
Determination of Chewing Count from Video Recordings Using Discrete Wavelet Decomposition and Low Pass Filtration


Abstract
1. Introduction
- We record chewing video data from 100 subjects at three speeds (slow, normal, and fast).
- We use image processing techniques to isolate and extract the videos of the subject’s face away from artifacts.
- We extract signals corresponding to the various movements during the chewing action.
- We propose two algorithms to count the number of chews automatically based on Discrete Wavelet Decomposition and low pass filters.
- We achieve a low mean percentage error in automatically counting the number of chews.
2. Background and Related Work
2.1. Chewing and Health
2.2. Automatic Chew Counting
3. Material and Methods
3.1. Ethical Approvals
3.2. Procedure
3.3. Participants
3.4. Data Collection
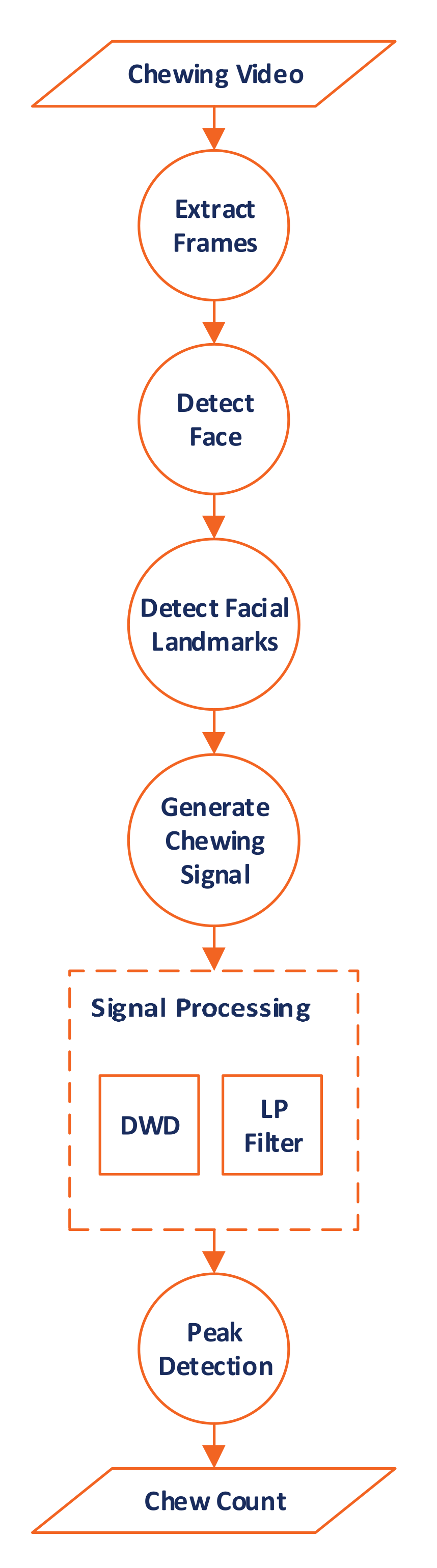
3.5. Determining the Chew Count
3.5.1. Face Detection
- The image is converted to gray scale, which reduces the overhead. However, once the face is detected, the location is marked in the colored image.
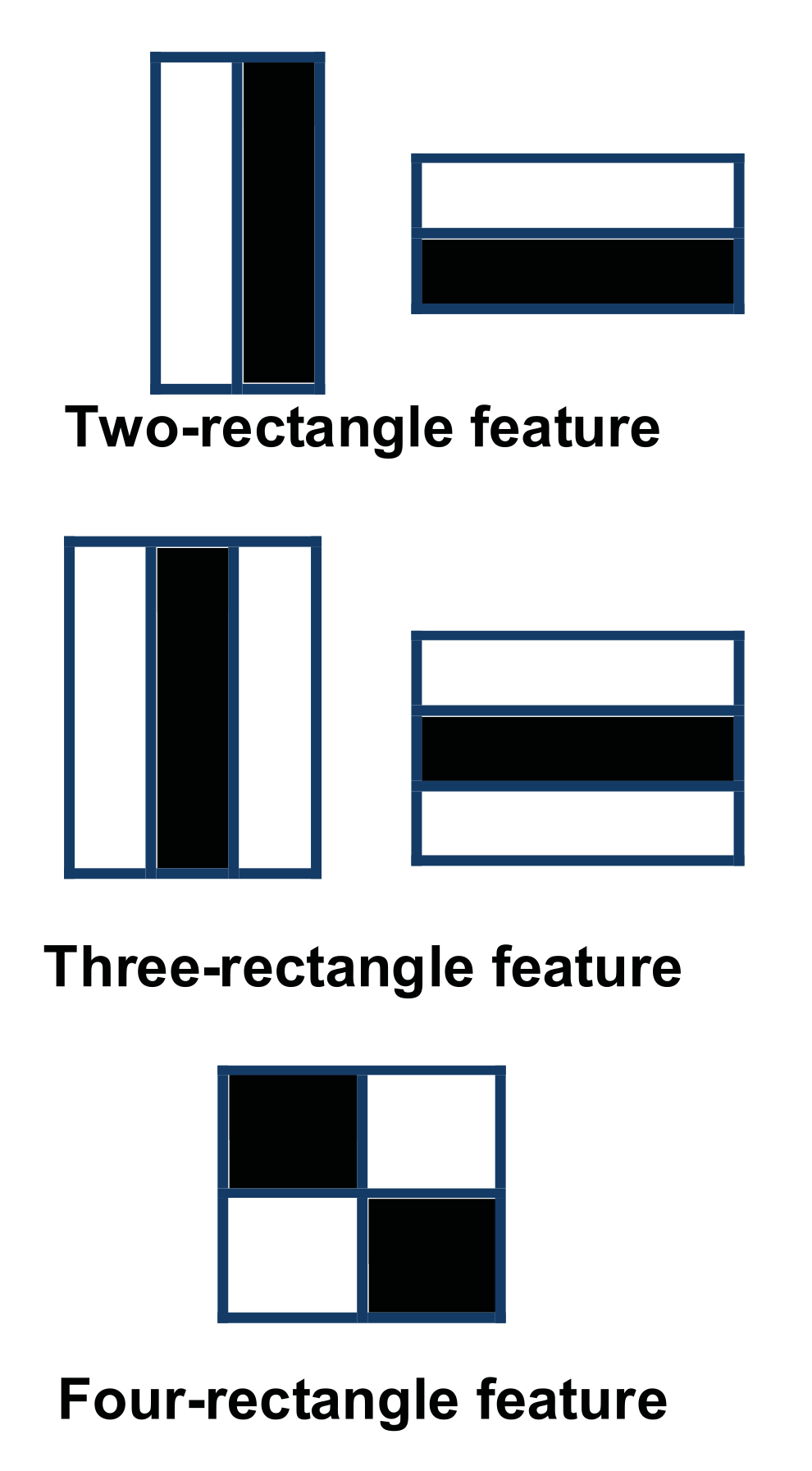
- The image is scanned to search for intensity differences that may represent facial features. This is done using boxes called Haar rectangles [34].These boxes are moved so that every tile in the image is covered. Figure 2 shows a set of three Haar features (HFs); two-rectangle, three-rectangle, and four-rectangle. These features represent regions with different shades in an image. For example, the eyebrows will appear darker in comparison to the surrounding skin. Similarly, the top of the nose may seem brighter than the sides.
