
SafeDrive: Hybrid Recommendation System Architecture for Early Safety Predication Using Internet of Vehicles




Abstract
1. Introduction
- We developed a SmartDrive recommendation system for drivers’ driving skill management and prediction using the concept of the machine learning model.
- We propose a dynamic driver profile (DDP) approach to analyse individual drivers’ behaviors to identify a driver’s risk pattern based on four risk-score levels such as high-risk, medium-risk, low-risk, and no-risk.
- We show improvements in the prediction accuracy of the recommendations are evaluated on the three performance errors: mean squared error (MSE), mean absolute percentage error (MAPE), and mean absolute error (MAE) for the Saudi Arabian traffic accident and violation data to identify trends, recognize underlying factors influencing traffic accidents, and provide recommendations and key findings and insights.
2. Related Work
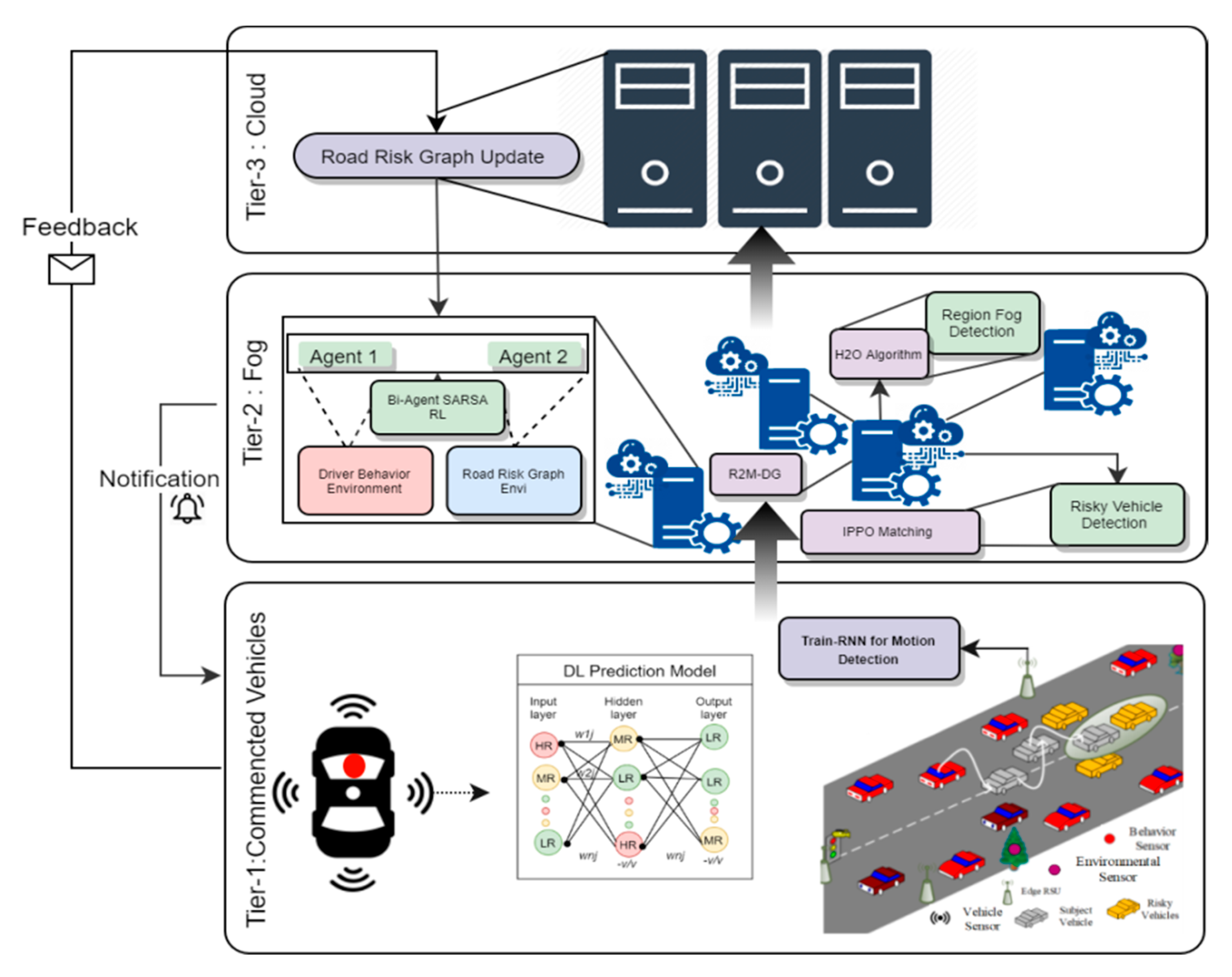
3. Hybrid Recommendation System Architecture
- Tier 1 (Connected Vehicles): This tier includes the intelligent connected vehicles which have in-built sensors such as speed, acceleration etc. It includes the on board unit (OBU) and edge road side units (E-RSUs) to enhance the processing speed.
