1. Introduction
Human action recognition has many application scenarios in the real world, such as security surveillance, health care systems, autonomous driving and human-computer interaction [
1,
2,
3,
4,
5]. There are two main research directions in this field: using RGB video or skeleton sequences as model inputs. In recent years, skeleton-based action recognition is attracting more and more interest due to the following three advantages [
6,
7,
8,
9,
10,
11]: Firstly, the skeleton data can be easily acquired by low-cost depth sensors [
12] (e.g., Microsoft Kinect, Asus Xtion, etc.) or pose estimation algorithms [
13,
14,
15]. Secondly, biological studies have proved that the skeleton, as a high-level representation of the human body, is informative and discriminative to express human activities [
16]. Thirdly, compared with the RGB videos, the skeleton data are more robust in terms of illumination, clothing textures, background clutter, variations in viewpoints, etc. [
17,
18,
19]. For the above reasons, our work focuses on the task of skeleton-based action recognition.
The earlier deep-learning-based methods in this field use Recurrent Neural Networks (RNN) or Convolutional Neural Networks (CNN), which have achieved much better performance than hand-crafted methods [
20,
21,
22]. Nevertheless, whether they model the skeleton data as a sequence of vectors like the RNNs do, or model them as 2D pseudo images like the CNNs do, they all neglect that the human skeleton is naturally a non-Euclidean graph-structured composed of vertices and edges. Based on this judgment, Yan et al. [
23] proposed a spatial-temporal graph convolutional network (ST-GCN) representing human joints as vertices and the bones as edges. The ST-GCN improves the accuracy of action recognition to a new level, and substantial ST-GCNs are subsequently proposed based on it [
24,
25,
26,
27,
28,
29,
30,
31,
32,
33,
34,
35]. However, there are still two problems to be addressed in these methods.
The first problem lies in the temporal domain. The forms of human actions are many and varied. According to the human cognitive process of action understanding, some actions can be recognized by just a glimpse, such as “writing”. While some actions, such as “wear a shoe”, need a much longer observation before they can be recognized. For another example, the action “nod head/bow” is a sub-action of the action “pickup”, which requires the model to be sensitive to both short-duration and long-duration actions. However, the temporal GCL of the ST-GCNs utilizes only one fixed kernel size 9 × 1 which is obviously not enough to cover all the temporal dynamics. Besides, the kernel size is relatively large, which increases the number of parameters and reduces model efficiency.
The second problem lies in the spatial domain. Tran et al. [
36] demonstrate that by means of 3D CNNs, the RGB-based action recognition can yield accuracy advantages over 2D CNNs. Moreover, by factorizing the 3D CNNs to spatial-only and temporal-only components, further performance improvements can be achieved. The ST-GCNs borrow this finding and construct the basic block of the networks by serially connecting a spatial GCL and a temporal GCL. Although this kind of construction is concise and efficient, it mixes the spatial cues into temporal cues, resulting in weakened spatial representation and limited model performance. For example, the actions ”touch head” and ”touch neck” look very similar. Their slight difference lies in the distance between the hand and the head or neck, which requires the model to be sensitive to the spatial aspect. However, the ST-GCNs are confused when distinguishing them.
To address the above two problems, we propose a novel model namely enhanced spatial and extended temporal graph convolutional network (EE-GCN).
Figure 1 shows the overall framework and
Figure 2 shows the details of the basic block of the model. For the first problem, we employ multiple convolution kernels with different sizes instead of the fixed one to comprehensively aggregate discriminative temporal cues from shorter to longer terms. Notably, smaller kernel sizes (no bigger than 9 × 1) are chosen for fewer parameters and higher model efficiency. As one kernel corresponds to one convolution layer, how to combine these layers is another problem we face. Inspired by the success of VoVNetV2 [
37], we propose to concatenate the consecutive layers by a one-shot aggregation (OSA) + effective squeeze-excitation (eSE) structure which well balances the performance and efficiency. As shown in
Figure 2b, the OSA module connects the layers by two pathways. The first pathway is to connect these layers in series to obtain a larger receptive field. The second pathway is the connection between each layer and the final output, so the final output features are the aggregation of all the temporal features extracted by different convolution kernels. The eSE module is then used to explore the interdependency between the output channels, which can be seen as a channel attention mechanism. For the second problem, we propose a new paradigm of the basic block structure which incorporates a parallel structure to the original tandem structure. Specifically, after the spatial GCL, we insert an additional spatial GCL in parallel with the temporal GCLs. With the combination of tandem and parallel relationships between the spatial and temporal GCLs, our model is much more effective for capturing complex spatial-temporal features.
