Modeling Car-Following Behaviors and Driving Styles with Generative Adversarial Imitation Learning


Abstract
1. Introduction
2. Related Work
2.1. Theoretical-Driven Car-Following Models
2.2. Behavior Cloning Car-Following Models
2.3. Reinforcement Learning
2.4. Inverse Reinforcement Learning
2.5. Generative Adversarial Imitation Learning
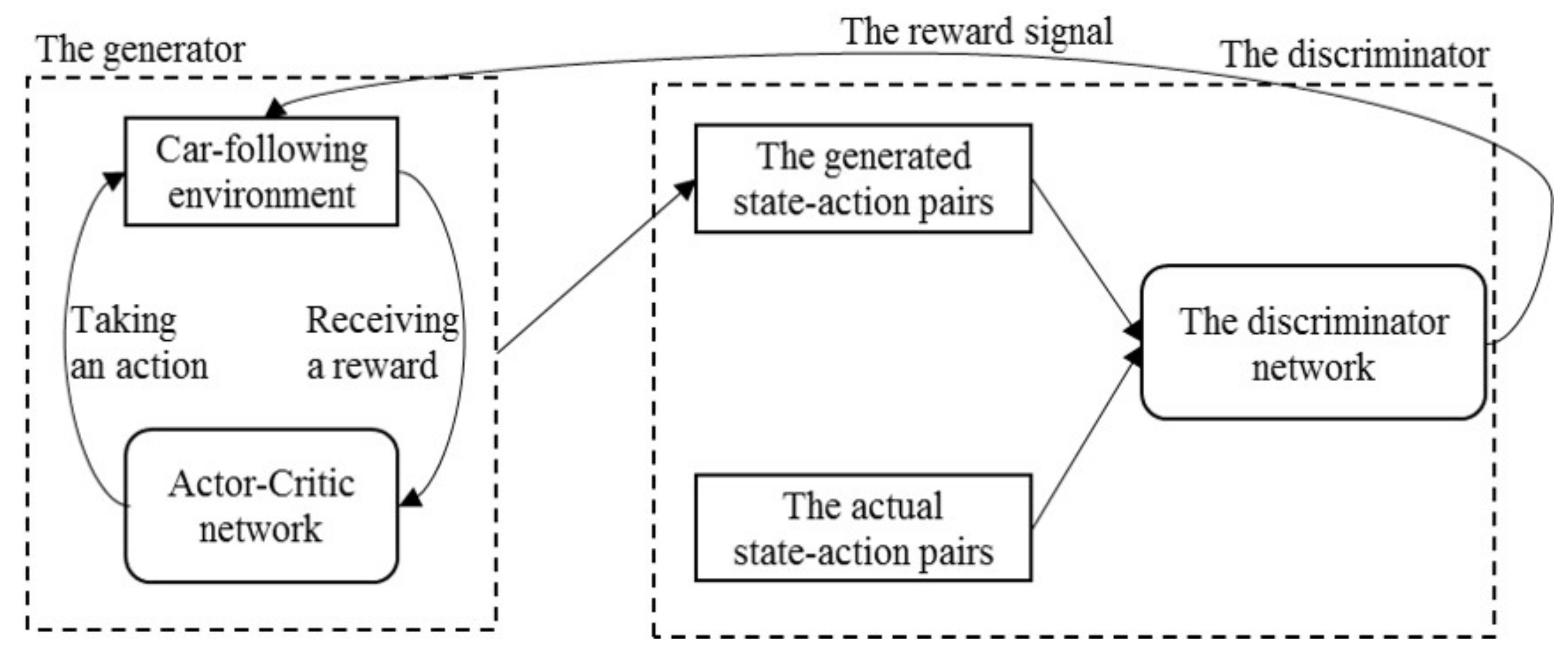
3. The Proposed Model
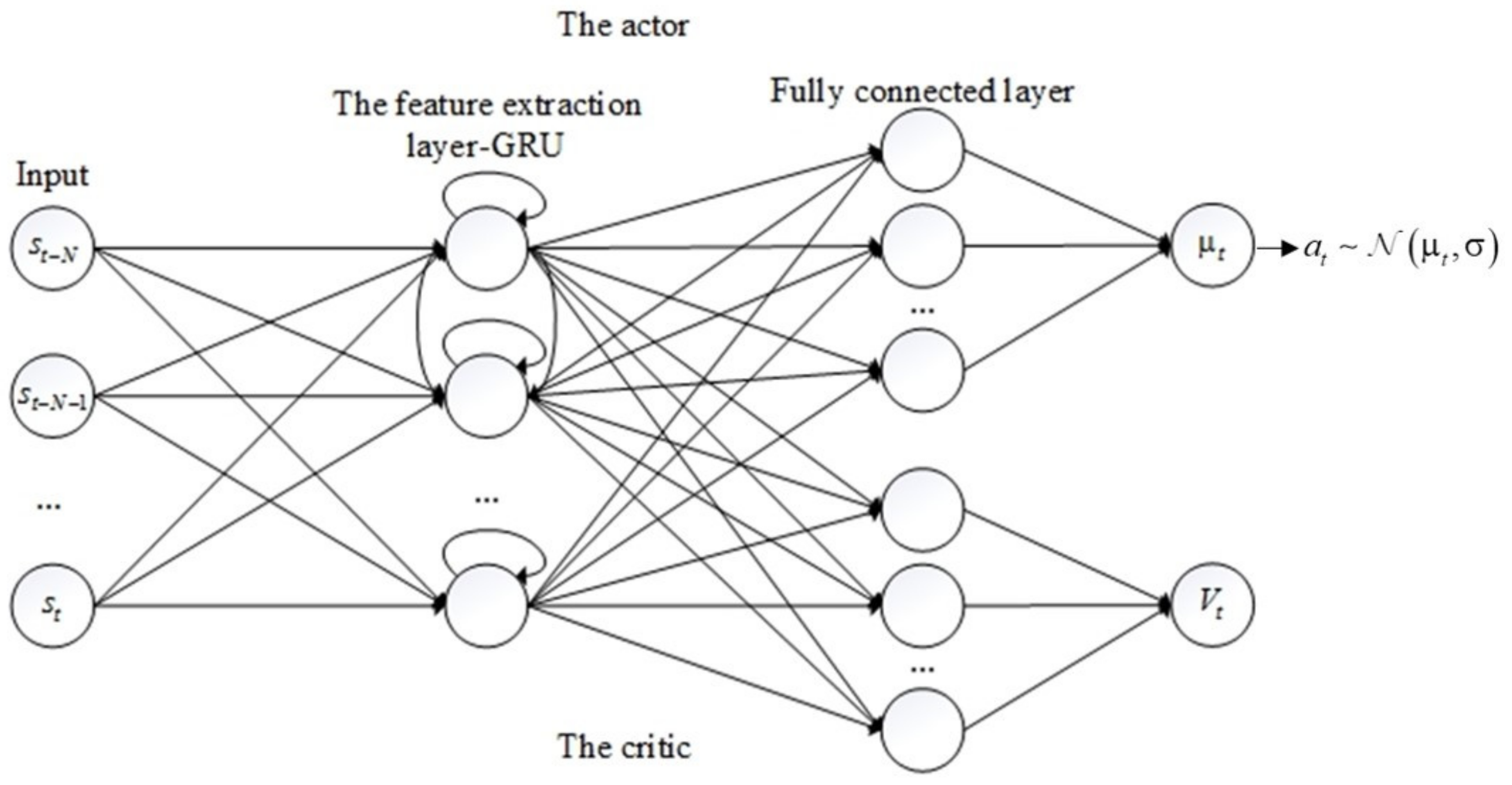
3.1. The Generator
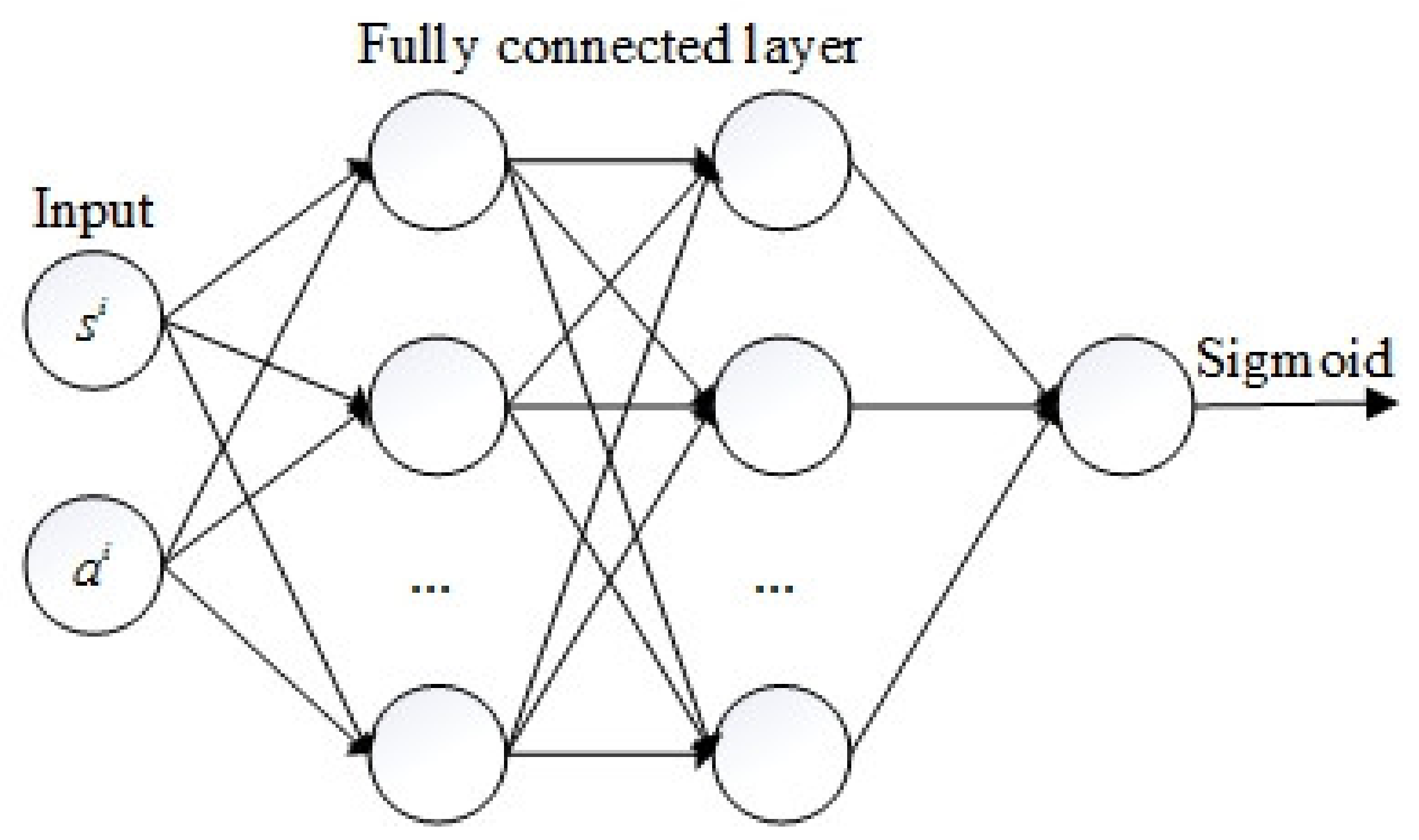
3.2. The Discriminator
3.3. The Proposed Algorithm
| Algorithm 1: Algorithm for modeling drivers’ car-following behaviors |
| Input: The collected state-action pairs of drivers denoted as D Output: 1: The strategy of drivers denoted as 2: Algorithm begins: 3: Randomly initialize the parameters of the discriminator and the actor-critic networks as and . 4: For to N, repeat the following steps 5: Using the policy output by the actor-critic parameterized by to interact with the car-following environment, record the interaction history as the generated state-action pairs 6: Update the parameters of the discriminator for three times from to with the generated samples and the actual samples using the Adam rule and the loss . 7: Use the updated discriminator parameterized by to provide rewards (Equation (11)) for the environment, update the parameters of the actor-critic networks from to using the Adam rule and the loss . 8: Algorithm end |
4. Data Description
4.1. The Experiments
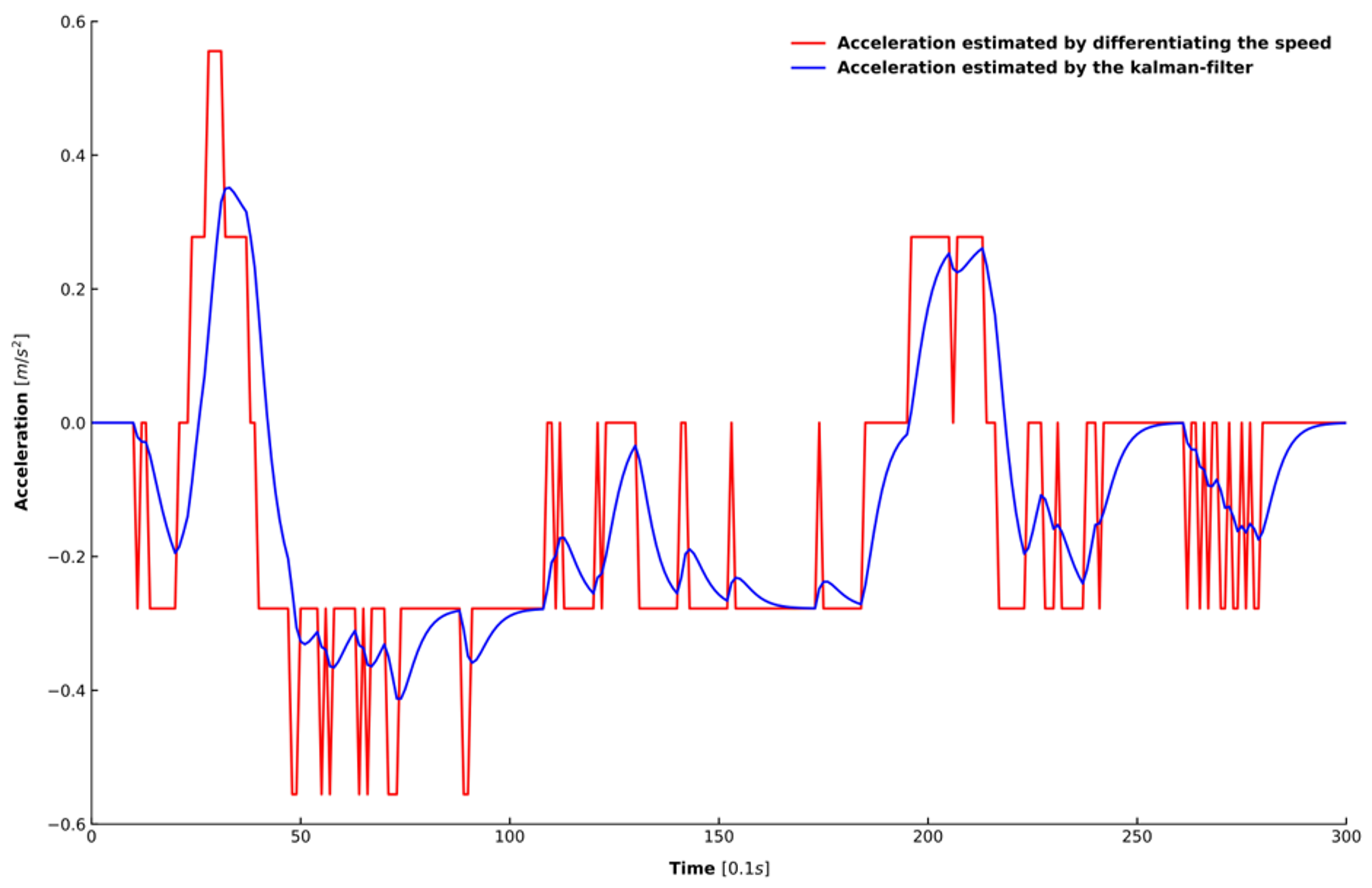
4.2. Car-Following Periods Extraction