- Each box is represented by a matrix of values corresponding to the pixel color intensities in that box. The darker the pixel the closer the corresponding value to 1. A Feature is generated by the difference between the sum of pixel values in the dark region and the sum of pixel values in the light region.
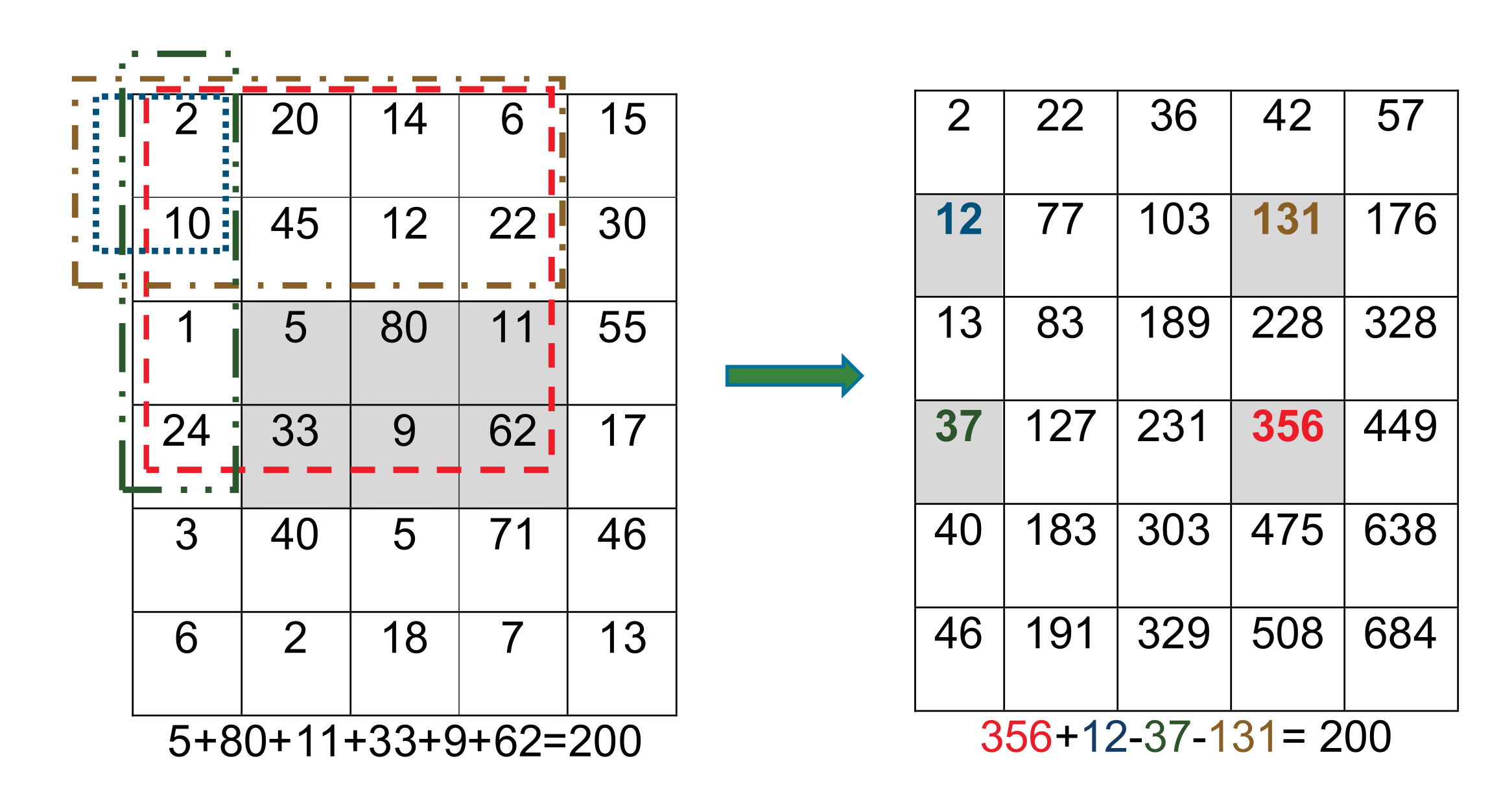
- The previous calculations can cause high computational overhead because of the large number of pixels. Therefore, the process is adjusted to use an integral image (i.e., a summed-area table). Each value, , in the integral image is the summation of all pixel values that lie above and to the left of in the original image inclusively, see Equation (1). Figure 3 shows an example matrix representing the original image and the corresponding integral image. Using the integral image, calculating the intensities of any rectangular area of any size in the original image requires four values only. Moreover, the integral image is calculated with a single pass over all pixels. This method greatly improves the efficiency of calculating the Haar feature rectangles.