- Tier 2 (Fog Computing): This tier includes distributed fog nodes, each responsible for monitoring and handling separate regions in Tier 1. The fog nodes have processing abilities higher than E-RSUs.
- Tier 3 (Cloud Computing): This is the uppermost tier and includes a centralized cloud server which maintains the continuous monitoring information generated from the Tier 1 and Tier 2 devices.
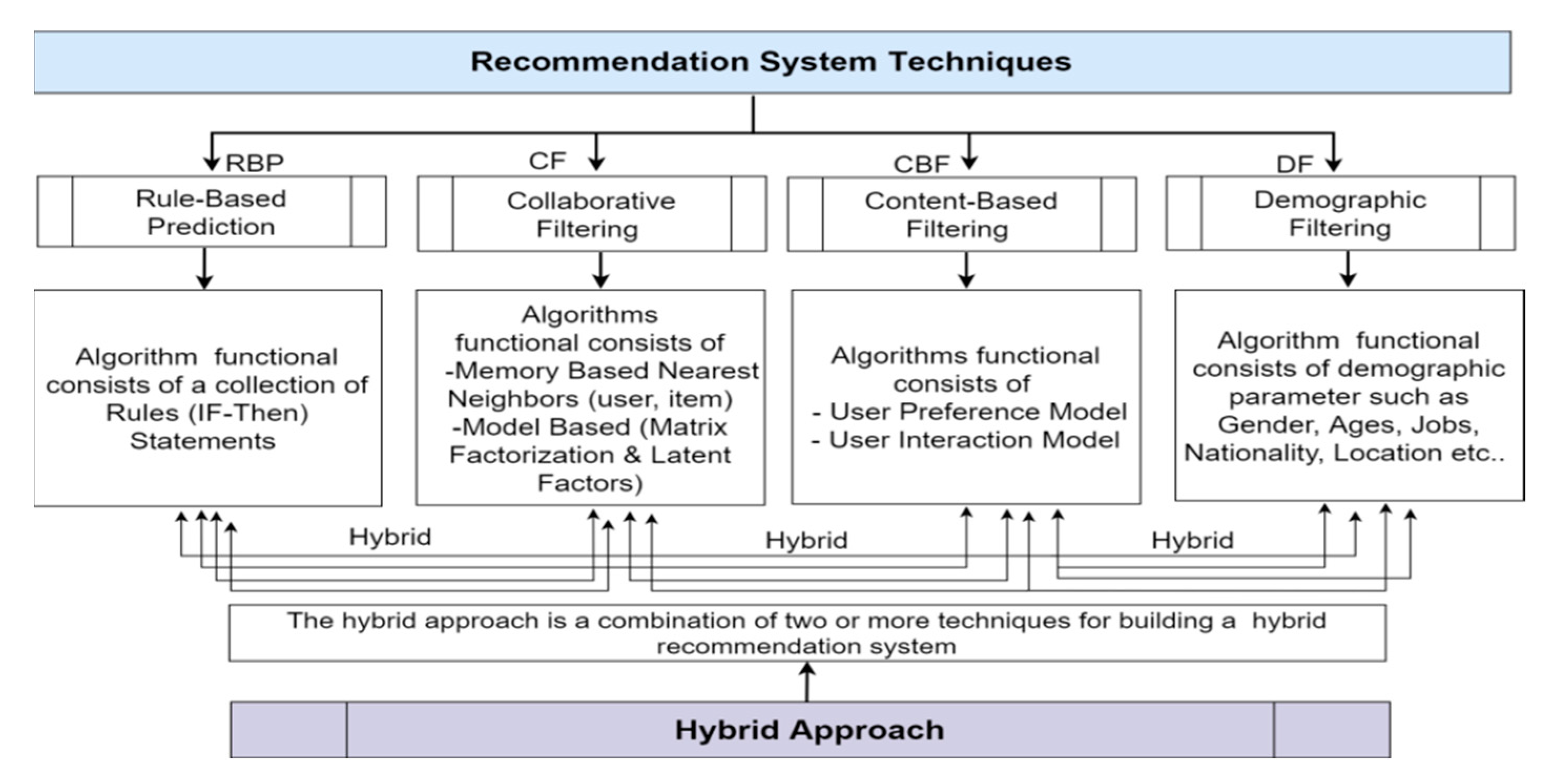
3.1. Hybrid Recommendation System
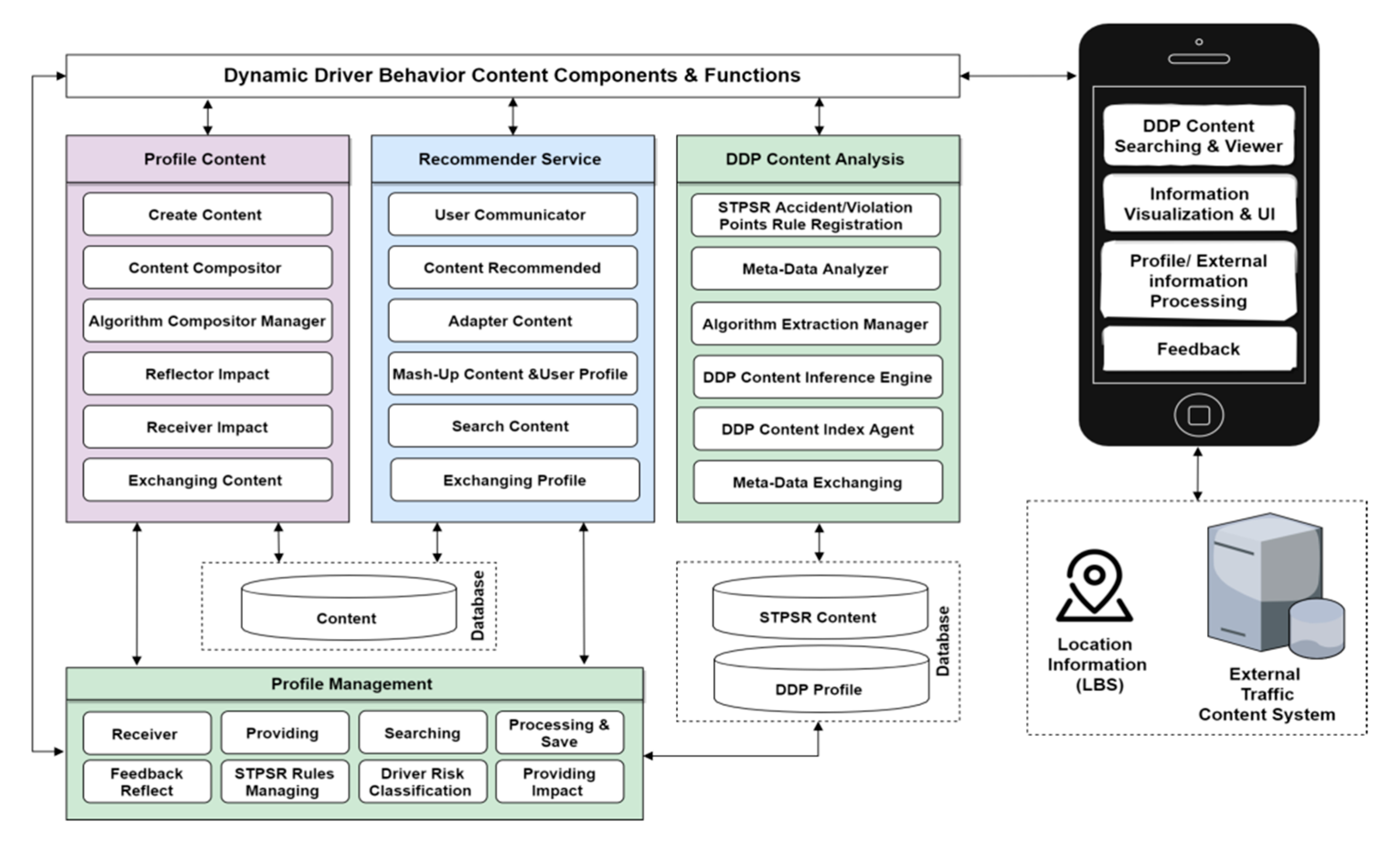
3.2. Dynamic Driver Profile (DDP)
3.3. DDP Components
- User profile contents processing and management;
- Recommendation processing and services;
- Driver behaviors analysis processing; and
- Profile management and processing.
- The user profile contents processing and management system includes functions that allow the user to register and create a new profile, search and manage profile information, and process feedback into a system database. The user profile includes basic user information and external situational information such as location, time, etc. In the profile analysis, there is a process for storing profiles for users and providing patterns to each module which is linked with the profile module’s interface, shown in Figure 5.
- The recommendation processing and services model consists of three main functions, which are user and contents profile filtering, hybrid recommendations, and machine learning processing to provide content to users through integration of driver behaviors and the dynamic user’s profile contextual information. When a recommended list of contents is provided to users, prioritization of contents is made considering the user’s feedback as reflected and provided in the contents, and then the contents can be served according to the determined contents. The mobile application is an application that shows the contents to users, and it is also a module that transmits user profile information onto the platform.
- The driver behaviors risk analysis process uses rule-based classification, the risk matrix classifies the parameters using the Saudi Traffic Points System Regulation (STPSR). The rules for deciding the number of points calculated for every violation/accident of traffic regulation risk likelihood are divided into 4 risk score levels, which are high, medium, low risk, and no risk drivers, determined based on driver historical violation/accident records to predict current and future driver risk scores using the STPSR system. To predict the driver’s risk score we used this equation: human errors (HE) + violation group (VG) = prediction driver risk score (PDRS) during a 12 month period, as shown in Table 1.
