Prediction of Human Activities Based on a New Structure of Skeleton Features and Deep Learning Model


 , ,
, ,
Abstract
1. Introduction
2. Related Works
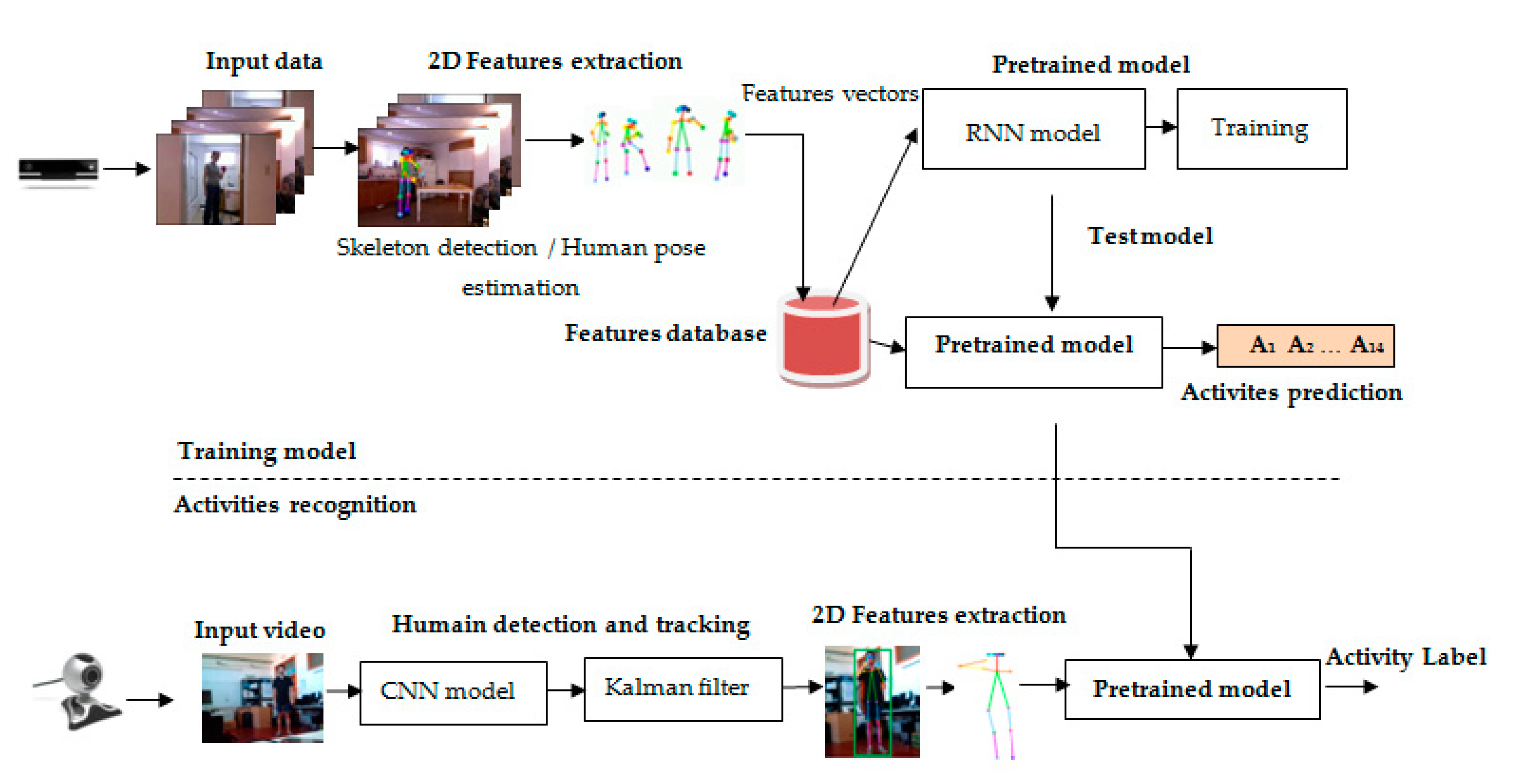
