Ma, Y. Robust Face Recognition via Sparse Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 210–227. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Yang, M.; Feng, X. Sparse representation or collaborative representation: Which helps face recognition? In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 471–478. [Google Scholar] [CrossRef]









Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).