
Severity Grading and Early Retinopathy Lesion Detection through Hybrid Inception-ResNet Architecture


 , , ,
, , ,  , ,
, ,  , and
, and
Abstract
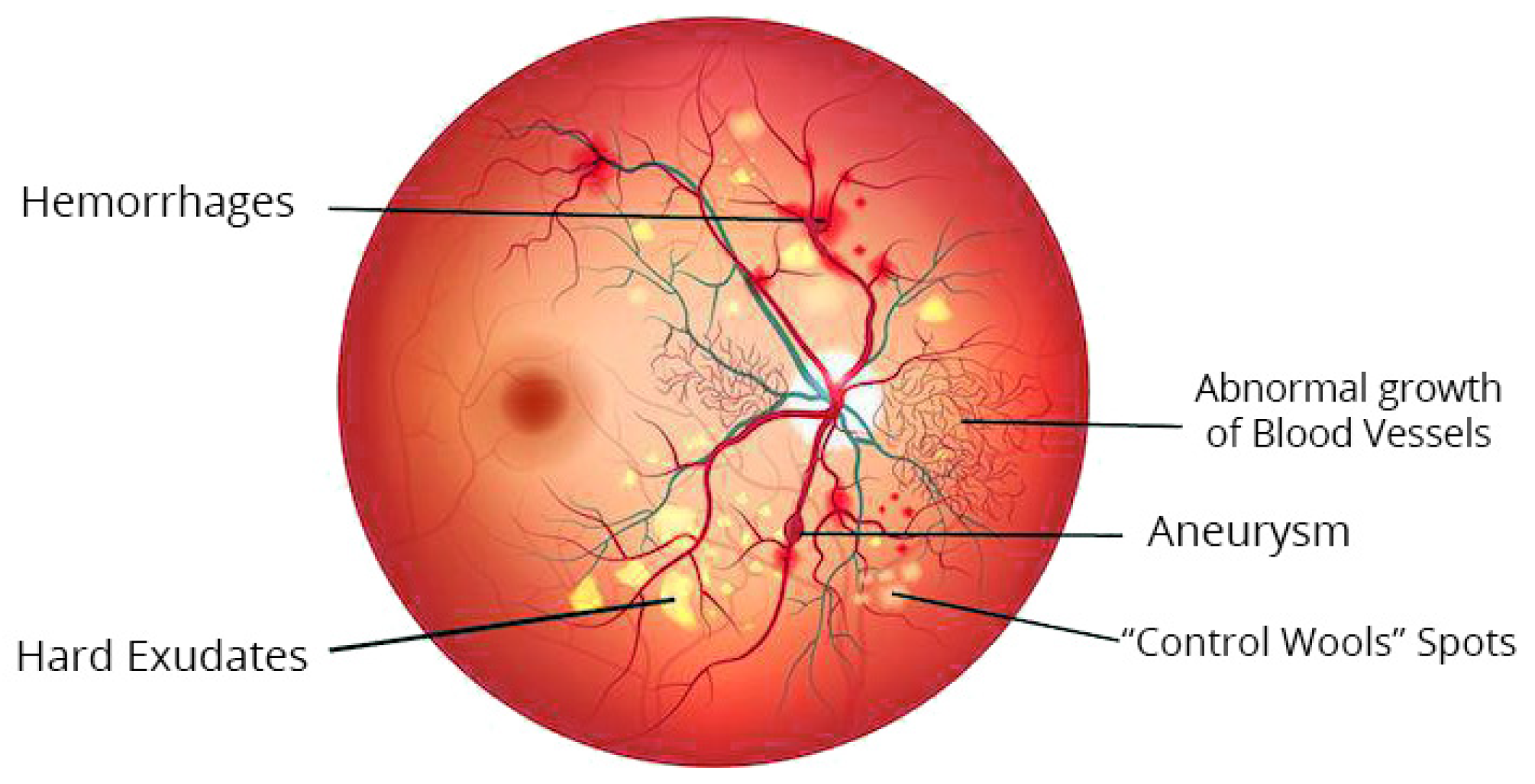
:1. Introduction
2. Related Work
2.1. Earlier DR Classification Techniques
2.2. Class-Imbalance Feature Learning
2.3. ResNet and Deeply Supervised Nets
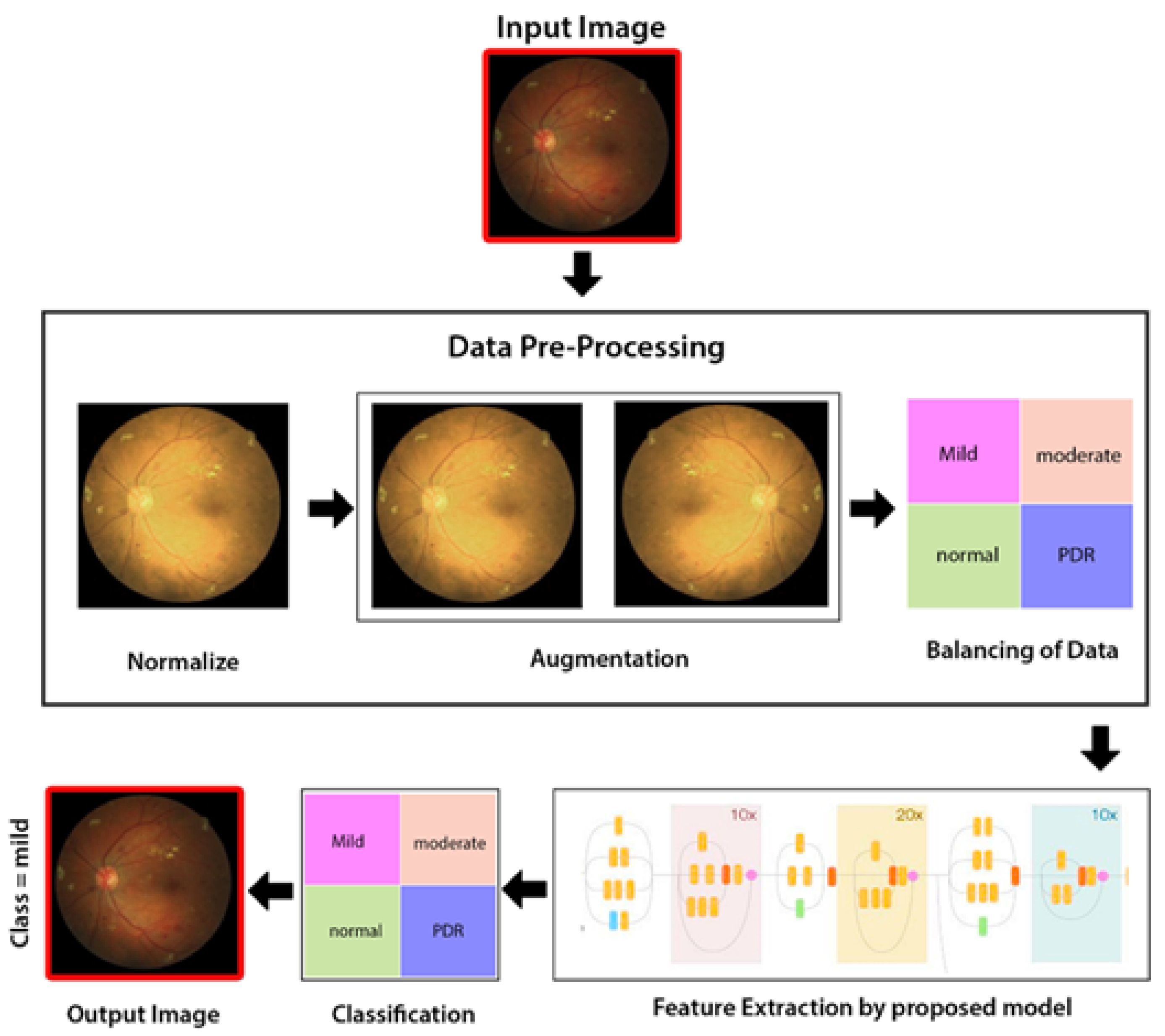
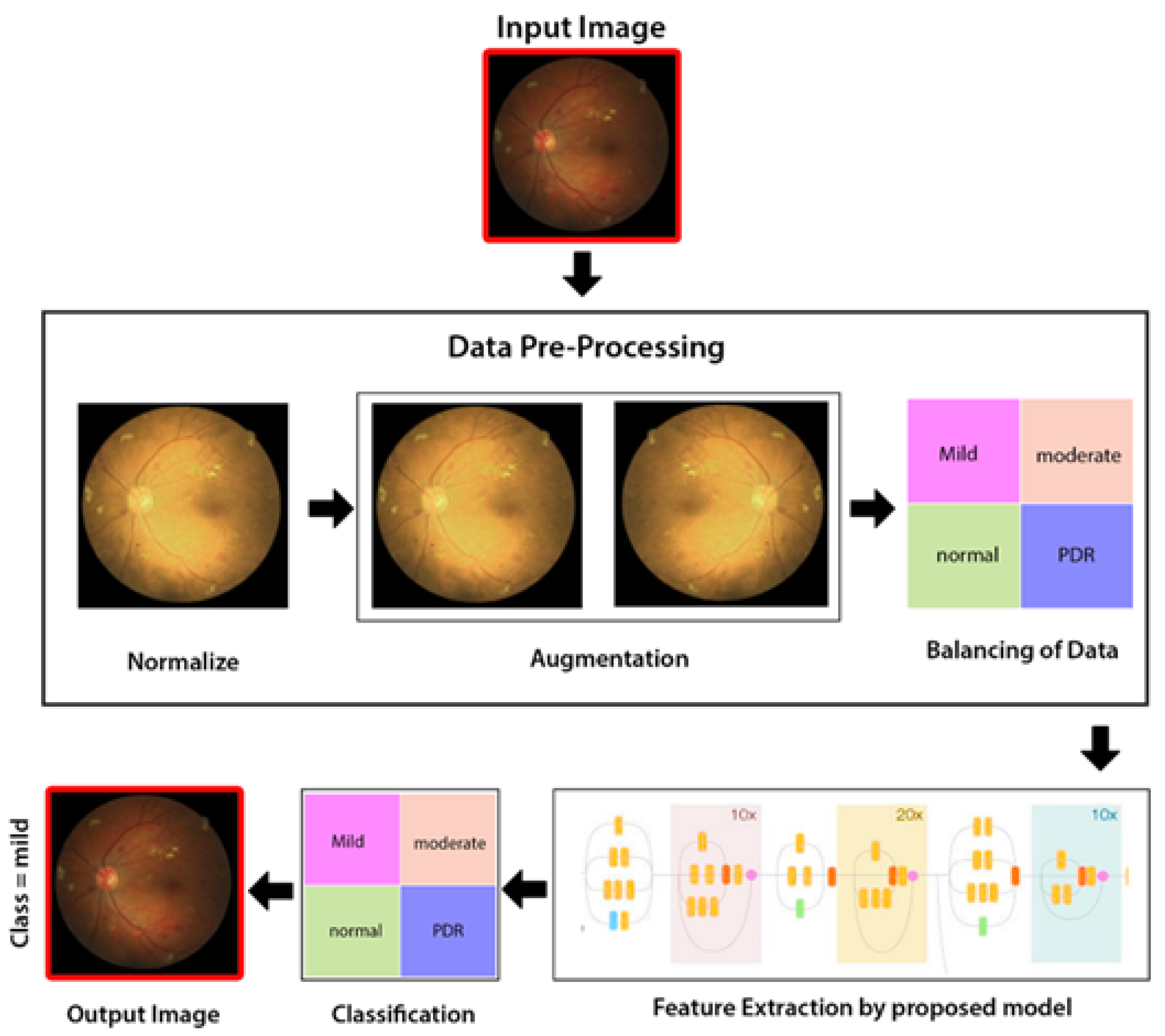
