
An Empirical Study of Training Data Selection Methods for Ranking-Oriented Cross-Project Defect Prediction

Abstract
:1. Introduction
- (1)
- We conducted an extensive comparative study on the impacts of nine training data selection methods on the performance of ROCPDP. To the best of our knowledge, this was the first attempt to perform such a large-scale empirical study on training data selection methods in the context of ROCPDP.
- (2)
- We evaluated the performances of training data selection methods using both the module-based ranking performance measure (FPA) and the LOC-based ranking performance measure (Norm(Popt)), and employed a state-of-the-art multiple comparison technique (double Scott–Knott test) to rank and cluster the training data selection methods into distinct groups. Therefore, software quality teams are provided with more choices for practical applications.
2. Related Work and Background
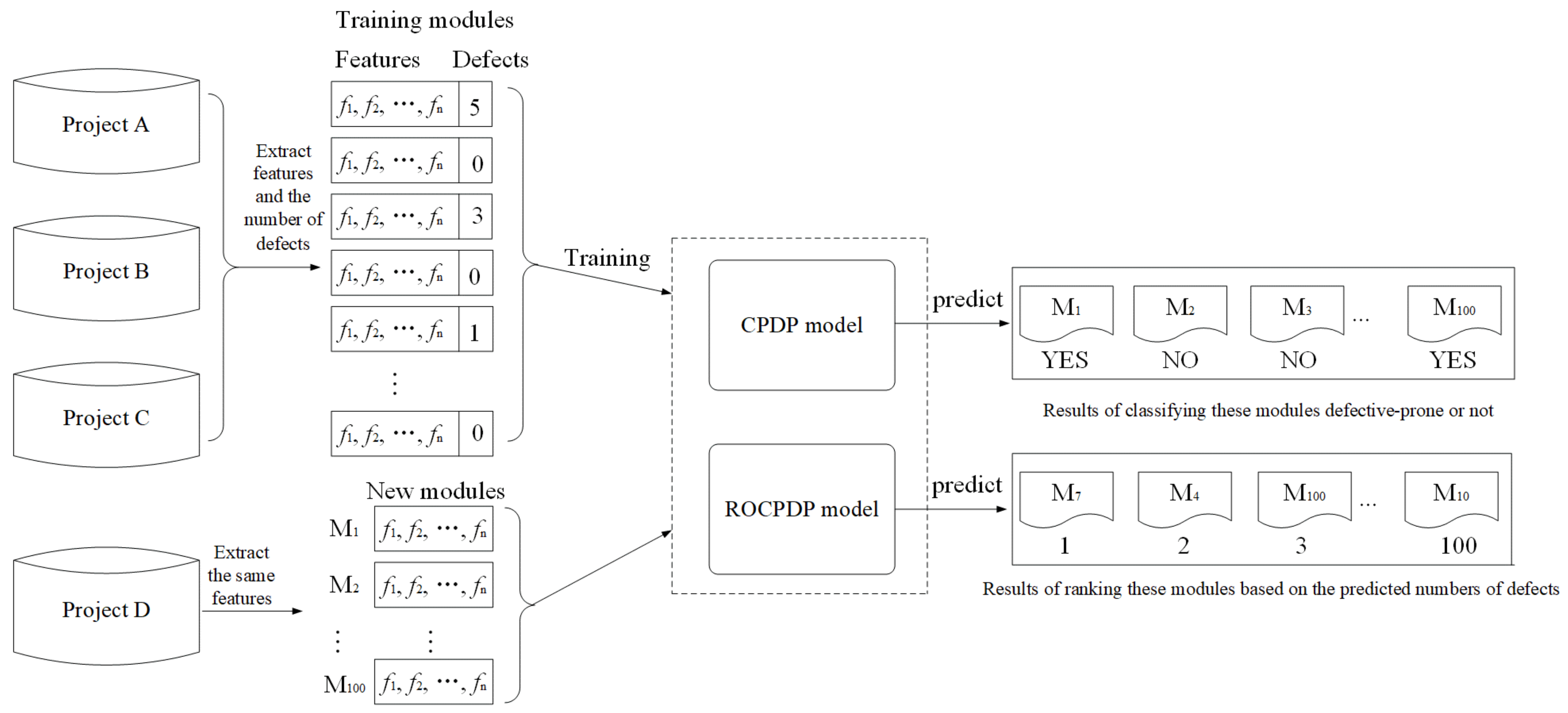
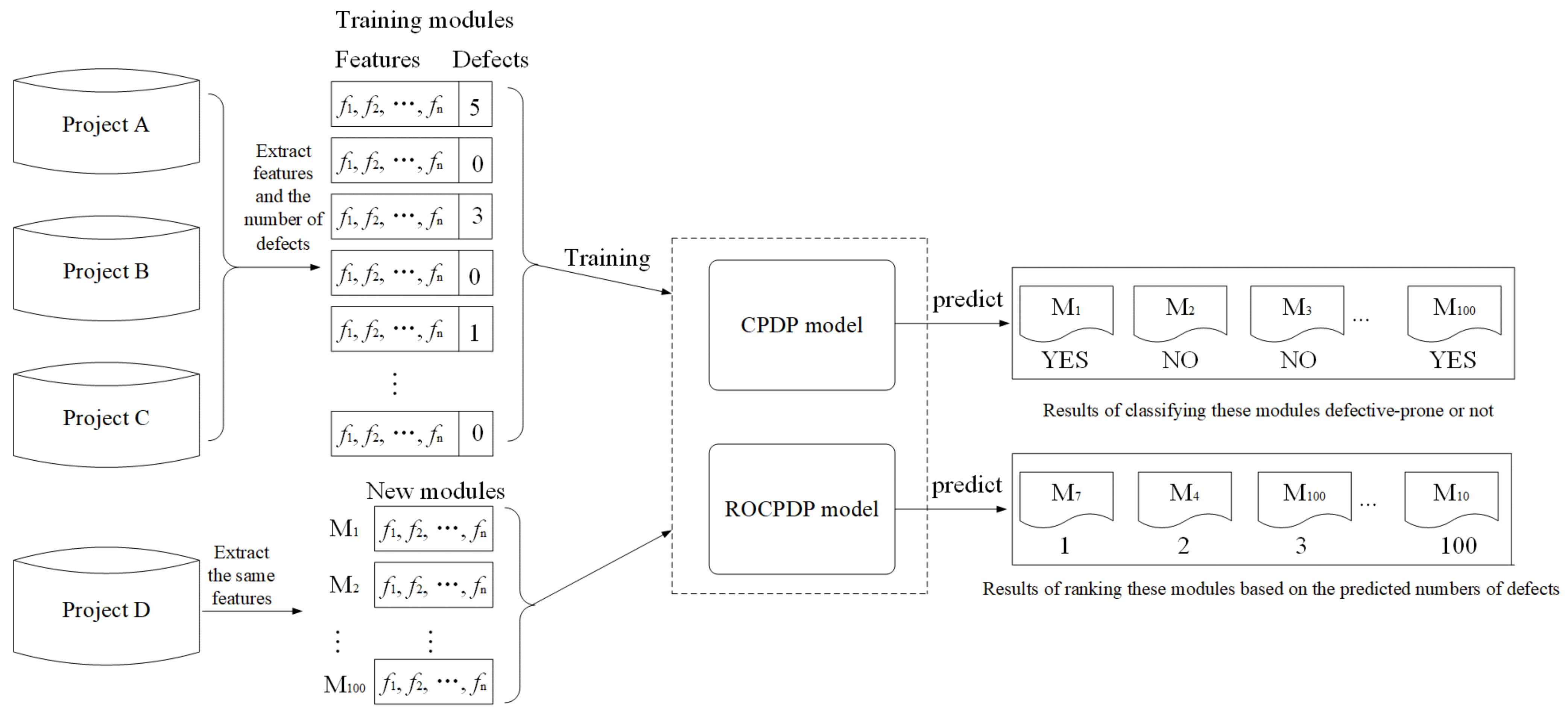
2.1. ROCPDP
2.2. SDP and RODP
2.3. CPDP
3. Training Data Selection Method
3.1. Global Filter (GF): Using All CP Data
3.2. Burak Filter (BF): WP Data Guided Filter
3.3. Peters Filter (PF): CP Data Guided Filter
3.4. Kawata Filter (KF): Density-Based Spatial Clustering Guided Filter
3.5. Yu Filter (YF): Hierarchical-Based Spatial Clustering Guided Filter
3.6. He Filter (HF): Distribution Characteristic Guided Filter
3.7. HeBurak Filter (HBF): Distribution Characteristic and WP Data Guided Filter
3.8. HePerters Filter (HPF): Distribution Characteristic and CP Data Guided Filter
3.9. Li filter (LF): Distribution Characteristic and Density-Based Partitioning Clustering Guided Filter
4. Experimental Setup
4.1. Datasets
4.2. Research Questions
- -
- CP data: all data from the other projects.
- -
- WP data: remaining 90% of the data of that project.
- -
- CP data: all data from the other projects.
- -
- WP data: remaining 10% data of that project.