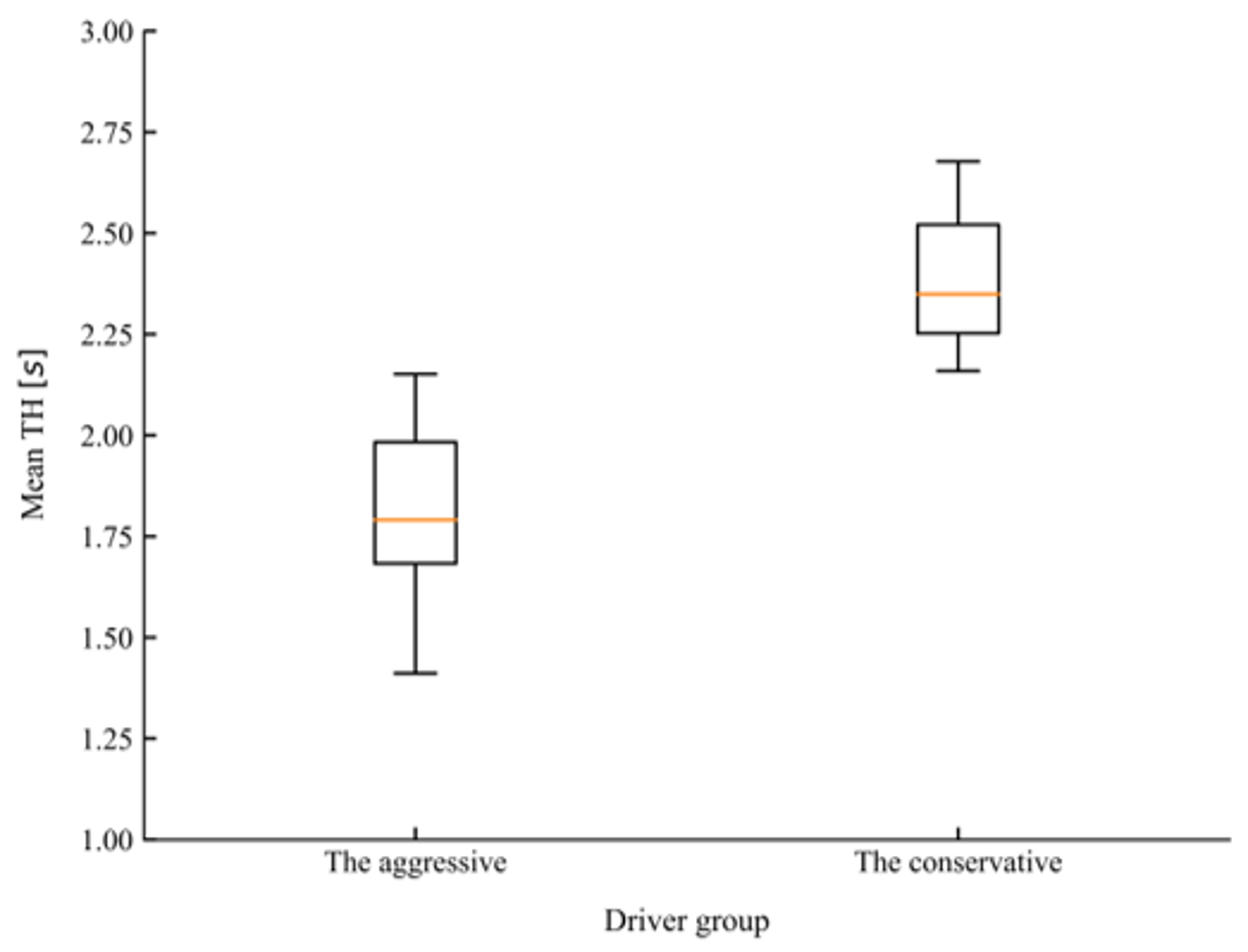
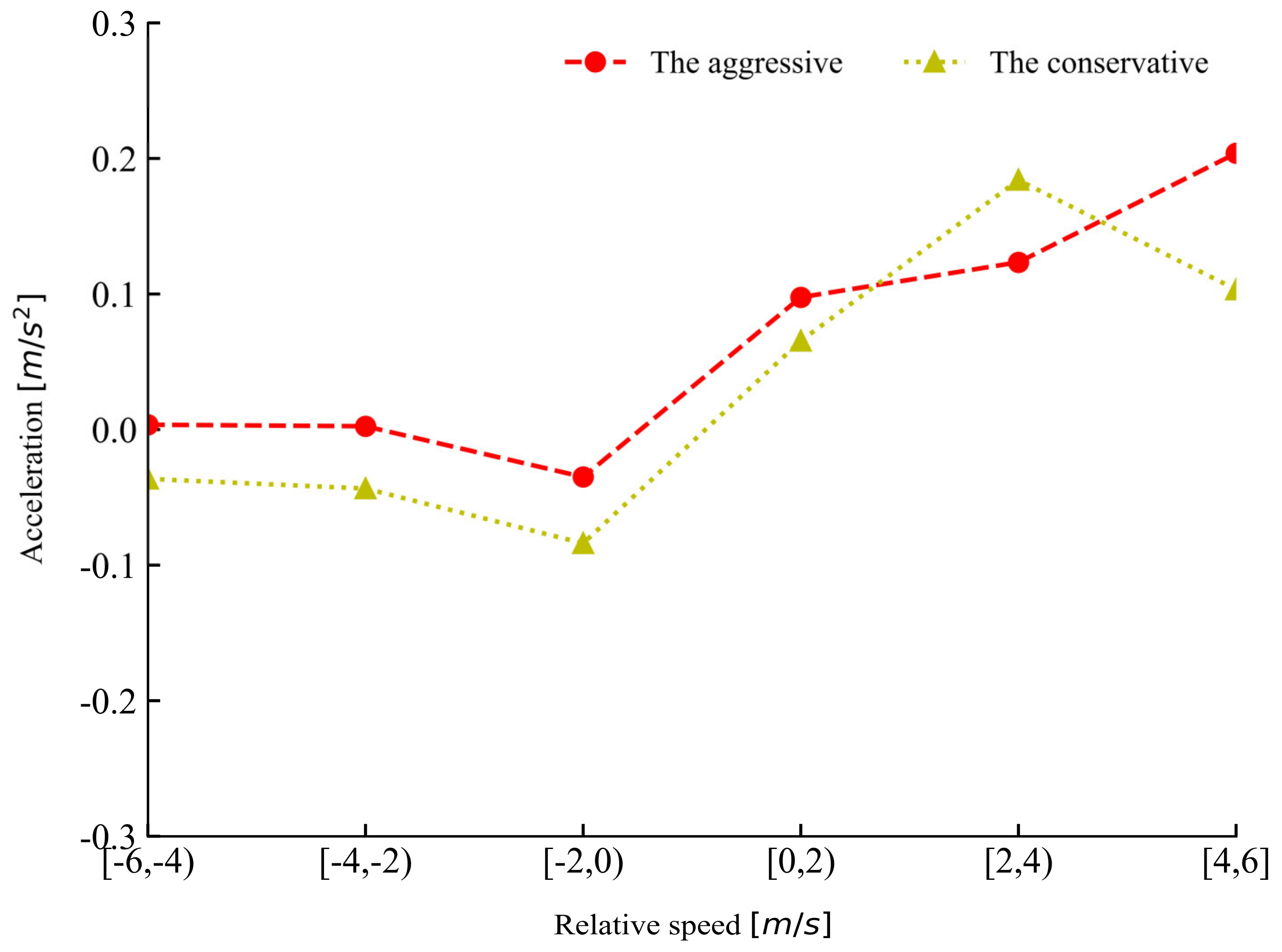
4.3. Driving Style Clustering Based on K-Means
5. Model Training and Evaluation
5.1. Simulation Setup
5.2. Evaluation Matrix
5.2.1. Root Mean Square Percentage Error
5.2.2. Kullback-Leibler Divergence
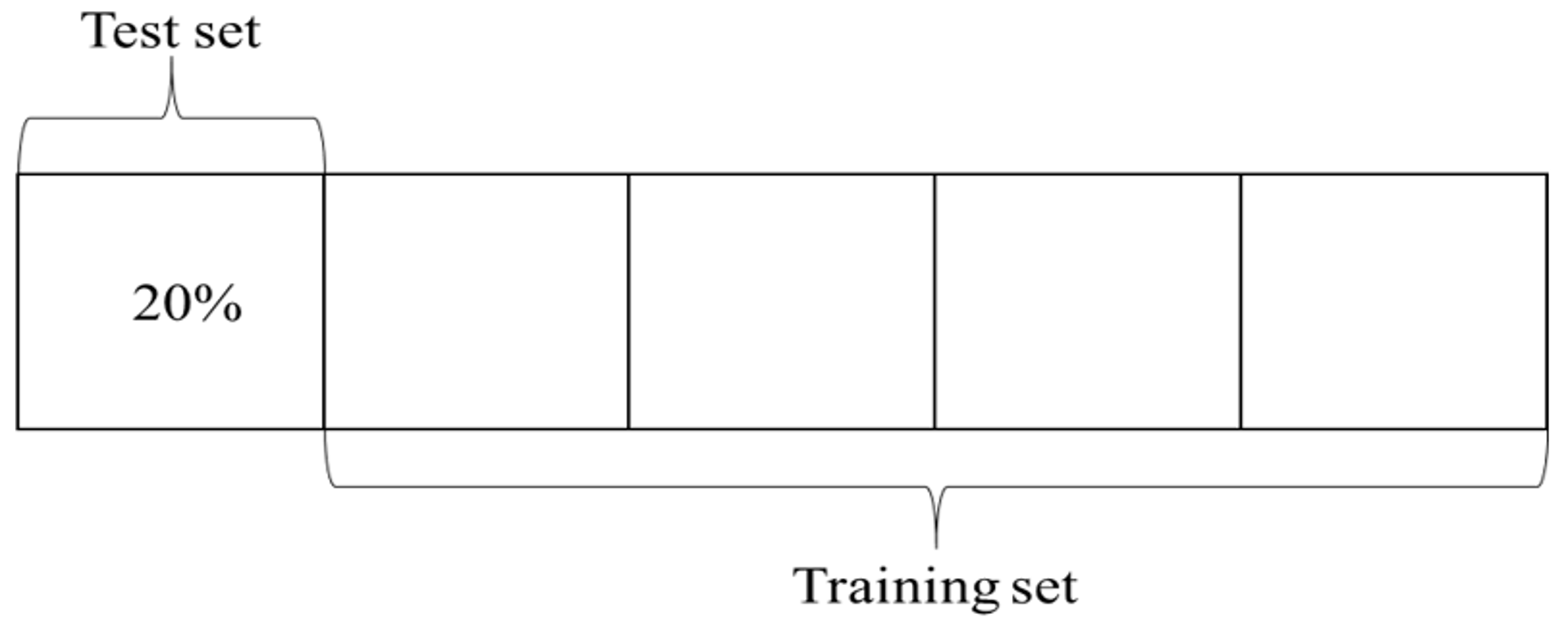
5.3. Cross-Validation
5.4. Models Investigated
5.4.1. IDM
5.4.2. RNN Based Model
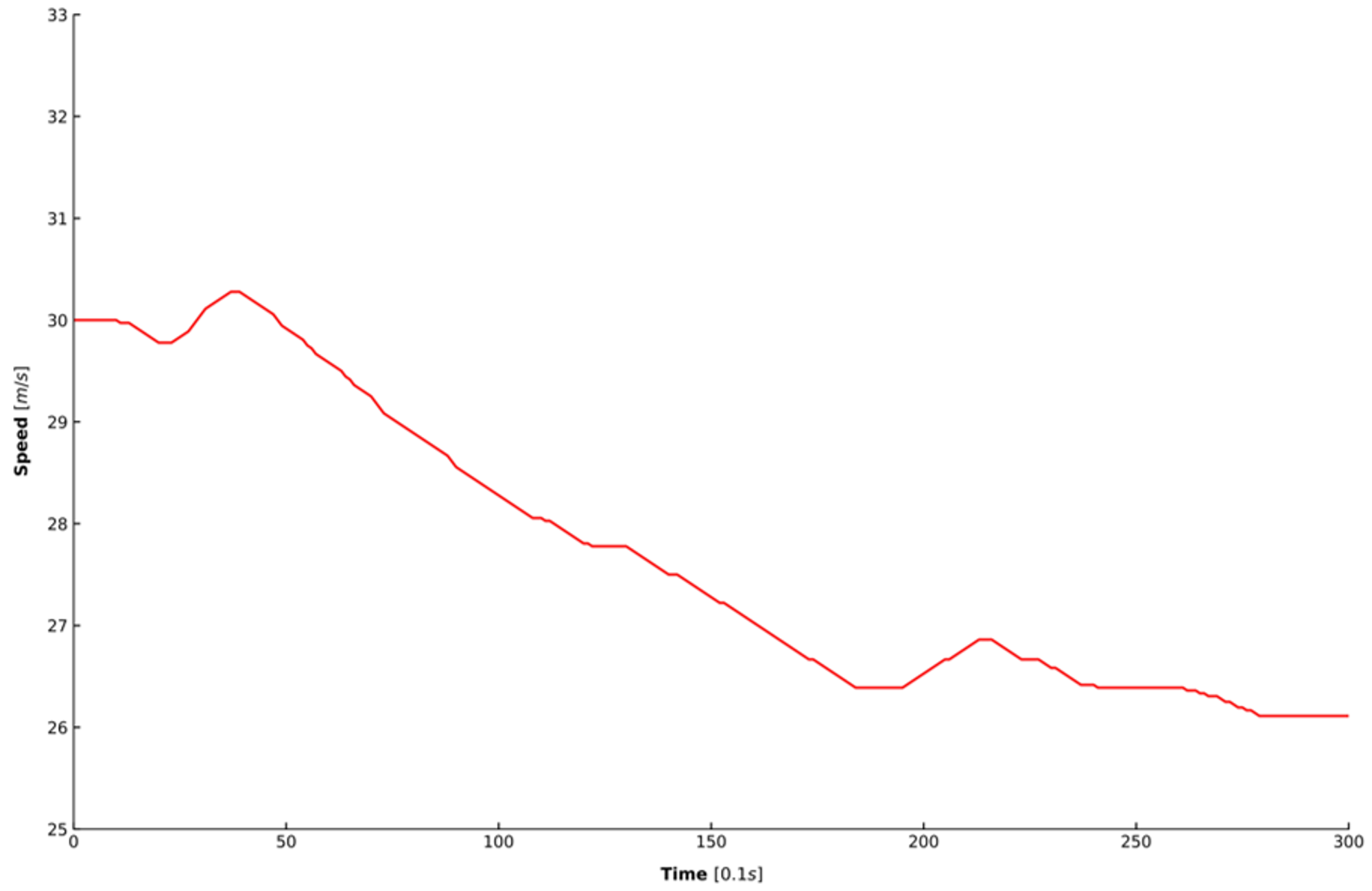
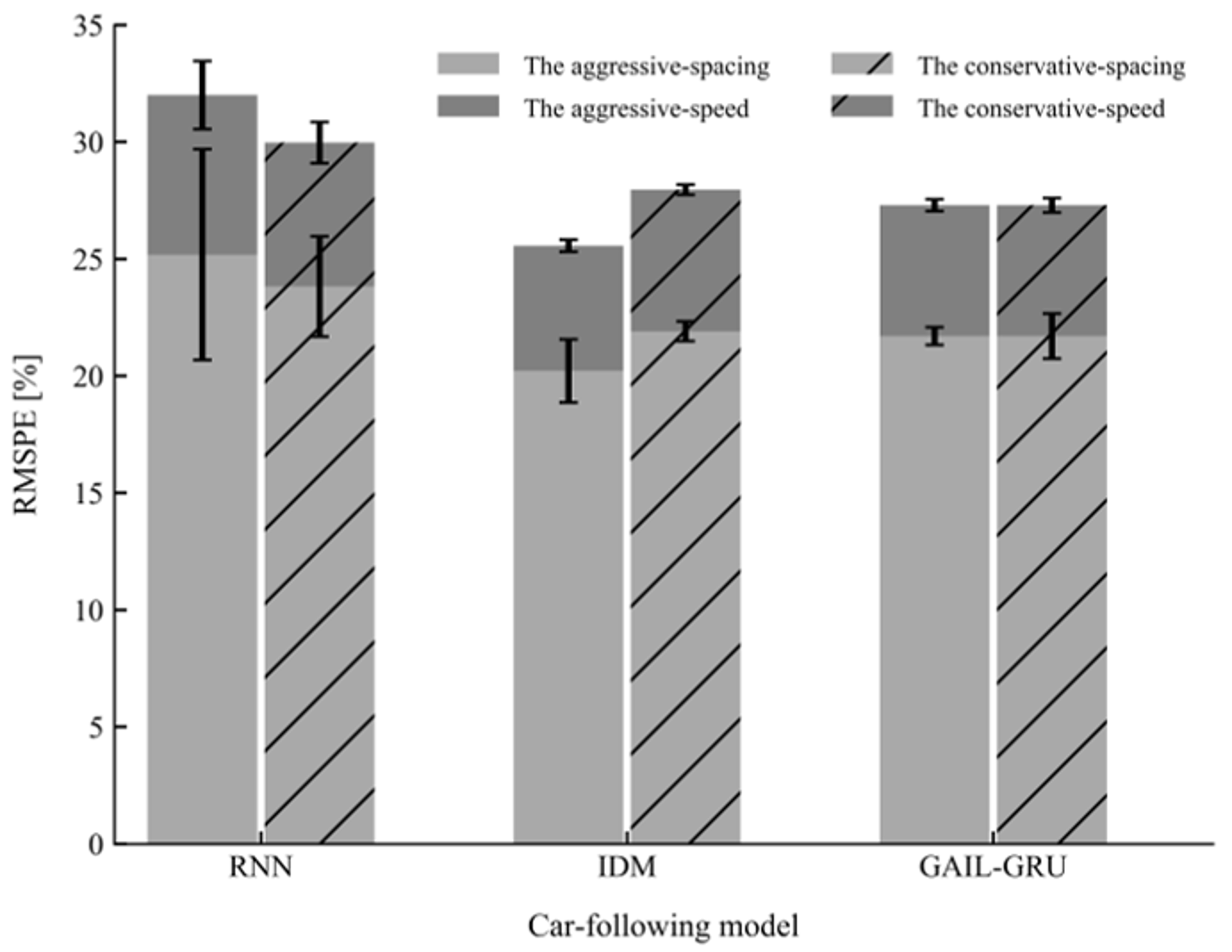
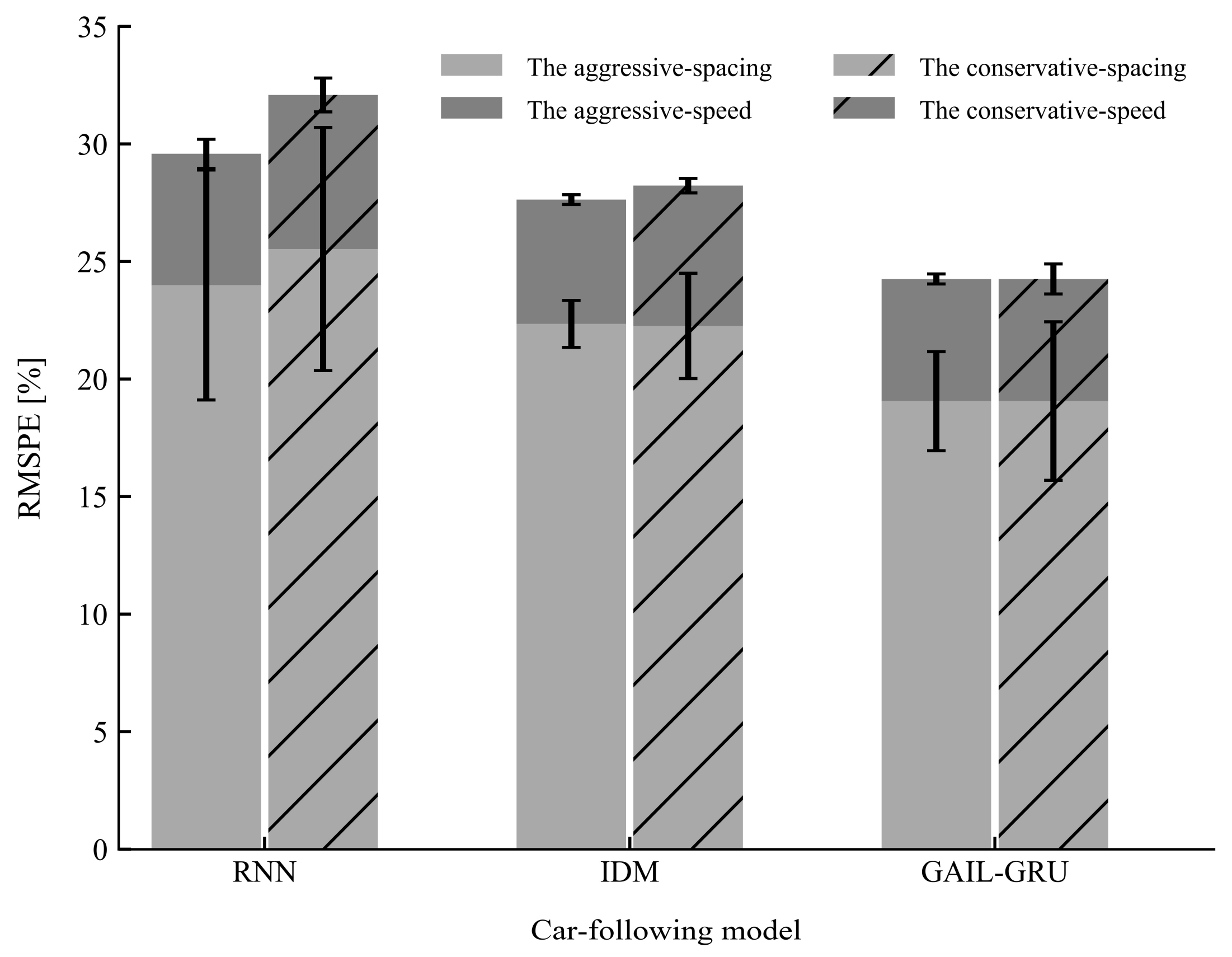
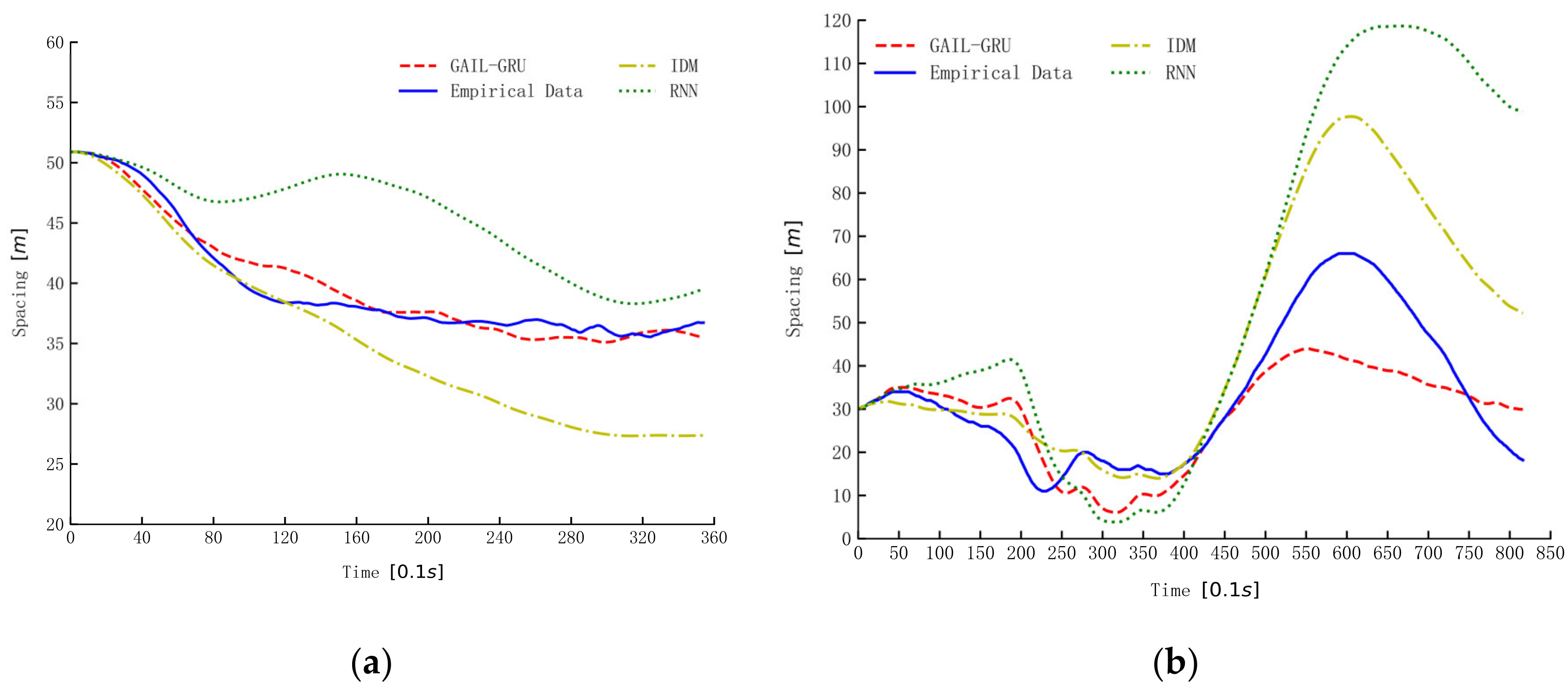
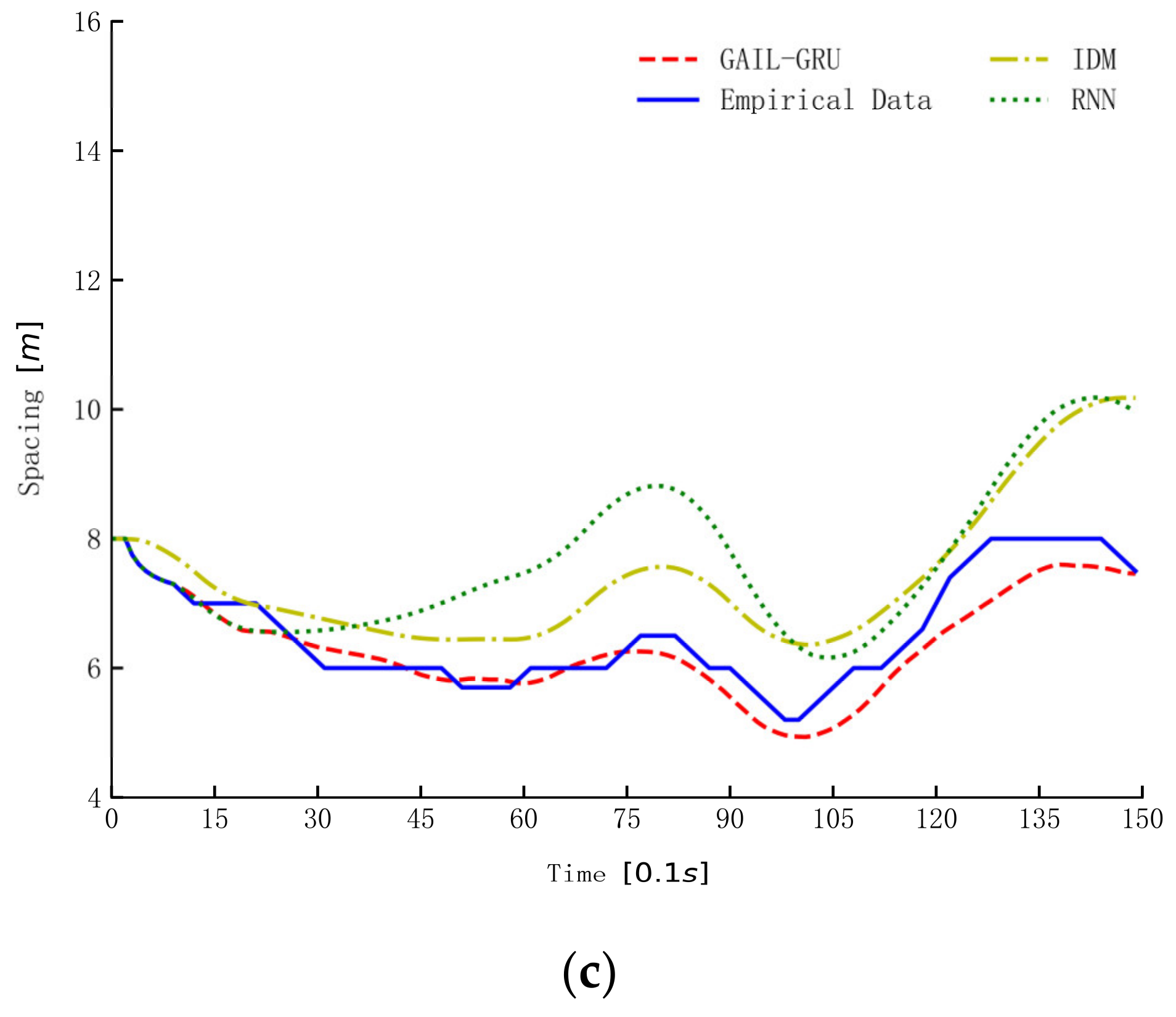
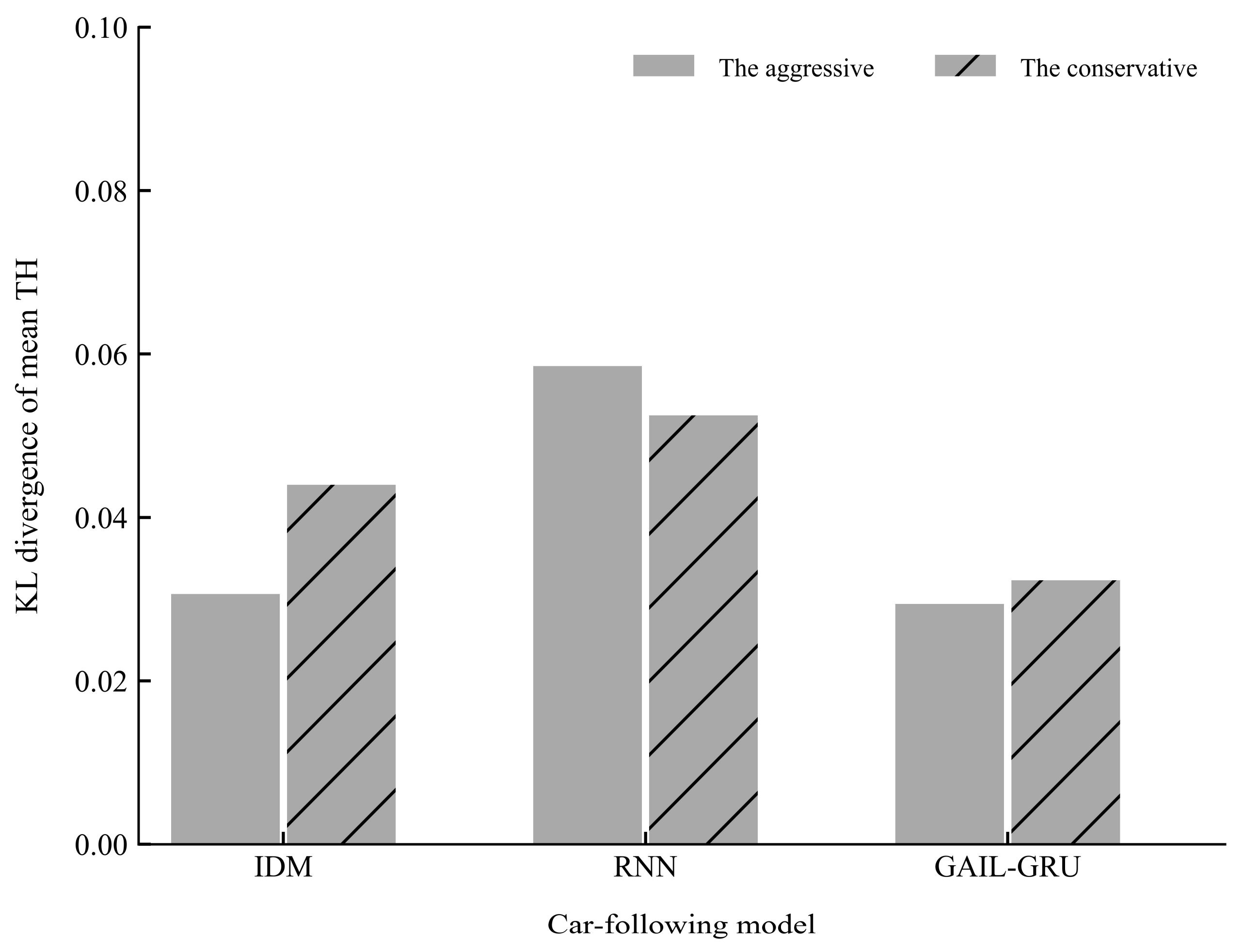
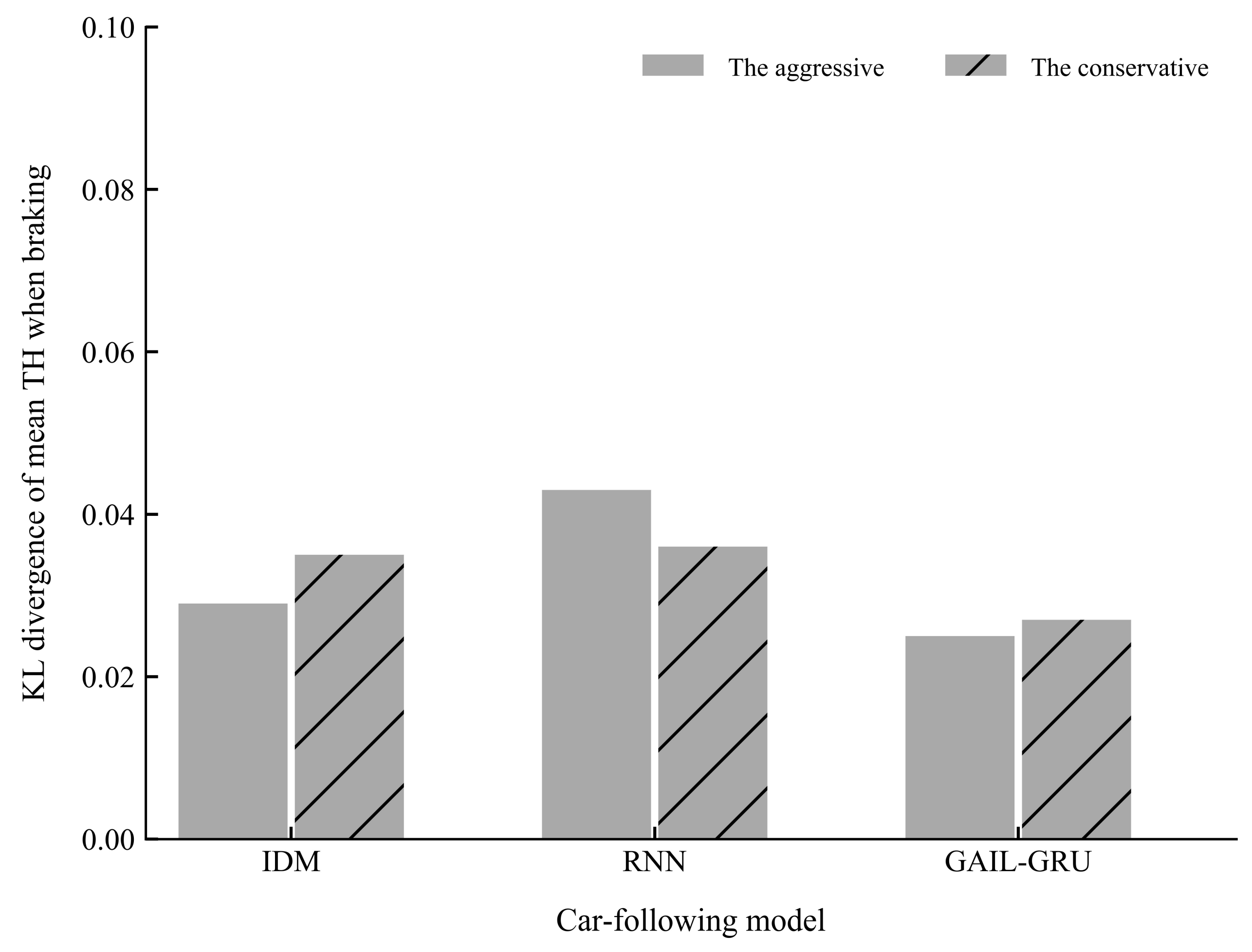
6. Results
7. Discussion
Author Contributions
Funding
Conflicts of Interest
References
- Brackstone, M.; McDonald, M. Car-following: A historical review. Transp. Res. Part F Traffic Psychol. Behav. 1999, 2, 181–196. [Google Scholar] [CrossRef]
- Peng, H. Evaluation of driver assistance systems-a human centered approach. In Proceedings of the 6th International Symposium on Advanced Vehicle Control, Hiroshima, Japan, 9–13 September 2002. [Google Scholar]
- Simonelli, F.; Bifulco, G.N.; De Martinis, V.; Punzo, V. Human-Like Adaptive Cruise Control Systems through a Learning Machine Approach. In Applications of Soft Computing; Springer: Berlin/Heidelberg, Germany, 2009; pp. 240–249. [Google Scholar]
- Kuderer, M.; Gulati, S.; Burgard, W. Learning driving styles for autonomous vehicles from demonstration. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 2641–2646. [Google Scholar]
