Acoustic Sensor Data Flow for Cultural Heritage Monitoring and Safeguarding


 , ,
, , 

Abstract
:1. Introduction
- (1)
- Design and development of a Wireless Acoustic Sensor Network to record audio signals in remote areas
- (2)
- Application of Transfer Learning to finetune a Deep Convolutional Neural Network in order to detect audio sources of interest
- (3)
- Design of a flexible audio signal ontology that can be used to detect audio-based events for the Cultural Heritage domain
- (4)
- Publication (in the publicly available STORM cloud) of the generated audio-based events exploiting the Linked Open Data paradigm.
2. Related Work
2.1. Wireless Sensor Networks
2.2. Audio Signal Processing
2.3. Deep Learning on Audio Signals
2.4. Semantic Reasoning for Audio-Based Event Detection
→ p(arg1,arg2,…,argn)
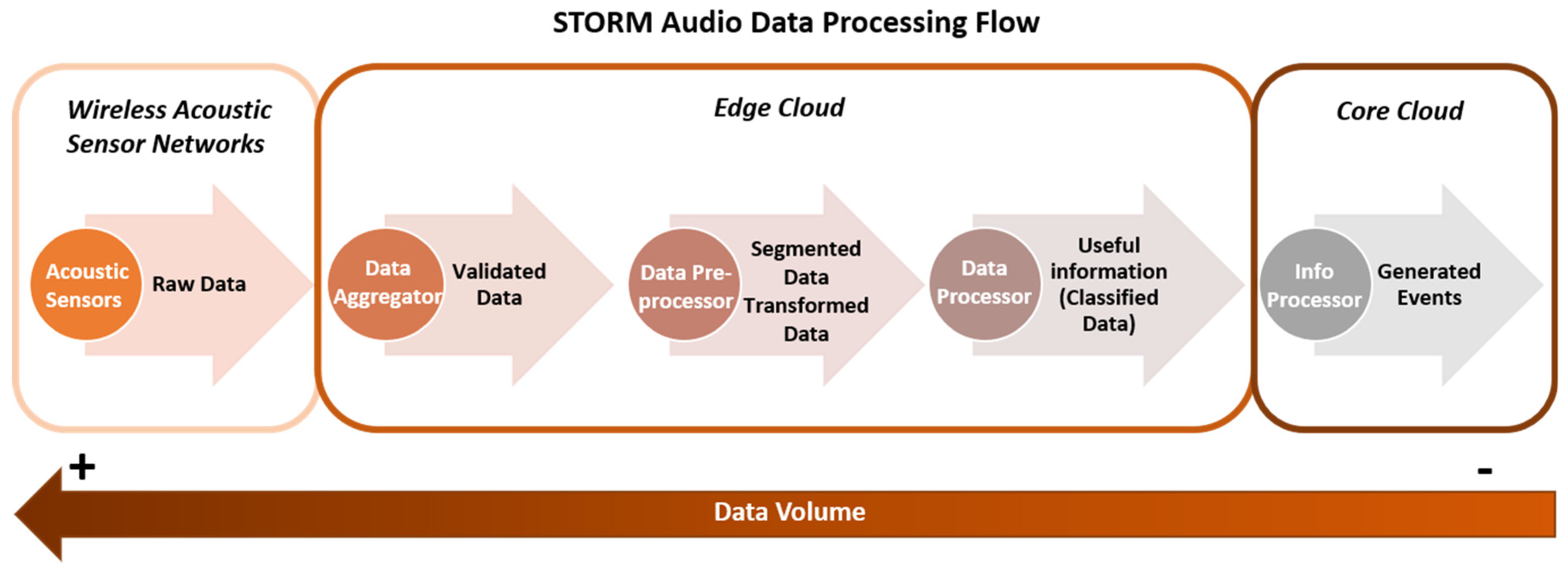
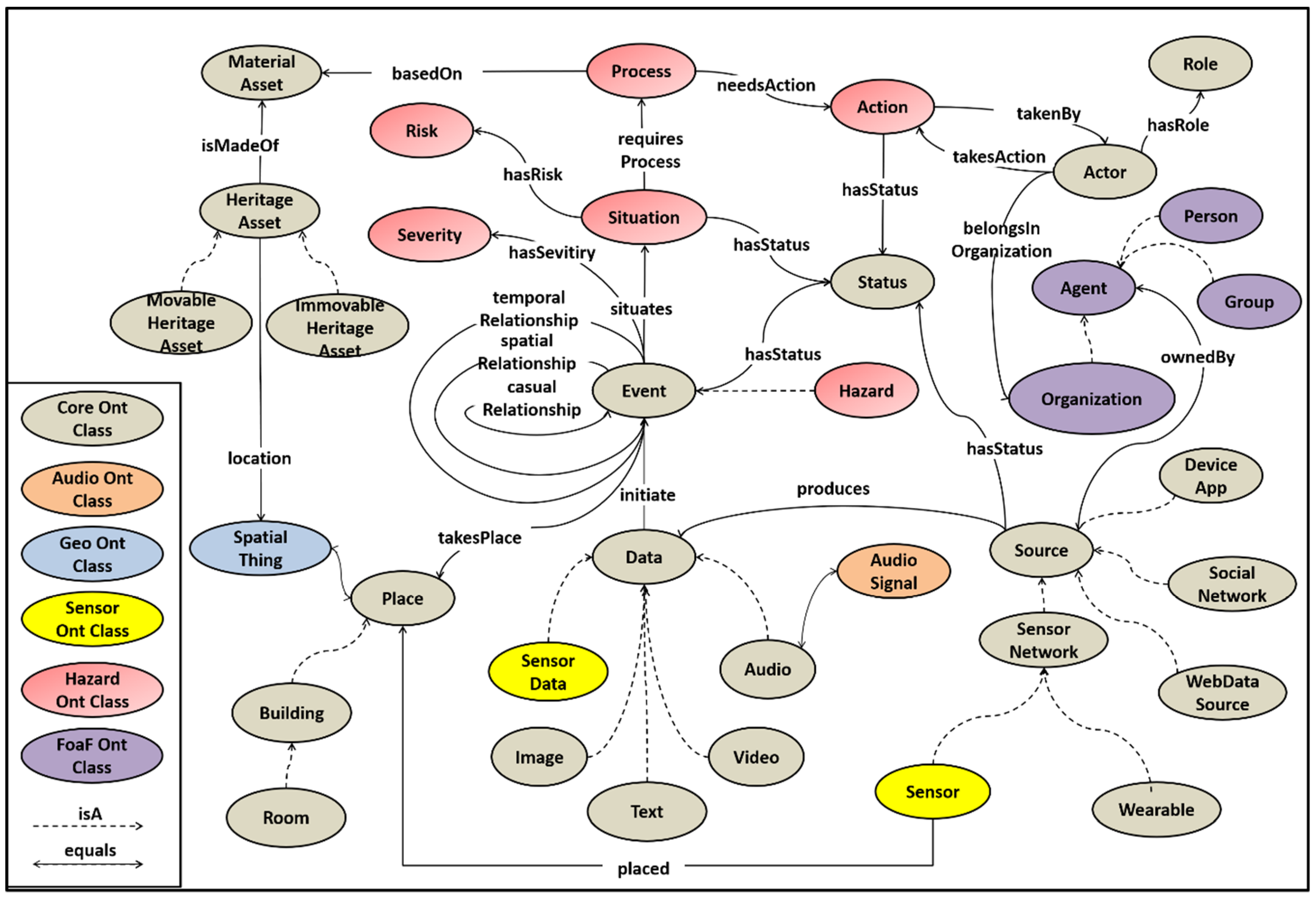
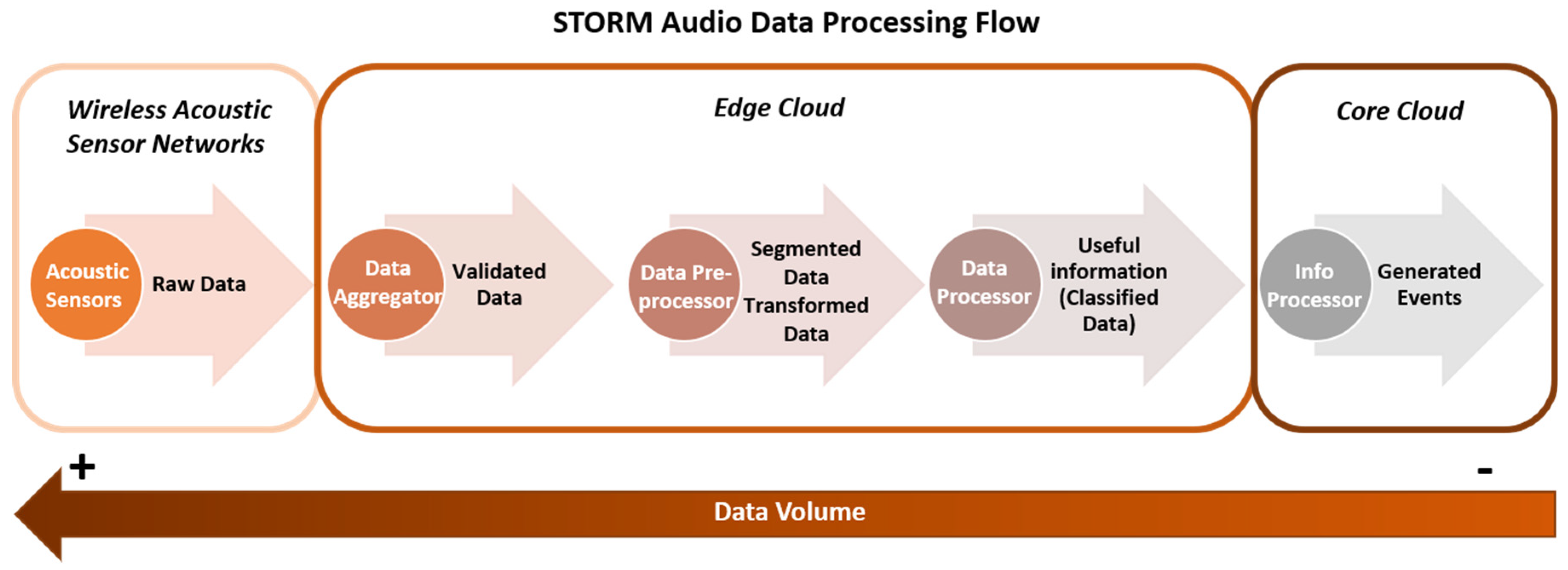
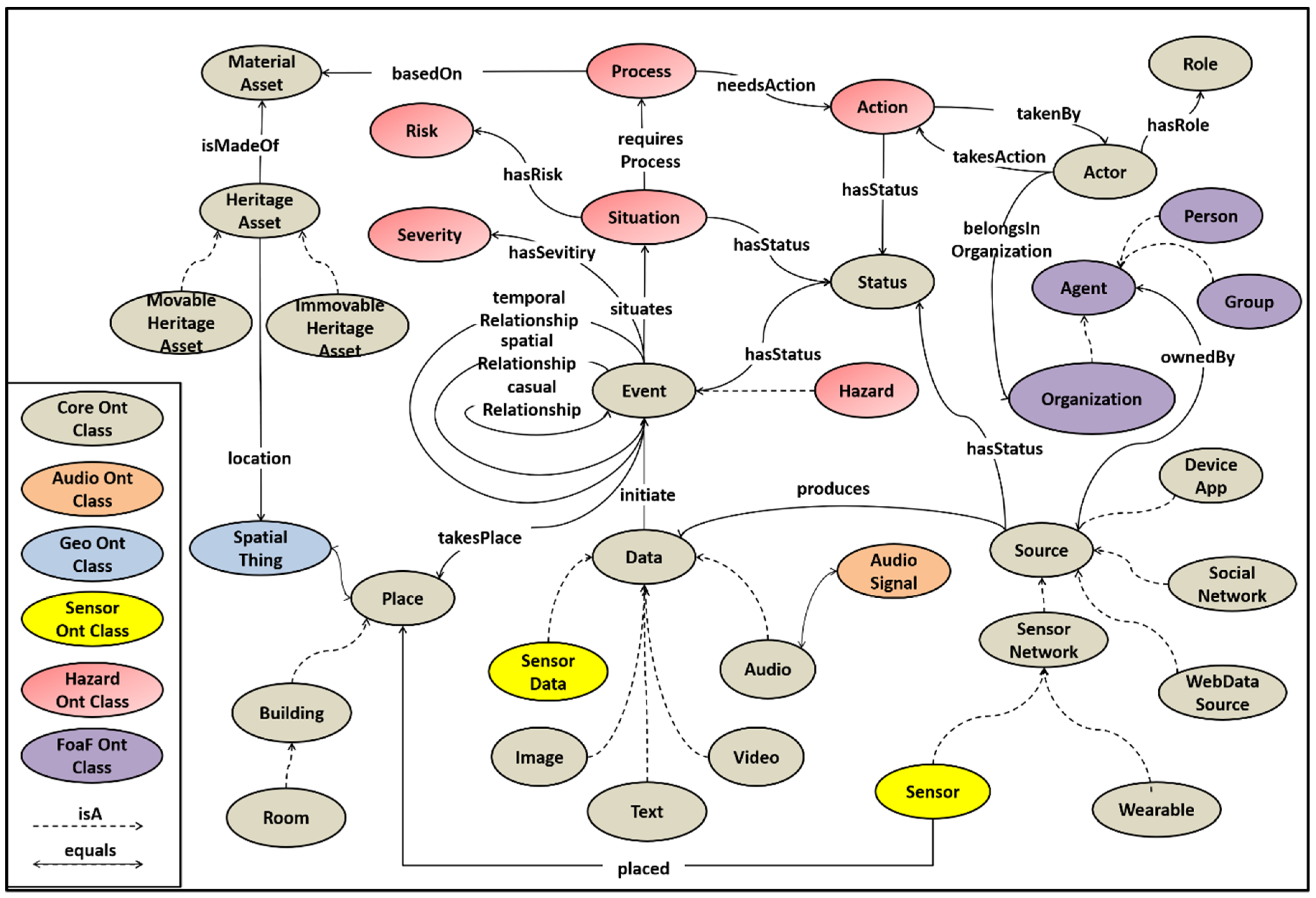
3. Acoustic Data Flow on the STORM Platform
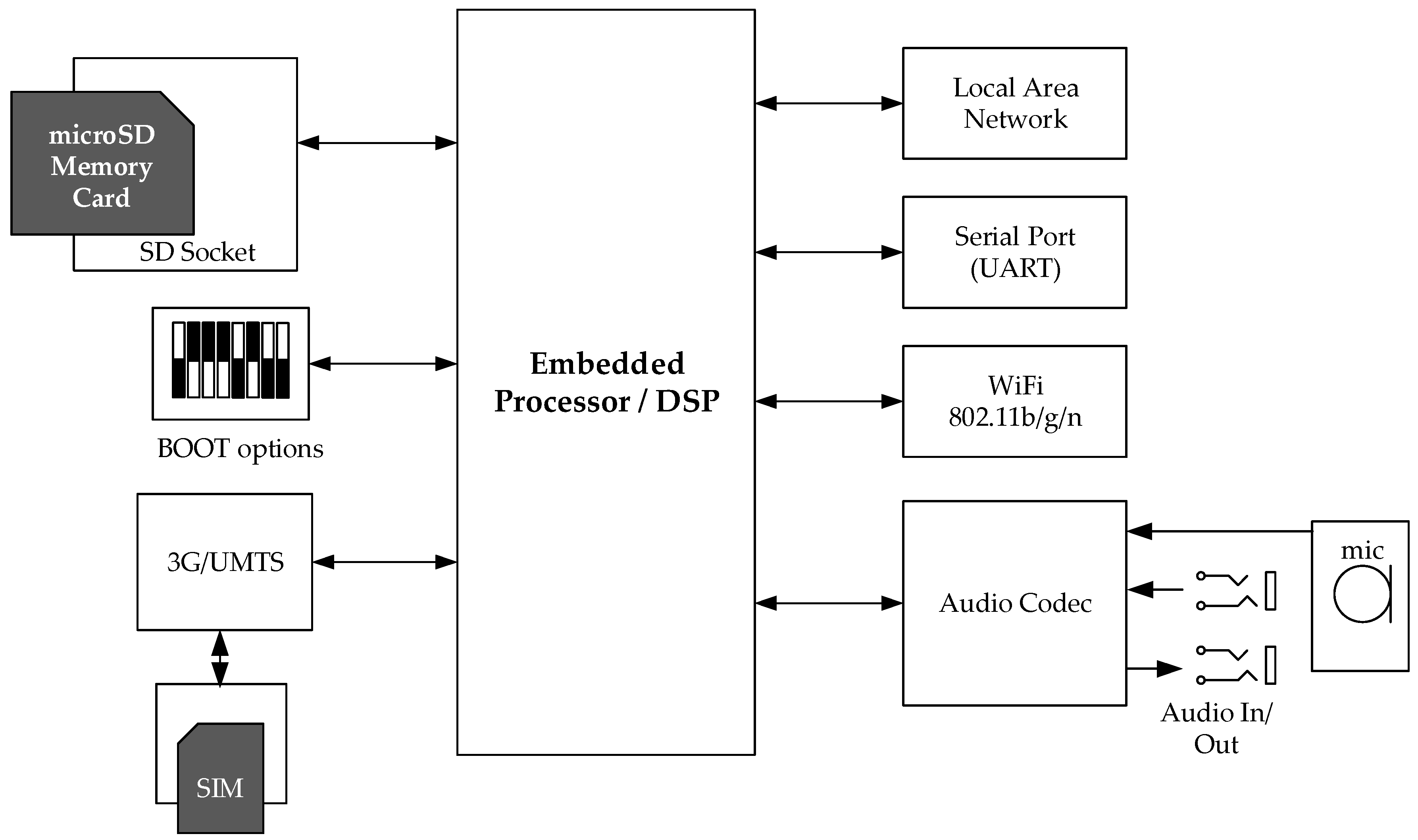
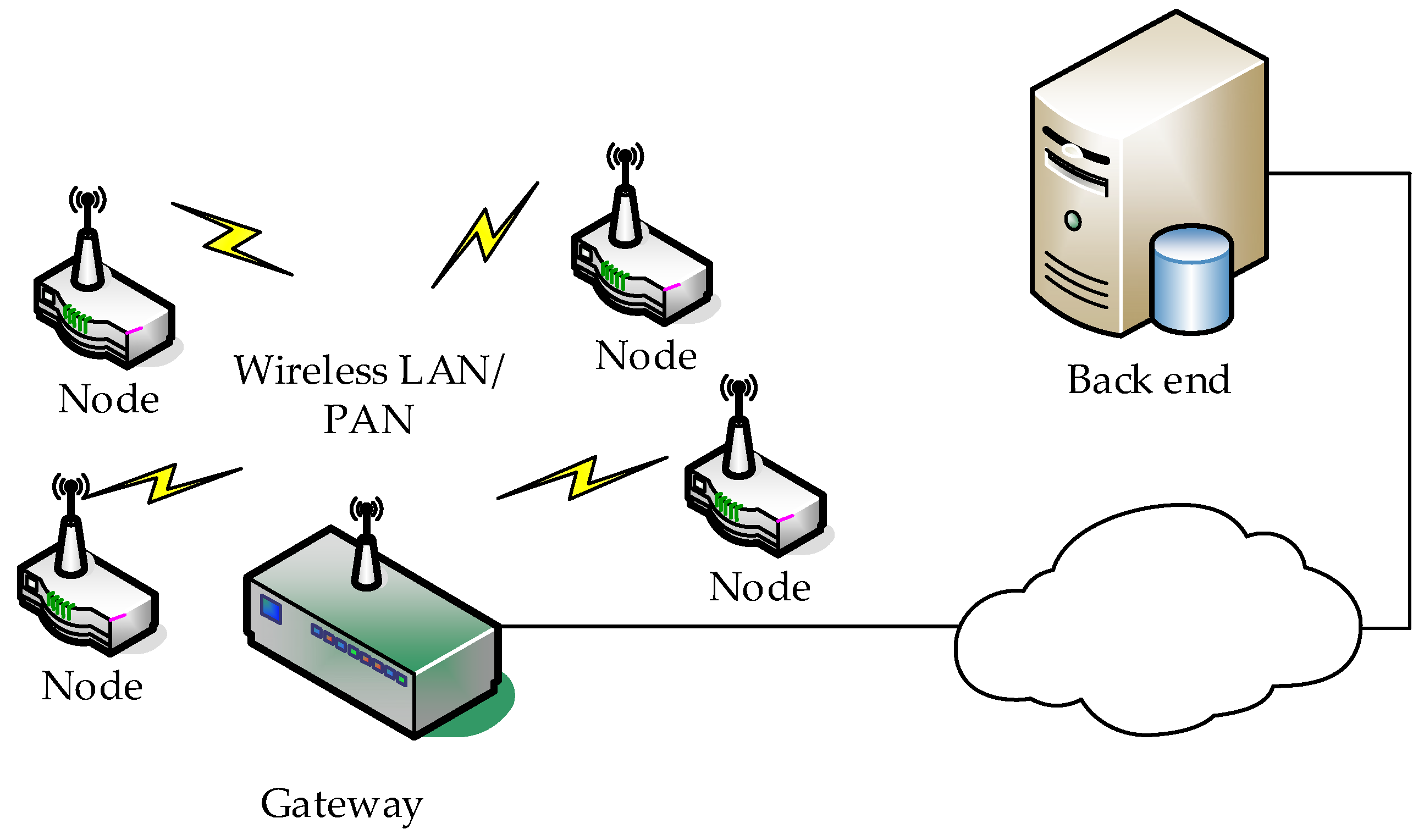
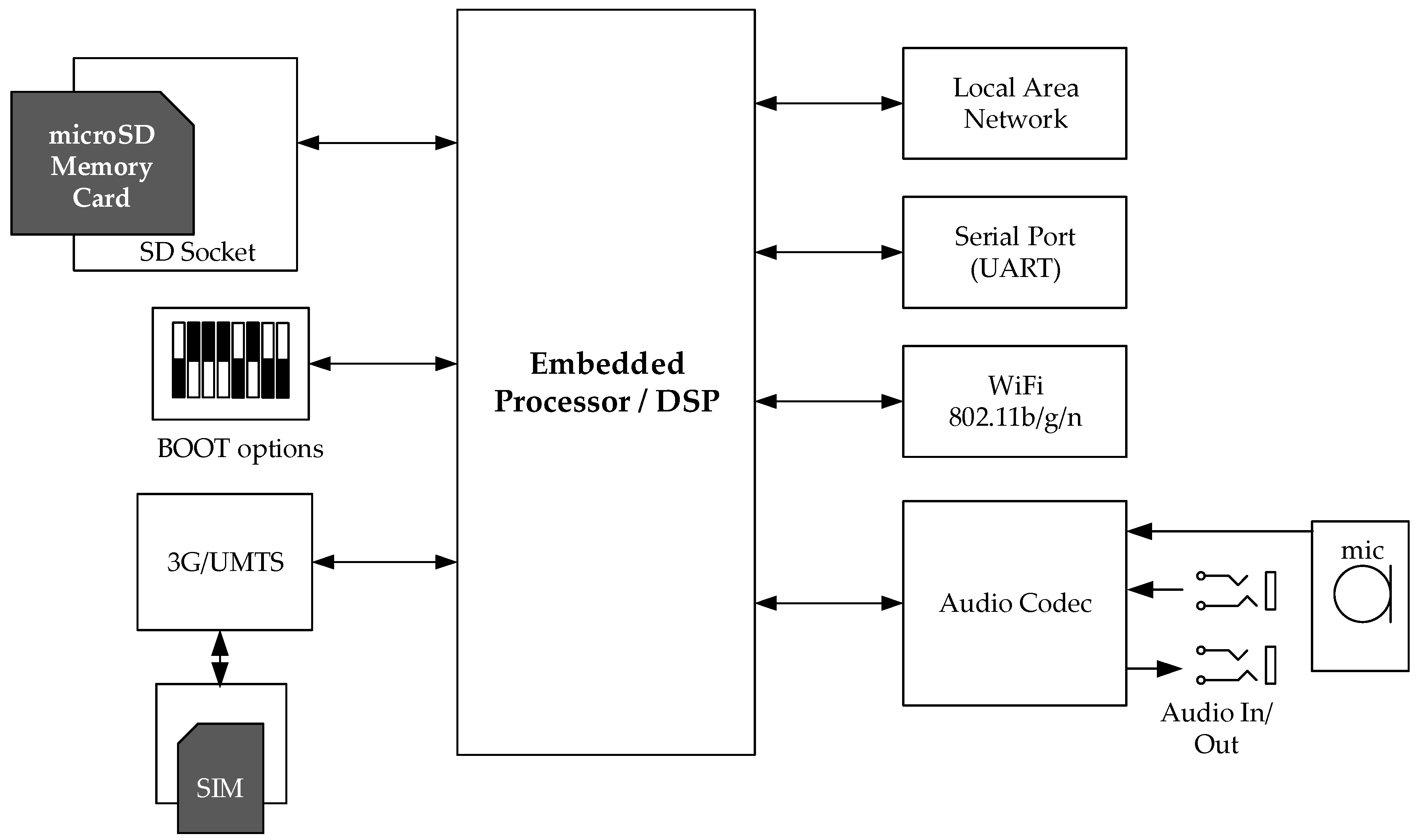
3.1. Wireless Acoustic Sensor Networks
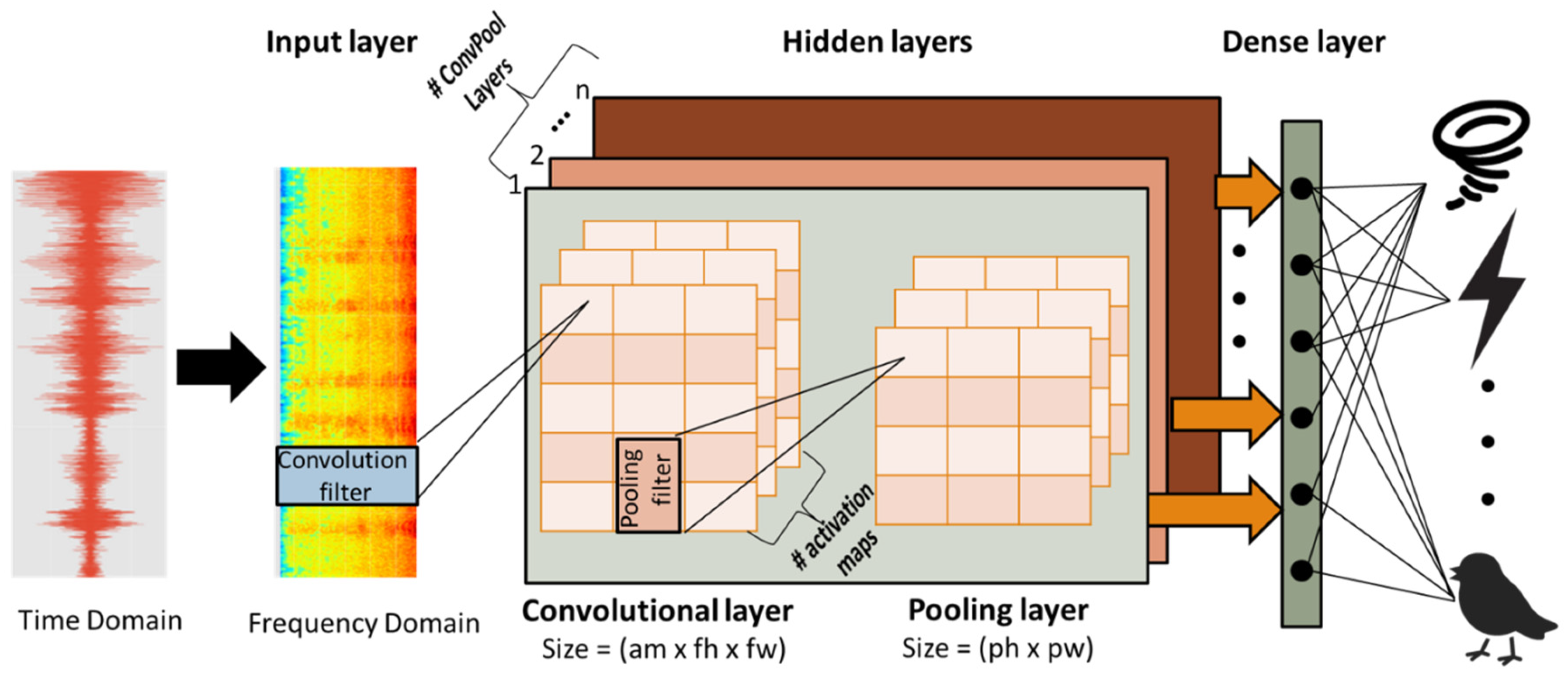
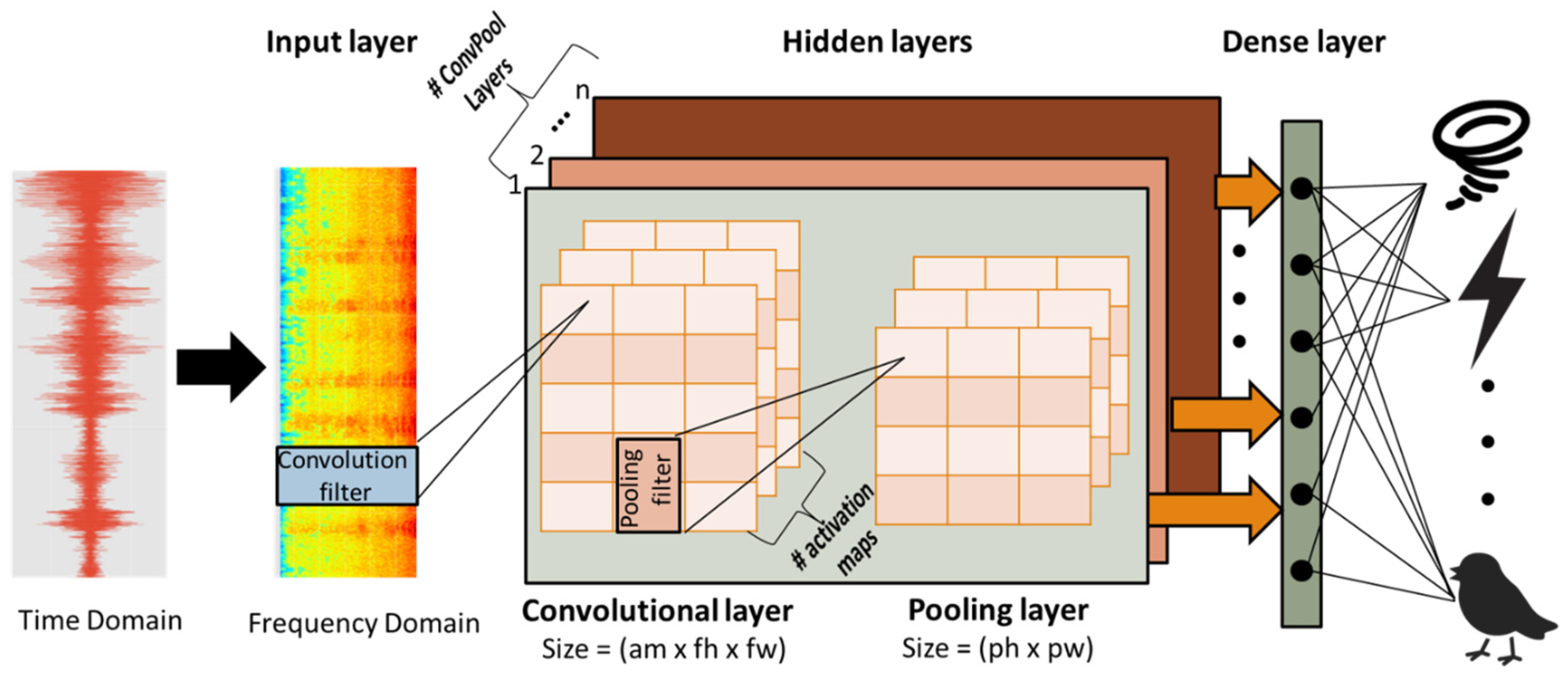
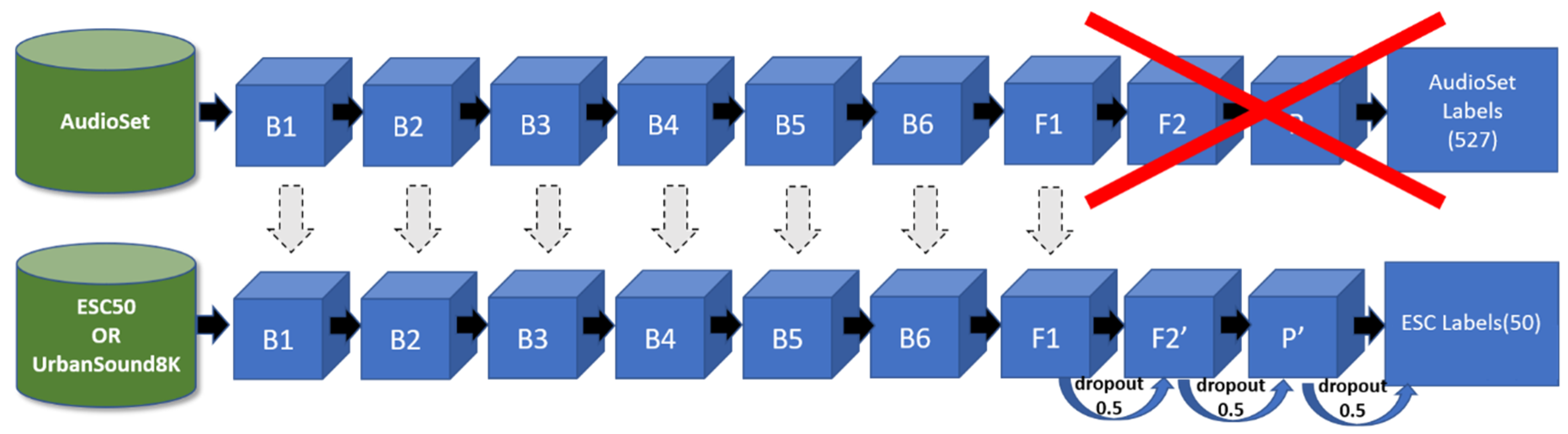
3.2. Deep Learning Model Architecture