3. Proposed System for the Classification of Human Activities
3.1. Model Training
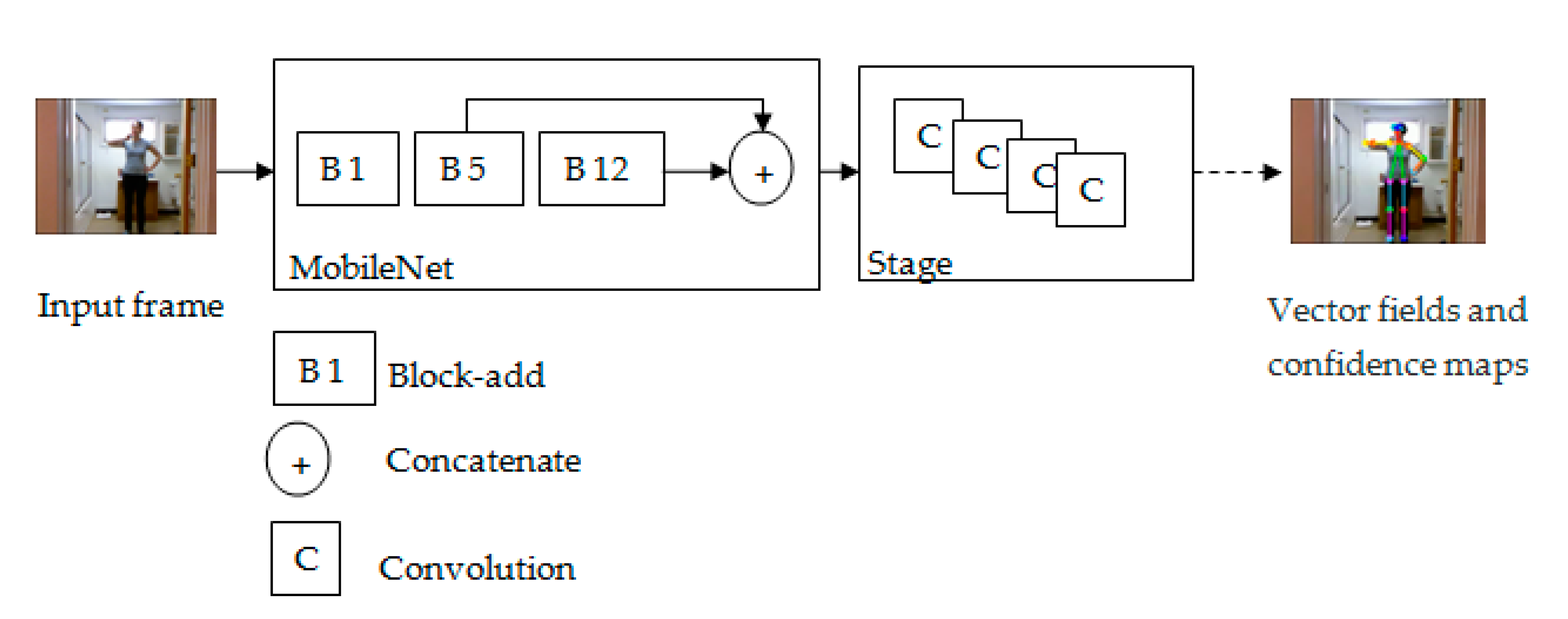
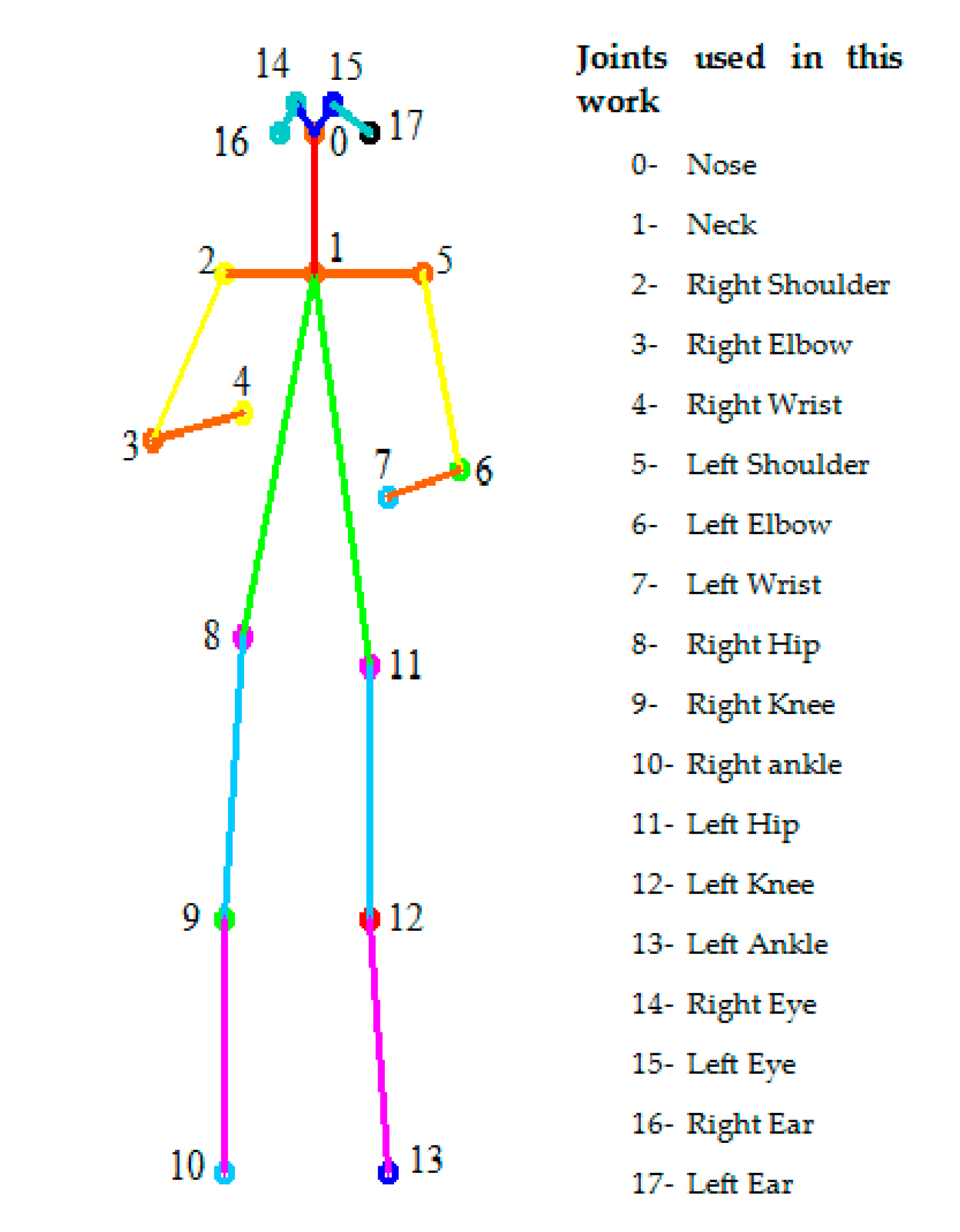
3.1.1. Human Pose Estimation and Skeleton Detection
