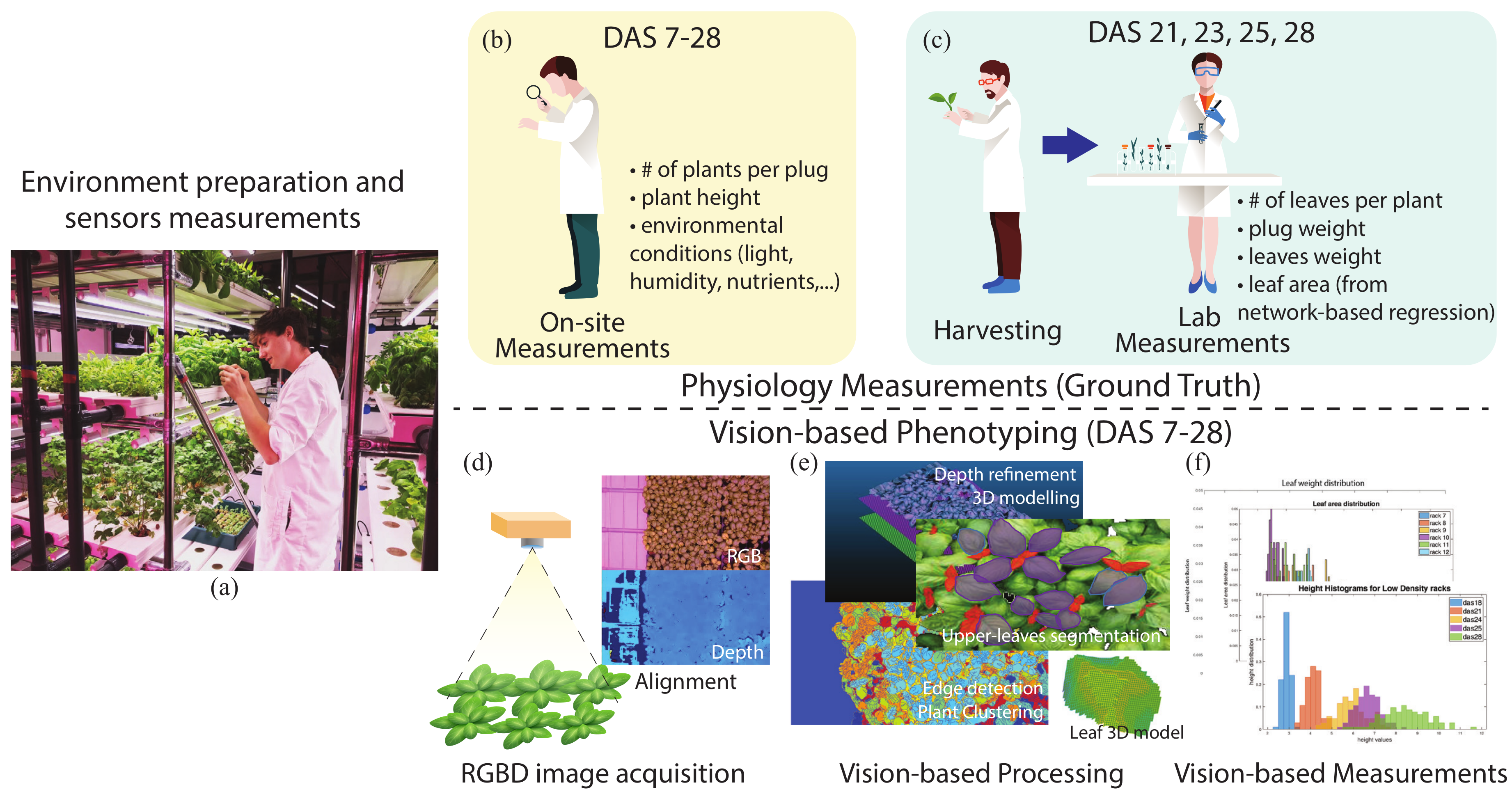
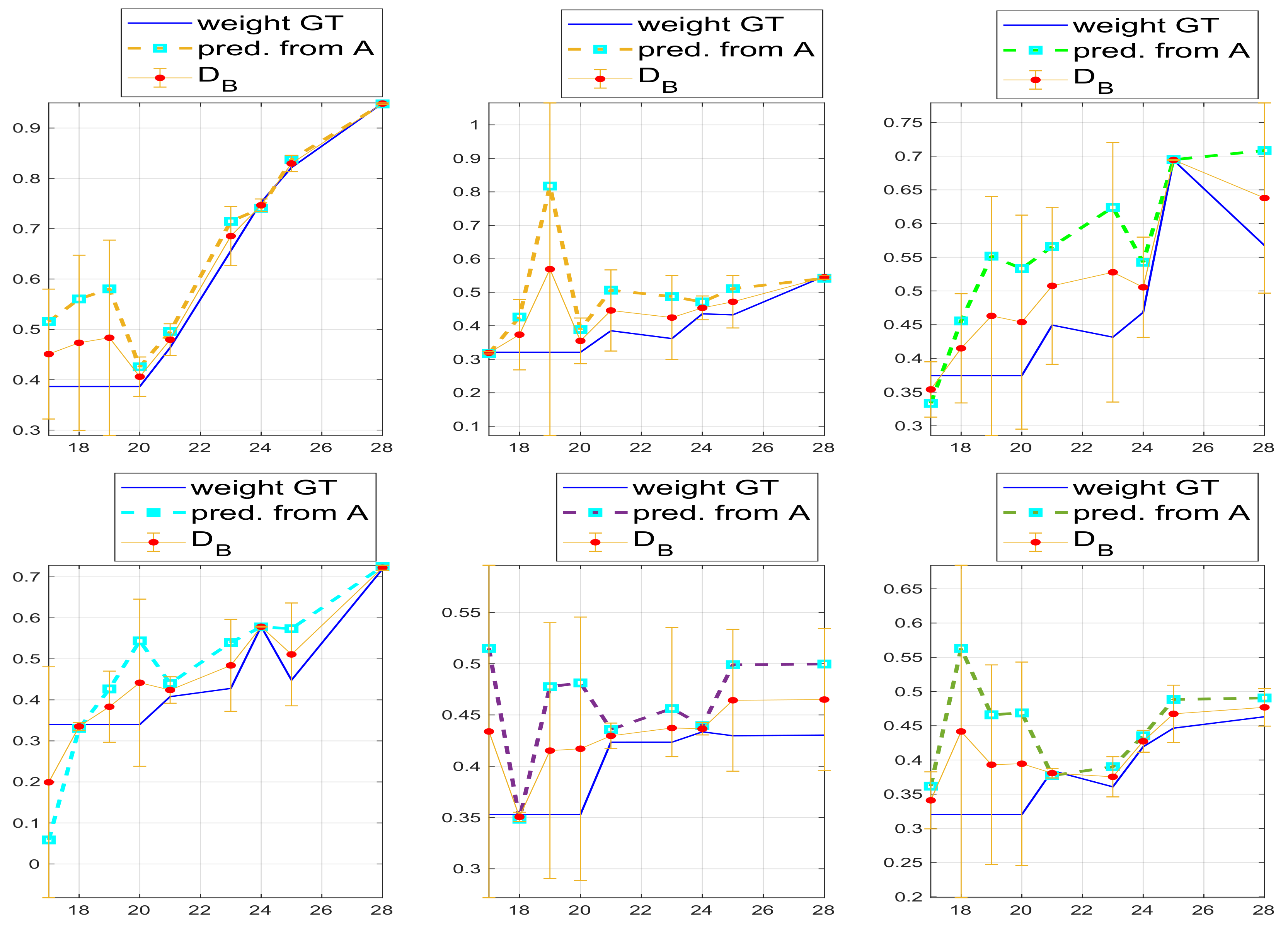
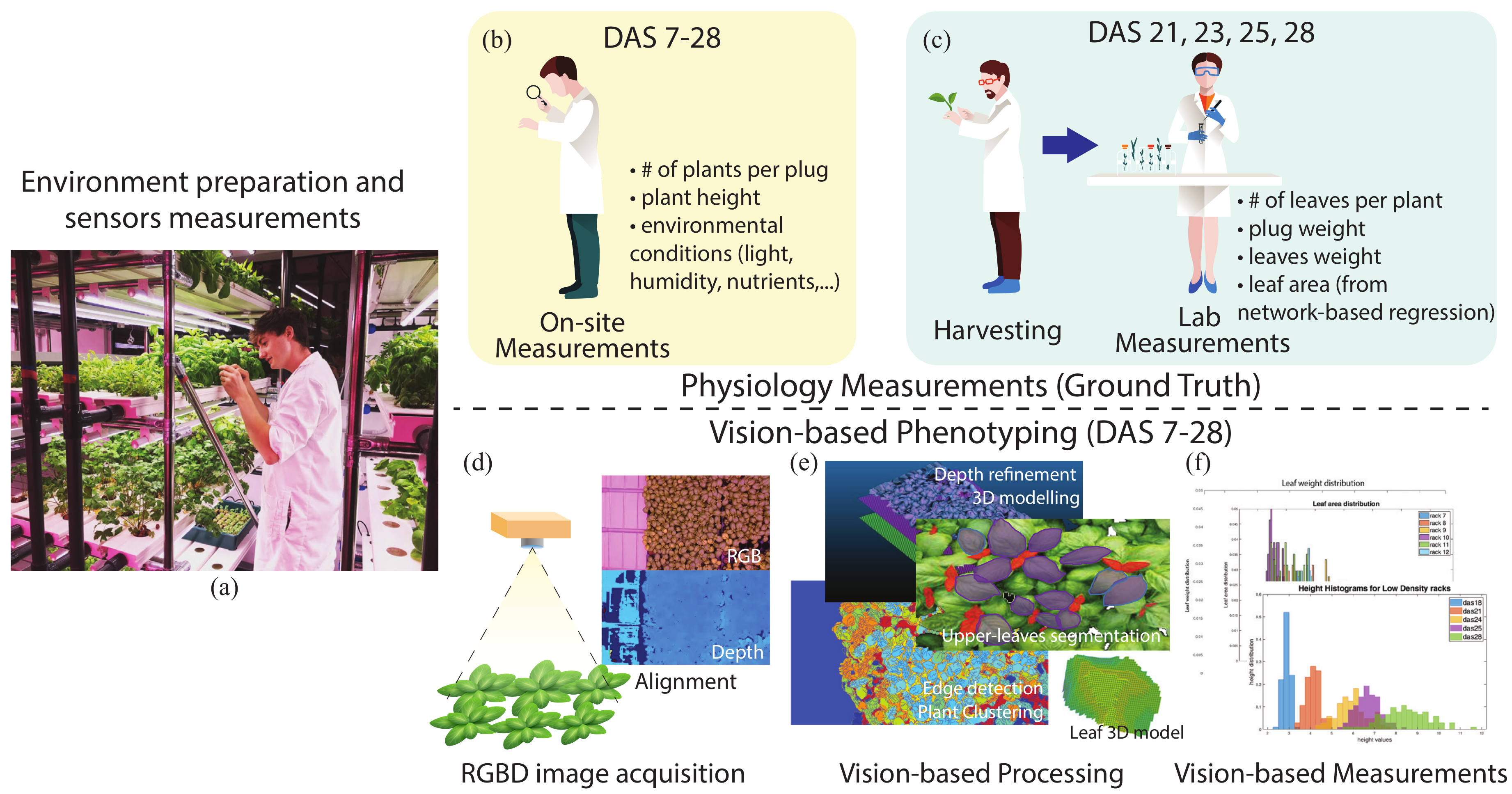
Our task was to predict the height of the plant from DAS 7 to DAS 28 and to predict both the leaf size of the visible layer of leaves for the last DAS (DAS 21 to 28) and leaf weight.
4.1. Acquisition and Noise Removal
To collect images for the entire DAS cycle, we positioned commercial close range RGBD sensors [
14], one for each rack layer, at about 54.3 cm from the rack plane and at 50.5 cm from tray plane, as illustrated in
Figure 2. The cameras were fixed at 50.5 cm from the plant substrate and 54.5 cm from the bottom of the trays, because this distance represents the typical distance between the LEDs and plant base in a VFAL. Each high density tray contains 144 plugs and each low density tray contains 104 plugs. Since each frame images two trays, each image collects either
plugs for the high density layers or
plugs for the low density layer.
An RGBD image realizes two representations: a color image with three color channels (R, G and B), returning a tensor of size and a depth map with only the depth values, namely each pixel at the x and y coordinates of the image specifies the depth value d, given in mm, indicating how far away the imaged object is.
The RGBD sensor has intrinsic parameters denoted by a matrix
K, specifying the sensor focal length
f, the scale values
and
specifying the number of pixels per mm., a skew parameter
s and the center of projection
, hence:
The intrinsic matrix allows projecting a point in space measured in mm into a point on the image plane, measured in pixels, and to deproject a pixel on the image plane to a point in space. Together with the intrinsic