- B1: 16 convolutional filters with a size of (3, 3), i.e., W1 has shape (3, 3, 1, 16). This is followed by batch normalization and a ReLU activation function. The output is convolved with another 16 convolutional filters with a size of (3, 3), i.e., W 2 has shape (3, 3, 16, 16). This is followed by batch normalization and a ReLU activation function, and a (2, 2) strided max-pooling operation.
- B2: 32 convolutional filters with a size of (3, 3), i.e., W3 has shape (3, 3, 16, 32). This is followed by batch normalization and a ReLU activation function. The output is convolved with another 32 convolutional filters with a size of (3, 3), i.e., W 4 has shape (3, 3, 32, 32). This is followed by batch normalization and a ReLU activation function, and a (2, 2) strided max-pooling operation.
- B3: 64 convolutional filters with a size of (3, 3), i.e., W5 has shape (3, 3, 32, 64). This is followed by batch normalization and a ReLU activation function. The output is convolved with another 64 convolutional filters with a size of (3, 3), i.e., W 6 has shape (3, 3, 64, 64). This is followed by batch normalization and a ReLU activation function, and a (2, 2) strided max-pooling operation.
- B4: 128 convolutional filters with a size of (3, 3), i.e., W7 has shape (3, 3, 64, 128). This is followed by batch normalization and a ReLU activation function. The output is convolved with another 128 convolutional filters with a size of (3,3), i.e., W 8 has shape (3, 3, 128, 128). This is followed by batch normalization and a ReLU activation function, and a (2, 2) strided max-pooling operation.