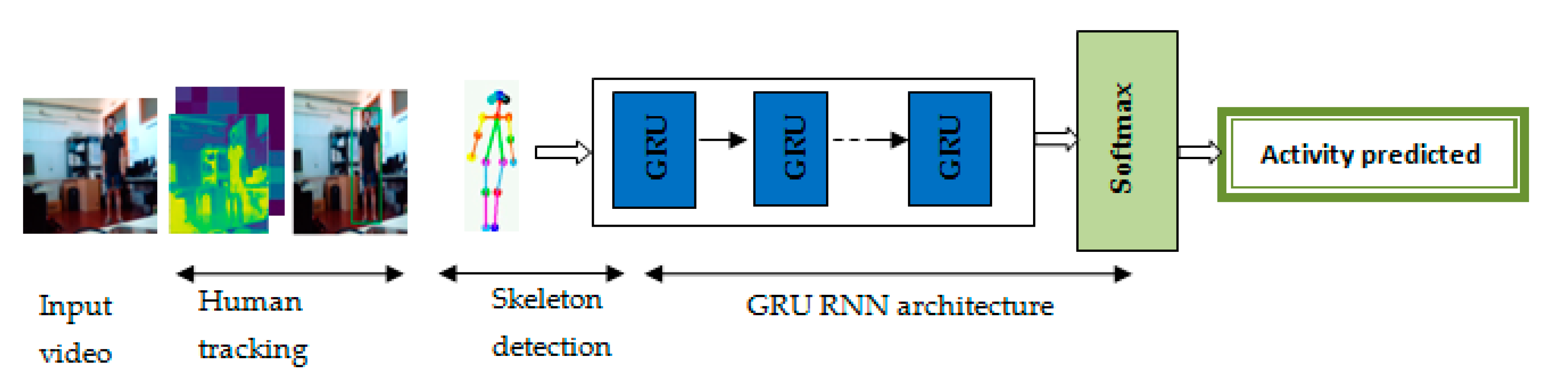
3.1.2. Deep Learning Model
3.2. Activity Recognition
- -
- The collection of 14 activities in one input video and real-time reading of human activities using a standard webcam.