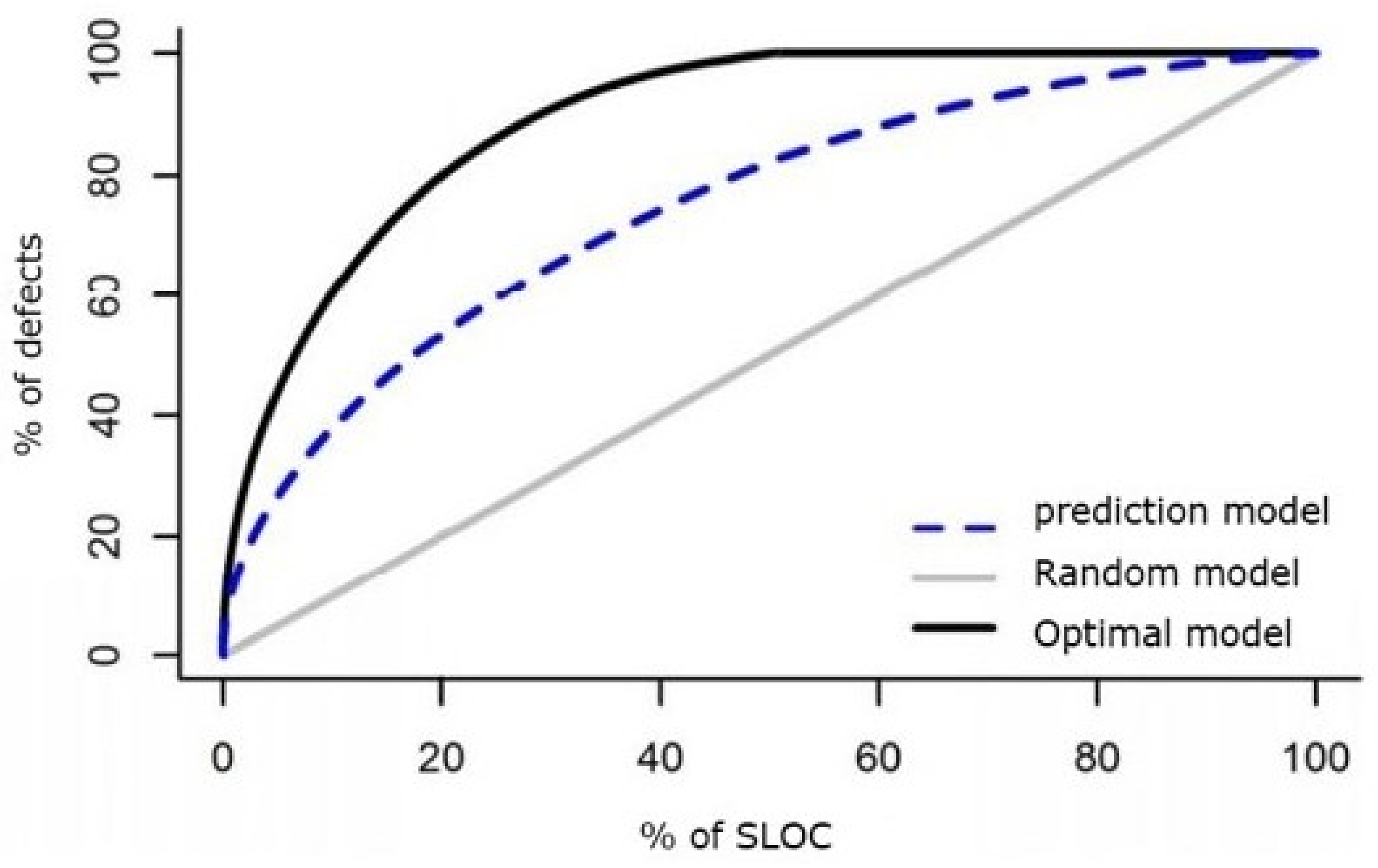
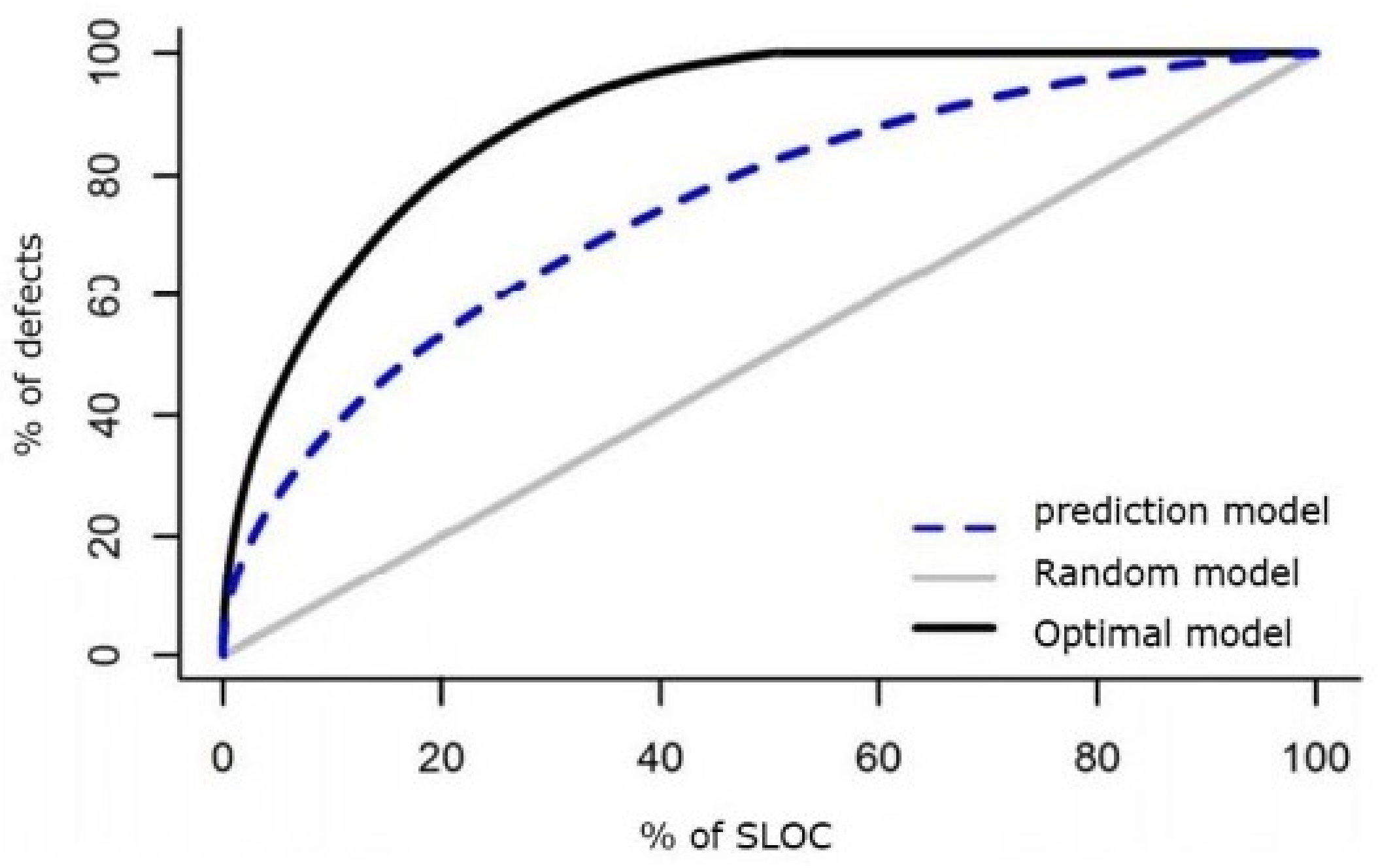
4.3. Performance Measures
4.4. Modeling Techniques
- (1)
- Naïve Bayes (NB), logistic regression (LR), classification and regression tree (CART), bagging, random forest (RF), and k-nearest neighbors (KNN) have been widely used in SDP studies. These classification algorithms can rank all software modules with respect to their probability of containing defect(s). For example, the Naïve Bayes algorithm can output a score indicating the likelihood that a module is defective. However, these algorithms do not employ the information of the number of defects. In addition, Mende et al. [49] investigated the performances of these algorithms for RODP in terms of CE and Popt. Experimental results show that these algorithms had bad performances in terms of CE and Popt. Therefore, we do not employ these classification algorithms to build the ROCPDP model.
- (2)
- The work that originally designed for RODP was limited. Yang et al. proposed LTR [18], which directly optimizes the performance measure (i.e., FPA) to obtain a ranking function. Chen et al. [40] and Rathore et al. [41] conducted an empirical investigation of many regression algorithms to predict bug numbers, and the results showed that DTR, LR, and BRR achieved better performance in terms of AAE and RMSE. Nguyen et al. [42] investigated Ranking SVM and RankBoost for RODP, and found that these algorithms outperformed the linear regression algorithm. Therefore, we compare LTR with DTR, LR, BRR, Ranking SVM and RankBoost. Experimental results showed that LTR significantly outperformed the compared algorithms in terms of FPA and Norm(Popt) using the 11 datasets in Table 1 through ten cross-validation. It is also consistent with the view of Liu et al. [36] that the listwise approach generally outperforms the pointwise approach and pairwise approach. Therefore, we use LTR to build the ROCPDP model.
4.5. Statistic Comparison Tests
- (1)
- We computed the effect size, Cliff’s [54], to quantify the amount of difference between two methods. By convention, the magnitude of the difference is considered as trivial (|| < 0.147), small (0.147–0.33), moderate (0.33–0.474), or large (>0.474).
- (2)
- Scott–Knott Test: Scott–Knott test [55] is a multiple comparison technique that employs hierarchical clustering algorithm to conduct the statistical analysis. The test divides the training data selection methods into significantly different groups. There is no significantly difference among the training data selection methods in the same group, whereas the training data selection methods in different groups have significant differences. In this study, we used the novel double Scott–Knott test [56] to cluster these training data selection methods into different groups: In the first step of the test, we divided the training data selection methods into significantly distinct groups with the 100 FPA and Norm(Popt) values on each dataset as the inputs. Therefore, each method had different rankings among different datasets. In the second step of the test, we used the Scott–Knott test to get the final rankings of the methods with all rankings of each method obtained in the first step as the input.