- Scanning the image using the rectangular boxes will generate a set of intensity values, which form the input to the classification process. The output of this step indicates whether or not a feature is likely to be part of the face. The Viola-Jones algorithm uses adaptive boosting (AdaBoost), which employs a weak learner constraint to select few features out of thousands of possible features. The algorithm training dataset contained 4960 annotated facial images as well as 9544 other images without faces [32].
- Cascaded or ensemble classification. This step further refines the classification process by attempting to discard the background regions by increasing the complexity of classifiers in cascade. The collective effect of the weak classifiers selects the best combination of features and their associated weights.where is the value of the pixel at .


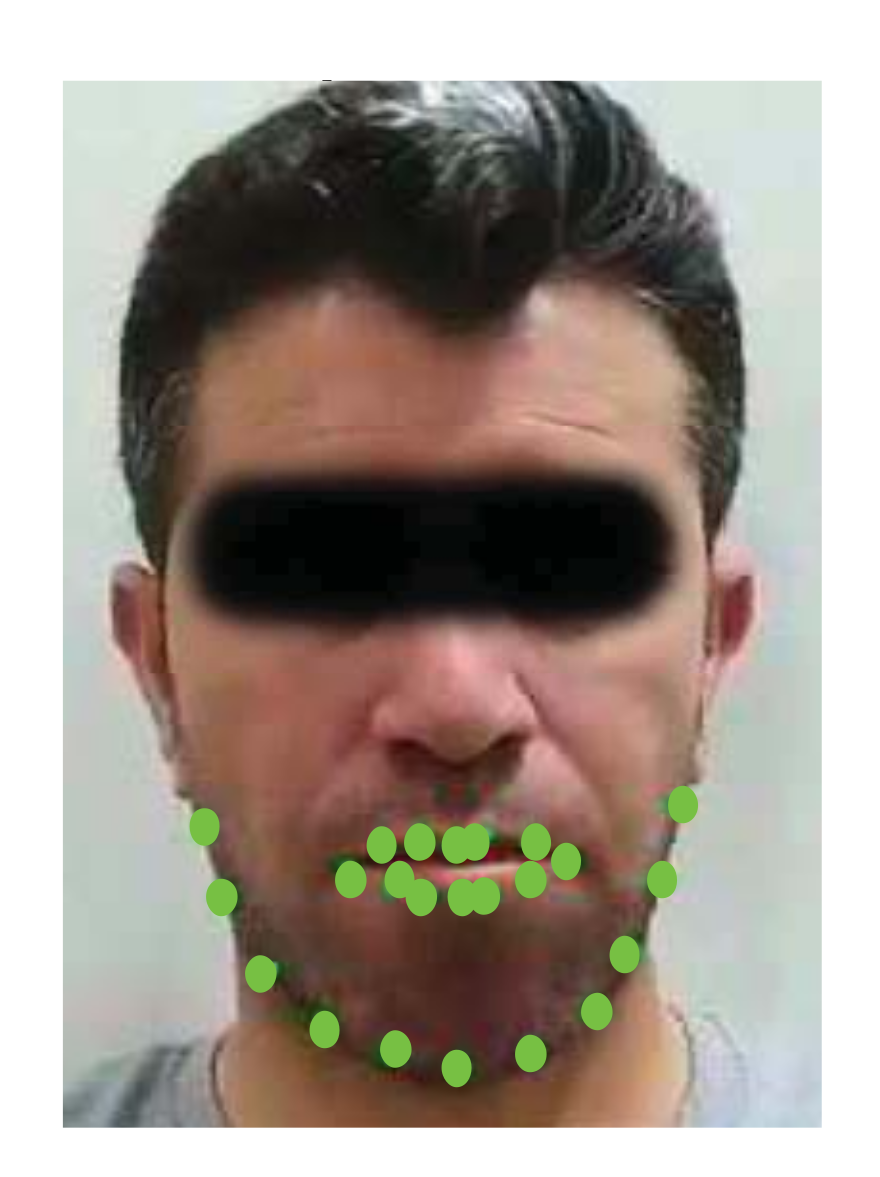
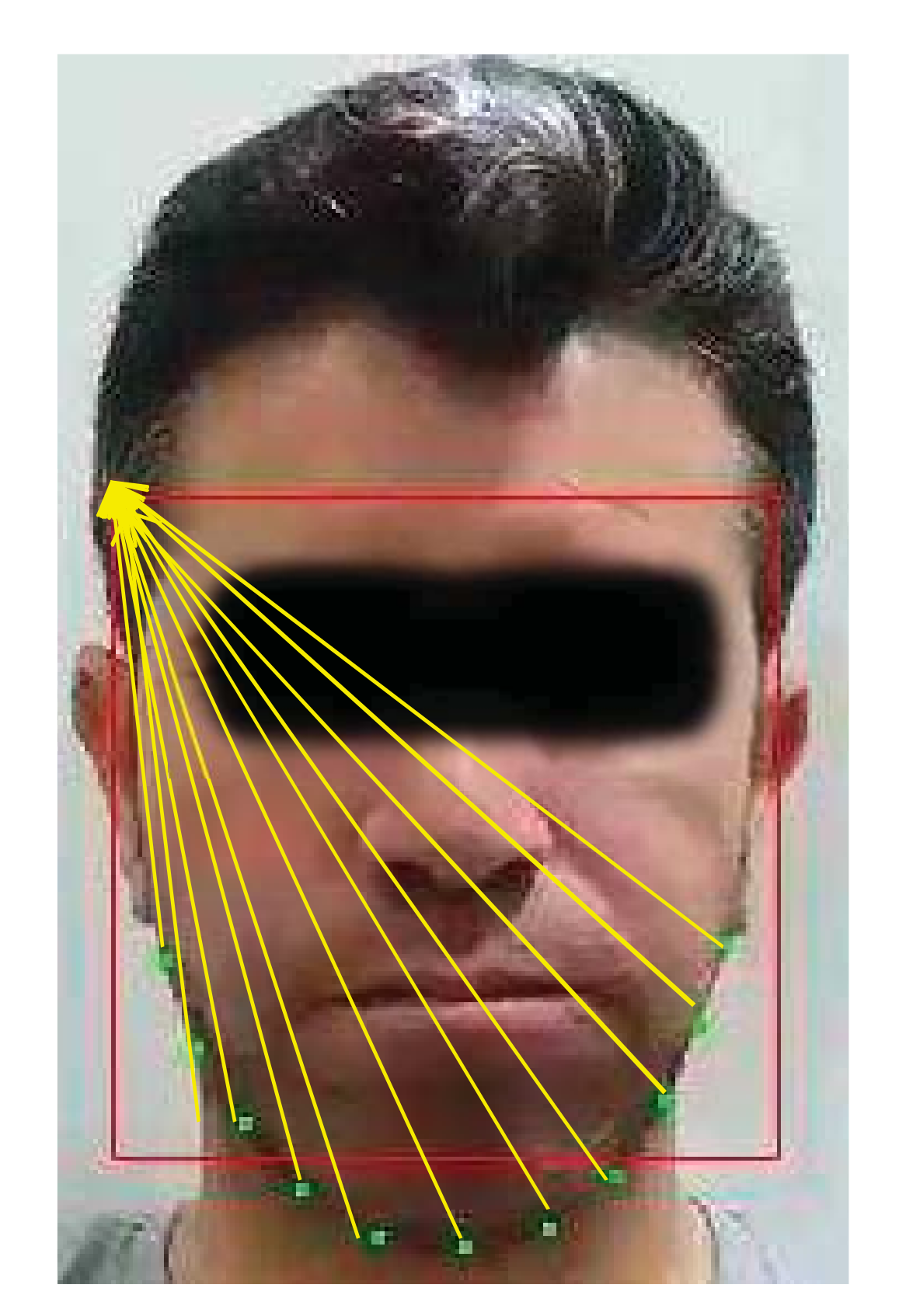
3.5.2. Facial Landmarks Detection
