
A Cost-Efficient High-Speed VLSI Architecture for Spiking Convolutional Neural Network Inference Using Time-Step Binary Spike Maps

 ,
,
Abstract
:1. Introduction
2. Background
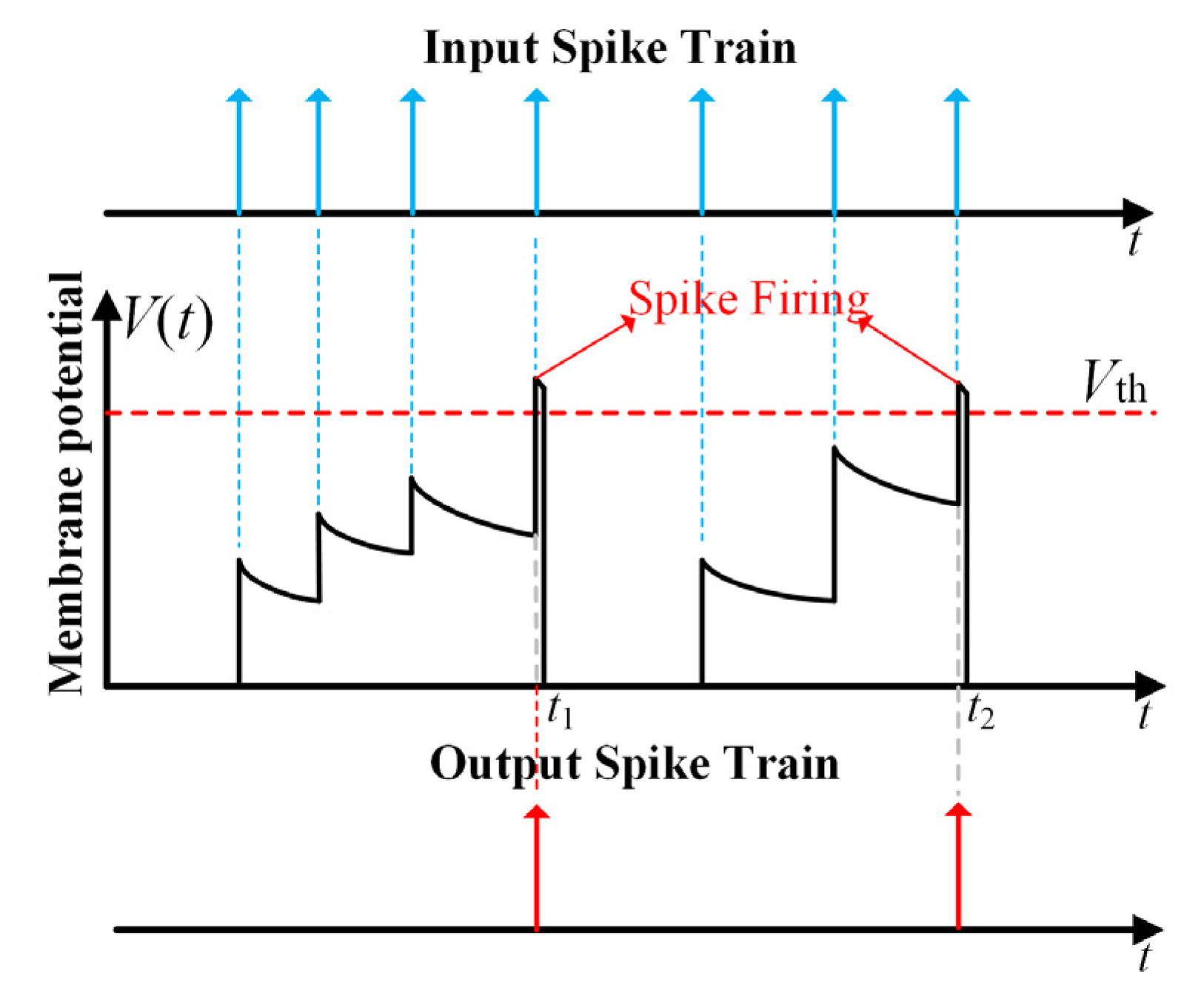
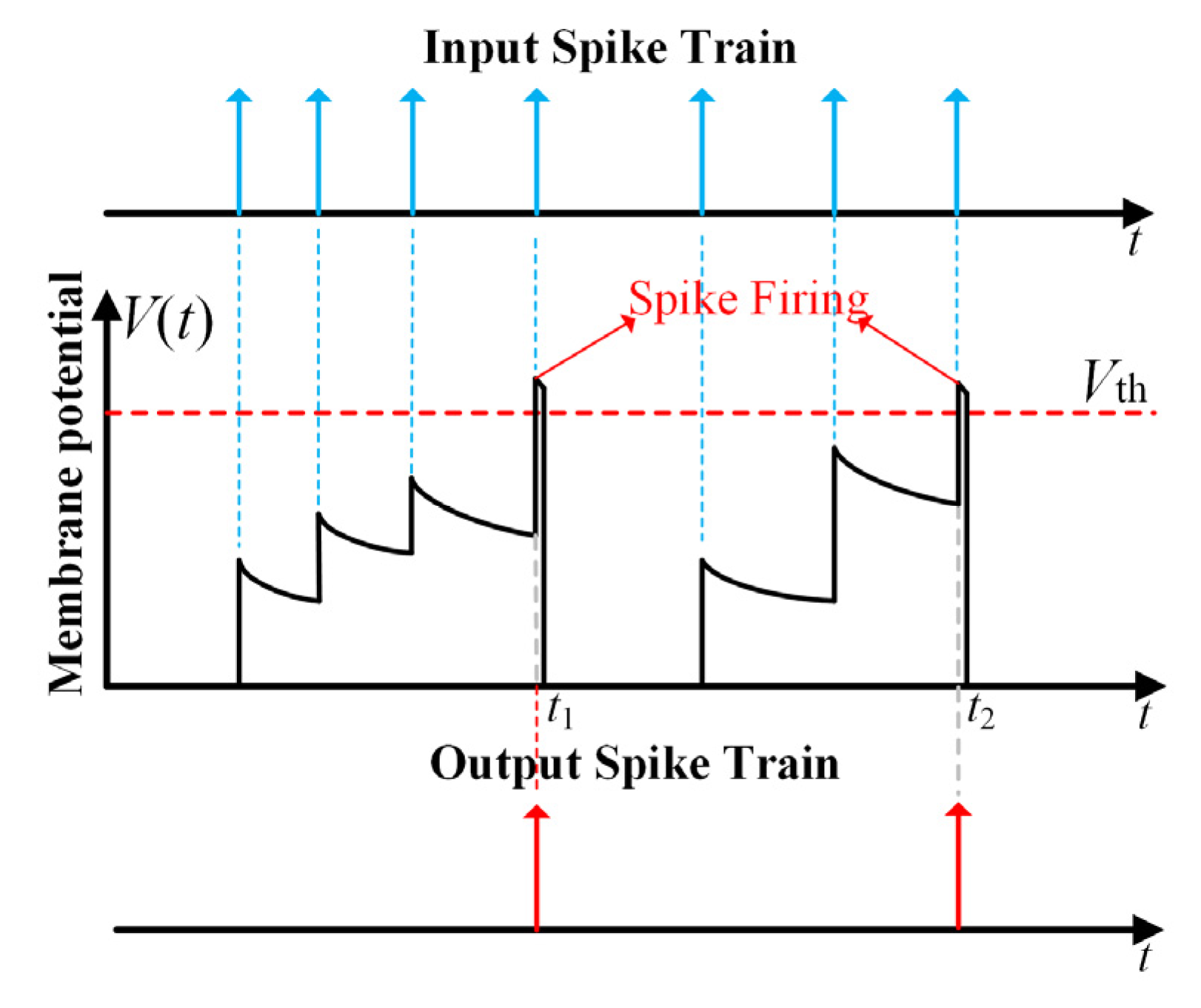
2.1. Biological Spiking Neuron Model
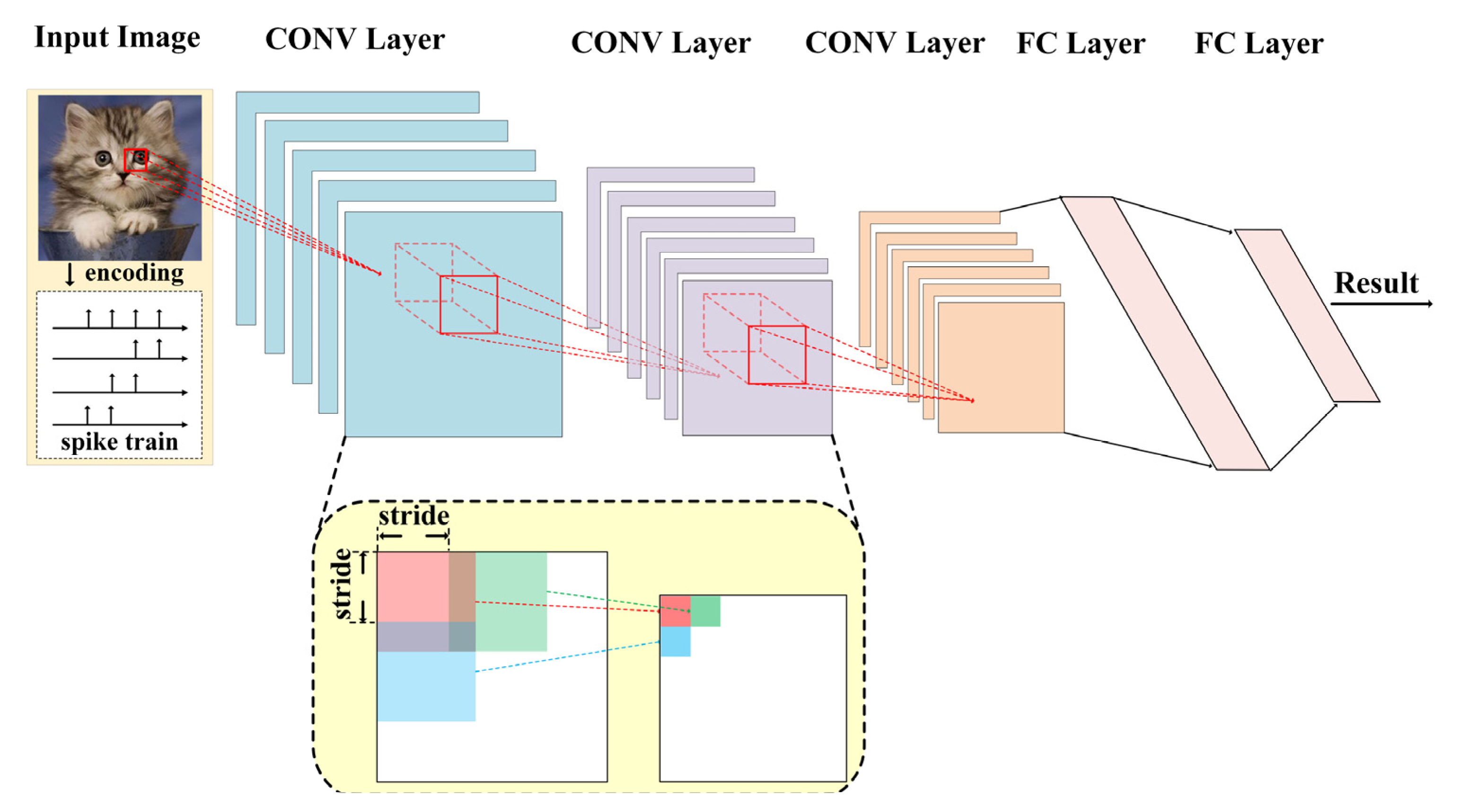
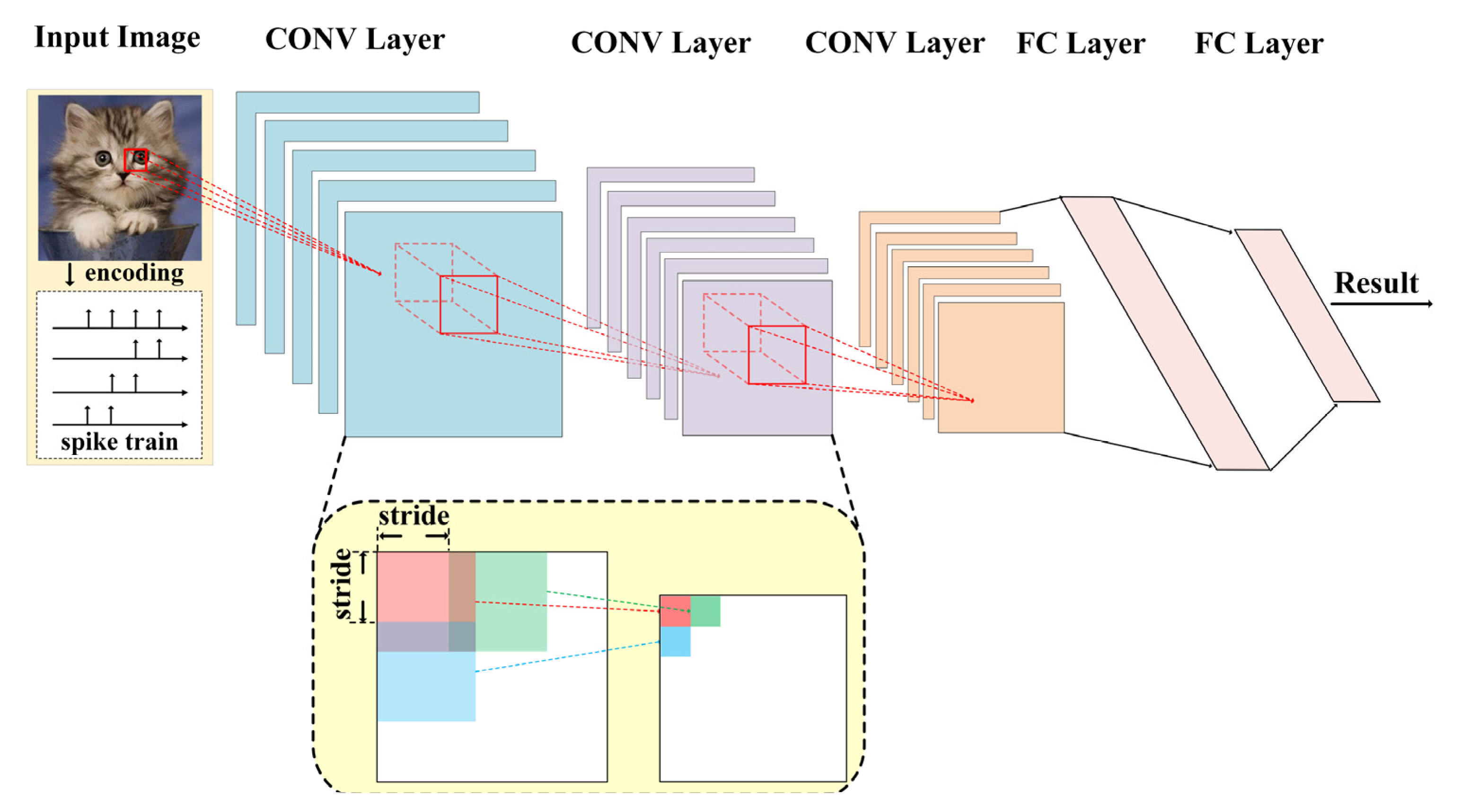
2.2. Spiking Convolution Neural Network
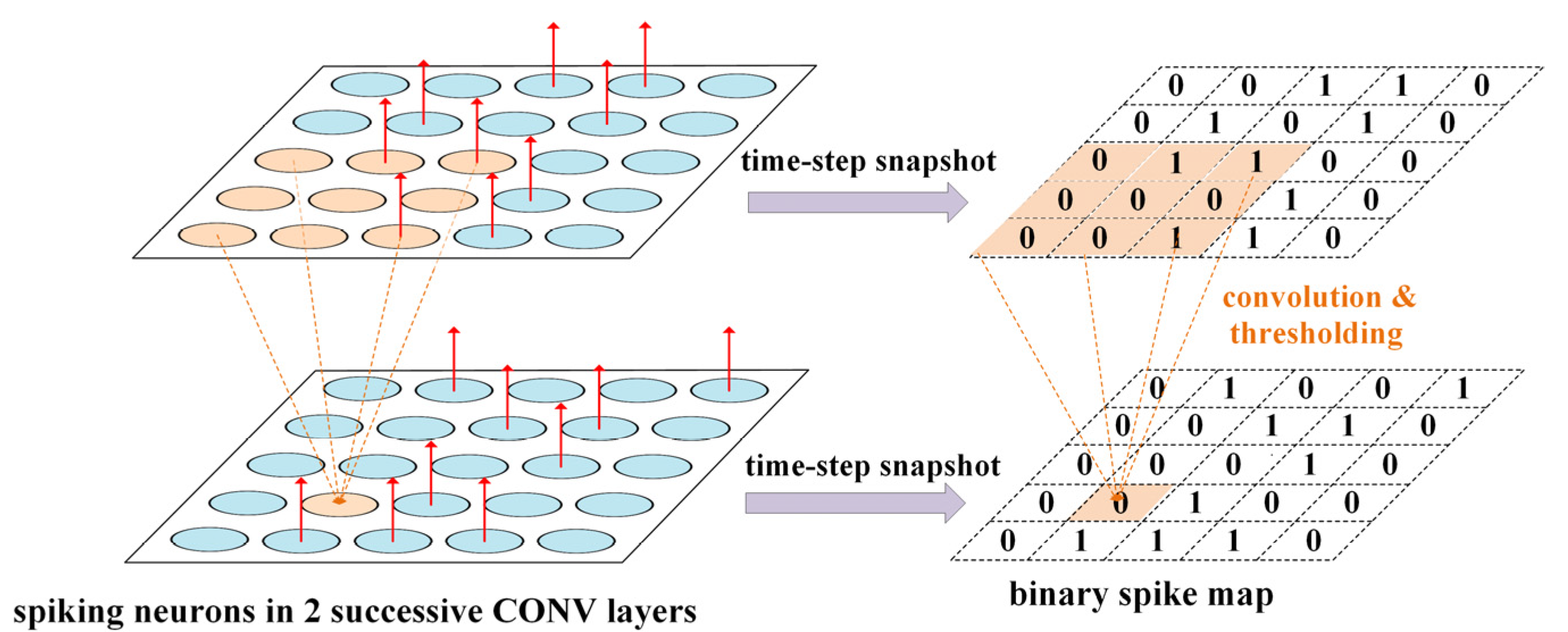
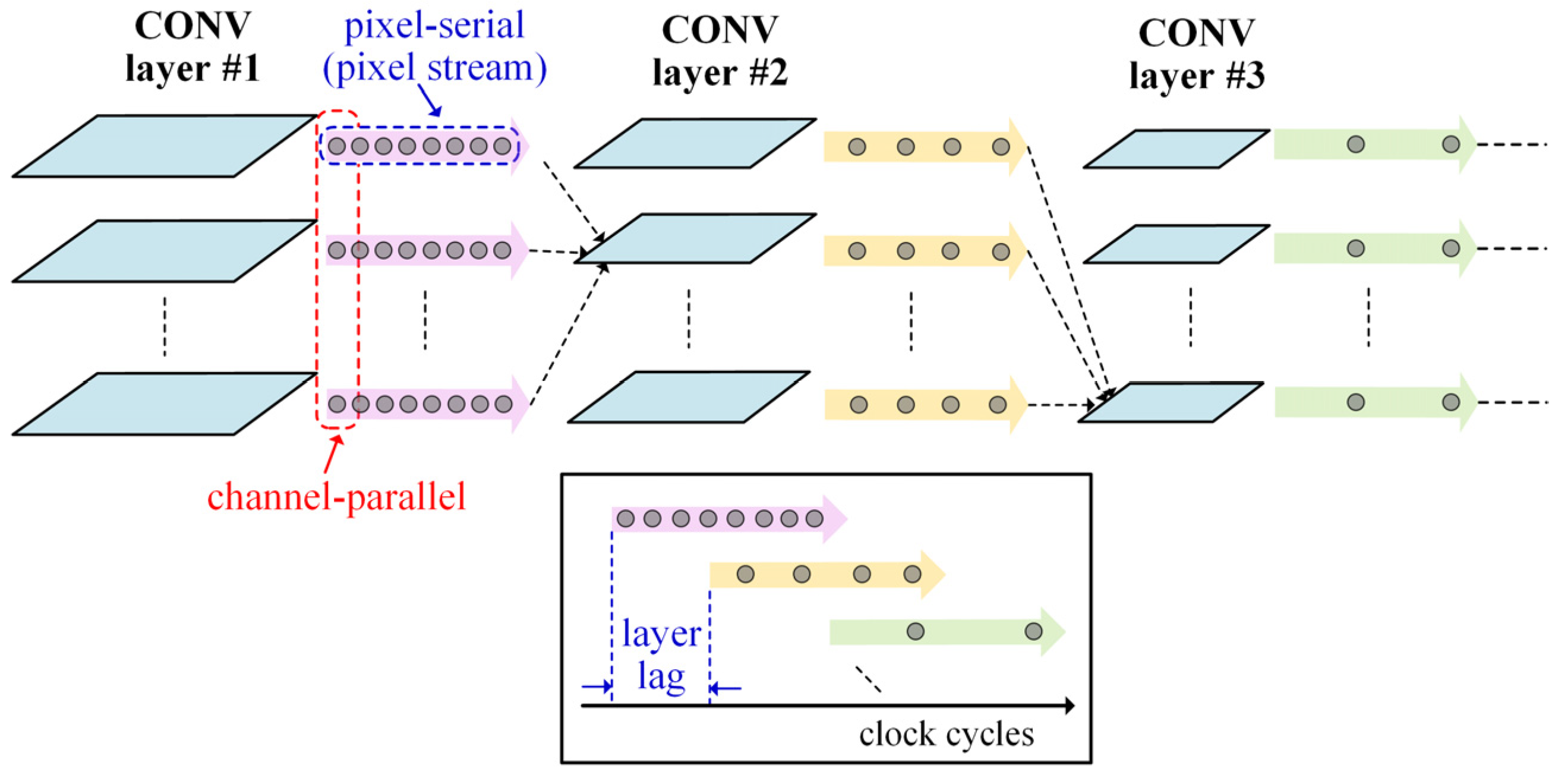
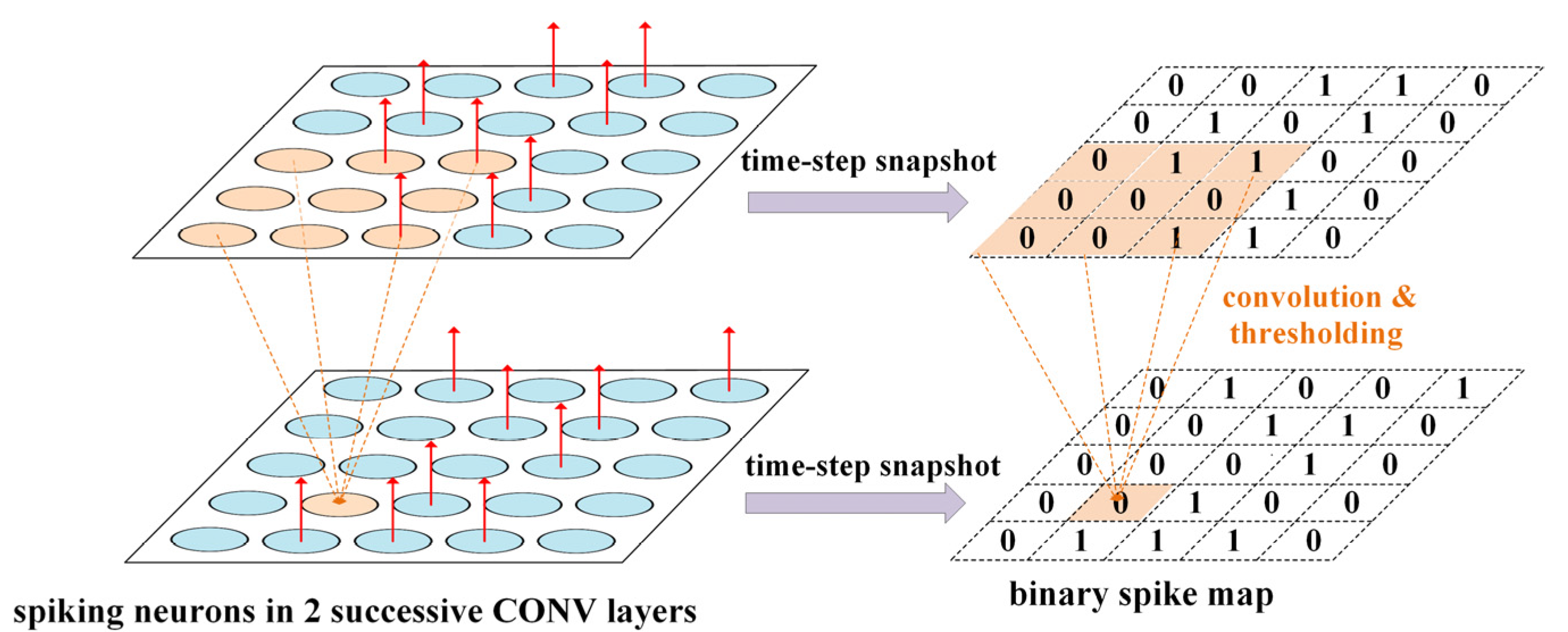
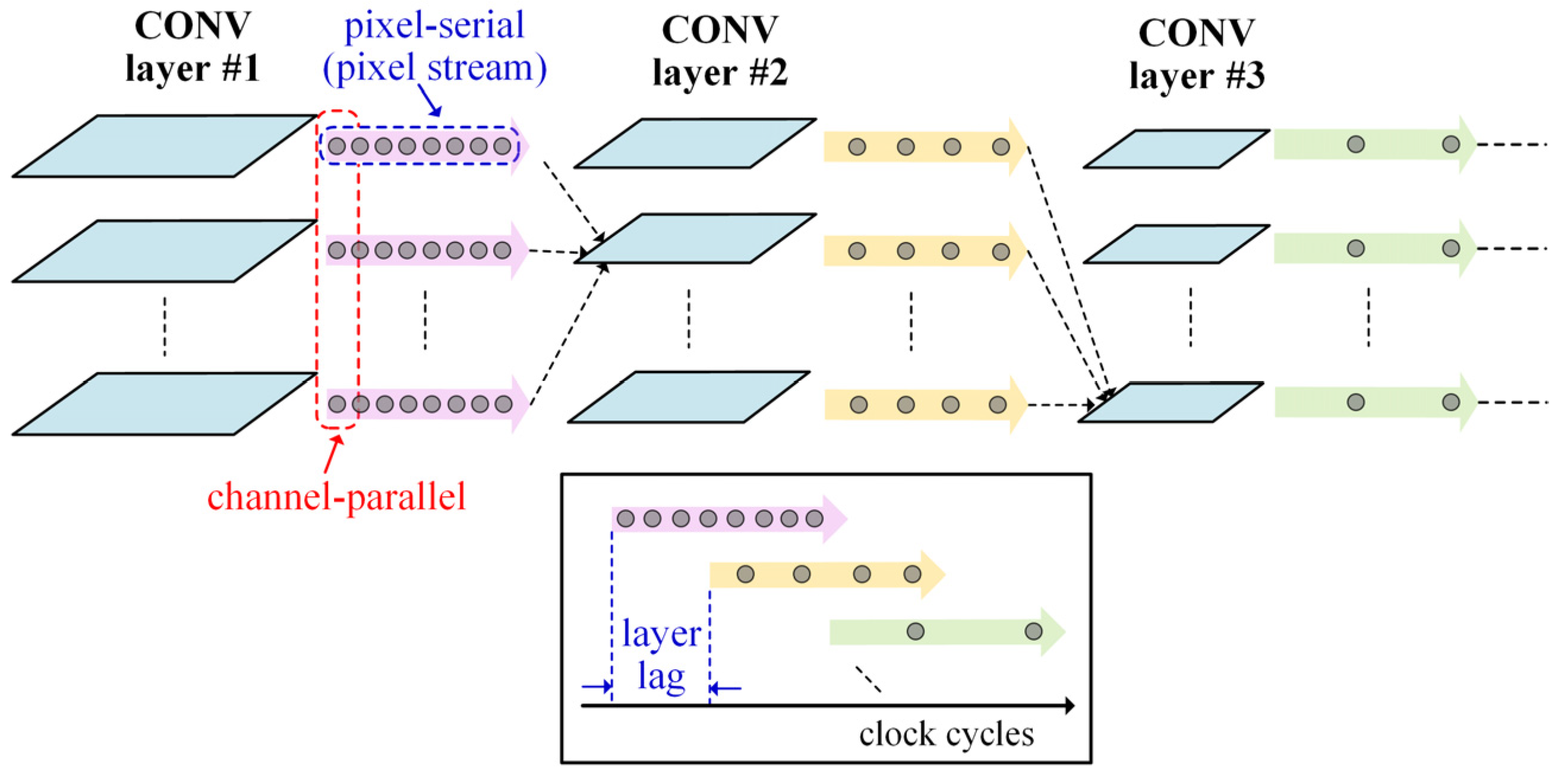
3. Proposed Spike Map Stream Processing Mechanism
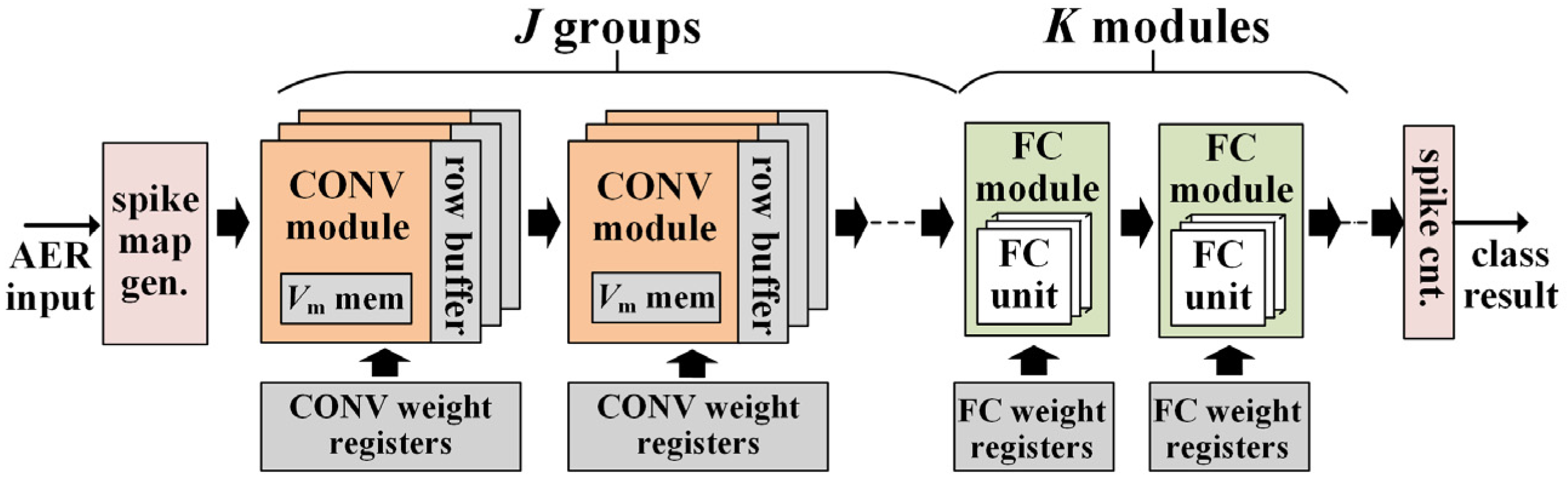
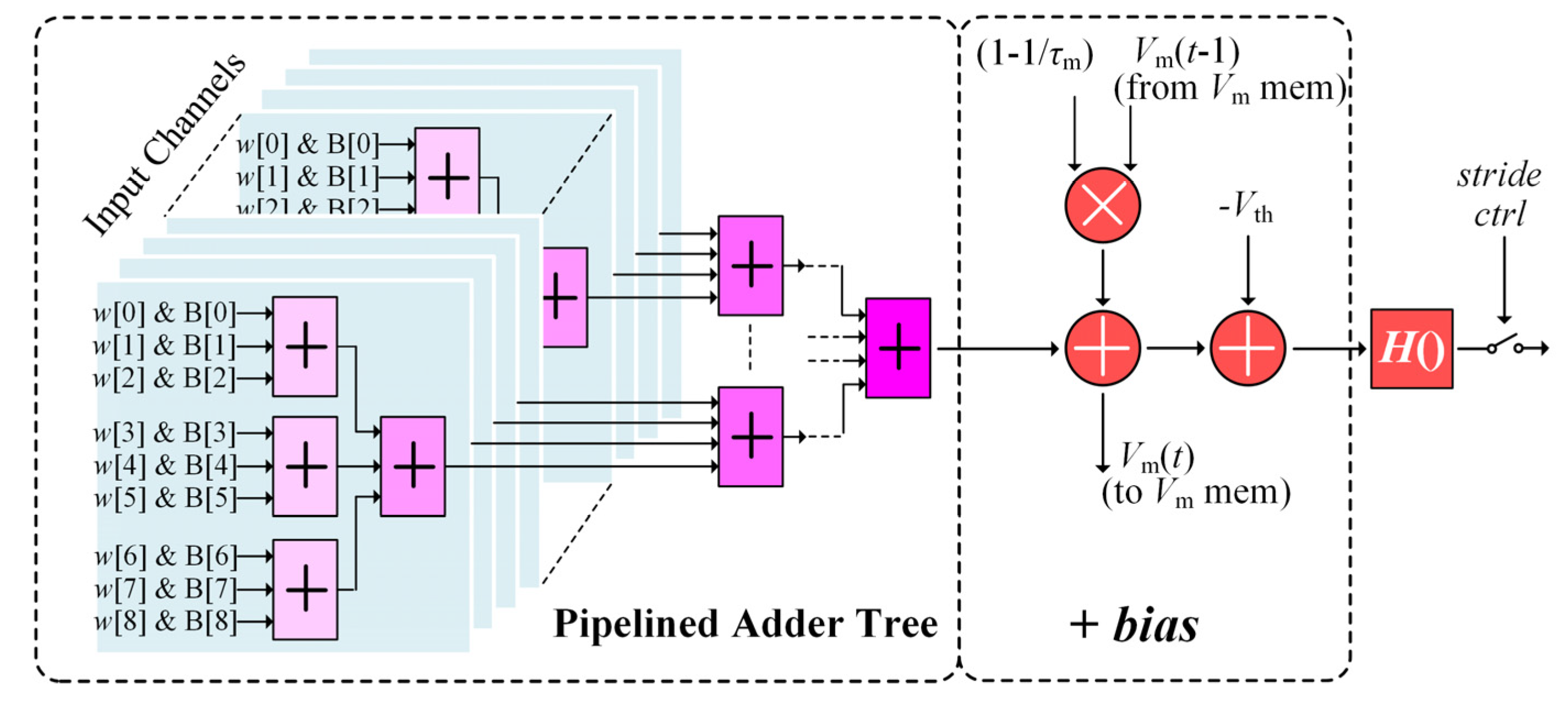
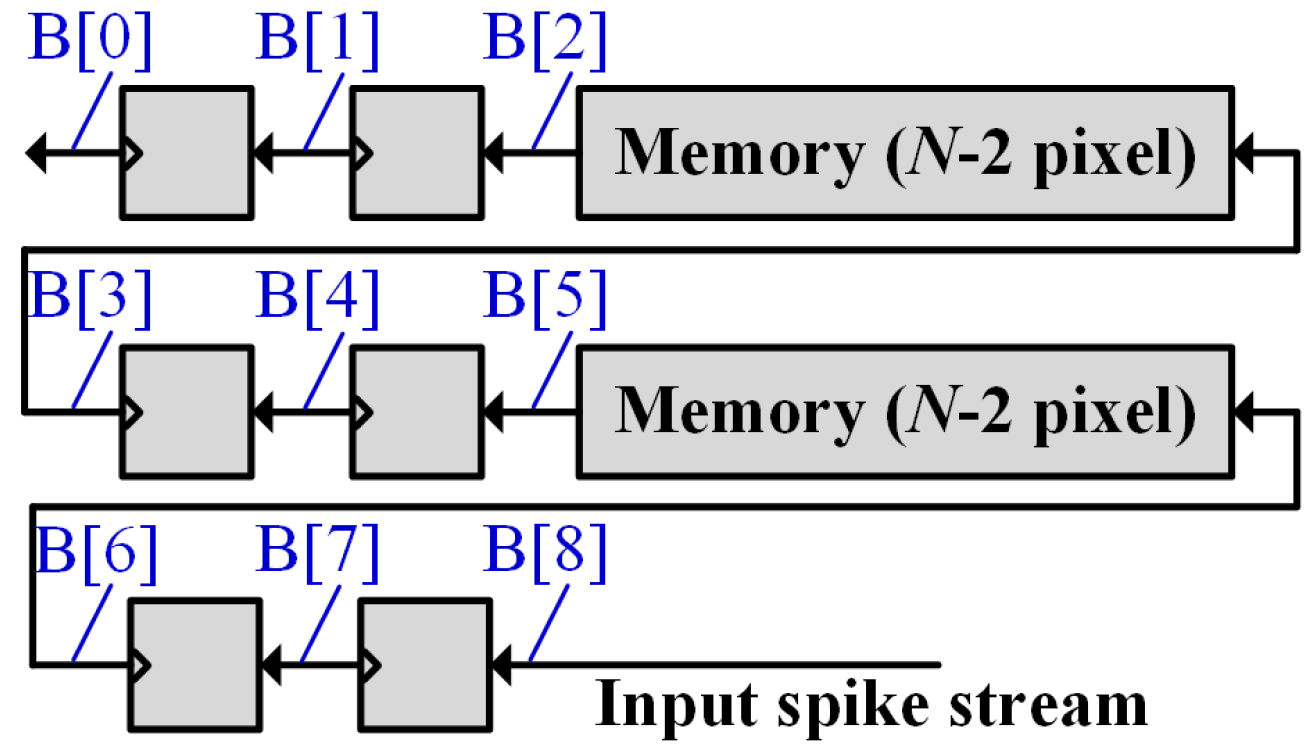
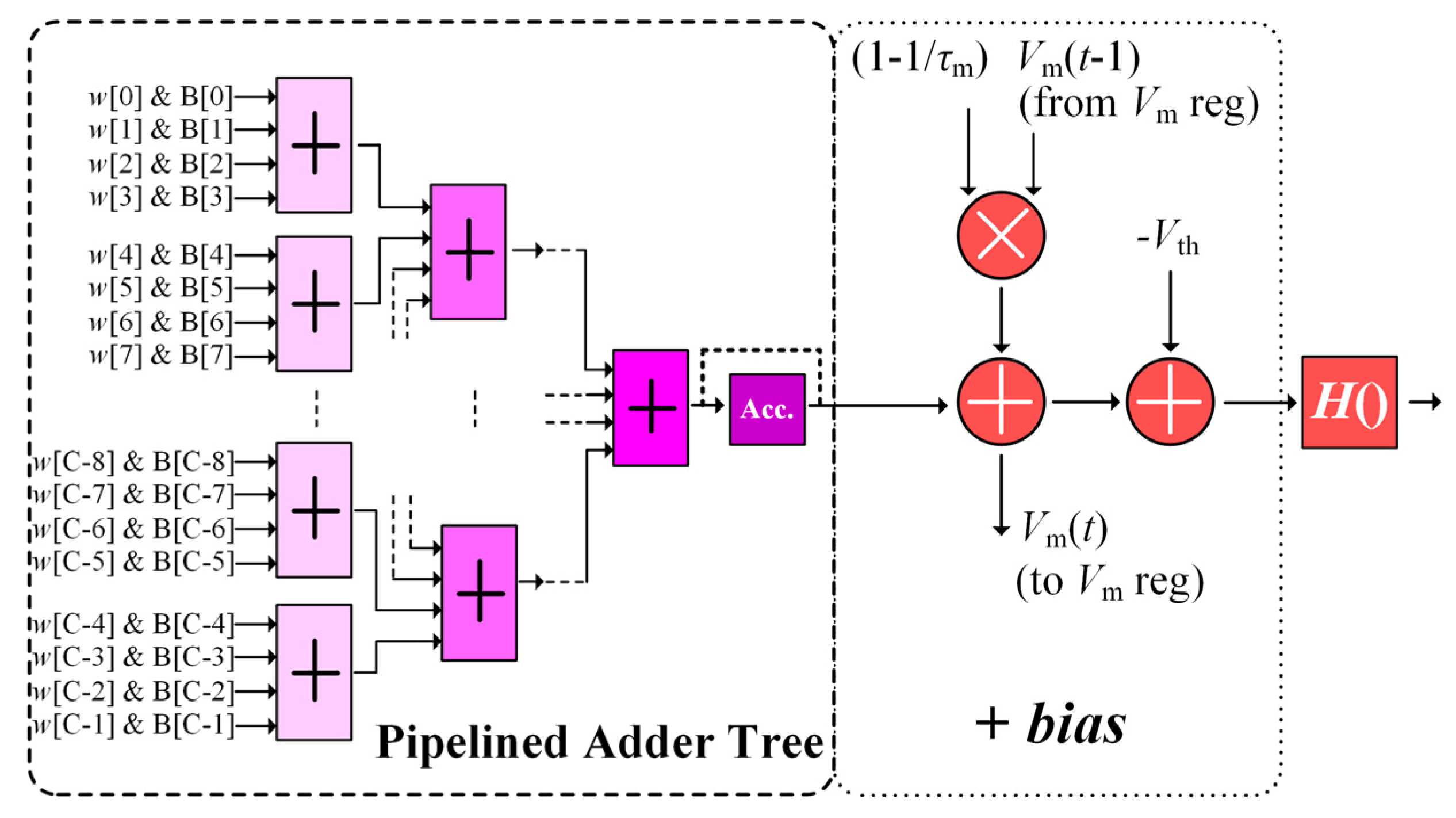
4. VLSI Architecture
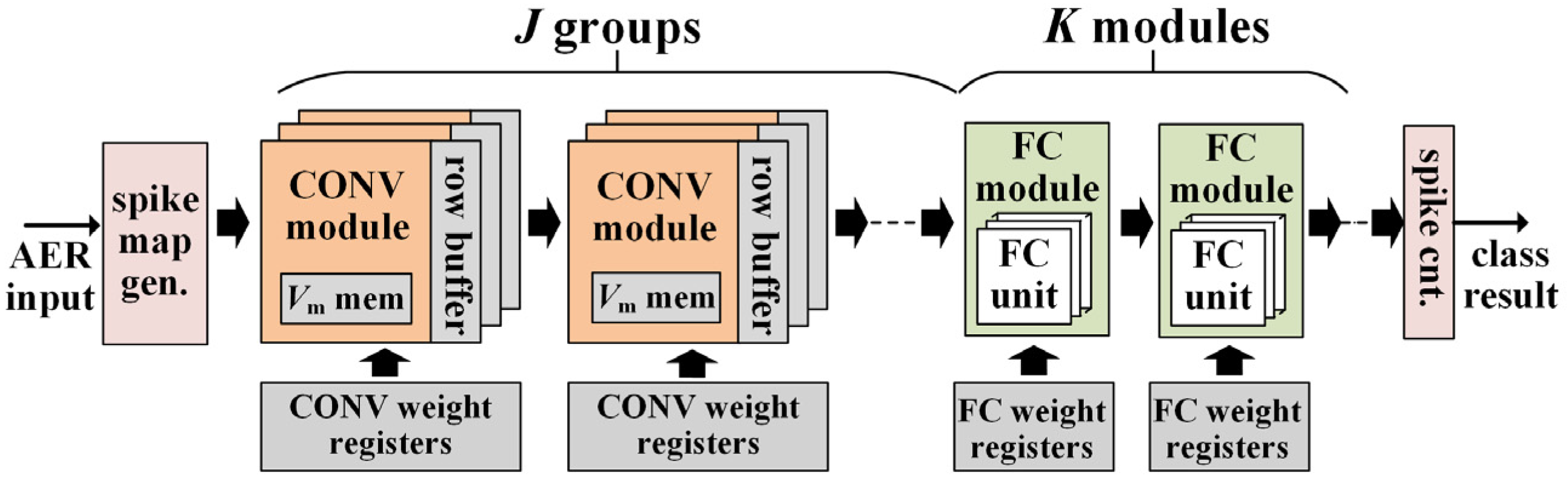
4.1. Architecture Overview
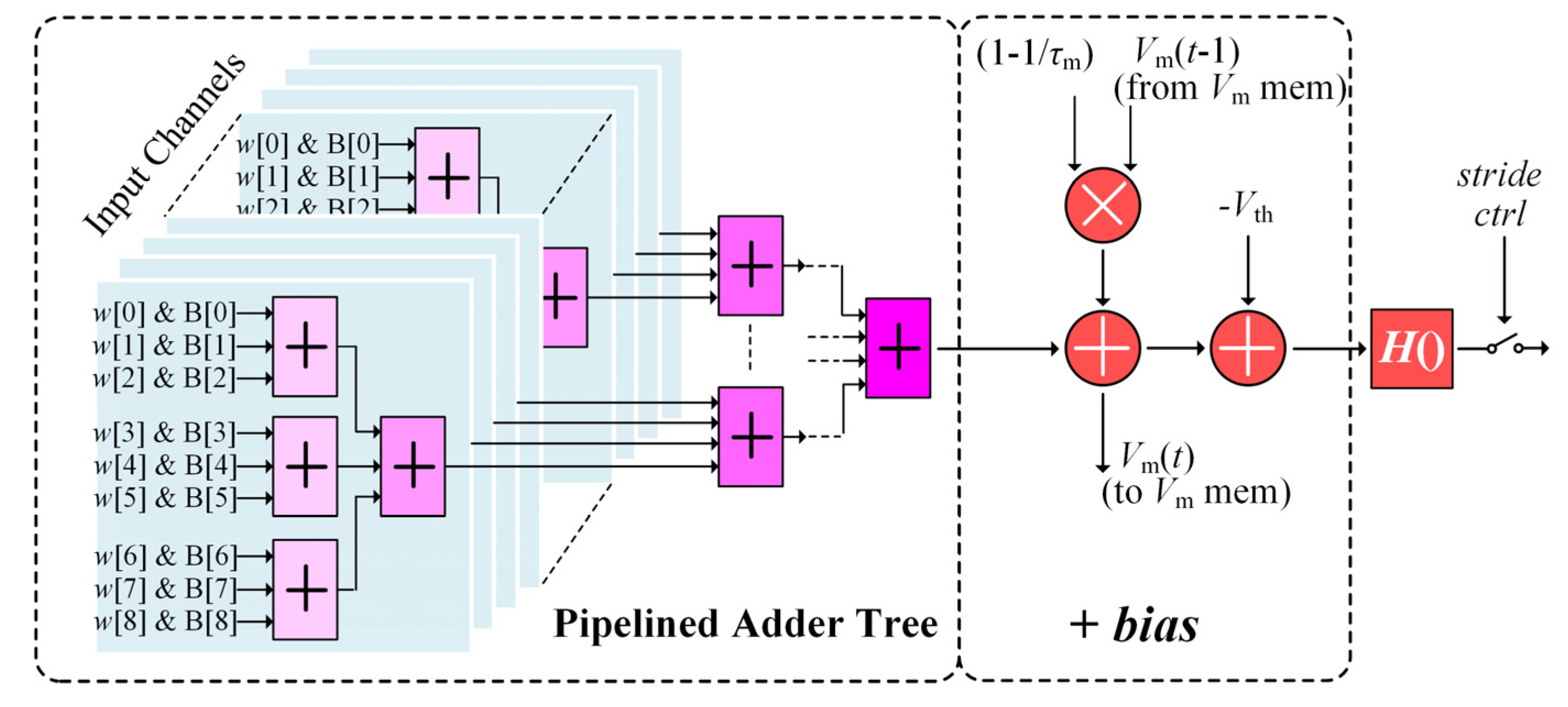
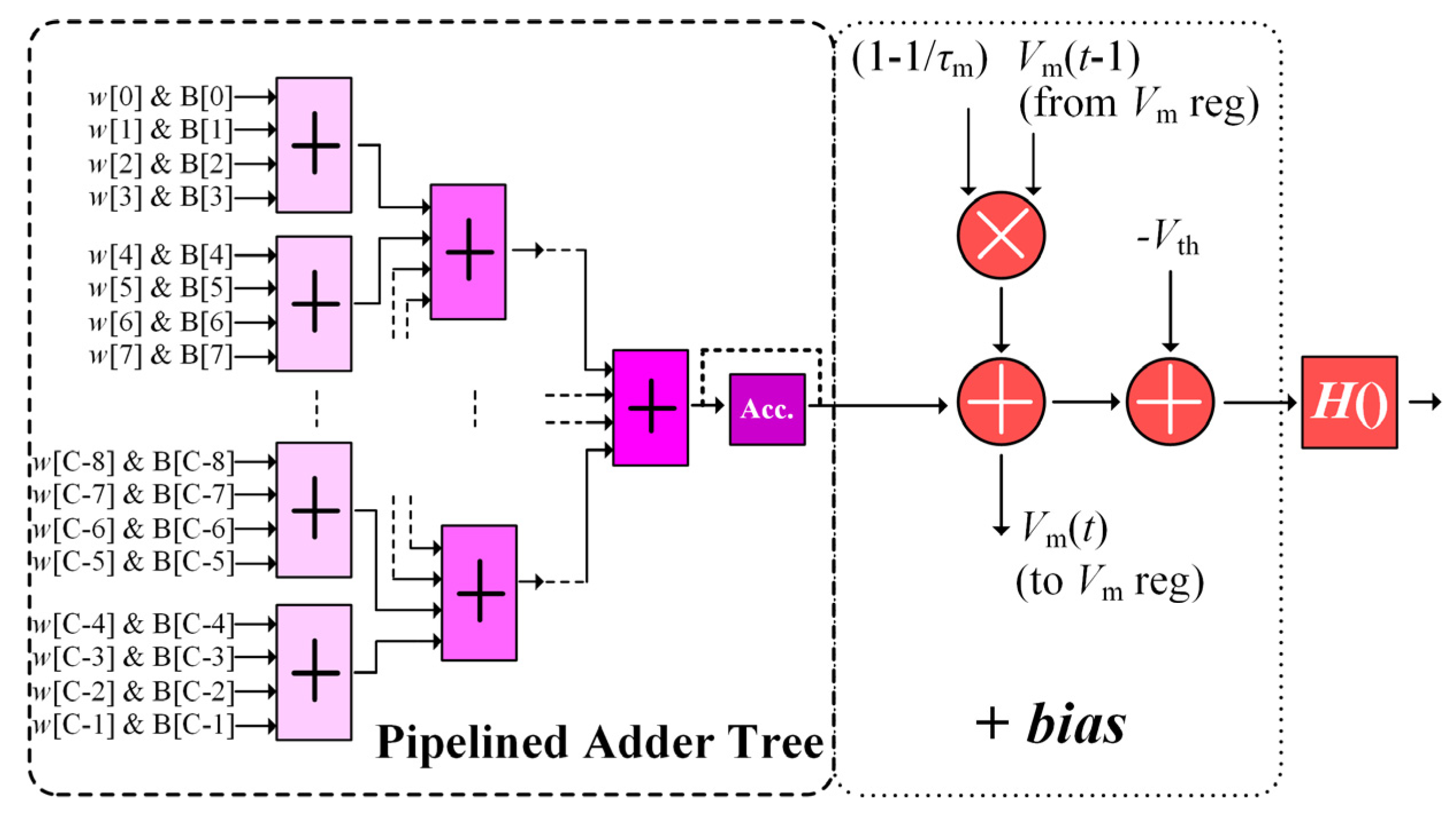
4.2. CONV Module Circuit
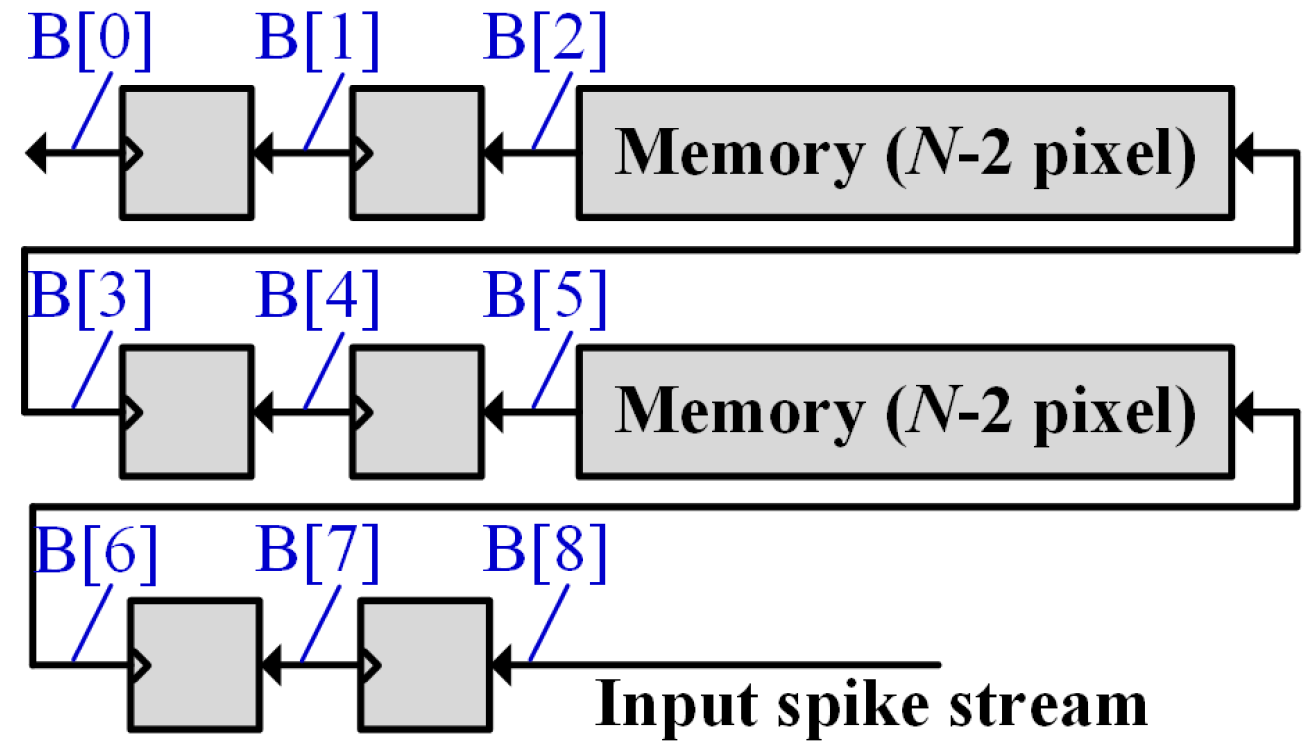
4.3. Pixel Row Buffer
4.4. FC Unit Circuit
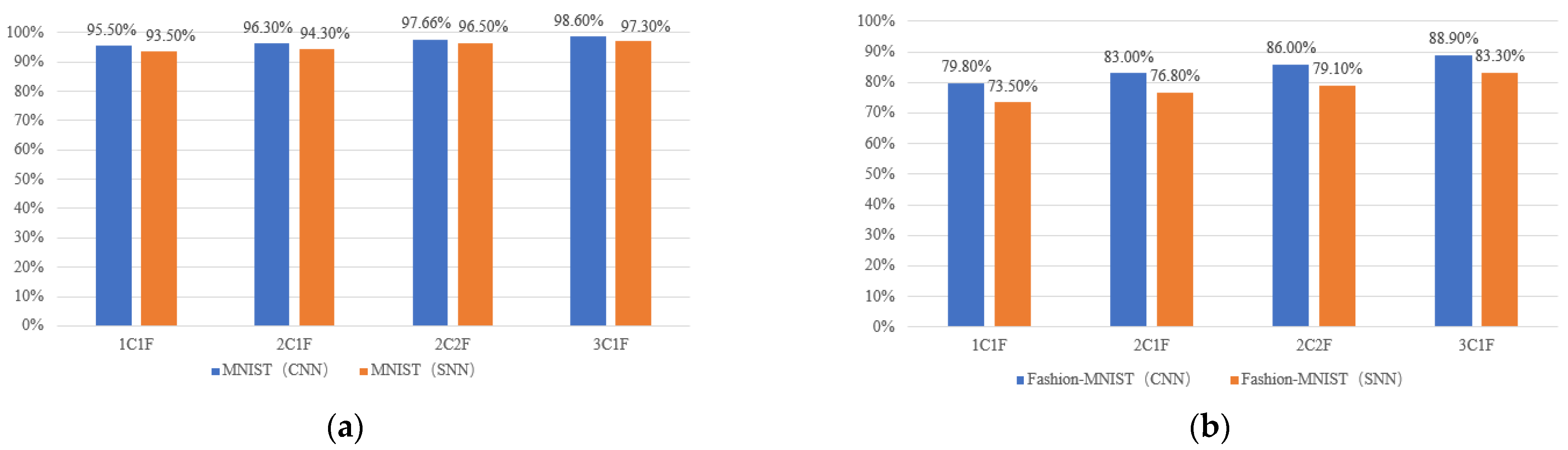
5. Experimental Results
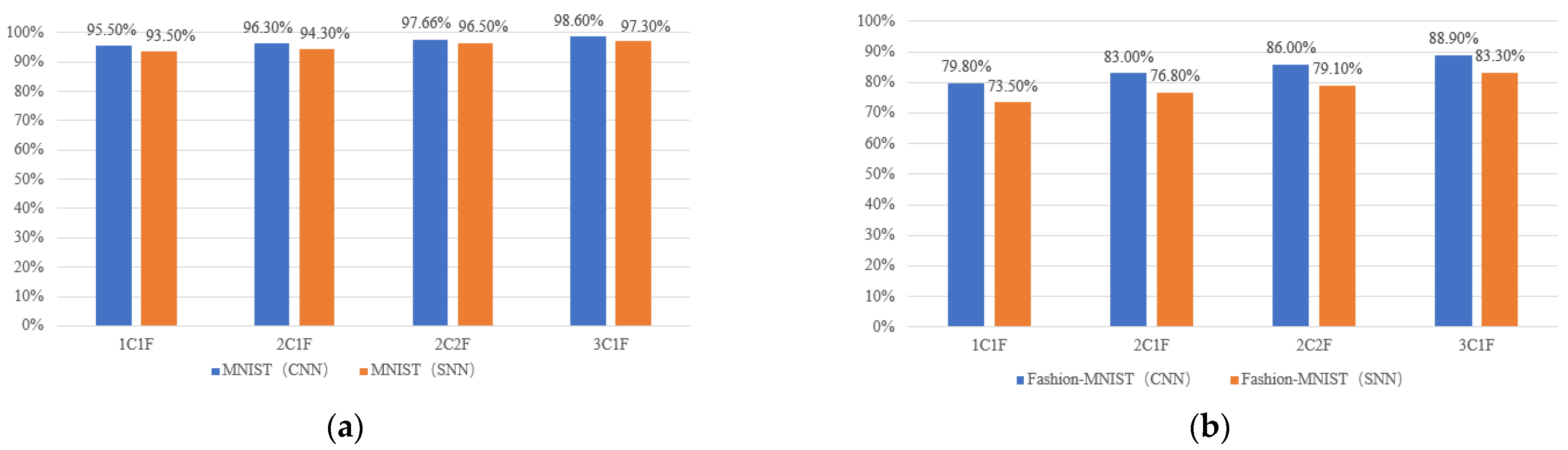
5.1. FPGA Prototype
5.2. Comparsion and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Indiveri, G.; Liu, S.-C. Memory and Information Processing in Neuromorphic Systems. Proc. IEEE 2015, 103, 1379–1397. [Google Scholar] [CrossRef] [Green Version]
- Seo, J.S.; Brezzo, B.; Liu, Y.; Parker, B.D.; Esser, S.K.; Montoye, R.K.; Rajendran, B.; Tierno, J.A.; Chang, L.; Modha, D.S.; et al. A 45nm CMOS neuromorphic chip with a scalable architecture for learning in networks of spiking neurons. In Proceedings of the 2011 IEEE Custom Integrated Circuits Conference (CICC), San Jose, CA, USA, 19–21 September 2011; pp. 1–4. [Google Scholar]