- -
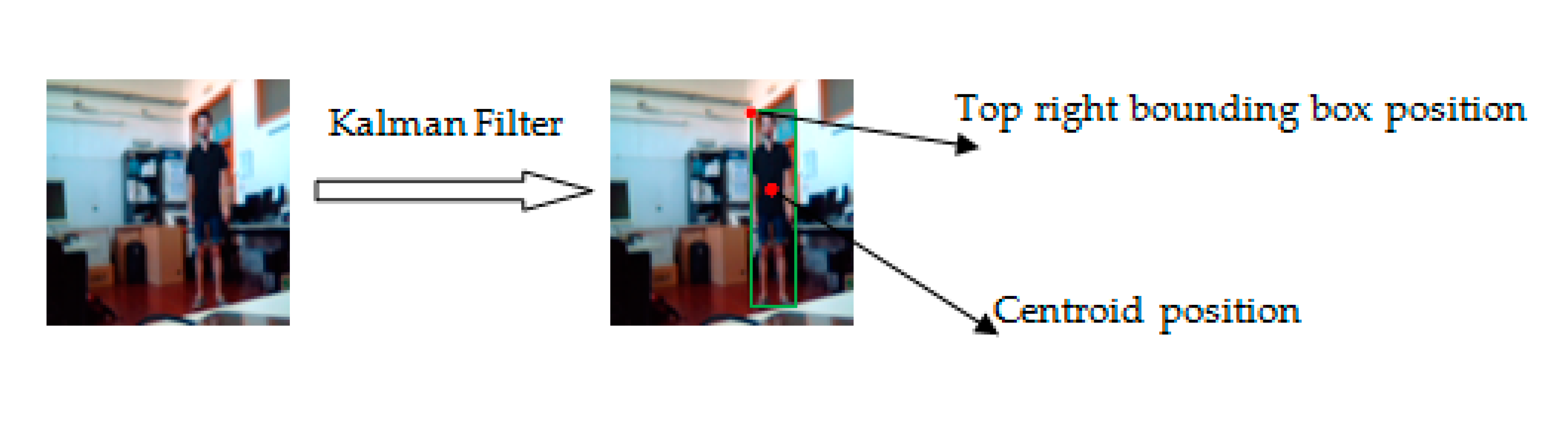
- Human tracking using the pre-trained transfer learning Convolutional Neural Network (CNN) model Inception V3 and the Kalman filter.
- -
- Two-dimensional feature extraction using human pose estimation and skeleton detection.
- -
- Human activity recognition.
4. Experimental Results
4.1. Dataset
4.2. Implementation Details
4.3. Activity Recognition
4.4. Comparisons with the State-Of-The-Art Method
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Rodríguez-Moreno, I.; Martínez-Otzeta, J.M.; Sierra, B.; Rodriguez, I.; Jauregi, E. Video Activity Recognition: State-of-the-Art. Sensors 2019, 19, 3160. [Google Scholar] [CrossRef] [PubMed]
- Wren, C.R.; Azarbayejani, A.J.; Darrell, T.J.; Pentland, A.P. Integration Issues in Large Commercial Media Delivery Systems; SPIE: Washington, DC, USA, 1996. [Google Scholar] [CrossRef]
- Elgammal, A.; Harwood, D.; Davis, L. Non-parametric model for background subtraction. In Computer Vision—ECCV 2000; Springer: Berlin, Germany, 2000; pp. 751–767. [Google Scholar] [CrossRef]
- Barnich, O.; Van Droogenbroeck, M. ViBE: A powerful random technique to estimate the background in video sequences. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 945–948. [Google Scholar] [CrossRef]
- McFarlane, N.J.B.; Schofield, C.P. Segmentation and tracking of piglets in images. Mach. Vis. Appl. 1995, 8, 187–193. [Google Scholar] [CrossRef]
- Lucas, B.D.; Kanadee, T. Aniterative image registration technique with an application tostereovision. In Proceedings of the Imaging Understanding Workshop, Pittsburgh, PA, USA, 24–28 August 1981; pp. 121–130. [Google Scholar]
- Horn, B.K.; Schunck, B.G. Determining optical flow. In Techniques and Applications of Image Understanding; Technical Symposium East; International Society for Optics and Photonics: Washington, DC, USA, 1981; Volume 17, pp. 185–203. [Google Scholar] [CrossRef]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005. [Google Scholar] [CrossRef]
- Comaniciu, D.; Meer, P. Mean shift analysis and applications. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999. [Google Scholar] [CrossRef]
- Gao, Y.; Xiang, X.; Xiong, N.; Huang, B.; Lee, H.J.; Alrifai, R.; Jiang, X.; Fang, Z. Human Action Monitoring for Healthcare based on Deep Learning. IEEE Access 2018, 6, 52277–52285. [Google Scholar] [CrossRef]
- Adama, D.A.; Lotfi, A.; Langensiepen, C.; Lee, K.; Trindade, P. Human activity learning for assistive robotics using a classifier ensemble. Soft Comp. 2018, 22, 7027–7039. [Google Scholar] [CrossRef]
- Albu, V. Measuring Customer Behavior with Deep Convolutional Neural Networks; BRAIN. Broad Research in Artificial Intelligence and Neuroscience: Bacau, Romania, 2016; pp. 74–79. [Google Scholar] [CrossRef]