3. Methodology
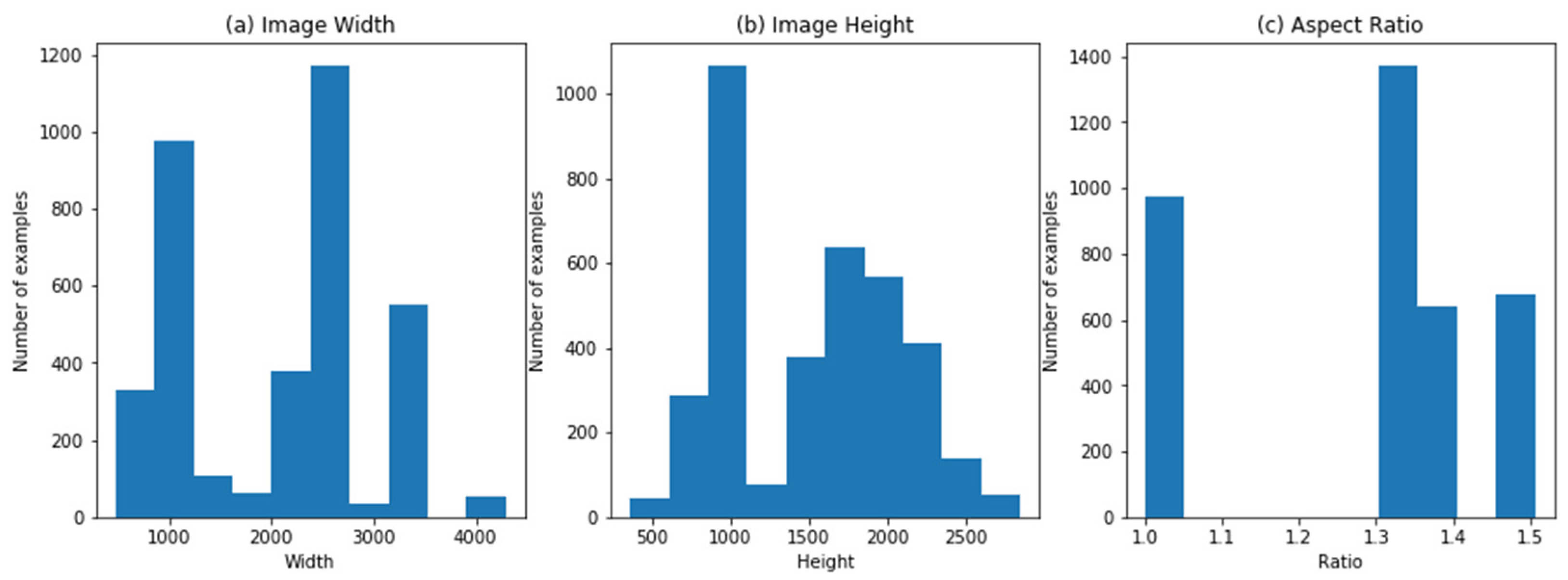
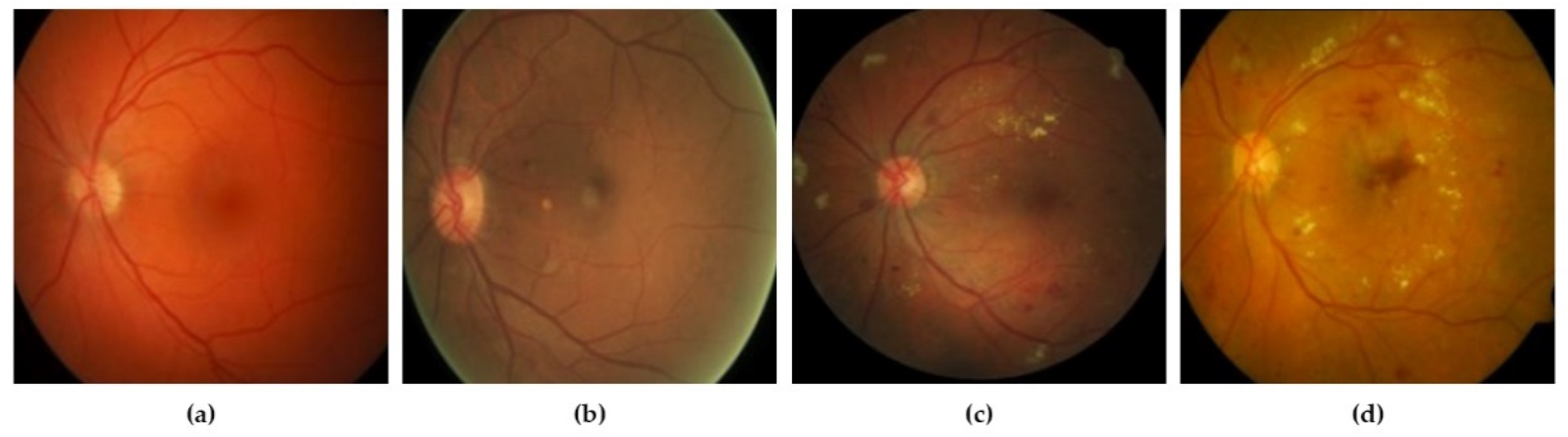
3.1. Dataset Collection
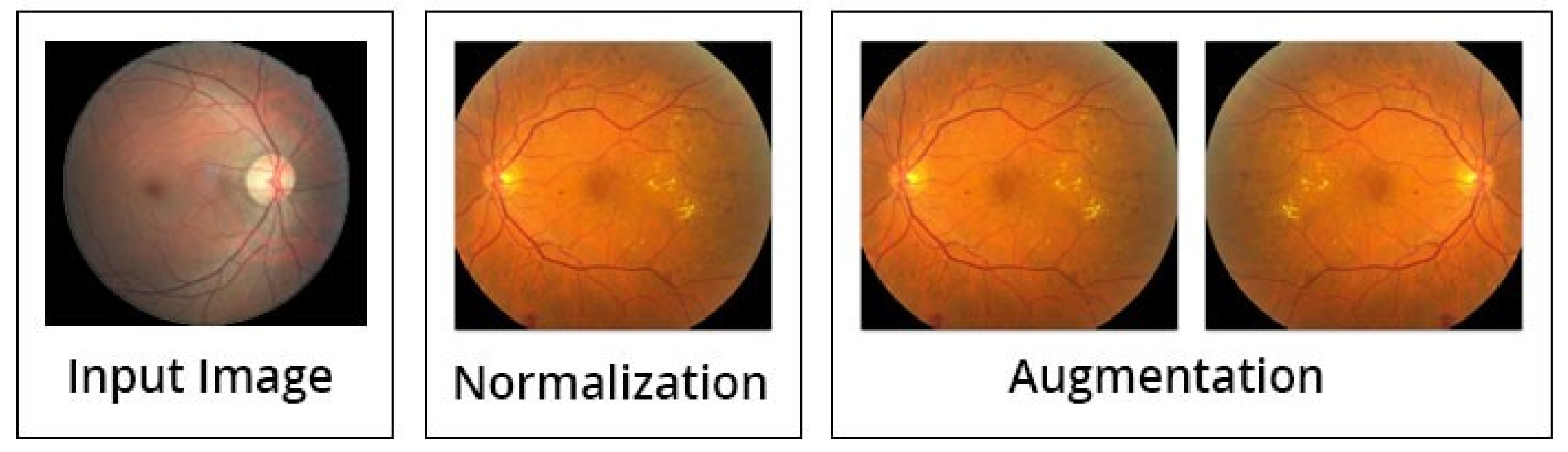
3.2. Image Preprocessing
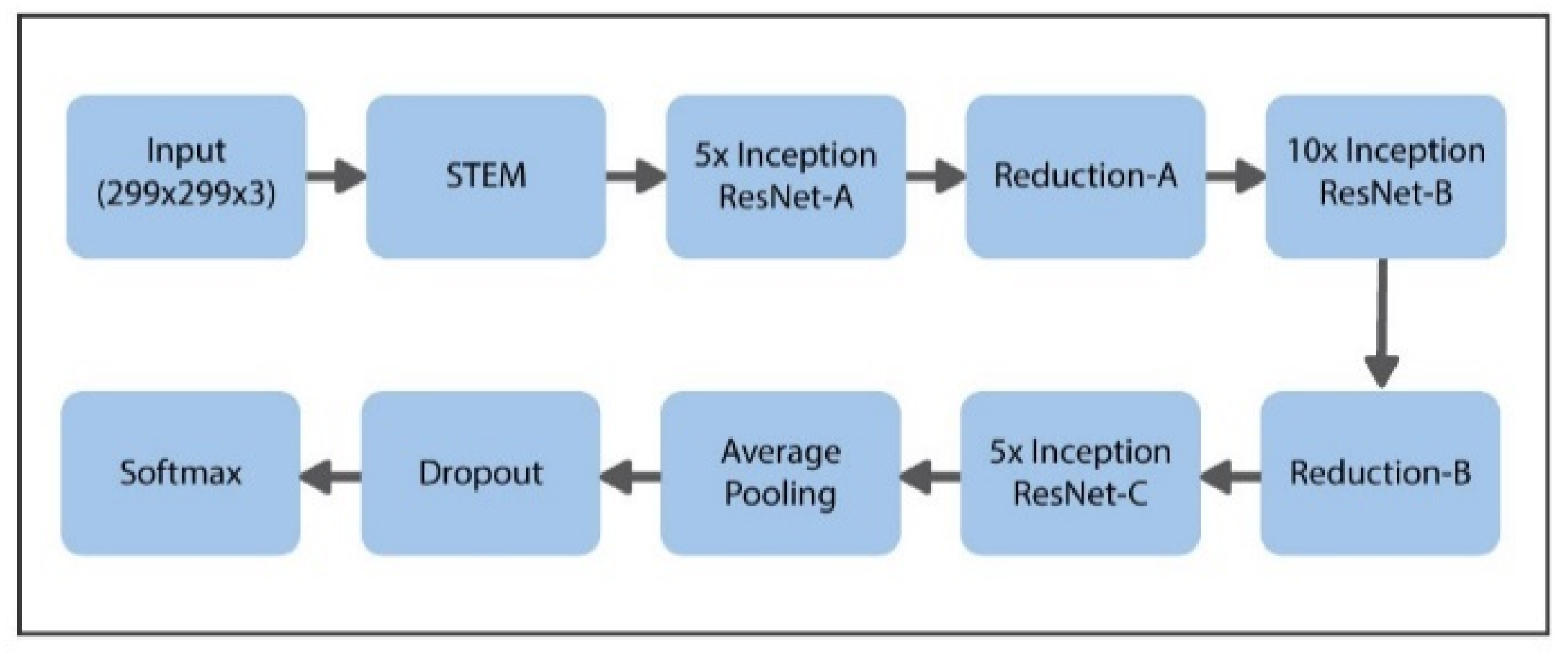
3.3. Deep Learning Inception-ResNet Model
- Pretraining: As in medical imaging, the dataset is limited in numbers (N = 3662). That is why by using the transfer learning technique, we train our model twice, firstly on a larger dataset of ImageNet. Although the data of ImageNet are slightly different from the images of retina, the ImageNet dataset might help our network to learn and understand the edges and shapes in the first phase. However, to train the model about target domain of retinopathy in the second phase, we further train the proposed model on a larger dataset featuring around 35,000 retina images.