- The lower lip moves up and down during crushing the bolus in between the upper and lower jaws. Furthermore, the lower lip moves slightly to the left and right during the bolus motion in the mouth, but the motion of the lower lip decreases when the subject swallows. Moreover, the lower lip motion is undiscernible when the chewing speed is too slow and when the food texture is neither solid nor crispy. In addition, the separation between the two lips increases when the subject is taking a bite.
- The upper lip motion is unbeneficial for counting chews as it is undiscernible across video frames. This mainly due to its connection to the immobile maxilla.
- The corner points on the edge of the mouth move in an oval trajectory, which could be a result of smiling or other facial expressions. Thus, they were ignored.
- Up and down during for crushing/chewing the food.
- Sideways during bolus motion across the mouth sides.
- A large downward movement for every food bite.

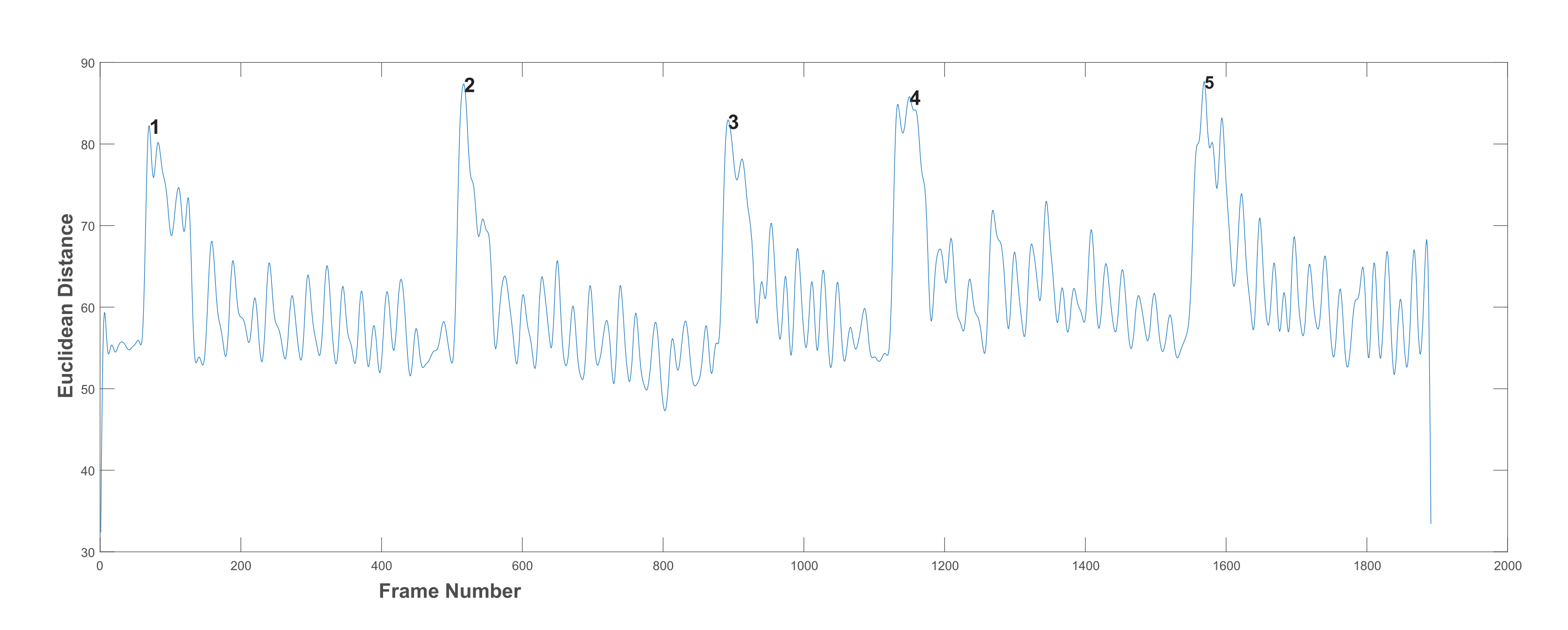