- Sim, G.; Min, K.; Ahn, S.; Sunwoo, M.; Jo, K. Deceleration Planning Algorithm Based on Classified Multi-Layer Perceptron Models for Smart Regenerative Braking of EV in Diverse Deceleration Conditions. Sensors 2019, 19, 4020. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Lu, X.; Ren, C.; Zhao, H. Fusion Modeling Method of Car-Following Characteristics. IEEE Access 2019, 7, 162778–162785. [Google Scholar] [CrossRef]
- Wang, X.; Jiang, R.; Li, L.; Lin, Y.; Zheng, X.; Wang, F. Capturing Car-Following Behaviors by Deep Learning. IEEE Trans. Intell. Transp. Syst. 2018, 19, 910–920. [Google Scholar] [CrossRef]
- Hao, S.; Yang, L.; Shi, Y. Data-driven car-following model based on rough set theory. In IET Intelligent Transport Systems; Institution of Engineering and Technology: London, UK, 2018; Volume 12, pp. 49–57. [Google Scholar]
- Papathanasopoulou, V.; Antoniou, C. Towards data-driven car-following models. Transp. Res. Part C Emerg. Technol. 2015, 55, 496–509. [Google Scholar] [CrossRef]
- Zhou, M.; Qu, X.; Li, X. A recurrent neural network based microscopic car following model to predict traffic oscillation. Transp. Res. Part C Emerg. Technol. 2017, 84, 245–264. [Google Scholar] [CrossRef]
- Zhu, M.; Wang, X.; Wang, Y. Human-like autonomous car-following model with deep reinforcement learning. Transp. Res. Part C Emerg. Technol. 2018, 97, 348–368. [Google Scholar] [CrossRef]
- Codevilla, F.; Santana, E.; López, A.M.; Gaidon, A. Exploring the limitations of behavior cloning for autonomous driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9329–9338. [Google Scholar]