To verify the superiority of our EE-GCN, extensive experiments are conducted on three large-scale benchmark datasets for skeleton-based recognition: NTU-RGB+D 60 [
9], NTU-RGB+D 120 [
38], and Kinetics-Skeleton [
39]. Our method proves its merits from the results.
Overall, the main contributions of this work are summarized as follows:
- (1)
We propose an EE-GCN which can substantially facilitate spatial-temporal feature learning. To efficiently and comprehensively extract the temporal discriminative features, we propose to construct the temporal graph convolution with multiple smaller kernel sizes instead of the typically larger one. Moreover, the corresponding temporal GCLs are concatenated by an OSA + eSE structure which can well balance performance in terms of accuracy and speed.
- (2)
On the basis of the extended temporal convolution, we propose a new paradigm of the basic block structure to enhance the spatial convolution. While retaining the original spatial GCL, we add the same layer in parallel with the temporal GCLs. This hybrid structure, which contains both tandem and parallel connections, can further increase model performance.
- (3)
We empirically demonstrate that our model outperforms previous state-of-the-art methods.
4. Experiments
In this section, we first evaluate the performance and efficiency of our proposed model by exhaustive ablation studies. Unless otherwise stated, the ablation studies are performed on the X-Sub setting of NTU-RGB + D 60 using only the joint data. We then make a head-to-head comparison with other state-of-the-art methods on three large-scale datasets: NTU-RGB + D 60 [
9], NTU-RGB + D 120 [
38], and Kinetics-Skeleton [
39].
4.1. Datasets
4.1.1. NTU-RGB + D 60
NTU-RGB + D 60 [
9] is the most widely used dataset for skeleton-based human action recognition. It contains 56,800 skeleton sequences which are categorized into 60 action classes. The samples are performed by 40 different subjects in a lab environment and captured by three cameras with different view angles. There are 25 joints with 3D coordinates in each human skeleton, and one or two subjects in each sample. The authors of the dataset recommend reporting the model performance under two settings: (1) cross-view (X-View), the samples captured by cameras 2 and 3 are used for training, and those captured by camera 1 are used for testing. (2) cross-subject (X-Sub), the samples captured from half of the subjects are used for training, and the remaining samples are used for testing.
4.1.2. NTU-RGB + D 120
NTU-RGB + D 120 [
38] is currently the largest in-door-captured dataset for the task, which is an extension of NTU-RGB + D 60. It contains 114,480 skeleton samples which are categorized into 120 action classes. These samples are performed by 106 subjects and captured from 32 different camera setups. The authors of the dataset recommend reporting the model performance under two settings: (1) cross-setup (X-Setup), the samples captured from the camera setups with even IDs are used for training, and the rest are used for testing. (2) cross-subject (X-Sub), the samples performed by 53 subjects are used for training, and the remaining samples are used for testing.
There are no more than two persons in each sample of the two datasets above. We follow the pre-processing method of [
24] for the datasets: if there is only one body in the sample, we add an extra body which is padded with 0.
4.1.3. Kinetics-Skeleton
Kinetics [
39] is a more challenging human action recognition dataset than NTU-RGB + D 60 and 120. A total of 300,000 video samples of this dataset are collected from YouTube and categorized into 400 action classes. The skeleton data are extracted using the OpenPose [
13] toolbox, which contains 18 joints per human body. Each joint is represented by 2D spatial coordinates and a confidence score. There are 240,000 samples for training and the rest for testing. We set the size of the input tensor of Kinetics the same as [
23], which contains two bodies in each frame.
