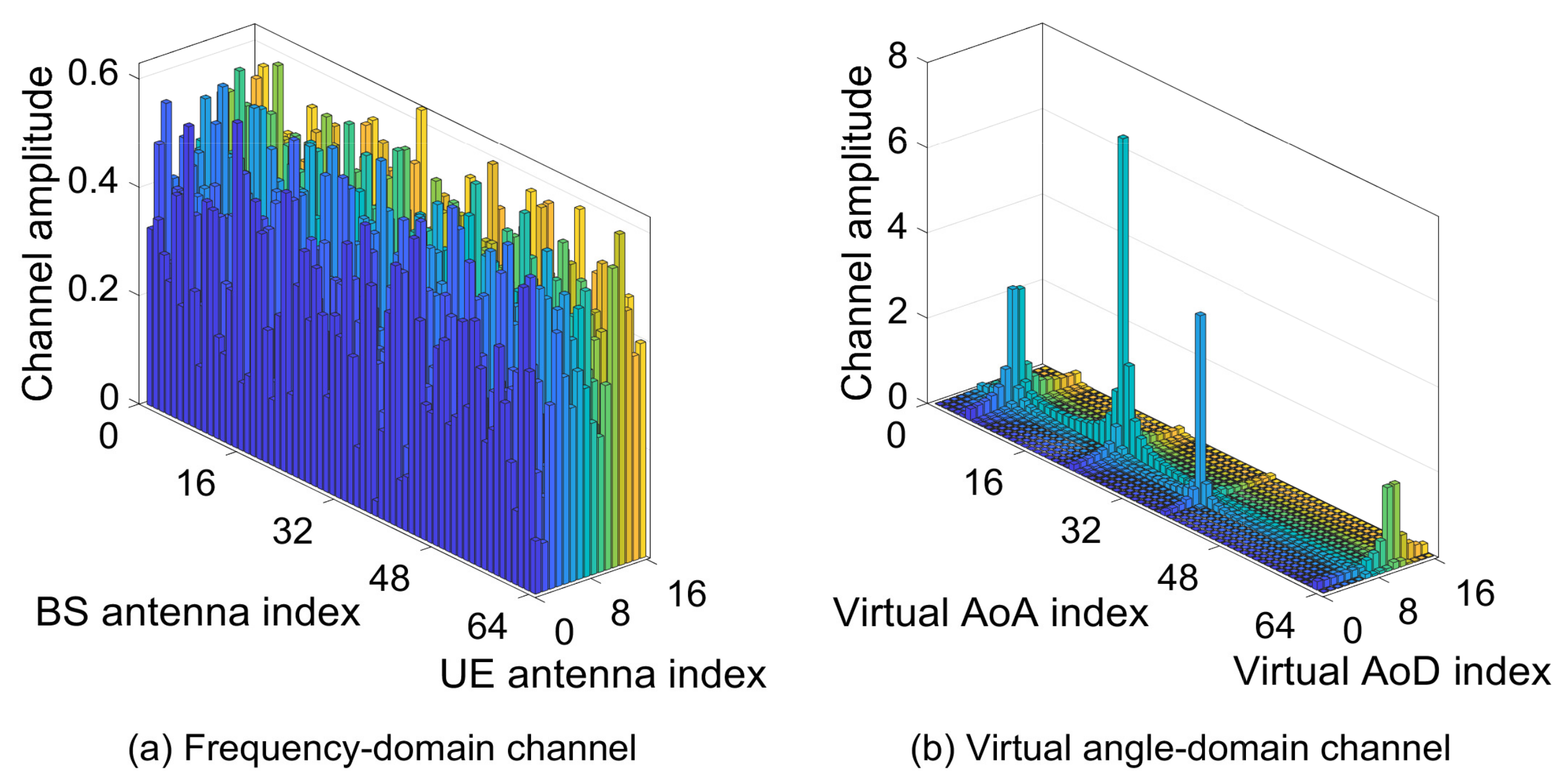
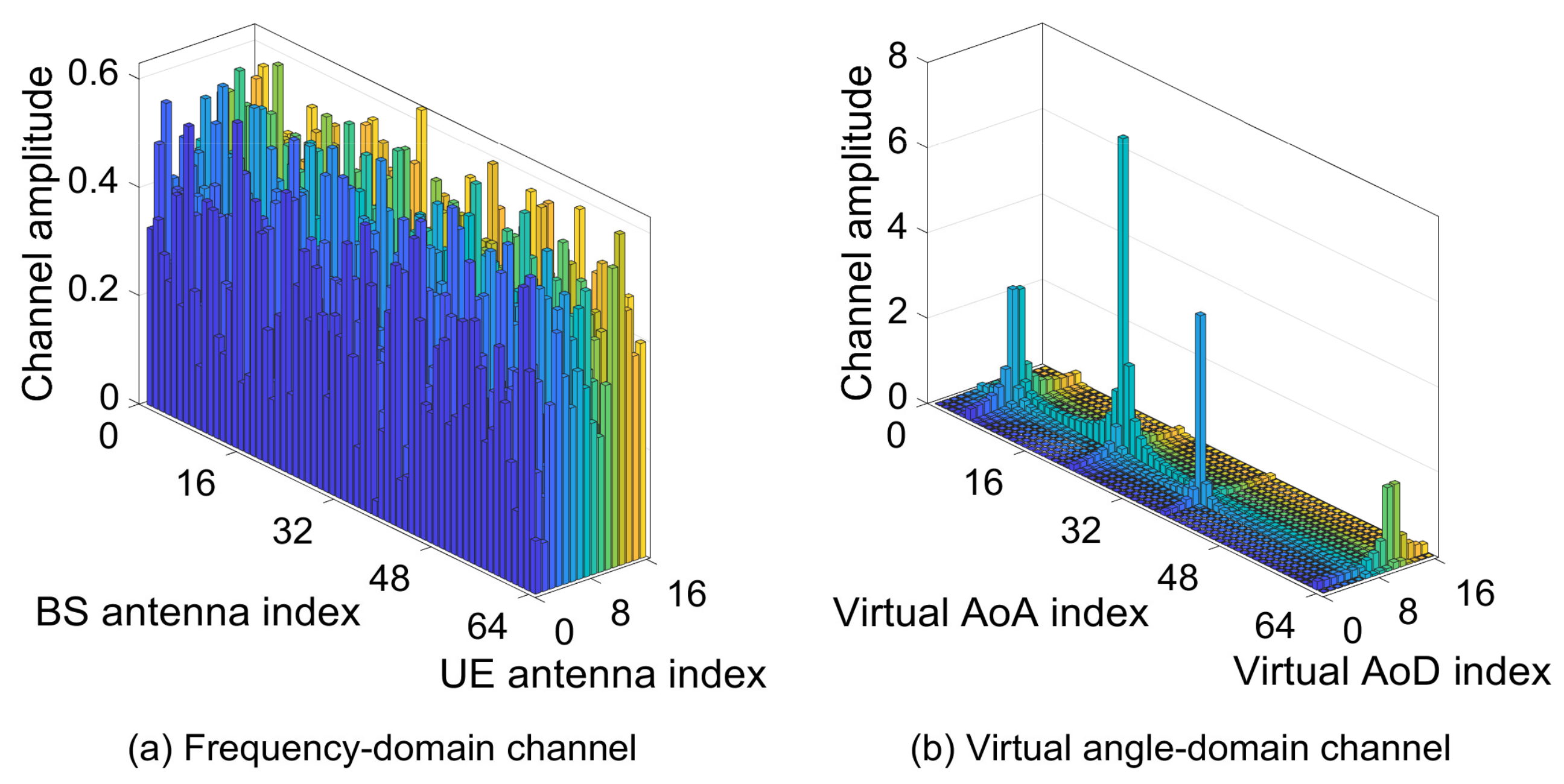
1. Introduction
Massive MIMO is a key technology for the fifth-generation (5G) communication systems [
1]. Thanks to the shorter wavelength of the millimeter wave (mmWave) signal, the numerous antennas are packed into a compact-size array, which facilitates the commercial deployment of massive MIMO systems [
2], but under the consideration of the high power consumption of Analog-to-Digital Converters (ADCs), the hybrid beamforming architecture, that divides the precoder and the combiner into the analog and digital domains, is developed to solve it and regarded as an effective alternative [
3,
4]. In this hybrid architecture system, the precoding is crucial and dependent on the acquisition of accurate channel state information (CSI). However, the number of pilots used for channel estimation will increase linearly with that of antennas and users in the wireless systems. As a result, the channel estimation with fewer pilots is a significant challenge in the hybrid mmWave massive MIMO systems [
3].