- Painkras, E.; Plana, L.A.; Garside, J.; Temple, S.; Galluppi, F.; Patterson, C.; Lester, D.; Brown, A.D.; Furber, S. SpiNNaker: A 1-W 18-Core System-on-Chip for Massively-Parallel Neural Network Simulation. IEEE J. Solid-State Circuits 2013, 48, 1943–1953. [Google Scholar] [CrossRef]
- Akopyan, F.; Sawada, J.; Cassidy, A.; Alvarez-Icaza, R.; Arthur, J.V.; Merolla, P.; Imam, N.; Nakamura, Y.Y.; Datta, P.; Nam, G.-J.; et al. TrueNorth: Design and Tool Flow of a 65 mW 1 Million Neuron Programmable Neurosynaptic Chip. IEEE Trans. Comput. Des. Integr. Circuits Syst. 2015, 34, 1537–1557. [Google Scholar] [CrossRef]
- Benjamin, B.V.; Gao, P.; McQuinn, E.; Choudhary, S.; Chandrasekaran, A.R.; Bussat, J.M.; Alvarez-Icaza, R.; Arthur, J.V.; Merolla, P.A.; Boahen, K. Neurogrid: A mixed-analog-digital multichip system for large-scale neural simulations. Proc. IEEE 2014, 102, 699–716. [Google Scholar] [CrossRef]
- Qiao, N.; Mostafa, H.; Corradi, F.; Osswald, M.; Stefanini, F.; Sumislawska, D.; Indiveri, G. A reconfigurable on-line learning spiking neuromorphic processor comprising 256 neurons and 128 K synapses. Front. Neurosci. 2020, 9, 141. [Google Scholar] [CrossRef]
- Davies, M.; Srinivasa, N.; Lin, T.-H.; Chinya, G.; Cao, Y.; Choday, S.H.; Dimou, G.; Joshi, P.; Imam, N.; Jain, S.; et al. Loihi: A Neuromorphic Manycore Processor with On-Chip Learning. IEEE Micro 2018, 38, 82–99. [Google Scholar] [CrossRef]
- Frenkel, C.; Lefebvre, M.; Legat, J.D.; Bol, D. A 0.086-mm2 12.7-pJ/SOP 64k-Synapse 256-Neuron Online-Learning Digital Spiking Neuromorphic Processor in 28-nm CMOS. IEEE Trans. Biomed. Circuits Syst. 2019, 13, 145–158. [Google Scholar]