4.2. Training Details
All experiments are conducted on PyTorch 1.0 platform with 4 GeForce RTX1080Ti GPUs. We use stochastic gradient descent (SGD) with Nesterov momentum (0.9) as the optimization strategies of our method. For every two steps, we update the network parameters and reset the gradients. The cross-entropy is used as the loss function and the weight decay is set to 0.0001.For NTU-RGB + D 60, 120, and Kinetics-Skeleton, we set the batch size to 36, 36, and 108, the initial learning rate to 0.3 which is divided by 10 at epochs {30, 45, 55}, {30, 50, 65}, {45, 60, 70}, and the total epochs to 70, 75, 80, respectively.
Figure 5 shows the performance and convergence speed of our model in the training and testing process. It is evident that our model converges very quickly. Specifically, as shown in
Figure 5a, the learning rate is divided by 10 at epoch 30, which brings about a sharp increase of accuracy and converges the model to a relatively stable status. Although the accuracy of the training process rises to approximately 100% at epoch 40, the testing process keeps the accuracy around 89% which is the limit of our model.
Figure 5b also demonstrates the same trend. There is a sudden drop of the cross-entropy loss at epoch 30, and the loss of the training process decreases to approximately 0 at epoch 40. The testing process keeps the loss around 0.44 since then.
4.3. Ablation Study
We employ the following four networks to demonstrate the effectiveness of our proposed method:
Adaptive GCN (AGCN) [
24]. We use this method as the baseline because our model adopts its adaptive graph construction which is introduced in
Section 3.2.
Extended Temporal GCN (ETGCN), which is shown in
Figure 6a. Comparing with AGCN, the only difference lies in the utilization of our proposed temporal extension strategy which is introduced in
Section 3.3.
Enhanced Spatial GCN (ESGCN), which is shown in
Figure 6c. Comparing with AGCN, the only difference lies in the utilization of our proposed spatial enhancement strategy which is introduced in
Section 3.4.
EEGCN, which is shown in
Figure 2. This is our proposed network which integrates both extended temporal and enhanced spatial modeling strategies.
4.3.1. Temporal Extension Strategy
In this section, we use ETGCN to evaluate the performance of our temporal extension strategy. One of the key points of the strategy is the performance of using multiple temporal convolution kernels with different sizes. As the original kernel size is 9 × 1 which has been widely demonstrated to be powerful, we keep it in our proposed methods. For the selection of other kernel sizes, since more kernels and larger kernel sizes all bring more parameters, we employ no more than two kernels and no larger than 5 in kernel sizes to keep the efficiency of our model. Besides, we empirically set the number of output channels for each temporal GCL to be equal, which is 1/2 of the number of output channels for the corresponding block. The action recognition accuracies by ETGCN are reported in
Table 1. We can see that using only one kernel (row 2) achieves the worst performance (86.27%). Using two or three kernels brings significant improvements, ranging from 2.07% (row 3) to 2.41% (row 7). Overall, using three kernels is generally better than using two kernels. The effectiveness of the first key point is thus verified.
The other key point is the efficiency of the strategy. Obviously, the method using the original kernel size has the largest number of parameters (3.47 M). Benefiting from the use of OSA + eSE structure and smaller kernel sizes, the ETGCN reduces the number of parameters, ranging from 0.09 M (row 8) to 0.81 M (row 3), while improving performance. The utilization of kernel size 1 × 1 (rows 3, 6, 7) can also be seen as a bottleneck that reduces the computational costs. The second key point is thus verified. Considering that the combination of 1 × 1, 5 × 1, and 9 × 1 (row 7) achieves the best performance (88.68%) while reducing the number of parameters by 0.35 M, we adopt this combination.
Besides, to further investigate our temporal extension strategy, we propose another version of ETGCN named ETGCN V2 which is illustrated in
Figure 6b. Our motivation for this version is to follow the traditional block structure shown in
Figure 4, which includes a shortcut. Specifically, based on ETGCN, we first remove the shortcut of the temporal GCLs and then add a shortcut to the block. As shown in row 4 of
Table 2, the performance of ETGCN V2 is 87.47%, which is 1.2% higher than that of AGCN, proving the effectiveness of OSA + eSE. But it is 1.21% lower than ETGCN, which proves the superiority of the latter.