- Fine-tuning: After training the model on ImageNet and the larger retinal dataset, we fine-tune the proposed model on our limited target image set. We make the decisions of modelling depending upon the results of out-of-the-fold estimations.
- Interpretation: We sum up the predictions of the proposed model trained on various arrangements of training folds and also use the augmentation of test-time in order to further enhance the performance of the model.
3.4. Classification in First Phase
3.5. Classification in Second Phase
3.6. Performance Evaluation Metrics
4. Experimental Work
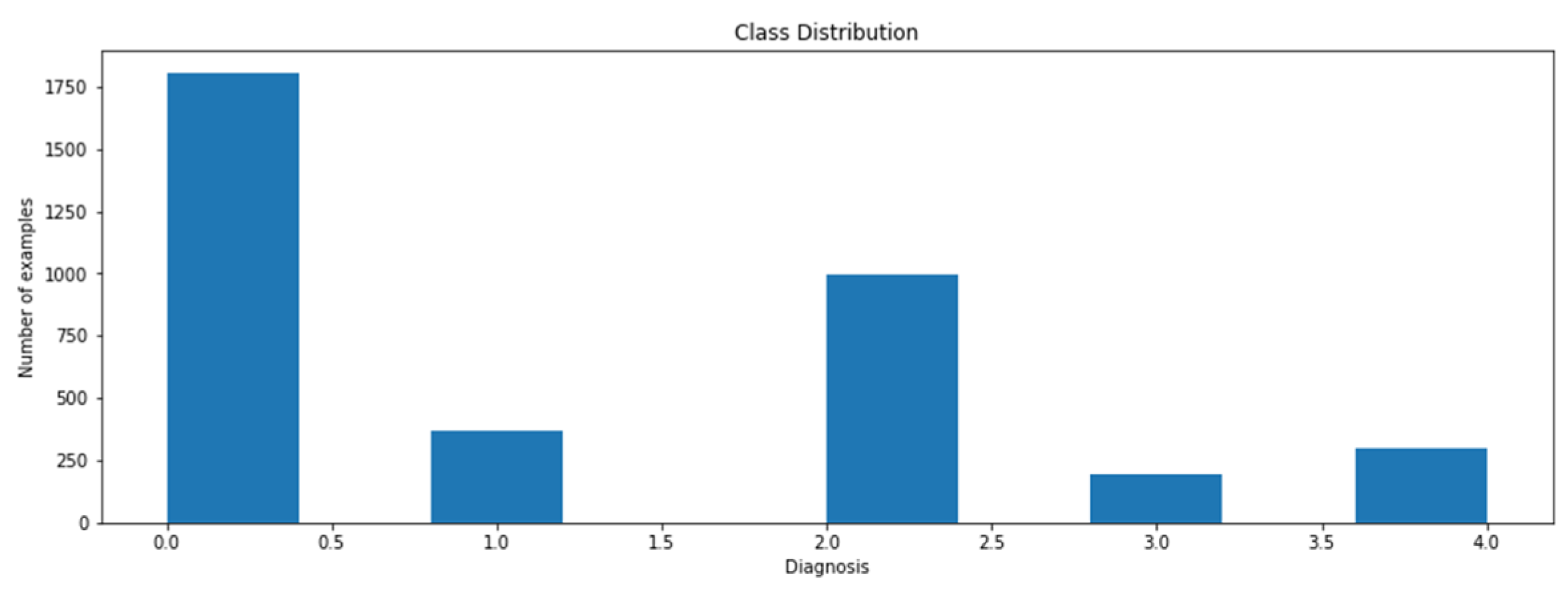
4.1. Dataset and Experimental Setup
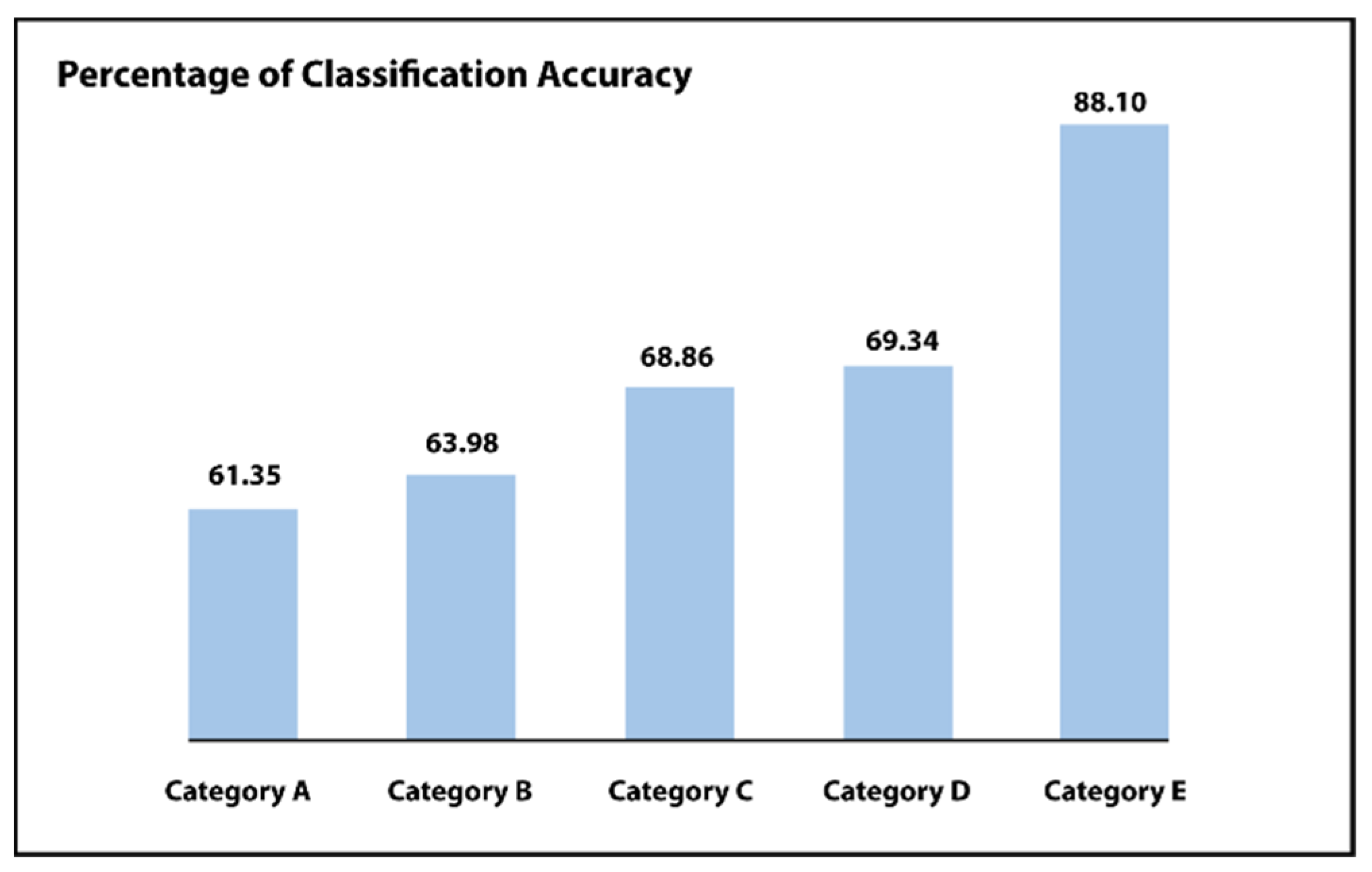
4.2. First Phase Results
- Category A: There is no preprocessing step. Only uses the unprocessed images.