5. Experimental Results
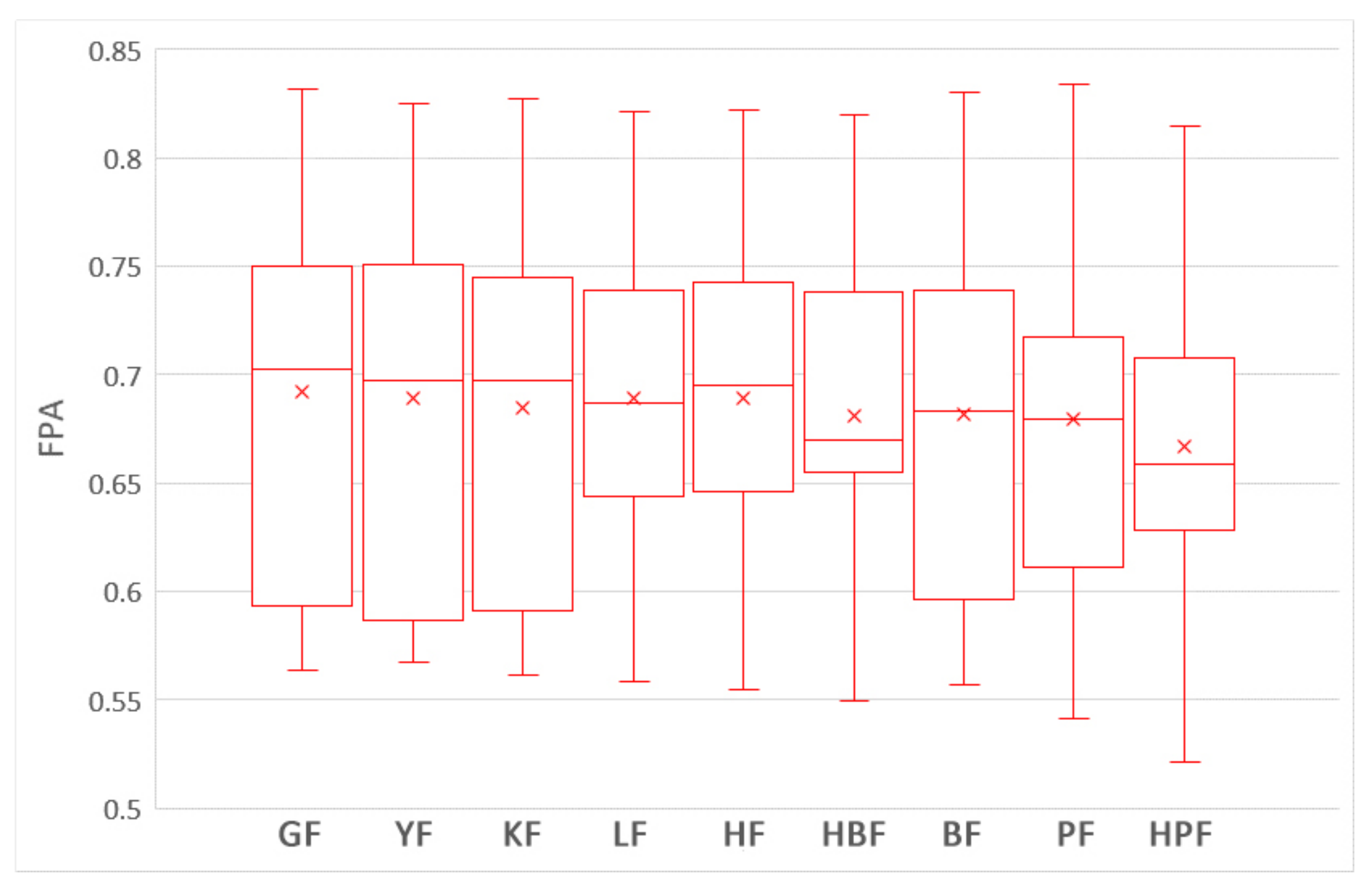
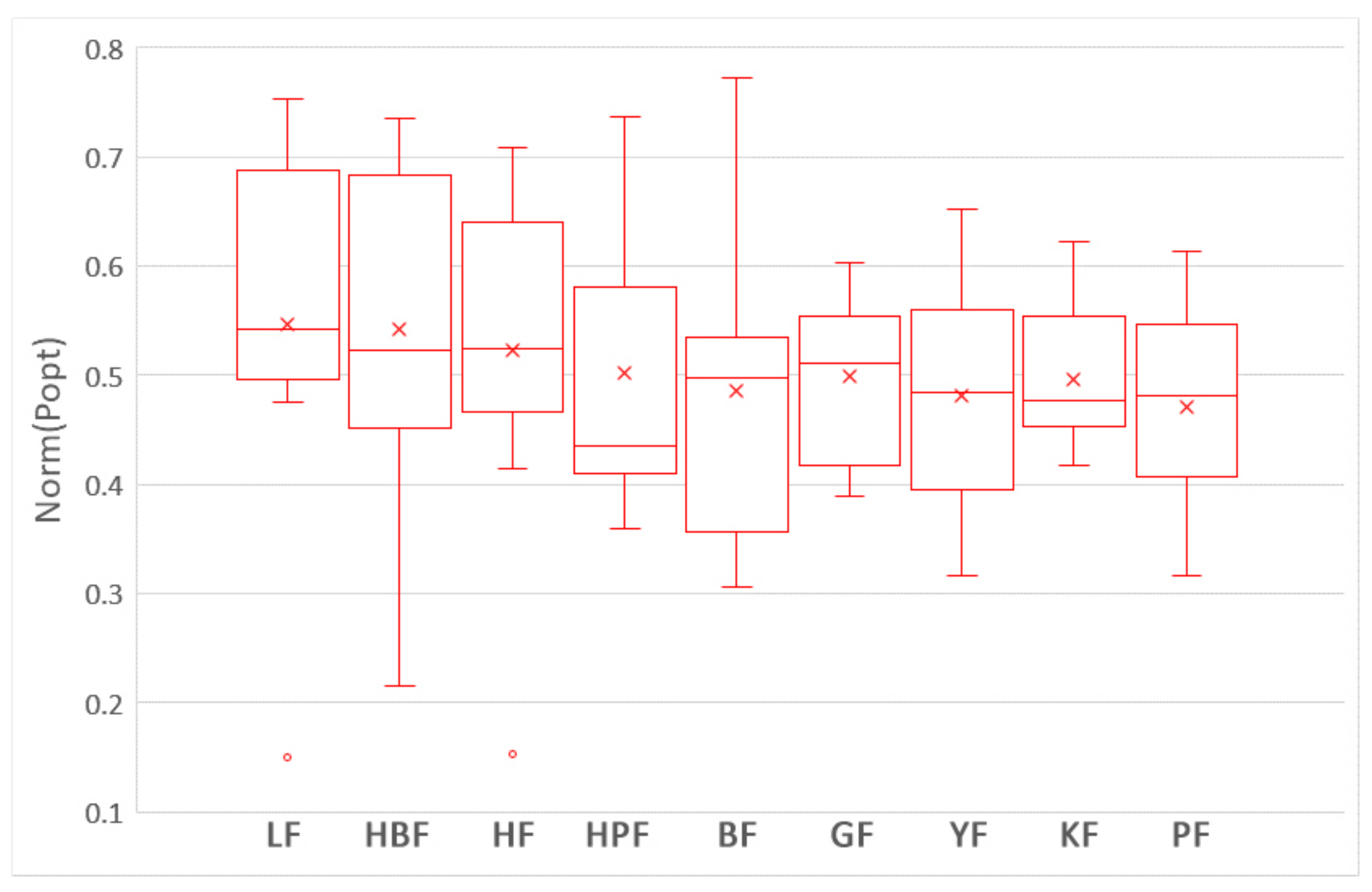
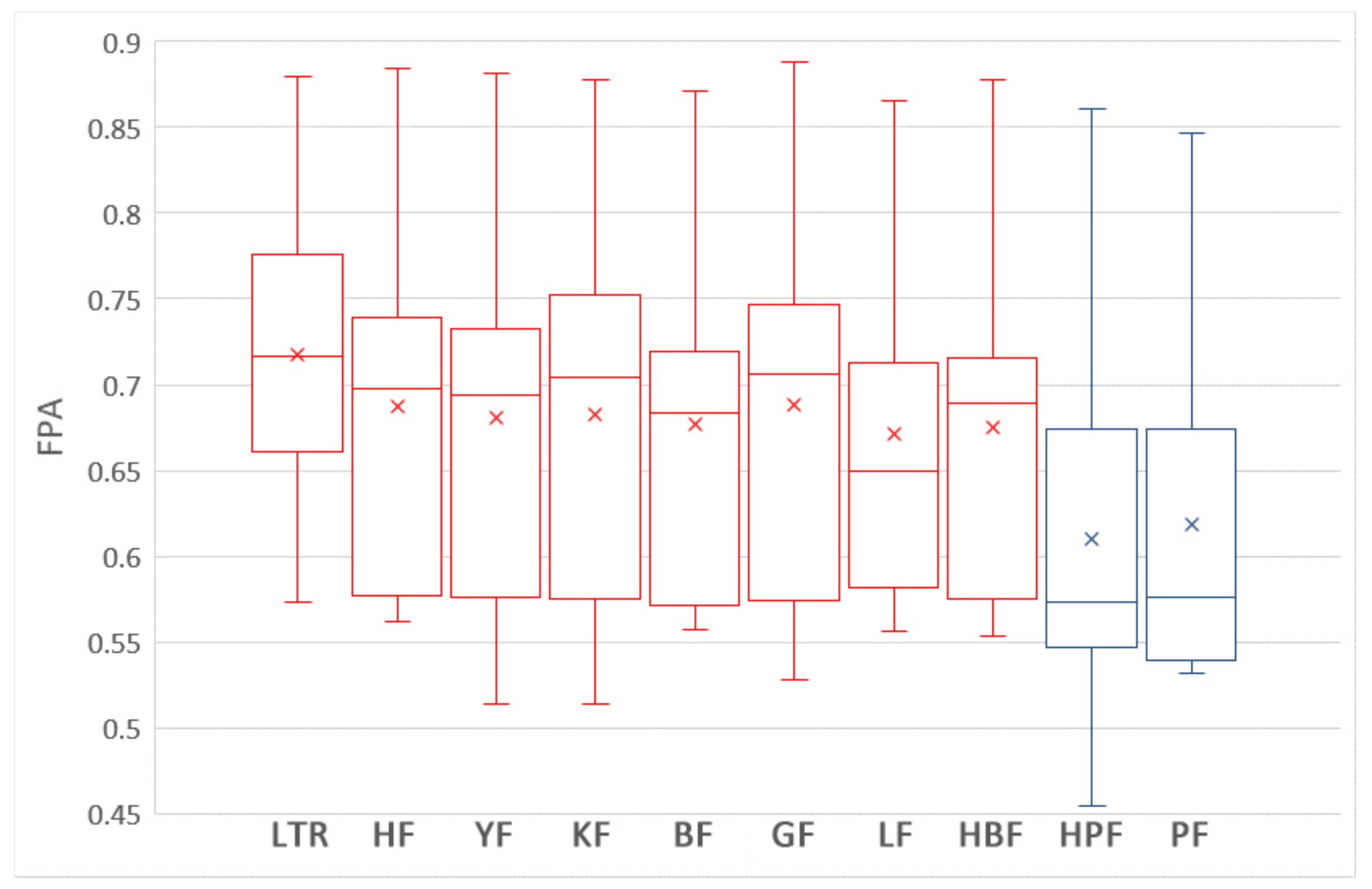
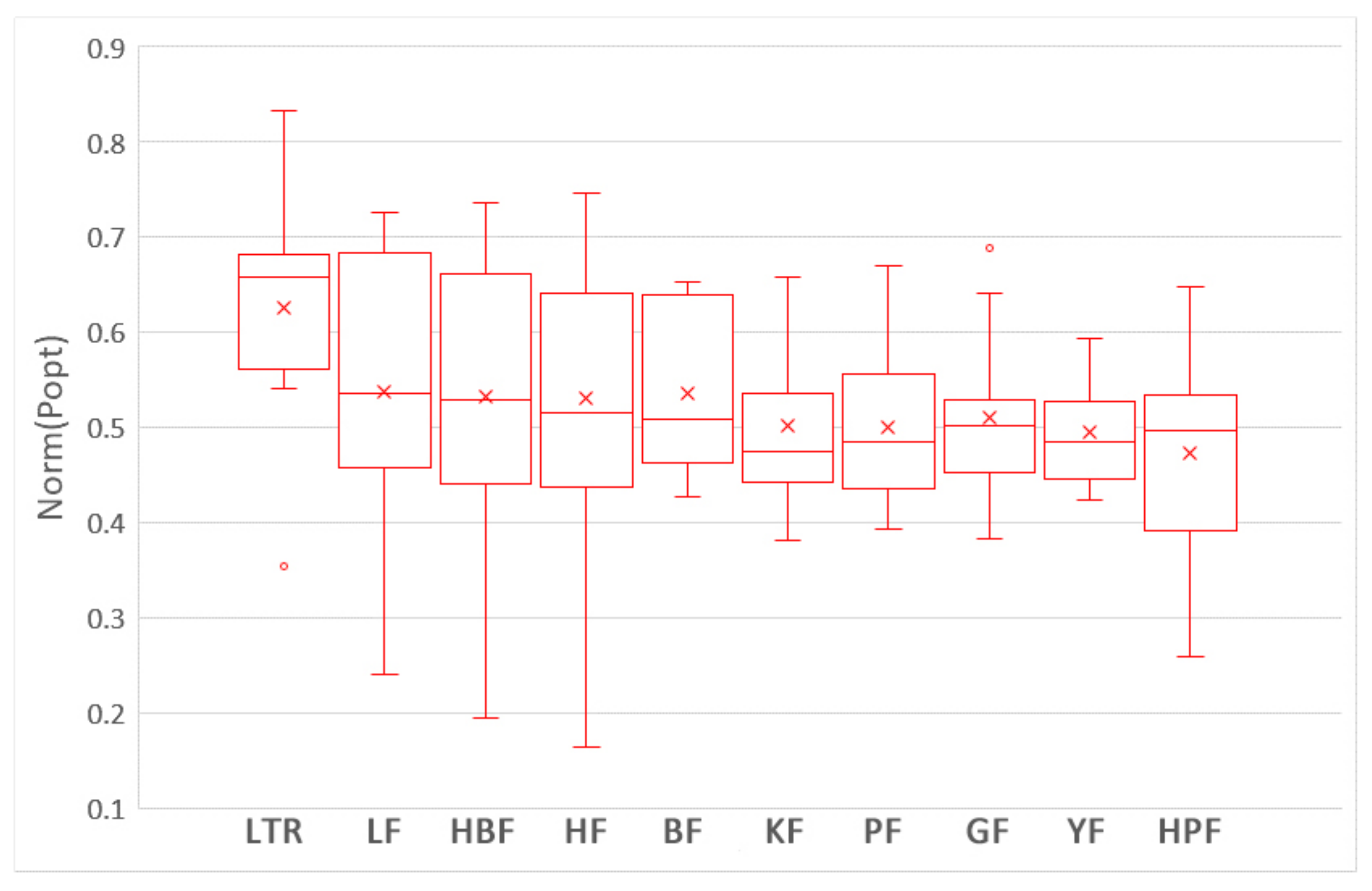
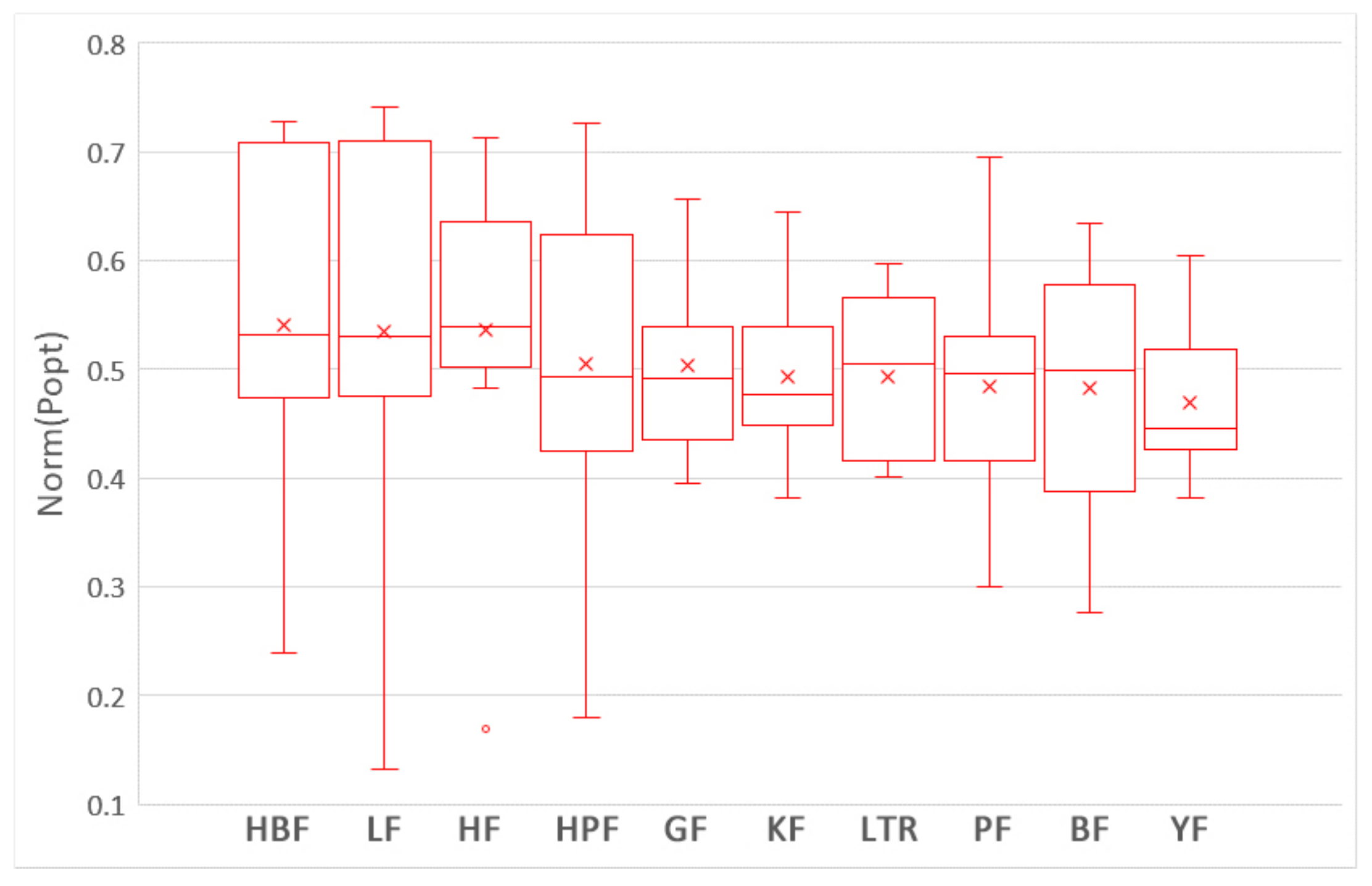
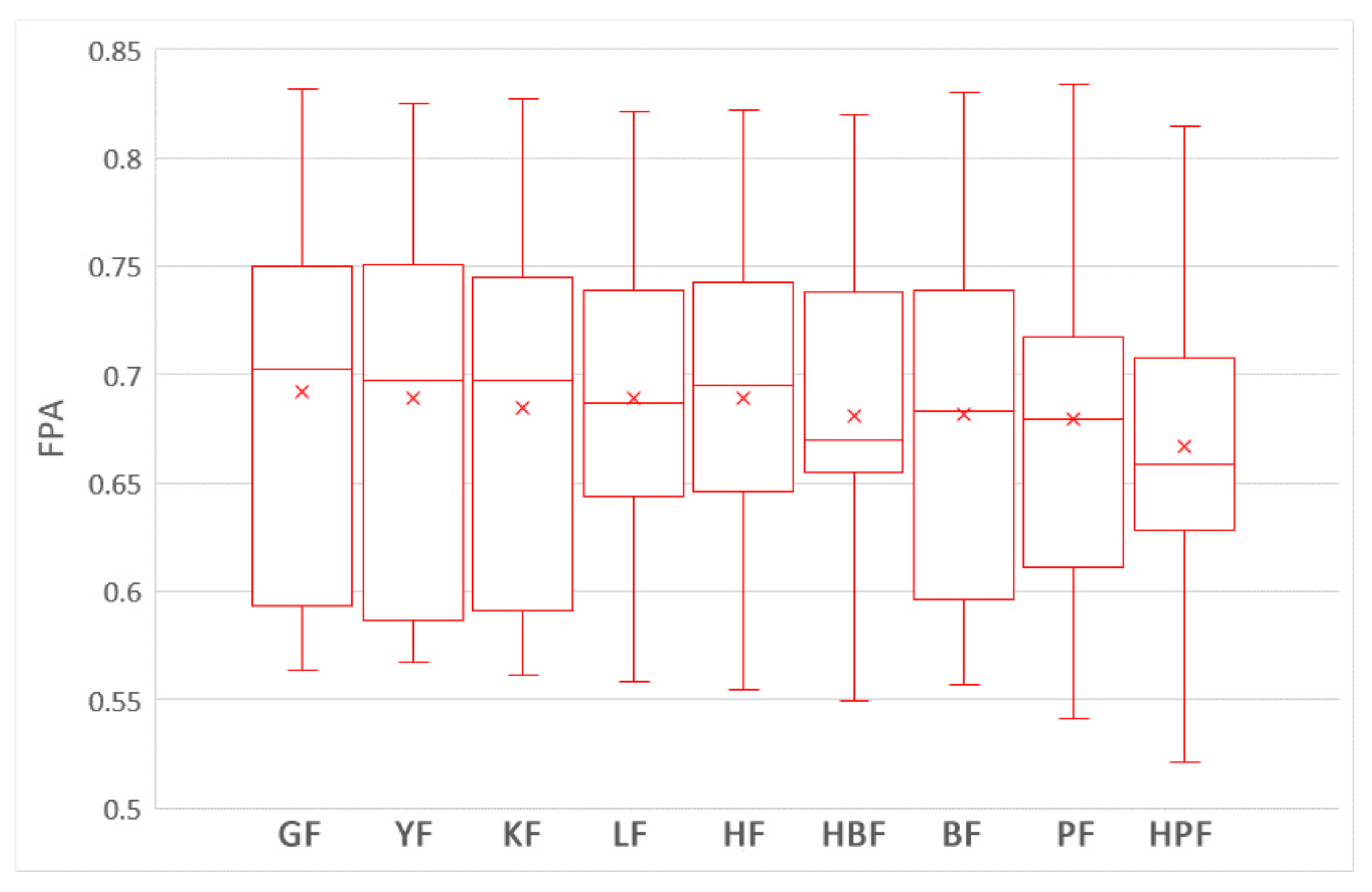
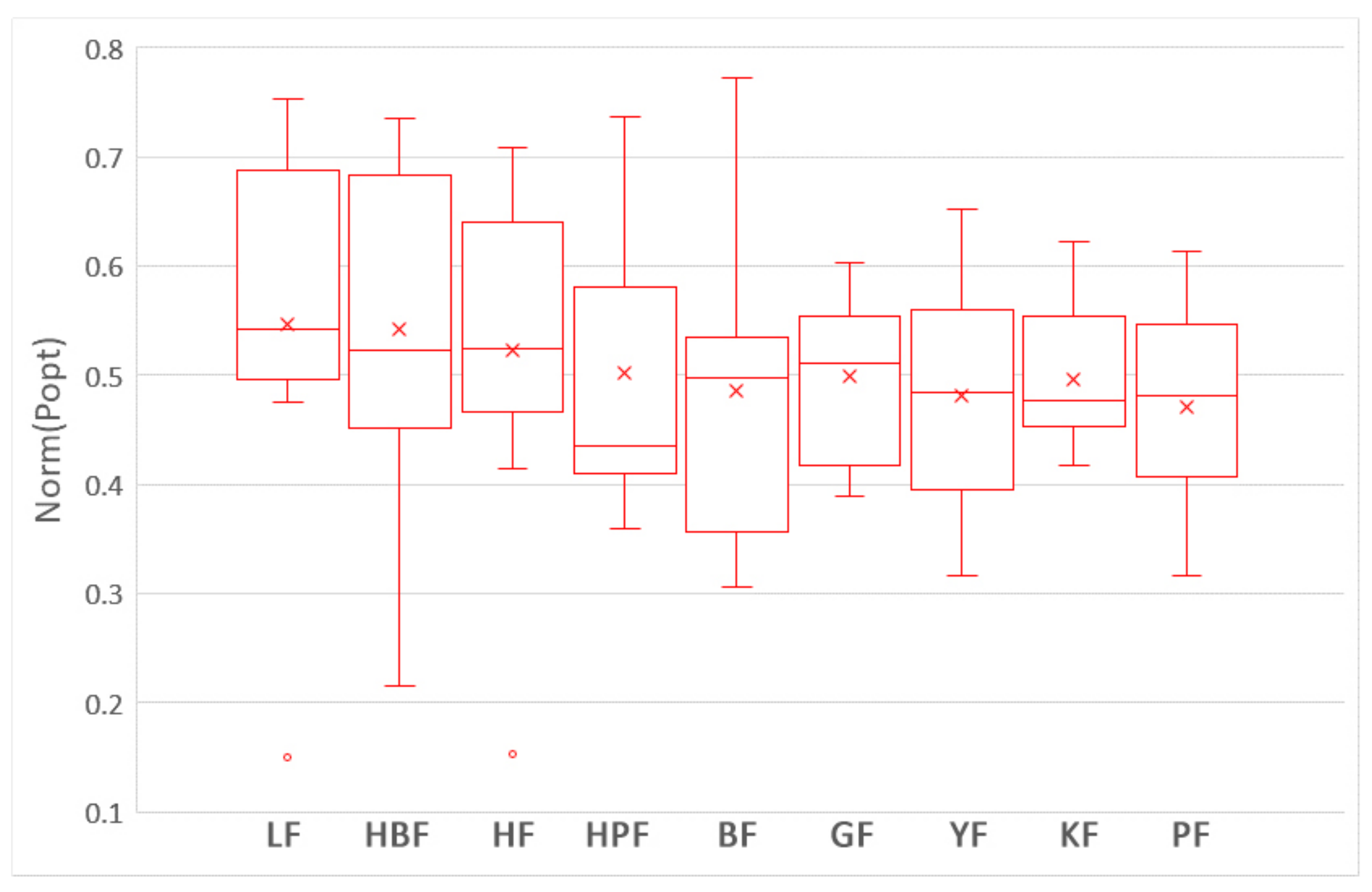
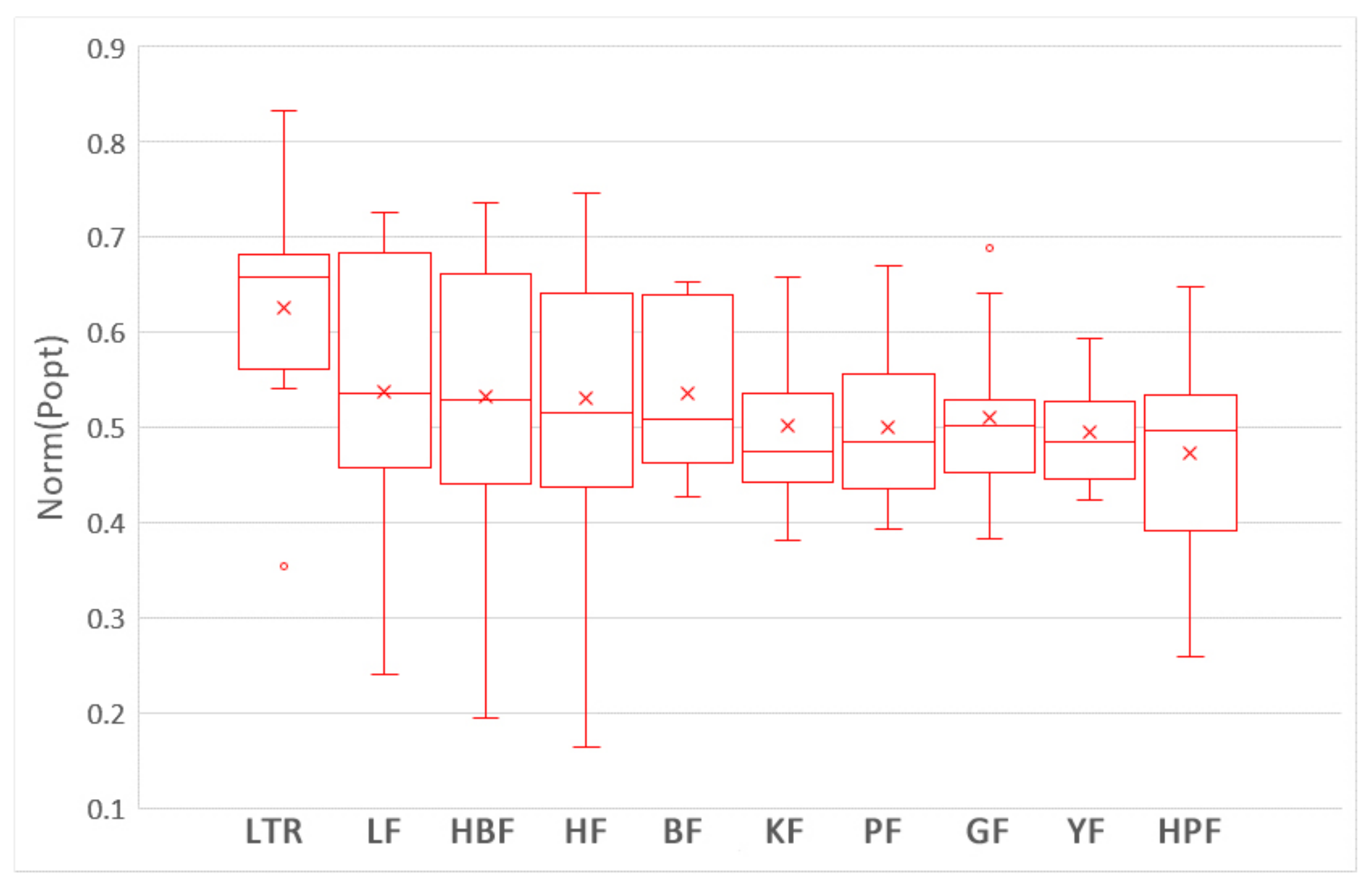
5.1. Which Training Data Selection Method Leads to Better Performance for ROCPDP?
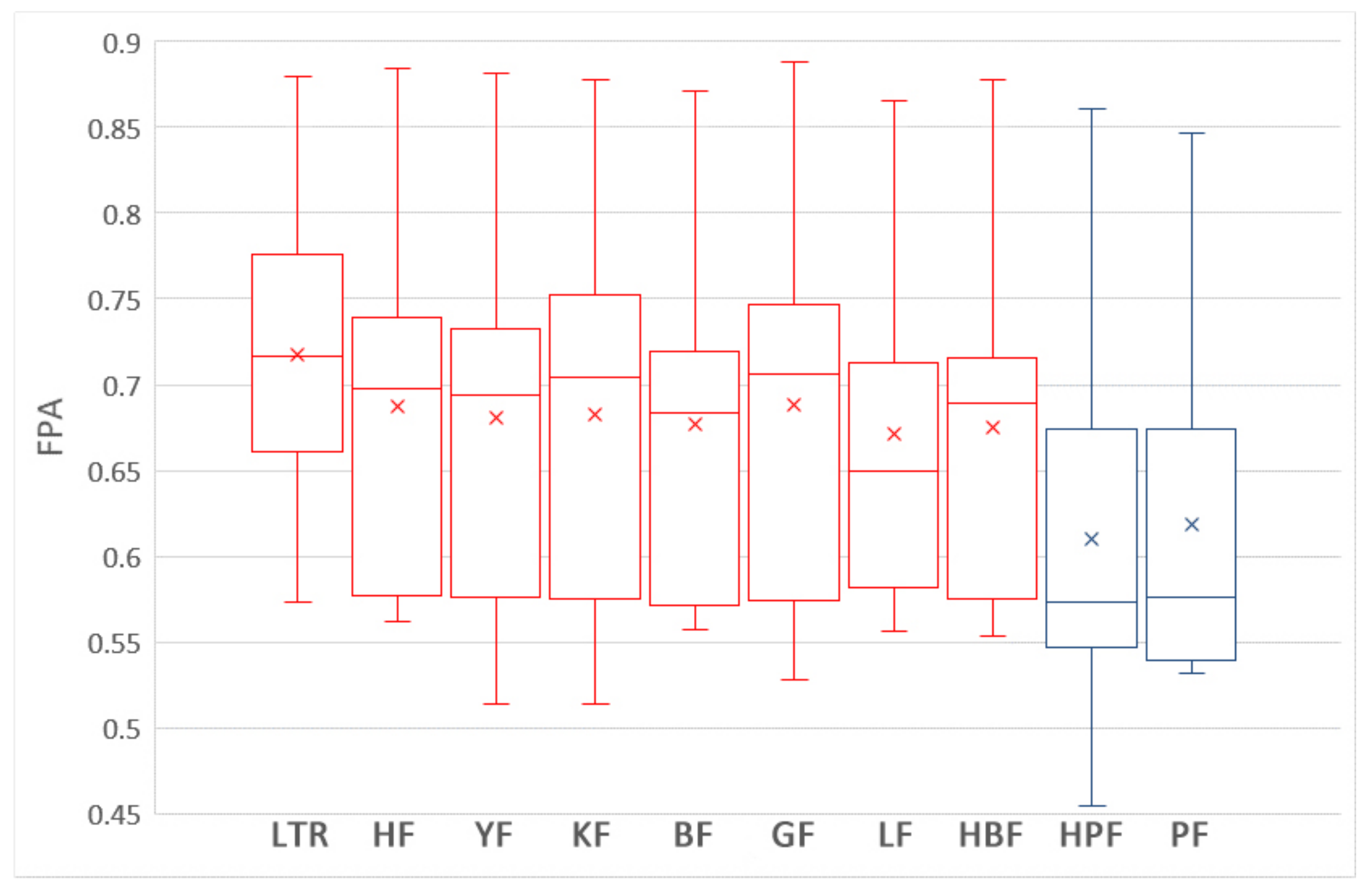
5.2. How Does Using Training Data Selection Methods and ROCPDP Models Perform Compared to ROWPDP Models Trained on Sufficient Historical WP Data?
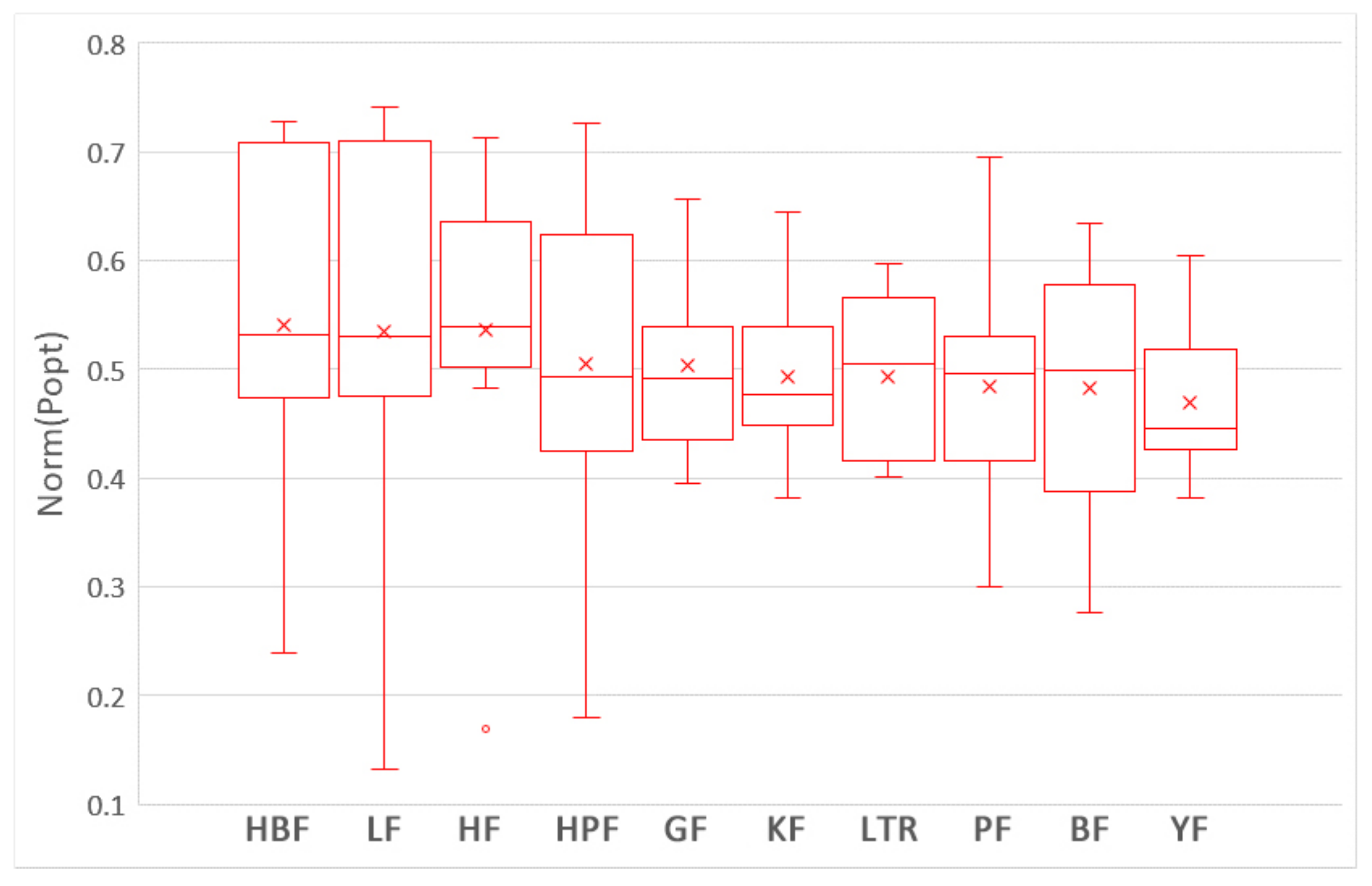
5.3. How Does Using Training Data Selection Methods and ROCPDP Models Perform Compared to ROWPDP Models Trained on Limited WP Data?
5.4. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bal, P.R.; Kumar, S. WR-ELM: Weighted regularization extreme learning machine for imbalance learning in software fault prediction. IEEE Trans. Reliab. 2020, 69, 1355–1375. [Google Scholar] [CrossRef]
- Sun, Z.; Zhang, J.; Sun, H.; Zhu, X. Collaborative filtering based recommendation of sampling methods for software defect prediction. Appl. Soft Comput. 2020, 90, 106163. [Google Scholar] [CrossRef]
- Xu, Z.; Liu, J.; Luo, X.; Yang, Z.; Zhang, Y.; Yuan, P.; Tang, Y.; Zhang, T. Software defect prediction based on kernel PCA and weighted extreme learning machine. Inf. Softw. Technol. 2019, 106, 182–200. [Google Scholar] [CrossRef]
- Yu, X.; Liu, J.; Yang, Z.; Liu, X. The bayesian network based program dependence graph and its application to fault localization. J. Syst. Softw. 2017, 134, 44–53. [Google Scholar] [CrossRef]
- Leitao-Junior, P.S.; Freitas, D.M.; Vergilio, S.R.; Camilo-Junior, C.G.; Harrison, R. Search-based fault localisation: A systematic mapping study. Inf. Softw. Technol. 2020, 123, 106295. [Google Scholar] [CrossRef]
- Zakari, A.; Lee, S.P.; Abreu, R.; Ahmed, B.H.; Rasheed, R.A. Multiple fault localization of software programs: A systematic literature review. Inf. Softw. Technol. 2020, 124, 106312. [Google Scholar] [CrossRef]
- Szajna, A.; Kostrzewski, M.; Ciebiera, K.; Stryjski, R.; Sciubba, E. Application of the deep CNN-based method in industrial system for wire marking identification. Energies 2021, 14, 3659. [Google Scholar] [CrossRef]
- Nguyen, T.P.K.; Beugin, J.; Marais, J. Method for evaluating an extended fault tree to analyse the dependability of complex systems: Application to a satellite-based railway system. Reliab. Eng. Syst. Saf. 2015, 133, 300–313. [Google Scholar] [CrossRef] [Green Version]
- Rahman, A.; Williams, L. Source code properties of defective infrastructure as code scripts. Inf. Softw. Technol. 2019, 112, 148–163. [Google Scholar] [CrossRef] [Green Version]
- Rebai, S.; Kessentini, M.; Wang, H.; Maxim, B. Web service design defects detection: A bi-level multi-objective approach. Inf. Softw. Technol. 2020, 121, 106255. [Google Scholar] [CrossRef]
- Rawat, M.S.; Dubey, S.K. Software defect prediction models for quality improvement: A literature study. Int. J. Comput. Sci. Issues 2012, 9, 288–296. [Google Scholar]
- Shippey, T.; Bowes, D.; Hall, T. Automatically identifying code features for software defect prediction: Using ast n-grams. Inf. Softw. Technol. 2019, 106, 142–160. [Google Scholar] [CrossRef]
- Ochodek, M.; Staron, M.; Meding, W. SimSAX: A measure of project similarity based on symbolic approximation method and software defect inflow. Inf. Softw. Technol. 2019, 115, 131–147. [Google Scholar] [CrossRef]
