1. Introduction
This paper presents a novel end-to-end Deep Neural Network (DNN) based framework, as
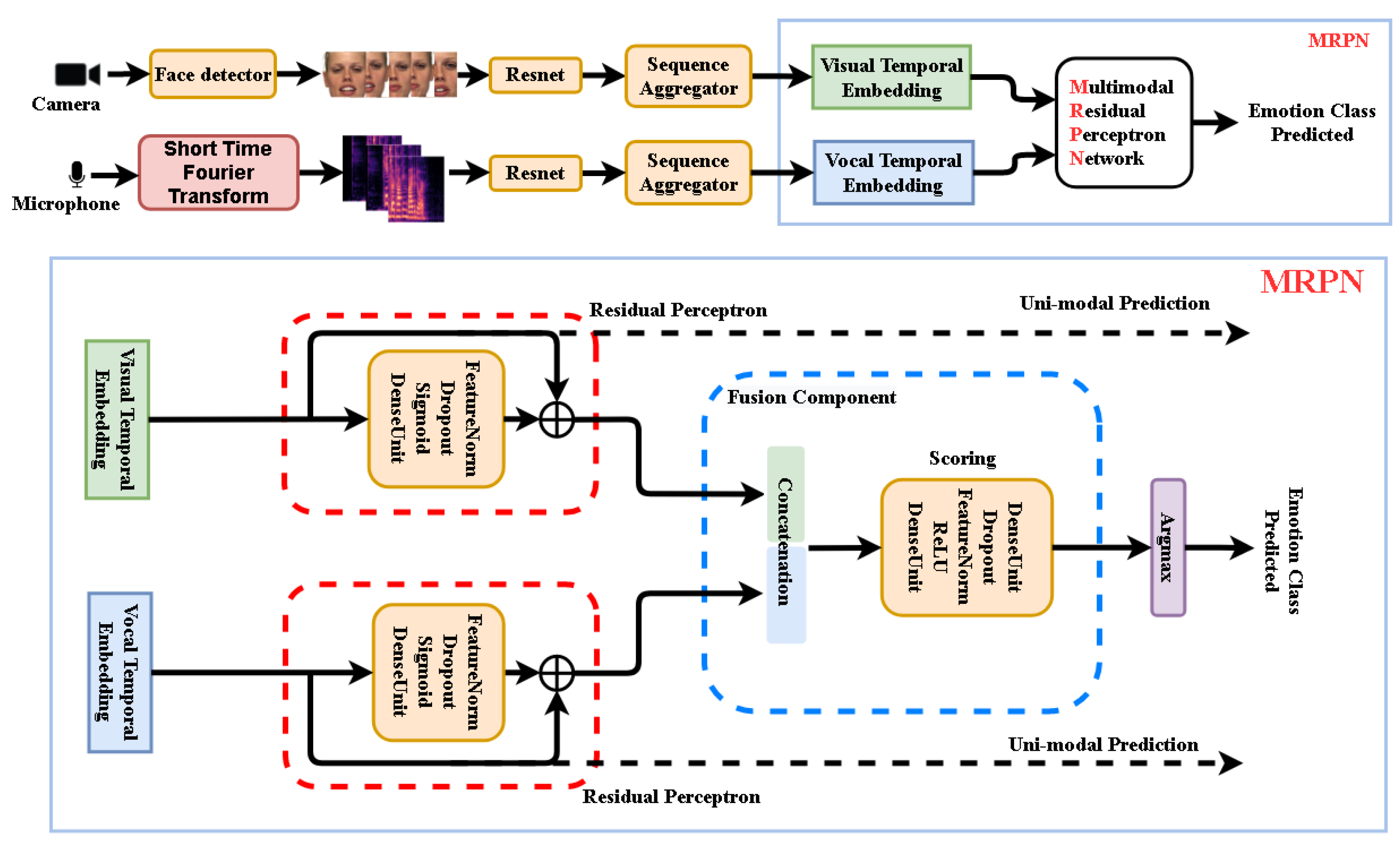
Figure 1 illustrates, addressing the Audio–Video Emotion Recognition (AVER) problem. Just like human beings understand emotional expressions in our daily social activates through multi-senses (e.g., visual, vocal, textually meaningful), neural computing units as part of intelligent artificial sensors are now playing important roles in emotion recognition tasks. Specialized sensors in Human–Computer Interaction (HCI) capture information responsible for understanding visual and vocal information just like we—the human beings—understand emotional expressions through our multi-senses.
1.1. Emotion Recognition from Face Expression and Voice Timbre
Intuitively, functionalities of intelligent artificial neurons are assigned with concepts similar to our brain cells, processing information from the very raw senses independently and appropriately to their types.
Visually, information captured by the camera is distributed to several frames as
Figure 2 shows. Discrete information in a single frame is firstly delivered to pattern extracting intelligent sensors for features such as Fisherfaces and Eigenfaces [
1] or the deep features from Convolutional Neural Networks (CNNs) [
2]. To fully preserve the information from the discrete signals, some Sequence Aggregation Component (SAC), e.g., Long Short Term Memory (LSTM) [
3] or Transformer [
4], is then needed to further process the extracted features. Finally, a classifier such as Support Vector Machine (SVM) or some neural dense layer takes the integrated features for the classification.
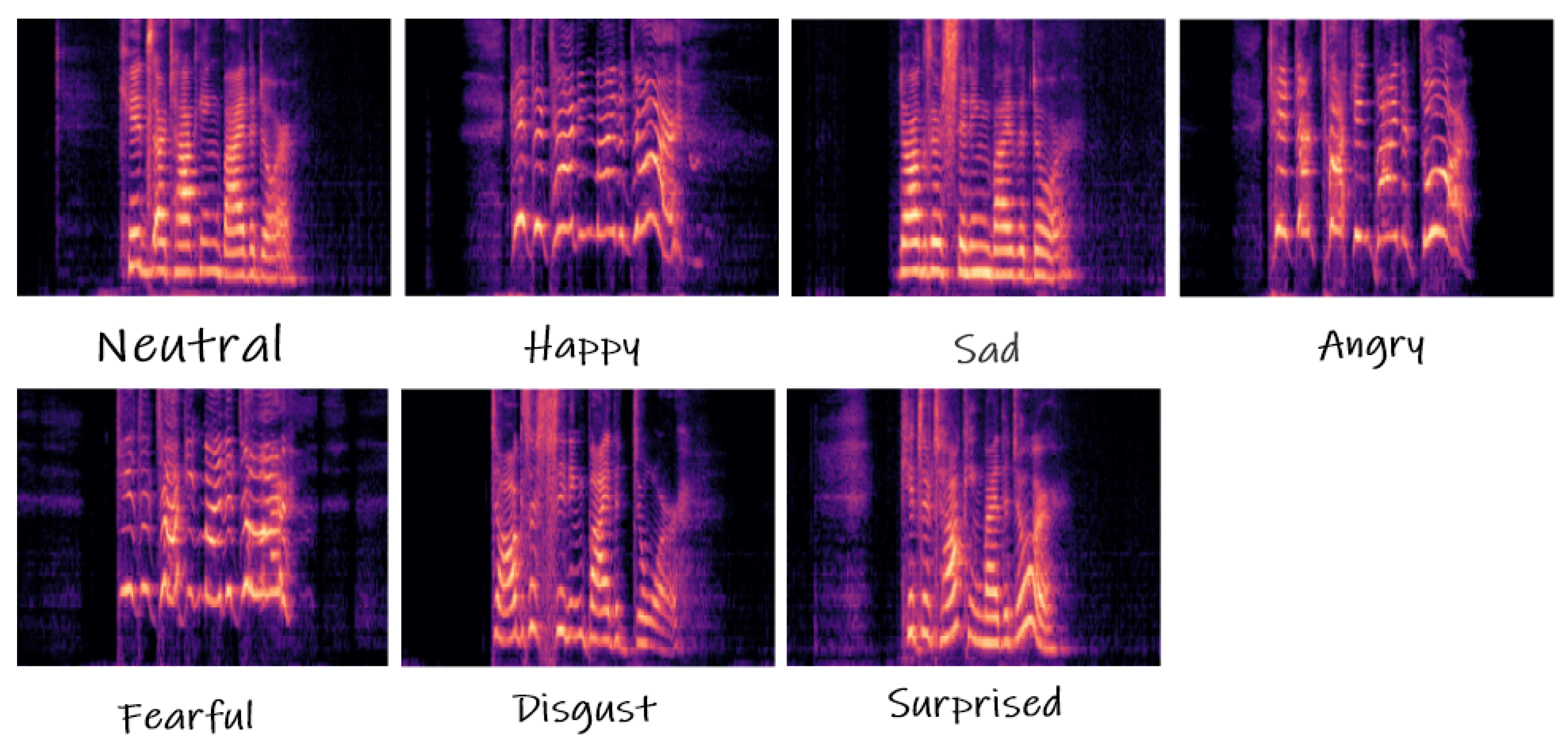
Raw vocal inputs are usually with 10,000 to 44,100 samples per second, while the visual frame rate is about 25–30 image frames per second. While raw digital signals in the time domain approximate the original signal precisely, their spectral representation, e.g., spectrogram frame, mel-spectrogram coefficients, or log mel-spectrogram frame, appeared more effectively for sound recognition. The spectral converted vocal signals have shown significant improvements in many classification problems, in spite of some limitations. Expression events do not last at the same time, thus the width of the spectrogram frames changes, which is not desirable for CNN pattern extractors. Therefore, the extracted features also need further processing from SAC which outputs integrated features.