3.5.3. Generation of the Chewing Signal
3.5.4. Chewing Signal Processing
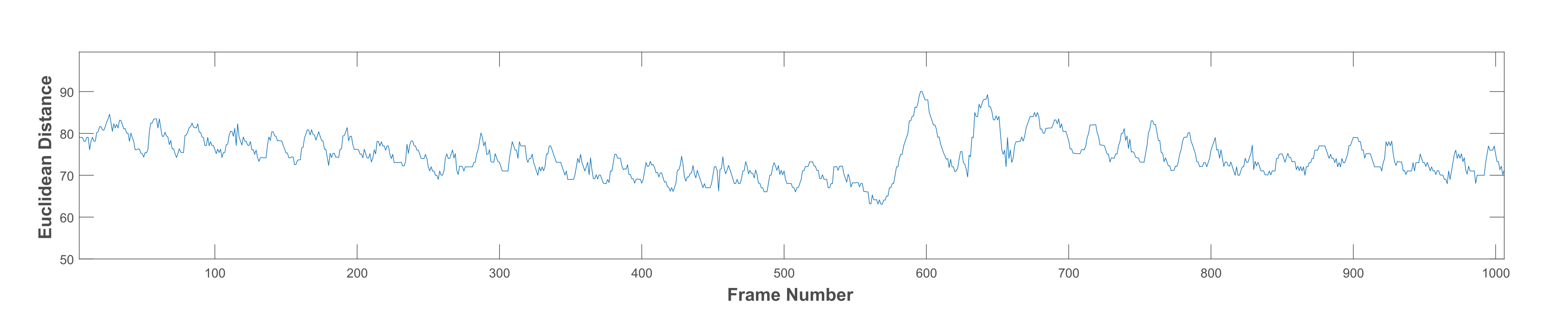
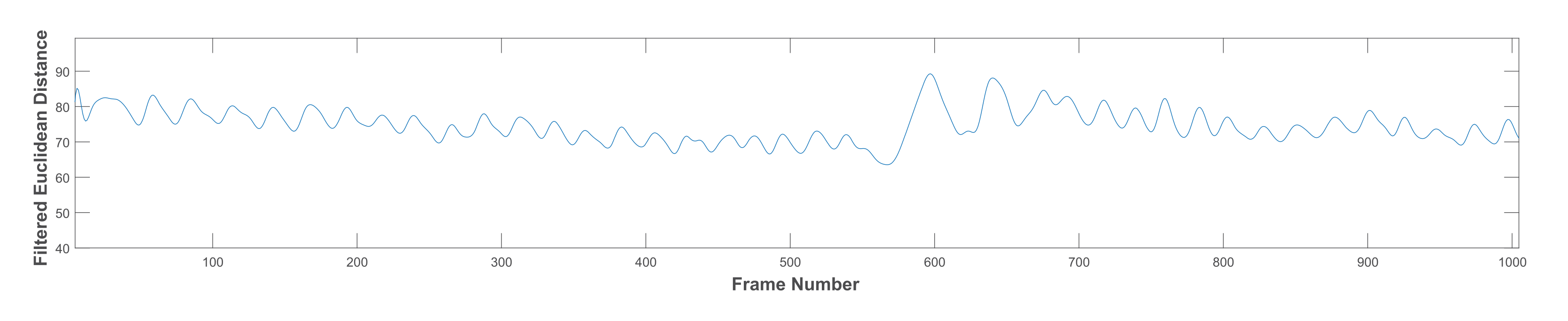
- Low pass filter (LPF): a LPF was designed with a cut-off frequency of 1 Hz and a sampling rate of 30 Hz [35]. It is a linear phase minimum order finite impulse response filter. The measured frequencies in the collected dataset ranged between 0.4 and 2.3 Hz for all chewing speeds. However, some of these frequencies resulted from variations in the mandible motion before the completion of one chew. Thus, the frequencies that are not representing actual chewing were removed. This was accomplished by assigning a proper passband frequency. Several passband frequencies and sampling rates were tested, and a 1 Hz passband frequency and 50 Hz sampling rate achieved the best results. Figure 7 shows the original signal with many fake peaks caused by noise. Whereas Figure 8 shows the smoothing of the signal and the elimination of most of these peaks after LPF application.