K distortion parameters are made available for radial corrections
such that the corrected coordinates
of a pixel are obtained as:
and
, where
is the distortion center,
are the distorted coordinates, and
, with
(see [
15]).
Typically, RGBD sensors require a procedure to align the RGB image to the depth image, which is also useful to obtain a point cloud from the depth map with points colored as in the RGB image. To map a depth image to a point cloud the usual formula, with
d the depth,
a rotation matrix and
the translation vector, is:
X, Y and Z are the coordinates of the scene with the camera as the global reference point, while and d are the corrected coordinates of the depth image.
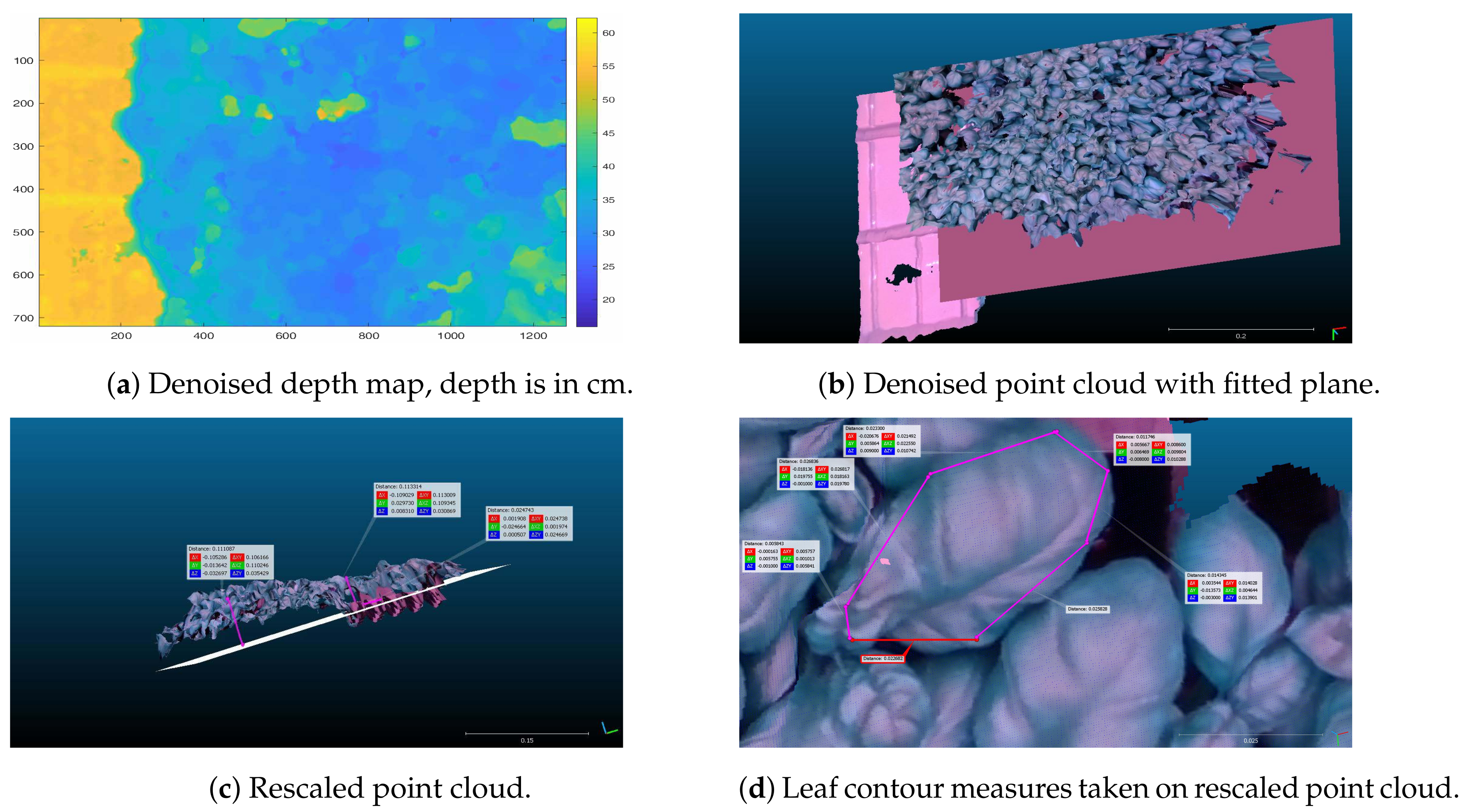
Because the camera is fixed, a single image is not quite dense, and there are points of reflection where the sensor does not return data. This can be observed in
Figure 3, where RGBD results without specific processing are shown. In particular, we can note in
Figure 3c the holes in the depth map, and in
Figure 3d that the produced point cloud is noisy. To address these problems and obtain an almost dense representation, we merged multiple consecutive depth maps and smoothed the resulting image with a Gaussian kernel. This merging makes sense, even though the camera is fixed, since natural flickering of the plants illumination and the ventilation, moving the leafs and their illumination, changes the image of the leaves, thus have the effect of small camera motions (see
Figure 4a).