- Category B: Simply the process of normalization is being used.
- Category C: Normalization as well as augmentation.
- Category D: Normalization as well as balancing of data.
- Category E: Implementing the normalization of the dataset, augmentation as well as balancing of data.
- Category F: Implementing the full normalization, augmentation as well as balancing. The last two categories include a three-step process.
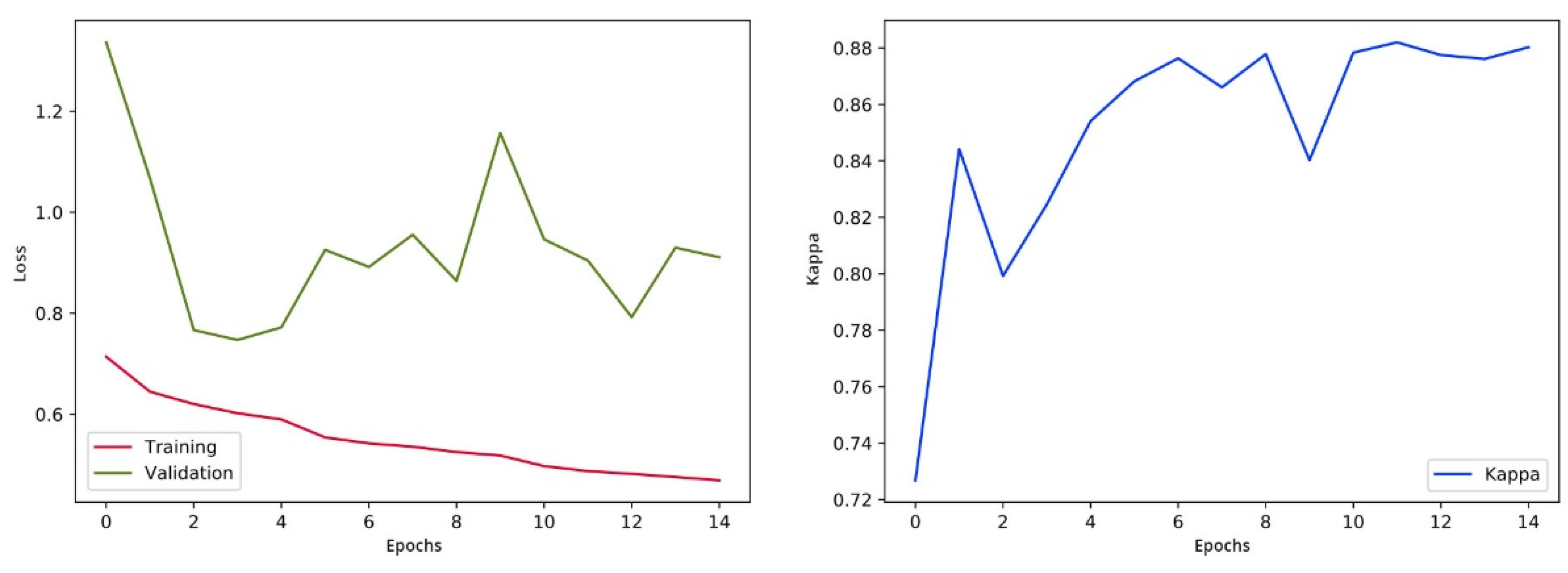
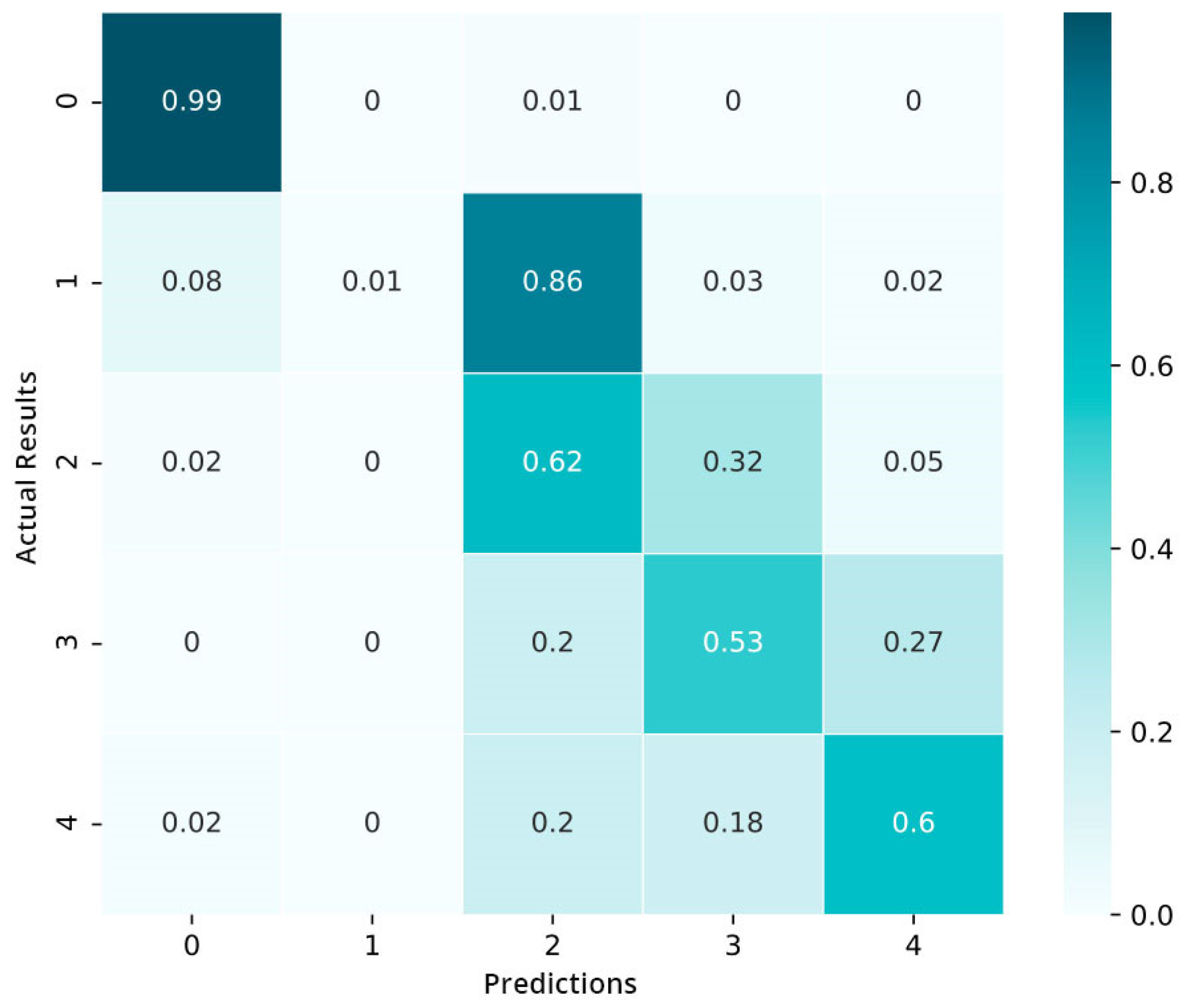
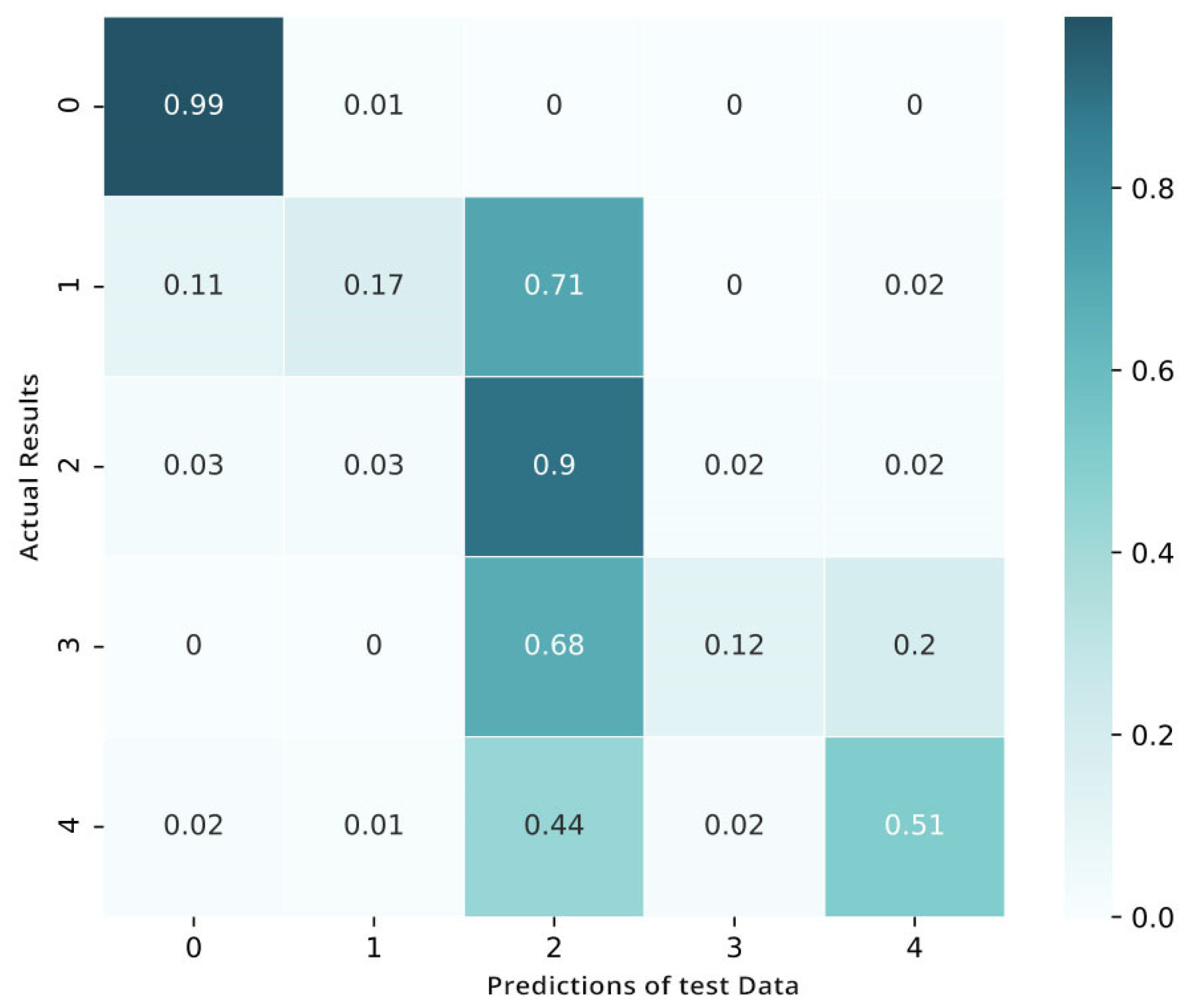
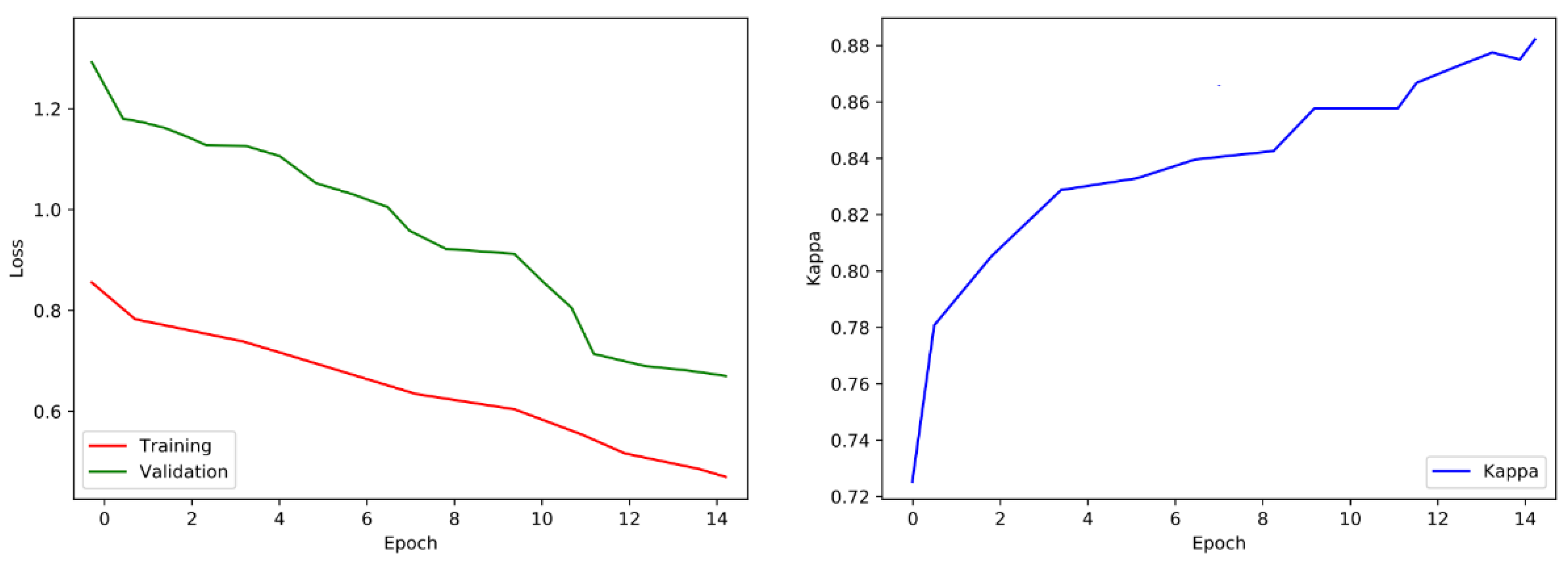
4.3. Second Phase Results
4.4. Analysis of the Performance and Complexity
5. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Khojasteh, P.; Aliahmad, B.; Kumar, D.K. Fundus images analysis using deep features for detection of exudates, hemorrhages and microaneurysms. BMC Ophthalmol. 2018, 18, 288. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pratt, H.; Coenen, F.; Broadbent, D.M.; Harding, S.P.; Zheng, Y. Convolutional neural networks for diabetic retinopathy. Procedia Comput. Sci. 2016, 90, 200–205. [Google Scholar] [CrossRef] [Green Version]
- Kotsiantis, S.; Kanellopoulos, D.; Pintelas, P. Handling imbalanced datasets: A review. GESTS Int. Trans. Comput. Sci. Eng. 2006, 30, 25–36. [Google Scholar]
- Eftekhari, N.; Pourreza, H.-R.; Masoudi, M.; Ghiasi-Shirazi, K.; Saeedi, E. Microaneurysm detection in fundus images using a two-step convolutional neural network. Biomed. Eng. Online 2019, 18, 67. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Li, T.; Li, W.; Wu, H.; Fan, W.; Zhang, W. Lesion detection and grading of diabetic retinopathy via two-stages deep convolutional neural networks. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Quebec City, QC, Canada, 11–13 September 2017; pp. 533–540. [Google Scholar]
- García, G.; Gallardo, J.; Mauricio, A.; López, J.; Del Carpio, C. Detection of diabetic retinopathy based on a convolutional neural network using retinal fundus images. In Proceedings of the International Conference on Artificial Neural Networks, Alghero, Italy, 11–14 September 2017; pp. 635–642. [Google Scholar]
- Gardner, G.G.; Keating, D.; Williamson, T.H.; Elliott, A.T. Automatic detection of diabetic retinopathy using an artificial neural network: A screening tool. Br. J. Ophthalmol. 1996, 80, 940–944. [Google Scholar] [CrossRef] [Green Version]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Aamir, A.H.; Ul-Haq, Z.; Mahar, S.A.; Qureshi, F.M.; Ahmad, I.; Jawa, A.; Sheikh, A.; Raza, A.; Fazid, S.; Jadoon, Z.; et al. Diabetes Prevalence Survey of Pakistan (DPS-PAK): Prevalence of type 2 diabetes mellitus and prediabetes using HbA1c: A population-based survey from Pakistan. BMJ Open 2019, 9, e025300. [Google Scholar] [CrossRef] [PubMed]
- Xiao, Z.; Zhang, X.; Geng, L.; Zhang, F.; Wu, J.; Tong, J.; Ogunbona, P.O.; Shan, C. Automatic non-proliferative diabetic retinopathy screening system based on color fundus image. Biomed. Eng. Online 2017, 16, 122. [Google Scholar] [CrossRef] [Green Version]
- Lam, C.; Yu, C.; Huang, L.; Rubin, D. Retinal lesion detection with deep learning using image patches. Investig. Ophthalmol. Vis. Sci. 2018, 59, 590–596. [Google Scholar] [CrossRef]
- Qummar, S.; Khan, F.G.; Shah, S.; Khan, A.; Shamshirband, S.; Rehman, Z.U.; Khan, I.A.; Jadoon, W. A deep learning ensemble approach for diabetic retinopathy detection. IEEE Access 2019, 7, 150530–150539. [Google Scholar] [CrossRef]