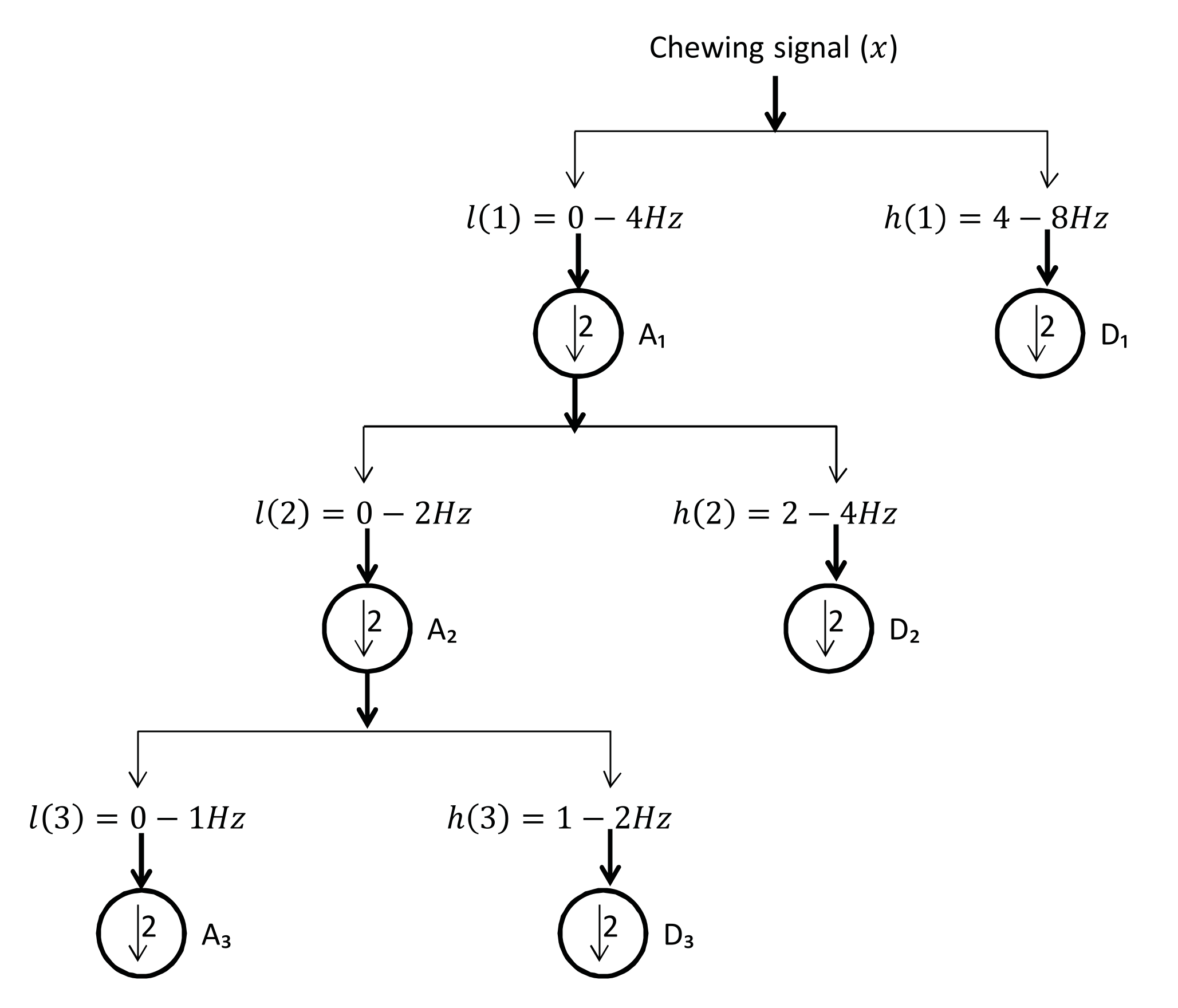
- Discrete wavelet decomposition (DWD): DWD is a discrete version of the continuous wavelet transform [36]. It retains the important features and reduces the computational complexity in comparison to the continuous wavelet transform [37]. In DWD, the signal is decomposed using low and high pass filters into approximation (A) and detail (D) coefficients, respectively. Further reduction to the frequency was achieved by applying the same procedure to the resulting approximation coefficients. A Daubechies mother wavelet with tab equal 4 was used, which achieve the best smoothing effect while retaining the important features. The sampling rate in the chewing signal was 30 Hz and the chewing signal frequency was 0–16 Hz, because of the noise in the signal that comes from the unwanted movements and from the fast chewing speed videos. Thus, three levels of decomposition were required to reach the closest frequency of chewing (i.e., 1–2 Hz) for normal speed, see Figure 9. This corresponds to 1 to 2 chews per second. The frequency resolution can be increased/decreased to match the chewing speed and the associated chewing signal frequency, see Figure 10.
3.5.5. Counting Chews
4. Results and Evaluation
4.1. Complexity Analysis
4.2. Performance Evaluation Metrics
4.3. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BMI | Body Mass Index |
| EMG | Electromyography |
| ANN | Artificial neural networks |
| AMM | Active appearance model |
| IRB | Institutional review board |
| KAUH | King Abdullah University Hospital |
| ICC | Intra-class correlation coefficient |
| HF | Haar feature |
| ERT | ensemble of regression trees |
| ED | Euclidean distance |
| LPF | Low pass filter |
| DWD | Discrete wavelet decomposition |
| MPH | Minimum-Peak-Height |
| PH | Peak heights |
| AE | Absolute error |
| MAPE | Mean absolute percentage error |
| RMSE | Root mean squared error |
References
- Fairburn, C.G.; Harrison, P.J. Eating disorders. Lancet 2003, 361, 407–416. [Google Scholar] [CrossRef]
- Fontana, J.M.; Higgins, J.A.; Schuckers, S.C.; Bellisle, F.; Pan, Z.; Melanson, E.L.; Neuman, M.R.; Sazonov, E. Energy intake estimation from counts of chews and swallows. Appetite 2015, 85, 14–21. [Google Scholar] [CrossRef]
- Farooq, M.; Sazonov, E. Automatic Measurement of Chew Count and Chewing Rate during Food Intake. Electronics 2016, 5, 62. [Google Scholar] [CrossRef]
- Fraiwan, M.; Almomani, F.; Hammouri, H. Body mass index and potential correlates among elementary school children in Jordan. Eat. Weight.-Disord.-Stud. Anorexia Bulim. Obes. 2021, 26, 629–638. [Google Scholar] [CrossRef] [PubMed]
- Révérend, B.J.D.L.; Edelson, L.R.; Loret, C. Anatomical, functional, physiological and behavioural aspects of the development of mastication in early childhood. Br. J. Nutr. 2013, 111, 403–414. [Google Scholar] [CrossRef] [PubMed]
- Grimm, E.R.; Steinle, N.I. Genetics of eating behavior: Established and emerging concepts. Nutr. Rev. 2011, 69, 52–60. [Google Scholar] [CrossRef] [PubMed]
- Bellisle, F. Why should we study human food intake behaviour? Nutr. Metab. Cardiovasc. Dis. 2003, 13, 189–193. [Google Scholar] [CrossRef]
- Okubo, H.; Murakami, K.; Masayasu, S.; Sasaki, S. The Relationship of Eating Rate and Degree of Chewing to Body Weight Status among Preschool Children in Japan: A Nationwide Cross-Sectional Study. Nutrients 2018, 11, 64. [Google Scholar] [CrossRef]
- Li, J.; Zhang, N.; Hu, L.; Li, Z.; Li, R.; Li, C.; Wang, S. Improvement in chewing activity reduces energy intake in one meal and modulates plasma gut hormone concentrations in obese and lean young Chinese men. Am. J. Clin. Nutr. 2011, 94, 709–716. [Google Scholar] [CrossRef]
- Zhu, Y.; Hollis, J.H. Increasing the Number of Chews before Swallowing Reduces Meal Size in Normal-Weight, Overweight, and Obese Adults. J. Acad. Nutr. Diet. 2014, 114, 926–931. [Google Scholar] [CrossRef]
- Lepley, C.; Throckmorton, G.; Parker, S.; Buschang, P.H. Masticatory Performance and Chewing Cycle Kinematics—Are They Related? Angle Orthod. 2010, 80, 295–301. [Google Scholar] [CrossRef]
- Spiegel, T. Rate of intake, bites, and chews—The interpretation of lean–obese differences. Neurosci. Biobehav. Rev. 2000, 24, 229–237. [Google Scholar] [CrossRef]
- Chen, H.; Iinuma, M.; Onozuka, M.; Kubo, K.Y. Chewing Maintains Hippocampus-Dependent Cognitive Function. Int. J. Med. Sci. 2015, 12, 502–509. [Google Scholar] [CrossRef] [PubMed]