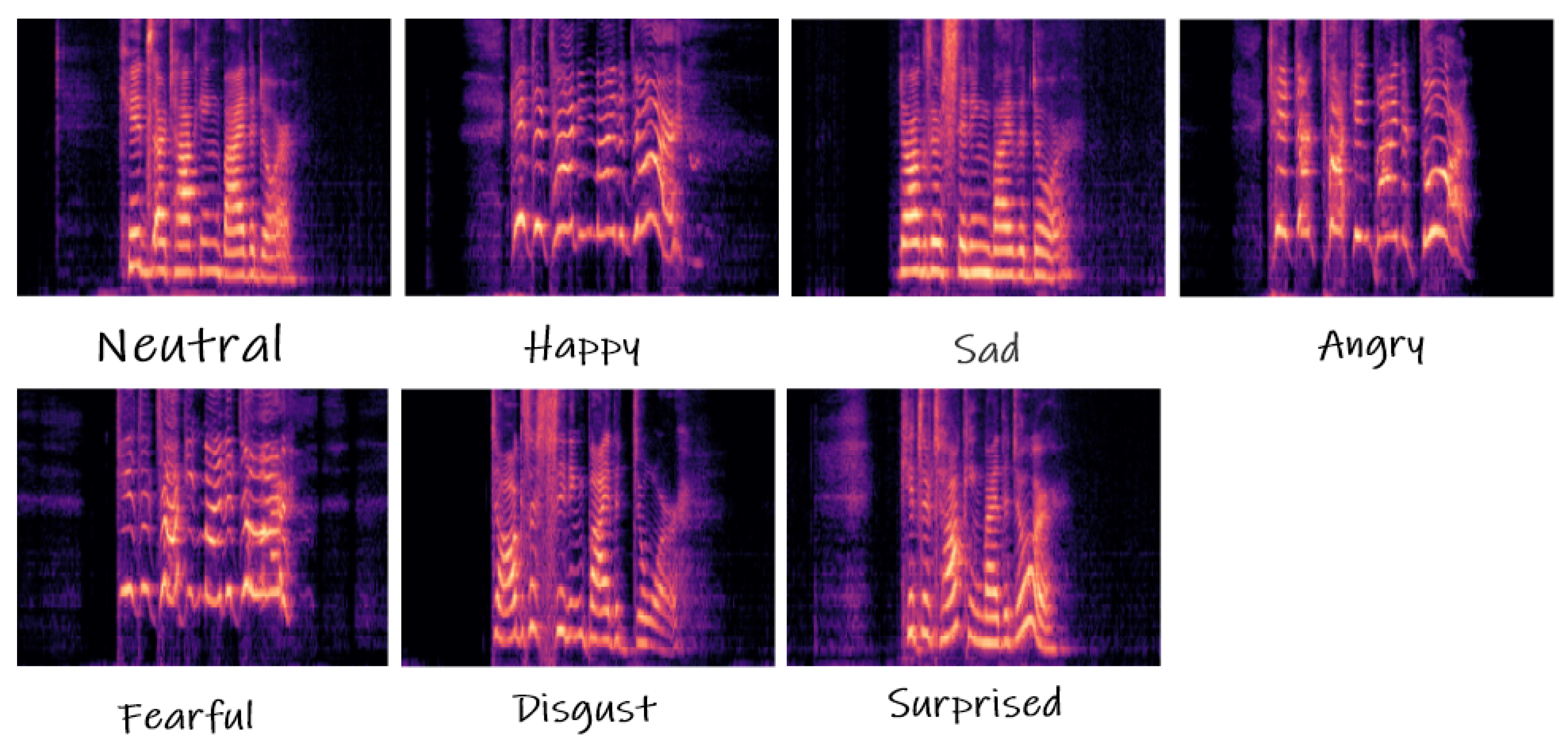
Figure 3 shows the expression events from different categories and with different time duration.
1.2. Multi-Modal Emotion Recognition
AVER solution also follows the sensation of human beings; people claim they hear the sound when looking at the sheet music, smell the odor when recalling the memory from a photo or see the sea sight from the smell of the air. The multi-sensation information is processed by different areas of our cerebral cortex, movement, hearing, seeing, etc., then highly correlated by some other brain areas. Thus, the decision made depends not just on the recognition of uni-modal sensations independently but also jointly.
The learning process of neural sensors should also mimic our learning process. The neurons shape their weights just like our cerebral cortex changes from the stimulation of the environments and looks for any correlation of them during the learning process in the supervised neural network sensors training. However, we claim the existing late fusion and end-to-end training strategies have their own advantages but also deficiencies.
1.3. Paper Contribution and Structure
This paper shows by experiments the deficiencies of two training strategies: Late fusion and end-to-end. The late fusion strategy takes trained static uni-modal networks and trains their fusing network components. The end-to-end strategy trains all the multi-modal and uni-modal components together. A novel architecture is proposed to take advantage of both solutions and avoid their side effects, respectively. We demonstrate superiority in the novel end-to-end mechanism and architecture comparing with the naive fusion mechanism in either late fusion or end-to-end training. The proposed DNN framework, data augmentation procedures, and network optimization strategy are discussed. A detailed analysis and discussion are presented by computing experiments on The Ryerson Audio–Visual Database of Emotional Speech and Song (RAVDESS) and Crowd-Sourced Emotional Multimodal Actors Dataset (Crema-d) datasets. Our major contributions are as follows:
- 1.
Multi-modal framework: We propose a novel within-modality Residual Perceptrons (RP) for efficient gradient blending for the neural network optimization using multi-term loss function in MRPN. The sub-networks and target loss functions produce superior parameterized multi-modal features, preserving the original knowledge of uni-modalities, which impedes inter-modal learning. The within-modality RP components reduce the side effects brought from such multi-term loss functions. As the result, we got significantly better performance over direct strategies including late fusion and end-to-end without MRPN.
- 2.
Time Augmentation of input frames: We demonstrate data augmentation in time involving randomly slicing over input frame sequences from both modalities improved the recognition performance to the state-of-art, even without MRPN. We show also the results that time augmentation does not solve the cases where uni-modal solutions are better than multi-modal solutions, yet solved by MRPN.
2. Related Work
2.1. Superiority in Multi-Modal Approach
Many have shown significant improvement of multi-modal solutions. N. Neverova et al. [
5] suggest gradual fusion involving the random dropping of separate channels, and this method was adopted by V. Vielzeuf et al. [
6] in the AVER solution for their best result.
Fusion at the early or late stage is discussed by others. R. Beard et al. [
7] proposed multi-modal feature fusion at the late stage, while E. Ghaleb et al. [
8] try to project features to a shared space in the early stage and provided external loss functions to minimize the distance of features from different modalities. A. Zadeh et al. [
9] proposed Multi-view Gated Memory to gate the multi-modal knowledge from LSTM in the time series. E. Mansouri-Benssassi and J. Ye [
10] archive early fusion by creating distinct multi-modal neuron groups.
S. Zhang et al. [
11] take features from CNN and 3D-CNN models for vocal and visual sources then make global averaging as video features. NC. Ristea et al. [
12] take the features extracted by CNNs from both modalities and exploit the fused features for classification purposes. E. Tzinis et al. [
13] take cross-modal and self-attention modules. Y. Wu et al. [
14] localize events crossing modalities. E. Ghaleb et al. [
15] suggest multi-modal emotion recognition metric learning to create a robust representation for both modalities.
2.2. Potential Failures in the Existing Solutions
Let us consider the human brain learning process again. Say the information is wrong in some of the sensory stimulation. A child learned an animal looks just like a dog but having the sound of the cat from the manipulated movies and this kid has never learned the dog and cat in a real-life environment. He will either see a dog and tell it is a cat or hear the cat sound and tell it is a dog. The situation can go even worse if the stimulation he learned from is also fuzzy within their own sensation.
His recognition is still intact to some extent that he can sometimes correctly recognize the visual or acoustic information pattern. However, the recognized information is distorted, along with the correlation of the inter-modal information. This made the distorted uni-modal knowledge he learned having also a negative impact on the other. The same concept we address to the current multi-modal neural network solutions. The within-modal and inter-modal noisiness of the learned pattern both contribute to the wrong recognition. Despite many advantages from the multi-modal solutions which boost the recognition performance of emotion recognition tasks, we hypothesize the uncontrolled fusion strategy, adopted by [
6,
7,
9,
11,
14,
16,
17,
18] could lead to potential deficiencies in either late fusion or end-to-end training strategy.
Though many have shown superior performance of late fusion strategy [
19,
20,
21], for instance, for audio events detection in video material, W. Wang et al. [
22] illustrate the results of naive fusion from multi-modal features can be worse than the best uni-modal approach. They propose blending the gradient flow by multi-task loss functions, which is referred to as multi-term loss function by us, from uni-modalities and multi-modality, which help better parameterization of the whole system in many other research areas. Though they suggest benefits from blending the gradient flows, multi-tasking could make the features hard to be optimized serving both uni-modal and multi-modal purposes suggested by many researchers [
23,
24,
25]. We demonstrate how this proposal can still fail in some inferior cases but is solved by the within-modal RP component in MRPN.
3. Hypothesis
In this section, we discuss our hypothesis where fuzzy information from the uni-modalities can cause chaos in not just the uni-modal neurons but also the correlation neurons, namely the fusion component.
3.1. Within-Modal Information Can Be Missing or Fuzzy
The missing or fuzzy information can be noticed in either visual or vocal modality emotion recognition solution, and then the success rate of recognition can not be increased noticeably. Missing information refers to feature data where emotion categories are confused with neutral categories in the uni-modality. Fuzzy information stands for feature data where one emotion category cannot be distinguished from another one in the uni-modality.
Namely, the visual modality results from the challenge FER-2013 [
26] for single image facial recognition have only improved about 4% to 76.8% over the past eight years by W. Wang et al. [
27].
Moreover, for video frames, HW. Ng et al. [
28] got 47.3% validation accuracy and 53.8% testing accuracy on EmotiW dataset [
29] using transfer learning and averaged temporal deep features. Similarly, for vocal solutions, the results for Interactive Emotional Dyadic Motion Capture dataset (IEMOCAP) [
30] with the raw inputs are reported around 76% by S. Kwon [
31] and 64.93% by S. Latif et al. [
32]. The recognition rate for these cases is far from optimal.
Apart from the design, functionality, and training of the neural network, the human voting for those datasets draws our concerns. As the teacher in supervised learning, almost all datasets related to emotion recognition have unsatisfactory knowledge. The ones who understand human emotions the best, the human beings themselves, cannot make a majority of the agreement to the author’s labeling. On average, the human rate of the emotional categories is 72% from IEMOCAP, human accuracy on FER-2013 [
26] is 65 ± 5%, Crema-d [
33] holds the accuracy of 63.6% and RAVDESS [
34] has the results of 72.3%.
All the reports point out that in every uni-modality, the information of data is never crystal, thus the learned knowledge of a uni-modality in emotion recognition, can be corrupted and uncontrolled by the network. We cannot identify or agree on which samples are wrong because the boundaries of the clusters are quite subjective.
3.2. End-to-End Modeling for Multi-Modal Data Can Be Distorted
Multi-modal solutions seem to find more generalized patterns via the extension of parameters. However, the fused features have left a backdoor for distorted pattern learning, the side effects are concealed by its benefits.