- Chen, G.K.; Kumar, R.; Sumbul, H.E.; Knag, P.C.; Krishnamurthy, R.K. A 4096-Neuron 1M-Synapse 3.8-pJ/SOP Spiking Neural Network With On-Chip STDP Learning and Sparse Weights in 10-nm FinFET CMOS. IEEE J. Solid-State Circuits 2018, 54, 992–1002. [Google Scholar] [CrossRef]
- Ma, D.; Shen, J.; Gu, Z.; Zhang, M.; Zhu, X.; Xu, X.; Xu, Q.; Shen, Y.; Pan, G. Darwin: A neuromorphic hardware co-processor based on spiking neural networks. J. Syst. Arch. 2017, 77, 43–51. [Google Scholar] [CrossRef]
- Frenkel, C.; Legat, J.-D.; Bol, D. MorphIC: A 65-nm 738k-Synapse/mm2 Quad-Core Binary-Weight Digital Neuromorphic Processor With Stochastic Spike-Driven Online Learning. IEEE Trans. Biomed. Circuits Syst. 2019, 13, 999–1010. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Zhang, Z.; Mao, R.; Xiao, J.; Chang, L.; Zhou, J. A Fast and Energy-Efficient SNN Processor with Adaptive Clock/Event-Driven Computation Scheme and Online Learning. IEEE Trans. Circuits Syst. 2021, 68, 1543–1552. [Google Scholar] [CrossRef]
- Kuang, Y.; Cui, X.; Zhong, Y.; Liu, K.; Zou, C.; Dai, Z.; Wang, Y.; Yu, D.; Huang, R. A 64K-Neuron 64M-1b-Synapse 2.64pJ/SOP Neuromorphic Chip With All Memory on Chip for Spike-Based Models in 65 nm CMOS. IEEE Trans. Circuits Syst. II Express Briefs 2021, 68, 2655–2659. [Google Scholar] [CrossRef]
- Detorakis, G.; Sheik, S.; Augustine, C.; Paul, S.; Pedroni, B.U.; Dutt, N.; Krichmar, J.; Cauwenberghs, G.; Neftci, E. Neural and synaptic array transceiver: A brain-inspired computing framework for embedded learning. Front. Neurosci. 2018, 12, 583. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition 2016, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Cao, Y.; Chen, Y.; Khosla, D. Spiking Deep Convolutional Neural Networks for Energy-Efficient Object Recognition. Int. J. Comput. Vis. 2015, 113, 54–66. [Google Scholar] [CrossRef]