- Ross, S.; Bagnell, D. Efficient reductions for imitation learning. In Proceedings of the 13th International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 661–668. [Google Scholar]
- Gao, H.; Shi, G.; Xie, G.; Cheng, B. Car-following method based on inverse reinforcement learning for autonomous vehicle decision-making. Int. J. Adv. Robotic Syst. 2018, 15, 1729881418817162. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Kuefler, A.; Morton, J.; Wheeler, T.; Kochenderfer, M. Imitating driver behavior with generative adversarial networks. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 204–211. [Google Scholar]
- Abbeel, P.; Ng, A.Y. Apprenticeship learning via inverse reinforcement learning. In Proceedings of the Twenty-First International Conference on Machine Learning, Banff, AL, Canada, 4–8 July 2004; p. 1. [Google Scholar]
- Zhang, Q.; Zhu, M.; Zou, L.; Li, M.; Zhang, Y. Learning Reward Function with Matching Network for Mapless Navigation. Sensors 2020, 20, 3664. [Google Scholar] [CrossRef]
- Ng, A.Y.; Russell, S.J. Algorithms for inverse reinforcement learning. Icml 2000, 1, 2. [Google Scholar]
- Wulfmeier, M.; Ondruska, P.; Posner, I. Maximum entropy deep inverse reinforcement learning. arXiv 2015, arXiv:1507.04888. [Google Scholar]
- Finn, C.; Levine, S.; Abbeel, P. Guided cost learning: Deep inverse optimal control via policy optimization. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 49–58. [Google Scholar]
- Pipes, L.A. An Operational Analysis of Traffic Dynamics. J. Appl. Phys. 1953, 24, 274–281. [Google Scholar] [CrossRef]