Figure 4 shows us the different clustering from shuffled train/validation sub-datasets in each uni-modal solution and multi-modal solution, respectively. The actors in the validation set are different than they are in the training set. Due to the missing and fuzzy information from the uni-modal data, the clustering of the same uni-modality shown in the top and bottom panels differs. It can be seen from the figure, for the same modality solutions, either from uni-modal or multi-modal, missing information is causing the overlapping clustering for the neutral category. The cases appear similarly for the overlapping of emotional categories caused by the fuzzy information. This suggests that patterns within uni-modality are hard to be generalized, aligned with human voting results mentioned.
Under such circumstances, we do not know which training sample is fuzzy in which modality, not just it causing the fuzzy direction of within-modal learning, but also inter-modal learning in end-to-end training, i.e., information in modality A is fuzzy while crystal in modality B, can results in correct learning for modality B yet fuzzy learning for modality A. In the end, the distribution of the wrong direction learned knowledge is unknown.
Figure 5 illustrates the source of deficiency in the architecture during the gradient backpropagation, wherein the blue frame denotes the fusion component. Namely, the concatenation unit of the features from different modalities can backpropagate the gradients modifying jointly weights in each modality, potentially distort the knowledge in some modality.
3.3. Late Fusion Modeling for Multi-Modal Data Can Be Insufficient
The late fusion seems to prevent the inter-modal learning of the system, however, not just the distribution of the fuzzy information to each modality is unknown, but also the clean data which holds the highly correlated information between modalities are. If the samples contain clean information in all modalities, then the frozen parameters of the shadow layers cannot make proper adjustments to learn inter-modal information from the joint gradient flow.
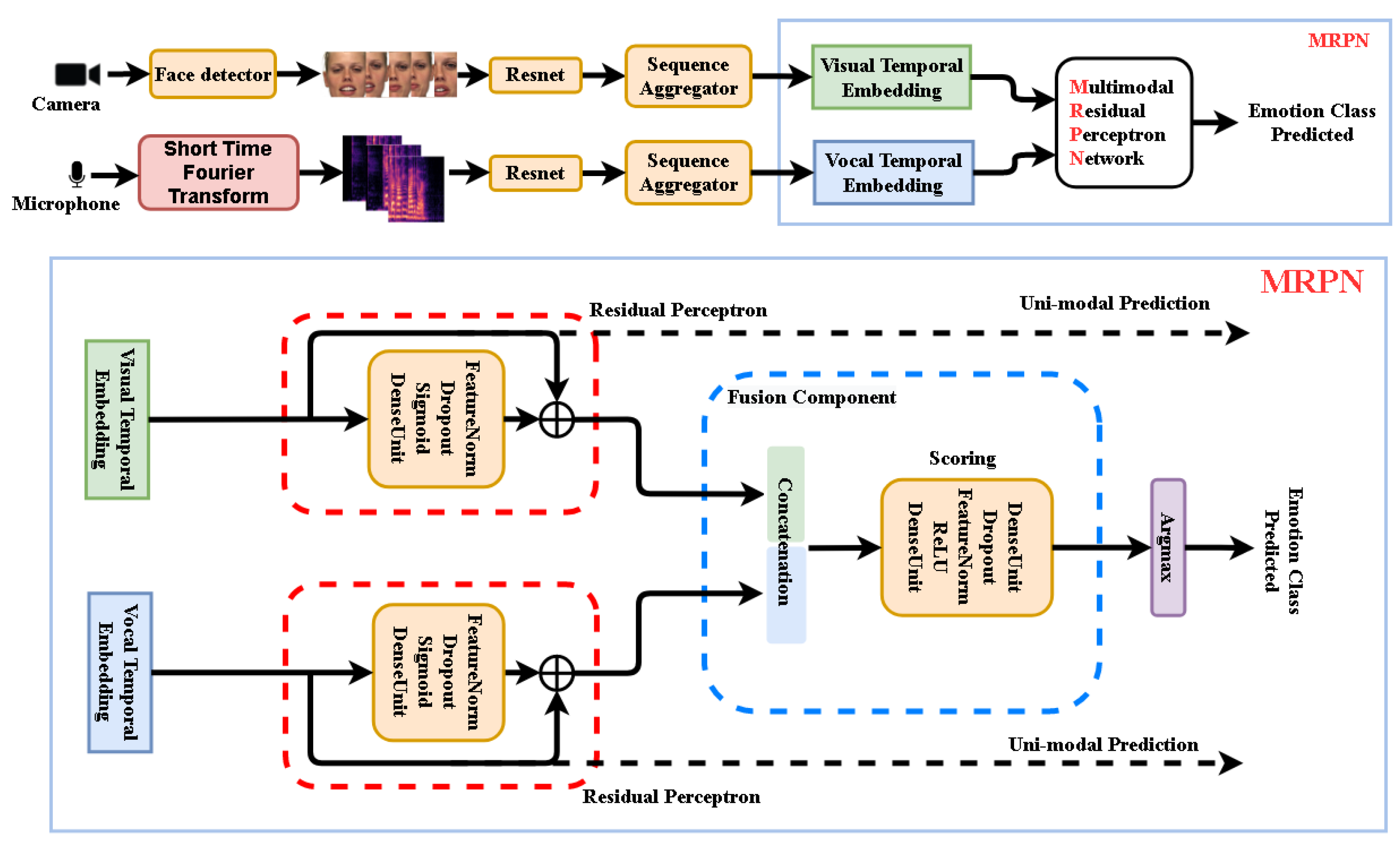
4. Proposed Methods
Addressing the mentioned issues, we proposed a novel MRPN along with a multi-term loss function for the better parameterization of the whole network taking advantage of both late fusion and end-to-end strategies while avoiding their deficiencies. MRPN can eliminate the problems without assuming the data is noisy or clean.
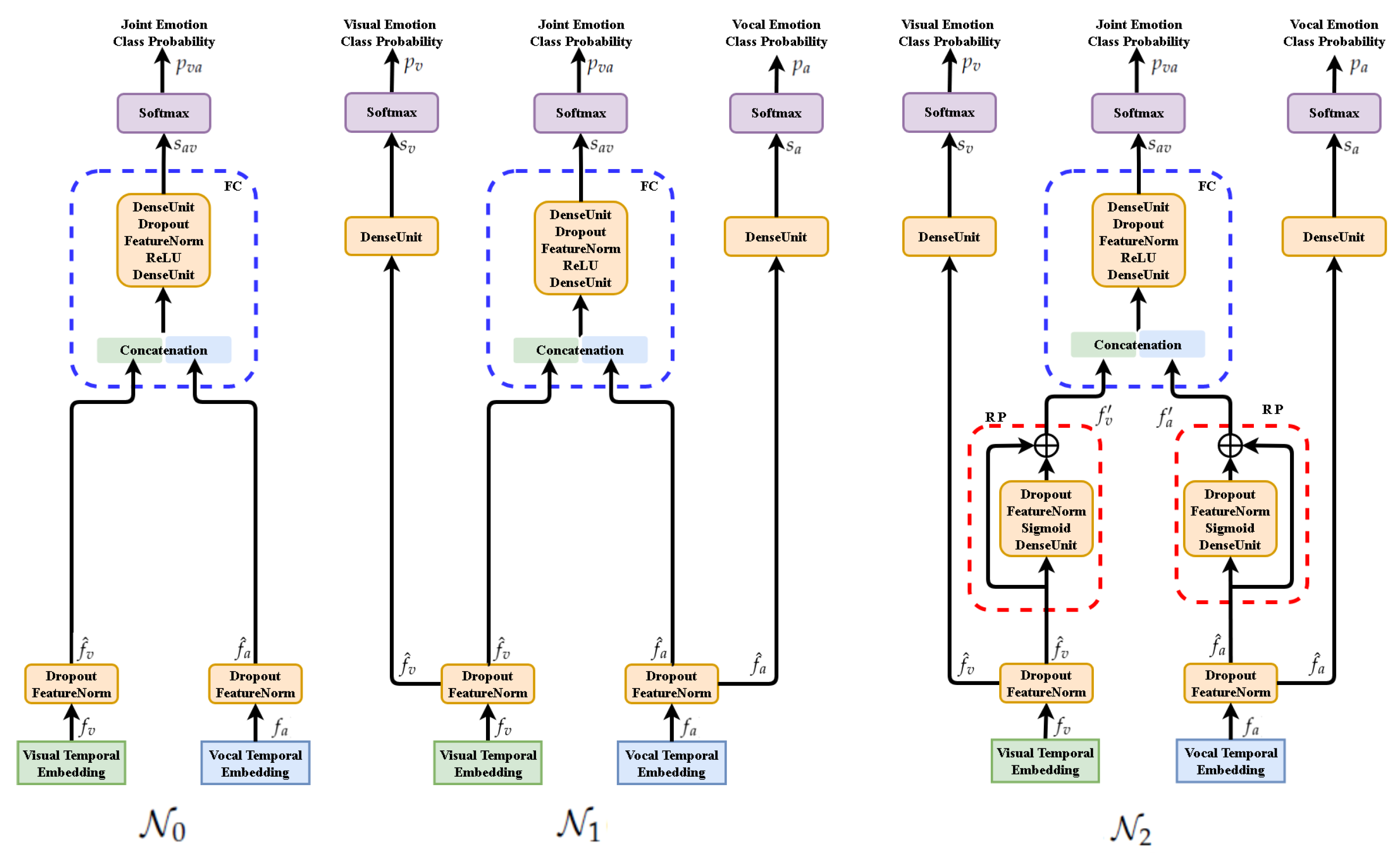
4.1. Functional Description of Analyzed Networks
The functional descriptions of the analyzed deep networks are presented for their training mode (see
Figure 6). They are based on the selected functionalities of neural units and components. We use index
m for inputs of any modality. In our experiments
or
.
- 1.
: Feature extractor for input temporal sequence of modality m, e.g., for video frames , for audio segments .
- 2.
: Aggregation component SAC for temporal feature sequence leading to temporal feature vector
, e.g.,
,
for video and audio features, respectively.
- 3.
Standard computing units: DenseUnit—affine (a.k.a. dense, full connection); Dropout—random elements dropping for model regularizing; FeatureNorm—normalization for learned data regularizing (batch norm is adopted in the current implementation); and Concatenate—joining feature maps; ReLU, Sigmoid—activation units.
- 4.
Scoring—component mapping feature vectors to class scores vector, usually composing the following operations:
- 5.
FusionComponent—concatenates its inputs
, then makes the statistical normalization, and finally produces the vector of class scores:
In our networks
are statistically normalized multi-modal features (
) or their residually updated form (
,
)—cf. those symbols in
Figure 6.