- B5: 256 convolutional filters with a size of (3, 3), i.e., W9 has shape (3, 3, 128, 256). This is followed by batch normalization and a ReLU activation function. The output is convolved with another 256 convolutional filters with a size of (3, 3), i.e., W 10 has shape (3, 3, 256, 256). This is followed by batch normalization and a ReLU activation function, and a (2, 2) strided max-pooling operation.
- B6: 512 convolutional filters with a size of (3, 3), i.e., W11 has shape (3, 3, 256, 512). This is followed by batch normalization and a ReLU activation function, and a (2, 2) strided max-pooling operation.
- F1: 1024 convolutional filters with a size of (3, 3), i.e., W12 has shape (3, 3, 512, 1024). This is followed by batch normalization and a ReLU activation function.
- F2: 527 convolutional filters with a size of (3, 3), i.e., W13 has shape (3, 3, 1024, 527). This is followed by batch normalization and a sigmoid activation function.
- P: a global average pooling function that has as input a tensor of shape (527, 10, 1) and as output a matrix of shape (527, 1). As a result, it averages the segments (~1 sec).
- output: 527 hidden units, i.e., W has the shape (527, 527), followed by a softmax activation function.
- F2’: 256 convolutional filters with a size of (3, 3), i.e., W13 has shape (3, 3, 1024, 256). This is followed by batch normalization and a sigmoid activation function.
- P’: a global max pooling function that has as input a tensor of shape (256, number of segments, 1) and as output a matrix of shape (256, 1).