- Zhao, B.; Ding, R.; Chen, S.; Linares-Barranco, B.; Tang, H. Feedforward Categorization on AER Motion Events Using Cortex-Like Features in a Spiking Neural Network. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 1963–1978. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kheradpisheh, S.R.; Ganjtabesh, M.; Thorpe, S.J.; Masquelier, T. STDP-based spiking deep convolutional neural networks for object recognition. Neural Netw. 2018, 99, 56–67. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, C.; Srinivasan, G.; Panda, P.; Roy, K. Deep Spiking Convolutional Neural Network Trained With Unsupervised Spike-Timing-Dependent Plasticity. IEEE Trans. Cogn. Dev. Syst. 2019, 11, 384–394. [Google Scholar] [CrossRef]
- Srinivasan, G.; Roy, K. ReStoCNet: Residual Stochastic Binary Convolutional Spiking Neural Network for Memory-Efficient Neuromorphic Computing. Front. Neurosci. 2019, 13, 189. [Google Scholar] [CrossRef] [PubMed]
- Xu, Q.; Peng, J.; Shen, J.; Tang, H.; Pan, G. Deep CovDenseSNN: A hierarchical event-driven dynamic framework with spiking neurons in noisy environment. Neural Netw. 2019, 121, 512–519. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, Z.; Zhu, W.; Yu, S.; Liu, L.; Wu, N. Deterministic conversion rule for CNNs to efficient spiking convolutional neural networks. Sci. China Inf. Sci. 2020, 63, 122402. [Google Scholar] [CrossRef] [Green Version]