- Chen, X.; Mu, Y.; Liu, K.; Cui, Z.; Ni, C. Revisiting heterogeneous defect prediction methods: How far are we? Inf. Softw. Technol. 2021, 130, 106441. [Google Scholar] [CrossRef]
- Li, N.; Shepperd, M.; Guo, Y. A systematic review of unsupervised learning techniques for software defect prediction. Inf. Softw. Technol. 2020, 122, 106287. [Google Scholar] [CrossRef] [Green Version]
- Jing, X.; Wu, F.; Dong, X.; Xu, B. An improved SDA based defect prediction framework for both within-project and cross-project class-imbalance problems. IEEE Trans. Softw. Eng. 2017, 43, 321–339. [Google Scholar] [CrossRef]
- Shepperd, M.J.; Bowes, D.; Hall, T. Researcher bias: The use of machine learning in software defect prediction. IEEE Trans. Softw. Eng. 2014, 40, 603–616. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Tang, K.; Yao, X. A learning-to-rank approach to software defect prediction. IEEE Trans. Reliab. 2015, 64, 234–246. [Google Scholar] [CrossRef]
- Turhan, B.; Menzies, T.; Bener, A.B.; Stefano, J.S.D. On the relative value of cross-company and within-company data for defect prediction. Empir. Softw. Eng. 2009, 14, 540–578. [Google Scholar] [CrossRef] [Green Version]
- Menzies, T.; Butcher, A.; Cok, D.R.; Marcus, A.; Layman, L.; Shull, F.; Turhan, B.; Zimmermann, T. Local versus global lessons for defect prediction and effort estimation. IEEE Trans. Softw. Eng. 2013, 39, 822–834. [Google Scholar] [CrossRef]
- Peters, F.; Menzies, T.; Marcus, A. Better cross company defect prediction. In Proceedings of the 10th Working Conference on Mining Software Repositories, MSR ’13, San Francisco, CA, USA, 18–19 May 2013; Zimmermann, T., Penta, M.D., Kim, S., Eds.; pp. 409–418. [Google Scholar]
- Kawata, K.; Amasaki, S.; Yokogawa, T. Improving relevancy filter methods for cross-project defect prediction. In Proceedings of the 3rd International Conference on Applied Computing and Information Technology, ACIT 2015/2nd International Conference on Computational Science and Intelligence, CSI 2015, Okayama, Japan, 12–16 July 2015; pp. 2–7. [Google Scholar]
- Yu, X.; Liu, J.; Peng, W.; Peng, X. Improving cross-company defect prediction with data filtering. Int. J. Softw. Eng. Knowl. Eng. 2017, 27, 1427–1438. [Google Scholar] [CrossRef]
- He, P.; Li, B.; Zhang, D.; Ma, Y. Simplification of training data for cross-project defect prediction. arXiv 2014, arXiv:1405.0773. [Google Scholar]
- Li, Y.; Huang, Z.; Wang, Y.; Fang, B. Evaluating data filter on cross-project defect prediction: Comparison and improvements. IEEE Access 2017, 5, 25646–25656. [Google Scholar] [CrossRef]
- Yu, X.; Liu, J.; Keung, J.W.; Li, Q.; Bennin, K.E.; Xu, Z.; Wang, J.; Cui, X. Improving ranking-oriented defect prediction using a cost-sensitive ranking SVM. IEEE Trans. Reliab. 2020, 69, 139–153. [Google Scholar] [CrossRef]
- You, G.; Wang, F.; Ma, Y. An empirical study of ranking-oriented cross-project software defect prediction. Int. J. Softw. Eng. Knowl. Eng. 2016, 26, 1511–1538. [Google Scholar] [CrossRef]
- Manjula, C.; Florence, L. Deep neural network based hybrid approach for software defect prediction using software metrics. Clust. Comput. 2019, 22, 9847–9863. [Google Scholar] [CrossRef]
- Yan, Z.; Chen, X.; Guo, P. Software defect prediction using fuzzy support vector regression. In Proceedings of the 7th International Symposium on Neural Networks, ISNN 2010, Shanghai, China, 6–9 June 2010; Zhang, L., Lu, B., Kwok, J.T., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6064, pp. 17–24. [Google Scholar]