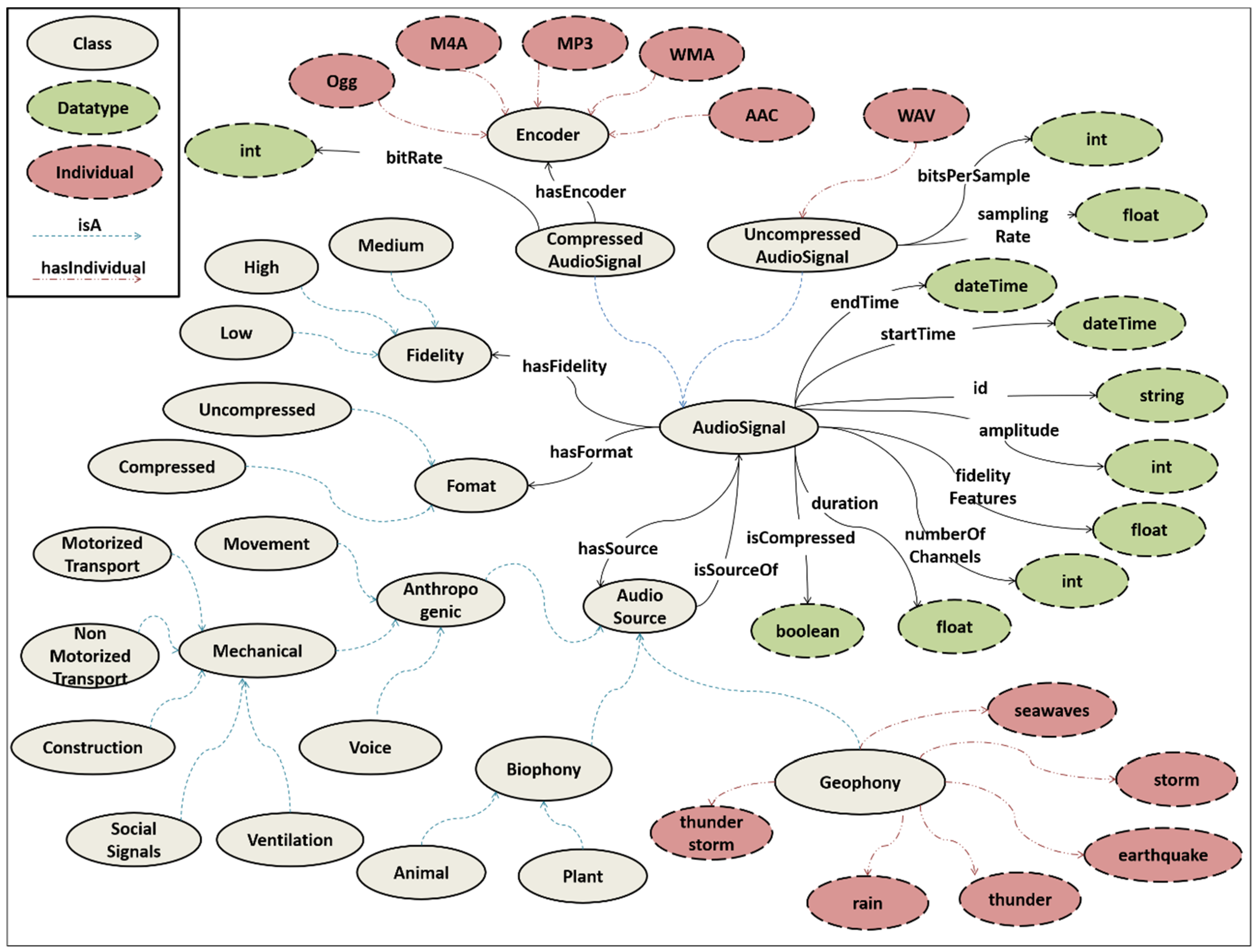
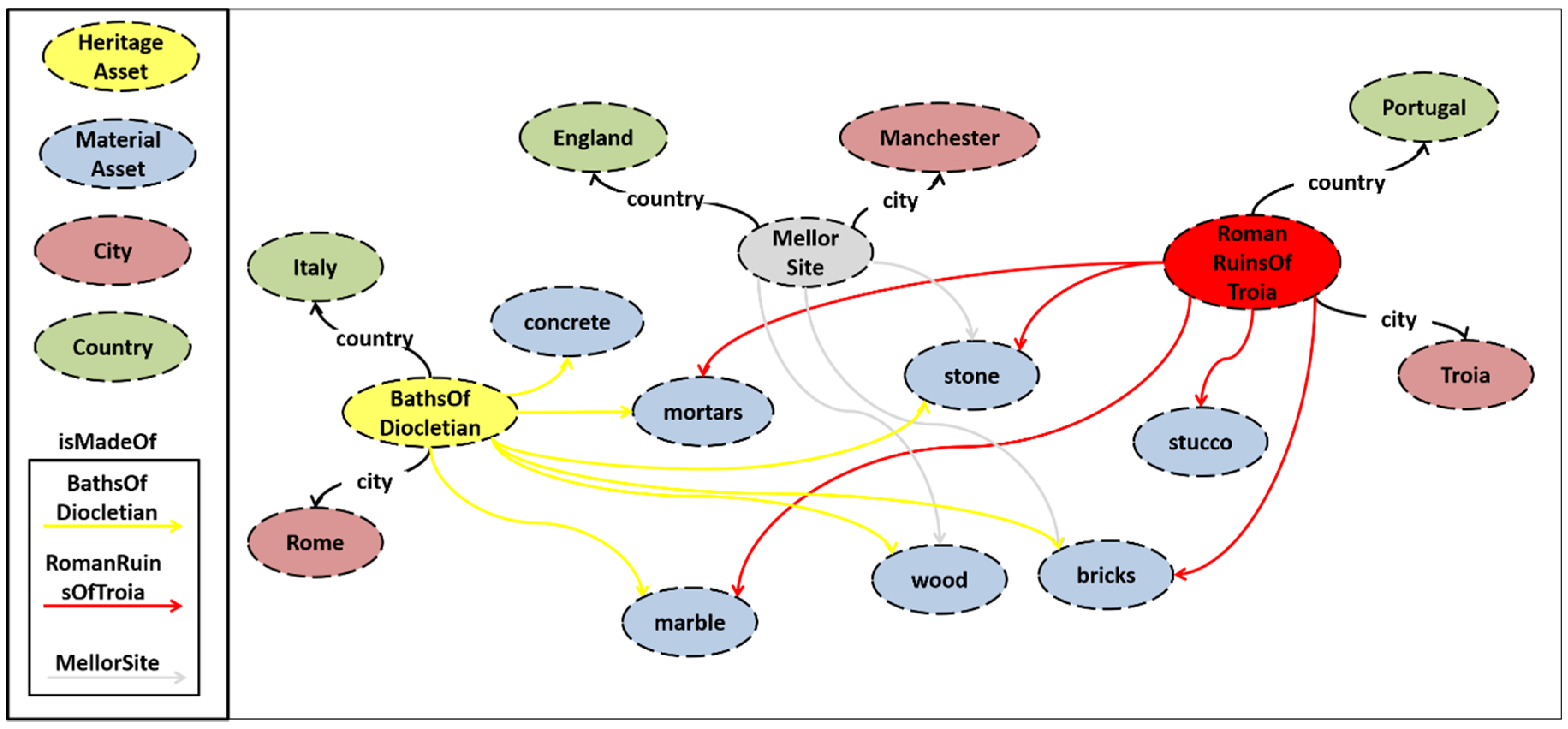
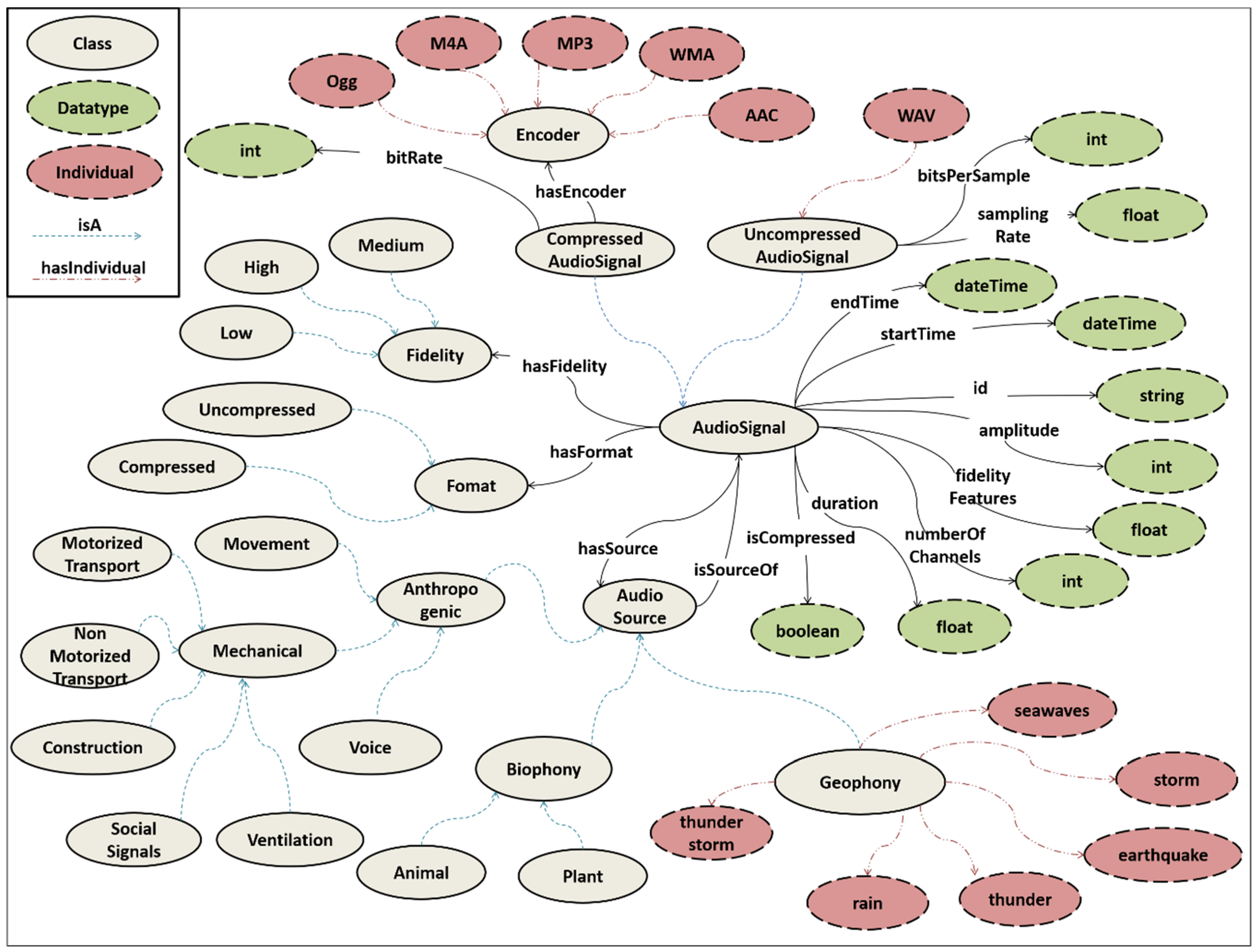
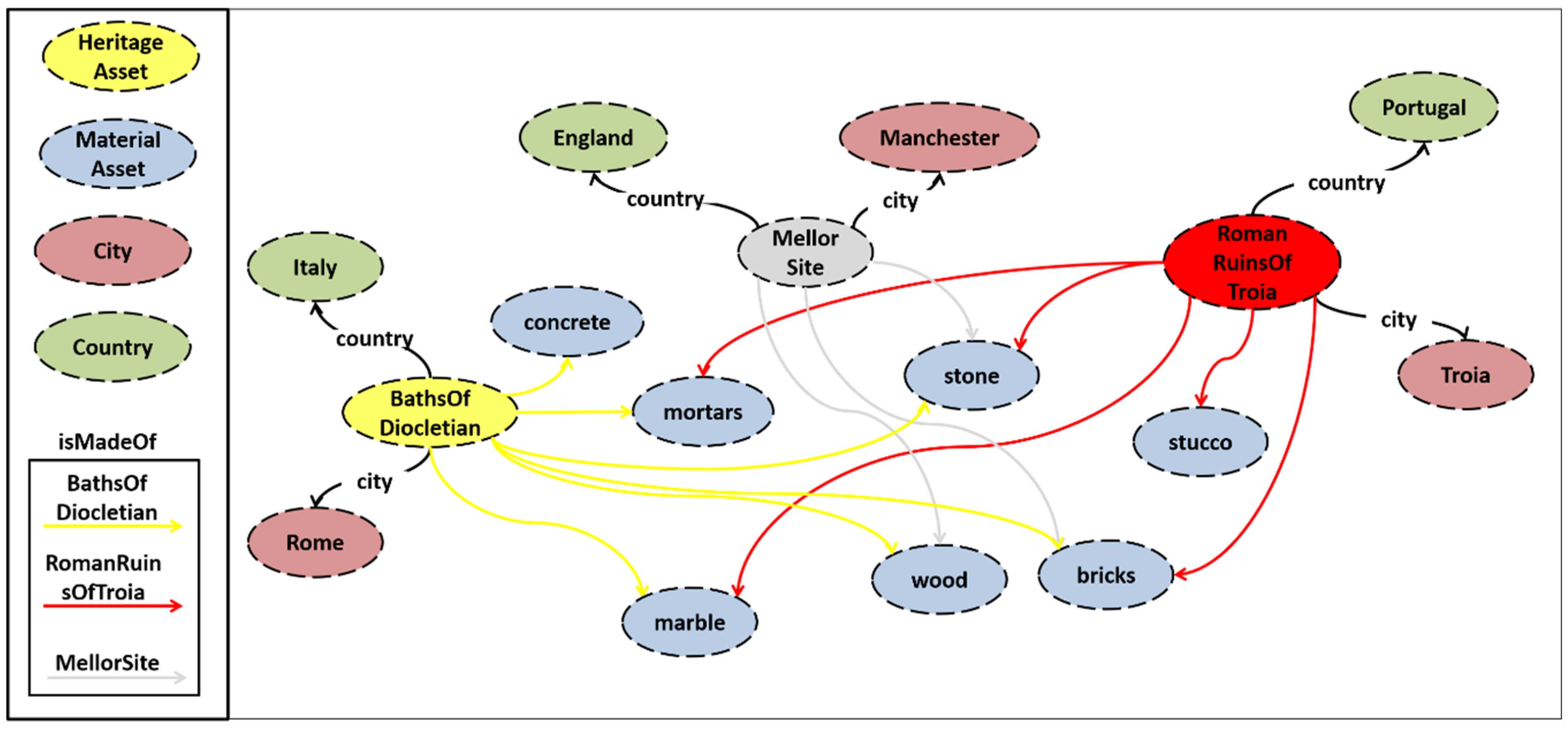
3.3. STORM Audio Ontology for Event Generation
4. Results and Discussion
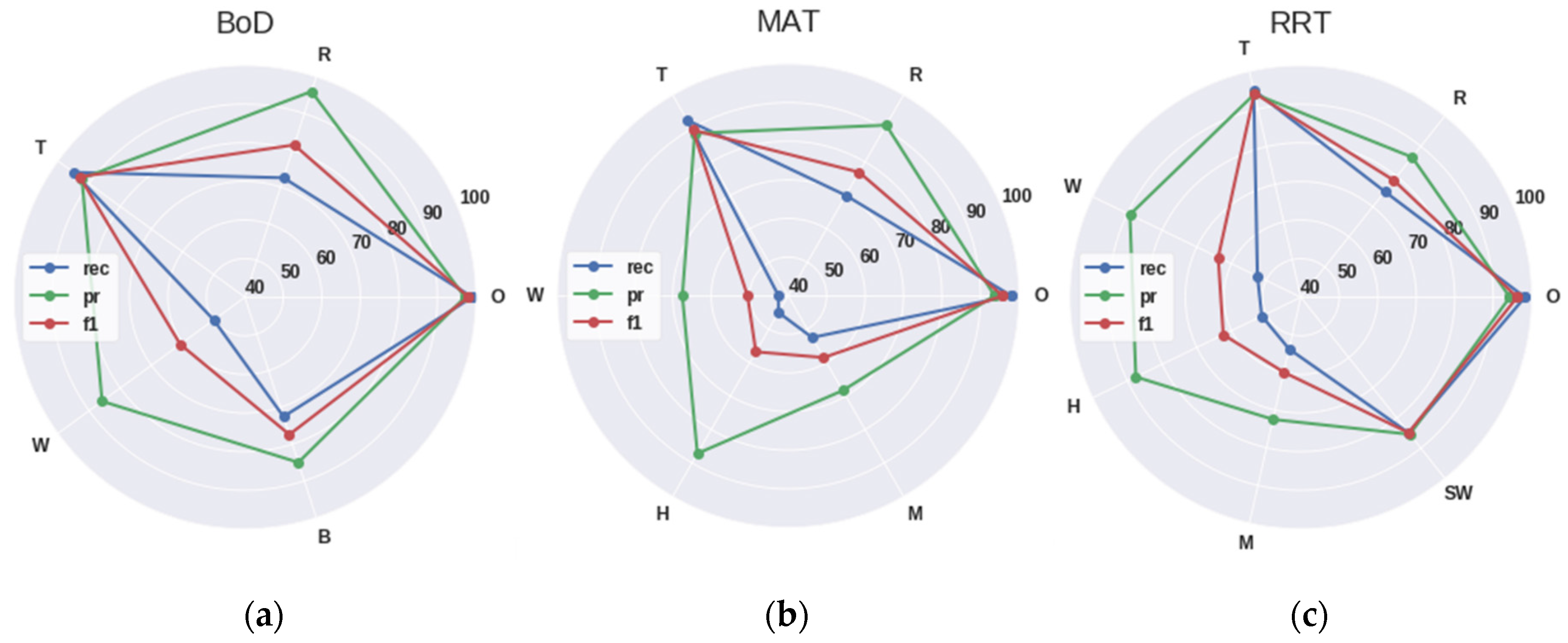
4.1. Experimental Sites
- Baths of Diocletian (BOD),
- Roman Ruins of Tróia (RRT), and
- Mellor Archaeological Trust (MAT).
- RRT site is located on a peninsula in Portugal, and as a result its stakeholders need to be aware of large sea waves,
- The MAT site is located on the edge of Stockport in Greater Manchester, which is a rural area and its stakeholders need to be aware of the potential for vandalism events, and
- BOD site, in contrast with the other two sites, is located in a crowded area (in the city of Rome), near the main train station. As a result, anthropogenic sounds are very common (i.e., not classified as abnormal activity), even in the middle of the night, and do not necessarily raise any suspicion.
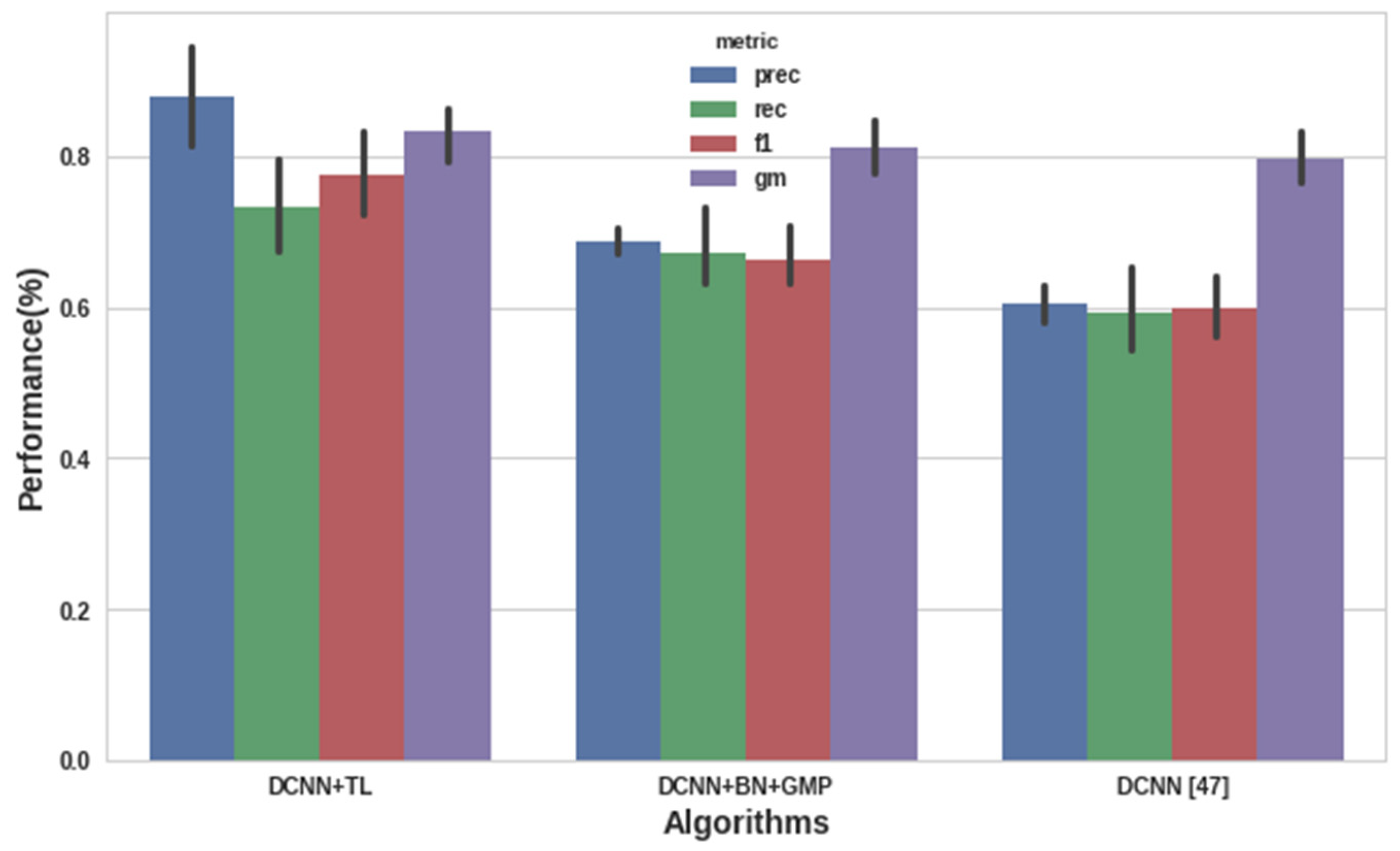
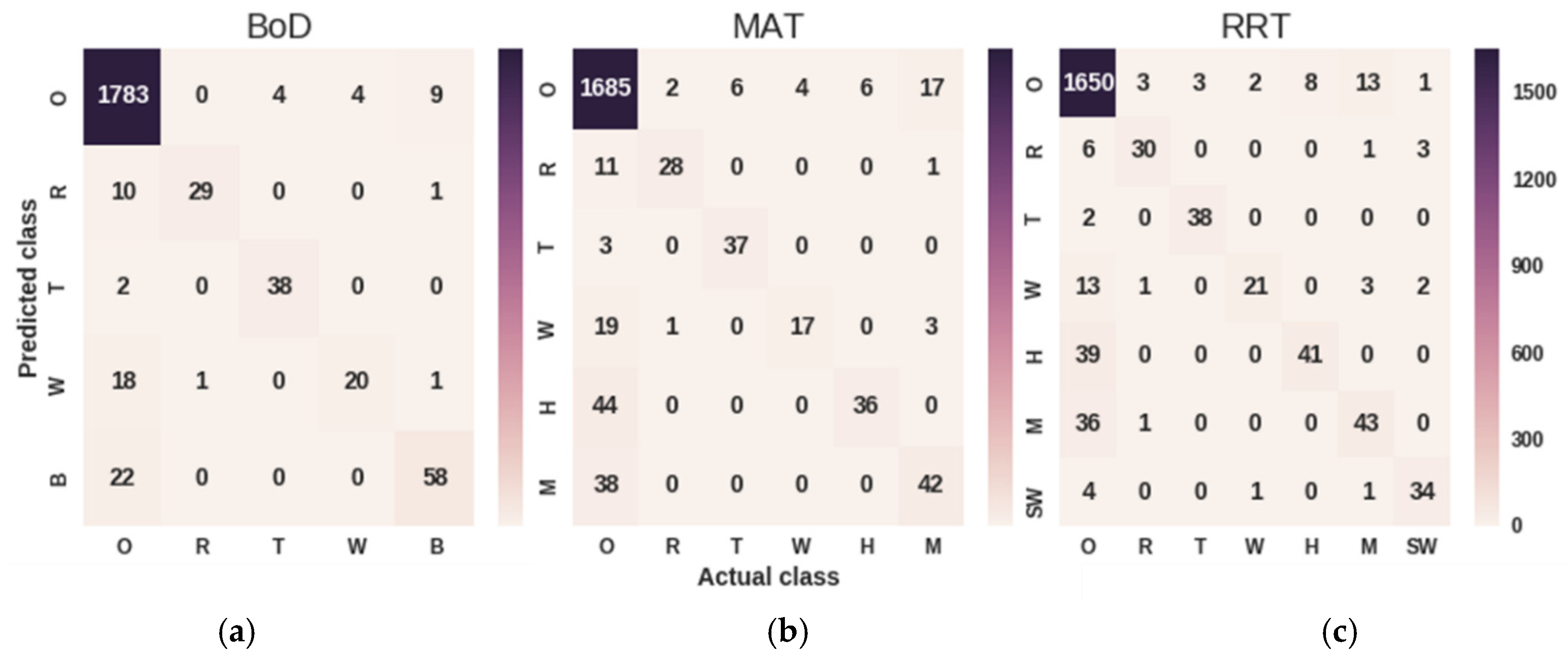
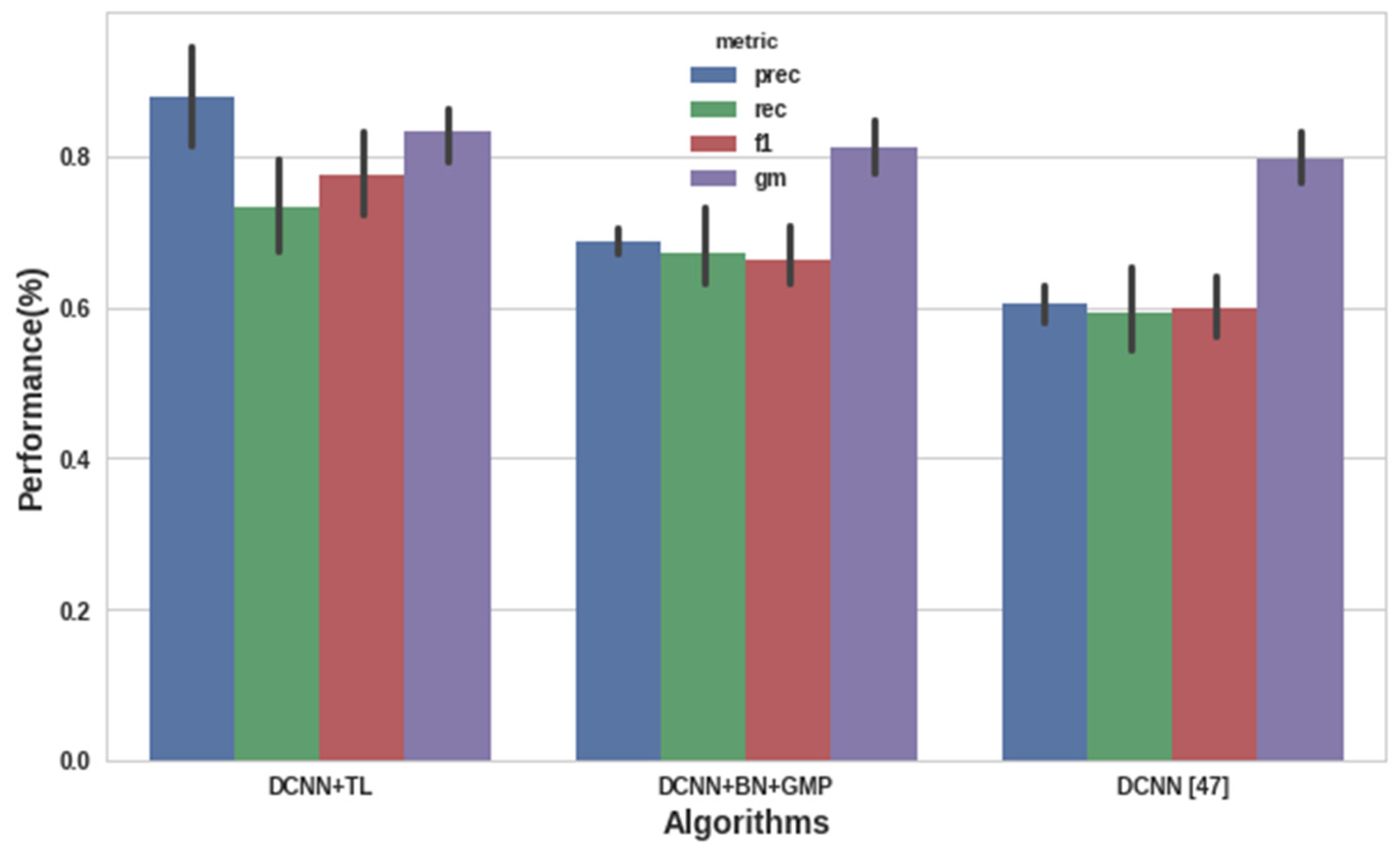
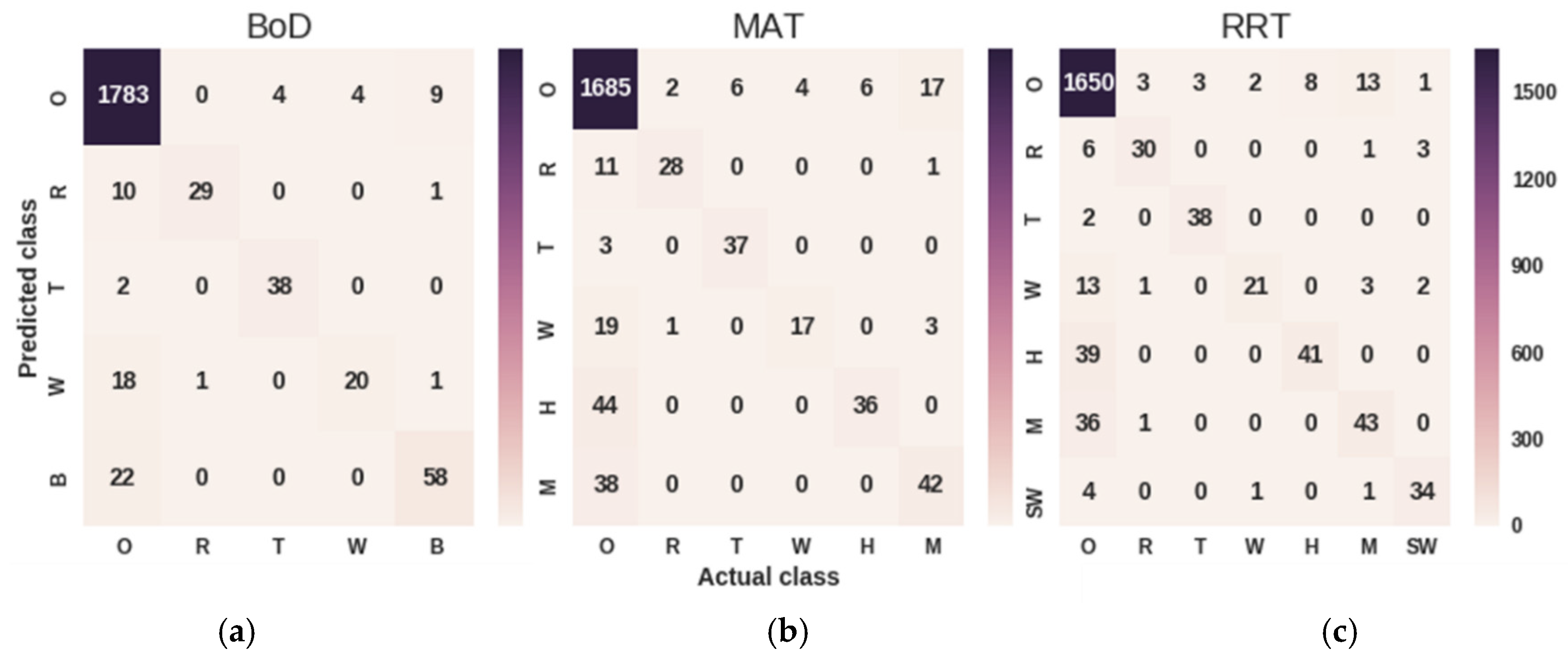
4.2. Datasets and Experimental Results of Deep ConvNet
4.4. STORM Audio -Based Semsantic Rules
5. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Towards an integrated approach to Cultural Heritage for Europe, European Commission. 2015. Available online: http://www.europarl.europa.eu/sides/getDoc.do?type=REPORT&reference=A8-2015-0207& language=EN (accessed on 21 February 2019).
- InHERIT: Promoting Cultural Heritage as a Generator of Sustainable Development, European Research Project. Available online: http://www.inherit.tuc.gr/en/home/ (accessed on 21 February 2019).
- Mergos, G.; Patsavos, N. Cultural Heritage as Economic Value: Economic Benefits, Social Opportunities and Challenges of Cultural Heritage for Sustainable Development, Report of the InHERIT European Research Project. 2017. Available online: http://www.inherit.tuc.gr/fileadmin/users_data/inherit/_uploads/%CE%9F2_Book_of_Best_Practices-f.pdf (accessed on 21 February 2019).
- European Union. Directive 2002/49/EC of the European Parliament and of the Council: relating to the assessment and management of environmental noise. Off. J. Eur. Commun. 2002, 189, 12–25. [Google Scholar]
- Kasten, E.P.; Gage, S.H.; Fox, J.; Joo, W. The remote environmental assessment laboratory’s acoustic library: An archive for studying soundscape ecology. Ecol. Inform. 2012, 12, 50–67. [Google Scholar] [CrossRef]
- Briggs, F.; Huang, Y.; Raich, R.; Eftaxias, K.; Lei, Z.; Cukierski, W.; Hadley, S.F.; Betts, M.; Fern, X.Z.; Irvine, J.; et al. The 9th annual MLSP competition: new methods for acoustic classification of multiple simultaneous bird species in a noisy environment. In Proceedings of the 2013 IEEE International Workshop on Machine Learning for Signal Processing, Southampton, UK, 22–25 September 2013; pp. 1–8. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. In Proceedings of the Neural Information Processing Systems, Lake Tahoe, Nevada, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Graves, A.; Mohamed, A.; Hinton, G.E. Speech recognition with deep recurrent neural networks. In Proceedings of the ICASSP 2013, Vancouver, Canada, 26–31 May 2013. [Google Scholar]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.Y.; Potts, C. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1631–1642. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G.E. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Kasnesis, P.; Patrikakis, C.Z.; Venieris, I.S. Changing the Game of Mobile Data Analysis with Deep Learning. IEEE IT Prof. Mag. 2017, 19, 17–23. [Google Scholar] [CrossRef]
- Hannun, A.Y.; Rajpurkar, P.; Haghpanahi, M.; Tison, G.H.; Bourn, C.; Turakhia, M.P.; Ng, A.Y. Cardiologist-level arrhythmia detection and classification in ambulatory electrocardiograms using a deep neural network. Nature 2019, 25, 65–69. [Google Scholar]
- STORM: Safeguarding Cultural Heritage through Technical and Organisational Resources Management, European Union’s H2020 Project. Available online: http://www.storm-project.eu/ (accessed on 20 February 2019).