The compressive sensing (CS)-based channel estimator is capable of exploiting the sparsity of channels to reduce the pilot overhead greatly and a lot of studies on this topic have been done. Some studies focus on the sparsity in the delay domain. In [
5], the orthogonal matching pursuit (OMP) algorithm is utilized to estimate the wideband mmWave delay-domain sparse channels. In [
6], an adaptive structured subspace pursuit algorithm at the user is proposed to estimate the delay-domain MIMO channels with the spatio-temporal common sparsity. The authors of [
7] propose a sparse channel recovery algorithm based on the vector approximate message passing (VAMP) for the massive MIMO delay-domain channels. Some works concentrate on the sparsity in the angular domain. For example, a distributed sparsity adaptive matching pursuit (DSAMP) algorithm is proposed in [
8], whereby the spatially common sparsity is exploited. In [
9], a novel sparse Bayesian learning (SBL) approach is utilized to recover the angular-domain block-sparse channels. In [
10], a structured turbo-CS algorithm is proposed to estimate the angular-domain massive MIMO channels which are modeled by a Markov chain prior. Furthermore, the work [
11] even jointly exploits the 3-D clustered structure of channels in the angular-delay domain and proposes an approximate message passing (AMP)-based estimation algorithm. However, all of above angular-domain sparse channel estimation schemes are based on the assumption that the angles exactly lie on the grids, or ignore the power leakage caused by grid mismatch. Recently, there are many off-grid channel estimation techniques. In [
12], the authors utilize the low-rank structure along with the sparsity in angular domain to improve the channel estimation performance, and the off-grid angles can be recovered with their algorithm successfully. In [
13], the angles are treated as random parameters and the grid-less quantized variational Bayesian channel estimation algorithm is proposed for antenna array systems with low resolution ADCs. Besides, the multi-dimensional variational line spectral estimation algorithm proposed in [
14] can be effectively applied for multi-dimensional off-grid angle estimation. In addition, a novel super-resolution downlink channel estimation approach developed from the SBL is provided in [
15], where the sampled angular grid points are treated as the underlying parameters.
The performance of these CS-based algorithms is affected by the measurement matrix which is usually associated with the signal processing operations in the system. If these operations are not carefully designed, the measurement matrix perhaps becomes detrimental to channel recovery. Recently, a CS algorithm, termed the SBL using approximate message passing with unitary transformation (UTAMP-SBL), is proposed by Luo et al. and it outperforms the state-of-the-art AMP-based SBL algorithms, the Gaussian generalized AMP-based SBL (GGAMP-SBL), in terms of robustness, speed and recovery accuracy for difficult measurement matrices [
16]. In this paper, we apply UTAMP-SBL to the sparse channel estimation to improve the performance. Specifically, the multi-user uplink channel estimation for hybrid architecture mmWave massive MIMO systems is studied as an example. And the angular-domain sparsity of the mmWave channels is fully exploited in our estimation. Additionally, this algorithm can be extended to other sparse channel estimation for the performance improvement. Simulation results verify that the UTAMP-SBL outperforms the other competitors.