- Chandler, R.E.; Herman, R.; Montroll, E.W. Traffic dynamics: Studies in car following. Oper. Res. 1958, 6, 165–184. [Google Scholar] [CrossRef]
- Gipps, P.G. A behavioural car-following model for computer simulation. Transp. Res. Part B Methodol. 1981, 15, 105–111. [Google Scholar] [CrossRef]
- Bando, M.; Hasebe, K.; Nakanishi, K.; Nakayama, A. Analysis of optimal velocity model with explicit delay. Phys. Rev. E 1998, 58, 5429–5435. [Google Scholar] [CrossRef]
- Kesting, A.; Treiber, M. Calibrating Car-Following Models by Using Trajectory Data: Methodological Study. Transp. Res. Record 2008, 2088, 148–156. [Google Scholar] [CrossRef]
- Panwai, S.; Dia, H. Comparative evaluation of microscopic car-following behavior. IEEE Trans. Intel. Transp. Syst. 2005, 6, 314–325. [Google Scholar] [CrossRef]
- Saifuzzaman, M.; Zheng, Z. Incorporating human-factors in car-following models: A review of recent developments and research needs. Transp. Res. Part C Emerg. Technol. 2014, 48, 379–403. [Google Scholar] [CrossRef]
- Jia, H.; Juan, Z.; Ni, A. Develop a car-following model using data collected by “five-wheel system”. In Proceedings of the 2003 IEEE International Conference on Intelligent Transportation Systems, Shanghai, China, 12–15 October 2003; Volume 341, pp. 346–351. [Google Scholar]
- Chong, L.; Abbas, M.M.; Medina, A. Simulation of Driver Behavior with Agent-Based Back-Propagation Neural Network. Transp. Res. Record 2011, 2249, 44–51. [Google Scholar] [CrossRef]
- Lefèvre, S.; Carvalho, A.; Borrelli, F. A Learning-Based Framework for Velocity Control in Autonomous Driving. IEEE Trans. Autom. Sci. Eng. 2016, 13, 32–42. [Google Scholar] [CrossRef]