- Kasnesis, P.; Kogias, D.G.; Toumanidis, L.; Xevgenis, M.G.; Patrikakis, C.Z.; Giunta, G.; Li Calsi, G. An IoE Architecture for the Preservation of the Cultural Heritage: The STORM Use Case. In Harnessing the Internet of Everything (IoE) for Accelerated Innovation Opportunities; IGI Global: Hershey, PA, USA, 2019; pp. 193–214. [Google Scholar]
- Rawat, P.; Singh, K.D.; Chaouchi, H.; Bonnin, J.M. Wireless sensor networks: A survey on recent developments and potential synergies. J. Supercomput. 2014, 68, 1–48. [Google Scholar] [CrossRef]
- Panatik, K.; Kamardin, K.; Shariff, S.; Yuhaniz, S.; Ahmad, N.; Yusop, O.; Ismail, S. Energy harvesting in wireless sensor networks: A survey. In Proceedings of the 2016 IEEE 3rd International Symposium on Telecommunication Technologies, Kuala Lumpur, Malaysia, 28–30 November 2016; pp. 53–58. [Google Scholar]
- Larmo, A.; Ratilainen, A.; Saarinen, J. Impact of CoAP and MQTT on NB-IoT System Performance. Sensors 2019, 19, 7. [Google Scholar] [CrossRef]
- Rodríguez-Pérez, N.; Caballero-Gil, P.; Toledo-Castro, J.; Santos-González, I.; Hernández-Goya, C. Monitoring Environmental Conditions in Airports with Wireless Sensor Networks. Proceedings 2018, 2, 1260. [Google Scholar] [CrossRef]
- Ali, A.; Ming, Y.; Chakraborty, S.; Iram, S. A Comprehensive Survey on Real-Time Applications of WSN. Future Internet 2017, 9, 77. [Google Scholar] [CrossRef]
- Dasios, A.; Gavalas, D.; Pantziou, D.; Konstantopoulos, C. Wireless sensor network deployment for remote elderly care monitoring. In Proceedings of the 8th ACM International Conference on PErvasive Technologies Related to Assistive Environments, Corfu, Greece, 1–3 July 2015. [Google Scholar] [CrossRef]
- Segura Garcia, J.; Pérez Solano, J.J.; Cobos Serrano, M.; Navarro Camba, E.A.; Felici Castell, S.; Soriano Asensi, A.; Montes Suay, F. Spatial Statistical Analysis of Urban Noise Data from a WASN Gathered by an IoT System: Application to a Small City. Appl. Sci. 2016, 6, 380. [Google Scholar] [CrossRef]
- Paulo, J.; Fazenda, P.; Oliveira, T.; Carvalho, C.; Felix, M. Framework to Monitor Sound Events in the City Supported by the FIWARE platform. In Proceedings of the 46th Congreso Español de Acústica, Valencia, Spain, 21–23 October 2015; pp. 21–23. [Google Scholar]
- Quintana-Suárez, M.A.; Sánchez-Rodríguez, D.; Alonso-González, I.; Alonso-Hernández, J.B. A Low Cost Wireless Acoustic Sensor for Ambient Assisted Living Systems. Appl. Sci. 2017, 7, 877. [Google Scholar] [CrossRef]
- Luque, A.; Romero-Lemos, J.; Carrasco, A.; Barbancho, J. Improving Classification Algorithms by Considering Score Series in Wireless Acoustic Sensor Networks. Sensors 2018, 18, 2465. [Google Scholar] [CrossRef]
- Bertrand, A. Applications and trends in wireless acoustic sensor networks: A signal processing perspective. In Proceedings of the 18th IEEE Symposium on Communications and Vehicular Technology in the Benelux (SCVT), Ghent, Belgium, 22–23 November 2011. [Google Scholar]
- Potirakis, S.M.; Nefzi, B.; Tatlas, N.-A.; Tuna, G.; Rangoussi, M. Design Considerations for an Environmental Monitoring Wireless Acoustic Sensor Network. Sens. Lett. 2015, 13, 549–555. [Google Scholar] [CrossRef]
- Tatlas, N.-A.; Potirakis, S.M.; Mitilineos, S.A.; Rangoussi, M. On the effect of compression on the complexity characteristics of WASN signals. Signal Process. 2015, 107, 153–163. [Google Scholar] [CrossRef]
- Despotopoulos, S.; Kyriakis-Bitzaros, E.; Liaperdos, I.; Nicolaidis, D.; Paraskevas, I.; Potirakis, S.M.; Rangoussi, M.; Tatlas, N.-A. Pattern recognition for the development of Sound Maps for environmentally sensitive areas. In Proceedings of the International Scientific Conference eRA-7, Athens, Greece, 27–30 September 2012; pp. 27–30. [Google Scholar]
- Paraskevas, I.; Potirakis, S.M.; Rangoussi, M. Natural soundscapes and identification of environmental sounds: A pattern recognition approach. In Proceedings of the 16th International Conference on Digital Signal Processing, Santorini-Hellas, Greece, 5–7 July 2009; pp. 473–478. [Google Scholar]
- Ghoraani, B.; Krishnan, S. Time-frequency matrix feature extraction and classification of environmental audio signals. IEEE Trans. Audiospeech Lang. Process. 2011, 19, 2197–2209. [Google Scholar] [CrossRef]
- Mesgarani, N.; Slaney, M.; Shamma, S. Discrimination of speech from nonspeech based on multiscale spectro-temporal modulations. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 920–930. [Google Scholar] [CrossRef]
- Scheirer, E.; Slaney, M. Construction and evaluation of a robust multi-feature speech/music discriminator. In Proceedings of the 1997 IEEE International Conference on Acoustics, Speech, and Signal Processing, Munich, Germany, 21–24 April 1997. [Google Scholar]
- Chu, S.; Narayanan, S.; Kuo, C.-C.J. Environmental sound recognition with time-frequency audio features. IEEE Trans. Audio Speech Lang. Process. 2009, 17, 1142–1158. [Google Scholar] [CrossRef]
- Hayashi, H.; Shibanoki, T.; Shima, K.; Kurita, Y.; Tsuji, T. A recurrent probabilistic neural network with dimensionality reduction based on time-series discriminant component analysis. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 3021–3033. [Google Scholar] [CrossRef]
- Eronen, A.J.; Peltonen, V.T.; Tuomi, J.T.; Klapuri, A.P.; Fagerlund, S.; Sorsa, T.; Lorho, G.; Huopaniemi, J. Audio-based context recognition. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 321–329. [Google Scholar] [CrossRef]
- Aucouturier, J.J.; Defreville, B.; Pachet, F. The bag-of-frames approach to audio pattern recognition: A sufficient model for urban soundscapes but not for polyphonic music. J. Acoust. Soc. Am. 2007, 122, 881–891. [Google Scholar] [CrossRef] [PubMed]
- Ntalampiras, S.; Potamitis, I.; Fakotakis, N. Acoustic detection of human activities in natural environments. J. Audio Eng. Soc. 2012, 60, 1–10. [Google Scholar]
- Hershey, S.; Chaudhuri, S.; Ellis, D.P.; Gemmeke, J.F.; Jansen, A.; Moore, R.C.; Plakal, M.; Platt, D.; Saurous, R.A.; Seybold, B.; et al. 2017CNN Architectures for Large-Scale Audio Classification. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 131–135. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Chapter 9: Convolutional networks. In Deep Learning (Adaptive Computation and Machine Learning Series); MIT Press: Cambridge, MA, USA, 2016; pp. 330–372. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. arXiv, 2015; arXiv:1512.00567. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- AudioSet: A Large-Scale Dataset of Manually Annotated Audio Events. Available online: https://research.google.com/audioset/ (accessed on 21 February 2019).
- UrbanSound8K: Urban Sound Datasets. Available online: https://serv.cusp.nyu.edu/projects/urbansounddataset/urbansound8k.html (accessed on 21 February 2019).
- Salamon, J.; Bello, J.P. Unsupervised feature learning for urban sound classification. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, QLD, Australia, 19–24 April 2015. [Google Scholar]
- Coates, A.; Ng, A.Y. Learning feature representations with K-means. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 561–580. [Google Scholar]
- Piczak, K.J. Environmental sound classification with convolutional neural networks. In Proceedings of the 25th International Workshop on Machine Learning for Signal Processing (MLSP), Boston, MA, USA, 17–20 September 2015; pp. 1–6. [Google Scholar]
- Kumar, A.; Raj, B. Deep CNN Framework for Audio Event Recognition using Weakly Labeled Web Data. In Proceedings of the NIPS Workshop on Machine Learning for Audio Signal Processing, Long Beach, CA, USA, 8 December 2017. [Google Scholar]
- Piczak, K.J. ESC: Dataset for Environmental Sound Classification. In Proceedings of the ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 1015–1018. [Google Scholar]
- Salamon, J.; Bello, J.P. Deep Convolutional Neural Networks and Data Augmentation for Environmental Sound Classification. IEEE Signal Process. Lett. 2017, 24, 279–283. [Google Scholar] [CrossRef]
- Kumar, A.; Khadkevich, M.; Fugen, C. Knowledge Transfer from Weakly Labeled Audio using Convolutional Neural Network for Sound Events and Scenes. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 326–330. [Google Scholar]
- Aran djelović, R.; Zisserman, A. Look, Listen and Learn. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 609–617. [Google Scholar]
- Mousheimish, R.; Taher, Y.; Zeitouni, K.; Dubus, M. PACT-ART: Enrichment, Data Mining, and Complex Event Processing in the Internet of Cultural Things. In Proceedings of the 2016 12th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), Naples, Italy, 28 November–1 December 2016. [Google Scholar]
- Gruber, T.R. Toward Principles for the Design of Ontologies Used for Knowledge Sharing. Int. J. Hum.-Comput. Stud. 1993, 43, 907–928. [Google Scholar] [CrossRef]
- Audio Features Ontology Specification. Available online: http://motools.sourceforge.net/doc/audio_features.html (accessed on 21 February 2019).
- Wilmering, T.; Fazekas, G.; Sandler, M.B. The Audio Effects Ontology. In Proceedings of the International Society for Music Information Retrieval (ISMIR), Curitiba, Brazil, 4–8 November 2013; pp. 215–220. [Google Scholar]
- Gemmeke, J.F.; Ellis, D.P.W.; Freedman, D.; Jansen, A.; Lawrence, W.; Moore, R.C.; Plakal, M.; Ritter, M. Audio set: An ontology and human-labeled dataset for audio events. In Proceedings of the IEEE International Conference on Acoustics Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017. [Google Scholar]
- Russell, S.; Norvig, P. Knowledge Representation. In Artificial Intelligence: A Modern Approach, 3rd ed.; Prentice-Hall: Upper Saddle River, NJ, USA, 2010; pp. 437–479. [Google Scholar]
- Hatala, M.; Kalantari, L.; Wakkary, R.; Newby, K. Ontology and Rule Based Retrieval of Sound Objects in Augmented Audio Reality System for Museum Visitors. In Proceedings of the 2004 ACM Symposium on Applied Computing, Nicosia Cyprus, 14–17 March 2004; pp. 1045–1050. [Google Scholar]
- Nguyen, C.P.; Pham, N.Y.; Castelli, E. First Steps to an Audio Ontology-Based Classifier for Telemedicine. In Proceedings of the International Conference on Advanced Data Mining and Applications, Xi’an, China, 14–16 August 2006; pp. 845–855. [Google Scholar]
- Perperis, T.; Giannakopoulos, T.; Makris, A.; Kosmopoulos, D.I.; Tsekeridou, S.; Perantonis, S.J.; Theodoridis, S. Multimodal and ontology-based fusion approaches of audio and visual processing for violence detection in movies. Expert Syst. Appl. 2011, 38, 14102–14116. [Google Scholar] [CrossRef]
- OMAP-L132 C6000 DSP+ ARM Processor. Available online: http://ww.ti.com/lit/ds/symlink/omap-l132.pdf (accessed on 24 February 2019).
- Digital SiSonic Microphone. Available online: https://media.digikey.com/pdf/Data Sheets/Knowles Acoustics PDFs/SPV0840LR5H-B.pdf (accessed on 22 March 2019).
- CC3100MOD SimpleLink ™ Certified Wi-Fi Network Processor Internet-of-Things Module Solution for MCU Applications. Available online: http://www.ti.com/lit/ds/symlink/cc3100mod.pdf (accessed on 24 February 2019).
- LE910 Telit. Available online: https://www.telit.com/wp-content/uploads/2017/11/Telit_LE910-V2_Datasheet.pdf (accessed on 24 February 2019).
- GitHub Weak Feature Extractor Repository. Available online: https://github.com/anuragkr90/weak_feature_extractor (accessed on 20 February 2019).
- STORM Audio Signal Ontology. Available online: http://consert.puas.gr/ontologies/as-storm.owl (accessed on 20 February 2019).
- Salamon, J.; Jacoby, C.; Bello, J.P. A Dataset and Taxonomy for Urban Sound Research. In Proceedings of the 22nd ACM international conference on Multimedia, San Francisco, CA, USA, 27 October–1 November 2014; pp. 1041–1044. [Google Scholar]
- STORM Core Ontology. Available online: http://demo-storm.eng.it/ontologies/storm_core_ontology.owl (accessed on 20 February 2019).
- STORM Sensors Ontology. Available online: https://storm.inov.pt/ontologies/storm_sensors_ontology.owl (accessed on 20 February 2019).
- STORM Event Ontology. Available online: http://demo-storm.eng.it/ontologies/storm_event_ontology.owl (accessed on 20 February 2019).
- FOAF Ontology. Available online: http://xmlns.com/foaf/spec/ (accessed on 20 February 2019).
- Geo Ontology. Available online: http://www.w3.org/2003/01/geo/wgs84_pos (accessed on 20 February 2019).
- Freesound. Available online: http://freesound.org/ (accessed on 21 February 2019).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2014. [Google Scholar]
- Luque, A.; Carrasco, A.; Martín, A.; Heras, A. The impact of class imbalance in classification performance metrics based on the binary confusion matrix. Pattern Recognit. 2019, 91, 216–231. [Google Scholar] [CrossRef]
- Tharwat, A. Classification Assessment Methods. Appl. Comput. Inform. 2018. [Google Scholar] [CrossRef]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- JSON for Linking Data. Available online: https://json-ld.org/ (accessed on 21 February 2019).
- Hartig, O.; Bizer, C.; Freytag, J.C. Executing SPARQL Queries over the Web of Linked Data. In Proceedings of the International Semantic Web Conference (ISWC), Chantilly, VA, USA, 25–29 October 2009; pp. 293–309. [Google Scholar]
- Apache Kafka, Distributed streaming platform. Available online: https://kafka.apache.org/ (accessed on 21 February 2019).
- Apache Jena. Available online: https://jena.apache.org/ (accessed on 21 February 2019).
- DBpedia Ontology. Available online: http://mappings.dbpedia.org/server/ontology/classes/ (accessed on 21 February 2019).