- Maintaining a single profile for the user preserves a consistent experience by giving the user an intuitive management system which is allowed by the profile management and feedback processing. Exchanging and managing refer to extracting driver risk behavior and user profile elements by analyzing profile contents, and then linking them with data storage. The content manager also automatically constructs contents generated by the STPSR index violation/accident, the DDP element analysis management, and the general effect/efficacy information of the driver risk behavior, and then stores them in the database. The effect of the information is generated from the feedback of the user and the profile information reflecting information stored in the profile databased. However, the first priority of this paper is to enhance the quality of road safety for the individual in the field of intelligent traffic recommendation services, which can be done by integrating the user and vehicle information, violation and accident records, and driver habits into integrated customized contents, which in turn requires hybrid learning recommendation processing [21].
4. Deep Learning Modeling and Data Classification for DDP
| Algorithm 1 Driver Accident/Violation Classification System |
| 1: X ← User List |
| 2: Y ← List of Varying User Lists |
| 3: neuralnet.Create() |
| 4: neuralnet.addLayer1 |
| 5: neuralnet.addLayer2 |
| 6: neuralnet.addLayer3 |
| 7: lossmsc.Compute() |
| 8: epoch = 1000 |
| 9: for i in epoch do |
| 10: neuralnet.fit(X, Y) |
| 11: return neuralnet.predictedval() |
| 12: function SHOW ACCIDENT(ID, year) |
| 13: if numaccidents > 0 then |
| 14: print(ID, date, Vehicle No., Penalty Pts, Mistake) |
| 15: function SHOW VIOLATIONS(ID, year) |
| 16: if numviolations > 0 then |
| 17: print(ID, date of stop, Vehicle No., Penalty Pts) |
| 18: function SHOW DRIVER(ID) |
| 19: print(ID, Age, Gender, Nationality) |
| 20: function EVALUATE DRIVER(ID, year, accidentdata, violationdata, driverdata) |
| 21: if totalpoints <= 4 then |
| 22: print(No Risk) |
| 23: else if totalpoints <= 25 then |
| 24: print(Low Risk) |
| 25: else if totalpoints <= 50 then |
| 26: print(Medium Risk) |
| 27: else if totalpoints > 50 then |
| 28: print(High Risk) |
| 29: print(Total Penalty Points) |
4.1. Generating and Preprocessing DDP Dataset
4.2. Analysis of Accidents in Saudi Arabia
4.3. Predicting Driver Risk Classification
4.4. Accident and Violation Classification
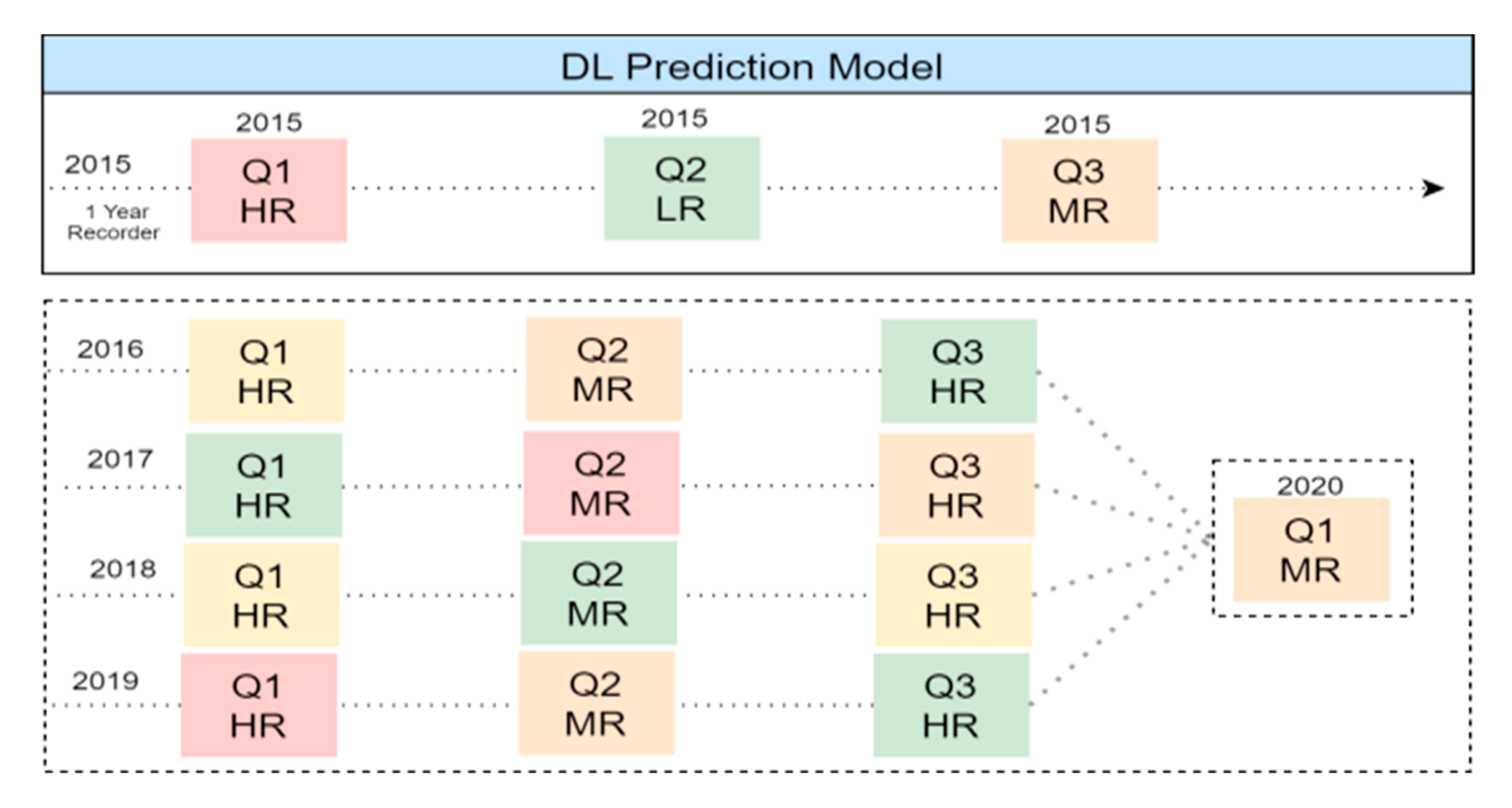
4.5. Measure Driving Risk: Driver Varies over Time
5. Performance and Evaluation
5.1. Experimental Environment