In fact, because the point cloud results from the depth images, all taken from the same vantage point, as the camera is fixed (see
Figure 2), noise elimination is not trivial and may result in removal of useful points. To reduce the noise, we first fitted a plane to the point cloud, parallel to the tray surface, thus eliminating all points beyond the plane (see
Figure 4b,c). Further, we used the well known Iterative Closest point (ICP) algorithm [
16,
17], exploiting two point clouds from merged depth maps to clean points with loose correspondences to the common fitted plane.
Finally, the point cloud was rescaled using a known metric of the imaged objects, namely the dimension of the cell where plugs are put in, and the tray dimension. This step is required for two reasons: first because the camera, despite being fixed, is not well aligned with the tray plane, and secondly because the intrinsic parameters mapping pixels to mm are not sufficiently accurate. To rescale, we considered four points, which are the four vertices of a visible cell on the tray, namely the cell where plugs are located, which we know are separated by 30 mm, and computed the transformation
mapping the current points to the expected ones. The transformation
is an affine transformation including rotation, translation and scaling, such that:
, where
is the expected matrix formed by the four points in real world dimension, and
is the matrix of points as measured on the point cloud. According to the transformation, effective measures can be taken on the point cloud also at close distance, as illustrated in
Figure 4d.
We actually used the depth map for the height prediction (next section) and the point cloud for the leaf area and weight prediction.