- Wang, J.; Shen, B.; Chen, Y. Compressed C4.5 models for software defect prediction. In Proceedings of the 2012 12th International Conference on Quality Software, Xi’an, China, 27–29 August 2012; Tang, A., Muccini, H., Eds.; IEEE: Piscataway, NJ, USA, 2012; pp. 13–16. [Google Scholar]
- Okutan, A.; Yildiz, O.T. Software defect prediction using bayesian networks. Empir. Softw. Eng. 2014, 19, 154–181. [Google Scholar] [CrossRef] [Green Version]
- Petric, J.; Bowes, D.; Hall, T.; Christianson, B.; Baddoo, N. Building an ensemble for software defect prediction based on diversity selection. In Proceedings of the 10th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement, ESEM 2016, Ciudad Real, Spain, 8–9 September 2016; pp. 1–10. [Google Scholar]
- Yu, X.; Bennin, K.E.; Liu, J.; Keung, J.W.; Yin, X.; Xu, Z. An empirical study of learning to rank techniques for effort-aware defect prediction. In Proceedings of the 26th IEEE International Conference on Software Analysis, Evolution and Reengineering, SANER 2019, Hangzhou, China, 24–27 February 2019; pp. 298–309. [Google Scholar] [CrossRef]
- Li, W.; Zhang, W.; Jia, X.; Huang, Z. Effort-aware semi-supervised just-in-time defect prediction. Inf. Softw. Technol. 2020, 126, 106364. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, D.; Zhao, Y.; Cui, Z.; Ni, C. Software defect number prediction: Unsupervised vs. supervised methods. Inf. Softw. Technol. 2019, 106, 161–181. [Google Scholar] [CrossRef]
- Liu, T. Learning to rank for information retrieval. In Proceedings of the 33rd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2010, Geneva, Switzerland, 19–23 July 2010; Crestani, F., Marchand-Maillet, S., Chen, H., Efthimiadis, E.N., Savoy, J., Eds.; p. 904. [Google Scholar]
- Gao, K.; Khoshgoftaar, T.M. A comprehensive empirical study of count models for software fault prediction. IEEE Trans. Reliab. 2007, 56, 223–236. [Google Scholar] [CrossRef]
- Rathore, S.S.; Kumar, S. Predicting number of faults in software system using genetic programming. In Proceedings of the 2015 International Conference on Soft Computing and Software Engineering, SCSE’15, Berkeley, CA, USA, 5–6 March 2015; Elsevier: Amsterdam, The Netherlands, 2015; Volume 62, pp. 303–311. [Google Scholar]
- Rathore, S.S.; Kumar, S. A decision tree regression based approach for the number of software faults prediction. ACM SIGSOFT Softw. Eng. Notes 2016, 41, 1–6. [Google Scholar] [CrossRef]
- Chen, M.; Ma, Y. An empirical study on predicting defect numbers. In Proceedings of the 27th International Conference on Software Engineering and Knowledge Engineering, SEKE 2015, Pittsburgh, PA, USA, 6–8 July 2015; Xu, H., Ed.; pp. 397–402. [Google Scholar]
- Rathore, S.S.; Kumar, S. An empirical study of some software fault prediction techniques for the number of faults prediction. Soft Comput. 2017, 21, 7417–7434. [Google Scholar] [CrossRef]
- Nguyen, T.T.; An, T.Q.; Hai, V.T.; Phuong, T.M. Similarity-based and rank-based defect prediction. In Proceedings of the 2014 International Conference on Advanced Technologies for Communications (ATC 2014), Hanoi, Vietnam, 15–17 October 2014; pp. 321–325. [Google Scholar]
- Liu, C.; Yang, D.; Xia, X.; Yan, M.; Zhang, X. A two-phase transfer learning model for cross-project defect prediction. Inf. Softw. Technol. 2019, 107, 125–136. [Google Scholar] [CrossRef]