- Majd, L. Human action recognition using support vector machines and 3D convolutional neural networks. Intern. J. Adv. Intel. Inf. 2017, 3, 47–55. [Google Scholar] [CrossRef]
- Murad, A.; Pyun, J.-Y. Deep Recurrent Neural Networks for Human Activity Recognition. Sensors 2017, 17, 2556. [Google Scholar] [CrossRef] [PubMed]
- Qin, Z.; Zhang, Y.; Meng, S.; Qin, Z.; Choo, K.-K.R. Imaging and fusing time series for wearable sensors based human activity recognition. Inf. Fusion 2020, 53, 80–87. [Google Scholar] [CrossRef]
- Ning, Z.; Zeyuan, H.; Sukhwan, L.; Eungjoo, L. Human Action Recognition Based on Global Silhouette and Local Optical Flow. In Proceedings of the International Symposium on Mechanical Engineering and Material Science, Suzhou, China, 17–19 November 2017. [Google Scholar] [CrossRef]
- Nicolas, B.; Li, Y.; Chris, P.; Aaron, C. Delving Deeper into Convolutional Networks for Learning Video Representations. Computer Vision and Pattern Recognition. arXiv 2016, arXiv:1511.06432. [Google Scholar]
- Xu, Z.; Hu, J.; Deng, W. Recurrent convolutional neural network for video classification. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Seattle, WA, USA, 11–15 July 2016. [Google Scholar] [CrossRef]
- Baldominos, A.; Saez, Y.; Isasi, P. Evolutionary Design of Convolutional Neural Networks for Human Activity Recognition in Sensor-Rich Environments. Sensors 2018, 18, 1288. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Feng, Y.; Han, J.; Zhen, X. Realistic human action recognition: When deep learning meets VLAD. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016. [Google Scholar] [CrossRef]
- Zhao, R.; Ali, H.; van der Smagt, P. Two-stream RNN/CNN for action recognition in 3D videos. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017. [Google Scholar] [CrossRef]
- Faria, D.R.; Premebida, C.; Nunes, U. A probabilistic approach for human everyday activities recognition using body motion from RGB-D images. In Proceedings of the 23rd IEEE International Symposium on Robot and Human Interactive Communication, Edinburgh, UK, 25–29 August 2014. [Google Scholar] [CrossRef]
- Koppula, H.S.; Gupta, R.; Saxena, A. Learning human activities and object affordances from RGB-D videos. Int. J. Robot. Res. 2013, 32, 951–970. [Google Scholar] [CrossRef]
- Ni, B.; Pei, Y.; Moulin, P.; Yan, S. Multilevel Depth and Image Fusion for Human Activity Detection. IEEE Trans. Cybern. 2013, 43, 1383–1394. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Liu, Z.; Wu, Y.; Yuan, J. Learning Actionlet Ensemble for 3D Human Action Recognition. IEEE Trans. Pattern Anal. Machin. Intel. 2014, 36, 914–927. [Google Scholar] [CrossRef] [PubMed]