- Kori, A.; Chennamsetty, S.S.; Alex, V. Ensemble of convolutional neural networks for automatic grading of diabetic retinopathy and macular edema. arXiv 2018, arXiv:1809.04228. [Google Scholar]
- Porwal, P.; Pachade, S.; Kamble, R.; Kokare, M.; Deshmukh, G.; Sahasrabuddhe, V.; Meriaudeau, F. Indian diabetic retinopathy image dataset (IDRiD): A database for diabetic retinopathy screening research. Data 2018, 3, 25. [Google Scholar] [CrossRef] [Green Version]
- Orlando, J.I.; Prokofyeva, E.; Del Fresno, M.; Blaschko, M.B. An ensemble deep learning based approach for red lesion detection in fundus images. Comput. Methods Programs Biomed. 2018, 153, 115–127. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chudzik, P.; Majumdar, S.; Calivá, F.; Al-Diri, B.; Hunter, A. Microaneurysm detection using fully convolutional neural networks. Comput. Methods Programs Biomed. 2018, 158, 185–192. [Google Scholar] [CrossRef]
- Quellec, G.; Charrière, K.; Boudi, Y.; Cochener, B.; Lamard, M. Deep image mining for diabetic retinopathy screening. Med. Image Anal. 2017, 39, 178–193. [Google Scholar] [CrossRef] [Green Version]
- Ting, D.S.W.; Cheung, C.Y.-L.; Lim, G.; Tan, G.S.W.; Quang, N.D.; Gan, A.; Hamzah, H.; Garcia-Franco, R.; San Yeo, I.Y.; Lee, S.Y. Development and validation of a deep learning system for diabetic retinopathy and related eye diseases using retinal images from multiethnic populations with diabetes. JAMA 2017, 318, 2211–2223. [Google Scholar] [CrossRef]
- Gargeya, R.; Leng, T. Automated identification of diabetic retinopathy using deep learning. Ophthalmology 2017, 124, 962–969. [Google Scholar] [CrossRef] [PubMed]
- Gulshan, V.; Peng, L.; Coram, M.; Stumpe, M.C.; Wu, D.; Narayanaswamy, A.; Venugopalan, S.; Widner, K.; Madams, T.; Cuadros, J. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA 2016, 316, 2402–2410. [Google Scholar] [CrossRef] [PubMed]
- Mookiah, M.R.K.; Acharya, U.R.; Chua, C.K.; Lim, C.M.; Ng, E.; Laude, A. Computer-aided diagnosis of diabetic retinopathy: A review. Comput. Biol. Med. 2013, 43, 2136–2155. [Google Scholar] [CrossRef] [PubMed]
- Roychowdhury, S.; Koozekanani, D.D.; Parhi, K.K. DREAM: Diabetic retinopathy analysis using machine learning. IEEE J. Biomed. Health Inform. 2013, 18, 1717–1728. [Google Scholar] [CrossRef]
- Nayak, J.; Bhat, P.S.; Acharya, R.; Lim, C.M.; Kagathi, M. Automated identification of diabetic retinopathy stages using digital fundus images. J. Med. Syst. 2008, 32, 107–115. [Google Scholar] [CrossRef] [PubMed]
- Acharya, R.; Chua, C.K.; Ng, E.; Yu, W.; Chee, C. Application of higher order spectra for the identification of diabetes retinopathy stages. J. Med. Syst. 2008, 32, 481–488. [Google Scholar] [CrossRef] [PubMed]
- Adarsh, P.; Jeyakumari, D. Multiclass SVM-based automated diagnosis of diabetic retinopathy. In Proceedings of the 2013 International Conference on Communication and Signal Processing, Melmaruvathur, India, 3–5 April 2013; pp. 206–210. [Google Scholar]
- Tang, Y.; Wu, X. Saliency detection via combining region-level and pixel-level predictions with CNNs. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 809–825. [Google Scholar]
- Lee, C.-Y.; Xie, S.; Gallagher, P.; Zhang, Z.; Tu, Z. Deeply-supervised nets. In Proceedings of the Artificial Intelligence and Statistics, San Diego, CA, USA, 9–12 June 2015; pp. 562–570. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 770–778. [Google Scholar]