- Zimmermann, T.; Nagappan, N.; Gall, H.C.; Giger, E.; Murphy, B. Cross-project defect prediction: A large scale experiment on data vs. domain vs. process. In Proceedings of the 7th joint meeting of the European Software Engineering Conference and the ACM SIGSOFT International Symposium on Foundations of Software Engineering 2009, Amsterdam, The Netherlands, 24–28 August 2009; van Vliet, H., Issarny, V., Eds.; pp. 91–100. [Google Scholar]
- Bin, Y.; Zhou, K.; Lu, H.; Zhou, Y.; Xu, B. Training data selection for cross-project defection prediction: Which approach is better? In Proceedings of the 2017 ACM/IEEE International Symposium on Empirical Software Engineering and Measurement, ESEM 2017, Toronto, ON, Canada, 9–10 November 2017; Bener, A., Turhan, B., Biffl, S., Eds.; pp. 354–363. [Google Scholar]
- Ryu, D.; Choi, O.; Baik, J. Value-cognitive boosting with a support vector machine for cross-project defect prediction. Empir. Softw. Eng. 2016, 21, 43–71. [Google Scholar] [CrossRef]
- Zhang, F.; Zheng, Q.; Zou, Y.; Hassan, A.E. Cross-project defect prediction using a connectivity-based unsupervised classifier. In Proceedings of the 38th International Conference on Software Engineering, ICSE 2016, Austin, TX, USA, 14–22 May 2016; Dillon, L.K., Visser, W., Williams, L.A., Eds.; pp. 309–320. [Google Scholar]
- Bettenburg, N.; Nagappan, M.; Hassan, A.E. Think locally, act globally: Improving defect and effort prediction models. In Proceedings of the 9th IEEE Working Conference of Mining Software Repositories, MSR 2012, Zurich, Switzerland, 2–3 June 2012; Lanza, M., Penta, M.D., Xie, T., Eds.; pp. 60–69. [Google Scholar]
- Mende, T.; Koschke, R. Revisiting the evaluation of defect prediction models. In Proceedings of the 5th International Workshop on Predictive Models in Software Engineering, PROMISE 2009, Vancouver, BC, Canada, 18–19 May 2009; Ostrand, T.J., Ed.; ACM: New York, NY, USA, 2009; p. 7. [Google Scholar]
- Chidamber, S.R.; Kemerer, C.F. A metrics suite for object oriented design. IEEE Trans. Softw. Eng. 1994, 20, 476–493. [Google Scholar] [CrossRef] [Green Version]
- Kafura, D.G.; Reddy, G.R. The use of software complexity metrics in software maintenance. IEEE Trans. Softw. Eng. 1987, 13, 335–343. [Google Scholar] [CrossRef]
- McCabe, T.J. A complexity measure. IEEE Trans. Softw. Eng. 1976, 2, 308–320. [Google Scholar] [CrossRef]
- Kostrzewski, M. Sensitivity analysis of selected parameters in the order picking process simulation model, with randomly generated orders. Entropy 2020, 22, 423. [Google Scholar] [CrossRef] [Green Version]
- Macbeth, G.; Razumiejczyk, E.; Ledesma, R.D. Cliff’s delta calculator: A non-parametric effect size program for two groups of observations. Univ. Psychol. 2011, 10, 545–555. [Google Scholar] [CrossRef]
- Scott, A.J.; Knott, M. A cluster analysis method for grouping means in the analysis of variance. Biometrics 1974, 30, 507–512. [Google Scholar] [CrossRef] [Green Version]
- Ghotra, B.; McIntosh, S.; Hassan, A.E. Revisiting the impact of classification techniques on the performance of defect prediction models. In Proceedings of the 37th IEEE/ACM International Conference on Software Engineering, ICSE 2015, Florence, Italy, 16–24 May 2015; Bertolino, A., Canfora, G., Elbaum, S.G., Eds.; Volume 1, pp. 789–800. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Project | Description | #Modules | #Defects | %Defects | Max | Avg |
|---|---|---|---|---|---|---|
| Ant 1.7 | A Java-based, shell independent build tool | 125 | 33 | 16.0 | 3 | 1.65 |