- 6.
SoftMax—computing unit for normalization of class scores to class probabilities:
- 7.
CrossEntropy—a divergence of probability distributions used as loss function. Let
p is the target probability distribution. Then the following loss functions are defined:
where
is multi-term loss function implying the gradient blending in the backpropagation stage.
- 8.
ResPerceptron (Residual Perceptron)—component performing statistical normalization for the dense unit (perceptron) computing residuals for normalized data. In our solution it transforms a modal feature vector
into
, as follows:
Three networks are defined for further analysis:
- 1.
Network
with fusion component and loss function
:
- 2.
Network
with fusion component and fused loss function
:
- 3.
Network
with normalized residual perceptron, fusion component and fused loss function
:
For the networks
detailed in
Figure 6, we can observe:
- 1.
All instances of FeatureNorm unit are implemented as batch normalization units.
- 2.
In testing mode only the central branch of networks are active while the side branches are inactive as they are used only to compute the extra terms of the extended loss function.
- 3.
The above facts make network architectures equivalent in the testing mode. However, the models trained for those architectures are not the same, as weights are optimized for different loss functions.
- 4.
In the testing mode all Dropout units are not active, as well.
- 5.
The architecture of FusionComponent is identical for all three networks. The difference between models of and networks follows from the different loss functions while the difference between models of and networks is implied by using ResPerceptron (RP) components in network.
- 6.
To control the range of affine combinations computed by Residual Perceptron (RP) component, we use Sigmoid activations instead of the ReLU activations exploited in other components. The experiments confirm the advantage of this design decision.
- 7.
The Residual Perceptron (RP) was introduced in the network to implement better parameterization of within-modal features before their fusion.
4.2. MRPN Components’ Role in Multi-Term Optimization
- 1.
As we discussed in the hypothesis section, the late fusion strategy has the advantage of preserving the best information in each uni-modality since the uni-modality extracts generalized deep features which suffer little from the outliers of their own modality, i.e., a small amount of wrongly labeled data in uni-modal solutions will not contribute to the generalized feature patterns; they are “filtered out” by the uni-modal neural network. Thus the additional term of loss functions implies the blended gradient in the shallow layers of each uni-modality, and helped for better parameterization of the features before fusion, preserving the knowledge as uni-modalities are trained respectively. The above facts make the end-to-end strategy suffer less inter-modal information as late fusion does.
- 2.
However, the multi-term optimization can result in extracting inferior uni-modal features as the input to the fusion component. This problem was mentioned in the literature [
23,
24,
25]. RP is introduced to make modified uni-modal features, instead of storing all knowledge for uni-modal and multi-modal purposes in one unit, causing the clash of loss converging from two directions, the uni-modal and multi-modal knowledge can be stored in the original uni-modal features and modified multi-modal features, creating a new path for the gradient flow. RP can preserve the best of the uni-modal solution while the modified features from the short-cut can still fulfill the purpose of integrating new multi-modal features.
The mentioned two novel properties make MRPN free from side-effects of late fusion and end-to-end strategy while preserving their own advantages.
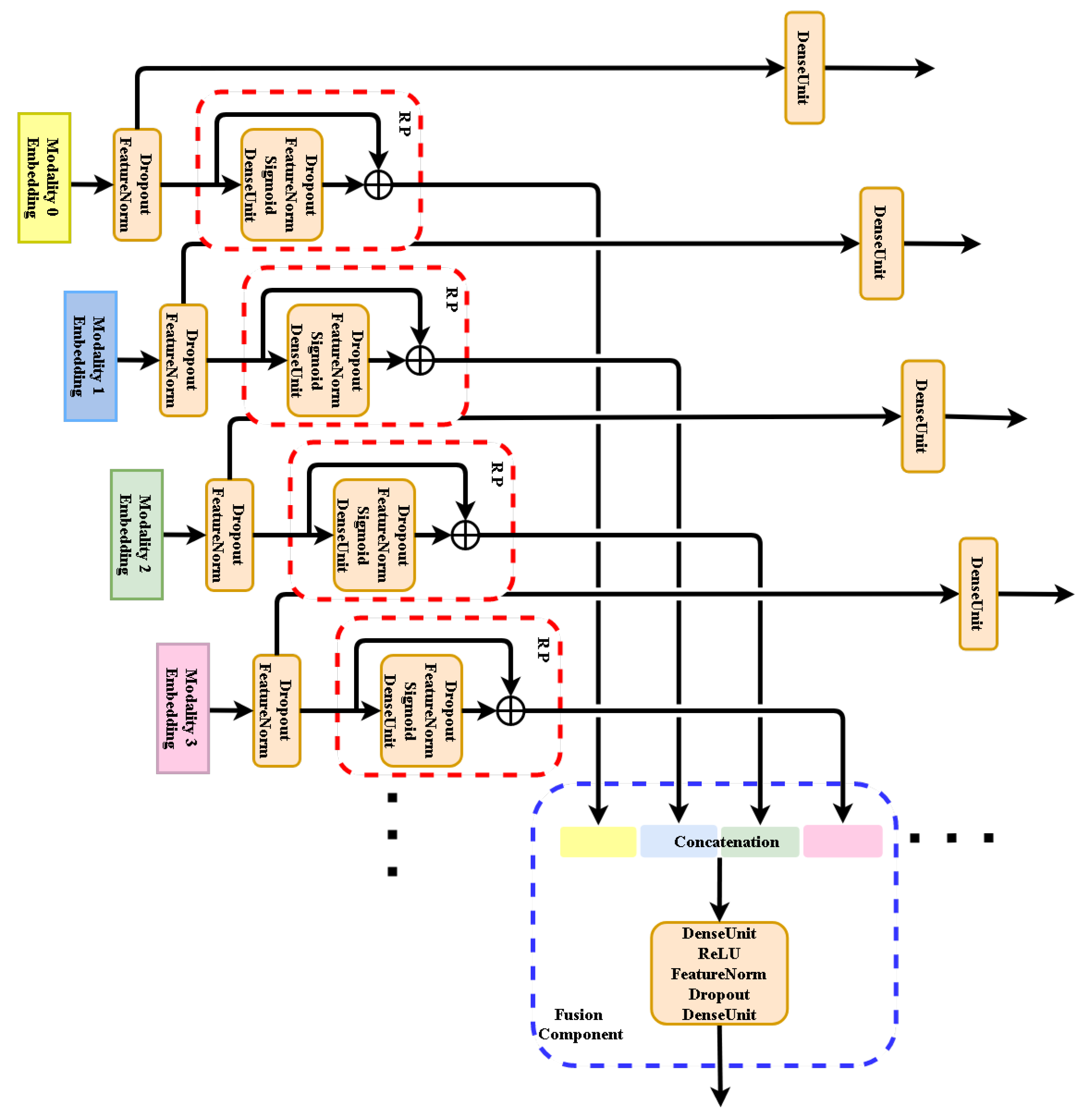
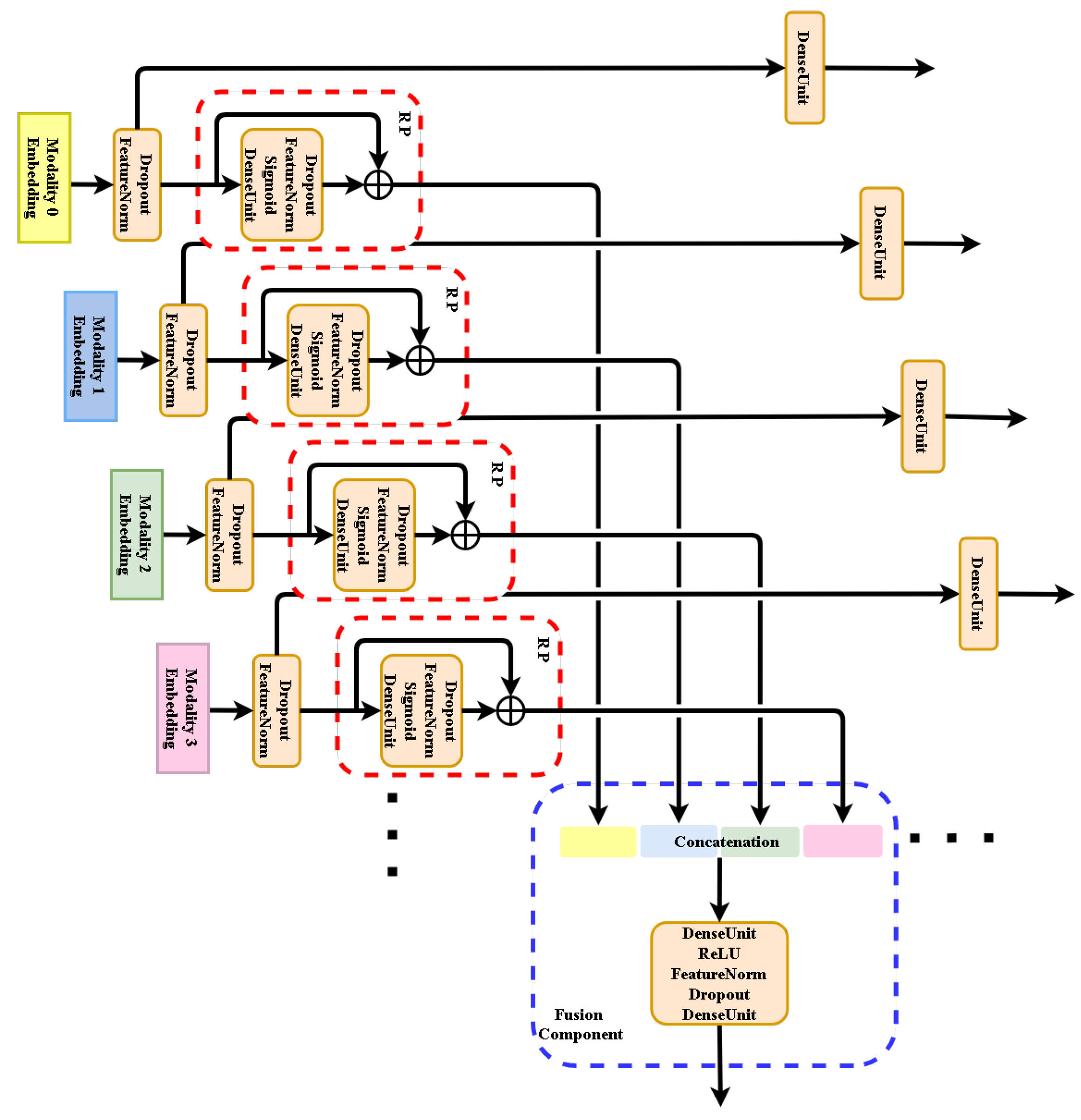
4.3. MRPN in General Multi-Modal Applications
We suggest that MRPN can be adopted in any multi-modal application that involves many multi-modal inputs and one target function or many multi-modal inputs and many multi-modal target functions as
Figure 7 shows. In both cases MRPN benefits from many terms of loss functions as the numbers of uni-modalities, updating the whole system together while avoiding learning from inter-modal fuzzy information. MRPN is general to be compatible with any other proposed mechanism.