5.2. Model Performance Evaluation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Singh, D.; Singh, M. Internet of Vehicles for Smart and Safe Driving. In Proceedings of the International Conference on Connected Vehicles and Expo (ICCVE), Shenzhen, China, 19–23 October 2015. [Google Scholar]
- WHO. Available online: https://www.who.int/news-room/fact-sheets/detail/road-traffic-injuries (accessed on 26 April 2021).
- Petraki, V.; Ziakopoulos, A.; Yannis, G. Combined impact of road and traffic characteristic on driver behavior using smartphone sensor data. Accid. Anal. Prev. 2020, 144, 105657. [Google Scholar] [CrossRef] [PubMed]
- Absher, M.O.I. STPSR Traffic Violations & Penalties, Category, Violations, Extra Measures That Might Be Taken Thereon, Ministry of Interior, Kingdom of Saudi Arabia, National Information Center. 2017. Available online: www.moi.gov.sa (accessed on 19 August 2020).
- Yadav, P.; Jung, S.; Singh, D. Machine Learning-based Real-Time Vehicle Data Analysis for Safe Driving Modeling. In Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing (SAC), Limassol, Cyprus, 8–12 April 2019; pp. 1355–1358. [Google Scholar]
- Minhas, A.A.; Jabbar, S.; Farhan, M.; Islam, M.N.U. Smart methodology for safe life on roads with active drivers based on real-time risk and behavioral monitoring. J. Ambient. Intell. Humaniz. Comput. 2019, 1–13. [Google Scholar] [CrossRef]
- Zhao, H.; Yu, H.; Li, D.; Mao, T.; Zhu, H. Vehicle Accident Risk Prediction Based on AdaBoost-SO in VANETs. IEEE Access 2019, 7, 14549–14557. [Google Scholar] [CrossRef]
- Benterki, A.; Boukhnifer, M.; Judalet, V.; Maaoui, C. Artificial Intelligence for Vehicle Behavior Anticipation: Hybrid Approach Based on Maneuver Classification and Trajectory Prediction. IEEE Access 2020, 8, 56992–57002. [Google Scholar] [CrossRef]
- Xing, Y.; Lv, C.; Cao, D. Personalized Vehicle Trajectory Prediction Based on Joint Time-Series Modeling for Con-nected Vehicles. IEEE Transact. Veh. Technol. 2020, 69, 1341–1352. [Google Scholar] [CrossRef]
- Abbas, M.T.; Jibran, M.A.; Afaq, M.; Song, W. An adaptive approach to vehicle trajectory prediction using multimodel Kalman filter. Trans. Emerg. Telecommun. Technol. 2020, 31. [Google Scholar] [CrossRef]
- Jeong, Y.; Kim, S.; Yi, K. Surround Vehicle Motion Prediction Using LSTM-RNN for Motion Planning of Autonomous Vehicles at Multi-Lane Turn Intersections. IEEE Open J. Intell. Transp. Syst. 2020, 1, 2–14. [Google Scholar] [CrossRef]
- Li, P.; Abdel-Aty, M.; Yuan, J. Real-time crash risk prediction on arterials based on LSTM-CNN. Accid. Anal. Prev. 2020, 135, 105371. [Google Scholar] [CrossRef] [PubMed]