- Camuñas-Mesa, L.; Zamarreno-Ramos, C.; Linares-Barranco, A.; Jiménez, A.J.A.; Gotarredona, M.T.S.; Linares-Barranco, B. An Event-Driven Multi-Kernel Convolution Processor Module for Event-Driven Vision Sensors. IEEE J. Solid-State Circuits 2011, 47, 504–517. [Google Scholar] [CrossRef]
- Camuñas-Mesa, L.A.; Domínguez-Cordero, Y.L.; Linares-Barranco, A.; Serrano-Gotarredona, T.; Linares-Barranco, B. A configurable event-driven convolutional node with rate saturation mechanism for modular ConvNet systems implementation. Front. Neurosci. 2018, 12, 63. [Google Scholar] [CrossRef] [Green Version]
- Tapiador-Morales, R.; Linares-Barranco, A.; Jimenez-Fernandez, A.; Jimenez-Moreno, G. Neuromorphic LIF row-by-row multiconvolution processor for FPGA. IEEE Trans. Biomed. Circuits Syst. 2018, 13, 159–169. [Google Scholar] [PubMed]
- Frenkel, C.; Legat, J.D.; Bol, D. A 28-nm convolutional neuromorphic processor enabling online learning with spike-based retinas. In Proceedings of the 2020 IEEE International Symposium on Circuits and Systems (ISCAS), Seville, Spain, 12–14 October 2020; pp. 1–5. [Google Scholar]
- Kang, Z.; Wang, L.; Guo, S.; Gong, R.; Deng, Y.; Dou, Q. ASIE: An Asynchronous SNN Inference Engine for AER Events Processing. In Proceedings of the 2019 25th IEEE International Symposium on Asynchronous Circuits and Systems (ASYNC), Hirosaki, Japan, 12–15 May 2019. [Google Scholar]
- Wang, S.-Q.; Wang, L.; Deng, Y.; Yang, Z.-J.; Guo, S.-S.; Kang, Z.-Y.; Guo, Y.-F.; Xu, W.-X. SIES: A Novel Implementation of Spiking Convolutional Neural Network Inference Engine on Field-Programmable Gate Array. J. Comput. Sci. Technol. 2020, 35, 475–489. [Google Scholar] [CrossRef]