4.2. Height Prediction
Given the basic setting described above, we next elaborate about automatic plant height computation at each defined DAS step.
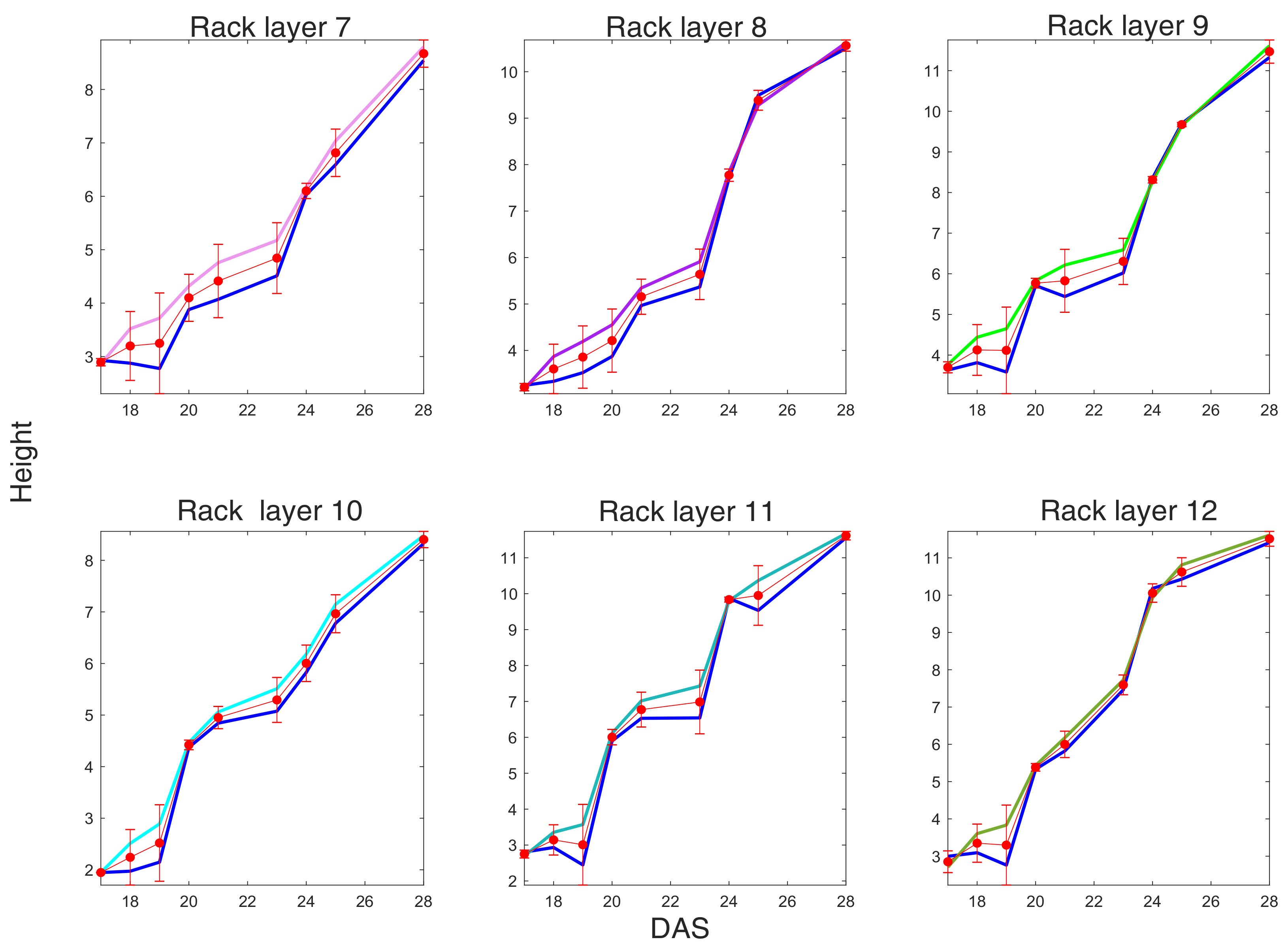
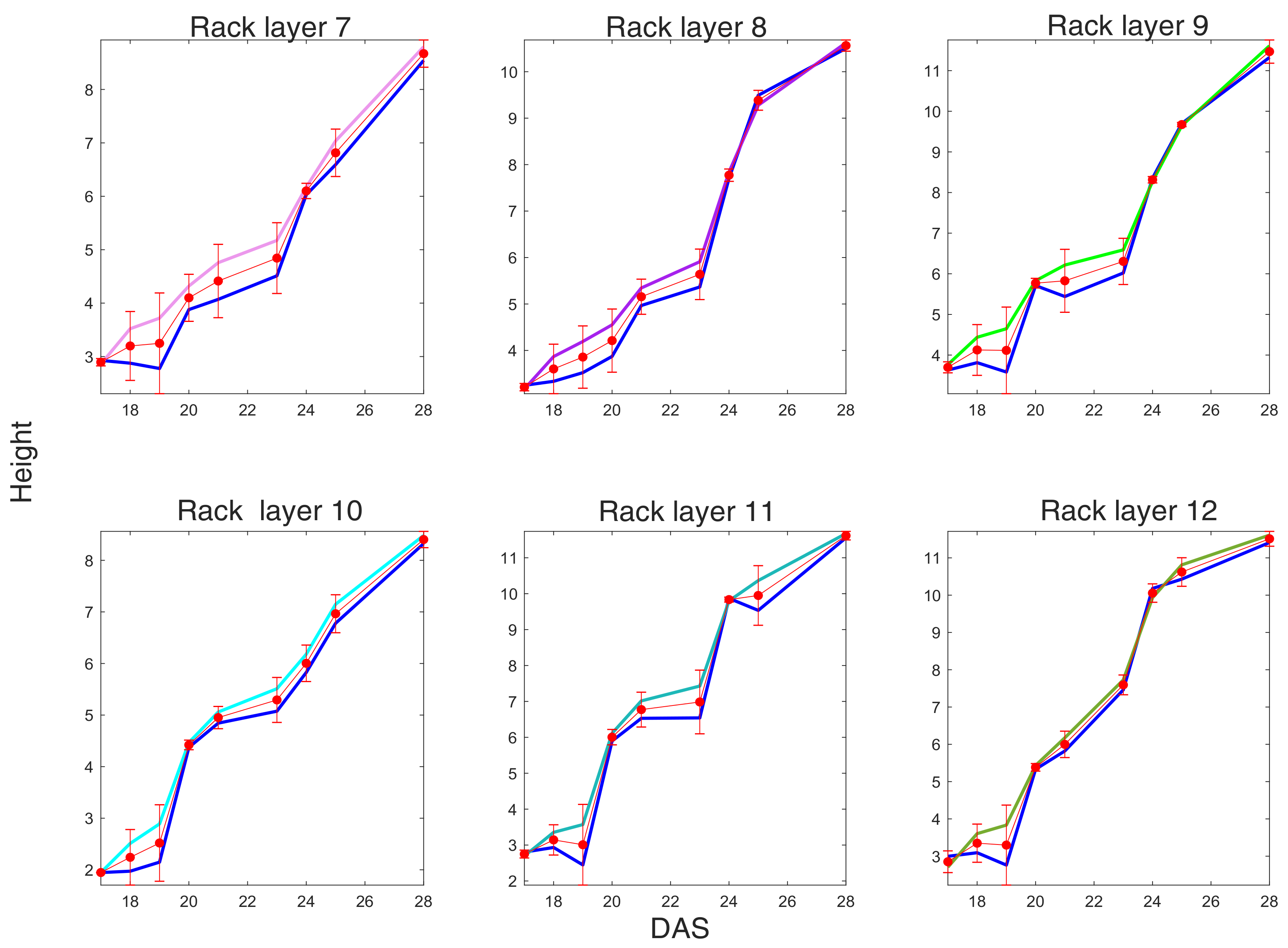
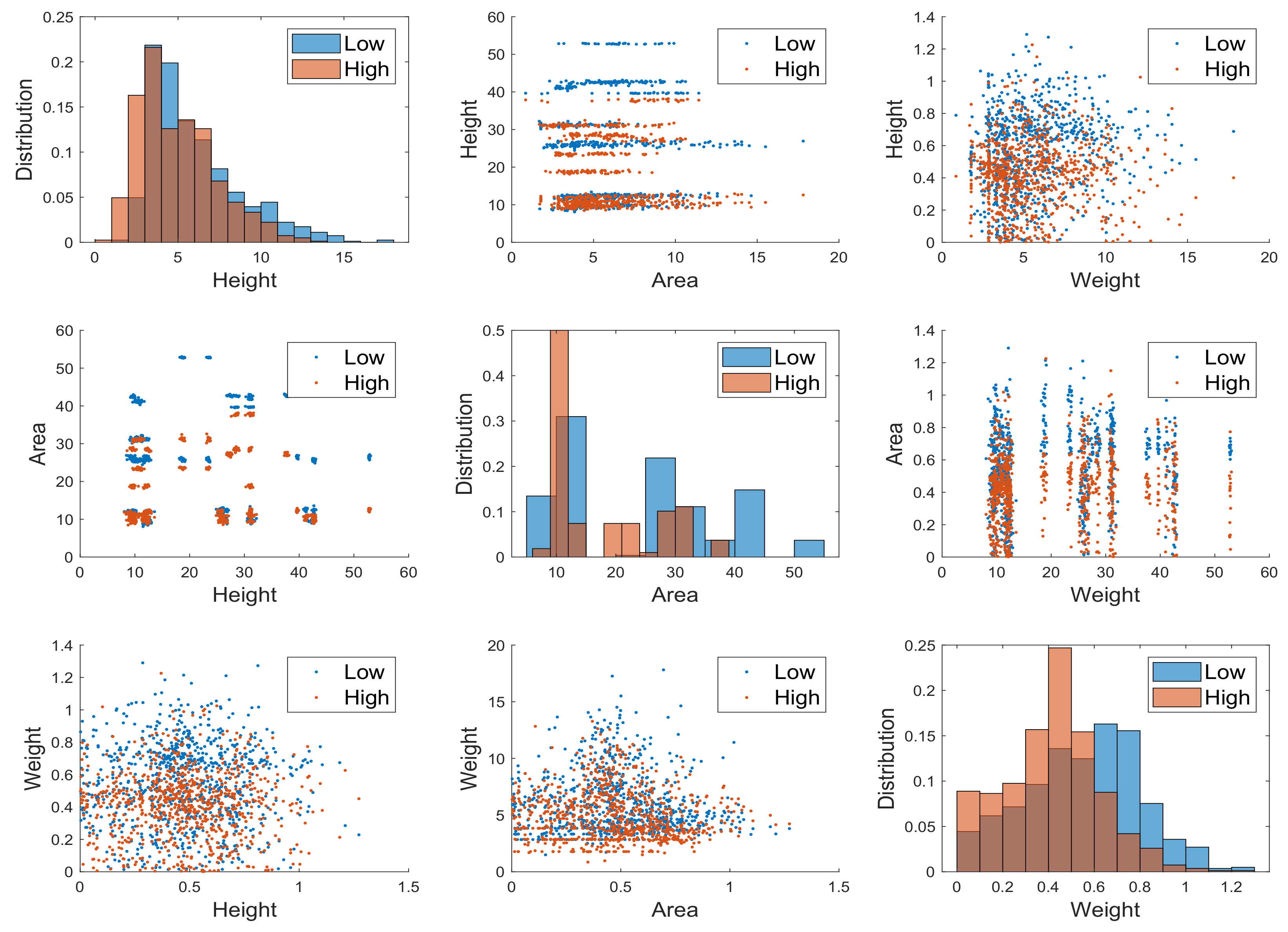
A relevant insight given by the agronomists in height computation is the difference amid plants at growth stages, namely DAS, according to plant density (see
Section 5.1). This information can be hardly assessed by the average growth for each tray and the heights standard deviation. In fact, it is interesting to note, for example, that the standard deviation significantly increases at later growth steps and according to density, namely the most dense trays have lower standard deviation because both plants competitiveness and lack of space stabilize plants growth at similar heights. Note that, because there are more than one plants in each plug, the agronomists measure the highest plant. However, it seems necessary to predict the height surface according to the region where each plant grows, namely near the cell on the tray where its plug is located.
To obtain height measures for each tray and each DAS, we considered the depth maps obtained day by day for each rack involved in the experiments. However, the plant surface provided both by the point cloud and the depth map hardly distinguishes individual plants, especially at later stages, at which only a carpet of leaves is visible.
To obtain quite precise measurements for each cell, where plugs are located, we need to recover the cells, which at later stage are clearly not visible.