- Wang, W.; Xi, J.; Hedrick, J.K. A Learning-Based Personalized Driver Model Using Bounded Generalized Gaussian Mixture Models. IEEE Trans. Veh. Technol. 2019, 68, 11679–11690. [Google Scholar] [CrossRef]
- Arora, S.; Doshi, P. A survey of inverse reinforcement learning: Challenges, methods and progress. arXiv 2018, arXiv:1806.06877. [Google Scholar]
- Ziebart, B.D.; Maas, A.L.; Bagnell, J.A.; Dey, A.K. Maximum entropy inverse reinforcement learning. In Proceedings of the Twenty-Third AAAI Conference on Artificial Intelligence, Chicago, IL, USA, 13–17 July 2008; pp. 1433–1438. [Google Scholar]
- Ziebart, B.D.; Bagnell, J.A.; Dey, A.K. Modeling interaction via the principle of maximum causal entropy. J. Contrib. 2010. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Finn, C.; Christiano, P.; Abbeel, P.; Levine, S. A connection between generative adversarial networks, inverse reinforcement learning, and energy-based models. arXiv 2016, arXiv:1611.03852. [Google Scholar]
- Ho, J.; Ermon, S. Generative adversarial imitation learning. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 4565–4573. [Google Scholar]
- Fernando, T.; Denman, S.; Sridharan, S.; Fookes, C. Learning temporal strategic relationships using generative adversarial imitation learning. arXiv 2018, arXiv:1805.04969. [Google Scholar]