- Mallidi, S.K.; Vangipurapu, V.V. IoT Based Smart Vehicle Monitoring System. Int. J. Res. Comput. Sci. 2018, 9, 738–741. [Google Scholar] [CrossRef]
- Chang, W.; Chen, L.; Su, K. DeepCrash: A Deep Learning-Based Internet of Vehicles System for Head-On and Sin-gle-Vehicle Accident Detection With Emergency Notification. IEEE Access 2019, 7, 148163–148175. [Google Scholar] [CrossRef]
- Rehman, G.-U.; Ghani, A.; Zubair, M.; Naqvi, S.H.A.; Singh, D.; Muhammad, S. IPS: Incentive and Punishment Scheme for Omitting Selfishness in the Internet of Vehicles (Iov). IEEE Access 2019, 7, 109026–109037. [Google Scholar] [CrossRef]
- Bylykbashi, K.; Qafzezi, E.; Ikeda, M.; Matsuo, K.; Barolli, L. Fuzzy-based Driver Monitoring System (FDMS): Im-plementation of two intelligent FDMSs and a testbed for safe driving in VANETs. Future Gener. Comput. Syst. 2020, 105, 665–674. [Google Scholar] [CrossRef]
- Bhatti, F.; Shah, M.A.; Maple, C.; Islam, S.U. A Novel Internet of Things-Enabled Accident Detection and Reporting System for Smart City Environments. Sensors 2019, 19, 2071. [Google Scholar] [CrossRef] [PubMed]
- Kunt, M.M.; Aghayan, I.; Noii, N. Prediction for traffic accident severity: Comparing the artificial neural network, genetic algorithm, combined genetic algorithm and pattern search methods. Transport 2012, 26, 353–366. [Google Scholar] [CrossRef]
- Lu, L.; Yuan, Y.; Chen, X.; Li, Z. A Hybrid Recommendation Method Integrating the Social Trust Network and Local Social Influence of Users. Electronics 2020, 9, 1496. [Google Scholar] [CrossRef]
- Zambrano-Martinez, J.L.; Calafate, C.T.; Soler, D.; Cano, J.-C.; Manzoni, P. Modeling and Characterization of Traffic Flows in Urban Environments. Sensors 2018, 18, 2020. [Google Scholar] [CrossRef] [PubMed]
- Jamal, A.; Rahman, M.T.; Al-Ahmadi, H.M.; Mansoor, U. The Dilemma of Road Safety in the Eastern Province of Saudi Arabia: Consequences and Prevention Strategies. Int. J. Environ. Res. Public Health 2019, 17, 157. [Google Scholar] [CrossRef] [PubMed]
- Kasana, R.; Kumar, S.; Kaiwartya, O.; Yan, W.; Cao, Y.; Abdullah, A.H. Location error resilient geographical routing for vehicular ad-hoc networks. IET Intell. Transp. Syst. 2017, 11, 450–458. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accident Points System Human Errors (HE) | Traffic Violation Groups (VG) | Predication Driver Risk Score (PDRS) Every 12 Month | |
|---|---|---|---|
|
| Total Points | Risk Group |
| 0 ≤ 4 | None | ||
| 5 ≥ 25 | Low | ||
| 26 ≥ 50 | Med | ||
| 50> | High | ||
| National_ID | Age | Gender | License | Nationality | |
|---|---|---|---|---|---|
| 0 | 90928938 | 43 | M | Yes | Indian |
| 1 | 83545661 | 74 | F | Yes | Pakistani |