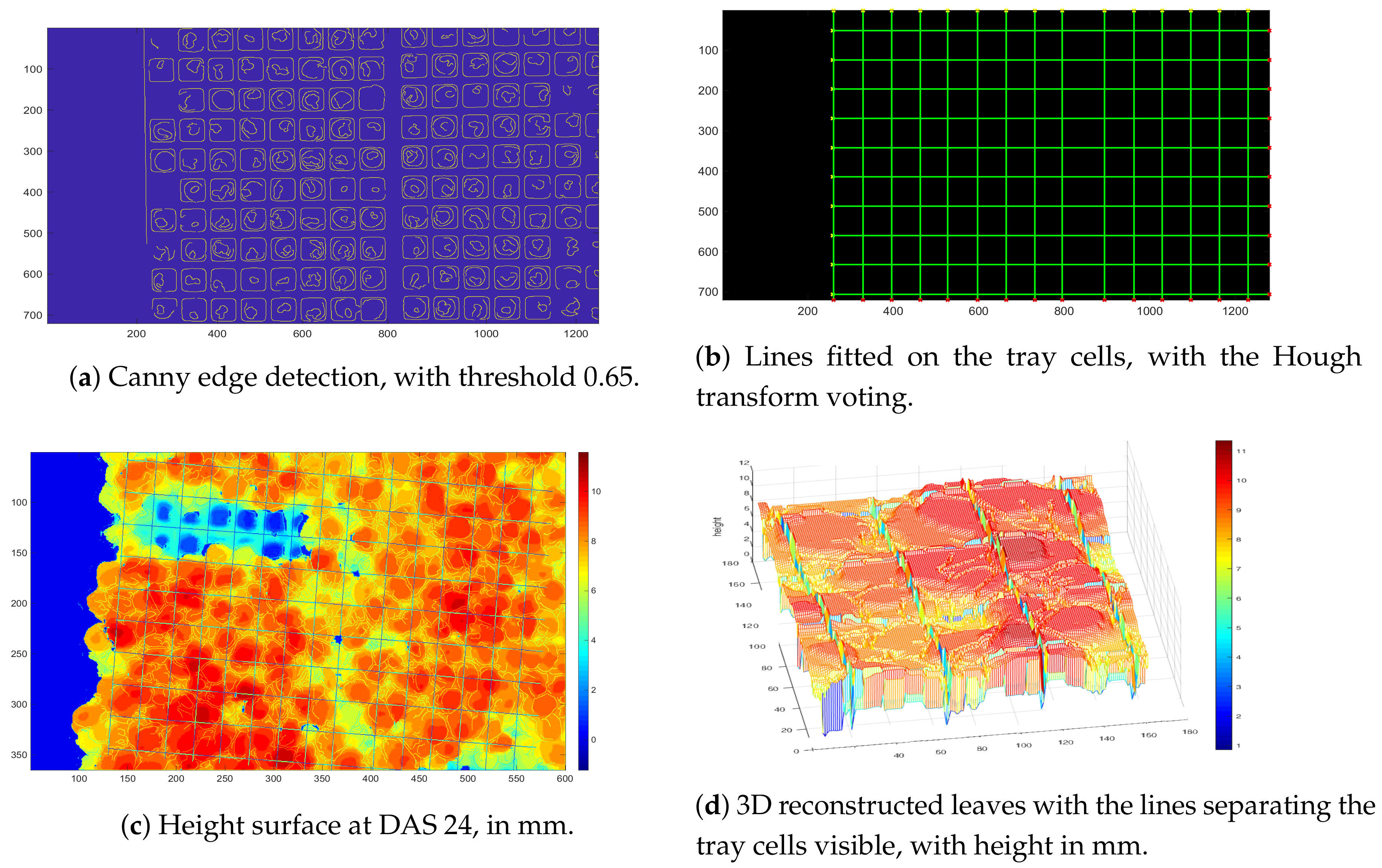
To this end, we fitted lines to the tray images taken at the early DAS. Lines were computed first computing a Canny edge detector of images of early stages, where the tray cells are still visible. The Canny edge detection is shown in
Figure 5, where the image is obviously rectified and undistorted. Then, from the binary image of the edges, the lines were obtained with the Hough transform, and a new binary matrix
L, with zeroes at the line locations, was obtained. Then, letting
M be the depth map and
L be the image of the line fitted, the new depth map with the line fitted is
, with ∘ the pointwise Hadamard product.
The new depth map
returns the distance between the camera and the plants, except for the lines bounding the cells, where plugs are located (see
Figure 5), where as mentioned above the value is zero.
As noted above, the x and y coordinates are given in pixel. In other words, the depth map is a surface covering an area of pixels, while the tray area measures 110 cm × 63 cm. However, since the depth d is measured in millimeters, computing the height rescaling is not required.
Finally, the plants height surface was obtained by subtracting from the depth map the distance to the plane parallel to the tray surface, which is known to be 505 mm, as noted above.
Let
be the distance between the camera image plane
and the surface plane
of the tray, measured along the ray normal to the camera image plane, and let
be the depth map, with lines bounding the cells. The depth map was smoothed by convolving it with a Gaussian kernel of size
with
. Then, the plant height surface
was computed as:
with
Gaussian noise, possibly not reduced by smoothing.
To compute the height of plants relative to a plug, we only need to consider all the points within the cell bound by the appropriate vertices. Indeed, we can just consider the projection on the plane of the surface points, as far as the
z coordinate (note that we name it
z because it is the plant height, not the depth
d) is not zero. First, note that
V is a vertex on the tray lines if all its four-connected points are equal to 0. Therefore, let
be a vertex of the approximate rectangle bounding a tray cell,
. Let
be the projection on the plane of a point
on the surface height,
. Then,
is within a cell
q bounded by the vertices
iff the vertices are connected and:
Then, the set of points on the height surface of a cell
q is
. This defined, it is trivial to determine the highest and average height for each cell
q, and the height variance within a cell:
Here, , with the set cardinality.