| Camel 1.6 | An integration framework based on Enterprise Integration Patterns | 965 | 500 | 19.5 | 28 | 2.66 |
| Ivy 2.0 | A dependence manager focusing on flexibility and simplicity | 352 | 56 | 11.4 | 3 | 1.4 |
| Jedit 4.3 | A cross platform programmer’s text editor | 492 | 12 | 2.2 | 2 | 1.09 |
| Log4j 1.2 | A logging package for printing log output | 205 | 498 | 92.2 | 10 | 2.63 |
| Lucene 2.4 | A core search library | 340 | 632 | 59.7 | 30 | 3.11 |
| Poi 3.0 | Java API for Microsoft documents format | 442 | 500 | 63.6 | 19 | 1.78 |
| Synapse 1.2 | A lightweight and high-performance Enterprise Service Bus | 256 | 145 | 33.6 | 9 | 1.69 |
| Velocity 1.6 | A template language engine | 229 | 190 | 34.1 | 12 | 2.44 |
| Xalan 2.7 | An XSLT processor for transforming XML documents into HTML, text, or other XML document types | 803 | 531 | 48.2 | 9 | 1.37 |
| Xerces 1.4 | A Java-based XML parser | 588 | 1596 | 74.3 | 62 | 3.65 |
| No. | Feature | Name | Description |
|---|---|---|---|
| 1 | wmc | Weighted methods per class | A class with more member functions than its peers is considered to be more complex and therefore more error prone |
| 2 | dit | Depth of inheritance tree | It’s defined as the maximum length from the node to the root of the tree |
| 3 | noc | Number of children | Number of direct descendants (subclasses) for each class |
| 4 | cbo | Coupling between object classes | Increased when the methods of one class access services of another |
| 5 | rfc | Response for a class | Number of methods invoked in response to a message to the object |
| 6 | lcom | Lack of cohesion in methods | Number of pairs of methods that do not share a reference to an instance variable |
| 7 | ca | Afferent couplings | How many other classes use the specific class |
| 8 | ce | Efferent couplings | How many other classes is used by the specific class |
| 9 | npm | Number of public methods | npm metric simply counts all the methods in a class that are declared as public |
| 10 | lcom3 | Another lack of cohesion measure | m, a count the methods, attributes in a class. µ(a) is the number of methods accessing an attribute. |
| 11 | loc | Lines of code | Total lines of code in this file or package |
| 12 | dam | Data access metric | Ratio of private (protected) attributes to total attributes |
| 13 | moa | Measure of aggregation | Count of the number of data declarations (class fields) whose types are user defined classes |
| 14 | mfa | Measure of functional abstraction | Number of methods inherited by a class plus number of methods accessible by member methods of the class |
| 15 | cam | Cohesion among methods of class | #different method parameters types divided by (#different method parameter types in a class)*(#methods) |
| 16 | ic | Inheritance coupling | Number of parent classes to which a given class is coupled (includes counts of methods and variables inherited) |
| 17 | cbm | Coupling between methods | Total number of new/redefined methods to which all the inherited methods are coupled |
| 18 | amc | Average method complexity | Number of Java byte codes |
| 19 | max_cc | Maximum McCabe’s cyclomatic complexity | Maximum McCabe’s cyclomatic complexity seen in class |
| 20 | avg_cc | Average McCabe’s cyclomatic complexity | Average McCabe’s cyclomatic complexity seen in class |
| GF | BF | PF | KF | YF | HF | HBF | HPF | LF | ||
|---|---|---|---|---|---|---|---|---|---|---|
| FPA | GF | 0.181 | 0.208 | 0.069 | 0.167 | −0.236 | −0.278 | 0.056 | −0.389 | |