- Shan, J.; Akella, S. 3D human action segmentation and recognition using pose kinetic energy. In Proceedings of the 2014 IEEE International Workshop on Advanced Robotics and Its Social Impacts, Evanston, IL, USA, 11–13 September 2014. [Google Scholar] [CrossRef]
- Cippitelli, E.; Gasparrini, S.; Gambi, E.; Spinsante, S. A Human Activity Recognition System Using Skeleton Data from RGBD Sensors. Comput. Intel. Neurosci. 2016, 2016, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Gaglio, S.; Re, G.L.; Morana, M. Human Activity Recognition Process Using 3-D Posture Data. IEEE Trans. Hum. Mach. Syst. 2015, 45, 586–597. [Google Scholar] [CrossRef]
- Manzi, A.; Dario, P.; Cavallo, F. A Human Activity Recognition System Based on Dynamic Clustering of Skeleton Data. Sensors 2017, 17, 1100. [Google Scholar] [CrossRef] [PubMed]
- Srijan, D.; Michal, K.; Francois, B.; Gianpiero, F. A Fusion of Appearance based CNNs and Temporal evolution of Skeleton with LSTM for Daily Living Action Recognition. arXiv 2018, arXiv:1802.00421v1. [Google Scholar]
- Cruz-Silva, J.E.; Montiel-Pérez, J.Y.; Sossa-Azuela, H. 3-D Human Body Posture Reconstruction by Computer Vision; LNAI 11835; Springer: Cham, Switzreland, 2013; pp. 579–588. [Google Scholar] [CrossRef]
- Khaire, P.; Kumar, P.; Imran, J. Combining CNN Streams of RGB-D and Skeletal Data for Human Activity Recognition. Pattern Recognition Letters; Elsevier: Amsterdam, The Netherlands, 2018. [Google Scholar] [CrossRef]
- Ji, Y.; Xu, F.; Yang, Y.; Shen, F.; Shen, H.T.; Zheng, W.-S. A Large-scale RGB-D Database for Arbitrary-view Human Action Recognition. In Proceedings of the ACM Multimedia Conference on Multimedia Conference—MM ’18, Seoul, Korea, 12–16 October 2020. [Google Scholar] [CrossRef]
- Wang, P.; Li, W.; Ogunbona, P.; Wan, J.; Escalera, S. RGB-D-based human motion recognition with deep learning: A survey. In Computer Vision and Image Understanding; Elsevier: Amsterdam, The Netherlands, 2018; pp. 118–139. [Google Scholar] [CrossRef]
- Wan, J.; Escalera, S.; Perales, F.J.; Kittler, J. Articulated motion and deformable objects. In Pattern Recognition; Springer: Berlin, Germany, 2010; Volume 79, pp. 55–64. [Google Scholar] [CrossRef]
- Pham, H.H.; Salmane, H.; Khoudour, L.; Crouzil, A.; Zegers, P.; Velastin, S.A. Spatio–Temporal Image Representation of 3D Skeletal Movements for View-Invariant Action Recognition with Deep Convolutional Neural Networks. Sensors 2019, 19, 1932. [Google Scholar] [CrossRef] [PubMed]
- Jaouedi, N.; Boujnah, N.; Bouhlel, M.S. fvA New Hybrid Deep Learning Model for Human Action Recognition. J. King Saud Univ. Comput. Inf. Sci. 2020, 32, 447–453. [Google Scholar] [CrossRef]