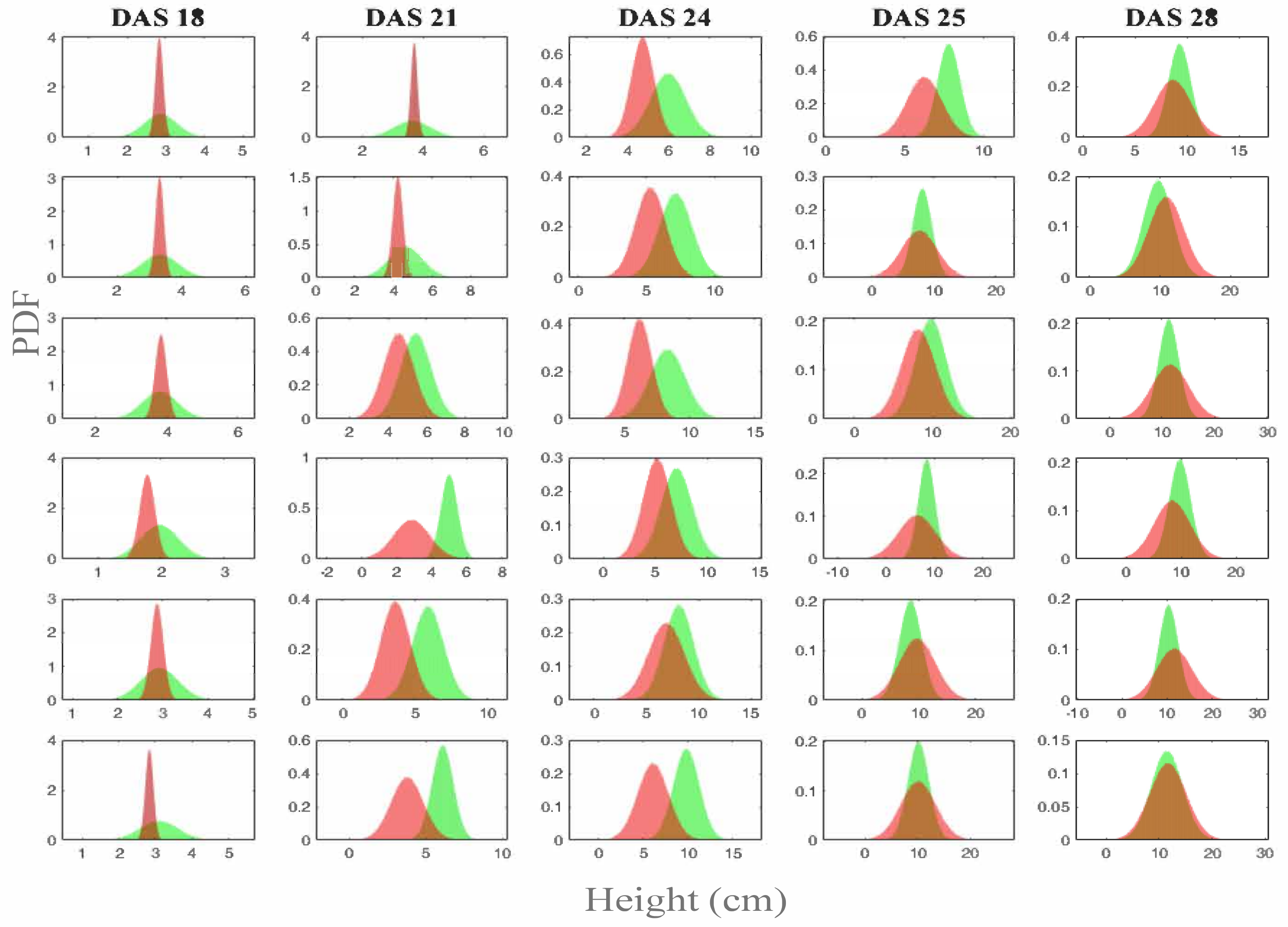
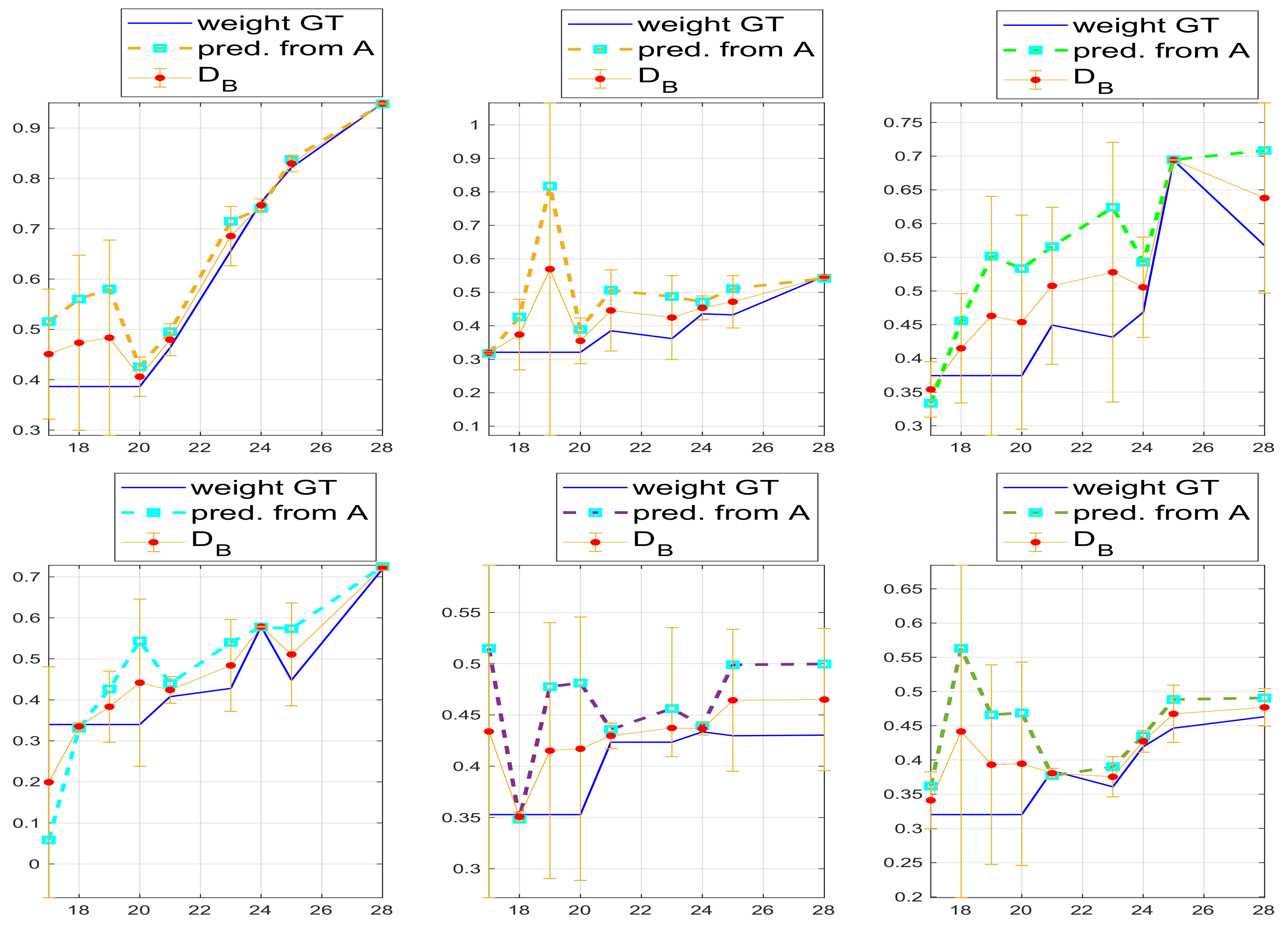
The results and comparison of the predicted height with the measured ones, according to the modeled surface, are given in
Section 5.
4.3. Leaf Area and Weight
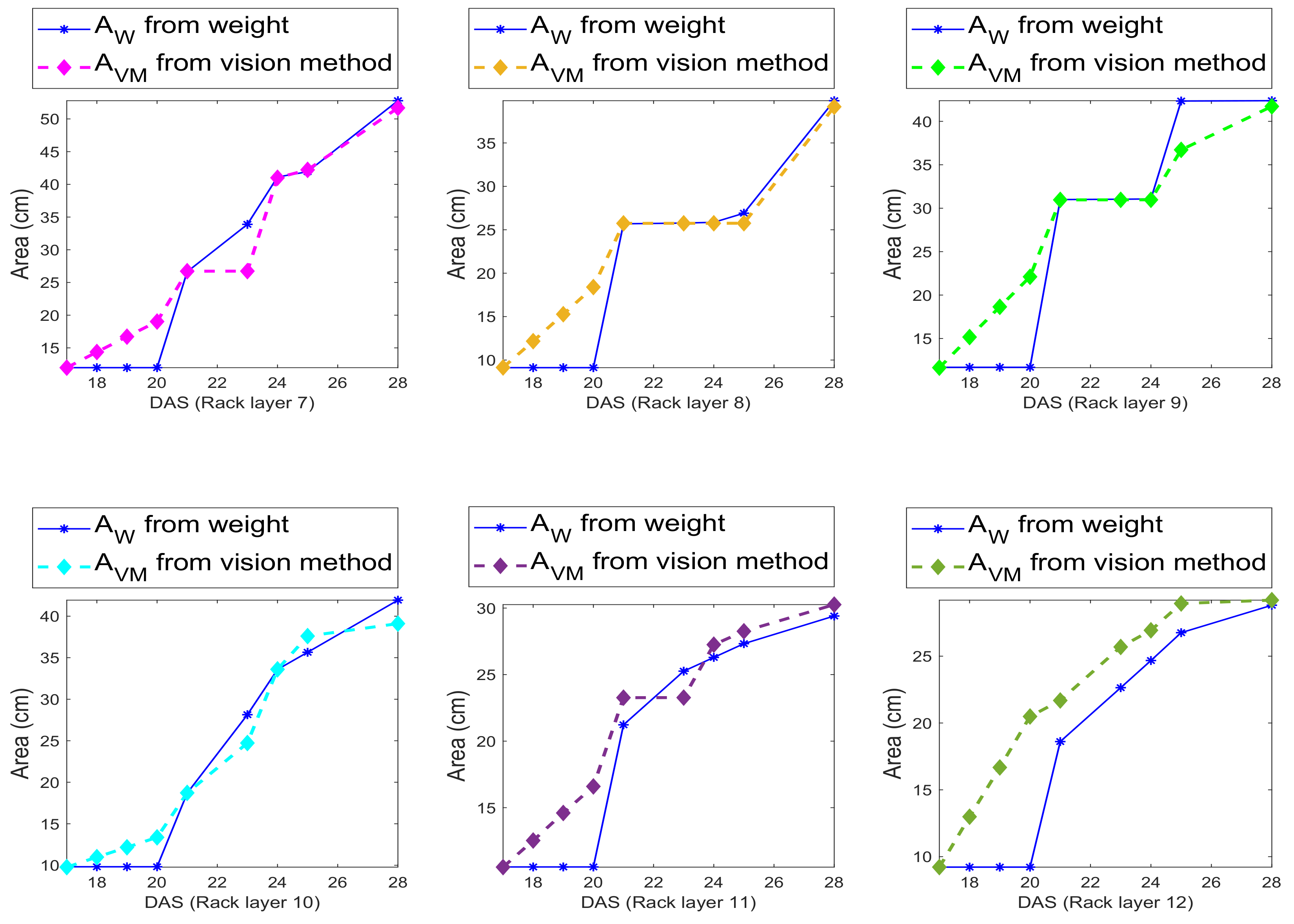
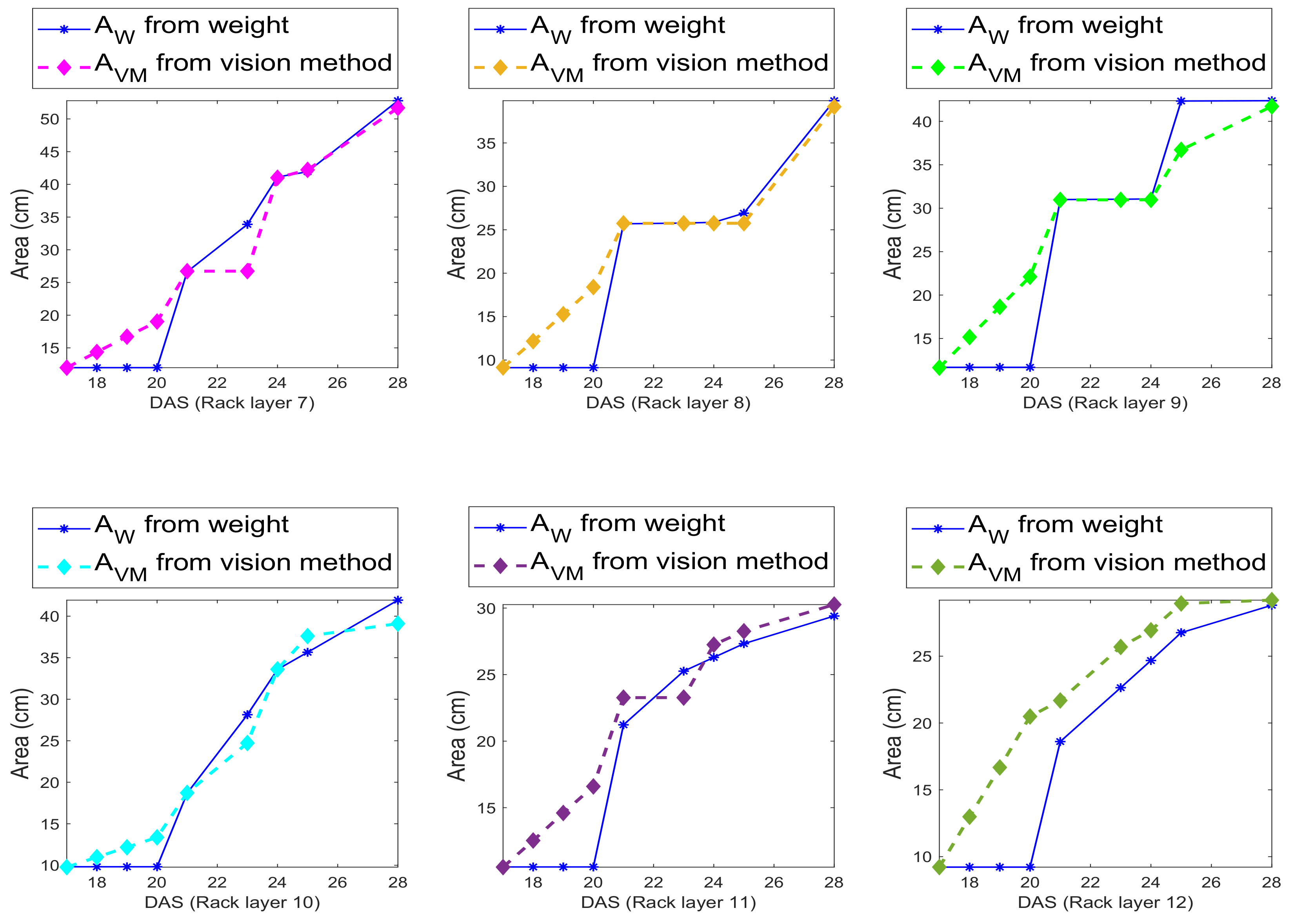
In this section, we discuss the computation of both leaf area and leaf weight. We recall that leaf area was not measured by the agronomists, however they collected the weight of the leaves of the plants in a plug, and the number of leaves. Furthermore, they made available, from previous studies, a sample of leaves for the considered species with area and weight. From this sample, they measured , where is the weight of a basil leaf, is the area of the leaf and is the density. From this sample, the weight, and the knowledge of the number of leaves, we derived a reference ground truth for leaf area to be directly comparable with our predicted leaf area.
From the predicted leaf area, using the density, we computed the leaf weight. However, we could not predict thus far the number of leaves in a plant or the number of plants in a plug.
For predicting the leaf area, we proceeded as following. We computed instance segmentation of superficial leaves at DAS 18, 21, 24 and 28. Using the colored mask and Equation (
2), we projected the mask to the point cloud to obtaini a surface well approximating in dimension and shape the considered leaf. Because each point of the projected mask is colored, the mask can also be segmented from the point cloud, simply selecting all points with the specific color. Note that the point cloud can be saved as a matrix of dimension
where
N is the number of points, the first three column are the point locations and the last three the associated color.
Then, we fitted a mesh surface to the chosen leaf, eliminating all the redundant meshes. The process is shown in