- Clevert, D.-A.; Unterthiner, T.; Hochreiter, S. Fast and accurate deep network learning by exponential linear units (elus). arXiv 2015, arXiv:1511.07289. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Yu, L.; Zhang, W.; Wang, J.; Yu, Y. Seqgan: Sequence generative adversarial nets with policy gradient. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Zhu, M.; Wang, X.; Tarko, A.; Fang, S.E. Modeling car-following behavior on urban expressways in Shanghai: A naturalistic driving study. Transp. Res. Part C Emerg. Technol. 2018, 93, 425–445. [Google Scholar] [CrossRef]
- Thiemann, C.; Treiber, M.; Kesting, A. Estimating Acceleration and Lane-Changing Dynamics from Next Generation Simulation Trajectory Data. Transp. Res. Record 2008, 2088, 90–101. [Google Scholar] [CrossRef]
- Welch, G.; Bishop, G. An Introduction to the Kalman Filter; University of North Carolina: Chapel Hill, NC, USA, 1995. [Google Scholar]
- Boer, E.R. Car following from the driver’s perspective. Transp. Res. Part F Traffic Psychol. Behav. 1999, 2, 201–206. [Google Scholar] [CrossRef]
- Mata-Carballeira, Ó.; Gutiérrez-Zaballa, J.; del Campo, I.; Martínez, V. An FPGA-Based Neuro-Fuzzy Sensor for Personalized Driving Assistance. Sensors 2019, 19, 4011. [Google Scholar] [CrossRef] [PubMed]
- Liu, T.; Fu, R.; Ma, Y.; Liu, Z.; Cheng, W. Car-following Warning Rules Considering Driving Styles. China J. Highw. Transp. 2020, 33, 170–180. [Google Scholar]
- Aranganayagi, S.; Thangavel, K. Clustering categorical data using silhouette coefficient as a relocating measure. In Proceedings of the International Conference on Computational Intelligence and Multimedia Applications (ICCIMA 2007), Sivakasi, Tamil Nadu, 13–15 December 2007; pp. 13–17. [Google Scholar]