The remainder of this paper is organized as follows. In
Section 2, the hybrid millimeter wave massive MIMO system model is introduced. In
Section 3, the uplink sparse channel estimation with UTAMP-SBL is described. In
Section 4, the Cramér-Rao bound (CRB) is provided as a performance benchmark. Simulation results are provided and the performance is discussed in
Section 5. Conclusions are given in
Section 6.
Notations: and ⊗ denote the conjugate transpose operation and the Kronecker product. ⊙ and ⊘ represent the componentwise vector multiplication and the componentwise vector division. denotes vectorizing the matrix as a vector. , and denote the identity matrix, the all-one column vector and the all-zero column vector, respectively. returns a diagonal matrix with the elements of vector on its main diagonal. represents the Gaussian distribution of the complex vector with mean and covariance matrix . denotes a Gamma distribution with shape parameter and rate parameter . denotes the expectation of the function with respect to probability density . Finally, denotes equality up to a constant scale factor.
3. Uplink Channel Estimation with UTAMP-SBL
Focus on the channel estimation of the single subcarrier and the subscript
p is omitted for conciseness,
Let
,
, so the sizes of
,
and
are
,
and
, respectively, where
. In order to characterize the sparsity of
, the Gaussian prior model is adopted, i.e.,
where
and
. Define the singular value decomposition (SVD) of
is
, where
is an orthogonal matrix and
. Perform unitary transformation to (
9) and we have
where
,
and
follows
. Define
and the likelihood function of
is
According to the Bayesian rule, the joint probability density function is
where the Dirac function factor
is adopted first in [
20] to facilitate the derivation of the algorithm. The factor graph of the factorization (
13) is shown in
Figure 2. The UTAMP-SBL algorithm will be derived from message-passing on this graph and applied to the channel estimation.
Firstly, we consider the massages between node
and node
. According to the sum-product algorithm, the massage from function node
to variable node
is
. The massage from variable node
to function node
is defined as
. So the belief
can be calculated as
, where the mean and variance are
Then, we focus on the massages between node
and node
. Similarly, the massage from function node
to variable node
is defined as
. And the massage from variable node
to function node
is defined as
. So the belief
is calculated as
, where the mean and variance are
For the sparse channel estimation, the mean of the belief is the estimated channel.
Next, the variable
,
,
and
mentioned above can be updated with the UTAMP which is derived from the AMP. In the UTAMP, the means and variances are calculated by [
16]
where the intermediate variables
and
are given by [
16]
Besides, there are several model parameters need to be learned at each iteration. For the noise precision
, it can be updated with the expectation-maximization (EM) algorithm [
16]
For the variable
, according to the sum-product algorithm, the componentwise massage from function node
to variable node
is
The message from variable node
to function node
is
. Consequently, the belief
is expressed as
So,
is the mean of this distribution, i.e.,
when we set
. For the parameter
, it is difficult to renewed, but there is an effective way found in [
16] and we use it directly. As a result,
is calculated by
The process of the channel estimation with UTAMP-SBL is given in Algorithm 1. In this algorithm, the iteration will be halted if the number of it reaches the maximum value
or
.
| Algorithm 1 Uplink channel estimation with UTAMP-SBL. |
Input: The received signal and the matrix .
Output: The estimated sparse channel .
- 1:
Initialization: SVD , , , , , , , - 2:
repeat - 3:
Calculate the mean and variance as ( 16). - 4:
Calculate the mean and variance as ( 14). - 5:
Update the noise variance as ( 18). - 6:
Calculate the mean and variance as ( 17). - 7:
Calculate the mean and variance as ( 16). - 8:
Calculate the mean and variance as ( 15). - 9:
Calculate the variance according to ( 21). - 10:
Update the parameter according to ( 22). - 11:
until halt
|
The computational complexity of the UTAMP-SBL is dominated by the complex multiplications required for matrix-vector operations. At the stage of initialization, the complexity of SVD is
[
21]. The matrix-vector product of
is
. At the stage of iteration, the complexity of calculating
and
are respectively
and
in the step 3 of Algorithm 1. The calculations of remaining steps only involve the component-wise vector multiplication or scalar operations which bring a small amount of complex multiplication compared with matrix-vector product. Therefore, the computational complexity of them is omitted. When the iteration reaches
T, the total complexity is
. Discarding the low-order terms, the total complexity is
.