- Sung, J.; Ponce, C.; Selman, B.; Saxena, A. Unstructured human activity detection from RGBD images. In Proceedings of the IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Shabaninia, E.; Naghsh-Nilchi, A.R.; Kasaei, S. A weighting scheme for mining key skeletal joints for human action recognition. In Multimedia Tools and Applications; Springer: Berlin, Germany, 2019; Volume 78, pp. 31319–31345. [Google Scholar]
- Sedmidubsky, J.; Elias, P.; Zezula, P. Effective and efficient similarity searching in motion capture data. In Multimedia Tools and Applications; Springer: Berlin, Germany, 2018; pp. 12073–12094. [Google Scholar] [CrossRef]
- Yang, K.; Ding, X.; Chen, W. Multi-Scale Spatial Temporal Graph Convolutional LSTM Network for Skeleton-Based Human Action Recognition. In Proceedings of the 2019 International Conference on Video, Signal and Image Processing, Wuhan, China, 29–31 October 2019; pp. 3–9. [Google Scholar] [CrossRef]
- Elias, P.; Sedmidubsky, J.; Zezula, P. Understanding the Gap between 2D and 3D Skeleton-Based Action Recognition. In Proceedings of the IEEE International Symposium on Multimedia, San Diego, CA, USA, 9–11 December 2019. [Google Scholar] [CrossRef]
- Carrara, F.; Elias, P.; Sedmidubsky, J.; Zezula, P. LSTM-based real-time action detection and prediction in human motion streams. In Multimedia Tools and Applications; Springer: Berlin, Germany, 2019; Volume 78, pp. 27309–27331. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Methods | Interpretation |
|---|---|---|
| AlbuSlava 2016 [13] and Majed Latah 2017 [14] | 3D CNN | Spatial features |
| Murad and Ryun 2017 [15] and Qin et al. [16] | Deep recurrent neural networks and multimodal sensors | Motion features |
| Ning et al., 2017 [17] | Local optical flow of a global human silhouette | Motion features |
| Nicolas et al., 2016 [18] | GRU + RCN | Spatio-temporal features |
| Xu et al., 2016 [19] and Baldominos et al. [20] | RCNN | Spatio-temporal features |
| Zhang et al., 2016 [21] | Vector of locally aggregated descriptors, SIFT and ISA | Spatio-temporal features |
| Zhao et al., 2017 [22] | RNN + GRU + 3D CNN | Spatio-temporal features |
| Faria et al., 2012 [23] | Dynamic Bayesian mixture model | Skeleton features |
| Koppula et al., 2013 [24] | HMM | Skeleton features |
| Bingbing et al., 2013 [25] | Histogram of oriented gradient and SVM | Spatio-temporal features |
| Wang et al., 2014 [26] | LOM | Skeleton features |
| Shan and Akella 2014 [27] and Enea et al., 2016 [28] | Pose Kinetic Energy + SVM | Skeleton features |
| Gaglio et al., 2015 [29] | Kmeans + HMM + SVM | Skeleton features |
| Manzi et al.,2017 [30] | Kmeans + Sequential Minimal Optimization | Skeleton features |