Figure 6 and
Figure 7.
As noted in
Section 3, we can measure leaf area only for the surface leaves not occluded by more than
by other leaves. To obtain this partial yet significant result, we resorted to leaf segmentation with Mask R-CNN [
18], a well known deep network for instance segmentation. We used our implementation in Tensorflow, which is freely available on GitHub (See
https://github.com/alcor-lab).
As is well known, CNNs typically require a huge collection of data for training, and in our case well known datasets such as COCO (
https://github.com/cocodataset/cocoapi) could not be used. In addition, we noted that leaves completely change aspect after the early DAS, namely around DAS 17, when they gain a characteristic grain.
Therefore, we decided to collect both small and large leaves of almost mature plants, starting from DAS 17.
We collected only 270 labeled large leaves and 180 small leaves, with LabelMe (See
http://labelme2.csail.mit.edu/Release3.0/browserTools/php/matlab_toolbox.php) and following Barriuso and Torralba [
19], selecting images from Rack 7, the first experiment and DAS 17, 18, 19, 21, 23, 24, and 28. We considered only Rack 7, to make testing on the remaining racks clearer. However, in the end, we also used Rack 7 for testing, although we delivered separate tests to not corrupt results.
We tested the network on two resolutions, as shown in
Figure 6, obtaining very good results for both training and testing. The accuracy of each large leaf recognition is given within each bounding box; note that small leaf accuracy is not shown.
It is apparent that, because the number of samples is so small, leaves occluded by more than of the area are not recognized. However, we noticed that the samples we could collect from the rack surface are good representatives of the whole leaves set. Furthermore, as explained in the sequel, this does not affect significantly the measured area.