- Heidarpur, M.; Ahmadi, A.; Ahmadi Mand Azghadi, M.R. CORDIC-SNN: On-FPGA STDP Learning with Izhikevich Neurons. IEEE Trans. Circuits Syst. I Regul. Pap. 2019, 66, 2651–2661. [Google Scholar] [CrossRef]
- Rueckauer, B.; Lungu, I.A.; Hu, Y.; Pfeiffer, M.; Liu, S.C. Conversion of continuous-valued deep networks to efficient event-driven networks for image classification. Front. Neurosci. 2017, 11, 682. [Google Scholar] [CrossRef]
- Ju, X.; Fang, B.; Yan, R.; Xu, X.; Tang, H. An FPGA implementation of deep spiking neural networks for low-power and fast classification. Neural Comput. 2020, 32, 182–204. [Google Scholar] [CrossRef]
- Diehl, P.U.; Cook, M. Unsupervised learning of digit recognition using spike-timing-dependent plasticity. Front. Comput. Neurosci. 2015, 9, 99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, T.; Shi, C.; Zhou, X.; Lin, Y.; He, J.; Gan, P.; Li, P.; Wang, Y.; Liu, L.; Wu, N.; et al. CompSNN: A lightweight spiking neural network based on spatiotemporally compressive spike features. Neurocomputing 2021, 425, 96–106. [Google Scholar] [CrossRef]
- Shi, C.; Wang, T.; He, J.; Zhang, J.; Liu, L.; Wu, N. DeepTempo: A Hardware-Friendly Direct Feedback Alignment Multi-Layer Tempotron Learning Rule for Deep Spiking Neural Networks. IEEE Trans. Circuits Syst. II Express Briefs 2021, 68, 1581–1585. [Google Scholar] [CrossRef]
- Lazzaro, J.; Wawrzynek, J. A multi-sender asynchronous extension to the AER protocol. In Proceedings of the Sixteenth Conference on Advanced Research in VLSI 1995, Chapel Hill, NC, USA, 27–29 March 1995; pp. 158–169. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Yu, Q.; Tang, H.; Tan, K.C.; Li, H. Rapid Feedforward Computation by Temporal Encoding and Learning With Spiking Neurons. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 1539–1552. [Google Scholar] [CrossRef] [PubMed]