- Chuhuaicura, P.; Dias, F.J.; Arias, A.; Lezcano, M.F.; Fuentes, R. Mastication as a protective factor of the cognitive decline in adults: A qualitative systematic review. Int. Dent. J. 2019, 69, 334–340. [Google Scholar] [CrossRef] [PubMed]
- Lin, C. Revisiting the link between cognitive decline and masticatory dysfunction. BMC Geriatr. 2018, 18, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Hansson, P.; Sunnegårdh-Grönberg, K.; Bergdahl, J.; Bergdahl, M.; Nyberg, L.; Nilsson, L.G. Relationship between natural teeth and memory in a healthy elderly population. Eur. J. Oral Sci. 2013, 121, 333–340. [Google Scholar] [CrossRef]
- Vu, T.; Lin, F.; Alshurafa, N.; Xu, W. Wearable Food Intake Monitoring Technologies: A Comprehensive Review. Computers 2017, 6, 4. [Google Scholar] [CrossRef]
- Moraru, A.M.O.; Preoteasa, C.T.; Preoteasa, E. Masticatory function parameters in patients with removable dental prosthesis. J. Med. Life 2019, 12, 43–48. [Google Scholar] [CrossRef]
- Rustagi, S.; Sodhi, N.S.; Dhillon, B. A study to investigate reproducibility of chewing behaviour of human subjects within session recordings for different textured Indian foods using electromyography. Pharma Innov. J. 2018, 7, 5–9. [Google Scholar]
- Smit, H.J.; Kemsley, E.K.; Tapp, H.S.; Henry, C.J.K. Does prolonged chewing reduce food intake? Fletcherism revisited. Appetite 2011, 57, 295–298. [Google Scholar] [CrossRef]
- Révérend, B.L.; Saucy, F.; Moser, M.; Loret, C. Adaptation of mastication mechanics and eating behaviour to small differences in food texture. Physiol. Behav. 2016, 165, 136–145. [Google Scholar] [CrossRef]
- Farooq, M.; Sazonov, E. Comparative testing of piezoelectric and printed strain sensors in characterization of chewing. In Proceedings of the 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015. [Google Scholar]
- Amft, O.; Kusserow, M.; Troster, G. Bite Weight Prediction From Acoustic Recognition of Chewing. IEEE Trans. Biomed. Eng. 2009, 56, 1663–1672. [Google Scholar] [CrossRef]
- Bedri, A.; Li, R.; Haynes, M.; Kosaraju, R.P.; Grover, I.; Prioleau, T.; Beh, M.Y.; Goel, M.; Starner, T.; Abowd, G. EarBit. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2017, 1, 1–20. [Google Scholar] [CrossRef]
- Papapanagiotou, V.; Diou, C.; Zhou, L.; van den Boer, J.; Mars, M.; Delopoulos, A. A novel approach for chewing detection based on a wearable PPG sensor. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016. [Google Scholar]
- Hossain, D.; Ghosh, T.; Sazonov, E. Automatic Count of Bites and Chews From Videos of Eating Episodes. IEEE Access 2020, 8, 101934–101945. [Google Scholar] [CrossRef] [PubMed]
- Cadavid, S.; Abdel-Mottaleb, M.; Helal, A. Exploiting visual quasi-periodicity for real-time chewing event detection using active appearance models and support vector machines. Pers. Ubiquitous Comput. 2011, 16, 729–739. [Google Scholar] [CrossRef]
- Nyamukuru, M.T.; Odame, K.M. Tiny Eats: Eating Detection on a Microcontroller. In Proceedings of the 2020 IEEE Second Workshop on Machine Learning on Edge in Sensor Systems (SenSys-ML), Sydney, Australia, 21 April 2020. [Google Scholar]
- Little, M.A.; Varoquaux, G.; Saeb, S.; Lonini, L.; Jayaraman, A.; Mohr, D.C.; Kording, K.P. Using and understanding cross-validation strategies. Perspectives on Saeb et al. GigaScience 2017, 6, gix020. [Google Scholar] [CrossRef] [PubMed]
- Bartko, J.J. The Intraclass Correlation Coefficient as a Measure of Reliability. Psychol. Rep. 1966, 19, 3–11. [Google Scholar] [CrossRef]
- Shrout, P.E.; Fleiss, J.L. Intraclass correlations: Uses in assessing rater reliability. Psychol. Bull. 1979, 86, 420–428. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2001), Kauai, HI, USA, 8–14 December 2001; pp. 511–518. [Google Scholar]
- Kazemi, V.; Sullivan, J. One millisecond face alignment with an ensemble of regression trees. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition 2014, Columbus, OH, USA, 23–28 June 2014; pp. 1867–1874. [Google Scholar]
- Wilson, P.I.; Fernandez, J.D. Facial feature detection using Haar classifiers. J. Comput. Sci. Coll. 2006, 21, 127–133. [Google Scholar]
- Rabiner, L. Approximate design relationships for low-pass FIR digital filters. IEEE Trans. Audio Electroacoust. 1973, 21, 456–460. [Google Scholar] [CrossRef][Green Version]
- Shensa, M. The discrete wavelet transform: Wedding the a trous and Mallat algorithms. IEEE Trans. Signal Process. 1992, 40, 2464–2482. [Google Scholar] [CrossRef]