Furthermore, we make an in-depth analysis of our ETGCN based on each action.
Figure 7 and
Table 3 list the improvements of ETGCN over AGCN. We can observe that in all the 60 actions, there are 47 actions that achieve improvements by 14% to 1%, 4 actions have no changes, and only 9 actions get slightly lower accuracies. Take the action “10. clapping” for example. As shown in
Table 4, our ETGCN achieves 81% accuracy with 14% improvements over AGCN [
24]. In AGCN [
24], 16% of “10.clapping” samples are misclassified as “34.rub hands together”, while in ETGCN, this percentage is reduced to 7%.
Figure 8 illustrates these two actions. They look very similar in the initial execution phase, which all bring the open hands together. But from the perspective of temporal evolution, they are very different. The action “10.clapping” is to alternately separate and close two hands with a characteristic frequency pattern. But the action “34.rub hands together” is to move the two hands back and forth while keeping them closed. Thanks to the advantages of the long-term motion trend modeling, our ETGCN can classify them more accurately. We give another example to illustrate further. As shown in
Table 4, 88% of “35.nod head/bow” samples are correctly classified by AGCN [
24], while in ETGCN, the percentage is 96%. This action is easily confused with five classes of actions: “6.pickup”, “16.wear a shoe”, “17.take off a shoe”, “43.falling”, and “48.nausea or vomiting”. Obviously, these actions are similar at the beginning of the executions, which all start with head bowing and bending. In other words, the action “35.nod head/bow” is a sub-action of the other five classes of actions. As shown in
Figure 9, the follow-up motions of “6.pickup” include leg bending and hand stretching, while the action “35.nod head/bow” does not include these motions. Therefore, the long-term motion trend modeling ability of ETGCN is useful in this situation and
Table 4 proves its effectiveness.
4.3.2. Spatial Enhancement Strategy
As introduced in
Section 3.4, we enhance the spatial features by adding an additional spatial GCL in parallel with the temporal GCLs for each basic block. Row 5 of
Table 2 demonstrates the superiority of this new block structure paradigm. Our ESGCN achieves 87.84% accuracy, with 1.57% improvements over AGCN [
24].
Figure 7 and