4.4. Pre-Processing
Our data pre-processing includes the procedures for both modality inputs, namely spatial and time-dependent augmentation are applied.
- 1.
Spatial data augmentation for visual frames:
The facial area for the visual input frames is cropped using a CNN solution from Dlib library [
35]. Once the facial area is cropped, spatial video augmentation is applied during the training phase. The same random augmentation parameters are applied for all frames of a video source illustrated in
Figure 8.
- 2.
Time dependent data augmentation for visual frames:
Obviously, expressions from the same category do not last the same duration. To make our system robust to the inconsistent duration of the emotion events, we perform data augmentation in time by randomly slicing the original frames as
Figure 9 illustrates. Such operation should also avoid too few input frames missing information of the expression events. Thus the training segments are selected to have at least one-second duration unless the original duration of the file is less than that.
- 3.
Spatial data augmentation for vocal frames: Raw audio inputs are resampled at 16 kHz and standardized by their mean and standard deviation without any denoising or cutting, to remove influence from the distance of the speaker to the microphone, or subjective base volume of the speaker. The standardized wave is then divided into one-second segments and converted to spectrograms by a Hann windowing function of size 512 and hop size of 64.
The above facts specify the size of the spectrogram at 256 × 250, approaching the required input shape of Resnet-18—the CNN extractor used in our experiment. The chunk size using such inputs for Resnet-18 [
36] is close to its desired performance utilizing the advantage in the middle deep features.
- 4.
Time dependent augmentation for vocal frames: Similar to the time augmentation in visual inputs, raw audio inputs are also randomly sliced. The raw data is further over-sampled in both the training and testing mode by a hopping window. A window of 0.2 s, 1/5 duration of the input segments to the CNN extractor is specified. The oversampling further improved our results by the increasing number of deep features from the output deep feature sequences of CNN to the SAC. The mechanism grants the opportunity for the SAC to investigate more details of the temporal information in the deep feature vectors.
5. Computational Experiments and Their Discussion
This section presents an evaluation regarding the advantages of our proposed framework and time-dependent augmentation. Two datasets, RAVDESS and Crema-d are employed for this purpose. The improvement of the time-augmentation mechanism is analyzed in the naive fusion model which brought us state-of-art results even without MRPN design. The inferior cases in such common neural multi-modal solutions are detected and discussed in the comparison. Improvement of MRPN is then presented, not just in the detected inferior sub-datasets, but also in general data samples.
5.1. Datasets
RAVDESS and Crema-d differ in numbers of expression categories, total files, identifies, and also video quality.
- 1.
RAVDESS dataset includes both speech and song files. For the speech recognition proposal, we only use the speech files from the dataset. It contains 2880 files, 24 actors (12 female, 12 male), state two lexically identical statements. Speech includes calm, happy, sad, angry, fearful, surprise, and disgusted expressions. Each expression is produced at two levels of emotional intensity (normal, strong), with an additional neutral expression, in a total of 8 categories. It is the most recent video-audio emotional dataset with the highest video quality in this research area to our best knowledge.
- 2.
Crema-d dataset consists of visual and vocal emotional speech files in a range of basic emotional states (happy, sad, anger, fear, disgust, and neutral). 7442 clips of 91 actors with diverse ethnic backgrounds were rated by multiple raters in three modalities: Audio, visual, and audio-visual.
For both datasets, the training set and testing set are separated using similar concepts as 10-fold inter-validation. Additionally, identities of the actors are also separated in train and val sets to prevent the results from leaning on the actors. Around 10% of the actors are used for validation while the remaining 90% are used for training, male and female actors are balanced in each set. We rotate the split train/validation sub-datasets to get multiple results over the whole dataset. The crema-d dataset has fewer categories for the classification tasks, but from the report of the authors themselves, Crema-d holds the accuracy of 63.6% from human recognition for six categories which are less than RAVDESS at 72.3% for eight categories. The resolution of the video source is verified not the cause of the worse performance. The better results in the RAVDESS dataset, in our opinion, are the more crystal and natural emotion information inside the RAVDESS dataset.
5.2. Model Organization and Computational Setup
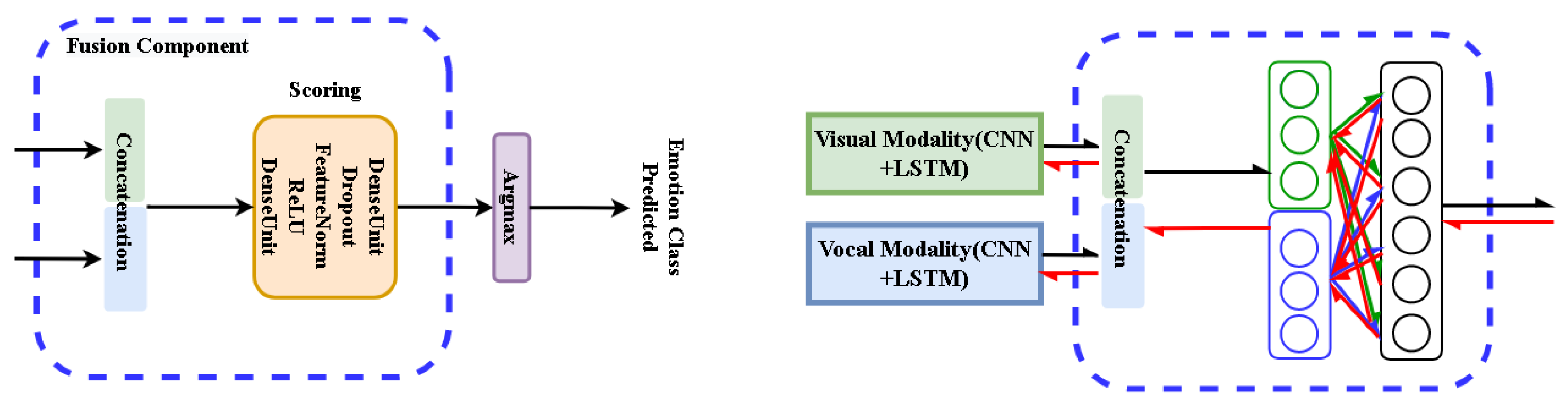
The naive fusion model
, advanced fusion network
, which is equivalent to the Facebook [
22] solution and the
(MRPN) have the same CNN extractors at the initial stage of the training. To compare the impact of strategy from features fusion only, CNN extractor architecture is fixed to Resnet-18 [
36].
The CNN in visual modality is initialized from a facial image expression recognition task, the challenge FER2013 [
26]. As for vocal modality, The CNN is pretrained on the voice recognition task from VoxCeleb dataset [
37]. The initialization of the CNN extractors made the whole system much easier to be optimized.
AdaMW optimizer is adopted for the model optimization, with the initial learning rate at , decreased two times if validation loss is not dropping over ten epochs.
5.3. Data Augmentation Cannot Generalize Multi-Modal Feature Patterns
This subsection illustrates the improvement of time-dependent augmentation. The improvement also proves that the inferior case of multi-modal solution does not depend on the with-modal patterns. The single modality solutions in our experiments (shown in
Table 1) take pretrained Resnet-18 as extractors and LSTM cells as SACs. The naive multi-modal solution takes twice of the components with an additional fusion layer as
Figure 6 illustrates on the left panel. Adopting time-dependent augmentation shows overall performance improvements on either single or multi-modal solutions. The Table notations are presented in the follows:
In the variational train/val sub-datasets in
Table 1, Ax,y stands for the validation files that came from actor x and y, odd number notes for a male actor, and even number for a female actor.
5.4. Discussion on Inferior Multi-Modal Cases
The time augmentation shows overall improvements in either uni-modal or multi-modal approach, yet the inferior case where uni-modal solution better than multi-modal solution still exists, which suggests data augmentation cannot generalize multi-modal features. Only one inferior case is detected in
Table 1 of the case A9,10, but we argue such deficiency is common in fuzzy multi-modal data. The pattern learning ability from both modalities is well enough, both solutions have performance over 85% in cases like A7,8 and A1,2. However, the ratio of mismatched learned and target patterns are ranging along with the shuffling of the sub-datasets.
The degeneration of the performance became visible only because the percentage of the pattern mismatched samples has passed some kind of threshold in the training set. If so, by eliminating or reducing such side effects, overall improvements should be expected for any train and testing sub-dataset.