5. Simulation Results
The simulation parameters are chosen as follows,
,
,
,
,
,
and
. The pilots, precoders and combiners are generated according to [
17]. In order to evaluate the performance, the normalized MSE (NMSE)
between the estimated channel
and the real channel
is introduced. We compare the NMSE performance for the OMP [
5], SBL [
9], EM-BBG-VAMP [
7], SuRe-CSBL [
15], TurboCS [
10], UTAMP-SBL, and the CRB derived in
Section 4.
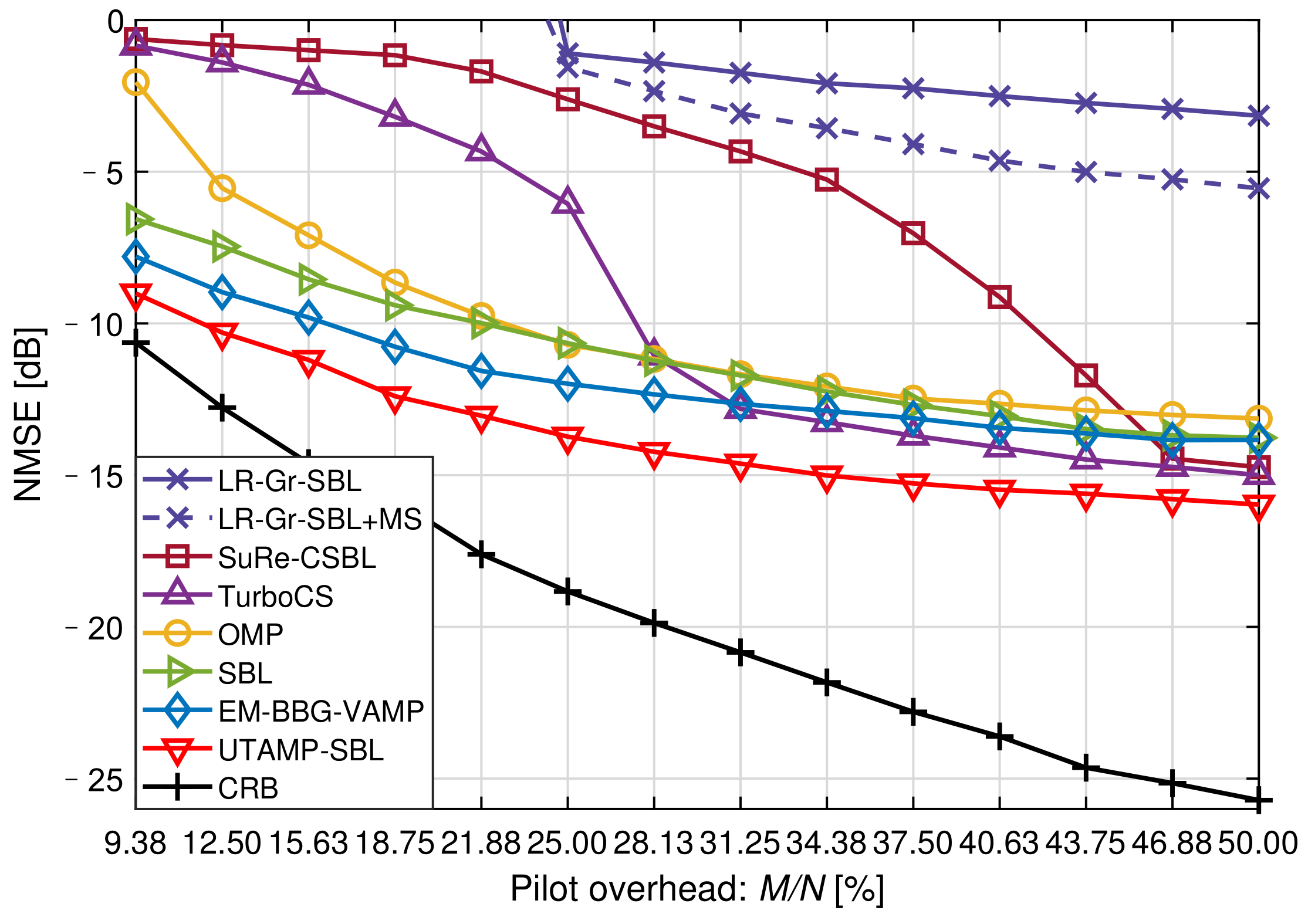
Figure 3 shows the NMSE versus the pilot overhead at
. As defined in
Section 3,
N is the dimension of the received signal
and
M is the dimension of the sparse channel
. In this simulation, the pilot overhead is denoted as
. We can find that the off-grid algorithm, SuRe-CSBL, could not achieve the desired performance when the pilot is insufficient in spite of it is the winners in [
15]. The SBL, EM-BBG-VAMP and UTAMP-SBL work well with 9.38% pilot overhead compared with other algorithms. Thus, when the pilot overhead is extremely low, the