Table 3 show that in all the 60 actions, there are 43 actions that achieve improvements by 9% to 1%, 8 actions have no changes, and only 9 actions get lower accuracies. We select two of these actions for in-depth analysis: “47.touch neck” and “44.touch head”. In AGCN [
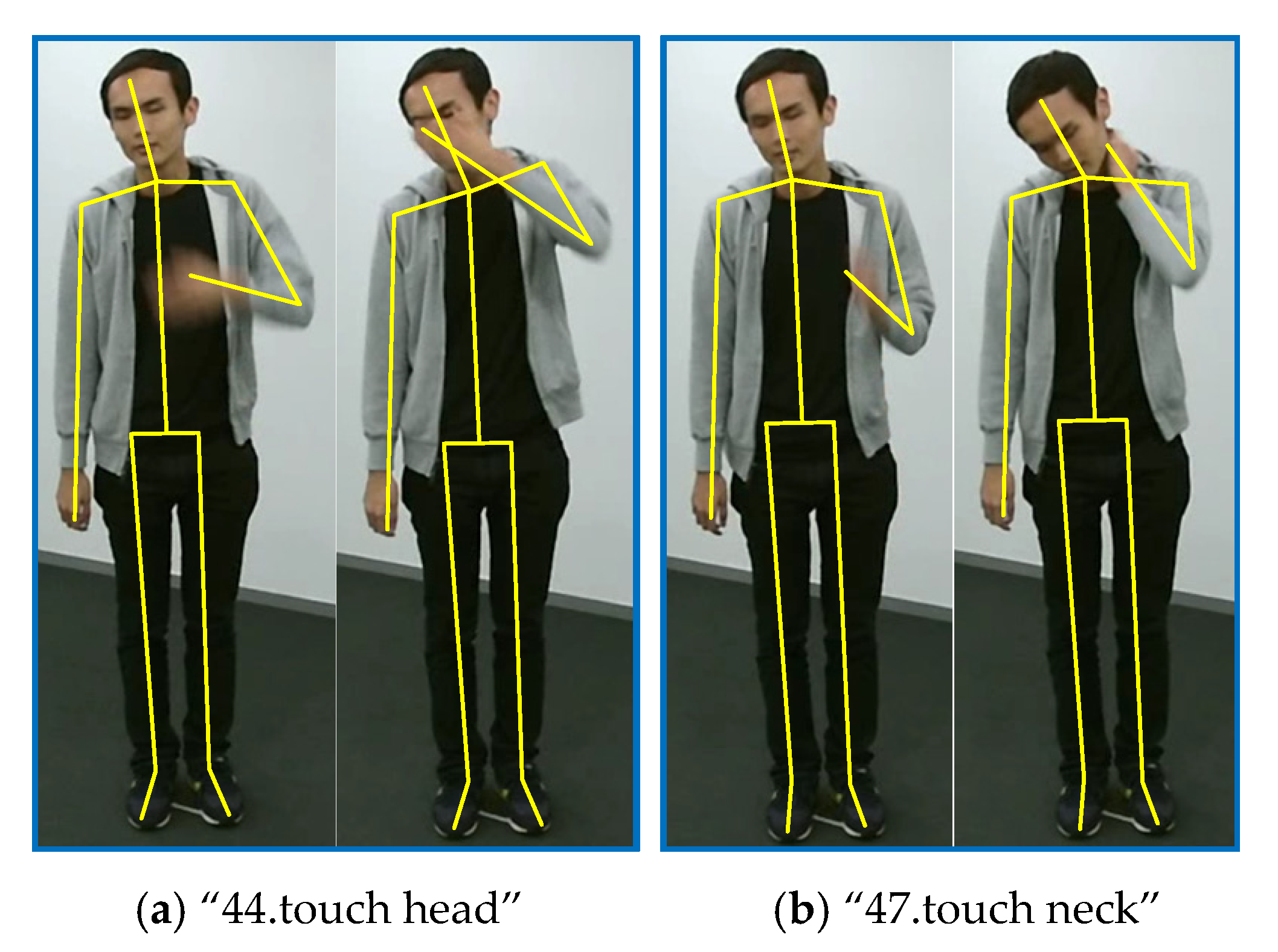
24], there are 77% of action “47.touch neck” samples are correctly classified, and 11% samples are misclassified as action “44.touch head”. In contrast, in our ESGCN, the first percentage rises to 84% and the second percentage drops to 3%. These two actions are illustrated in
Figure 10. We can observe that they are all performed by raising one hand and touching the corresponding body part, which means that they are very similar in execution stages for the temporal domain. But in the spatial domain, these two actions can be easily classified by measuring the distance between the hand and the head or neck. Our spatial enhancement strategy can capture this difference more effectively.
To further demonstrate the effectiveness of our new block structure paradigm, we also propose another version of ESGCN named ESGCN V2 which is shown in
Figure 6d. This version retains the traditional tandem structure while adding a spatial GCL in parallel. As shown in row 6 of
Table 2, its accuracy is 87.52%, which is 1.25% higher than AGCN [
24], proving the effectiveness of adding an additional spatial GCL. But it is 0.32% lower than ESGCN, so we adopt the latter structure in our final model.
4.3.3. Enhanced Spatial and Extended Temporal Graph Convolution
In this section, we evaluate the performance of our final model. As shown in row 7 of
Table 2, our EEGCN achieves 89.28% accuracy which is the highest in
Table 2, with 3.01% improvements over AGCN [
24]. The results also demonstrate the complementarity between our ESGCN and ETGCN. As shown in
Figure 7 and
Table 3, in all the 60 actions, up to 52 actions achieve improvements by 14% to 1%, four actions have no changes, and only four actions gave lower accuracies.
Here we also propose another version of EEGCN named EEGCN V2 which is shown in
Figure 6e. It is constructed based on ETGCN, which adds an additional spatial GCL in parallel. As shown in row 8 of
Table 2, its performance is 89.17%, which is 2.9% higher than AGCN [
24], demonstrating the advantages of our enhanced spatial and extended temporal strategies. But it is 0.11% lower than EEGCN, so we adopt the latter version in our model.