- Hussain, A.; Draz, U.; Ali, T.; Tariq, S.; Irfan, M.; Glowacz, A.; Daviu, J.A.A.; Yasin, S.; Rahman, S. Waste Management and Prediction of Air Pollutants Using IoT and Machine Learning Approach. Energies 2020, 13, 3930. [Google Scholar] [CrossRef]
- Ali, G.; Ali, T.; Irfan, M.; Draz, U.; Sohail, M.; Glowacz, A.; Sulowicz, M.; Mielnik, R.; Bin Faheem, Z.; Martis, C. IoT Based Smart Parking System Using Deep Long Short Memory Network. Electronics 2020, 9, 1696. [Google Scholar] [CrossRef]
- Shaf, A.; Ali, T.; Farooq, W.; Javaid, S.; Draz, U.; Yasin, S. Two classes classification using different optimizers in convolutional neural network. In Proceedings of the 2018 IEEE 21st International Multi-Topic Conference (INMIC), Karachi, Pakistan, 1–2 November 2018; pp. 1–6. [Google Scholar]
- Ali, T.; Masood, K.; Irfan, M.; Draz, U.; Nagra, A.; Asif, M.; Alshehri, B.; Glowacz, A.; Tadeusiewicz, R.; Mahnashi, M.; et al. Multistage Segmentation of Prostate Cancer Tissues Using Sample Entropy Texture Analysis. Entropy 2020, 22, 1370. [Google Scholar] [CrossRef] [PubMed]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Title 1 | Approach | Databases | Results |
|---|---|---|---|
| Orlando et al., 2018 [15] | Patch-based convolutional NN and conventional candidate selection trailed by random forest (RF) and including the manually made features | Messidor, E-Ophtha, and DIARETDB1 | DR Screening on Messidor |
| Areas beneath the ROC curve = 0.893 Sensitivity = 0.911 | |||
| Need for referral on Messidor | |||
| Area under the receiver’s operating characteristic curve = 0.934 Sensitivity = 0.974 | |||
| Areas beneath the ROC curve = 0.893 Sensitivity = 0.954 | |||
| Chudzik et al., 2018 [16] | CNN based on Patch technique and loss function (LF) | ROC, E-Ophtha, and DIARETDB1 | Free-response receiver operating characteristic Curves |
| Quellec et al., 2017 [17] | Pixel-based visualization with image-based CNN, and classifier named as spatiotemporal features map (STFM) | Private, DIARETDB1, and Kaggle | Required for recommendation on Kaggle test-dataset |
| Areas beneath the ROC curve = 0.893 Sensitivity = 0.954 | |||
| Ting et al., 2017 [18] | Group of eight image-based convolutional NNs which use a variation of the VGG-Net | Personally collected dataset | Screening of diabetic retinopathy |
| Area under the receiver’s operating characteristic curve = 0.936 | |||
| Required for recommendation | |||
| Areas beneath the ROC curve = 0.893 Sensitivity = 0.958 | |||
| Gargeya et al., 2017 [19] | Minor image-based convolutional NN, augmentation of data by rotation, contrast, and intensity enhancement, evaluated on more than 75,000 images | EyePACS-1 dataset for training and Messidor-2 dataset for testing | Required for a recommendation of diabetic retinopathy on Messidor-2 |
| Area under the receiver’s operating characteristic curve = 0.94 | |||
| Sensitivity = 0.93 | |||
| Specificity = 0.87 | |||
| Gulshan et al., 2016 [20] | A collection of Inception-V3 architecture that is trained on more than 100,000 images, including many grades for each image and two images for each subject | Messidor-2, Private and (EyePACS)-1 | Required for a recommendation of diabetic retinopathy on Messidor-2 |
| Area under the receiver’s operating characteristic curve = 0.999 |
| Category | Preprocessing | Labels | Number of Images | Classification Accuracy | |||
|---|---|---|---|---|---|---|---|
| Normal | Augmentation | Balancing | Inception-ResNet | State-of-the-Art NN | |||
| A | Not used | Not used | Not used | Mild DR | 27 | 0 | 0 |
| Moderate DR | 171 | 57.82 | 71.03 | ||||