- Alafeef, M.; Fraiwan, M. Smartphone-based respiratory rate estimation using photoplethysmographic imaging and discrete wavelet transform. J. Ambient Intell. Humaniz. Comput. 2019, 11, 693–703. [Google Scholar] [CrossRef]
- Ren, J.; Kehtarnavaz, N.; Estevez, L. Real-time optimization of Viola-Jones face detection for mobile platforms. In Proceedings of the 2008 IEEE Dallas Circuits and Systems Workshop: System-on-Chip- Design, Applications, Integration, and Software, Richardson, TX, USA, 19–20 October 2008; pp. 1–4. [Google Scholar] [CrossRef]
- Bodini, M. A Review of Facial Landmark Extraction in 2D Images and Videos Using Deep Learning. Big Data Cogn. Comput. 2019, 3, 14. [Google Scholar] [CrossRef]
- Barina, D. Real-time wavelet transform for infinite image strips. J. Real-Time Image Process. 2020, 18, 585–591. [Google Scholar] [CrossRef]
- Bland, J.M.; Altman, D. Statistical methods for assessing agreement between two methods of clinical measurement. Lancet 1986, 327, 307–310. [Google Scholar] [CrossRef]
- Farooq, M.; Sazonov, E. Linear regression models for chew count estimation from piezoelectric sensor signals. In Proceedings of the 2016 10th International Conference on Sensing Technology (ICST), Nanjing, China, 11–13 November 2016. [Google Scholar] [CrossRef]
- Taniguchi, K.; Kondo, H.; Tanaka, T.; Nishikawa, A. Earable RCC: Development of an Earphone-Type Reliable Chewing-Count Measurement Device. J. Healthc. Eng. 2018, 2018, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Zhou, G.; Ma, Y.; Hu, L.; Chen, Z.; Chen, Y.; Zhao, H.; Jung, W. Eating detection and chews counting through sensing mastication muscle contraction. Smart Health 2018, 9, 179–191. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M.J. Robust Real-Time Face Detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Annotator∖Chewing Speed | Fast | Medium | Slow |
|---|---|---|---|
| All | 0.91 | 0.94 | 0.96 |
| 1 & 2 | 0.88 | 0.90 | 0.92 |
| 2 & 3 | 0.83 | 0.90 | 0.95 |
| 1 & 3 | 0.90 | 0.94 | 0.95 |
| Chewing Speed | LPF | DWD | ||||
|---|---|---|---|---|---|---|
| Slow | 5.42 | 0 | 4.61 | 5.72 | 0 | 4.8 |
| Normal | 7.47 | 0 | 6.85 | 7.45 | 0 | 6.85 |
| Fast | 9.84 | 0 | 9.55 | 10.32 | 0 | 10.42 |
| Chewing Speed | MAPE (LPF) | MAPE (DWD) |
|---|---|---|
| Slow | 6.48% | 9.09% |
| Normal | 7.76% | 7.03% |
| Fast | 8.38% | 8.31% |
| Chewing Speed | RMSE (LPF) | RMSE (DWD) |
|---|---|---|
| Slow | 5.56 | 7.64 |
| Normal | 7.93 | 7.09 |
| Fast | 13.03 | 13.43 |
| Study | Avg Error ± SD | Counting Method | No. of Subjects | |
|---|---|---|---|---|
| Farooq and Sazonov [3] | 10.40% ± 7.03% | Peak detection in manually annotated segments | 30 | |
| 15.01%± 11.06% | Counting in ANN classified epochs | 30 | ||
| Farooq and Sazonov [22] | 8.09% ± 7.16% | Piezoelectric strain sensor | 5 | |
| 8.26% ± 7.51% | Piezoelectric strain sensor | 5 | ||
| Farooq and Sazonov [42] | 9.66% ± 6.28% | Linear regression of piezoelectric sensor signal | 10 | |
| Bedri et al. [24] | F1-score = 90.9% | Acoustic sensor | 10 | |
| Cadavid et al. [27] | Avg agreement = 93% | SVM classification of AMM spectral features | 37 | |
| Taniguchi et al. [43] | Precision = 0.958 | Earphone sensor | 6 | |
| Wang et al. [44] | 12.2% | Triaxial accelerometer on the temporalis | 4 | |
| Hossain et al. [26] | Mean accuracy 88.9% ±7.4% | Deep learning and affine optical flow | 28 | |
| This paper | 5.42% ± 4.61 (slow) 7.47% ± 6.85 (normal) 9.84% ± 9.55 (fast) | Image processing of chewing videos | 100 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alshboul, S.; Fraiwan, M. Determination of Chewing Count from Video Recordings Using Discrete Wavelet Decomposition and Low Pass Filtration. Sensors 2021, 21, 6806. https://doi.org/10.3390/s21206806
Alshboul S, Fraiwan M. Determination of Chewing Count from Video Recordings Using Discrete Wavelet Decomposition and Low Pass Filtration. Sensors. 2021; 21(20):6806. https://doi.org/10.3390/s21206806
Chicago/Turabian StyleAlshboul, Sana, and Mohammad Fraiwan. 2021. "Determination of Chewing Count from Video Recordings Using Discrete Wavelet Decomposition and Low Pass Filtration" Sensors 21, no. 20: 6806. https://doi.org/10.3390/s21206806
APA StyleAlshboul, S., & Fraiwan, M. (2021). Determination of Chewing Count from Video Recordings Using Discrete Wavelet Decomposition and Low Pass Filtration. Sensors, 21(20), 6806. https://doi.org/10.3390/s21206806