- Diehl, P.U.; Neil, D.; Binas, J.; Cook, M.; Liu, S.C.; Pfeiffer, M. Fast-classifying, high-accuracy spiking deep networks through weight and threshold balancing. In Proceedings of the IEEE International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 1–8. [Google Scholar]
- Neil, D.; Liu, S.C. Minitaur, an event-driven FPGA-based spiking network accelerator. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2014, 22, 2621–2628. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configuration | SCNN Model Structure |
|---|---|
| 1C1F 1 | 16c2-10 |
| 2C1F | 16c2-32c2-10 |
| 2C2F | 6c2-32c32-32-10 |
| 3C1F | 16c1-16c2-32c2-10 |
| Configuration | Logic Resource | Memory Resource | Power Consumption 1 | |||
|---|---|---|---|---|---|---|
| LUT as Logic (218,600) | FF (437,200) | DSP (900) | Block RAM (545) | LUT as Mem (70,400) | ||
| 1C1F | 8904 (4.07%) | 10,269 (2.35%) | 26 (2.89%) | 88 (16.15%) | 64 (0.09%) | 0.519 W |
| 2C1F | 64,640 (29.57%) | 102,982 (23.55%) | 58 (6.44%) | 24 (4.40%) | 4960 (7.05%) | 0.959 W |
| 2C2F | 93,202 (42.63%) | 136,882 (31.31%) | 90 (10.00%) | 26 (4.77%) | 6123 (8.70%) | 1.168 W |
| 3C1F | 87,172 (39.88%) | 147,832 (33.81%) | 74 (8.22%) | 32 (5.87%) | 6000 (8.52%) | 1.241 W |
| Ref. | Time (s) | Accuracy (%) |
|---|---|---|
| [19] | 8649 | 95.01 |
| [40] | 7825 | 78.5 |
| [41] | 5000 | 99.1 |
| Ours (3C1F) | 7.84 | 97.3 |
| Ref. | Implementation | Clock Freq. (MHz) | Power (mW) | Frame Rate (fps) | Model | Benchmark | Accuracy (%) |
|---|---|---|---|---|---|---|---|
| [8] | ASIC | 75 | 0.48 | N/A | SNN | MNIST | 84.5 |
| [9] | ASIC | 105 | 0.16 | 160 | SNN | MNIST | 89 |