Given a leaf mask, as obtained from the RGB images, first, it was projected on the depth map, as shown in the lower panels of
Figure 6 and, further, using Equation (
2), the points of the point cloud were obtained [
20,
21]. Note that the projection of a depth map point
into space coordinates
allows recovering the colors as well. To maximally exploit the segmentation masks for each image, we assigned a different color to each mask, so that when two masks were superimposed it was easy to distinguish to which mask leaf points belong. More precisely, the color masks were projected into space together with the points on the plants surface height (the depth map) and, because each mask was assigned a different color, we could use them as an indicator function:
Note that, to exemplify, we assumed that the mask for leaf j is green.
Since we used more than a depth image, thereby generating more than one point cloud, for the leaves occluded on the RGB image there are two possibilities. Either the occlusion remains the same in space or it can be resolved; however, the mask does not extend on the parts which have been disoccluded in space. In this last case, to recover the occluded part of the leaf not distinguishable by the lack of the segmentation mask, we resorted to the computation of normals using
k-nearest neighbor and fitting a plane to close points. As is well known, for three points on the plane, the normal is simply obtained as the cross product of the vectors linking them, further normalized to a unit vector. Given points
on the boundary
b of a mask, the boundary is moved according to the normals to close by points
. Normals are assigned a cost according to the distance to the points on the boundary and according to the cosine angle between the normal on the boundary and normal beyond it:
The above essentially assigns a cost to each point beyond the boundary of a leaf mask, by choosing only those points whose cost of the normal is less than a threshold obtained empirically, hence it allows to extend, when this is possible, the regions of occluded leaves, without significant risks.
Having obtained the segmented leaves in space, and recalling that the space is suitably scaled so that distances correspond to real world distances, from the transformation of pixels into mm, we could measure the leaf area, even though in many cases the leaf was not full, because of occlusions, as noted above.
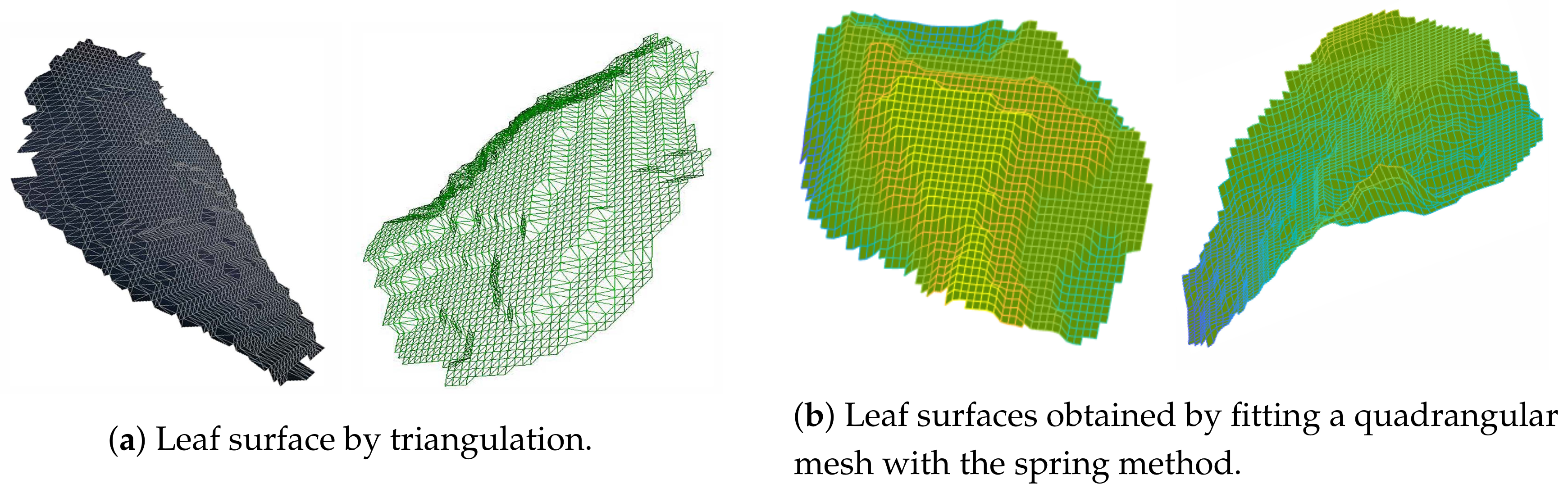
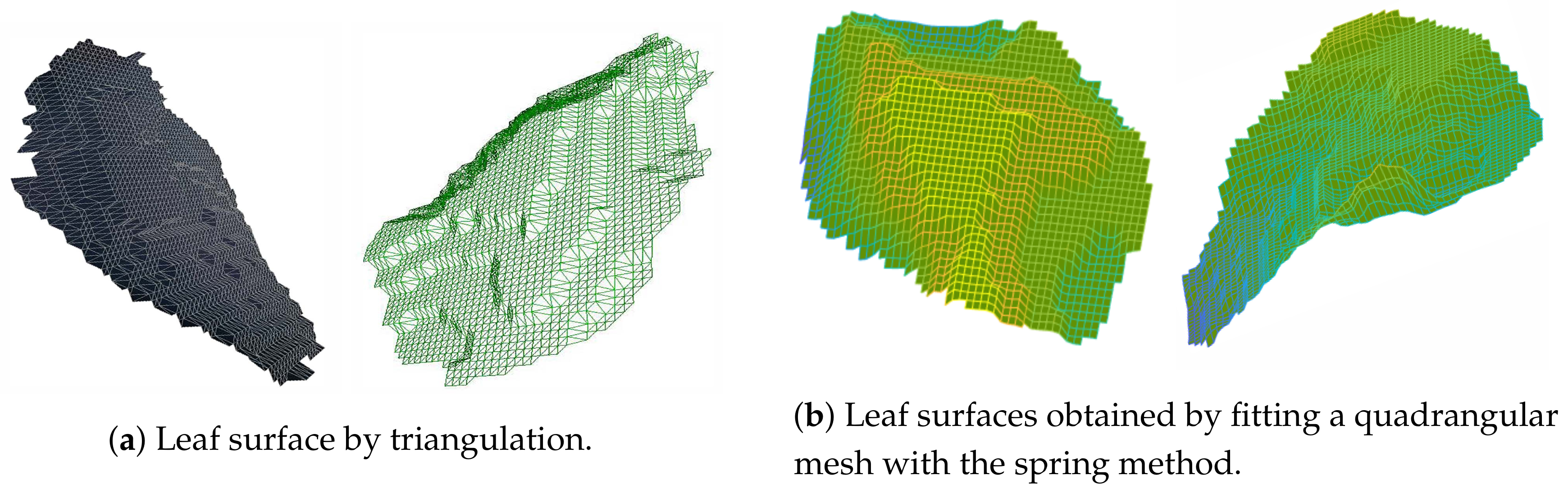
To obtain the leaf area, we built both a triangulation and a quadrangular mesh. The triangulation, despite being more precise, is more costly and the triangles do not have the same shape and size, therefore area computation requires looking at each triangle. The triangulation can be appreciated
Figure 7a.
To fit the quadrangular mesh to the leaf points, we used the spring method (see [
22]) solving the fitting as a non-linear least square problem, with relaxation.
The results of the fitting for the quadrangular meshes are given in
Figure 7b.
Finally, we checked if a mesh is occupied by one or more points, and if it is not, then the specific mesh was removed, but only if it is on the boundary. We can see in
Figure 7 that the result is sufficiently accurate, for measuring area, clearly not for graphical representations, and it is quite fast. The only difficulty is the choice of the size of the quadrangles, which determines the smoothness of the shape and, obviously, the goodnesses of fit, yet augmenting the computation cost.
Hence, the leaf area is simply: , where each is determined by the choice of the size of the quadrangular meshes.
The results on the accuracy of the computation are given in
Section 5. To obtain the leaf weight, we simply used the above density formula, and obtained the weight multiplying the recovered area with the density
. For the weight, we show the accuracy in
Section 5.

 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}