| Normal DR | 169 | 79.00 | 56.55 | ||||
| PDR | 153 | 55.52 | 52.88 | ||||
| Final | 520 | 61.35 | 45.13 | ||||
| B | Used | Not used | Not used | Mild DR | 27 | 0 | 0 |
| Moderate DR | 171 | 28.41 | 29.51 | ||||
| Normal DR | 169 | 81.00 | 78.51 | ||||
| PDR | 153 | 88.13 | 81.41 | ||||
| Final | 520 | 63.98 | 46.17 | ||||
| C | Used | Used | Not used | Mild DR | 52 | 0 | 0 |
| Moderate DR | 332 | 36.62 | 13.77 | ||||
| Normal DR | 334 | 88.00 | 97.58 | ||||
| PDR | 310 | 93.62 | 83.49 | ||||
| Final | 1028 | 68.86 | 48.46 | ||||
| D | Used | Not used | Used | Mild DR | 30 | 41.86 | 71.59 |
| Moderate DR | 25 | 41.86 | 12.76 | ||||
| Normal DR | 45 | 72.43 | 11.66 | ||||
| PDR | 50 | 94.43 | 98.86 | ||||
| Final | 150 | 69.34 | 47.04 | ||||
| E | Used | Used | Used | Mild DR | 55 | 92.34 | 92.34 |
| Moderate DR | 55 | 67.66 | 21.23 | ||||
| Normal DR | 55 | 98.95 | 55.33 | ||||
| PDR | 100 | 90.95 | 93.33 | ||||
| Final | 265 | 88.10 | 65.00 | ||||
| Techniques | Labels | Data | CA% | |
|---|---|---|---|---|
| ResNet | Inception-ResNet | |||
| Two-stage proposed system (Case E) | Mild | 50 | 93.33 | 93.33 |
| Moderate | 50 | 20 | 66.67 | |
| Normal | 50 | 53.33 | 100 | |
| Severe | 50 | 86.66 | 93.33 | |
| PDR | 50 | 86.67 | 87.33 | |
| Total | 1250 | 65.00 | 86.67 | |
| Inception/ResNet ensemble | Total Images | 56 | 83.90 | |
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | 2.0 | 1.5 | 2.0 | 1.5 |
| 1 | 2.5 | 2.0 | 2.0 | 2.0 |
| 2 | 2.0 | 2.0 | 2.0 | 2.5 |
| 3 | 3.0 | 2.0 | 2.0 | 2.5 |
| 4 | 2.0 | 1.5 | 2.0 | 2.0 |
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | 1.0000 | 0.9634 | 0.9563 | 0.9544 |
| 1 | 0.9634 | 1.0000 | 0.9696 | 0.9480 |
| 2 | 0.9563 | 0.9696 | 1.0000 | 0.9488 |
| 3 | 0.9544 | 0.9480 | 0.9468 | 1.0000 |
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| Count | 1927.00 | 1927.00 | 1927.00 | 1927.00 |
| Std | 0.9737 | 0.9740 | 0.9706 | 0.9610 |
| Mean | 1.6877 | 1.7113 | 1.7162 | 1.6511 |
| min | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| 25% | 1.4000 | 2.0001 | 2.0001 | 1.3751 |
| 50% | 2.0001 | 2.0001 | 2.0001 | 2.0001 |
| 75% | 2.0001 | 2.0001 | 2.0001 | 2.0001 |
| max | 4.100 | 4.100 | 4.100 | 4.100 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yasin, S.; Iqbal, N.; Ali, T.; Draz, U.; Alqahtani, A.; Irfan, M.; Rehman, A.; Glowacz, A.; Alqhtani, S.; Proniewska, K.; et al. Severity Grading and Early Retinopathy Lesion Detection through Hybrid Inception-ResNet Architecture. Sensors 2021, 21, 6933. https://doi.org/10.3390/s21206933
Yasin S, Iqbal N, Ali T, Draz U, Alqahtani A, Irfan M, Rehman A, Glowacz A, Alqhtani S, Proniewska K, et al. Severity Grading and Early Retinopathy Lesion Detection through Hybrid Inception-ResNet Architecture. Sensors. 2021; 21(20):6933. https://doi.org/10.3390/s21206933
Chicago/Turabian StyleYasin, Sana, Nasrullah Iqbal, Tariq Ali, Umar Draz, Ali Alqahtani, Muhammad Irfan, Abdul Rehman, Adam Glowacz, Samar Alqhtani, Klaudia Proniewska, and et al. 2021. "Severity Grading and Early Retinopathy Lesion Detection through Hybrid Inception-ResNet Architecture" Sensors 21, no. 20: 6933. https://doi.org/10.3390/s21206933
APA StyleYasin, S., Iqbal, N., Ali, T., Draz, U., Alqahtani, A., Irfan, M., Rehman, A., Glowacz, A., Alqhtani, S., Proniewska, K., Brumercik, F., & Wzorek, L. (2021). Severity Grading and Early Retinopathy Lesion Detection through Hybrid Inception-ResNet Architecture. Sensors, 21(20), 6933. https://doi.org/10.3390/s21206933