- STORM Linked Open Data Endpoint. Available online: http://vm16.openstack.puas.gr/ (accessed on 20 February 2019).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | SubClass | Symbol | RRT | BOD | MAT |
|---|---|---|---|---|---|
| Geophony | Rain | R | Yes | Yes | Yes |
| Sea Waves | SW | Yes | No | No | |
| Thunderstorm | T | Yes | Yes | Yes | |
| Wind | W | Yes | Yes | Yes | |
| Biophony | Birds | B | No | Yes | No |
| Anthropogenic | Human | H | Yes | No | Yes |
| Mechanical | M | Yes | No | Yes |
| Method Name | ESC-50 |
|---|---|
| Deep CNN [47] | 64.5% |
| Deep CNN + Batch Normalization + Global Max Pooling | 73.15% |
| Random Forest [49] | 44.3% |
| Support Vector Machines (SVM) [49] | 39.6% |
| k-Nearest Neighbors (k-NN) [49] | 32.2% |
| Semi-supervised TL [52] | 79.3% |
| Human Performance [49] | 81.3% |
| Deep CNN TL | 81.65% |
| Layer | 1 | 2 | 3 | 4 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| type | C | BN/RL | MP | Dr | C | BN/RL | MP | Dr | C | BN/RL | GMP | Dr | D | S |
| filter | 5 × 5 | n/a | 4 × 4 | n/a | 5 × 5 | n/a | 2 × 2 | n/a | 5 × 5 | n/a | n/a | n/a | 128 × 50 | n/a |
| kernel size | 32 | n/a | n/a | n/a | 64 | n/a | n/a | n/a | 128 | n/a | n/a | n/a | n/a | n/a |
| prob | n/a | n/a | n/a | 0.25 | n/a | n/a | n/a | 0.25 | n/a | n/a | n/a | 0.5 | n/a | n/a |
| Data Format | Example |
|---|---|
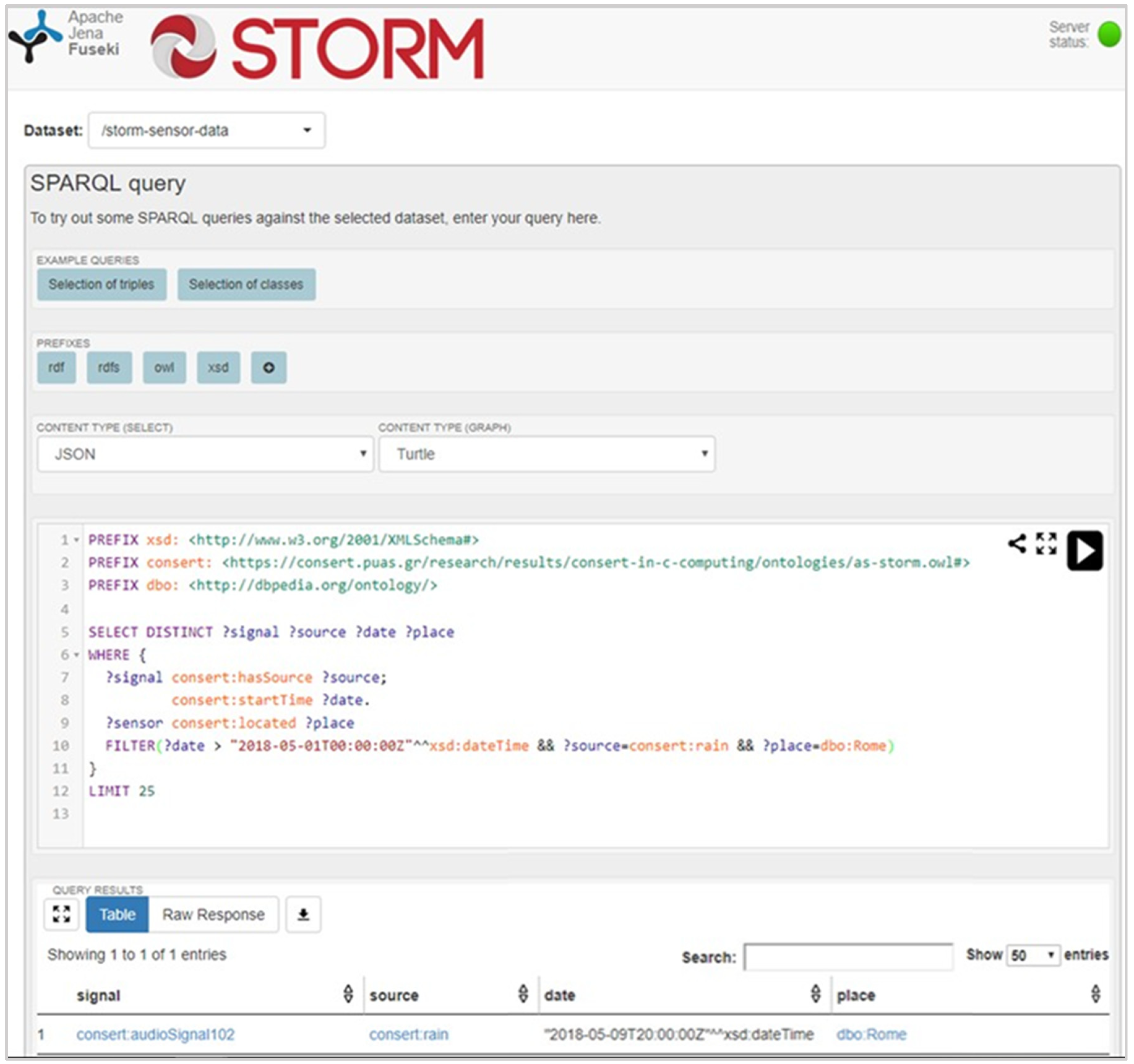
| JSON_LD | { "@context": { "audio": "https://consert.puas.gr/ontologies/as-storm.owl#", "xsd": "http://www.w3.org/2001/XMLSchema#", "sensor": "https://storm.inov.pt/ontologies/storm_sensors_ontology.owl#", "audio:hasSource": { "@type": "@id" }, "audio:produces": { "@type": "@id" }, "audio:startTime": { "@type": "xsd:dateTime" }, "audio:endTime": { "@type": "xsd:dateTime" } }, "@graph": [ { "@id": "audio:sensorBOD", "@type": "sensor:AcousticSensor", "audio:produces": "audio:audioSignal101", "audio:id": "59e9a3aee74cae04002b1a33" }, { "@id": "audio:audioSignal101", "@type": "audio:audioSignal", "audio:hasSource": "audio:thunderstorm", "audio:startTime": "2018-05-09T20:00:00Z", "audio:endTime": "2018-05-09T20:00:05Z" }, { "@id": "audio:thunderstorm", "@type": "audio:audioSource" } ] } |
| N-Triples | @prefix audio: <http://consert.puas.gr/ontologies/as-storm.owl#> @prefix core: <http://demo-storm.eng.it/ontologies/storm_core_ontology.owl#> @prefix event: <http://demo-storm.eng.it/ontologies/storm_event_ontology.owl#> @prefix sensor: <https://storm.inov.pt/ontologies/storm_sensors_ontology.owl> @prefix rdf: < http://www.w3.org/1999/02/22-rdf-syntax-ns# > @prefix xsd: < http://www.w3.org/2001/XMLSchema > <https://consert.puas.gr/ontologies/as-storm.owl#audioSignal101> rdf:type audio:audioSignal; audio:startTime "2018-05-09T20:00:00Z"^^<http://www.w3.org/2001/XMLSchema#dateTime>; audio:endTime "2018-05-09T20:00:05Z"^^<http://www.w3.org/2001/XMLSchema#dateTime>; audio:hasSource audio:thunderstorm. <https://consert.puas.gr/ontologies/as-storm.owl#sensorBOD> rdf:type sensor:AcousticSensor; audio:id "59e9a3aee74cae04002b1a33"; audio:produces audioSignal101. <https://consert.puas.gr/ontologies/as-storm.owl#thunderstorm> rdf:type audio:audioSource. |
| List of Prefixes | |
| audio: <http://consert.puas.gr/ontologies/as-storm.owl#> core: <http://demo-storm.eng.it/ontologies/storm_core_ontology.owl#> event: <http://demo-storm.eng.it/ontologies/storm_event_ontology.owl#> sensor: <https://storm.inov.pt/ontologies/storm_sensors_ontology.owl> rdf: < http://www.w3.org/1999/02/22-rdf-syntax-ns# > | |
| Rule Name | Description in Jena rules |
| strongWindsBOD | (?s rdf:type sensor:AcousticSensor) (?a rdf:type audio:AudioSignal) (?s sensor:hasData ?a) (?s core:placed core:BathsOfDiocletian) (?a audio:hasSource audio:wind) -> (?a core:initiate ?e) (?e event:hasCategory event:strongWinds) |
| strongWindsΜAΤ | (?s rdf:type sensor:AcousticSensor) (?a rdf:type audio:AudioSignal) (?s sensor:hasData ?a) (?s core:placed core:MellorSite) (?a audio:hasSource audio:wind) -> (?a core:initiate ?e) (?e event:hasCategory event:strongWinds) |
| strongWindsRRT | (?s rdf:type sensor:AcousticSensor) (?a rdf:type audio:AudioSignal) (?s sensor:hasData ?a) (?s core:placed core:RomanRuinsOfTroia) (?a audio:hasSource audio:wind) -> (?a core:initiate ?e) (?e event:hasCategory event:strongWinds) |
| highWavesRRT | (?s rdf:type sensor:AcousticSensor) (?a rdf:type audio:AudioSignal) (?s sensor:hasData ?a) (?s core:placed core:RomanRuinsOfTroia) (?a audio:hasSource audio:seawaves) -> (?a core:initiate ?e) (?e event:hasCategory event:highWaves) |
| thunderStormBOD | (?s rdf:type sensor:AcousticSensor) (?a rdf:type audio:AudioSignal) (?s sensor:hasData ?a) (?s core:placed core:BathsOfDiocletian) (?a audio:hasSource audio:thunderstorm) -> (?a core:initiate ?e) (?e event:hasCategory event:thunderStorm) |
| thunderStormMAT | (?s rdf:type sensor:AcousticSensor) (?a rdf:type audio:AudioSignal) (?s sensor:hasData ?a) (?s core:placed core:MellorSite) (?a audio:hasSource audio:thunderstorm) -> (?a core:initiate ?e) (?e event:hasCategory event:thunderStorm) |
| thunderStormRRT | (?s rdf:type sensor:AcousticSensor) (?a rdf:type audio:AudioSignal) (?s sensor:hasData ?a) (?s core:placed core:RomanRuinsOfTroia) (?a audio:hasSource audio:thunderstorm) -> (?a core:initiate ?e) (?e event:hasCategory event:thunderStorm) |
| intenseRainfallBOD | (?s rdf:type sensor:AcousticSensor) (?a rdf:type audio:AudioSignal) (?s sensor:hasData ?a) (?s core:placed core:BathsOfDiocletian) (?a audio:hasSource audio:rain) -> (?a core:initiate ?e) (?e event:hasCategory event:intenseRainfall) |
| intenseRainfallMAT | (?s rdf:type sensor:AcousticSensor) (?a rdf:type audio:AudioSignal) (?s sensor:hasData ?a) (?s core:placed core:MellorSite) (?a audio:hasSource audio:rain) -> (?a core:initiate ?e) (?e event:hasCategory event:intenseRainfall) |
| intenseRainfallRRT | (?s rdf:type sensor:AcousticSensor) (?a rdf:type audio:AudioSignal) (?s sensor:hasData ?a) (?s core:placed core:RomanRuinsOfTroia) (?a audio:hasSource audio:rain) -> (?a core:initiate ?e) (?e event:hasCategory event:intenseRainfall) |
| animalStampedeBOD | (?s rdf:type sensor:AcousticSensor) (?a rdf:type audio:AudioSignal) (?s sensor:hasData ?a) (?s core:placed core:BathsOfDiocletian) (?a audio:hasSource audio:bird) -> (?a core:initiate ?e) (?e event:hasCategory event:animalStampede) |
| possibleVandalismMAT | (?s rdf:type sensor:AcousticSensor) (?a rdf:type audio:AudioSignal) (?s sensor:hasData ?a) (?h rdf:type audio:Anthropogenic) (?s core:placed core:MellorSite) (?a audio:hasSource ?h) (?a audio:hour ?hst) lessThan(?hst, 7) greaterThan(?hst, 22) -> (?a core:initiate ?e) (?e event:hasCategory event:vandalism)] |
| possibleVandalismRRT | (?s rdf:type sensor:AcousticSensor) (?a rdf:type audio:AudioSignal) (?s sensor:hasData ?a) (?h rdf:type audio:Anthropogenic) (?s core:placed core:RomanRuinsOfTroia) (?a audio:hasSource ?h) -> (?a core:initiate ?e) (?e event:hasCategory event:vandalism) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kasnesis, P.; Tatlas, N.-A.; Mitilineos, S.A.; Patrikakis, C.Z.; Potirakis, S.M. Acoustic Sensor Data Flow for Cultural Heritage Monitoring and Safeguarding. Sensors 2019, 19, 1629. https://doi.org/10.3390/s19071629
Kasnesis P, Tatlas N-A, Mitilineos SA, Patrikakis CZ, Potirakis SM. Acoustic Sensor Data Flow for Cultural Heritage Monitoring and Safeguarding. Sensors. 2019; 19(7):1629. https://doi.org/10.3390/s19071629
Chicago/Turabian StyleKasnesis, Panagiotis, Nicolaos-Alexandros Tatlas, Stelios A. Mitilineos, Charalampos Z. Patrikakis, and Stelios M. Potirakis. 2019. "Acoustic Sensor Data Flow for Cultural Heritage Monitoring and Safeguarding" Sensors 19, no. 7: 1629. https://doi.org/10.3390/s19071629
APA StyleKasnesis, P., Tatlas, N.-A., Mitilineos, S. A., Patrikakis, C. Z., & Potirakis, S. M. (2019). Acoustic Sensor Data Flow for Cultural Heritage Monitoring and Safeguarding. Sensors, 19(7), 1629. https://doi.org/10.3390/s19071629