| Srijan et al., 2018 [31], Cruz et al. [32] and Khaire et al. [33] | RGB-D + CNN + LSTM model | Skeleton and contextual features |
| Yanli et al., 2018 [34] | VS-CNN | Skeleton and contextual features |
| Hug et al., 2019 [35] | The conversion of the distance value of two joints to colors points + CNN | Skeleton and contextual features |
| Proposed approach | CNN (Inception V3 + mobileNet) + GRU + RNN + Kalman filter | Skeleton + spatio-temporal features |
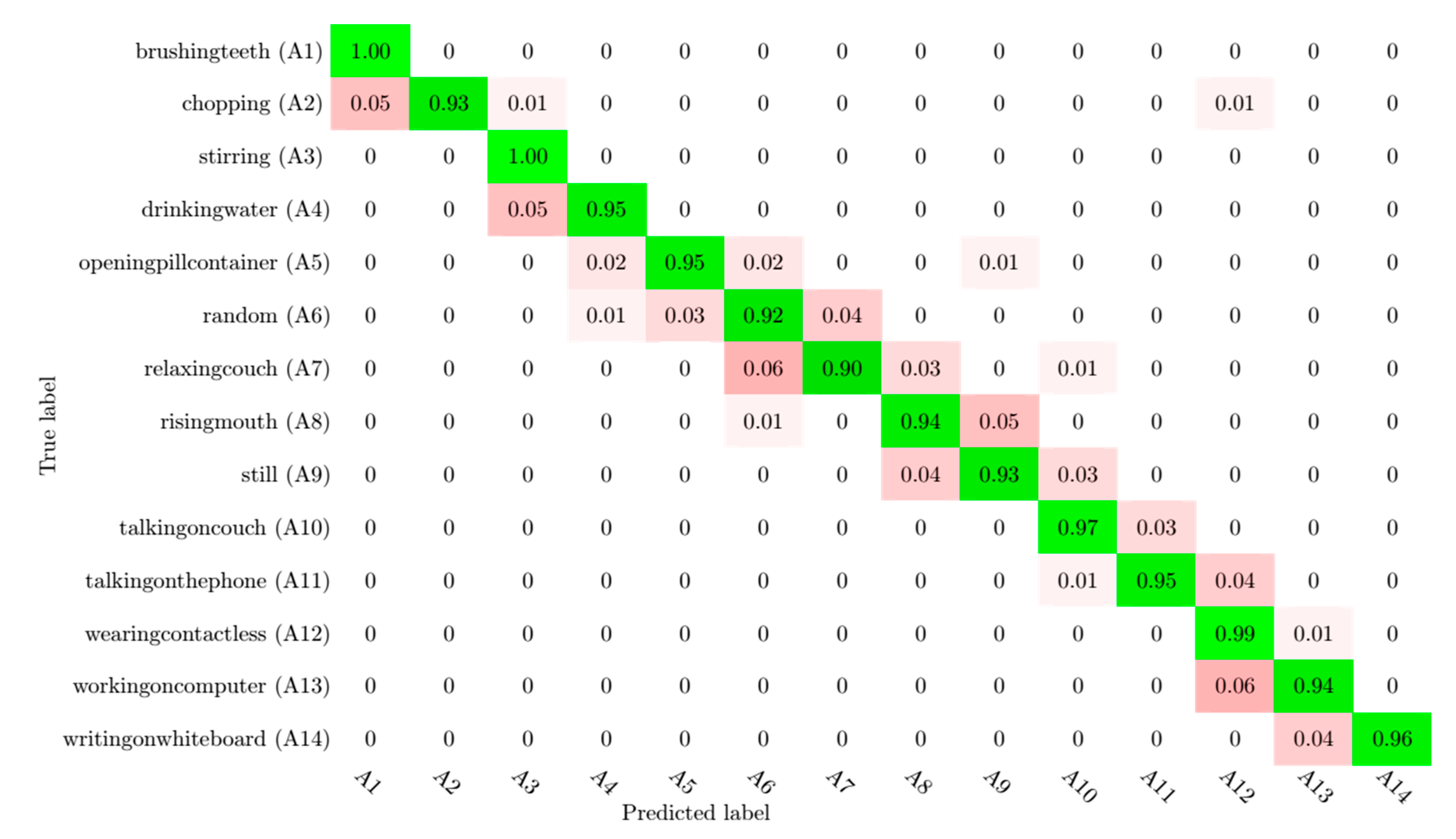
| A1 | A2 | A3 | A4 | A5 | A6 | A7 | A8 | A9 | A10 | A11 | A12 | A13 | A14 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Recall | 1 | 0.93 | 1 | 0.95 | 0.95 | 0.92 | 0.90 | 0.94 | 0.93 | 0.97 | 0.95 | 0.99 | 0.94 | 0.96 |
| Precision | 0.95 | 1 | 0.94 | 0.96 | 0.96 | 0.91 | 0.95 | 0.93 | 0.93 | 0.95 | 0.97 | 0.90 | 0.95 | 1 |
| F1 | 0.97 | 0.96 | 0.96 | 0.95 | 0.95 | 0.91 | 0.92 | 0.93 | 0.93 | 0.96 | 0.96 | 0.94 | 0.94 | 0.98 |
| Location | Activity | Prediction (%) |
|---|---|---|
| Bathroom | Brushing teeth Rinsing mouth Wearing contact lenses | 100% 94% 99% |
| Bedroom | Drinking water Opening pill container | 95% 95% |
| Kitchen | Cooking (chopping) Cooking (stirring) Still | 93% 100% 93% |
| Living room | Random Relaxing on couch Talking on phone Talking on couch | 92% 90% 95% 97% |
| Office | Writing on board Working on computer | 96% 94% |
| Average | 95.5% |
| Methods | Year | Acc. (%) |
|---|---|---|
| Dynamic Bayesian Mixture Model [23] | 2014 | 91.9% |
| Support Vector Machine + Hidden Markov Model [26] | 2015 | 77.3% |
| Multiclass Support Vector Machine [25] | 2016 | 93.5 |
| Classifier Ensemble [12] | 2018 | 92.3% |
| Weighted 3D joints [41] | 2019 | 94.4% |
| Our System | 2020 | 95.5% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jaouedi, N.; Perales, F.J.; Buades, J.M.; Boujnah, N.; Bouhlel, M.S. Prediction of Human Activities Based on a New Structure of Skeleton Features and Deep Learning Model. Sensors 2020, 20, 4944. https://doi.org/10.3390/s20174944
Jaouedi N, Perales FJ, Buades JM, Boujnah N, Bouhlel MS. Prediction of Human Activities Based on a New Structure of Skeleton Features and Deep Learning Model. Sensors. 2020; 20(17):4944. https://doi.org/10.3390/s20174944
Chicago/Turabian StyleJaouedi, Neziha, Francisco J. Perales, José Maria Buades, Noureddine Boujnah, and Med Salim Bouhlel. 2020. "Prediction of Human Activities Based on a New Structure of Skeleton Features and Deep Learning Model" Sensors 20, no. 17: 4944. https://doi.org/10.3390/s20174944
APA StyleJaouedi, N., Perales, F. J., Buades, J. M., Boujnah, N., & Bouhlel, M. S. (2020). Prediction of Human Activities Based on a New Structure of Skeleton Features and Deep Learning Model. Sensors, 20(17), 4944. https://doi.org/10.3390/s20174944