To further evaluate the effectiveness of our EEGCN, we conduct it with all the four data modalities on both X-View and X-Sub benchmarks. The results are reported in
Table 5. Comparing with AGCN [
24], EEGCN brings significant improvements, ranging from 0.92% (joint motion) to 1.44% (bone) on X-View, and 2.78% (bone motion) to 3.01% (joint) on X-Sub. Since the accuracies on X-View are already very high, the improvements on X-Sub are relatively more significant.
4.4. Comparison to Other State-of-the-Art Methods
As introduced in
Section 3.1, to make a fair comparison, we follow the traditional four-stream strategy which introduces four data modalities into our EEGCN. We denote our model using the joint data as 1s-EEGCN, our model using joint and bone data as 2s-EEGCN, our model using joint, bone, and their motions data as 4s-EEGCN. Note that although some methods [
51,
54] use only one stream, they fuse two types of information in the early stage to achieve better accuracies. To verify the superiority and generality of our method, we compare EEGCN with other state-of-the-art networks on NTU-RGB + D 60 [
9], NTU-RGB + D 120 [
38], and Kinetics-Skeleton [
39]. We have also marked the number of streams used by these methods which are divided into two categories: non-GCN-based and GCN-based methods. The results are reported in
Table 6,
Table 7 and
Table 8.
We can observe that the GCN-based methods generally perform better than the traditional deep learning-based methods (i.e., CNNs and RNNs), demonstrating the effectiveness of incorporating the graph information into the network. For the NTU-RGB + D 60 dataset, our 1s-EEGCN achieves 89.3% accuracy on X-Sub, 95.3% accuracy on X-View, with 1.3% and 0.2% improvements respectively over 1s-AAGCN [
28] which is also derived from AGCN [
24]. Compared with all other methods, our 2s-EEGCN achieves the highest accuracy on X-Sub benchmark, even 0.4% higher over the current best performance method (i.e., 4s-Shift-GCN [
30]). Our 4s-EEGCN improves the accuracies to a new level. For the NTU-RGB+D 120 dataset, our 1s-EEGCN is comparable with 2s-AGCN [
24]. Our 2s-EEGCN exceeds all previously reported performance. Our 4s-EEGCN sets a new performance record again, which outperforms the current state-of-the-art 4s-Shift-GCN [
30] at 1.5% on X-Sub, 1.3% on X-Set. Our method also shows its superiority on the Kinetics-Skeleton dataset which is more challenging. Overall, on all the three large-scale datasets, our three settings of EEGCN outperform other state-of-the-art methods using the same number of streams, especially our 4s-EEGCN is superior to all existing methods under all evaluation settings.
5. Conclusions
In this paper, we propose an enhanced spatial and extended temporal graph convolutional network for the skeleton-based action recognition task. For the temporal dimension, multiple relatively small kernel sizes are employed to extract temporal discriminative features. The corresponding layers are concatenated by a powerful yet efficient OSA + eSE structure. For the spatial dimension, a new paradigm of the block structure is proposed to enhance the spatial features, which expands the basic block structure from only tandem connection to a combination of tandem and parallel connections. Based on this, we add an additional spatial GCL in parallel with the temporal GCLs. Our method delivers state-of-the-art performance. In practical applications, our model can be applied to security surveillance systems, health care systems, and human-computer interaction systems, etc.
Despite the superiority of our EEGCN, there are still several issues to be addressed. Firstly, although our temporal extension strategy has been proved to be efficient, the efficiency of our spatial enhancement strategy still needs to be improved. Adding an additional spatial GCL will obviously increase the number of parameters of the model. It may be worth a try to reduce the number of spatial convolution channels or basic blocks. Secondly, the low-level features (i.e., joints, bones, and their motions) have shown their power in improving the performance of the model. However, the multi-stream construction is inefficient which doubles or even quadruples the number of parameters of the model. So we recommend more exploration of fusing the variable low-level features to just one stream. Thirdly, the joint semantics (e.g., frame index and joint type) can also provide discriminative information [
54]. So the next step of our work will focus on how to incorporate the joint semantics into our EEGCN.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}