- Punzo, V.; Montanino, M. Speed or spacing? Cumulative variables, and convolution of model errors and time in traffic flow models validation and calibration. Transp. Res. Part B Methodol. 2016, 91, 21–33. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Spacing (m) | Speed (m/s) | ||||
|---|---|---|---|---|---|---|
| Mean | Min | Max | Mean | Min | Max | |
| Aggressive | 34.15 | 2.27 | 120.00 | 18.57 | 2.50 | 33.70 |
| Conservative | 42.79 | 3.91 | 119.90 | 17.47 | 1.49 | 34.84 |
| Type | Acceleration (m/s2) | Relative Speed (m/s) | ||||
| Mean | Min | Max | Mean | Min | Max | |
| Aggressive | −0.01 | −3.14 | 1.64 | −0.42 | −12.45 | 5.80 |
| Conservative | −0.04 | −1.80 | 1.40 | −0.52 | −8.85 | 5.02 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Y.; Fu, R.; Wang, C.; Zhang, R. Modeling Car-Following Behaviors and Driving Styles with Generative Adversarial Imitation Learning. Sensors 2020, 20, 5034. https://doi.org/10.3390/s20185034
Zhou Y, Fu R, Wang C, Zhang R. Modeling Car-Following Behaviors and Driving Styles with Generative Adversarial Imitation Learning. Sensors. 2020; 20(18):5034. https://doi.org/10.3390/s20185034
Chicago/Turabian StyleZhou, Yang, Rui Fu, Chang Wang, and Ruibin Zhang. 2020. "Modeling Car-Following Behaviors and Driving Styles with Generative Adversarial Imitation Learning" Sensors 20, no. 18: 5034. https://doi.org/10.3390/s20185034
APA StyleZhou, Y., Fu, R., Wang, C., & Zhang, R. (2020). Modeling Car-Following Behaviors and Driving Styles with Generative Adversarial Imitation Learning. Sensors, 20(18), 5034. https://doi.org/10.3390/s20185034