SuRe-CSBL, TurboCS and OMP are not sensible choices. It is also shown that the UTAMP-SBL performs distinctly better than the other estimators with the same pilot overhead. From another side, it is also concluded that the UTAMP-SBL can accurately estimate the channels with fewer pilots. For example, when the NMSE performance meets −10 dB, the OMP, SBL and EM-BBG-VAMP respectively need 22.66%, 21.88%, 16.41% pilot overhead. However, the UTAMP-SBL only needs 11.72% overhead, which means the pilot overhead is reduced by 28.58% compared with the EM-BBG-VAMP.
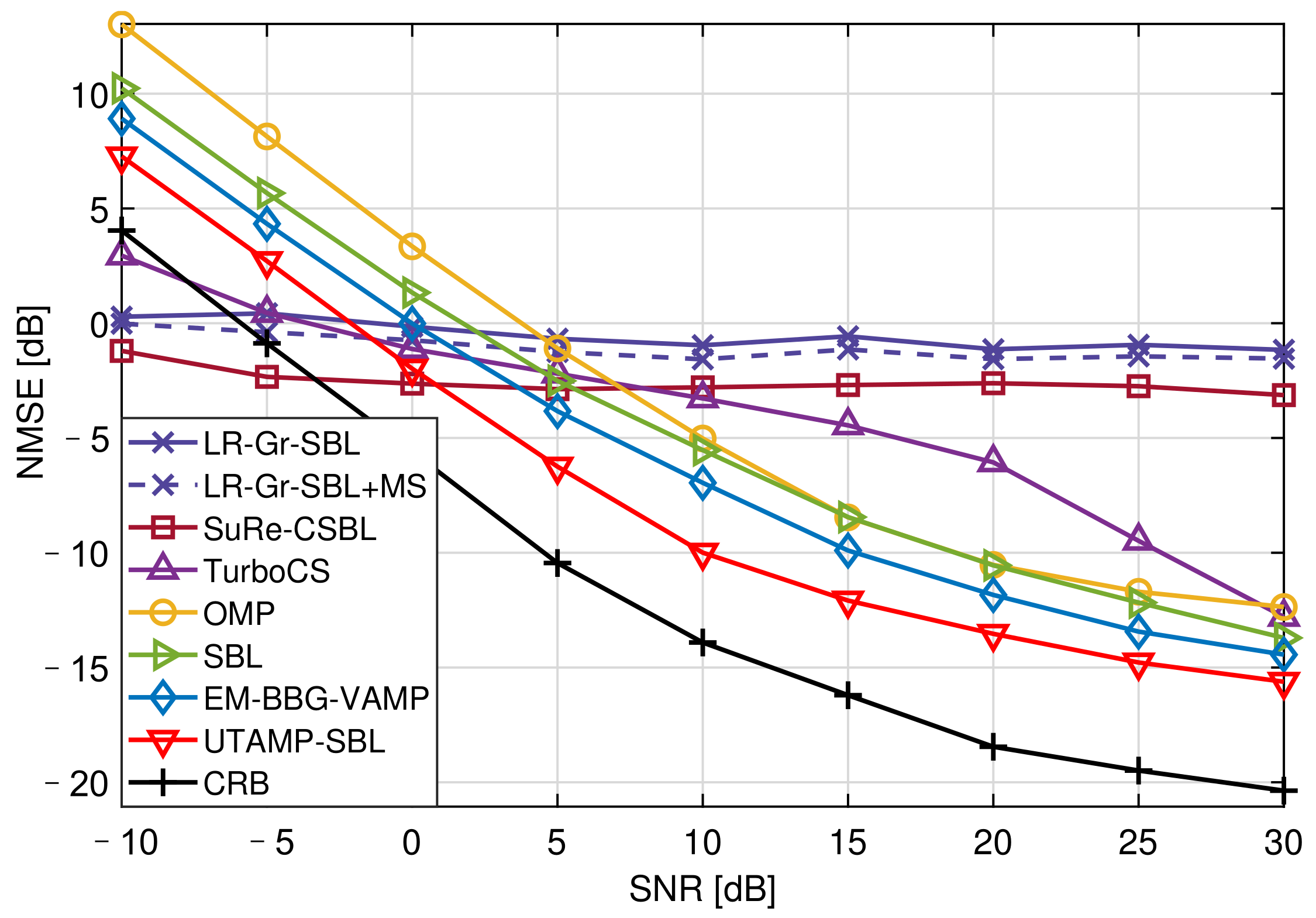
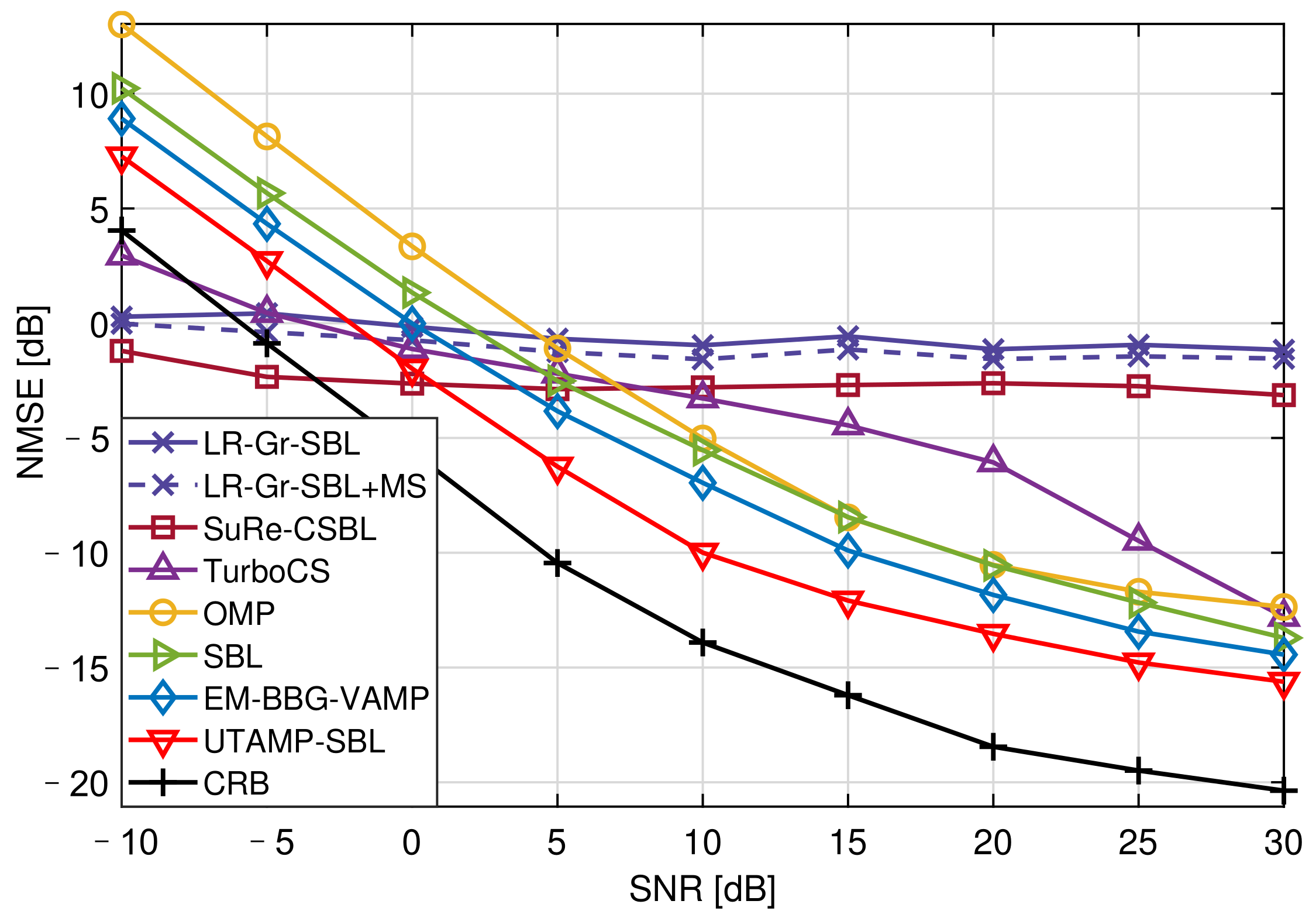
Figure 4 shows the NMSE versus the SNR with 25.00% pilot overhead. Due to insufficient of pilots, the SuRe-CSBL and TurboCS could not estimate the channels well, even if their NMSEs are lower than CRB at low SNRs. It is observed that the UTAMP-SBL has the best performance compared with the other competitors. This is because the UTAMP-SBL is robust to different types of difficult measurement matrices, such as non-zero mean, rank-deficient, correlated, or ill-conditioned matrix [