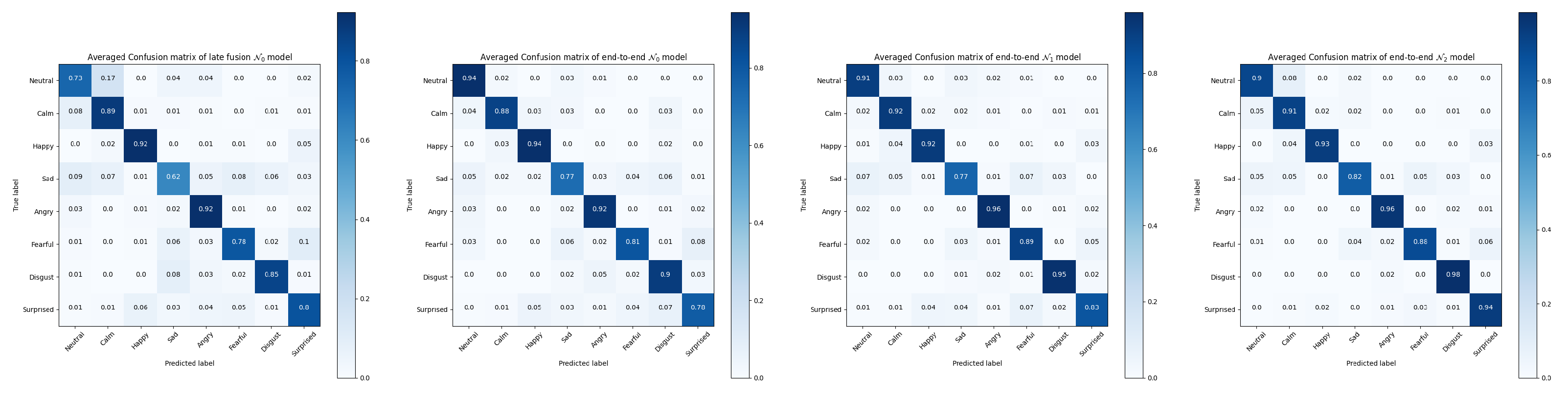
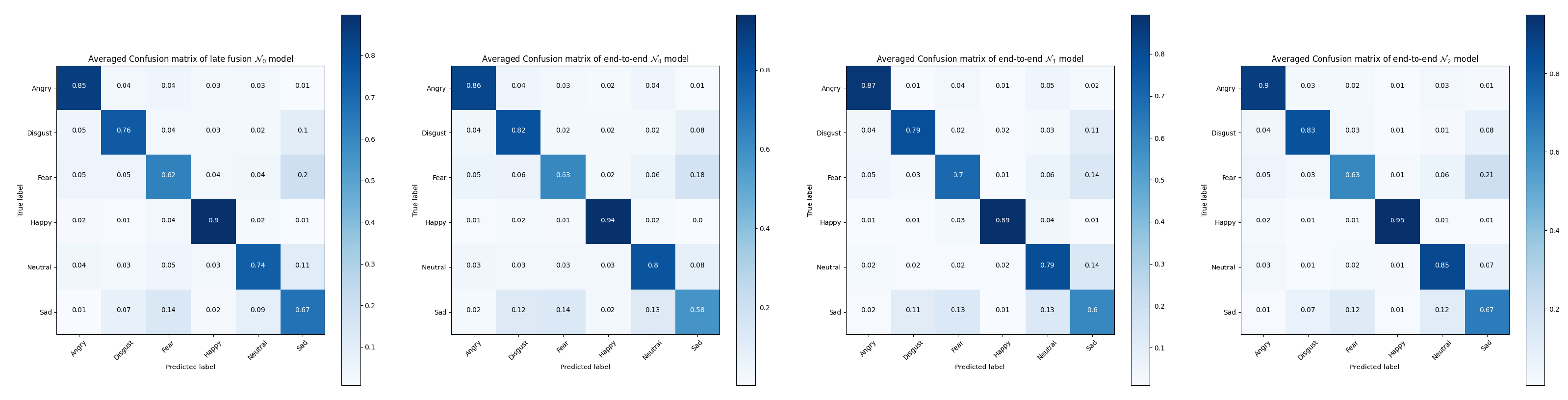
5.5. Improvement of MRPN
This subsection addresses the improvement of MRPN preventing the side-effects in the existing late fusion and end-to-end strategies we hypothesized as
Table 2 and
Table 3 illustrate. The end-to-end strategy of
, which takes multi-term loss function helped the better parameterization shows improved average performance over naive end-to-end and late fusion training strategies, yet it can still fail in some cases. Our proposed MRPN on the contrary demonstrates the same performance or most improvement in any circumstance.
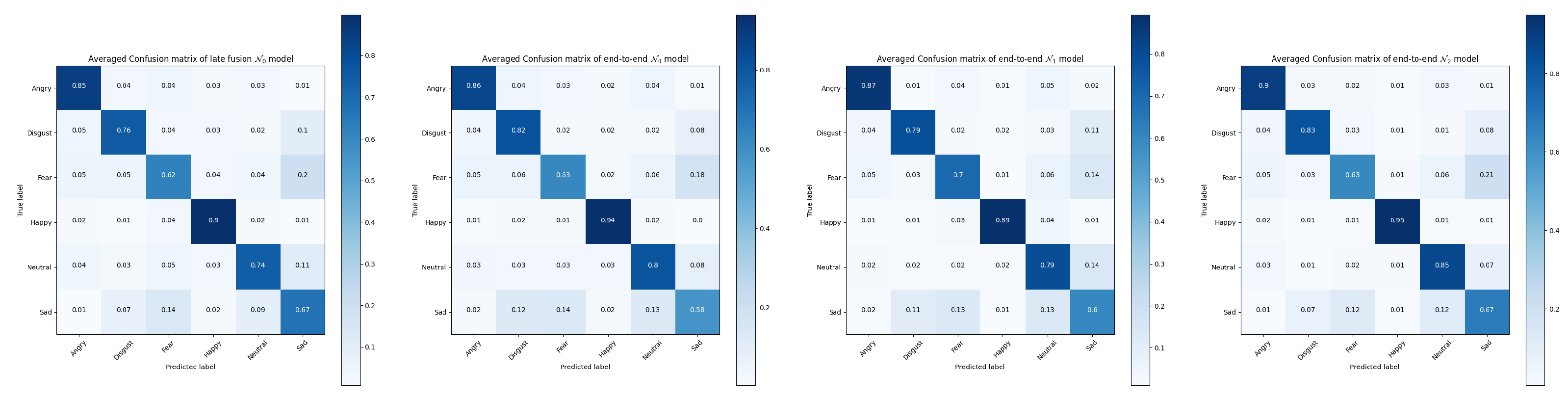
It can been seen from the confusion matrices in
Figure 10 and
Figure 11 the averaged improvements of
(MRPN) over the late fusion and end-to-end
models. Performance on some specific categories shows a slight decrease for MRPN, especially for the categories of calm and neutral expressions because they are naturally close to each other in the RAVDESS dataset.
does not always perform better than the existing solutions, the almost 6% improvements of
(MRPN) over
suggests the level of data fuzziness can make the end-to-end multi-term optimization even harder without proposed RP components. The overall improvements suggest that multi-modal patterns are more generalized from the solution of
(MRPN).
5.6. Comparing Baseline with SOTA
Our proposed MRPN shows stat-or-art results on both datasets. It has no conflicts with any potential advantages from another novel mechanism. The detailed results are presented in
Table 4. Experiments regarding the pretraining of the CNN extractors and the time augmentation have made the network robust to overcome the overfitting issues regarding the small amount of the training and testing data.
Additionally, replacement of LSTM of Bidirectional LSTM and Transformer as aggregator has been conducted but no noticeable differences of them as sequence aggregators can be seen. As for Transformer, the average feature is taken from the decoded outputs, the concept follows from Vision Transformer (VIT) [
38].
6. Conclusions
This paper focuses on explaining the potential deficiencies in the existing fusion layer of the multi-modal approach to AVER tasks using late fusion or end-to-end strategy. The proposed MPRN architecture along with the multi-term loss function makes superior fused features from multi-modal sources. We observe the elimination of inferior cases of multi-modal solutions with respect to uni-modal solutions.
Our results achieve an average accuracy of 91.4% on the RAVDESS dataset and 83.15% on the Crema-d dataset. MRPN solution contributes to a better average recognition rate of approximately 2%. We have observed the maximum improvement of MRPN for a subset to be around 90% from nearly 80%.
The proposed data pre-processing by time augmentation makes general overall rate improvements for both the uni-modal and multi-modal data. It also illustrates data augmentation cannot generalize multi-modal features due to the deficiencies in the existing multi-modal solutions.
Moreover, the MRPN concept shows its potential for multi-modal classifiers dealing with signal sources not only of optical and acoustical type.
Author Contributions
Conceptualization, X.C. and W.S.; Data curation, X.C.; Formal analysis, X.C. and W.S.; Investigation, X.C. and W.S.; Methodology, X.C. and W.S.; Project administration, X.C. and W.S.; Resources, X.C. and W.S.; Software, X.C. and W.S.; Supervision, W.S.; Validation, X.C. and W.S.; Visualization, X.C. and W.S.; Writing—original draft, X.C. and W.S.; Writing—review & editing, X.C. and W.S. All authors have read and agreed to the published version of the manuscript.