| BF | 0.180 | 0.083 | −0.028 | 0.042 | −0.292 | −0.306 | −0.069 | −0.417 | ||
| PF | 0.125 | 0.027 | −0.167 | −0.056 | −0.375 | −0.375 | −0.069 | −0.523 | ||
| KF | 0.097 | −0.125 | −0.069 | 0.083 | −0.292 | −0.306 | 0.083 | −0.458 | ||
| YF | 0.027 | −0.152 | −0.097 | −0.042 | −0.319 | −0.347 | −0.042 | −0.431 | ||
| HF | 0.069 | −0.111 | −0.097 | 0.042 | 0.042 | −0.111 | 0.194 | −0.167 | ||
| HBF | 0.194 | 0.083 | 0.138 | 0.125 | 0.166 | 0.208 | 0.222 | −0.097 | ||
| HPF | 0.278 | 0.194 | 0.166 | 0.208 | 0.236 | 0.277 | 0.181 | −0.319 | ||
| LF | 0.097 | −0.125 | −0.111 | 0 | 0.111 | 0.083 | −0.125 | −0.292 | ||
| GF | BF | PF | KF | YF | HF | HBF | HPF | LF | LTR | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| FPA | GF | −0.181 | 0.042 | 0.069 | 0.194 | −0.25 | −0.306 | 0.125 | −0.194 | −0.638 | |
| BF | 0.153 | 0.25 | 0.264 | 0.333 | −0.027 | −0.083 | 0.333 | −0.042 | −0.569 | ||
| PF | 0.402 | 0.431 | 0.014 | 0.014 | −0.236 | −0.319 | 0.125 | −0.263 | −0.708 | ||
| KF | 0.056 | −0.111 | −0.389 | 0.014 | −0.194 | −0.264 | 0.139 | −0.236 | −0.694 | ||
| YF | 0.083 | −0.097 | −0.403 | 0.014 | −0.333 | −0.333 | 0.042 | −0.264 | −0.75 | ||
| HF | 0.055 | −0.125 | −0.486 | −0.014 | −0.069 | −0.056 | 0.264 | −0.014 | −0.444 | ||
| HBF | 0.111 | 0 | −0.403 | 0.056 | 0.056 | 0.514 | 0.319 | −0.056 | −0.444 | ||
| HPF | 0.458 | 0.472 | −0.414 | 0.458 | 0.458 | 0.153 | 0.444 | −0.333 | −0.75 | ||
| LF | 0.153 | 0.097 | −0.403 | 0.097 | 0.153 | 0.153 | 0.056 | −0.389 | 0.361 | ||
| LTR | −0.194 | −0.361 | −0.597 | −0.25 | −0.292 | −0.222 | −0.333 | −0.667 | −0.389 | ||
| GF | BF | PF | KF | YF | HF | HBF | HPF | LF | LTR | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| FPA | GF | 0.069 | 0.097 | 0.111 | 0.278 | −0.375 | 0.306 | −0.028 | −0.292 | 0.278 | |
| BF | 0.056 | 0.014 | 0.042 | 0.194 | −0.361 | −0.306 | −0.069 | −0.278 | 0.014 | ||
| PF | 0.125 | 0.056 | 0.069 | 0.194 | −0.431 | −0.375 | −0.083 | −0.347 | −0.083 | ||
| KF | 0.056 | −0.028 | −0.097 | −0.111 | −0.042 | −0.069 | 0.222 | −0.472 | 0.056 | ||
| YF | 0.069 | −0.056 | −0.056 | −0.014 | −0.611 | −0.486 | −0.208 | −0.528 | −0.032 | ||
| HF | 0.111 | −0.042 | −0.083 | 0.069 | 0.014 | −0.056 | 0.25 | 0.056 | 0.111 | ||
| HBF | 0.166 | 0.097 | −0.042 | 0.139 | 0.125 | 0.097 | 0.236 | 0.042 | 0.166 | ||
| HPF | 0.236 | 0.208 | 0.083 | 0.236 | 0.222 | 0.222 | −0.139 | −0.236 | 0.027 | ||
| LF | 0.111 | 0 | −0.083 | 0.506 | 0.027 | −0.028 | −0.097 | −0.25 | 0.125 | ||
| LTR | 0.416 | 0.389 | 0.375 | 0.403 | 0.403 | 0.458 | 0.431 | 0.347 | 0.444 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, H.; Dai, H.; Peng, W.; Hu, W.; Li, F. An Empirical Study of Training Data Selection Methods for Ranking-Oriented Cross-Project Defect Prediction. Sensors 2021, 21, 7535. https://doi.org/10.3390/s21227535
Luo H, Dai H, Peng W, Hu W, Li F. An Empirical Study of Training Data Selection Methods for Ranking-Oriented Cross-Project Defect Prediction. Sensors. 2021; 21(22):7535. https://doi.org/10.3390/s21227535
Chicago/Turabian StyleLuo, Haoyu, Heng Dai, Weiqiang Peng, Wenhua Hu, and Fuyang Li. 2021. "An Empirical Study of Training Data Selection Methods for Ranking-Oriented Cross-Project Defect Prediction" Sensors 21, no. 22: 7535. https://doi.org/10.3390/s21227535
APA StyleLuo, H., Dai, H., Peng, W., Hu, W., & Li, F. (2021). An Empirical Study of Training Data Selection Methods for Ranking-Oriented Cross-Project Defect Prediction. Sensors, 21(22), 7535. https://doi.org/10.3390/s21227535