16]. This feature is crucial for the practical application of this algorithm. In the channel estimation, the measurement matrix
is usually related to the complex signal processing operations as described in
Section 2.3, so it can be a difficult matrix. Therefore, the UTAMP-SBL with strong robustness performs better in the channel estimation. Moreover, the matrix inversion step of SBL causing the high complexity is avoided by replacing the E-step in the EM with UTAMP, and the algorithm complexity is reduced [
16].
Figure 5 provides the NMSE versus the number of iterations at different SNRs with 25.00% pilot overhead, which illustrates the convergences of the algorithms. Since the algorithms, SuRe-CSBL, TurboCS, are not suitable for our channel estimation when the pilot overhead is 25.00%, only the convergences of the OMP, SBL, EM-BBG-VAMP and UTAMP-SBL are compared. When
, the OMP fails to converge even if the number of iterations reaches 300, and the NMSE performance decreases with the increasing iterations. This shows that the OMP is not suitable for the low SNR cases. The SBL, EM-BBG-VAMP and UTAMP-SBL require about 100 iterations to converge. When
, the OMP is still with the worst convergence and the UTAMP-SBL is with the best convergence. However, when
, the EM-BBG-VAMP converges slightly faster than the UTAMP-SBL. From the results, the EM-BBG-VAMP converges within 20 iterations while the UTAMP-SBL requires about 40 iterations. And these two algorithms are both faster than the SBL and the OMP. Additionally, in this figure, only the performance of the UTAMP-SBL becomes better with the iteration at all SNRs, while that of other algorithms sometimes deteriorates with the iteration. This further demonstrates the advantage of the UTAMP-SBL in convergence. From above observation and analysis, the UTAMP-SBL is superior to the comparison algorithms in the convergence speed and the NMSE performance.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}