Funding
Beside statutory support of Warsaw University of Technology this research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AVER | Audio video emotion recognition |
| CNN | Convolution Neural Network |
| Crema-d [33] | Crowd-sourced Emotional multi-modal Actors Dataset |
| DNN | Deep Neural Network |
| HCI | Human–Computer Interaction |
| FC | Fully connected layer |
| IEMOCAP [30] | Interactive emotional dyadic motion capture dataset |
| LSTM | Long Short Term Memory |
| MRPN | multi-modal Residual Perceptron Network |
| RAVDESS [34] | The Ryerson Audio–Visual Database of Emotional Speech and Song |
| RP | Residual Perceptron |
| SAC | Sequence Aggregation Component |
| SOTA | State of the Art Solution |
| STFT | Short-term Fourier transformation |
| SVM | Support Vector Machine |
| VIT [38] | Vision Transformer |
References
- Belhumeur, P.N.; Hespanha, J.a.P.; Kriegman, D.J. Eigenfaces vs. Fisherfaces: Recognition Using Class Specific Linear Projection. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 711–720. [Google Scholar] [CrossRef] [Green Version]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Neverova, N.; Wolf, C.; Taylor, G.W.; Nebout, F. ModDrop: Adaptive multi-modal gesture recognition. arXiv 2015, arXiv:1501.00102. [Google Scholar] [CrossRef] [Green Version]
- Vielzeuf, V.; Pateux, S.; Jurie, F. Temporal Multimodal Fusion for Video Emotion Classification in the Wild. arXiv 2017, arXiv:1709.07200. [Google Scholar]
- Beard, R.; Das, R.; Ng, R.W.M.; Gopalakrishnan, P.G.K.; Eerens, L.; Swietojanski, P.; Miksik, O. Multi-Modal Sequence Fusion via Recursive Attention for Emotion Recognition. In Proceedings of the 22nd Conference on Computational Natural Language Learning; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 251–259. [Google Scholar]
- Ghaleb, E.; Popa, M.; Asteriadis, S. Multimodal and Temporal Perception of Audio-visual Cues for Emotion Recognition. In Proceedings of the 2019 8th International Conference on Affective Computing and Intelligent Interaction (ACII), Cambridge, UK, 3–6 September 2019; pp. 552–558. [Google Scholar]
- Zadeh, A.; Liang, P.P.; Mazumder, N.; Poria, S.; Cambria, E.; Morency, L.P. Memory Fusion Network for Multi-view Sequential Learning. arXiv 2018, arXiv:1802.00927. [Google Scholar]
- Mansouri-Benssassi, E.; Ye, J. Speech Emotion Recognition With Early Visual Cross-modal Enhancement Using Spiking Neural Networks. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Zhang, S.; Zhang, S.; Huang, T.; Gao, W.; Tian, Q. Learning Affective Features with a Hybrid Deep Model for Audio–Visual Emotion Recognition. IEEE Trans. Cir. Syst. Video Technol. 2018, 28, 3030–3043. [Google Scholar] [CrossRef]
- Ristea, N.; Duţu, L.C.; Radoi, A. Emotion Recognition System from Speech and Visual Information based on Convolutional Neural Networks. In Proceedings of the 2019 International Conference on Speech Technology and Human–Computer Dialogue (SpeD), Timisoara, Romania, 10–12 October 2019; pp. 1–6. [Google Scholar]
- Tzinis, E.; Wisdom, S.; Remez, T.; Hershey, J.R. Improving On-Screen Sound Separation for Open Domain Videos with Audio–Visual Self-attention. arXiv 2021, arXiv:2106.09669. [Google Scholar]
- Wu, Y.; Zhu, L.; Yan, Y.; Yang, Y. Dual Attention Matching for Audio–Visual Event Localization. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Ghaleb, E.; Popa, M.; Asteriadis, S. Metric Learning-Based Multimodal Audio–Visual Emotion Recognition. IEEE MultiMedia 2020, 27, 37–48. [Google Scholar] [CrossRef] [Green Version]
- Noroozi, F.; Marjanovic, M.; Njegus, A.; Escalera, S.; Anbarjafari, G. Audio–Visual Emotion Recognition in Video Clips. IEEE Trans. Affect. Comput. 2019, 10, 60–75. [Google Scholar] [CrossRef]
- Hossain, M.S.; Muhammad, G. Emotion recognition using deep learning approach from audio–visual emotional big data. Inf. Fusion 2019, 49, 69–78. [Google Scholar] [CrossRef]
- Ma, F.; Zhang, W.; Li, Y.; Huang, S.L.; Zhang, L. Learning Better Representations for Audio–Visual Emotion Recognition with Common Information. Appl. Sci. 2020, 10, 7239. [Google Scholar] [CrossRef]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Gool, L.V. Temporal Segment Networks: Towards Good Practices for Deep Action Recognition. arXiv 2016, arXiv:1608.00859. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-Stream Convolutional Networks for Action Recognition in Videos. arXiv 2014, arXiv:1406.2199. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. arXiv 2018, arXiv:1705.07750. [Google Scholar]
- Wang, W.; Tran, D.; Feiszli, M. What Makes Training Multi-Modal Classification Networks Hard? In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–18 June 2020; pp. 12692–12702. [Google Scholar]
- Standley, T.; Zamir, A.R.; Chen, D.; Guibas, L.; Malik, J.; Savarese, S. Which Tasks Should Be Learned Together in Multi-task Learning? arXiv 2020, arXiv:1905.07553. [Google Scholar]
- Caruana, R. Multitask Learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Yu, T.; Kumar, S.; Gupta, A.; Levine, S.; Hausman, K.; Finn, C. Gradient Surgery for Multi-Task Learning. arXiv 2020, arXiv:2001.06782. [Google Scholar]
- Goodfellow, I.J.; Erhan, D.; Carrier, P.L.; Courville, A.; Mirza, M.; Hamner, B.; Cukierski, W.; Tang, Y.; Thaler, D.; Lee, D.H.; et al. Challenges in representation learning: A report on three machine learning contests. Neural Netw. 2015, 64, 59–63. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Fu, Y.; Sun, Q.; Chen, T.; Cao, C.; Zheng, Z.; Xu, G.; Qiu, H.; Jiang, Y.G.; Xue, X. Learning to Augment Expressions for Few-shot Fine-grained Facial Expression Recognition. arXiv 2020, arXiv:2001.06144. [Google Scholar]
- Ng, H.W.; Nguyen, V.D.; Vonikakis, V.; Winkler, S. Deep Learning for Emotion Recognition on Small Datasets Using Transfer Learning. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction; Association for Computing Machinery: New York, NY, USA, 2015; pp. 443–449. [Google Scholar]
- Dhall, A.; Kaur, A.; Goecke, R.; Gedeon, T. EmotiW 2018: Audio–Video, Student Engagement and Group-Level Affect Prediction. In Proceedings of the 20th ACM International Conference on Multimodal Interaction, Boulder, CO, USA, 16–20 October 2018; pp. 653–656. [Google Scholar]
- Busso, C.; Bulut, M.; Lee, C.C.; Kazemzadeh, A.; Mower Provost, E.; Kim, S.; Chang, J.; Lee, S.; Narayanan, S. IEMOCAP: Interactive emotional dyadic motion capture database. Lang. Resour. Eval. 2008, 42, 335–359. [Google Scholar] [CrossRef]
- Mustaqeem; Kwon, S. A CNN-Assisted Enhanced Audio Signal Processing for Speech Emotion Recognition. Sensors 2020, 20, 183. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Latif, S.; Rana, R.; Qadir, J.; Epps, J. Variational Autoencoders for Learning Latent Representations of Speech Emotion. arXiv 2017, arXiv:1712.08708. [Google Scholar]
- Cao, H.; Cooper, D.G.; Keutmann, M.K.; Gur, R.C.; Nenkova, A.; Verma, R. CREMA-D: Crowd-Sourced Emotional Multimodal Actors Dataset. IEEE Trans. Affect. Comput. 2014, 5, 377–390. [Google Scholar] [CrossRef] [Green Version]
- Livingstone, S.R.; Russo, F.A. The Ryerson Audio–Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLoS ONE 2018, 13, e0196391. [Google Scholar] [CrossRef] [Green Version]
- King, D.E. Dlib-Ml: A Machine Learning Toolkit. J. Mach. Learn. Res. 2009, 10, 1755–1758. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Nagrani, A.; Chung, J.S.; Zisserman, A. VoxCeleb: A Large-Scale Speaker Identification Dataset. 2017. Available online: https://arxiv.org/pdf/1706.08612.pdf (accessed on 12 August 2021).
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Mustaqeem; Sajjad, M.; Kwon, S. Clustering-Based Speech Emotion Recognition by Incorporating Learned Features and Deep BiLSTM. IEEE Access 2020, 8, 79861–79875. [Google Scholar] [CrossRef]
Figure 1.
The proposed multi-modal emotion recognition system using Deep Neural Network (DNN) approach. Upper part: Video frames and audio spectral segments get independent temporal embeddings to be fused by our multi-modal Residual Perceptron Network (MRPN). Lower part: MRPN performs in each modality normalizations via the proposed residual perceptrons and then scores their concatenated outputs in the fusion component. The uni-modal prediction branches are only active in training mode.
Figure 1.
The proposed multi-modal emotion recognition system using Deep Neural Network (DNN) approach. Upper part: Video frames and audio spectral segments get independent temporal embeddings to be fused by our multi-modal Residual Perceptron Network (MRPN). Lower part: MRPN performs in each modality normalizations via the proposed residual perceptrons and then scores their concatenated outputs in the fusion component. The uni-modal prediction branches are only active in training mode.
Figure 2.
Video frames of visual facial expressions selected from RAVDESS (Ryerson Audio–Visual Database of Emotional Speech and Song) dataset.
Figure 2.
Video frames of visual facial expressions selected from RAVDESS (Ryerson Audio–Visual Database of Emotional Speech and Song) dataset.
Figure 3.
Mel spectrograms of vocal timbres selected from RAVDESS (Ryerson Audio–Visual Database of Emotional Speech and Song) dataset.
Figure 3.
Mel spectrograms of vocal timbres selected from RAVDESS (Ryerson Audio–Visual Database of Emotional Speech and Song) dataset.
Figure 4.
Visualization (t-SNE algorithm) of deep features clustering from two different setups where the train/validation sets are shuffled. The clustering with respect to emotion classes are listed. 0: Neutral; 1: Calm; 2: Happy; 3: Sad; 4: Angry; 5: Fearful; 6: Disgust; 7: Surprised. Top part: Clustering results from one setup of uni-modalities and multi-modality. Left part: Only image modality. Middle part: Only audio modality. Right part: Multi-modality. Down part: Clustering results from the other setup where train/validation sets are shuffled.
Figure 4.
Visualization (t-SNE algorithm) of deep features clustering from two different setups where the train/validation sets are shuffled. The clustering with respect to emotion classes are listed. 0: Neutral; 1: Calm; 2: Happy; 3: Sad; 4: Angry; 5: Fearful; 6: Disgust; 7: Surprised. Top part: Clustering results from one setup of uni-modalities and multi-modality. Left part: Only image modality. Middle part: Only audio modality. Right part: Multi-modality. Down part: Clustering results from the other setup where train/validation sets are shuffled.
Figure 5.
Distorted gradients backpropagation in some modality since the gradients from fused layer makes impact on gradients flow into neural weights of both modalities.
Figure 5.
Distorted gradients backpropagation in some modality since the gradients from fused layer makes impact on gradients flow into neural weights of both modalities.