| [10] | ASIC | 25 | 21 | 6.25 | SNN | MNIST | 93.8 |
| [25] | ASIC | 100 | 200 | 127 1 | SCNN | Poker-DVS | N/A |
| [26] | FPGA | 50 | 0.85 | 0.4 | SCNN | Poker-DVS | 96 |
| [27] | FPGA | 100 | 59 | 111 | SCNN | Poker-DVS | N/A |
| [30] | FPGA | 200 | N/A | N/A | SCNN | MNIST | 99.16 |
| [33] | FPGA | 150 | 4600 | 164 | SCNN | MNIST | 98.94 |
| [42] | FPGA | 75 | 1500 | 6.58 | SNN | MNIST | 92 |
| ours (3C1F) | FPGA | 100 | 1241 | 1250 | SCNN | MNIST | 97.3 |
| Fashion-MNIST | 83.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Yang, J.; Shi, C.; Lin, Y.; He, W.; Zhou, X.; Yang, X.; Liu, L.; Wu, N. A Cost-Efficient High-Speed VLSI Architecture for Spiking Convolutional Neural Network Inference Using Time-Step Binary Spike Maps. Sensors 2021, 21, 6006. https://doi.org/10.3390/s21186006
Zhang L, Yang J, Shi C, Lin Y, He W, Zhou X, Yang X, Liu L, Wu N. A Cost-Efficient High-Speed VLSI Architecture for Spiking Convolutional Neural Network Inference Using Time-Step Binary Spike Maps. Sensors. 2021; 21(18):6006. https://doi.org/10.3390/s21186006
Chicago/Turabian StyleZhang, Ling, Jing Yang, Cong Shi, Yingcheng Lin, Wei He, Xichuan Zhou, Xu Yang, Liyuan Liu, and Nanjian Wu. 2021. "A Cost-Efficient High-Speed VLSI Architecture for Spiking Convolutional Neural Network Inference Using Time-Step Binary Spike Maps" Sensors 21, no. 18: 6006. https://doi.org/10.3390/s21186006
APA StyleZhang, L., Yang, J., Shi, C., Lin, Y., He, W., Zhou, X., Yang, X., Liu, L., & Wu, N. (2021). A Cost-Efficient High-Speed VLSI Architecture for Spiking Convolutional Neural Network Inference Using Time-Step Binary Spike Maps. Sensors, 21(18), 6006. https://doi.org/10.3390/s21186006