| 2 | 07316072 | 89 | M | Expired | SAUDI Arabs |
| 3 | 07677590 | 34 | M | Expired | Pakistani |
| 4 | 22584531 | 23 | F | Yes | Indian |
| Driver ID | Vehicle | Vehicle_Number | Vehicle Type | Make | Model | Year | Color | |
|---|---|---|---|---|---|---|---|---|
| 0 | 737 | 02-Automobile-HONDA-ACCORD-1990.0-BLUE | CXP 104 | 2 | Autmobile HONDA | ACCORD | 1990.0 | BLUE |
| 1 | 771 | 02-Automobile-HONDA-FIT-2010.0-SILVER | MNZ 788 | 2 | Autmobile HONDA | FIT | 2010.0 | SILVER |
| 2 | 2236 | 02-Automobile-BMW-2S-2007.0-SILVER | OBV 546 | 2 | Autmobile BMW | 2S | 2007.0 | SILVER |
| 3 | 4046 | 02-Automobile-HONDA-ACCORD-2013.0-BLACK | ALG 828 | 2 | Autmobile HONDA | ACCORD | 2013.0 | BLACK |
| 4 | 4445 | 02-Automobile-HONDA-ACCORD-1998.0-GREEN | DDL 041 | 2 | Autmobile HONDA | ACCORD | 1998.0 | GREEN |
| Driver ID | Event | Latitude | Longitude | Speed (km/h) | Time Stamp (TS) |
|---|---|---|---|---|---|
| 0 | Timed Event | 34.186631 | −118.088102 | 64.0 | 2020-11-01 00:00:02.430 |
| 0 | Distance Event | 34.186060 | −118.089241 | 53.0 | 2020-11-01 00:00:05.600 |
| 0 | Distance Event | 34.186408 | −118.089560 | 34.0 | 2020-11-01 00:00:13.640 |
| 0 | Distance Event | 34.187479 | −118.088915 | 33.0 | 2020-11-01 00:00:26.070 |
| 0 | Distance Event | 34.188665 | −118.086459 | 32.0 | 2020-11-01 00:00:35.090 |
| 0 | Distance Event | 34.188171 | −118.087279 | 47.0 | 2020-11-01 00:00:46.330 |
| 0 | Distance Event | 34.189409 | −118.086420 | 24.0 | 2020-11-01 00:00:55.320 |
| 0 | Timed Event | 34.188765 | −118.086086 | 35.0 | 2020-11-01 00:01:02.770 |
| 0 | Distance Event | 34.189057 | −118.085112 | 43.0 | 2020-11-01 00:01:06.610 |
| 0 | Distance Event | 34.190146 | −118.083935 | 48.0 | 2020-11-01 00:01:14.530 |
| Parameters | Explain |
|---|---|
| HR, MR.LR | Driver ID/risk criteria _initial input unityi |
| Wnj | Weight_increased, decreased |
| −v/v | BiasValue = (−1.0 and 1.0) |
| knn | k-nearest neighbors learning methods |
| USER/Quarters | Year 1 | Year 2 | Year 3 | Year 4 | Year 5 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Q1 | Q2 | Q3 | Q1 | Q2 | Q3 | Q1 | Q2 | Q3 | Q1 | Q2 | 03 | Q1 | Q2 | Q3 | |
| U1 | SP_LR | 16P_LR | 13P_LR | 2P_NR | 0P_NR | 4P_NR | 90P_HR | 53P_HR | 79P_HR | 27P_MR | 35P_MR | 50P_MR | 63P_HR | 70P_HR | 83P_HR |
| U2 | 0P_NR | 0P_NR | 2P_NR | BP_LR | 12P_LR | 20P_LR | 66P_HR | 83P_HR | 54P_HR | 72P_HR | 55P_HR | B0P_HR | 22P_MR | 30P_MR | 48P_MR |
| U3 | 66P_HR | 52P_HR | 72P_HR | 49P_MR | 36P_MR | 28P_MR | 25P_LR | 13P_LR | 6P_LR | SSP_HR | 62P_HR | 52P_HR | 86P_HR | 90P_HR | 95P_HR |
| U4 | 28P_MR | 40P_MR | 38P_MR | SP_LR | 12P_LR | 24P_LR | 2P_NR | 2P_NR | 2P_NR | 86P_HR | 60P_HR | 75P_HR | 36P_MR | 48P_MR | 28P_MR |