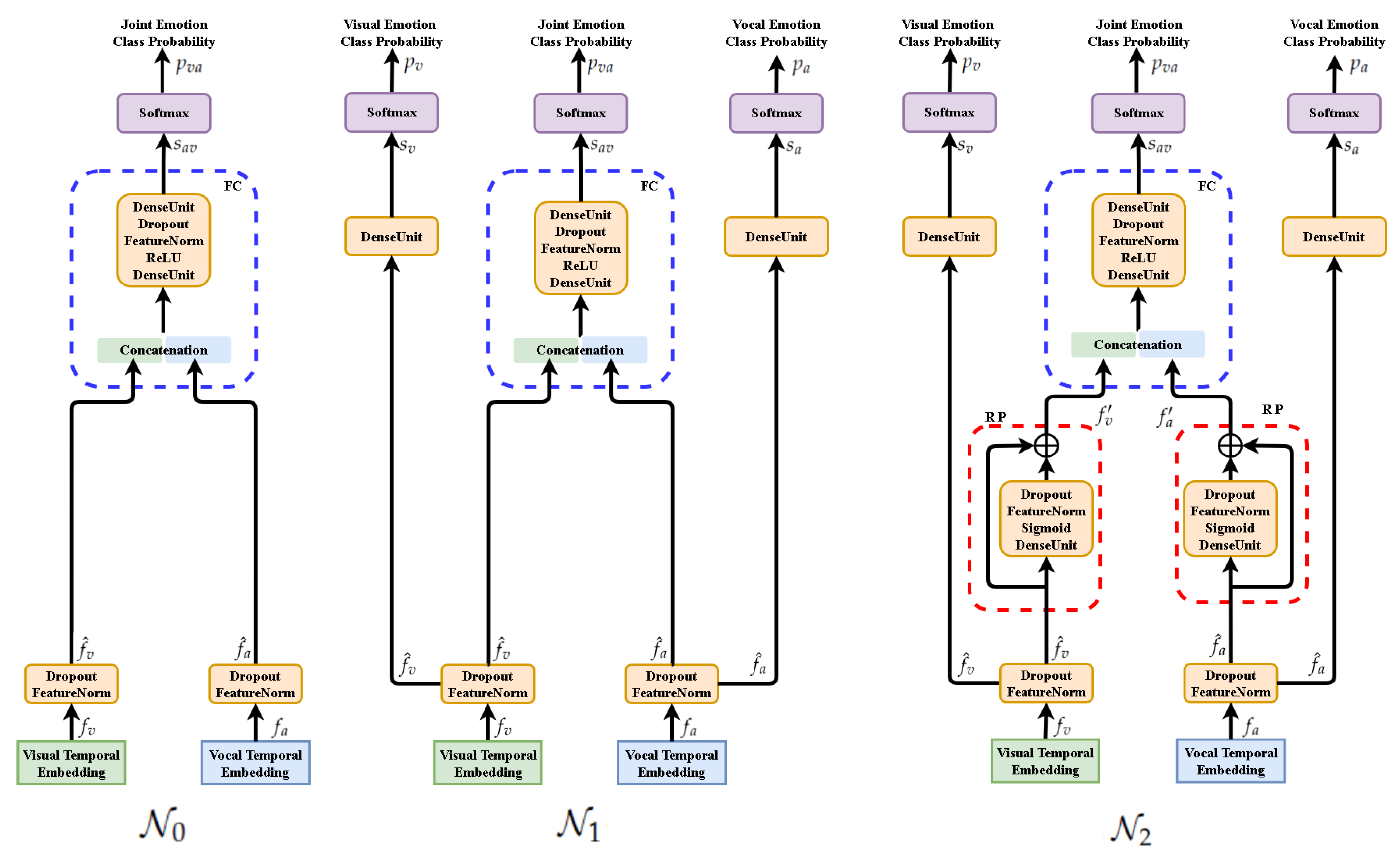
Figure 6.
Evolution of network design for multi-modal fusion (presented for training mode).
: Fusion component (FC) only.
([
22]): Beside FC, independent scoring of each modality is considered.
: Extending
network by Residual Perceptrons (RP) in each modality branch.
Figure 6.
Evolution of network design for multi-modal fusion (presented for training mode).
: Fusion component (FC) only.
([
22]): Beside FC, independent scoring of each modality is considered.
: Extending
network by Residual Perceptrons (RP) in each modality branch.
Figure 7.
Generalization of our MRPN fusion approach to many modalities. It could be used for either regression or classification applications.
Figure 7.
Generalization of our MRPN fusion approach to many modalities. It could be used for either regression or classification applications.
Figure 8.
Visual comparison of augmentation procedure for cropped video frames. Top part: Original video frames. Middle part: Applying random augmentation parameters—same for all frames. Bottom part: Applying random augmentation parameters—different for each frame.
Figure 8.
Visual comparison of augmentation procedure for cropped video frames. Top part: Original video frames. Middle part: Applying random augmentation parameters—same for all frames. Bottom part: Applying random augmentation parameters—different for each frame.
Figure 9.
Examples of time dependent augmentation for visual frames. Top part: Original frames. Middle part: Sliced frames start at beginning of the original frames. Bottom part: Sliced frames start at the middle of the original frames.
Figure 9.
Examples of time dependent augmentation for visual frames. Top part: Original frames. Middle part: Sliced frames start at beginning of the original frames. Bottom part: Sliced frames start at the middle of the original frames.
Figure 10.
Averaged confusion matrices of tested models for RAVDESS dataset.
Figure 10.
Averaged confusion matrices of tested models for RAVDESS dataset.
Figure 11.
Averaged confusion matrices of tested models for Crema-d dataset.
Figure 11.
Averaged confusion matrices of tested models for Crema-d dataset.
Table 1.
Comparison of single modalities models with model (RAVDESS cases): VM—Visual Modality only; AM—Audio Modality only; JM—Joint Modalities ( model); T—having time augmentation by signal random slicing; NT—not having time augmentation.
Table 1.
Comparison of single modalities models with model (RAVDESS cases): VM—Visual Modality only; AM—Audio Modality only; JM—Joint Modalities ( model); T—having time augmentation by signal random slicing; NT—not having time augmentation.
| RAVDESS | A1,2 | A3,4 | A5,6 | A7,8 | A9,10 | A11,12 |
|---|
| AM (NT) | 70.8% | 55.0% | 57.5% | 74.1% | 43.5% | 65.8% |
| AM (T) | 71.6% | 77.5% | 71.6% | 90.0% | 55.8% | 69.1% |
| VM (NT) | 82.5% | 70.0% | 66.7% | 74.1% | 80.3% | 63.3% |
| VM (T) | 86.6% | 75.0% | 70.6% | 76.6% | 87.3% | 69.1% |
| JM (NT) | 90.8% | 89.1% | 85.2% | 89.3% | 78.5% | 85.5% |
| JM (T) | 97.5% | 90.3% | 87.5% | 97.5% | 86.5% | 87.5% |
| RAVDESS | A13,14 | A15,16 | A17,18 | A19,20 | A21,22 | A23,24 |
| AM (NT) | 59.8% | 57.5% | 51.6% | 55.5% | 55.8% | 63.3% |
| AM (T) | 70.0% | 69.1% | 57.5% | 63.3% | 68.3% | 68.3% |
| VM (NT) | 71.3% | 60.0% | 63.3% | 70.8% | 65.8% | 70.8% |
| VM (T) | 73.3% | 65.0% | 64.1% | 78.3% | 66.6% | 74.1% |
| JM (NT) | 77.5% | 75.5% | 76.3% | 85.2% | 82.8% | 80.0% |
| JM (T) | 82.4% | 79.6% | 83.2% | 89.0% | 85.5% | 84.2% |
Table 2.
Comparison for RAVDESS of MRPN approach (network ) with late fusion strategy (), end-to-end strategy (), and advanced end-to-end fusion strategy ().
Table 2.
Comparison for RAVDESS of MRPN approach (network ) with late fusion strategy (), end-to-end strategy (), and advanced end-to-end fusion strategy ().
| RAVDESS | A1,2 | A3,4 | A5,6 | A7,8 | A9,10 | A11,12 |
|---|
| (late fusion) | 61.6% | 92.1% | 87.5% | 96.6% | 66.6% | 87.5% |
| (end-to-end) | 97.5% | 90.3% | 87.5% | 97.5% | 86.5% | 87.5% |
| (end-to-end) | 97.5% | 89.1% | 88.3% | 97.5% | 90.0% | 90.0% |
| (end-to-end) | 97.5% | 92.1% | 90.8% | 97.5% | 91.4% | 90.0% |
| RAVDESS | A13,14 | A15,16 | A17,18 | A19,20 | A21,22 | A23,24 |
| (late fusion) | 80.8% | 85.0% | 81.6% | 87.5% | 86.6% | 65.8% |
| (end-to-end) | 82.4% | 79.6% | 83.2% | 89.0% | 85.5% | 84.2% |
| (end-to-end) | 77.5% | 89.1% | 86.6% | 92.5% | 89.1% | 90.6% |
| (end-to-end) | 84.3% | 89.7% | 89.8% | 93.3% | 90.6% | 90.6% |
Table 3.
Comparison for Crema-d of MRPN approach (network ) with simple fusion strategy (), and advanced fusion strategy ().
Table 3.
Comparison for Crema-d of MRPN approach (network ) with simple fusion strategy (), and advanced fusion strategy ().
| Crema-d | S1 | S2 | S3 | S4 | S5 |
|---|
| (late fusion) | 76.5% | 79.9% | 76.6% | 62.3% | 78.2% |
| (end-to-end) | 77.3% | 81.3% | 79.2% | 74.8% | 78.6% |
| (end-to-end) | 72.6% | 82.3% | 77.3% | 74.8% | 74.2% |
| (end-to-end) | 79.5% | 83.0% | 83.0% | 76.8% | 81.9% |
| Crema-d | S6 | S7 | S8 | S9 | |
| (late fusion) | 81.8% | 78.8% | 80.0% | 77.5% | |
| (end-to-end) | 82.0% | 75.1% | 79.5% | 77.5% | |
| (end-to-end) | 82.0% | 74.8% | 79.3% | 75.8% | |
| (end-to-end) | 82.0% | 80.0% | 80.5% | 78.6% | |
Table 4.
Comparison of our fusion models with others recent solutions. Options used: IA—image augmentation; WO—without audio overlapping; VA—video frames augmentation; and AO—audio overlapping; X symbol—there is no report from authors for the given dataset.
Table 4.
Comparison of our fusion models with others recent solutions. Options used: IA—image augmentation; WO—without audio overlapping; VA—video frames augmentation; and AO—audio overlapping; X symbol—there is no report from authors for the given dataset.
| Model (Our) | RAVDESS | Crema-d |
|---|
| (end-to-end), Resnet18 + LSTM, IA | 83.20% | 77.25% |
| (end-to-end), Resnet18 + LSTM, VA + WO | 85.20% | 79.25% |
| (late fusion), Resnet18 + LSTM, VA + AO | 81.6% | 76.84% |
| (end-to-end), Resnet18 + LSTM, VA + AO | 87.55% | 81.30% |
| (end-to-end), Resnet18 + LSTM, VA + AO [22] | 89.8% | 77.0% |
| MRPN (end-to-end), Resnet18 + LSTM, VA + AO | 90.8% | 83.00% |
| MRPN (end-to-end), Resnet18 + Transformer(avg), VA + AO | 91.4% | 83.15% |
| (OpenFace/COVAREP features + LSTM) + Attention [7] | 58.33% | 65.00% |
| Dual Attention + LSTM [8] | 67.7% | 74.00% |
| Resnet101 + BiLSTM [39] | 77.02% | X |
| custom CNN [12] | X | 69.42% |
| Early Cross-modal + MFCC + MEL spectrogram [10] | 83.6% | X |
| CNN + Fisher vector + Metric learning [15] | X | 66.5% |
| custom CNN + Spectrogram [31] | 79.5% (Audio) | X |
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}