| U5 | 70P_HR | 75P_HR | SSP_HR | 4P_NR | 4P_NR | 4P_NR | 47P_MR | 28P_MR | 45P_MR | SP_LR | 24P_LR | 16P_LR | 0P_NR | 2P_NR | 0P_NR |
| USER | Y1 | Y2 | Y3 | Y4 | Y5 | Total Points | 5 Years Average | Risk Score Results |
|---|---|---|---|---|---|---|---|---|
| U1 | 24P_LR | 2P_NR | 53P_HR | 50P_MR | 53P_HR | 182 | 36.4 | Medium-Risk |
| U2 | 4P_NR | 15P_LR | 75P_HR | 83P_HR | 26P_MR | 203 | 40.6 | Medium-Risk |
| U3 | 59P_HR | 50P_MR | 25P_LR | 83P_HR | 53P_HR | 270 | 54.0 | High-Risk |
| U4 | 37P_MR | 6P_LR | 2P_NR | 90P_HR | 32P_MR | 167 | 33.4 | Medium-Risk |
| U5 | 65P_H R | 4P_NR | 40P_MR | 10P_LR | 0P_NR | 119 | 23.8 | Low-Risk |
| Evaluation Criteria | Formula | Functional |
|---|---|---|
| MAE | Mean absolute error is less sensitive to the outlier values and cannot solve the scalability issues. | |
| MAPE | Mean absolute percentage error works in a similar manner to MAE but is normalized by true observation. It measures the recommendation accuracy in percentage. | |
| MSE | Mean squared error is capable of solving the cold-start and scalability issues as it works by measuring the combination of both bias and variance. |
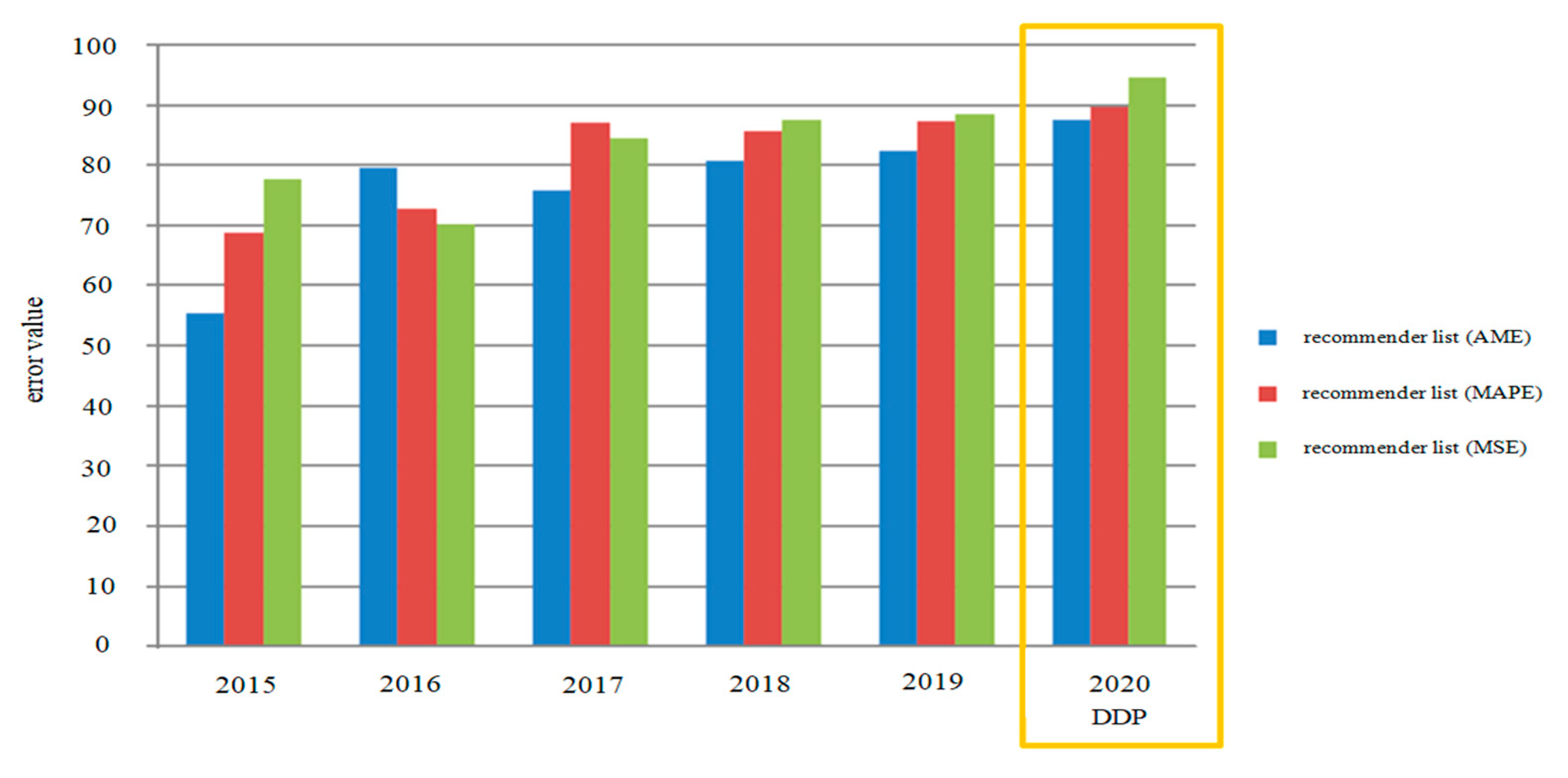
| Comparison of the Proposed DPP Predication Model During 5-Years Top Recommendation List of Average Error Results | DDP | |||||
|---|---|---|---|---|---|---|
| Model | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 Prediction |
| rec_list (MAE) | 54.78/55.33 | 79.5/79.6 | 75.17/75.72 | 80.22/82.77 | 82.379/83.443 | 87.11/88.41 |
| rec_list (MAPE) | 68.12/68.67 | 72.25/72.81 | 86.45/87 | 85.14/86.69 | 87.329/88.384 | 89.16/90.18 |
| rec_list (MSE) | 77.9/77.64 | 69.65/70.2 | 84.3/84.58 | 87.6/88.15 | 88.369/89.424 | 94.16/95.12 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nouh, R.; Singh, M.; Singh, D. SafeDrive: Hybrid Recommendation System Architecture for Early Safety Predication Using Internet of Vehicles. Sensors 2021, 21, 3893. https://doi.org/10.3390/s21113893
Nouh R, Singh M, Singh D. SafeDrive: Hybrid Recommendation System Architecture for Early Safety Predication Using Internet of Vehicles. Sensors. 2021; 21(11):3893. https://doi.org/10.3390/s21113893
Chicago/Turabian StyleNouh, Rayan, Madhusudan Singh, and Dhananjay Singh. 2021. "SafeDrive: Hybrid Recommendation System Architecture for Early Safety Predication Using Internet of Vehicles" Sensors 21, no. 11: 3893. https://doi.org/10.3390/s21113893
APA StyleNouh, R., Singh, M., & Singh, D. (2021). SafeDrive: Hybrid Recommendation System Architecture for Early Safety Predication Using Internet of Vehicles. Sensors, 21(11), 3893. https://doi.org/10.3390/s21113893